Embed Size (px)
Citation preview

The Design and Implementation of Log-Structure File System
M. Rosenblum and J. Ousterhout

Introduction CPU Speed increases dramatically Memory Size increased
Most “Read” hits in cache Disk improves only on the size but access is
still very slow due to seek and rotational latency “Write” must go to disk eventually
As a result “Write” dominate the traffic Application has disk-bound problem

Overview of LFS Unix FFS
Random write Scan entire disk Very slow restore consistency after crash
LFS Write new data to disk in sequence Eliminate “seek” Faster crash recovery The most recent log always at the end

Traditional Unix FFS Spread information around the disk
Layout file sequentially but physically separates different files
Inode separate from file contents Takes at least 5 I/O for each seek to
create new file Causes too many small access Only use 5% disk bandwidth
Most of the time spent on seeking

Sprite LFS Inode not at fixed position
It written to the log Use inode map to maintain the current location of the
inode It divided into blocks and store in the log Most of the time in cache for fast access (rarely need
disk access) A fixed checkpoint on each disk store all the inode
map location Only one single write of all information to disk
required + inode map update All information in a single contiguous segment
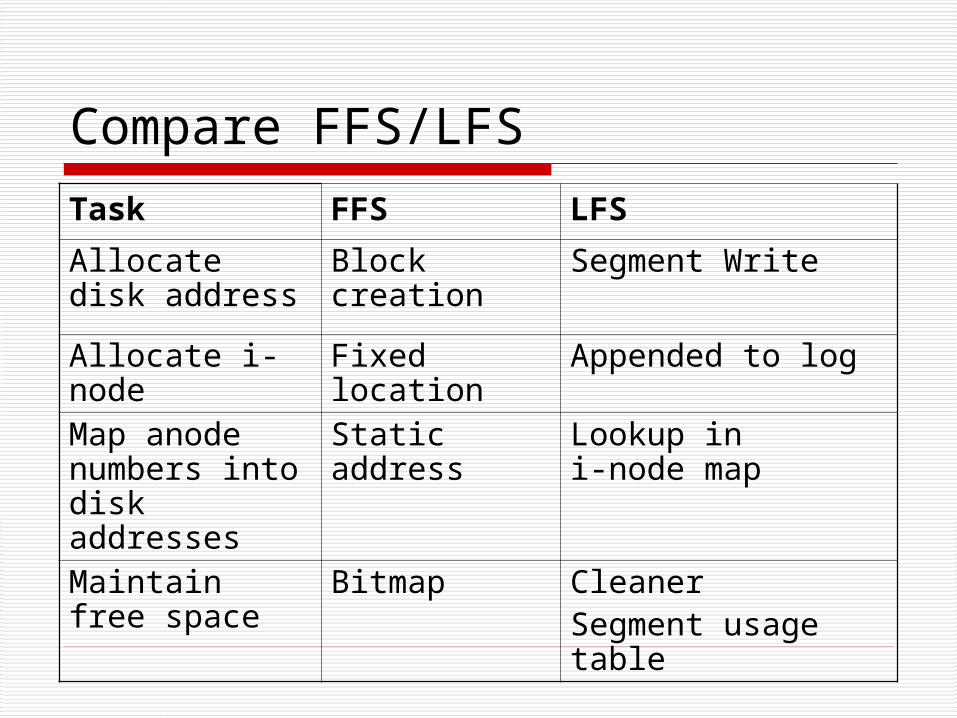
Compare FFS/LFS
Task FFS LFS
Allocate disk address
Block creation
Segment Write
Allocate i-node Fixed location
Appended to log
Map anode numbers into disk addresses
Static address
Lookup ini-node map
Maintain free space
Bitmap CleanerSegment usage table

Space Management
Goal: keep large free extents to write new data
Disk divided into segments (512kB/1MB)
Sprite Segment Cleaner Threading between segments Copying within segment

Threading
Leave the live data in place Thread the log through the free
extents Cons
Free space become many fragmented Large contiguous write won’t be possible LFS can’t access faster

Copying and Compacted
Copy live data out of the log Compact the data when it written
back Cons: Costly

Segment Cleaning Mechanism
Read a number of Segments into memory
Check if it is live data If true, write it back to a smaller
number of clean segments Mark segment as clean

Segment summary block
Identify each piece of information in segment
Version number + inode = UID Version number incremented in inode
map when file deleted If UID of block mismatch to that in
inode map when scanned, discard the block

Cleaning Policies
Sprite starts cleaning segment when the number of clean segment drops below a threshold
It uses the write cost to compare the cleaning policies "write cost" is the average amount of
time the disk is busy per byte of new data written
uuN
uNuNN
1
2
1
1
writtendata new
writtenand read bytes totalcost Write
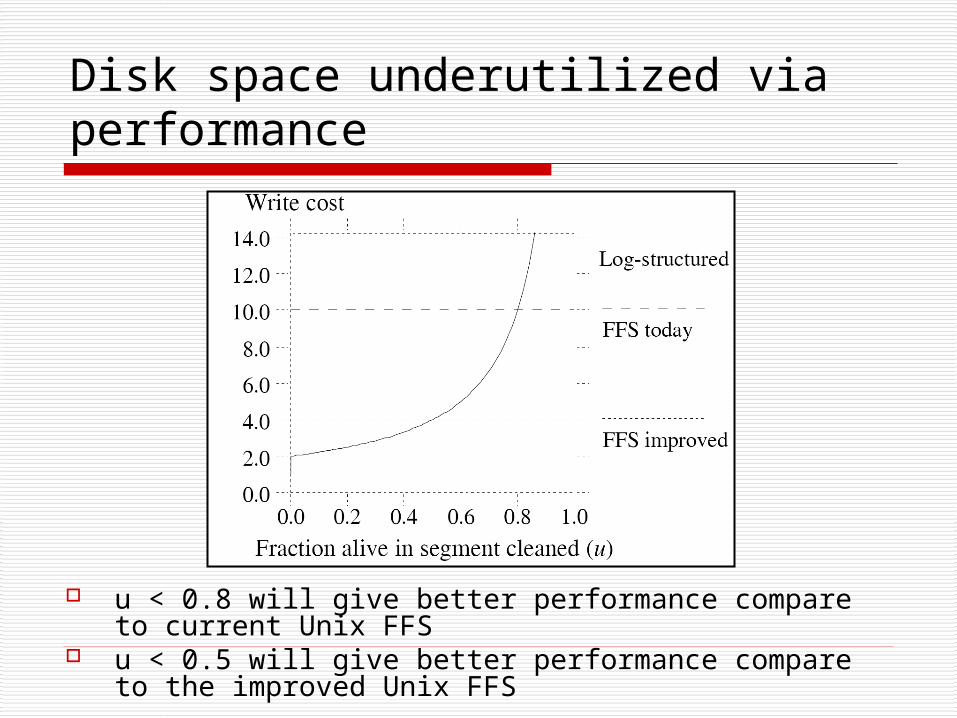
Disk space underutilized via performance
u < 0.8 will give better performance compare to current Unix FFS
u < 0.5 will give better performance compare to the improved Unix FFS

Simulate more real situation Data random access pattern
Uniform Hot and cold
10% is hot and select 90% of the time 90% is cold and select 10% of the time
Cleaner use “Greedy Policy” Choose the least-utilized segment to clean
Conclude hot and cold data should treat differently

Cost Benefit Policy
“Cold” data is more stable and will likely last longer
Assume “Cold” data = older (age) Clean segment with higher ratio Group by age before rewrite
u
ageu
cost
agegenerated spacefree
cost
benefit
1
1
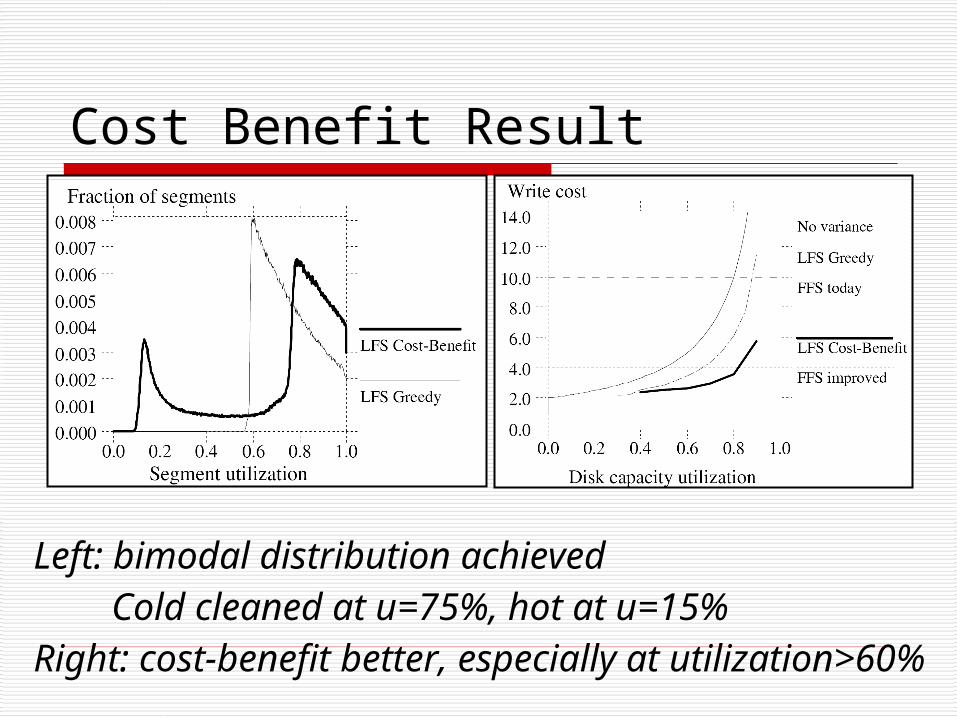
Left: bimodal distribution achieved Cold cleaned at u=75%, hot at u=15%Right: cost-benefit better, especially at utilization>60%
Cost Benefit Result

Crash Recovery Traditional Unix FFS:
Scan all metadata Very costly especially for large storage
Sprite LFS Last operations locate at the end of the log Fast access, recovery quicker Checkpoint & roll-forward Roll-forward hasn’t integrated to Sprite while the
paper was written Not focus here
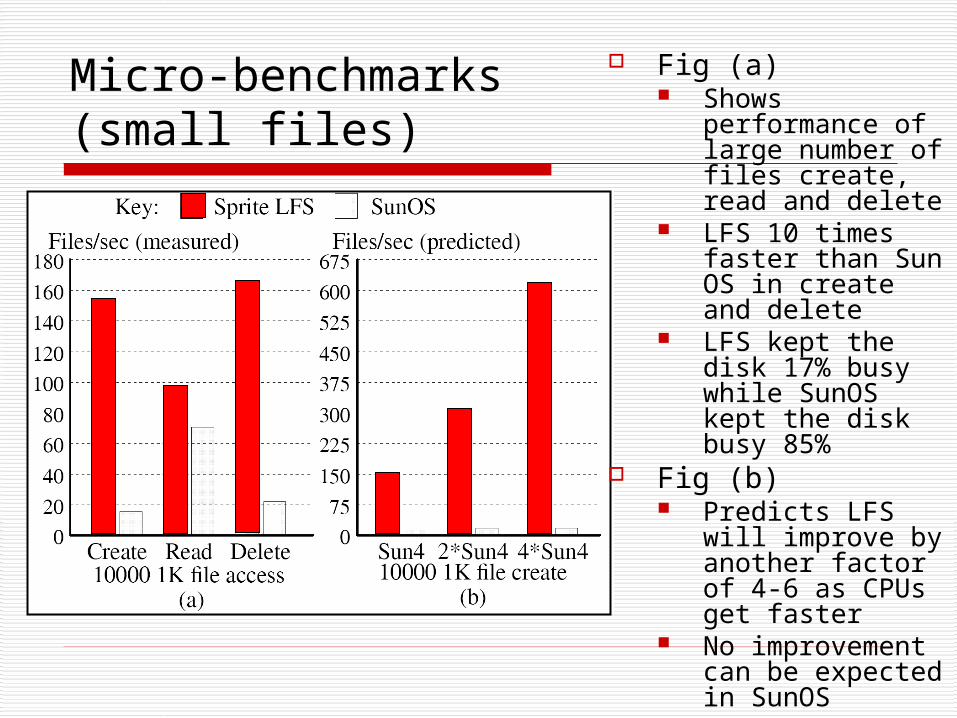
Micro-benchmarks(small files)
Fig (a) Shows
performance of large number of files create, read and delete
LFS 10 times faster than Sun OS in create and delete
LFS kept the disk 17% busy while SunOS kept the disk busy 85%
Fig (b) Predicts LFS will
improve by another factor of 4-6 as CPUs get faster
No improvement can be expected in SunOS
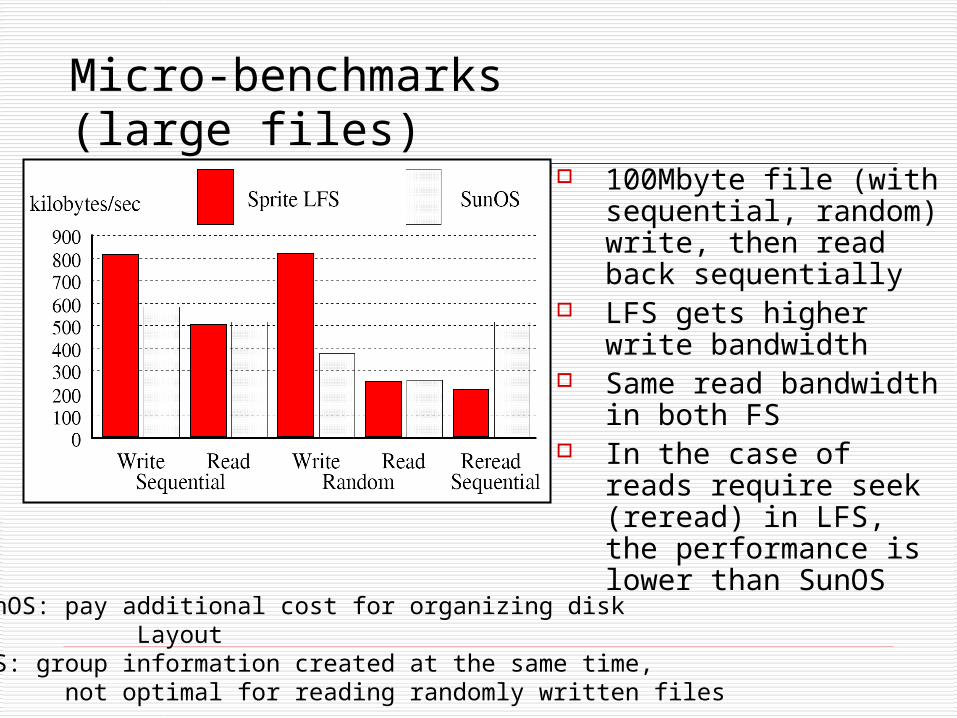
Micro-benchmarks(large files)
100Mbyte file (with sequential, random) write, then read back sequentially
LFS gets higher write bandwidth
Same read bandwidth in both FS
In the case of reads require seek (reread) in LFS, the performance is lower than SunOS
- SunOS: pay additional cost for organizing disk Layout- LFS: group information created at the same time, not optimal for reading randomly written files
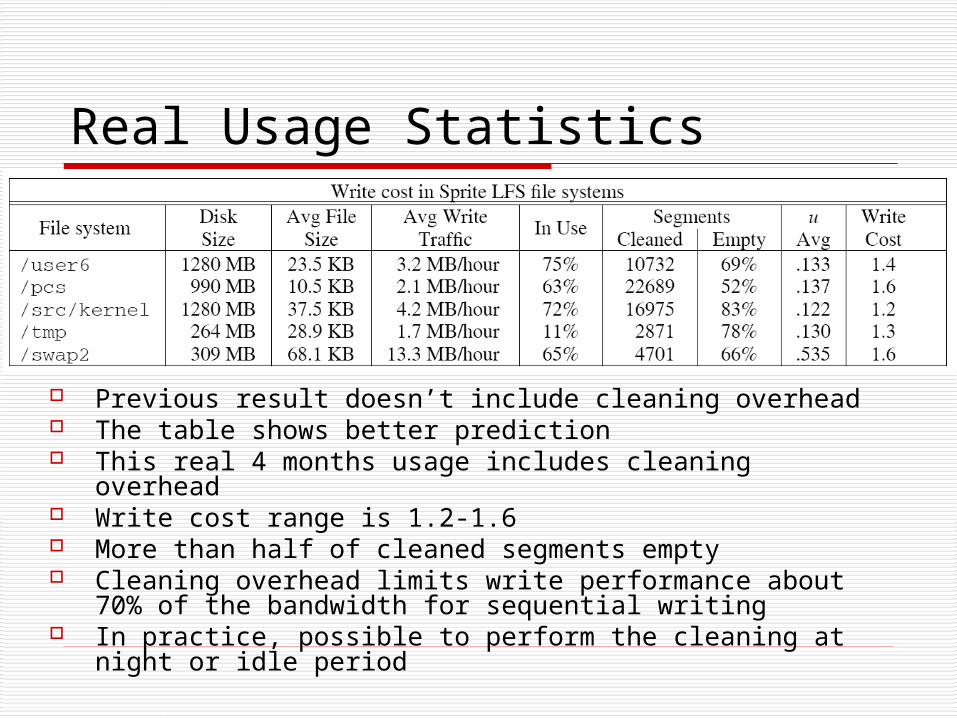
Real Usage Statistics
Previous result doesn’t include cleaning overhead The table shows better prediction This real 4 months usage includes cleaning overhead Write cost range is 1.2-1.6 More than half of cleaned segments empty Cleaning overhead limits write performance about
70% of the bandwidth for sequential writing In practice, possible to perform the cleaning at night
or idle period

Thank You =)
~The end~




























