Embed Size (px)
Citation preview

TM
Shared Memory ParallelismShared Memory Parallelism
Programming in the SGI Environment

TM
Parallel Programming on SGIParallel Programming on SGI• Automatic parallelization with APC
– Fortran and C compiler option: -apo– HPF: pghpf (Portland Group), xHPF (third party)
• parallelization by inserting OpenMP compiler directives (using the -mp compiler option)– Fortran !$omp parallel, !$omp do– C #pragma omp parallel
• Low-Level parallelism– Posix standard Pthreads– SGI library sproc()– UNIX native fork()– Sequent library m_fork()
• Message Passing– PVM, MPI– shmem
• Definition of number of parallel threads (man pe_environ)– SMP (APC and OpenMP, sproc): setenv OMP_NUM_THREADS n– MPI: mpirun -np n prog

TM
SMP ProgrammingSMP Programming The parallelism in the code:
• can be found by the compiler
• can be asserted by the programmer with directives to help the compiler to analyze the code– compiler analyzes data access rules based on the additional
information presented
• can be forced by the programmer with directives/pragmas– compiler has to be told about data access rules
(shared/private)– explicit synchronization is often necessary to access the
shared data
• can be forced by the programmer with library calls – POSIX Pthreads

TM
Automatic ParallelizationAutomatic Parallelization

TM
Automatic ParallelizationAutomatic Parallelization
% setenv OMP_NUM_THREADS 4

TM
Automatically Parallelizable CodeAutomatically Parallelizable Code
• linear assignments:
• reductions:
• triangular assignments
• NOT parallelizable:– early exits
DO I=1,N S = S + X(I)ENDDO
DO I=1,N A(I) = B(I) + X(I)ENDDO
DO I=1,N DO J=I,N A(J,I) = B(J,I) + X(I)ENDDO

TM
Compiler AssertionsCompiler Assertions Assertions help the compiler to deal with data dependencies that cannot be analyzed based on program semantics alone: C*$* (NO) CONCURRENTIZE #pragma (no) concurrentize
– (not) to apply parallel optimizations, the scope is the entire compilation unit
C*$* ASSERT DO (SERIAL) #pragma serial C*$* ASSERT DO (CONCURRENT) #pragma concurrent
– implement the required action for the loop (nest) immediately following the directive
C*$* ASSERT PERMUTATION(A) #pragma permutation(a)– similar to the IVDEP directive, asserts that the indirect addressing with index
array A in the following loop nest will not alias to the same storage location
C*$* ASSERT CONCURRENT CALL #pragma concurrent call– asserts that the following loop nest can be parallel despite subroutine
invocations that cannot be analyzed for side effects
-LNO:ignore_pragmas compiler option is used to disable these directives

TM
Assertion ExamplesAssertion Examples
• The compiler is analyzing the code given the information in the assertion and does automatic parallelization if possible
• even with the c*$* assert do (concurrent) directive, the compiler will not make loops parallel where it finds obvious data dependencies
• If it does not work, next step is to introduce the parallelization directive with explicit rules for variable usage given by the user (e.g. OpenMP semantics)
do … do …c*$* assert do (serial)
do … do … enddo
enddo enddoenddo
Compiler will not parallelize the outer loops,
since the inner loop must be serial
Compiler might parallelize the inner loops
C*$* assert concurrent calldo I=1,n call do_parallel_work(I)enddo
C*$* assert permutation(i1)do k=1,nsite A(i1(k)) = A(i1(k))+force*B(k)*B(k)enddo

TM
Manual ParallelizationManual Parallelization When parallelizing a program (or part of it) manually, one needs to consider the following:
• what is the highest level of parallelism (Coarse-grain vs fine-grain parallelism)
• which data should be shared and which is private
• how the data should be distributed between processors (this is special optimization with CC-NUMA programming)
• how the work should be distributed between processors (or select automatic work distribution by the compiler)
• can threads have simultaneous access to shared data, such that race conditions can occur

TM
Creation of Parallel RegionsCreation of Parallel Regions With OpenMP, the syntax is: C$ OMP PARALLEL [clause[,clause]…] ……… code to run in parallel C$ OMP END PARALLEL
#pragma omp parallel [clause[,clause]…] { /* this code is run in parallel OMP_NUM_THREADS times */ } clause specifies the data association rules (default, shared, private) for each variable (array, common block) internally, compiler generates a subroutine call to the body of parallel code. The data definitions determine how variables are passed to that subroutine Old syntax: C$ DOACROSS #pragma parallel !$ par parallel …… !$ par end parallel
Transition fordata association

TM
Data Status AssociationData Status Association In a serial program:• global data
– variables at a fixed well known address (global variables)• subroutine arguments, common blocks, externals
• local data– variables with address known only to a single block of code
• automatic variables, (re-)created on the stack• variables with address allocated at load time (static)
» all DATA, SAVE, -static compiled programs• dynamic variables allocated at run time
» malloc, ALLOCATE, etc.
Parallel program has additional qualification:• shared data
– variables that can be accessed by every thread• private data
– variables with address known only to a single thread• volatile data
– special type variables that can be changed outside of program• synchronization data

TMData Status Transition in Parallel Data Status Transition in Parallel ProgramsPrograms In parallel programs following transition takes place:
• It is safe to work with the automatic local variables that are allocated on the stack. In a parallel region each thread of execution gets its own private stack- these variables are automatically private
• Especially hazardous are the static local variables. Since these are allocated on the heap, their address is the same in different threads
• Dynamic variables are mostly created on the heap , therefore shared in parallel program. However, when allocation happens from a parallel region these variables become private
• OpenMP syntax allows declaration of the status of each variable. However, in a call hierarchy the variables would assume their default status as specified above
Serial program Parallel program
Global variables Shared variables
Automatic variables Private variables
Static local variables Shared variables
Dynamic variables Shared or private variables

TM
Volatile VariablesVolatile Variables Volatile variables get special attention from the compiler• data that gets updated may be allocated in a register as part of
compiler optimization• a write to shared data in one thread may therefore not be visible
by another thread until the register is flushed to memory• this is mostly incorrect behaviour that can lead to a deadlock or
incorrect results • variables such that an update has to propagate immediately to
all threads have to be declared volatile• compiler performs no optimizations on volatile variables, nor on
the code around them, such that every write to volatile variable is flushed to memory
• there is a performance penalty associated with volatile variables• Syntax:
– Fortran VOLATILE var-list– C volatile “type” var-list

TM
Synchronization VariablesSynchronization Variables To be found in man sync(3F):
•call synchronize perform atomically k->j Operation and return the old or the new value:
•
OP stands for the functions:– add, sub, or, and, xor, nand;
i,j,k,l can be integer*4 or integer*8 variables
•
all these functions are guaranteed to be atomic and will be performed on globally visible arguments
i = fetch_and_OP(j,k) <- atomically i=j, j OP k
i = OP_and_fetch(j,k) <- atomically j OP k, i=j
l = compare_and_swap(j,k,i)<- (j==k)? j=i,l=1 : l=0
i = lock_test_and_set(j,k) <- atomically: i=j, j=k
call lock_release(i) <- atomically: i=0
Full memory barrier:memory references will not cross FMB

TM
Workload DistributionWorkload Distribution• Load imbalance is the condition when some processors do more
work then others. Load imbalance will lead to bad scalability.• Load imbalance can be diagnosed by profiling the programs and
comparing the execution times for code in different threads• In OpenMP, compiler accepts directives for work distribution:
– C$OMP DO SCHEDULE(type[,chunk]) where type is• STATIC iterations are divided into pieces at compile time (default)
• DYNAMIC iterations assigned to processors as they finish, dynamically. This requires synchronization after each chunk iterations.
• GUIDED pieces reduce exponentially in size with each dispatched piece
• RUNTIME schedule determined by an environment variable OMP_SCHEDULE With RUNTIME it is illegal to specify chunk.
• Compiler accepts -mp_schedtype=type switch
SCHEDULE(STATIC,6)26 iter on 4 processors
SCHEDULE(GUIDED,4)26 iter on 4 processors

TMExample: Example: Parallel Region in Parallel Region in FORTRANFORTRAN Compiler directives are enabled with the -mp switch or -apo switch. With -apo automatic parallelization is requested.
• In this example all loops can be made parallel automatically (-apo)
SUBROUTINE MXM(A,B,C,LM,M,N,N1) DIMENSION A(M,L), B(N1,M), C(N1,L)
DO 100 K=1,L DO 100 I=1,N C(I,K) = 0.0100 CONTINUE
C$OMP PARALLEL DO DO 110 K=1,L DO 110 I=1,N DO 110 J=1,M C(I,K) = C(I,K) + B(I,J)*A(J,K)110 CONTINUE END
Will be run serially, unless-apo is specified
Default variable type association rules:all variables shared (I.e. A,B,C are shared)Induction variables I,J,K will be found automatically and assigned private scope

TM
Parallelization Examples/3Parallelization Examples/3 Code with shared data
three solutions possible:• scratch array f should be declared local in the subroutine• f should be isolated in special common block /scratch/, which
– could be declared c$omp threadprivate(scratch), or– could be loaded with the flag -Wl,-Xlocal,scratch_
• f could be extended as f(*,”numthreads”)
Common //a(im,jm),b(im,jm),c(im,jm),d(im,jm),f(im)do j=1,jm call dowork(j)enddoend
subroutine dowork(j)Common //a(im,jm),b(im,jm),c(im,jm),d(im,jm),f(im)do I=1,im f(I) = (a(I,j) + b(I,j))*3.141592*j c(I,j) = f(I)**3enddoend
Making this loop parallel will lead toincorrect results, because all threadswill use same address for scratch array f

TM
False Sharing False Sharing Bad data or work distribution can lead to false sharing• example:
• processor P0 does only even iterations• processor P1 does only odd iterations• both processors read and write same cache lines• each write invalidates the cache line of the pear processor
• each processor runs cache coherency protocol on the cache lines, thus the cache lines will ping-pong from one cache to another
for(i=myid; i<n; i+= nthr) { a[i] = b[i] + c[i];}
a[0]
a[2]
a[4]
a[6]
a[8]
a[1]
a[3]
a[5]
a[7]
a[9]
Cache line
P0 P1a[1] is loaded,but not used
a[0] is loaded,but not used
Number of processors
Per
form
ance
1 2 ...
etc.,normal behaviour
False Sharing

TM
Scalability & Data DistributionScalability & Data Distribution The Scalability of parallel programs might be affected by:• Amdahl law for the parallel part of the code
– plot elapsed run times as function of number of processors• Load balancing and work distribution to the processors
– profiling the code will reveal significant run times for libmp library routines– compare perfex for event counter 21 (fp operations) for different threads
• False sharing of the data– perfex high value of cache invalidation events (event counter 31: store/prefetch
exclusive to shared block in scache)• Excessive synchronization costs
– perfex high value for store conditionals (event counter 4)
When cache misses account for only a small percentage of the run time, the program makes good use of the memory and its performance will not be affected by data placement
– diagnose significant memory load with perfex statistics: high value of memory traffic
Program scalability will be improved with data placement if there is:• memory contention on one node• excessive cache traffic

TM
Why Distribute?Why Distribute?
CC-NUMA architecture optimization. If:• all data initialized on one node
– memory bottle neck
• all shared data on one node– serialization of the CC
• data used from different node– large interconnect traffic– average net latency on SGI3800:
16 proc
L2 Cache
L2 Cache
R1*000
Mem/DirBedrock
ASIC
R1*000 R1*000
R1*000
L2 Cache
L2 Cache
L2 Cache
L2 Cache
R1*000
Mem/DirBedrock
ASIC
R1*000 R1*000
R1*000
L2 Cache
L2 Cache
L2 Cache
L2 Cache
R1*000
Mem/Dir BedrockASIC
R1*000 R1*000
R1*000
L2 Cache
L2 Cache
memory
Processor(s)~(1/2 log2(p/16)+1)50 ns

TM
SGI Additions to OpenMP SGI Additions to OpenMP
Data Distribution Extensions:
• IRIX dplace command• setenv _DSM_PLACEMENT (FIRST_TOUCH|ROUND_ROBIN)
• compiler directives:– !$sgi distribute a(*,BLOCK,CYCLIC(5))– !$sgi distribute_reshape a(*,BLOCK,…)

TM
Default Distribution: “First Touch”Default Distribution: “First Touch”
IRIX strategy for data placement: • respect program distribution directives
• allocation on the node where data is initialized
• allocation on the node where memory is available
PARAMETER (PAGESIZE=16384, SIZEDBLE=8)REAL, ALLOCATABLE:: WORK(:)!! Distribution directive not availableREAD *, MXALLOCATE(WORK(MX))
!$OMP PARALLEL DEFAULT(PRIVATE) SHARED(WORK,MX)ID = OMP_GET_THREAD_NUM()NP = OMP_GET_NUM_THREADS()
NPAGES = MX*SIZEDBLE/PAGESIZE
DO I=ID,NPAGES-NP+1,NP !! round-robin distribution of pages: WORK(1+I*PAGESIZE/SIZEDBLE) = 0.0ENDDO
!$OMP END PARALLEL
TM
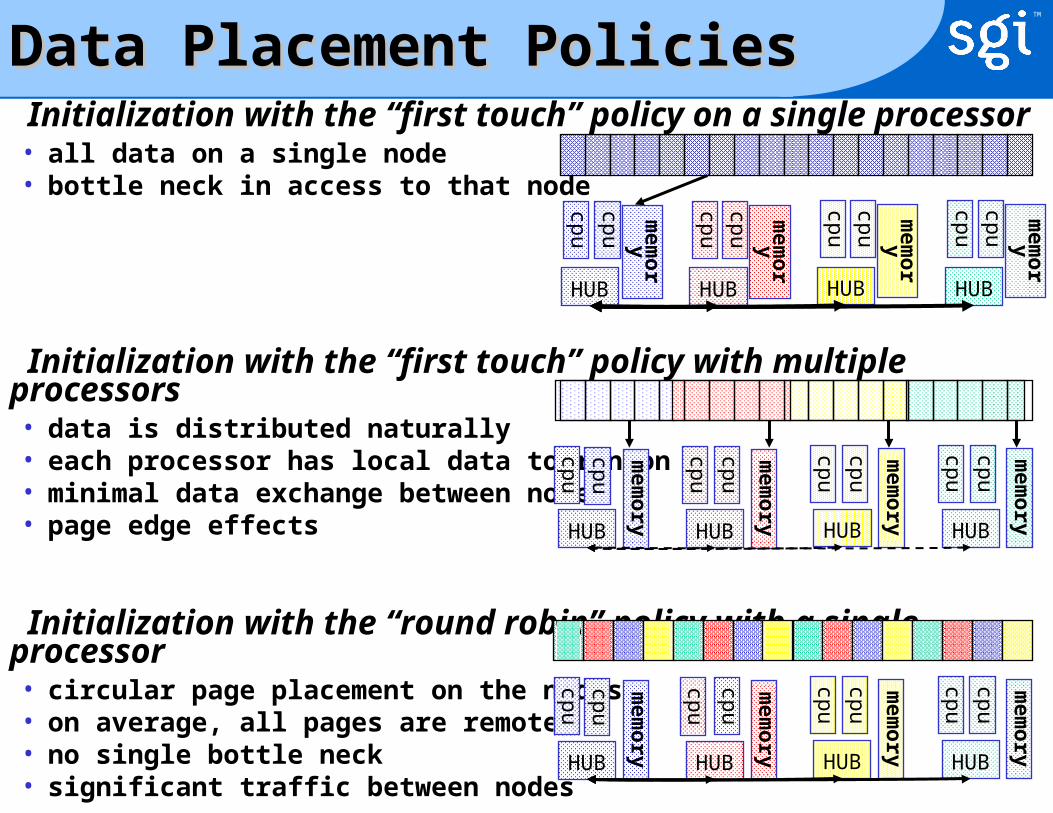
Data Placement Policies Data Placement Policies Initialization with the “first touch” policy on a single processor• all data on a single node• bottle neck in access to that node
Initialization with the “first touch” policy with multiple processors• data is distributed naturally• each processor has local data to run on• minimal data exchange between nodes• page edge effects
Initialization with the “round robin” policy with a single processor• circular page placement on the nodes• on average, all pages are remote• no single bottle neck• significant traffic between nodes
HUB
cpu
memor
y
cpu
HUBcpu
memor
y
cpu
HUB
cpu
memor
y
cpu
HUB
cpu
memor
y
cpu
HUB
cpu
memory
cpu
HUB
cpu
memory
cpu
HUB
cpu
memory
cpu
HUB
cpu
memory
cpu
HUB
cpu
memory
cpu
HUB
cpu
memory
cpu
HUB
cpu
memory
cpu
HUB
cpu
memory
cpu

TM
Example: Data DistributionExample: Data Distribution To avoid the bottle neck resulting from memory allocation on a single node:• Perform initialization in parallel, such that each processor initializes
data that it is likely to access later for calculation• Use explicit data placement compiler directives (e.g. C$ distribute )
• Enable environment variable for data placement (setenv _DSM_PLACEMENT)
• Use dplace command (with appropriate options) to start the program execution
REAL*8 A(N),B(N),C(N),D(N)C$DISTRIBUTE A(BLOCK),B(BLOCK),C(BLOCK),D(BLOCK)DO I=1,N A(I) = 0.0 B(I) = I/2 C(I) = I/3 D(I) = I/7ENDDOC$OMP PARALLEL DODO I=1,N A(I) = B(I) + C(I) + D(I)ENDDO

TM
Data Initialization: ExampleData Initialization: Example The F90 allocatable arrays should be initialized explicitly to place the pages:
PARAMETER (PAGESIZE=16384, SIZEDBLE=8)REAL, ALLOCATABLE:: WORK(:)
READ *, MXRVARALLOCATE(WORK(MXRVAR))
!$OMP PARALLEL DEFAULT(PRIVATE) SHARED(WORK,MXRVAR)ID = OMP_GET_THREAD_NUM()NP = OMP_GET_NUM_THREADS()NBLOCK = MXRVAR/NPNPAGES = MXRVAR*SIZEDBLE/PAGESIZENLOWER = ID*NBLOCKNUPPER = NLOWER + NBLOCKNLOWER = NLOWER + 1NUPPER = MIN(NUPPER,MXRVAR)
c round-robin distribution of pages:DO I=ID,NPAGES-NP+1,NP
WORK(1+I*PAGESIZE/SIZEDBLE) = 0.0ENDDO
!$OMP END PARALLEL

TM
Data Distribution DirectivesData Distribution Directives Compiler supports the following data distribution directives: !$SGI DISTRIBUTE A(shape[,shape]…) ONTO(n[,m]…)
#pragma distribute … – define regular distribution of an array with given shape– the shape can be
• BLOCK• CYCLIC(k)• * (default: do not distribute)
– the placement of the pages will not violate Fortran/C rules for data usage and therefore the exact shape is not guaranteed, in particular no padding at page boundary
!$SGI DISTRIBUTE_RESHAPE A(shape[,shape]…) ONTO(n[,m]…) #pragma distribute_reshape …
– define reshaped distribution of an array with given shape, i.e exact mapping of the data to the given shape. The shape parameters are as for the DISTRIBUTE directive
!$SGI DYNAMIC A #pragma dynamic … – permit dynamic redistribution of an array A
!$SGI REDISTRIBUTE A(shape[,shape]…) #pragma redistribute … – executable statement; forces redistribution of a (previously distributed) array A
!$SGI PAGE_PLACE A(…) #pragma page_place … – specify distribution by pages
!$SGI AFFINITY(i)=[DATA(A(I))|THREAD(I)] #pragma affinity … – the affinity clause specifies that iteration i should execute on the processor who’s
memory contains element A(i) or which runs THREAD i

TM
Data Distribution: Examples/1Data Distribution: Examples/1 Regular data distributions to 4 processors:
if the requested distribution incurs significant page boundary effects (example: (5)) - reshaping of array data is necessary
1) !$SGI DISTRIBUTE X(BLOCK)
2) X(CYCLIC) or X(CYCLIC(1))
X(CYCLIC(3))3)
Y(*,BLOCK)
Real*8 Y(1000,1000)c$sgi distribute Y(*,block)each individual portion is a contiguous piece of size 8*106/PI.e. for 4 processors it is 2 MB/piece
4)
Y(BLOCK,*)
Real*8 Y(1000,1000)c$sgi distribute Y(block,*)each individual portion is still of size 8*106/P, but each contiguous piece should be only 8*103/P,I.e. for 4 processors it is 2 KB (<16 KB page size)
5)
Y(BLOCK,BLOCK)6)

TM
Data Distributions: Examples/2Data Distributions: Examples/2 Regular data distributions on 6 processors; the ONTO clause changes the aspect ratio:
Regular data distribution can be re-distributed: C$SGI DISTRIBUTE A(BLOCK,BLOCK,BLOCK) ONTO (2,2,8) C$SGI DYNAMIC A … c - executable statement, can appear anywhere in the code: C$SGI REDISTRIBUTE A(BLOCK,BLOCK,BLOCK) ONTO (1,1,32)
Y(BLOCK,BLOCK)7)
8) Y(BLOCK,BLOCK) ONTO (2,3)
9) Y(BLOCK,BLOCK) ONTO (1,*)
Should be constant integer

TM
Data Reshaping Restrictions/1Data Reshaping Restrictions/1 The DISTRIBUTE_RESHAPE directive declares that the program makes no assumptions about the storage lay out of the array
Array reshaping is legal only under certain conditions :• an array can be declared with only one of these options
– default (no (re-)shaping)– distribute– distribute_reshape– it will keep the declared attribute for the duration of the program
• reshaped array cannot be re-distributed
• a reshaped array cannot be equivalenced to another array– explicitly through an equivalence statment– implicitly through multiple declarations of a common block
• if an array in a common block is reshaped, all declarations of that common block must:– contain an array at the same offset within the common block– declare that array with the same number of dimensions and same size– specify the same reshaped distribution for the array

TM
Data Reshaping Restrictions/2Data Reshaping Restrictions/2• when reshaped array is passed as an actual argument to a subroutine:
– if reshaped array is passed as a whole (I.e. call sub(A)), the formal parameter should match exactly the number of dimensions and their size
– if only elements of reshaped array are passed ( I.e. call sub(A(0)) or call sub(A(I)), the called procedure treats the incoming parameter as non-distributed
– for elements of reshaped array, the declared bounds on the formal parameter are required not to exceed the size of the distributed array portion passed in as actual argument. Example:
– compiler performs consistency check on the legality of the reshaping:• -MP:dsm=ON (default)• -MP:check_reshape={ON|OFF}(default OFF)generation of run-time consistency checks
• -MP:clone={ON|OFF}(default ON)automatically generate clones of procedures called with thereshaped parameters
Real*8 A(1000)c$ distribute_reshape A(cyclic(5)) do I=1,1000,5 call mysub(A(I)) enddo end
subroutine mysub(X) real*8 X(5)
… end

TM
Data Reshaping Restrictions/3Data Reshaping Restrictions/3 Consider also the following restrictions:
• BLOCK DATA (i.e. statically) initialized data cannot be reshaped
• alloca(3) or malloc(3) arrays cannot be reshaped
• F90: a dynamically sized automatic array can be distributed, but an F90 allocatable array is not
• cannot mix I/O for a reshaped array with namelist I/O of a function call in the same I/O statement
• a common block containing a reshaped array cannot be linked -Xlocal

TM
Data Distribution: AffinityData Distribution: Affinity usage of AFFINITY clause:• data form: thread form:
iterations are scheduled such that each processor does iterations over data that is placed in the memory near to that processor
REAL*8 A(N),B(N),Q!$SGI DISTRIBUTE A(BLOCK),B(BLOCK)C INITIALIZATION: DO I=1,N A(I) = 1 - I/2 B(I) = -10 + 0.01*(I*I) ENDDOC REAL WORK: DO IT=1,NITERS Q = 0.01*ITC$OMP PARALLEL DOC$SGI AFFINITY(I)=DATA(A(I)) DO I=1,N A(I) = A(I) + Q*B(I) ENDDO ENDDO
REAL*8 A(N),B(N),Q!$SGI DISTRIBUTE A(BLOCK),B(BLOCK)C INITIALIZATION: DO I=1,N A(I) = 1 - I/2 B(I) = -10 + 0.01*(I*I) ENDDOC REAL WORK: DO IT=1,NITERS Q = 0.01*ITC$OMP PARALLEL DOC$SGI AFFINITY(I)=thread(I/(N/P)) DO I=1,N A(I) = A(I) + Q*B(I) ENDDO ENDDO

TM
The The dplacedplace Program Program dplace - shell level tool for Data Placement:• declare number of threads to use• declare number of memories to use• specify the topology of the memories• specify the distribution of threads on to memories• specify the distribution of virtual addresses on to memories• specify text/data/stack page sizes• specify migration policy and threshold• dynamically migrate virtual address ranges between memories• dynamically move threads from one node to another
• see man dplace(1) Note: dplace switches off the _DSM_… environment variables
dplace [-place file] [-verbose][-mustrun][-data_pagesize size][-stack_pagesize size][-text_pagesize size][-migration threshold] program arguments

TM
dplacedplace: Placement File: Placement File The file must include:• the number of memories being used and their topology:
– memories M in topology [none|cube|cluster|physical near]
• number of threads
– threads N
• assignment of threads to memories:
– run thread n on memory m [using cpu k]– distribute threads [t0:t1:[:dt]] across memories
[m0:m1[:dm]] [block [m]] | [cyclic [k]]
• optional specifications for policy:
– policy stack|data|text pagesize N [k|K]– policy migration n [%]– mode verbose [on|off|toggle]
Example: memories ($OMP_NUM_THREADS+1)/2 in topology cubethreads $OMP_NUM_THREADSdistribute threads across memories

TM
Data Distribution: page_placeData Distribution: page_place Useful for irregular and dynamically allocated data structures: #pragma page_place (A, index-range, thread-id)
C$SGI PAGE_PLACE (A, index-range, thread-id)
Note: page_place is useful only for initial placement of the data, it has no effect if pages have been created already
Parameter (n=8*1024*1024)real*8 a(n)p=1
c$ p = omp_get_max_threads()
c- distribute using block mappingnpp=(n + p-1)/p ! Number of elements per processor
c$omp parallel do do I=0,p-1
c$sgi page_place (a(1+I*npp), npp*8, I)enddo

TM
Environment Variables: ProcessEnvironment Variables: Process OMP_NUM_THREADS (default max(8,#cpu))
• sets the number of threads to use during execution. If OMP_DYNAMIC is set to TRUE, this is the maximum number of threads
OMP_DYNAMIC TRUE|FALSE (default TRUE)
• enables or disables dynamic adjustment of parallel threads to load on the machine. The adjustment can take place at the start of each parallel region Setting OMP_DYNAMIC to FALSE will switch MPC_GANG ON
MPC_GANG ON|OFF (default OFF)• With gang scheduling all parallel threads are started simultaneously and
the time quantum is twice as long as normal. To obtain higher priority for parallel jobs it is often necessary to use:
setenv OMP_DYNAMIC FALSEsetenv OMP_DYNAMIC FALSE setenv MPC_GANG OFFsetenv MPC_GANG OFF _DSM_MUSTRUN (default not set)
• to lock threads to a cpu where it happened to be started
_DSM_PPM (default 2/4 processes per node)
• if _DSM_PPM is set to 1 only one process will be started on each node

TM
Environment Variables: ProcessEnvironment Variables: Process

TM
Environment Variables: ProcessEnvironment Variables: Process

TM
Environment Variables: SizeEnvironment Variables: Size MP_SLAVE_STACKSIZE (default 16 MB (4 MB >64 threads))
• stack size of the slave processes. The stack space is private, an adjustment of this size might be necessary if machine has constrains on memory
MP_STACK_OVERFLOW (default ON)
• stack size checking. Some programs overflow their allocated stack, while still functioning correctly. This variable has to be set OFF in that case.
PAGESIZE_STACK (default 16 KB)
PAGESIZE_DATA (default 16 KB)
PAGESIZE_TEXT (default 16 KB)
• specifies the page size for stack, data and text segments. Sizes can be specified in KBytes or Mbytes in power of 2: 64 KB, 256 KB, 1 MB, 4 MB. If the system does not have requested pages available, it might choose smaller page size silently.

TM
Environment Variables: DSMEnvironment Variables: DSM _DSM_PLACEMENT (default FIRST_TOUCH)
• memory allocation policy for stack, data and text segments. This variable can be set to the following values:– FIRST_TOUCH allocate pages close to the process which requested them– ROUND_ROBIN allocate pages alternating the nodes where processes run
_DSM_OFF (default not set)
• data placement directives will not be honoured if _DSM_OFF is set to ON. In particular, that is the mechanism that dplace program is using to force the specified data distribution in an executable. E.g.
dplace -place file myprogram• will set _DSM_OFF to ON and proceed with specifications in file.
_DSM_VERBOSE (default not set)
• when set, reports memory allocation decisions to stdout.
man pe_environ(5) page for other useful environment variables.

TM
Case Study: Maxwell CodeCase Study: Maxwell Code
• For scalar optimization, NX,NY,NZ have been adjusted to uneven values and arrays H,E have been padded to avoid cache trashing
• Now parallelization can be attempted to further increase performance on a parallel machine– automatic parallelization with the -apo compiler option– manual parallelization approach
• Study the performance implications of the different parallelization approaches
REAL EX(NX,NY,NZ),EY(NX,NY,NZ),EZ(NX,NY,NZ) !Electric fieldREAL HX(NX,NY,NZ),HY(NX,NY,NZ),HZ(NX,NY,NZ) !Magnetic field…DO K=2,NZ-1 DO J=2,NY-1 DO I=2,NX-1 HX(I,J,K)=HX(I,J,K)-(EZ(I,J,K)-EZ(I,J-1,K))*CHDY +(EY(I,J,K)-EY(I,J,K-1))*CHDZ HY(I,J,K)=HY(I,J,K)-(EX(I,J,K)-EX(I,J,K-1))*CHDZ +(EZ(I,J,K)-EZ(I-1,J,K))*CHDX HZ(I,J,K)=HZ(I,J,K)-(EY(I,J,K)-EY(I-1,J,K))*CHDX +(EX(I,J,K)-EX(I,J-1,K))*CHDYENDDO ENDDO ENDDO
here NX=NY=NZ = 32, 64, 128, 256 (i.e. with real*4 elements: 0.8MB, 6.3MB, 50MB, 403MB)

TM
The Maxwell program is automatically parallelized with: f77 -apo -O3 maxwell.f There are 3 parallel sections:
• Initialization
• Calculation of H
• Calculation of E
There are no data dependencies in each of the lops; The compiler divided k-loop iterations among N processors
Case Study: Maxwell Code Case Study: Maxwell Code Automatic ParallelizationAutomatic Parallelization
DO K=1,NZ DO J=1,NY DO I=1,NX
HX(I,J,K)=1E-3/(I+J+K) EX(I,J,K)=1E-3/(I+J+K)
….ENDDO ENDDO ENDDO
DO K=2,NZ-1 DO J=2,NY-1 DO I=2,NX-1 HX(I,J,K)=HX(I,J,K)-(EZ(I,J,K)-EZ(I,J-1,K))*CHDY +(EY(I,J,K)-EY(I,J,K-1))*CHDZ HY(I,J,K)=HY(I,J,K)-(EX(I,J,K)-EX(I,J,K-1))*CHDZ +(EZ(I,J,K)-EZ(I-1,J,K))*CHDX HZ(I,J,K)=HZ(I,J,K)-(EY(I,J,K)-EY(I-1,J,K))*CHDX +(EX(I,J,K)-EX(I,J-1,K))*CHDYENDDO ENDDO ENDDO
DO K=2,NZ-1 DO J=2,NY-1 DO I=2,NX-1 EX(I,J,K)=EX(I,J,K)-(HZ(I,J,K)-HZ(I,J-1,K))*CHDY +(HY(I,J,K)-HY(I,J,K-1))*CHDZ EY(I,J,K)=EY(I,J,K)-(HX(I,J,K)-HX(I,J,K-1))*CHDZ +(HZ(I,J,K)-HZ(I-1,J,K))*CHDX EZ(I,J,K)=EZ(I,J,K)-(HY(I,J,K)-HY(I-1,J,K))*CHDX +(HX(I,J,K)-HX(I,J-1,K))*CHDYENDDO ENDDO ENDDO
1
2
3
Iterations(for statistics)
TM
Scalability of Auto-ParallelizationScalability of Auto-Parallelization
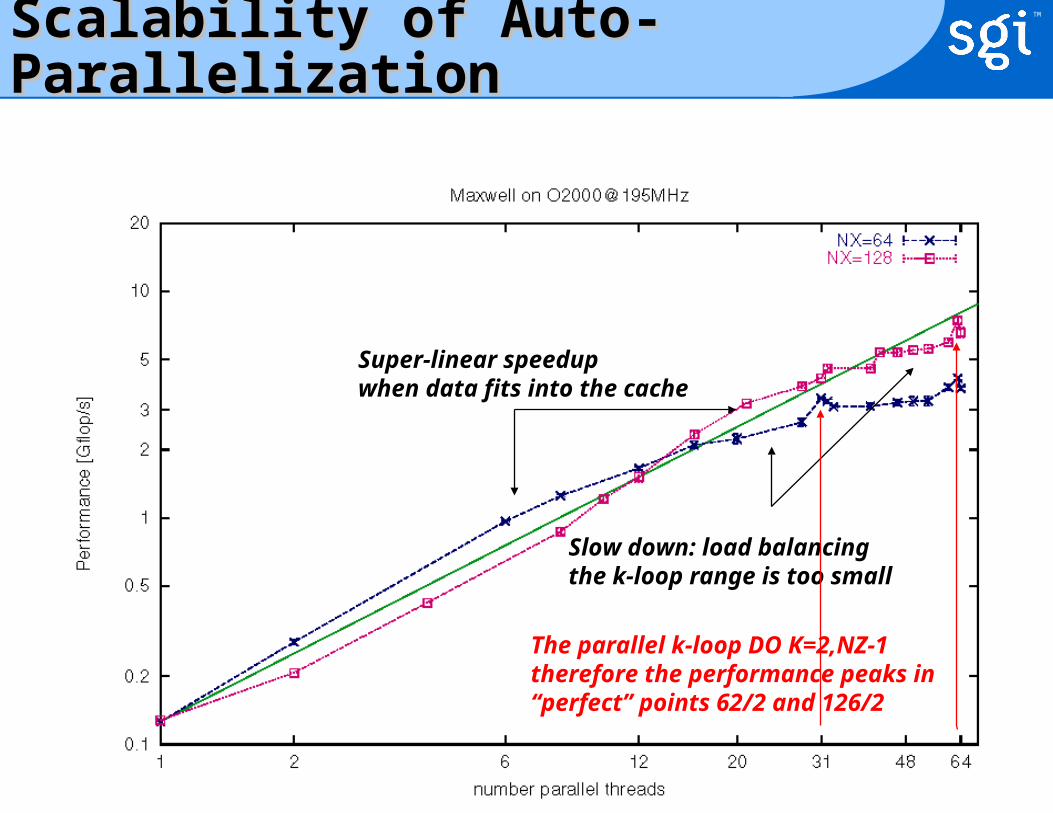
Slow down: load balancingthe k-loop range is too small
Super-linear speedupwhen data fits into the cache
The parallel k-loop DO K=2,NZ-1therefore the performance peaks in“perfect” points 62/2 and 126/2

TM
Case Study: Workload DistributionCase Study: Workload Distribution
Parallelization with directives c$omp parallel doc$sgi nest(k,j)in front of the properly nested loop nest

TM
Case Study: Data PlacementCase Study: Data Placement
Data traffic from/to a singlenode limits the scalability
Most datais in cache
Write backtraffic
Data distribution directive: c$distribute
Data placement with environment variable: setenv _DSM_PLACEMENT ROUND_ROBINThere is no single bottle neck, but most data is remote
since the default page placement strategy is the “first touch” strategy, all pages end up in a memory of a single node where the program starts.
Parallel initialization can be forced to be done serially with the directive c*$* assert do(serial)

TM
Parallel Thread CreationParallel Thread Creation There are several mechanisms to create a parallel processing stream:
• Library call:
• compiler level (compiler directives)
• automatic parallelization (-apo)
• At low level all shared memory parallelization pass from sproc call to create threads of control with global address space
sproc() (Shared Memory Fork)m_fork() (simpler sproc)pthread_create (Posix threads)start_pes (shmem init routine)
Fork() UNIX MPI_init() MPI start up
Shared address space Disjoint address space
C$doacross (SGI old syntax)c$par parallel (ANSI X3H5 spec)!$omp parallel (OpenMP specs)#pragma omp parallel

TM
Compile Time ActionsCompile Time Actions Each parallel region (either found automatically or via directive):• is converted into a subroutine call executed by each parallel thread
• The subroutine contains the execution body of the parallel region
• the arguments to the subroutine contain scheduling parameters (loop ranges)
• the new subroutine name:– derived from _mpdo_sub_#– will appear in the profile
• data in the parallel region:– private data:
• local (automatic) variables in the newly created subroutine
– shared data• will be passed well known address
to the new subroutine
Subroutine daxpy(n,a,x,y)real*8 a,x(n),y(n)do I=1,n y(I) = y(I)+a*x(I)enddoend
Subroutine daxpy(n,a,x,y)real*8 a,x(n),y(n)
integer*4 args_LOCAL_NTRIP = n/__mp_sug_numthreads_func$()_LOCAL_START = 1+__mp_my_thread_id()*_LOCAL_NTRIP_INCR = 1args(1) = _LOCAL_STARTargs(2) = _LOCAL_NTRIPargs(3) = _INCRargs(4) = 0call sproc$(_mpdo_daxpy_1,%VAL(PR_SALL),args)END
subroutine _mpdo_daxpy_1(_LOCAL_START, _LOCAL_NTRIP,_INCR,_INF)do I=_LOCAL_START,_LOCAL_NTRIP y(I) = y(I)+a*x(I)enddoend

TM
Run Time ActionsRun Time Actions
Master process (p0)
mp_setup()or
!$omp parallel
sproc()create shared memoryprocess group
Serial execution
p1
p2
pn-1
__mp_slave_wait_for_work()
barrier
!$omp parallel
p1 par_loop
p2 par_loop
pn-1 par_loop
p0 par_loop__mp_simple_sched(par_loop)
Serial execution
__mp_wait_for_completion()
__mp_barrier_nthreads()
__mp_barrier
_master()
When the parallel threads are spawn:• they spin in __mp_slave_wait_for_work()Master enters parallel region:•passes the address of the _mpdo subroutine to the slaves• at the end of parallel region all threads synchronize• slaves go back to spin in __mp_slave_wait_for_work()• master continues with serial execution

TM
Timing and Profiling MP ProgramTiming and Profiling MP Program• To obtain timing information for an MP program
– setenv OMP_NUM_THREADS n– time a.out– example:
n=1 time output: 9.678u 0.091s 0:09.86 98.9% 0+0k 0+1io 0pf+0wn=2 time output:10.363u 0.121s 0:05.72 183.2% 0+0k 3+8io 3pf+0wfrom this output we derive the following performance data:processors User+System Elapsed 1 9.77 9.86 2 10.48 5.72therefore the parallel overhead is 7.3%, the Speedup is 1.72
• use Speedshop to obtain profiling information for an MP program– setenv OMP_NUM_THREADS n– ssrun -exp pcsamp a.out– each thread will create a separate (binary) profiling file
• foreach file (a.out.pcsamp.*)• prof $file• end
S(2) = 9.86/5.727.3%

TM
Slave execution: 103 1s( 20.6) 1s( 20.6) divfree (./CWIROS:DIVFREE.f) 96 0.96s( 19.2) 2s( 39.7) ROWKAP (./CWIROS:KAPNEW.f) 67 0.67s( 13.4) 2.7s( 53.1) ITER (./CWIROS:CHEMIE.f) 40 0.4s( 8.0) 3.1s( 61.1) FLUXY (./CWIROS:KAPNEW.f) 35 0.35s( 7.0) 3.4s( 68.1) __expf ( .. fexp.c) 30 0.3s( 6.0) 3.7s( 74.1) __mp_barrier_nthreads (..libmp.so) 26 0.26s( 5.2) 4s( 79.2) FLUXX (./CWIROS:KAPNEW.f) 24 0.24s( 4.8) 4.2s( 84.0) KAPPA (./CWIROS:KAPNEW.f) 23 0.23s( 4.6) 4.4s( 88.6) __mp_slave_wait_for_work (.. libmp.s) 11 0.11s( 2.2) 4.5s( 90.8) TWOSTEP (./CWIROS:CHEMIE.f)
Master execution: 124 1.2s( 24.0) 1.2s( 24.0) divfree (./CWIROS:DIVFREE.f) 93 0.93s( 18.0) 2.2s( 42.1) ROWKAP (./CWIROS:KAPNEW.f) 76 0.76s( 14.7) 2.9s( 56.8) ITER (./CWIROS:CHEMIE.f) 36 0.36s( 7.0) 3.3s( 63.8) FLUXY (./CWIROS:KAPNEW.f) 27 0.27s( 5.2) 3.6s( 69.0) __expf (.. libm/fexp.c) 23 0.23s( 4.5) 3.8s( 73.4) FLUXX (./CWIROS:KAPNEW.f) 22 0.22s( 4.3) 4s( 77.7) KAPPA (./CWIROS:KAPNEW.f) 15 0.15s( 2.9) 4.2s( 80.6) __mp_barrier_master (.. libmp.so) 15 0.15s( 2.9) 4.3s( 83.5) diff (./CWIROS:DIFF.f) 9 0.09s( 1.7) 4.4s( 85.3) TWOSTEP (./CWIROS:CHEMIE.f)
• compare times (seconds) for each important subroutine to determine load balance• evaluate contribution of libmp: pure overhead
MP SpeedShop Example OutputMP SpeedShop Example Output

TM
Example Profile AnalysisExample Profile Analysis
func 0 1 funcT funcS scalar__mpdo_output_3 19.7 19.5 39.2 49.3 10.7__mpdo_output_2 3.5 3.4 6.9__mpdo_output_1 1.6 1.6 3.2 matrix 9.3 9.4 18.7 18.6…__mpdo_predic_3 4.7 4.7 9.5 28.2 26.8__mpdo_predic_2 4.6 4.6 9.2__mpdo_predic_1 4.7 4.8 9.5
Running: ssrun -fpcsampx pipe.xAnalyzing: prof pipe.x.fpcsampx.*
threads Serial timespar reg subr
False Sharing
OK

TM
SummarySummary• Auto-Parallelizing Compilers can do a lot, but they are limited
to loop level parallelism and in analysis of data dependencies
• Manual parallelization with directives is easy to implement, however care must be given to the treatment of data
• It is important to understand the exact semantics of the parallelization directives
• To obtain scalable performance it is often necessary to make program parallel at coarse-grain level, e.g. across subroutine invocations
• To obtain scalable performance it is often necessary to take care of proper data distribution on the machine
• It is necessary to profile parallel programs to diagnose cases of load imbalance and parallelization overhead.





























