Embed Size (px)
Citation preview

Abstract
EFFECTIVE OPTIMIZATION TECHNIQUES FOR A PARALLEL
FILE SYSTEM
by Raghvendran M
Significant work has been done in evolving parallel IO architectures, IO interfaces and other programming techniques. However, only a few mechanisms currently exist that bridge the gap between the IO architectures and the programming abstractions. A Parallel File System is the prime mechanism to deliver the high performance parallel IO on multiprocessor machines for a wide class of scientific and engineering applications.
With the evolution of commodity clusters (called High Performance Computation or HPC clusters) as a cost-effective computing platform for parallel computing, it is necessary to have an optimized and portable parallel file system to satisfy applications’ IO needs. The existing parallel IO mechanisms on such clusters, based on NFS, provide dismal IO performance due to architectural limitation in disallowing de-clustering of file data as well as due to the heavy weight nature of the protocol. Owing to mismatched semantics between the application IO characteristics and parallel IO architectural features, several other IO architectures based on shared or cluster file systems also perform badly in the cluster base parallel computing environment. The parallel file system represents an appropriate split in the semantics in the parallel application IO path, where parallel IO mechanisms and other optimization

techniques could be implemented at the IO platform level and exported through feature-rich platform-independent interfaces.
In spite of significant amount of research in parallel IO techniques, portable parallel file systems lack do not incorporate these findings and are not commonly used. Many of the optimization techniques for the parallel IO in the literature, such as prefetching, have not had any general-purpose implementations nor have been validated for a wide class of application workloads or access patterns. There are many issues (such as timeliness) that need investigation for prefetching to be effective. The incorporation of parallel IO optimization techniques in the commodity clusters setup has not been satisfactory.
We establish the parallel file system as the right abstraction for parallel IO on a commodity cluster from the performance and management perspectives. We also evaluate various optimization techniques for parallel file system on a commodity cluster with the objective of providing a fast scratch space on a real cluster-based supercomputer such as the C-DAC PARAM Padma (ranked 171st in July 2003 edition of TOP 500 [35] list).
We extend a data prefetching technique for the parallel file system architecture and demonstrate its effectiveness with a policy based feedback loop. Other optimization techniques for improving a parallel file system are investigated to improve its performance. This thesis makes contributions in the areas of analysis and design of these optimization techniques for a parallel file system, such as an online

predictive prefetching mechanism with adaptive policy control, an adaptive flow control mechanism for supporting collective calls from the architectural perspective and techniques for managing large data structure and efficient file processing in the file system design.
A parallel file system incorporating the above stated optimizations has been implemented on C-DAC's PARAM Padma, a one-teraflop 54-node cluster based parallel processing system. These optimizations show significant improvement for the targeted application IO workloads on this cluster.

TABLE OF CONTENTS
TABLE OF CONTENTS...............................................................................................I
LIST OF FIGURES.....................................................................................................III
LIST OF TABLES.......................................................................................................IV
ACKNOWLEDGMENTS.............................................................................................V
GLOSSARY.................................................................................................................VI
1. INTRODUCTION..................................................................................................1
1 PARALLEL APPLICATION IO CHARACTERISTICS.....................................................22 IO INTERFACES AND OTHER ABSTRACTIONS.........................................................33 EVOLUTION OF CLUSTER BASED PARALLEL IO ARCHITECTURES...........................4
3.1 NFS based Parallel IO architecture.............................................................43.2 Evolution of Parallel File System.................................................................5
4 PERFORMANCE OPTIMIZATION STRATEGIES FOR PARALLEL FILE SYSTEM.............64.1 Adaptive prefetching.....................................................................................64.2 Adaptive IO pipeline.....................................................................................74.3 Out of core computation...............................................................................74.4 Optimizations in the code design..................................................................7
5 CONTRIBUTIONS OF THE THESIS............................................................................86 THESIS ORGANIZATION.........................................................................................8
2. BACKGROUND AND RELATED WORK.......................................................10
1 QUALITATIVE ASSESSMENT OF PARALLEL IO ARCHITECTURES...........................102 PARALLEL FILE SYSTEMS....................................................................................163 APPLICATION IO WORKLOAD CHARACTERISTICS................................................174 OPTIMIZATIONS...................................................................................................17
4.1 Discussion on prefetching techniques.........................................................18
3. IO WORKLOAD AND ITS FITNESS TO PARALLEL FILE SYSTEM (PFS) ARCHITECTURE.......................................................................................................20
1 WORKLOAD CHARACTERISTICS...........................................................................202 GENERATING THE WORKLOAD............................................................................22
2.1 b_eff_io.......................................................................................................222.2 BTIO...........................................................................................................23

3 SUN PFS............................................................................................................234 SUN PFS SOFTWARE ARCHITECTURE.................................................................255 MEETING THE REQUIREMENTS BASED ON WORKLOAD CHARACTERISTICS..........266 SCOPE FOR IMPROVEMENT IN SUN PFS..............................................................27
4. C-DAC PFS: OPTIMIZATIONS........................................................................28
1 ADAPTIVE PREDICTIVE PREFETCHING..................................................................291.1 Prefetch mechanism...................................................................................30
2 ADAPTIVE COMMUNICATION BUFFER RESIZING...................................................352.1 The I/O time cost model..............................................................................36
3 OPTIMIZATIONS IN THE SUN PFS IMPLEMENTATION...........................................383.1 Design of large data structure....................................................................393.2 Unified buffering in the IO server...............................................................40
5. RESULTS.............................................................................................................42
1 TEST INFRASTRUCTURE......................................................................................422 RESULTS OF THE OPTIMIZATIONS........................................................................42
2.1 File System Characterization.....................................................................432.2 NFS experiment results...............................................................................442.3 Distributed-NFS experiment results...........................................................472.4 Prefetch mechanism and framework results...............................................482.5 Adaptive communication buffer optimization results..................................542.6 Design of large data structures – enhanced R-B trees – results..................562.7 Unified buffering in IO server results.........................................................57
3 INTEGRATED VERSION RESULTS..........................................................................57
6. CONCLUSION & FUTURE WORK.................................................................60
1 FUTURE WORK...................................................................................................60
REFERENCES.............................................................................................................62
ii

LIST OF FIGURES
FIGURE 1: THREE TIER ARCHITECTURE FOR STORAGE...................................................................10FIGURE 2: POTENTIAL PARALLELISM IN A HPC CLUSTER .............................................................11FIGURE 3: SUN PFS ARCHITECTURE..................................................................................................24FIGURE 4: SOFTWARE COMPONENTS OF SUN PFS.........................................................................24FIGURE 5: THE DATA LAYOUT OF A PFS FILE..................................................................................26FIGURE 6: C-DAC PFS ARCHITECTURE............................................................................................29FIGURE 7: PREFETCHING FRAMEWORK AND PREDICTOR. ARCHITECTURE SCHEMATIC............30FIGURE 8: LZ EXAMPLE........................................................................................................................32FIGURE 9: PPM EXAMPLE.....................................................................................................................33FIGURE 10: PREFETCH POLICY............................................................................................................35FIGURE 11: SYSTEM MODEL FOR COLLECTIVE IO...........................................................................36FIGURE 12: NODE OF THE MODIFIED RED-BLACK TREE.................................................................40FIGURE 13:INTERNAL STRUCTURE OF IO SERVER...........................................................................41FIGURE 14: COMPARISON OF NFS AND PFS FOR B_EFF_IO. READ/WRITE WORKLOADS FOR
TYPE 0 (75 % OF TARGETED WORKLOAD) SHOWN. FOR OTHERS, ONLY THE READ WORKLOAD IS SHOWN. PFS HAS 4 IO SERVERS...................................................................45
FIGURE 15: HIT RATE FOR B_EFF_IO IN PURE PREFETCH MODE..................................................49FIGURE 16: HIT RATE IN BTIO IN PURE PREFETCH MODE............................................................49FIGURE 17: HITRATE IN PARKBENCH (MATRIX 3D)IN PURE PREFETCH MODE..........................50FIGURE 18: PERFORMANCE READINGS OF B_EFF_IO ON PFS WITH PREFETCH MECHANISM.
AS WITH PREVIOUS READINGS, READ & WRITE WORKLOAD FOR ONLY TYPE 0 IS SHOWN. PFS HAS 2 IO SERVERS..............................................................................................52
FIGURE 19: IMPACT OF ADAPTIVE BUFFER OPTIMIZATION OF B_EFF_IO BENCHMARKS THAT HAVE COLLECTIVE IO CALLS.......................................................................................................55
FIGURE 20: IOTEST BENCHMARK TO SHOW IMPACT OF R-B TREE ORGANIZATION OF BLOCK TRANSLATION ENTRIES IN PFS...................................................................................................57
Figure 21: Performance figure of integrated C-DAC PFS and base PFS for b_eff_io.........................................................................................................................................59
iii

LIST OF TABLES
TABLE 1:DESIGN TRADEOFFS IN CLIENT FILE SYSTEM....................................................................14TABLE 2: BTIO RESULTS ON 16 NODES; PFS HAS 4 IO SERVERS............................................47TABLE 3: BTIO RESULTS ON 16 NODES; PFS CONFIGURATIONS WITH 4 IO SERVERS.........54Table 4:BTIO results on 32 nodes; PFS configurations with 4 IO servers...........55
iv

ACKNOWLEDGMENTS
Firstly, my heartfelt gratitude for my advisor Prof. K Gopinath, who through these years of association has made me a better person. His caring nature, enthusiasm and plentiful encouragement have made this thesis see the light of the day.
Handling work at office as well as the research has never been easy. I thank Mr. Mohan Ram, my supervisor at C-DAC and Mr. G. L. Ganga Prasad, my advisor at C-DAC, for providing the ‘space’ and the resources.
Much of the engineering gone into to make C-PFS work on large supercomputing system at C-DAC has been due to my ‘Storage’ teammates at C-DAC. Thanks to Rolland & Rashmi for the hard work and thoughtful discussions. Thanks to Viraj, Sundar and Bala for the unstinted support.
Lastly, my parents and in-laws have been pillars of support, putting up with my excuses for not finishing the thesis, with patience. I dedicate this thesis to my wife – Shyam.
v

GLOSSARY
Sequential A sequential request is the one that begins at a higher offset than the point where the previous request from that compute node ended.
Consecutive A consecutive request is a sequential request that precisely begins where the previous request ended.
Access interval Number of bytes between the end of one request and the beginning of the next.
Concurrent sharing. A file is concurrently shared if two or more processes have it opn at the same time. Depending on the mode of the open, it could be read-sharing or write sharing; when the modes are not same, it is said to be concurrently shared.
vi

C h a p t e r 1
1. INTRODUCTION
The evolution of various abstractions in parallel IO has been a result of tension between ease of programming and machine architecture efficiency. Many abstractions have evolved to exploit the progress in the machine architectures while some others provide more expressive programming models to organize data as per the application’s computing logic. These have been in the form of low-level IO interfaces such as HPF IO [1], Scalable IO Initiative Low-level API [2], MPI-IO [3] or Data libraries/models such as NetCDF [4], HDF5 [5], River [6] apart from techniques such as out-of-core computations and other data management tools. Various mechanisms and techniques have evolved that bridge the two requirements without much compromise in loss of program organization semantics and the underlying architectural efficiency. But the techniques requiring serious user intervention, such as adapting an application to a new API or paradigm, have not been much successful, as they typically require complex rework.
From the architecture perspective, the fundamental technique for providing high performance IO has been de-clustering of file data across multiple disks; this leads to complex data layouts and organization. Even on a particular physical organization of the disks, the parametric design space for providing high performance parallel IO is often so large that generally a compromise is made to efficiently

support only a few workloads of interest. So, to get performance, the application programmer is forced to tune the application access pattern to match the systems’ optimized workload pattern. Often the implementation of the IO software stack on such a setup is adhoc (being too tightly integrated with application etc), making it difficult to export the software feature and functionality at the general-purpose cluster platform level (e.g. multitasking, multi-user support).
As many of the interfaces and abstractions for parallel IO have evolved in the application domain, their implementations tend to be too tightly coupled with that application domain and may not efficiently support general application class workload access pattern.
We discuss the usefulness of the parallel file system in decoupling the parallel IO optimization techniques from the abstractions. We incorporate new optimization techniques to improve the PFS performance for common workload access patterns. The results of these optimizations have been experimentally verified with the representative scientific workload on the target platforms – C-DAC’s cluster-based PARAM machines [15] (latest being PARAM Padma, ranked 171st in July 2003 edition of TOP 500 list). The parallel file system with the optimizations has been deployed on these systems.
PARAM machines are cluster-based supercomputers having PARAMNET-II [16] as well as Gigabit Ethernet as the cluster interconnects. The communication substrate for these clusters is based on C-DAC’s user-level lightweight protocol implementation – KSHIPRA [33]. KSHIPRA provides MPI-2 [17] as the distributed programming abstraction.
2

1 Parallel application IO characteristicsApplication level characterization studies [7] indicate that though wide variability exists in the access patterns among the applications, they are typically ‘patterned’. They exhibit a certain structure and regularity in the access patterns – these are generated when the application threads use high-level IO interfaces. These interfaces commonly provide complex data abstractions such as multidimensional structures and arrays. Previous work in this parallel application IO workload analysis has leveraged the data access pattern information towards the design of the various parallel file system optimization techniques [8] as well as refinement of interfaces and abstractions [2] [3].
2 IO interfaces and other abstractionsMany optimization techniques require extra information from the application for its effective operation. Information on non-contiguous IO, collective IO, non-blocking IO and other hints could be used by the underlying system to improve the IO performance by matching the appropriate lower level system primitive to the IO request. Many such interfaces for parallel IO management, at various levels, have been proposed – HPF, SIO LLAPI, MPI-IO.
HPF IO is a set of extensions to Fortran through which application developers can provide hints to the compiler on the data distribution and loop parallelization. This interface supports data parallel applications by providing a notion of global data structures with facilities to perform data decomposition on them.
3

SIO (Scalable IO Initiative) provides a low-level API (LLAPI) with minimal features for parallelism. Targetted at IO subsystem developers, it provides primitives for various IO access patterns and consistency models. No major parallel IO software has been developed using SIO LLAPI.
MPI-IO has been the most popular interface in the distributed memory parallel machines for program development. Integration with MPI [17] has provided it with a rich set of abstractions such as groups, communicators, send/receive model that could be used in the IO programming also. Some of the useful features are – construction of non-contiguous structure types using ‘data types’, support for both independent and collective modes of operations, non-blocking and split-collective IO calls.
In all the above approaches, the ‘view’ or the application data layout of the file is not stored along with the data but computed during the execution, used and subsequently discarded. Hence, data access optimizations to the files cannot be performed by any other application or library, unless the application is running. High-level libraries evolved as the need for complex file structures was felt as compared to plain byte-sequential UNIX file model. Some of the high level libraries in use are NetCDF, HDF.
Data models represent the object-oriented approach to the data management. Non-trivial data model are typically tied to the application domains though the file metadata could be accessed and intrepreted. Data is accessed by a name (rather than a pathname), could be annotated and have a standard layout.
4

NetCDF provides annotated rectangular arrays of basic types and is widely used in atmospheric science applications. HDF5 gives a notion of ‘dataspace’ (dataset structure without a type) with an abstraction for groups, facilitating namespace management.
3 Evolution of cluster based parallel IO architecturesGiven the commodity nature of the cluster, the de-facto storage access mechanism in practice in such an environment is NFS.
3.1 NFS based Parallel IO architectureNFS provides stateless file sharing and hence needs protection mechanisms for correct operation during concurrent operations where certain consistency guarantees are needed. This is not provided by the standard NFS client.
The fundamental architectural problem with using standard NFS components, in delivering the parallel IO performance, is the lack of NFS’ ability to aggregate the distributed storage. Lack of control on caching & buffering as well as lack of scalable & integrated locking mechanisms in NFS coupled with a typical heavy weight implementation makes it inefficient to provide parallel IO. This is shown in subsequent sections. Performance-enhancing techniques [9] notwithstanding, the NFS based system continues to be network limited for parallel IO workload. Some work has been done using NFS protocol but it requires customized NFS clients to provide parallel IO [10] to avoid the network bandwidth limitation.
5

A commodity setup to provide logical de-clustering of files has been experimented for providing parallel IO with NFS. In this setup, called ‘distributed NFS’, multiple NFS servers on different nodes serve the same storage presented by a shared or a cluster file system such as SUN QFS, VERITAS CFS etc. It has been shown [34] that such commodity based solutions fail due to semantic mismatch between application expressed concurrency and the strong consistency provided by the shared file systems.
This brings out the motivation for exploring other mechanisms for providing parallel IO in commodity cluster environment.
3.2 Evolution of Parallel File SystemA parallel file system represents a system level abstraction that provides key benefits of the parallel IO techniques at the multiprocessor platform level, typically optimized for a class of workload. It provides structure for various smart algorithms as well as other techniques such as caching, buffering and prefetching to work together and provide performance for the targeted application workload. These techniques have been shown to be very effective in accelerating specific application workloads [11]. If these techniques are not adaptive with respect to the changing access patterns and architectural behavior, heavy performance penalty is incurred for non-conforming workloads. But a file system structure often provides opportunity for supporting various workloads by providing flexible mechanisms to change the file system behavior (e.g. Intel PFS [37]). A file system view can also leverage common storage management tools and practices for managing parallel IO storage space.
6

The PFS implementations, by design, distributes the data and aggregates the concurrent IO data paths to the distributed storage to provide higher bandwidth. The cluster based PFS implementations have typically been provided by the vendors but are non-portable. The commercial implementations are tightly integrated with other cluster components and deliver very high IO throughput to the scientific applications. But these implementations are proprietary and vertically integrated and hence are not portable across platforms. Given the trend of Beowulf-like clusters that are built out of commodity components, in particular for scientific computing, there is compelling need for portable parallel IO implementation mechanisms. Parallel Virtual File System (PVFS) [12], Sun PFS [13] etc implementations have been a step towards that direction.
4 Performance optimization strategies for parallel file systemBecause of the large design space, parallel file systems typically target a specific workload. This provides a lot of opportunity for optimizations to support different workloads.
The current work provides a parallel file system for C-DAC’s tera-scale supercomputer system (PARAM Padma system ranked 171st in July 2003 edition of TOP 500 list). Due to the time required and complexity of an ab initio project on a parallel file system, an open source parallel file system from Sun Microsystems has been used as a starting point. But the open source version had stability problems in terms of memory leaks and race conditions and hence was unusable as such. The effort in debugging this is significant as the parallel file system is part of a real operational system.
7

Many optimizations for the parallel file system have become possible both due to the characteristics of the targeted workload as well as opportunities for increasing the sophistication of the base code implementation.
4.1 Adaptive prefetchingPrefetching has been used in multitude of environments to tolerate the latency of data arrival – CPU-memory complexes, file and storage systems, applications etc. As indicated above, the IO access patterns in the parallel applications and in the targeted workloads in particular, though complex, tend to be structured and regular providing an opportunity for prefetching of data. Usefulness of this technique by discerning the application IO access pattern has been demonstrated to some extent in the PFS community [11] [14]. But the efficacy of this technique to actually tolerate disk latency (by eliminating disk accesses) has not been demonstrated in a production environment. Factors such as timeliness of the prefetch, provision of a feedback loop in the prefetching mechanism that significantly impact the performance in practice have not been studied in literature. We have developed a novel adaptive predictive prefetching technique based on text compression technique for this purpose.
4.2 Adaptive IO pipelineIn a cluster with distributed disks, it is also important to maintain an adaptive pipeline between the clients and the disks so that IO channels from the clients to the disks are efficiently utilized. This technique, similar to the memory interleaving in computer architectures, is effective in tolerating the disk latency particularly in
8

the ‘de-clustered file’ environment for certain ‘collective’ workloads. The current work demonstrates the performance improvement in parallel IO due to this mechanism.
4.3 Out of core computationThis is typically used when data size is larger than the main memory and the ‘paging’ or ‘staging’ is performed by the application itself depending on its computation locality. Since this is an application level technique, we do not consider this technique further.
4.4 Optimizations in the code designThese optimizations assume significance in a real system dealing with large data and metadata sets in a file system scenario. An inadequate attention to these aspects can hinder the benefits proffered by other architectural optimizations. These aspects have been handled inefficiently in the Sun PFS – the base PFS code.
4.4.1 Handling large data structures efficientlyIn a file system scenario, data structures storing block descriptions are typically large (>10000) in number and require frequent access. The data structure organization needs to optimally handle lookup, extent-building operations efficiently.
4.4.2 Buffer handling in the file systemIn the parallel file system environment, concurrent accesses to the same block (not necessarily the same byte range) could generate multiple IOs on the same block leading to multiple copies of the same block in the file-processing module wasting memory as well as
9

processing time. Consistency is generally not an issue as the IO issuers typically impose the IO order.
5 Contributions of the thesisThe contributions of the thesis are as follows:
Demonstrating the performance benefits of a user-level parallel file system1 as compared to traditional IO architectures for parallel IO, qualitatively and quantitatively.
Development of novel optimization techniques for cluster based parallel IO – adaptive online predictive prefetching and buffer control.
Newer designs for the handling of large data structures and the control flow for processing file/subfile requests in parallel file systems, in general.
6 Thesis organizationChapter 2 provides the background material and related work on the parallel IO architectures, application workload as well as PFS optimizations.
Chapter 3 discusses the targeted workload in detail.
1 The parallel file system is implemented as user level daemons with a VFS module to maintain binary compatibility with UNIX IO applications. IO, though the MPI-IO interface for high performance uses MPI for IPC, whose implementation on PARAM machines is provided by KSHIPRA, the user-level protocol suite comprising of user level implementations of Active Messages and Virtual Interface Architecture.
10

Chapter 4 provides the details about the base parallel file system (the Sun PFS) – its architecture and organization, data layout, high-level control flow of the processing of file/subfile requests.
Chapter 5 provides the details of new optimizations developed for the base PFS system. C-DAC PFS (C-PFS) is the base parallel file system enhanced with the optimizations.
Chapter 6 discusses the results of the base PFS, optimized PFS as well as the NFS based parallel IO architecture.
The thesis ends with discussion on future work.
11

C h a p t e r 2
2. BACKGROUND AND RELATED WORK
We now present a qualitative performance assessment of cluster based parallel IO architectures that provide MPI-2 messaging infrastructure (similar to PARAM machines).
1 Qualitative assessment of parallel IO architecturesThis section discusses the various software related factors that affect the performance in the storage architecture and the need to consider the performance aspects at every software layer while architecting
the storage solution.
Figure 1: Three tier architecture for storage
The architecture we consider for discussion is given in Figure 1.
Storage
Cluster compute or application nodes
Storage servers
LAN
SAN
12

The parallelism while performing a single-application IO is critical to HPC clusters while system throughput is important for a home directory workload. A production facility should support both the
workloads among many others to be useful. Figure 2 depicts the various software layers.
Figure 2: Potential parallelism in a HPC cluster
To achieve end-to-end parallelism in IO, all layers – from application to the storage boxes- must provide sufficient primitives to express concurrent IO operations. The same applies in the case of fault tolerance and load-balancing features too – that the issue needs to be addressed in all the layers. The description of Figure 2 is given below:
Application layer. The application needs to perform IO in parallel using a parallel IO interface, say a messaging cum IO layer such as
Application layer
MPI/UNIX messaging layer
Client File System
Storage server layer; NFS server or UFS server or shared file system IO through
various paths
13

MPI-IO interface or distributed application using UNIX-IO interface. We consider MPI as the messaging layer for further discussion.
MPI/UNIX layer. The MPI implementation such as MPICH [18] needs to translate application’s parallel IO expressed in the programming interface layer into underlying file systems’ parallel operations. There could be a loss in parallelism in this layer if the underlying file system does not provide sufficient correctness guarantees for concurrent operations. MPI needs to hold locks on the appropriate resources to ensure application correctness thus serializing some of the parallel accesses. Most conservative approach is to collect the IO into a single process and perform IO.
Various implementations of MPI provide different degrees of parallelism, some of them dictated by the features of the underlying file system.
MPI implementation serializes the IO by letting a master process (on one of the client nodes) collect the data and perform IO on the underlying client file system – say, NFS file system. So, only one client process performs IO on the underlying file system.
MPI implementation such as MPICH implementation with ROMIO [9] tries to retain the application expressed parallelism by using parallel IO techniques. ROMIO is optimized for performing parallel IO on NFS [19]. For a single application-level IO request consisting of widely distributed non-contiguous byte ranges, ROMIO lets multiple client nodes to perform IO in
14

large sequential chunks. The data is then exchanged between client nodes. There could incur some overhead as most of the data read could go unused in such scenarios.
MPI implementation that performs true parallel IO on a parallel file system e.g. IBM MPI implementation on IBM GPFS [20].
Client file system layer. The client file system provides the file system namespace and is the visible layer of the storage. The ‘directory-tree’ view of the file system is provided at this layer. In the cluster environment, the client file system provides a single file system namespace across all the clients, provides a ‘specified’ (could be UNIX-like, Andrew File System [21] -like session, causal, relaxed etc) consistency model integrated with locking and error model. In short, the behavior of the file system is provided by the client-access file system. The key deployment aspects of the client file system are performance & file system availability. The performance can be characterized into system throughput (ST) and single application performance (SAP). A key aspect of the system flexibility is the fraction of ST achieved by SAP. File system availability implies maintaining the file system view on the client nodes in the face of server failure(s)2. Client file system designs fundamentally differ in these terms:
2 Client node failure, per se, is not included in this scope because, as per the specification,
client file system should be available on all client nodes and restarting or migrating the application computation is the responsibility of cluster manager or the application itself. But the error model of the client file system would, however, govern the state of the file system data and metadata when the client node crashes.
15

Data layout of the file system metadata & data on the multiple servers (Block or file level stripping).
Method of access (Exclusive access of a data portion from a server or load balanced).
Visible storage portion on servers. If the entire storage portion is visible on all the servers, this could be used for fail-over method when a server fails. Depending on the design of client file system and the server overhead for maintaining the shared state, the ‘shared storage visibility’ could be used for adaptive load balancing the requests of client file system on the servers even when there are no server failures. This visibility could be achieved through a Storage Area Network (SAN) configuration or by replication methods.
The following table lists various tradeoffs in the client file system. These representative application classes are assumed – Meta Data Intensive (MDI) and Content Data Intensive (CDI). Both the applications contain multiple processes. MDI uses large amount of small files and mainly perform metadata operations – such as compilation job. CDI uses few large files and performs large amounts file IO.
Block level layout & access File level layout & access
16

Excl.
ser
ver c
ontro
l on
stor
age
porti
ons
* Blocks of a single file are striped across servers; all the servers serve accesses on single file. * Best layout and access for CDI-SAP and also CDI-ST.* Better for MDI-SAP and MDI-ST.
* Different servers serve different portions of the global file system tree or Single server serves all the files for a set of client nodes* Best layout and access for MDI-ST. For better results for MDI-SAP, IO configuration needs to be integrated with cluster manager.* For better results in CDI-ST, IO configuration needs to be integrated with cluster manager. Not good for CDI-SAP.
Shar
ed se
rver
co
ntro
l on
stor
age
porti
ons
* Same advantage as above in respective cases. * Shared server control could be used to provide storage availability by fail-over technique in respective cases. Mechanism of re-mapping storage portions to a different server needs to be done by the fail over mechanism and communicated to the cluster manager. If the shared control is used adaptively, not just for fail-over case, it could be used for load balancing of client workload on server layer. This adaptive mechanism will be the best for ST & SAP with CDI or MDI. It is made possible by the SAN shared storage.
Table 1:Design tradeoffs in client file system
In special cases, even a single node can saturate the IO bandwidth of server layer such as when a large compute server runs an IO intensive application and has trunked Gigabit Ethernet interface to LAN.
The various possible deployments are discussed next.
NFS as client access file system. This belongs to the ‘Exclusive server control on storage portions’ & ‘File level layout and access’ category. Either the global file system is grafted by mounting various NFS file systems (case 1) or a set of client nodes mount the entire file system from a single node (case 2).
o Case1: MDI ST performs better. SAP performs better provided files are distributed across all the servers;
17

Typically this setup is not backed by SAN and hence fail-over is not possible; SAP performance is bounded by single server performance.
o Case 2: Provided the client compute nodes are selected such that all the servers are ‘covered’, CDI-SAP is as good as CDI or MDI ST where multiple servers can serve the same file; The NFS server layer typically sits on cluster or shared file systems that provide the global file system view; This scenario arises, as the NFS protocol is IP based and there is no virtual IP. Hence a set of client nodes mounts from a server
PFS as the client access file system. This belongs to ‘Exclusive server control on storage portions’ & ‘block level layout and access’ category. Each file IO uses scatter-gather operations on the various servers to complete the IO operation. A server failure renders the whole file system inaccessible, unless another server takes over the portion served by the failed server.
Shared-control file system. The client file system does not mount from a single server. The storage is accessed as entire files or blocks. For the sake of management, certain portions of storage are accessed from a certain server. Since, storage can be accessed from any server, alternate servers could serve storage for load balancing or fail over.
18

Storage server layer: These servers provide the access to the storage. Depending on the configuration of the storage, they could export local disks or shared storage volumes. Storage servers could in turn stripe the data across the Host Bus Adapters (HBAs) to multiple storage boxes. Storage boxes could implement RAID or other forms of data organization for performance/redundancy mechanisms. Various configurations of the server layer are:
Each of the servers in the server layer exports its local file system. The clients construct the global view by mounting them appropriately. The visibility of the local file systems to other servers depends on the SAN configuration.
Storage server layer exports shared storage space as a cluster or shared or SAN file system. Such file systems typically extend the single node file system behavior semantics to provide UNIX semantics on the shared file system at the server layer. NFS servers run on the individual servers and export the shared file system to the client nodes. In other words, NFS runs as an application of the shared file system. But there is no coordination among the NFS servers to maintain consistency/coherency of data.
To summarize, while the parallel IO architectures provide for multiple data paths to aggregate bandwidth, the commodity components fail to integrate efficiently to provide the required benefit. So, a portable mechanism for PFS implementation with the following architectural characteristics is desired:
19

Provide distributed and concurrent data paths from multiple client nodes to the distributed storage space so that parallel IO can exploit the aggregate bandwidth and provide low latency.
Applications may not demand UNIX-like consistency. So, a framework that provides ‘flexible consistency’ policy through scalable serializing mechanisms– such as locking is needed, so that client nodes could attain a desirable consistency level.
2 Parallel file systemsThe key characteristic of parallel file system is its ability to handle concurrent access to and fine grain partitioning of large files. Concurrent access is provided as a feature by the means of shared file pointer for a set of processes. PFS is optimized for handling IO to large files and may not be optimized for meta-data intensive workloads.
Some of commercial PFSes are IBM GPFS [20], Intel PFS, SGI XFS. IBM GPFS is latest commercial incarnation of IBM Vesta parallel file system [22]. Vesta file system supports two-dimensional files and provides primitives to control the data layout, striping factor on an individual file basis. File views can be set on a per open basis which enables the file system to handle concurrency efficiently. Unlike Vesta, GPFS is a general-purpose file system with enterprise features - like reliability availability - and optimized for streaming applications. It provides a cache coherent, UNIX semantics file model on all the cluster nodes (including non disk attached nodes). Intel PFS manages concurrency and file pointers through six IO modes.
20

Each of the modes has a different set of file access semantics and performance characteristics. Structurally and semantics wise SGI XFS is similar to IBM GPFS.
Apart from Sun PFS, Parallel Virtual File System (PVFS) – an open source PFS implementation is available. But like Sun PFS it has minimal performance enhancing features. Additionally, PVFS has no kernel module (VFS) interface. Though this feature is not critical to the application performance, it is important from the system administration viewpoint as existing storage management software could be directly used.
3 Application IO workload characteristicsNieuwejaar [7] has studied the IO workload characteristics of scientific and engineering applications. The characterization was done by tracing the scientific application executions on different parallel processing machines in multiple production facilities for extended duration of time. For the current work, we use the workload from the above study as the general representative workload.
4 OptimizationsMuch of the work in parallel IO research concentrates on reducing disk accesses [19] by aggregating smaller IO accesses or optimizing collective calls. Two-phase IO suggested in [19] optimizes the collective IO by accessing all the data in extent bounded by first and the last byte range. This extent is contiguously partitioned among the
21

IO nodes that then perform IO on a single IO chunk. In the next phase, the data is exchanged between the nodes to get the appropriate data – data shuffling. This approach has limited effectiveness – may perform more IO than necessary for small and widely distributed data ranges; hence the benefit is highly workload dependent.
4.1 Discussion on prefetching techniquesPrefetching for the PFS, has been studied to some extent in the community [14] [11]. Kotz identifies a fixed set of common access patterns based on the workload study and uses predictive prefetching for future data access. However, this approach performs very badly for new access patterns and also not extensible or flexible to accommodate new access patterns.
The approach used by [11] for prefetching is pretty comprehensive. Hierarchical predictors at local (per thread) level and at global (application level) coordinate to classify the IO patterns. The local predictor follows the same model as [14] but uses an analytical model based on Artificial Neural Network (ANN) to perform the classification making the implementation easier; and so has same drawback as [14]. The global predictor uses dynamic probabilistic function to determine future accesses using Hidden Markov Model (HMM) [23] for prediction. While HMM based model can recognize and probabilistically classify new access patterns, both ANN and HMM need learning duration before they can be effective. In this approach, the predictor adaptively changes the underlying parallel file systems’ caching, consistency and prefetching policies based on
22

its internal state. Unlike prefetching of blocks, ‘predictor’ performs intelligent filesystem policy control. Hence, this requires explicit identification and classification of access patterns for controlling the file system policies. The drawback is new patterns that may require a different policy will be handled as that of the ‘probabilistically nearest’ access pattern as the access pattern classification is done apriori. Also, this approach requires comprehensive and deep support from the underlying file system that exposes the policy control mechanisms of file system structures.
However, none of the above approaches incorporate the feedback mechanism – either on the effectiveness of the predictor or the timeliness of the prefetch requests - that could have a negative impact in practice as prefetching is pure overhead when not useful.
Vitter [24] suggests a prefetching technique based on text compression methods. As the compression methods use dynamic probability text sequences to encode the text symbols, the intuition could be used to predict future sequences using the probability state. Kroeger [25] uses this technique effectively to prefetch files in a single node system.
We use the technique stated in [24] as it does provide probability states for new access patterns as they occur in the sequence and does not rely on explicit classification of the access patterns of interest. However, as in previous cases, we are not aware of any framework using this mechanism that incorporates a feedback loop.
23

C h a p t e r 3
3. IO WORKLOAD AND ITS FITNESS TO PARALLEL FILE SYSTEM (PFS) ARCHITECTURE
In the previous chapter, the performance impact of several IO architectural alternatives was explored. The workload ‘sweet spot’ of these various architectural alternatives have been identified and it is shown, in brief, that for the scientific and engineering workload, PFS architecture provides the best match to the targeted IO workload. In this chapter, we analyze the IO workload characteristics in detail and also show with an example Parallel File System – SUN PFS, to illustrate the ‘good’ design points of PFS from the workload perspective.
1 Workload characteristicsThe studies on IO characterization of parallel scientific and engineering applications have been far and few in between. Nevertheless, the studies have been comprehensive and capture the access patterns at the node as well as the application level. The studies analyze the application IO signatures – temporal and spatial access patterns, request sizes, and sequential and highly irregular access patterns. Since IO workload has deep performance implications for the IO architectures the workload characterization help develop more effective parallel file system policies.
24

Nieuwejaar [7] has identified common parallel application IO workload characteristics by tracing the production workloads over a variety of widely used platforms – iPSC/860, CM-5. This study has identified strong common trends in the workload characteristics that could be used as workload generalizations for parallel IO architecture design. Reed [38] traces three different applications on a particular parallel computing platform, at the individual file access level coupled with an analysis of source code and essentially reinforces the IO characterization conclusions in [7]. Since, the work at NCSA [38] has been published very recently, we assume the adaptive file system policies based on this IO characterizations to be very relevant.
The summary of common parallel application workload characteristics from the above studies is given below. The workload characteristics are also restated as a ‘design wish’.
Files between jobs are not shared. The application typically proceeds in pipelined functionally phased manner with files shared (no concurrent sharing) between phases. So, parallel IO architecture need not focus on meta-data intensive workloads such as web-server workload.
Rarely files are read-write. The IO operations on a particular file are mostly read-only or write-only. So, the read and the write data paths can be optimized separately.
Write traffic is higher than read. So, there will be a greater gain in optimizing write IO data path.
25

Write files are rarely concurrently shared but read files are mostly concurrently shared. So, expensive concurrency control mechanisms can be avoided for the same data region. It should be noted that files could be concurrently written rarely to the overlapping data regions.
Most of the request sizes are small (<4000 bytes) but most of the data is transferred through large requests. The IO architecture should optimize small IO access.
Within a phase, parallel reads occur in a structured manner repetitively over different portions of the file. Since, data regions are rarely re-accessed, caching technique will not provide performance. However, this structured access should be used to improve access performance.
Most of the IO happens in synchronous- sequential mode. So, the design can avoid keeping expensive data copies.
In C-DAC, the target application that has been available for evaluation is a seismic application whose access pattern characteristic – simple synchronous-sequential, is already captured above in the common workload characteristics.
The studies conclude that parallel file system designs that rely on a single, system-imposed file system policy is unlikely to be successful and the exploitation of the IO access pattern knowledge is crucial in obtaining a substantial fraction of the peak IO performance. The thesis presents some of the adaptive techniques based on the access pattern characteristics.
26

2 Generating the workload2.1 b_eff_iob_eff_io [26] is a parameterized test suite that can be used to simulate most of the parallel application IO patterns. Hence, we have used it for evaluating our parallel file system implementation as one target workload. b_eff_io measures the system performance of file accesses in “first write”, “rewrite”, and “read” modes. The access patterns generated are strided (with individual and shared file pointers) and segmented collective accesses to one shared file per application; as well as non-collective access to one file per process. The number of parallel processes accessing the files is also varied. To normalize the effects of the optimizations that are dependent on peculiar buffer alignments, the performance is measured both for ‘well-formed’ (in terms of the IO size being a power-of-two) as well as non-well formed buffers. But primarily, the accesses in this application are structured – not random – and hence mimic many typical workloads of scientific applications. These patterns are discussed in detail in the results section.
2.2 BTIOAnother application kernel used to evaluate the performance of the parallel IO architecture is BTIO [27], which is representative of the Computational Fluid Dynamics (CFD) applications on the PARAM machines. The file generated by BTIO is a write-only file. The write workload is patterned at two levels. A segment is appended at every time step, and with in a time step, the client-writes happen in strided and sequential fashion. From each of the clients’ perspective, the writes are sequential in a file segment before the writes start in the
27

next segment. The segments are arranged consecutively in the output file. The write intervals are fine grain, regular and the write request size is constant. There is no read sharing or write sharing at the byte-level but due to the fine grain nature of the workload, there could be block level sharing. The workload generated, in abstract, is structured write or allocate-write with no reuse of application data (except as false shared disk blocks). The definition of the terms in italic is given in the Glossary section.
The next chapter examines an example Parallel File System – SUN PFS and shows that the above application workload characteristics is best matched by the PFS architecture. The architecture of the Sun PFS and the MPI implementation on top of it is described in detail in [28]. However, even with PFS architecture providing best match from the performance perspective, many optimizations are still possible given the IO access pattern characteristics. The following section provides a background so that the optimizations could be subsequently described.
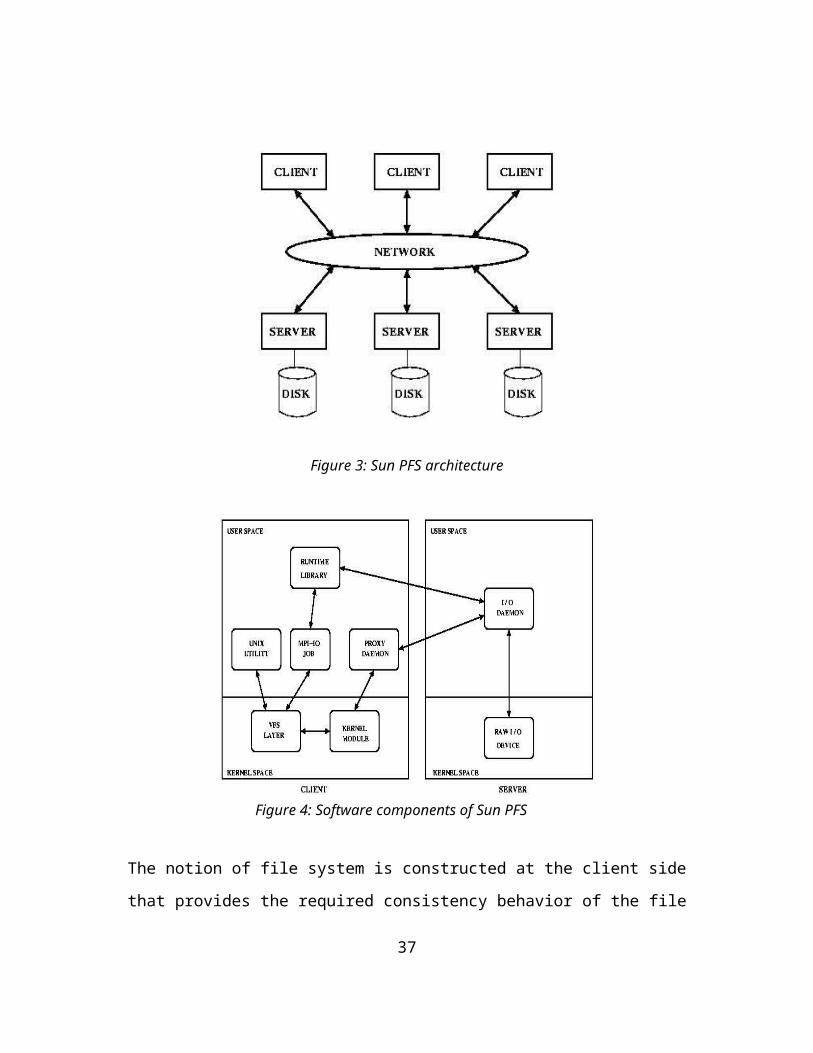
3 SUN PFSThe SUN PFS system follows the client-server paradigm with multiple file servers. The file data is striped on all the file servers with each file server managing the ‘striped’ data of the files on the locally attached disks. The clients access the data by issuing requests to the servers and reconstruct the file data. A file server can handle multiple disks belonging to multiple file systems. Simply put, an aggregation of disks (along with associated file servers) constitutes a PFS. This is depicted in the figure 3.
28

Figure 3: Sun PFS architecture
Figure 4: Software components of Sun PFS
The notion of file system is constructed at the client side that provides the required consistency behavior of the file system. The
29

servers simply provide access to the managed storage objects and maintain the locks on the storage objects (but does not enforce access control as in OBSD architecture [29]). The servers fully manage the data object as far as the allocation, creation, de-allocation and the destroy operations of the storage objects. The file system operations are implemented as communication operations between the clients and the file servers. The client-server model of Sun PFS does not involve any inter-client or inter-server communication, thus simplifying the state maintenance in the file system design. Both MPI-IO and UNIX interfaces are provided on the client nodes. UNIX interface is implemented through a VFS module. MPI-IO interface uses MPI implementation for communication. The inodes or the meta-data of the parallel file system is again maintained on the server in a distributed fashion. So, there is no requirement of a persistent store on the client nodes.
4 SUN PFS software architectureThe software components of Sun PFS is depicted in the Figure 4.
The runtime library provides the MPI-IO interface to the application program on the client node. The MPI-IO interface is implemented on the Sun PFS. The VFS layer provides the UNIX interface with binary compatibility. Both the interfaces share the file system namespace. To ease debugging, the interaction between the VFS component and the server or IO daemon is handled by a ‘proxy’ daemon. The IO daemon runs on the server node and provides the access to the locally attached storage. The file system and file metadata is accessed and manipulated only through the VFS interface; runtime
30

library is used to only accelerate the data access. IO daemon is a multi-threaded process that provides an OBSD-like interface that performs block and directory management. IO daemon provides minimal buffering capabilities.
The data layout of a PFS file is depicted in Figure 5.
Figure 5: The data layout of a PFS file
A logical PFS file is a collection of subfiles, with each subfile residing on an IO daemon configured in the cluster. The PFS file is de-clustered across the file servers and hence each chunk on the IO server can be independently accessed.
31

5 Meeting the requirements based on workload characteristics
Avoiding the meta-data cache in the client increases the cost of meta-data operations on the client but also avoids expensive concurrency mechanisms among the clients for the meta-data and hence provides a simpler data path from application to storage by avoiding the VFS layer during the normal IO access. De-clustering of data improves the IO operation performance as seen in Chapter 2.
The server-client protocol is synchronous as the workload is also mostly synchronous-sequential. The data caches are also avoided, as the data reuse is very minimal in the applications - data is read once, processed, new data is generated and written to a new file.
As seen, the SUN PFS provides the right architecture for the parallel IO but there is still a lot of scope improvement this in the next section.
6 Scope for improvement in Sun PFSWhile the Sun PFS provides the parallel IO architecture, the performance enhancement opportunities exist such as new techniques to hide disk latency as well as new designs to handle large data structures and processing of file/subfiles. New techniques could leverage on the applications’ ‘regular access pattern’ access characteristics to provide better performance. By learning on the IO patterns, data could be accessed in advance to hide the disk latency. One such technique investigated is predictive prefetching that uses effective predictive predictors to prefetch data. Also flow control
32

mechanisms ensure efficient parallel IO pipeline between clients and the storage. Apart from these techniques, module design level optimizations such as unified buffering in the IO server and large data structures’ design have also been investigated that are a manifestation of the code implementation but provide significant performance improvement for the overall parallel IO system.
We describe and analyze the above stated performance enhancements to the base SUN PFS along with the results in the subsequent chapters.
33

C h a p t e r 5
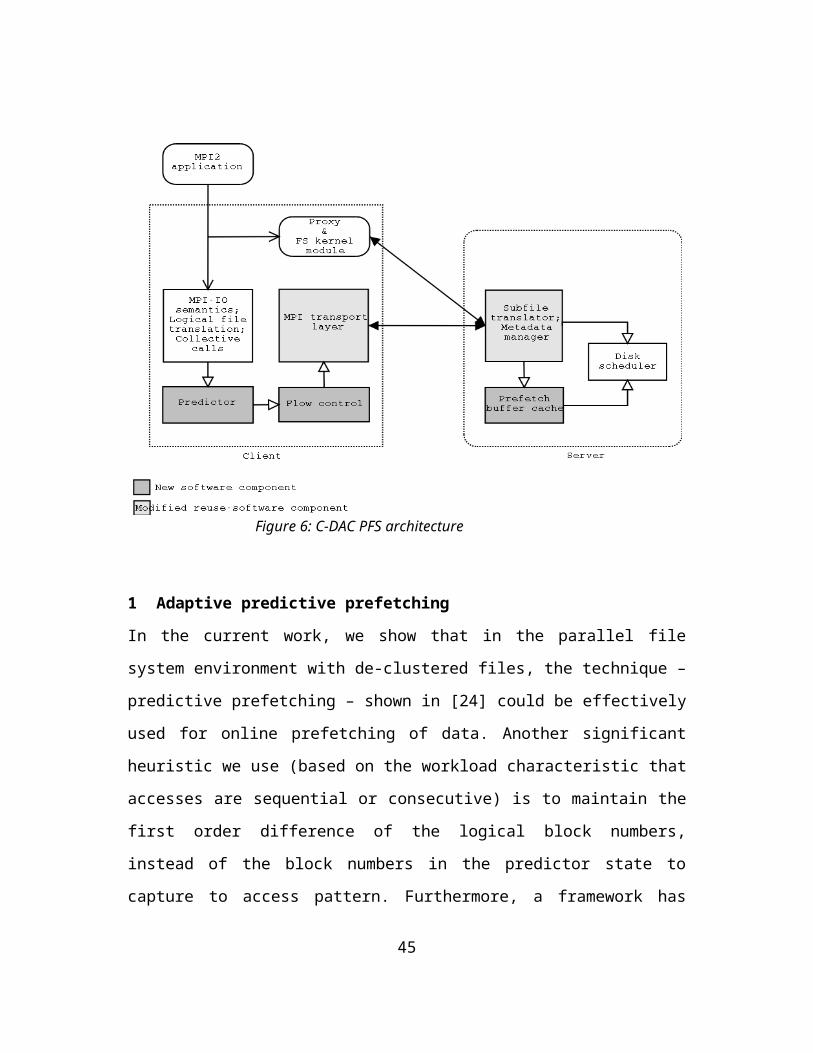
4. C-DAC PFS: OPTIMIZATIONS
C-PFS essentially retains the same architecture, file system layout and structure and access methods as the Sun PFS but has optimized parallel IO techniques. The focus of the parallel IO optimizations is:
A disk being the slowest component in the IO pipeline, minimize accesses to the disk wherever possible. Techniques could be buffering to merge accesses or caching whenever data is reused.
o As seen in the previous section, the targeted workload is either read-once or write-once-no-read type (except internally due to false sharing), caching technique may not help. Buffering may help reducing disk accesses provided locality information is available. Also, caching could be very complex in a distributed environment, hence it has not been considered for optimization.
Hide the disk latency to the computation. Possible techniques to implement this technique could be prefetching or asynchronous IO access – if applications appropriately use asynchronous MPI-IO calls.
34

o Prefetching could be beneficial in targeted workload due to structured access patterns. Support for asynchronous IO is provided in base Sun PFS.
Adaptive communication buffer resizing.
o An important consideration in a striped access system such as PFS during a collective MPI-IO call is to maintain a ‘distributed pipeline’ in such a way that network and disk bandwidths are efficiently utilized. This may involve adaptively packetizing the IO buffer.
The above techniques should use bounded memory resources and avoid copies and should be computationally efficient to avoid any overheads.
The modified software architecture of the Sun PFS after incorporating the above changes is shown in Figure 6.
35

Figure 6: C-DAC PFS architecture
1 Adaptive predictive prefetchingIn the current work, we show that in the parallel file system environment with de-clustered files, the technique – predictive prefetching – shown in [24] could be effectively used for online prefetching of data. Another significant heuristic we use (based on the workload characteristic that accesses are sequential or consecutive) is to maintain the first order difference of the logical block numbers, instead of the block numbers in the predictor state to capture to access pattern. Furthermore, a framework has been devised that provides feedback on the effectiveness of the predictors – determined both by goodness of prefetch algorithm and the relative arrival of prefetch requests with the data requests (that is IO pipeline
36

behavior). The number of blocks prefetched as well as the frequency of issue of prefetch requests is adaptively changed based on the feedback, so that it is most effective. The mechanism and the framework have been integrated with the Sun PFS architecture.
Figure 7: Prefetching framework and predictor. Architecture schematic
1.1 Prefetch mechanismThe predictors are local predictors and are part of each process of the parallel application as shown in Figure 7. Each of the predictors, hence, executes concurrently. Prefetch buffers are maintained in the IO servers and are maintained in LRU fashion.
The two predictors that we implement are based on the text compression techniques namely Limpel-Ziv (LZ) algorithm and Prediction by Partial Matching (PPM) [30]. The first order difference of the block numbers is used in the algorithm. Our experience shows that the first order difference suffices to identify an access pattern in most cases.
37
APIs for integrating new predictors have been provided so that user can specify different predictors without recompiling the application.
1.1.1 LZ predictorThe LZ method breaks the input string into substrings and builds a parse tree as it progresses through the string of block differences. Each path from the root to a leaf node represents a substring. When a new block arrives the difference between the last block number and the new block number is determined. It is then checked to see if the current node of the parse tree, which may be the root node in the case of a new substring or any other node if an existing substring is revisited, has a child with this difference. If yes then its count is incremented and it is made the current node. Otherwise a new node is added as a child of the current node in which case a new substring has been formed and hence the current node is set to the root again. If an existing substring is revisited then the visit counts of the nodes along that path are incremented. Predictions are made by following the most probable path from the current node. Adding the differences in the nodes along the most probable path to the current block number gets the predicted block numbers.
Figure 8 shows this using an example. Suppose we were to predict the next 4 blocks after 43. Since the current node is the root and the current block number is 43, the next four blocks after following the most probable path (root-> 1(5) -> 2(4) -> 1(2) -> 1(1)) would be 44, 46, 47, 48.
The nodes in the tree are proportional to the number of substrings. In such a case the tree may keep growing for a large file. It is therefore
38

necessary to put an upper bound on the number of nodes in the tree and update the tree by deleting the least probable paths.
Figure 8: LZ example
1.1.2 PPM predictorThe PPM technique is based on Finite Multi-Order Context Modeling where the models condition their predictions on few immediately preceding symbols that form the context. The length of the context is called the order.
The block differences are placed in a tree based data structure with a visit count associated with each node. The height of the tree is limited by the maximum order. A path from the root to a node represents a context that has been seen previously. An array of k pointers indicates the nodes at the contexts from 0 to k-1 at 0 to k-1 levels in the tree. When a new block arrives, the difference between
39

the last block number and the new block number is determined. Then the children of each of the current contexts, C(i) where i = 0 to k-1, are checked to see if they have this difference. If such a child exists then this sequence has occurred before, so the context C(i+1) is set to point to this child and its count is incremented. Otherwise this sequence has occurred for the first time and so a child denoting this difference is created and the context C(i+1) is set to point to the new node. All the contexts are updated in this manner for every new block. Predictions are made either by taking the most probable path of all the contexts or the most probable path at the highest context.
Figure 9 shows how PPM algorithm works using an example. The tree grows in breadth while the height remains constant. The tree should be updated regularly to keep the number of nodes below a certain threshold limit by removing the less probable subtrees at the root node.
40
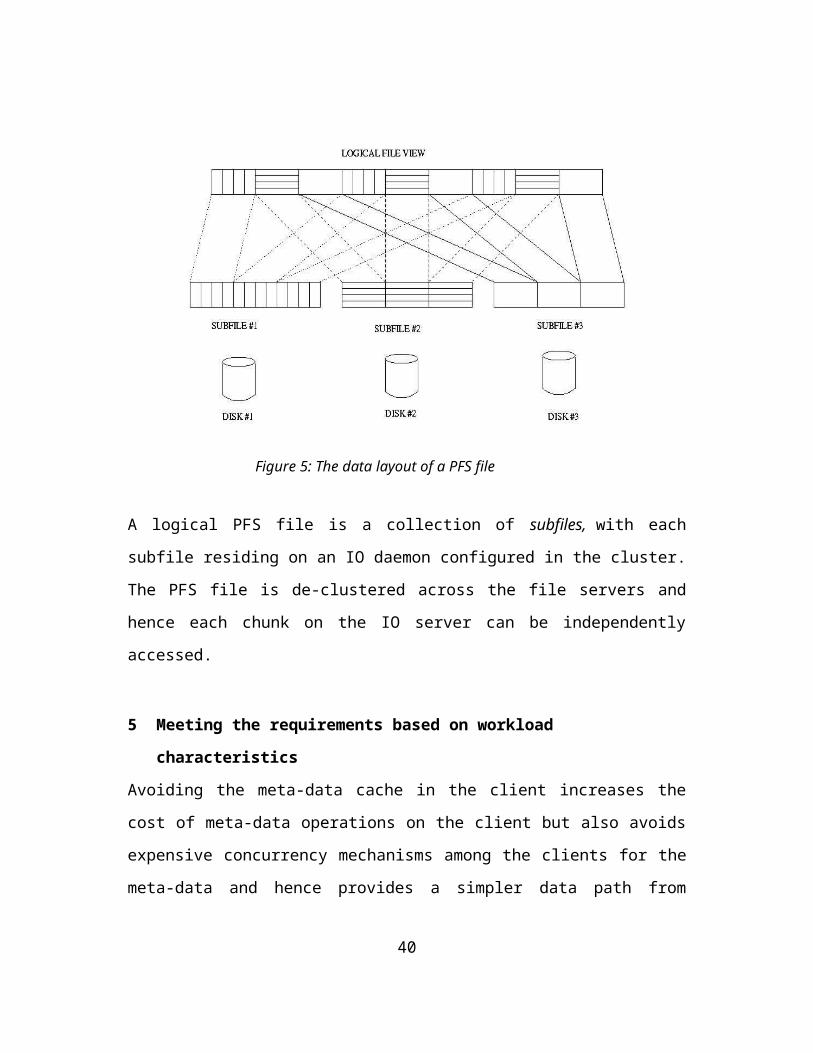
Figure 9: PPM example
1.1.3 Prefetch mechanism integration with Sun PFSThe predictor is part of client process runtime library that issues prefetch commands and prefetch buffers are maintained in the IO servers to avoid consistency problems. As the files are de-clustered, if the predictor is in the IO server, it would be difficult to ascertain the application access pattern, as it would get only the translated portion of logical file access pattern. One more advantage of predictor being in runtime library is that the application can plug in its own predictor in the framework. Prefetch block sequence is obtained before translation to IO server is done and prefetch request is issued to each of the IO servers after translating the logical block numbers. Prefetch buffers interpose between user requests and the disk on the IO server and are maintained in LRU order.
1.1.4 Prefetch frameworkThis framework controls the behavior of the prefetch request processing on the IO server. The framework ascertains the efficacy of the predictor algorithm, and even if so, whether prefetch request is processed in time to satisfy the subsequent data request(s). The feedback is sent to the prefetch command issuer (usually the client).
The prefetch request fetches a window of blocks that satisfy more than one subsequent data requests. The terms we use are: the prefetch window, which is the set of blocks that are prefetched to benefit the next few data requests, and the time window, which is the gap between two subsequent prefetch requests measured in terms of the number of intermediate data requests. The values of these two
41

windows may vary across the application. We adopt a heuristic approach.
We start with some predefined prefetch window on the client side. A prefetch request may be followed by many data requests but we do not know how many data requests the blocks of a particular prefetch request may cover. So we set the time between two prefetch requests to some heuristic value, say the next prefetch request is sent after 'n' data requests. The prefetch window and time window sizes are adjusted depending on the following factors on the server side.
o Prefetch Window Fully/Partially Satisfied (WFS/WPS).
o High/Low Hit Rate (HHR/LHR).
WFS means that the next prefetch request arrives only after the previous one is completed. WPS means that the next prefetch request arrives too early. This may occur because the previous predictors were not very accurate and so some data requests too had to be scheduled along with the prefetch requests thereby requiring the prefetch requests to take a longer time for completion. Figure 10 explains policy decision tree incorporated in prefetch framework to tune the prefetch issuer behavior. The hit rate is measured as usage of the prefetch buffers requested between two prefetch requests by data requests.
42

Figure 10: Prefetch policy
2 Adaptive communication buffer resizingIn PFS, the clients access data across the network through the IO servers. IO servers maintain staging buffers for these accesses. These buffers are populated by the disk and consumed by the network for read requests and vice-versa for write requests. It is observed that if there is a mismatch between network and disk bandwidths, either the network or the disk will idle waiting for the other sub-system to finish using the buffer. The idling period depends on the size of the staging buffer as well as the relative speeds of network and disk. Disk and network processing can be pipelined by
43

choosing a disk buffer size that matches the relative disk and network bandwidths and the amount of data requested by the various clients.
We model this situation and arrive at the packetization strategy. Figure 11 depicts the model for the collective IO.
Figure 11: System model for collective IO
2.1 The I/O time cost modelLet us assume that we have parallel file system with m servers, and there are n clients which are part of an application trying to access a common size of data such that at each server d bytes of data to be accessed from disk (assuming that single disk is configured) and to be transferred to n clients.
So at each server, time spent T , for the entire IO is
44

T = d bytes access from disk + d/n data transfer to n clients
T = d/d_bw + Od + ((d/n)/n_bw + On) * n
where,
d_bw - disk bandwidth
Od - disk latency (seek time + access time)
n_bw - network bandwidth
On - network latency (round trip)
Now if we split the data d at each server into k parts such that the disk and network access can be pipelined,
T = d/(k*d_bw) + Od // first disk access
+ (k-1 ) *max ((Od + (d/(k*d_bw))), (d/(k * n_bw))+On*n)
// pipelined access
+ ((d/(k*n_bw)) + On*n) // last network access
if network limited(d_bw > n_bw)
(Differentiating to find max value of k),
k=sqrt(d/(n*On*d_bw))
otherwise
k=sqrt(d/(Od*n_bw))
2.1.1 Scenario with m IO serversAs the parallel file system has multiple I/O servers, the correct I/O time cost model can be built only when we consider all the servers, that is an application I/O is complete when it receives the requested data from all the I/O servers as the data is distributed equally among all the I/O servers in round robin manner. So in any access the I/O
45
cost is the sum of d bytes disk access at each server (assuming that the n clients access result in d bytes at each server) and accessing the respective parts (d/n) at client from all the servers.
T = d/d_bw + Od + ((d/n)/n_bw + On) * m
Now if we split the d bytes into k parts such that disk and network operation can be pipelined,
T = (d/(k*d_bw)+Od) // first disk access
+(k-1 )* max ((d/(k*d_bw)+Od),((d*m)/(n*k*n_bw)+On*m))
// pipelined access
+((d*m)/(n*k*n_bw)+On*m) // last network access
if network limited(d_bw > n_bw*(n/m)
(Differentiating to find the max value of k),
k=sqrt(d/(m*d_bw*On))
otherwise
k=sqrt((d*m)/(n*n_bw*Od))
So, based on the relative speeds of the disk and network and number of participants in a collective IO operation, the individual messages from the clients will be packetized to maintain the IO pipeline.
3 Optimizations in the Sun PFS implementationThe above optimizations focused have been motivated by the parallel file system architecture. As mentioned earlier, in practice, there are many factors that affect the performance of the PFS. We focus next
46

on following optimizations that are based on the implementation of Sun PFS.
Design of large data structures.
o Scientific applications typically tend to operate on large files. The metadata information needs to be kept on highly efficient data structures.
Unified buffering in IO server.
3.1 Design of large data structureThe block list mentioned in Figure 13, in the IO server, maintains the logical to physical translation block numbers. For a large file, this data structure could contain large number of entries with each entry maintaining the translation for the logical block. The operations on this data structure are: insert translation, extent build, change translation, and purge translation. In the original implementation, purge translation was not implemented and also the block list was implemented as a linear list.
A pluggable framework has been implemented where the other modules in the IO server, accesses block list through abstract data structure operations. For the ease of implementation while retaining performance benefit, principle of red-black trees [31] as opposed to B-trees, AVL trees etc is used to implement the block list. A modified version of R-B trees is used –
Each node in the R-B tree is a fixed size bucket containing the block translations. An upper and lower bound (of logical block
47

numbers) describe the bucket, which are dynamic. All the logical block translations of the blocks between the bounds, whose translation exist and are required, are maintained in this bucket in sorted order. Figure 12 depicts a node of this tree.
For efficient linear search, each bucket node will have at least half the entries filled.
A depth first search of this data structure will be used for the extent building.
Figure 12: Node of the modified red-black tree
48

3.2 Unified buffering in the IO serverThe IO server does not attempt to perform concurrency control on the storage it manages. Since, the clients perform locking at byte range level, mutually exclusive ranges could fall in same block. The IO accesses on the byte ranges, in the current design, will be performed as multiple separate read-modify-write requests as well as could be present in two different staging buffers in the IO server. The internal design has been changed so that a unified buffer is maintained with the accesses as an attached list.
The various lists as shown in Figure 13 – data requests, disk requests, ready buffers - could have copies of the same block as per the original design. The modified version has at most single buffer copy for each data block managed by the IO server.
Figure 13:Internal structure of IO server
49

C h a p t e r 6
5. RESULTS
1 Test InfrastructureThe C-PFS has been developed and tested on these platforms.
PARAM Padma: Cluster of 40 nodes of IBM POWER4 1.0 GHz 4-way SMP machines interconnected by Gigabit Ethernet – with 8 being IO nodes with locally attached disk; disk attachment is across Ultra SCSI rated at 80 MBps.
PARAM 10000: Cluster of 20 nodes of Sun UltraSPARC-II 300 MHz 4-way SMP machines interconnected by Fast Ethernet – with 4 being IO nodes with locally attached disk; disk attachment is across Ultra SCSI rated at 40 MBps.
The tests are conducted on smaller clusters also. Generally, in the test configuration, the client nodes to IO server ratio is maintained at 4:1, unless specified otherwise. The file system block size is 32 Kbytes.
For the NFS configuration, the NFS server is one of the cluster nodes specified above.
The test applications are b_eff_io and BTIO. B_eff_io is synthetic benchmark where ‘problem’ size increases with the increasing
50

number of processes while BTIO has constant problem size with increasing number of processes.
2 Results of the optimizationsIn this section the results of the optimizations done are discussed. We primarily use b_eff_io and BTIO for benchmarking.
2.1 File System CharacterizationAs mentioned earlier, we will characterize the file system against the commonly used access patterns in parallel applications. B_eff_io benchmark will be used to generate the workload. We first co-relate the b_eff_io access patterns with target workload as mentioned in [7]. The benchmark generates accesses for first write, rewrite and read modes for varying buffer sizes. The patterns are:
Type 0 - strided collective access, scattering large chunks in memory to/from disk.
o Synchronous–sequential mode of access with equal amount of data from the nodes. There is no byte-sharing. Operations from the nodes could execute in any order.
Type1 - strided collective access, but one read or write call per disk chunk.
o Same as 0. But operation execution needs to be in order.
o Type 0 and 1 constitute 78% of access in scientific workload.
51

Type2 - noncollective access to one file per MPI process, i.e., to separate files.
o Local-independent mode of access.
o Type 2 constitutes 0.88 % of access in scientific workload.
Type 3 - same as (2), but the individual files are assembled to one segmented file.
o Global independent mode of access. Each node accesses a different segment in the concurrently shared file.
Type 4 - same as (3), but the access to the segmented file is done collectively.
o Same as 3. But the accesses are collective – in-step among all the nodes.
o Type 3 & 4 constitute 11.9 % of access in scientific workload.
These access types characterize the file system ability to handle multiple exclusive streams of data access.
2.1.1 B_eff_io execution characteristicsB_eff_io is a timed benchmark. Roughly, the benchmark spends equal amount of time on each type of access (0, 1, 2, 3, 4 etc). Within a type, the IO operation is repeated till the time elapses. In general,
52

about 60 % of the traffic is generated by type 0 alone, and rest of the traffic generated is equally divided among the other types.
2.2 NFS experiment resultsWe compare the results of the NFS based parallel IO setup with that of PFS.
The b_eff_io is run on an 8-node client setup of PARAM Padma. For PFS, we use a 4-node IO server setup and a single node serves NFS.
Figure continued on the next page
53

Figure 14: Comparison of NFS and PFS for b_eff_io. Read/Write workloads for type 0 (75 % of targeted workload) shown. For others, only the read workload is shown. PFS has 4 IO servers
The figure 14 depicts the performance comparison between PFS and NFS for b_eff_io. Read and write behavior is shown for type 0. As the behavior between the reads and writes is roughly the same on the other types, only the read graphs are produced for the other types.
54

NFS behavior: For all the types, NFS shows the same behavior – there is a ‘plateau’ effect beyond 1 MB and no scaling with respect to the request size. Also, the performance does not degrade for non-well formed request sizes. This means the bottleneck could fundamentally be in the NFS architecture than the NFS protocol. Possible NFS architectural change could be de-clustering of files to give better performance. NFS shows negative scaling when the number of client processes are increased.
PFS behavior: PFS shows good scaling with the increasing request size. However, for types – 1, 2 and 3, there is negative scaling when the number of client processes is increased. Performance slightly comes down for non well-formed request sizes. For type 0, the performance and scalability for both read and write is very good showing the architectural benefits of PFS.
Analysis: PFS performs better than NFS for all the types and shows scalability both with respect to request size as well as number of processes, in both read and write modes, except in three types (that constitute nearly 20 % of the workload seen in a typical scientific application workload [7]). Type 1 requires writes from the processes to happen in specific order. PFS graphs show that this ordering mechanism is not scalable. Type 2 is local independent workload; the performance figures for type 2 indicate that handling multiple files is not scalable in PFS. This is as per design as PFS is optimized for large file access. Type 3 performs uncoordinated segmented file access from multiple processes. The negative scalability with the number of processes in type 3 is – PFS does not perform buffering at the IO server level; the uncoordinated accesses from different
55

processes, though to a file, fall in different file regions. So, multiple small IO requests result in decreased scalability as the number of processes grows resulting in increase in the number of file segments.
For types other than 0, the performance is poor initially for both NFS and PFS as data is written in single small chunks and also PFS is optimized for large access. As PFS is optimized for handling large requests, it performs poorly for small requests
Table 2: BTIO results on 16 nodes; PFS has 4 IO servers
BTIO has even more fine grain access pattern and can be seen to incur heavy penalty with NFS kind of architecture as can be seen in Table 2.
On the whole, the PFS performs better than NFS on all types. As per the targeted workload (more than 80 % of the workload types) – type 0, type 3 & type 4 – PFS performs far better than NFS.
2.3 Distributed-NFS experiment resultsAs can be seen, the parallel IO architecture based on NFS architecture performs very poorly for scientific workload, we experimented with a commodity (based on NFS) setup that provides a logical de-clustering of files.
Num Procs PFS NFSClass B (9 procs)
1940 secs
10552 secs
Class B (64 procs)
3725 secs
Not measured
56

A 6 node (each node 4-way Sun UltraSPARC 900 MHz with 2 Gigabit interfaces and 2 host bus adapter to Storage Area Network) IO server tier running Sun QFS exports that same storage on all the IO nodes. Each of the IO server nodes run NFS server, effectively exporting the same storage. Client nodes in PARAM Padma run standard NFS clients and each client mounts from an IO server (statically fixed policy). So, an application running on multiple client nodes can perform IO through different IO server, thus in a logically de-clustered fashion.
The b_eff_io test is conducted with 4 client nodes in the PARAM Padma cluster, all mounting the same storage from different servers. The performance is abysmally poor as well as the data integrity is not maintained. The data integrity problem arises due to lack of synchronization between the NFS servers. The poor performance is attributed to strong consistency semantics offered by QFS. In PFS, even though there is no coordination between the IO servers, client nodes synchronize and decide the desired consistency level. While in the QFS based scenario with NFS access, there is no coordination between either the clients or the servers. The results have not been shown, as data integrity is not maintained.
The results of the various optimizations are described now.
2.4 Prefetch mechanism and framework resultsThe core component of the prefetch framework is the predictor module that captures the data block access history and predicts the future block accesses.
57

2.4.1 Predictor moduleTo characterize the LZ based predictor module behavior without any external influence – pure prefetching, we simulate the application execution using the block trace. The block trace is fed to the predictor module and the module output – which is the predicted block list – is analyzed with the subsequent data block requests (As mentioned earlier, the first order difference is stored in the predictor module, not the actual block numbers).
The hit rate for a prefetch request is – the percentage of prefetch blocks from the current prefetch request, used by the data requests between the current prefetch request and the subsequent prefetch request. This approach does not measure coverage of data blocks in the subsequent IO accesses in the current prefetch request. This is because, in practice, the prefetch requests could be serviced along with the data requests and are useful only if they arrive before the data requests. So, the focus of the optimization is to fetch enough blocks that is constrained by availability of buffers and how soon the data requests will follow; the hit rate measures how usefully, the prefetch blocks satisfy the subsequent data requests (or sub sets of).
The prefetch policy discussed subsequently adjusts the prefetch window size depending on its effectiveness – predict correctly, timely service of prefetch request. The Figures 15, 16 & 17 depict the performance of LZ predictor for b_eff_io, BTIO and parkbench [36] benchmarks, with a prefetch window size of 8.
58

Figure 15: Hit rate for b_eff_io in pure prefetch mode
Figure 16: Hit rate in BTIO in pure prefetch mode
59

Figure 17: Hitrate in Parkbench (matrix 3D)in pure prefetch mode
It can be seen that 65% of the blocks prefetched during BTIO application run, 78 % of the blocks prefetched during b_eff_io benchmark and 87 % of the blocks prefetched during parkbench run will satisfy the subsequent data accesses. The effectiveness of the predictor, in practice, will however, depend on run time behavior of disks and the timing of client request issues.
2.4.2 Prefetch mechanismThe prefetch mechanism with the LZ predictor is tested with the b_eff_io benchmark. The results are provided for an 8-client node setup with 2 IO server setup in PARAM Padma cluster. The application run configuration is varied as 4-node and 8-node runs with 1 process/node and 2 processes/node. Only the read graphs with 1 process/node are shown as the write/rewrite graph characteristic matches the read.
60

A careful observation of the result graphs shown in the Figure 18 suggests that prefetching mechanism does not change the b_eff_io behavior or the characteristics of the parallel IO behavior but just enhances the performance for some patterns.
Figure continued on next page
61

Figure 18: Performance readings of b_eff_io on PFS with prefetch mechanism. As with previous readings, read & write workload for only type 0 is shown. PFS has 2 IO servers
Type 0 gives the best increase in performance among all the access types. This is because in type 0, every process performs IO in terms of an IO segment in every IO call. The IO segment has multiple non-contiguous chunks from a process in strided fashion. The IO pattern formed by IO segments from all the processes globally forms consecutive sequence on the logical file. This helps in firstly, faster building of IO pattern in the predictor state and secondly, coalesced IO access. Almost 75 % of the traffic generated in the benchmark is generated from this type.
In all the other types, the process’ IO segment contains exactly one IO chunk and the global IO segment is a much smaller contiguous segment than type 0.
62

For the prefetching optimization, types 1 & 2 do not show any performance improvement, type 3 actually shows performance degradation and type 4 shows slight improvement in performance.
B_eff_io, as mentioned earlier, generates five types of traffic patterns (types 0, 1, 2, 3, 4). The fraction of total traffic handled during type 1 is one-tenth of the total traffic generated by the benchmark and IO is synchronous as well as performed in single chunks and IO requests are spread across many chunk sizes. So, building of predictor state for useful prefetching is not effective as seen from the performance figures.
Types 2 and 3 perform uncoordinated independent accesses. Prefetch mechanism at this time, has a global LRU policy for buffer replacement and does not recognize individual prefetch streams from the clients (though hit rates are measured on a per client basis). In this scenario, there could be contention for buffers and a fast client could replace some useful buffers for another client. The buffer contention has been observed and its impact can be seen in degradation of performance for accesses of type 2 & 3.
Type 4 too performs independent accesses but they are coordinated so the contention for the buffers is limited unlike the previous case.
Also, as the number of processes increases per node, due to the buffer contention, the efficacy of prefetch mechanism comes down.
An important consideration, in practice, is memory management of prefetch buffers and this significantly impacts the effectiveness of the prefetch mechanism. Currently, the prefetch buffers are statically
63

allocated to a certain fraction of available memory. Since, fast allocation and deallocation of prefetch buffers is essential for its effectiveness, having large number of prefetch buffers could have a negative impact unless managed with fast buffer-management mechanism. At this time, we are using a simple buffer management policy to manage prefetch buffer that is not scalable for large number of prefetch buffers.
Results for BTIO are shown below,
Table 3: BTIO results on 16 nodes; PFS configurations with 4 IO servers
BTIO workload, as discussed above, has fine grained partitioned regions. BTIO is a ‘constant output file size ’ application written over a fixed set of iterations. This means writes from the processes are more fine grained and small, and given the block size of 32K, more writes will hit the same block. And the predictor will pick up this pattern faster. As the workload is otherwise, extending writes only, prefetching may not help as currently prefetch does not do preallocation of blocks.
Num Procs PFS (with prefetch)
PFS
Class B (9 procs)
2084 secs 1940 secs
Class B (64 procs)
3006 secs 3725 secs
64

In conclusion, given the access pattern distribution, prefetch mechanism performs better for more than 80 % of the common access patterns in the scientific and engineering applications.
2.5 Adaptive communication buffer optimization resultsThis optimization targets the large collective calls. We show impact of this optimization on the b_eff_io types that use collective calls – 0, 1 and 4 (Figure 19). The readings have been taken on 32 nodes of PARAM Padma (1 process/node) configured with 4 IO servers.
Only type 1 shows some improvement while there is minimal impact on the other patterns.
65

Figure 19: Impact of adaptive buffer optimization of b_eff_io benchmarks that have collective IO calls
Impact of this optimization on BTIO -
Table 4:BTIO results on 32 nodes; PFS configurations with 4 IO servers
2.6 Design of large data structures – enhanced R-B trees – results
The design of the data structures with large number of entries has significant impact on the performance. This is demonstrated by the iotest benchmark. In the benchmark a large file is consecutively constructed in 64 iterations. The performance results and the final file size is shown in the Figure 20. In this configuration, PFS contains 2 IO servers and there is 1 client node. In the base PFS, the time to
Num Procs PFS PFS with buffer optimization
Class A (25 procs)
1255 secs
1215 secs
66

append successive IO block takes incrementally more time due to linear block translation list. The PFS with R-B tree implementation shows that each successive append to the file takes the same time irrespective of position of append.
Figure continued on next page
67
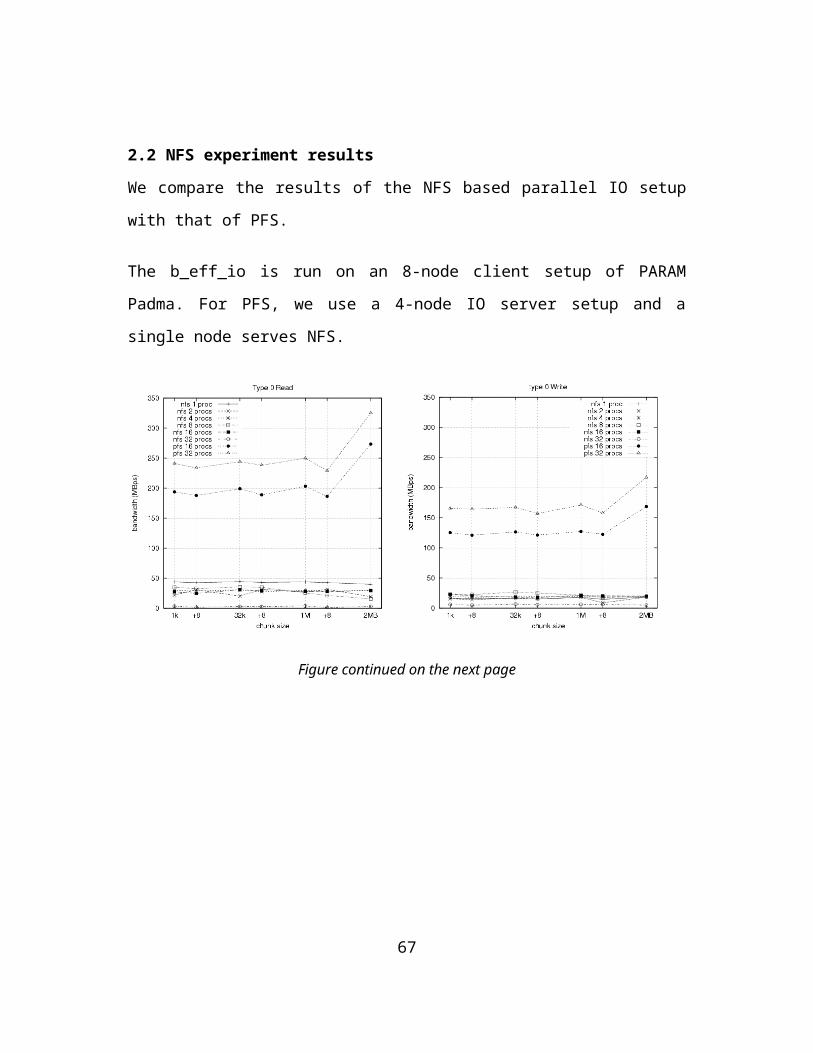
Figure 20: Iotest benchmark to show impact of R-B tree organization of block translation entries in PFS
2.7 Unified buffering in IO server resultsTo implement the prefetching mechanism, unified buffering in IO server is required to maintain correctness of the file system. Even though it does not give significant performance gain, it results in better memory resource utilization in the base implementation.
3 Integrated version resultsThe integrated version of C-DAC PFS with all the optimizations has been run on a large cluster configuration. While the individual optimizations on the base PFS show performance improvement, the integrated version does not show significant improvement for types other than 0. Upon investigation, it is observed that all the optimizations are not totally independent and could have side effects.
68
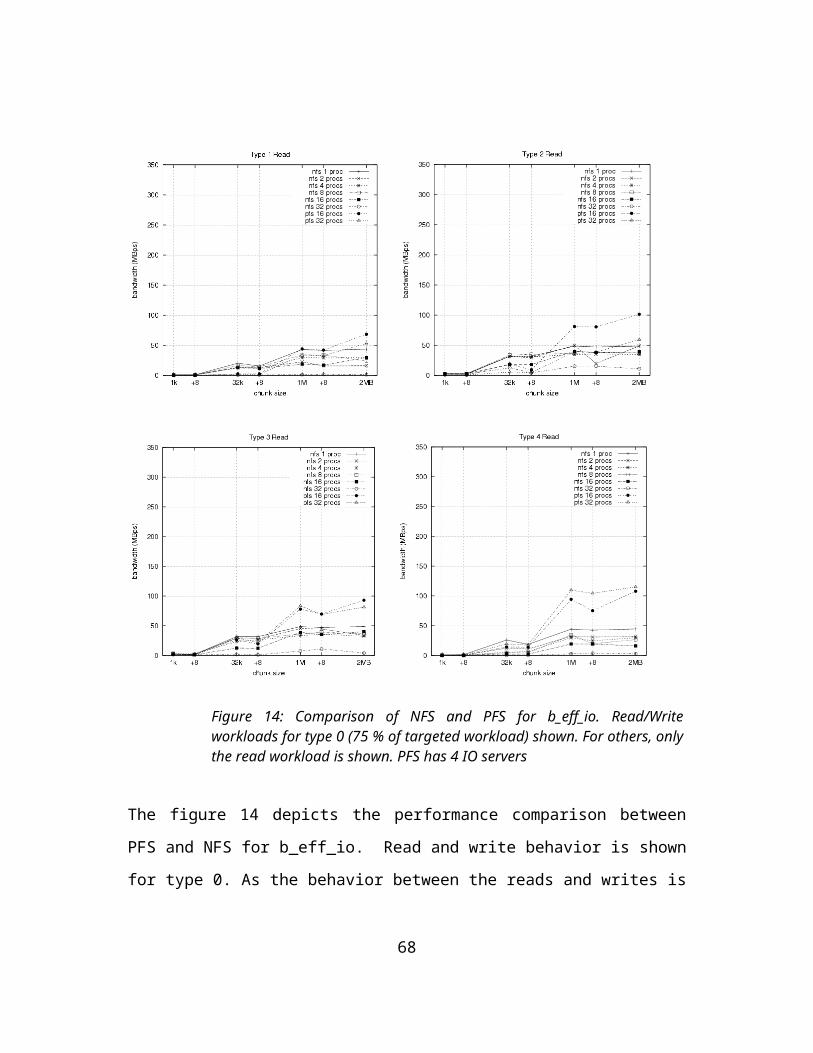
The adaptive buffer optimization models the IO access as though all the data comes from the disk, while some of the data could have been prefetched. This can introduce inaccuracies in the models for maintaining an efficient IO pipeline. Similarly, prefetching also introduces inaccuracies in the IO pipeline.
Similarly, coalescing can introduce inaccuracies in the models of other optimizations3
Integrating multiple optimizations so that there are no negative interactions between them is not a well-understood subject and needs further investigations. The performance results are given in Figure 21. The runs have been performed on PARAM Padma. The client nodes run 1 process/node and ratio of client to IO nodes is maintained at 4:1. In the following figures AxB denotes – A is number of clients and B is number of IO nodes.
3 Even in the compiler area there has been some work to represent optimizations formally and to represent their interactions, in practice, the many optimizations are ordered based on experience and any significant understanding of the interactions between them
69

Type 0 Type 1
Type 2 Type 3
Type 4
Figure 21: Performance figure of integrated C-DAC PFS and base PFS for b_eff_io
70

C h a p t e r 7
6. CONCLUSION & FUTURE WORK
In this work, we motivate the need for parallel file system in commodity-based clusters targeted at parallel scientific applications. We also demonstrate a practical approach to workload driven optimizations to a parallel file system. The optimizations have been motivated from the opportunities we had in the architecture to support the targeted workload as well as the base code we took for parallel file system implementation.
We report on design and implementation of newer optimizations for PFS, such as a novel prefetching scheme. The multiple optimizations done to the base PFS show better performance establishing the usefulness of the techniques used. Furthermore, it also establishes that PFS architecture shows better performance than the NFS architecture. The thesis has also touched upon the practical aspects in implementation that need attention. The optimized PFS now provides high performance parallel IO for applications written using MPI-IO interface by delivering good aggregate performance to the client nodes. The system is currently deployed in a tera-scale cluster, PARAM Padma (ranked 171st in July 2003 edition of TOP 500 list) running scientific and engineering applications providing fast scratch space.
71

1 Future WorkThe current C-DAC PFS has better performance and stability than its base implementation. But it still can be used as a fast scratch space only as it lacks enterprise features such as online capacity expansion, backup, snapshot etc. While it may be justified to maintain the separation so far, there is a compelling need to merge the capabilities. One such system evolution has been that of IBM’s GPFS that has evolved from PIOFS to Vesta to GPFS. The current work could evolve in such a direction. This is enabled by emergence of flexible, modular file system architectures such as Lustre [32] that provides the necessary infrastructural support for this activity.
Prefetching mechanism could also evolve to make it more scalable – better memory management of prefetch buffers and local LRU replacement policy of the buffers.
Currently, the predictions are done at the client-tier of the three-tier storage architecture. Due to de-clustering technique and the workload patterns, it may so happen that small strided access patterns at the client level could actually form large sequential IO at the IO server tier. A global access pattern analysis at the IO server could coalesce the IO as well as the prefetch requests for reducing the disk accesses.
72

REFERENCES
[1] High Performance Fortran. The official HPF-1 standard. Scientific Programming, 2(1-2);1-170, Spring-Summer 1993
[2] The official SIO Low-Level API standard. Proposal for a common file system programming interface version 1.0. http://www.pdl.cs.cmu/SIO/SIO.html, 1996
[3] The MPI-IO Committee. MPI-IO: A Parallel File I/O Interface for MPI, Version 0.5. http://lovelace.nas.nasa.gov/MPI-IO, April 1996.
[4] Rew, R., and G. Davis. NetCDF: An interface for scientific data access. IEEE computer Graphics and Applications, 10(4):76-82, July 1990
[5] HDF5 – A New Generation of HDF. http://hdf.ncsa.uiuc.edu/HDF5 [6] Arpaci-Dusseau, et. al. Cluster I/O with River: Making the fast case
common. In Proceedings of IOPADS’99, May 1999[7] Nieuwejaar, Nils, et. al. File access characteristics of parallel scientific
workloads. IEEE Transactions on Parallel and Distributed Systems, 7(10): 1075-1088, October 1996
[8] Nieuwejaar, Nils, et. al. The Galley parallel File System. Parallel Computing, 23(4-5):447-476, June 1997
[9] Thakur, Rajeev, et. al. A case for using MPI’s derived datatypes to improve IO performance. In Proceedings of SC98, November 1998
[10] Garcia, Felix, et. Al. An Expandable Parallel File System Using NFS servers. In Proceedings of VECPAR 2002. 2002.
[11] Tara, Madhyastha, et. al. Exploiting Input/Output Access Pattern Classification. In Proceedings of SC97. 1997
[12] Ibrahim F. Haddad. PVFS: A Parallel Virtual File System for Linux Clusters. Linux Journal, Volume 2000, Issue 80. November 2000
[13] Sun Microsystems white paper. Sun Parallel File System. Feb. 1998[14] Kotz, David, et. al. Practical Prefetching techniques for Parallel File
System. In Proceedings of the first international conference on Parallel and distributed information systems. 1991
[15] PARAM Padma and PARAM 10000, http://www.cdacindia.com [16] C-DAC. ParamNet-II product brochure.
http://www.cdacindia.com/html/htdg/products.asp [17] The MPI-2 specification. http://www.mpi-forum.org/docs/docs.html
73

[18] MPICH. A Portable MPI implementation. http://www-unix.mcs.anl.gov/mpi/mpich/
[19] Thakur, Rajeev, et. al. An extended two-phase method for accessing sections of out-of-core arrays. Scientific Programming, 5(4), Winter1996
[20] Prost, Jean-Pierre, et. al. MPI-IO/GPFS, an optimized implementation of MPI-IO on top of GPFS. In Proceedings of Supercomputing 2001. 2001
[21] Silberschatz, Avi., et. al. Operating System Concepts text book. John Wiley & Sons, Inc. 2003.
[22] Corbett, Peter, et. al. The Vesta File System. ACM Transactions on Computer Systems, 14(3):225-264, August 1996
[23] Rabiner, Lawrence. A Tutorial on Hidden Markov Models and selected applications in speech recognition. In Proceedings of the IEEE, 77(2), February 1989
[24] Vitter, Jeffery, et. al. Optimal Prefetching via Data Compression. Journal of the ACM, 43(5), 771-793. September 1996
[25] Kroeger, Tom, et. al. Design and Implementation of a Predictive File Prefetching Algorithm. USENIX Annual Technical conference. 2001
[26] Rolf Rabensiefner, et. al. Effective File-I/O Bandwidth Benchmark. In Proceedings of EUROPAR 2000. 2000.
[27] NAS Application I/O benchmark – BTIO. http://parallel.nas.nasa.gov/MPI-IO/btio/btio-download.html
[28] Len Wisniewski. et. al. Sun MPI I/O: Efficient I/O for parallel applications. In Proceedings of SC99. 1999.
[29] Anderson, D., Object Based Storage: A Vision. http://www.t10.org [30] Bell, Timothy., et. al. Text Compression. Pearson Education textbook
publication. February 1990.[31] Cormen, T., et. al. Introduction to Algorithms Second Edition. MIT Press.
2001.[32] Lustre home page. The Lustre book. http://www.lustre.org/docs.html [33] C-DAC KSHIPRA product brochure
http://www.cdacindia.com/html/ssdgblr/hpccbsw.asp[34] Raghvendran M. Internal position paper on C-DAC Terascale
Computing Facility (CTSF) storage, 2004.[35] TOP 500 website. http://www.top500.org [36] PARKBENCH.
http://www.performance.ecs.soton.ac.uk/index.html
74
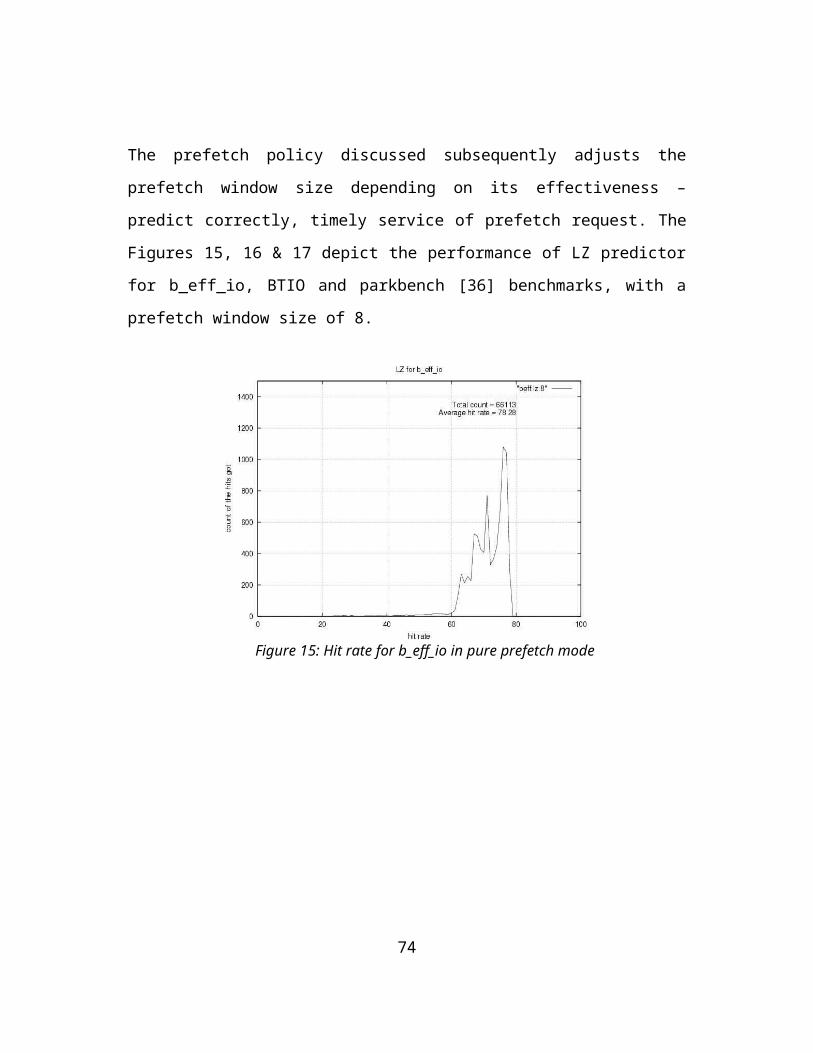
[37] Intel Corporation. Paragon System User’s Guide. April 1996.[38] Reed, Daniel (editor). Scalable Input/Output – Achieving System
Balance. MIT Press. 2004
75
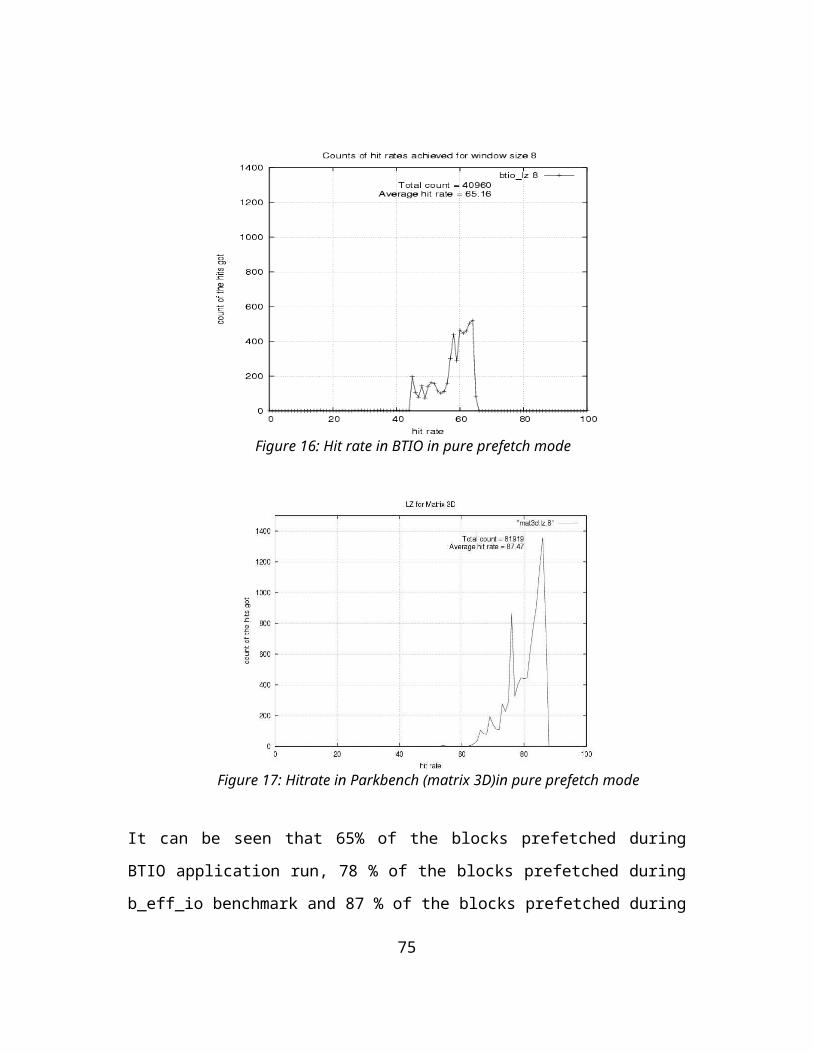
4





























