Embed Size (px)
Citation preview

1
1
The Importance of Being ConsistentDB2 for z/OS and Copy Services for IBM System z
Florence Dubois
IBM DB2 for z/OS Development
Session Code: F09
Thursday 5th May, 2011 8:30AM-9:30AM | Platform: DB2 for z/OS
This presentation will tell you everything you need to know about the Copy Services for
IBM System z (DASD replication functions) and what is required to ensure data
consistency.

2
Agenda
• Introduction
• IBM Remote Copy Services
• Metro Mirror
• z/OS Global Mirror
• Global Copy
• Global Mirror
• DB2 Restart Recovery
• Tune for fast restart
• Optimise GRECP/LPL recovery
• FlashCopy
• FlashCopy and DB2
• FlashCopy and Remote Copy Services
• Conclusion
Objectives:
Introduce and compare Metro Mirror (PPRC), z/OS Global Mirror (XRC), Global Copy
and Global Mirror
Address the most common myths and misconceptions about these solutions
Discuss important concepts and functions such as Rolling Disaster, Consistency Groups,
HyperSwap and FREEZE policies (GO|STOP)
Provide hints and tips on how to tune for fast DB2 restart and how to optimise
GRECP/LPL recovery
Look at how DB2 uses FlashCopy, and discuss all the gotchas of combining FlashCopy
and Remote Copy Services

3
Introduction
• Everything should start with the business objectives
• ‘Quality of Service’ requirements for applications
• Availability
• High availability? Continuous operations? Continuous availability?
• Restart quickly? Mask failures?
• Performance
• In case of a Disaster
• Recovery Time Objective (RTO)
• How long can your business afford to wait for IT services to be resumed following a disaster?
• Recovery Point Objective (RPO)
• What is the acceptable time difference between the data in your production system and the
data at the recovery site (consistent copy)?
• In other words, how much data is your company willing to lose/recreate following a disaster?
• Need to understand the real business requirements and expectations
• These should drive the infrastructure, not the other way round

4
Introduction …
• Dependent writes
• The start of a write operation is dependent upon the completion of a previous write
to a disk in either the same storage subsystem or a different storage subsystem
• For example, typical sequence of write operations for a database update transaction:
1. An application makes an update and the data page is updated in the buffer pool
2. The application commits and the log record is written to the log device on storage subsystem 1
3. The update to the table space is externalized to storage subsystem 2
4. A log record is written to mark that the table space update has completed successfully
• Consistency
• Preserve the order of dependent writes
• For databases, consistent data provides the capability to perform a database restart
rather than a database recovery
• Restart can be measured in minutes while recovery could be hours or even days

5
Metro Mirror
• a.k.a. PPRC (Peer-to-Peer Remote Copy)
• Disk-subsystem-based synchronous replication
• Limited distance
• Over-extended distance can impact the performance of production running on the primary site
2
3
1
4
Host I/O
P S
(1) Write to primary volume (disk subsystem cache and NVS)
(2) Metro Mirror sends the write I/O to secondary disk subsystem
(3) Secondary disk subsystem signals write complete when the updated data is in its cache and NVS
(4) Primary disk subsystem returns Device End (DE) status to the application

6
Metro Mirror …
• Misconception #1: Synchronous replication always guarantees data
consistency of the remote copy
• Answer:
• Not by itself…
• Metro Mirror operates at the device level (like any other DASD replication function)
• Volume pairs are always consistent
• But in a rolling disaster, cross-device (or boxes) consistency is not guaranteed
• An external management method is required to maintain consistency

7
Metro Mirror …
• Traditional example of multiple disk subsystems
• In a real disaster (fire, explosion, earthquake), you can not expect your complex
to fail at the same moment. Failures will be intermittent, gradual, and the disaster
will occur over seconds or even minutes. This is known as the Rolling Disaster.
S3
S4
P3
P4
S1
S2
P1
P2
Devices suspend on this
disk subsystem but writes
are allowed to continue (*)
(*) Volume pairs are defined with
CRIT(NO) - Recommended
Updates continue to be sent
from this disk subsystem
Devices on
secondary disk
subsystems are not
consistent
Network failure causes
inability to mirror data to
secondary site

8
Metro Mirror …
• Example of suspend event for a single volume
S1
S2
P1
P2
1) Temporary communications problem causes P1-S1
pair to suspend e.g. network or SAN event
2) During this time no I/O occurs
to P2 so it remains duplex
3) Subsequent I/O to P2 will be
mirrored to S2
4) S1 and S2 are now not consistent and if the problem
was the first indication of a primary disaster we are
not recoverable

9
Metro Mirror …
• Consistency Group function combined with external automation
S1
S2
P1
P2
1) Network failure causes
inability to mirror data to
secondary site
2) The volume pair defined with CGROUP(Y) that first
detects the error will go into an ‘extended long busy’
state and IEA494I is issued
3) Automation is used to detect the alert and issue the
CGROUP FREEZE command(*) to all LSS pairs
5) Automation issues the CGROUP RUN(*) command to
all LSS pairs releasing the long busy. Secondary
devices are still suspended at a point-in-time
4) CGROUP FREEZE(*) deletes Metro Mirror
paths, puts all primary devices in long busy
and suspends primary devices
(*) or equivalent
Without automation, it can take a very long time to suspend all devices with
intermittent impact on applications over this whole time

10
Metro Mirror …
• Misconception #1: Synchronous replication always guarantees data
consistency of the remote copy
• Answer:
• In case of a rolling disaster, Metro Mirror alone does not guarantee data
consistency at the remote site
• Need to exploit the Consistency Group function AND external automation to
guarantee data consistency at the remote site
• Ensure that if there is a suspension of a Metro Mirror device pair, the whole environment
is suspended and all the secondary devices are consistent with each other
• Supported for both planned and unplanned situations

11
Metro Mirror …
• Misconception #2: Synchronous replication guarantees zero data loss in a
disaster (RPO=0)
• Answer
• Not by itself…
• The only way to ensure zero data loss is to immediately stop all I/O to the primary
disks when a suspend happens
• e.g. if you lose connectivity between the primary and secondary devices
• FREEZE and STOP policy in GDPS/PPRC
• GDPS will reset the production systems while I/O is suspended
• Choosing to have zero data loss really means that
• You have automation in place that will stop all I/O activity in the appropriate circumstances
• You accept a possible impact on continuous availability at the primary site
• Systems could be stopped for a reason other than a real disaster (e.g. broken remote copy link
rather than a fire in the computer room)

12
Metro Mirror …
• Misconception #3: Metro Mirror eliminates DASD subsystem as single point
of failure (SPOF)
• Answer:
• Not by itself...
• Needs to be complemented by a non-disruptive failover HyperSwap capability
e.g.,
• GDPS/PPRC Hyperswap Manager
• Basic Hyperswap in TPC-R
P S
applicationapplication
UCB
PPRC
UCB1) Failure event detected
2) Mirroring
suspended and I/O
quiesced to ensure
data consistency
3) Secondary
devices made
available using
failover command
4) UCBs swapped
on all systems in
the sysplex and I/O
resumed

13
z/OS Global Mirror
• a.k.a. XRC (eXtended Remote Copy)
• Combination of software and hardware functions for asynchronous
replication WITH consistency
• Involves a System Data Mover (SDM) on z/OS in conjunction with disk
subsystem microcode
3
1
2
Host I/O
P
4
S
J5
SDM
(1) Write to primary volume
(2) Primary disk subsystem posts I/O complete
Every so often (several times a second):
(3) Offload data from primary disk subsystem to SDM
(4) CG is formed and written from the SDM’s buffers to the SDM’s journal data sets
(5) Immediately after the CG has been hardened on the journal data sets, the records are written to their
corresponding secondary volumes

14
z/OS Global Mirror …
• Use of Time-stamped Writes and Consistency Groups to ensure data
consistency
• All records being written to z/OS Global Mirror primary volumes are time stamped
• Consistency Groups are created by the SDM
• A Consistency Group contains records that the SDM has determined can be safely
written to the secondary site without risk of out-of-sequence updates
• Order of update is preserved across multiple disk subsystems in the same XRC session
• Recovery Point Objective
• Amount of time that secondary volumes lag behind the primary depends mainly on
• Performance of the SDM (MIPS, storage, I/O configuration)
• Amount of bandwidth
• Use of device blocking or write pacing
• Pause (blocking) or slow down (pacing) I/O write activity for devices with very high update rates
• Objective: maintain a guaranteed maximum RPO
• Should not be used on the DB2 active logs (increased risk of system slowdowns)

15
Global Copy
• a.k.a. PPRC-XD (Peer-to-Peer Remote Copy Extended Distance)
• Disk-subsystem-based asynchronous replication WITHOUT consistency
3
4
1
2
Host I/O
P S
(1) Write to primary volume
(2) Primary disk subsystem posts I/O complete
At some later time:
(3) The primary disk subsystem initiates an I/O to the secondary disk subsystem to transfer the data (only
changed sectors are sent if the data is still in cache)
(4) Secondary indicates to the primary that the write is complete - primary resets indication of modified track

16
Global Copy …
• Misconception #4: Global Copy provides a remote copy that would be usable
in a disaster
• Answer:
• Not by itself…
• Global Copy does NOT guarantee that the arriving writes at the local site are
applied to the remote site in the same sequence
• Secondary copy is a ‘fuzzy’ copy that is just not consistent
• Global Copy is primarily intended for migrating data between sites or between
disk subsystems
• To create a consistent point-in-time copy, you need to pause all updates to the
primaries and allow the updates to drain to the secondaries
• E.g., Use the -SET LOG SUSPEND command for DB2 data

17
Global Mirror
• Combines Global Copy and FlashCopy Consistency Groups
• Disk-subsystem-based asynchronous replication WITH consistency
3
7
1
2
Host I/O
A
1
0
0
0
0
1
0
1
0
0
0
0
1
0
Consistency group
Co-ordination and formation Consistency group save
B
C
Global Copy
Data transmission
(1) Write to primary volume
(2) Primary disk subsystem posts I/O complete
At some later time:
(3) Global Copy is used to transmit data asynchronously between primary and secondary
At predefined time interval:
(4) Create point-in-time copy CG on A-disks – Write I/Os queued for short period of time (usually < 1 ms)
(5) Drain remaining CG data to B-disk
(6) FlashCopy used to save CG to C-disks
(7) Primary disk system notified to continue with the Global Copy process
6
5
4

18
Global Mirror …
• Recovery Point Objective
• Amount of time that the FlashCopy target volumes lag behind the primary
depends mainly on
• Bandwidth and links between primary and secondary disk subsystems
• Distance/latency between primary and secondary
• Hotspots on secondary in write intensive environments
• No pacing mechanism
• Designed to protect production performance at the expense of the mirror currency
• RPO can increase significantly if production write rates exceed the available resources
19
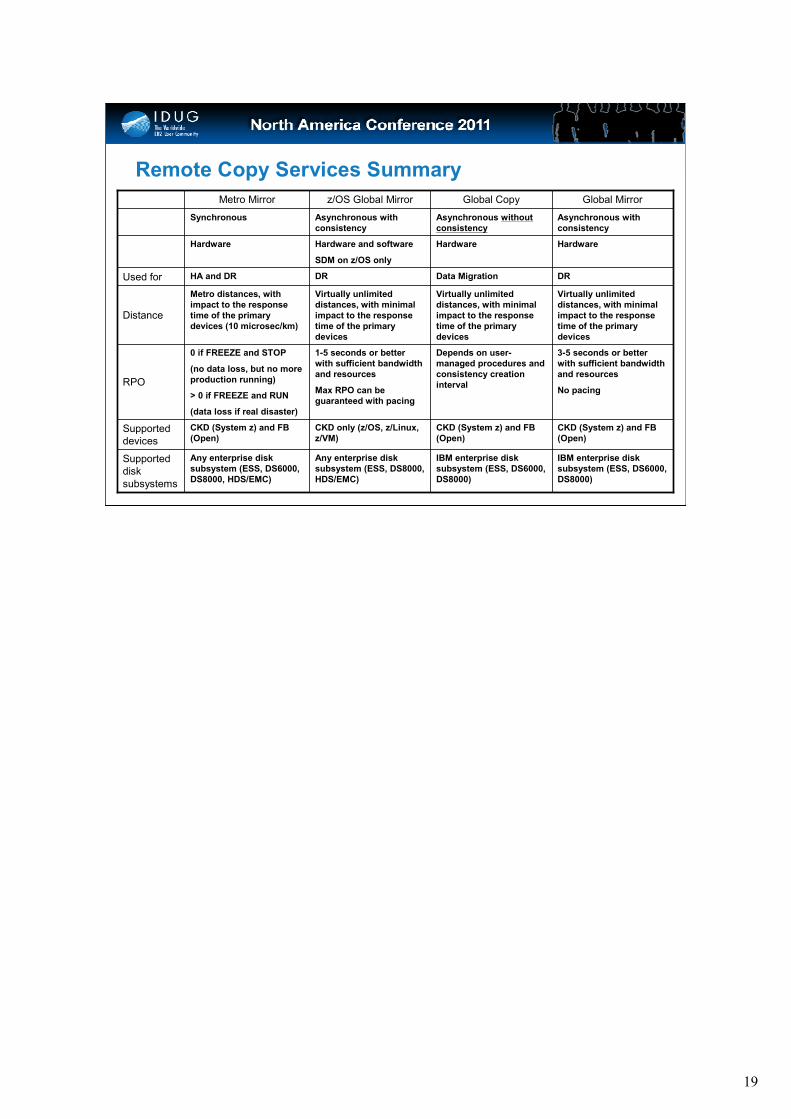
Remote Copy Services Summary
IBM enterprise disk
subsystem (ESS, DS6000,
DS8000)
CKD (System z) and FB
(Open)
Depends on user-
managed procedures and
consistency creation
interval
Virtually unlimited
distances, with minimal
impact to the response
time of the primary
devices
Data Migration
Hardware
Asynchronous without
consistency
Global Copy
IBM enterprise disk
subsystem (ESS, DS6000,
DS8000)
CKD (System z) and FB
(Open)
3-5 seconds or better
with sufficient bandwidth
and resources
No pacing
Virtually unlimited
distances, with minimal
impact to the response
time of the primary
devices
DR
Hardware
Asynchronous with
consistency
Global Mirror
Any enterprise disk
subsystem (ESS, DS8000,
HDS/EMC)
CKD only (z/OS, z/Linux,
z/VM)
1-5 seconds or better
with sufficient bandwidth
and resources
Max RPO can be
guaranteed with pacing
Virtually unlimited
distances, with minimal
impact to the response
time of the primary
devices
DR
Hardware and software
SDM on z/OS only
Asynchronous with
consistency
z/OS Global Mirror
HA and DRUsed for
Hardware
Synchronous
CKD (System z) and FB
(Open)Supported
devices
Any enterprise disk
subsystem (ESS, DS6000,
DS8000, HDS/EMC)
Supported
disk
subsystems
0 if FREEZE and STOP
(no data loss, but no more
production running)
> 0 if FREEZE and RUN
(data loss if real disaster)
RPO
Metro distances, with
impact to the response
time of the primary
devices (10 microsec/km)Distance
Metro Mirror
20
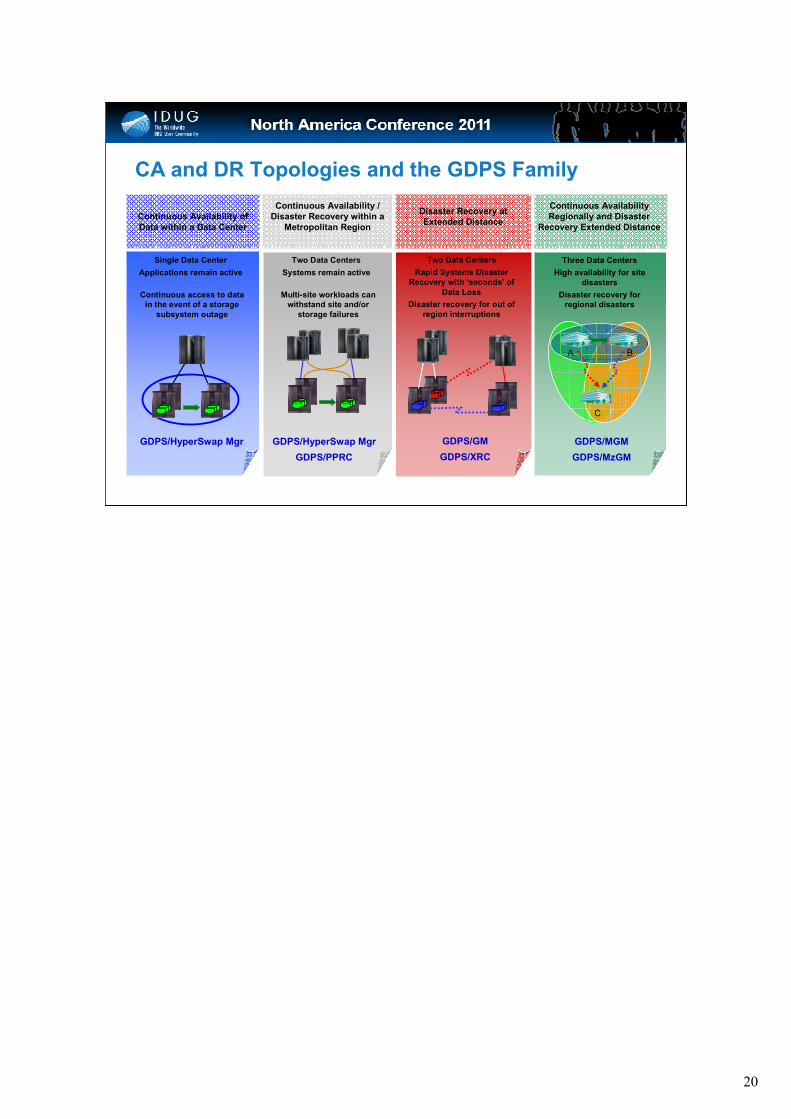
Two Data Centers
Rapid Systems Disaster
Recovery with ‘seconds’ of
Data Loss
Disaster recovery for out of
region interruptions
Multi-site workloads can
withstand site and/or
storage failures
Two Data Centers
Systems remain active
Continuous Availability /
Disaster Recovery within a
Metropolitan Region
GDPS/HyperSwap Mgr
GDPS/PPRC
Continuous Availability
Regionally and Disaster
Recovery Extended Distance
Continuous Availability of
Data within a Data Center
Continuous access to data
in the event of a storage
subsystem outage
Single Data Center
Applications remain active
GDPS/HyperSwap Mgr
Disaster Recovery at
Extended Distance
GDPS/GM
GDPS/XRC
Three Data Centers
High availability for site
disasters
Disaster recovery for
regional disasters
GDPS/MGM
GDPS/MzGM
A B
C
CA and DR Topologies and the GDPS Family

21
DB2 Restart Recovery
• Key ingredient for disk-based DR solutions
• Normal DB2 restart
• Re-establishes DB2 data consistency through restart recovery mechanisms
• Directly impact the ability to meet the RTO
• Must NOT be intended on a mirrored copy that is not consistent
• Guaranteed inconsistent data which will have to be fixed up
• No way to estimate the damage
• After the restart it is too late if the damage is extensive
• Damage may be detected weeks and months after the event
• Data sharing: Do not forget to delete all CF structures owned by the group
• Otherwise, guaranteed logical data corruption

22
DB2 Restart Recovery …
• Tune for fast restart
• Take frequent system checkpoints (2-5 minutes)
• Long-running URs
• Aggressively monitor for long running URs
• Start conservatively when enabling this tracking and adjust the values downwards
progressively
• Initial recommendations
• URLGWTH = 10 (K log records)
• URCHKTH = 5 (system checkpoints)
• Automatically capture warning messages DSNJ031I (URLGWTH) and DSNR035I
(URCHKTH) and/or post process IFCID 0313 records (if Statistics Class 3 is on)
• Need management ownership and process for getting ‘rogue’ applications fixed up in a timely
manner
• Use DB2 Consistent restart (Postponed Abort)
• Limit backout of long-running URs
• LBACKOUT=AUTO
• BACKODUR=5 (interval is 500K log records if time-based checkpoint frequency)

23
DB2 Restart Recovery …
• Optimise GRECP/LPL Recovery
• Frequent castout
• Low CLASST (0-5)
• Low GBPOOLT (5-25)
• Low GBPCHKPT (2-4)
• Use CLOSE YES as design default for tablespaces and indexes
• Set ZPARM LOGAPSTG (Fast Log Apply) to maximum buffer size of 100MB
• Develop an optimised procedure to perform the GRECP/LPL recovery
• Determine objects in GRECP/LPL status that require recovery action
• Start with DB2 Catalog and Directory objects first
• Generate optimal set of jobs to drive GRECP/LPL recovery
• Limit number of objects per -STA DB command to 20-30 objects
• Limit number of -STA DB command per member to 10 (based on 100MB of FLA storage)
• Spread -STA DB commands across all available members

24
DB2 Restart Recovery …
• Optimise GRECP/LPL Recovery …
• DB2 9 can automatically initiate GRECP/LPL recovery at the end of both normal
restart and disaster restart when a GBP failure condition is detected
• Why would I still need a procedure for GRECP/LPL recovery?
• If for any reason the GRECP recovery fails
• Objects that could not be recovered will remain in GRECP status and will need to be
recovered by issuing -START DATABASE commands
• If the GBP failure occurs after DB2 restart is complete
• GRECP/LPL recovery will have to be initiated by the user
• Highly optimised user-written procedures can still outperform the automated
GRECP/LPL recovery on DB2 9
• May want to turn off automated GRECP/LPL recovery if aggressive RTO
• DB2 -ALTER GBPOOL …. AUTOREC(NO)

25
FlashCopy
S
T
1
0
0
0
0
1
0
S
T
1
0
0
0
0
1
0
S
T
1
0
0
0
0
1
0
PIT copy technology on the disk subsystem
When a FlashCopy is issued the copy is available immediately
A bitmap tracks the relationship between source and target tracks
Read and write activity are possible on
both the source and target devices
Writes to the source may cause a copy on write if
the track has not been copied to the target
Reads of tracks on the target that have not been
copied from the source will be redirected to the
source
An optional background copy process
will copy all tracks from the source to the
target which will end the relationship
Several options available for FlashCopy including
• Incremental FlashCopy
• Consistent FlashCopy
• Multiple FlashCopy relationships
• Dataset level FlashCopy
• Space Efficient FlashCopy (OA30816)
• Remote Pair FlashCopy

26
FlashCopy and DB2
• Many applications of the PIT copy created by FlashCopy, e.g.
• Cloning of environments
• Protection during resynchronisation of replication solutions
• System-level PIT backup
• When using FlashCopy to take backups outside of DB2’s control
• Use the DB2 command -SET LOG SUSPEND to temporarily ‘freeze’ all DB2
update activity
• Ensures the PIT copy is a valid base for recovery
• Externalises any unwritten log buffers to active log datasets
• But does not guarantee that the latest version of the data is externalised to DASD
• Need to go through DB2 restart recovery to re-establish DB2 data consistency
• For Data Sharing, you must issue the command on each data sharing member and
receive DSNJ372I before you begin the FlashCopy

27
FlashCopy and DB2 …
• IBM DB2 for z/OS utilities makes more and more use of FlashCopy
• Dataset FC for COPY
• Dataset FC for inline copy in REORG TABLESPACE, REORG INDEX, REBUILD INDEX, LOAD
• FC image copies with consistency and no application outage (SHRLEVEL CHANGE)
• FCIC accepted as input to RECOVER, COPYTOCOPY, DSN1COPY, DSN1COMP, DSN1PRNT
V10
• Incremental FC for BACKUP SYSTEM
• Dataset FC for RECOVER with system-level backup (SLB) as input
• Dataset FC for CHECK DATA SHRLEVEL CHANGE and CHECK LOB SHRLEVEL CHANGE
V9
• BACKUP SYSTEM
• RESTORE SYSTEM
• Dataset FC support for CHECK INDEX SHRLEVEL CHANGE
V8

28
FlashCopy and Remote Copy Services
• FlashCopy and Global Mirror or z/OS Global Mirror (XRC)
• Restriction: A FlashCopy target cannot be established on a device that is part of a
Global Mirror or z/OS Global Mirror volume pair
• What does this mean for the DB2 utilities?
• BACKUP SYSTEM
• The copy pool backup needs to be defined outside of Global Mirror or z/OS Global Mirror
• Object-level RECOVER from SLB
• Standard I/O (slower) is always used when restoring data from a system-level backup
• Consider specifying FASTREPLICATION(DATASETRECOVERY(NONE)) in DFSMShsm
• Eliminates the overhead of always failing the FC before dropping to standard I/O
• RESTORE SYSTEM
• Cannot use FlashCopy to restore the entire DB2 system from a copy pool backup
• But can use a system level backup on tape
• To use FlashCopy to restore the entire DB2 system to a PIT, need to disable mirroring before
running the RESTORE SYSTEM utility

29
FlashCopy and Remote Copy Services
• FlashCopy and Global Mirror or z/OS Global Mirror (XRC) …
• What does it mean for the DB2 utilities? …
• CHECK INDEX|DATA|LOB SHRLEVEL CHANGE
• FlashCopy cannot be used if the temporary shadow dataset is allocated on a mirrored device
• Standard DSS copy will be used
• While the shadow copy is being created, the object is in Read Only mode
• ZPARM UTIL_TEMP_STORCLAS can be used to specify an explicit storage class
• Allow the CHECK utility to use a pool of volumes that are not mirrored
• APAR PM19034 (V9/V10)
• New ZPARM CHECK_FASTREPLICATION (PREFERRED|REQUIRED)
• PREFERRED (default V9) >> Standard I/O will be used if Flash Copy cannot be used
• REQUIRED (default V10) >> CHECK will fail if Flash Copy cannot be used

30
FlashCopy and Remote Copy Services
• FlashCopy and Global Mirror or z/OS Global Mirror (XRC) …
• What does it mean for the DB2 utilities? …
• FlashCopy image copies
• FlashCopy cannot be used if the image copy dataset is allocated on a mirrored device
• Image copy is still taken, but will always use standard I/O (slower)
• Can use SMS to allocate the image copy dataset on a pool of volumes that are not mirrored
• Up to 4 additional sequential format image copies can be created at the same time
• Protection against DASD failure
• Possibility of remote image copy for DR
• RECOVER using FlashCopy image copies
• Standard I/O is always used when recovering from a FlashCopy image copy (slower)
• APAR PM26762
• New ZPARM REC_FASTREPLICATION (NONE|PREFERRED|REQUIRED)
• Consider specifying REC_FASTREPLICATION = NONE >> Eliminates the overhead of
always failing the FC before dropping to standard I/O

31
FlashCopy and Remote Copy Services …
• FlashCopy and Metro Mirror (prior to IBM Remote Pair FlashCopy)
• By default, same restrictions as with Global Mirror and z/OS Global Mirror
• Option FCTOPPRCPrimary on DFSMSdss COPY command was introduced to
allow FlashCopy to Metro Mirror primary volumes
• Support for DFSMShsm in APAR OA23849
• Warning: The Metro Mirror pair will go into Duplex Pending state
• Not acceptable in most cases
• Secondary site may not be recoverable and HyperSwap would fail
S2
P1
P2 Metro Mirror – Duplex Pending
FlashCopy target data will be
available once the Metro Mirror
pair is back in duplex
S1Metro Mirror - Duplex

32
FlashCopy and Remote Copy Services …
• FlashCopy and Metro Mirror (with IBM Remote Pair FlashCopy, aka Preserve Mirror FlashCopy)
• A FlashCopy command issued at the primary site is mirrored at the secondary site
• The FlashCopy source and target volumes must be Metro Mirror primary devices
• Must have microcode and APARs in order to use new function
S1
S2
P1Metro Mirror - Duplex
P2
FlashCopy issued from
one Metro Mirror
device to another
Metro Mirror - Duplex
FlashCopy is executed on
target disk subsystem and
response sent back to host
Primary disk subsystem checks to see if
it is possible to do the FlashCopy on the
remote disk subsystem

33
FlashCopy and Remote Copy Services …
• Preserve Mirror FlashCopy
• z/OS DFSMSdss – New optional sub-keywords to FCTOPPRCPRIMARY
• FCTOPPRCPrimary(PresMirNone)
• If the target volume is a Metro Mirror primary device, the pair will go into a ‘duplex pending’
state as a result of a FlashCopy operation
• This is the default if sub-keyword is not specified
• FCTOPPRCPrimary(PresMirPref)
• If the target volume is a Metro Mirror primary device, the pair may go into a ‘duplex pending’
state as a result of a FlashCopy operation
• FCTOPPRCPrimary(PresMirReq)
• If the target volume is a Metro Mirror primary device, the pair must not go into a ‘duplex
pending’ state as a result of a FlashCopy operation
• This is the option GDPS customers should always use
• As before, if you don’t specify FCTOPPRCPrimary
• A PPRC primary volume is not eligible to become a FlashCopy target volume
• This is the default for DFSMSdss COPY command
• Same restrictions as with Global Mirror and z/OS Global Mirror

34
FlashCopy and Remote Copy Services …
• Preserve Mirror FlashCopy and DB2 utilities
• DB2 utilities using DFSMShsm (BACKUP SYSTEM, RESTORE SYSTEM, RECOVER from SLB)
• Preserve mirror attribute is set at the copy pool level via the SMS definition panel
• FRBACKUP to PPRC Primary Vols allowed (NO|PN|PP|PR)
• FRRECOV to PPRC Primary Vols allowed (NO|PN|PP|PR)
• Default (NO): FCTOPPRCPrimary will not be passed to DFSMSdss
• PPRC primary volumes cannot be used as FlashCopy target volumes
• Other DB2 utilities using Flash Copy (CHECK DATA, CHECK INDEX, CHECK LOB, COPY, REORG
TABLESPACE, REORG INDEX, REBUILD INDEX, LOAD, RECOVER)
• Preserve mirror attribute is set via ZPARM
• APAR PM26762 (V9/V10): FLASHCOPY_PPRC (blank|NONE|PREFERRED|REQUIRED)
• blank (default V9) >> FCTOPPRCPrimary will not be passed to DFSMSdss
• REQUIRED (default V10) >> If the target volume is a Metro Mirror primary device and preserve
mirror cannot be used, the utility will use standard I/O
• Unless …
CHECK_FASTREPLICATION = REQUIRED >> CHECK will fail
REC_FASTREPLICATION = REQUIRED >> RECOVER will fail

35
Conclusion
• Need clear and consistent objectives for Continuous Availability (CA) and
Disaster Recovery (DR)
• In line with the business requirements and expectations
• Clearly differentiate CA and DR to ensure clarity of the objectives for functionalities
• Examples
• Running with a multi-site workload is generally done to provide faster restart in case of site failures
(DR) but can compromise the exploitation of CA capabilities
• RPO=0 (no data loss) can only be achieved with a FREEZE/STOP policy which can impact the
availability of production running on the primary site (‘false positive’)
• The more aggressive the SLAs, the more investments are required (escalating)
• Hardware (e.g. extra DASD)
• Automated, optimised procedures
• Testing and practice

36
Conclusion …
• Data consistency is of paramount importance
• Any sign of inconsistency found in your testing should be driven to root cause
• Broken pages, data/index mismatches, etc.
• A DB2 cold start, or any form of conditional restart, will lead to data corruption and loss of data
• Practice, practice, practice
• Test in anger and not simulated
• Continually validate recovery procedures to maintain readiness
• Verify that RPO/RTO objectives are being met
• Do not throw away your ‘standard’ DB2 log-based recovery procedures
• Even though it should be a very rare occurrence, it is not wise to start planning for mass recovery when the failure actually occurs, e.g.
• Plan A for Disaster Recovery has failed
• Local recovery on the primary site following wide-spread logical corruption

37
Looking for More Information?
• Redbooks
• Disaster Recovery with DB2 UDB for z/OS, SG24-6370
• GDPS Family - An Introduction to Concepts and Capabilities, SG24-6374
• DS8000 Copy Services for IBM System z, SG24-6787
• DS8000 Remote Pair FlashCopy (Preserve Mirror), REDP-4504
• Manuals
• z/OS DFSMS Advanced Copy Services, SC35-0428
• z/OS DFSMSdfp Storage Administration, SC26-7402
• z/OS DFSMShsm Storage Administration, SC35-0421

38
38
Florence DuboisIBM DB2 for z/OS Development
Session F09
The Importance of Being ConsistentDB2 for z/OS and Copy Services for IBM System z
Florence Dubois is an IBM Certified Senior IT Specialist and a member of the
DB2 for z/OS Development SWAT team. In this role, she consults for worldwide
customers on a variety of technical topics, including implementation and
migration, design for high performance and availability, performance and tuning,
system health checks, disaster recovery. Florence presents regularly at
conferences and has co-authored several IBM Redbooks publications.
38





























