Embed Size (px)
Citation preview

0.5 setgray00.5 setgray0.250.5 setgray0.50.5 setgray0.750.5 setgray1
0.5 setgray0 0.5 setgray0.25 0.5 setgray0.5 0.5 setgray0.75 0.5 setgray1
Theoretische Grundlagen der Aggregation in
OLAP-ModellenOLTP and OLAP Schemata
Towards a Sound Treatment of Aggregation Functions and OLAP Databases
Free University Berlin, Dept. of Business Administration and Economics
Institute of Production, Information Systems and Operations Research
Colloquium
May 12, 2005
Bernhard Thalheim (& Hans-Joachim Lenz)Technologie der Informationssysteme
Institut fur Informatik, Christian-Albrechts-Universitat zu Kiel, BRD
Kolmogorow-Professor e.h. der Lomonossow-Universitat Moskau
1

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
DBIS/TIS in DD, Kuwait, HRO, CB, KI
IS Engineering
Interactive media
z
Integration, farms
?
Information services
9
DB modeling
z?9
(Object-)relational theory
z
ER theory
?
OO/XML theory
9
DB theory
9 ? z
Theoria cum praxi
Demanding projects with industrial partners
as impulse for novel theory development
and expertise for teaching and students
2

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The Information System Engineering Chair@ CAU Kiel�� ��One goody of the German university system: Research stability
Research @ ISE: or what you cannot expect
Codesign of database applications structuring, functionality, distri-
bution and interactivity
B. Thalheim, Entity-Relationship Modeling. Springer, Berlin, 2000
Database and information systems theory
Website development
K.-D. Schewe, B. Thalheim,
Design and Development of Web Information Systems.
Springer, Berlin 2005?, 2006
Component architectures of information systems
Content management systems on demand - the Kiel approach
3

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The Information System Engineering Chair@ CAU Kiel�� ��Another goody of the German university system: Partner selectivity
Projects - for students, knowledge enhancement and leisure
Websites: Information sites, e-learning sites, community sites, e-
government sites
35 successful website development projects
and a good number of “experience-gaining” projects
Media on merge on demand, portfolio, profile and history:
radio/tv + video+ internet + news paper
Database and information systems development,
maintenance, emergency management, tuning
application library with more than 4.500 large applications
Database integration, embedded databases
Partners: Berlin-Brandenburg Graduate school, CoreMedia, VW,
Dataport
4

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The Information System Engineering Chair@ CAU Kiel
�� ��Main goody of the German university system: Integrated teaching and research
Internet information services
�j
Intelligent information systems
R
Applications of information systems
?
Database technologyand programming
Distributedinformation systems
Engineering ofinformation systems
Information systemstheory
?
Foundations of database systems
9
R
z
• CS II (Algorithms and data structures), CS III (Software engineering)
• Contemporary courses: Intelligent information systems, Artificial intelligence, None-classical
logics, Problem solving strategies, Web databases, Website engineering, Programming of
information-intensive services, Knowledge bases
• Service courses within other study programs
5

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Overview��
��Nothing is more practical than a good theory (A.N. Kolmogorow)
(1) Quick look onto OLTP and OLAP engines
(2) The pitfalls, misunderstandings, practice, and theory of aggregation
functions
Yet another chapter in the book of stupidity or
Know what you are doing
(3) The OLAP cube
Towards a sound foundation
(4) OLAP-OLTP schemata
Our proposal to overcome the problems
(5) Methodology of OLTP-OLAP application development
Provable properties and quality criteria
There are three kinds of lie: lies, damned lies and statistics.attributed to Benjamin Disraeli (1804-81) by Mark Twain (Autobiography, 1924)
6

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
OLTP and OLAP�� ��Database System Architecture
Appli-cationsystem
(workflow(functio-nality))
Presen-tationsystem(playout(story))
?6
-
�
DBMS
Data-base
DBS =
DBMS +{ DB }
Storage management
Compiler
Communication subsystem
Operatingsystem
Synchronizationof parallelaccess
Datadictionary
6 ?
Data manager Buffer manager
Transactionmanagement
Scheduler
Recoverymanager
Code generation Distribution management
OptimizerAccess plangeneration
Updateprocessor
Queryprocessor Integrity
control andenforcement
Logbook
6?
-�
Input-outputprocessor
Parser Pre-compiler
Authoritycontrol
Supportingsystems(graphicaletc. )
6? 6?
7

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
OLTP and OLAP�� ��Generalized Data Warehouse Architecture
OLAP/DW SystemLegacyData
ForeignData
OLTPdata
Micro-dataimportexporttools-
-
-
-Content
managementsystem
-Macro-dataextractorsdatabasemining
EIS/DSSuser
-
-
-
Businessunit user
Anonymoususer
Active acquisition
Storage
User profiles
Data suites Access, historymanager
Gate
Purger
Paymentmanager
Workspace
Unit, applet,data provider
Units generator
8
ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
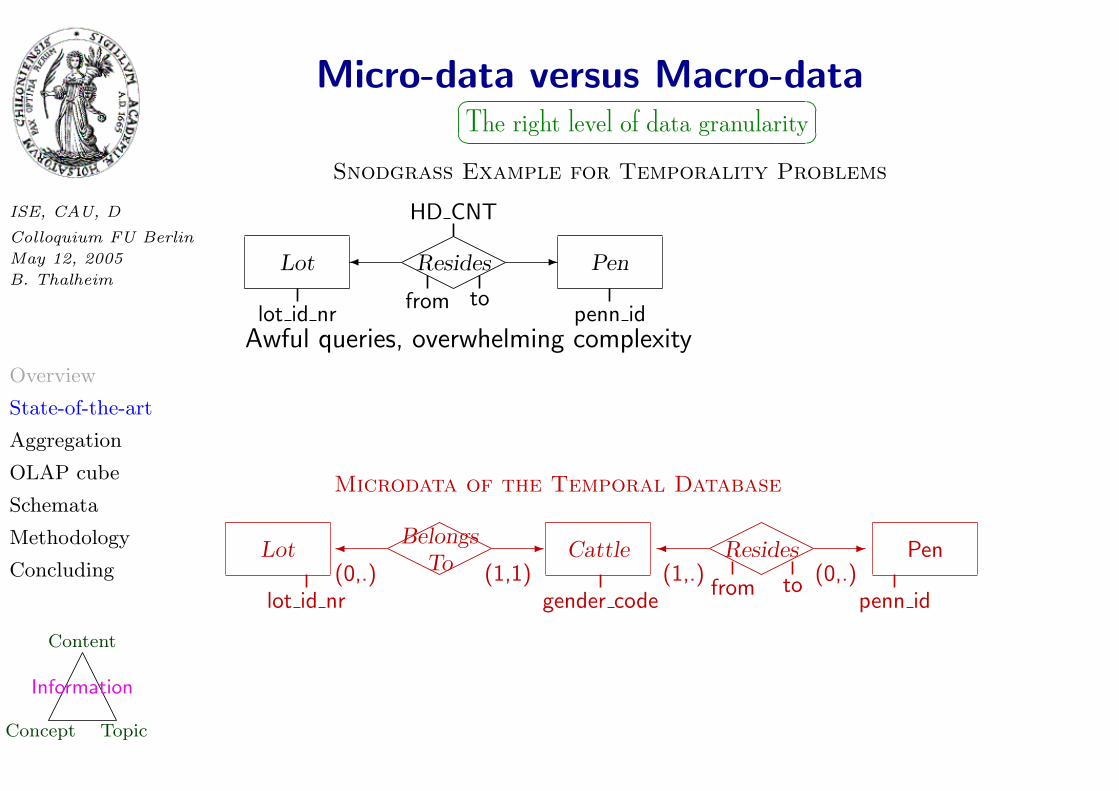
Micro-data versus Macro-data�� ��The right level of data granularity
Snodgrass Example for Temporality Problems
Lot Pen
HD CNT
penn idlot id nrfrom to
� -Resides
Awful queries, overwhelming complexity
Microdata of the Temporal Database
(0,.) (1,1) (1,.) (0,.)
� -BelongsTo
Lot Cattle
lot id nr gender code penn idfrom to
� -Resides Pen
9

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Micro-data versus Macro-data�� ��The right level of data granularity
Typical Snodgrass query: “Give the History of Lots being co-resident in a Pen”
select L1.Lot Id num, L2.Lot Id Num, L1.Pen Id, L1.From Date, L1.To Datefrom Lot Loc as L1, Lot Loc as L2where L1.Lot Id num< L2.Lot Id num and L1.Fdyd Id = L2.Fdyd Id
and L1.Pen Id= L2.Pen Id and L1.From Date= L2.From Dateand L1.To Date<= L2.To Date
unionselect L1.Lot Id num, L2.Lot Id Num, L1.Pen Id, L1.From Date, L2.To Datefrom Lot Loc as L1, Lot Loc as L2where L1.Lot Id num< L2.Lot Id num and L1.Fdyd Id = L2.Fdyd Id and ...
unionselect L1.Lot Id num, L2.Lot Id Num, L1.Pen Id, L2.From Date, L1.To Datefrom Lot Loc as L1, Lot Loc as L2where L1.Lot Id num< L2.Lot Id num and L1.Fdyd Id = L2.Fdyd Id and ...
unionselect L1.Lot Id num, L2.Lot Id Num, L1.Pen Id, L2.From Date, L2.To Datefrom Lot Loc as L1, Lot Loc as L2where L1.Lot Id num< L2.Lot Id num and L1.Fdyd Id = L2.Fdyd Id
and L1.Pen Id = L2.Pen Id and L1.From Date > L1.From Dateand L2.To Date <= L1.To Date;
select distinct L1.Lot ID, L2.Lot ID, R1.Pen ID, R2.From, min(R1.To, R2.To)from Cattle C1, Cattle C2, Resides R1, Resides R2, Lot L1, Lot L2where L1.Lot ID = C1.BelongsTo and L2.Lot ID = C2.BelongsTo and
R1.Cattle ID = C1.Cattle ID and R2.Cattle ID = C2.Cattle ID andR1.Pen ID = R2.Pen ID and R1.From <= R2.From andR2.From < R1.To and L1.Lot ID <> L2.Lot ID;
10

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The Hierarchy Paradox
UniversityLectures
� -HeldOn
Room
#Participants
#Participants
WorkingDay
6
-IsA Day � -OrganizedOn
EveningLectures
TitleRoom
Scheduling Schema on University and Evening Lectures
� -HeldOnLectures Day
#Participants
Cube A: Participants per Lecture and Day
� -UsageRoom Day
#TotalUsage
Cube B: Usage of Rooms per Day
11
ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
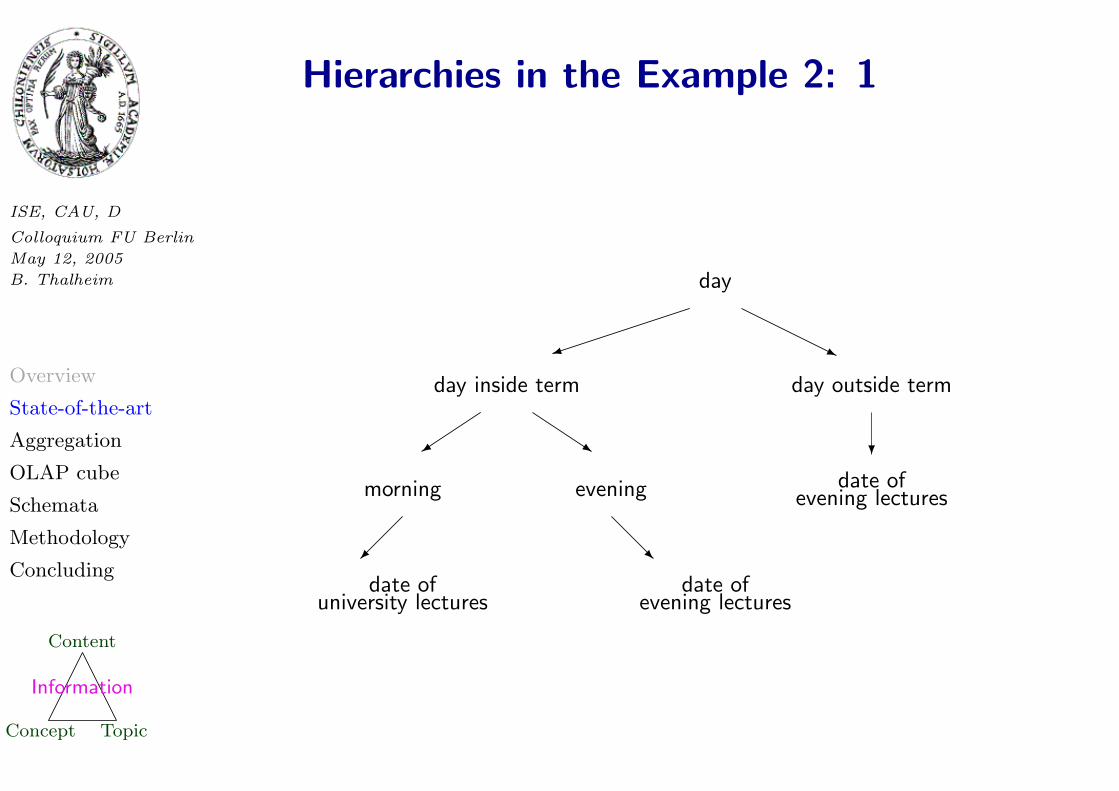
Hierarchies in the Example 2: 1
date ofuniversity lectures
date of
evening lectures
R
morning evening
+
day inside term
s
day
)
date ofevening lectures
j
day outside term
?
12

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Hierarchies in the Example 2: 2
working day
day
non-working day
q
date
?
evening
q
j
date ofevening lecturesat working days
morning
�
day
inside term
j
date of
university lectures
dayoutside term
13

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Cube B Data in the Example 2Day category Room utilization Daytime # of rooms
working occupied morning 20
working occupied evening 12
working free morning 10
working free evening 4
non-working occupied morning 2
non-working occupied evening 8
non-working free morning 6
non-working free evening 16
Daytime Working day Non-working day All days
Evening 75 % 33 % 50 %
Morning 67 % 25 % 58 %
14

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Cube B Data in the Example 2Day category Room utilization Daytime # of rooms
working occupied morning 20
working occupied evening 12
working free morning 10
working free evening 4
non-working occupied morning 2
non-working occupied evening 8
non-working free morning 6
non-working free evening 16
Daytime Working day Non-working day All days
Evening 75 % 33 % 50 %
Morning 67 % 25 % 58 %
15

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Weighted Cube B Data in the Example 2
Day category Room utilization Daytime # of rooms
working occupied morning 20
working occupied evening 12
working free morning 10
working free evening 4
non-working occupied morning 2
non-working occupied evening 8
non-working free morning 6
non-working free evening 16
Daytime Working day Non-working day All days
Evening (75 % , 1630 ) (33 % , 24
30 ) (50 %, 2430 )
Morning (67 %, 3030 ) (25 %, 8
30 ) (58 %, 3030 )
The hierarchy paradox
16

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The Simpson Paradox�� ��Revisited but based on a classical OLAP example
model Chevy Ford ALL
color blue white blue white ALL
year 90 91 90 91 90 91 90 91 ALL
count 187 155 131 108 217 180 151 125 1254
count(*) by model, color, year (data under independence constraint)
Ratios ’Market Share Percentages of Chevy’
p(chevy|blue, 90) =187
187 + 217· 100 = 46%
p(chevy|blue, 91) =155
335· 100 = 46%
p(chevy|white, 90) =131
282· 100 = 46%
p(chevy|white, 90) =108
233· 100 = 46%
Market share of sold units where model = ‘chevy’constant for both colors over years 90-91
17

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The Simpson Paradox�� ��Revisited but based on a classical OLAP example
model Chevy Ford ALL
year 90 91 90 91 ALL
count 187 155 217 180 1254
count (*) by model, year
p(chevy, 90) =308
686· 100 ≈ 46%
p(chevy, 91) =263
568· 100 ≈ 46%
coherent with the results before
global independence assumption (integrity constraint) on the data spacespanned by the attributes ‘model’, ‘year’ and ‘color’, cite
18

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The Simpson Paradox�� ��Revisited but based on a classical OLAP example
Tm: model Chevy Ford ALL
count 581 673 1254
Ty: year 90 91 ALL
count 739 515 1254
Tc: color blue white ALL
count 687 567 1234
Table 1: Marginal tables Tm, Ty, Tc used to generate ??
insert and delete operations
model Chevy Ford ALL
color blue white blue white ALL
year 90 91 90 91 90 91 90 91 ALL
count 255 156 88 82 174 102 222 175 1254
count (*) by model, color, year
19

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The Simpson Paradox�� ��Revisited but based on a classical OLAP example
p(chevy|blue, 90) =255
429· 100 ≈ 59%
p(chevy|blue, 91) =156
258· 100 ≈ 60%
Market share of a blue car of type ‘chevy’ increases slightly over years
Increase of the share is stronger for white cars:
p(chevy|white, 90) =88
310· 100 ≈ 28%
p(chevy|white, 91) =82
257· 100 ≈ 32%
20

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The Simpson Paradox�� ��Revisited but based on a classical OLAP example
Slice now over ‘color’, πyear,count
model Chevy Ford ALL
year 90 91 90 91 ALL
count 324 238 396 277 1254
count (*) by model, year
p(chevy, 90) =308
686· 100 ≈ 46%
p(chevy, 91) =263
568· 100 ≈ 46%
The bad guy:
j�
Z (color)
X (year) Y (model)
Dependency graph XYZ with separator (influential) attribute Z
21

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Other Problematic OLAP Applications�� ��Discoveries of H.-J. Lenz
Non-commutative operators: Let O be a given set of numeric opera-
tors. Let o1 ∈ O be a linear operator and o2 ∈ O a non-linear operator.
Then it is generally not true that o1 ◦ o2 = o2 ◦ o1 .
Perfect aggregation: The perfect homomorphism H : y = y exists if
and only if y = SAT ∨ A = S+AT+ where S+(T+) is the Moore-Penrose
inverse of S(T ). x
?
A
T S
A
y
Y
-
-X
6
Summarizability and cover properties
Extensions of These Cases
Non-confluence of aggregations
Identifiability and inclusion/exclusion computation
22

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
n-Pass Aggregation Functions I�� ��Basics
• turn data (micro-data) into information (macro-data)by (one-pass) aggregation
(statistical) summary from that data
• count (tally)
• average (arithmetic mean)not understood for non-linear relative values (pH)
beside other ‘average’ values
• geometric average (√a× b),
quadratic average (√
1n(a21 + ...+ a2n))
• median (just as many cases with a value below it as above it)[measure of central tendency]
‘statistical median’: left or right, dividing the data
into two half
‘financial median’: average of the highest value in the
lower half and the lowest value in the higher half
• sum (total)
• min, max
23

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
n-Pass Aggregation Functions II�� ��First problems due to SQL
• null values, default values
• count({ (Null) }) = 1
• sum({ (Null) }) = sum({ (0) }) = 0
sum(∅) = count(∅) = 0
sum({di|di = NULL, di = ti(A)}) = sum({di|di = ti(A)})
• max({ (Null) }) = min({ (Null) }) = undef or
max({ (Null) }) = maxValue min({ (Null) }) = minValue
SQL assumptions:
max(∅) = max(∅) = NULL
similarly fancy for data types TIME, DATETIME,
STRING, VARSTRING
e.g., MAX(temporal) farthest in the future or most recent
• avg(∅) = NULL
RCno−null[A] = {|{ di|di = NULL, di = ti(A), ti ∈ RC }|}
avg(RCno−null[A]) =
sum(RCno−null[A])
count(RCno−null[A])
avg(RCno−null[A]) = avg(Bag2Set(RC
no−null[A]))
24

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
n-Pass Aggregation Functions�� ��Towards more complex functionality
• Cumulative or running statistics
relation of each data value to the whole data
changes in an aggregate value over time or any dimension set
banded reports, control break reports, OLAP dimensions
“total amount of sales broken down by salesman within territories”
based on two-pass reports
1. properties of a group as a whole2. second pass to produce the results for each row in the group
“What percentage each customer contributes to total sales?”
“Total sales in each territory, ordered from high to low!”
• Key - area computations
• regions: contiguous n values that are the same
• runs: set of consecutive values within a sequence
• sub-sequences: set of consecutive unique data within a sequence
25

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
n-Pass Aggregation Functions�� ��Examples of complex functions
• running totals (tracking changes over time (bank account))
running differences (tracking differences over time since the
last moment)
• cumulative percentage (what percentage of the whole set of
data values the current subset of data values is)
ranking (integers that represent the ordinal values (first,
second, ..) of the elements of a set based on one of the values)
cross tabulation (two-dimensional spreadsheet generation)
[cross join, outer join, subquery]
• mode (most frequently occurring value)
n-modal distribution (n most frequently occurring values)
weak descriptive statistic (minor DB changes with major reflection)
mode with threshold variation
• standard deviation (√∑
k(xk − EX)2 ), variance
average deviation (how much values drift away from the average)
26

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Aggregation Functions: General Definition
Family F = {f0, ...., fk, ..., fω}fk : Bagk → Num (maps a bag on dom(Mj) with k elements
to a numerical range Num)
Minimum preserving: fk(min, ....,min) = minNum min ∈ dom(Mj)
Maximum preserving: fk(max, ...,max) = maxNum max ∈ dom(Mj)
Monotone according to the order of dom(Mj) and T (k ≥ 1)
Idempotent: fk(x, ...., x) = x for all x ∈ dom(Mj)
Continuous: limxi→x f(xi) = f(x) for all sequences xi of size k
Lipschitz property: |fk(x1, ..., xk)− fk(y1, ..., yk)|≤ c
∑ni=1 |xi − yj | for some constant c
Symmetric: fk(x1, ..., xk) = fk(xρ(1), ..., xρ(k)) for any k-permutation ρ
Self-identical: fk(x1, ..., xk) = fk+1(x1, ..., xk, fk(x1, ..., xk))
Shift-invariant: fk(x1 + b, ..., xk + b) = fk(x1, ..., xk) + b
Homogeneous: fk(bx1, ..., bxk) = bfk(x1, ..., xk)
Additive: fk(x1 + y1, ..., xk + yk) = fk(x1, ..., xk) + fk(y1, ..., yk)
Associative: fr(fk1(x1), ..., fkr (xr)) = fk1+...+kr (x1, ..., xr)
27

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Aggregation Functions: Properties�� ��Be careful with the average functions used for OLAP
• max, min are minimum preserving, maximum preserving, idempo-
tent, continuous, symmetric, self-identical, additive, homogeneous,
associative, and obey the Lipschitz property,
• sum is 1-minimum preserving, 1-maximum preserving, 1-monotone,
continuous, symmetric, homogeneous, additive, associative, obeys
the Lipschitz property, and
not idempotent, not self-identical, not shift-invariant,
• avg is minimum preserving, maximum preserving, 1-monotone,
idempotent, continuous, symmetric, shift-invariant, homogeneous,
additive, obeys the Lipschitz property,
is not self-identical, not associative,
• count is continuous, symmetric, associative, obeys the Lipschitz
property,
not idempotent, not self-identical, not shift-invariant, not homoge-
neous, not additive.
28

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Classes of Aggregation Functions:Distributive (Inductive) Functions
preserving partitions of sets
∀f ∃g f(X) = g(f(X1), ..., f(Xn))
X = X1 ∪X2 ∪ ... ∪Xn, Xi ∩Xj = ∅ , i = j
types T , T ′, collection type CT on T , operations ∪CT , ∩CT , ∅CT on CT
h0 ∈ T ′ h1 : T → T ′ h2 : T ′ × T ′ → T ′
srech0,h1,h2(∅CT ) = h0
srech0,h1,h2(|{|s|}|) = h1(s) for |{|s|}|srech0,h1,h2(R
C1 ∪CT RC
2 ) = h2(srech0,h1,h2(RC1 ), srech0,h1,h2(R
C2 ))
iff RC1 ∩CT RC
2 = ∅CT
• sum = srec0,Id,+ for relations without nulls
sumnull0 = srec0,h0Id
,+ h0f (s) =
{0 if s = NULL
f(s) if s = NULL
sumnullundef = srec0,hundefId
,+ hundeff (s) =
{undef if s = NULL
f(s) if s = NULL
• count = srec0,1,+ countnull1 = srec0,h01,+
, countnullundef = srec0,hundef1 ,+
• max = srecNULL,Id,max min = srecNULL,Id,min for sets, bags
max, maxundef are different functions
29

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Classes of Aggregation Functions:Algebraic Functions
Finite algebraic expressions based on distributive functions
• average:(++)
sum
count(??)
sum
countnull1
(??)sum
countnullundef
(SQL!?)sumnull0
count(+!)
sumnull0
countnull1
(??)sumnull0
countnullundef
(+?!)sumnullundef
count(??)
sumnullundef
countnull1
(++)sumnullundef
countnullundef
remember SQL x0= 0
• variance (∑
k(xk − EX)2 · pk EX =∑
k xk · pk )
• ratio values (e.g. consumption)
most of them can be extended to distributive functions
e.g. avgnull0,1 based on ordering on pairs (value, occ#)
30

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Classes of Aggregation Functions: HolisticFunctions
the vast majority of functions
no storage bound for computing sub-aggregates
mostFrequent, n-mostFrequent
statistical and financial median
rank
averageDeviation
geometric key-area computations
computable over temporal views (on temporal views ...)
distinction between raw data and ‘data’
maintenance of identification becomes the main issue
data warehouse data
versions of data, temporality
31

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Invariance of FunctionsGiven: aggregation function ψ
database function f ,
e.g., view function, selection function
Problem: does the application of f change the aggregation ?
Can we delay computation of aggregation to the view?
Is there a need to compute results based on raw data only?
D
?
f
ψ ψ
f(D)-
ψ(D) = ψ(f(D))�
f isψ-invariant
in Dif
ψ(f(D)) = ψ(D)
32

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Invariance Examples
• Bag2Set: (DISTINCT)
• min-, max-invariant
• not sum-invariant
sum-invariant for sets
• not avg-invariant
avg-invariant for sets without NULL’s
• Project: invariant for all distributive functions
• Select, Join: not invariant for most aggregation functions
• Union, Difference, Intersection: mostly not invariant
• Renaming: invariant for all aggregation functions
33

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Repairing Approaches1. Aggregation Transformation
Abstraction functionf
Aggregation functionΨf
Aggregation functionψ
Abstraction functionF
ψ(D)Ψf (f(D))
=F (ψ(D))
D f(D)
-
-
? ?
Problem: find the f -transformation Ψf of ψ
infeasible
34

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Repairing Approaches1. Aggregation Transformation
Abstraction functionf
Aggregation functionΨf
Aggregation functionψ
Abstraction functionF
ψ(D)Ψf (f(D))
=F (ψ(D))
D f(D)
-
-
? ?
Problem: find the f -transformation Ψf of ψ
infeasible
35

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Repairing Approaches2. Preparing Explicit Aggregation
g - ψ-supplement of f
∃ψ∗∀D ψ∗(g(f(D),D)) = ψ(D)
D
?
(f, g)
ψ ψ∗
g(f(D),D)-
ψ(D) = ψ∗(g(f(D),D))+
Supposition: g is based on the mapping of algebraic functions to dis-
tributive functions
36

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Observation Supporting the Supposition
supplement function which generates the occurrence number for each
value
for instance for
f = Bag2Set
• sum∗ = srec0,h,+ for h((v, n)) = n · v
• count∗ = srec0,h′,+for h((v, n)) = n , count = srec0,1,+
• avgnull0,1 =sumnull0
countnull1extended to
avgnull∗0,1 =sumnull∗0
countnull∗1
37

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Behavior of Aggregation Functions
Subset sensitivity: For given D, ψ and a selection condition α:
ψ(D) = ψ(σα(D))
All classical aggregation functions are subset-sensitive.
Critical operations: selection, join, intersection, difference
Object invariance: All objects are residing after application of the
operation.
Object-invariant functions are min- and max-invariant.
Value-set invariance: All values of the domain considered are re-
maining.
Set-value invariant functions are min- and max-invariant.
38

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Behavior within HierarchiesPoly-Hierarchy Lattices
generalizing the characteristic function h to Boolean lattices of classes
C1, ..., Cm:
L(Ci1 , ...Cin) - intersection Ci1 ,..., Cincounting based on the exclusion/inclusion property:
ψ(D) =∑m
i=1 ψ(Ci)−∑m−1
j=1
∑nk=j+1 ψ(L(Cj , Ck)) +−...
+(−1)r−1 ∑1≤j1<...<jr≤m ψ(L(Cj1 , ...Cjr )) + ....
+(−1)m−1ψ(L(C1, ..., Cm))
Distributive aggregation functions can be computed based on the ex-
clusion/inclusion principle.
If an abstraction function f is distributive with the exclusion/inclusion principle then f is ψ-
invariant for distributive aggregation functions.
39

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Algebraic Aggregation FunctionsHandling Through Distributive Functions
D
?
Aggregationfunction
Extendedaggregationfunction
Forgetfulfunctor
ψ(D)-
ψ∗(D)
3
Example: average
h1({s}) = (1, s)
h2((i, k)(j, l)) = (i+ j,i · k + j · l
i+ j)
40

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Supplements for Algebraic FunctionsGiven a database abstraction f and an algebraic aggregation function
ψ. If a ψ-supplement g of f exists then the function ψ∗ is distributive.
Collapseability along MVD Trees
Collapsing along MVD trees is invariant for distributive functions.
Collapsing along MVD trees is invariant for algebraic functions.
41

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The OLAP Cube: DefinitionThe cube is defined by
• a partially ordered set of dimensions D called lattice
({L1, ..., Ln, ALL},≼),
• a family of composite, equivalence-invariant and monotone func-
tions ancLi,Lj such that for each pair Li ≼ Lj in each dimension
the function ancLi,Lj maps each element of the domain dom(Li)
to an element of dom(Lj),
• a family of relationships descLi,Lj inverse to ancLi,Lj ,
• a cube schema (L1, ..., Ln,M1, ...,Mk)
with key {L1, ..., Lm},
• a set of aggregation functions
agg1(M1,1), ..., agg1(M
1,p1), ..., aggk(Mk,pk) and
• a cube algebra consisting of navigation, selection, projection and
split functions.
42

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The Query Operations of the OLAP Cube
Basic drill-down functions: decomposing groups of data along a
hierarchy
refine grouping for one dimension Li ≽ L′i
values for fact values on M1, ...,Mk through ancLi,L
′i by decompo-
sition
require additivity property
Basic dice functions: projection
require additive property along Li ≽ L′i.
Basic slice functions: selection
Basic roll-up functions : opposite of the basic drill-down
require disjointness property
Additional functions: join functions, union functions, rotation or pivot-
ing functions, rename functions
43

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Some General ResultsRoll-up functions are neither sum-invariant nor avg-invariant in general.
Roll-up functions are not min- or max-invariant in general.
Rearrangement functions are min-, max-, sum- and avg-invariant.
Summarizability cannot be obtained for relations after application of
any subset-generating function.
Summarizing is correct for union of classes if an exclusion constraint
is valid for classes to which union is applied.
Summarizability cannot be maintained for functions after application
of which identification of objects is lost.
Summarizability cannot be obtained trough collapsing hierarchies.
44

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Some General ExtensionsSummarizability cannot be obtained moving up to generalizations of
classes.
Summarizability is maintained moving downwards through functional
dependencies.
Summarizability is correct on separting collapsing hierarchies if the
portion is used for the supplement.
Summarizability can be maintained on the basis of identification
properties of values.
45

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The OLTP-OLAP Specification FrameF = (A,O,Ψ,M)
Set A of aggregation functions
Set O of OLAP query operations
Set M of modeling assumptions
Set Ψ of properties
Cube C satisfies F
• OLTP-OLAP transformations are restricted to A
• fact domains fulfill Ψ
• modeling assumptions are valid for C
Domain types: precision and accuracy, granularity, and ordering
nominal, absolute, rank, ratio, atomar, complex, interval types
Domains: scales, classifications, default and neutral values
Domain values: extended by measures, e.g. relative, absolute, linear and non-linear
Domain values: transformed by casting functions to values of other domain types
46

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
OLTP-OLAP Modeling Assumptions
• Disjointness: OLTP-OLAP transformations restricted to group-
ings with disjoint groups
• Completeness: Groupings cover the entire set of database ob-
jects.
• P-subset invariance: Fact values are stable if the OLTP
database is restricted to objects based on the policy P.
• P-union invariance: Fact values are stable if the OLTP database
is extended by new objects depending on the policy P.
• Equidistance: Linear transformations
47

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
The Good Message�� ��EER Functions Enable Complete OLAP
• operations on views (selection as dice, projection as slice, general-
ized relational algebra)
• calculation functions, visualization functions
• group-by as roll-up (drill-up), un-nest as drill-down
• schema restructuring operation for unfold (e.g., drill-down), fold
(nest), classification
B. Thalheim, Entity-Relationship Modeling –
Foundations of Database Technology.
Springer 2000, 640pp.
48

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Modeling Assumptions: Drill-DownFunctions
Decomposing groups of data along a hierarchy, refine grouping
Observation 1.Drill-down functions are well defined if the cube construction is
based on disjointness and completeness modeling assumptions.
Observation 2.Drill-down functions are well defined if data granularity is guaranteed
at leaf level L1 and no structural null are used at any level Li (i > 1)
in between.
49

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Modeling Assumptions: Roll-Up Functions
used for combining groups along a hierarchy, i.e., for fusion of groups.
Problematic for collapsing hierarchiesespecially in the case of algebraic and holistic aggregation functions
Observation 3.Roll-up functions are only well-defined if data granularity is guaran-
teed at leaf level L1 and no structural null are used at any level Li(i > 1) in between.
Observation 4.Roll-up functions must be query-invariant, i.e. for the roll-up func-
tion f and the query function ψ:
ψ(x1, ...xn) = ψ(f(x1), ...., f(xn)) .
Observation 5.The Simpson paradox is observed if for groups at roll-up level Lp ≼Lr(∀j(f(Gij) < f(Gkj))) ⇒ f(
∑nj=1Gij) < f(
∑nj=1Gkj)
50

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Modeling Assumptions: Dice Functions
! projection, marginalization (statistics),∑
unions of values
unproblematic for distributive functions combinable with repairing functions
Observation 6.The Simpson paradox is observed if for groups at roll-up level Lp ≼ Lr
(∀j(f(Gij) < f(Gkj))) ⇒ f(∑n
j=1Gij) < f(∑n
j=1Gkj)
Observation 7.Dice functions can only correctly be applied if the cube construction is based
on union invariance, i.e. aggr(⊔∗o∈Gi
value(o)) = ⊔∗o∈Gi
(aggr(value(o))) for
groups Gi along dimensions.
If f is distributive then the ⊔∗ ≡ f .
If f is algebraic then repair functions must be applied.
Observation 8.Dice functions can only be used along dimensions for which constraints among
cube dimensions are not lost, i.e. Σ|π(X) |= π(X)(Σ).
Observation 9.Dice functions must be based on disjointness and completeness modeling as-
sumptions.
51

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Modeling Assumptions: Slice Functions
Requirement for applicability: query-invariance,
for the roll-up function f and the query function ψ:
ψ(x1, ...xn) = ψ(f(x1), ...., f(xn)) .
Observation 10.
Slice functions must be subset invariant.
Constraints invalidated by subset construction are those integrity con-
straints that have to be expressed through ∀∃-constraints, e.g., in-
clusion dependencies, multivalued dependencies, tuple-generating con-
straints.
52

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Modeling Assumptions: OLTP-OLAPTransformations
Modeling pragmatism, e.g.,
• instead of arithmetic average function: mean average, weighted average, root
mean square, average mean, moving average, weighted average
very sensitive to extreme values such as outliers and may be distorted by them
• arithmetic averages may be normalized by skew functions
Averages are measures of central tendency. The median is the middle-most value in
an ordered set.
Observation 11.Application of median instead of mean average functions for aggregation leads
to more stable OLAP query operations.Observation 12.Harmonic mean functions n∑n
i=11xi
are shift-invariant, additive, symmetric, con-
tinuous, and homogeneous.Observation 13.Geometric mean functions n√x1 · x2 · ... · xn provide a better picture for relative
scales among values and are OLAP query invariant.Observation 14.The sampling frequency must be based on the Sampling Theorem and the
generalizations of Nyquist.
53

ISE, CAU, D
Colloquium FU Berlin
May 12, 2005
B. Thalheim
Overview
State-of-the-art
Aggregation
OLAP cube
Schemata
Methodology
Concluding
Concept Topic
Content
Information
Concluding
• Aggregation functions and OLAP computation functions do not fit
to each other
• Aggregation functions are too powerful
• Variety of paradoxes
• Development of an application repository for OLAP applications
• Our solution: OLTP-OLAP spefication frame
• Derivation or proof of modeling assumptions
• Development of methodologies for OLAP applications
• Future research: Constraints and OLAP functions
• Future research: Theory of database aggregations and abstractions
54


![Categories of OLAP - ir.nuk.edu.tw08]CategoriesofOLAP.pdf1 Categories of OLAP Categories of OLAP tools MOLAP, ROLAP, HOLAP, DOLAP OLAP extension to SQL ROLLUP, CUBE, RANK() OVER, Windowing](https://img.pdfslide.us/doc/110x75/5e0b59f2ce10385c4841823b/categories-of-olap-irnukedutw-08-categories-of-olap-categories-of-olap-tools.jpg)


























