Embed Size (px)
Citation preview

Overview
• Recording archiving and sharing the process and the results of experimental data is a challenge
What to store?
How to store it?
Why?

Science is complicated

Technology
• Complex experimental workflow• Advances in instrumentation• High-through methods

Analysis is complicated
12181 acatttctac caacagtgga tgaggttgtt ggtctatgtt ctcaccaaat ttggtgttgt 12241 cagtctttta aattttaacc tttagagaag agtcatacag tcaatagcct tttttagctt 12301 gaccatccta atagatacac agtggtgtct cactgtgatt ttaatttgca ttttcctgct 12361 gactaattat gttgagcttg ttaccattta gacaacttca ttagagaagt gtctaatatt 12421 taggtgactt gcctgttttt ttttaattgg gatcttaatt tttttaaatt attgatttgt 12481 aggagctatt tatatattct ggatacaagt tctttatcag atacacagtt tgtgactatt 12541 ttcttataag tctgtggttt ttatattaat gtttttattg atgactgttt tttacaattg 12601 tggttaagta tacatgacat aaaacggatt atcttaacca ttttaaaatg taaaattcga 12661 tggcattaag tacatccaca atattgtgca actatcacca ctatcatact ccaaaagggc 12721 atccaatacc cattaagctg tcactcccca atctcccatt ttcccacccc tgacaatcaa 12781 taacccattt tctgtctcta tggatttgcc tgttctggat attcatatta atagaatcaa

Analysis
• New algorithms and software• Data integration• From multiple sources• Genomics• Proteomics• Metabolomics• Neuroscience• Systems biology
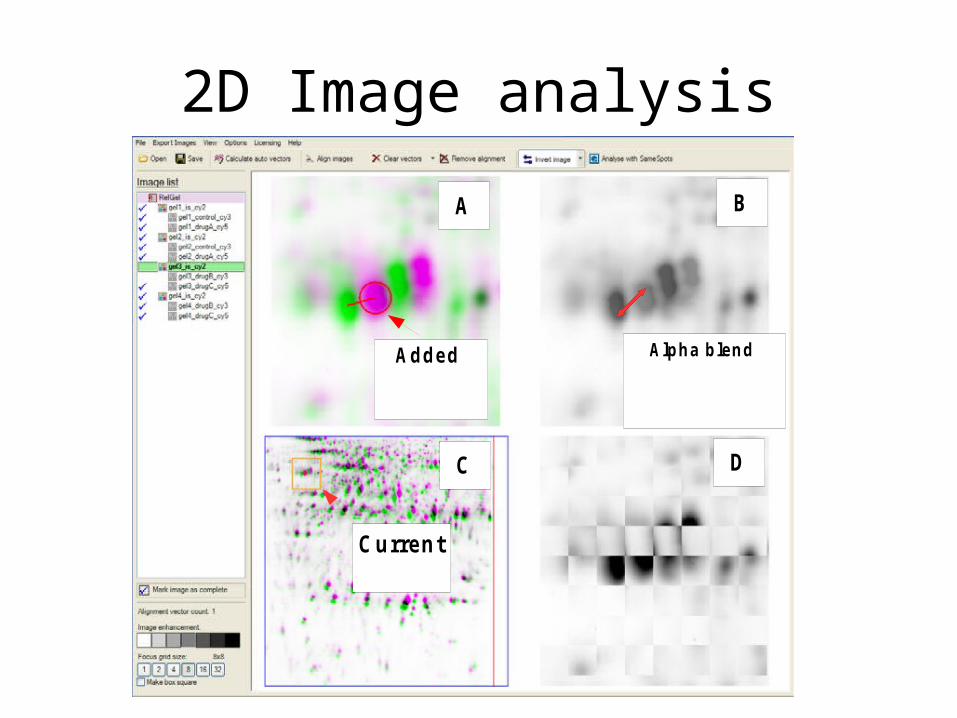
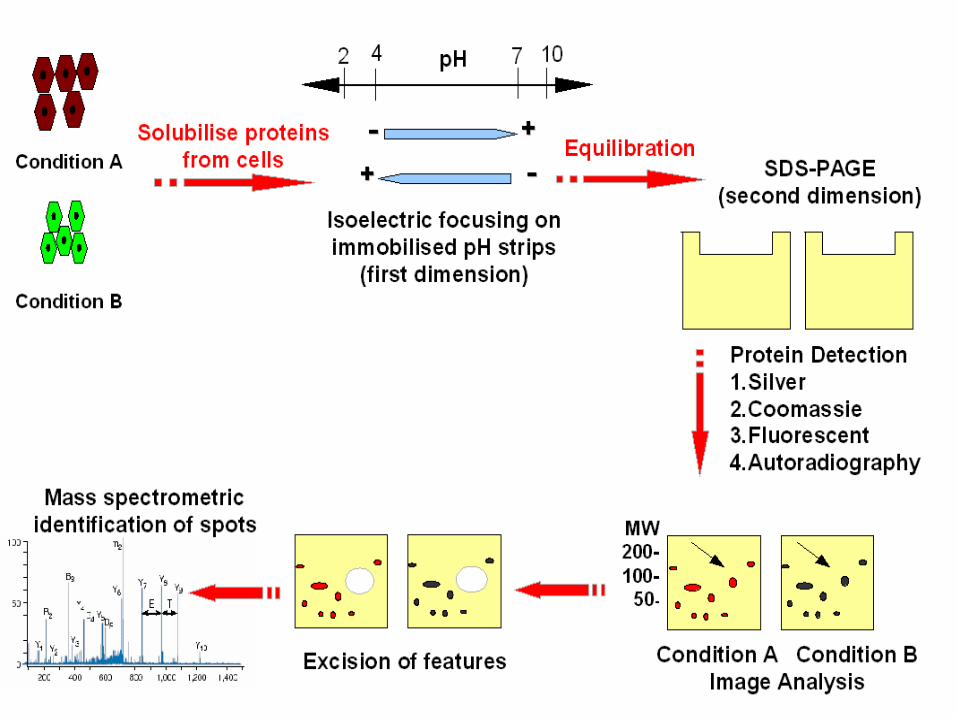
2D Image analysis
A B
C D
Added alignment
vector
Alpha blend display anim ates betw een current
and reference
Currentfocus

Problems
• “In the standard model, one collects data, publishes a paper or papers and then gradually loses the original dataset.”
• THE NEW KNOWLEDGE ECONOMY AND SCIENCE AND TECHNOLOGY POLICY Geoffrey Bowker, University of California, San Diego

Problems
• Large, complex datasets are commonplace,
• Heterogeneous data formats– Vendor specific, Lab specific
• Multitude of analysis methods– Proprietary, open source

Benefits
• Knowledge discovery – results
• Sharing of best practice
• Evaluation of results
• Sharing of data
• Re-use

Re-use of neuroscience datasets
• Data that is shared and can be interpreted can often be used to address multiple questions.
• Data that have been collected with one question in mind often turn out to be highly valuable to address other questions
• (1) Hippocampus recordings for mapping place fields were the basis for high-profile papers addressing questions concerning temporal organization of neural codes (PMID: 12891358 ).
• (2) Paired recordings using extracellular and intracellular electrodes originally collected for detecting dendritically generated action potentials provide ground truth for testing and comparing spike-sorting techniques (PMID: 10899214 ).

CARMENCode, Analysis, Repository and Modelling for e-Neuroscience
www.carmen.org.uk
Engineering and Physical Sciences Research Council

Virtual Laboratory for Neurophysiology
• Enabling sharing and collaborative exploitation of data, analysis code and expertise that are not physically collocated

Cost
• Infrastructure
• Acquisition – data and metadata
• Developing a common representation
• Potential benefits are not always experienced by data producers
• Lab experimenter vs bioinformatician
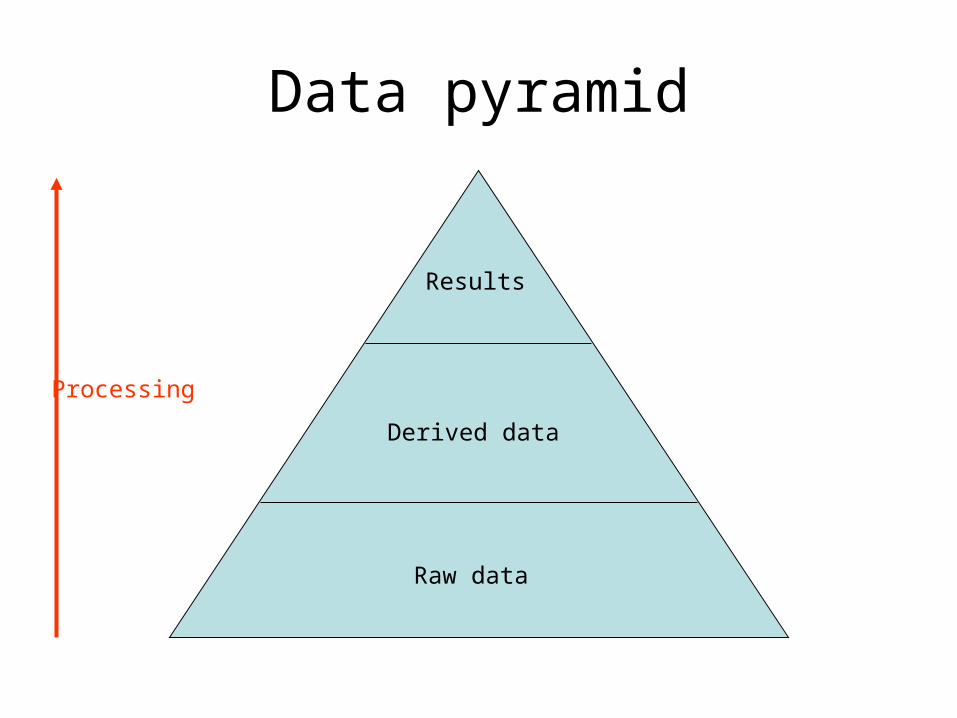
Data pyramid
Raw data
Derived data
Results
Processing
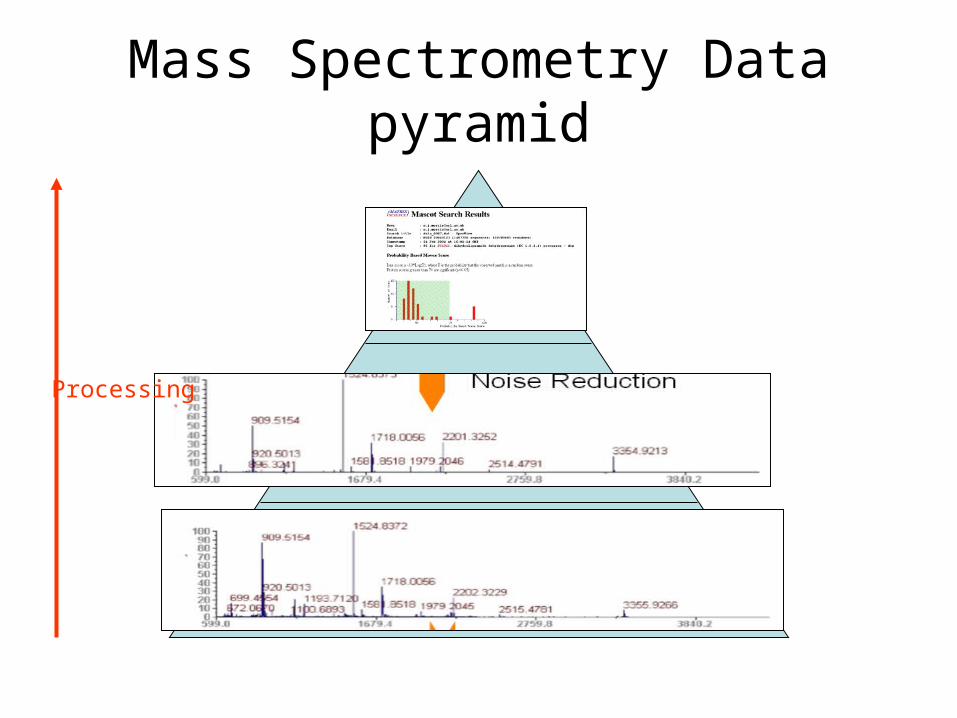
Mass Spectrometry Data pyramid
Raw data
Derived data
Results
Processing

How do we store the data?
• Dictated by form of access• Raw data, typically vendor specific formats for
vendor specific software analysis• Derived data – unlimited formats – higher level
of access required to determine results• Results – often queries over derived data• Problematic if derived data are represented in
inconsistent structures • – consistent representation is valuable

Metadata
• Description of results• Sample• How it was generated• Equipment• Processing steps• Expensive to capture• Important to validate
result
Lab-book
Lab-book
Lab-book
Lab-book
Lab-book
Lab-book
Lab-book
Lab-book
Lab-book

Standards
• Science is a challenge• Scientific data is complex• Different data representations add further
complexity to complex science• We need a common representation of data
to get back to just complex science• Lots of individuals have created formats in
isolation – only works for their data in their lab

What is a standard?
• “established by consensus and approved by a recognized body, that provides, for common and repeated use, rules, guidelines or characteristics for activities or their results, aimed at the achievement of the optimum degree of order in a given context“
• BSI -• http://www.bsi-global.com/en/Standards-and-Publications/About-standards/Glossary/

Community standards development
KnowledgeKnowledge
Standards: allow working together for knowledge discovery

Standards bodies
• W3C -World wide web consortium (W3C)
• IEEE - Institute of Electrical and Electronics Engineers
• OMG – Object management group
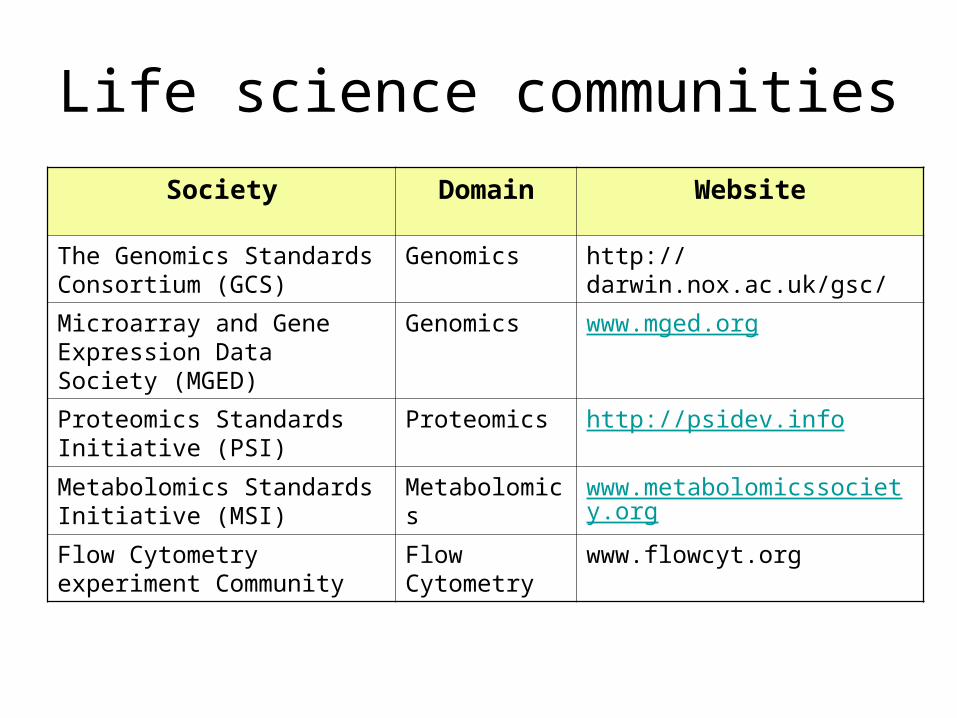
Life science communities
Society Domain Website
The Genomics Standards Consortium (GCS)
Genomics http://darwin.nox.ac.uk/gsc/
Microarray and Gene Expression Data Society (MGED)
Genomics www.mged.org
Proteomics Standards Initiative (PSI)
Proteomics http://psidev.info
Metabolomics Standards Initiative (MSI)
Metabolomics www.metabolomicssociety.org
Flow Cytometry experiment Community
Flow Cytometry
www.flowcyt.org

Technologies for data standards
• Important to adopt a technology that provides a clear representation of the domain
• The model and the model documentation capture a shared understanding of the domain
• Many technologies exist which support modelling
• Each focuses on a different use such a validation, code generation and data transmission

Technologies being used
• Simple text documents or spreadsheets
• XML - Extensible Markup Language
• RDF – Resource Description Framework
• UML – Unified Modeling Language
• OWL – Web ontology Language
• OBO – Open Biomedical Ontology format

Simple documents
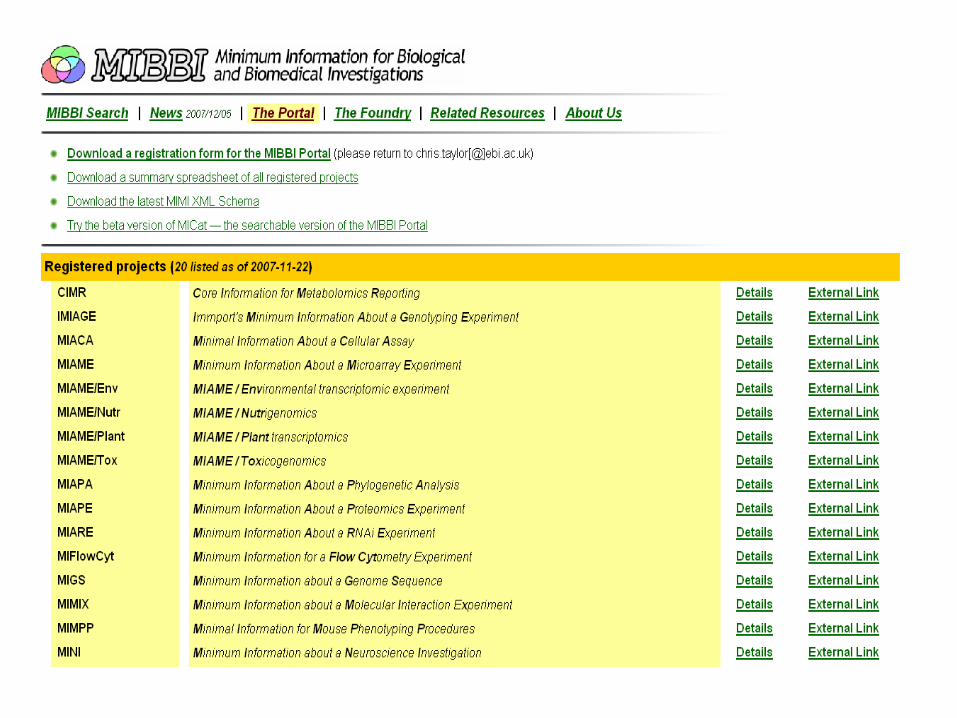
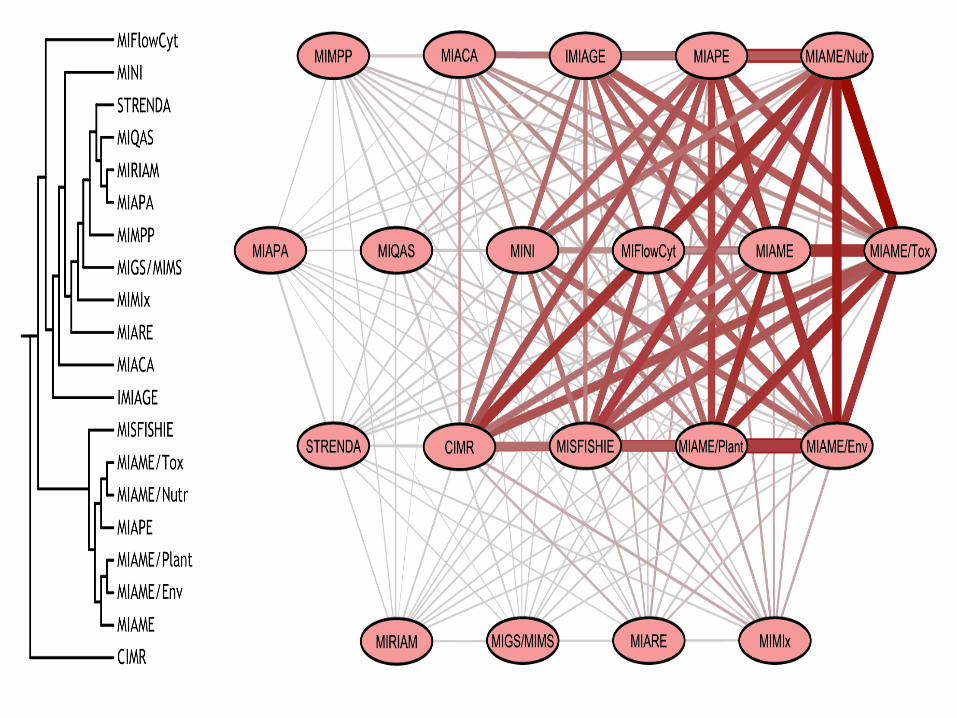
• A list of what is required
• MIxxx Minimum information XXX
• MIAME
• Minimum information about a Microarray Experiment
• MAIPE
• Minimum information about a Proteomics Experiment

MIAPE:GE
• Identifies the minimum information required to report the use of n-dimensional gel electrophoresis in a proteomics experiment

XML
• Widely used for representing biological information• Mark up sections with elements• Validates against a schema
<lecture><to>Bioinformatics students</to><from>Frank Gibson</from><title>Representation of scientific data </title><feedback>Students all fell asleep </feedback></lecture>

UML
• An implementation independent model
• Allows multiple technology implementations of the same model
• Such as
• XML, JAVA, Relational tables
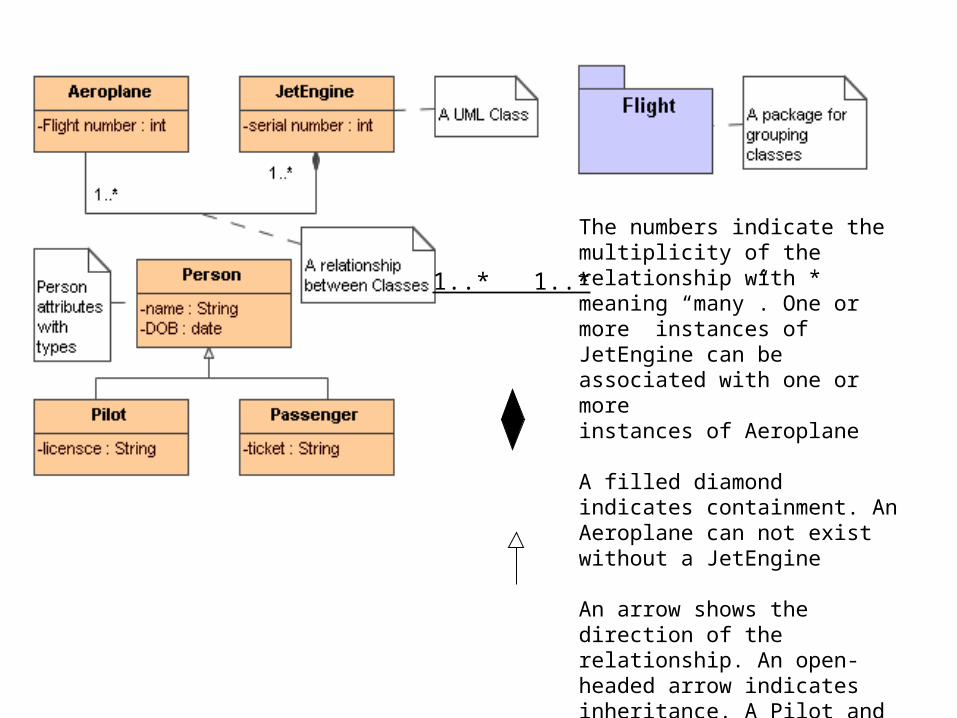
The numbers indicate the multiplicity of the relationship with * meaning “many”. One or more instances of JetEngine can be associated with one or more instances of Aeroplane
A filled diamond indicates containment. An Aeroplane can not exist without a JetEngine
An arrow shows the direction of the relationship. An open-headed arrow indicates inheritance. A Pilot and a Passenger are both instances of Person, inheriting the attributes “name” and “DOB”.
1..* 1..*
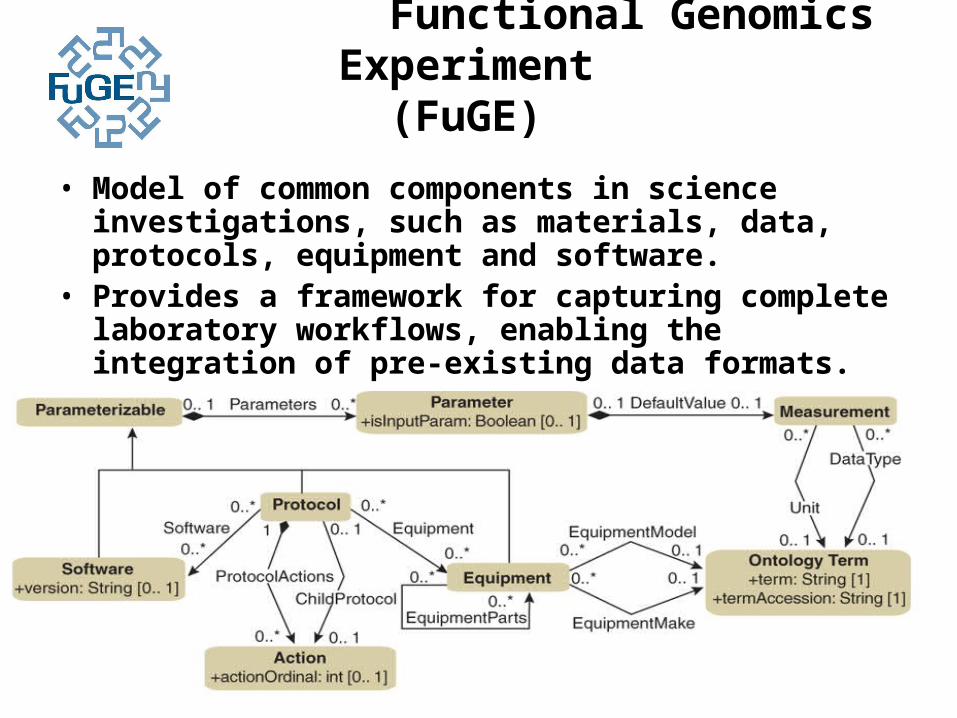
Functional Genomics Experiment (FuGE)
• Model of common components in science investigations, such as materials, data, protocols, equipment and software.
• Provides a framework for capturing complete laboratory workflows, enabling the integration of pre-existing data formats.
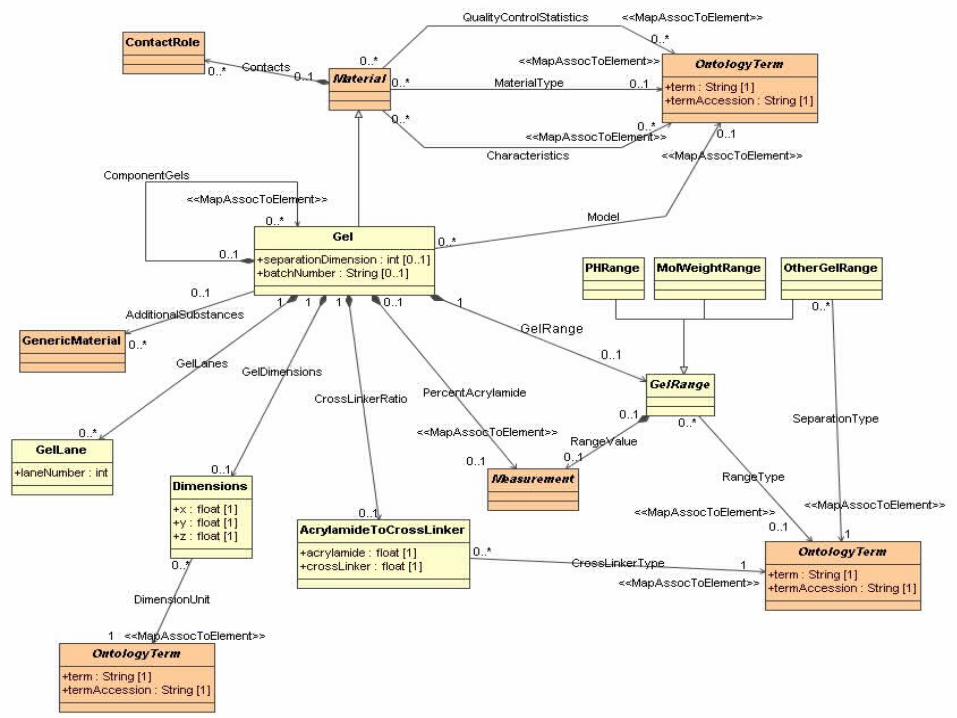
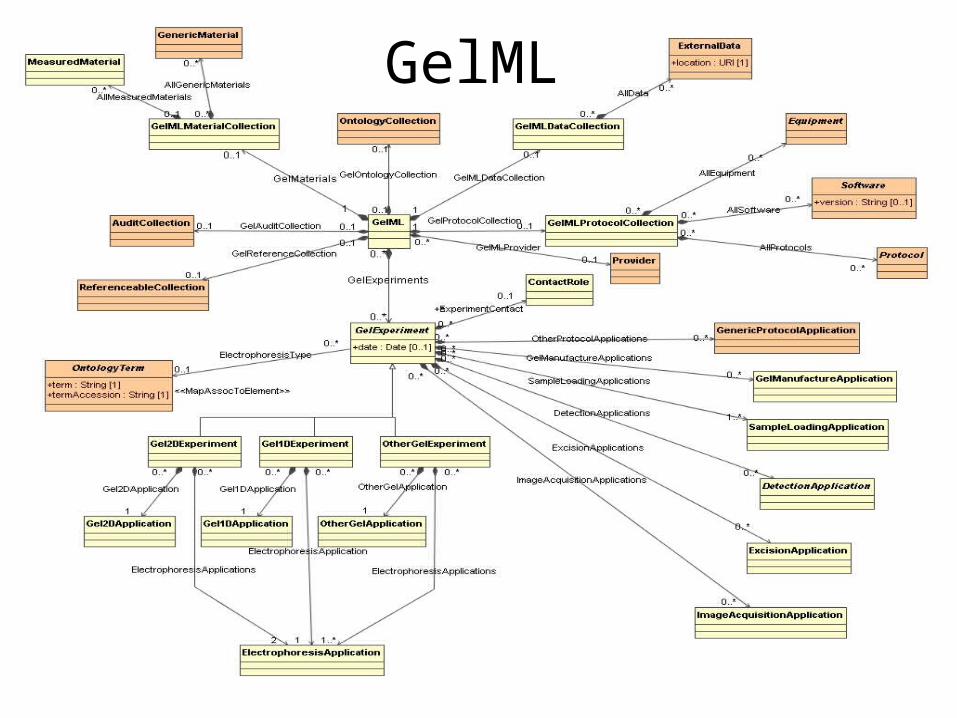
GelML
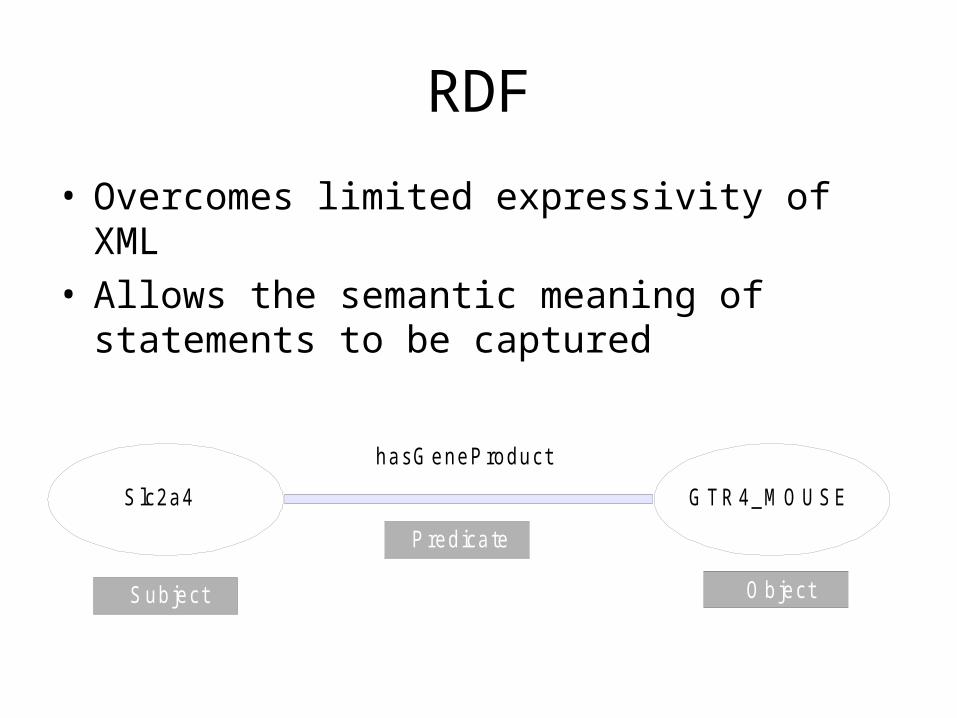
RDF
• Overcomes limited expressivity of XML• Allows the semantic meaning of statements to
be captured
G TR 4_M O U SESlc2a4
hasG eneProduct
Subject
P redicate
O bject
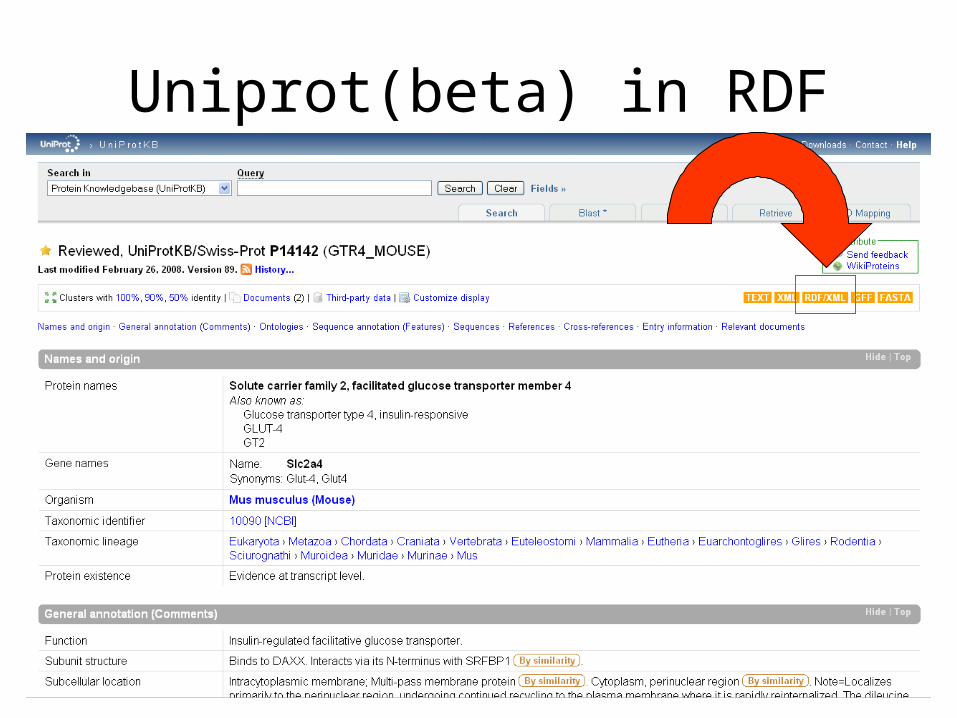
Uniprot(beta) in RDF

Ontolgies for Life science
• Emergence has occurred for two reasons
• Consistent annotation of data
• To add meaning and understanding that can be interpreted computationaly
• Bio-ontologies registered on the OBO foundry
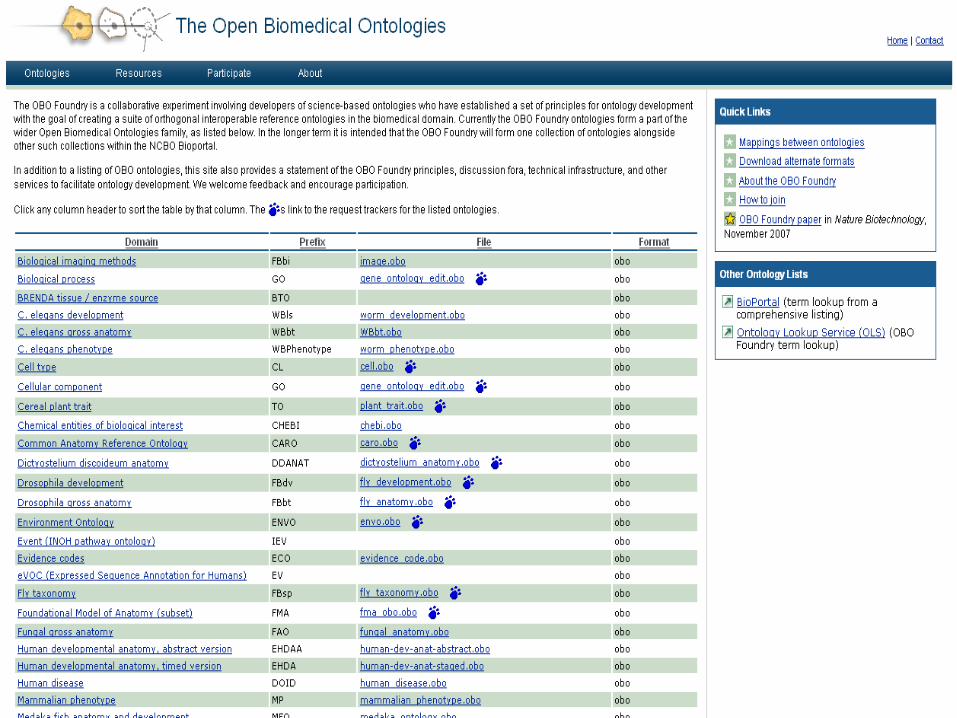

Bio-ontologies
• OBO format
• Flat file format, more suited to controlled vocabularies, made popular by GO
• OWL
• W3C recommendation, designed for computers not humans
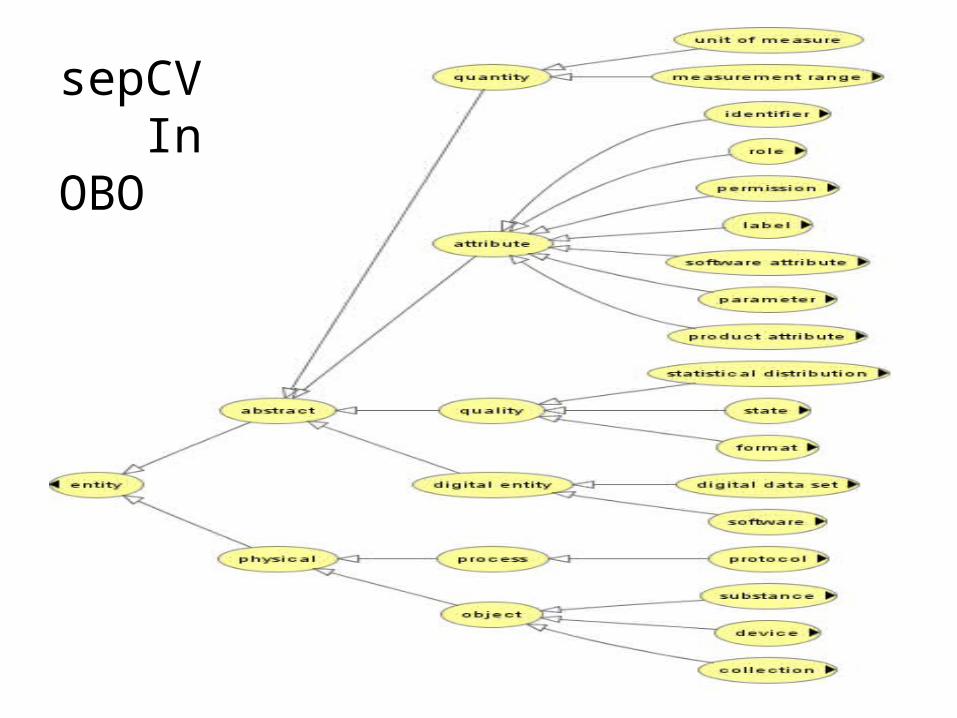
sepCV InOBO

OBI
• An ontology for all investigations in the life sciences
• Implemented in OWL• Large community
involvement• sepCV to be
integrated within OBI

Tools
• Tools are important• Biologist don’t want to look at XML• Need data entry tools – a website…• Direct export of data and metadata from
instruments• Equipment vendors and manufactures need to
be involved in the “community” of standards development
• Tools lag behind development of the standard

Symba - data entry and storage

The Representation of Scientific Data
The Road Map

Patience
• Standards development is slow it requires
• A measure of technical and political consensus
• An organisational framework
• Individuals who are willing to contribute time and expertise, both domain experts and knowledge engineers (modellers)

The Problem
• Identify the problem
• Identify the users that need the problem solved
• Requirements gathering – what do the users need?
• See if someone else has already done it!
• If so, use it and go to the pub

Implementation
• Define the problem – MIxxx
• Model the problem – UML (FuGE)
• Generate an implementation (XML)
• Define semantics - Ontologies

Testing and ReviewStage One: Requirements gathering
– Extensive interactions with the community– Consideration of several (informal) use cases– Internal generation of first draft of guidelines
Stage Two: Module Testing– Guidelines used to document real experiments– Feedback gathered on coherence and practical usability
Stage Three: Committee review– Build an invited panel of leaders in the particular technique– Send draft for ‘review’ by experts on an individual basis– Final round of discussion by panel on email list
Stage Four: Controlled release– Make the module publicly available– Recommend to organised groups and proactive individuals– Provide mechanisms to gather feedback– Released alongside practical examples of use cases
Stage Five: Enforcement– Offer the module to journals, repositories and funders for review, with a view to their enforcing it
(either to get published, or to get money)
Cycle
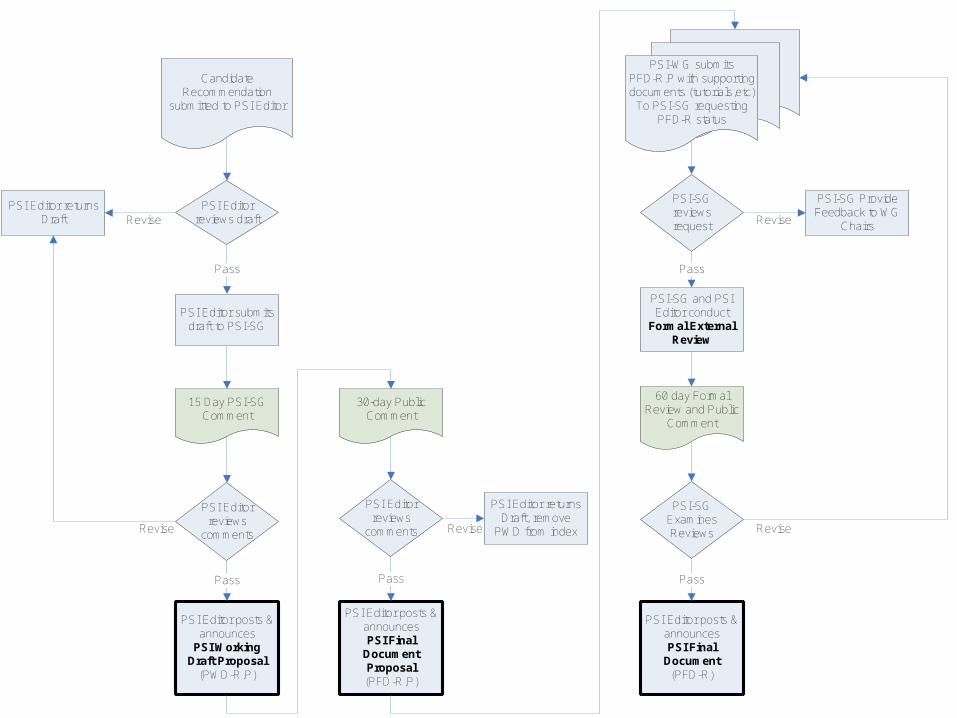
Candidate Recommendation
submitted to PSI Editor
PSI Editor reviews draft
PSI Editor submits draft to PSI-SG
PSI Editor returns Draft Revise
Pass
15 Day PSI-SG Comment
PSI Editor reviews
comments
PSI Editor posts & announces
PSI Working Draft Proposal
(PWD-R.P)
Revise
Pass
30-day Public Comment
PSI Editor reviews
comments
PSI Editor returns Draft, remove
PWD from indexRevise
PSI Editor posts & announces PSI Final
Document Proposal(PFD-R.P)
Pass
PSI-WG submits PFD-R.P with supporting documents (tutorials,etc)
To PSI-SG requestingPFD-R status
PSI-SG reviews request
PSI-SG Provide Feedback to WG
Chairs
PSI-SG and PSI Editor conduct
Formal External Review
Pass
Revise
60 day Formal Review and Public
Comment
PSI-SG Examines Reviews Revise
PSI Editor posts & announces PSI Final
Document(PFD-R)
Pass

Tool support
• Tool support
• Can occur in parallel but often after release
• Abstraction away from the model
• Simple data entry – often website
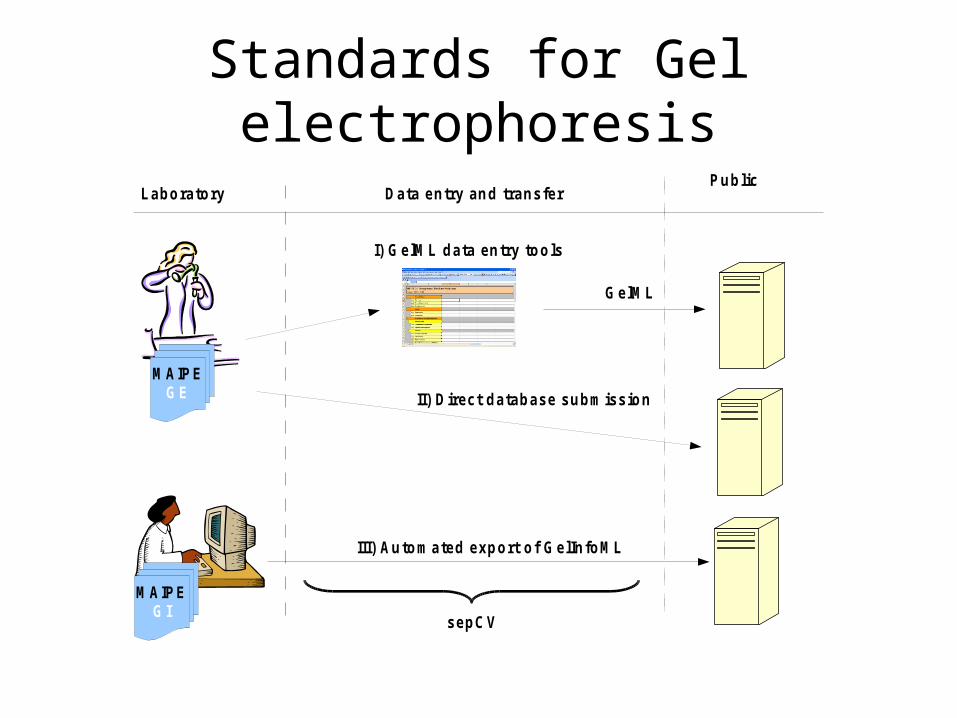
Standards for Gel electrophoresis
MAIPEGE
MAIPEGI
LaboratoryPublic repositoriesData entry and transfer
I) GelML data entry tools
GelML
II) Direct database submission
III) Automated export of GelInfoML
sepCV

Pitfalls
• Re-invention. Don’t re-invent the wheel! If it exists use it
• Over ambition: pragmatic compromise don’t over complicate it or it will not get used. - keep it simple stupid
• Under investment – money, time, but most importantly with the people that will use it.

What is the point?
• Facilitate consistent computational analysis
• Develop one piece of code to do one thing instead of lots of code to do one thing
• Easier lab management of data
• Storage and analysis
• Allow data integration and systems biology
• Efficient science

Take away message
• Mixx
• FuGE
• OBI
• They have done the hard work
• Re-use, extend and contribute

Questions?

Data mining
mine
mine
Keepout
mine
Data is mine, mine mine….
Data store






























