Embed Size (px)
Citation preview

Simple, Fast, and Practical Non-Blocking and Blocking Concurrent
Queue Algorithms
Presenter: Jim Santmyer
By: Maged M. Micheal Michael L. Scott
Department of Computer Science, University of Rochester

Simple, Fast, and Practical Non-Blocking and Blocking Concurrent
Queue Algorithms
Contributions from Past Presentations by:Ahmed Badran (Cs510-2008)
Joseph Rosenski (Cs510-2006)

Agenda
Presentation of the Issues
Non-Blocking Queue Algorithm
Two Lock Concurrent Queue Algorithm
Performance
Conclusion

Issue – Concurrent FIFO queues
Must synchronize access to insure correctnessTwo types of synchronize (Generally)
- BlockingAllows slower process to delay faster process
- Non-blocking Guarantee if there are one or more active processes trying to perform operations on a shared data structure, SOME operation will complete within a finite number of time steps.

Issue – Blocking
Blocking algorithms in general- Uses locks- May deadlock- Processes may wait for arbitrarily long times- Lock/unlock primitives need to interact with
scheduling logic to avoid priority inversion- Possibility of starvation

Issue – Blocking
If Blocking used for queues:
- Two Locks better than one- Allows concurrency between enqueue and
dequeue processes
- Use Dummy node to prevent contention

Issue – Blocking, Why two locks?
Queue with one lock:P1(enqueue) – acquires lock & finishesP2(enqueue) – acquires lock & proceedsP3(dequeue) – Blocked, P2 has lock
A more efficient algorithm would allow P3 to proceed as soon as P1 has completed, i.e. when there is a node available to be dequeued.

Issue – Blocking Using Two Locks
Two locks allows, one for tail pointer updates and a second lock for updates to the head pointer.- Enqueue process locks tail pointer- Dequeue process locks head pointer
A dummy node prevents contention because enqueue process does not access head pointer/lock and dequeue process does not access tail pointer/lock.
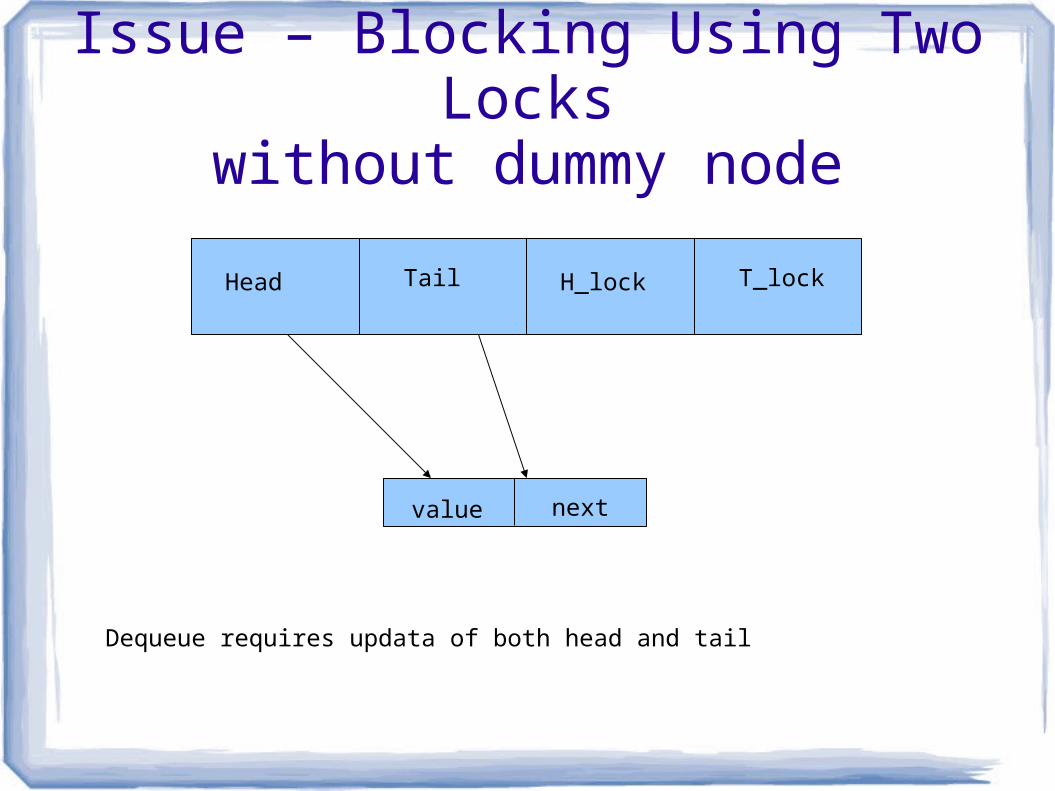
Issue – Blocking Using Two Lockswithout dummy node
value next
Head Tail H_lock T_lock
Dequeue requires updata of both head and tail

Issue – Blocking Using Two Lockswithout dummy node
Head Tail H_lock T_lock
Dequeue requires updata of both head and tail
O O

Issue – Blocking Using Two Lockswithout dummy node
Head Tail H_lock T_lock
Enqueue requires updata of both tail and head
O O
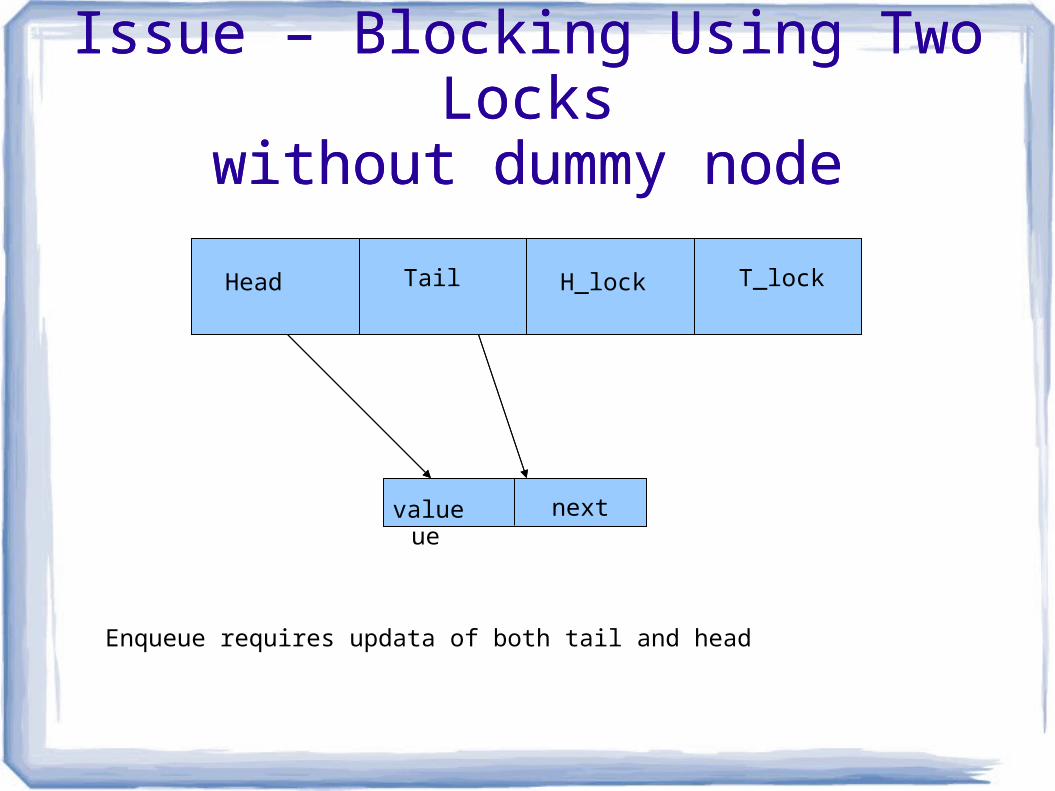
Issue – Blocking Using Two Lockswithout dummy node
value next
Head Tail H_lock T_lock
Issue – Blocking Using Two Lockswithout dummy node
value next
Head Tail H_lock T_lock
Enqueue requires updata of both tail and head
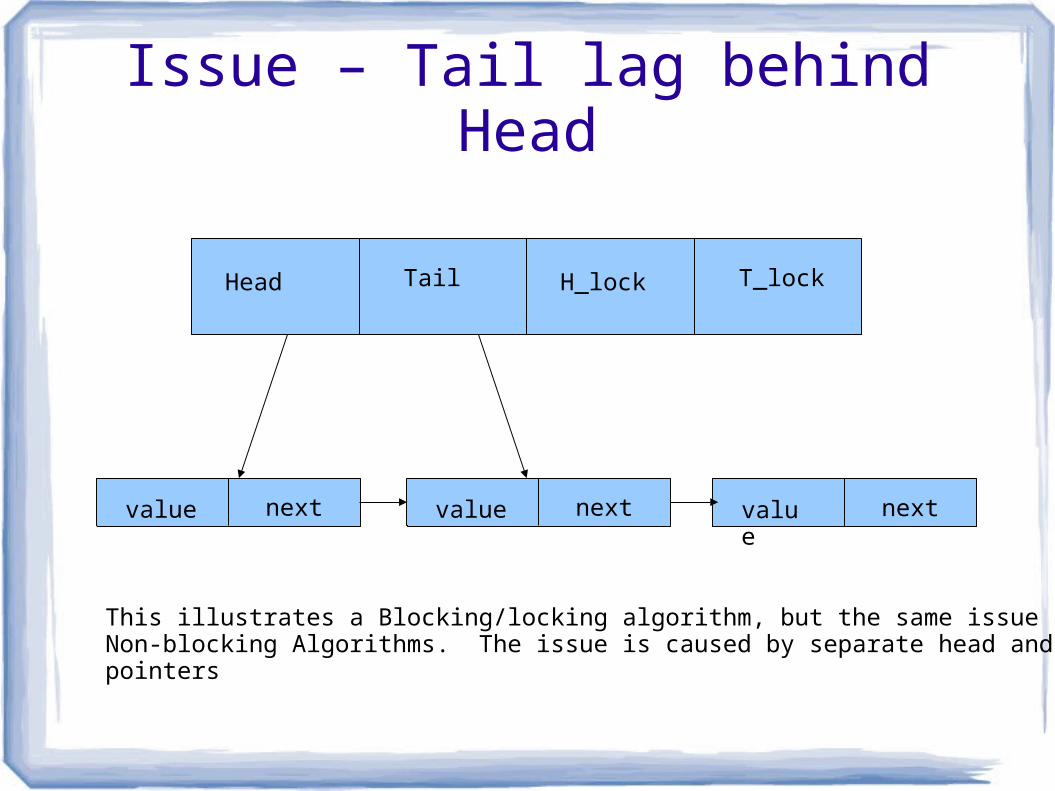
Issue – Tail lag behind Head
value next value nextvalue next
Head Tail H_lock T_lock
This illustrates a Blocking/locking algorithm, but the same issue applies toNon-blocking Algorithms. The issue is caused by separate head and tail pointers
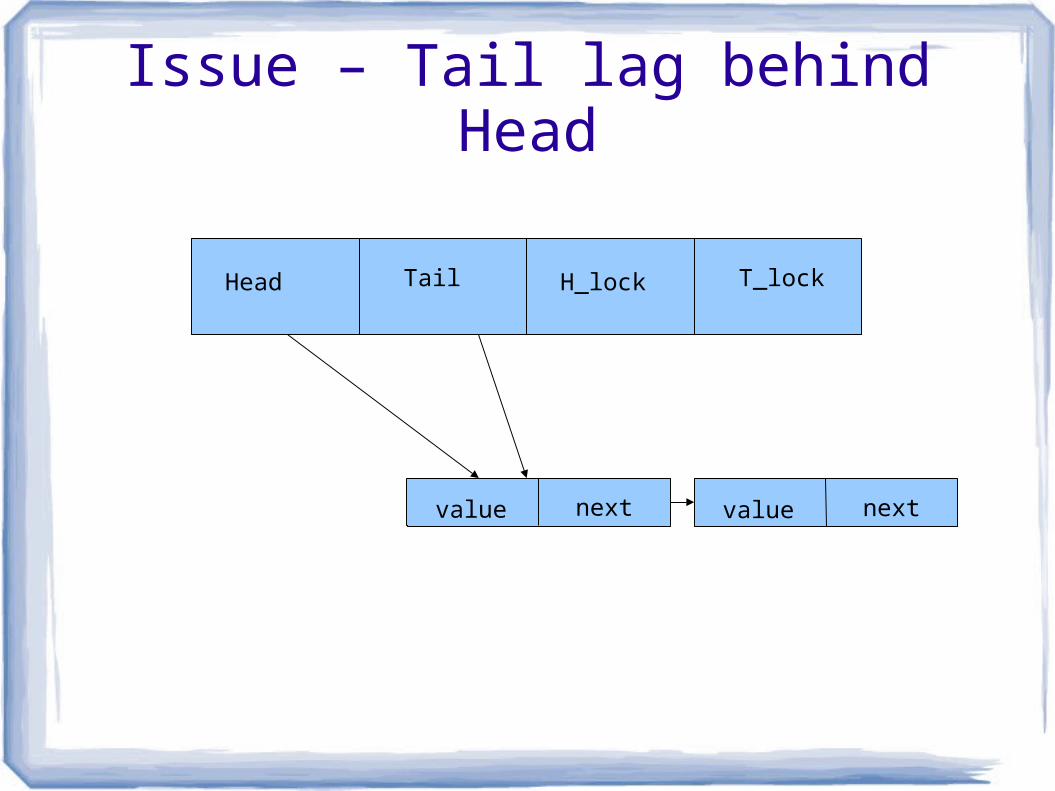
Issue – Tail lag behind Head
value nextvalue next
Head Tail H_lock T_lock
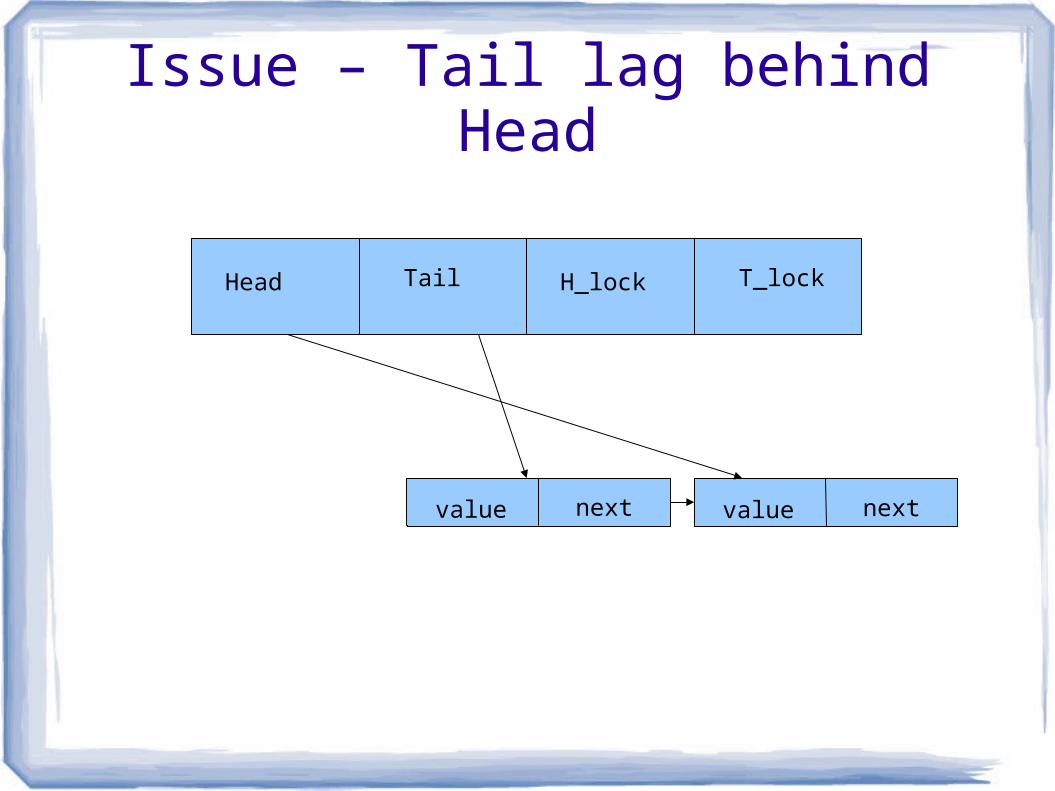
Issue – Tail lag behind Head
value nextvalue next
Head Tail H_lock T_lock
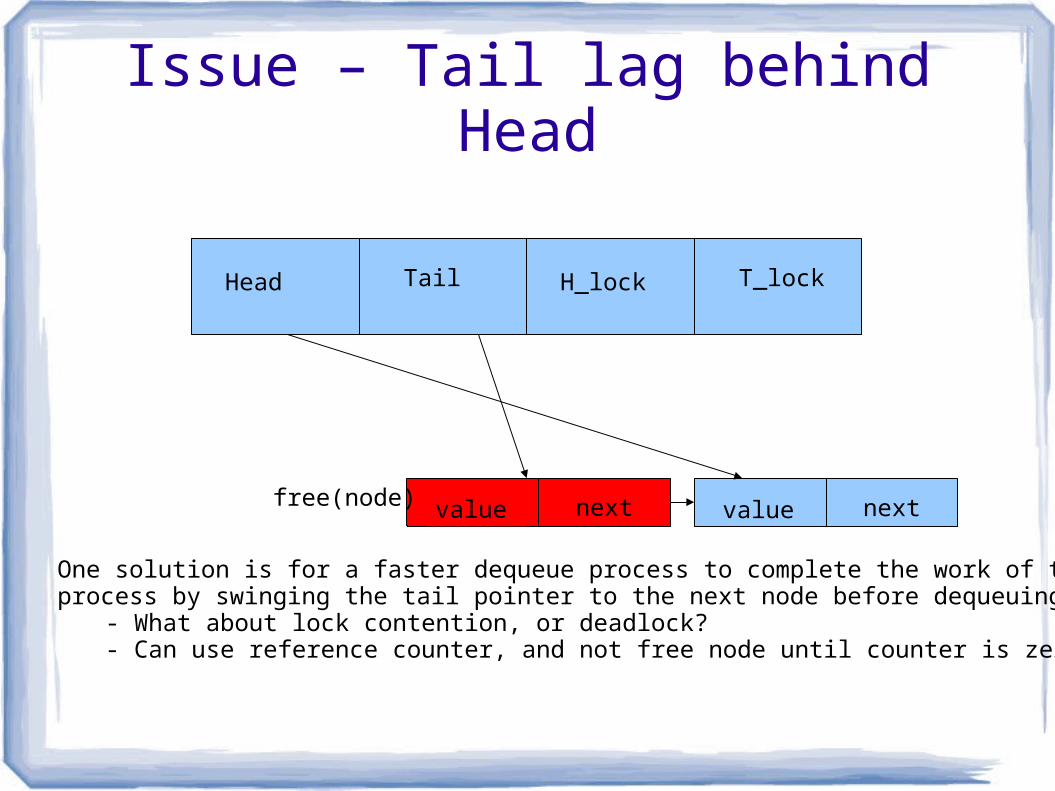
Issue – Tail lag behind Head
value nextvalue next
Head Tail H_lock T_lock
free(node)
One solution is for a faster dequeue process to complete the work of the slower enqueueprocess by swinging the tail pointer to the next node before dequeuing the node.
- What about lock contention, or deadlock?- Can use reference counter, and not free node until counter is zero
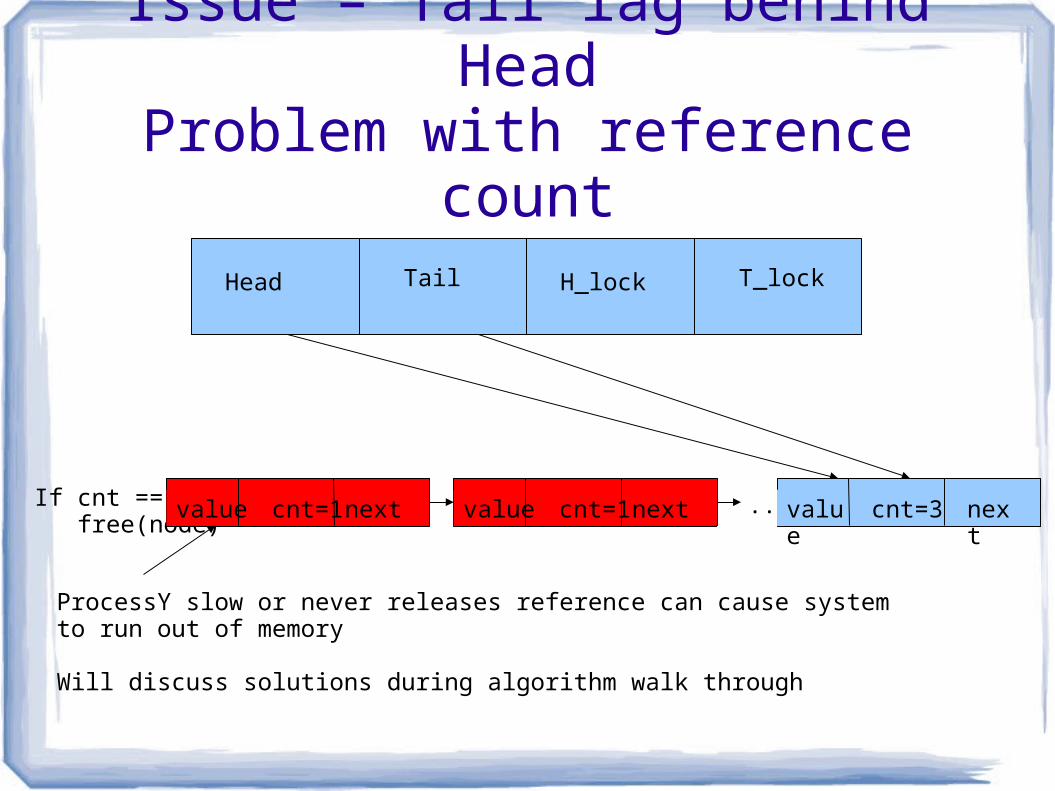
Issue – Tail lag behind HeadProblem with reference count
Head Tail H_lock T_lock
If cnt == 0 free(node)
value nextcnt=1
ProcessY slow or never releases reference can cause systemto run out of memory
Will discuss solutions during algorithm walk through
value nextcnt=1 ... value nextcnt=3

Non-Blocking Algorithms
Optimistic
Have a structure similar to:
Initialize local structuresBegin loop
Do some work If CAS == true
breakEnd loop

Issue - Linearizability
A data structure gives an external observer the illusion that the operations takes effect instantaneously
This requires that there be a specific point during each operation at which it is considered to “take effect”.

Issue - Linearizability
Similar to Serializability in Databases- History instead of Transactions- Invocations/responses vs Reads/Writes

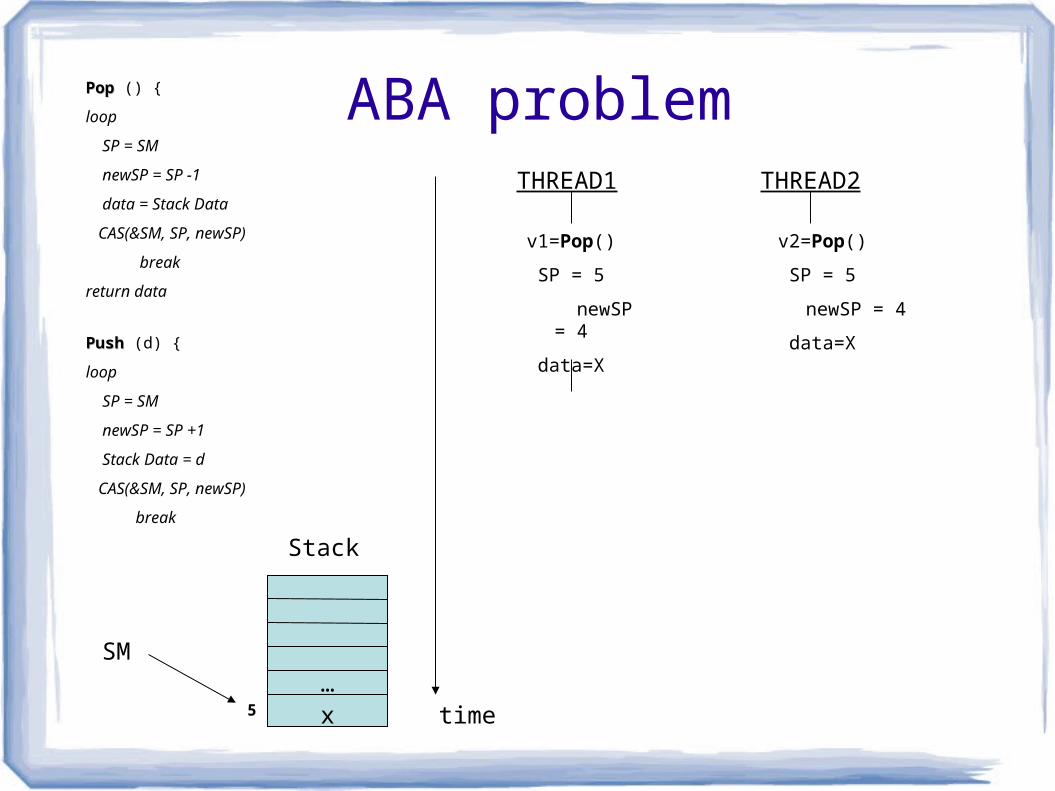
ABA problem
SM
5
Stack
THREAD1 THREAD2
v1=Pop()
SP = 5
newSP = 4
data=X
time
v2=Pop()
SP = 5
newSP = 4
data=X
x
PopPop () {
loop
SP = SM
newSP = SP -1
data = Stack Data
CAS(&SM, SP, newSP)
break
return data
PushPush (d) {
loop
SP = SM
newSP = SP +1
Stack Data = d
CAS(&SM, SP, newSP)
break
…
ABA problemTHREAD1 THREAD2
time
v1=Pop()
SP = 5
newSP = 4
data=X
PopPop () {
loop
SP = SM
newSP = SP -1
data = Stack Data
CAS(&SM, SP, newSP)
break
return data
PushPush (d) {
loop
SP = SM
newSP = SP +1
Stack Data = d
CAS(&SM, SP, newSP)
break
v2=Pop()
SP = 5
newSP = 4
data=X
SM
5
Stack
x…

ABA problem
SM4
Stack
THREAD1 THREAD2
time
v2=Pop()
SP = 5
newSP = 4
data=X
CAS(&SM,SP,newSP)
v2 = x
x…
v1=Pop()
SP = 5
newSP = 4
data=X
PopPop () {
loop
SP = SM
newSP = SP -1
data = Stack Data
CAS(&SM, SP, newSP)
break
return data
PushPush (d) {
loop
SP = SM
newSP = SP +1
Stack Data = d
CAS(&SM, SP, newSP)
break
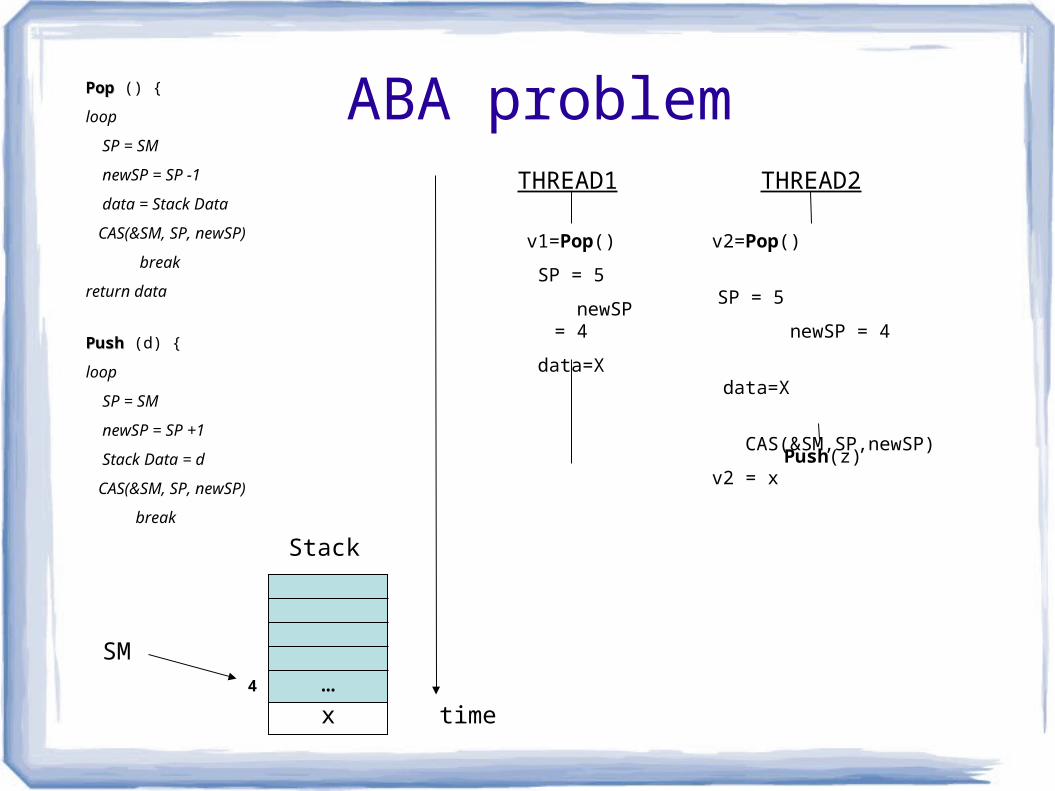
ABA problem
SM4
Stack
THREAD1 THREAD2
time
Push(z)
x…
v1=Pop()
SP = 5
newSP = 4
data=X
PopPop () {
loop
SP = SM
newSP = SP -1
data = Stack Data
CAS(&SM, SP, newSP)
break
return data
PushPush (d) {
loop
SP = SM
newSP = SP +1
Stack Data = d
CAS(&SM, SP, newSP)
break
v2=Pop()
SP = 5
newSP = 4
data=X
CAS(&SM,SP,newSP)
v2 = x
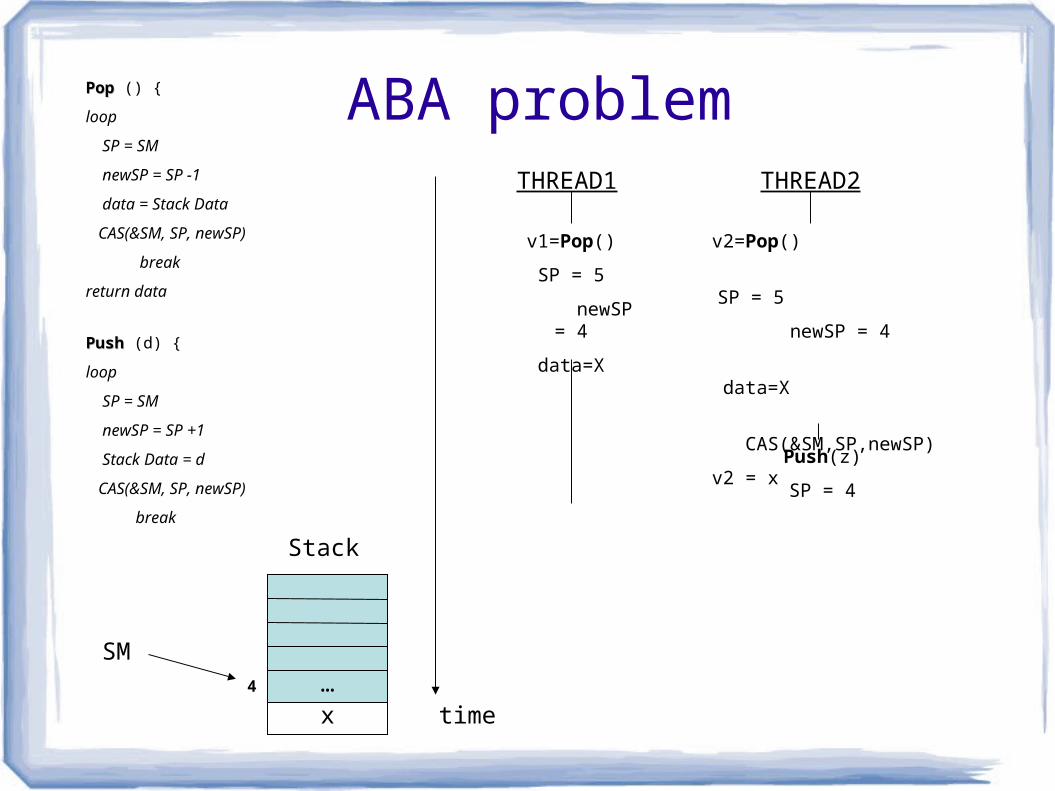
ABA problem
SM4
Stack
THREAD1 THREAD2
time
Push(z)
SP = 4
x…
v1=Pop()
SP = 5
newSP = 4
data=X
PopPop () {
loop
SP = SM
newSP = SP -1
data = Stack Data
CAS(&SM, SP, newSP)
break
return data
PushPush (d) {
loop
SP = SM
newSP = SP +1
Stack Data = d
CAS(&SM, SP, newSP)
break
v2=Pop()
SP = 5
newSP = 4
data=X
CAS(&SM,SP,newSP)
v2 = x
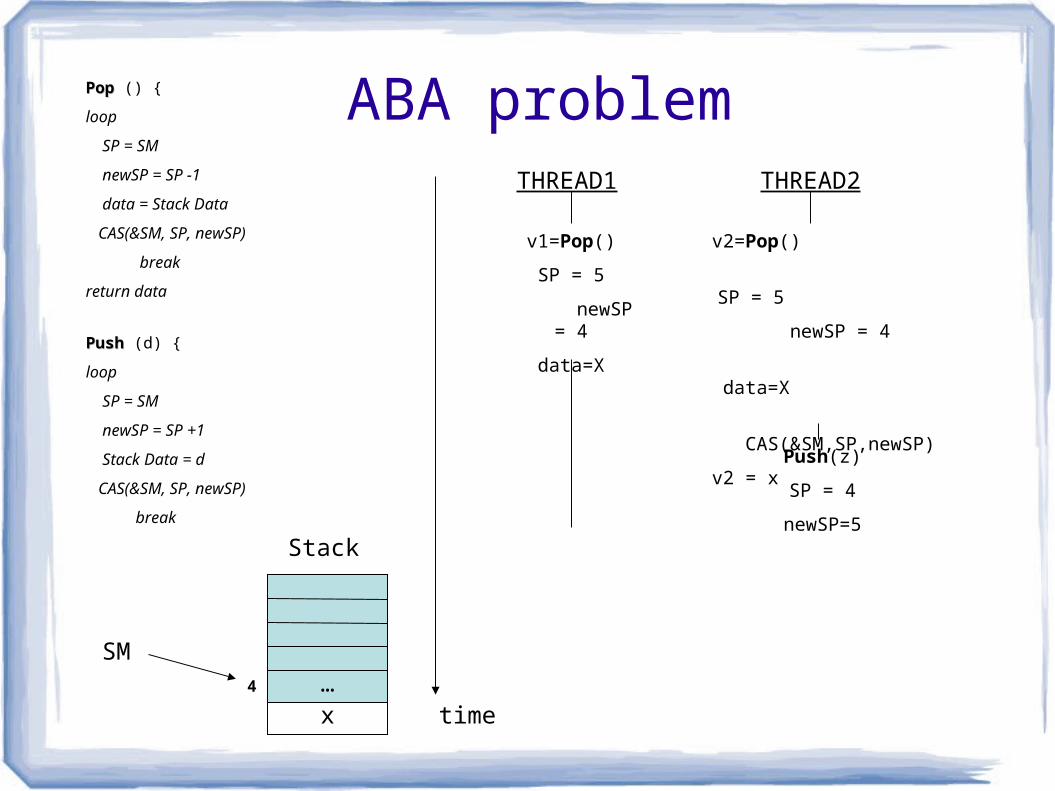
ABA problem
SM4
Stack
THREAD1 THREAD2
time
Push(z)
SP = 4
newSP=5
x…
v1=Pop()
SP = 5
newSP = 4
data=X
PopPop () {
loop
SP = SM
newSP = SP -1
data = Stack Data
CAS(&SM, SP, newSP)
break
return data
PushPush (d) {
loop
SP = SM
newSP = SP +1
Stack Data = d
CAS(&SM, SP, newSP)
break
v2=Pop()
SP = 5
newSP = 4
data=X
CAS(&SM,SP,newSP)
v2 = x
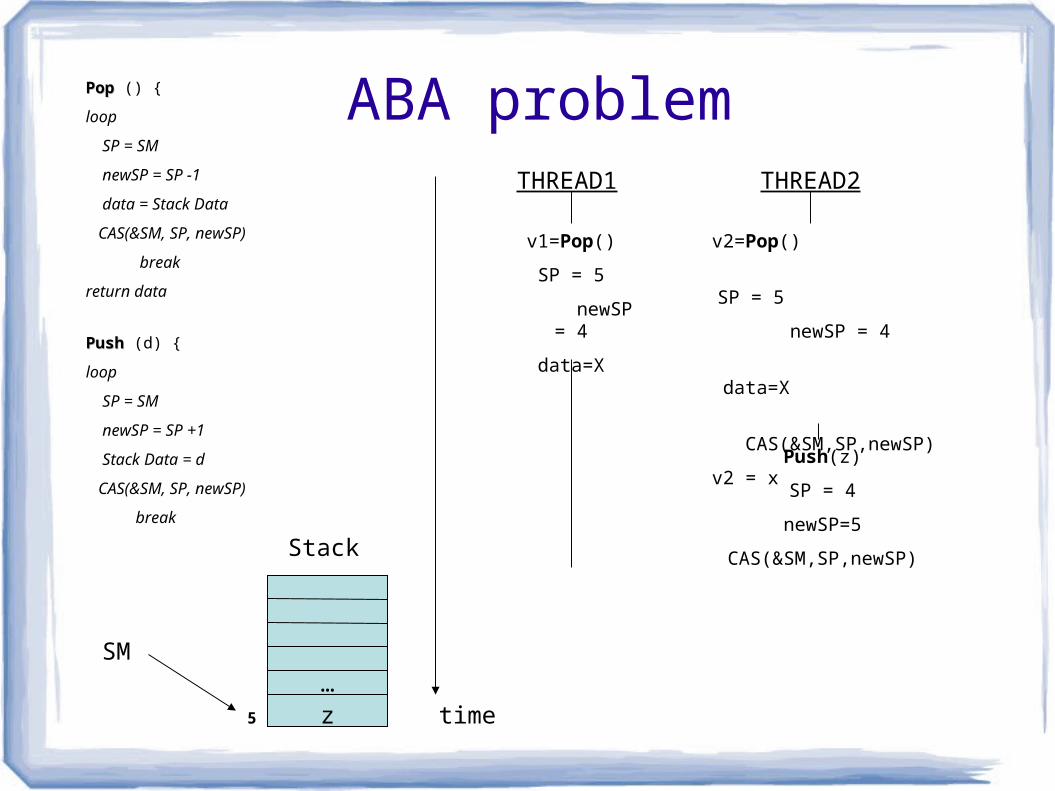
ABA problem
SM
5
Stack
THREAD1 THREAD2
time
Push(z)
SP = 4
newSP=5
CAS(&SM,SP,newSP)
z…
v1=Pop()
SP = 5
newSP = 4
data=X
PopPop () {
loop
SP = SM
newSP = SP -1
data = Stack Data
CAS(&SM, SP, newSP)
break
return data
PushPush (d) {
loop
SP = SM
newSP = SP +1
Stack Data = d
CAS(&SM, SP, newSP)
break
v2=Pop()
SP = 5
newSP = 4
data=X
CAS(&SM,SP,newSP)
v2 = x

ABA problem
SM
5
Stack
THREAD1 THREAD2
time
Push(z)
SP = 4
newSP=5
CAS(&SM,SP,newSP)
z
CAS(&SM,SP,newSP)
…
v1=Pop()
SP = 5
newSP = 4
data=X
PopPop () {
loop
SP = SM
newSP = SP -1
data = Stack Data
CAS(&SM, SP, newSP)
break
return data
PushPush (d) {
loop
SP = SM
newSP = SP +1
Stack Data = d
CAS(&SM, SP, newSP)
break
v2=Pop()
SP = 5
newSP = 4
data=X
CAS(&SM,SP,newSP)
v2 = x
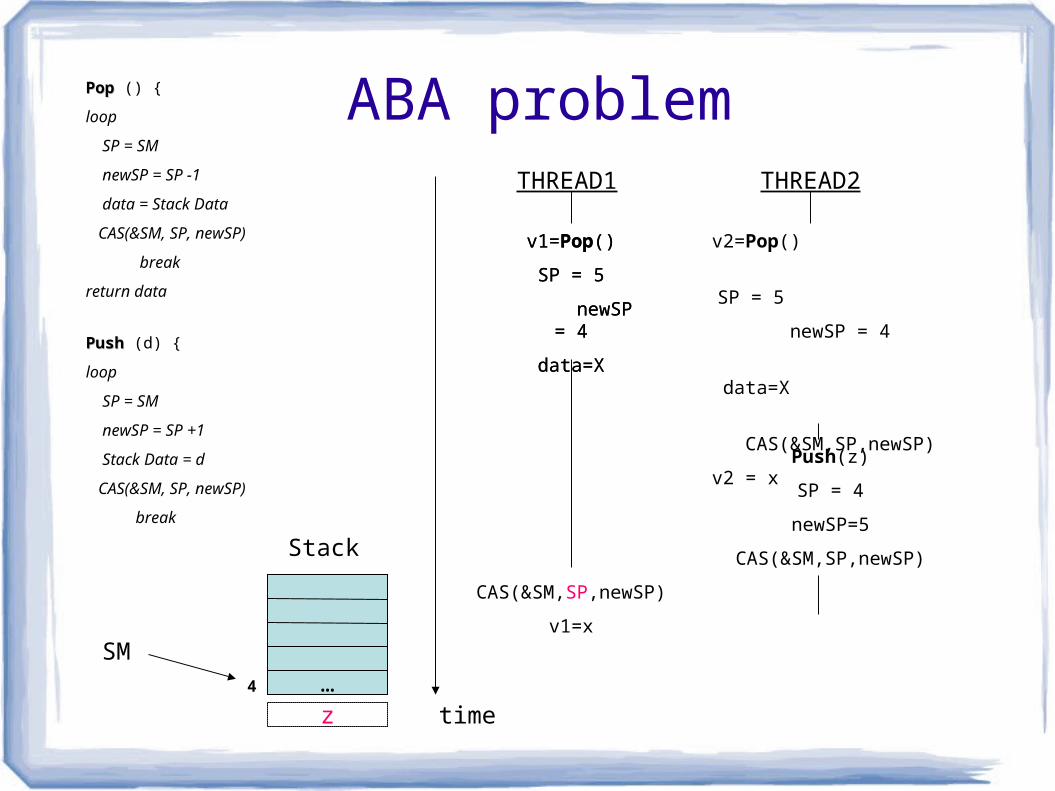
ABA problem
SM4
Stack
THREAD1 THREAD2
time
Push(z)
SP = 4
newSP=5
CAS(&SM,SP,newSP)
z
CAS(&SM,SP,newSP)
v1=x
…
v1=Pop()
SP = 5
newSP = 4
data=X
v1=Pop()
SP = 5
newSP = 4
data=X
PopPop () {
loop
SP = SM
newSP = SP -1
data = Stack Data
CAS(&SM, SP, newSP)
break
return data
PushPush (d) {
loop
SP = SM
newSP = SP +1
Stack Data = d
CAS(&SM, SP, newSP)
break
v2=Pop()
SP = 5
newSP = 4
data=X
CAS(&SM,SP,newSP)
v2 = x
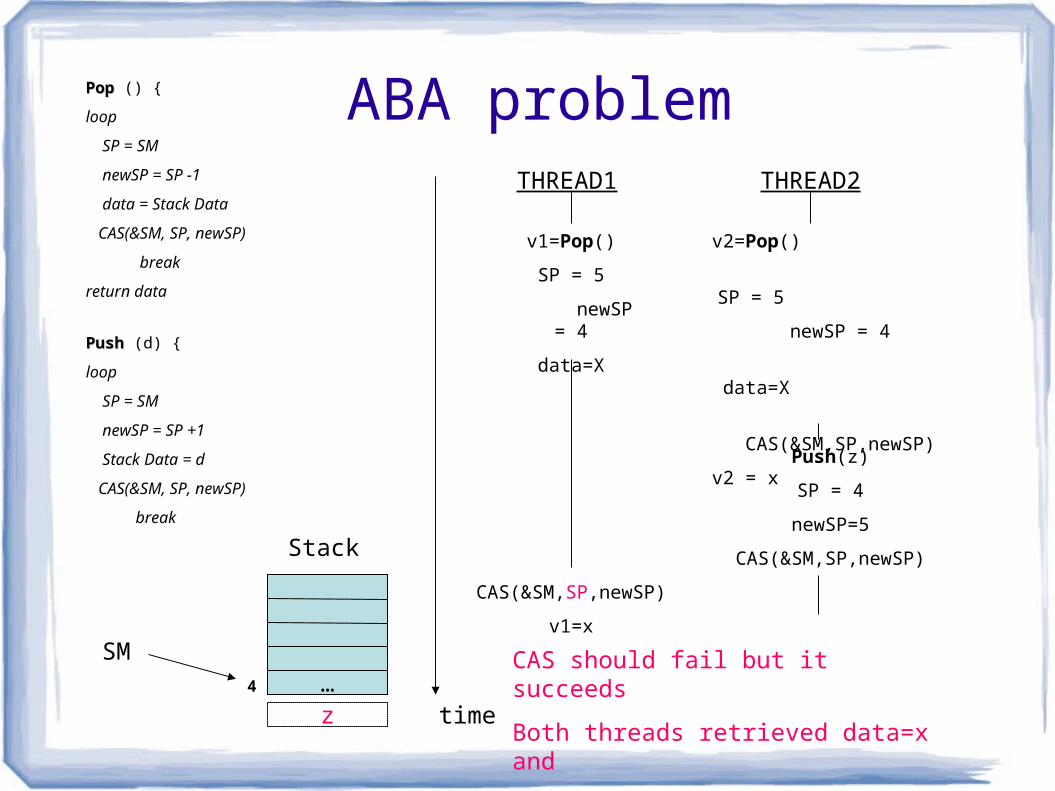
ABA problem
SM4
Stack
THREAD1 THREAD2
time
Push(z)
SP = 4
newSP=5
CAS(&SM,SP,newSP)
z
CAS(&SM,SP,newSP)
v1=x
…CAS should fail but it succeeds
Both threads retrieved data=x and
More important, the stack is now corrupt
v1=Pop()
SP = 5
newSP = 4
data=X
PopPop () {
loop
SP = SM
newSP = SP -1
data = Stack Data
CAS(&SM, SP, newSP)
break
return data
PushPush (d) {
loop
SP = SM
newSP = SP +1
Stack Data = d
CAS(&SM, SP, newSP)
break
v2=Pop()
SP = 5
newSP = 4
data=X
CAS(&SM,SP,newSP)
v2 = x

ABA Solution
Add a modification counter to the pointer- atomic update of pointer and counter- can use double word CAS
- Not available on most platforms- Pack pointer and counter into single word
- Use single word CAS to update- Authors solution

Correctness Properties
1. The linked list is always connected
2. Nodes are only inserted after the last node in the linked list.
3. Nodes are only deleted from the beginning of the linked list
4. Head always points to the first node in the linked list
5. Tail always points to a node in the linked list.

Algorithm – Non blocking, Globals
structure pointer_t {ptr: pointer to node t, count: unsigned integer}
structure node_t {value: data type, next: pointer_t}
structure queue_t {Head: pointer_t, Tail: pointer_t}
ptr count
Head Tail
ptr count ptr count
valuenext
ptr count
(packed Word)
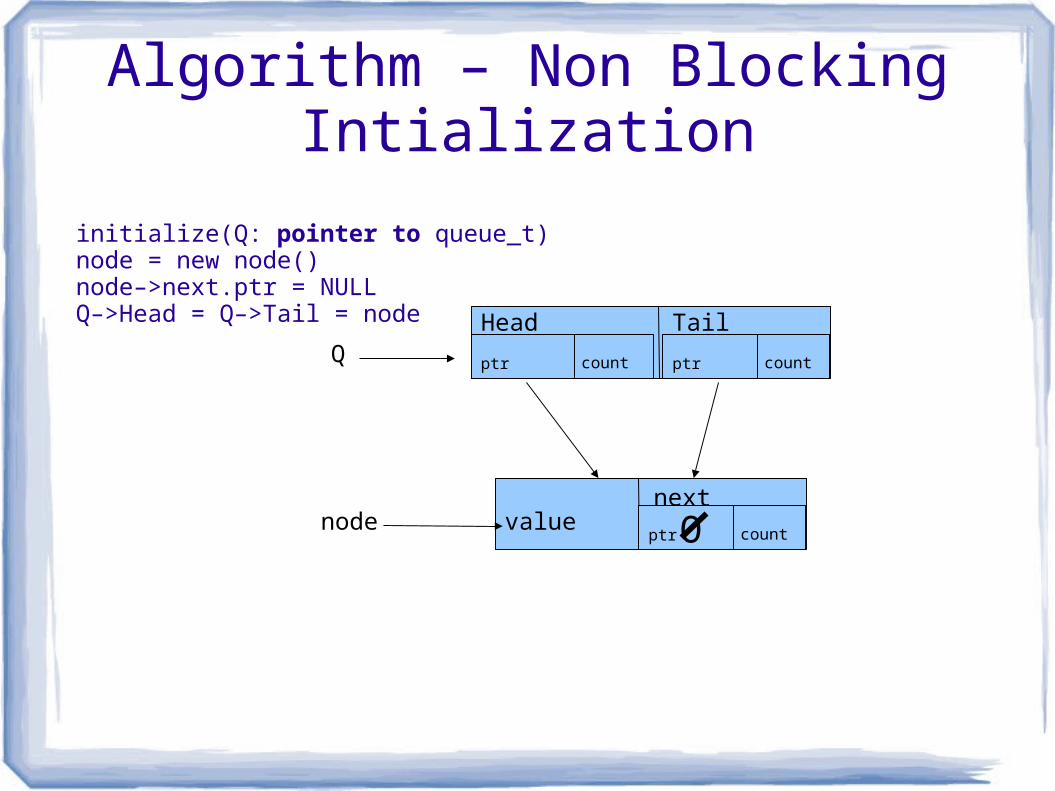
Algorithm – Non Blocking Intialization
initialize(Q: pointer to queue_t)node = new node() node–>next.ptr = NULL Q–>Head = Q–>Tail = node
Q
valuenext
ptr count
Head Tail
ptr count ptr count
node O
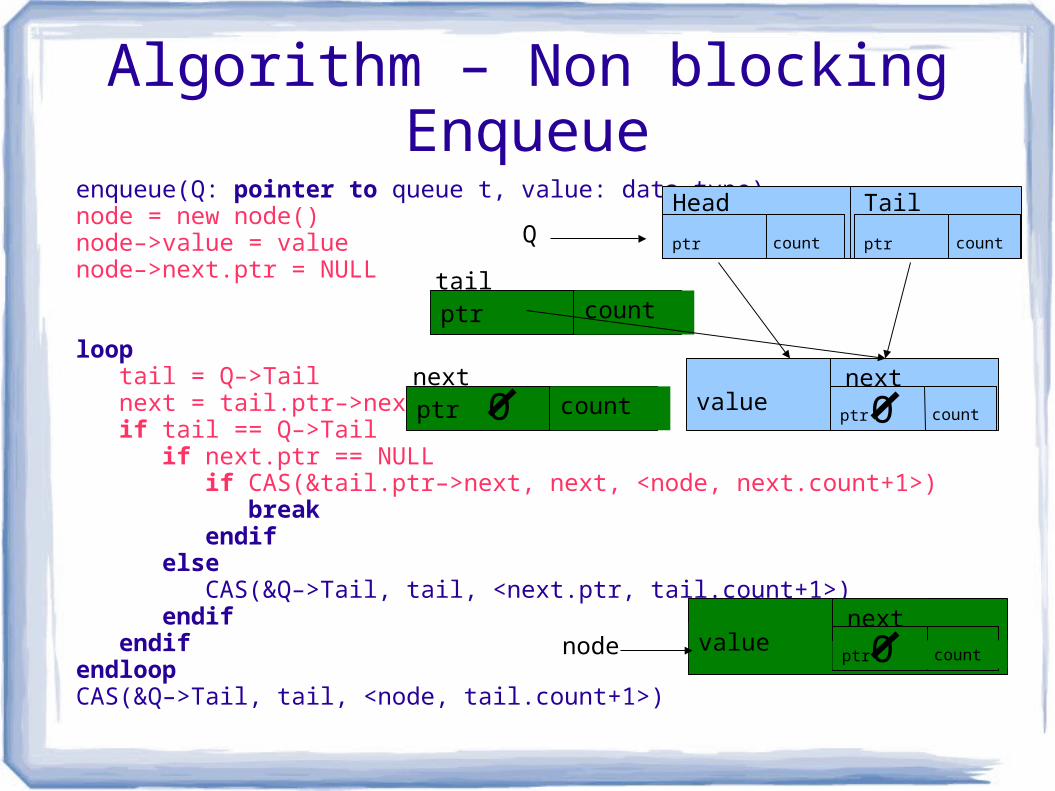
Algorithm – Non blocking Enqueueenqueue(Q: pointer to queue t, value: data type)node = new node() node–>value = value node–>next.ptr = NULL
loop tail = Q–>Tail next = tail.ptr–>next if tail == Q–>Tail if next.ptr == NULL if CAS(&tail.ptr–>next, next, <node, next.count+1>) break endif else CAS(&Q–>Tail, tail, <next.ptr, tail.count+1>) endif endifendloopCAS(&Q–>Tail, tail, <node, tail.count+1>)
Q
valuenext
ptr count
Head Tail
ptr count ptr count
tail
valuenext
ptr countOnode
ptr countnext
ptr count
O O
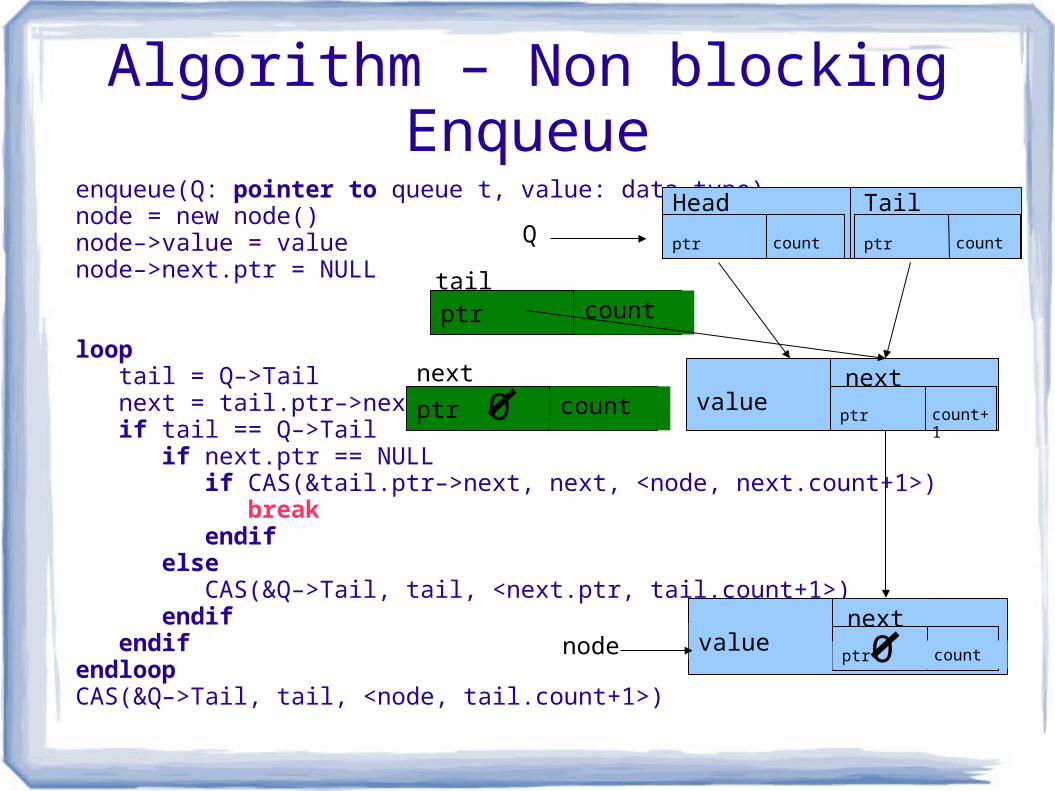
Algorithm – Non blocking Enqueueenqueue(Q: pointer to queue t, value: data type)node = new node() node–>value = value node–>next.ptr = NULL
loop tail = Q–>Tail next = tail.ptr–>next if tail == Q–>Tail if next.ptr == NULL if CAS(&tail.ptr–>next, next, <node, next.count+1>) break endif else CAS(&Q–>Tail, tail, <next.ptr, tail.count+1>) endif endifendloopCAS(&Q–>Tail, tail, <node, tail.count+1>)
Q
valuenext
ptr count+1
Head Tail
ptr count ptr count
valuenext
ptr countO
tail
node
ptr countnext
ptr count
O
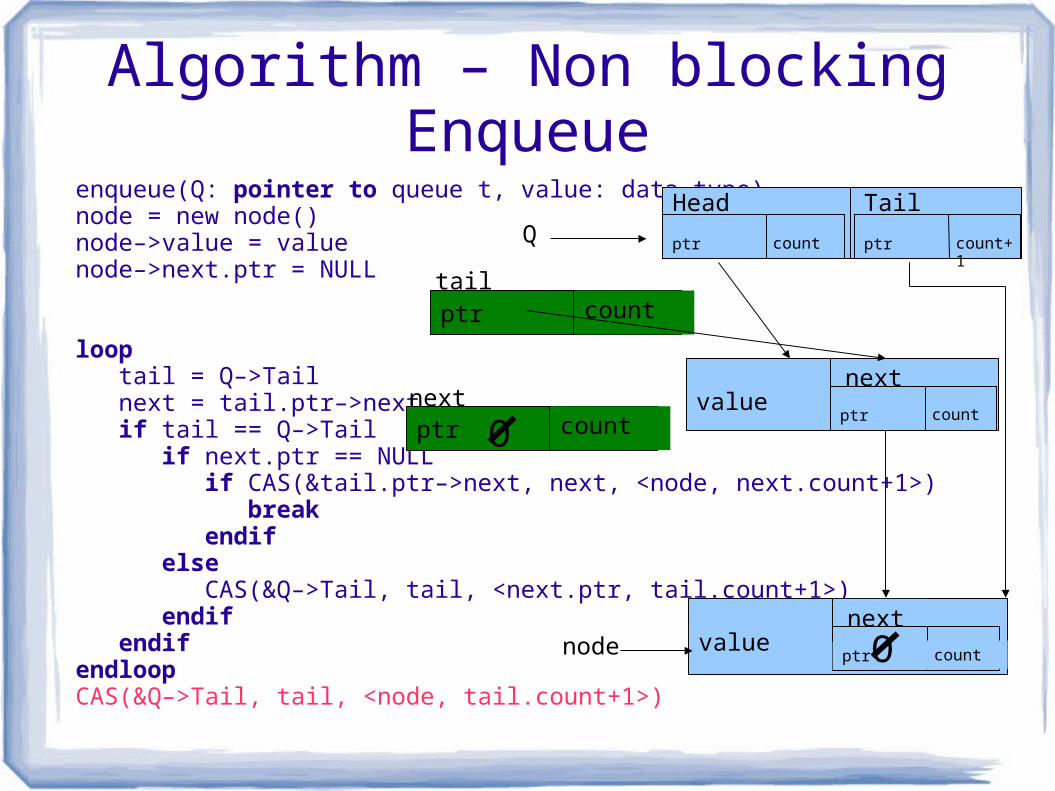
Algorithm – Non blocking Enqueueenqueue(Q: pointer to queue t, value: data type)node = new node() node–>value = value node–>next.ptr = NULL
loop tail = Q–>Tail next = tail.ptr–>next if tail == Q–>Tail if next.ptr == NULL if CAS(&tail.ptr–>next, next, <node, next.count+1>) break endif else CAS(&Q–>Tail, tail, <next.ptr, tail.count+1>) endif endifendloopCAS(&Q–>Tail, tail, <node, tail.count+1>)
Q
valuenext
ptr count
Head Tail
ptr count ptr count+1
valuenext
ptr countO
tail
node
ptr countnext
ptr count
O
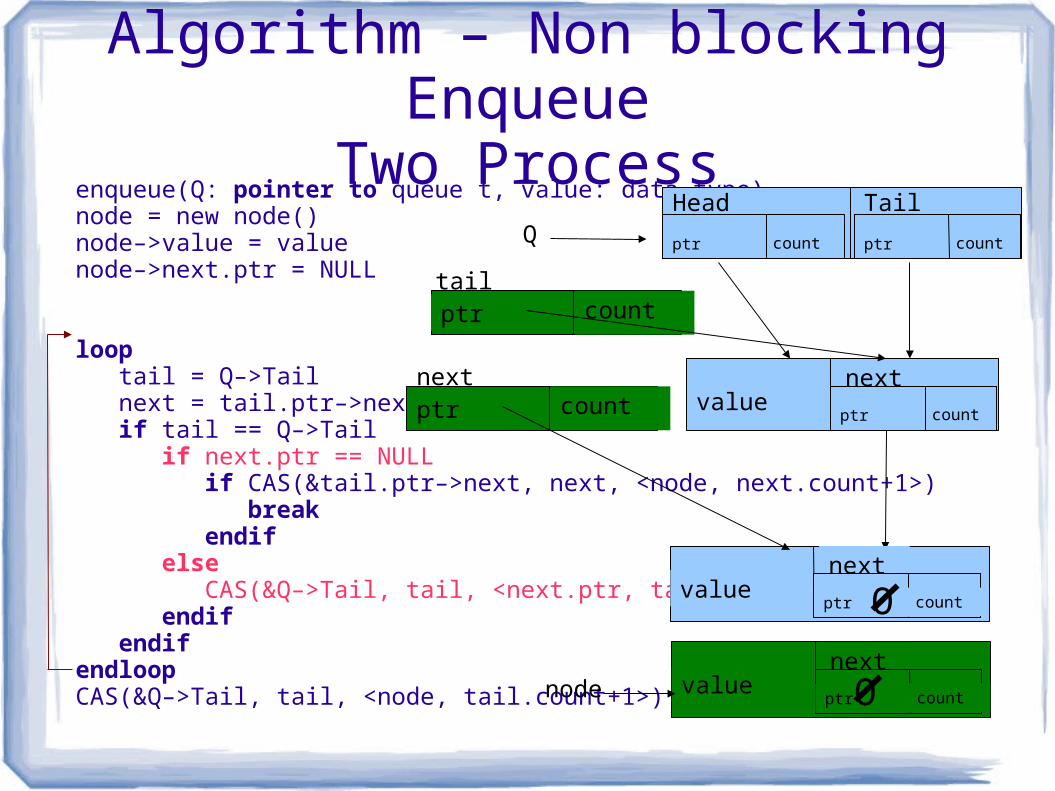
Algorithm – Non blocking EnqueueTwo Process
enqueue(Q: pointer to queue t, value: data type)node = new node() node–>value = value node–>next.ptr = NULL
loop tail = Q–>Tail next = tail.ptr–>next if tail == Q–>Tail if next.ptr == NULL if CAS(&tail.ptr–>next, next, <node, next.count+1>) break endif else CAS(&Q–>Tail, tail, <next.ptr, tail.count+1>) endif endifendloopCAS(&Q–>Tail, tail, <node, tail.count+1>)
Q
valuenext
ptr count
Head Tail
ptr count ptr count
valuenext
ptr countO
tail
ptr countnext
ptr count
valuenext
ptr countOnode
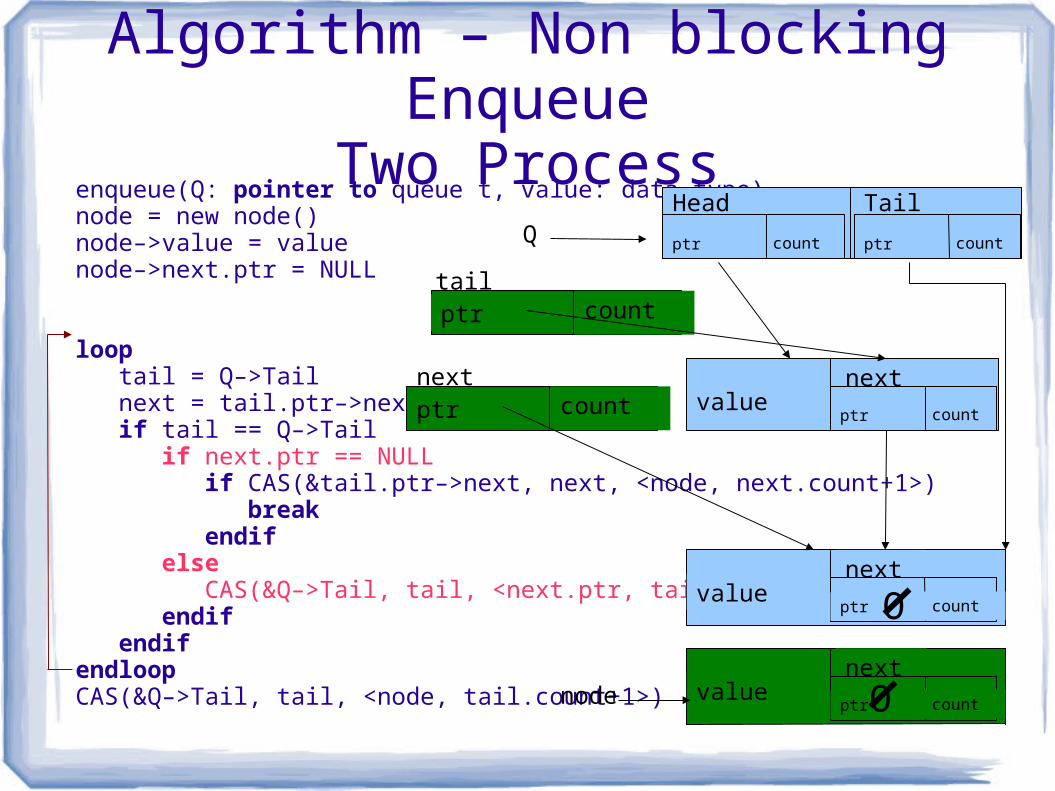
Algorithm – Non blocking EnqueueTwo Process
enqueue(Q: pointer to queue t, value: data type)node = new node() node–>value = value node–>next.ptr = NULL
loop tail = Q–>Tail next = tail.ptr–>next if tail == Q–>Tail if next.ptr == NULL if CAS(&tail.ptr–>next, next, <node, next.count+1>) break endif else CAS(&Q–>Tail, tail, <next.ptr, tail.count+1>) endif endifendloopCAS(&Q–>Tail, tail, <node, tail.count+1>)
Q
valuenext
ptr count
Head Tail
ptr count ptr count
valuenext
ptr countO
tail
ptr countnext
ptr count
valuenext
ptr countOnode
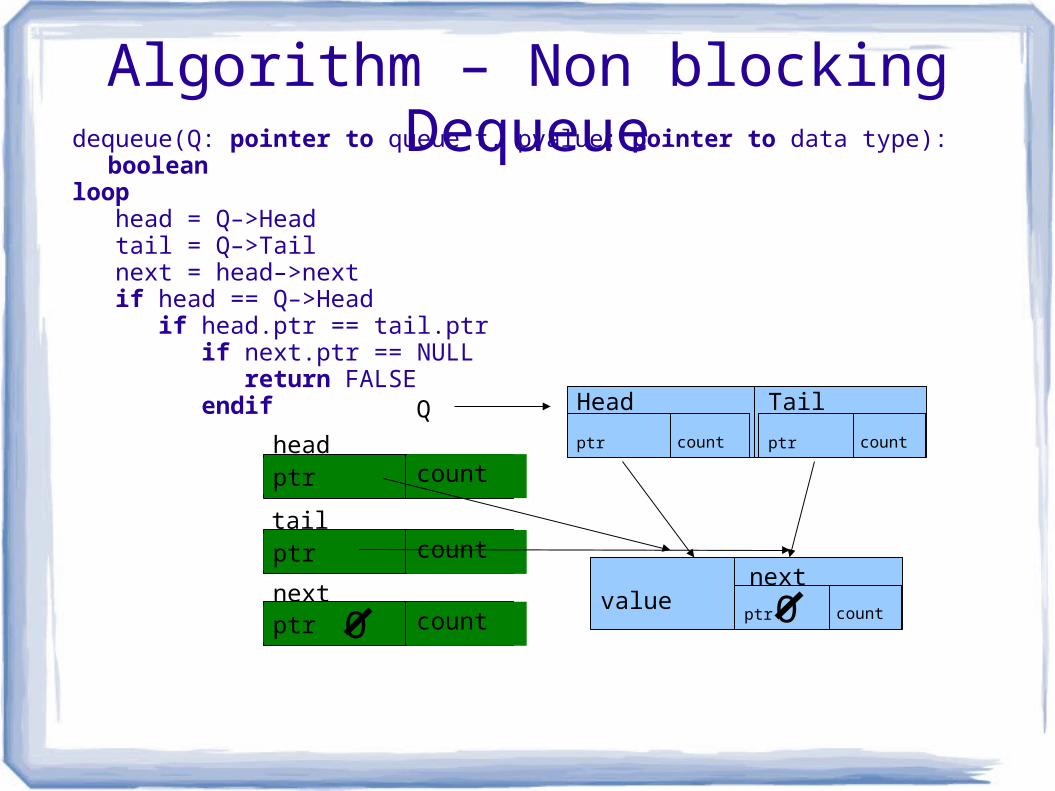
Algorithm – Non blocking Dequeuedequeue(Q: pointer to queue t, pvalue: pointer to data type): booleanloop head = Q–>Head tail = Q–>Tail next = head–>next if head == Q–>Head if head.ptr == tail.ptr if next.ptr == NULL return FALSE endif Q
valuenext
ptr count
Head Tail
ptr count ptr count
ptr count
ptr count
ptr count
head
tail
next
O O
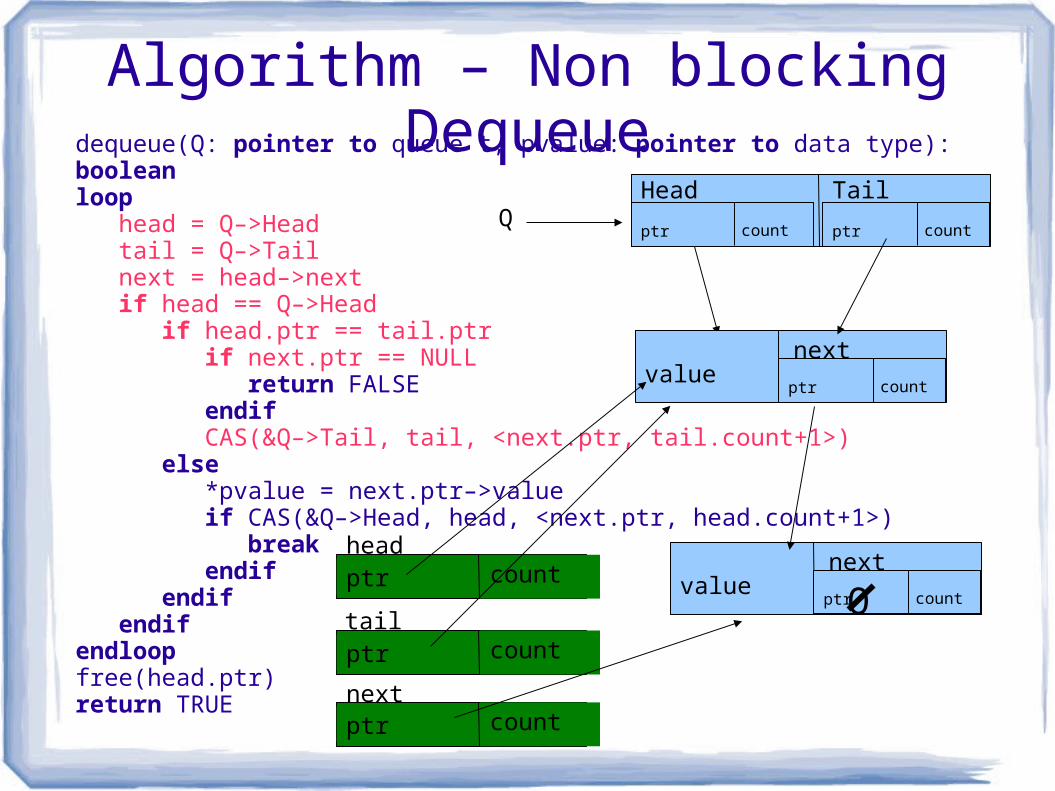
Algorithm – Non blocking Dequeuedequeue(Q: pointer to queue t, pvalue: pointer to data type): booleanloop head = Q–>Head tail = Q–>Tail next = head–>next if head == Q–>Head if head.ptr == tail.ptr if next.ptr == NULL return FALSE endif CAS(&Q–>Tail, tail, <next.ptr, tail.count+1>) else *pvalue = next.ptr–>value if CAS(&Q–>Head, head, <next.ptr, head.count+1>) break endif endif endifendloopfree(head.ptr) return TRUE
Q
valuenext
ptr count
Head Tail
ptr count ptr count
ptr count
ptr count
ptr count
head
tail
next
valuenext
ptr count
O
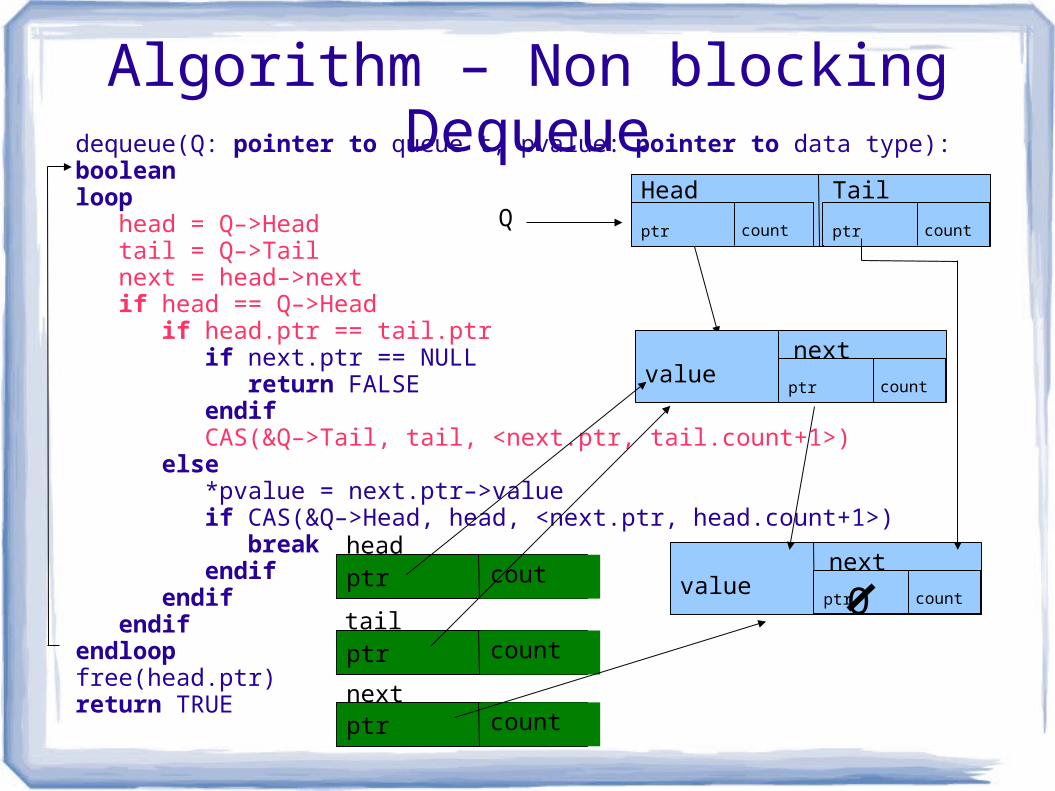
Algorithm – Non blocking Dequeuedequeue(Q: pointer to queue t, pvalue: pointer to data type): booleanloop head = Q–>Head tail = Q–>Tail next = head–>next if head == Q–>Head if head.ptr == tail.ptr if next.ptr == NULL return FALSE endif CAS(&Q–>Tail, tail, <next.ptr, tail.count+1>) else *pvalue = next.ptr–>value if CAS(&Q–>Head, head, <next.ptr, head.count+1>) break endif endif endifendloopfree(head.ptr) return TRUE
Q
valuenext
ptr count
Head Tail
ptr count ptr count
ptr count
ptr cout
ptr count
head
tail
next
valuenext
ptr count
O
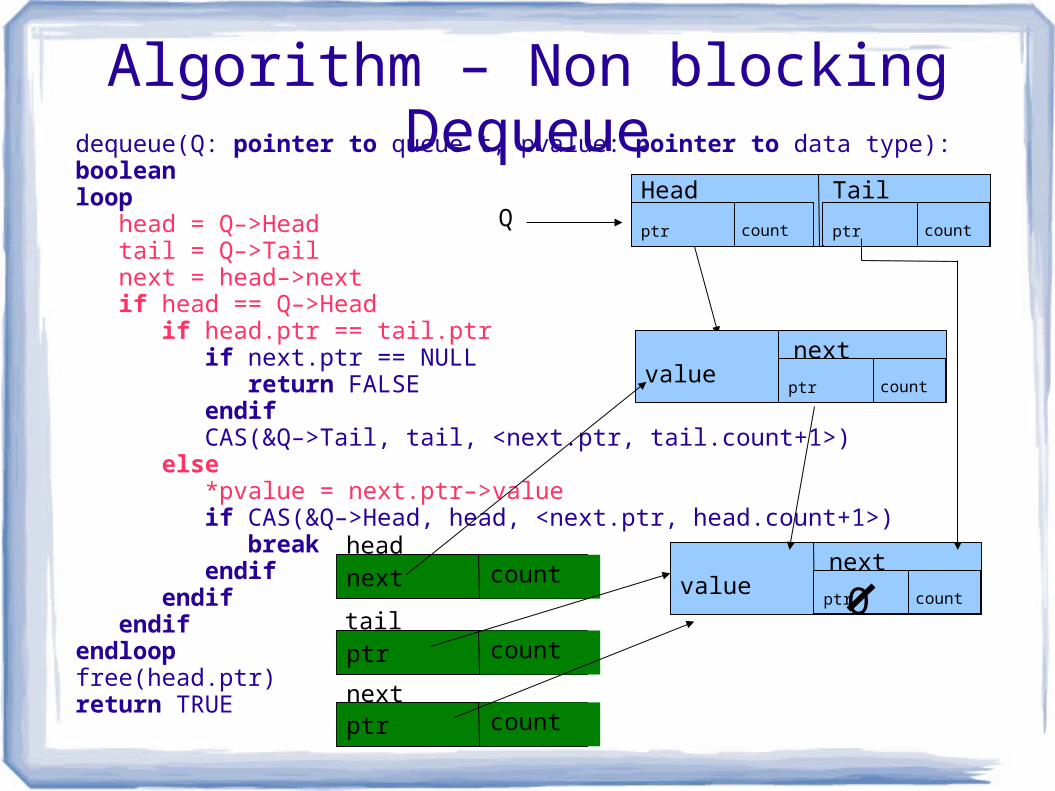
Algorithm – Non blocking Dequeuedequeue(Q: pointer to queue t, pvalue: pointer to data type): booleanloop head = Q–>Head tail = Q–>Tail next = head–>next if head == Q–>Head if head.ptr == tail.ptr if next.ptr == NULL return FALSE endif CAS(&Q–>Tail, tail, <next.ptr, tail.count+1>) else *pvalue = next.ptr–>value if CAS(&Q–>Head, head, <next.ptr, head.count+1>) break endif endif endifendloopfree(head.ptr) return TRUE
Q
valuenext
ptr count
Head Tail
ptr count ptr count
ptr count
next count
ptr count
head
tail
next
valuenext
ptr count
O
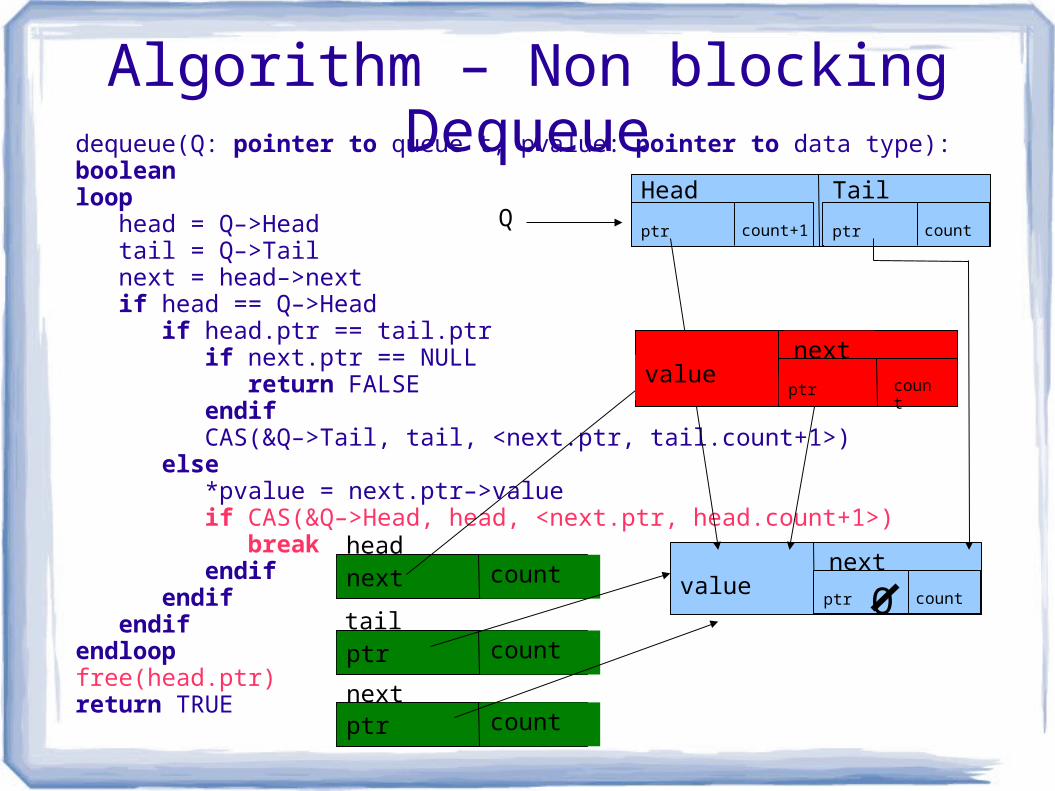
Algorithm – Non blocking Dequeuedequeue(Q: pointer to queue t, pvalue: pointer to data type): booleanloop head = Q–>Head tail = Q–>Tail next = head–>next if head == Q–>Head if head.ptr == tail.ptr if next.ptr == NULL return FALSE endif CAS(&Q–>Tail, tail, <next.ptr, tail.count+1>) else *pvalue = next.ptr–>value if CAS(&Q–>Head, head, <next.ptr, head.count+1>) break endif endif endifendloopfree(head.ptr) return TRUE
Q
valuenext
ptr count
Head Tail
ptr count+1 ptr count
ptr count
next count
ptr count
head
tail
next
O
valuenext
ptr count
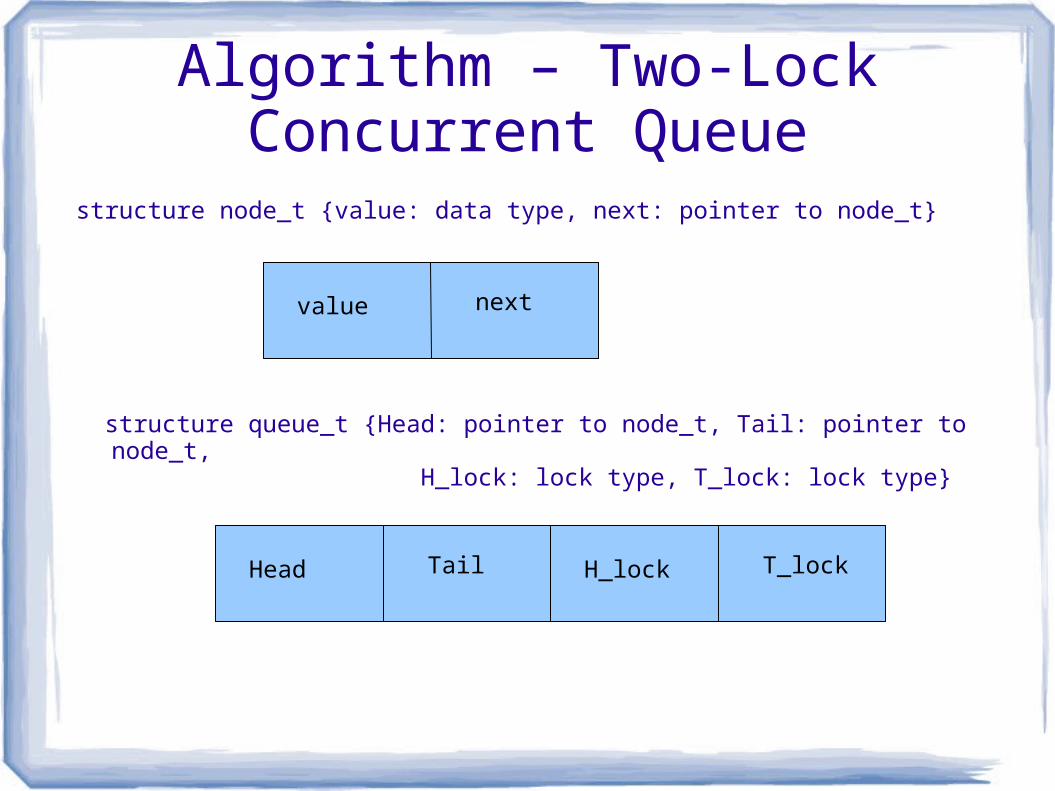
Algorithm – Two-Lock Concurrent Queue
structure node_t {value: data type, next: pointer to node_t}
structure queue_t {Head: pointer to node_t, Tail: pointer to node_t, H_lock: lock type, T_lock: lock type}
value next
Head Tail H_lock T_lock
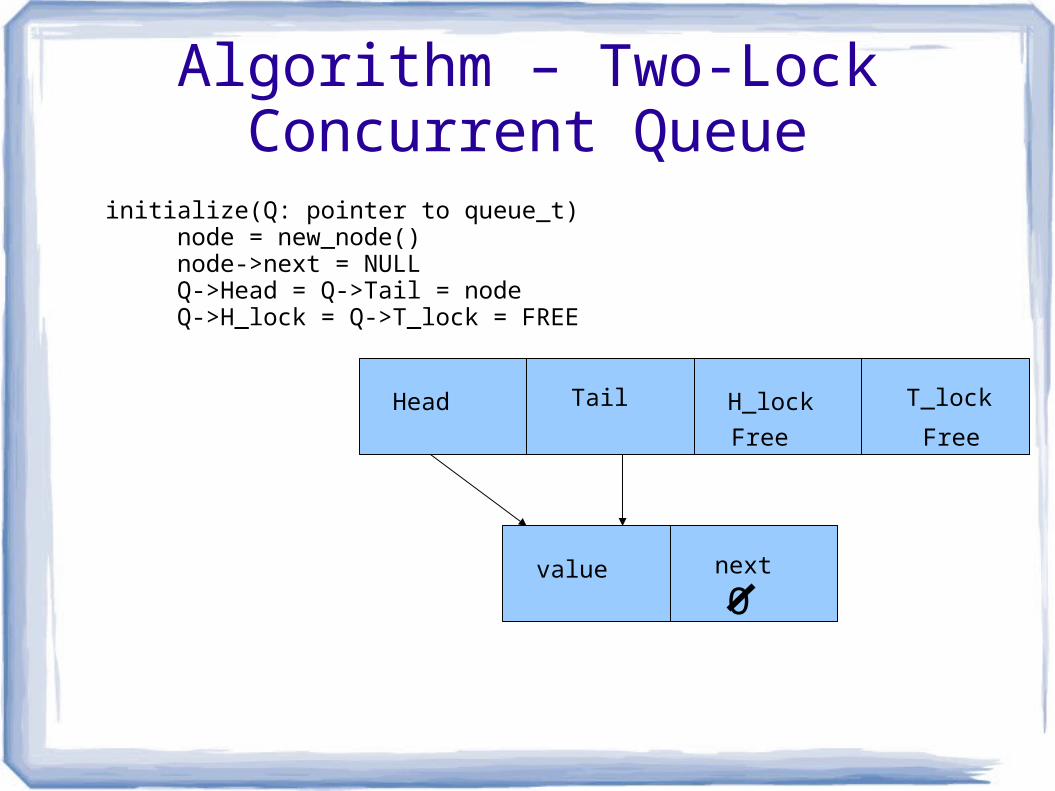
Algorithm – Two-Lock Concurrent Queue
value next
Head Tail H_lock T_lock
initialize(Q: pointer to queue_t) node = new_node() node->next = NULL Q->Head = Q->Tail = node Q->H_lock = Q->T_lock = FREE
O
Free Free
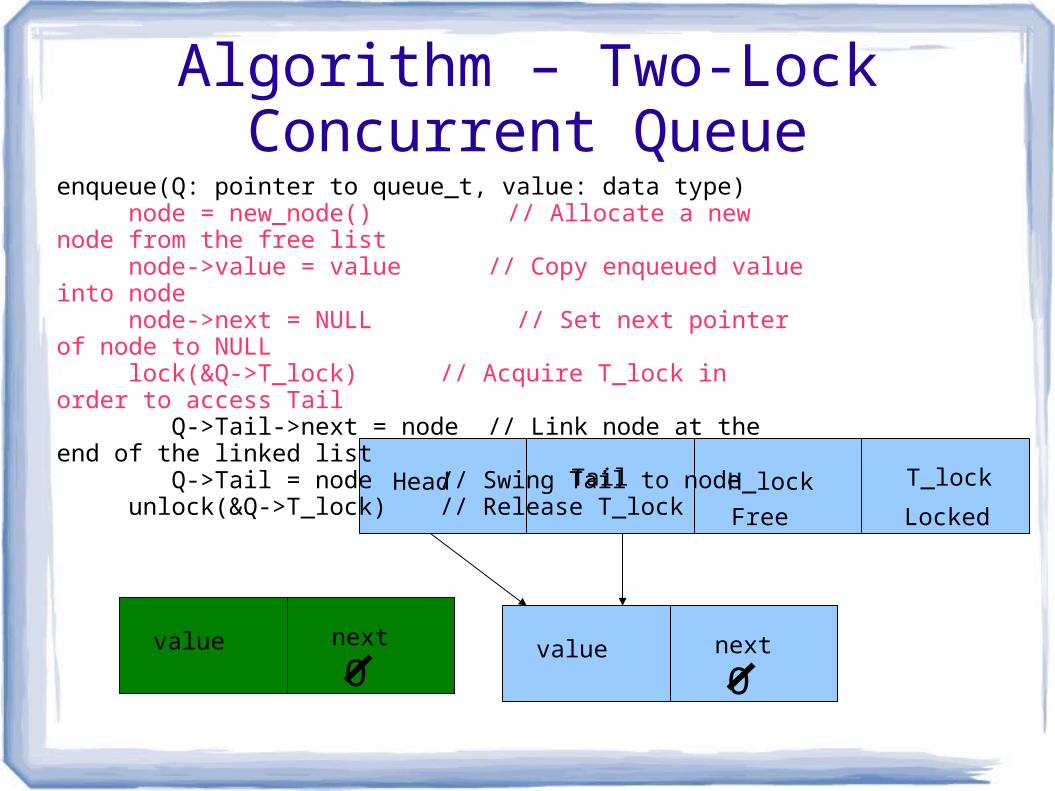
Algorithm – Two-Lock Concurrent Queue
value next
Head Tail H_lock T_lock
O
Free Locked
enqueue(Q: pointer to queue_t, value: data type) node = new_node() // Allocate a new node from the free list node->value = value // Copy enqueued value into node node->next = NULL // Set next pointer of node to NULL lock(&Q->T_lock) // Acquire T_lock in order to access Tail Q->Tail->next = node // Link node at the end of the linked list Q->Tail = node // Swing Tail to node unlock(&Q->T_lock) // Release T_lock
value next
O

Algorithm – Two-Lock Concurrent Queue
Head Tail H_lock T_lock
value next
Free Locked
enqueue(Q: pointer to queue_t, value: data type) node = new_node() // Allocate a new node from the free list node->value = value // Copy enqueued value into node node->next = NULL // Set next pointer of node to NULL lock(&Q->T_lock) // Acquire T_lock in order to access Tail Q->Tail->next = node // Link node at the end of the linked list Q->Tail = node // Swing Tail to node unlock(&Q->T_lock) // Release T_lock
value next
O
Algorithm – Two-Lock Concurrent
Head Tail H_lock T_lock
value next
Locked Locked
value next
O
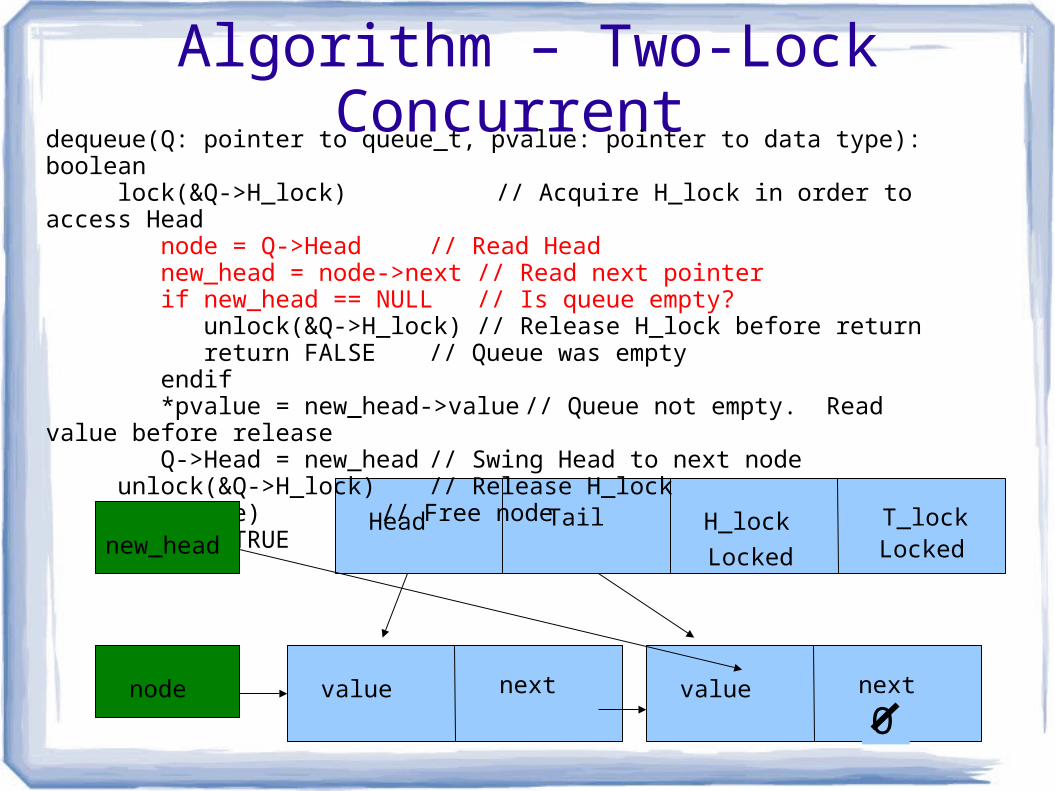
dequeue(Q: pointer to queue_t, pvalue: pointer to data type): boolean lock(&Q->H_lock) // Acquire H_lock in order to access Head node = Q->Head // Read Head new_head = node->next // Read next pointer if new_head == NULL// Is queue empty? unlock(&Q->H_lock) // Release H_lock before return return FALSE // Queue was empty endif *pvalue = new_head->value // Queue not empty. Read value before release Q->Head = new_head // Swing Head to next node unlock(&Q->H_lock) // Release H_lock free(node) // Free node return} TRUE
node
new_head
Algorithm – Two-Lock Concurrent
Head Tail H_lock T_lock
value next
Free Locked
value next
O
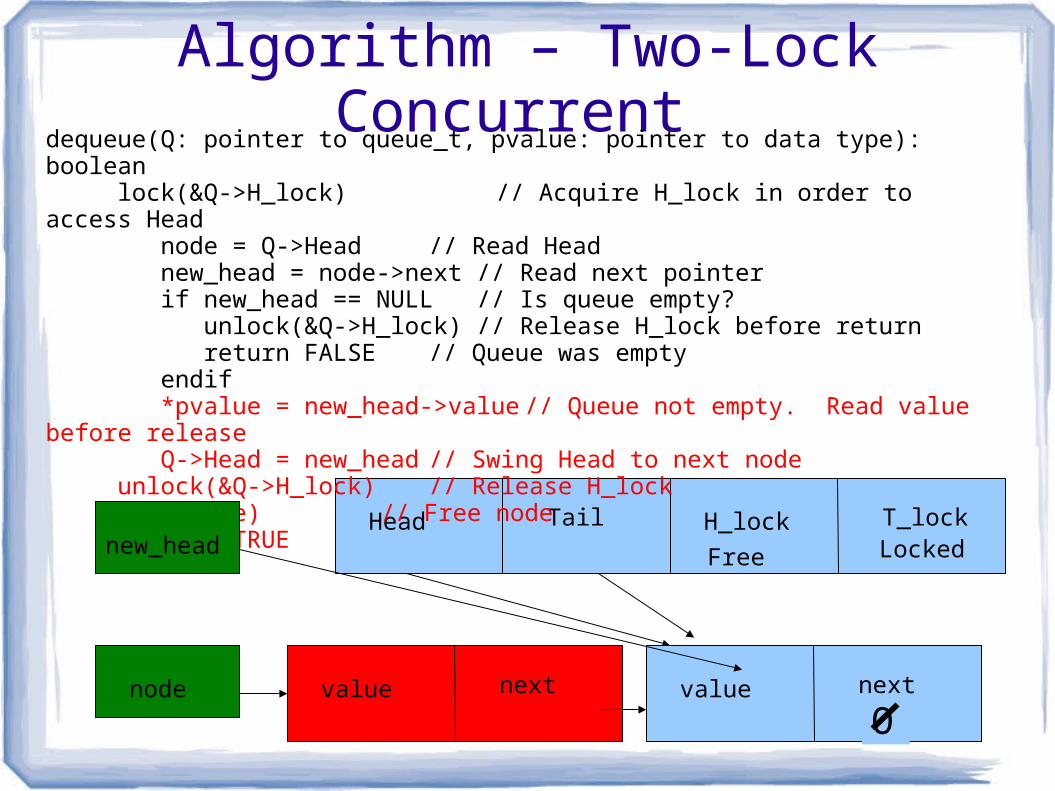
dequeue(Q: pointer to queue_t, pvalue: pointer to data type): boolean lock(&Q->H_lock) // Acquire H_lock in order to access Head node = Q->Head // Read Head new_head = node->next // Read next pointer if new_head == NULL// Is queue empty? unlock(&Q->H_lock) // Release H_lock before return return FALSE // Queue was empty endif *pvalue = new_head->value // Queue not empty. Read value before release Q->Head = new_head // Swing Head to next node unlock(&Q->H_lock) // Release H_lock free(node) // Free node return} TRUE
node
new_head

Performance ParametersNet execution time for one million
enqueue/dequeue pairs
12-processor Silicon Graphics Challenge multiprocessor
Algorithms compiled with using highest optimization level
Including many hand optimizations
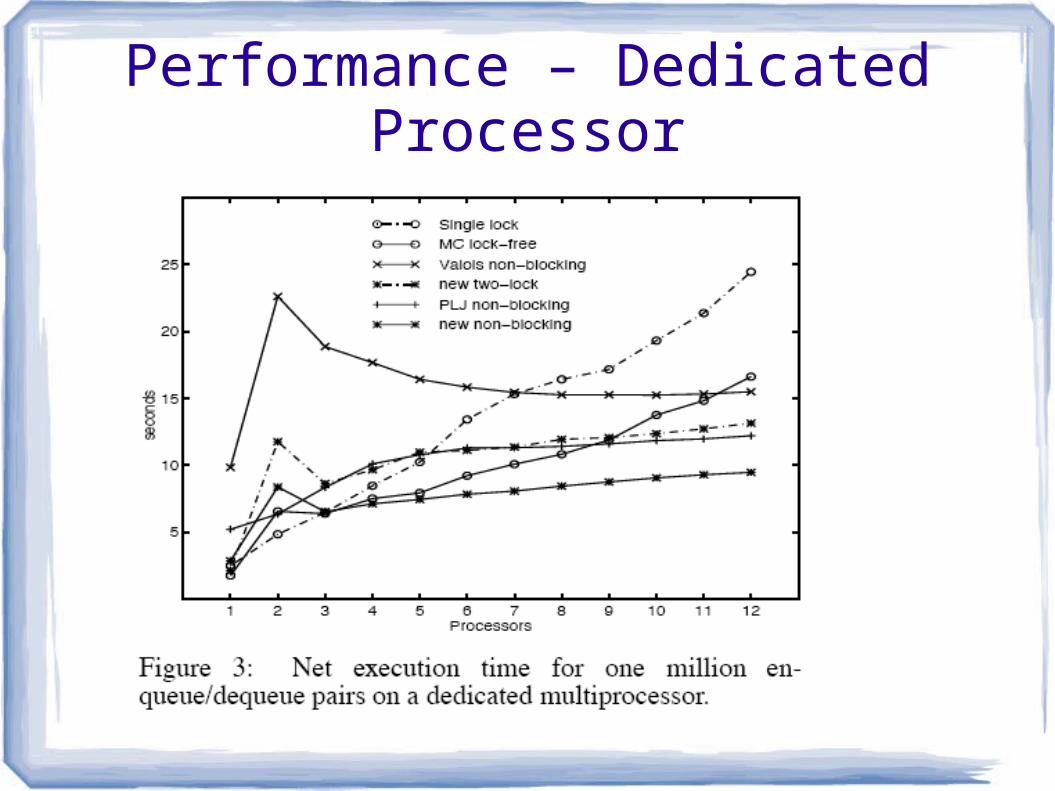
Performance – Dedicated Processor
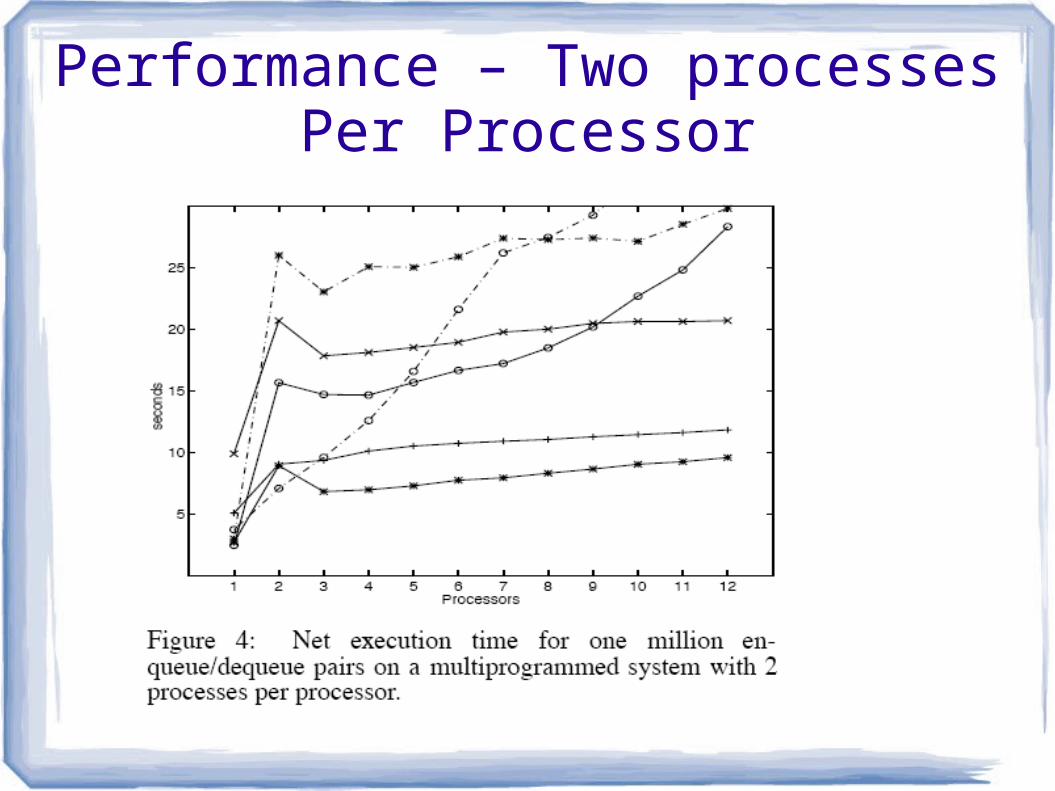
Performance – Two processes Per Processor
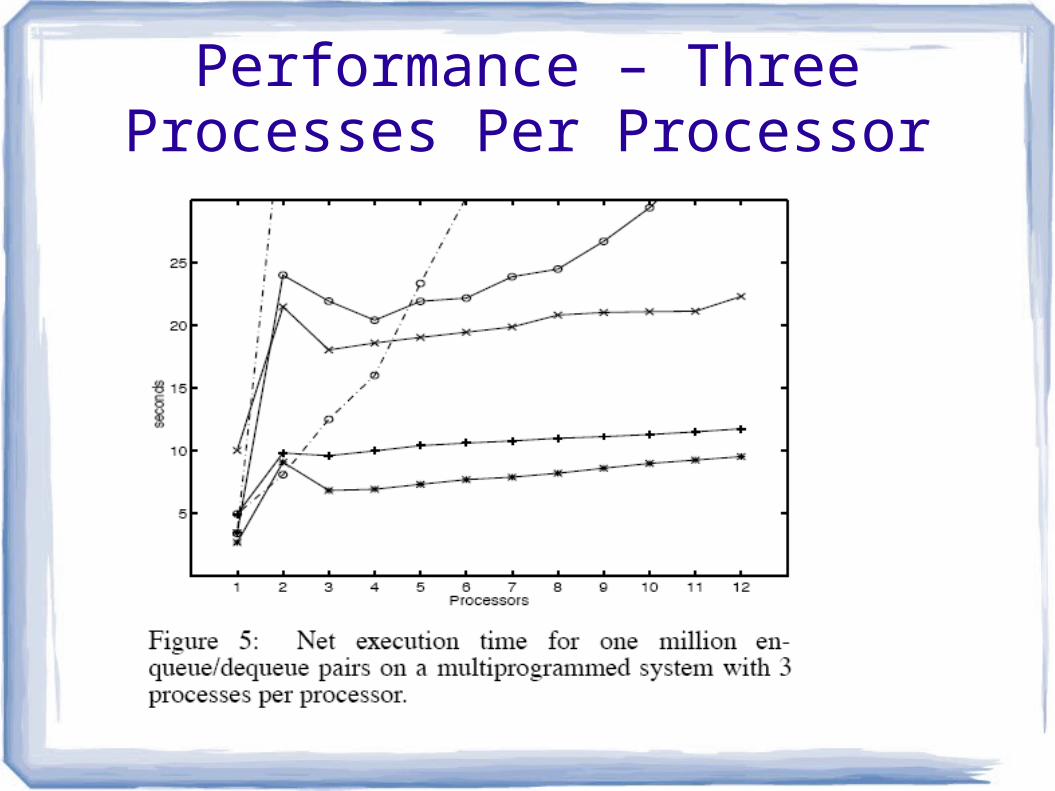
Performance – Three Processes Per Processor

ConclusionNBS clear winner for multiprocessor multiprogrammed systems
Above 5 processors, use the new non-blocking queue
If hardware only supports test-and-set use two lock queue
For two or less processors use a single lock algorithm for queues





























