Embed Size (px)
DESCRIPTION
Sorting. divide and conquer. Divide-and-conquer. a recursive design technique solve small problem directly divide large problem into two subproblems, each approximately half the size of the original problem solve each subproblem with a recursive call - PowerPoint PPT Presentation
Citation preview

Sorting
divide and conquer

Divide-and-conquer a recursive design technique
solve small problem directly divide large problem into two subproblems,
each approximately half the size of the original problem
solve each subproblem with a recursive call combine the solutions of the two
subproblems to obtain a solution of the larger problem

Divide-and-conquer sorting
General algorithm: divide the elements to be sorted into two
lists of (approximately) equal size sort each smaller list
(use divide-and-conquer unless the size of the list is 1)
combine the two sorted lists into one larger sorted list

Divide-and-conquer sorting Design decisions:
How is list partitioned into two lists? How are two sorted lists combined?
Common techniques: Mergesort
trivial partition, merge to combine Quicksort
sophisticated partition, no work to combine

Mergesort
divide array into first half and last half sort each subarray with recursive call merge together two sorted subarrays
use a temporary array to do the merge

mergesortpublic static void mergesort(
int[] data, int first, int n){ int n1, n2; // sizes of subarrays
if (n>1) { n1 = n / 2; n2 = n – n1;
mergesort(data, first, n1); mergesort(data, first+n1, n2);
merge(data, first, n1, n2); } }
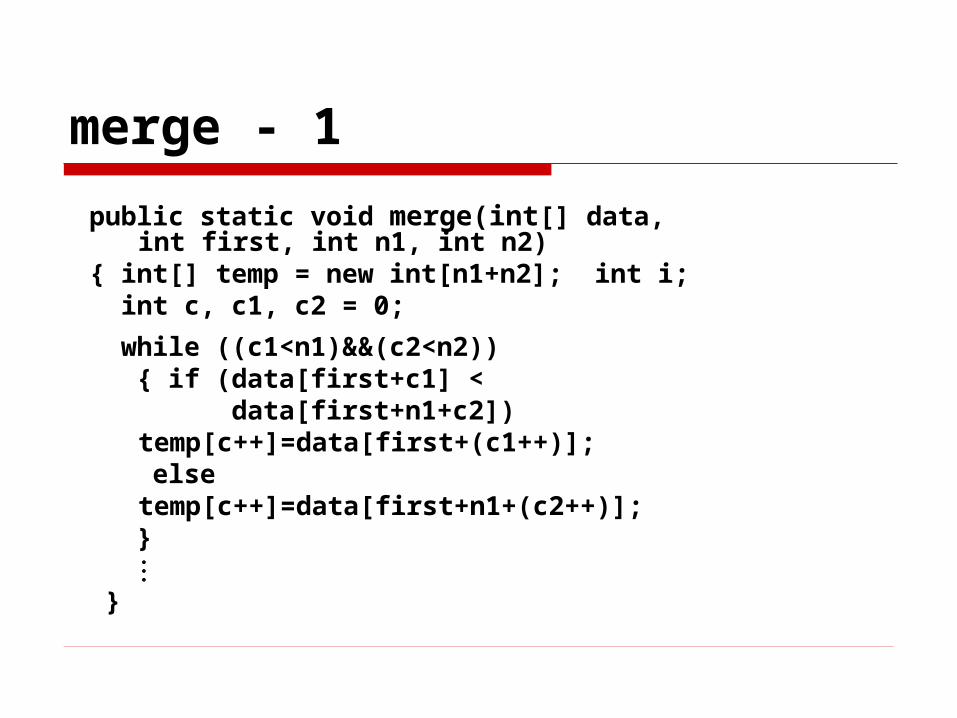
merge - 1
public static void merge(int[] data, int first, int n1, int n2)
{ int[] temp = new int[n1+n2]; int i; int c, c1, c2 = 0;
while ((c1<n1)&&(c2<n2)) { if (data[first+c1] < data[first+n1+c2])
temp[c++]=data[first+(c1++)]; else
temp[c++]=data[first+n1+(c2++)]; } }

merge -2public static void merge(int[] data,
int first, int n1, int n2){ while (c1 < n1)
temp[c++]=data[first+(c1++); while (c2 < n2 )
temp[c++]=data[first+n1+(c2++)];
for (i=0; i<n1+n2; i++) data[first+i] = temp[i];}

Analysis of Mergesort depth of recursion:
Θ(log n) no. of operations needed to merge at
each level of recursion:
Θ(n) overall time:
Θ(n log n) best, average, and worst cases

Advantages of Mergesort
• conceptually simple• suited to sorting linked lists of
elements because merge traverses each linked list
• suited to sorting external files; divides data into smaller files until can be stored in array in memory
• stable performance
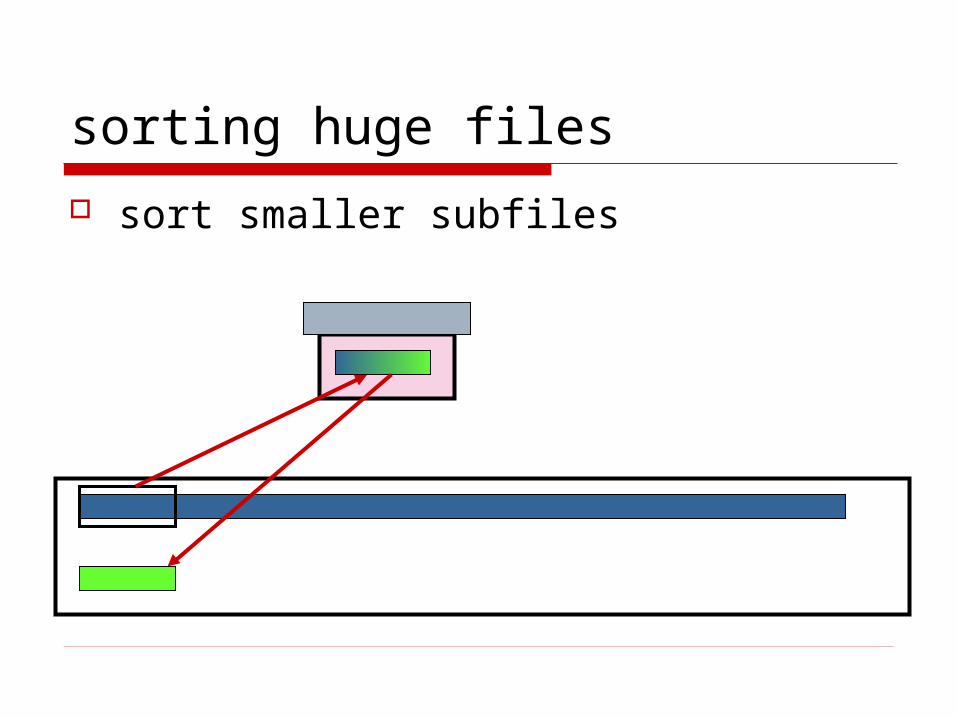
sorting huge files
sort smaller subfiles

sorting huge files
sort smaller subfiles
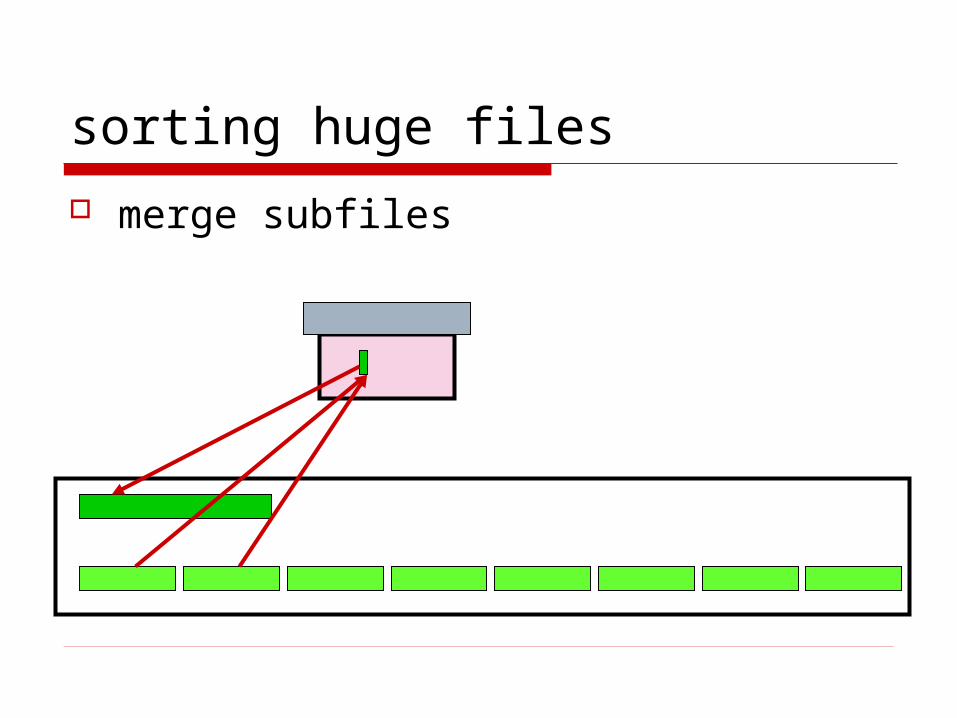
sorting huge files
merge subfiles
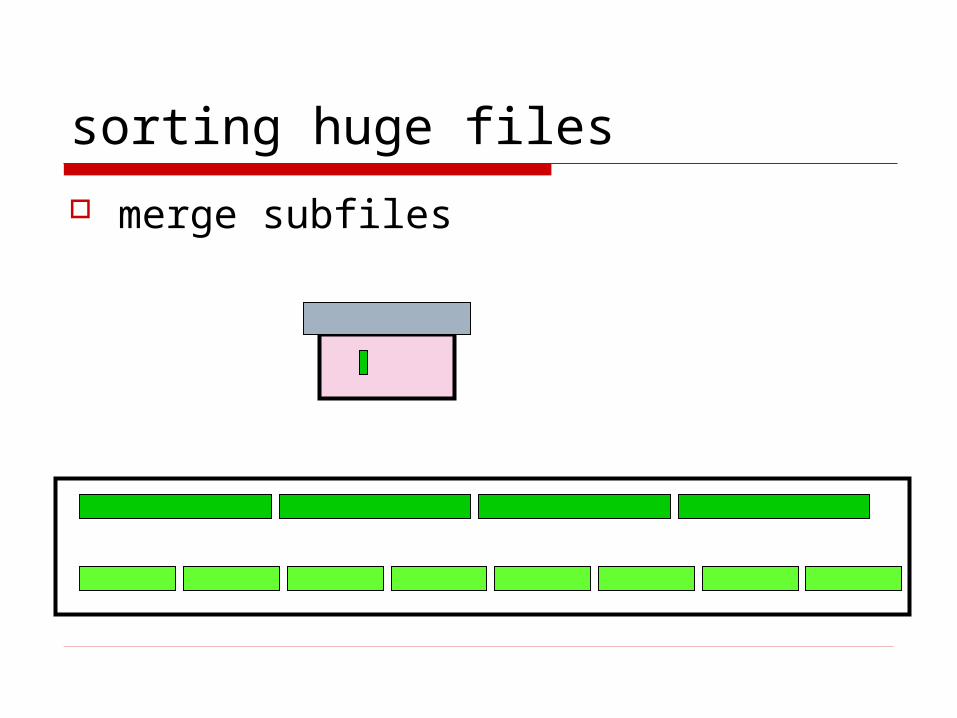
sorting huge files
merge subfiles
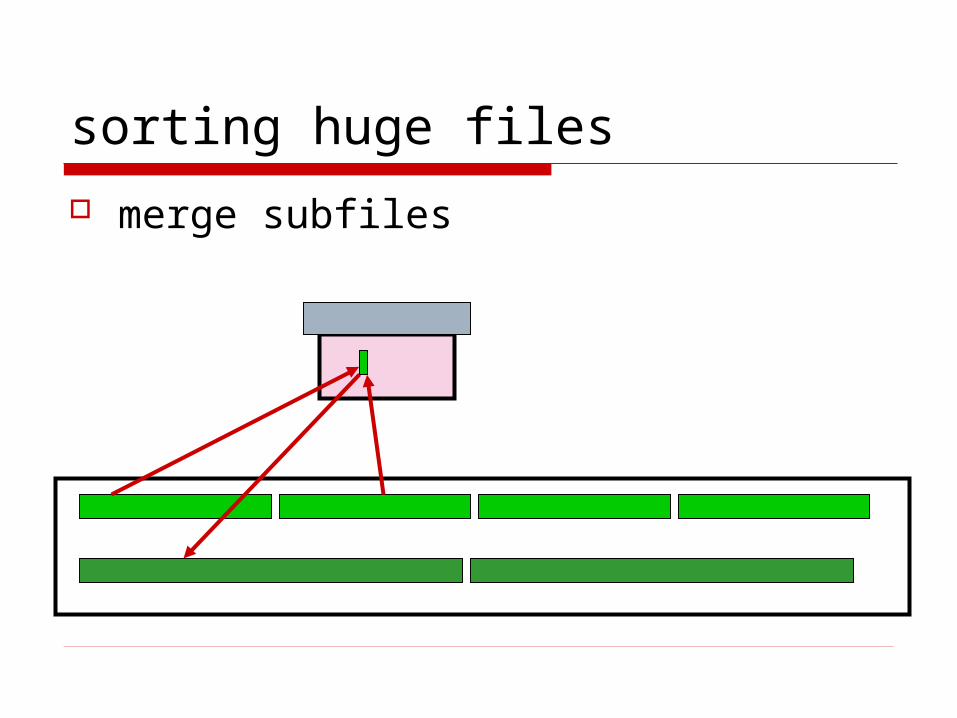
sorting huge files
merge subfiles
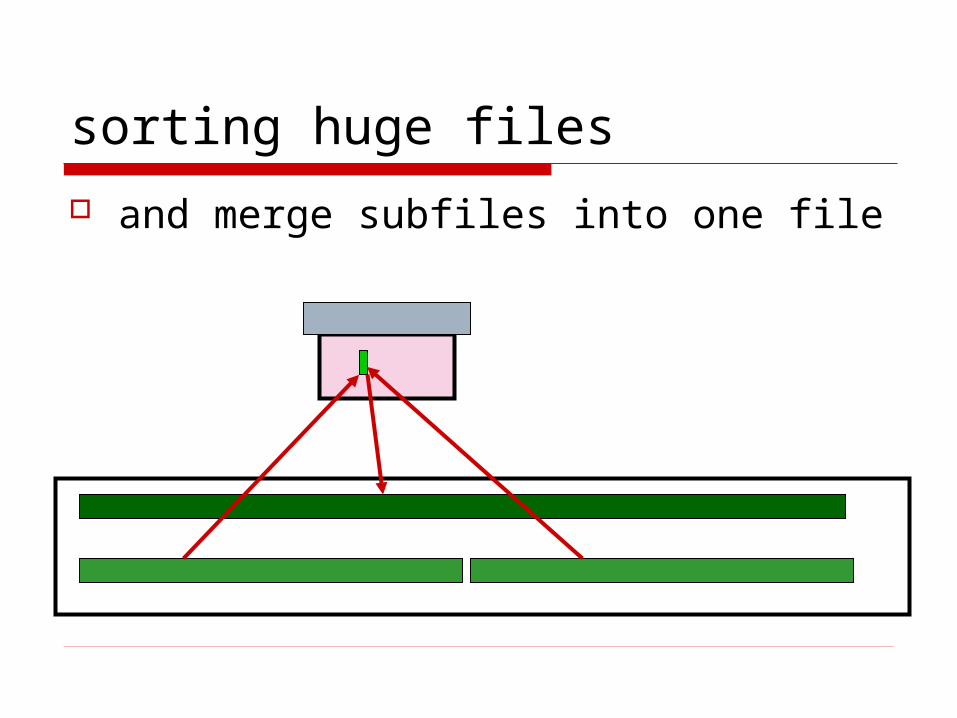
sorting huge files
and merge subfiles into one file
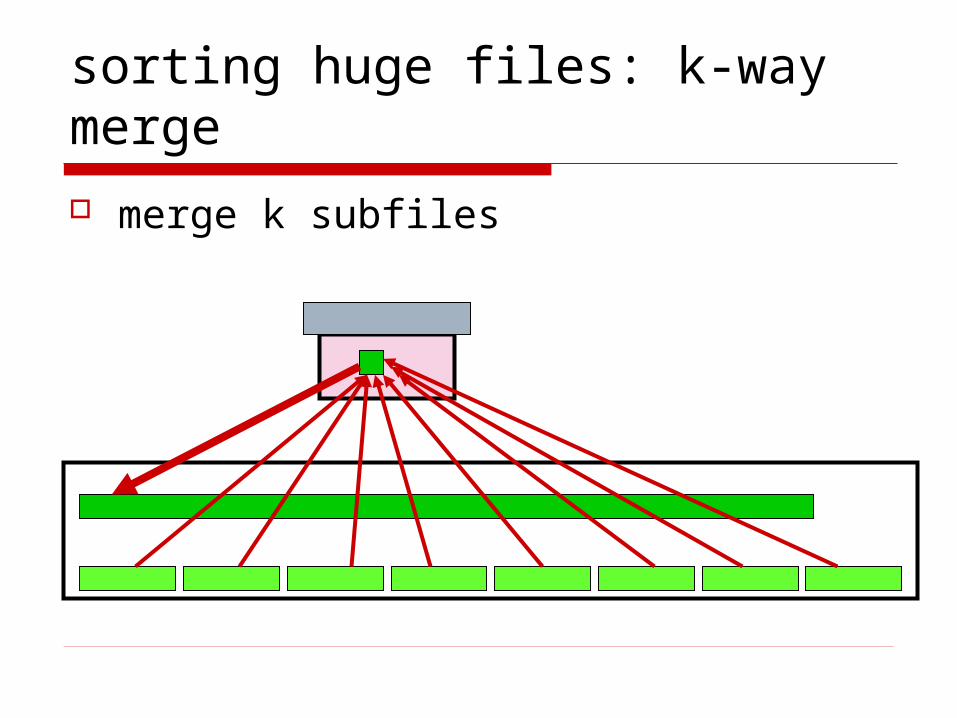
sorting huge files: k-way merge
merge k subfiles

Quicksort choose a key to be the “pivot” key
design decision: how to choose pivot divide the list into two sublists:
1) keys less than or equal to pivot2) keys greater than pivot
sort each sublist with a recursive call first sorted sublist, pivot, second sorted
sublist already make one large sorted array

quicksortpublic static void quicksort(
int[] data, int first, int n){ int n1, n2; int pivotIndex; if (n>1) { pivotIndex=partition(data, first, n);
n1 = pivotIndex – first; n2 = n – n1 – 1; quicksort(data, first, n1); quicksort(data, pivotIndex+1, n2); }}

partitioning the data setpublic static int partition (int[] data, int first, int n){ int pivot = data[first]; //first array element as pivot int tooBigIndex = first+1; int tooSmallIndex = first+n-1; while (tooBigIndex <= tooSmallIndex) {while ((tooBigIndex < first+n-1) && (data[tooBigIndex]< pivot)) tooBigIndex++; while (data[tooSmallIndex]> pivot) tooSmallIndex--; if (tooBigIndex < tooSmallIndex) swap(data, tooBigIndex++, tooSmallIndex--); } data[first]=data[tooSmallIndex]; data[tooSmallIndex]=pivot; return tooSmallIndex;}
implies swapping elements equal to the pivot! why?

Choosing pivot How does method choose pivot?
- first element in subarray is pivot When will this lead to very poor
partitioning?- if data is sorted or nearly sorted.
Alternative strategy for choosing pivot?1. middle element of subarray2. look at three elements of the subarray, and
choose the middle of the three values.

Pivot as median of three elements
advantages: reduces probability of worst case
performance removes need for sentinel to stop
looping

Additional improvements
instead of stopping recursion when subarray is 1 element, use 10-15 elements as stopping case, and sort small subarray without recursion (eg. insertionsort)
as above, but don’t sort each small subarray. At end, use insertionsort, which is efficient for nearly sorted arrays

Additional improvements
remove recursion – manage the stack directly (in an int array of indices) and always stack the larger subarray
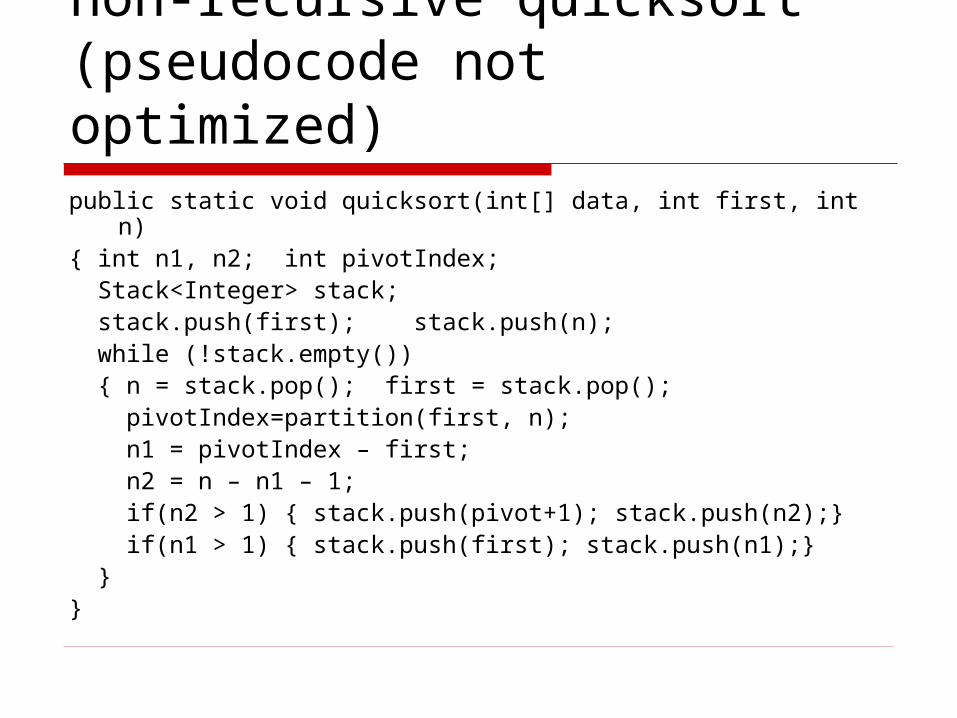
non-recursive quicksort(pseudocode not optimized)public static void quicksort(int[] data, int first, int n){ int n1, n2; int pivotIndex; Stack<Integer> stack; stack.push(first); stack.push(n); while (!stack.empty()) { n = stack.pop(); first = stack.pop(); pivotIndex=partition(first, n); n1 = pivotIndex – first; n2 = n – n1 – 1; if(n2 > 1) { stack.push(pivot+1); stack.push(n2);} if(n1 > 1) { stack.push(first); stack.push(n1);} }}

non-recursive quicksort(some optimization)public static void quicksort(int[] data, int first, int n){ int n1, n2; int pivotIndex; Stack<Integer> stack; stack.push(first); stack.push(n); while (!stack.empty()) { n = stack.pop(); first = stack.pop(); pivotIndex=partition(first, n); n1 = pivotIndex – first; n2 = n – n1 – 1; if(n2 > 1) { stack.push(pivot+1); stack.push(n2);} if(n1 > 1) { stack.push(first); stack.push(n1);} }}
inline method code
replace stack objectwith array
avoid consecutivepushing and popping
sort short subarraysby insertionsort

Analysis of Quicksort depth of recursion:
Θ(log n) on average
Θ(n) worst case no. of operations needed to partition at each
level of recursion:
Θ(n) overall time:
Θ(n log n) on average
Θ(n2) worst case

Advantages of Quicksort
• in-place (doesn’t require temporary array)
• worst case time extremely unlikely• usually best algorithm for large arrays

Quicksort tuned forrobustness and speed
no internal method calls – local stack insertion sort for small sets swap of elements equal to pivot pivot as median of three

Radix Sort
sorting by digits or bits
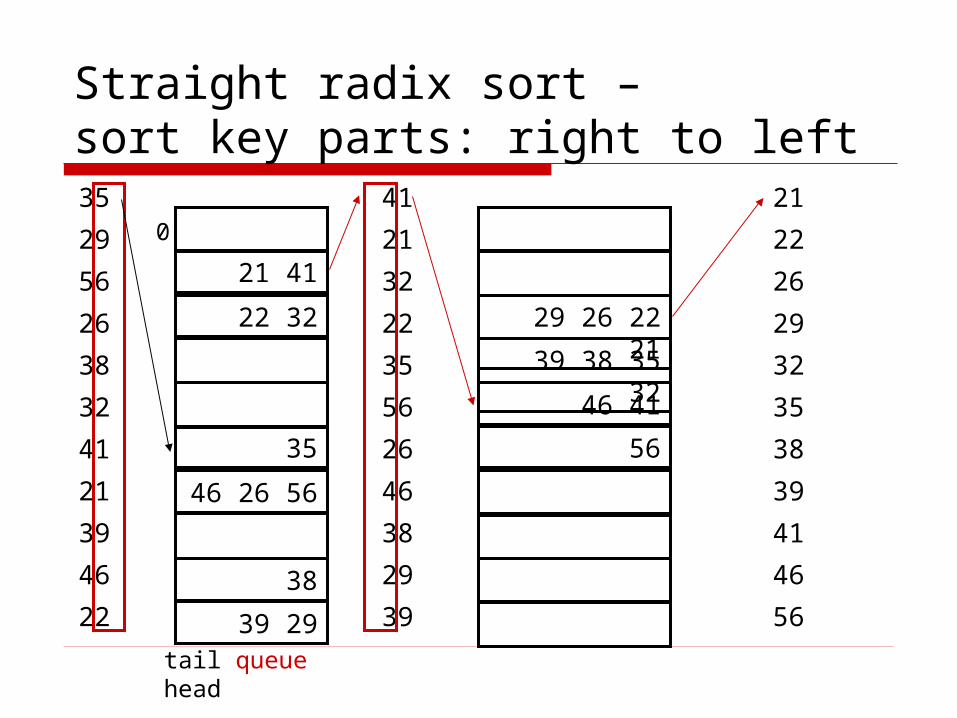
Straight radix sort –sort key parts: right to left35
29
56
26
38
32
41
21
39
46
22
21 41
22 32
35
46 26 56
38
39 29
41
21
32
22
35
56
26
46
38
29
39
29 26 22 21
39 38 35 32
46 41
56
21
22
26
29
32
35
38
39
41
46
56
tail queue head
0

Straight radix sort pseudocode
a[n] array of integers, length n, D decimal digits
q[10] queues
for (p=0; p<D; p++) for (i=0; i<n; i++) q[(a[i]/10^p)%10].insert(a[i]) i=0; for (j=0; j<10; j++) while (q[j].notEmpty()) a[i] = q[j].remove() i++

Straight radix sort performance
O(nD) D is number of digits n ≈ 10D D ≈ log10 n O( n log n )

Radix sort needs significant extra space – queues only known O(n log n) sorting method for
humans famous TV sorting method…

IBM 082 card sorter 1949

IBM (Hollerith) punch card

IBM 80 card sorter 1925

Herman Hollerith’s tabulator 1890





























