Embed Size (px)
Citation preview

Tema 5. La curva normal tipificada
1
Tema 5 ___________________
La curva normal tipificada
Índice
1.Introducción ................................................................................................................. 2 2.Poblaciones de tipo normal (curva de Gauss). ...................................................... 3 3.Distribución normal tipificada. ................................................................................... 6 3.1.Cálculo de probabilidades y áreas con la curva normal tipificada. ............. 8 3.1.1. Tablas impresas. ...................................................................................... 8 3.1.2. Tablas on line. ........................................................................................ 12 3.2.De vuelta a las variables originales ................................................................ 14 Ejemplos. ........................................................................................................... 14
En este tema estudiaremos la forma, características y utilidad que tiene la curva normal tipificada en la estadística. La curva normal es una función de distribución a la que se acoplan multitud de variables que interesan a la psicología. Y sobre todo, es muy importante que comprendas bien los conceptos relacionados con ella porque constituirán las bases de la que hemos denominado estadística inferencial. Cualquier tipo de conclusión que derive de la aplicación de una prueba estadística en el ámbito de las inferencias, será una conclusión probabilística, esto es, una conclusión que llevará asociado un determinado margen de error. Que entiendas que dicha probabilidad de error tiene su correspondencia con áreas determinadas en la función de distribución correspondiente es el objetivo que se persigue en este tema tomando como referencia la curva normal.

Tema 5. La curva normal tipificada
1. Introducción.
En Psicología, una población es, generalmente, un conjunto de sujetos sobre los cuales deseamos extrapolar el comportamiento observado en grupos de sujetos de menor tamaño –muestras-. Por ejemplo, se puede pretender conocer las principales preferencias de ocio de los habitantes de una población a partir de un subconjunto más pequeño de la misma, o el coeficiente intelectual de los alumnos de una determinada escuela -o sus niveles de motivación por una determinada materia- seleccionando a los individuos de un aula en particular. Algunas veces –sobre todo en ámbitos generalmente aplicados- el estudio recae sobre todo el conjunto de sujetos de la población. Es el caso de abarcar, por ejemplo, a todos los sujetos de interés cuando deseamos hacer un censo por edad y sexo de todas las personas que acuden a nuestra consulta terapéutica; o el caso de conocer las notas medias de bachiller de todos los sujetos con los que vamos a trabajar durante un curso instruyéndoles en una determinada habilidad. En estos casos el interés está centrado exhaustivamente en todos los sujetos que interesa estudiar –la población-, aunque ésta no sea muy amplia. Sin embargo, otras muchas veces la pretensión es ir más allá de los sujetos con los que en concreto se centra el estudio extrapolando sus resultados a otros que en principio no han participado en él. Este es el denominado proceso de la generalización o inferencia estadística. Para que dicho proceso de inferencia sea válido es necesario que los sujetos del estudio –sujetos de la muestra- sean sujetos representativos de la población a la que pertenecen y ello es posible gracias a su extracción de acuerdo a un procedimiento aleatorio. Una muestra sesgada (sujetos voluntarios o escogidos por orden de llegada) no garantizan las inferencias sobre la población a la que pretendemos generalizar resultados. Existen diferentes métodos de muestreo. El más conocido es el denominado muestreo aleatorio simple mediante el cual una vez identificados todos y cada uno de los sujetos de la población (con un número o código determinado, por ejemplo), todos ellos tienen la misma probabilidad de pertenecer a la muestra. Lo que hay que decidir es qué número de sujetos concreto van a configurarla en función de determinados criterios (error muestral, coste económico, disponibilidad de sujetos, etc…). Otros procedimientos de muestreo aleatorio muy conocidos son el muestreo estratificado y el de conglomerados1. Una vez seleccionada la muestra de acuerdo al procedimiento más adecuado, el trabajo de recolección de datos y su análisis recae siempre sobre la muestra
11 En el muestreo estratificado se definen grupos de sujetos diferentes o estratos en la población y la selección aleatoria de sujetos se hace para cada uno de estos estratos procurando casi siempre respetar la representatividad o proporción poblacional de estos estratos de la población en la muestra. En el muestreo por conglomerados la población se estructura en grupos (como clases o equipos deportivos) y se aleatorizan estos grupos como un todo a la hora de la selección aunque una vez seleccionados estos grupos a veces se decida posteriormente qué sujetos concretos dentro de los grupos van a formar parte definitivamente parte de la muestra.
Tema 5. La curva normal tipificada
3
y es a través de estos datos muestrales por los que se infiere el comportamiento de las poblaciones. Diferenciaremos así entre los que son valores o índices estadísticos representativos de las muestras (como promedios, proporciones, índices de variación, etc…) y los parámetros que serían aquéllos si los midiéramos en la población. Para notar los valores estadísticos se utilizan letras latinas y para sus correspondientes poblacionales letras griegas. Por ejemplo, estos son algunos de los estadísticos y sus parámetros correspondientes usados con asiduidad:
Estadístico Parámetro Media 𝑋� µ Proporción p π Desviación tipo 𝑆𝑋 σX
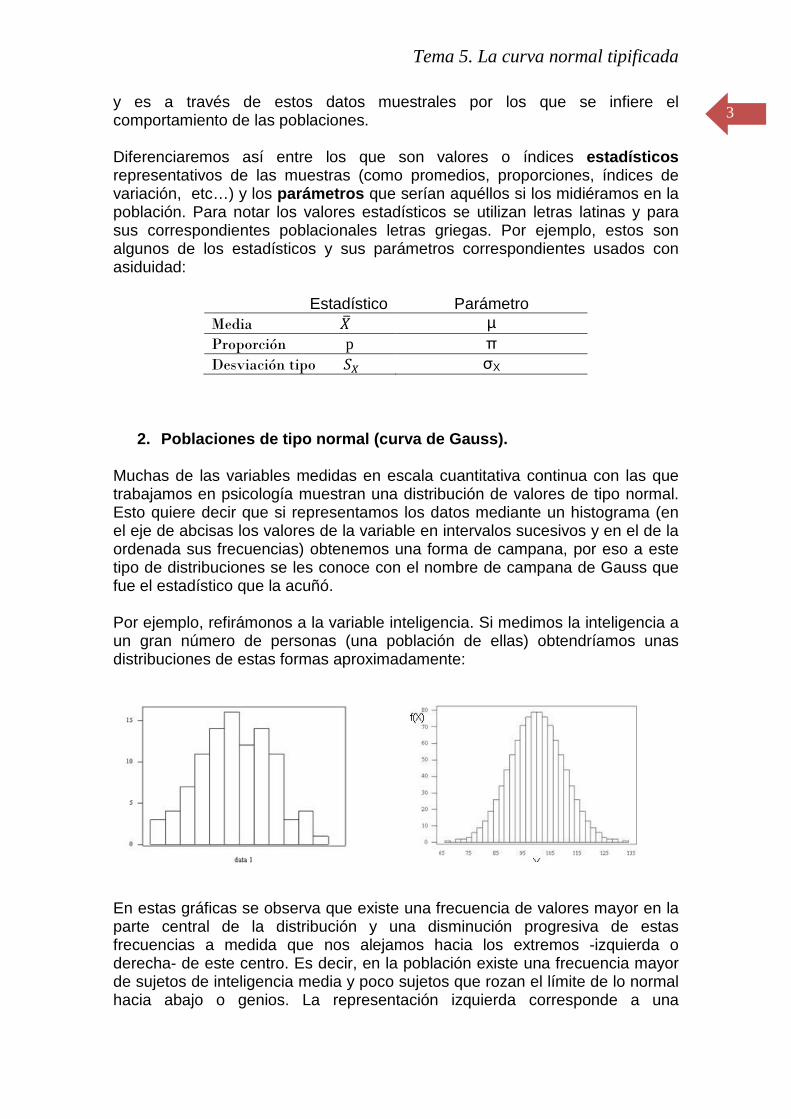
2. Poblaciones de tipo normal (curva de Gauss). Muchas de las variables medidas en escala cuantitativa continua con las que trabajamos en psicología muestran una distribución de valores de tipo normal. Esto quiere decir que si representamos los datos mediante un histograma (en el eje de abcisas los valores de la variable en intervalos sucesivos y en el de la ordenada sus frecuencias) obtenemos una forma de campana, por eso a este tipo de distribuciones se les conoce con el nombre de campana de Gauss que fue el estadístico que la acuñó. Por ejemplo, refirámonos a la variable inteligencia. Si medimos la inteligencia a un gran número de personas (una población de ellas) obtendríamos unas distribuciones de estas formas aproximadamente:
En estas gráficas se observa que existe una frecuencia de valores mayor en la parte central de la distribución y una disminución progresiva de estas frecuencias a medida que nos alejamos hacia los extremos -izquierda o derecha- de este centro. Es decir, en la población existe una frecuencia mayor de sujetos de inteligencia media y poco sujetos que rozan el límite de lo normal hacia abajo o genios. La representación izquierda corresponde a una
Tema 5. La curva normal tipificada
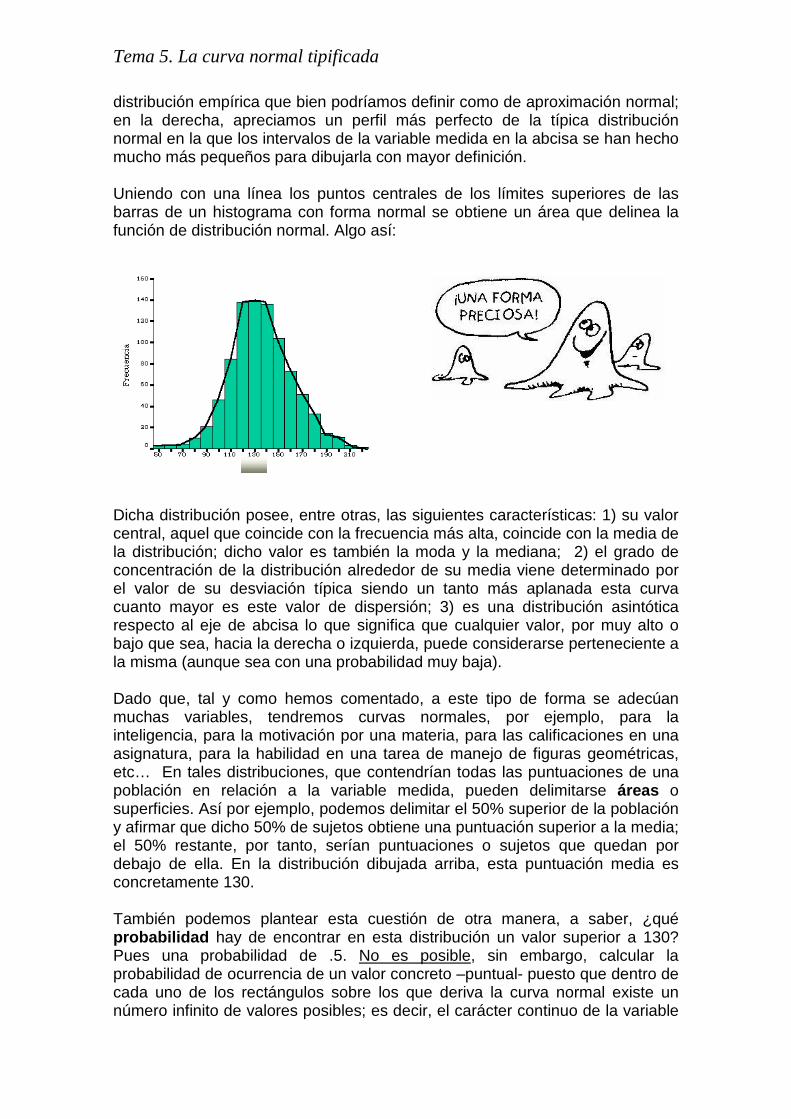
distribución empírica que bien podríamos definir como de aproximación normal; en la derecha, apreciamos un perfil más perfecto de la típica distribución normal en la que los intervalos de la variable medida en la abcisa se han hecho mucho más pequeños para dibujarla con mayor definición. Uniendo con una línea los puntos centrales de los límites superiores de las barras de un histograma con forma normal se obtiene un área que delinea la función de distribución normal. Algo así:
Dicha distribución posee, entre otras, las siguientes características: 1) su valor central, aquel que coincide con la frecuencia más alta, coincide con la media de la distribución; dicho valor es también la moda y la mediana; 2) el grado de concentración de la distribución alrededor de su media viene determinado por el valor de su desviación típica siendo un tanto más aplanada esta curva cuanto mayor es este valor de dispersión; 3) es una distribución asintótica respecto al eje de abcisa lo que significa que cualquier valor, por muy alto o bajo que sea, hacia la derecha o izquierda, puede considerarse perteneciente a la misma (aunque sea con una probabilidad muy baja). Dado que, tal y como hemos comentado, a este tipo de forma se adecúan muchas variables, tendremos curvas normales, por ejemplo, para la inteligencia, para la motivación por una materia, para las calificaciones en una asignatura, para la habilidad en una tarea de manejo de figuras geométricas, etc… En tales distribuciones, que contendrían todas las puntuaciones de una población en relación a la variable medida, pueden delimitarse áreas o superficies. Así por ejemplo, podemos delimitar el 50% superior de la población y afirmar que dicho 50% de sujetos obtiene una puntuación superior a la media; el 50% restante, por tanto, serían puntuaciones o sujetos que quedan por debajo de ella. En la distribución dibujada arriba, esta puntuación media es concretamente 130. También podemos plantear esta cuestión de otra manera, a saber, ¿qué probabilidad hay de encontrar en esta distribución un valor superior a 130? Pues una probabilidad de .5. No es posible, sin embargo, calcular la probabilidad de ocurrencia de un valor concreto –puntual- puesto que dentro de cada uno de los rectángulos sobre los que deriva la curva normal existe un número infinito de valores posibles; es decir, el carácter continuo de la variable
Tema 5. La curva normal tipificada
5
que medimos posibilita que existan infinitos valores entre dos cualesquiera de la distribución con lo que la probabilidad de ocurrencia de uno concreto sería infinitésima. En base a lo argumentado, las preguntas pertinentes que podemos plantear cuando trabajamos con distribuciones normales son del tipo: “¿Qué valor de la distribución deja por debajo de sí al 70% de los sujetos?”, “por debajo de la puntuación 120, ¿qué porcentaje de sujetos hay?, o “¿qué probabilidad tenemos de encontrar una puntuación entre los valores 150 y 180?”, o también, ¿cuál es la probabilidad de encontrar un valor de X por encima de 160 y por debajo de 130?. Es decir, todas son preguntas que intentan dilucidar probabilidades o áreas entre determinadas puntuaciones o, al revés, identificar valores o puntuaciones que demarcan o limitan determinadas áreas o probabilidades.
Puntuación/es → Área (probabilidad) Área (probabilidad) → Puntuación/es
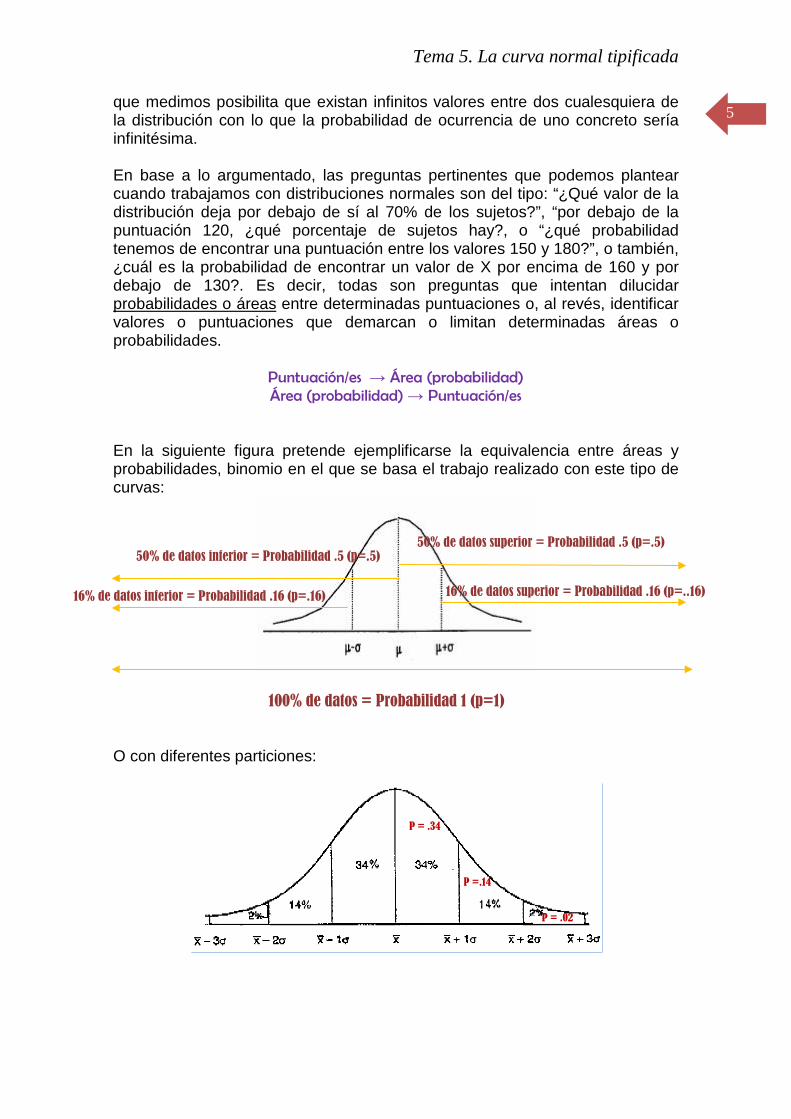
En la siguiente figura pretende ejemplificarse la equivalencia entre áreas y probabilidades, binomio en el que se basa el trabajo realizado con este tipo de curvas:
100% de datos = Probabilidad 1 (p=1) O con diferentes particiones:
50% de datos superior = Probabilidad .5 (p=.5) 50% de datos inferior = Probabilidad .5 (p=.5)
P = .34
P =.14
P = .02
16% de datos superior = Probabilidad .16 (p=..16)
16% de datos inferior = Probabilidad .16 (p=.16)

Tema 5. La curva normal tipificada
3. Distribución normal tipificada. Trabajar con múltiples curvas normales asociadas a cada una de las variables que nos interesan sería un trabajo ingente pues obligaría a medir a cada una de ellas en poblaciones, calcular sus correspondientes distribuciones, estadísticos y funciones. La solución es la de tener como referencia una única distribución que sirva de comodín a todas las posibles. Esta es la distribución normal tipificada o estandarizada.
Necesitaremos, pues, ser capaces de transformar las variables X "normales" con su correspondiente media y desviación típica –N (µ,σ)- en variables Z que sigan una distribución normal estándar N(0,1). Este proceso de llevar cualquier distribución normal a una N (0,1) se llama "tipificación de la variable".
Como vemos, todas estas puntuaciones tipificadas tendrán de media 0 y de desviación típica 1. Por eso, al final tendremos una única distribución normal tipificada que nos servirá para trabajar con todas las variables, independientemente de sus correspondientes puntuaciones directas o escalas. Demostremos cómo el valor promedio de puntuaciones z es 0 y su correspondiente desviación tipo es 1: Como sabemos, una puntuación z se expresa de la siguiente manera:
𝑧 = 𝑋−𝜇𝜎
.
Su promedio:
𝑧̅ =∑ 𝑧𝑁
=∑ �𝑋 − 𝑋�
𝜎 �
𝑁=
∑(𝑋 − 𝑋�)𝑁𝜎
Desarrollando la expresión del numerador ∑(𝑋 − 𝑋�):
∑(𝑋 − 𝑋�) = ∑ 𝑋 − 𝑁𝑋�= ∑ 𝑋 − 𝑁 ∑ 𝑋𝑁
, , ∑ 𝑋 − ∑ 𝑋 = 0 Así pues,
𝑧̅ =0
𝑁𝜎= 0
Su desviación típica:
𝜎2 =∑(𝑧 − 𝑧̅)2
𝑁= �
(𝑧 − 0)2
𝑁=
∑ �𝑋 − 𝑋�𝜎 �
2
𝑁=
∑(𝑋 − 𝑋�)2 ∙ 1𝜎2
𝑁=
∑(𝑋 − 𝑋�)2
𝑁∙
1𝜎2
= 𝜎2 ∙1
𝜎2 = 1
𝜎2 = 1 → 𝜎 = √1 = 1

Tema 5. La curva normal tipificada
7
Supongamos que medimos en una determinada población la variable inteligencia por un lado y por otro la variable motivación, ambas de distribución normal. Las medias y las desviaciones típicas (DT) de estas variables y su traducción a puntuaciones típicas son: Variables (𝜇) (𝜎𝑿) 𝜇𝑧 𝜎𝑍 Inteligencia 110 15 0 1 Motivación 55 8 0 1
En términos de distribuciones gráficas tendríamos: IntelIgencIa MotIvacIón
Una vez que tenemos como referencia esta única distribución normal tipificada de media 0 (μ=0) y desviación típica 1 (σ=1), podemos operar siempre con ella y volver si es necesario a las puntuaciones originales cuando queramos conocer un valor empírico en la escala original. La relación entre z y X es la siguiente:
𝑧𝑖 =𝑋𝑖 − 𝑋�
𝑆𝑋
Así pues, podemos transformar un valor determinado de z a su correspondiente X fácilmente:
𝝁 =110 𝝁 =55
𝝈𝑿 =15 𝝈𝑿= 8
μ= 0 μ+1 σ μ- 1σ
σ=1 Distribución de valores z (Curva normal tipificada)

Tema 5. La curva normal tipificada
𝑋𝑖 = (𝑧𝑖 ∙ 𝑆𝑋) + 𝑋�
3.1. Cálculo de probabilidades y áreas con la curva normal tipificada. Una vez que conocemos cuál es la forma de la distribución normal tipificada, sus principales características y sus parámetros, podemos conocer las porciones de áreas que acumula dentro de dos valores dados de z, o por encima o por debajo de un determinado valor z. Como ya existen cálculos formalizados de estas porciones, podemos consultarlos para responder a este tipo de interrogantes. Dichos cálculos se resumen en las denominadas tablas de la distribución normal tipificada. Existen varios formatos. Antiguamente, el uso se centraba exclusivamente en las tablas impresas que el investigador consultaba para averiguar áreas asociadas a determinados valores z o a la inversa, identificar valores de z que limitaban determinadas áreas o porciones de la curva. Actualmente, no tiene sentido recurrir a dichas tablas pues existen recursos informáticos más precisos, fáciles de manejar y más exactos. De todas formas, como todavía este tipo de tablas aparecen en muchos manuales de estadística y en páginas docentes on line para el estudio del tema, dedicaremos parte de este capítulo a exponerlas y explicar cómo se manejan. 3.1.1. Tablas impresas.
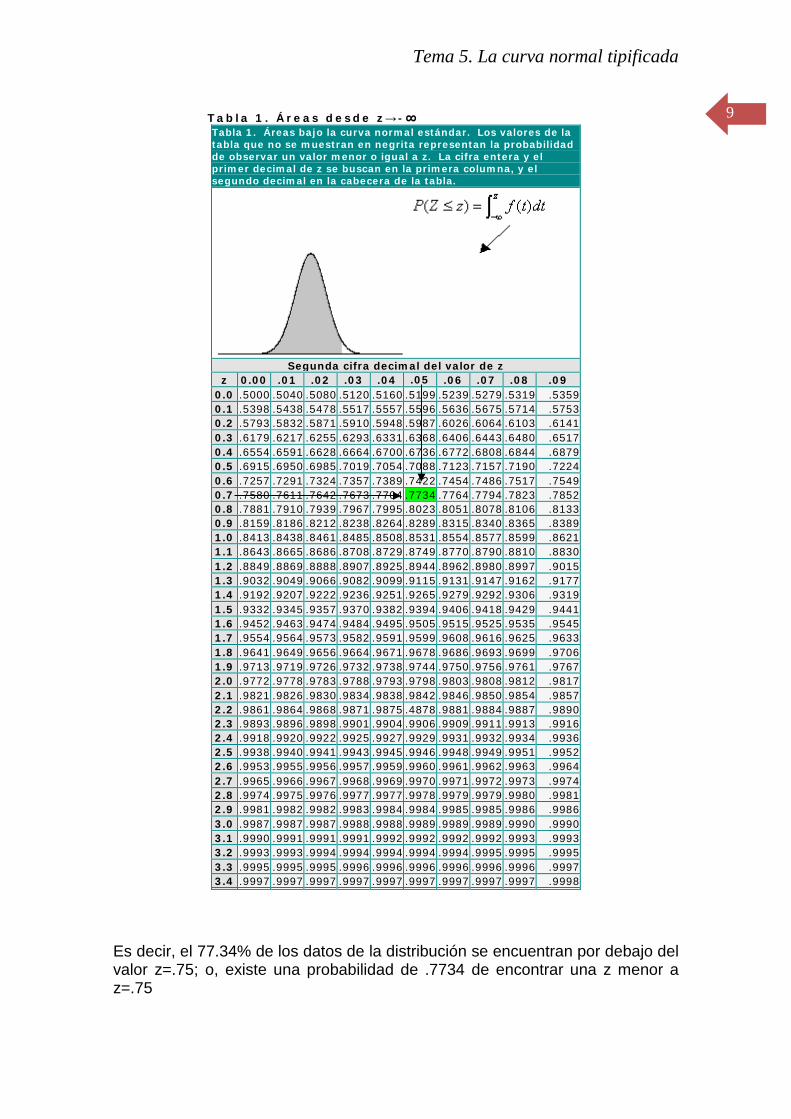
Supongamos que deseamos conocer qué porción del área de la curva normal se encuentra por debajo de un determinado valor de z; o lo que es lo mismo, qué probabilidad tenemos de encontrar un valor Z más pequeño que una z dada. Se trata de calcular P(Z ≤ z) . En la siguiente tabla aparece sombreada dicha área:
Pues bien, podemos conocer la porción que ocupa dicho sombreado cambiando el valor de z –mayor o menor, desplazándolo a lo largo de la curva-en la tabla impresa que sigue (desde z=0 a z=3.9). Para valores z negativos se realiza la operación correspondiente conociendo que la curva es simétrica respecto al centro. Por ejemplo, supongamos que deseamos saber qué área de la curva se encuentra por debajo de un valor z=0.75 (P(Z ≤ 0.75) (0.7 en fila y 0.05 en columna). El área es .7734:
z
Tema 5. La curva normal tipificada
9
Tabla 1. Áreas desde z→-∞
Tabla 1. Áreas bajo la curva normal estándar. Los valores de la tabla que no se muestran en negrita representan la probabilidad de observar un valor menor o igual a z. La cifra entera y el primer decimal de z se buscan en la primera columna, y el segundo decimal en la cabecera de la tabla.
Segunda cifra decimal del valor de z z 0.00 .01 .02 .03 .04 .05 .06 .07 .08 .09
0.0 .5000 .5040 .5080 .5120 .5160 .5199 .5239 .5279 .5319 .5359 0.1 .5398 .5438 .5478 .5517 .5557 .5596 .5636 .5675 .5714 .5753 0.2 .5793 .5832 .5871 .5910 .5948 .5987 .6026 .6064 .6103 .6141 0.3 .6179 .6217 .6255 .6293 .6331 .6368 .6406 .6443 .6480 .6517 0.4 .6554 .6591 .6628 .6664 .6700 .6736 .6772 .6808 .6844 .6879 0.5 .6915 .6950 .6985 .7019 .7054 .7088 .7123 .7157 .7190 .7224 0.6 .7257 .7291 .7324 .7357 .7389 .7422 .7454 .7486 .7517 .7549 0.7 .7580 .7611 .7642 .7673 .7704 .7734 .7764 .7794 .7823 .7852 0.8 .7881 .7910 .7939 .7967 .7995 .8023 .8051 .8078 .8106 .8133 0.9 .8159 .8186 .8212 .8238 .8264 .8289 .8315 .8340 .8365 .8389 1.0 .8413 .8438 .8461 .8485 .8508 .8531 .8554 .8577 .8599 .8621 1.1 .8643 .8665 .8686 .8708 .8729 .8749 .8770 .8790 .8810 .8830 1.2 .8849 .8869 .8888 .8907 .8925 .8944 .8962 .8980 .8997 .9015 1.3 .9032 .9049 .9066 .9082 .9099 .9115 .9131 .9147 .9162 .9177 1.4 .9192 .9207 .9222 .9236 .9251 .9265 .9279 .9292 .9306 .9319 1.5 .9332 .9345 .9357 .9370 .9382 .9394 .9406 .9418 .9429 .9441 1.6 .9452 .9463 .9474 .9484 .9495 .9505 .9515 .9525 .9535 .9545 1.7 .9554 .9564 .9573 .9582 .9591 .9599 .9608 .9616 .9625 .9633 1.8 .9641 .9649 .9656 .9664 .9671 .9678 .9686 .9693 .9699 .9706 1.9 .9713 .9719 .9726 .9732 .9738 .9744 .9750 .9756 .9761 .9767 2.0 .9772 .9778 .9783 .9788 .9793 .9798 .9803 .9808 .9812 .9817 2.1 .9821 .9826 .9830 .9834 .9838 .9842 .9846 .9850 .9854 .9857 2.2 .9861 .9864 .9868 .9871 .9875 .4878 .9881 .9884 .9887 .9890 2.3 .9893 .9896 .9898 .9901 .9904 .9906 .9909 .9911 .9913 .9916 2.4 .9918 .9920 .9922 .9925 .9927 .9929 .9931 .9932 .9934 .9936 2.5 .9938 .9940 .9941 .9943 .9945 .9946 .9948 .9949 .9951 .9952 2.6 .9953 .9955 .9956 .9957 .9959 .9960 .9961 .9962 .9963 .9964 2.7 .9965 .9966 .9967 .9968 .9969 .9970 .9971 .9972 .9973 .9974 2.8 .9974 .9975 .9976 .9977 .9977 .9978 .9979 .9979 .9980 .9981 2.9 .9981 .9982 .9982 .9983 .9984 .9984 .9985 .9985 .9986 .9986 3.0 .9987 .9987 .9987 .9988 .9988 .9989 .9989 .9989 .9990 .9990 3.1 .9990 .9991 .9991 .9991 .9992 .9992 .9992 .9992 .9993 .9993 3.2 .9993 .9993 .9994 .9994 .9994 .9994 .9994 .9995 .9995 .9995 3.3 .9995 .9995 .9995 .9996 .9996 .9996 .9996 .9996 .9996 .9997 3.4 .9997 .9997 .9997 .9997 .9997 .9997 .9997 .9997 .9997 .9998
Es decir, el 77.34% de los datos de la distribución se encuentran por debajo del valor z=.75; o, existe una probabilidad de .7734 de encontrar una z menor a z=.75
Tema 5. La curva normal tipificada
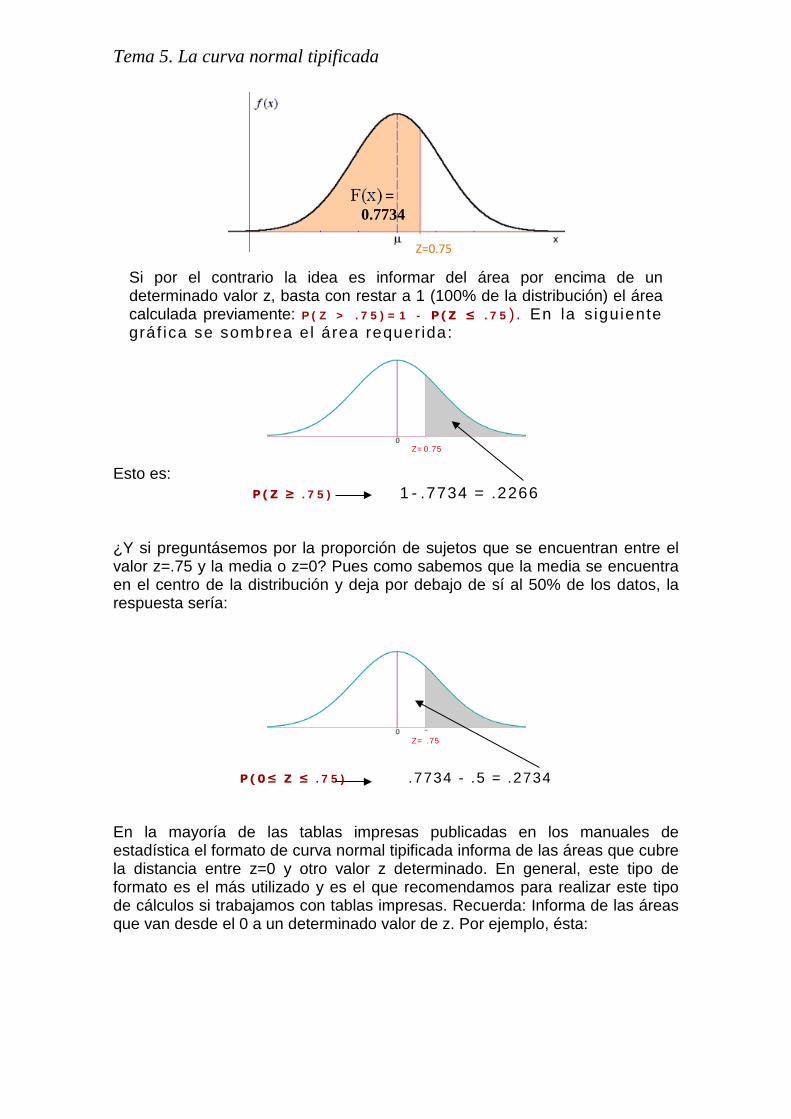
Si por el contrario la idea es informar del área por encima de un determinado valor z, basta con restar a 1 (100% de la distribución) el área calculada previamente: P(Z > .75)=1 - P(Z ≤ .75) . En la s iguiente gráf ica se sombrea el área requerida:
Esto es:
P(Z ≥ .75) 1- .7734 = .2266 ¿Y si preguntásemos por la proporción de sujetos que se encuentran entre el valor z=.75 y la media o z=0? Pues como sabemos que la media se encuentra en el centro de la distribución y deja por debajo de sí al 50% de los datos, la respuesta sería:
P(0≤ Z ≤ .75) .7734 - .5 = .2734
En la mayoría de las tablas impresas publicadas en los manuales de estadística el formato de curva normal tipificada informa de las áreas que cubre la distancia entre z=0 y otro valor z determinado. En general, este tipo de formato es el más utilizado y es el que recomendamos para realizar este tipo de cálculos si trabajamos con tablas impresas. Recuerda: Informa de las áreas que van desde el 0 a un determinado valor de z. Por ejemplo, ésta:
Z=0.75
= 0.7734
Z=0.75 Z=0.75
Z= .75

Tema 5. La curva normal tipificada
11
. Tabla 2. Áreas desde z=0→∞ P(0≤ Z ≤ z)
Z 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.0 0.0000 0.0040 0.0080 0.0120 0.0160 0.0199 0.0239 0.0279 0.0319 0.0359 0.1 0.0398 0.0438 0.0478 0.0517 0.0557 0.0596 0.0636 0.0675 0.0714 0.0753 0.2 0.0793 0.0832 0.0871 0.0910 0.0948 0.0987 0.1026 0.1064 0.1103 0.1141 0.3 0.1179 0.1217 0.1255 0.1293 0.1331 0.1368 0.1406 0.1443 0.1480 0.1517 0.4 0.1554 0.1591 0.1628 0.1664 0.1700 0.1736 0.1772 0.1808 0.1844 0.1879 0.5 0.1915 0.1950 0.1985 0.2019 0.2054 0.2088 0.2123 0.2157 0.2190 0.2224 0.6 0.2257 0.2291 0.2324 0.2357 0.2389 0.2422 0.2454 0.2486 0.2517 0.2549 0.7 0.2580 0.2611 0.2642 0.2673 0.2704 0.2734 0.2764 0.2794 0.2823 0.2852 0.8 0.2881 0.2910 0.2939 0.2967 0.2995 0.3023 0.3051 0.3078 0.3106 0.3133 0.9 0.3159 0.3186 0.3212 0.3238 0.3264 0.3289 0.3315 0.3340 0.3365 0.3389 1.0 0.3413 0.3438 0.3461 0.3485 0.3508 0.3531 0.3554 0.3577 0.3599 0.3621 1.1 0.3643 0.3665 0.3686 0.3708 0.3729 0.3749 0.3770 0.3790 0.3810 0.3830 1.2 0.3849 0.3869 0.3888 0.3907 0.3925 0.3944 0.3962 0.3980 0.3997 0.4015 1.3 0.4032 0.4049 0.4066 0.4082 0.4099 0.4115 0.4131 0.4147 0.4162 0.4177 1.4 0.4192 0.4207 0.4222 0.4236 0.4251 0.4265 0.4279 0.4292 0.4306 0.4319 1.5 0.4332 0.4345 0.4357 0.4370 0.4382 0.4394 0.4406 0.4418 0.4429 0.4441 1.6 0.4452 0.4463 0.4474 0.4484 0.4495 0.4505 0.4515 0.4525 0.4535 0.4545 1.7 0.4554 0.4564 0.4573 0.4582 0.4591 0.4599 0.4608 0.4616 0.4625 0.4633 1.8 0.4641 0.4649 0.4656 0.4664 0.4671 0.4678 0.4686 0.4693 0.4699 0.4706 1.9 0.4713 0.4719 0.4726 0.4732 0.4738 0.4744 0.4750 0.4756 0.4761 0.4767 2.0 0.4772 0.4778 0.4783 0.4788 0.4793 0.4798 0.4803 0.4808 0.4812 0.4817 2.1 0.4821 0.4826 0.4830 0.4834 0.4838 0.4842 0.4846 0.4850 0.4854 0.4857 2.2 0.4861 0.4864 0.4868 0.4871 0.4875 0.4878 0.4881 0.4884 0.4887 0.4890 2.3 0.4893 0.4896 0.4898 0.4901 0.4904 0.4906 0.4909 0.4911 0.4913 0.4916 2.4 0.4918 0.4920 0.4922 0.4925 0.4927 0.4929 0.4931 0.4932 0.4934 0.4936 2.5 0.4938 0.4940 0.4941 0.4943 0.4945 0.4946 0.4948 0.4949 0.4951 0.4952 2.6 0.4953 0.4955 0.4956 0.4957 0.4959 0.4960 0.4961 0.4962 0.4963 0.4964 2.7 0.4965 0.4966 0.4967 0.4968 0.4969 0.4970 0.4971 0.4972 0.4973 0.4974 2.8 0.4974 0.4975 0.4976 0.4977 0.4977 0.4978 0.4979 0.4979 0.4980 0.4981 2.9 0.4981 0.4982 0.4982 0.4983 0.4984 0.4984 0.4985 0.4985 0.4986 0.4986 3.0 0.4987 0.4987 0.4987 0.4988 0.4988 0.4989 0.4989 0.4989 0.4990 0.4990
Resolviendo el mismo problema planteado antes -la proporción de sujetos que se encuentran entre el valor z=.75 y la media- tendríamos en este caso que localizar el área de la curva que queda entre z=0 y z=.75 (P(0≤ Z ≤ .75) . El área es .2734.

Tema 5. La curva normal tipificada
Como indicábamos antes, preguntar por un área de la distribución es lo mismo que preguntar por probabilidades de ocurrencia. Si las preguntas anteriores sobre áreas se tradujeran a probabilidades de ocurrencia las respuestas serían las mismas. Así: Pregunta 1 ¿Cuál es la probabilidad de encontrar un valor inferior a z=.75? .7734 Pregunta 2 ¿Cuál es la probabilidad de encontrar un valor superior a z=.75? .2266 Pregunta 3 ¿Cuál es la probabilidad de encontrar un valor comprendido entre la media y
z=.75? .2734 3.1.2. Tablas on line. Veamos ahora cómo podemos hacer este trabajo de manera más cómoda y elegante manejando algunas de las tablas on line que nos proporciona la web. En esta dirección http://graphpad.com/quickcalcs/PValue1.cfm podemos desenvolvernos en este sentido. Indicamos un determinado valor de z y nos informa sobre el valor de probabilidad (p) de encontrar un valor superior o inferior a dicha z. En definitiva, de lo que informa el programa es de la probabilidad de que ocurra un valor mayor en magnitud –en valor absoluto- a la z indicada (por lo tanto mayor a z y menor a –z). Por ejemplo, si queremos calcular el área para z=1.96, nos informará del área o probabilidad de encontrar un valor mayor a z=1.96 más la probabilidad de encontrar un valor más pequeño que –z = -1.96. La respuesta obtenida es .05 (.025 por debajo de –z más .025 por encima de +z). Esto es lo que se denomina una p bilateral, término que será retomado más tarde cuando se trate con las pruebas de significación estadística. La siguiente figura ilustra lo explicado:
+ =
0.2734
p = 0.025 p = 0.025
-1.96 +1.96
p = 0.025 p = 0.025 p = 0.05
Tema 5. La curva normal tipificada
13
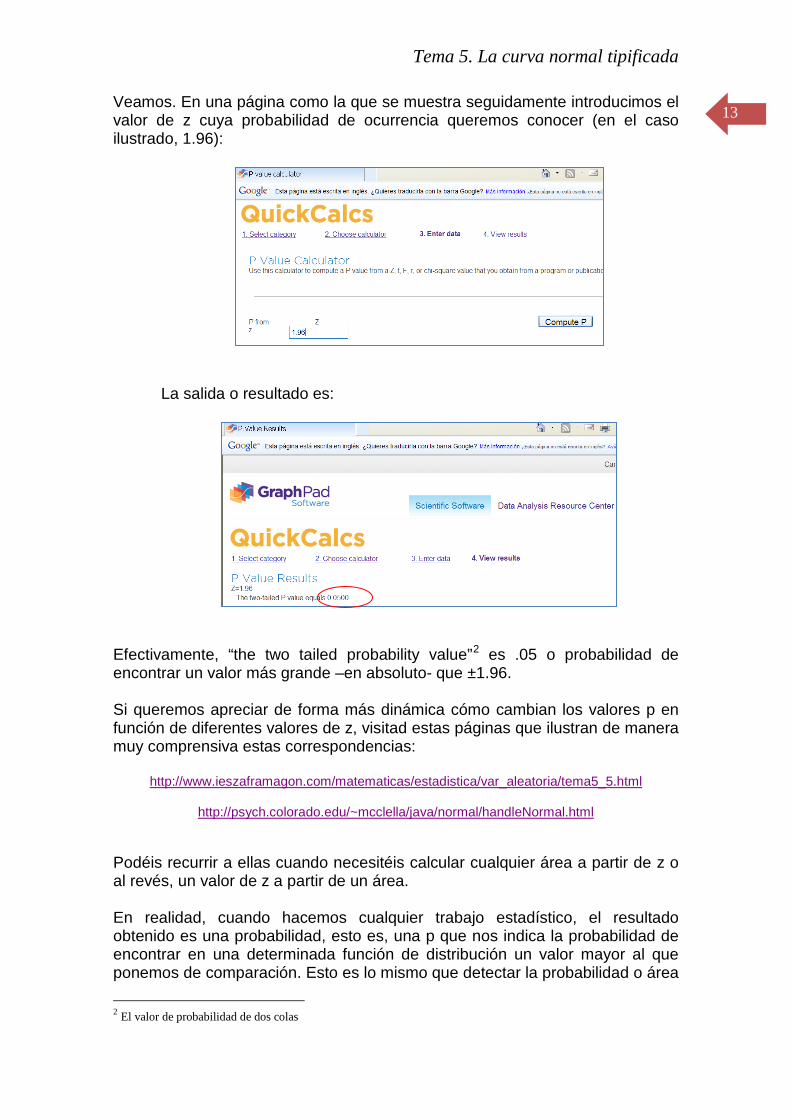
Veamos. En una página como la que se muestra seguidamente introducimos el valor de z cuya probabilidad de ocurrencia queremos conocer (en el caso ilustrado, 1.96):
La salida o resultado es:
Efectivamente, “the two tailed probability value”2 es .05 o probabilidad de encontrar un valor más grande –en absoluto- que ±1.96. Si queremos apreciar de forma más dinámica cómo cambian los valores p en función de diferentes valores de z, visitad estas páginas que ilustran de manera muy comprensiva estas correspondencias:
http://www.ieszaframagon.com/matematicas/estadistica/var_aleatoria/tema5_5.html
http://psych.colorado.edu/~mcclella/java/normal/handleNormal.html Podéis recurrir a ellas cuando necesitéis calcular cualquier área a partir de z o al revés, un valor de z a partir de un área. En realidad, cuando hacemos cualquier trabajo estadístico, el resultado obtenido es una probabilidad, esto es, una p que nos indica la probabilidad de encontrar en una determinada función de distribución un valor mayor al que ponemos de comparación. Esto es lo mismo que detectar la probabilidad o área
2 El valor de probabilidad de dos colas

Tema 5. La curva normal tipificada
por encima del estadístico que tenemos como referencia. En los temas siguientes sobre estimación y decisión estadística profundizaremos más sobre estos conceptos.
3.2. De vuelta a las variables originales. Normalmente el objetivo es aportar respuestas no sobre las puntuaciones en la curva normal tipificada sino en las escalas originales en que se han medido las variables. Por ejemplo, si nos han encargado conocer la inteligencia media de los estudiantes de nuevo ingreso en la carrera de ingeniería, nuestra respuesta no será muy acogida –ni entendida- en ámbitos no académicos si afirmamos que el 50% de los sujetos que emprenden el estudio de dicha disciplina tiene como mínimo una inteligencia z=0 o que el 16% superior tiene aproximadamente una inteligencia mínima de z= 1. Tenemos que informar en la escala original de la variable, al menos, en aquella escala que sea entendida por la población interesada. Es por eso que el último paso en el trabajo con la curva normal tipificada es reconvertir los valores z o probabilidades a las puntuaciones originales de donde partieron. En resumen, podemos identificar tres pasos cuando planteemos problemas con la tabla normal tipificada para averiguar probabilidades. 1.- Transformar la/s puntuación/es originales de la variable en puntuación/es z. 2.- Averiguar en las tablas impresas o tablas on line, las probabilidades o áreas asociadas a las z calculadas (llevándose a cabo las operaciones que sean necesarias en base a lo requerido, por ejemplo, sumar o restar áreas). 3.- Retornar a la escala original de la variable para responder en el mismo lenguaje en el que se planteó la pregunta.
Ejemplo 1: Tratemos de contestar a la pregunta, ¿qué porcentaje de sujetos tendrán una inteligencia superior a 125 sabiendo que la distribución de la población se comporta normalmente, su media es 110 y su desviación tipo 15? Como idea previa, sabemos que se trata de un valor de X que se encuentra a la derecha de la curva (125>110). Tendremos que calcular el área que va desde la puntuación 125 hacia el extremo derecho de la curva:
𝜇 =110
𝜎𝑋 =15
¿z? →X=125

Tema 5. La curva normal tipificada
15
Paso 1. La z correspondiente a esta puntuación sabiendo que 𝑋� = 110 𝑦 𝜎 =15 es:
𝑧 = 𝑋−𝑋�
𝜎𝑋 = 125−110
15= 1
𝜇 =110 X=125→z=1 La puntuación X=125 es una z = 1 y por tanto se sitúa a 1 desviación tìpica por encima de la media. Paso 2. Opción a) Miramos en la tabla 2 de arriba -P(0≤ Z ≤ z)- el área por debajo de este valor z=1 hasta z=0 (fila 1.0 y columna 0.00) que es .3413. Como lo que queremos conocer es qué área es la que está por encima de esta z=1 restamos al área completa derecha de la curva (.5) este valor (.3413). El resultado será el área que deseamos conocer:
𝑃(𝑍 ≥ 1) = .5 − .3413 = .1587 Como nos piden la información en términos de porcentaje de sujetos:
0.1587𝑥100 = 15.87% Opción b) También podemos averiguar dicha probabilidad o área usando algunas de las tablas en las direcciones on line referidas. Por ejemplo, si pinchamos en la segunda de ellas y coloreamos en rosa el área por debajo de z=1, obtenemos una p = .84:

Tema 5. La curva normal tipificada
Efectivamente, P (-∞≤ z ≤ 1) = .84, por lo que el área que deseamos conocer (P z ≥ 1) = 1 - .84 = .16, un valor prácticamente igual al calculado antes (.1587). Paso 3. Recordemos que la puntuación en directas correspondiente a esta z=1 era 125. Así que la respuesta a la pregunta planteada será: El 15.87% ≈ 16% de los sujetos tendrán una inteligencia superior a 125. Los pasos seguidos se resumen en la siguiente tabla:
¿Qué porcentaje de sujetos están por encima de X=125? P1. Trasformar X a z P2. Calcular p asociada a z P3. Traducir a escala original
X=125 → z=1 P(Z ≥ 1) = .1587 ≈ .16
“el 16% de sujetos tiene una inteligencia superior a 125”
Ejemplo 2
En la misma distribución normal anterior: ¿Entre qué puntuaciones de inteligencia se encontrará el 40% central de la distribución? Pasos 1 y 2. El área referida (40%) es aquella que delimita alrededor de la media una porción de .20 hacia derecha y .20 hacia la izquierda, respectivamente (.40/2=.20). Buscamos los valores z que delimitan dicha área. Opcion a) La tabla 2 nos indica que P(0 ≤ Z ≤ z)=.20 se corresponde con una z=.53 aproximadamente (si hacemos una regla de tres, el valor exacto de z para el área .20 es 0.528). Opción b) Igualmente, si desplazamos el límite del área color rosa de la distribución on line de antes de manera que deje hasta la media un área de .20 (.30, pues, en color rosa), obtenemos un valor de z=.53:

Tema 5. La curva normal tipificada
17
Justamente el área con la que estamos jugando es .40 (.20 a cada lado de la media). Paso 3. z=.528 corresponde a una puntuación empírica (X) de:
𝑧 =𝑋 − 𝜇
𝜎,, .528 =
𝑋 − 11015
, , 𝑋 = (. 528 ∙ 15) + 110 = 117.92 Dado que esta puntuación 117.92 (límite del área .20 sobre la media) mostrará una distancia respecto a la media igual que aquella que límite el .20 por debajo de ella, tenemos:
117.92 − 110 = 7.92 102.08 110 ± 7.92 117.92 Así pues, el 40% central de la distribución obtendrá puntuaciones en inteligencia dentro de este margen: 102.08 y 117.92.
¿Entre qué puntuaciones de inteligencia se encontrará el 40% central de la distribución?
P1 y P2. Conocer z a partir de un área P3. Traducir a escala original P(0 ≤ Z ≤ ¿z?)=.20
z= .53 𝑧 =
𝑋 − 𝜇𝜎
,, .528 =𝑋 − 110
15, , 𝑋 = 117.92
Entre 117.92 y 102.08 (110-7.92)



























