Embed Size (px)
Citation preview

Spark
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
Presentation by Antonio Lupher
[Thanks to Matei for diagrams & several of the nicer slides!]
October 26, 2011
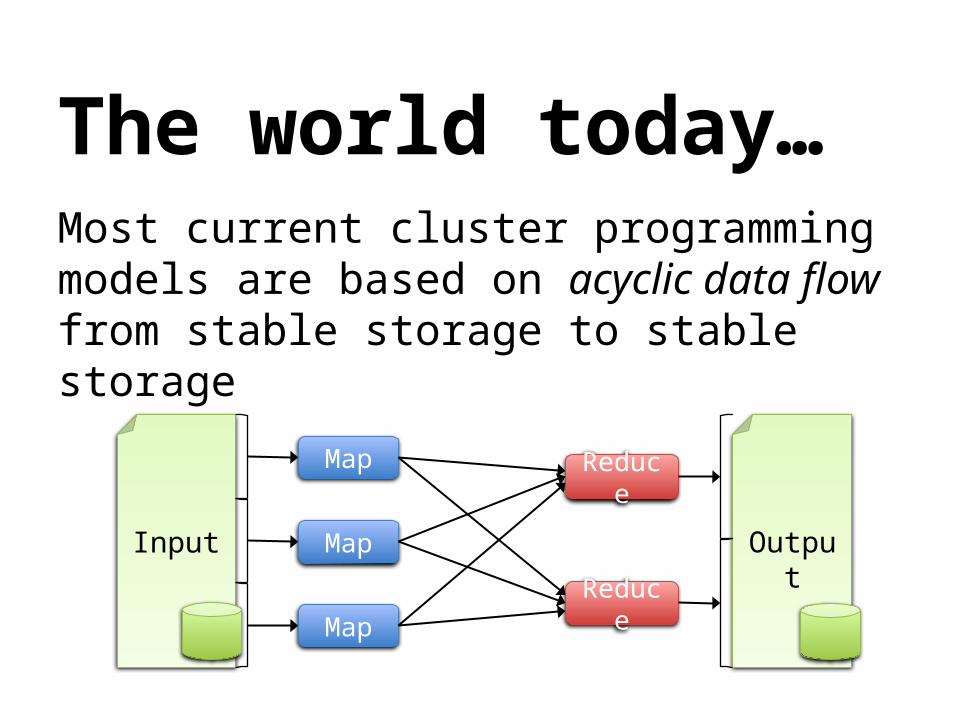
The world today…Most current cluster programming models are based on acyclic data flow from stable storage to stable storage
Map
Map
Map
Reduce
Reduce
Input Output

The world today…
Benefits: decide at runtime where to run tasks and automatically recover
from failures
Most current cluster programming models are based on acyclic data flow from stable storage to stable storage

… butInefficient for applications that repeatedly reuse working set of data:»Iterative machine learning, graph algorithms • PageRank, k-means, logistic regression, etc.
»Interactive data mining tools (R, Excel, Python)• Multiple queries on the same subset of data
Reload data from disk on each query/stage of execution
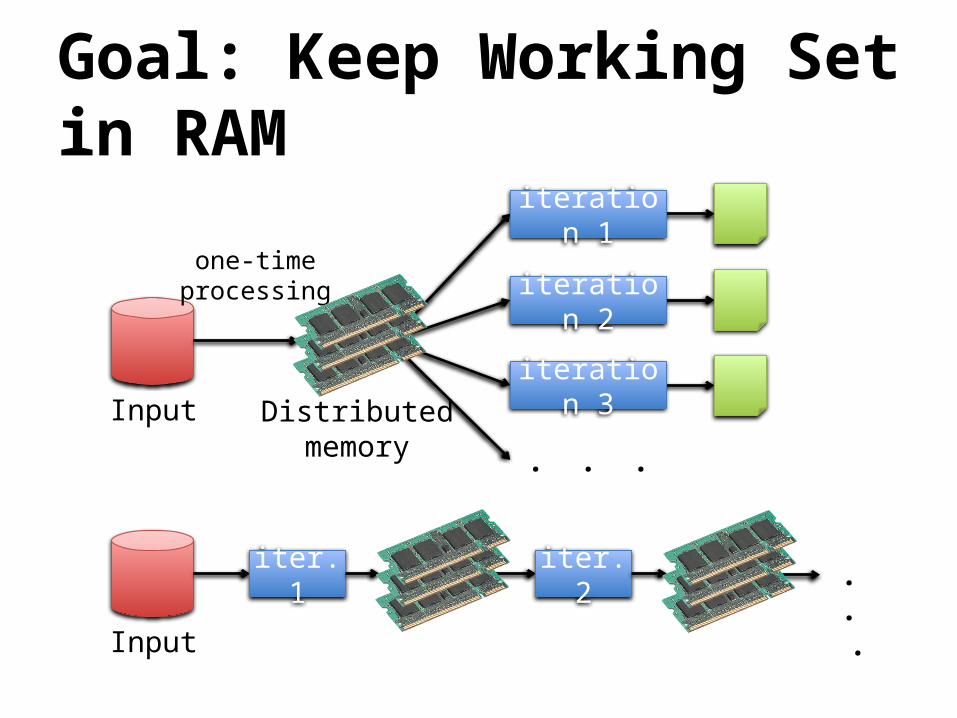
Distributedmemory
Input
iteration 1
iteration 2
iteration 3
. . .
iter. 1 iter. 2 . . .
Input
Goal: Keep Working Set in RAM
one-timeprocessing

RequirementsDistributed memory abstraction must be
»Fault-tolerant»Efficient in large commodity clusters
How to provide fault tolerance efficiently?

RequirementsExisting distributed storage abstractions offer an interface based on fine-grained updates
»Reads and writes to cells in a table»E.g. key-value stores, databases,
distributed memory
Have to replicate data or logs across nodes for fault tolerance
»Expensive for data-intensive apps, large datasets

Resilient Distributed Datasets (RDDs)
»Immutable, partitioned collection of records
»Interface based on coarse-grained transformations (e.g. map, groupBy, join)
»Efficient fault recovery using lineage• Log one operation to apply to all elements• Re-compute lost partitions of dataset on failure• No cost if nothing fails

RDDs, cont’d»Control persistence (in RAM vs. on disk)• Tunable via persistence priority: user specifies
which RDDs should spill to disk first
»Control partitioning of data• Hash data to place data in convenient
locations for subsequent operations
»Fine-grain reads

ImplementationSpark runs on Mesos
=> share resources with Hadoop & other apps
Can read from any Hadoop input source (HDFS, S3, …)
SparkHadoo
pMPI
Mesos
Node Node Node Node
…
Language-integrated API in Scala~10,000 lines of code, no changes to Scala Can use interactively from interpreter

Spark OperationsTransformations
»Create new RDD by transforming data in stable storage using data flow operators• Map, filter, groupBy, etc.
»Lazy: don’t need to be materialized at all times• Lineage information is enough to compute
partitions from data in storage when needed

Spark OperationsActions
»Return a value to application or export to storage• count, collect, save, etc.
»Require a value to be computed from the elements in the RDD => execution plan

Spark Operations
Transformations
(define a new RDD)
mapflatMap
filtersample
groupByKeyreduceByKey
unionjoin
cogroupcrossProductmapValues
sortpartitionBy
Actions(return a result
to driver program)
countcollectreducelookupsave

RDD RepresentationCommon interface:
»Set of partitions»Preferred locations for each partition»List of parent RDDs»Function to compute a partition given
parents»Optional partitioning info (order, etc.)
Capture a wide range of transformations
»Scheduler doesn’t need to know what each op does
Users can easily add new transformations
»Most transformations implement in ≤ 20 lines

RDD RepresentationLineage & Dependencies
»Narrow dependencies• Each partition of parent RDD is used by at most
one partition of child RDD– e.g. map, filter
• Allow pipelined execution
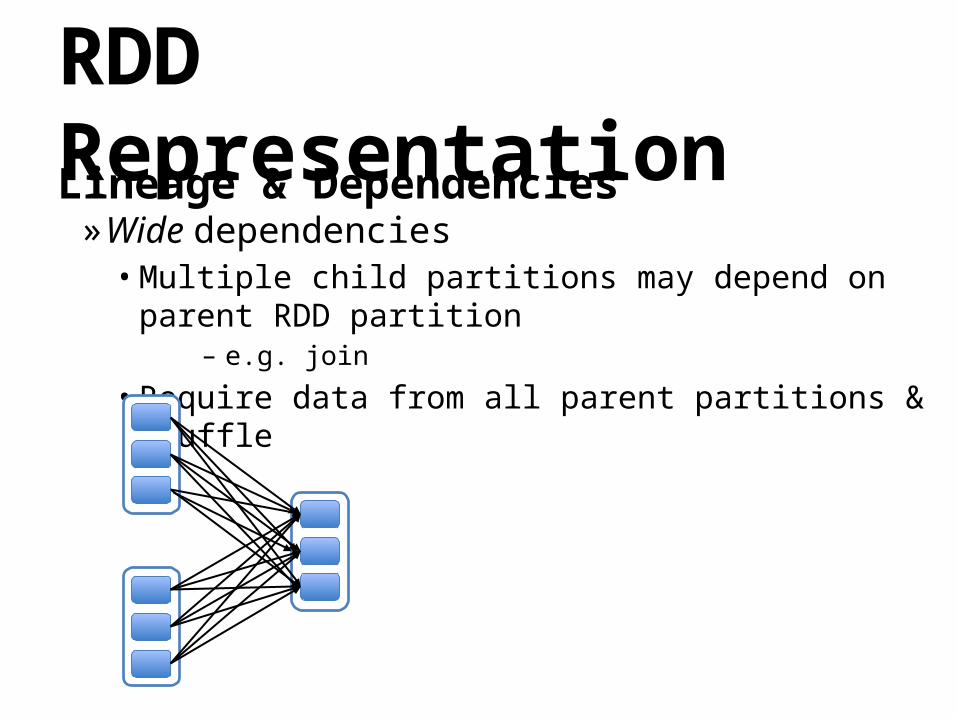
RDD RepresentationLineage & Dependencies
»Wide dependencies• Multiple child partitions may depend on parent
RDD partition– e.g. join
• Require data from all parent partitions & shuffle
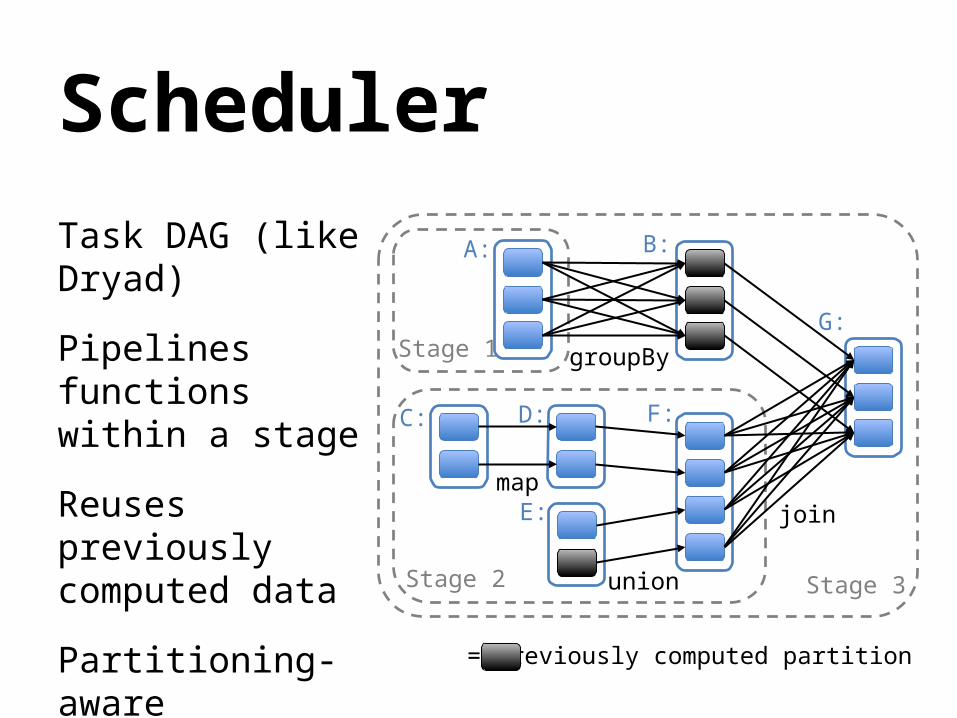
Scheduler
Task DAG (like Dryad)
Pipelines functionswithin a stage
Reuses previouslycomputed data
Partitioning-awareto avoid shuffles
join
union
groupBy
map
Stage 3
Stage 1
Stage 2
A: B:
C: D:
E:
F:
G:
= previously computed partition

RDD RecoveryWhat happens if a task fails?
»Exploit coarse-grained operations• Deterministic, affect all elements of collection
– Just re-run the task on another node if parents available
– Easy to regenerate RDDs given parent RDDs + lineage
»Avoids checkpointing and replication• but you might still want to (and can)
checkpoint:– long lineage => expensive to recompute – intermediate results may have disappeared, need
to regenerate– Use REPLICATE flag to persist
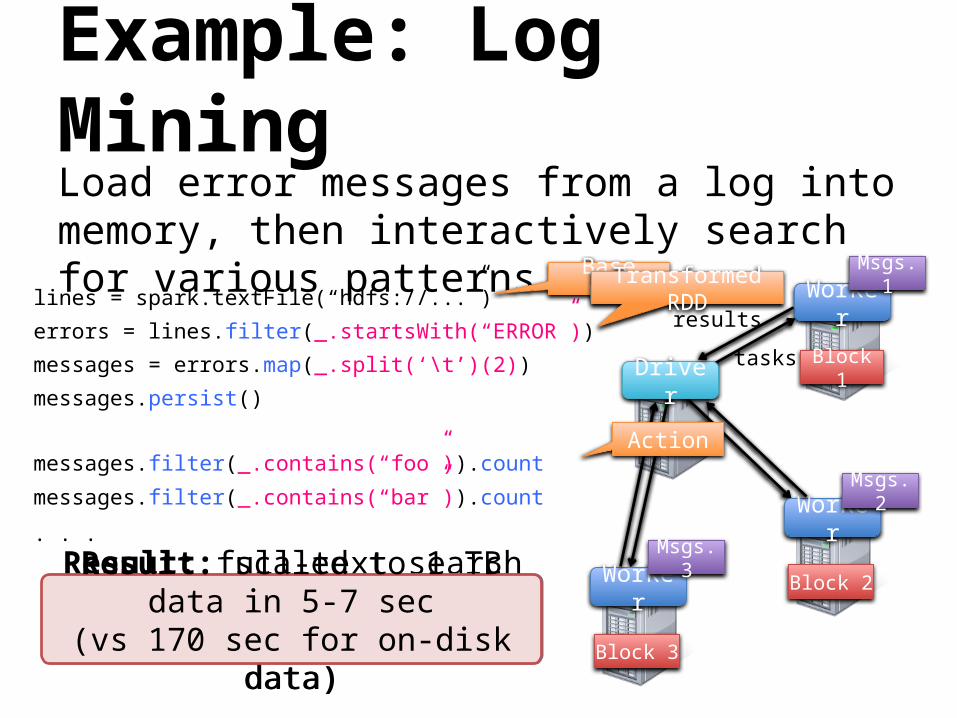
Example: Log MiningLoad error messages from a log into memory, then interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(_.startsWith(“ERROR”))
messages = errors.map(_.split(‘\t’)(2))
messages.persist()Block 1
Block 2
Block 3
Worker
Worker
Worker
Driver
messages.filter(_.contains(“foo”)).count
messages.filter(_.contains(“bar”)).count
. . .
tasks
results
Msgs. 1
Msgs. 2
Msgs. 3
Base RDD
Transformed RDD
Action
Result: full-text search of Wikipedia in <1 sec (vs 20
sec for on-disk data)
Result: scaled to 1 TB data in 5-7 sec
(vs 170 sec for on-disk data)
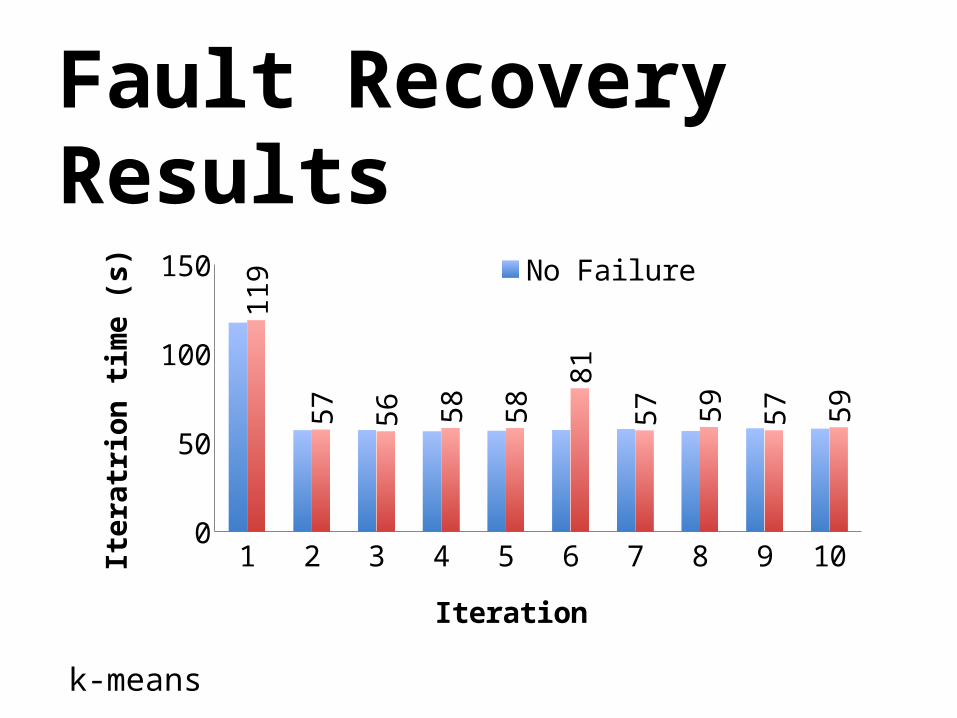
Fault Recovery Results
1 2 3 4 5 6 7 8 9 100
20406080
100120140
119
57
56 58
58
81
57 59
57 59
No Failure
Iteration
Itera
trio
n t
ime (
s)
k-means

Performance
Outperforms Hadoop by up to 20x»Avoiding I/O and Java object
[de]serialization costs
Some apps see 40x speedup (Conviva)
Query a 1TB dataset w/5-7 sec. latencies
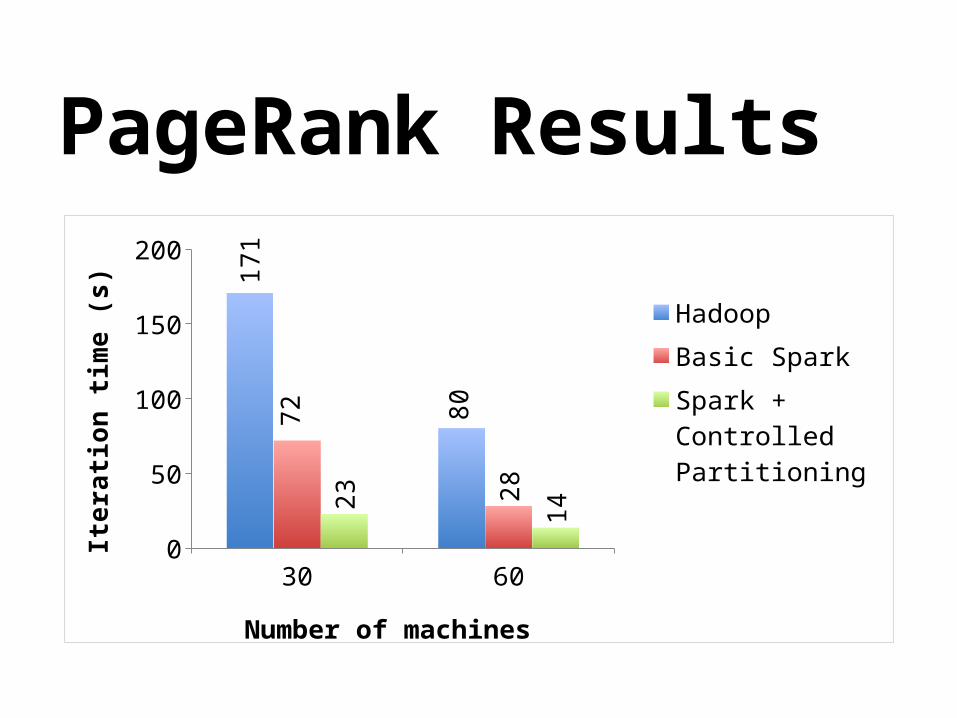
PageRank Results
30 600
20406080
100120140160180 1
71
80
72
28
23
14
Hadoop
Basic Spark
Spark + Con-trolled Partition-ing
Number of machines
Itera
tio
n t
ime (
s)
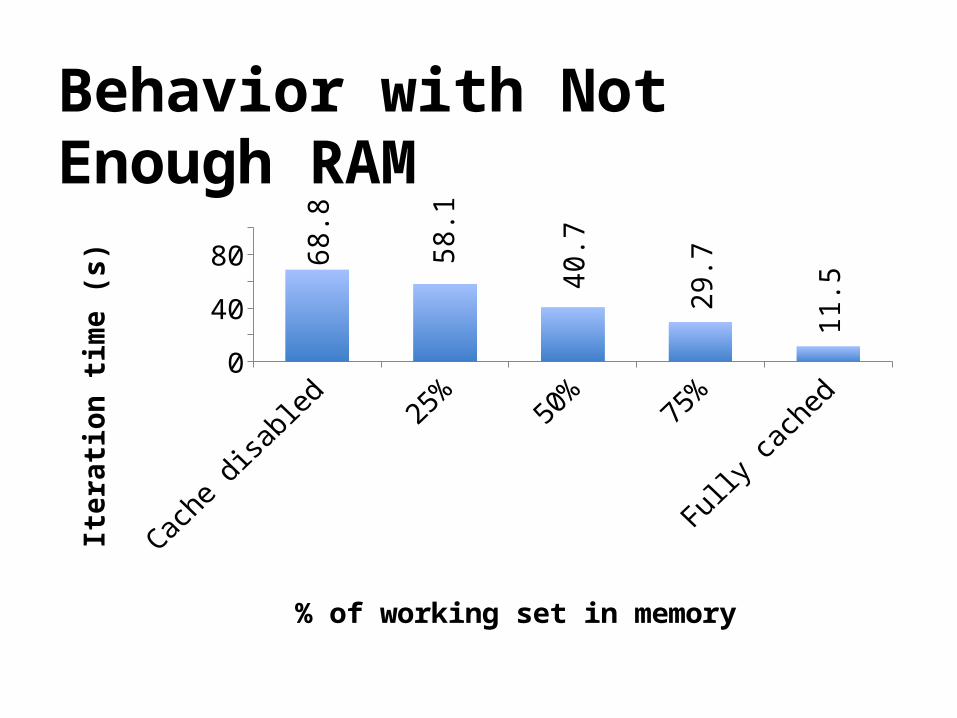
Behavior with Not Enough RAM
Cache disabled
25% 50% 75% Fully cached
0
20
40
60
80
10068.8
58.1
40.7
29.7
11.5
% of working set in memory
Itera
tion
tim
e (
s)
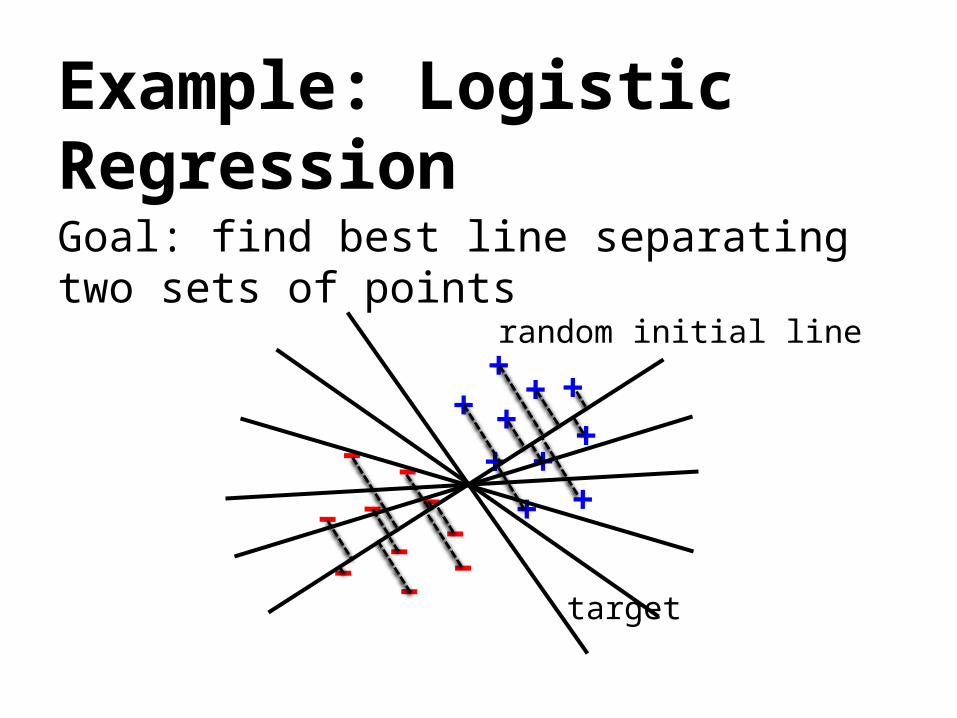
Example: Logistic RegressionGoal: find best line separating two sets of points
+
–
++
+
+
+
++ +
– ––
–
–
–
––
+
target
–
random initial line

Logistic Regression Code
val points = spark.textFile(...).map(parsePoint).persist()
var w = Vector.random(D)
for (i <- 1 to ITERATIONS) { val gradient = points.map(p => (1 / (1 + exp(-p.y*(w dot p.x))) - 1) * p.y * p.x ).reduce((a,b) => a+b) w -= gradient}
println("Final w: " + w)
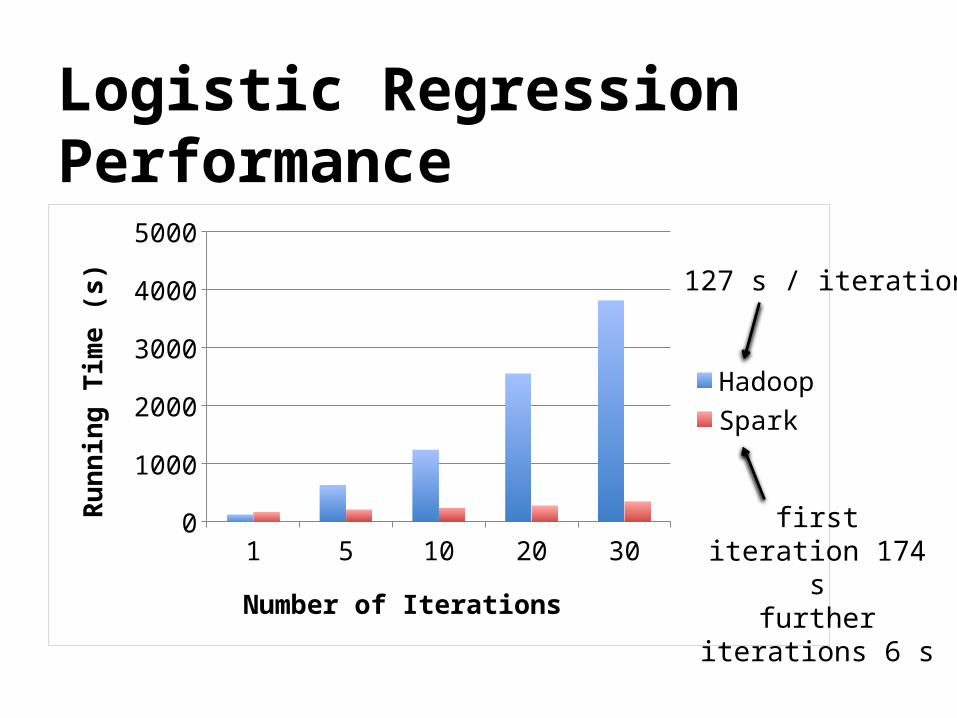
Logistic Regression Performance
1 5 10 20 300
50010001500200025003000350040004500
Hadoop
Number of Iterations
Ru
nn
ing
Tim
e (
s) 127 s / iteration
first iteration 174 s
further iterations 6 s

More ApplicationsEM alg. for traffic prediction (Mobile Millennium)
In-memory OLAP & anomaly detection (Conviva)
Twitter spam classification (Monarch)
Pregel on Spark (Bagel)
Alternating least squares matrix factorization

Mobile MillenniumEstimate traffic using GPS on taxis

Conviva GeoReport
Aggregations on many keys w/ same WHERE clause
40× gain comes from:»Not re-reading unused columns or filtered records»Avoiding repeated decompression» In-memory storage of deserialized objects
Spark
Hive
0 2 4 6 8 10 12 14 16 18 20
0.5
20
Time (hours)

Use transformations on RDDs instead of Hadoop jobs
»Cache RDDs for similar future queries»Many queries re-use subsets of data• Drill-down, etc.
»Scala makes integration with Hive (Java) easy… or easier
(Cliff, Antonio, Reynold)
SPARK

ComparisonsDryadLINQ, FlumeJava
»Similar language-integrated “distributed collection” API, but cannot reuse datasets efficiently across queries
Piccolo, DSM, Key-value stores (e.g. RAMCloud)»Fine-grained writes but more complex fault recovery
Iterative MapReduce (e.g. Twister, HaLoop), Pregel» Implicit data sharing for a fixed computation pattern
Relational databases»Lineage/provenance, logical logging, materialized views
Caching systems (e.g. Nectar)»Store data in files, no explicit control over what is
cached
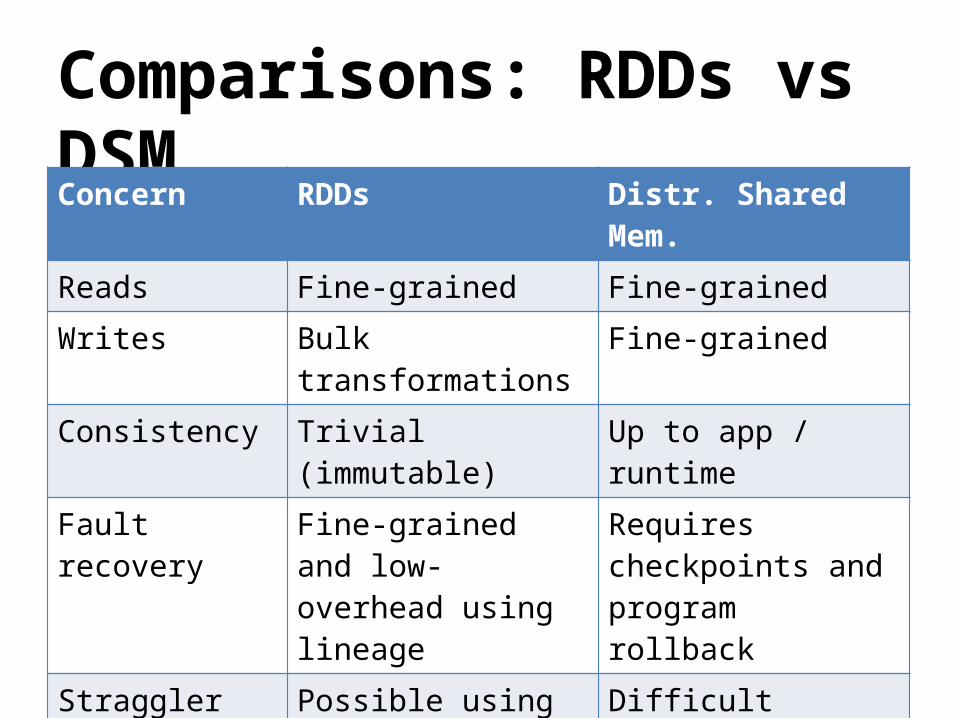
Comparisons: RDDs vs DSMConcern RDDs Distr. Shared
Mem.
Reads Fine-grained Fine-grained
Writes Bulk transformations
Fine-grained
Consistency Trivial (immutable) Up to app / runtime
Fault recovery Fine-grained and low-overhead using lineage
Requires checkpoints and program rollback
Straggler mitigation
Possible using speculative execution
Difficult
Work placement
Automatic based on data locality
Up to app (but runtime aims for transparency)
Behavior if not enough RAM
Similar to existing data flow systems
Poor performance (swapping?)

SummarySimple & efficient model, widely applicable
»Express models that previously required a new framework efficiently, i.e. same optimizations
Achieve fault tolerance efficiently by providing coarse-grained operations and tracking lineage
Exploit persistent in-memory storage + smart partitioning for speed

Thoughts: Tradeoffs
»No fine-grain modifications of elements in collection• Not the right tool for all applications
– E.g. storage system for web site, web crawler, anything where you need incremental/fine-grain writes
»Scala-based implementation• Probably won’t see Microsoft use it anytime
soon– But concept of RDDs is not language-specific
(abstraction doesn’t even require functional language)

Thoughts: InfluenceFactors that could promote adoption
»Inherent advantages • in-memory = fast, RDDs = fault-tolerant
»Easy to use & extend»Already supports MapReduce, Pregel
(Bagel)• Used widely at Berkeley, more projects coming
soon• Used at Conviva, Twitter
»Scala means easy integration with existing Java applications• (subjective opinion) More pleasant to use than
Java

VerdictShould spark enthusiasm in cloud crowds





























