Embed Size (px)
Citation preview

Pág
ina1
TALLER DE SISTEMAS OPERATIVOS
CLAVE DE LA ASIGNATURA: SCA-1026
―PORTAFOLIO DE EVIDENCIAS DEL CURSO COMPLETO‖
Profesora: VALVERDE JARQUIN REYNA
ALUMNO:
SILVA MARTINEZ LUIS ENRIQUE
AULA: I7 GRUPO: ISA 4to SEMESTRE
HORA: 12:00pm a 13:00pm
CARRERA:
OAXACA DE JUAREZ. OAX. A 03/06/2013
Índice

Pág
ina2
Índice de Temario Página Unidad I
1 Configuración de Estaciones de Trabajos. 10 1.2. Requerimientos de instalación. 10 1.3. Configuración básica. 10 1.3.1. Métodos de instalación. 10 1.3.2. Inicio de la instalación. 11 1.3.3. Del entorno del usuario. 11 1.3.4. Configuración del sistema. 11 1.3.5. Configuración de seguridad. 11 1.3.6. Configuración de red. 11 1.5. Comandos y aplicaciones 12 1.5.1 Manejo de archivos 14 1.5.2 Instalación y ejecución de aplicaciones 17
Unidad II 2 Servidores con software propietario. 19 2.1. Características del software propietario. 19 2.2. Características de instalación para servidores. 20 2.2.1. Instalación. 20 2.2.2. Configuración. 22 2.3. Administración de recursos. 23 2.3.1. Tipos de recursos. 23 2.3.2. Administración de los recursos. 24 2.3.3. Administración de cuentas de usuario y de equipo. 25 2.3.4. Administración de grupos. 27 2.3.5. Administración del acceso a recursos. 29 2.3.6. Administración de los servicios de impresión. 30 2.4. Medición y desempeño. 31 2.4.2. Herramientas de medición. 31 2.4.3. Indicadores de desempeño. 32 2.4.4. Roadmap. 33 2.5. Seguridad e integridad. 33 2.5.1. Seguridad por software. 33 2.5.2. Seguridad por hardware. 34 2.5.3. Plantillas de seguridad para proteger los equipos. 34 2.5.4. Configuración de la auditoria. 35 2.5.5. Administrar registros de seguridad. 35

Pág
ina3
Unidad III 3 Servidores con software libre. 36 3.1. Introducción Servidores con software libre. 37 3.1.1. Historia y evolución Servidores con software libre. 37 3.1.2. Estructura del sistema operativo. 40 3.2. Requerimientos de Instalación. 44 3.3.1. Métodos de instalación. 45 3.3.2. Instalación. 46 3.3.4. Niveles de ejecución. 48 3.4. Estructura de directorios. 49 3.4.1. Preparación y administración de los sistemas de archivos. 49 3.4.2. Montaje y desmontaje de dispositivos. 51 3.5. Comandos y aplicaciones. 56 3.5.1. Manejo del sistema de archivos. 56 3.5.2. Instalación y ejecución de aplicaciones. 57
Unidad IV 4.1 Introducción. 66 4.1.1. Interoperabilidad. 66 4.1.2. Neutralidad tecnológica. 68 4.2. Intercambio de archivos. 68 4.2.1. Formatos de archivos abiertos. 69 4.2.2. Formatos de archivos estándares ISO. 69 4.3. Recursos remotos. 70 4.3.1. Impresión. 70 4.3.2. Escritorio remoto. 71 4.3.3. RPC. 71 4.4. Acceso a sistemas de archivos. 71 4.4.1. Acceso a formatos de disco 72 4.4.2. Herramientas para el acceso a formatos de disco. 76 4.5. Emulación del Sistema operativo. 80 4.5.1. Ejecución de binarios de otros sistemas operativos. 80 4.5.2. Herramientas para la ejecución de binarios. 82 4.6. Virtualización. 86 4.6.2. Herramientas para la emulación de hardware. 88

Pág
ina4
Índice de imagen Pagina Unidad I
Img. 01 Manejo de archivos 14
Img. 02 Selección de archivos 14
Img. 03 Selección de archivos diferentes 15 Img. 04 Mover archivo 15 Img. 05 Copiar archivo 16
Img. 06 Eliminar archivo 16
Img. 07 Archivos y directorios 17 Unidad III
Img. 01 Permisos 57 Img. 02 Dar permiso ―Ejecutable‖ 58 Img. 03 Ejecutar desde consola 58 Img. 04 Comando ―ls‖ 59 Img. 05 Comando ―ls -l‖ 60 Img. 06 Instalación 60
Unidad IV Img. 01 Interoperabilidad Sincrónica 66 Img. 02 Interoperabilidad Asíncrona 67 Img. 03 Interoperabilidad Asíncrona 74 Img. 04 Inicio Windows 76 Img. 05 Administración de discos 76 Img. 06 Expandir volumen 77 Img. 07 Seleccionar disco 77 Img. 08 Particiones actuales 78 Img. 09 Reducir volumen 78 Img. 10 Tamaño de nuevo disco 79 Img. 11 Nueva partición 79 Img. 12 Aplicación Scanelf 85 Img. 13 Especificadores 86

Pág
ina5
Índice de Anexos
Práctica No.- 1 Probar 30 comandos (los más comunes) Img. 01 Comando ls 90 Img. 02 Comando history, pwd 90 Img. 03 Comando who, uname –m, uname –s, uname –n, uname –r, uname -v
91
Img. 04 Comando ps 91 Img. 05 Comando uptime, hwclock –show, hostname 92 Img. 06 Comando top 92 Img. 07 Comando pstree 93 Img. 08 Comando uname –a, free 93 Img. 09 Comando apt-get install tree 94 Img. 10 Comando nano 94 Img. 11 Comando df 95 Img. 12 Comando ls 95 Img. 13 Comando ls 96 Img. 14 Comando tree 96 Img. 15 Comando top -a 97 Practica No.- 2 mapa conceptual para software libre y para software con licencia
Img. 01 Software con licencia 98 Img. 02 Software libre 98 Práctica No.- 3 Probar los comandos vistos en clases. 1.- $touch prueba 100 2.- ls -l 100 3.- file prueba 100 5.- nano prueba 100 6.- wget 100 7.- ls -l 101 8.- /home/alumno ls -l 101 9.- -silva index.html 102 10.- ln –s /usr/games/gnomine enl_debil_gnomine 102 11.- ls –l | less 103 12.- ls –l | less 104 13.- ls -l 104 14.- chmod o-rwx f1 f2 f3 105 15.- chmod ugo-rx f1 105 16.- chmod u+r f1 106 17.- nano 106

Pág
ina6
18.- chmod 106 19.- chmod ug+rx,ug-w,o-rwx mensaje 106 20.- less 107 21.- chmod ug+r, ugo+wx 107 22.- ls -l 107 23.- cd /home/silva/ 108 24.- chmod a-r dir1 108 25.- ls -l 108 26.- less fich11 109 27.- less fich22 109 28.- ls dir3 109 29.- adduser cuasi 110 30.- chmod ug+rw,ug –x 110 31.- su cuasi 110 32.- less fich41 110 33.- chown cuasi fich41 111 34.- less fich41 111 35.- chgrp cuasi fich41 111 36. su 111 37.- umask a-rwx 112 38.- umask a-r 112 Práctica No.- 4 Probar los comandos vistos en clases 1.- Man: Es el paginador del manual del sistema. 113 2.- less/etc/passwd 113 3.- Man ls: 113 4.- ls –l /etc/passwd 113 5.- nano /etc/passwd 113 6.- less /ect/group 113 7.- adduser: 114 8.- cat /etc/passwd /etc/group > usuario_y_grupos_linux 114 9.- su 114 10.- sudo adduser alumno2 115 11.- su luis 115 12.- sudo usermod –a –G admin alumno 115 13.- adduser 115 14.- Reiniciar 116 15.- passwd 116 16.- cdm 116

Pág
ina7
17.- buscar un archivo con more 117 18.- more lee.txt 117 19.- Editar un archivo con edit 117 20.- help 117 21.- net user 118 22.-net localgroup 118 23.- net user cuasi /add 119 24.- net localgroup administradores 119 25.- net localgroup administradores 120 27.-net localgroup administradores ―cuasi‖ /add 120 Práctica No.- 5 DE GESTIÓ_ DE PROCESOS Paso 1.- ¿Qué es el PID de un proceso en GNU/Linux? 121 Paso 2.- ¿Qué diferencia hay entre la opción –a y la opción –x de la orden ps?
121
Paso 3. ¿Qué es el número NICE de un proceso? 121 Paso 4. Listar todos los archivos que contengan la cadena ―.jpg‖ 121 Paso 5. Ejecutar otra vez la orden anterior, pero esta vez con la prioridad más baja
122
Paso 6. Abrir otro terminal, y mientras la orden anterior se ejecuta, mediante la opción less mostrar los datos
122
Paso 7. Visualizar mediante el editor vi el archivo 122 Paso 8. En otro terminal, obtener el PID del editor vi y el PID de su proceso padre
123
Paso 9. Mediante la orden top establecer una prioridad normal al editor vi 123 Paso 10. Ejecutar el navegador WEB mozilla desde el terminar en segundo plano
123
Paso 11. Listar todos los archivos terminados en .gif del sistema de directorios
124
Paso 12. Mediante la orden jobs listar todos los trabajos en segundo plano 124 Paso 13. Mirar los procesos existentes en el sistema y lanzar un proceso 124 Paso 14. Mata el proceso ¿Qué observamos? ¿Aparecen los mismos procesos
124
Paso 15. Repetimos el paso 13 y el 14, pero ahora sólo queremos detener el proceso 13
125
Paso 16. ¿Cómo podemos hacer para que continúe el proceso en 1º plano? 125 Paso 17. Indica dos maneras para que un proceso detenido, continúe en 2º plano
125
Paso 18. Lanzar un proceso en 2º plano y obtener su PID. ¿Cuál es su número?
125
Paso 19. En un proceso lanzado en 2º plano ¿seguirá mostrando su salida en el top?
126
Paso 20. Detén y vuelve a recontinuar en 2º 126

Pág
ina8
Práctica No.- 6 Instalación de postgres 1. - root@luis-VirtualBox:~# apt-get install postgresql postgresql-client pgadmin3
127
2. - root@luis-VirtualBox:/# psql --version 128 3. - root@luis-VirtualBox:/# sudo su postgres -c "psql template1" 128 4.- root@luis-VirtualBox:/# sudo su postgres -c passwd 129 5.- root@luis-VirtualBox:/# cd /etc/postgresql/9.1/main/ 129 6.- root@luis-VirtualBox:/etc/postgresql/9.1/main# ls 129 7.- root@luis-VirtualBox:/etc/postgresql/9.1/main# nano postgresql.conf 129 8.- root@luis-VirtualBox:/etc/postgresql/9.1/main# sudo service postgresql restart
129
Practica No.- 7 Crear una base de datos (Postgres) 1.- luis@luis-VirtualBox:~$ su postgres 130 2.- postgres@luis-VirtualBox:/home/luis$ psql biblioteca 130 3.- biblioteca=# select * from usuario; 130 4.-biblioteca=# insert into usuario values(0937,'Rubén','Vicente Guerrero); 130 5.- biblioteca=# insert into usuario values(1009,'Fernando','Matamoros); 130 6.- biblioteca=# select * from usuario; 130 7.- biblioteca=# insert into usuario values(1235,'Nadia','Calle caporales 5ta); 130 8.- biblioteca=# insert into usuario values(3645,'Valeria','Armenta y López); 131 9.- biblioteca=# insert into usuario values(6775,'José','JP. García #45’); 131 10.- biblioteca=# insert into usuario values(7214,'Joaquín','Mier y Terán); 131 11.- biblioteca=# insert into usuario values(8756,'Lourdes','Crespo #496); 131 12.- biblioteca=# insert into usuario values(9571,'Lupita','And. Juchatengo); 131 13.- biblioteca=# insert into usuario values(9873,'Oscar','Av. Hidalgo); 131 14.- biblioteca=# insert into usuario values(9875,'Roberto','And. Rio); 131 15.- biblioteca=# select * from usuario; 131 16.- insertar datos en libro 132 17.-biblioteca=# insert into libro values(00001,'Cien años de soledad'); 132 18.-biblioteca=# insert into libro values(00002,'La catedral','César); 132 19.- biblioteca=# insert into libro values(00003,'El Aleph','Jorge Luis); 132 20.- biblioteca=# insert into libro values(00004,'Rayuela','Julio); 132 21.- biblioteca=# insert into libro values(00005,'Viaje al centro de la tierra'); 132 22.- biblioteca=# insert into libro values(00006,'Pedro Paramo','Juan); 132 23.-biblioteca=# insert into libro values(00007,'Moby Dick','Herman); 133 24.- biblioteca=# insert into libro values(00008,'Los Miserables','Victor); 133 25.- biblioteca=# insert into libro values(00009,'Las batallas en el de); 133 26.- biblioteca=# insert into libro values(00010,'Las aventuras de Sherlock); 133 27.- Actualizar base de datos 134

Pág
ina9
28.- biblioteca=# UPDATE libro SET id_libro = 00010 WHERE id_libro; 134 29.- biblioteca=# select * from libro; 134 30.- biblioteca=# UPDATE libro SET id_libro = 00012 WHERE id_libro; 134 31.- biblioteca=# select * from libro; 134 32.- biblioteca=# UPDATE libro SET id_libro = 00012 WHERE id_libro; 134 33.- biblioteca=# UPDATE libro SET nombre_libro = 'trueno' WHERE; 135 34.- Eliminar registros de la base de bados 135 35.- biblioteca=# DELETE FROM libro WHERE editorial = 'SM'; 135 36.- tabla modificada 135 Compilación del kernel en Ubuntu (Adaptando el procesador Corei7 y acelerar el tiempo de ejecución de los gráficos)
1.-apt-get install build-essential y kernel-package. 137 2.- comando apt-get install linux-source 137 3.- xz -dk linux-3.9.4.tar.xz 138 4.- apt-get install libncurses5-dev 138 5.- make menuconfig 139 6.- modificaremos nuestro kernel 139 7.- ―Processor family (Generic-x86-64) —>‖ y presiona [ENTER]. 140 8.- Core 2/newer Xeon 140 9.- Preemption Model (Voluntary Kernel Preemption (Desktop)) 141 10.- Preemptible Kernel (Low-Latency Desktop)‖ y presionamos [ENTER]. 141 11.- Timer frequency a 1000Hz 142 12.- Guardamos los cambios 143 13.- make 144 14.- Termina de compilar 144 15.- make modules 145 16.- make install 145 17.- Actualizamos el grub 146 18.- Reiniciamos, y ya estaremos ocupando el nuevo kernel 147

Pág
ina1
0
1 Configuración de Estaciones de Trabajos
1.2. Requerimientos de instalación Microsoft Windows 7 Ultímate
1 GHz o más rápido 32-bit (x86) o procesador de 64 bits (x64).
1 GB de RAM (32-bit) o 2 GB de RAM (64-bit)
Espacio disponible en disco rígido de 16 GB (32 bits) o 20 GB (64 bits).
Dispositivo de gráficos DirectX 9 con WDDM 1.0 o superior del controlador. Requisitos Mínimos para instalar Ubuntu Linux
Procesador Intel™ o compatible a 200 Mhz
256 Mb de RAM
Tarjeta SVGA
3 Gib de espacio libre en el disco duro Requisitos Recomendados para instalar Ubuntu Linux
Procesador Intel™ o compatible a 1 Ghz
512 Mb de RAM
Aceleradora gráfica 3D compatible con OpenGL
5 Gb de espacio libre en el disco duro
1.3. Configuración básica
1.3.1. Métodos de instalación Métodos Para Instalar Un Sistema Operativo Existen varios métodos para instalar un SO. El método seleccionado para la instalación depende del hardware del sistema, el SO elegido y los requerimientos del usuario. Existen cuatro opciones básicas para la instalación de un nuevo SO:
Instalación Limpia Una instalación limpia se realiza en un sistema nuevo o donde no exista ruta de actualización entre el SO actual y el que se está instalando. Elimina todos los datos de la partición donde se instala el SO y exige que se vuelva a instalar el software de aplicación. Un sistema de computación nuevo requiere una instalación limpia. Cuando el SO existente se ha dañado es necesario realizar una instalación limpia.
Instalación por Actualización Si se conserva la misma plataforma de SO, por lo general es posible realizar una actualización. Con una actualización se preservan las opciones de configuración del sistema, las aplicaciones y los datos. Sólo se remplazan los archivos del SO antiguo por los del nuevo.
Instalación por Arranque Múltiple Se puede instalar más de un SO en una computadora para crear un sistema de arranque múltiple. Cada SO tiene su propia partición y puede tener sus propios archivos y sus propias opciones de configuración. En el inicio, se presenta al usuario un menú donde puede seleccionar el SO que desee. Sólo se puede ejecutar un SO por vez, y el SO elegido tiene el control absoluto del hardware.
Instalación por Virtualización

Pág
ina1
1
La virtualización es una técnica que permite ejecutar varias copias de un mismo SO en el mismo grupo de hardware, o tener varios SO en un solo ordenador de esta manera podemos ejecutar varios SO a la vez gracias a la virtualización pero todo depende de las capacidades del sistema, porque cada SO virtual ocupa recursos del SO principal es decir que estos se dividen en los SO.
1.3.2. Inicio de la instalación Si el ordenador en el que queremos instalarlo dispone de una unidad óptica de DVD no tendremos más que grabar la imagen de disco descargada y arrancar el ordenador con ella. Pero, si nuestro ordenador no dispone de una DVD y si no disponemos de un lector externo, podemos utilizar un USB. Solo tenemos que hacer boteable nuestra USB.
1.3.3. Del entorno del usuario Como instalamos Windows 7, trae aplicaciones o programas que a veces no los necesitamos, los podemos quitar con el fin de aumentar el rendimiento de nuestro SO. Esto depende de cada usuario cada quien lo puede configurar de acuerdo a sus gustos o necesidades.
1.3.4. Configuración del sistema En este punto debemos de ver que nuestro SO arranque bien es decir que al iniciar sección no dilate mucho, en este caso que instalamos Windows 7 es un SO que trae muchas opciones de aplicaciones que inician al arrancar Windows para esto solo debemos de cambiar la configuración, desde msconfig. Con los demás SO no hay tanto problema.
1.3.5. Configuración de seguridad Al hablar de Windows es necesario contar con un antivirus, ya que Windows no cuenta con una seguridad como los sistema libres, esa es una de las mayores ventajas de los SO libres, Al configurar el antivirus tenemos una forma de estar un poco seguros además de que Windows cuenta con un Firewall el cual detenta las amenazas a nuestro SO.
1.3.6. Configuración de red En este caso si nosotros al instalar el Windows 7 estamos conectados a una red,
Windows automáticamente la detecta y tan solo es cuestión de seguir los pasos para
que se configure la red, de esta manera cada vez que Windows arranque se conectara a
la red de manera automática, siempre y cuando esté al alcance. Pero si no contamos
con una red al estar instalando el SO. Lo podemos hacer cuando ya estemos utilizando
Windows 7 tan solo tenemos que dar clic derecho en equipo, posterior mente clic
izquierdo a propiedades, nos mostrara una ventana en la cual agregaremos nuestra red.
Software propietario. Se refiere a cualquier programa informático en el que los
usuarios tienen limitadas las posibilidades de usarlo, modificarlo o redistribuirlo (con o
sin modificaciones), o cuyo código fuente no está disponible o el acceso a éste se
encuentra restringido.

Pág
ina1
2
1.5. Comandos y aplicaciones
1.- MS-DOS(Microsoft-disk operating system)
Sistema operativo en disco de Microsoft sistema operativo de un solo usuario para PC
de Microsoft, es casi la versión idéntica de IBM, que se llama *Dos* genéricamente. 2.- FORMAT (comando externo).
Sistema operativo de Microsoft por encargo de IBM, para equipar a los
ordenadores PC que había desarrollado. Format: comando del sistema operativo MS-DOS cuya misión es formatear las
unidades de almacenamiento (discos duros y disquetes).
Formatear es preparar un disco o disquete para trabajar o almacenar datos. Este
tiene como objetivo dar formato al disco del driver. Este crea un nuevo directorio raíz
y tabla de asignación de archivos para el disco. También puede verificar si hay
factores defectuosos en el disco y podrá borrar toda la información que este
contenga. 3.- CLS (comando interno)
Comando del sistema operativo MS-DOS cuya misión es limpiar la pantalla. Una
vez limpia la pantalla coloca el cursor en la parte superior izquierda de la misma. 4.- MD
Crea un directorio 5.- Comandos Internos
Son aquellos comandos cuyas instrucciones son cargadas a la memoria RAM.
Estos comandos no necesitan la presencia del disco de sistema operativo. Entre
ellos encontramos: COPY CLS
DEL O ERASE DIR
TYPE DATE
RENAME MD
TIME VER

Pág
ina1
3
6.- Comandos Externos
Estos comandos necesitan mucha capacidad de memoria para mantenerse dentro de
ella al mismo tiempo, por lo tanto son grabados en el disco, y podemos asesarlos
cuando sea necesario. Son llamados externos porque estos están grabados fuera de
la memoria RAM. Entre estos están: CLRDSK DISP COMP
DELTREE TREE
DOSKEY RESTORE
FORMAT DISK COPY
ATTRIB LAVEL 7.- VOL (comando interno)
Tiene como objetivo mostrar el volumen del disco y su número de serie si existen.
8.- DOS KEY (comando externo)
Nos permite mantener residente en memoria RAM las órdenes que han sido
ejecutadas en el punto indicativo. 9.- PRINT
Comando que nos permite imprimir varios ficheros de textos sucesivamente. 10.- RESTORE
Este comando restaura los archivos que se hagan hecho copia de seguridad 11.- BACK SLASH
Comando que pasa de un directorio a otro principal. 12.- CONFIG. SYS
Copia los archivos del sistema y el interpretador de comandos al disco que
especifique. 13.- DIR
Sirve para ver los archivos, directorios y subdirectorios que se encuentran en el
disco duro o en un disquete.

Pág
ina1
4
14.-F DISK
Permite crear varias peticiones en un disco duro y seleccionar, cuál de ellas será la partición, es simplemente una división del disco duro que el MS-DOS trata como un área individual de acceso.
15.- DATE (comando interno)
Permite modificar y visualizar la fecha del sistema. 16.- DELTREE (comando externo)
Usado para borrar un directorio raíz no importa que contenga subdirectorios con
todos sus contenidos. 17.- RD (rmdir)
Remueve o borra directorios, para borrar el directorio debe estar en blanco.
1.5.1 Manejo de archivos
Formas para seleccionar los archivos: Selección simple de un archivo o carpeta: para seleccionar un elemento, ya sea una
carpeta o un archivo, basta con hacer clic sobre éste y el elemento en
cuestión quedará seleccionado, apareciendo resaltado de este modo:
Img. 01 Manejo de archivos
Selección de archivos o carpetas consecutivos: para seleccionar varios archivos o carpetas consecutivos, haremos un clic en el primer elemento y, manteniendo pulsada la tecla <Shift>, haremos clic en el último elemento. De esta forma, el conjunto de elementos queda seleccionado.
Img. 02 Selección de archivos

Pág
ina1
5
Selección de archivos o carpetas no consecutivos: para seleccionar archivos o carpetas no consecutivos, primero haremos un clic sobre el primer elemento y, manteniendo pulsada la tecla <Control>, iremos haciendo clic sobre cada elemento a seleccionar. Cuando el último elemento haya sido seleccionado, soltaremos la tecla <Control>.
Img. 03 Selección de archivos diferentes
Seleccionar todo el contenido: Podemos seleccionar todo el contenido de una carpeta pulsando la combinación de las letras <Control + E>.
Para mover o cortar: uno o varios archivos de una carpeta a otra distinta primero seleccionamos la carpeta o el archivo y lo arrastramos hacia donde lo queremos mover.
Img. 04 Mover archivo

Pág
ina1
6
Copiar: Si queremos copiar un archivo o una carpeta tenemos que seleccionar el archivo o la carpeta y presionar la tecla <Control> y arrastrar el archivo adonde lo queremos copiar.
Img. 05 Copiar archivo
Borrar o Eliminar archivos o carpetas: para eliminar archivos o carpetas podemos utilizar la tecla <suprimir>.
Img. 06 Eliminar archivo

Pág
ina1
7
1.5.2 Instalación y ejecución de aplicaciones La instalación de aplicaciones es el nombre que recibe el proceso mediante el cual el software queda en condiciones de ser utilizado. Este es el proceso que se realiza, es los programas actuales, con la ayuda de asistentes y/o programas instaladores que vuelven transparentes muchas de las acciones para los usuarios.
Durante el proceso de instalación se realizan, en general, las siguientes operaciones:
1. Copia de los archivos ejecutables, archivos auxiliares y bibliotecas del
programa al disco duro de la computadora. 2. Modificación de los archivos config.sys y autoexec.bat, archivos de
inicialización del sistema operativo, en algunos casos.
3. Inscripción en el win.ini y/o system.ini cuando se trata de programas que funcionan bajo Windows.
Manejo de archivos en Linux ARCHIVOS Y DIRECTORIOS El sistema de archivos de Linux está organizado en archivos y directorios. Un archivo es una colección de datos que se almacena en un medio físico y a la cual se le asigna un nombre. Los archivos, a su vez, están agrupados en conjuntos llamados directorios. Un directorio puede tener subdirectorios, formándose así una estructura jerárquica con la forma de un árbol invertido. El directorio inicial de esa jerarquía se denomina directorio raíz y se simboliza con una barra de división (/). El sistema de archivos de un sistema Linux típico está formado por los siguientes directorios bajo el directorio raíz:
Img. 07 Archivos y directorios

Pág
ina1
8
Ejecutar comando/aplicación de consola como superusuario
En ocasiones hay que ejecutar algún comando (o un programa) que necesita derechos de administrador (o superusuario) para poder realizar una acción. Por ejemplo si queremos renombrar el /etc/X11/inicio.conf o para instalar un programa. Si intentamos usar directamente el comando ―cp‖ o ―aptitude install‖ nos dirá que no ha podido hacer la acción y que tenemos ―Permiso denegado―.
En los sistemas Ubuntu tenemos un comando que nos permite ejecutar aplicaciones en modo administrador, tan sólo hay que precederlo con ―sudo―. Así pues para hacer una copia de un fichero en un directorio donde no tenemos acceso y para instalar una aplicación tendríamos que hacerlo así:
$ sudo cp /etc/X11/inicio.conf /etc/X11/inicio.conf.backup $ sudo aptitude install firefox
Nos pedirá la contraseña y tras escribirla hará lo que le hemos pedido.

Pág
ina1
9
2 Servidores con software propietario
2.1. Características del software propietario El software propietario, o no software libre, es un software cuya duplicación, alteración o uso está limitado, lo que significa que el software que no cumpla con los criterios de la definición el software libre. Esto toma la forma de limitaciones legales, hardware o software en uso, divulgación, modificación o evolución.
Características: -Facilidad de adquisición (puede venir preinstalado con la compra del pc, o encontrarlo fácilmente en las tiendas). - Existencia de programas diseñados específicamente para desarrollar una tarea. - Las empresas que desarrollan este tipo de software son por lo general grandes y pueden dedicar muchos recursos, sobretodo económicos, en el desarrollo e investigación. - Interfaces gráficas mejor diseñadas. - Más compatibilidad en el terreno de multimedia y juegos. - Mayor compatibilidad con el hardware. - No existen aplicaciones para todas las plataformas (Windows y Mac OS). - Imposibilidad de copia. - Imposibilidad de modifación. - Restricciones en el uso (marcadas por la licencia). - Imposibilidad de redistribución. - Por lo general suelen ser menos seguras. - El coste de las aplicaciones es mayor. - El soporte de la aplicación es exclusivo del propietario. - El usuario que adquiere software propietario depende al 100% de la empresa propietaria.

Pág
ina2
0
2.2. Características de instalación para servidores
2.2.1. Instalación
Requisitos: Procesador Mínimo: 1GHZ en 32bits(x86), 1.4GHZ en 64bits(x64) Recomendado: 2GHZ o más
Memoria Mínimo: 512MB Recomendado: 2 GB o más Máximo (porque todo tiene tope): en 32bit de 4 a 64GB, en 64 bit de 32gb a 2 TB. Disco Duro Mínimo: 10GB Recomendado: 40GB o más 1) Revisar si las aplicaciones a correr en el servidor son compatibles Para hacer esta revisión puede usar el Microsoft Application Compatibility Toolkit.
2) Desconectar los UPS de la administración Esto es en casi de que tenga UPS conectados al servidor por puerto serial. Si es así, desconectarlos antes de iniciar la instalación.
3) Hacer BackUp El BackUp debe incluir todos los documentos, bases de datos, etc, así como las configuraciones necesarias para que el servidor funcione una vez instalado. Estas informaciones de configuración son importantes, especialmente la de aquellos servidores que proveen infraestructura de red, como DHCP. Cuando haga el backup, asegúrese de incluir las particiones de boteo y de sistema, además del System State. 4) Deshabilitar el antivirus El software antivirus puede interferir con la instalación. Por ejemplo, al antivirus escanear cada archivo que está copiando la instalación, esta se hace más lenta.
5) Ejecute el Windows Memory Diagnostic Tool Este se ejecute para revisar y probar la memoria RAM del servidor.
6) Tener disponible los drivers de los discos Si está usando unidades de discos de alta capacidad, probablemente necesitara durante la instalación proveer los drivers de estos equipos. Ponga estos drivers en un CD, DVD o USB para insertarlos en la instalación y ubíquelos en la forma siguiente: amd64 para computadoras 64bits, i386 para computadoras de 32 bits, o ia64 para computadoras de procesadores Itanium.

Pág
ina2
1
7) Asegúrate de que tu Windows Firewall está encendido por defecto Debido a que las aplicaciones del servidor pueden recibir solicitudes de conexiones no deseadas, es mejor activar el Firewall y así se evita que se interrumpa la instalación, además de que solo las aplicaciones que se desean se conecten lo harán. Para ello, verifique antes de la instalación que puertos usan tales aplicaciones para que las especifique en las excepciones del firewall.
8) Prepare su ambiente de Active Directory para la actualización de Windows Server 2008 Antes de añadir un controlador de dominio que corra en Windows Server 2008 en un ambiente de Active Directory que corra en Windows 2000 Server o Windows Server 2003, necesita actualizar el ambiente. Para ello debe seguir los siguientes pasos:
Para preparar una Foresta:
a) Inicie sesión con un usuario administrador de dominio o Enterprise Admin.
b) Desde el DVD de instalación de Windows Server 2008 copie el folder\sources\adprep a $\sysvol\
c) Abra una ventana de Command Prompt, vaya al directorio$\sysvol\adrep\ y ejecute "adrep /forestprep"
d) Si está instalando un Controlador de Dominio "Red Only" (RODC), ejecute "adprep /rodcprep"
e) Deje que se apliquen todos los cambios antes de pasar a la instalación. Para reparar un Dominio
a) Inicie sesión con un usuario administrador de dominio.
b) Desde el DVD de instalación de Windows Server 2008 copie el older\sources\adprep a $\sysvol\
c) Abra una ventana de Command Prompt, vaya al directorio$\sysvol\adprep\ y ejecute "adrep /domainprep /gpprep"
Después de estos pasos, se pueden añadir más controladores de dominio que corran WS2008 a los dominios que ya se han preparado.
1. E instalamos: 2. Iniciamos desde cd/dvd 3. Seleccionamos el idioma y el teclado 4. Introducimos la clave 5. Seleccionamos la versión a instalar 6. Seguimos con los siguientes pasos estándar… Hasta terminar con la instalación

Pág
ina2
2
2.2.2. Configuración Una vez instalado el sistema operativo y en la ventana de comandos del escritorio (una vez cambiada la contraseña del administrador) empezaremos con la configuración del equipo. 1. Cambiar el nombre de equipo: C:\windows\system32>netdomrenamecomputer%computername%/newname:<Nombre> 2. Cambiar el grupo de trabajo: C:\windows\system32>Wmiccomputersystemwherename="%computername%" call joindomainorworkgroup name="<Nombre>‖ 3. Operaciones en Dominio: a. Unir el equipo al dominio: C:\windows\system32> netdomjoin%computername%/domain:<Dominio> /userd:<Usuario> /password:* b. Quitar el equipo del dominio: C:\windows\system32> netdomremove%computername%/domain:<Dominio> /userd:<Usuario> /password:* 4. Configuración de fecha y hora: C:\windows\system32 > control timedate.cpl 5. Configuración regional de idioma: C:\windows\system32 > control intl.cpl 6. Configuración de usuarios: a. Crear un usuario local [o en dominio]: C:\windows\system32 > net user <nombre> * /add [/domain] b. Crear un grupo local [o en dominio]: C:\windows\system32 > net localgroup <nombre> /add [/domain] c. Agregar usuarios locales [o en dominio] a un grupo: C:\windows\system32 > net localgroup <nombre> /add [/domain] <user1> <user2> <grupo1> Para eliminar usuarios, grupos o usuarios de grupos son los mismos comandos pero con el modificador /del en vez de /add. 7. Configuración de red: a. Identificar el interfaz para configurar: C:\windows\system32 >netsh interface ipv4 show interfaces
b. Configurar el direccionamiento IP: C:\windows\system32 >netsh interface ipv4 set address name=<id> source=static <IP> <MASK> <Gateway> c. Configurar los servidores DNS: C:\windows\system32>netshinterfaceipv4adddnsservername=<id>address=<IP> index=1 d. Configurar Proxy: C:\windows\system32>netshwinhttpsetproxy<DireccionProxy>bypasslist=‖<local>‖
8. Actualizaciones automáticas: a. Habilitar: C:\windows\system32 >cscript scregedit.wsf /AU 4 b. Deshabilitar:

Pág
ina2
3
C:\windows\system32 >cscript scregedit.wsf /AU 1 9. Activar el sistema operativo: a. Introducir el número de serie: C:\windows\system32 >cscript slmgr.vbs /ipk XXXXX-XXXXX-XXXXX-XXXXX-XXXXX b. Activar a través de internet: C:\windows\system32 > cscript slmgr.vbs /ato 10. Habilitar escritorio remoto: C:\windows\system32 >cscript scregedit.wsf /ar 0 a. Habilitar autenticación a nivel de red para conectar por escritorio remoto: C:\windows\system32 >cscript scregedit.wsf /cs 1 11. Administración de roles y características: a. Generar un listado: C:\windows\system32 >oclist > listado.txt
b. Buscar algo en concreto: C:\windows\system32 >oclist | find ‗dns‘ c. Instalar un rol: C:\windows\system32 > start /w ocsetup NombreDelPaquete
2.3. Administración de recursos 2.3.1- Tipos de recursos Los Servicios de Internet Information Server (IIS) se pueden instalar en un clúster de servidores. Para obtener más información sobre cómo se ejecuta IIS en un clúster de servidores, vea la documentación en pantalla de IIS. Puede instalar Message Queue Server en un clúster de servidores. Para obtener más información acerca de los tipos de recurso de Message Queue Server y Desencadenadores de Message Queue Server, y acerca de cómo se ejecutan en un clúster de servidores, vea Microsoft Message Queue Server. Puede instalar el Coordinador de transacciones distribuidas (DTC, Distributed Transaction Coordinator) en un clúster de servidores. Para obtener más información acerca del tipo de recurso del Coordinador de transacciones distribuidas y acerca de cómo se ejecuta en un clúster de servidores, vea Coordinador de transacciones distribuidas. Esta sección también trata los temas y tipos de recursos siguientes:
Tipo de recurso Disco físico Tipos de recursos Servicio DHCP y Servicio WINS Tipo de recurso Cola de impresión Tipo de recurso compartido de archivos Tipo de recurso Dirección de Protocolo Internet (IP) Tipo de recurso Quórum local Tipo de recurso Conjunto de nodos mayoritario Tipo de recurso Nombre de red Tipo de recurso Aplicación genérica Tipo de recurso Secuencia de comandos genérica Tipo de recurso Servicio genérico Tipo de recurso del Servicio de instantáneas de volumen

Pág
ina2
4
2.3.2- Administración de recursos Administración del filtrado de archivos. Define reglas de filtrado que supervisan o bloquean los intentos de guardar determinados tipos de archivos en un volumen o un árbol de carpetas por parte de los usuarios. Permite crear y aplicar plantillas de filtrado con exclusiones de archivos estándar. Administración de informes de almacenamiento. Genera informes integrados que permiten llevar un seguimiento del uso de cuotas, de las actividades de filtrado de archivos y de los patrones de uso del almacenamiento. También puede aplicar directivas de cuotas y de filtrado de archivos cuando se aprovisiona una carpeta compartida o por medio de una interfaz de línea de comandos. El Administrador de recursos del sistema de Windows sólo administra los recursos del procesador cuando la carga combinada del procesador es superior al 70 por ciento. Puede usar el Administrador de recursos del sistema de Windows para:
Administrar los recursos del sistema (procesador y memoria) con directivas preconfiguradas, o crear directivas personalizadas que asignen recursos por procesos, por usuarios, por sesiones de Servicios de Escritorio remoto o por grupos de aplicaciones de Internet Information Services (IIS).
Usar reglas de calendario para aplicar diferentes directivas en momentos diferentes, sin intervención manual o reconfiguración.
Seleccionar automáticamente directivas de recursos que se basen en propiedades del servidor o eventos (como, por ejemplo, eventos o condiciones de clúster), o en los cambios en la memoria física instalada o el número de procesadores.
Recopilar los datos de uso de los recursos localmente o en una base de datos SQL personalizada. Los datos de uso de los recursos de varios servidores se pueden consolidar en un solo equipo que ejecute el Administrador de recursos del sistema de Windows.
Crear un grupo de equipos para facilitar la organización de los servidores Host de sesión de Escritorio remoto (Host de sesión de RD) que desee administrar. Las directivas de un grupo entero de equipos se pueden exportar o modificar fácilmente. Ventajas de la administración de recursos Puesto que Windows Server 2008 R2 está diseñado para ofrecer el máximo posible de recursos a las tareas que no dependen del sistema operativo, un servidor que ejecuta un solo rol normalmente no requiere la administración de recursos. No obstante, cuando hay instalados varios servicios y aplicaciones en un solo servidor, éstos no tienen en cuenta los demás procesos. Normalmente, una aplicación o un servicio no administrados utilizan todos los recursos disponibles para completar una tarea. Por lo tanto, es importante utilizar una herramienta como el Administrador de recursos del sistema de Windows para administrar los recursos del sistema en los servidores multipropósito. La utilización del Administrador de recursos del sistema de Windows supone dos ventajas clave:

Pág
ina2
5
Se pueden ejecutar más servicios en un solo servidor porque se puede mejorar la disponibilidad de los servicios mediante recursos administrados de forma dinámica.
Los usuarios o administradores del sistema de máxima prioridad pueden obtener acceso al sistema incluso en los momentos de máxima carga de los recursos. Métodos de la administración de recursos El Administrador de recursos del sistema de Windows incluye cinco directivas de administración de recursos integradas que se pueden usar para implementar rápidamente la administración. Además, se pueden crear directivas de administración de recursos personalizadas adaptadas a sus necesidades. Directivas de administración de recursos integradas Para habilitar directivas de administración de recursos integradas, seleccione el tipo de directiva que se desea utilizar. No es necesario realizar ninguna otra configuración.
2.3.3. Administración de cuentas de usuario y de equipo
Las cuentas de usuario y de equipo (así como los grupos) se denominan también principales de seguridad. Los principales de seguridad son objetos de directorio a los que se asigna automáticamente identificadores de seguridad (SID), que se utilizan para tener acceso a los recursos del dominio. Una cuenta de usuario o de equipo se utiliza para: Autenticar la identidad de un usuario o equipo. Una cuenta de usuario permite que un usuario inicie una sesión en equipos y dominios con una identidad que puede ser autenticada por el dominio. Para obtener información acerca de la autenticación, vea Control de acceso en Active Directory. Cada usuario que se conecta a la red debe tener su propia cuenta de usuario y su propia contraseña única. Para aumentar la seguridad, debe evitar que varios usuarios compartan una misma cuenta. Autorizar o denegar el acceso a los recursos del dominio. Después de que el usuario haya sido autenticado, se le autoriza o deniega el acceso a los recursos del dominio según los permisos explícitos asignados a dicho usuario en el recurso. Para obtener más información, vea Información de seguridad para Active Directory. Administrar otros principales de seguridad. Active Directory crea un objeto de principal de seguridad externo en el dominio local para representar cada principal de seguridad de un dominio de confianza externo. Para obtener más información acerca de los principales de seguridad externos, vea Cuándo se debe crear una confianza externa.
Proteger cuentas de usuarios Si un administrador de red no modifica ni deshabilita los derechos y permisos de las cuentas integradas, cualquier usuario o servicio malintencionado podría usarlos para iniciar una sesión, de manera ilegal, en un dominio mediante la identidad Administrador o Invitado. Una práctica recomendable de seguridad para proteger estas cuentas consiste en cambiar sus nombres o deshabilitarlas. Dado que una cuenta de usuario con el nombre cambiado conserva su identificador de seguridad (SID), conserva también todas las demás propiedades, como su descripción, la contraseña, la pertenencia al grupo, el perfil de usuario, la información de cuenta y todos los permisos y derechos de usuario asignados.

Pág
ina2
6
Para obtener la seguridad que proporciona la autenticación y autorización de usuarios, cree una cuenta de usuario individual para cada usuario que participe en la red, mediante Usuarios y equipos de Active Directory. Cada cuenta de usuario, incluidas las cuentas Administrador e Invitado, puede agregarse a un grupo para controlar los derechos y permisos asignados a la cuenta. Al usar las cuentas y grupos apropiados para la red se garantiza que los usuarios que se conectan a una red se puedan identificar y sólo puedan tener acceso a los recursos permitidos. Puede contribuir a defender su dominio contra posibles intrusos exigiendo contraseñas seguras e implementando una directiva de bloqueo de cuentas. Las contraseñas seguras reducen el riesgo de suposiciones inteligentes y ataques de diccionario contra las contraseñas. Para obtener más información, vea Contraseñas seguras y Prácticas recomendadas de contraseñas para contraseñas. Una directiva de bloqueo de cuentas reduce la posibilidad de que un intruso ponga en peligro el dominio mediante repetidos intentos de inicio de sesión. Para ello, la directiva de bloqueo de cuentas determina cuántos intentos de inicio de sesión incorrectos puede tener una cuenta de usuario antes de ser deshabilitada. Para obtener más información, vea Aplicar o modificar la directiva de bloqueo de cuentas.

Pág
ina2
7
2.3.4. Administración de grupos
Un grupo es una colección de cuentas de usuario. Los grupos simplifican la administración permitiendo asignar los permisos y derechos a un grupo de usuarios en lugar de tener que asignar los permisos a cada cuenta de usuario individual. Los usuarios pueden ser miembros de más de un grupo. Cuando se asignan permisos, se da a los usuarios la capacidad de acceder a recursos específicos y se define el tipo de acceso que tienen. Por ejemplo, si varios usuarios necesitaran leer el mismo archivo, se añadirían sus cuentas de usuario a un grupo. Entonces se dará a ese grupo el permiso de leer el archivo. Los derechos permiten a los usuarios realizar tareas de sistema, tales como cambiar la hora en un equipo, realizar copias de seguridad o restaurar archivos, o iniciar una sesión localmente. Además de las cuentas de usuario se pueden añadir contactos, equipos y otros grupos a un grupo. Cuando se añaden equipos a un grupo se puede simplificar el proceso de conceder una tarea de sistema para que un equipo acceda a un recurso de otro equipo. Antes de todo, vamos a ver los diferentes tipos y ámbitos de los grupos, que se seleccionará en la ventana de creación de un grupo.
Los grupos de seguridad tienen habilitada esta característica y por tanto pueden utilizarse en la asignación de derechos de usuario y en los permisos del recurso, o, en la aplicación de directivas de grupo basadas en AD o directivas de equipo. El uso de un grupo en lugar de usuarios de forma individual simplifica mucho la administración. Los grupos pueden crearse para recursos o tareas en particular, y cuando se efectúan cambios en la lista de usuarios que necesitan acceso, sólo debe modificarse la pertenencia de grupo para reflejar los cambios en cada recurso que utiliza este grupo.
Para llevar a cabo tareas administrativas, los grupos de seguridad pueden definirse dentro de distintos niveles de responsabilidad. La granularidad que podemos aplicar es vasta, de hecho una estructura de grupos funcional es una de las maneras de simplificar la administración de la empresa. Los grupos de seguridad también pueden usarse con propósitos de correo electrónico, lo que significa que aúnan ambos propósitos. Además del tipo, los grupos disponen de un ámbito a seleccionar. El ámbito, simplemente, marca los límites de quién puede ser miembro, y dónde puede utilizarse el grupo. Sólo los grupos de seguridad pueden usarse para delegar control y asignar acceso a recursos. Una clasificación teniendo en cuenta el ámbito quedaría:
Grupos locales de dominio. Grupos globales. Grupos universales.

Pág
ina2
8
Tipos de grupos Windows 2008 Server incluye dos tipos de grupos: seguridad y distribución. Esto es debido a que se necesitan grupos a los cuales se les va a dar perisologías sobre un recurso del dominio o grupos que solo van a ser utilizados como listas de correo. Grupos de seguridad El sistema operativo Windows 2000 utiliza solamente grupos de seguridad, los cuales se utilizan para asignar permisos para acceder a los recursos. Los programas diseñados para buscar en el almacén de Active Directory también pueden utilizar los grupos de seguridad por motivos no relacionados con la seguridad, tales como mandar mensajes de correo electrónico a una serie de usuarios al mismo tiempo. Por ello, un grupo de seguridad también tiene capacidades de un grupo de distribución. Grupos de distribución Las aplicaciones utilizan grupos de distribución como listas para funciones no relacionadas con la seguridad. Se utilizan grupos de distribución cuando la única función del grupo no está relacionada con la seguridad, tal como mandar mensajes de correo electrónico a un grupo de usuarios al mismo tiempo. No se pueden utilizar grupos de distribución para asignar permisos. Ámbito de los grupos Cuando se crea un grupo se debe seleccionar un tipo de grupo y un ámbito del grupo. Los ámbitos de los grupos permiten utilizar los grupos de forma diferente para asignar permisos. El ámbito de un grupo determina dónde se puede utilizar el grupo en la red. Los tres ámbitos de los grupos son dominio local, global y universal. Grupos locales de dominio Los grupos locales de dominio se utilizan frecuentemente para asignar permisos a los recursos Grupos Globales Los grupos globales se utilizan frecuentemente para organizar los usuarios que comparten requisitos de acceso similares a la red. Grupos Universales Los grupos universales se utilizan para asignar permisos a recursos relacionados en varios dominios.

Pág
ina2
9
2.3.5. Administración del acceso a recursos Como administrador del sistema, usted puede controlar y supervisar la actividad del sistema. Puede definir límites sobre quién puede utilizar determinados recursos. Puede registrar el uso de recursos y supervisar quién los está utilizando. También puede configurar los sistemas para minimizar el uso indebido de los recursos. Limitación y supervisión del superusuario El sistema requiere una contraseña root para el acceso del superusuario. En la configuración predeterminada, un usuario no puede iniciar sesión de manera remota en un sistema como root. Al iniciar sesión de manera remota, el usuario debe utilizar el nombre de usuario y, luego, el comando su para convertirse en root. Puede supervisar quién ha utilizado el comando su, en especial, aquellos usuarios que están intentando obtener acceso de superusuario. Para conocer los procedimientos para supervisar al superusuario y limitar el acceso al superusuario, consulte Supervisión y restricción de superusuario (mapa de tareas). Configuración del control de acceso basado en roles para reemplazar al superusuario El control de acceso basado en roles (RBAC) está diseñado para limitar las capacidades del superusuario. El superusuario (usuario root) tiene acceso a todos los recursos del sistema. Con RBAC, puede reemplazar root con un conjunto de roles con poderes discretos. Por ejemplo, puede configurar un rol para manejar la creación de cuentas de usuario y otro rol para manejar la modificación de archivos del sistema. Una vez que haya establecido un rol para manejar una función o un conjunto de funciones, puede eliminar esas funciones de las capacidades de root. Cada rol requiere que un usuario conocido inicie sesión con su nombre de usuario y contraseña. Después de iniciar sesión, el usuario asume el rol con una contraseña de rol específica. Como consecuencia, alguien que se entera de la contraseña root tiene una capacidad limitada para dañar el sistema. Para obtener más información sobre RBAC, consulte Control de acceso basado en roles (descripción general). Prevención del uso indebido involuntario de los recursos del equipo puede prevenir que los usuarios y que usted realicen errores involuntarios de las siguientes formas: Puede evitar ejecutar un caballo de Troya si configura correctamente la variable
PATH. Puede asignar un shell restringido a los usuarios. Un shell restringido previene los
errores del usuario al guiar a los usuarios a las partes del sistema que necesitan para su trabajo. De hecho, mediante una configuración cuidadosa, usted puede asegurarse de que los usuarios sólo accedan a las partes del sistema que los ayudan a trabajar de manera eficiente.
Puede establecer permisos restrictivos para los archivos a los que los usuarios no necesitan acceder.

Pág
ina3
0
2.3.6. Administración de los servicios de impresión
Windows Server® 2008 R2, se puede compartir impresoras en una red y centralizar las tareas de administración del servidor de impresión y de las impresoras de red mediante el complemento Administración de impresión de Microsoft Management Console (MMC). Administración de impresión le ayuda a supervisar las colas de impresión y recibir notificaciones cuando las colas de impresión interrumpen el procesamiento de los trabajos de impresión. Además permite migrar los servidores de impresión e implementar conexiones de impresora con directivas de grupo. Herramientas para administrar un servidor de impresión Hay dos herramientas principales que se pueden usar para administrar un servidor de impresión de Windows:
1. Administrador del servidor 2. Administración de impresión
En Windows Server 2008 R2, se puede usar el Administrador del servidor para instalar el rol de servidor y los servicios de rol de Servicios de impresión y documentos. El Administrador del servidor incluye además una instancia del complemento Administración de impresión que se puede usar para administrar el servidor local. Administración de impresión proporciona detalles actualizados sobre el estado de las impresoras y los servidores de impresión de la red. Puede usar Administración de impresión para instalar conexiones de impresora en un grupo de equipos cliente de forma simultánea y para supervisar de forma remota las colas de impresión. Administración de impresión facilita la búsqueda de impresoras con errores mediante filtros. Además, se pueden enviar notificaciones por correo electrónico o ejecutar scripts cuando una impresora o un servidor de impresión precisen atención. Administración de impresión puede mostrar más datos (como los niveles de tóner o de papel) en las impresoras que incluyen una interfaz de administración basada en web.
El Gestor de Impresión supone para los administradores un ahorro de tiempo importante a la hora de instalar impresoras en equipos cliente, así como al administrarlas y supervisarlas. En vez de tener que instalar y configurar conexiones de impresora en equipos individuales, el Gestor de Impresión se puede usar con directivas de grupo para agregar automáticamente conexiones de impresora a la carpeta Impresoras y faxes de un equipo cliente.
Esta es una manera eficaz y que ahorra tiempo cuando se agregan impresoras para muchos usuarios que requieren acceso a la misma impresora, como por ejemplo usuarios en el mismo departamento o todos los usuarios en la ubicación de una sucursal.

Pág
ina3
1
2.4. Medición y desempeño 2.4.1-Desempeño
El sistema está optimizado para que las búsquedas tengan una respuesta muy rápida (si el servidor y la red lo permiten). El interfaz está optimizado para facilitar y hacer más eficiente la labor de los bibliotecarios. Por ejemplo, para devolución de libros se requiere un solo paso. Para prestar un libro se requieren dos pasos: ingresar el código del usuario e ingresar el número del ítem a prestar (o código de barras). Puede usar el Monitor de rendimiento de Windows para examinar el modo en el que los programas que ejecuta afectan al rendimiento del equipo, tanto en tiempo real como mediante la recopilación de datos de registro para su análisis posterior. El Monitor de rendimiento de Windows usa contadores de rendimiento, datos de seguimiento de eventos e información de configuración, que se pueden combinar en conjuntos de recopiladores de datos.
2.4.2-Herramientas de medición El Monitor de confiabilidad y rendimiento de Windows es un complemento de Microsoft Management Console (MMC) que combina la funcionalidad de herramientas independientes anteriores, incluidos Registros y alertas de rendimiento, Server Performance Advisor y Monitor de sistema. Proporciona una interfaz gráfica para personalizar la recopilación de datos de rendimiento y sesiones de seguimiento de eventos.
También incluye el Monitor de confiabilidad, un complemento de MMC que lleva un seguimiento de los cambios producidos en el sistema y los compara con los cambios de estabilidad del sistema, proporcionando una vista gráfica de su relación. Las herramientas de rendimiento de Windows (WPT) del kit contiene herramientas de análisis de rendimiento que son nuevas para el SDK de Windows para Windows Server 2008 y. NET Framework 3.5. El kit de WPT es útil a un público más amplio, incluyendo los integradores de sistemas, fabricantes de hardware, desarrolladores de controladores y desarrolladores de aplicación general. Estas herramientas están diseñadas para medir y analizar el sistema y el rendimiento de las aplicaciones en Windows Vista, Windows Server 2008, y más tarde. Herramientas de rendimiento de Windows están diseñados para el análisis de una amplia gama de problemas de rendimiento, incluyendo los tiempos de inicio de aplicación, los problemas de arranque, llamadas de procedimiento diferido y la actividad de interrupción (CPD y ISRS), los problemas del sistema de respuesta, uso de recursos de aplicación, y las tormentas de interrupción. Estas herramientas se incluyen con el SDK de Windows (a partir de Windows Server SDK Feb'08 2008). Últimas QFE de estas herramientas también están disponibles para descarga en este centro de desarrollo. El MSI que contiene estas herramientas están disponibles en el directorio bin del SDK (uno por la arquitectura).

Pág
ina3
2
2.4.3-Indicadores de desempeño Los indicadores del rendimiento de un computador son una serie de parámetros que conforma un modelo simplificado de la medida del rendimiento de un sistema y son utilizados por los arquitectos de sistemas, los programadores y los constructores de compiladores, para la optimización del código y obtención de una ejecución más eficiente. Dentro de este modelo, estos son los indicadores de rendimiento más utilizados: Turnaround Time El tiempo de respuesta. Desde la entrada hasta la salida, por lo que incluye accesos a disco y memoria, compilación, sobrecargas y tiempos de CPU. Es la medida más simple del rendimiento. En sistemas multiprogramados no nos vale la medida del rendimiento anterior, ya que la máquina comparte el tiempo, se produce solapamiento E/S del programa con tiempo de CPU de otros programas. Necesitamos otra medida como es el TIEMPO CPU USUARIO. Tiempo de cada ciclo ( ) El tiempo empleado por cada ciclo. Es la constante de reloj del procesador. Medida en nanosegundos. Frecuencia de reloj (f) Es la inversa del tiempo de ciclo. f = 1/. Medida en Megahertz. Total de Instrucciones (Ic) Es el número de instrucciones objeto a ejecutar en un programa. Ciclos por instrucción (CPI) Es el número de ciclos que requiere cada instrucción. Normalmente, CPI = CPI medio. En Analysis Services, un KPI es un conjunto de cálculos asociados a un grupo de medida de un cubo, que se usa para evaluar el éxito empresarial. Normalmente, estos cálculos son una combinación de expresiones MDX (Expresiones multidimensionales) o miembros calculados. Los KPI también tienen metadatos adicionales que proporcionan información acerca de cómo deberían las aplicaciones cliente mostrar los resultados de los cálculos de KPI. Un KPI administra información sobre un objetivo establecido, la fórmula real del rendimiento registrada en el cubo y medidas para mostrar la tendencia y el estado del rendimiento. Para definir las fórmulas y otras definiciones acerca de los valores se un KPI se usa AMO. La aplicación cliente usa una interfaz de consulta, como ADOMD.NET, para recuperar y exponer los valores de KPI al usuario final. Para obtener más información, vea ADOMD.NET. Un objeto Kpi simple se compone de la información básica, el objetivo, el valor real logrado, un valor de estado, un valor de tendencia y una carpeta donde se ve el KPI. La información básica incluye el nombre y la descripción del KPI. El objetivo es una expresión MDX que se evalúa como un número. El valor real es una expresión MDX que se evalúa como un número. El estado y el valor de tendencia son expresiones MDX que se evalúan como un número. La carpeta es una ubicación sugerida para el KPI que se va a presentar al cliente.

Pág
ina3
3
2.4.4-Roadmap Un RoadMap (que podría traducirse como hoja de ruta) es una planificación del desarrollo de un software con los objetivos a corto y largo plazo, y posiblemente incluyendo unos plazos aproximados de consecución de cada uno de estos objetivos. Se suele organizar en hitos o "milestones", que son fechas en las que supuestamente estará finalizado un paquete de nuevas funcionalidades. Para los desarrolladores de software, se convierte en una muy buena práctica generar un Roadmap, ya que de esta forma documentan el estado actual y posible futuro de su software, dando una visión general o específica de hacia dónde apunta a llegar el software. La expresión Roadmap se utiliza para dar a conocer el "trazado del camino" por medio del cual vamos a llegar del estado actual al estado futuro. Es decir, la secuencia de actividades o camino de evolución que nos llevará al estado futuro.
2.5. Seguridad e integridad 2.5.1.- Seguridad por software La seguridad del sistema de software, un elemento de la seguridad total y programa de desarrollo del software, no se puede permitir funcionar independientemente del esfuerzo total. Los sistemas múltiples simples y altamente integrados están experimentando un crecimiento extraordinario en el uso de computadoras y software para supervisar y/o controlar subsistemas o funciones seguridad-críticos. A especificación del software el error, el defecto de diseño, o la carencia de requisitos seguridad-crítico genéricas pueden contribuir a o causar un fallo del sistema o una decisión humana errónea. Para alcanzar un nivel aceptable de la seguridad para el software usado en usos críticos, la ingeniería de la seguridad del sistema de software se debe dar énfasis primario temprano en la definición de los requisitos y el proceso del diseño conceptual del sistema. El software Seguridad-crítico debe entonces recibir énfasis de la gerencia y análisis continuos de la ingeniería a través del desarrollo y ciclos vitales operacionales del sistema.

Pág
ina3
4
2.5.2 Seguridad por hardware
La seguridad del hardware se refiere a la protección de objetos frente a intromisiones provocadas por el uso del hardware. A su vez, la seguridad del hardware puede dividirse en seguridad física y seguridad de difusión. En el primer caso se atiende a la protección del equipamiento hardware de amenazas externas como manipulación o robo. Todo el equipamiento que almacene o trabaje con información sensible necesita ser protegido, de modo que resulte imposible que un intruso acceda físicamente a él. La solución más común es la ubicación del equipamiento en un entorno seguro. La seguridad de difusión consiste en la protección contra la emisión de señales del hardware. El ejemplo más común es el de las pantallas de ordenador visibles a través de las ventanas de una oficina, o las emisiones electromagnéticas de algunos elementos del hardware que adecuadamente capturadas y tratadas pueden convertirse en información. De nuevo, la solución hay que buscarla en la adecuación de entornos seguros.
2.5.3-Plantillas de seguridad para proteger los equipos Las plantillas de seguridad predefinidas se proporcionan como punto de partida para la creación de políticas de seguridad que pueden personalizarse para satisfacer diferentes necesidades de organización. Puede personalizar las plantillas con las plantillas de seguridad de complemento. Una vez que personalizar las plantillas de seguridad predefinidas, se pueden utilizar para configurar la seguridad en un equipo individual o miles de ordenadores. Puede configurar los equipos individuales con la configuración de seguridad y análisis de complemento, el Secedit de línea de comandos, o mediante la importación de la plantilla en Directiva de seguridad local . Puede configurar varios equipos mediante la importación de una plantilla en la configuración de Seguridad de la extensión de directiva de grupo , que es una extensión de directiva de grupo. También puede utilizar una plantilla de seguridad como punto de partida para el análisis de un sistema de agujeros de seguridad potenciales o violaciones de las políticas mediante el uso de la configuración y análisis de seguridad en. De forma predeterminada, las plantillas de seguridad predefinidas se almacenan en: systemroot \ Seguridad \ Plantillas

Pág
ina3
5
2.5.4. Configuración de la auditoria La auditoría suele realizarse a posteriori en sistemas manuales, es decir que se examinan las recientes transacciones de una organización para determinar si hubo ilícitos. La auditoría en un sistema informático puede implicar un procesamiento inmediato, pues se verifican las transacciones que se acaban de producir. Un registro de auditoría es un registro permanente de acontecimientos importantes acaecidos en el sistema informático:
Se realiza automáticamente cada vez que ocurre tal evento. Se almacena en un área altamente protegida de sistema. Es un mecanismo importante de detección
El registro de auditoria debe ser revisado cuidadosamente y con frecuencia. Las revisiones deben hacerse:
Periódicamente: Se presta atención regular mente a los problemas de seguridad. Al azar: Se intenta atrapar alos intrusos desprevenidos.
2.5.5. Administrar registros de seguridad El registro de seguridad para Windows está lleno de información muy bien, pero a menos que sepa cómo controlar, gestionar y analizar la información, se va a llevar mucho más tiempo para obtener la información que desee salir de ella. En este artículo se describen algunos de los consejos y trucos que pueden ser utilizados para cavar mejor la información que necesita salir del registro de seguridad, haciendo más fácil su trabajo, que sea más eficiente, y mejor la seguridad global de la red. Toda la información registrada en el registro de seguridad está controlada por Auditoría. La auditoría es la configuración y gestionado por la directiva de grupo. Puede administrar la directiva de grupo local (gpedit.msc) o por medio de Active Directory mediante el Group Policy Management Console (GPMC). Le recomiendo usar la GPMC y administrar la auditoría mediante Active Directory. Esto es mucho más eficiente y 1/10o el trabajo como su gestión a nivel local.

Pág
ina3
6
Introducción servidores con software libre
Software libre características
El software libre es un programa o secuencia de instrucciones usada por un dispositivo de procesamiento digital de datos para llevar a cabo una tarea específica o resolver un problema determinado, sobre el cual su dueño renuncia a la posibilidad de obtener utilidades por las licencias, patentes, o cualquier forma que adopte su derecho de propiedad sobre él.
Otra característica es que se encuentra disponible el código fuente del software,
por lo que puede modificarse el software sin ningún límite, y sin pago a quien lo
inventó o lanzó al mercado.
El software libre (en inglés free software, aunque esta denominación también se confunde a veces con "gratis" por la ambigüedad del término "free" en el idioma inglés, por lo que también se usa "libre software" y "lógica libre") es la denominación del software que respeta la libertad de los usuarios sobre su producto adquirido y, por tanto, una vez obtenido puede ser usado, copiado, estudiado, modificado, y redistribuido libremente. Según la Free Software Foundation, el software libre se refiere a la libertad de los usuarios para ejecutar, copiar, distribuir, estudiar, modificar el software y distribuirlo modificado.
El software libre suele estar disponible gratuitamente, o al precio de costo de la distribución a través de otros medios; sin embargo no es obligatorio que sea así, por lo tanto no hay que asociar software libre a "software gratuito" (denominado usualmente freeware), ya que, conservando su carácter de libre, puede ser distribuido comercialmente ("software comercial"). Análogamente, el "software gratis" o "gratuito" incluye en ocasiones el código fuente; no obstante, este tipo de software no es libre en el mismo sentido que el software libre, a menos que se garanticen los derechos de modificación y redistribución de dichas versiones modificadas del programa. Tampoco debe confundirse software libre con "software de dominio público".
Éste último es aquel software que no requiere de licencia, pues sus derechos de explotación son para toda la humanidad, porque pertenece a todos por igual.
Cualquiera puede hacer uso de él, siempre con fines legales y consignando su autoría original. Este software sería aquel cuyo autor lo dona a la humanidad o cuyos derechos de autor han expirado, tras un plazo contado desde la muerte de este, habitualmente 70 años. Si un autor condiciona su uso bajo una licencia, por muy débil que sea, ya no es del dominio público.

Pág
ina3
7
3.1.1. Historia y evolución servidores con software libre
El Software Libre es el software que se caracteriza por proporcionar en sus licencias
el permiso para usarlo en cualquier máquina y en cualquier situación, para
modificarlo, mejorarlo o corregirlo y para redistribuirlo libremente.
Software libre no es software gratis, sino aquel que cumple con estas
condiciones, si bien, no parece posible obtener contraprestación económica por él,
como de hecho ocurre, siendo de coste cero la obtención de la práctica totalidad
del software libre.
Así pues, tenemos un concepto de software opuesto al software propietario con el
que no se distribuye el código fuente, impidiendo así su modificación, y en cuyas
licencias se indican los términos y las restricciones de uso y distribución, en
ocasiones bastantes fuertes.
Lo que diferencia el software libre del software propietario no es el que
dispongamos del código fuente del mismo, si bien esta es una condición necesaria
para tener las libertades descritas anteriormente, ni el precio, la diferencia está en
los términos de la licencia.
Para comprender el nacimiento de este tipo de software nos tenemos que remontar
al año 1979, cuando la Universidad de Berkeley distribuyó código de programas
que ha desarrollado para el sistema operativo UNIX bajo una licencia denominada
BSD (Berkeley Software Distribution), es la primera aparición en escena de lo que
más tarde se denominará software libre.
Estos primeros programas distribuidos bajo licencia BSD son utilidades para UNIX y
entre ellas se encuentra una implementación de un protocolo de comunicaciones,
el TCP/IP.
En 1980 la NSF (National Science Foundation) mejora el protocolo TCP/IP y
comienza a utilizarlo para el intercambio de información entre ordenadores de
universidades e investigadores de todo el mundo. Esta mejora de TCP/IP era
abierta y se distribuía con el código fuente de su implementación, es el nacimiento de
la red de Internet.
En 1984 aparece en escena una de las figuras más importante dentro del software
libre, Richard Stallman, que lidera en este año un proyecto científico denominado
GNU dentro del Instituto Tecnológico de Massachussets. Al año siguiente, aparece la
primera versión de un sistema operativo denominado igual que el proyecto
lanzado, GNU (Gnu’s not Unix).

Pág
ina3
8
Este sistema operativo es gratuito y se distribuye junto con su código fuente bajo
una licencia denominada Gnu Public License (GPL).
En este mismo año 1985, Richard Stallman crea la Free Software Foundation, y
aparece la primera definición formal de Software Libre, proporcionada por la FSF:
Un software es software libre cuando el usuario del mismo tiene estas cuatro
libertades:
Libertad 0. Libertad de uso con cualquier propósito.
Libertad 1. Libertad de adaptación a sus necesidades.
Libertad 2. Libertad para distribuirlo.
Libertad 3. Libertad de mejora y libre distribución de estas mejoras.
No se dice explícitamente, pero para tener estas cuatro libertades el usuario debe
disponer del código fuente de los programas.
En 1991, Linus Torvalds, un estudiante sueco de la universidad de Helsinky crea un
kernel de sistema operativo denominado Linux, y un año más tarde, fruto de la
colaboración con el proyecto GNU, aparece el sistema operativo GNU/Linux, que se
denominó Linux, si bien, la mayor parte del código procedía del proyecto GNU de
Stallman.
La siguiente fecha importante en la historia del software libre es 1997, cuando Eric
Raymond publica el artículo ―The Cathedral and the Bazaar‖, en el Raymond
explica con detalle como una serie de programadores trabajando en colaboración en
su tiempo libre (Bazaar) pueden producir software de mayor calidad que los
producidos por los talentos contratados por las grandes compañías de software
(Cathedral). Las teorías expuestas en este artículo como las de liberar versiones
del programa a menudo de forma que los usuarios puedan probar los programas y se
obtengan pronto respuestas sobre su funcionamiento y que con un grupo muy
amplio de programadores y usuarios, los problemas se identificarán con rapidez y la
solución será obvia para alguien, hacen que las grandes compañías (IBM,
Netscape, Sun, etc.) se fijen en el fenómeno del software libre y empiecen a
colaborar con él. Raymond crea la OpenSource Inciative (OSI). Con la aparición de
la OSI aparece también una nueva definición de lo que se conoce como
OpenSource (software de fuente abierta), mucho más elaborada, y que está en
continua evolución, existiendo ya la versión 1.9 de esta definición.

Pág
ina3
9
No existe una definición única de lo que denominamos software libre, tenemos la de
la FSF, la de la OSI, también otras como la de la comunidad de Debian
(DFSG). Todas estas definiciones se traducen en licencias de uso que llegan a un
mayor o menor compromiso con uno u otro de los dos objetivos contradictorios en los
que se basan todas sus licencias:
Garantizar a los usuarios una total libertad sobre el software distribuído.
Establecer restricciones de forma que se garantice que el software derivado o
integrado siga siendo software libre.
Aunque cuando hacemos referencia a Software Libre no distinguimos entre si es
Free Software u OpenSource, pero existen pequeñas diferencias entre las
definiciones de la FSF, de la OSI y de Debian, derivadas del compromiso acordado
entre los dos conceptos expuestos anteriormente, lo que hace que existan licencias
aceptadas por uno pero no aceptadas por el otro. Pero estas diferencias son muy
pequeñas, y en la práctica se pueden considerar similares los conceptos.
Hoy en día existe una división radical entre los partidarios y los no partidarios del
software libre, existiendo posturas totalmente radicalizadas en ambos bandos que
hace que los debates, artículos y ponencias acerca de las debilidades y fortalezas en
los proyectos de software libre se vean empañados por esta lucha. Eric Raymond ha
insistido en que el debate no debe ser si Windows o Linux o Microsoft o Red Hat,
Suse, Debian, que el verdadero debate debe ser software de fuente cerrada frente a
software de fuente abierta.

Pág
ina4
0
3.1.2. Estructura del sistema operativo
El sistema operativo Linux se genera inspirándose en dos sistemas operativos, el
sistema abierto UNIX creado en 1969 por Ken Thompson y Dennis Ritchie en los
laboratorios de Bell. De este sistema se toman sus características,
especificaciones y funcionamiento. Mas el sistema educativo Minix creado en 1987
por Andrew S. Tanenbaum del cual se toma la estructura y código del núcleo. Con
todo esto en 1991 Linus Torvalds crea Linus’s Unix = Linux Kernel, esto es crea
solo el núcleo del sistema sin la capa de servidores, manejadores, aplicaciones
gráficas, etc. que serán creadas posteriormente por otros autores. El código del
núcleo lo podemos encontrar en la dirección (www.kernel.org). El núcleo actual
tiene aproximadamente 1,5 millones de líneas de código, y representa menos del 50
por ciento de todo el código del sistema.
CARACTERISTICAS DEL NÚCLEO
Su código es de libre uso.
Escrito en lenguaje C, compilado con gcc, primera capa en ensamblador.
Ejecutable en varias plataformas hardware.
Se ejecuta en máquinas con arquitectura de 32 bits y 64 bits.
Estaciones de trabajo y servidores.
Código y funcionamiento escrito bajo la familia de estándares POSIX
(Portable Operating System Interface).
Soporta CPU’s con uno o varios microprocesadores (SMP) symmetric
multiprocessing.
Multitarea.
Multiusuario.
Gestión y protección de memoria.
Memoria virtual.
Varios sistemas de ficheros.
Comunicación entre procesos (señales, pipes, IPC, sockets).
Librerías compartidas y dinámicas.
Permite trabajar en red TCP/IP.
Soporte grafico para interfase con el usuario.
Estable, veloz, completo y rendimiento aceptable.
Funcionalmente es muy parecido a UNIX.
Más de 100.000 usuarios.
Actualizado, mejorado, mantenido y ampliado por la comunidad de usuarios
(modelo ―bazar‖, contrapuesto al modelo ―catedral‖).

Pág
ina4
1
Arquitectura del núcleo
Veamos los objetivos más importantes que se han tenido en cuenta a la hora de
diseñar el núcleo, basados en claridad, compatibilidad, portabilidad, robusto,
seguro y veloz.
CLARO:
Claridad y velocidad son dos objetivos normalmente contrapuestos. Los diseñadores
suelen sacrificar claridad por velocidad. La claridad complementa la robustez del
sistema y facilita la realización de cambios y mejoras. Podemos encontrar reglas
de estilo en el fichero /usr/src/Documentation/CodingStyle.
COMPATIBLE:
Diseñado bajo la normativa POSIX. Soporta ejecutar ficheros Java. Ejecuta
aplicaciones DOS, con el emulador DOSEMU. Ejecuta algunas aplicaciones Windows
a través del proyecto WINE. Se mantiene compatibilidad con ficheros Windows a
través de los servicios SAMBA. Soporta varios sistemas de ficheros ext2 y ext3
(sistemas de ficheros nativos),ISO-9660 usado sobre los CDROMs, MSDOS, NFS
(Network File System), etc. Soporta protocolo de redes TCP/IP, soporta protocolo de
AppleTalk (Macintosh), también protocolos de Novell IPX (Internetwork Packet
Exange), SPX (Sequenced Packet Exange), NCP (NetWare Core Protocol), y IPv6 la
nueva versión de IP. Mantiene compatibilidad con una variedad de dispositivos
hardware.
MODULAR:
El núcleo define una interfaz abstracta a los subsistemas de ficheros denominada
VFS (Virtual File System Interface), que permite integrar en el sistema varios
sistemas de ficheros reales. También mantiene una interface abstracta para
manejadores binarios, y permite soportar nuevos formatos de ficheros ejecutables
como Java.
PORTABLE:
Mantiene una separación entre código fuente dependiente de la arquitectura y
código fuente independiente de la arquitectura, que le permite ejecutar Linux en
diversas plataformas como Intel, Alpha, Motorola, Mips, PowerPC, Sparc,
Universidad de Las Palmas de Gran Canaria 1-2Introducción Linux
Macintoshes, Sun, etc. Existen versiones del núcleo específicas para portátiles, y
PAD’s.

Pág
ina4
2
ROBUSTO Y EGURO:
El disponer de las fuentes, permite a la comunidad de usuarios modificar los
errores detectados y mantener el sistema constantemente actualizado. Dispone de
mecanismos de protección para separar y proteger los programas del sistema de
los programas de los usuarios. Soporta cortafuego para protección de intrusos.
VELOZ:
Este es el objetivo más demandado por los usuarios, si bien no suele ser un
objetivo crucial. El código está optimizado así encontramos la primera capa del
núcleo escrita en ensamblador.
ESTRUCTURA MONOLÍTICA O MACRONÚCLEO (Unix)
• El núcleo es un único gran proceso.
• La utilización de un procedimiento se llama directamente, no necesita
mensajes, por lo que es más rápido.
• Actualizaciones, implican recompilar todo el núcleo.
ESTRUCTURA DE LINUX
• Linux mantiene una estructura monolítica, pero admite módulos cargables.
• Módulos pueden ser manejadores de dispositivos, y se cargan cuando se
necesitan.
La organización de los sistemas operativos se puede establecer por capas , dependiendo de las funciones que el sistema operativo puede realizar.
Las funciones que puede realizar el sistema son:
Ejecución y control de aplicaciones o programas. Gestión, Control y Administración de dispositivos o periféricos. Gestión, Control y Administración de los usuarios. Control de procesos. Control de errores del sistema y programas. Control y Gestión de la seguridad

Pág
ina4
3
Las capas en las cuales se puede estructurar básicamente un sistema son las siguientes:
Gestión del procesador (Nivel 1)
Una parte del sistema operativo está encargada de la gestión de la unidad central de proceso. El sistema operativo se encarga de gestionar la prioridad entre procesos.
Gestión de la memoria (Nivel 2)
Una parte del sistema operativo está encargada de la gestión y asignación de la memoria a los procesos o aplicaciones, impidiendo que las zonas de memoria ocupadas por aplicaciones no sean ocupadas por otras aplicaciones.
Gestión de procesos (Nivel 3)
Una parte del sistema operativo está encargada de la gestión de procesos, iniciando, deteniendo y finalizando los mismos dependiendo del usuario o de las órdenes recibidas por el sistema operativo.
Gestión Entrada/Salida y Almacenamiento (Nivel 4)
Una parte del sistema operativo está encargada de la gestión de los procesos que establecen acciones con los dispositivos de almacenamiento o dispositivos de entrada y salida. Gestión de información (Nivel 5)
El sistema operativo gestiona archivos, directorios, atributos de los anteriores y
otras características para identificar la información con la que trabaja el sistema
operativo.

Pág
ina4
4
3.2. Requerimientos de instalación
Los requisitos mínimos «recomendados», teniendo en cuenta los efectos de
escritorio, deberían permitir ejecutar una instalación de Ubuntu Server 12.04 LTS
Procesador x86 a 700 MHz.
Memoria RAM de 512 MiB.
Disco Duro de 5 GB (swap incluida).
Tarjeta gráfica y monitor capaz de soportar una resolución de 1024x768.
Lector de DVD o puerto USB.
Conexión a Internet puede ser útil.
Los efectos de escritorio, proporcionados por Compiz, se activan por defecto en
las siguientes tarjetas gráficas:
Intel (i915 o superior, excepto GMA 500, nombre en clave «Poulsbo»)
NVidia (con su controlador propietario o el controlar abierto
incorporado Nouveau)
ATI (a partir del modelo Radeon HD 2000 puede ser necesario el
controlador propietario fglrx)

Pág
ina4
5
3.3.1. Métodos de instalación
CD-ROM
Si posee un lector de CD-ROM y tiene los CD-ROMs de Red Hat Enterprise
Linux, puede utilizar este método.
Disco duro
Si ha copiado las imágenes ISO de Red Hat Enterprise Linux en el disco
duro local, puede utilizar este método. Necesitará un disquete o CD-ROM de
arranque.
NFS
Si está realizando la instalación desde un servidor NFS utilizando imágenes
ISO o una imagen réplica de Red Hat Enterprise Linux, puede utilizar este
método. Necesitará un CD-ROM de arranque (utilice la opción de
arranque linux askmethod). Tenga en cuenta que las instalaciones NFS
también se pueden realizar en el modo GUI.
FTP
Si está realizando la instalación directamente desde un servidor FTP, utilice
este método. Necesitará un CD-ROM de arranque (use la opción de arranque
linux askmethod).
HTTP
Si está realizando la instalación directamente desde un servidor Web HTTP,
utilice este método. Necesitará un CD-ROM de arranque (use la opción de
arranque linux askmethod).

Pág
ina4
6
3.3.2. Instalación
Instalación de Linux
En la actualidad, la distribución Red Hat es una de las distribuciones más
populares ya que el procedimiento de instalación es muy simple. De hecho, este
procedimiento simplemente le pide que elija de una lista de dispositivos periféricos
principales y que escoja los idiomas y los paquetes que se van a instalar. Los
pasos de la instalación son los siguientes:
Elección del idioma: elija el idioma para el procedimiento de instalación.
Elección del teclado: si desea un teclado en francés que posea caracteres con
acentos, elija fr-latin1.
Elección del soporte de instalación: en caso de que usted posea un CD de
instalación de Linux, elija CD-ROM. De lo contrario (en el caso de que lo haya
descargado), elija Hard drive.
Elección del estilo de instalación: Aquí puede elegir actualizar un sistema
existente o una instalación completa desde cero.
Tipo de instalación: el sistema le permite elegir entre estación de trabajo,
servidor o personalizada. La elección de una instalación personalizada le dará
más flexibilidad.
Elección de los adaptadores SCSI: si usted tiene un adaptador SCSI, debería
elegir la opción sí a esta pregunta. El sistema de instalación tratará de detectar
su hardware. En caso de que esta búsqueda automática no arroje ningún
resultado, sólo debe introducir una línea de parámetros para especificar de qué
tipo de adaptador SCSI se trata como así también conocer la IRQ y la dirección
de memoria. La línea de comando encontrará una tarjeta "AHA1520" con la
dirección 0x140 y IRQ 10:
aha152x=0x140,10.
Partición del disco duro: esta distribución le permitirá particionar el disco duro
en este nivel del proceso de instalación (a menos que ya lo haya hecho
anteriormente) y le permitirá elegir entre druid disk y fdsik. Elección del disco
rígido.
Partición del disco duro: El software le pedirá que elija de una lista el disco duro
que desea particionar.
eliminación de particiones innecesarias: en fdisk, use la tecla "d" para eliminar
las particiones innecesarias (¡asegúrese de no borrar las particiones de
Windows!).
creación de particiones Linux: las teclas n y p le permitirán crear particiones
swap y raíz así como cualquier otra partición que necesite. Se le solicitará el
número del primer cilindro de la partición así como su tamaño (en MB).

Pág
ina4
7
Selección de puntos de montaje: En una pantalla se proponen las diferentes
particiones que puede montar. Seleccione las particiones que desea montar y
nómbrelas una tras otra mediante la especificación del punto de montaje. Se
debe especificar la raíz: representa la partición principal y se la debe nombrar
como /. A cada partición que quiera utilizar en Linux le debe asignar un punto
de montaje (/home por ejemplo o /mnt/dos para su partición DOS, en caso de
que quiera montarla automáticamente después de la instalación).
Selección de la partición swap: Después, el sistema le pedirá que elija la
partición que se usará como memoria secundaria.
Formateo de particiones: debe seleccionar todas las particiones nuevas que
creó. ¡Asegúrese de no formatear ninguna partición que contenga datos!
Elección de paquetes: esta opción de una lista simplemente le pide que elija los
elementos que se instalarán.
Instalación/copia de paquetes: el sistema instalará todos los paquetes requeridos
uno por uno. ¡Esta operación puede llevar un tiempo muy largo! (hasta media
hora...)
Configuración de la red: se aplica a todos los equipos que tengan una tarjeta de
red (no un módem).
Elección del huso horario: elija el huso horario apropiado para su país (para
Francia, Bélgica y Suiza, elija Europa/París, para Québec, depende...).
Elección de servicios de inicio del sistema: puede elegir de una lista los servicios
que se activarán en cada inicio de sistema. A prioriapmd, netfs y
sendmail no le serán muy útiles si su equipo no es un servidor.
Elección de la impresora: una serie de preguntas le permitirá configurar su
impresora. Tendrá que elegir opciones de una lista y especificar el puerto al que
está conectada.
Registro de la contraseña: se le pedirá que introduzca una contraseña para la
cuenta del superusuario (raíz, es decir, un usuario que posee todos los
derechos.
Una vez que haya completado todos los pasos, el equipo se reiniciará y aparecerá el siguiente indicador:
LILO
:
Sólo introduzca linux para iniciar el sistema en Linux y dos para ir a su partición
DOS, en la que encontrará Windows 9x, DOS u otro...
Una vez que inició el sistema en Linux e introdujo su nombre y contraseña de
superusuario (root), debe instalar (a priori) una interfaz gráfica que sea más fácil
de usar que la consola (modo de texto).

Pág
ina4
8
3.3.4. Niveles de ejecución.
En Linux
El sistema operativo GNU/Linux puede aprovechar los niveles de ejecución a
través de los programas del proyecto sysvinit. Después de que el núcleo Linux ha
arrancado, el programa init lee el archivo /etc/inittab para determinar el
comportamiento para cada nivel de ejecución. A no ser que el usuario especifique
otro valor como un parámetro de autoarranque del núcleo, el sistema intentará
entrar (iniciar) al nivel de ejecución por defecto.
La mayor parte de usuarios de sistemas puede comprobar el nivel de ejecución
actual con cualquiera de los comandos siguientes:
$ runlevel # como usuario root
$ who -r # como cualquier usuario
Niveles de ejecución típicos en Linux
La mayoría de las distribuciones Linux, definen los siguientes niveles de ejecución
adicionales:
Los 7 niveles de ejecución (runlevels) estándares
Nivel de ejecución Nombre o denominación Descripción
Alto: Alto o cierre del sistema (Apagado).
Modo de usuario único: (Monousuario) No configura la interfaz de red o los
demonios de inicio, ni permite que ingresen otros usuarios que no sean el
usuario root, sin contraseña. Este nivel de ejecución permite reparar
problemas, o hacer pruebas en el sistema.
Multiusuario: Multiusuario sin soporte de red.
Multiusuario con soporte de red: Inicia el sistema normalmente.
No usado.
Multiusuario gráfico (X11) Similar al nivel de ejecución 3 + display manager. Reinicio Se reinicia el sistema.

Pág
ina4
9
Estructura de directorios
3.4.1. preparación y administración de los sistemas de archivos
TIPOS DE PARTICIONES Y SISTEMAS DE ARCHIVOS
Particionar un disco duro es realizar una división en él de modo que, a efectos
prácticos, el sistema operativo crea que tienes varios discos duros, cuando en
realidad sólo hay un único disco físico dividido en varias partes. De este modo, se
pueden modificar o borrar particiones sin afectar a los demás datos del disco.
Las particiones básicas se llaman primarias y puede haber a lo sumo 4. Esto
puede ser suficiente para nuestros intereses. Como a veces no es así, se crearon
las particiones extendidas que pueden albergar otras particiones dentro, llamadas
lógicas.
Los sistemas de archivos indican el modo en que se gestionan los archivos dentro de
las particiones. Según su complejidad tienen características como previsión de
apagones, posibilidad de recuperar datos, indexación para búsquedas rápidas,
reducción de la fragmentación para agilizar la lectura de los datos, etc. Hay varios
tipos, normalmente ligados a sistemas operativos concretos. A continuación se
listan los más representativos:
Fat32 o vfat: Es el sistema de archivos tradicional de MS-DOS y las primeras
versiones de Windows. Por esta razón, es considerado como un sistema universal,
aunque padece de una gran fragmentación y es un poco inestable.
ntfs: Es el nuevo sistema de Windows, usado a partir del 2000 y el XP. Es muy
estable. El problema es que es privativo, con lo cual otros sistemas operativos no
pueden acceder a él de manera transparente. Desde Linux sólo se recomienda la
lectura, siendo la escritura en estas particiones un poco arriesgada.
Ext2: Hasta hace poco era el sistema estándar de Linux. Tiene una fragmentación
bajísima, aunque es un poco lento manejando archivos de gran tamaño.
Ext3: Es la versión mejorada de ext2, con previsión de pérdida de datos por fallos
del disco o apagones. En contraprestación, es totalmente imposible recuperar
datos borrados. Es compatible con el sistema de archivos ext2. Actualmente es el
más difundido dentro de la comunidad GNU/Linux y considerado el estándar de
facto.

Pág
ina5
0
Ext4: Es un sistema de archivos con registro por diario (en inglés Journaling),
anunciado el 10 de octubre de 2006, como una mejora compatible de ext3. La
principal novedad en Ext4 es Extent, o la capacidad de reservar un área contigua
para un archivo; esto puede reducir y hasta eliminar completamente la
fragmentación de archivos. Es el sistema de archivos por defecto desde Ubuntu
Jaunty.ReiserFS: Es el sistema de archivos de última generación para Linux. Organiza
los archivos de tal modo que se agilizan mucho las operaciones con éstos. El
problema de ser tan actual es que muchas herramientas (por ejemplo, para recuperar
datos) no lo soportan.
Swap: Es el sistema de archivos para la partición de intercambio de Linux. Todos los
sistemas Linux necesitan una partición de este tipo para cargar los programas y no
saturar la memoria RAM cuando se excede su capacidad. En Windows, esto se hace
con el archivo pagefile.sys en la misma partición de trabajo, con los problemas
que conlleva.
Ya se ha comentado que las particiones son como discos duros independientes, y así
aparece en Windows. Cabe recordar que en Linux no existe el concepto de unidad
(C:, D:, etc.) sino que las particiones se montan en el árbol de carpetas. Eso no
nos debe preocupar mucho. Sólo comentar que la carpeta raíz de ese árbol se
denota con / y que las particiones se suelen montar en la carpeta /media.

Pág
ina5
1
3.4.2 Montaje y desmontaje de dispositivos.
Montar equivale a crear un acceso desde un directorio a una unidad o dispositivo. No significa copiar sino establecer un enlace entre tal directorio y el dispositivo. Desmontarla es eliminar ese enlace. A los usuarios de MS-DOS os sonará a algo parecido que se hacía con las unidades comprimidas dblspace o drivespace. Su equivalente en sistemas windows son las unidades virtuales que instalan programas tales como el clone cd, que para poder leer una imagen iso es necesario montarla de un modo similar a como se hace en GNULinux.
De forma predeterminada LINUX nos ofrece directorios en los que se montan dispositivos comúnmente utilizados, /floppy en el que accedemos a las disqueteras y otro llamado /cdrom para unidades ópticas. Esto no es común para todas las distribuciones, pero dado que lo más probable es que estéis utilizando Guadalinex, ésta si lo distribuye así. No obstante, cada quien puede montar las cosas tal y como prefiera, lo más normal es que los dispositivos se monten dentro de un directorio llamado /mnt. El montaje, tanto de Linux en modo gráfico, como de windows, se hace automáticamente al intentar acceder a la unidad, pero en el modo texto de Linux se montan de forma prácticamente manual.
COMANDO PARA MONTAR DISPOSITIVOS
mount Formato: mount -t La t indica que a continuación se especificará el montaje obligatorio con formatos:
ext2 (formato de linux).
ext3 (formato de linux para montaje de sistemas de archivos).
reisers (formato de linux utilizado en servidores).
vfat (formato fat utilizado para disketes y para particiones win9x). ntfs
(formato para particiones windows nt/2000/xp).
iso9660 (dispositivos pticos).
Este tipo de montaje extendido solamente puede hacerlo el ROOT, los usuarios podrán hacer exclusivamente el montaje reducido. Como ya vimos en otras entregas, todos los dispositivos se encuentran en el
directorio DEV
/dev/hda0 primer disco duro, partición primaria (la partición que generalmente contiene a windows)

Pág
ina5
2
/dev/fd0 disquetera /dev/sda pendrive /dev/cdrom (dispositivos ópticos). el dispositivo (/dev/cdrom es en realidad un enlace simbólico al dispositivo real (en próximas entregas hablaremos de los enlaces y sus tipos), que puede ser /dev/hdb o /dev/hdc...).
En realidad, como estamos viendo, un punto de montaje no es otra cosa que un enlace a un dispositivo desde un directorio, por ejemplo, el directorio /mnt
La orden que nos permite Averiguar las particiones y su tipo que hay en el disco duro es:
fdisk -l /dev/hda (hda equivale al disco duro en su totalidad). Una vez hayamos averiguado el formato y el nombre de la partición, podemos montar la unidad o la partición:
Por ejemplo, podremos MONTAR la partición de disco que contiene Windows del siguiente modo:
Creamos una carpeta (con cualquier nombre, por ejemplo, windows) en /mnt (no me cansaré de repetiros que tengáis mucho cuidado con las mayúsculas ya que para GNULinux no es lo mismo Windows que windows). Asimismo deberemos tener en cuenta que no se podrá utilizar la orden mount para montar estando dentro del propio directorio de montaje (/mnt), hay que, portanto, estar en otra ubicación antes de utilizar la orden:
mount -t ntfs /dev/hda1 /mnt/windows -t es el modificador que indica formato extendido con tipo obligatorio. El formato es en este ejemplo ntfs válido para windows nt/2000/xp. Podría ser vfat para versiones 9x de windows. Las particiones en ntfs en linux se montan para sólo lectura debido a la gran cantidad de permisos o atributos que existen en este tipo de formatos y no podremos hacer cambios (os comento, no recuerdo si lo hice antes, aunque creo que no porque todavía no hablamos del tema, que los archivos de Unix/linux solamente tienen tres tipos de permiso: lectura, escritura y ejecución; desde luego que esto no lo hace ser más inseguro que cualquier otro sistema, la verdad es que solamente con estos tres atributos nos sobra). En vfat si son de lectura y escritura. Si no supiéramos el sistema de archivos, en lugar de especificarlo, se puede poner el modificador auto (el cual sustituye a cualquier tipo

Pág
ina5
3
ext2, ntfs,etc...). Normalmente lo detectará bien y no nos dará ningún tipo de problema. hda1 será en este caso la partición que contiene el windows
Otro ejemplo podría ser montar un cd-rom
Antes de hacerlo deberemos verificar que haya un cd dentro de la unidad, en otro caso dará error (esto también pasará con las disqueteras)
mount -t iso9660 /dev/cdrom /cdrom Dará mensaje de que se monta sólo para lectura y que está protegido contra escritura por ser un cd.
También se podría realizar el montaje con formato reducido: mount /dev/cdrom (sólo en algunos casos ya que depende mucho de cada distribución)
Para poder utilizar el formato reducido en el montaje de unidades hay que examinar el fichero /etc/fstab y tener en cuenta su contenido, ya que allí es donde se especificarán los dispositivos que son montados de este modo y en qué lugares y por quien puede ser utilizado.
Si editamos el fichero con cualquier editor, en una siguiente entrega hablaremos del más común que es VI, encontraremos, entre otras, algo parecido a la siguiente línea: /dev/cdrom /cdrom iso9660 defaults,ro,user,noexec,noauto 0 0
La opción «defaults» es en realidad un conjunto de opciones. Al indicar defaults se están agrupando las siguientes opciones: rw: Montar el sistema de archivos de lectura y escritura. suid: Permitir el uso de identificadores de los bits SUID y SGID. dev: Interpretar dispositivos especiales de caracteres o bloques en el sistema de archivos. Noauto: que no monte automáticamente. Es importante porque si no hay cd rom dentro de la unidad, nos daría error en el inicio al intentar montarla sin tener cd dentro (también pasa con las disqueteras). También es importante la opción user, que permite que el dispositivo sea montado por cualquier otro usuario que no sea el root, lo que, en realidad, no es otra cosa que la posibilidad de montar con la opción reducida. Para montar unidades como un usuario (no root) hay que tener en cuenta que un usuario no podrá utilizar el formato extendido para montarlo, sólo el reducido. En el fichero fstab estará especificado por el root dónde se puede montar y el usuario.
No podrá montar en ningún otro sitio en el que el administrador no lo haya previsto.

Pág
ina5
4
DESMONTAR DISPOSITIVO
Al igual que ocurría cuando montábamos dispositivos, tampoco se puede desmontar en el directorio de montaje, por lo que será necesario salirse de él antes de ejecutar la orden.
umount dispositivo
EJEMPLO: umount /dev/hda1
No se debe retirar un diskette antes de desmontarlo o posiblemente acabaremos por hacer que el sistema se desestabilice y se cuelgue. La regla es, cuando se trate de dispositivos que se muevan, primero se desmonta y después se retira.
MOUNT (sin parámetros)nos ofrecerá la INFORMACIÓN SOBRE los MONTAJES
DESMONTAR Y SACAR EL CD.
Estando en root se ejecutará la orden eject
Comprobar los Sistemas de Archivos:
Es sabido que en GNULinux los sistemas de archivos se corrompen menos que en Windows, esto no significa que no lo hagan, si, por ejemplo, se han desmontado inadecuadamente debido a un apagado en caliente o por un corte de fluido eléctrico, el sistema comprobará, en el arranque, los sistemas de archivos en busca de ficheros dañados o corrompidos. Esta comprobación se realizará también de forma automática periódicamente cada cierto número de encendidos del sistema.
También tendremos la posibilidad de realizar revisiones manualmente siempre que lo decidamos oportuno. El comando utilizado para comprobar un sistema de archivos dependerá del tipo de sistema en cuestión. Para sistemas de archivos ext2fs (el que usaremos en GNULinux habitualmente), el comando será e2fsck.
e2fsck -av /dev/hda2

Pág
ina5
5
Esto comprobará el sistema de archivos de /dev/hda2 y corregirá automáticamente cualquier error que pudiera haber allí. Es muy aconsejable, por no decir que obligatorio, desmontar el sistema de archivos antes de verificarlo. La única excepción a esto es el sistema de archivos raíz (/), que no se puede desmontar, debido a que está siendo usado y es imposible no hacerlo así. Tras haber comprobado un sistema de archivos es imprescindible que reinicialicemos el sistema inmediatamente, si se hizo alguna corrección al sistema de archivos. Si fsck informa que ha corregido algún error en el sistema de archivos, se debe apagar el sistema con shutdown -r, o reboot para re arrancarlo. Esto permite a Linux sincronizar su información acerca del sistema de archivos cuando fsck lo modifique.
Existe un sistema de archivos llamado /proc el cual no necesita nunca ser comprobado. /proc es un sistema de archivos virtual, gestionado directamente por el núcleo, y como tal sistema virtual es imposible que sufra corrupciones.

Pág
ina5
6
Comandos y aplicaciones
3.5.1. manejo del sistema de archivos
Los sistemas de archivos más comunes utilizan dispositivos de almacenamiento de
datos (Disco, Duros, CDS, Floppys, USB Flash, etc...) que permiten el acceso a los
datos como una cadena de bloques de un mismo tamaño, a veces llamados
sectores, usualmente de 512 bytes de longitud. El software del sistema de archivos
es responsable de la organización de estos sectores en archivos y directorios y
mantiene un registro de qué sectores pertenecen a qué archivos
y cuáles no han sido utilizados.
Ejemplos de sistemas de archivos de disco:
* EFS
* EXT2
* EXT3
* FAT (sistemas de archivos de DOS y
Windows)
* UMSDOS
* FFS
* Fossil
* HFS (para Mac OS)
* HPFS
* ISO 9660 (sistema de archivos de solo lectura
para CD•ROM)
* JFS
* kfs
* MFS (para Mac OS)
* Minix
* NTFS (sistemas de archivos de Windows NT •
XP)
* OFS
* ReiserFS
* Reiser4
* UDF (usado en DVD y en algunos CD•ROM)
* UFS
* XFS

Pág
ina5
7
3.5.2. Instalación y ejecución de aplicaciones
1º- Dar al archivo permisos de ejecución
Como medida de seguridad, Linux no deja ejecutar ningún archivo salvo que tú le des los permisos necesarios, para ello hacemos click derecho sobre el archivo, vamos a Propiedades > Permisos y marcamos la casilla "Permitir ejecutar archivo como un programa". En el escritorio de Gnome / Ubuntu Unity aparecerá lo siguiente:
Img. 01 Permisos
Nota: Esta captura de pantalla es del escritorio Gnome, si usas otro entorno de escritorio distinto aparecerá algo parecido.
Si usas el escritorio KDE aparecerá esto y deberás marcar "es ejecutable":

Pág
ina5
8
Img. 02 Dar permiso ―Ejecutable‖
2º- Formas de ejecutar archivos
Una vez le hemos dado los permisos, hay varias formas de ejecutar el archivo: - Lo más rápido es hacer click encima de ellos y seleccionar la opción "ejecutar". - Si eso no te funciona ejecutaremos los archivos desde la consola. Una forma
rápida de ejecutarlo así es abrir un terminal, arrastrar el archivo dentro y darle a
Intro (ver ejemplo), pero si esto tampoco te funciona lee el paso 3.
3º) Ejecutar archivos desde la consola
Una vez hayas abierto el terminal estarás situado en tu carpeta de usuario (en
este ejemplo el usuario es "comu" y su carpeta personal es /home/comu ). Con el
comando pwd podemos comprobar el directorio en el que estamos y con
lspodemos ver el contenido de la carpeta:
Img. 03 Ejecutar desde consola

Pág
ina5
9
Img. 04 Comando ―ls‖
Como el archivo a ejecutar lo hemos guardado en el escritorio, debemos navegar
hasta él. El escritorio suele estar en/home/tu_usuario/Escritorio. Con el
comando ls ya hemos visto que aparece la carpeta Escritorio dentro de nuestra
carpeta personal.
Usamos el comando cd para navegar por los directorios. Por ejemplo, si estamos
en /home/comu y queremos ir a/home/comu/Escritorio ejecutaremos cd Escritorio
Nota: Los terminales de comandos Unix (Linux) distinguen entre letras mayúsculas
y minúsculas, así que si ejecutas "cd escritorio" te dará un error porque está mal
escrito.
Ya estamos en la carpeta Escritorio. Si por algún motivo quisiéramos salir de esta
carpeta y volver al directorio anterior usaríamos el comando cd ..
Ahora ejecutamos ls para comprobar que el archivo que buscamos está aquí:

Pág
ina6
0
Img. 05 Comando ―ls -l‖
Vemos que en la carpeta Escritorio hay una imagen en formato png, varios
lanzadores (accesos directos .desktop) y el archivo ejecutable que queremos
instalar. Para ejecutarlo, simplemente escribimos ./ y el nombre del archivo, en
nuestro caso ./RealPlayer11.bin
El resultado: Se ejecutará el archivo (en este caso es un instalador y tendremos
que seguir las instrucciones que nos aparezcan para que se instale el programa
correctamente).
Img. 06 Instalación

Pág
ina6
1
Antes de acabar: Para ejecutar un archivo como administrador debes ejecutarlo
con la orden sudo antes del comando. O sea: sudo ./RealPlayer11.bin
Suele ser conveniente instalar los programas como administrador para que se
instalen para todos los usuarios del sistema y no solo para el tuyo (para trabajar
todo el rato como administrador ejecuta sudo su). Por otro lado, debes tener
cuidado y no ejecutar como administrador los archivos que no sean de confianza,
ya que estos pueden tener acceso a todo tu sistema operativo, pudiéndolo poner
en peligro.
Administración de recurso
3.6.1. Cuentas de usuario, grupos, permisos, servicios de impresión.
2 Usuarios y grupos.
Un usuario Unix representa tanto a una persona (usuario real) como a
una entidad que gestiona algún servicio o aplicación (usuario lógico o
ficticio) [2]
se corresponde con un identificador único (UID) y con una cuenta, donde
se almacenan sus datos personales en una zona de disco reservada.
Un grupo es una construcción lógica –con un nombre y un identificador
(GID) únicos– usada para conjuntar varias cuentas en un propósito común
[1], compartiendo los mismos permisos de acceso en algunos recursos.
Cada cuenta debe estar incluida como mínimo en un grupo de usuarios,
conocido como grupo primario o grupo principal.
2.1. Características generales de una cuenta.
Las características que definen la cuenta de un usuario son:
• Tiene un nombre y un identificador de usuario (UID) únicos en el
sistema.
• Pertenece a un grupo principal.
• Puede pertenecer a otros grupos de usuarios.
• Puede definirse una información asociada con la persona propietaria
de la cuenta.
• Tiene asociado un directorio personal para los datos del usuario.
• El usuario utiliza en su conexión un determinado intérprete de
mandatos, donde podrá ejecutar sus aplicaciones y las utilidades del
sistema operativo.

Pág
ina6
2
• Debe contar con una clave de acceso personal y difícil de averiguar
por parte de un impostor.
• Tiene un perfil de entrada propio, donde se definen las
características iniciales de su entorno de operación.
• Puede tener una fecha de caducidad.
• Pueden definirse cuotas de disco para cada sistema de archivos.
• Es posible contar con un sistema de auditoria que registre las
operaciones realizadas por el usuario.
Ficheros del sistema.
Linux proporciona varios métodos para la definir los usuarios que pueden
conectarse al sistema. Lo típico es definir localmente en cada servidor las
cuentas de los usuarios y grupos, aunque también pueden usarse métodos
externos de autentificación, que permiten que varias máquinas compartan las
mismas definiciones para sus usuarios comunes.
La siguiente tabla muestra los ficheros del sistema involucrados en el
proceso de definición de los usuarios locales.
Formato Descripción
/etc/passwd
Usuario:x:UID:GID:Descrip:Direct:Shell..
. Fichero principal de descripción de
usuarios locales. Sus campos son:
1. Nombre de usuario.
2. No usado (antiguamente,clave).
3. Identificador de usuario (UID).
4. Identificador del grupo primario.
/etc/shadow
Usuario:clave:F1:N1:N2:N3:N4:Caduc:.
..
Fichero oculto que incluye la codificación y las restricciones de las
claves de
acceso a las cuentas. Sus campos son:
1. Nombre de usuario.
2. Clave codificada.
3. Fecha del último cambio de clave.
4. Días hasta que la clave pueda ser cambiada.
5. Días para pedir otro cambio de clave.
6. Días para avisar del cambio de la clave.

Pág
ina6
3
/etc/group
Grupo:x:GID:Usuarios...
Contiene la definición de los grupos de usuarios. Sus campos son:
1. Nombre del grupo.
2. No usado (antiguamente, clave del grupo).
3. Identificador del grupo (GID).
4. Lista de miembros (separada por comas).
/etc/gshadow
Grupo:Clave:Admins:Usuarios...
Fichero oculto y opcional que contiene las claves de Grupos privados
campos son:
1. Nombre del grupo.
2. Clave codificada (opcional).
3. Lista de usuarios administradores.
4. Lista de usuarios normales.
Permisos.
Uno de los elementos principales de la seguridad en Unix es el buen uso de
los permisos para acceder a ficheros y directorios. Todo usuario –no sólo el
administrador– debe tener claros los conceptos más básicos para evitar
que otro usuario lea, modifique o incluso borre datos de interés [4]
.
El usuario administrador –al tener el control completo del sistema–
también puede realizar operaciones sobre los ficheros y directorios de
cualquier usuario (técnica que puede ser utilizada para evitar que un
usuario pueda acceder a su propio directorio personal).
Este hecho hace imprescindible que los responsables de la máquina
tengan especial cuidado cuando utilicen la cuenta del usuario root.
Los permisos de acceso se dividen principalmente en dos categorías:
• permisos normales,
• permisos especiales.
Por otro lado, los permisos también se subdividen en tres grupos:
• permisos para el propietario,
• permisos para su grupo de usuarios,
• permisos para el resto de usuarios del sistema,
Las listas de control de acceso (ACL) permiten asignar permisos de
forma específica a conjuntos de usuarios y grupos.

Pág
ina6
4
Permisos normales.
Cada usuario tiene un nombre de conexión único en el ordenador y pertenecerá a
uno o varios grupos de usuarios. El propietario de un fichero o directorio puede
seleccionar qué permisos desea activar y cuales deshabilitar.
Para comprobarlo de manera más clara, tómese el primer grupo de valores
obtenidos con el mandato ls -l, que permitirá observar los permisos. Estos 11
caracteres indican:
• 1 carácter mostrando el tipo: fichero (-), directorio (d), enlace (l),
tubería (p), enlace simbólico (l), etc.
• 3 caracteres para los permisos del propietario.
• 3 caracteres para los permisos de otros usuarios del grupo.
• 3 caracteres para los permisos del resto de usuario.
• 1 carácter opcional que indica si hay definida una ACL.
Según el tipo de entrada del directorio, los caracteres de permisos normales
pueden variar de significado:
Ficheros: Lectura (r): el usuario puede leer el fichero.
Escritura (w): el usuario puede escribir en el fichero.
Ejecución (x): el usuario puede ejecutar el fichero (siempre que sea un ejecutable o un guión de intérprete de mandatos).
Directorios: Lectura (r): el usuario puede leer el contenido del directorio. Escritura
(w): el usuario puede crear, modificar y borrar entradas del directorio. Acceso (x):
el usuario puede acceder al directorio y puede usarlo como directorio actual
(ejecutando la orden cd).
Este permiso posibilita proteger cierta información
de un directorio padre y, sin embargo, acceder a la
información de los directorios hijos.
Permisos normales Valor octal
Notación
simbólica
Propietario: Lectura 400
u+r Escritura 200 u+w
Ejecución / Acceso 100
u+x Grupo: Lectura 40 g+r
Escritura 20 g+w
Ejecución / Acceso 10 g+x
Resto de usuarios: Lectura 4
o+r Escritura 2 o+w
Ejecución / Acceso 1 o+x

Pág
ina6
5
Permisos especiales Valor octal
Notación
simbólica
Propietario: Usuario activo (SUID) 4000 u+s
Grupo: Grupo activo (SGID) 2000 g+s
Resto de usuarios: Directorio de
intercambio
1000 +t
Cambiando permisos con chmod:
Lo más habitual es utilizar el comando chmod para administrar permisos, del
siguiente modo:
[chmod] [modo] [permisos] [fichero/s]
Como modo sólo veremos elmoro '-R', para cambiar los permisos de un modo
recursivo dentro
de los directorios.
[albertux@debian]$ chmod -R 755 mi_directorio
[albertux@debian]$ ls -l
[albertux@debian]$
drwxr-xr-x 2 albertux albertux 4096 2007-07-13 13:57 mi_directorio
Otra manera de añadir o quitar permisos, será utilizando estos modos:
a Indica que se aplicará a todos.(all)
u Indica que se aplicará al usuario. (user)
g Indica que se aplicará al grupo.(grupo)
o Indica que se aplicará a otros.(otero)
+ Indica que se añade el permiso.
- Indica que se quita el permiso.
r Indica permiso de lectura.
w Indica permiso de escritura.
x Indica permiso de ejecución

Pág
ina6
6
4.1.1. Interoperabilidad
Interoperabilidad entre servidores heterogéneos.
Los diferentes casos de interoperabilidad pueden caracterizarse mediante tres
dimensiones básicas:
-Servidor de Aplicaciones (CORBA, J2EE, .NET).
-Rol del sistema (cliente o servidor).
-Tipo de interacción (sincrónica, asíncrona).
Asimismo, para cada caso, se pueden analizar propiedades tales como: si es un
mecanismo nativo, si sigue un estándar o es ad-hoc, si traslada contexto transaccional del
cliente al servidor, nivel de robustez.
En este artículo se analizan diferentes casos y se describen las experiencias de
interoperabilidad consistentes en cruzamientos de invocaciones cliente/servidor,
sincrónicas y asíncronas, entre las plataformas CORBA, J2EE y Microsoft, utilizando los
productos CORBA Orbacus, J2EE JBoss, y Microsoft .NET. La Tabla 1 resume las
opciones analizadas para invocaciones sincrónicas. Se marca con (*) las opciones
implementadas.
Tabla 1. Opciones de Interoperabilidad Sincrónica
Cliente
Servidor
Microsoft .NET CORBA J2EE
MS .NET Nativa (*) No analizado Web Services (*).
JCA.
Adaptadores
propietarios.
CORBA No analizado Nativa (*) RMI sobre IIOP (*)
J2EE Web Services (*).
Adaptadores
propietarios.
RMI sobre IIOP (*). Nativa (*)
Img. 01 Interoperabilidad Sincrónica
La Tabla 2 resume las opciones analizadas para invocaciones asíncronas. Se marca con
(*) las opciones implementadas.
Tabla 2. Opciones de Interoperabilidad Asíncrona
Cliente

Pág
ina6
7
Cliente
Servidor
Microsoft .NET CORBA J2EE
MS .NET Nativa (*) No analizado Web Services + ASIX.
CORBA No analizado Nativa (*) Gateway(*)
J2EE Web Services (*).
Gateway(*) Nativa (*)
Img. 02 Interoperabilidad Asíncrona
Interoperabilidad entre J2EE y Microsoft .NET.
La interoperabilidad entre J2EE y .NET puede ser resuelta de diferentes formas. Las dos
opciones más estandarizadas son los Web Services y los J2EE Connector Architecture
(JCA), descriptos en la sección anterior. Otras opciones son los adaptadores propietarios,
por ejemplo ActiveX Bridge y Ja.NET. ActiveX Bridge permite el acceso desde
componentes COM a EJBs en el servidor de aplicaciones IBM WebSphere. Ja.NET es un
producto que provee un puente entre el mundo Java y .NET y es propietario de
INTRINSYC.
En el contexto planteado de conexión J2EE-.NET, los Web Services presentan las
siguientes ventajas: (i) Puede utilizarse en conexiones sobre HTTP, lo cual lo hace
utilizable para conexiones a través de Internet; (ii) permite interacción tanto sincrónica
como asíncrona; (iii) son multilenguaje; (iv) tienen un nivel de desarrollo y compromiso
empresarial muy importante en múltiples plataformas.
Esto se traduce, por ejemplo, en la disponibilidad de herramientas de desarrollo. Como
desventaja principal de los Web Services, se destaca que no incluye, al momento, control
de transacciones y de seguridad. Por su parte los JCA, presentan como ventaja principal
que incluyen mecanismos de control de transacciones y seguridad, compatibles con los
de J2EE.
Como desventajas de JCA se señalan: (i) desarrollo prácticamente nulo en plataforma
Microsoft y especialmente .NET. (ii) Mecanismo fuertemente basado en Java. En
resumen, en la disyuntiva de elegir entre Web Services y JCA, se deben tener en
consideración los siguientes factores: (i) Uso exclusivo en red local vs. abierto a Internet.
Mientras que en el primer caso los JCA serían una opción aplicable, el segundo lleva a
usar http, y por lo tanto Web Services. (ii) Sistemas centrados en Java y/o J2EE vsmulti-
plataforma/lenguaje. El primer caso sería abordable con JCA, mientras que el segundo
lleva a usar Web Services como forma de hacer portable y transparente los mecanismos
de interoperabilidad. Los otros tipos de conectores presentan como ventajas el hecho de
estar desarrollados específicamente para resolver la interacción J2EE con Microsoft, y
como desventaja principal la falta de estandarización.

Pág
ina6
8
La opción de Servidor J2EE y Cliente .NET se implementó publicando un Web Service
sobre el servidor J2EE. Para esto se exportó una clase de J2EE como un Web Service
(Figura 2). Para realizar la implementación se utilizó la herramienta JBuilder 7, que genera
en forma automática los componentes necesarios. Entre esos componentes generados
está el archivo WSDL, que permite importar las funcionalidades del Web Service desde un
cliente, lo cual es fácilmente realizable desde la plataforma .NET.
4.1.2 Neutralidad tecnológica
En referencia al proyecto estudio que propone ―la revisión del software libre en las
reparticiones públicas‖, que fue presentado últimamente en el congreso nacional por un
senador y donde el ministro de obras públicas realizó un lobby para rechazar dicha
petición. Me gustaría entregar algunas apreciaciones personales en cuanto al concepto de
neutralidad tecnológica que fue usado como argumentación para rechazar la iniciativa.
Vamos a la primera pregunta: Si existe neutralidad tecnológica, ¿ Por qué no hay una ley
que exija al comercio nacional vender computadores con alternativas de software libre ?.
Este punto es bastante importante, ya que prácticamente se obliga a algunos
consumidores y/o empresas a pagar por licencias de software que no serán usadas, creo
que esta es una práctica de dominio abusivo de las grandes empresas hacia los
consumidores. Cada día son más las personas y empresas que compran un computador
o notebook con licencias de sistemas operativos que no usarán, la primera acción que
realizan después de la compra es cambiar el sistema operativo a uno libre. Si el
consumidor por ejemplo exige comprar un notebook sin licencia, no podrá comprar ese
notebook, esto debido a todo el comercio en el país vende notebook con licencia, luego
donde está la neutralidad. -Señor empresario que usa software libre, usted está pagando
licencias que no usa-.
4.2 Intercambio de archivos Es una red de computadoras en los que todos y algunos aspectos funcionan sin clientes,
ni servidores fijos, sino una serie de nodos que se comportan como iguales entre si. Es
decir, actúan simultáneamente como clientes y servidores respecto a los demás nodos.
Las redes P2P permiten el intercambio directo de información, en cualquier formato entre
los ordenadores interconectados.
Normalmente este tipo de redes se implementan como redes superpuestas construidas en
la capa de aplicación de redes públicas como Internet. El hecho de que sirvan para
compartir a intercambiar información de forma directa entre dos o más usuarios ha
propiciado que parte de los usuarios lo utilicen para intercambiar archivos cuyo contenido
está sujeto a leyes de copyright lo que ha generado una gran polémica entre defensores y
detractores de estos sistemas.

Pág
ina6
9
Las redes peer to peer aprovechan, administran y optimizan el uso del ancho de la banda
de los demás usuarios de la red por medio de la conectividad entre los mismos y
obtienen así mas rendimiento en las conexiones y transferencias que con
algunos métodos centralizados convencionales, donde una cantidad relativamente
pequeña de servidores provee el total del ancho de banda y recursos compartidos para un
servicio o aplicación.
Los ficheros a compartir de cualquier tipo (audio, vídeo, software, texto, etc.) Este tipo de
red también suele usarse en telefónica voip para hacer más eficiente la transmisión de
datos en tiempo real.
4.2.2 Formato de archivos abiertos
Diremos que un formato de archivo es abierto si el modo de representación de sus datos
es transparente y/o su especificación está disponible públicamente. Los formatos abiertos
son, ordinariamente, estándares determinados por autoridades públicas o instituciones
internacionales cuyo objetivo es establecer normas para interoperabilidad de software. No
obstante hay casos de formatos abiertos promovidos por compañías que eligen hacer la
especificación de los formatos usados por sus productos disponibles públicamente.
Debería notarse que un formato abierto puede ser codificado en una forma transparente
(leíble en cualquier editor de texto: este es el caso de lenguajes marcados) o en forma
binaria (no leíble en un editor de texto pero enteramente decodificable una vez que las
especificaciones del formato son conocidas).
La definición actual y más aceptada de sistemas abiertos es un entorno que implementa
especificaciones lo suficientemente amplias para interfaces, servicios y formatos de datos
auxiliares a fin de que todas las aplicaciones adecuadamente diseñadas:
· Permitan transferencia ("porting") sin cambios o cambios mínimos en una variedad de
arquitecturas de equipo
· Funcionen con aplicaciones en sistemas locales y remotos que tienen diversas
arquitecturas
Interactúen con usuarios de una manera común que permita transferir fácilmente
los conocimientos técnicos de los usuarios entre diferente arquitecturas de equipos
Las especificaciones abiertas son especificaciones mantenidas por un proceso abierto de
consenso público. Contienen generalmente normas internacionales a medida que son
adoptadas. También pueden contener especificaciones formuladas por empresas o
consorcios privados cuando el mantenimiento de la especificación se transfiere a un
proceso con consenso o control público.
Las influencias para contribuir en la dirección del entorno de sistemas abiertos son
variadas. Estas influencias se clasifican en cuatro categorías principales:
· Estándares de jure - Los estándares de jure son producidos por un grupo con
condición jurídica, y emanan de una institución del gobierno o una organización
internacional reconocida. Para crear el estándar, el grupo de jure debe seguir un proceso
abierto que permite a todos participar para llegar al consenso. Este proceso para lograr el
consenso es el más prolongado de todos los procesos de sistemas abiertos. La
Clasificación Internacional de Enfermedades de la Organización Mundial de la Salud
(CIE) es un ejemplo de estándar de jure.

Pág
ina7
0
· Consorcios - Desde 1988 se han formado muchos consorcios de sistemas abiertos. Los
consorcios son generalmente organizaciones sin fines de lucro financiadas por miembros
con un interés común en definir algún aspecto del entorno de los sistemas abiertos. Los
consorcios a menudo incorporan estándares de facto y de jure existentes; luego
abordan otras necesidades de los usuarios con un proceso abierto. En este proceso, los
miembros definen los perfiles y los estándares para áreas sin estándares de facto o de
jure. El Nivel de Salud 7 (Health Level 7 o HL7), por ejemplo, es un ejemplo de las normas
para formato de los mensajes de datos de los proveedores de asistencia sanitaria.
· Proveedores de tecnología - Los proveedores de tecnología en realidad producen una
tecnología utilizable (código fuente) para un entorno de sistemas abiertos con la
incorporación de especificaciones de facto, de jure y otras de consorcios existentes
4.2.3 Formatos de archivos estándares iso. Es un archivo que posee una copia idéntica de determinado sistema de archivos. Es decir que podría haber imágenes iso producidas en base a copias de una partición de un disco duro, de un diskette, de una memoria usb, o de un CD o DVD, aunque este último caso es el más común, dado que suelen distribuirse vía Internet imágenes completas de s.o. u otro tipo de software. VENTAJAS Es evitar la pérdida de datos o la modificación de la estructura del sistema de archivos tal como era el original. Es un método excelente para conservar un CD o DVD, hasta que puedas volcarlo en un disco grabable. Sirve para combatir el problema del espacio físico. FUNCIÓN Puede quemarse en DVD-R/RW O CD-R/RW depende del tamaño del archivo. Se conoce como imagen, ya que al ser insertado tiene una especie de directorios que le indican al equipo desde que parte del volumen comenzar.
4.3 Recursos remotos
Hablamos de recursos remotos o de reda los que tiene disponible otra máquina en la red.
En el gráfico siguiente, si me sitúo en PC1, tendré como recursos locales las carpetas,
programas, etc. del ordenador en el que trabajo, en cambio podré utilizar la impresora
(recurso remoto) conectada en PC2, si ese recurso se comparte.
4.3.1 Impresión
Es una parte del software que convierte los datos a imprimir al formato específico de una
impresora. El propósito de un controlador es permitir a las aplicaciones imprimir
dejándoles aparte de los detalles técnicos de cada modelo de impresora.
En Windows, los drivers de las impresoras hacen uso de GDI (basado en PostScript) o
XPS. Las aplicaciones usan los mismos Apis para imprimir tanto por pantalla como en
papel. Las impresoras que usan GDI nativamente son comúnmente llamadas Winprinters
y son incompatibles con otros sistemas operativos.

Pág
ina7
1
A la hora de compartir una impresora el proceso es el mismo que es de una carpeta,
primero se instala la impresora en el equipo como local. Seguidamente se comparte,
IMPRESORA/ botón derecho COMPARTIR. Se establece desde la ficha SEGURIDAD los
permisos que se consideran a los usuarios. Desde los equipos que pertenezcan a la
misma red se puede agregar dicha impresora y así usarla para imprimir. Si la impresora
esta enchufada a un equipo, para que los demás equipos puedan imprimir, éste tiene que
estar encendido, y mientras imprime se ralentiza el funcionamiento del equipo.
4.3.2 Escritorio remoto
Se trata de la interfaz gráfica desde la cual podemos manejar de forma remota un equipo,
como si estuviésemos sentados frente a la máquina.
Pues precisamente la que su nombre indica. Desde poder conectarse a equipos de una
misma red local (máquinas con pocos recursos (terminales tontos), poder prescindir de
más de un monitor y periféricos conectados o simplemente la comodidad de administrarlo
desde uno solo.
Hasta iniciar sesión en equipos a los que no se tiene acceso físico a través de la Red, y
trabajar con ellos como uno local.
4.3.3 Rpc (remote procedure call)
En Unix es posible tener en ejecución un programa en C con varias funciones que pueden
ser llamadas desde otros programas. Estos otros programas pueden estar corriendo en
otros ordenadores conectados en red.
Supongamos, por ejemplo, que tenemos un ordenador muy potente en cálculo
matemático y otro con un buen display para gráficos. Queremos hacer un programa con
mucho cálculo y con unos gráficos "maravillosos". Ninguno de los dos ordenadores
cumple con ambos requisitos. Una solución, utilizando RPC (Llamada a procedimientos
remotos), consiste en programar las funciones matemáticas en el ordenador de cálculo y
publicar dichas funciones.
Estas funciones podrán ser llamadas por el ordenador gráfico, pero se ejecutarán en el
ordenador de cálculo. Por otro lado, hacemos nuestros gráficos en el ordenador gráfico y
cuando necesitemos algún cálculo, llamamos a las funciones del ordenador de cálculo.
4.4 Acceso a sistemas archivos
Un sistema de archivos ( file system ) es una estructura de directorios con algún tipo de
organización el cual nos permite almacenar, crear y borrar archivos en diferenctes
formatos. En esta sección se revisarán conceptos importantes relacionados a los sistemas
de archivos.
Métodos de acceso en los sistemas de archivos

Pág
ina7
2
Los métodos de acceso se refiere a las capacidades que el subsistema de archivos
provee para accesar datos dentro de los directorios y medios de almacenamiento en
general. Se ubican tres formas generales: acceso secuencial, acceso directo y acceso
directo indexado.
Acceso secuencial: Es el método más lento y consiste en recorrer los componentes de un
archivo uno en uno hasta llegar al registro deseado. Se necesita que el orden lógico de
los registros sea igual al orden físico en el medio de almacenamiento. Este tipo de acceso
se usa comunmente en cintas y cartuchos.
Acceso directo: Permite accesar cualquier sector o registro inmediatamente, por medio de
llamadas al sistema como la de seek. Este tipo de acceso es rápido y se usa comúnmente
en discos duros y discos o archivos manejados en memoria de acceso aleatorio. _ Acceso
directo indexado: Este tipo de acceso es útil para grandes volúmenes de información o
datos. Consiste en que cada arcivo tiene una tabla de apuntadores, donde cada
apuntador va a la dirección de un bloque de índices, lo cual permite que el archivo se
expanda a través de un espacio enorme. Consume una cantidad importante de recursos
en las tablas de índices pero es muy rápido.
4.4.1. Acceso a formatos de disco (fat-16/fat-32/vfat/ntfs/xfs/extfs)
El primer sistema de archivos en ser utilizado en un sistema operativo de Microsoft fue el
sistema FAT, que utiliza una tabla de asignación de archivos.
La tabla de asignación de archivos es en realidad un índice que crea una lista de
contenidos del disco para grabar la ubicación de los archivos que éste posee. Ya que los
bloques que conforman un archivo no siempre se almacenan en el disco en forma
contigua (un fenómeno llamado fragmentación), la tabla de asignación permite que se
mantenga la estructura del sistema de archivos mediante la creación de vínculos a los
bloques que conforman el archivo. El sistema FAT es un sistema de 16 bits que permite la
identificación de archivos por un nombre de hasta 8 caracteres y tres extensiones de
caracteres. Es por esto que el sistema se denomina FAT16. Para mejorar esto, la versión
original de Windows 95 (que usa el sistema FAT16 ) se lanzó al mercado con una
administración FAT mejorada en la forma del sistema VFAT(Virtual FAT [FAT Virtual] ).
VFAT es un sistema de 32 bits que permite nombres de archivos de hasta 255caracteres
de longitud. Sin embargo, los programadores tenían que asegurar una compatibilidad
directa para que los entornos (DOS) de 16 bits aún pudieran acceder a estos archivos.
Por ende, la solución fue asignar un nombre para cada sistema. Por esta razón se pueden
usar nombres extensos de archivos en Windows 95 y, aun así, acceder a ellos en DOS. El
sistema de archivos FAT es un sistema de 16 bits. Esto implica que las direcciones de
clúster no pueden ser mayores a 16 bits. El número máximo de clústers al que se puede
hacer referencia con el sistema FAT es, por consiguiente, 216(65536) clústers. Ahora
bien, ya que unclúster se compone de un número fijo (4,8,16,32,...) de sectores de 512
bytes contiguos, el tamaño máximo de la partición FAT se puede determinar multiplicando
el número de clústers por el tamaño de un clúster. Con clústers de 32Kb, el tamaño
máximo de una partición es, porlo tanto, de 2GB.Además, un archivo sólo puede ocupar

Pág
ina7
3
un número integral de clústers. Esto significa que si un archivo ocupa varios clústers, el
último solamente estará ocupado en forma parcial y no se podrá utilizar el espacio
disponible. Como resultado, cuanto menor sea el tamaño del clúster, menor será el
espacio desperdiciado. Se estima que un archivo desecha un promedio de medio clúster,
lo cual significa que en una partición de 2 GB, se perderán 16KB por archivo.
FAT-32
Aunque el VFAT era un sistema inteligente, no afrontaba las limitaciones de FAT16. Como
resultado, surgió un nuevo sistema de archivos en Windows 95 OSR2 (el cual no sólo
contaba con una mejor administración FAT como fue el caso de VFAT). Este sistema de
archivos, denominado FAT32 utiliza valores de 32 bits para las entradas FAT. De hecho,
sólo se utilizan28 bits, ya que 4 bits se reservan para su uso en el futuro. Cuando surgió el
sistema de archivos FAT32, el máximo número de clústers por partición aumentó de
65535 a 268.435.455 (228-1). Por lo tanto, FAT32 permite particiones mucho másgrandes
(hasta 8 terabytes). Aunque en teoría, el tamaño máximo de una partición FAT32 esde 8
TB, Microsoft lo redujo, voluntariamente, a 32 GB en los sistemas 9x de Windows para
promover NTFS (ref.:http://support.microsoft.com/default.aspx?scid=kb;en;184006). Ya
que una partición FAT32 puede contener muchos clústers más que una partición FAT16,
es posible reducir significativamente el tamaño de los clústers y, así, limitar también el
espacio desperdiciado del disco. Por ejemplo, con una partición de 2 GB, es posible usar
clústers de4KB con sistemas FAT32 (en lugar de clústers de 32KB con sistemas FAT16),
que reducen el espacio desperdiciado por un factor de 8.El intercambio radica en que
FAT32 no es compatible con las versiones de Windows previas alOEM Service Release 2.
Un sistema que arranque con una versión anterior simplemente noverá este tipo de
particiones. Asimismo, las utilidades de administración de un disco de 16 bits, como ser
versiones antiguasde Norton Utilities, ya no funcionarán correctamente. En términos de
realización, el uso de unsistema FAT32 en lugar de un sistema FAT16 tendrá como
resultado una leve mejora, de aproximadamente 5%, en el rendimiento.
¿Sistemas de archivos FAT16 o FAT32?
Debido a que el número de clústers es limitado, el tamaño máximo de una partición
depende del tamaño de cada clúster. Veamos el tamaño máximo de la partición según el
tamaño del clúster y el sistema de archivos utilizado:

Pág
ina7
4
Img. 03 Interoperabilidad Asíncrona
Al formatear un disco rígido, deberá decidir el tipo de sistema de archivos que utilizará y
seleccionar el que le brinde el espacio disponible más cercano al tamaño que desea.
VFAT
(Virtual File Allocation Table - Tabla virtual de asignación de archivos). Controlador virtual
del sistema de archivos que puede instalarse en Windows Workgroups y Windows 95. La
VFAT es una interfaz entre las aplicaciones y la FAT. Opera en modo protegido de 32
bits(presente en los Intel 386 y superiores) y provee acceso de alta velocidad para la
manipulación de archivos. También tiene soporte para nombres largos de hasta 255
caracteres.
NTFS
NTFS es el sistema de archivos preferido para esta versión de Windows. Tiene muchos
beneficios respecto al sistema de archivos FAT32, entre los que se incluye:
capacidad de recuperarse a partir de algunos errores relacionados con el disco
automáticamente, lo que FAT32 no puede hacer.
sos y cifrado para restringir el acceso a
archivos específicos para usuarios aprobados
El sistema de ficheros NTFS se introdujo con la primera versión de Windows NT,y es
totalmente distinto de FAT. Provee de mucha mas seguridad, compresión fichero por

Pág
ina7
5
fichero y encriptación. Es el sistema de ficheros por defecto para nuevas instalaciones
como Windows XP o 2000, y si vas a actualizar una versión previa de Windows, se te
preguntará si quieres convertir tu sistema de ficheros NTFS. Puedes convertir FAT16 o
FAT32 a NTFS en cualquier momento. El problemas era volver atrás ya que tendrías que
reformatear el disco y será algo más complicado. Las ventajas que tiene sobre FAT son
sobre todo la forma de tratar las estructuras de datos para mejorar el rendimiento, la
fiabilidad y el uso del espacio en disco. Las mejoras de seguridad incluyen el soporte de
listas de acceso. NTFS utiliza una tabla de ficheros maestra (MFT) para localizar todos los
ficheros dentro de un volumen NTFS. Todos los datos críticos son duplicados para
permitir recuperación en caso de errores, asegurandose de que la perdida en un sector no
significará la perdida de toda la partición. También puede recuperar datos de un sector
dañado y asegurar de que ese sector no sea usado de nuevo.
XFS
Es un sistema de archivos de 64 bits con journaling de alto rendimiento creado por SGI
(antiguamente Silicon Graphics Inc.) para su implementación de UNIX llamada IRIX. En
mayo de 2000, SGI liberó XFS bajo una licencia de código abierto.
XFS se incorporó a Linux a partir de la versión 2.4.25, cuando Marcelo Tosatti
(responsable dela rama 2.4) lo consideró lo suficientemente estable para incorporarlo en
la rama principal dedesarrollo del kernel.Los programas de instalación delas distribuciones
de SuSE, Gentoo, Mandriva,Slackware, FedoraCore, Ubuntu y Debian ofrecen XFS como
un sistema de archivos más. En FreeBSD el soporte para solo-lectura de XFS se añadió a
partir de diciembre de 2005 y en junio de 2006 un soporte experimental de escritura fue
incorporado a FreeBSD-7.0-CURRENT
HISTORIA
XFS es el más antiguo de los sistema de archivos con journaling disponible para la
plataforma UNIX, tiene un código maduro, estable y bien depurado. Su desarrollo lo
comenzó en 1993 la compañía Silicon Graphics Inc., y apareció por primera vez en el IRIX
5.3 en 1994.El sistema de archivos fue liberado bajo la GNU General Public License en
mayo de 2000 y posteriormente portado a GNU/Linux, apareciendo por primera vez en
una distribución entre el2001 y el 2002.
Capacidad
XFS soporta un sistema de archivos de hasta 9 exabytes,aunque esto puede variar
dependiendo de los límites impuestos por el sistema operativo.En sistemas GNU/Linux de
32 bits, el límite es 16 terabytes.
Grupos de asignación
Los sistemas de archivos XFS están particionados internamente en grupos de asignación,
que son regiones lineares de igual tamaño dentro del sistema de archivos. Los archivos y
los directorios pueden crear grupos de asignación. Cada grupo gestiona sus inodos y su
espacio libre de forma independiente, proporcionando escalabilidad y
paralelismo múltiples hilos pueden realizar operaciones de E/S simultáneamente en el
mismo sistema de archivos.

Pág
ina7
6
Extfs
Se trata del driver que permite leer y escribir discos formateados EXT2 o EXT3 e incluso
formatearlos con la Utilidad de Discos. Viene de perlas para los que tienen que compartir
discos con equipos Linux o que tienen discos multimedia que usan este formato (el Dune,
por ejemplo).
4.4.2 Herramientas para el acceso a formatos de disco.
Expandir volúmenes.
Haga clic en Iniciar, en el cuadro de búsqueda, teclee mmc y presione intro.
Img. 04 Inicio Windows
Puede que se le requiera la Contraseña de Administrador.
Con la consola de mmc abierta, haga clic en Archivo, Agregar/Quitar Complementos.
Con el diálogo de Agregar y Quitar Complementos, haga clic en Administración de
Equipos y haga clic en Agregar. En el siguiente cuadro de diálogo, asegúrese de que el
equipo local está seleccionado y haga clic en Finalizar. Haga clic en Aceptar.
Expanda Administración del Equipo, expanda Almacenamiento y haga clic en
Administración de Discos.
Img. 05 Administración de discos
Seleccione la partición que desea expandir. (Recuerde que para poder expandir una
partición usted necesita espacio libre adicional en el mismo disco).
Haga clic con la derecha en la partición y haga clic en Extender Volumen.

Pág
ina7
7
En mi ejemplo, voy a expandir mi ―C-Drive‖ con los 9.77 GB de espacio restantes que no
están asignados en mi disco.
Img. 06 Expandir volumen
El diálogo del Asistente para Extender Volúmenes se inicia. Haga clic en Siguiente.
Seleccione el disco que desea extender y seleccione la cantidad de espacio de disco en la
que quiere expandirlo.
Img. 07 Seleccionar disco

Pág
ina7
8
El Diálogo de Finalización del Asistente para extender volúmenes aparece en pantalla.
Haga clic en Finalizar.
Img. 08 Particiones actuales
Su disco está ahora expandido.
Reducir Volúmenes.
Reducir volúmenes es tan fácil como Extender Volúmenes. Siga estos rápidos y fáciles
pasos para reducir un volumen (o partición) en un disco existente.
Inicie la Gestión de Disco de Windows Vista tal y como vimos en Extender Volúmenes.
MMC
Haga clic con la derecha en el volumen que desea reducir y haga clic en Reducir
Volumen.
Img. 09 Reducir volumen

Pág
ina7
9
El cuadro de diálogo de Reducir aparece en pantalla. Entre la cantidad de espacio de
disco a reducir. En mi ejemplo, voy a reducir mi espacio de disco existente en C-Drive en
10GB. (10000MB). Haga clic en Reducir.
Img. 10 Tamaño de nuevo disco
El proceso de reducir empieza. Este puede llevar varios minutos dependiendo del tamaño
del disco y el tamaño a reducir. En mi ejemplo de 10GB en un disco de 120GB, el proceso
tardó menos de 30 segundos.
Img. 11 Nueva partición
Su disco ha sido reducido ahora en la cantidad elegida.
Convertir su disco duro o partición en NTFS.
Siga estos rápidos y fáciles pasos para convertir una partición o disco existente en
formato NTFS. Nota: Este proceso no puede ser deshecho. Usted no puede convertir
NTFS de vuelta otra vez a FAT32. Para poder convertir una partición NTFS existente a un
archivo de sistema FAT32, usted necesitará reformatear la partición (esto destruirá todos
los datos existentes en la partición).

Pág
ina8
0
4.5 Emulación del SO
Un Emulador es un programa informático que permite ejecutar en un sistema operativo
programas creados para otras plataformas. Se trata de simular mediante software una
determinada arquitectura de hardware y un determinado sistema operativo. Así, el
emulador convierte mágicamente una computadora con Windows o Linux en otro
ordenador distinto o en una consola de video-juegos.
Se han emulado con éxito las primeras computadoras personales que llegaron al
mercado, como Sinclair, Commodore o Amstrad entre otros muchos, así como consolas
de Atari o Nintendo. Pero también se han conseguido emular los sistemas de las
máquinas recreativas antiguas con la posibilidad de jugar a miles de juegos exactamente
iguales a los que se podían encontrar en los salones recreativos.
También se ha creado software que permite a cualquiera convertir los juegos originales en
archivos ROM que pueden ser ejecutados por el emulador. Si posees los juegos
originales pero no quieres hacer tú mismo la conversión desde los discos, cintas de
cassette o cartuchos, puedes buscar en la red y descargar los ficheros ROM. Lo primero que necesitas es descargar algún emulador e instalarlo en tu sistema. Al
pulsar en el botón, según los casos, iniciarás la descarga directa del archivo o se te abrirá
una ventana con la página de los creadores, muchas están en inglés, pero sólo se trata de
seleccionar el download correspondiente a tu sistema operativo.
4.5.1. Ejecución de binarios de otros sistemas operativos
Linux soporta la carga de aplicaciones binarias de usuario desde disco. Más
interesantemente, los binarios pueden ser almacenados en formatos diferentes y la
respuesta del sistema operativo a los programas a través de las llamadas al sistema
pueden desviarla de la norma (la norma es el comportamiento de Linux) tal como es
requerido, en orden a emular los formatos encontrados en otros tipos de UNIX (COFF,
etc) y también emular el comportamiento de las llamadas al sistema de otros tipos
(Solaris, UnixWare, etc). Esto es para lo que son los dominios de ejecución y los formatos
binarios.
Cada tarea Linux tiene una personalidad almacenada en su ##task_struct## (##p-
>personality##). Las personalidades actualmente existentes (en el núcleo oficial o en el
parche añadido) incluyen soporte para FreeBSD, Solaris, UnixWare, OpenServer y
algunos otros sistemas operativos populares. El valor de ##current->personality## es
dividido en dos partes:
~1) tres bytes altos - emulación de fallos: ##STICKY_TIMEOUTS##,
##WHOLE_SECONDS##, etc.
~1) byte bajo - personalidad propia, un número único.

Pág
ina8
1
Cambiando la personalidad, podemos cambiar la forma en la que el sistema operativo
trata ciertas llamadas al sistema, por ejemplo añadiendo una ##STICKY_TIMEOUT## a
##current->personality## hacemos que la llamada al sistema select(2) preserve el valor
del último argumento (timeout) en vez de almacenar el tiempo no dormido. Algunos
programas defectuosos confían en sistemas operativos defectuosos (no Linux) y por lo
tanto suministra una forma para emular fallos en casos donde el código fuente no está
disponible y por lo tanto los fallos no pueden ser arreglados.
El dominio de ejecución es un rango contiguo de personalidades implementadas por un
módulo simple. Usualmente un dominio de ejecución simple implementa una personalidad
simple, pero a veces es posible implementar personalidades "cerradas" en un módulo
simple sin muchos condicionantes.
Los dominios de ejecución son implementados en ##kernel/exec_domain.c## y fueron
completamente reescritos para el núcleo 2.4, comparado con el 2.2.x. La lista de dominios
de ejecución actualmente soportada por el núcleo, a lo largo del rango de personalidades
que soportan, está disponible leyendo el archivo ##/proc/execdomains##. Los dominios de
ejecución, excepto el ##PER_LINUX##, pueden ser implementados como módulos
dinámicamente cargados.
La interfaz de usuario es a través de la llamada al sistema personality(2), la cual establece
la actual personalidad del proceso o devuelve el valor de ##current->personality## si el
argumento es establecido a una personalidad imposible. Obviamente, el comportamiento
de esta llamada al sistema no depende de la personalidad.
La interfaz del núcleo para el registro de dominios de ejecución consiste en dos funciones:
~- ##int register_exec_domain(struct exec_domain *)##: registra el dominio de ejecución
enlazándolo en una lista simplemente enlazada ##exec_domains## bajo la protección de
escritura del spinlock read-write ##exec_domains_lock##. Devuelve 0 si tiene éxito,
distinto de cero en caso de fallo.
~- ##int unregister_exec_domain(struct exec_domain *)##: desregistra el dominio de
ejecución desenlazándolo desde la lista ##exec_domains##, otra vez usando el spinlock
##exec_domains_lock## en modo de escritura. Retorna 0 si tiene éxito.
El motivo por el que ##exec_domains_lock## es read-write es que sólo las peticiones de
registro y desregistro modifican la lista, mientras haciendo cat /proc/filesystems llama
##fs/exec_domain.c:get_exec_domain_list()##, el cual necesita sólo acceso de lectura a
la lista. Registrando un nuevo dominio de ejecución define un "manejador lcall7" y un
mapa de conversión de número de señales. Actualmente, el parche ABI extiende este
concepto a los dominios de ejecución para incluir información extra (como opciones de
conector, tipos de conector, familia de direcciones y mapas de números de errores).

Pág
ina8
2
Los formatos binarios son implementados de una forma similar, esto es, una lista
simplemente enlazada de formatos es definida en ##fs/exec.c## y es protegida por un
cierre read-write ##binfmt_lock##. Tal como con ##exec_domains_lock##, el
##binfmt_lock## es tomado para leer en la mayoría de las ocasiones excepto para el
registro/desregistro de los formatos binarios. Registrando un nuevo formato binario
intensifica la llamada al sistema execve(2) con nuevas funciones
##load_binary()/load_shlib()##. Al igual que la habilidad para ##core_dump()##. El método
##load_shlib()## es usado sólo por la vieja llamada al sistema uselib(2) mientras que el
método ##load_binary()## es llamada por el ##search_binary_handler()## desde
##do_execve()## el cual implementa la llamada al sistema execve(2).
4.5.2. Herramientas para la ejecución de binarios
La seguridad de un sistema es más que configurar decentemente un cortafuegos y los servicios del mismo. Los binarios que se ejecutan y las librerías que se cargan pueden ser también vulnerables a los ataques. Aunque las vulnerabilidades exactas no se conocen hasta que son descubiertas, hay algunas formas de evitar que ocurran.
Un vector posible de ataque es escribir y ejecutar segmentos en un programa o librería,
permitiendo a usuarios maliciosos ejecutar su código a través de un aplicación o librería vulnerable.
Esta guía le informará acerca de cómo usar el paquete pax-utils para encontrar e identificar binarios problemáticos. También hablaremos del uso de pspax (una herramienta para ver las capacidades específicas de PaX) y de dumpelf (una herramienta que muestra una estructura C conteniendo una copia funcional de un objeto dado).
Pero antes de empezar con esto, daremos alguna información sobre objetos. Los usuarios familiarizados con los segmentos y el enlazado dinámico no aprenderán nada en la siguiente sección y pueden continuar con la sección Extraer información ELF de los binarios.
Objetos ELF
Todos los binarios ejecutables de su sistema están estructurados de una forma determinada, permitiendo al núcleo Linux cargar y ejecutar el fichero. Realmente esto se aplica a más objetos que los binarios ejecutables planos: esto también sirve para los objetos compartidos, hablaremos de esto más adelante.
La estructura de estos binarios se define en el estándar ELF. El acrónimo ELF significa Formato Ejecutable y Enlazable. Si está interesado en los detalles internos, eche
un vistazo a la Especificación Genérica de ELF o a la página del manual elf(5).

Pág
ina8
3
Un ejecutable ELF consta de las siguientes partes:
La cabecera ELF contiene información del tipo de fichero (si es un ejecutable, una
librería compartida,...), la arquitectura destino, la localización en el fichero de la Cabecera del Programa, Cabecera de Sección y de la Cabecera de las Cadenas de Texto así como la localización de la primera instrucción ejecutable.
La Cabecera del Programa informa al sistema acerca de cómo debe crear un
proceso desde el fichero binario. Realmente se trata de una tabla que contiene entradas para cada segmento del programa. Cada entrada contiene el tipo, direcciones (físicas y virtuales), tamaño, derechos de acceso,...
La Cabecera de Sección es una tabla que contiene una entrada para cada sección
en el programa. Cada una de estas entradas contiene el nombre, tipo, tamaño,... así como la información que contiene la sección.
Datos, conteniendo las secciones y segmentos mencionados arriba.
Una sección es una pequeña unidad que contiene datos específicos: instrucciones, datos variables, tabla de símbolos, información de relocalización y demás. Un segmento es una colección de secciones. Los segmentos son unidades que son transferidas a la memoria.
Objetos compartidos
Antiguamente, las aplicaciones binarias contenían todo lo que necesitaban para operar de forma correcta. Estos binarios se denominaban binarios enlazados estáticamente. Éstos consumían mucho espacio debido a que las aplicaciones utilizaban las mismas funciones una y otra vez.
Un objeto compartido contiene la definición e instrucciones para esas funciones. Cada aplicación que las necesita puede enlazar dinámicamente este objeto compartido de forma que puede beneficiarse de la funcionalidad ya existente.
Una aplicación que está enlazada dinámicamente con un objeto compartido contiene símbolos, referencias a la funcionalidad real. Cuando se carga esta aplicación en
memoria, en primer lugar pedirá la enlazador dinámico que resuelva todos y cada uno de los símbolos que tiene definidos. El enlazador dinámico cargará el objeto compartido apropiado en memoria y resolverá las referencias simbólicas entre ellos.
Segmentos y secciones
El modo en que se revisa el fichero ELF, depende de la vista que tengamos del mismo: cuando estamos tratando con un fichero binario en Vista de Ejecución, el fichero ELF contiene segmentos. Cuando el fichero está en Vista de Enlazado, el fichero contiene secciones. Un segmento se extiende una o más secciones (continuas).

Pág
ina8
4
2. Extraer información ELF de los binarios
La aplicación scanelf
La aplicación scanelf es parte del paquete app-misc/pax-utils. Con esta aplicación se puede mostrar información específica de la estructura del binario ELF. La siguiente tabla resume las distintas opciones.
Opción Opción larga
Descripción
-p --path Escanea todos los directorios en el entorno PATH
-l --ldpath Escanea todos los directorios en /etc/ld.so.conf
-R --recursive Escanea los directorios de forma recursiva
-m --mount No salirse de los puntos de montaje cuando se escanee de forma recursiva
-y --symlink No escanear enlaces simbólicos
-A --archives Escanear archivos (ficheros .a)
-L --ldcache Utiliza la información de ld.so.cache (usar con -r/-n)
-X --fix Intentar corregir aquello que vaya 'mal' (usar con -r/-e)
-z [arg] --setpax [arg]
Ajustar EI_PAX/PT_PAX_FLAGS a [arg] (usar con -Xx)
Opción Opción larga
Descripción
-x --pax Imprimir marcas PaX
-e --header Imprimir marcas GNU_STACK/PT_LOAD
-t --textrel Imprimir información TEXTREL
-r --rpath Imprimir información RPATH
-n --needed Imprimir la información NEEDED
-i --interp Imprimir información INTERP
-b --bind Imprimir información BIND
-S --soname Imprimir información SONAME

Pág
ina8
5
-s [arg] --symbol [arg]
Buscar el símbolo especificado
-k [arg] --section [arg]
Encontrar la sección especificada
-N [arg] --lib [arg] Encontrar la librería especificada
-g --gmatch Usar strncmp para cotejar librerías (usar con -N)
-T --textrels Localizar la causa de TEXTREL
-E [arg] --etype [arg] Imprimir solo aquéllos ficheros ELF que coinciden con ET_DYN, ET_EXEC ...
-M [arg] --bits [arg] Imprimir solo los ficheros que coinciden con los bits numéricos indicados
-a --all Imprime toda la información escaneada (-x -e -t -r -b)
Opción Opción larga
Descripción
-q --quiet Solo muestra aquello que va 'mal'
-v --verbose Salida ampliada (se puede especificar más de una vez)
-F [arg] --format [arg]
Usar un formato específico para la salida
-f [arg] --from [arg] Leer la entrada desde un fichero
-o [arg] --file [arg] Escribir la salida a un fichero
-B --nobanner No mostrar la cabecera
-h --help Imprimir esta ayuda y salir
-V --version Imprimir la versión y salir
Img. 12 Aplicación Scanelf

Pág
ina8
6
Los especificadores de formato para la opción -F se muestran en la siguiente tabla. Anteponga un carácter % (salida ampliada) o # (salida silenciosa) a cada especificador a su antojo.
Especificador Nombre completo Especificador Nombre completo
F Nombre de fichero x Ajustes PaX
e STACK/RELRO t TEXTREL
r RPATH n NEEDED
i INTERP b BIND
s Símbolo N Librería
o Tipo p Nombre del fichero
f Base del nombre del fichero
k Sección
a ARCH/e_machine
Img. 13 Especificadores
4.6 Virtualización
Virtualización es la técnica empleada sobre las características físicas de algunos recursos
computacionales, para ocultarlas de otros sistemas, aplicaciones o usuarios que
interactúen con ellos. Esto implica hacer que un recurso físico, como un servidor, un
sistema operativo o un dispositivo de almacenamiento, aparezca como si fuera varios
recursos lógicos a la vez, o que varios recursos físicos, como servidores o dispositivos de
almacenamiento, aparezcan como un único recurso lógico.
Por ejemplo, la virtualización de un sistema operativo es el uso de una aplicación de
software para permitir que un mismo sistema operativo maneje varias imágenes de los
sistemas operativos a la misma vez.
Esta tecnología permite la separación del hardware y el software, lo cual posibilita a su
vez que múltiples sistemas operativos, aplicaciones o plataformas de cómputo se ejecuten
simultáneamente en un solo servidor o PC según sea el caso de aplicación.
Hay varias formas de ver o catalogar la virtualización, pero en general se trata de uno de
estos dos casos: virtualización de plataforma o virtualización de recursos.
todos sus componentes (los cuales no necesariamente son todos los de la máquina física)
y prestarle todos los recursos necesarios para su funcionamiento. En general, hay un

Pág
ina8
7
software anfitrión que es el que controla que las diferentes máquinas virtuales sean
atendidas correctamente y que está ubicado entre el hardware y las máquinas virtuales.
Dentro de este esquema caben la mayoría de las formas de virtualización más conocidas,
incluidas la virtualización de sistemas operativos, la virtualización de aplicaciones y la
emulación de sistemas operativos.
vistos como uno solo, o al revés, dividir un recurso en múltiples recursos independientes.
Generalmente se aplica a medios de almacenamiento. También existe una forma de
virtualización de recursos muy popular que no es sino las redes privadas virtuales o VPN,
abstracción que permite a un PC conectarse a una red corporativa a través de la Internet
como si estuviera en la misma sede física de la compañía.
VENTAJAS DE LA VIRTUALIZACION
Los usuarios serán provistos con dos o más ambientes de trabajo completamente
independientes entre sí según se requiera. Si se manejan dos como en la mayoría de los
casos, un ambiente de trabajo sería abierto para que usuarios hagan efectivamente en él
lo que quieran, agregando dispositivos e instalando cualquier software que elijan. El
segundo ambiente estaría cerrado o restringido; es decir, donde el usuario solo tendría
acceso a lo que es crítico para la organización y sus negocios. De esta forma, si el primer
ambiente sufre una caída o colapso, el segundo ambiente sigue trabajando haciendo que
el negocio no pare.
En caso de que la organización constantemente ocupe estar cambiando de aplicaciones
por cuestiones de su negocio, la virtualización permite conservar los mismos equipos
terminales o de trabajo, y realizar todos los cambios de versiones y plataformas vía un
entorno virtual izado en la red y teniendo como fuente al servidor.
DESVENTAJAS DE LA VIRTUALIZACION
El uso de la virtualización representa conflictos con el licenciamiento que aplican los
fabricantes de software. El software de virtualización representa un desafío para los tipos
de licencia por usuario existentes actualmente, por lo cual es probable que cambien las
reglas respecto al licenciamiento de software. Claro está que su instalación y
administración requiere de personal calificado en TI, mas su uso puede ser transparente
para un usuario promedio corporativo.
En fechas próximas veremos algunas herramientas de virtualización, esto para aquellas
organizaciones que consideren implementar esta práctica tecnológica, como parte de su
estrategia de negocios y operación

Pág
ina8
8
4.6.2 Herramientas para emulación de hardware
Una de las últimas herramientas de emulación de sistemas operativos que han aparecido
es VirtualBox. Este tipo de herramientas permiten crear un PC virtual dentro de un PC real
para poder instalar en él uno o varios sistemas operativos que serán totalmente
independientes del sistema operativo real, y así poder trabajar con ellos.
VirtualBox es desarrollado por la empresa InnoTek. Hay dos versiones: una personal
(VirtualBox Open Source Edition) que es totalmente open source y otra para empresas
(VirtualBox) que por el momento es gratuita pero no permite el acceso al código y
necesita una licencia especial. La versión con licencia tiene una serie de características
exclusivas:
• Soporte para USB
• Soporte para escritorio remoto (Remote Desktop Protocol, RDP).
• USB sobre RDP.
• Carpetas compartidas.
El sistema operativo anfitrión de VirtualBox puede ser tanto Windows 32-bit como Linux
32-bit aunque para poder ejecutar VirtualBox en Linux es necesario instalar una serie de
librerías adicionales, en concreto, libxalan-c, libxerces-c y la versión 5 de libstdc++. La
versión de VirtualBox para MAC está en desarrollo en fase pre-alfa así que de momento
los "maqueros" tendrán que esperar un tiempo para disfrutar de este emulador de PC.
En concreto, los sistemas operativos anfitriones Windows o Linux pueden ser:
• Windows 2000, service pack 3 y superiores.
• Windows XP, todos los service packs.
• Windows Server 2003.
• Debian GNU/Linux 3.1 (sarge) y etch.
• Fedora Core 4 y 5.
• Gentoo Linux.
• Redhad Enterprise Linux 3 y 4.
• SUSE Linux 9 y 10.
• Ubunto 5.10 (Breezy Badger), 6.06 (Dapper Drake), 6.10 (Edgy Eft)
Los sistemas operativos que se pueden emular con VirtualBox son Windows (3.x, 95, 98,
ME, NT 4.0, 2000, XP, Server 2003, Vista), Linux (2.2, 2.4 y 2.6), OS/2, NetBSD,
FreeBSD, OpenBSD, Netware, Solaris y L4. Debe quedar claro que se tiene que disponer
de licencia, en caso de ser necesario, y de los CDs de instalación para los sistemas
operativos que se quieren emular con VirtualBox o con cualquier otra herramienta de
virtualización.
Requisitos mínimos de instalación
Para poder crear máquinas virtuales con VirtualBox que emulen uno o varios sistemas
operativos se necesitan una serie de requisitos:
• Un procesador x86 razonablemente potente. Cualquier procesador AMD o Intel
reciente puede valer.
• Dependiendo del sistema operativo que se pretenda emular se necesitará más o
menos memoria RAM. Para hacer un cálculo aproximado se necesitan al menos 512 MB
para el sistema operativo anfitrión más la cantidad que necesite el sistema operativo a

Pág
ina8
9
instalar. Se puede instalar disponiendo de menos memoria aunque en este caso el
rendimiento se verá disminuido.
• El espacio en disco que ocupa VirtualBox es pequeño, por ejemplo, la versión para
Windows ocupa alrededor de 45 MB, aunque los sistemas operativos a emular pueden
requerir bastante espacio en disco, del orden de GB.

Pág
ina9
0
Práctica No. 1 Probar 30 comandos en consola (los más
comunes)
Img. 01 Comando ls
Img. 02 Comando history, pwd

Pág
ina9
1
Img. 03 Comando who, uname –m, uname –s, uname –n, uname –r, uname -v
Img. 04 Comando ps

Pág
ina9
2
Img. 05 Comando uptime, hwclock –show, hostname
Img. 06 Comando top

Pág
ina9
3
Img. 07 Comando pstree
Img. 08 Comando uname –a, free

Pág
ina9
4
Img. 09 Comando apt-get install tree
Img. 10 Comando nano

Pág
ina9
5
Img. 11 Comando df
Img. 12 Comando ls

Pág
ina9
6
Img. 13 Comando ls
Img. 14 Comando tree
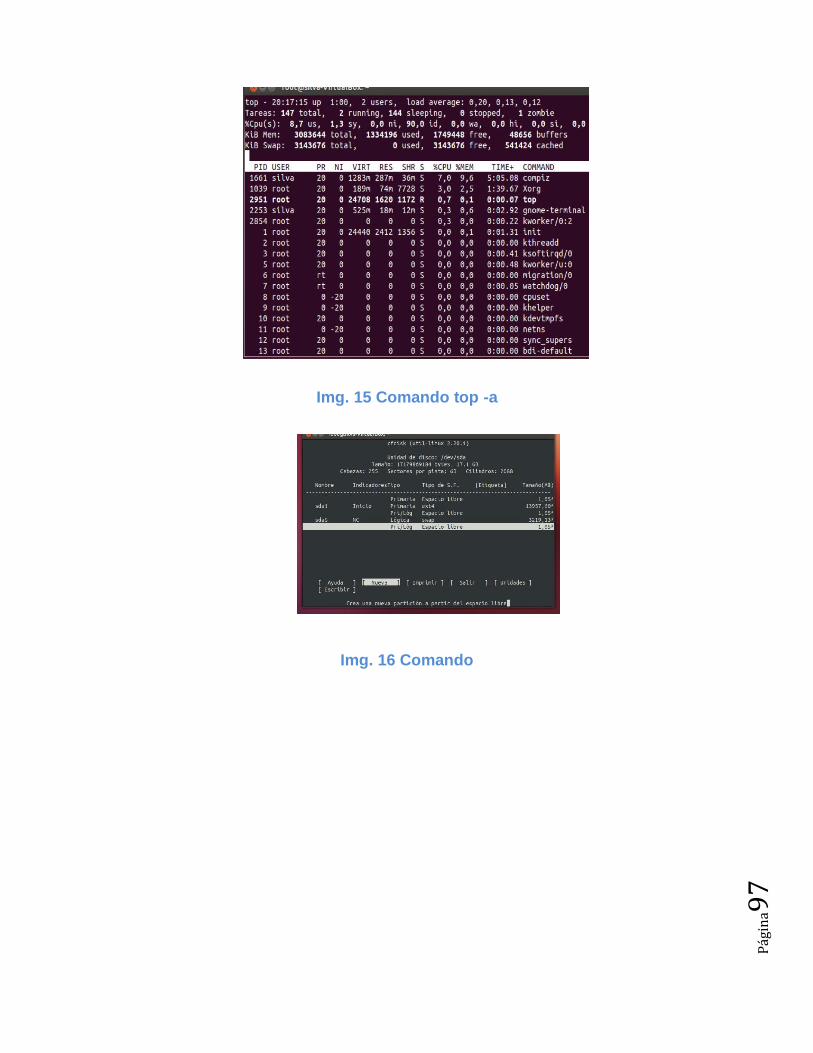
Pág
ina9
7
Img. 15 Comando top -a
Img. 16 Comando

Pág
ina9
8
Practica 2 mapa conceptual para software libre y para software con licencia
Img. 01 Software con licencia
Img. 02 Software libre

Pág
ina9
9
Comparación entre los Sistemas Operativos libres y los
de licencia
Los sistemas operativos con licencia son muy buenos, en el aspecto
gráfico y en que todo lo hacen ver muy fácil, esta sería su mayor
ventaja, obviamente que para los que lo utilizan para las cosas
básicas, y al no tener conocimientos sobre comandos, no se les hace
muy amigable.
Pero si nos vamos a lo nuestro, obviamente son mejores los libres,
tienen un mejor rendimiento, soportan más procesos a la vez, si se
cuenta con experiencia amplia en programación podemos
estructurarlo a nuestra manera, todo lo que se hace en un sistema
con licencia se hace con un sistema libre, tal vez no es tan llamativa
la Shell pero esta es la herramienta más poderosa de todo sistema
operativo.

Pág
ina1
00
Práctica 3 Probar los comandos vistos en clases. 1.- $touch prueba | crea un nuevo archivo ¿Qué ha sucedido? Comprueba el cometido del mandato ―touch‖ por medio de ―man touch‖ (o ―info touch‖). | Nos muestra información sobre el comando..
2.- ls -l Vamos a comprobar ahora el tipo de fichero a que corresponde ―prueba‖. Ejecuta el mandato ―ls -l‖. De los 10 caracteres primeros que obtienes en su descripción (-rw-r--r--), el primero (-) corresponde con el tipo de fichero. En este caso corresponde a un archivo, donde el usuario tiene permiso de lectura
y escritura, el grupo solo permiso de lectura y otros también solo de lectura.
3.- file prueba Un mandato util en Linux que nos permite saber qué tipo de fichero tenemos delante es el mandato file. Ejecuta el mandato ―file prueba‖. ¿Qué información te ha facilitado sobre el fichero? Que el archivo está vacío o en blanco
5.- nano prueba Ejecuta nano sobre el fichero prueba (nano prueba). Cambia su contenido. Apunta ahora el resultado de realizar ―file prueba‖.
ASCII text
6.- wget Vamos ahora a capturar una página web por medio del mandato ―wget‖. Puedes ejecutar ―man wget‖ para saber algo más sobre este mandato. Ejecuta: $wget

Pág
ina1
01
7.- ls -l Observa (por medio de ―ls -l‖ o por medio del entorno de ventanas) que en tu escritorio ha aparecido un fichero de nombre ―index.html‖ (o ―index.htm‖) que corresponde con la página de inicio de tu sitio web. Vamos a ejecutar sobre el mismo el mandato: $file index.html ¿Qué respuesta obtienes?
8.- /home/alumno ls -l Otro elemento típico del sistema de ficheros de Linux son los directorios. En Linux los directorios es tan implementados de manera interna como archivos que contienen listas de archivos. Sitúate en tu carpeta de inicio (/home/alumno o directamente ~). Ejecuta el mandato: $ls –l
Qué tipo de fichero es Escritorio (cuál es la primera letra de su descripción)? Comprueba su significado en http://en.wikipedia.org/wiki/Unix_file_types. Ejecuta también el mandato: $file Escritorio .Que respuesta has obtenido? Es un directorio Por último, ejecuta el mandato: $stat Escritorio Apunta el número de enlaces (fuertes) que existen a Escritorio.
Acceso: (0755/drwxr/-xr-x) Uid: (1000/ silva) Gid: (1000/ silva)
Acceso: 2013-02-27 21:06:35.573599957 -0600
Modificacion 2013-02-26 20:46:15.555980858- 0600

Pág
ina1
02
9.- -silva index.html Una aplicación que puede ser útil para encontrar ficheros en los sistemas Linux es ―find‖. Puedes ejecutar ―man find‖ para aprender algo más sobre la misma. El mandato ―find‖ debe tener privilegios para poder acceder a las distintas carpetas de nuestro sistema. Si quieres buscar un fichero en todo el sistema, deberias usarlo con ―sudo‖. Si solo quieres buscar un fichero en tu directorio personal, lo anterior no es necesario. Ejecuta los mandatos: $find /home/alumno –name index
.Que salida has obtenido? $sudo find / -name gnomine
10.- ln –s /usr/games/gnomine enl_debil_gnomine Los dos tipos de ficheros anteriores (ficheros normales y directorios) no son los unicos que podemos encontrar en un sistema Linux. En la practica anterior ya vimos cómo crear enlaces débiles y fuertes a un fichero. Desde el Escritorio crea un enlace débil al fichero ―/usr/games/gnomine‖. $ln –s /usr/games/gnomine enl_debil_gnomine En el mismo Escritorio ejecuta ahora los mandatos: $file enl_debil_gnomine

Pág
ina1
03
Apunta el resultado obtenido $ls –l $stat enl_debil_gnomine Localiza la informacion referente a los permisos del fichero. 11.- ls –l | less Otros dos tipos de ficheros bastante comunes en los sistemas Linux son los dispositivos de bloques y de caracteres. Los mismos se utilizan para representar algunos dispositivos hardware tales como discos duros o tarjetas de sonido, o también las propias terminales del sistema. Dirígete a la carpeta ―/dev‖. Ejecuta el mandato:

Pág
ina1
04
12.- ls –l | less Apunta algunos de los dispositivos cuyo nombre reconozcas (―tty…‖ corresponde con terminales, ―sd…‖ corresponde con los dispositivos de almacenamiento 13.- ls -l Muévete al escritorio. Crea un fichero ―mensaje‖ y escribe en el mismo un texto sencillo. Crea también tres ficheros de texto f1, f2 y f3 con el contenido que quieras. Comprueba con ―ls -l‖ los permisos que han sido asignados a cada uno de los ficheros.

Pág
ina1
05
14.- chmod o-rwx f1 f2 f3 Deniega al ―resto de usuarios‖ todos los permisos sobre f1, f2 y f3. $chmod o-rwx f1 f2 f3 (El carácter ―-‖ se utiliza para quitar los permisos, el carácter ―+‖ para asignarlos). Comprueba con ―ls -l‖ los cambios ocurridos.
15.- chmod ugo-rx f1 Deniega a todos los usuarios los permisos de lectura y ejecución de f1. $chmod ugo-rx f1 (tambien es posible chmod a-rx f1) Comprueba con ―ls -l‖ que el cambio ha tenido lugar. Intenta acceder al fichero (por ejemplo con less). Apunta el resultado. 16.- chmod u+r f1 Concede permiso de lectura al propietario de f1: $chmod u+r f1 Comprueba que el cambio ha tenido lugar. Trata de ejecutar ―less f1‖ y anota el resultado.

Pág
ina1
06
17.- nano Comprueba el permiso de escritura del propietario de f1. Asegurate de que no lo tiene (si lo tiene elimínalo). Trata de editar el fichero por medio de nano y apunta el resultado. 18.- chmod Concede, con un solo mandato, permisos de lectura y ejecución y deniega el de escritura sobre f1 y f2 al grupo y al propietario, sin modificar el del resto de usuarios. 19.- chmod ug+rx,ug-w,o-rwx mensaje Concede, con un solo mandato, permisos de lectura y ejecución, y deniega el permiso de escritura sobre ―mensaje‖ al grupo y al propietario, y deniega todos los permisos al resto de usuarios. Una posibilidad sería la siguiente, pero puedes explorar otras: $chmod ug+rx,ug-w,o-rwx mensaje

Pág
ina1
07
20.- less Deniega todos los permisos a todos los usuarios sobre el fichero ―mensaje‖. Intenta ejecutar el fichero. Apunta el resultado. 21.- chmod ug+r, ugo+wx Concede el permiso de lectura al propietario y al grupo de mensaje, el de escritura y ejecucion al propietario y al resto de usuarios, y deniega el resto de permisos. Comprueba el resultado. 22.- ls -l Sobre el fichero mensaje, concede lectura y escritura al propietario, ejecucion al grupo y lectura y ejecucion a otros, denegando el resto de permisos.

Pág
ina1
08
23.- cd /home/silva/ Crea en tu escritorio tres directorios (mkdir) llamados dir1, dir2 y dir3. Dentro de cada uno de ellos crea un fichero con el contenido que desees, de nombres fich11, fich22 y fich33. Copia en dir3 el fichero mensaje. Puedes comprobar por medio de ―ls -lR‖ la estructura de directorios de que dispones ahora. 24.- chmod a-r dir1 Deniega a todos los usuarios (puedes abreviarlo con ―a‖) el permiso de lectura de dir1, el de escritura de dir2 y el de búsqueda (ejecucion) de dir3. Comprueba que la operación se ha completado con éxito (ls -l). 25.- ls -l Trata de listar el contenido del directorio dir1. Apunta el resultado.

Pág
ina1
09
26.- less fich11 Muévete a dir1. Muestra el contenido del fichero fich11 por medio de less. Apunta el resultado. 27.- less fich22 Sitúate en dir2 y muestra la lista de ficheros que contiene. Muestra el contenido del fichero fich22, intenta modificarlo y apunta que ha ocurrido. Intenta crear un nuevo fichero en dir2 y borrar fich22. 28.- ls dir3 Sitúate en el Escritorio. Intenta mostrar la lista de ficheros que dir3 contiene. Anota el resultado. Intenta mostrar el contenido de fich33 y crear y borrar un fichero en dir3. Apunta el resultado.

Pág
ina1
10
29.- adduser cuasi Vamos ahora a crear un nuevo usuario en nuestra máquina. Utiliza el mandato: $sudo adduser cuasi Completa los datos necesarios. 30.- chmod ug+rw,ug –x Crea un nuevo directorio dir4. Dentro del mismo crea dos ficheros fich41 y fich42. Modifica los permisos de fich41 de tal modo que el usuario y su grupo tengan permisos de lectura y escritura, y el resto de usuarios no tenga ningún permiso. 31.- su cuasi Cambia la sesión al usuario cuasi creado: $su cuasi 32.- less fich41 Comprueba y apunta el resultado al intentar leer (less) el fichero fich41.

Pág
ina1
11
33.- chown cuasi fich41 Veamos ahora cómo podemos cambiar el propietario de un fichero. Ejecuta el mandato: $chown cuasi fich41 Apunta el resultado. .Como puedes solucionarlo? Inténtalo. .Ha funcionado? Si no es así, vuelve otra vez a logarte como usuario ―alumno‖ y completa la acción. .Te ha hecho falta ahora usar ―sudo‖? 34.- less fich41 Trata de acceder ahora al fichero ―fich41‖. .Lo has conseguido? .Por qué? 35.- chgrp cuasi fich41 Cambia el grupo de pertenencia del fichero fich41 a ―cuasi‖ por medio del mandato: $chgrp cuasi fich41 (Quizá debas usar ―sudo‖ para completar el mandato anterior). Trata de acceder de nuevo al fichero fich41 con less. .Lo ha conseguido? 36. Logate como cuasi. Trata de acceder al fichero. .Lo has conseguido?

Pág
ina1
12
37.- umask a-rwx El mandato umask nos permite definir una máscara de usuario que se aplicara a todos los ficheros que se creen a partir de que la máscara sea definida. Puedes encontrar informacion sobre el mismo en http://es.wikipedia.org/wiki/Umask. Ejecuta la siguiente mascara: $umask a-rwx Crea un nuevo fichero fich43. Comprueba los permisos que se han asignado al mismo. 38.- umask a-r Crea una nueva mascara tal que solo el propietario tenga acceso (lectura) a los nuevos ficheros. Crea un fichero fich44 y compruébalo.

Pág
ina1
13
Práctica 4 Probar los comandos vistos en clases
1.- Man: Es el paginador del manual del sistema.
2.- Man less: El comando less nos sirve para leer un archivo
less/etc/passwd
El primero:
El último:
3.- Man ls:
Nos muestra los archivos o directorios que hay dentro de un directorio
4.-
ls –l /etc/passwd
Nos muestra la información(detallada) sobre los permisos
5.- nano /etc/passwd
Trate de eliminar al último usuario y al guardar los cambios me marco
―permiso denegado‖
Porque estaba desde un usuario, y esto solo le pertenece al root
6.- less /ect/group
Leer el fichero group
El primero:

Pág
ina1
14
El último:
7.- adduser:
adduser cuasi crea al usuario cuasi y pide un contraseña para él. Por
defecto, se crea un grupo personal este usuario y éste será el grupo
por defecto.
useradd:
Nos permite crear un usuario y establecer sus propiedades.
8.- cat /etc/passwd /etc/group > usuario_y_grupos_linux
9.- su
Este comando nos permite cambiar de usuario obviamente que para
hacerlo nos pide la contraseña

Pág
ina1
15
10.- sudo adduser alumno2
El usuario alumno no puede crear más usuarios ya que no pertenece
al grupo admin
11.- su luis
Cambiar a usuario de grupo admin
12.- sudo usermod –a –G admin alumno
Al cambiar al alumno al grupo admin se ha convertido en un seudoer
13.- adduser
Al aser los cambios estavez si deja crear un nuevo usuario

Pág
ina1
16
14.- Reiniciar
Cambiar de usuario reiniciar la maquina
15.- passwd
Con un usuario que sea del grupo admin también puede cambiar las
contraseñas de los demás usuarios
16.- cdm
help more

Pág
ina1
17
17.- buscar un archivo con more
18.- more lee.txt
19.- Editar un archivo con edit
20.- help

Pág
ina1
18
21.- net user
22.-net localgroup

Pág
ina1
19
23.- net user cuasi /add
24.-

Pág
ina1
20
25.- net localgroup administradores
27.-net localgroup administradores ―cuasi‖ /add

Pág
ina1
21
Práctica 5 DE GESTIÓ_ DE PROCESOS
Paso 1. ¿Qué es el PID de un proceso en GNU/Linux? En linux cada proceso al ser creado tiene un número asociado que se le asigna cuando es creado. Los PIDs son números enteros únicos para todos los procesos sistema.
Paso 2. ¿Qué diferencia hay entre la opción –a y la opción –x de laorden ps? -a Muestra los procesos creados por cualquier usuario y asociados a un terminal. -x Muestra los procesos que no están asociados a ningún terminal del usuario. Útil para ver los ―demonios‖ (programas residentes) no iniciados desde el terminal.
Paso 3. ¿Qué es el número NICE de un proceso?
define la prioridad relativa de un proceso con respecto a los demás que están en la cola de procesos.
Permite al usuario modificar la prioridad de ejecución de un proceso.
¿Qué valores puede tomar el parámetro NICE? El parámetro nice puede tomar valores comprendidos entre -20 y +19.
¿Qué usuarios pueden cambiar este parámetro?
Puede ser cambiada por el dueño de un proceso o por el administrador del sistema.
Paso 4. Listar todos los archivos que contengan la cadena ―.jpg‖ dentro de la estructura de directorios del sistema. Usar la orden ls y grep.

Pág
ina1
22
Paso 5. Ejecutar otra vez la orden anterior, pero esta vez con la prioridad más baja posible.
Paso 6. Abrir otro terminal, y mientras la orden anterior se ejecuta, mediante la orden ps listar todos los procesos asociados al terminal del usuario actual y obtener el PID del proceso ls. Con la orden renice otorgar la máxima prioridad a la orden ls. Después con la orden kill terminar el proceso de la manera ―más correcta‖ posible.
Paso 7. Visualizar mediante el editor vi el archivo que contiene la información de los usuarios del sistema. Ejecutar el programa vi con la máxima prioridad posible.

Pág
ina1
23
Paso 8. En otro terminal, obtener el PID del editor vi y el PID de su proceso padre mediante la orden pstree.
Paso 9. Mediante la orden top establecer una prioridad normal al editor vi y después terminar el proceso del editor.
Paso 10. Ejecutar el navegador WEB mozilla desde el terminar en segundo plano. Indicar el número de trabajo y su PID.

Pág
ina1
24
Paso 11. Listar todos los archivos terminados en .gif del sistema de directorios del sistema y almacenarlo en el archivo todoslosgif. Ejecutar esta orden en segundo plano. Paso 12. Mediante la orden jobs listar todos los trabajos en segundo plano del terminal. Paso 13. Mirar los procesos existentes en el sistema y lanzar un proceso que dure 600 segundos en 1º plano (p.e. sleep 600) Paso 14. Mata el proceso ¿Qué observamos? ¿Aparecen los mismos procesos que al principio?

Pág
ina1
25
Paso 15. Repetimos el paso 13 y el 14, pero ahora sólo queremos detener el proceso (no cancelarlo). ¿Qué observamos? ¿Aparecen los mismos procesos que al principio? Paso 16. ¿Cómo podemos hacer para que continúe el proceso en 1º plano? ¿Se puede hacer con la orden kill? Si se puede con el kill Utilizando el singcon. Paso 17. Indica dos maneras para que un proceso detenido, continúe en 2º plano. NOTA: En lugar del comando sleep, prueba con firefox, para ver mejor el efecto Paso 18. Lanzar un proceso en 2º plano y obtener su PID. ¿Cuál es su número de trabajo y nº de proceso?

Pág
ina1
26
Paso 19. En un proceso lanzado en 2º plano ¿seguirá mostrando su salida en la pantalla desde la que se dio la orden de ejecución? Busca un ejemplo. Paso 20. Detén y vuelve a recontinuar en 2º plano un proceso lanzado en 2º plano

Pág
ina1
27
Practica No.- 6 Instalación de postgres
1. - root@luis-VirtualBox:~# apt-get install postgresql postgresql-client pgadmin3
Leyendo lista de paquetes... Hecho
Creando árbol de dependencias
Leyendo la información de estado... Hecho
El paquete indicado a continuación se instaló de forma automática y ya no es necesarios.
linux-headers-3.5.0-17
Use «apt-get autoremove» para eliminarlo.
Se instalarán los siguientes paquetes extras:
libpq5 libwxbase2.8-0 libwxgtk2.8-0 pgadmin3-data pgagent postgresql-9.1
postgresql-client-9.1 postgresql-client-common postgresql-common
Paquetes sugeridos:
libgnomeprintui2.2-0 postgresql-contrib oidentd ident-server locales-all
postgresql-doc-9.1
Se instalarán los siguientes paquetes NUEVOS:
libpq5 libwxbase2.8-0 libwxgtk2.8-0 pgadmin3 pgadmin3-data pgagent
postgresql postgresql-9.1 postgresql-client postgresql-client-9.1
postgresql-client-common postgresql-common
0 actualizados, 12 se instalarán, 0 para eliminar y 331 no actualizados.
Se necesita descargar 13,6 MB de archivos.
Se utilizarán 44,1 MB de espacio de disco adicional después de esta operación.
¿Quiere continuar [S/n]? s
Des:1 http://mx.archive.ubuntu.com/ubuntu/ quantal-updates/universe libwxbase2.8-0
amd64 2.8.12.1-11ubuntu3.1 [593 kB]
Des:2 http://mx.archive.ubuntu.com/ubuntu/ quantal-updates/universe libwxgtk2.8-0
amd64 2.8.12.1-11ubuntu3.1 [3.272 kB]
Des:3 http://mx.archive.ubuntu.com/ubuntu/ quantal-updates/main libpq5 amd64 9.1.9-
0ubuntu12.10 [78,0 kB]

Pág
ina1
28
Des:4 http://mx.archive.ubuntu.com/ubuntu/ quantal/universe pgadmin3-data all 1.14.2-2
[3.957 kB]
Des:5 http://mx.archive.ubuntu.com/ubuntu/ quantal/universe pgadmin3 amd64 1.14.2-2
[2.350 kB]
Des:6 http://mx.archive.ubuntu.com/ubuntu/ quantal/universe pgagent amd64 3.2.1-1 [39,3
kB]
Des:7 http://mx.archive.ubuntu.com/ubuntu/ quantal/main postgresql-client-common all
136 [25,5 kB]
Des:8 http://mx.archive.ubuntu.com/ubuntu/ quantal-updates/main postgresql-client-9.1
amd64 9.1.9-0ubuntu12.10 [711 kB]
Des:9 http://mx.archive.ubuntu.com/ubuntu/ quantal/main postgresql-common all 136 [96,1
kB]
Des:10 http://mx.archive.ubuntu.com/ubuntu/ quantal-updates/main postgresql-9.1 amd64
9.1.9-0ubuntu12.10 [2.478 kB]
Des:11 http://mx.archive.ubuntu.com/ubuntu/ quantal/main postgresql all 9.1+136 [5.468
B]
Des:12 http://mx.archive.ubuntu.com/ubuntu/ quantal/main postgresql-client all 9.1+136
[5.482 B]
Descargados 13,6 MB en 2min. 45seg. (82,1 kB/s)
2. - root@luis-VirtualBox:/# psql --version
psql (PostgreSQL) 9.1.9
3. - root@luis-VirtualBox:/# sudo su postgres -c "psql template1"
psql (9.1.9)
Type "help" for help.

Pág
ina1
29
template1=# ALTER USER postgres WITH PASSWORD 'lesm';
ALTER ROLE
template1=# \q
4.- root@luis-VirtualBox:/# sudo su postgres -c passwd
Introduzca la nueva contraseña de UNIX:
Vuelva a escribir la nueva contraseña de UNIX:
passwd: contraseña actualizada correctamente
5.- root@luis-VirtualBox:/# cd /etc/postgresql/9.1/main/
6.- root@luis-VirtualBox:/etc/postgresql/9.1/main# ls
environment pg_hba.conf postgresql.conf
pg_ctl.conf pg_ident.conf start.conf
7.- root@luis-VirtualBox:/etc/postgresql/9.1/main# nano postgresql.conf
8.- root@luis-VirtualBox:/etc/postgresql/9.1/main# sudo service postgresql restart
* Restarting PostgreSQL 9.1 database server [ OK ]
root@luis-VirtualBox:/etc/postgresql/9.1/main#

Pág
ina1
30
Practica No.- 7 Crear una base de datos (Postgres)
1.- luis@luis-VirtualBox:~$ su postgres
Contraseña:
2.- postgres@luis-VirtualBox:/home/luis$ psql biblioteca
psql (9.1.9)
Type "help" for help.
3.- biblioteca=# select * from usuario;
id_usuario | nombre_usuario | domicilio | ciudad | tel_user
------------+----------------+-----------+--------+----------
(0 rows)
4.-biblioteca=# insert into usuario values(0937,'Rubén','Vicente Guerrero
s/n','Oaxaca',2354678);
INSERT 0 1
5.- biblioteca=# insert into usuario values(1009,'Fernando','Matamoros
#15','Oaxaca',5073456);
INSERT 0 1
6.- biblioteca=# select * from usuario;
id_usuario | nombre_usuario | domicilio | ciudad | tel_user
------------+----------------+----------------------+--------+----------
937 | Rubén | Vicente Guerrero s/n | Oaxaca | 2354678
1009 | Fernando | Matamoros #15 | Oaxaca | 5073456
(2 rows)
7.- biblioteca=# insert into usuario values(1235,'Nadia','Calle caporales 5ta
etapa','Quintana-roo',6709874);
INSERT 0 1

Pág
ina1
31
8.- biblioteca=# insert into usuario values(3645,'Valeria','Armenta y López
#9','Puebla',5142315);
INSERT 0 1
9.- biblioteca=# insert into usuario values(6775,'José','JP. García #45','D.F',5098364);
INSERT 0 1
10.- biblioteca=# insert into usuario values(7214,'Joaquín','Mier y Terán
#987','Yucatán',4597875);
INSERT 0 1
11.- biblioteca=# insert into usuario values(8756,'Lourdes','Crespo
#496','Puebla',0976253);
INSERT 0 1
12.- biblioteca=# insert into usuario values(9571,'Lupita','And. Juchatengo mza.
69','D.F',7878564);
INSERT 0 1
13.- biblioteca=# insert into usuario values(9873,'Oscar','Av. Hidalgo
#105','Guerrero',8997834);
INSERT 0 1
14.- biblioteca=# insert into usuario values(9875,'Roberto','And. Rio Tlapaneco mza.
70','Tlaxcala',4543526);
INSERT 0 1
15.- biblioteca=# select * from usuario;
id_usuario | nombre_usuario | domicilio | ciudad | tel_user
------------+----------------+----------------------------+--------------+----------
937 | Rubén | Vicente Guerrero s/n | Oaxaca | 2354678
1009 | Fernando | Matamoros #15 | Oaxaca | 5073456
1235 | Nadia | Calle caporales 5ta etapa | Quintana-roo | 6709874
3645 | Valeria | Armenta y López #9 | Puebla | 5142315
6775 | José | JP. García #45 | D.F | 5098364
7214 | Joaquín | Mier y Terán #987 | Yucatán | 4597875

Pág
ina1
32
8756 | Lourdes | Crespo #496 | Puebla | 976253
9571 | Lupita | And. Juchatengo mza. 69 | D.F | 7878564
9873 | Oscar | Av. Hidalgo #105 | Guerrero | 8997834
9875 | Roberto | And. Rio Tlapaneco mza. 70 | Tlaxcala | 4543526
(10 rows)
---------------------------------------------------------------
16.- insertar datos en libro
17.-biblioteca=# insert into libro values(00001,'Cien años de soledad','Gabriel García
Márquez','Plaza & Janes S.A.','1975');
INSERT 0 1
18.-biblioteca=# insert into libro values(00002,'La catedral','César
Malloquí','SM','2000');
INSERT 0 1
19.- biblioteca=# insert into libro values(00003,'El Aleph','Jorge Luis
Borges','Losada','1949');
INSERT 0 1
20.- biblioteca=# insert into libro values(00004,'Rayuela','Julio cortázar','Alfaguara y
el Diario Clarín','2004');
INSERT 0 1
21.- biblioteca=# insert into libro values(00005,'Viaje al centro de la tierra','Julio
Verne','Santillana','2004');
INSERT 0 1
22.- biblioteca=# insert into libro values(00006,'Pedro Paramo','Juan
Rulfo','Biblioteca escolar de plaza y Janes','1955');
INSERT 0 1

Pág
ina1
33
23.-biblioteca=# insert into libro values(00007,'Moby Dick','Herman
Melville','SM','1986');
INSERT 0 1
24.- biblioteca=# insert into libro values(00008,'Los Miserables','Victor Marie
Hugo','Hugo,V','2006');
INSERT 0 1
25.- biblioteca=# insert into libro values(00009,'Las batallas en el desierto','José
Emilio Pacheco','Txalaparta','2001');
INSERT 0 1
26.- biblioteca=# insert into libro values(00010,'Las aventuras de Sherlock
Holmes','Sin Arthur Consan Doyle','Anaya','1990');
INSERT 0 1
biblioteca=#
id_libro | nombre_libro | autor | editorial |
fecha_edi
----------+----------------------------------+-------------------------+-------------------------------------+-------
----
1 | Cien años de soledad | Gabriel García Márquez | Plaza & Janes S.A.
| 1975
2 | La catedral | César Malloquí | SM | 2000
3 | El Aleph | Jorge Luis Borges | Losada | 1949
4 | Rayuela | Julio cortázar | Alfaguara y el Diario Clarín |
2004
5 | Viaje al centro de la tierra | Julio Verne | Santillana |
2004
6 | Pedro Paramo | Juan Rulfo | Biblioteca escolar de plaza y
Janes | 1955
7 | Moby Dick | Herman Melville | SM | 1986
8 | Los Miserables | Victor Marie Hugo | Hugo,V |
2006

Pág
ina1
34
9 | Las batallas en el desierto | José Emilio Pacheco | Txalaparta
| 2001
10 | Las aventuras de Sherlock Holmes | Sin Arthur Consan Doyle | Anaya
| 1990
(10 rows)
-----------------------------------------------
27.- Actualizar base de datos
-------------------------------------
28.- biblioteca=# UPDATE libro SET id_libro = 00010 WHERE id_libro = 00012;
UPDATE 0
29.- biblioteca=# select * from libro;
30.- biblioteca=# UPDATE libro SET id_libro = 00012 WHERE id_libro = 00010;
UPDATE 1
31.- biblioteca=# select * from libro;
32.- biblioteca=# UPDATE libro SET id_libro = 00012 WHERE id_libro = 00010;
UPDATE libro SET id_libro = 00014 WHERE id_libro = 00009;UPDATE libro SET
id_libro = 00016 WHERE id_libro = 00008;UPDATE libro SET id_libro = 00018
WHERE id_libro = 00007;
UPDATE 0
UPDATE 1
UPDATE 1
UPDATE 1

Pág
ina1
35
33.- biblioteca=# UPDATE libro SET nombre_libro = 'trueno' WHERE nombre_libro =
'Cien años de soledad'; UPDATE libro SET nombre_libro = 'El laberinto' WHERE
nombre_libro = 'La catedral';UPDATE libro SET nombre_libro = 'Solitarios' WHERE
nombre_libro = 'Rayuela';UPDATE libro SET nombre_libro = 'Invensibles' WHERE
nombre_libro = 'Viaje al centro de la Tierra';
UPDATE 1
UPDATE 1
UPDATE 1
UPDATE 0
-------------------------------------
34.- Eliminar registros de la base de bados
-----------------------------------------
35.- biblioteca=# DELETE FROM libro WHERE editorial = 'SM'; DELETE FROM libro
WHERE autor = 'César Mallorquí';
DELETE 2
DELETE 0
biblioteca=#
---------------------------------------------------
36.- tabla modificada
-------------------------------------------------
id_libro | nombre_libro | autor | editorial |
fecha_edi
----------+----------------------------------+-------------------------+-------------------------------------+-------
----
3 | El Aleph | Jorge Luis Borges | Losada | 1949
5 | Viaje al centro de la tierra | Julio Verne | Santillana |
2004
6 | Pedro Paramo | Juan Rulfo | Biblioteca escolar de plaza y
Janes | 1955

Pág
ina1
36
12 | Las aventuras de Sherlock Holmes | Sin Arthur Consan Doyle | Anaya
| 1990
14 | Las batallas en el desierto | José Emilio Pacheco | Txalaparta
| 2001
16 | Los Miserables | Victor Marie Hugo | Hugo,V |
2006
1 | trueno | Gabriel García Márquez | Plaza & Janes S.A. |
1975
4 | Solitarios | Julio cortázar | Alfaguara y el Diario Clarín |
2004
(8 rows)

Pág
ina1
37
Compilación del kernel en Ubuntu (Adaptando el procesador
Corei7 y acelerar el tiempo de ejecución de los gráficos)
INTRODUCCION:
La siguiente configuración se realizó a la versión del kernel 3.9.4, pues es la
versión más reciente. Anteriormente contábamos con la versión:
Haremos esto para mejorar el aprovechamiento de procesadores de nueva
generación, en este caso el Core i7 de Intel, además de modificar el tiempo de
respuesta del entorno gráfico y por ultimo aumentaremos la frecuencia de las
interrupciones para realizar tareas de planificación.
DESARROLLO: 1.- Lo primero que debemos hacer después de habernos logueados como root es instalar los paquetes: apt-get install build-essential y kernel-package.
2.-Para obtener la otra parte del kernel, utilizamos el siguiente comando apt-get install linux-source

Pág
ina1
38
El archivo que se baja se guarda en el directorio /usr/src/ vamos a ese
directorio y tecleamos un ls
3.- Ahora vamos a descomprimir el archivo, para ello escribimos: xz -dk linux-3.9.4.tar.xz
tenemos un archivo .tar lo que significa que debemos descomprimirlo otra vez, pero ahora tecleamos. tar jxvf linux-3.9.4.tar 4.- ahora tenemos que instalar el siguiente paquete apt-get install libncurses5-dev esto es para que podamos ocupar el menuconfig

Pág
ina1
39
5.- Ahora teclearemos make menuconfig con este comando se nos mostrara la interface del kernel donde podemos modificar los parámetros del mismo, tener cuidado con lo que movemos.
6.- Aquí es donde modificaremos nuestro kernel en nuestro caso decidimos cambiar la configuración del procesador para mejorar su rendimiento de los procesadores de nueva generación para hacer esto nuestra maquina debe contar con un procesador intel core i7 Nos movemos con las teclas de dirección hasta la opción de ―Processor type and
features‖ y presiona una sola vez [ENTER].

Pág
ina1
40
7.-Llegarás a esta página en la cual haremos uno de los cambios más específicos para el procesador, como ya mencioné antes, esta optimización la haremos para el Core i7. Dirígete a la opción ―Processor family (Generic-x86-64) —>‖ y presiona [ENTER].
8.-Una vez en este punto notarás que tenemos varios procesadores para seleccionar, pon el cursor sobre la opción ―Core 2/newer Xeon‖ y oprime [ENTER]. Con esto habremos cambiado la marcha por defecto del kernel, volviéndolo de un kernel genérico a un kernel específico para un procesador, Core 2 Duo o superior, y dentro de esta categoría están también los procesadores core i3, core i5, core i7 de primera y segunda generación.

Pág
ina1
41
9.-Nos desplazamos un poco más abajo, hasta encontrar ―Preemption Model
(Voluntary Kernel Preemption (Desktop))‖ y volvemos a dar [ENTER].
10.-Una vez en esta página, seleccionamos ―Preemptible Kernel (Low-Latency Desktop)‖ y presionamos [ENTER]. En esta ocasión le estamos indicando al kernel qué tipo de respuesta esperamos de los entornos gráficos, en este caso es una respuesta de latencia baja o de modo inmediato.

Pág
ina1
42
11. – Como ultima configuración, vamos a cambiar el valor de la opción Timer frequency a 1000Hz

Pág
ina1
43
12.- Guardamos los cambios Damos [ENTER] en Ok
Salimos dando [ENTER] en Exit

Pág
ina1
44
13.- Ahora viene lo más importante tecleamos make para que comience a compilar nuestro nuevo kernel. Nos mostrara algo así. Debemos ser pacientes esto demorara un poco.
14.- Al finalizar de compilar nos mostrara algo así

Pág
ina1
45
15.- Ahora debemos compilar los módulos del kernel, para esto ocupamos el comando make modules
al final nos muestra algo así
16.- Posteriormente debemos realizar la instalación del nuevo kernel en nuestra máquina, con el comando make install al final nos muestra esto...

Pág
ina1
46
17.- Actualizamos el grub

Pág
ina1
47
18.- Reiniciamos, y ya estaremos ocupando el nuevo kernel

Pág
ina1
48
Bibliografía www.websecurity.es/centro-seguridad-windows-7
http://www.todowindows7.com/index.php/
http://aliciamayorquinvazquez.blogspot.mx/p/opcion-1.html
http://taller-so.blogspot.mx/p/unidad-1.html
http://taller-sistemas-operativos.blogspot.mx/p/unidad-1_19.html
http://taller-so.blogspot.mx/p/unidad-2_29.html
http://tallersistemasoperativosnattt.blogspot.mx/p/unidad-1.html
http://taller-so-masv93.blogspot.mx/p/unidad.html
http://tallersistemasoperativosnattt.blogspot.mx/p/unidad-3.html
http://tallerdesistemasoperativositsg.blogspot.mx/p/unidad-iii.html





























