Embed Size (px)
Citation preview

State Space Partition Algorithms for Stochastic Systemswith Applications to Minimum Spanning Trees
Christos AlexopoulosSchool of Industrial and Systems Engineering, Georgia Institute of Technology, Atlanta, Georgia 30332-0205
Jay A. JacobsonAir Force Personnel Operations Agency, Analysis Division, 1235 Jefferson Davis Highway,Suite 301, Arlington, Virginia 22202
We investigated state space partition methods for com-puting probability measures related to the operationof stochastic systems and present new theoretical re-sults concerning their efficiency. These methods it-eratively partition the system state space, produc-ing at each step progressively tighter bounds thatcan be used for constructing simple and efficientMonte Carlo routines for estimating the probabilitiesof interest. We apply our findings to the evaluationof measures related to minimum spanning trees ingraphs whose edges have independent discrete ran-dom weights. Specifically, we seek to compute the dis-tribution of the weight of a minimum spanning tree andthe probability that a given edge belongs to a mini-mum spanning tree. Both of these unsolved problemsare shown to be #P-hard. The algorithms for the mini-mum spanning tree problems are immediately applica-ble to other matroid problems with randomly weightedelements. © 2000 John Wiley & Sons, Inc.
Keywords: stochastic networks; spanning reees; reliability;Monte Carlo methods
1. INTRODUCTION
Much work has been done on a variety of problemsthat arise in the area of network optimization, resultingin a rich and elegant theory [1, 19]. Network optimiza-tion problems are unique among integer and combina-torial optimization problems in that efficient algorithmsfor their solution generally exist. These tools can solvean extensive array of optimization problems, includingmany that do not naturally involve networks.
Received 7 December 1997; accepted 24 August 1999Correspondence to: C. Alexopoulos; e-mail: [email protected] grant sponsor: AFOSR; contract grant number: F49620-93-1-0043
c© 2000 John Wiley & Sons, Inc.
In practice, the situation is often complicated by thefact that some network parameters (e.g., link travel timesor capacities) are not known with certainty. In such cases,by assigning probabilities to many possible parametersettings and then solving each resulting optimizationproblem separately, one can derive a distribution withwhich to make probabilistic statements about the valueof an optimal solution.
Example 1. Consider a system that can be modeled byan undirected, connected graph G = (V, E) whose ver-tices represent regional centers and whose edges repre-sent means of linking the centers. A spanning tree is amaximally acyclic connected subgraph of G, so namedbecause it spans V. Suppose that each edge has a non-negative weight (cost). An important problem in networkoptimization, with a variety of efficient solution methods,is the identification of a spanning tree with minimumtotal weight. Instances of the minimum spanning tree(MST) problem include building a pipeline network toconnect a number of towns using the smallest possibleamount of pipe; constructing a computer system com-posed of high-frequency circuitry, where it is desirableto minimize wire length to reduce capacitance; connect-ing a number of computer sites by high-speed lines atleast cost; and linking isolated villages with telephonelines that will follow a cheapest subset of the existingroad links. An indirect application arises when we seekto find, for each pair of nodes, a path that minimizesthe maximum edge weight encountered on the path (asin remote travel, where we might wish to minimize thelongest distance between towns) [1].
It is not hard to imagine a probabilistic structure forthe edge weights in these examples. For the pipeline net-work, it is possible that only crude preliminary surveyshave been done so that exact pipe requirements are notknown. Using probability distributions for the cost ofeach link of pipeline can help to quantify this uncertainty.
NETWORKS, Vol. 35(2), 118–138 2000

FIG. 1. Network with 10 nodes and 21 edges.
Similarly, capacitance estimates during the design phaseof the computer system may be better represented byrandom variables. Alternatively, a system may behave ina known probabilistic fashion. For example, travel timesbetween towns might depend on a number of randomfactors that could be represented by a probability distri-bution. Figure 1 shows a probabilistic graph consistingof 10 vertices connected by 21 undirected edges. Theedges have independent weights with probability func-tions given in Table 1 (see Appendix). [The weight ofedge (1, 2) takes values 2, 8, or 12 with respective prob-abilities 0.90, 0.08, and 0.02.]
In a stochastic MST model, the following measureshave practical importance: (a) The probability that thenodes can be connected via a spanning tree with totalweight not exceeding a given threshold d; (b) the entiredistribution of the MST weight; and (c) the criticality in-dex of an edge defined as the probability that this edgebelongs to an MST. The cardinality of the system statespace is the biggest obstacle in the evaluation of theseperformance measures. For instance, the network in Ex-ample 1 has 321 ≈ 10 billion states and the evaluationof the distribution of the weight of an MST by a com-plete enumeration of the state space requires 10 billionexecutions of an MST algorithm. If each edge has fourpossible settings, 421 ≈ 4 quadrillion such executions areneeded. It is this exponential explosion of work that hasmotivated the development of techniques which seek toevaluate only a fraction of these possible settings withoutsacrificing the quality of the resulting information.
Ball et al. [8] conducted a comprehensive survey ofmethods for evaluating a broad assortment of networkreliability and related problems. The problems in Exam-ple 1 were cast as multistate performability problems.After reviewing the stochastic maximum flow, shortestpath, and PERT problems (whose solutions they treatedin some detail), the authors pointed out that “more elab-orate models could include a wide variety of measures ofsystem operation,” with examples being measures relatedto stochastic minimum spanning trees and minimum-cost flows. They also noted that exact solution methods
for multistate performability problems typically involveconvolutions or max (min) operations (arbitrary series ofwhich are known to be #P-hard, even for variables thathave only two possible values), or involve transforma-tions into problems with two-state variables (a processthat typically replaces each variable having q possiblevalues by q two-state variables).
One of the most effective heuristic approaches forcomputing performability measures of multistate sys-tems relies on an iterative partition of the system statespace. This approach was introduced by Doulliez andJamoulle [12] for problems related to maximum flowsin networks with discrete arc capacities and was im-proved by Shogan [20]. (See [2] for corrections on both[12] and [20].) Recently, Alexopoulos [3] developed statespace partition algorithms for measures related to short-est paths in networks with discrete random arc lengths.
In short, a partition algorithm computes a performa-bility measure by iteratively partitioning portions of thestate space into sets with known contribution to the mea-sure and sets with unknown contribution (undeterminedsets). The algorithm terminates when no undeterminedsets remain to be processed. In effect, a partition algo-rithm is a type of factoring or branch-and-bound proce-dure, where the nodes of the search tree are the undeter-mined sets (see [16, Section 2.1] for details). At any stageof the branching process, the user can compute boundsand use the information associated with the remainingundetermined sets in effective Monte Carlo experiments[4, 5]. The bounds tighten after each iteration and even-tually become equal to the value of the measure.
A frequently ignored advantage of partition methodsover other related techniques (such as the most probablestates method; see Section 6.1.1 of [8]) is their indepen-dence from the state probabilities. As a result, one cansimultaneously compute or estimate the measure of in-terest for a variety of distributions on the same statespace [5].
The effectiveness of a partition algorithm dependson (a) how quickly a set can be partitioned, (b) thesize/growth of the search tree, and (c) the total prob-ability of the undetermined states that contribute to themeasure under consideration. Issue (b) was addressed in[2, 3] by using an LIFO set processing policy or by stor-ing the undetermined sets in a heap ordered by the re-spective set probabilities. References [12, 20, 2, 4, 5] usethe same method to partition a set; basically, they makeno attempt to optimize the partition. The algorithms in[3] use a knapsack heuristic to maximize the size of thecontributing set. This heuristic is also part of the algo-rithm in Section 6.2, but the algorithms under consider-ation in this paper are more elaborate as they considerseveral options for partitioning a set. Further, the parti-tion technique for the evaluation of the criticality indexof an edge (see Example 1) has no resemblance to exist-ing techniques.
NETWORKS–2000 119

Special cases of MST problems have been treatedin some detail. Gilbert [15] considered the problem ofbuilding MSTs to connect points randomly placed in thetwo-dimensional unit circle according to a Poisson pro-cess. Frieze [14] examined the case of the complete graphon n nodes whose edge weights are independent, iden-tically distributed random variables. Assuming that thecommon distribution function satisfied certain smooth-ness requirements, he derived the limiting behavior (asn → ∞) of the expected MST weight. Steele [21] andBertsimas [9] strengthened this result, known as the ζ(3)limit. Bertsimas and van Rysin [10] developed asymp-totic results for MSTs built to connect n points uniformlyand independently distributed in the (multidimensional)unit ball. Kulkarni [18] considered networks with inde-pendent exponentially distributed edge weights and eval-uated the distribution of the MST weight and criticalityindices by means of Markov processes. Bailey [6] ex-tended Kulkarni’s methodology to the general case ofminimization on matroids with exponentially distributedelement weights. Jain and Mamer [17] studied the prob-lem of finding the distribution of the MST weight andits mean in a network whose edge weights are indepen-dent (not necessarily discrete) random variables. Theydeveloped an upper bound for the mean that proved tobe better than the naive bound obtained by solving thedeterministic MST with expected edge weights. Proce-dures for approximating the distribution function, whichinvolved convolutions and Laplace–Stieltjes transforms,were demonstrated for exponentially distributed edgeweights. Clearly, the MST problems listed in Example 1deserve more attention. In particular, the computation ofcriticality indices has been studied only in [18], for thecase of exponentially distributed edge weights.
This paper advances the state of knowledge in severalways: Section 2 presents a common framework withinwhich a wide range of partition algorithms (as, i.e., thosein [12, 20, 2, 3, 4, 5]) may be discussed. Section 3 ex-plores several theoretical issues related to the partitionof a set and discovers one reason why overall algo-rithmic effectiveness can be poor for apparently well-conceived implementation strategies. Section 4 reviewsa Monte Carlo sampling scheme based on stratification.Sections 5-7 present new partition algorithms for com-puting measures related to spanning trees in networkswith discrete random edge weights. We prove that theevaluations of these measures are #P-hard problems andtest the efficacy of the proposed algorithms by severalexamples in Section 8. Section 9 suggests extensions toother stochastic matroid settings, and Section 10 offersconclusions. The Appendix contains the tables.
2. PARTITION ALGORITHMS
This section contains a general description of statespace partition algorithms. Some mathematical prelim-
inaries are necessary to establish a framework withinwhich we may describe these methods and present the-oretical results concerning their use.
Consider a vector X = (X1, . . . , Xm) of discrete ran-dom variables with finite state spaces. Each compo-nent Xj takes on finite values wj(1), . . . , wj(nj) (whichwe refer to as weights) with respective probabilitiespj(1), . . . , pj(nj). An element of the state space of X is ofthe form x = (w1(l1), . . . , wm(lm)), where lj ∈ 1, . . . , njfor all j. In the interest of readability, we shall generallyrefer to the state x as simply l = (l1, . . . , lm), letting theindex (or level) lj stand for wj(lj). Let Ω be the set ofthe vectors l.
We assume that the random variables Xj are mutu-ally independent, so that the probability of the state x iscalculated easily as
P(x) = PX1 = w1(l1), . . . , Xm = wm(lm) =m∏
j=1pj(lj).
We will be dealing not with individual states, but withspecial types of sets which we call discrete intervals.
Definition. A subset of Ω is a discrete (multidimen-sional) interval with endpoints α and β (α ≤ β com-ponentwise) if it consists precisely of all states l =(l1, . . . , lm) satisfying lj ∈ αj, . . . , βj for all j. We de-note this interval by [α, β].
Example 2. Let m = 2, n1 = 4, and n2 = 3. Then, Ωconsists of 4 × 3 = 12 states, as shown in Figure 2. Thestates shown as open circles constitute the interval [α, β]with endpoints α = (2, 1) and β = (3, 3).
The probability of an interval can be easily calculated,again due to independence of the random variables, as
P[α, β] =m∏
j=1
βj∑i=αj
pj(i). (1)
This ease of calculation and the fact that intervals can bestored using just the endpoints α and β make intervalsattractive.
Suppose that the vector X represents the states of thecomponents of a system. The state of the system is de-scribed by the structure function
Φ(l) = 1(a set of structural constraints
are valid in state l), for l ∈ Ω,
r b b r
r b b r
r b b r
-
6
1 2 3 4
1
2
3
X1
X2
FIG. 2. Discrete interval given in Example 2.
120 NETWORKS–2000

where 1(·) is the indicator function. (Assume that thevalidity of these constraints can be checked for each statel.) A state l is called feasible (the system operates in statel) if Φ(l) = 1 or infeasible if Φ(l) = 0.
Definition. A subset of Ω is called feasible (infeasible)if all states of the set have been classified as feasible(infeasible). Sets with unclassified states will be calledundetermined. The maximal feasible (infeasible) subsetof Ω is called the feasible (infeasible) region and is de-noted ΩF (ΩI).
Clearly, Ω = ΩF ∪ ΩI. The remainder of this sec-tion focuses on the evaluation of the system reliabilityPF = PΩF.
The following assumption is fundamental to the ap-plicability of the methods under study:
Monotonicity Assumption. The structure function Φ ismonotone nonincreasing.
There are two kinds of random variables Xj: thosewhose weights are reduced to achieve feasibility andthose whose weights are increased to achieve feasi-bility.
Definition. The variable Xj is called lower feasible ifthe Monotonicity Assumption calls for wj(1) < · · · <wj(nj) or upper feasible if it calls for wj(1) > · · · >wj(nj).
Example 3. Suppose that the system is a directed net-work with a single source node s and a single terminalnode t. If Xj is the capacity of arc j, V(X) is the valueof a maximum s–t flow and PF = PV(X) ≥ c for somevalue c, then all Xj are upper feasible. Alternatively, ifXj is the length of arc j, S(X) is the value of a shortests–t path and PF = PS(X) ≤ d for some value d, thenall Xj are lower feasible. Furthermore, if PF is the prob-ability that an arc e is in a shortest s–t path, then Xe islower feasible and the remaining Xj are upper feasible(see [3]). We will revisit this classification in Section 7.
Remark. Section 6.1.2 of [8] focuses on the computa-tion of the reliability of a multistate system where allXj are upper feasible. The above assumptions and defi-nitions extend the domain of partition methods and givea uniform notation for feasible and infeasible intervals.
Lemma 1 is an immediate implication of the Mono-tonicity Assumption.
Lemma 1. For each l ∈ Ω:
(a) If l is feasible, then the interval F = l ∈ Ω : 1 ≤li ≤ li for i = 1, . . . , m is also feasible.
(b) If l is infeasible, then the interval I = l ∈ Ω : li ≤li ≤ ni for i = 1, . . . , m is also infeasible.
This lemma is valuable because it allows one to clas-sify an entire interval in Ω as feasible or infeasible basedsolely on the feasibility of a single state.
Definition. Consider an interval [α, β] in Ω. The stateα = (α1, . . . , αm) is called the extreme feasible candidatewhile the state β = (β1, . . . , βm) is the extreme infeasiblecandidate.
Remark. Note that this definition does not imply thatthe extreme feasible candidate is a feasible state or thatthe extreme infeasible candidate is an infeasible state. Ifthe extreme feasible candidate is found to be feasible,we may refer to it as the feasible extreme and, likewise,for the infeasible extreme.
A partition algorithm starts with the undetermined in-terval Ω and the obvious lower and upper bounds PF
l = 0and PF
u = 1, respectively, for PF. During each iteration,an undetermined interval is partitioned into feasible, in-feasible, and undetermined intervals. The probabilities ofthe feasible intervals are added to PF
l , the probabilitiesof the infeasible intervals are subtracted from PF
u , andthe undetermined intervals are filed in a list as input tosubsequent iterations. The bounds become progressivelytighter and are equal to PF at termination.
There are two basic approaches: Feasible partition at-tempts primarily to remove one large feasible interval,whereas infeasible partition seeks to remove one largeinfeasible interval. We shall describe feasible partitionin full generality; infeasible partition proceeds symmet-rically.
Each iteration begins with an undetermined intervalU = [α, β]. If α is infeasible, then Lemma 1 implies thatU is infeasible, its probability is subtracted from PF
u , andthe iteration ends. Otherwise, the state α is feasible. If βis feasible, then Lemma 1 implies that U is feasible, theprobability of U is added to PF
l , and, again, the iterationends. Otherwise, U clearly contains both feasible andinfeasible states and we proceed.
After this (optional) prescreening step, the focus is onthe identification and removal of a feasible interval fromU. Thus, we seek a feasible state l which is easily derivedand which will yield as large a feasible interval as pos-sible. We typically begin with our only known feasiblestate, α. We then increase the levels of the componentsof X as much as possible while remaining feasible (in-creasing weights of lower feasible components, decreas-ing weights of upper feasible components). Alternatively,it is sometimes advantageous to begin at the infeasiblestate β and push down until feasibility is achieved. Ineither event, we generally stop short of “as much as pos-sible” in the interest of efficiency. Often, a fairly deepcutoff state can be derived with reasonable effort and topush a moderate amount further would incur significantcost. After completing this step, we obtain a feasible in-terval:
F = l ∈ U : αj ≤ lj ≤ lj for j = 1, . . . , m (2)
and add the probability of F, PF, to the lower boundfor PF.
NETWORKS–2000 121

We may stop after determining F, breaking up the re-mainder of U into up to m undetermined intervals as weindicate below. However, since we wish to account foras many undetermined states as possible in each itera-tion, it makes sense to try to remove infeasible intervalsas well. This cannot be done naively. As we shall soonshow in Theorem 4, blindly removing even one infeasi-ble interval in addition to F can increase the number ofnew undetermined intervals by as much as m (thus caus-ing execution to slow down quickly). We will describea technique that allows us to remove up to m infeasibleintervals without increasing the number of undeterminedintervals needed to partition the remainder U \ F.
To identify these infeasible intervals, we turn again toLemma 1. This step is carried out individually and inde-pendently for each of the m components. For componentj, we start at the feasible extreme α and push the levelof only this component toward βj (increasing its weightif it is lower feasible, decreasing its weight if it is up-per feasible) as far as possible while remaining feasible.Here it is essential that we push as far as possible.
Definition. We define the limiting feasible index forcomponent j by
lj = maxγ : αj Ú γ Ú βj,
(α1, . . . , αj−1, γ, αj+1, . . . , αm) is feasible.
Note that for all j we have lj ≥ lj so that if lj = βj wecan set lj = βj with no additional effort.
If we are able to push lj all the way to βj, no infeasibleinterval is produced. Otherwise, we know that pushingthe weight of component j one more level while leavingall other variables at α yields an infeasible state and,hence, an infeasible interval. This infeasible interval is
Ij = l ∈ U : lj + 1 ≤ lj ≤ βj, αi ≤ li ≤ βi for i ≠ j.
Note that the intervals Ij are not disjoint (indeed, all con-tain the state β). In most cases, this is not a problem sincethe infeasible intervals are discarded en masse. In someapplications, though, infeasible intervals are retained forfurther analysis. For example, in Section 7, we discussusing this technique to calculate the (joint) probabilitythat an edge e is on an MST whose weight exceeds d.In such cases, it is necessary to partition the infeasiblestates. Recall that the union of the overlapping intervalsA1, . . . , Am can be partitioned into the intervals
A1 = A1
Aj = Aj \ (A1 ∪ · · · ∪ Aj−1) for j = 2, . . . , m.
By applying this principle to the present setting, we obtainthe disjoint infeasible intervals
Ij = l ∈ U : αi ≤ li ≤ li for i < j,
lj + 1 ≤ lj ≤ βj, (3)
αi ≤ li ≤ βi for i > j.
All that remains is to account for the portion of U thatis still undetermined. We wish to represent U \ (F ∪(∪m
j=1Ij)) as a disjoint union of intervals. We account forthe states “between” F and Ij for each j by defining theinterval
Uj = l ∈ U : lj + 1 ≤ lj ≤ lj, αi ≤ li ≤ li for i ≠ j.
Since the undetermined intervals Uj overlap, we partitiontheir union into
Uj = l ∈ U : αi ≤ li ≤ li for i < j,
lj + 1 ≤ lj ≤ lj, (4)
αi ≤ li ≤ li for i > j.
If we choose not to find infeasible intervals, we replaceli in (4) by βi.
Remark. The intervals Ij and Uj were obtained by con-sidering the overlapping intervals Ij and Uj in ascendingorder of their indices. An alternative partition is obtainedby considering the respective overlapping intervals in de-scending order of j. Since the determination of an or-dering that results in improved long-term performanceappears to be a hard problem, we adopt the ordering in(3) and (4).
Remark. The lower endpoints of the intervals U andUj differ only in the jth coordinate. For some appli-cations, the feasibility of the state (α1, . . . , αj−1, lj +1, αj+1, . . . , αm) can be checked with a small amount ofincremental effort. If this state is infeasible, then the en-tire interval Uj is infeasible. Otherwise, information ob-tained as a by-product of the validity check can be storedalong with the endpoints of Uj for use during the decom-position of Uj.
To summarize, procedure FEASIBLE(U) describesthe partition of a single undetermined interval U = [α, β]that is known (through prescreening) to contain feasibleand infeasible states. The list U contains all remainingundetermined intervals.
Procedure FEASIBLE(U )
1. Find a feasible cutoff state l.2. Determine limiting feasible indices lj. (If no infeasi-
ble intervals are sought, set l = β.)3. Set PF
l = PFl + PF.
4. For j = 1, . . . , m: If lj < βj, set PFu = PF
u − PIj,where Ij is defined by (3).
5. For j = 1, . . . , m: If lj < lj, file Uj in U, where Uj isdefined by (4).End
As indicated previously, feasible partition is just oneof the options for a given interval. Infeasible partition iscompletely symmetric and is summarized below:
122 NETWORKS–2000

Procedure INFEASIBLE(U )
1. Find an infeasible cutoff state l and the respectiveinfeasible interval I. Set PF
u = PFu − PI.
2. Determine limiting infeasible indices lj. (If no feasi-ble intervals are sought, go to step 4 with lj = αj andFj = ∅ for j = 1, . . . , m.)
3. For j = 1, . . . , m: Form Fj (symmetric to Ij in feasiblepartition). If Fj ≠ ∅, set PF
l = PFl + PFj.
4. Partition U\(I∪(∪mj=1Fj)) into undetermined intervals
analogously to (4).5. For j = 1, . . . , m: If lj > lj, file Uj in U.
End
We are now ready to present the partition algorithm.
Algorithm PARTITION(Ω)
1. Set U = Ω, PFl = 0, and PF
u = 1.While U ≠ ∅
2. Remove an interval U = [α, β] from U. If α is infea-sible, set PF
u = PFu − PU and skip step 3. If β is
feasible, set PFl = PF
l + PU and skip step 3.3. Perform either FEASIBLE(U) or INFEASIBLE(U).
End WhileEnd
Sometimes (as in the computation of criticality indicesfor the MST problem), we make a decision in each iter-ation as to how that interval will be partitioned (feasiblyor infeasibly), in the hope that this will allow us to buildthe “best” overall partition scheme.
Remark. A practical consideration here deals with thehandling of the list U of undetermined intervals. A num-ber of possibilities exist. Alexopoulos [2, 3] suggestedthat the LIFO processing discipline outperforms FIFOin keeping the list small. Alternatively, maintaining thelist by means of a heap sorted by set probability workswell when the objective is the quick computation of tightbounds. We have had very good results using a heap ini-tially (with the most probable undetermined interval ontop) and switching to LIFO when the probability of themost probable filed set is suitably small. All numericalresults in Section 8 use this form of list management.
3. THEORETICAL RESULTS CONCERNINGPARTITION ALGORITHMS
In this section, we present new results concerning thenumber of undetermined intervals produced in each it-eration of the partition algorithm described above. Thisappears to be a matter of great practical importance. Weshall investigate the consequences of removing variouscombinations of feasible and infeasible intervals, con-cluding that the methods given in Section 2 cannot beimproved upon in this regard.
We shall look chiefly at feasible partition. By sym-metry, the results also apply to infeasible partition. We
assume that we seek to partition an interval U = [α, β]for which α is a feasible state and β is an infeasiblestate.
Our first result concerns the number of undeterminedintervals needed to partition what remains of U after theremoval of a single feasible interval of the form (2).
Proposition 2. Let l ∈ U be a feasible state which differsfrom the state β in i positions (0 ≤ i ≤ m), and let Fbe the feasible interval defined by (2). Then, exactly iintervals are required to partition U \ F.
Proof. We have already seen that procedure FEA-SIBLE produces one undetermined interval for eachj ∈ 1, . . . , m with lj < βj. In the present setting, then,i intervals would be produced. Thus, we need only showthat it is not possible to partition U \ F using fewer thani intervals. We shall do this by using mathematical in-duction on m, the number of components.
The result holds for m = 2, as we now demonstrate.If i = 0, then l = β and U \ F = ∅. If i = 1, then ldiffers from β in one position, and, hence, U\F ≠ ∅, sothat it is not possible to cover U \ F with 0 sets. Finally,if i = 2, then it is impossible to cover the “L-shaped”set U \ F with 0 or 1 intervals.
Now suppose that the result holds for m − 1 vari-ables (X1, . . . , Xm−1) and consider the case for m vari-ables. It will be useful to view Ωm, the state space of(l1, . . . , lm), as consisting of nm ordered copies of Ωm−1,the state space of (l1, . . . , lm−1), indexed by 1, . . . , nm,and to view undetermined intervals U as being similarlymade up of ordered lower-dimensional undetermined in-tervals.
The result clearly holds when i = 0 or i = 1 by pre-cisely the same logic as was used above. Now supposethat 2 ≤ i ≤ m. We prove that it is impossible to parti-tion U \ F using fewer than i intervals by contradiction.In light of our previous remark, U will be viewed asconsisting of ordered (m − 1)-dimensional undeterminedintervals designated by Uαm , . . . , Uβm . The set F resides insets Uαm , . . . , Ulm
, where it forms similar sets Fαm , . . . , Flm(each Fj is oriented with respect to the other states in Uj
in the same way). We shall consider separately the caseslm = βm and lm < βm.
If lm = βm, then, clearly, i ≤ m−1 (l agrees with β inat least one position). In Uβm , the state l differs from thestate β in i positions. Any partition of U \ F consistingof fewer than i intervals clearly implies a partition ofUβm \Fβm consisting of fewer than i intervals, impossibleby the induction hypothesis. Thus, i intervals are needed.
If lm < βm, then in Ulm , the feasible state l differsfrom the state (β1, . . . , βm−1, lm) in i − 1 positions. Nowsuppose there is a partition of U \ F consisting of fewerthan i intervals. The number of intervals in this parti-tion must be i − 1 since a smaller number would implyan impossible partition of Ulm
\ Flm, as before. In fact,
NETWORKS–2000 123

each set in the partition must intersect Ulm, yielding a
nonempty interval that does not overlap with Flm. Since
all of U \ F must be covered by this partition, someinterval must contain a state in Ulm
\ Flm and the state(α1, . . . , αm−1, βm), which lies “above” F, impossible bythe definition of an interval. So i intervals are neededand the result is proved.
An important special case of Proposition 2 occurswhen l differs from the state β in only one position, inwhich case U \ F is an interval. Since the symmetric re-sult for infeasible intervals holds, we have the followingimmediate consequence:
Corollary. Let Ij, j = 1, . . . , m be a collection of in-feasible intervals, each of which is defined by an infeasi-ble state that differs from the state α in only one position.Then, U \ (∪m
j=1Ij) is an interval.
Proposition 2 and Corollary 3 imply that, as long aswe restrict ourselves to infeasible intervals whose defin-ing states differ from α in only one position, we mayremove infeasible intervals in addition to the feasible in-terval F without increasing the number of undeterminedintervals produced. Of course, a symmetric result is im-plied for removing feasible intervals along with an in-feasible interval. Thus, Corollary 3 clearly applies to thealgorithms in Section 2, and we have proved the follow-ing key result:
Theorem 3. The removal of infeasible ( feasible) inter-vals, each differing from the state α (β) in only one po-sition, from an undetermined interval in step 3 of algo-rithm PARTITION cannot increase the number of inter-vals needed to partition the remainder of U.
Thus, by using only one of procedures FEASIBLEand INFEASIBLE, we are able to remove both typesof intervals simultaneously without splintering theremaining undetermined states into many sets. Onemight wonder whether this fact distinguishes algorithmPARTITION in any way, or if, indeed, any routine de-signed to remove feasible and infeasible intervals wouldperform as well in this regard. The key to the answerlies in Theorem 4 below. (The cases in which iF ≤ 1 oriI ≤ 1 are already dealt with in Proposition 2.)
Theorem 4. Let lF be a feasible state that differs fromthe state β in iF > 1 positions, and let F be the corre-sponding feasible interval. Let lI be an infeasible statethat differs from the state α in iI > 1 positions, and let Ibe the corresponding infeasible interval. Then, the num-ber of intervals needed to partition U \ (F ∪ I) is
(a) greater than or equal to the number of intervals re-quired to partition U \ F;
(b) less that or equal to iF + iI − 1.
Proof. (a) We use induction on m. If m = 2, then weclearly have iF = iI = 2. Already Proposition 2 providesthat U\ F needs 2 intervals for its partition. Since iI = 2(i.e., lI lies strictly in the interior of U \ F), it is clearthat U \ (F ∪ I) is not a single interval. Thus, at least 2intervals are needed.
Now suppose that the result holds for m − 1 vari-ables (X1, . . . , Xm−1), and consider the case of m variables(X1, . . . , Xm). As before, it is useful to think of U as beingcomposed of ordered, indexed (m − 1)-dimensional un-determined sets Uαm , . . . , Uβm . We consider two separatecases:Case 1. (lF
j∗ ≥ lIj∗ for some j∗ ∈ 1, . . . , m): Without
loss of generality, assume that j∗ = m. If lFm = βm,
then, also, lIm = βm. In the (m − 1)-dimensional interval
Uβm , then, we have a feasible set Fβm = F ∩ Uβm whosedefining state lF differs from β in iF positions and aninfeasible set Iβm = I∩Uβm . By the induction hypothesis,the partition of Uβm \ (Fβm ∪ Iβm ) requires at least iF
intervals. Consequently, at least iF are needed to partitionthe set U \ (F ∪ I).
Now, suppose that lFm < βm. UlF
mcontains a feasible
interval FlFm
= F ∩ UlFm
whose defining state differs from(β1, . . . , βm−1, lF
m) in iF −1 positions and an infeasible setIlF
m. By the induction hypothesis, the partition of UlF
m\
(FlFm
∪ IlFm) requires at least iF −1 intervals. Note that, by
the definition of an interval, none of these iF−1 intervals,even when extended to all levels of U, can contain thestate (α1, . . . , αm−1, lF
m), which lies “above” F. So morethan these iF − 1 intervals are needed to partition U \(F ∪ I). This concludes Case 1.Case 2. (lF
j < lIj for all j ∈ 1, . . . , m): In this case,
necessarily lFj < βj for all j ∈ 1, . . . , m, so that iF = m.
Similarly, iI = m. Suppose there exists a partition of U \(F∪I) consisting of fewer than m intervals. This partitionintersects the (m−1)-dimensional interval Uαm to form apartition of Uαm \ Fαm (where Fαm = F ∩ Uαm ) consistingof fewer than m intervals. Now in Uαm , the defining stateof Fαm differs from the state (β1, . . . , βm−1, αm) in m − 1positions, and, hence, by Proposition 2, m − 1 intervalsare required to partition Uαm \ Fαm . Thus, the partitionof U \ (F ∪ I) requires m − 1 intervals, each of whichintersects Uαm in a nonempty interval outside of the set F.This means that one of these intervals must contain statesin Uαm \ Fαm and the state (α1, . . . , αm−1, lF
m + 1) (a state“above” F). This is not possible given the definition of aninterval. Thus, at least iF intervals are needed to partitionU \ (F ∪ I). This concludes Case 2 and the inductionargument.
(b) Let j∗ ∈ 1, . . . , m be such that lFj∗ < lI
j∗ . (We mustbe able to find j∗ since F and I cannot overlap.) Define
Uj∗ = l ∈ U : lFj∗ + 1 ≤ lj∗ ≤ lI
j∗ − 1
and αi ≤ li ≤ βi for i ≠ j∗.
(Note that Uj∗ = ∅ if lFj∗ = lI
j∗ − 1.) What remains,
124 NETWORKS–2000

then, is an interval
UF = [α, (β1, . . . , βj∗−1, lFj∗ , βj∗+1, . . . , βm)]
containing the feasible interval F (whose defining statediffers from UF’s upper endpoint in iF −1 positions) andan interval
UI = [(α1, . . . , αj∗−1, lIj∗ , αj∗+1, . . . , αm), β]
containing the infeasible interval I (whose defining statediffers from UI’s lower endpoint in iI − 1 positions). ByProposition 2, we partition UF using iF − 1 intervals andUI using iI − 1 intervals. Thus, counting Uj∗ , we haveused (iF − 1) + (iI − 1) + 1 = iF + iI − 1 intervals in thepartition.
To summarize, our goal here was to investigate theconsequences of removing infeasible intervals in addi-tion to a feasible interval. Procedure FEASIBLE guaran-tees no increase in the number of resulting undeterminedintervals. If, however, one attempts to also use infeasi-ble intervals that differ from the state α in more thanone position, then Theorem 4 implies that the number ofintervals needed to form a partition either remains thesame or increases. This brings us to the following result.(An analogous result holds when one attempts to removefeasible intervals in addition to an infeasible interval.)
Corollary. Consider an interval U = [α, β] with agiven feasible state l. Let D be the class of proceduresthat remove the feasible interval F = [α, l] and attemptto remove infeasible states. Then, procedure FEASIBLEis minimal in D with respect to the number of resultingundetermined intervals.
One additional observation must be made. Each al-gorithm based on state space partition involves a varietyof complex interactions that determine its ultimate effec-tiveness on a given problem. Experience indicates that nosingle objective (e.g., keeping the list of sets short, re-moving maximum probability, expending little compu-tational effort) can guarantee across-the-board success.Trying to generate few intervals per iteration does seemto play a big role. Nevertheless, because of the complexinterplay mentioned above, we will test in Section 8 a“mixed” approach that removes a single arbitrary infea-sible interval and an arbitrary feasible interval in eachiteration.
Before looking at spanning tree problems, we con-clude our discussion of partition methods by describinghow they can be used for producing bounds and provid-ing input for variance-reducing Monte Carlo estimationprocedures.
4. BOUNDS AND MONTE CARLOSAMPLING
In Section 2, we presented an algorithm for comput-ing PF exactly in a number of iterations that is typicallysmall (relative to |Ω|) for moderate-size problems. For
large problems, this may still represent an unacceptablecomputational workload. In such cases, the real strengthof algorithm PARTITION lies in its ability to generateprogressively tighter bounds that can be used as input toefficient Monte Carlo sampling routines. In this section,we briefly review the sampling plan in [3, 5]. This plancombines importance sampling (since it concentrates ona subspace of Ω) and stratified sampling (as it allocatesa predetermined number of samples to each set Ui).
Notice that the algorithm can be terminated when thenumber of existing undetermined intervals exceeds somefixed value or the undetermined probability PF
u − PFl is
less that an a priori bound (one only needs to modify thewhile loop condition). The following screening step canbe added to the algorithm:
4. For i = 1, . . . , k: Evaluate the extreme states of Ui. IfUi is feasible, set PF
l = PFl + PUi and remove Ui
from U. If Ui is infeasible, set PFu = PF
u − PUi andremove Ui from U.
The sampling plan is constructed as follows: Supposethat U = U1, . . . , Uk0 with Ui = [α(Ui), β(Ui)] andwrite
PFu − PF
l =k0∑
i=1
πi,
where
πi ≡ PUi =m∏
j=1Qij, for i = 1, . . . , k0,
andQij = Pαj(Ui) ≤ Xj ≤ βj(Ui).
Let n be the sample size. We use the proportional allo-cation rule to draw ni = nπi/(PF
u − PFl ) samples from
each Ui using the following algorithm:
Algorithm SAMPLE(U1, . . . ,Uk0 )
For i = 1, . . . , k0:For s = 1, . . . , ni:
1. For j = 1, . . . , m: Sample the in-dex lj with probabilities pj(r)/Qij,αj(Ui) ≤ r ≤ βj(Ui). That is, samplea Uniform(0, 1) number R and set (see[13] for an efficient algorithm)
lj = min
r : αj(Ui) ≤ r ≤ βj(Ui),
r∑v=αj (Ui )
pj(v)/Qij ≥ R
.
2. Set l(i:s) = (l1, . . . , lm).End
Let
Si =ni∑
s=1
1[l(i:s) ∈ ΩF], for i = 1, . . . , k0
NETWORKS–2000 125

be the number of feasible samples within the interval Ui.Then,
PF = PFl +
k0∑i=1
πi(Si/ni)
is an unbiased estimator of PF [i.e., E(PF) = PF] and hasvariance that is smaller than the variance of the crude(standard) Monte Carlo estimator for the same samplesize by a factor of at least
(√PF
u (1 − PFl ) −
√PF
l (1 − PFu )
)−2
.
In addition, the above sample plan requires less time andspace.
We now discuss the application of partitioning to theprobabilistic MST problems.
5. STOCHASTIC MST PROBLEMS
In the following sections, we present partition al-gorithms for MST problems in networks whose edgeshave discrete random weights. Specifically, suppose thatV = 1, . . . , n, E = 1, . . . , m and that the randomvariable Xj represents the weight of edge j ∈ E. Wedefine the random variable W(X) as the weight of anMST when edge weights are given by X. Before solv-ing these problems, it will be instructive to review prop-erties regarding the dynamics of MSTs when a singleedge changes weight. By knowing in advance the con-sequences of these actions, we can maintain or achieveproperties such as tree membership or tree weight. Webegin at an arbitrary state l = (l1, . . . , lm) with associatedMST T. We shall independently decrease or increase theweight of edges both on and off the tree T, addressing thefollowing questions for each action: (1) Does this actioncause T to cease being an MST, thus forcing a change intree membership? (2) Does this action change the weightof an MST? Properties 1–4 summarize well-known re-sults from [1]. For convenience, we shall use a shorthandnotation for some set operations; e.g., T ∪ i \ j willbe written as T + i − j.
Property 1 (Decreasing the weight of an edge j ∈ T) SinceT is an MST, it will surely remain so if the weightof one of its edges decreases. Of course, the weightof T will decrease by the amount of the reduction inthe weight of edge j.
Property 2 (Decreasing the weight of an edge j /∈ T) De-creasing the weight of j sufficiently can cause it todisplace an edge of T with a larger weight. Amongthe tree edges on C(j), the unique cycle that j formswith T, let i be an edge with the largest weight. Aslong as the weight of j does not drop below that of i,any reduction of j’s weight impacts neither T nor itsweight. Otherwise, T + j − i becomes an MST, withweight less than that of T, and further reductions inthe weight of j are governed by Property 1.
Property 3 (Increasing the weight of an edge j /∈ T) Sincej /∈ T, the weight of j can be increased arbitrarilywithout impacting T or its weight.
Property 4 (Increasing the weight of an edge j ∈ T) In-creasing the weight of j can cause T to cease beingan MST. Among those edges not on T whose cycleswith T contain j, let i be an edge with the small-est weight. As long as the weight of edge j does notexceed that of edge i, T remains an MST (althoughwith increased weight). Otherwise, T + i − j becomesan MST and further increases in the weight of j aregoverned by Property 3.
We shall refer to the process of exchanging edges be-tween an MST and the remainder of E as pivoting.
6. COMPUTING THE PROBABILITYDISTRIBUTION OF THE WEIGHTOF AN MST
In this section, we first consider the evaluation ofthe probability PW(X) ≤ d that there exists a span-ning tree with total weight less than or equal to a fixedd ≥ 0. Clearly, X1, . . . , Xm are all lower feasible. Thisproblem, like many that fit the general problem descrip-tion in Section 2, is provably hard. The proof of Propo-sition 5 is based on a reduction from the all-terminalreliability problem.
Proposition 5. The evaluation of PW(X) ≤ d for fixedd ≥ 0 is a #P-hard problem.
Proof. Consider an instance of the following #P-hardproblem [7]:
All-terminal Undirected Rational Network ReliabilityProblem (ATRP)
Inputs: Undirected network with edges that function or failindependently of each other. For edge i, the probabil-ity of failure is bi/ci, where bi is a nonnegative integerand ci is a positive integer such that bi ≤ ci.
Outputs: b and c, where c is a positive integer, b is a non-negative integer such that b ≤ c, and
Pthe system functions= Pthe network is connected= Pthere is a spanning tree
consisting of functioning edges= b/c.
To each edge i, assign the random weight
Xi =
0 with probability 1 − bi/ci
1 with probability bi/ci,
where the nonzero weight corresponds to failure. Then,evaluating PW(X) ≤ 0 is equivalent to finding theprobability that there is a spanning tree made up of func-tioning edges, that is, PW(X) ≤ 0 is equal to the all-terminal network reliability. Thus, the ability to evaluatePW(X) ≤ d implies the ability to solve ATRP. Since
126 NETWORKS–2000

ATRP is #P-complete, the evaluation of PW(X) ≤ d is#P-hard.
We are now in a position to discuss the application ofpartitioning to the present problem. Given the ground-work laid in Section 2, this will amount to little morethan specifying the mechanics of finding l and the lj’s.Sections 6.1 and 6.2 describe feasible partition algo-rithms, whereas Section 6.3 offers an infeasible partitionscheme. We present several algorithms to demonstratethe flexibility of algorithm PARTITION in Section 2.Finally, Section 6.4 contains a “mixed” routine based onthe partition discussed in the proof of Theorem 4.
6.1. Feasible Partition Algorithm I
We describe here a single iteration of the Feasible Par-tition algorithm I (FP-I), in which we partition an inter-val U = [α, β] that contains both feasible and infeasiblestates. To determine the feasible state l, we begin at thefeasible extreme α. For all j ∈ E, we set the edge weightat wj(αj) and find an MST, which we denote by T(α). Itis clear by Property 3 that any j /∈ T(α) can be raisedto weight wj(βj) without impacting T(α). Thus, with noadditional work, we may set lj = βj for j /∈ T(α) andlj = αj for j ∈ T(α), yielding a feasible state for whichm − n + 1 edges are cut as deeply as possible. (At thispoint, one could try to increase the weight of some edgeson T(α) using Property 4. Experimentation [16] has in-dicated that the considerable additional effort does notpay off.)
All that remains is to determine the limiting feasi-ble indices lj. We already have determined m − n + 1of them: Since lj ≥ lj for all j, our assignment of labove indicates that lj = βj for all j /∈ T(α). Increas-ing the weight of the tree edges requires, according toProperty 4, some preprocessing to determine what re-strictions there may be on such an action. Fortunately,though, since each lj is determined independently andstarting at the same state α, all the tree edges can bepreprocessed in one pass through the edges not in T(α)by the procedure SHORT below. For all j ∈ T(α), thisprocedure produces SHORT(j), the weight of an off-treeedge that would displace edge j if the weight of j wereto increase beyond SHORT(j).
Procedure SHORT
1. For j ∈ T(α): Set SHORT(j) = ∞.2. For i /∈ T(α): Find C(i), the unique cycle i forms
with T(α). For each j ∈ C(i) − i, set SHORT(j) =minSHORT(j), wi(αi).End
We proceed to find lj independently for each j ∈ T(α)as follows: If lj = βj, we set lj = βj. Otherwise, we needto contend with the implications of Property 4. Startingwith level αj, the weight of edge j is increased one level
at a time, paying close attention to whether wj(·) exceedsSHORT(j) (which would force j to pivot out of the MST)and whether the MST weight (with or without such apivot) exceeds d. Then, lj is set to the level below thatwhich caused W(·) to exceed d (or to βj if d is neverexceeded). Note that if edge j pivots out and the resultingMST still has feasible weight, lj = βj by Property 3.
The determination of l involves relatively little work.Procedure SHORT takes time O(mn), and the subsequentdetermination of the lj’s (which is done for the tree edgesonly) takes time O(n maxj∈E nj).
After limiting feasible indices have been determinedfor all edges, we are ready to partition as in Section 2and proceed to the next undetermined interval.
6.2. Feasible Partition Algorithm II
This section describes an algorithm that is similar tothe algorithms in [3] for stochastic shortest path prob-lems and is conceptually simpler than is FP-I. It alsopartitions in a slightly different way. Differences includea modified prescreening phase and a simplified partitionwhich results from not finding limiting indices lj.
We first state the algorithm. Explanations follow.
Algorithm FP-II
1. Set U = Ω, PFl = 0, and PF
u = 1.While U ≠ ∅
2. Remove an interval U = [α, β] from U. Find T(α), anMST at α, with weight W(α). If W(α) > d, then U isinfeasible; set PF
u = PFu − PU and skip steps 3–6.
3. Let Wβ(α) =∑
j∈T(α) wj(βj). If Wβ(α) ≤ d, thenW(β) ≤ d and U is feasible; set PF
l = PFl + PU
and skip steps 4–6.4. Set l = β and WT = Wβ(α). Sort the edges j ∈ T(α)
for which αj < βj in decreasing order of wj(βj) −wj(αj).
5. For each edge j ∈ T(α) in the order determined instep 4:
a. Set lj = αj and WT = WT − wj(βj) + wj(αj).b. If WT ≤ d: Set lj = maxγ : αj ≤ γ ≤
βj, WT − wj(αj) + wj(γ) ≤ d and go to step6.
6. Form F as in (2) and set PFl = PF
l + PF.For j ∈ E: If lj < βj, file Uj in U, where Uj is givenby (4) with l = β.End WhileEnd
A few comments need to be made about FP-II: Wefirst look at step 3. When the weights of the edges areraised to levels βj, the tree T(α) will not, in general, bea minimum spanning tree. However, if its weight Wβ(α)does not exceed d, then, by definition, neither will W(β),the weight of a minimum spanning tree at β. Thus, insuch a situation, we may declare U feasible without ac-tually making an MST evaluation at β.
NETWORKS–2000 127

If Wβ(α) > d, we cannot conclude that β is an infea-sible state. But we do know that there is a state withlj = βj for j /∈ T(α) and lj < βj for at least onej ∈ T(α), at which T(α) has feasible weight. (The statewith lj = αj for all j ∈ T(α) is clearly such a pointsince we know that W(α) ≤ d.) Consistent with ourusual goal of keeping the list of undetermined intervalssmall, we select from among the (potentially) many suchstates l one that minimizes the number of new undeter-mined intervals produced. In view of (4), Uj = ∅ onlyif lj = βj; hence, it is reasonable to choose a state l forwhich lj = βj for as many j ∈ T(α) as possible. Thus,we have a 0–1 knapsack problem. The available spacein the knapsack is d − W(α). Each arc j ∈ T(α) takesup space equal to wj(βj) − wj(αj) (here putting j in theknapsack means setting lj = βj) and all edges have equalvalue, say 1. Steps 4–5 apply a known knapsack heuris-tic, which is optimal in this case as stated in Proposition6 below. (If there is an edge j ∈ T(α) not included inthe knapsack whose weight is less than the weight of anedge i in the knapsack, these edges can be exchangedwithout changing the total value of the knapsack. Theexistence of such a pair of edges is impossible under theprocessing order in steps 4–5.) When the first edge j that“does not fit entirely” is found, we choose lj as large aspossible and leave the remaining tree edges i at levelsli = αi. Again, at this state l, we have a (not necessarilyminimum) spanning tree whose weight does not exceedd, so clearly W(l) ≤ d.
Proposition 6. Steps 4–5 in procedure FP-II yield a min-imum number of new undetermined intervals in each it-eration.
Finally, since only those edges j ∈ T(α) for whichαj < βj are considered in steps 4–5, we would like T(α)to contain as many edges as possible for which αj =βj (or even αj + 1 = βj). This motivates the followingpreprocessing of the edges prior to finding T(α):
w(j) =
wj(αj) − 2ε if αj = βj
wj(αj) − ε if αj + 1 = βj
wj(αj) otherwise,
where ε is suitably small. In this way, as many of these“preferred” edges as possible are included in the MST.After finding T(α), the true edge weights are restored sothat tree weight may be accurately computed.
6.3. Infeasible Partition Algorithm (InP)
We describe a single iteration of an Infeasible Parti-tion algorithm (InP), which begins at the infeasible ex-treme β (prescreening has verified its infeasibility) andpushes in, identifying an infeasible state l and limitinginfeasible indices lj. As before, the determination of lj
for each j and the determination of l, each beginning at
β, can be designed to be carried out in any order. Here,we first identify the limiting infeasible indices lj. After-ward, we use the fact that lj ≤ lj for j ∈ E during thederivation of l.
We begin by finding T(β), an MST at β, with weightW(β) > d. For j ∈ T(β), we can use Property 1 tofind lj with relative ease, since we can look at edge j inisolation, ignoring all other edges. We simply begin withlj = βj and lower one level at a time until either the MSTweight would drop to or below d with further reductionor lj hits αj while the tree weight is still infeasible.
On the other hand, finding lj for off-tree edges j iscomplicated by the fact that reducing the weight of edgej could force it into the MST, as discussed in Property 2.So, we identify C(j), the unique cycle that edge j formswith T(β), and identify i, an edge in C(j)−j with largestweight (at state β). We then decrease the weight of jone level at a time until either we hit αj and still havewj(αj) ≥ wi(βi), in which case lj = αj (here, we alsopreset lj = αj), or at some state the weight of j becomesstrictly less than that of i and T(β) + j − i is the newMST (here, we preset lj at the index prior to that whichforced j to enter the tree). If the new tree weight is stillinfeasible, we continue reducing the weight of j as fortree edges. If not, then lj is set at the level just prior tothe level at which j entered the tree.
It remains to derive the infeasible state l. Rather thanstarting from l = β, we begin with the state given by
lj =
βj if j ∈ T(β)as preset above if j /∈ T(β). (5)
It is clear, by Properties 1–4, that T(β) remains an MSTfor l with weight W(β). We may proceed from this stateto derive a deeper infeasible state. As mentioned earlier,lj ≥ lj for all j ∈ E. Thus, the state l serves as a floorfor the further reduction of l. In fact, it is likely that forsome edges j we already have lj = lj with l as definedby (5). Those edges will not be considered for furtherreduction. The remaining edges will be reduced one ata time as much as possible, governed by the applicableproperty, as long as the tree weight does not reach d.
This further reduction could be accomplished in manydifferent ways. The idea is to reduce as many edges aspossible and to reduce them as much as possible. To ac-complish the former goal, we want to avoid using edgesj ∈ T(β) for which wj(lj) − wj(lj − 1) is large since suchedges might bring the MST weight down to d all at once,preventing the reduction of other edges. The latter goalcauses us to give preference to edges with a lot of roomlj − lj for reduction. To try to accommodate both goals,we use an ordering of edges that is inspired by a knap-sack heuristic. This heuristic chooses items in decreasingorder of the ratio value/size. So, after eliminating edgeswith lj = lj from consideration, we first consider treeedges, followed by edges not on T(β), in decreasing or-der of the ratio (lj − lj)/[wj(lj) − wj(lj − 1)]. The weight
128 NETWORKS–2000

of each edge selected for reduction according to this ruleis decreased one level at a time until further reductioneither is not possible (i.e., lj = lj) or would result in afeasible state.
Once l has been determined, we run INFEASIBLE(U)and proceed to the next undetermined interval.
6.4. Mixed Partition Algorithm
In this section, we describe algorithm MP, a mixedpartition procedure that is essentially a combination ofFP-II and InP. In each iteration, the algorithm partitionsan undetermined interval U = [α, β] into one feasibleinterval F, one infeasible interval I, and up to 2m − 1new undetermined intervals.
Algorithm MP
1. Set U = Ω, PFl = 0, and PF
u = 1.While U ≠ ∅
2. Remove an interval U = [α, β] from U. Find T(β), anMST at β, with weight W(β). If W(β) ≤ d, then U isfeasible; set PF
l = PFl + PU and skip steps 3–6.
3. Find T(α), an MST at state α, with weight W(α). IfW(α) > d, then U is infeasible; set PF
u = PFu − PU
and skip steps 4–6.4. As in FP-II, derive a feasible state lF and the respec-
tive interval F based on the MST T(α).5. As in InP, derive an infeasible state lI and the respec-
tive interval I based on the MST T(β).6. Set PF
l = PFl +PF and PF
u = PFu −PI. Partition the
remainder U \ (F ∪ I) based on lF and lI as describedin the proof of Theorem 4. File the new undeterminedintervals in U.End WhileEnd
Section 3 showed that routines like MP can generatean increased number of undetermined intervals. Again,however, there are many factors that jointly determinethe ultimate performance characteristics of a partitionroutine. Examples in Section 8 will test the performanceof MP.
6.5. Computing the Entire Distribution ofthe MST Weight
The previous subsections contain partition algorithmsfor computing a single ordinate of the cumulative dis-tribution function of W(X). Calculating PW(X) Ú d issufficient for situations in which d represents an exist-ing constraint on MST weight (e.g., a capital or materialconstraint). But when that is not the case, it is instructiveto explore the full range of possible MST weights, calcu-lating associated probabilities and computing the meanand higher moments of W(X). In this section, we presentan algorithm that computes F(d) = PW(X) ≤ d for allrealizations d of W(X). In this setting, there are no feasi-ble/infeasible intervals. Rather, we call an interval [α, β]determined if all of its states have a common MST. To
partition an undetermined interval [α, β], we begin byfinding T(α), an MST computed with edge weights instate α. Properties 3 and 4 yield the determined intervaldefined by the state
lj =
αj if j ∈ T(α)βj if j /∈ T(α). (6)
Clearly, the interval F = [α, l] is determined with T(α)as the common MST.
This procedure is summarized below. The quantitiespl(d) are lower bounds for the probability (mass) func-tion p(d) = PW(X) = d. The description assumes inte-ger edge weights. Modifications would need to be madeonly in the data structures for the pl(d)’s and the man-ner in which they are accumulated if edge weights arenonintegral.
Procedure DIST
1. Find W(1, . . . , 1), W(n1, . . . , nm). For d = W(1, . . . , 1), . . . ,W(n1, . . . , nm), set pl(d) = 0. Set U = Ω.While U ≠ ∅
2. Remove an interval U = [α, β] from U. Find T(α), anMST at α, with weight W(α).
3. Set l as in (6).4. Set pl(W(α)) = pl(W(α)) + PF, where F is defined
by (2).5. For j ∈ E: If lj < βj, file Uj in U, where Uj is
defined by (4).End While
7. For d = W(1, . . . , 1), . . . , W(n1, . . . , nm): Set F(d) =∑di=W(1,...,1) pl(i).
End
Note that, in view of (6), at most n − 1 undeterminedintervals will be filed in step 5. Fewer than that numberare filed if αj = βj for some j ∈ T(α). For that reason,we would like to choose an MST that contains as manytree edges as possible with αj = βj. To accomplish this,we preprocess the edges in a manner similar to that usedin algorithm FP-II.
As usual, algorithm DIST may be terminated prior tocomplete partitioning of Ω to produce bounds (by mod-ifying the while loop condition). To produce bounds onF(d) = PW(X) ≤ d for all d, we replace step 7 withstep 7 and add step 8, as shown below:
7. For d = W(1, . . . , 1), . . . , W(n1, . . . , nm): Set Fl(d) =∑di=W(1,...,1) pl(i).
8. For all U = [α, β] ∈ U:For W(α) ≤ d < W(β): Set Fu(d) = Fu(d) + PU.For W(β) ≤ d ≤ W(n1, . . . , na): Set Fl(d) = Fl(d) +PU and Fu(d) = Fu(d) + PU.
7. COMPUTING CRITICALITY INDICESFOR THE STOCHASTIC MST PROBLEM
This section describes a procedure for computingPF(e) = Pedge e is on an MST, the criticality indexfor edge e.
NETWORKS–2000 129

Proposition 7. The evaluation of PF(e) = Pedge e ison an MST is a #P-hard problem.
Proof. Let G = (V, E) be a graph whose edgeshave random lengths with possible values in 0, 1. Lets, t ∈ V and let X be the vector of edge weights, whichcorrespond here to lengths. Let L(X) designate the (ran-dom) length of a shortest (s–t) path in G when edgelengths are given by X. The evaluation of PL(X) ≥ 1is #P-hard [4].
Now create an edge e = (s, t) with fixed length 1 andlet G′ = (V, E + e). Then, evaluating Pedge e is onan MST in G′ is equivalent to evaluating PL(X) ≥1. To see this, we need only establish that, for a givenrealization x of edge lengths, e is on an MST in G′ ifand only if L(x) ≥ 1. This is proved most easily by acontrapositive argument.
Suppose that e can be on no MST in G′. Consider anMST T, and let C(e) be the unique cycle that e formswith T. Every edge in C(e) − e must have zero length,for, otherwise, e could be pivoted in to replace an edgein C(e) − e with length 1, yielding an MST containing e.But C(e)−e necessarily is an (s–t) path with zero length.Then, L(x) = 0.
Now suppose that L(x) = 0. Consider P, an (s–t) pathin G of length 0, and an arbitrary MST T′ in G′. If P′ =P\T′ is nonempty, then we may pivot each edge in P′ intoT′ one at a time, arriving at a new MST T containing P.Since T is acyclic, e /∈ T. Furthermore, since necessarilyC(e) − e = P, e cannot be pivoted in to achieve an MSTcontaining e. Then, no MST contains e.
Therefore,
PF(e) = Pedge e is on an MST = PL(X) ≥ 1and the evaluation of PF(e) is #P-hard.
In finding PF(e), the feasible region consists of allstates in Ω at which edge e is on an MST. Before pre-senting any details of our procedure, we need to inves-tigate this definition of feasibility. Since Xe is lowerfeasible and Xj, j ≠ e, are upper feasible, we arrangethe edge weights so that we(1) < · · · < we(ne) andwj(1) > · · · > wj(nj) for j ≠ e. Propositions 8 and 9show how feasible and infeasible intervals can be ob-tained. They also imply that α is the extreme feasiblecandidate of an interval [α, β], whereas β is the extremeinfeasible candidate. Their proofs are direct implicationsof Properties 1–4.
Proposition 8. Consider an interval U = [α, β]. Supposethat edge e belongs to an MST at level l ∈ U. Then, e isin an MST for all states in the interval F defined by (2).
Proposition 9. Consider an interval U = [α, β]. Supposethat edge e is in no MST at level l ∈ U. Then, e is in noMST for any state in the interval I = l ∈ U : lj ≤ lj ≤βj for j = 1, . . . , m.
We shall now describe the partition algorithm. Theprescreening phase and the phase in which we decidewhether to partition feasibly or infeasibly are somewhatfree-flowing. A number of possible feasible and infea-sible states are investigated first, in the hope of deriv-ing a particularly effective and/or easily obtained cutoffstate. If that fails, we may choose between default fea-sible and infeasible partitions. Limiting indices lj willnot be used. Throughout, Properties 1–4 from Section 5will be used. Step 13 attempts to improve the existingbounds.
Algorithm CRIT(e)
1. Set U = Ω, PFl (e) = 0, and PF
u (e) = 1.While U ≠ ∅
2. Remove an interval U = [α, β] from U. Find T(β),an MST at the extreme infeasible candidate β. Ife ∈ T(β), go to step 3. Otherwise, find i1, the mostheavily weighted edge on the cycle e forms with T(β).If the edges e and βi1 have equal weights (we(βe) =wi1 (βi1 )), pivot e into T(β) and name the new treeT(β).
3. If e /∈ T(β), go to step 4. Otherwise, β is a feasiblestate so that U is feasible. Go to step 11.
4. If we(αe) > wi1 (βi1 ), then T(β) remains an MST whenall edges have minimum weight (edge e has weightwe(αe) and edges j ≠ e have weights wj(βj)). Callthis tree Tlow and go to step 5. Otherwise, decreasingthe weight of edge e will cause it to displace edge i1.Let le = maxγ : αe ≤ γ ≤ βe, we(γ) ≤ wi1 (βi1 ) andlj = βj for j ≠ e. Perform feasible partition and goto step 11.
5. Find T(α), an MST at the extreme feasible candidateα. If e ∈ T(α), go to step 6. Otherwise, find i2, themost heavily weighted edge on the cycle that e formswith T(α). If the edges e and i2 have equal weights,pivot edge e into T(α), name the new tree T(α), andgo to step 6. Otherwise, e is on no MST at α and Uis infeasible; go to step 11.
6. We have e ∈ T(α). We now seek to force e out ofthe MST by changing the levels of only a few edges,yielding an infeasible state. One preprocessing passthrough the edges not in T(α) (similar to the proce-dure SHORT, but slightly more involved) finds thefollowing:
a. j1 = the least weighted edge off T(α) whosecycle contains edge e, which could displace edgee if the weight of e is increased (in step 7).
b. j2 = an edge not in T(α) which has e (at levelβ) as its most heavily weighted cycle edge andfor which wj2 (βj2 ) < we(βe). If the weight of ehas been increased to we(βe) (in step 7), then theweight of edge j2 can be lowered (by raising itsindex from αj2 to βj2 ) in step 8 to force e outof the tree. If no such edge exists, let j2 = 0.
c. j3 = an edge not in T(α) whose cycle C(j3) withT(α) contains e and wj(βj) < we(βe) for all j ∈C(j3) − e (for use in step 9). If no such edge isfound, set j3 = 0.
130 NETWORKS–2000

Note: Even though all these edges might not beneeded, we may efficiently determine all three in timeO(mn), essentially the same amount of work neededto determine any one of them.
7. If we(βe) ≤ wj1 (αj1 ), then increasing the weight ofedge e to we(βe) does not force it out of the currentMST; go to step 8. Otherwise, this increase causesedge e to be displaced by j1. Set le = minγ : αe ≤γ ≤ βe, we(γ) > wj1 (αj1 ) and lj = αj for j ≠ e.Perform infeasible partition and go to step 11.
8. T(α) is now an MST when all edges are at maximumweight (edge e has weight we(βe) and edges j ≠ ehave weights wj(αj)). Call this tree Thigh. If j2 = 0, goto step 9. Otherwise, decreasing the weight of j2 willcause it to displace e from Thigh. Set le = βe, lj2 =minγ : αj2 ≤ γ ≤ βj2 , wj2 (γ) < we(βe) and lj = αj
for all other edges j. Perform infeasible partition andgo to step 11.
9. If j3 = 0, go to step 10. Otherwise, for j ∈ C(j3) − e,set lj = minγ : αj ≤ γ ≤ βj, wj(γ) < we(βe)and le = βe. Also, set lj3 = minγ : αj3 ≤ γ ≤βj3 , wj3 (γ) < we(βe) and lj = αj for all remainingedges j. Then e does not belong to an MST at statel. Perform infeasible partition and go to step 11.
10. We are left to choose from the default partitions.Choose the option below that yields fewer undeter-mined intervals:
a. Derive a feasible state from the known feasi-ble state obtained in step 8 (with Thigh an MSTand all edges at maximum weight) by settinglj = βj for j ∈ Thigh −e (the other edges on thetree can have their weights decreased), le = βe
(edge e stays at high weight), and lj = maxγ :αj ≤ γ ≤ βj, j does not displace e from Thighfor j /∈ Thigh (the edges off the tree can havetheir weights reduced as long as they do not al-ter tree membership). Perform feasible partitionand go to step 11.
b. Derive an infeasible state from the known in-feasible state obtained in step 4 (with Tlow anMST and all edges at minimum weight) by set-ting lj = αj for j /∈ Tlow (increasing the weightof the edges off the tree does not impact treemembership), le = αe, and lj = minγ : αj ≤γ ≤ βj, j stays in Tlow when edges j /∈ Tlow areat levels βj for j ∈ Tlow (the tree edges canhave their weights increased as long as they donot alter tree membership). Perform infeasiblepartition and go to step 11.
11. Add the probability of each generated feasible inter-val to PF
l (e). Subtract the probability of each gener-ated feasible interval from PF
u (e).12. If another stopping condition is met, go to step 13.
End While13. For all U ∈ U: Let α and β denote, respectively, the
lower and upper limiting states of U. Find T(α). Ife ∈ T(α) or if e can be pivoted into T(α) yielding analternate MST, set PF
l (e) = PFl (e) + PU.
14. Return bounds Pl(e) ≤ PF(e) ≤ Pu(e).End
A few comments are in order concerning algorithmCRIT. In steps 3–9, several attempts are made to findeasily identifiable feasible or infeasible states that willyield few undetermined intervals. If U is found to beall feasible in step 3, clearly no undetermined intervalsare produced. If reducing the weight of edge e in step4 yields a feasible state, then one undetermined intervalwill be produced. Finding U to be infeasible in step 5produces no undetermined intervals. If raising the weightof edge e from level αe causes it to pivot out of the treein step 7, then one undetermined interval is produced. Ifthe weight of edge j2 can be lowered so as to displaceedge e from Thigh in step 8, two undetermined intervalsare produced. Finally, if step 9 succeeds in identifyingan infeasible interval, we get undetermined intervals foredge e and each of the edges on the cycle formed by j3
with Thigh. If we are left with the default partitions ofstep 10, we get up to n − 1 undetermined intervals (ifwe partition feasibly) or up to m − n + 1 (if we partitioninfeasibly). In that case, the partition yielding the fewestnew undetermined intervals is used.
Remark. Procedure CRIT can be used with little mod-ification in a way similar to that given in [2] to computePedge e is on an MST and W(X) > d. Combining thismeasure with the output of FP-I, InP, or FP-II, one cancompute the conditional criticality index
Pedge e is on an MST | W(X) > d
=Pedge e is on an MST and W(X) > d
1 − PW(X) ≤ d .
These probabilities are useful in that they identify theedges that are likely to be MST members when the net-work cannot be connected feasibly. Of course, it takesa bit of extra work to produce them. We first run FP-I,InP-I, or FP-II, filing all generated infeasible intervals ina list I. If these are run to complete partition, the unionof the intervals in I is precisely the infeasible region ofΩ. These infeasible intervals are passed as input to algo-rithm CRIT (rather than starting with U = ∅ in step 1,we begin with U = I).
8. EXAMPLES
In this section, we demonstrate the performance ofthe various routines developed in this paper. All codeswere implemented in FORTRAN 77 and were executedon a SUN SPARCstation IPC. The implementation ofKruskal’s algorithm in Camerini et al. [11] was usedfor determining a minimum spanning tree. Except wherenoted, the list of undetermined intervals was kept in aheap sorted by probability until the most probable unde-termined interval had probability less than 10−20. Edgeweight distributions represent what we feel to be rea-sonable situations. Specifically, a high probability is as-signed to the lowest weight (the status quo) and low
NETWORKS–2000 131

probabilities are assigned to the higher weights (the oc-casional deviations from the status quo). All CPU timesquoted are in seconds. In all tables, PU represents thesum of the probabilities of undetermined intervals con-tained in the collection U.
Example 4. Consider the network in Figure 1 withthe edge-weight distributions in Table 1. For this ex-ample, the range of possible MST weights is fromW(1, . . . , 1) = 47 to W(3, . . . , 3) = 138. We computePW(X) ≤ 60 and PW(X) ≤ 90, these tree weightsbeing relatively extreme possible values, chosen todemonstrate the difference in feasible and infeasible par-titions. The results for F(60) are listed in Table 2, forF(90) in Table 3. It is apparent that algorithm FP-II out-performs its competitors in almost every possible mea-sure of effectiveness. We explore the reasons for thissuccess in Section 10. A partial listing of the cumulativedistribution function F(d) (from algorithm DIST in Sec-tion 6.5) is given in Table 4. Full partition took 445.91CPU seconds and required 634405 interval partitions.The bounds in the last two columns resulted after 100000intervals were partitioned in 69.63 CPU seconds. Criti-cality indices (from algorithm CRIT in Section 7) are inTable 5. Edge 10, which stands out as requiring morecomputational effort than do other edges, has a very lowcriticality index and achieved bounds of 0.0001852 and0.0003542 in 6.81 seconds after partitioning 500 inter-vals.
There are a few items worthy of comment: First, wenote the surprising efficacy of the algorithm CRIT. Notethat almost all edges required the evaluation of fewerthan 200 undetermined intervals. Since each such evalu-ation entails two MST evaluations, most edges requiredthe evaluation of about 400 states, or a minuscule frac-tion 3.8 × 10−8 of the state space. Even edge 10, whosecriticality index required the evaluation of many morestates, only looked at the fraction 8.0 × 10−6 of the statespace. Second, we comment on the bounds produced byalgorithm DIST for Table 4. Clearly, the bounds corre-sponding to small MST lengths (small values of d) con-verge more quickly than do those for large values ofd. This is due to the manner in which these probabili-ties are accumulated, starting at the feasible extreme andmoving up.
Example 5. We consider again the network in Figure1, but with a revised probability structure. Here, eachedge has two possible weights, as shown in Table 6. Forthis example, the possible MST weights range from 220to 444. The cardinality of the state space is just over 2million. In Table 7, we compute F(280), and in Table 8,we give results for F(400). FP-II is again seen to dom-inate the other algorithms, especially in the area of ex-ecution time. A partial listing of the cdf F(d) is givenin Table 9. Full partition required 6.96 CPU seconds
to partition 9743 intervals. Table 10 contains criticalityindices.
Again, we see the effectiveness of algorithm CRIT,which used a total of 539 interval evaluations to com-pute all 21 criticality indices. Most edges required theevaluation of fewer than 20 states, a fraction 9.5 × 10−6
of the state space. For a final demonstration of the per-formance of this algorithm, we close this section withthe following example:
Example 6. Consider a complete graph on 12 nodes (66edges). Each edge has three possible weights randomlychosen from 1, . . . , 10, and the associated probabili-ties were assigned as in Example 4. The cardinality ofthe state space is about 3.1 × 1031. Table 11 containsbounds on the criticality indices from algorithm CRIT.In each case, at most 100 intervals (a miniscule fraction3.2×10−30 of the states) were partitioned. The CPU timefor computing all the entries of the table was 180.09 sec-onds. This is an average of 2.73 seconds per edge. Notethat the bounds are especially tight for edges with highprobability of being MST members.
We would like to point out that the examples in thissection do not constitute a complete set of experiments.As the size of the system grows, the performance of thealgorithms deteriorates and one will eventually have torely on the sampling procedure in Section 4.
9. EXTENSION OF MST RESULTS TOOTHER STOCHASTIC MATROID PROBLEMS
The partition applications given in this paper weresuccessful due in no small measure to the matroid struc-ture of the MST problem. Note that spanning trees arebases for the graphic matroid with the ground set E andindependent sets being acyclic subgraphs. The followingmatroid properties were instrumental in making theseapplications more effective:
• Matroid problems can be solved by the greedy al-gorithm (here, Kruskal’s method), so that evaluatinga state (finding an optimal matroid base for a givenweighting of the elements of the ground set) can bedone efficiently.
• When one element of the ground set changes weight,it is relatively easy to determine whether a given baseis still optimal. Furthermore, by the exchangeabilityproperty of matroids, it is easy to form a new opti-mal base by pivoting, assuming some means exist forfinding the replacement element. This is importantbecause the alternative is to solve a new optimizationproblem every time an element changes weight.
Since all matroid problems share these features to anextent, it is reasonable to assume that there are otherstochastic matroid problems that will admit efficient so-lution by state space partition methods. The second pointis especially important. In our MST work, every ex-change of elements was accomplished by investigating
132 NETWORKS–2000

the unique cycle (minimal dependent set) formed by anedge not on an MST (an element of the ground set notin the optimal base) with the MST (the elements mak-ing up the optimal base). These comparisons resulted inefficient, unequivocal determination of the elements tobe exchanged. All matroid problems share this featureto some degree. In the general (nonmatroid) case, it isnot always easy to determine whether weight changescause a solution to cease being optimal or to remedy thesituation by identifying the elements to be exchanged(see [5, 3]).
10. CONCLUSIONS
This paper has accomplished two primary goals: Thefirst was to explore the use of state space partition tech-niques to evaluate probabilities related to the operationof stochastic systems. The results given here help tobroaden the range of applications suitable for partition-ing solutions and recommend strategies that are useful inimplementing the algorithms developed for these appli-cations. Our theoretical results support anecdotal find-ings concerning the types of intervals that can be re-moved effectively in partition algorithms. Of course, wehave looked primarily at managing the list of undeter-mined intervals. There are other factors that determinethe effectiveness of partition routines, so, in a sense, wehave taken a first step in what will hopefully be an ongo-ing analytical effort. Further theoretical work might payadditional dividends.
Our second goal was to solve the subject problems.The algorithms presented here are significant in helpingus characterize the behavior of MSTs in stochastic net-works. They are also significant in that they demonstratethe flexibility of the general method in Section 2. To re-view some of the options: (a) We may choose betweenprocedures FEASIBLE and INFEASIBLE; (b) we mayfind l starting from the same or the opposite extreme; (c)we may use limiting indices lj or not; and (d) we maydetermine l first and then the lj’s or the lj’s first and thenl. The effectiveness of the algorithms is, in part, due tothe attractive properties of matroids. We close with someobservations about the computational results of Section 8and some directions for further MST study.
First, it seems clear that, despite their sophistication,algorithms FP-I and InP cannot compete with FP-II interms of speed. Based on our experience, it appears that,frequently, a simpler, clever partition scheme performsbetter than one that labors to cut off as much of an inter-val as possible in each iteration. It also seems clear thatalgorithm MP did not outperform the best of the remain-ing algorithms either in terms of computational effort orin terms of achieving tight bounds.
Second, it would be useful to find applications for al-gorithm CRIT. For example, the following heuristic foridentifying the most probable MST appears to be rea-
sonable. After the computation of the criticality indicesfor all edges, we build a maximally acyclic connectedgraph by considering edges one at a time in decreasingorder of their criticality index, discarding any edge thatwould form a cycle. Investigating the effectiveness of thisheuristic seems worthy of future research, as does fur-ther study on solving other stochastic matroid problemsusing partition approaches.
ACKNOWLEDGMENT
We would like to thank the anonymous referee forseveral suggestions aimed at improving the readabilityof this paper.
REFERENCES
[1] R.K. Ahuja, T.L. Magnanti, and J.B. Orlin, NetworkFlows: Theory, Algorithms, and Applications, Prentice-Hall, Englewood Cliffs, NJ, 1993.
[2] C. Alexopoulos, A note on state-space decompositionmethods for analyzing stochastic flow networks, IEEETrans Reliab 44 (1995), 354–357.
[3] C. Alexopoulos, State space partitioning methods forstochastic shortest path problems, Networks 30 (1997),9–21.
[4] C. Alexopoulos and G.S. Fishman, Capacity expan-sion in stochastic flow networks, Prob Eng Info Sci6 (1992), 99–118.
[5] C. Alexopoulos and G.S. Fishman, Sensitivity analy-sis in stochastic flow networks using the Monte Carlomethod, Networks 23 (1993), 605–621.
[6] M.P. Bailey, Minimization on stochastic matroids,Technical Report NPS–55–90–01, Naval PostgraduateSchool, Monterey, CA, 1990.
[7] M.O. Ball, Computational complexity of network re-liability analysis: An overview, IEEE Trans Reliab 35(1987), 230–239.
[8] M.O. Ball, C.J. Colbourn, and J.S. Provan, Network re-liability, Handbooks in Operations Research and Man-agement Science, Vol. 7: Network Models, M.O. Ball,T.L. Magnanti, C.L. Monma, and G.L. Nemhauser (Ed-itors), Elsevier Science B.V., Amsterdam, 1995, pp.673–762.
[9] D.J. Bertsimas, The probabilistic minimum spanningtree problem, Networks 20 (1990), 245–275.
[10] D.J. Bertsimas and G. van Rysin, An asymptotic de-termination of the minimum spanning tree and min-imum matching constants in geometrical probability,Oper Res Lett 9 (1990), 223–231.
[11] P.M. Camerini, G. Galbiati, and F. Maffioli, Algorithmsfor finding optimum trees: Description, use and evalu-ation, Ann Oper Res 13 (1988), 265–397.
[12] P. Doulliez and E. Jamoulle, Transportation networkswith random arc capacities, RAIRO 3 (1972), 45–60.
[13] G.S. Fishman and L.R. Moore, Sampling from a dis-crete distribution while preserving monotonicity, AmStat 38 (1984), 219–223.
NETWORKS–2000 133

[14] A.M. Frieze, On the value of a random minimum span-ning tree problem, Discr Appl Math 10 (1985), 47–56.
[15] E.M. Gilbert, Random minimal trees, J SIAM 13(1965), 376–387.
[16] J.A. Jacobson, State space decomposition methods forsolving a class of stochastic network problems, Ph.D.dissertation, School of Industrial and Systems Engi-neering, Georgia Institute of Technology, Atlanta, GA,1993.
[17] A. Jain and J.W. Mamer, Approximations for the ran-dom minimal spanning tree with applications to net-work provisioning, Oper Res 36 (1988), 575–584.
[18] V.G. Kulkarni, Minimum spanning trees in undirectednetworks with exponentially distributed arc weights,Networks 16 (1986) 111–124.
[19] C. Papadimitriou and K. Stieglitz, Combinatorial Op-timization: Algorithms and Complexity, Prentice-Hall,Englewood Cliffs, NJ, 1982.
[20] A.W. Shogan, Modular decomposition and reliabilitycomputation in stochastic transportation networks hav-ing cutnodes, Networks 12 (1982), 255–275.
[21] J.M. Steele, Growth rates on Frieze’s ζ(3) limit forlengths of minimal spanning trees, Discr Appl Math18 (1987), 99–103.
APPENDIX: TABLES
TABLE 1. Input distribution for Examples 1 and 4.
Edge Weight (probability)1 = (1,2) 2.0 (0.90) 8.0 (0.08) 12.0 (0.02)2 = (1,3) 10.0 (0.85) 24.0 (0.12) 35.0 (0.03)3 = (1,4) 6.0 (0.88) 18.0 (0.10) 24.0 (0.02)4 = (2,5) 17.0 (0.75) 35.0 (0.20) 50.0 (0.05)5 = (2,6) 3.0 (0.68) 7.0 (0.25) 10.0 (0.07)6 = (2,3) 12.0 (0.85) 22.0 (0.11) 30.0 (0.04)7 = (3,7) 10.0 (0.80) 19.0 (0.14) 24.0 (0.06)8 = (3,8) 4.0 (0.75) 6.0 (0.17) 10.0 (0.08)9 = (3,4) 3.0 (0.84) 7.0 (0.13) 12.0 (0.03)
10 = (4,9) 21.0 (0.85) 33.0 (0.09) 45.0 (0.06)11 = (5,7) 8.0 (0.77) 14.0 (0.13) 18.0 (0.10)12 = (5,10) 15.0 (0.76) 21.0 (0.22) 25.0 (0.02)13 = (3,6) 5.0 (0.65) 10.0 (0.23) 12.0 (0.12)14 = (5,6) 18.0 (0.94) 27.0 (0.05) 36.0 (0.01)15 = (6,7) 25.0 (0.80) 38.0 (0.12) 50.0 (0.08)16 = (7,8) 20.0 (0.87) 30.0 (0.09) 40.0 (0.04)17 = (7,10) 4.0 (0.75) 9.0 (0.14) 15.0 (0.11)18 = (4,8) 9.0 (0.82) 13.0 (0.15) 20.0 (0.03)19 = (8,9) 15.0 (0.79) 28.0 (0.15) 45.0 (0.06)20 = (7,9) 10.0 (0.95) 17.0 (0.03) 30.0 (0.02)21 = (9,10) 8.0 (0.85) 14.0 (0.10) 25.0 (0.05)
TABLE 2. Computing F(60) = 0.826750 for Example 4.
Full partition 500 sets partitionedRoutine Sets Time Bounds Time |U| PUFP-I 790 5.63 .8197 .8279 3.67 192 .008157InP 7886 68.31 .6655 .9072 4.67 620 .2417FP-II 1421 1.30 .8188 .8298 0.67 128 .01102MP 2660 10.24 .8066 .8417 3.01 324 .03508
134 NETWORKS–2000

TABLE 3. Computing F(90) = 0.999995 for Example 4.
Full partition 500 sets partitionedRoutine Sets Time Bounds Time |U| PUFP-I 247853 1603.52 .9484 1.0000 3.39 516 .05156InP 205576 1655.32 .9842 1.0000 5.09 2506 .01580FP-II 127683 95.18 .9990 1.0000 0.76 686 .001010MP 506168 2115.43 .9004 1.0000 2.37 573 .09958
TABLE 4. Partial listing of the cdf F(d) for Example 4.
Full partition 100000 sets partitionedd F(d) Lower Upper
47.0 0.0984 0.0984 0.098448.0 0.1451 0.1451 0.145149.0 0.1839 0.1839 0.183950.0 0.2595 0.2595 0.259551.0 0.2790 0.2790 0.279052.0 0.3802 0.3802 0.380253.0 0.4426 0.4426 0.442654.0 0.5170 0.5170 0.517055.0 0.5817 0.5817 0.581756.0 0.6376 0.6376 0.637657.0 0.6932 0.6932 0.693358.0 0.7425 0.7423 0.742559.0 0.7889 0.7885 0.788960.0 0.8267 0.8261 0.826961.0 0.8621 0.8610 0.862462.0 0.8894 0.8873 0.889863.0 0.9126 0.9094 0.913264.0 0.9317 0.9270 0.932565.0 0.9469 0.9402 0.9481
......
......
70.0 0.9875 0.9684 0.9910...
......
...75.0 0.9976 0.9736 0.9995
......
......
80.0 0.9996 0.9782 0.9999...
......
...85.0 1.0000 0.9835 1.0000
NETWORKS–2000 135

TABLE 5. Criticality indices for Example 4.
Edge Criticality index # Sets Time1 0.9393 12 0.072 0.0432 11 0.063 0.5859 6 0.044 0.0490 3199 18.945 0.8227 200 1.186 0.0022 8 0.057 0.8004 77 0.468 0.9353 198 1.179 0.9084 9 0.05
10 0.0002 41939 248.2811 0.9068 174 1.0312 0.0833 9 0.0513 0.6991 16 0.0914 0.0099 169 1.0015 0.0000 1 0.0116 0.0002 12 0.0717 0.9007 4 0.0218 0.0764 10 0.0619 0.1629 13 0.0820 0.2319 10 0.0621 0.8655 8 0.05
TABLE 6. Input distribution for Example 5.
Edge Weight (probability)1 70.0 (0.95) 94.0 (0.05)2 25.0 (0.80) 52.0 (0.20)3 42.0 (0.70) 61.0 (0.30)4 26.0 (0.85) 50.0 (0.15)5 58.0 (0.70) 95.0 (0.30)6 15.0 (0.80) 43.0 (0.20)7 65.0 (0.60) 75.0 (0.40)8 59.0 (0.70) 98.0 (0.30)9 21.0 (0.90) 68.0 (0.10)
10 89.0 (0.85) 96.0 (0.15)11 32.0 (0.80) 67.0 (0.20)12 63.0 (0.75) 99.0 (0.25)13 66.0 (0.80) 98.0 (0.20)14 60.0 (0.90) 88.0 (0.10)15 32.0 (0.75) 48.0 (0.25)16 16.0 (0.70) 42.0 (0.30)17 56.0 (0.80) 71.0 (0.20)18 90.0 (0.95) 96.0 (0.05)19 17.0 (0.80) 45.0 (0.20)20 3.0 (0.60) 15.0 (0.40)21 50.0 (0.75) 66.0 (0.25)
136 NETWORKS–2000
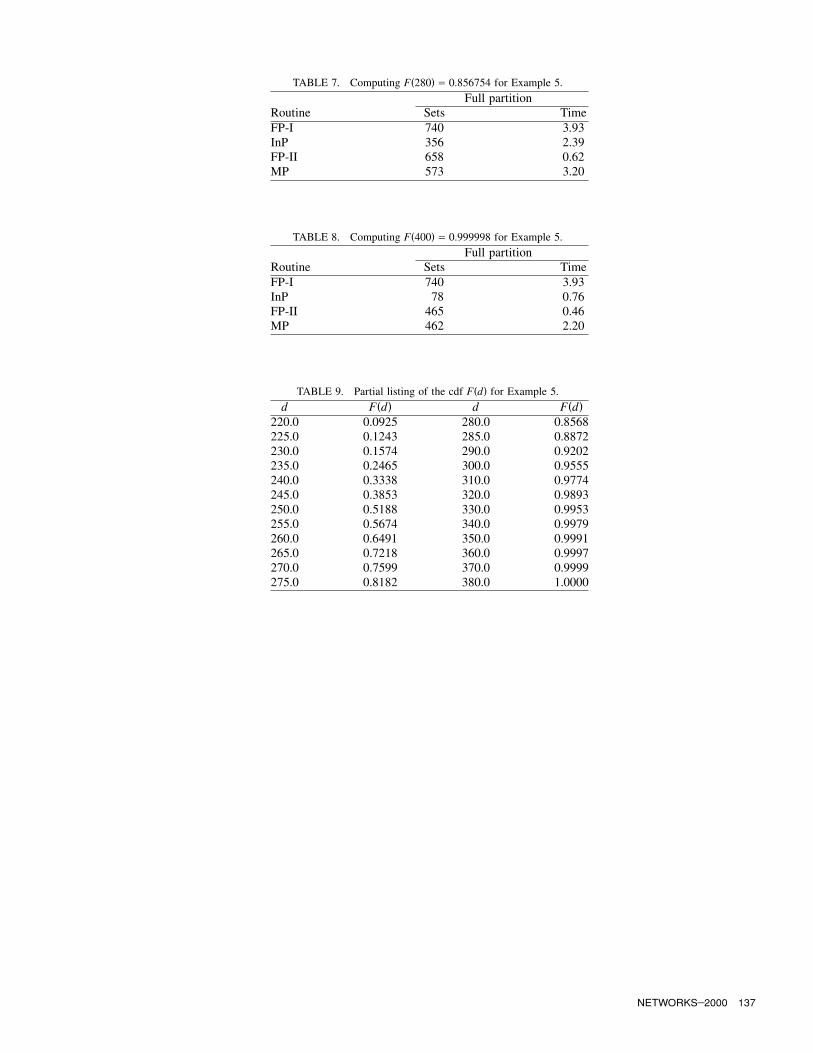
TABLE 7. Computing F(280) = 0.856754 for Example 5.
Full partitionRoutine Sets TimeFP-I 740 3.93InP 356 2.39FP-II 658 0.62MP 573 3.20
TABLE 8. Computing F(400) = 0.999998 for Example 5.
Full partitionRoutine Sets TimeFP-I 740 3.93InP 78 0.76FP-II 465 0.46MP 462 2.20
TABLE 9. Partial listing of the cdf F(d) for Example 5.
d F(d) d F(d)220.0 0.0925 280.0 0.8568225.0 0.1243 285.0 0.8872230.0 0.1574 290.0 0.9202235.0 0.2465 300.0 0.9555240.0 0.3338 310.0 0.9774245.0 0.3853 320.0 0.9893250.0 0.5188 330.0 0.9953255.0 0.5674 340.0 0.9979260.0 0.6491 350.0 0.9991265.0 0.7218 360.0 0.9997270.0 0.7599 370.0 0.9999275.0 0.8182 380.0 1.0000
NETWORKS–2000 137

TABLE 10. Criticality indices for Example 5.
Edge Criticality index # Sets Time1 0.0000 1 0.00662 0.8740 4 0.02633 0.2260 5 0.03294 1.0000 1 0.00665 0.1400 3 0.01976 1.0000 1 0.00667 0.0003 33 0.21688 0.0420 4 0.02639 0.9000 2 0.0131
10 0.0000 1 0.006611 0.8000 8 0.052612 0.0388 74 0.486213 0.0002 46 0.302214 0.0162 5 0.032915 1.0000 1 0.006616 0.7600 3 0.019717 0.2000 3 0.019718 0.0000 1 0.006619 0.2400 3 0.019720 1.0000 1 0.006621 0.7625 339 2.2272
TABLE 11. Criticality index bounds for Example 6.
Edge Lower bound Upper bound Edge Lower bound Upper bound1 .0094 .0384 34 .0000 .00092 .0002 .0031 35 .7500 .75253 .9500 .9500 36 .8000 .80004 .0009 .0018 37 .0016 .00375 .0020 .0054 38 .0000 .00956 .0003 .0045 39 .0028 .00487 .00004 .00007 40 .0012 .00278 .8500 .8500 41 .0000 .00019 .0002 .0012 42 .0019 .0042
10 .7014 .7080 43 .9000 .900011 .8000 .8000 44 .0000 .00000212 .0092 .0116 45 .0017 .011913 .0097 .0176 46 .8000 .800414 .0106 .0149 47 .00004 .000215 .0000 .0002 48 .0000 .000116 .0000 .0009 49 .9000 .900217 .8066 .8097 50 .0016 .017318 .0000 .0001 51 .0020 .004819 .0105 .0195 52 .9000 .900020 .7000 .7000 53 .0000 .000221 .8000 .8000 54 .8500 .850022 .0000 .0001 55 .0000 .000123 .0030 .0084 56 .0000 .000224 .8500 .8500 57 .0000 .000125 .000001 .00003 58 .0000 .00000526 .7018 .7463 59 .0010 .038027 .9000 .9000 60 .0000 .0000728 .0000 .0041 61 .8500 .850029 .0005 .0133 62 .7511 .751430 .9500 .9500 63 .0000 .009631 .7500 .7500 64 .8500 .850032 .0000 .00004 65 .9000 .900033 .9000 .9000 66 .0018 .0025
138 NETWORKS–2000












![Wrangling Phosphoproteomic Data to Elucidate Cancer ... · al scaling and t-distributed stochastic neighbor embedding (t-SNE, ref. [26]) using the minimum spanning tree method to](https://img.pdfslide.us/doc/110x75/5f0f54647e708231d4439f7b/wrangling-phosphoproteomic-data-to-elucidate-cancer-al-scaling-and-t-distributed.jpg)
















