Embed Size (px)
Citation preview

TMC BioGrid
A GCC Consortium
Ken KennedyCenter for High Performance Software
Research(HiPerSoft)
Rice University
http://www.cs.rice.edu/~ken/Presentations/BioGrid.pdf

Texas Medical Center BioGrid
• A Partnership under the Gulf Coast Consortia—Participants: Rice, UH, Baylor College of Medicine, MD
Anderson Cancer Center
• Goals—Foster research and development on application of Grid
computing technology to biomedicine—Construct a useful Grid computational infrastructure
• Current Infrastructure—Machines: Itanium and Opteron clusters at UH, Itanium
cluster at Rice, Pentium cluster at Baylor, MD Anderson pending
—Interconnection: 10 Gigabit optical interconnect among Rice,UH, Baylor, MD Anderson in progress, connection to National Lamda Rail pending
—Software: Globus + VGrADS software stack (see next slide)

BioGrid Principal Investigators
Don Berry, MD AndersonBradley Broom, MD Anderson
Wah Chiu, BaylorRichard Gibbs, Baylor
Lennart Johnsson, HoustonKen Kennedy, Rice
Charles Koelbel, RiceJohn Mellor-Crummey, Rice
Moshe Vardi, Rice

BioGrid Research
• Software Research—Virtual Grid Application Development Software (VGrADS)
Project– Producing software that will make it easy to develop
Grid applications with optimized performance– Automatic scheduling and launching on the Grid based
on performance models– Distribution of software stack to construct testbeds
• Applications—EMAN: 3D Image Reconstruction Application Suite (Baylor-
Rice-UH)– Automatically translated (by VGrADS) to Grid execution
with load-balanced scheduling—Script-based integration and analysis of experimental
cancer data bases planned (MD Anderson, Rice)

The VGrADS Team
• VGrADS is an NSF-funded Information Technology Research project
Keith Cooper
Ken Kennedy
Charles Koelbel
Linda Torczon
Rich Wolski
Fran Berman
Andrew Chien
Henri Casanova
Carl Kesselman
Lennart JohnssonDan Reed
Jack Dongarra
• Plus many graduate students, postdocs, and technical staff!
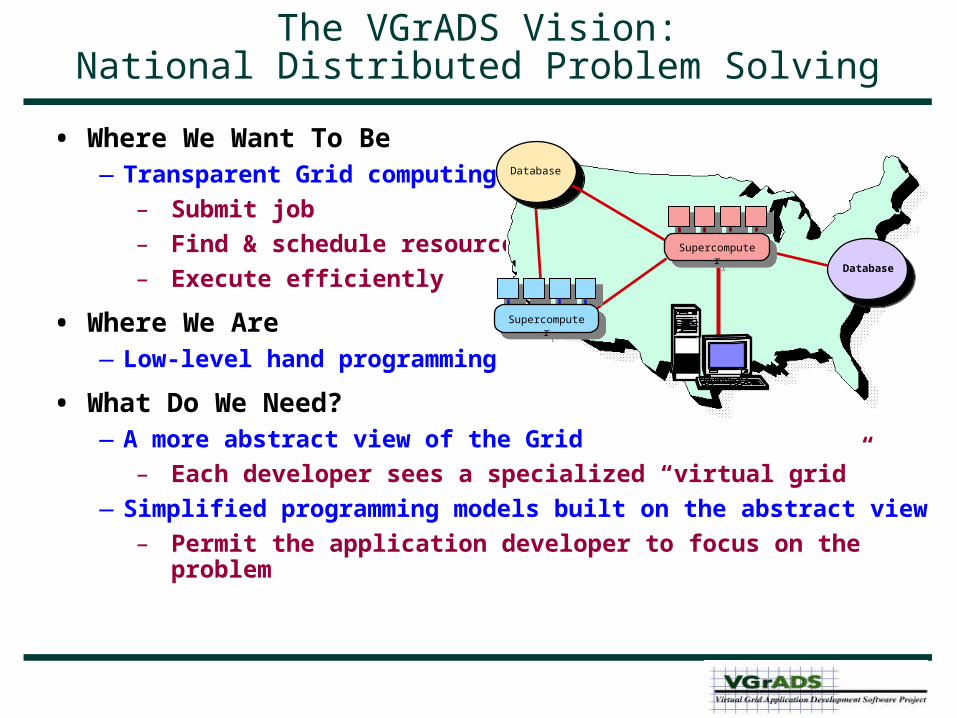
The VGrADS Vision:National Distributed Problem Solving
• Where We Want To Be—Transparent Grid computing
– Submit job– Find & schedule resources– Execute efficiently
• Where We Are—Low-level hand programming
• What Do We Need?—A more abstract view of the Grid
– Each developer sees a specialized “virtual grid”—Simplified programming models built on the abstract view
– Permit the application developer to focus on the problem
Database
DatabaseSupercompute
r
Supercomputer
Supercomputer
Supercomputer

Virtual Grids and Tools
• Abstract Resource Request—Permits true scalability by mapping from requirements to set of
resources– Scalable search produces manageable resource set
—Virtual Grid services permit effective scheduling– Fault tolerance, performance stability
• Look-Ahead Scheduling—Applications map to directed graphs
– Vertices are computations, edges are data transfers—Scheduling done on entire graph
– Using automatically-constructed performance models for computations
– Depends on load prediction (Network Weather Service)
• Abstract Programming Interfaces—Application graphs constructed from scripts
– Written in standard scripting languages (Python,Perl,Matlab)

Programming Tools
• Focus: Automating critical application-development steps—Building workflow graphs
– From Python scripts used by EMAN—Scheduling workflow graphs
– Heuristics required (problems are NP-complete at best)– Good initial results if accurate predictions of resource
performance are available (see EMAN demo)—Constructing of performance models
– Based on loop-level performance models of the application
– Requires benchmarking with (relatively) small data sets, extrapolating to larger cases
—Initiating application execution– Optimize and launch application on heterogeneous
resources

VGrADS Demos at SC04
• EMAN - Electron Microscopy Analysis [BCM, Rice, Houston]—3D reconstruction of particles from electron micrographs—Workflow scheduling and performance prediction to
optimize mapping
EMAN Refinement Process

EMAN Workflow Scheduling Experiment
• Testbed—64 dual processor Itanium IA-64 nodes (900 MHz) at Rice
University Terascale Cluster [RTC]—60 dual processor Itanium IA-64 nodes (1300 MHz) at
University of Houston [acrl]—16 Opteron nodes (2009 MHz) at University of Houston
Opteron cluster [medusa]
• Experiment—Ran the EMAN refinement cycle and compared running
times for “classesbymra”, the most compute intensive parallel step in the workflow
—Determine the 3D structure of the ‘rdv’ virus particle with large input data [2GB]
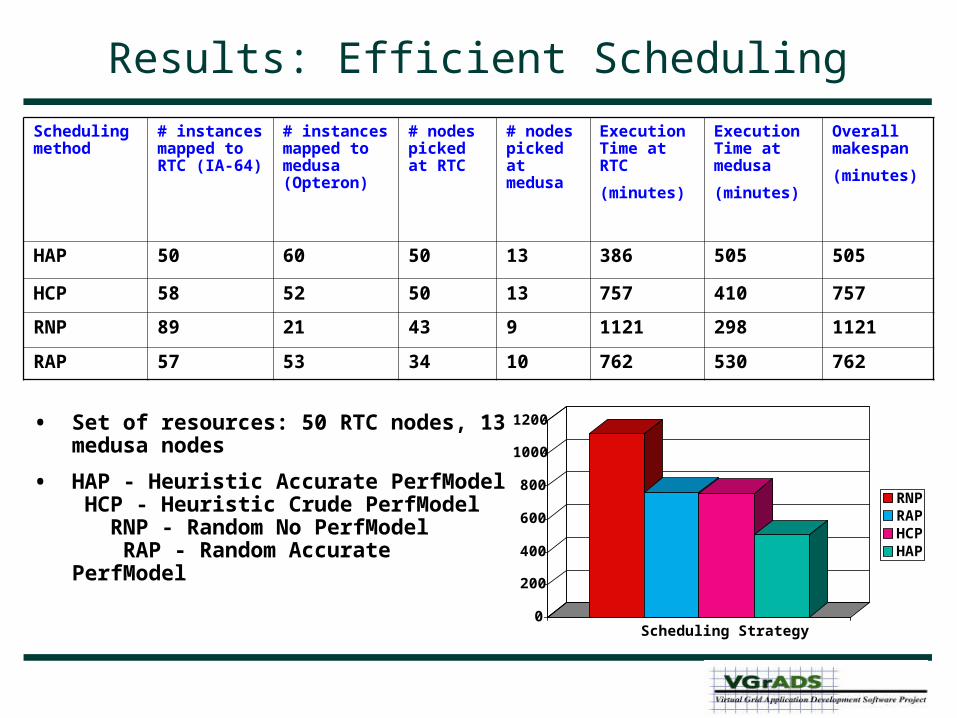
Results: Efficient Scheduling
Scheduling method
# instances mapped to RTC (IA-64)
# instances mapped to medusa (Opteron)
# nodes picked at RTC
# nodes picked at medusa
Execution Time at RTC
(minutes)
Execution Time at medusa
(minutes)
Overall makespan
(minutes)
HAP 50 60 50 13 386 505 505
HCP 58 52 50 13 757 410 757
RNP 89 21 43 9 1121 298 1121
RAP 57 53 34 10 762 530 762
0
200
400
600
800
1000
1200
Scheduling Strategy
RNPRAPHCPHAP
• Set of resources: 50 RTC nodes, 13 medusa nodes
• HAP - Heuristic Accurate PerfModel HCP - Heuristic Crude PerfModel RNP - Random No PerfModel RAP - Random Accurate PerfModel

Final Comments
• The TMC BioGrid—An effort to solve important problems in computational
biomedicine—Use the Grid to pool resources
– 10 Gbps interconnect– Pooled computational resources at the particpating
• The Challenge—Making it easy to build Grid applications
• Our Approach—Build on the VGrADS tools effort
– Performance model based scheduling on abstract Grids
• EMAN Challenge Problem—End goal: 3000 Opterons for 100 hours





























