Embed Size (px)
Citation preview

More CUDA 1
¨ Advanced programming ¤ Synchronization and atomics ¤ Warps and Occupancy ¤ Memory coalescing ¤ Shared Memory ¤ Streams and Asynchronous Execution ¤ Bank conflicts ¤ Other features

Synchronization and Atomics 2

Thread Scheduling
¨ Order of threads within a block is undefined! ¤ Threads are grouped in warps (32 threads/warp)
n AMD calls it “a wavefront” (64 threads/wavefront)
¨ Order in which thread blocks are mapped and scheduled is undefined! ¤ Blocks run to completion on one SM without preemption ¤ Can run in any order
n Any possible interleaving of blocks should be valid
¤ Can run concurrently OR sequentially
3

Global synchronization
¨ We launch many more blocks than physical SM’s. ¨ Each block might/should have more threads than the SM’s
cores
__global__ void my_kernel() { step1; // compute some values in a global array // wait for *all* threads to finish __my_global_barrier(); step2; // use the array }
int main() { dim3 blockSize(32, 32); dim3 gridSize(100, 100, 100); my_kernel<<<gridDim, blockDim>>>();}
4

Memory consistency
¨ Device (global) memory is not serially consistent ¤ No ordering guarantees in shared/global memory Rd/Wr
¨ Share data between streaming multiprocessors ¤ Potential write hazards!
¨ Use atomics to avoid data races for global (and shared) memory variables!
¨ Evolution: ¤ Fermi has reasonable atomics for both shared and global
memory ¤ Kepler increases global memory atomics performance vs.
Fermi ¤ Maxwell uses native support for shared memory atomics
n Much faster than Fermi and Kepler
5

Atomics
¨ Guarantee that only a single thread has access to a piece of memory during an operation ¤ Ordering is still arbitrary
¨ Different types of atomic instructions ¤ Atomic Add, Sub, Exch, Min, Max, Inc, Dec, CAS, And, Or,
Xor
¨ Both for device memory and shared memory
6

An example: image histogram 7
¨ The histogram of an image: the distribution of the pixels in the image. ¤ In practice: count the pixels of each color ¤ Useful image feature detection for image recognition.

// Determine frequency of colors in a picture. // Colors have already been converted into integers // between 0 and 255. // Each thread looks at one pixel, // and increments a counter __global__ void histogram(int* colors, int* buckets) { int i = threadIdx.x + blockDim.x * blockIdx.x; int c = colors[i]; buckets[c] += 1; }
8
An example: image histogram

// Determine frequency of colors in a picture. // Colors have already been converted into integers // between 0 and 255. // Each thread looks at one pixel, // and increments a counter __global__ void histogram(int* colors, int* buckets) { int i = threadIdx.x + blockDim.x * blockIdx.x; int c = colors[i]; buckets[c] += 1; }
9
An example: image histogram

// Determine frequency of colors in a picture. // Colors have already been converted into integers // between 0 and 255. // Each thread looks at one pixel, // and increments a counter atomically __global__ void histogram(int* colors, int* buckets) { int i = threadIdx.x + blockDim.x * blockIdx.x; int c = colors[i]; atomicAdd(&buckets[c], 1); }
10
An example: image histogram

CUDA: Warps and Occupancy 11
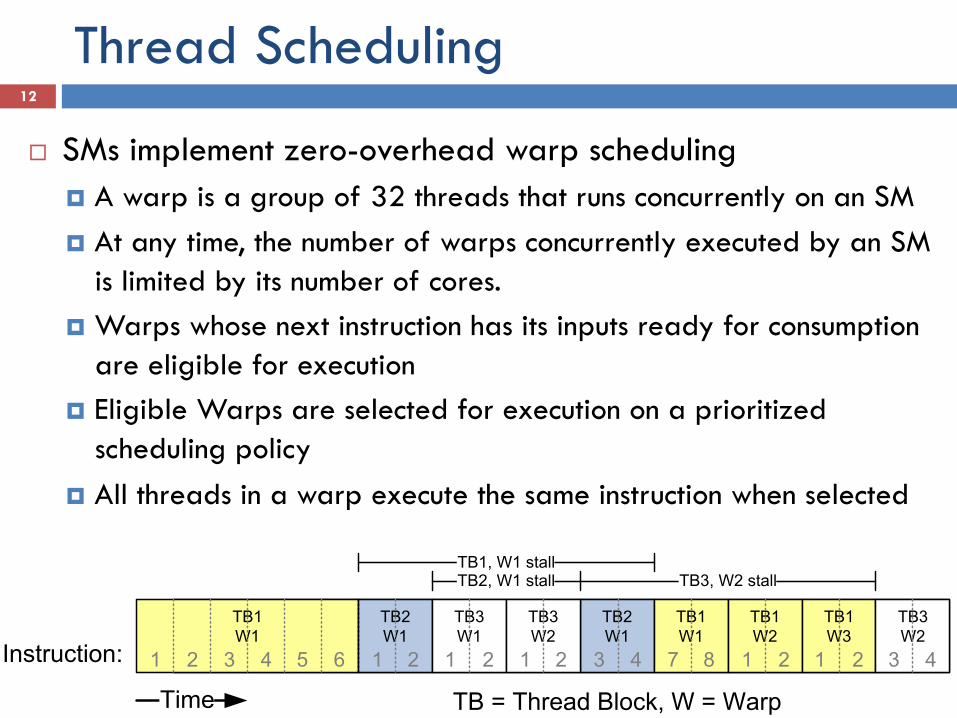
Thread Scheduling
¨ SMs implement zero-overhead warp scheduling ¤ A warp is a group of 32 threads that runs concurrently on an SM ¤ At any time, the number of warps concurrently executed by an SM
is limited by its number of cores. ¤ Warps whose next instruction has its inputs ready for consumption
are eligible for execution ¤ Eligible Warps are selected for execution on a prioritized
scheduling policy ¤ All threads in a warp execute the same instruction when selected
TB1W1
TB = Thread Block, W = Warp
TB2W1
TB3W1
TB2W1
TB1W1
TB3W2
TB1W2
TB1W3
TB3W2
Time
TB1, W1 stallTB3, W2 stallTB2, W1 stall
Instruction: 1 2 3 4 5 6 1 2 1 2 3 41 2 7 8 1 2 1 2 3 4
12

Stalling warps
¨ What happens if all warps are stalled? ¤ No instruction issued → performance lost
¨ Most common reason for stalling? ¤ Waiting on global memory
¨ If your code reads global memory every couple of instructions ¤ You should try to maximize occupancy
13

Occupancy
¨ What determines occupancy? ¨ Limited resources!
¤ Register usage per thread ¤ Shared memory per thread block
14

Resource Limits (1)
¨ Pool of registers and shared memory per SM ¤ Each thread block grabs registers & shared memory ¤ If one or the other is fully utilized no more thread blocks
TB 0
Registers Shared Memory
TB 1
TB 2
TB 0
TB 1
TB 2
TB 0
Registers
TB 1 TB 0
TB 1
Shared Memory
15

Resource Limits (2)
¨ Can only have P thread blocks per SM ¤ If they’re too small, can’t fill up the SM ¤ Need 128 threads / block on gt200 (4 cycles/instruction) ¤ Need 192 threads / block on Fermi (6 cycles/instruction)
¨ Higher occupancy has diminishing returns for hiding latency
16

Hiding Latency with more threads 17

How do you know what you’re using?
¨ Use compiler flags to get register and shared memory usage ¤ “nvcc -Xptxas –v”
¨ Use the NVIDIA Profiler ¨ Plug those numbers into CUDA Occupancy
Calculator
¨ Maximize occupancy for improved performance ¤ Empirical rule! Don’t overuse!
18


Thread divergence
¨ “I heard GPU branching is expensive. Is this true?”
__global__ void Divergence(float* dst,float* src ){ float value = 0.0f; if ( threadIdx.x % 2 == 0 )// active threads : 50% value = src[0] + 5.0f; else// active threads : 50% value = src[0] – 5.0f;
dst[index] = value;}

Execution 21
Worst case performance loss: 50% compared with the non divergent case.

Another example 22

Performance penalty? 23
¨ Depends on the amount of divergence ¤ Worst case: 1/32 performance
n When each thread does something different
¨ Depends on whether branching is data- or ID- dependent ¤ If ID – consider grouping threads differently ¤ If data – consider sorting
¨ Non-diverging warps => NO performance penalty ¤ In this case, branches are not expensive …

CUDA: Memory coalescing 24

Memory Coalescing 25
¨ Memory coalescing refers to combining multiple memory accesses into a single transaction

Caching vs. Coalescing 26
Caching

Caching vs. Coalescing 27
Caching Coalescing
vs.

Consider the stride of your accesses 28
__global__ void foo(int* input, float3* input2) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
// Stride 1, full bandwidth used!
int a = input[i];
// Stride 2, 50% of the bandwidth is wasted
int b = input[2*i+1];
// “Random” stride - ?? up to 7/8 bandwidth wasted
int c = input[f(i)];
}
Input[0] Input[1] Input[2] Input[3] Input[4] Input[5] Input[6] Input[7]
T0 T1 T2 T3 T4 T5 T6 T7
T0 T1 T2 T3
T7 T1 T4
Stride1
Stride2
“random”

Example: Array of Structures (AoS) 29
Struct AoS{
int key;
int value;
int flag;
};
record *d_AoS_data;
cudaMalloc((void**)&d_AoS_data, ...);
kernel {
threadID = blockDim.x * blockIdx.x + threadIdx.x;
// …
d_AoS_data[threadID].value += i; // wastes bandwidth!
// …
}

Example: Structure of Arrays (SoA) Struct SoA { int* keys; int* values; int* flags; }; SoA d_SoA_data; cudaMalloc((void**)&d_SoA_data.keys, ...); cudaMalloc((void**)&d_SoA_data.values, ...); cudaMalloc((void**)&d_SoA_data.flags, ...); kernel { threadID = blockDim.x * blockIdx.x + threadIdx.x; … d_SoA_data.values[threadID] += i; // full bandwidth! … }
30

Memory Coalescing*
¨ Group memory accesses in as few memory transactions as possible. ¤ 128-byte or 32-byte long lines
¨ Stride 1 access patterns are preferred! ¤ Other patterns can still get benefits
¨ Structure of arrays is often better than array of structures
¨ Unpredictable/ irregular access patterns ¤ Case-by-case performance impact
¨ No coalescing => performance loss 10 – 30x !
31
*http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/#axzz3nJ0kBsWe

CUDA: Using Shared Memory 32

Using shared memory 33
¨ Equivalent with providing software caching ¤ Explicit: Load data to be re-used in shared memory ¤ Use it for computation ¤ Explicit: Store results back to global memory
¨ All threads in a block share memory ¤ Load/Store: using all threads ¤ Barrier: __syncthreads
n Guard against using uninitialized data – not all threads have finished loading data to shared memory
n Guard against corrupting live data – not all threads have finished computing

A Common Programming Strategy
¨ Partition data into subsets that fit into shared memory
34

A Common Programming Strategy
¨ Handle each data subset with one thread block
35

A Common Programming Strategy
¨ Load the subset from device memory to shared memory, using multiple threads to exploit memory-level parallelism
36

A Common Programming Strategy
¨ Perform the computation on the subset from shared memory
37

A Common Programming Strategy
¨ Copy the result from shared memory back to device memory
38

Caches vs. Shared Memory 39
¨ Since Fermi, NVIDIA GPUs feature BOTH hardware L1 caches and shared memory per SM ¤ They share the same space
n ¾ Cache + ¼ Shared Memory OR n ¼ Cache + ¾ Shared Memory
¨ L1 Cache ¤ Hardware caching enabled
n The HW decides what goes in or out and when
¨ Shared memory ¤ Software manages what goes in/out ¤ Allows more complex access patterns to be cached

Example: Matrix multiplication 40
¨ C = A * B ¤ C(i,j) = sum(dot(row(A,i),col(B,j)))
¨ Parallelization strategy ¤ Each thread computes one C element ¤ 2D kernel B
C A

Matrix multiplication implementation 41
__global__ void mat_mul(float *a, float *b,
float *c, int width)
{
// calc row & column index of output element
int row = blockIdx.y*blockDim.y + threadIdx.y;
int col = blockIdx.x*blockDim.x + threadIdx.x;
float result = 0;
// do dot product between row of a and column of b
for(int k = 0; k < width; k++) {
result += a[row*width+k] * b[k*width+col]; }
c[row*width+col] = result;
}
B
CA

Matrix multiplication performance 42
Loads per dot product term 2 (a and b) = 8 bytes FLOPS 2 (multiply and add) AI 2 / 8 = 0.25 Performance GTX 580 1581 GFLOPs Memory bandwidth GTX 580 192 GB/s Attainable performance 192 * 0.25 = 48 GFLOPS Maximum efficiency 3.0 % of theoretical peak

Data reuse 43
¨ Each input element in A and B is read WIDTH times
¨ IDEA: ¤ Load elements into
shared memory ¤ Have several
threads use local version to improve memory bandwidth
B
C A
WIDTH

Using shared memory 44
¨ Partition kernel loop into phases ¨ In each thread block, load a tile
of both matrices into shared memory each phase
¨ Each phase, each thread computes a partial result
TILE_WIDTH
B
A C 1
1
3
2 3
2

Matrix multiply with shared memory 45
__global__ void mat_mul(float *a, float *b, float *c, int width) {
// shorthand int tx = threadIdx.x, ty = threadIdx.y; int bx = blockIdx.x, by = blockIdx.y;
// allocate tiles in shared memory __shared__ float s_a[TILE_WIDTH][TILE_WIDTH]; __shared__ float s_b[TILE_WIDTH][TILE_WIDTH];
// calculate the row & column index from A,B int row = by*blockDim.y + ty; int col = bx*blockDim.x + tx; float result = 0;

Matrix multiply with shared memory 46
// loop over input tiles in phases, p = crt. phase for(int p = 0; p < width/TILE_WIDTH; p++) { // collaboratively load tiles into shared memory s_a[ty][tx] = a[row*width + (p*TILE_WIDTH + tx)]; s_b[ty][tx] = b[(p*TILE_WIDTH + ty)*width + col]; // barrier: ALL writes to shared memory finished __syncthreads();
// dot product between row of s_a and col of s_b for(int k = 0; k < TILE_WIDTH; k++) { result += s_a[ty][k] * s_b[k][tx];
} // barrier: ALL reads of shared memory finished __syncthreads();
}
c[row*width+col] = result; }
B
A C 1 2 3
1
2
3

Use of Barriers in mat_mul 47
¨ Two barriers per phase: ¤ __syncthreads after all data is loaded into shared memory ¤ __syncthreads after all data is read from shared memory
n Second __syncthreads in phase p guards the load in phase p+1
¨ Formally, __synchthreads is a barrier for shared memory for a block of threads:
“void __syncthreads(); waits until all threads in the thread block have reached this point and all global and shared memory accesses made by these threads prior to __syncthreads() are visible to all threads in the block.”

Matrix multiplication performance 48
Original shared memory
Global loads 2N3 * 4 bytes (2N3 / TILE_WIDTH) * 4 bytes
Total ops 2N3 2N3
AI 0.25 0.25 * TILE_WIDTH
Performance GTX 580 1581 GFLOPs
Memory bandwidth GTX 580 192 GB/s
AI needed for peak 1581 / 192 = 8.23
TILE_WIDTH required to achieve peak 0.25 * TILE_WIDTH = 8.23, TILE_WIDTH = 32.9

CUDA: Streams 49

What are streams? 50
¨ Stream = a sequence of operations that execute on the device in the order in which they are issued by the host code.
¨ Same stream: In-Order execution ¨ Different streams: Out-of-Order execution
¨ Default stream = Synchronizing stream ¤ No operation in the default stream can begin until all
previously issued operations in any stream on the device have completed.
¤ An operation in the default stream must complete before any other operation in any stream on the device can begin.

Default stream: example 51
¤ All operations happen in the same stream ¤ Device (GPU)
n Synchronous execution n all operations execute (in order), one after the previous has finished
n Unaware of CpuFunction()¤ Host (CPU)
n Launches increment and regains control n *May* execute CpuFunction *before* increment has finished n Final copy starts *after* both increment and CpuFunction()
have finished
cudaMemcpy(d_a, a, numBytes,cudaMemcpyHostToDevice); increment<<<1,N>>>(d_a); CpuFunction(b);cudaMemcpy(a, d_a, numBytes,cudaMemcpyDeviceToHost);

Non-default streams 52
¨ Enable asynchronous execution and overlaps ¤ Require special creation/deletion of streams
n cudaStreamCreate(&stream1)n cudaStreamDestroy(stream1)
¤ Special memory operations n cudaMemcpyAsync(deviceMem, hostMem, size,
cudaMemcpyHostToDevice, stream1)
¤ Special kernel parameter (the 4th one) n increment<<<1, N, 0, stream1>>>(d_a)
¨ Synchronization ¤ All streams
n cudaDeviceSynchronize()
¤ Specific stream: n cudaStreamSyncrhonize(stream1)

Computation vs. communication 53
//Single stream, numBytes = 16M, numElements = 4McudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice); kernel<<blocks,threads>>(d_a, firstElement);cudaMemcpy(a, d_a, numBytes, cudaMemcpyDeviceToHost);
C1060 (pre-Fermi): 12.9ms
C2050 (Fermi): 9.9ms

Computation-communication overlap[1]* 54
for (int i = 0; i < nStreams; ++i) { int offset = i * streamSize; cudaMemcpyAsync(&d_a[offset], &a[offset], streamBytes, stream[i]); kernel<<blocks,threads,0,stream[i]>>(d_a, offset); cudaMemcpyAsync(&a[offset], &d_a[offset], streamBytes, stream[i]);}
C1060 (pre-Fermi): 13.63 ms (worse than sequential)
C2050 (Fermi): 5.73 ms (better than sequential)
https://github.com/parallel-forall/code-samples/blob/master/series/cuda-cpp/overlap-data-transfers/async.cu

Computation-communication overlap[2]* 55
for (int i = 0; i < nStreams; ++i) offset[i]=i * streamSize;for (int i = 0; i < nStreams; ++i) cudaMemcpyAsync(&d_a[offset[i]], &a[offset[i]], streamBytes,
cudaMemcpyHostToDevice, stream[i]);
for (int i = 0; i < nStreams; ++i) kernel<<blocks,threads,0,stream[i]>>(d_a, offset);
for (int i = 0; i < nStreams; ++i) cudaMemcpyAsync(&a[offset], &d_a[offset], streamBytes,
cudaMemcpyDeviceToHost, stream[i]);
C1060 (pre-Fermi): 8.84 ms (better than sequential)
C2050 (Fermi): 7.59 ms (better than sequential, worse than v1)
http://devblogs.nvidia.com/parallelforall/how-overlap-data-transfers-cuda-cc/

CUDA: Shared memory bank conflicts 56

Shared Memory Banks
¨ Shared memory is banked ¤ Only matters for threads within a warp ¤ Full performance with some restrictions
n Threads can each access different banks n Or can all access the same value
¨ Consecutive words are in different banks ¨ If two or more threads access the same bank but
different value, we get bank conflicts
57

Bank Addressing Examples: OK
n No Bank Conflicts n No Bank Conflicts
Bank 15
Bank 7 Bank 6 Bank 5 Bank 4 Bank 3 Bank 2 Bank 1 Bank 0
Thread 15
Thread 7 Thread 6 Thread 5 Thread 4 Thread 3 Thread 2 Thread 1 Thread 0
Bank 15
Bank 7 Bank 6 Bank 5 Bank 4 Bank 3 Bank 2 Bank 1 Bank 0
Thread 15
Thread 7 Thread 6 Thread 5 Thread 4 Thread 3 Thread 2 Thread 1 Thread 0
58

Bank Addressing Examples: BAD
n 2-way Bank Conflicts n 8-way Bank Conflicts
Thread 11 Thread 10 Thread 9 Thread 8
Thread 4 Thread 3 Thread 2 Thread 1 Thread 0
Bank 15
Bank 7 Bank 6 Bank 5 Bank 4 Bank 3 Bank 2 Bank 1 Bank 0
Thread 15
Thread 7 Thread 6 Thread 5 Thread 4 Thread 3 Thread 2 Thread 1 Thread 0
Bank 9 Bank 8
Bank 15
Bank 7
Bank 2 Bank 1 Bank 0 x8
x8
59

Trick to Assess Performance Impact
¨ Change all shared memory reads to the same value ¨ All broadcasts = no conflicts ¨ Will show how much performance could be
improved by eliminating bank conflicts
¨ The same doesn’t work for shared memory writes ¤ So, replace shared memory array indices with threadIdx.x ¤ (Could also be done for the reads)
60

CUDA: Many other features 61

HyperQ 62

Dynamic parallelism 63

Dynamic parallelism 64

GPUDirect 65

Backup slides 66

Example: Work queue
// For algorithms where the amount of work per item // is highly non-uniform, it often makes sense to // continuously grab work from a queue. __global__ void workq(int* work_q, int* q_counter, int queue_max, int* output) { int i = threadIdx.x + blockDim.x * blockIdx.x; int q_index = atomicInc(q_counter, queue_max); int result = do_work(work_q[q_index]); output[q_index] = result; }
67

Using shared memory
// Adjacent Difference application: // compute result[i] = input[i] – input[i-1]
__global__ void adj_diff_naive(int *result, int *input) {
// compute this thread’s global index unsigned int i = blockDim.x * blockIdx.x + threadIdx.x;
if(i > 0) {
// each thread loads two elements from device memory
int x_i = input[i]; int x_i_minus_one = input[i-1];
result[i] = x_i – x_i_minus_one;
} }
68

Using shared memory
// Adjacent Difference application: // compute result[i] = input[i] – input[i-1]
__global__ void adj_diff_naive(int *result, int *input) {
// compute this thread’s global index unsigned int i = blockDim.x * blockIdx.x + threadIdx.x;
if(i > 0) {
// each thread loads two elements from device memory
int x_i = input[i]; int x_i_minus_one = input[i-1];
result[i] = x_i – x_i_minus_one;
} }
69

Using shared memory
// Adjacent Difference application: // compute result[i] = input[i] – input[i-1]
__global__ void adj_diff_naive(int *result, int *input) {
// compute this thread’s global index unsigned int i = blockDim.x * blockIdx.x + threadIdx.x;
if(i > 0) {
// each thread loads two elements from device memory
int x_i = input[i]; int x_i_minus_one = input[i-1];
result[i] = x_i – x_i_minus_one;
} } The next thread also reads input[i]
70

Using shared memory __global__ void adj_diff(int *result, int *input) {
unsigned int i = blockDim.x * blockIdx.x + threadIdx.x;
__shared__ int s_data[BLOCK_SIZE]; // shared, 1 elt / thread
// each thread reads 1 device memory elt, stores it in s_data
s_data[threadIdx.x] = input[i];
// avoid race condition: ensure all loads are complete
__syncthreads();
if(threadIdx.x > 0) {
result[i] = s_data[threadIdx.x] – s_data[threadIdx.x–1];
} else if(i > 0) {
// I am thread 0 in this block: handle thread block boundary
result[i] = s_data[threadIdx.x] – input[i-1];
}
}
71

Using shared memory: coalescing __global__ void adj_diff(int *result, int *input) {
unsigned int i = blockDim.x * blockIdx.x + threadIdx.x;
__shared__ int s_data[BLOCK_SIZE]; // shared, 1 elt / thread
// each thread reads 1 device memory elt, stores it in s_data
s_data[threadIdx.x] = input[i]; // COALESCED ACCESS!
// avoid race condition: ensure all loads are complete
__syncthreads();
if(threadIdx.x > 0) {
result[i] = s_data[threadIdx.x] – s_data[threadIdx.x–1];
} else if(i > 0) {
// I am thread 0 in this block: handle thread block boundary
result[i] = s_data[threadIdx.x] – input[i-1];
}
}
72





























