Embed Size (px)
Citation preview

Semisupervised Learning for Computational LinguisticsNatural Language Processing Guest Lecture
Fall 2008Jason Baldridge
http://comp.ling.utexas.edu/jbaldrid

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 2
Whatʼs this story about? [Slide from Jim Martin]
17 the 13 and 10 of 10 a 8 to 7 s 6 in 6 Romney 6 Mr 5 that 5 state 5 for 4 industry 4 automotive 4 Michigan 3 on 3 his 3 have 3 are 2 would 2 with 2 up 2 think 2 technology
2 speech 2 primary 2 neck 2 is 2 further 2 fuel 2 from 2 former 2 energy 2 campaigning 2 billion 2 bill 2 at 2 They 2 Senator 2 Republican 2 Monday 2 McCain 2 He 2 Gov 1 wrong 1 who 1 upon 1 unions
1 unfunded 1 ultimately
1 trade 1 top 1 took
1 together 1 throughout
1 they 1 there 1 task
1 t 1 support
1 successive 1 standards
1 some 1 signed 1 shake
1 set 1 science
1 said 1 rise
1 research 1 requires
1 representatives 1 remarkably
1 recent 1 rebuild
1 raising 1 pushed
1 presidential 1 polls 1 policy 1 plight
1 pledged 1 plan
1 people 1 or 1 off
1 measure 1 materials 1 mandates
1 losses 1 litany
1 leading 1 leadership 1 lawmakers
1 killer 1 jobs 1 job 1 its
1 issues 1 indicated
1 independent 1 increase
1 including 1 imposing
1 him 1 heavily
1 has 1 greenhouse
1 gone 1 gas
1 future 1 forever 1 focused 1 flurry 1 fluid 1 first 1 final 1 field
1 federal 1 essentially
1 emphasizing 1 emissions 1 efficiency 1 economic
1 don 1 domestic
1 do 1 disinterested
1 die
1 development 1 delivered
1 days 1 criticized
1 could 1 costs
1 contest 1 come
1 childhood 1 cause 1 cap
1 candidates 1 by
1 bring 1 between
1 being 1 been 1 be
1 back 1 automobile 1 automakers
1 asserted 1 aiding 1 ahead 1 agenda 1 again 1 after
1 advisers 1 acknowledged
1 With 1 Washington
1 There 1 Recent
1 President 1 New 1 Mitt 1 Mike
1 Massachusetts 1 Lieberman
1 Joseph 1 John 1 Iowa
1 In 1 I
1 Huckabee 1 Hampshire 1 Economic
1 Detroit 1 Connecticut 1 Congress
1 Club 1 Bush
1 Arkansas 1 Arizona 1 America

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 3
The story [Slide from Jim Martin]
Romney Battles McCain for Michigan LeadBy MICHAEL LUO
DETROIT — With economic issues at the top of the agenda, the leading Republican presidential candidates set off Monday on a final flurry of campaigning in Michigan ahead of the state’s primary that could again shake up a remarkably
fluid Republican field.
Recent polls have indicated the contest is neck-and-neck between former Gov. Mitt Romney of Massachusetts and Senator John McCain of Arizona, with former Gov. Mike Huckabee of Arkansas further back.
Mr. Romney’s advisers have acknowledged that the state’s primary is essentially do-or-die for him after successive losses in Iowa and New Hampshire. He has been campaigning heavily throughout the state, emphasizing his childhood in Michigan
and delivered a policy speech on Monday focused on aiding the automotive industry.
In his speech at the Detroit Economic Club, Mr. Romney took Washington lawmakers to task for being a “disinterested” in Michigan’s plight and imposing upon the state’s automakers a litany of “unfunded mandates,” including a recent measure
signed by President Bush that requires the raising of fuel efficiency standards.
He criticized Mr. McCain and Senator Joseph I. Lieberman, independent of Connecticut, for a bill that they have pushed to cap and trade greenhouse gas emissions. Mr. Romney asserted that the bill would cause energy costs to rise and would
ultimately be a “job killer.”
Mr. Romney further pledged to bring together in his first 100 days representatives from the automotive industry, unions, Congress and the state of Michigan to come up with a plan to “rebuild America’s automotive leadership” and to increase
to $20 billion, from $4 billion, the federal support for research and development in energy, fuel technology, materials science and automotive technology.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Is language just bags of words?
The first slide captured the “meaning” of the text as a bag of words.
Discourse segments, sentence boundaries, syntax, word order are all ignored.
Roughly, all that matters is the set of words that occur and how often they occur.
4

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Thatʼs not the full story...
Texts are not just bags-of-words.
Order and syntax affect interpretation of utterances.
5
leg
on
manthe
dog
bit

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Thatʼs not the full story...
Texts are not just bags-of-words.
Order and syntax affect interpretation of utterances.
5
legonmanthe dogbit thethe

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Thatʼs not the full story...
Texts are not just bags-of-words.
Order and syntax affect interpretation of utterances.
5
legonmanthe dogbit thethe mandog

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Thatʼs not the full story...
Texts are not just bags-of-words.
Order and syntax affect interpretation of utterances.
5
legonmanthe dogbit thethe mandog

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Thatʼs not the full story...
Texts are not just bags-of-words.
Order and syntax affect interpretation of utterances.
5
legonmanthe dogbit thethe mandog
Subject
Object
Modifier
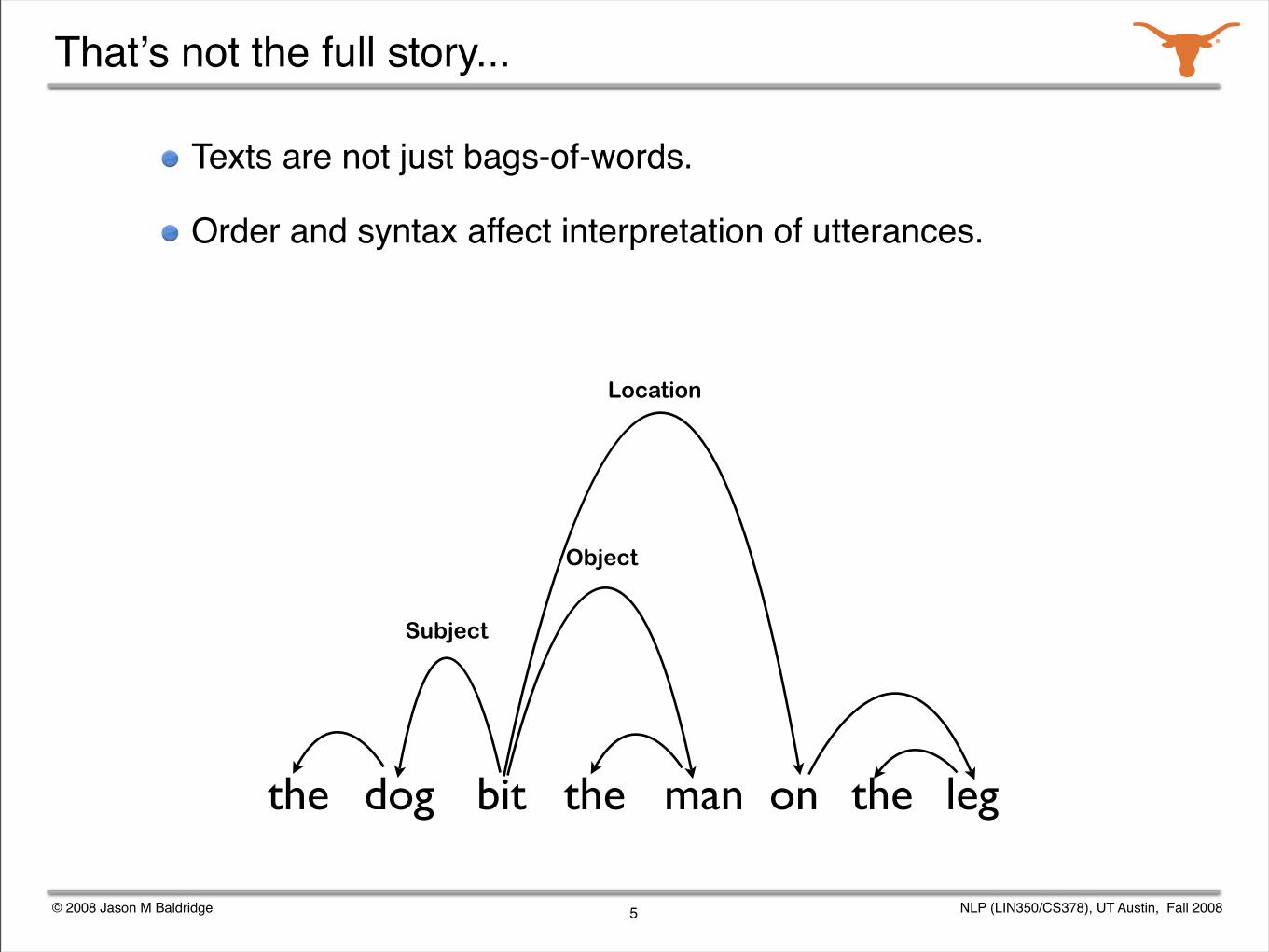
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Thatʼs not the full story...
Texts are not just bags-of-words.
Order and syntax affect interpretation of utterances.
5
legonmanthe dogbit thethe mandog
Subject
Object
Location

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
To get a spare tire (donut) for his car?
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
store where donuts shop? or is run by donuts?
or looks like a big donut? or made of donut?
or has an emptiness at its core?
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
I stopped smoking freshman year, but
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
Describes where the store is? Or when he stopped?
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
Well, actually, he stopped there from hunger and exhaustion, not just from work.
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
At that moment, or habitually?
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
That’s how often he thought it?
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
But actually, a coffee only stays good for about 10
minutes before it gets cold.
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
Similarly: In America a woman has a baby every 15 minutes. Our job is to
find that woman and stop her.
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
the particular coffee that was good every few hours? the donut store? the situation?
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
too expensive for what? what are we supposed to conclude about
what John did?
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008 6
Whatʼs hard about this story? [Slide from Jason Eisner]
how do we connect “it” to “expensive”?
John stopped at the donut store on his way home from work. He thought a coffee was good every few hours.
But it turned out to be too expensive there.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
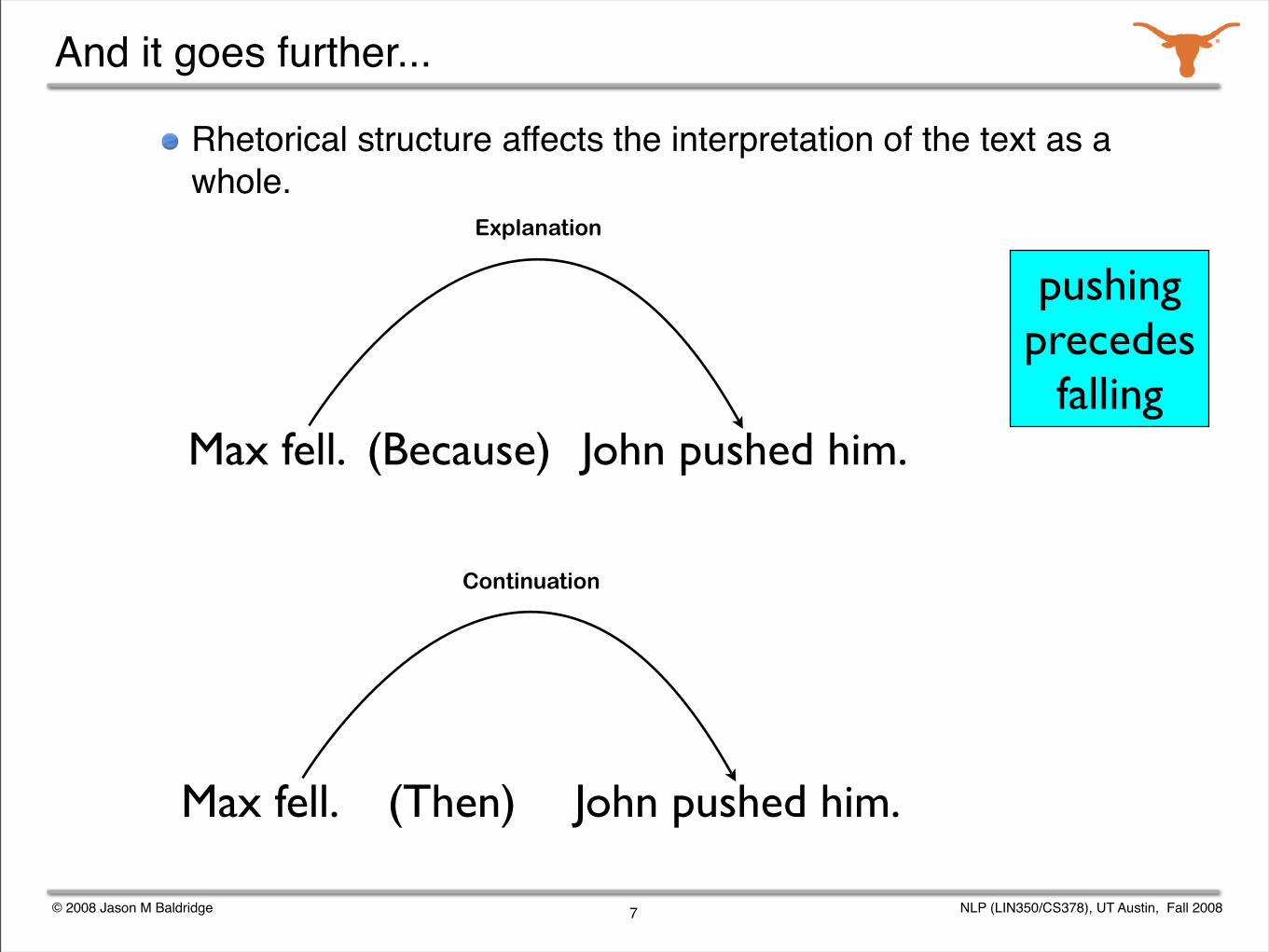
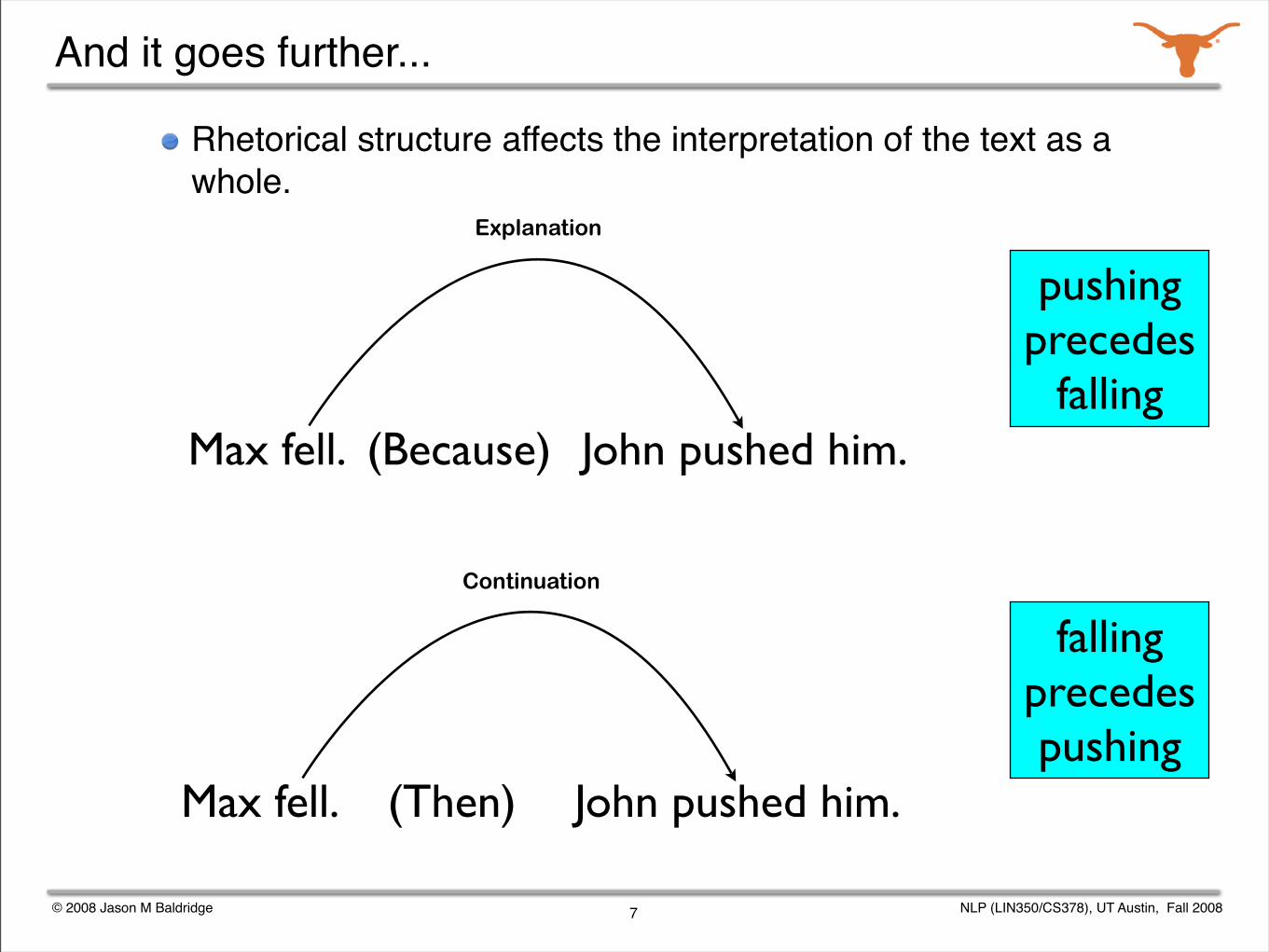
And it goes further...
Rhetorical structure affects the interpretation of the text as a whole.
7
Max fell. John pushed him.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
And it goes further...
Rhetorical structure affects the interpretation of the text as a whole.
7
Max fell. John pushed him.
Max fell. John pushed him.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
And it goes further...
Rhetorical structure affects the interpretation of the text as a whole.
7
Max fell. John pushed him.(Because)
Explanation
Max fell. John pushed him.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
And it goes further...
Rhetorical structure affects the interpretation of the text as a whole.
7
Max fell. John pushed him.(Because)
Explanation
Max fell. John pushed him.(Then)
Continuation
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
And it goes further...
Rhetorical structure affects the interpretation of the text as a whole.
7
Max fell. John pushed him.(Because)
Explanation
Max fell. John pushed him.(Then)
Continuation
pushing precedes
falling
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
And it goes further...
Rhetorical structure affects the interpretation of the text as a whole.
7
Max fell. John pushed him.(Because)
Explanation
Max fell. John pushed him.(Then)
Continuation
pushing precedes
falling
falling precedes pushing

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
What then?
Simple bag-of-words representations actually are the basis for many interesting and useful systems.
BUT there is much more going on with language that such a representation clearly doesnʼt capture.
Computers would be a lot more useful if they could handle our email, do our library research, talk to us... but they are fazed by natural human language.
How can we tell computers about language? (Or help them learn it as kids do?)
8

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
My research themesSyntax
categorial grammar (Baldridge & Krujff 2002,2003; Baldridge et al. 2007; Hoyt & Baldridge 2008)
parse selection (Baldridge and Osborne 2003, 2004, 2008)
dependency parsing (Caciki and Baldridge 2006, Wing and Baldridge 2006)
Discourse
coreference resolution (Baldwin et al. 1998; Denis and Baldridge 2007, 2008)
situation entities (Palmer et al. 2007)
discourse structure (Baldridge and Lascarides 2005, Baldridge et al 2007, Elwell and Baldridge 2008)
Semi-supervised learning
active learning and co-training (Baldridge and Osborne 2008, current work)
weakly supervised learning with HMMs (Baldridge 2008)
cross-lingual projection (Moon and Baldridge 2007)
9

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Outline
Active learning for parse selection
annotate only the most informative examples
Cross-lingual projection for bootstrapping POS taggers
use existing resources in combination with parallel corpora
Weakly supervised learning and cotraining for supertagging
use existing information or small seed more effectively
Unsupervised grammar induction
find structural adjacencies from raw text and bootstrap to learn categorial grammars
10

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
The big picture
Speech and text corpora augmented with linguistically informative annotations are generally considered useful.
However, they are expensive to create entirely by hand.
Much of the work involved in creating them is redundant and simple
Some annotation could thus potentially be automated.
Systems which use machine learning can offer high accuracy and would be able to perform such annotations, but some supervision is necessary.
How much effort is needed?
11

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
The big picture (contʼd)
We have a chicken-and-egg problem: how to build an accurate machine labeler with little or no training material and use it to reduce the human effort involved (towards various aims).
Goals may vary. We may want to
build accurate/interesting models as cheaply as possible
annotate a corpus as cheaply as possible.
Either way, we should utilize our resources as cleverly as possible.
12

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
The big picture (contʼd)
Solved problems arenʼt solved for all languages (e.g., language documentation)
tiny data sets
what are the tagsets? the orthography!!!???
“Solved” problems donʼt magically transfer to new domains
POS taggers get 98% on Penn treebank test sets, but can be horrible in other domains (short utterances, different spelling/orthography conventions), behave differently with less training data, etc.
13

Active learning for parse selection

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotation blues
A linguist wants to create a part-of-speech tagged corpus for English.
He has plenty of plain text available to him:
He faces annotating a and the as determiners again and again...
Pierre Vinken, 61 years old, will join the board as a nonexecutive director Nov. 29.
Mr. Vinken is chairman of Elsevier N.V., the Dutch publishing group.
A form of asbestos once used to make Kent cigarette filters has caused a high percentage of cancer deaths among a group of workers exposed to it more than 30 years ago, researchers reported.
15
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate everything (= unhappy linguist)
16
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate everything (= unhappy linguist)
16
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate everything (= unhappy linguist)
16
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
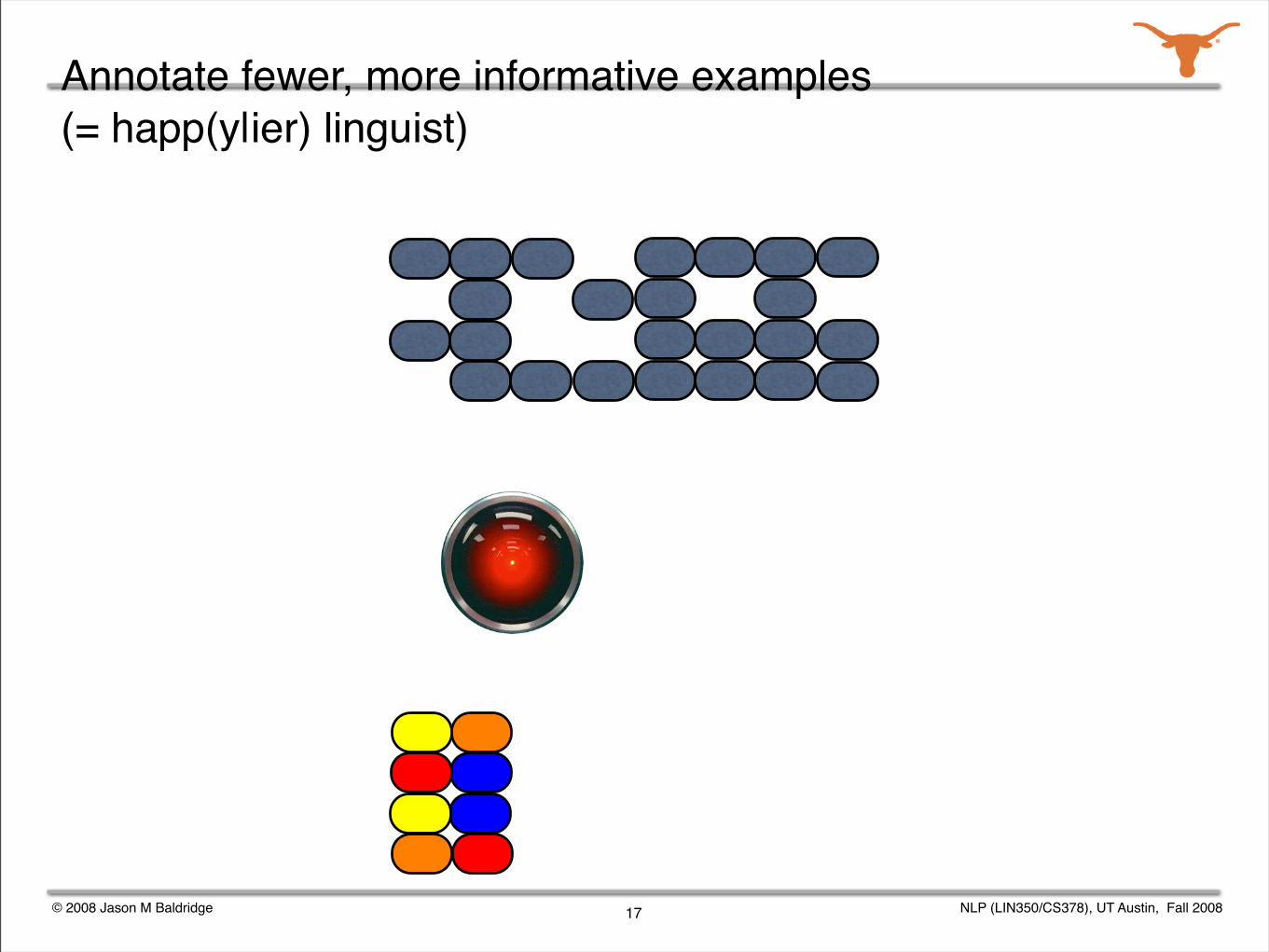
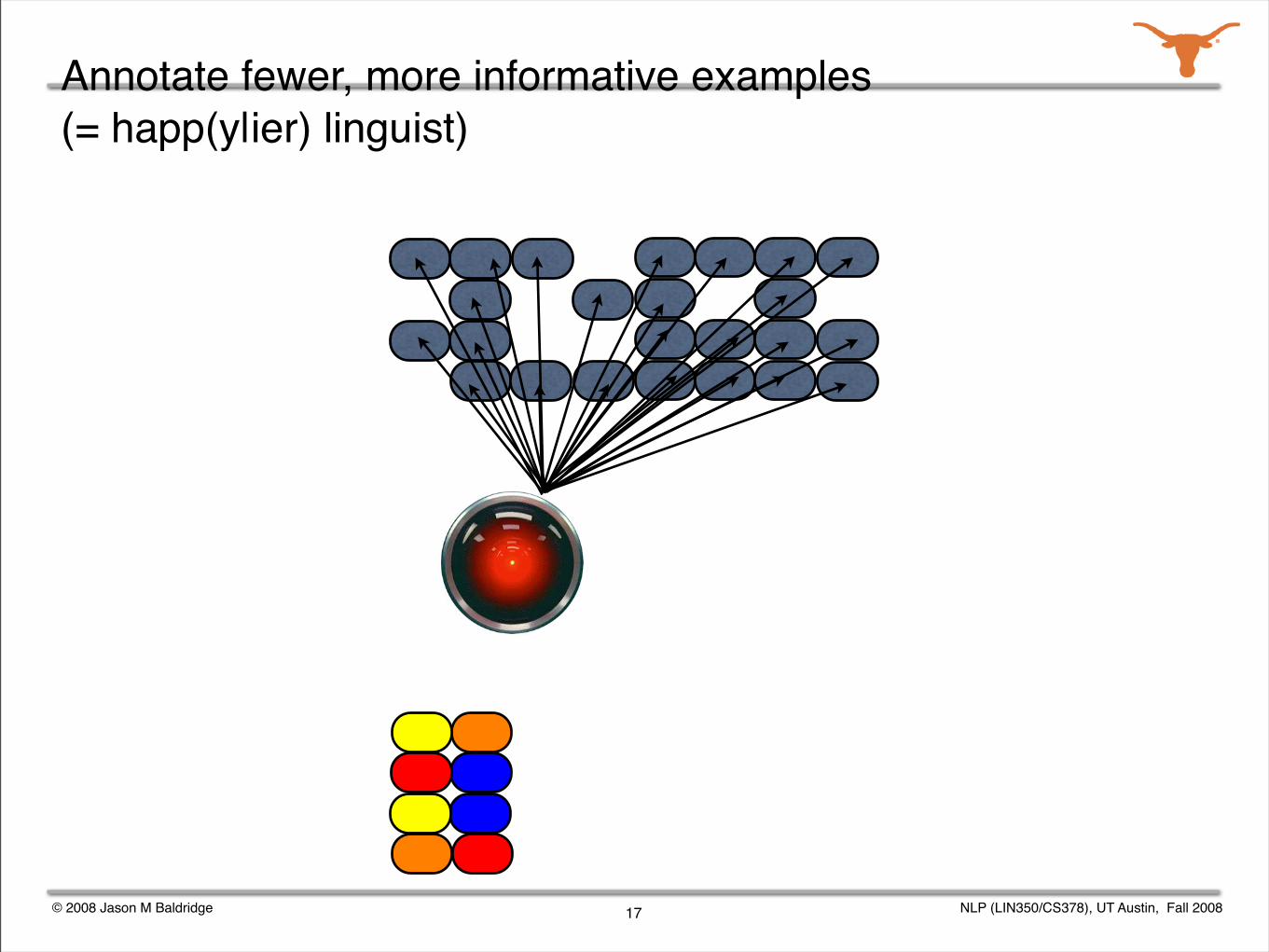
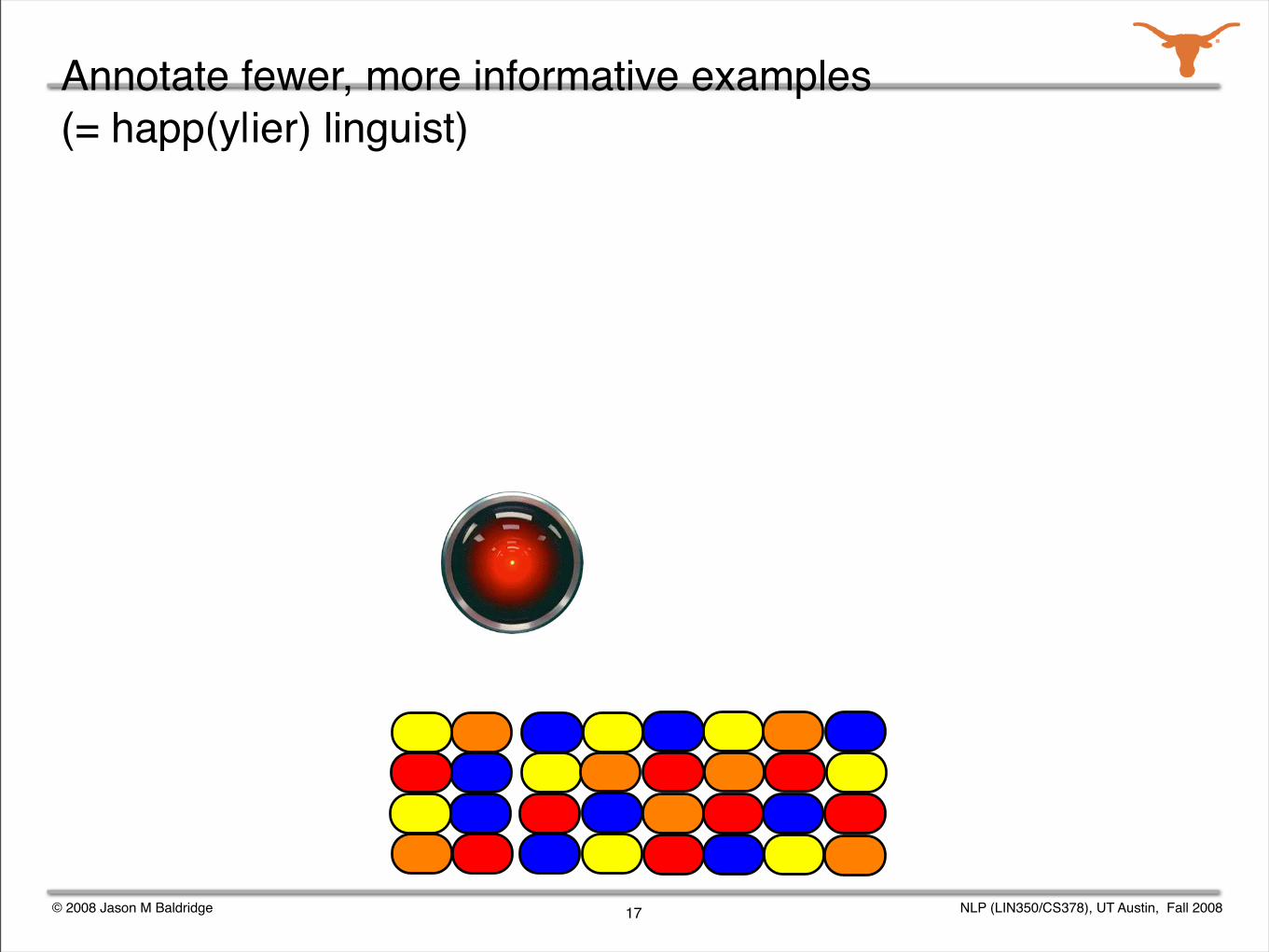
Annotate fewer, more informative examples (= happ(y|ier) linguist)
17
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate fewer, more informative examples (= happ(y|ier) linguist)
17
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate fewer, more informative examples (= happ(y|ier) linguist)
17
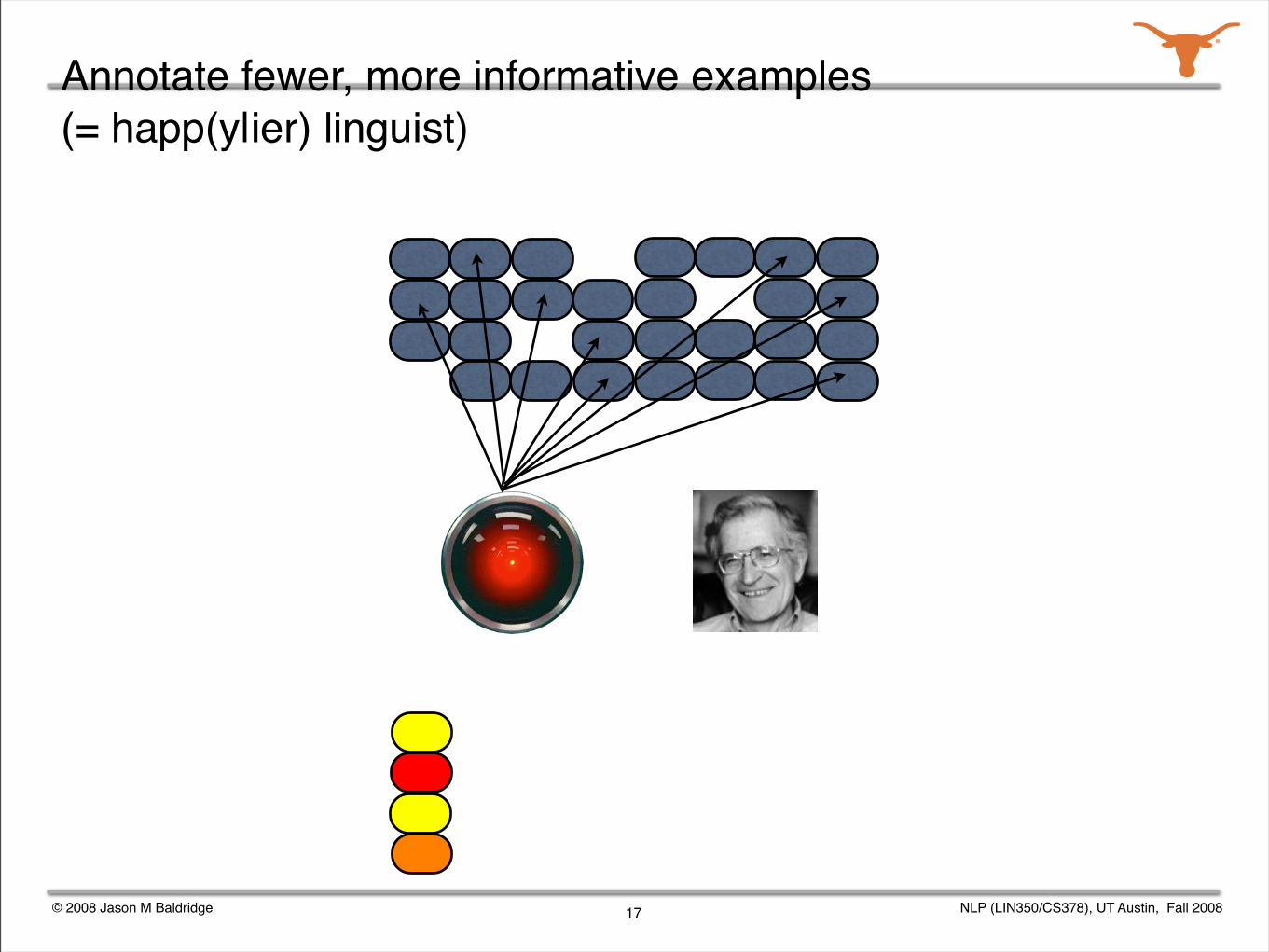
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate fewer, more informative examples (= happ(y|ier) linguist)
17
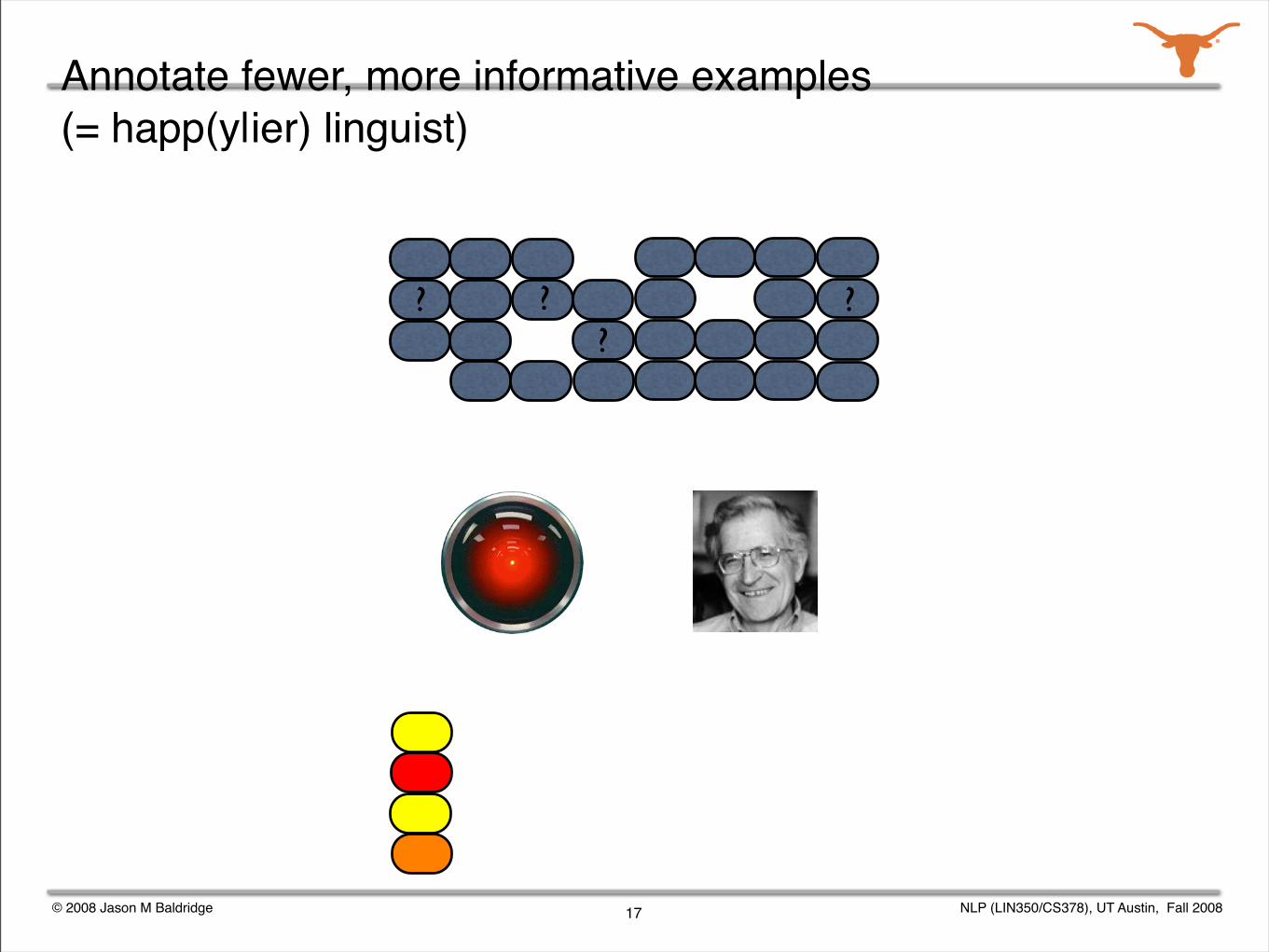
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate fewer, more informative examples (= happ(y|ier) linguist)
??
??
17
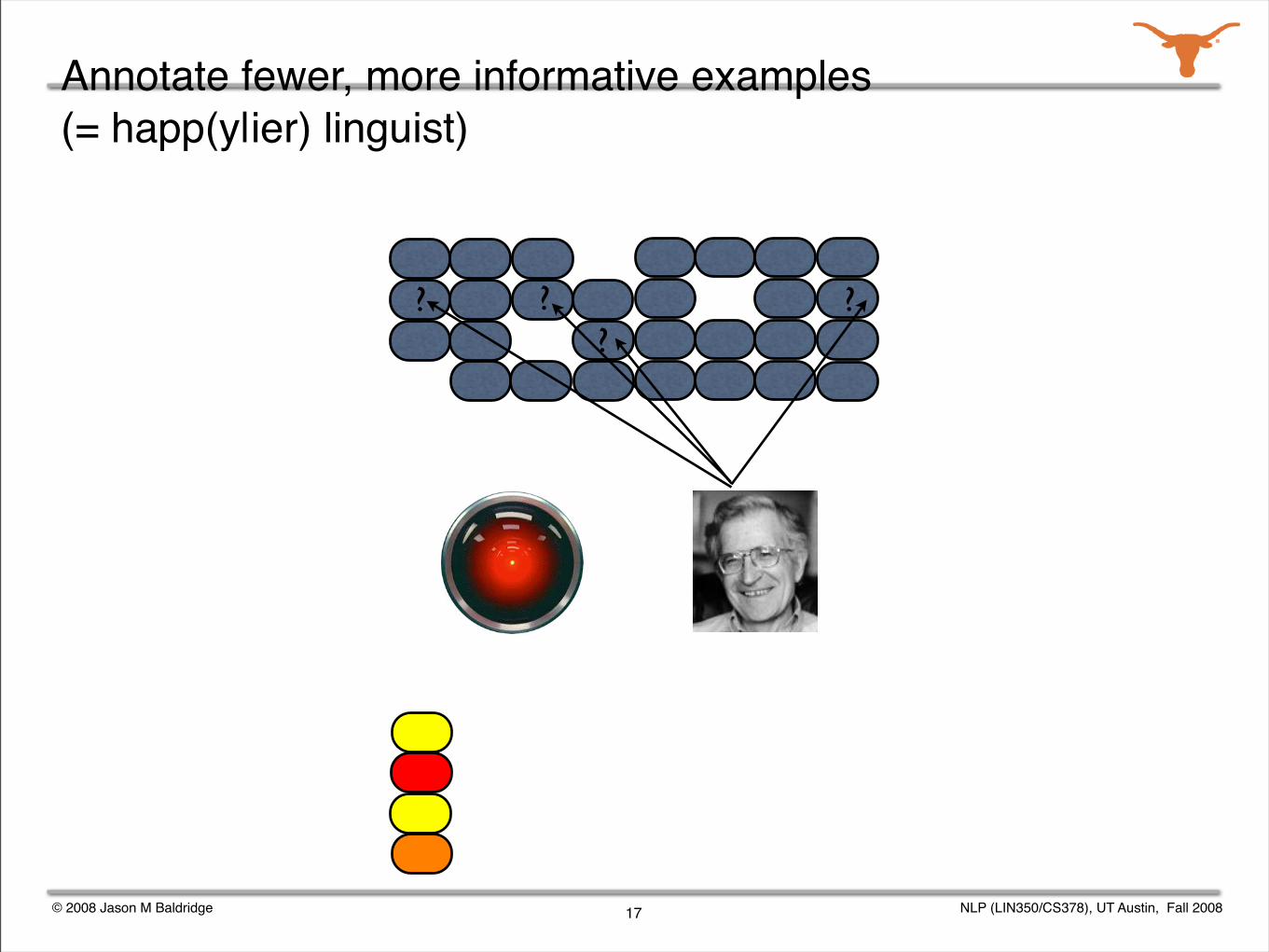
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate fewer, more informative examples (= happ(y|ier) linguist)
??
??
17

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate fewer, more informative examples (= happ(y|ier) linguist)
17
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate fewer, more informative examples (= happ(y|ier) linguist)
17
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate fewer, more informative examples (= happ(y|ier) linguist)
17
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Annotate fewer, more informative examples (= happ(y|ier) linguist)
17

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Active learning for parse selection
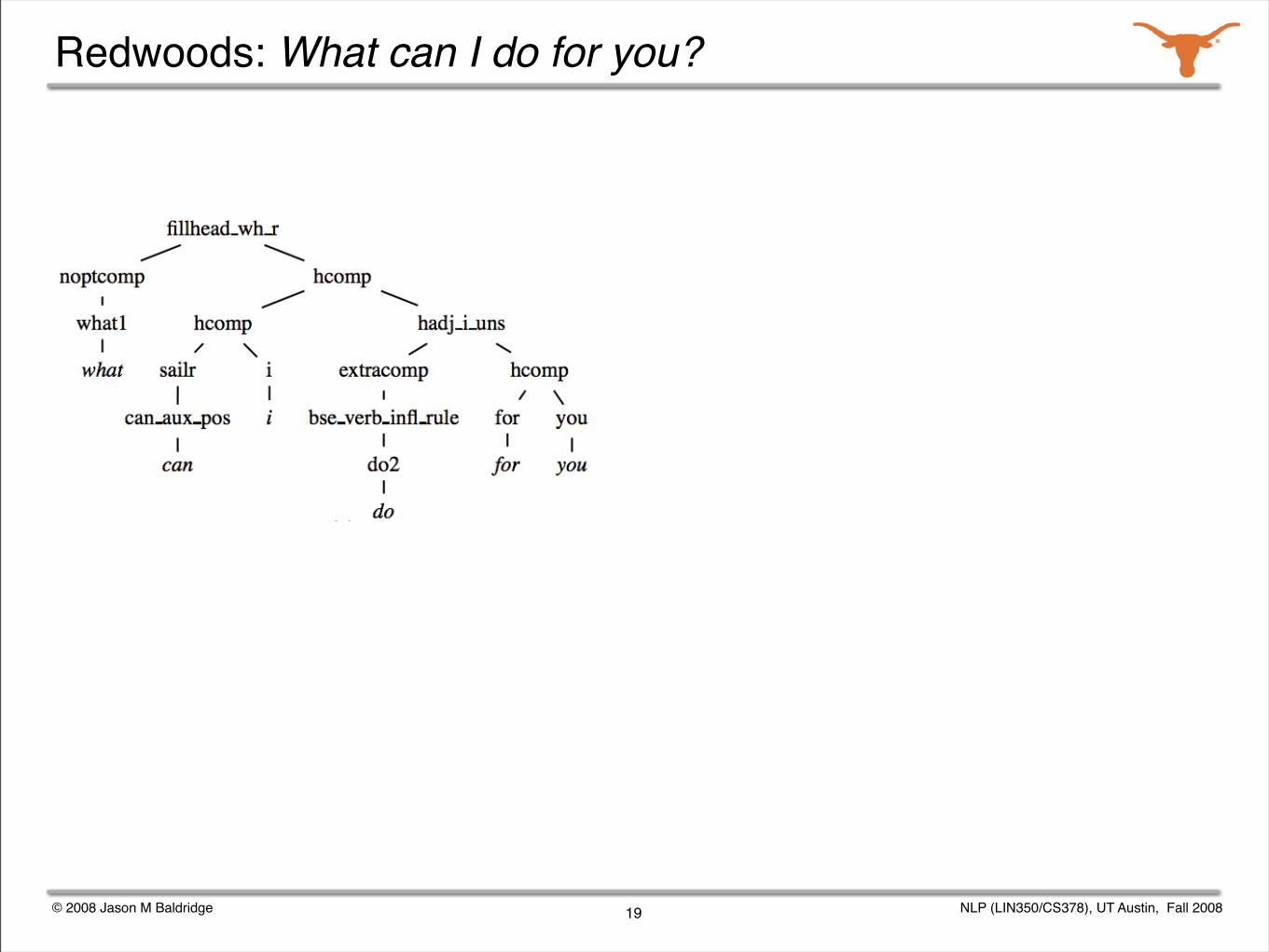
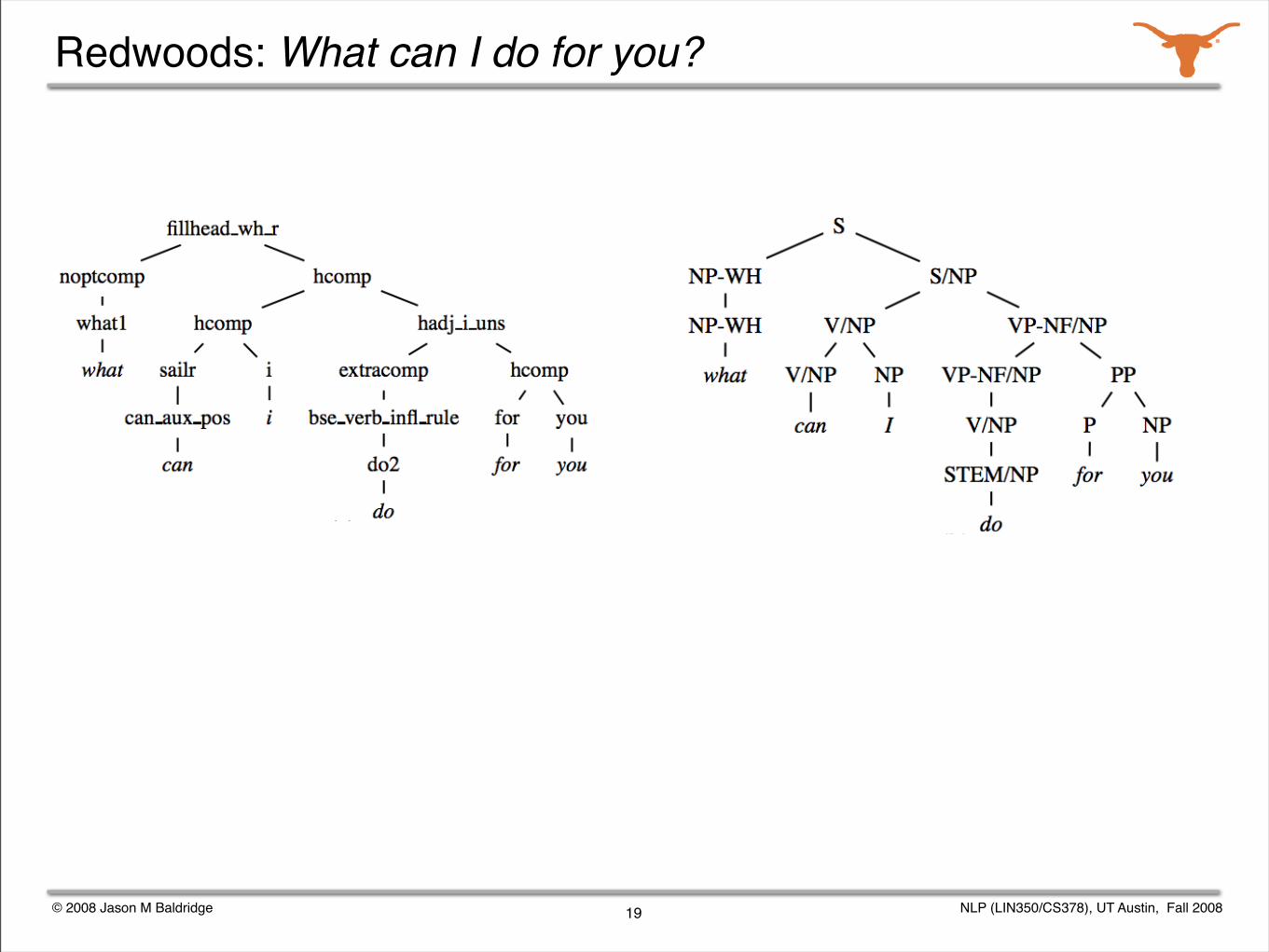
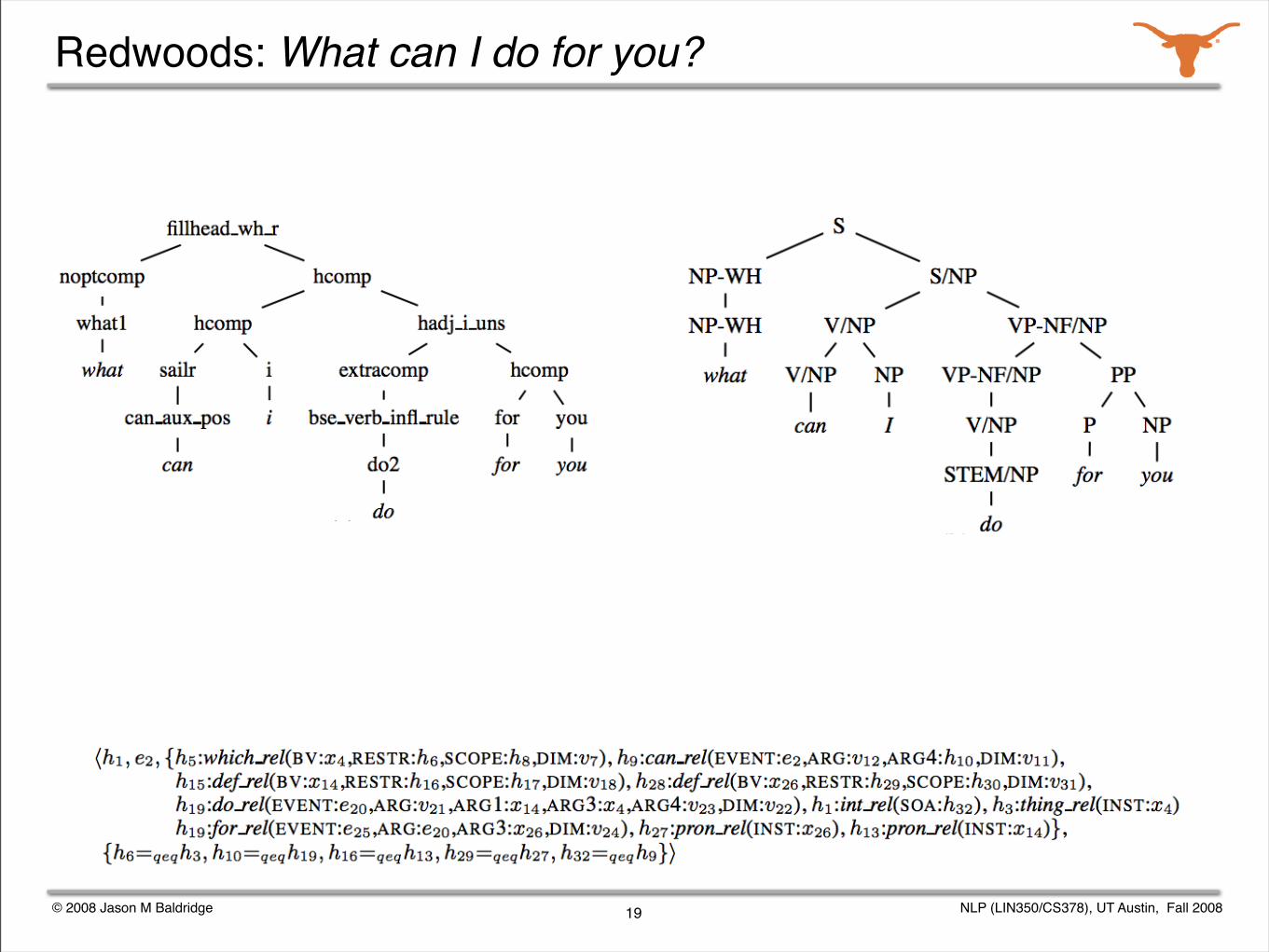
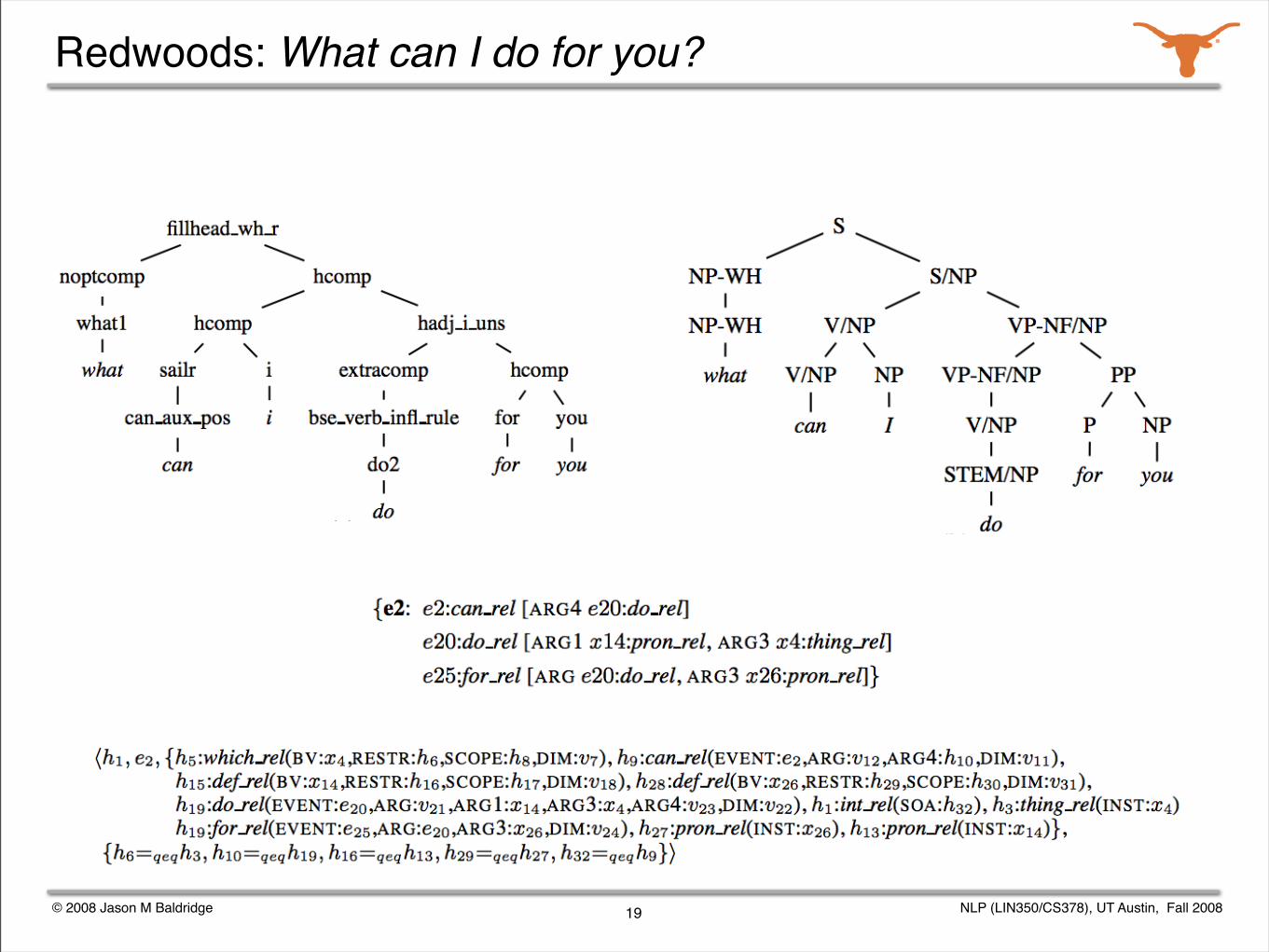
Given a grammar, we can enumerate all the possible analyses for a sentence.
Parse selection is the task of identifying the correct analysis out of all those produced by a grammar.
The Redwoods treebank contains the analyses output by the English Resource Grammar for over 12,000 sentences from appointment scheduling and travel planning dialogs.
The correct analysis for each sentence was chosen by a human annotator.
We studied various active learning and semi-automated annotation techniques for the corpus.
18
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Redwoods: What can I do for you?
19
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Redwoods: What can I do for you?
19
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Redwoods: What can I do for you?
19
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Redwoods: What can I do for you?
19
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Redwoods: What can I do for you?
19

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
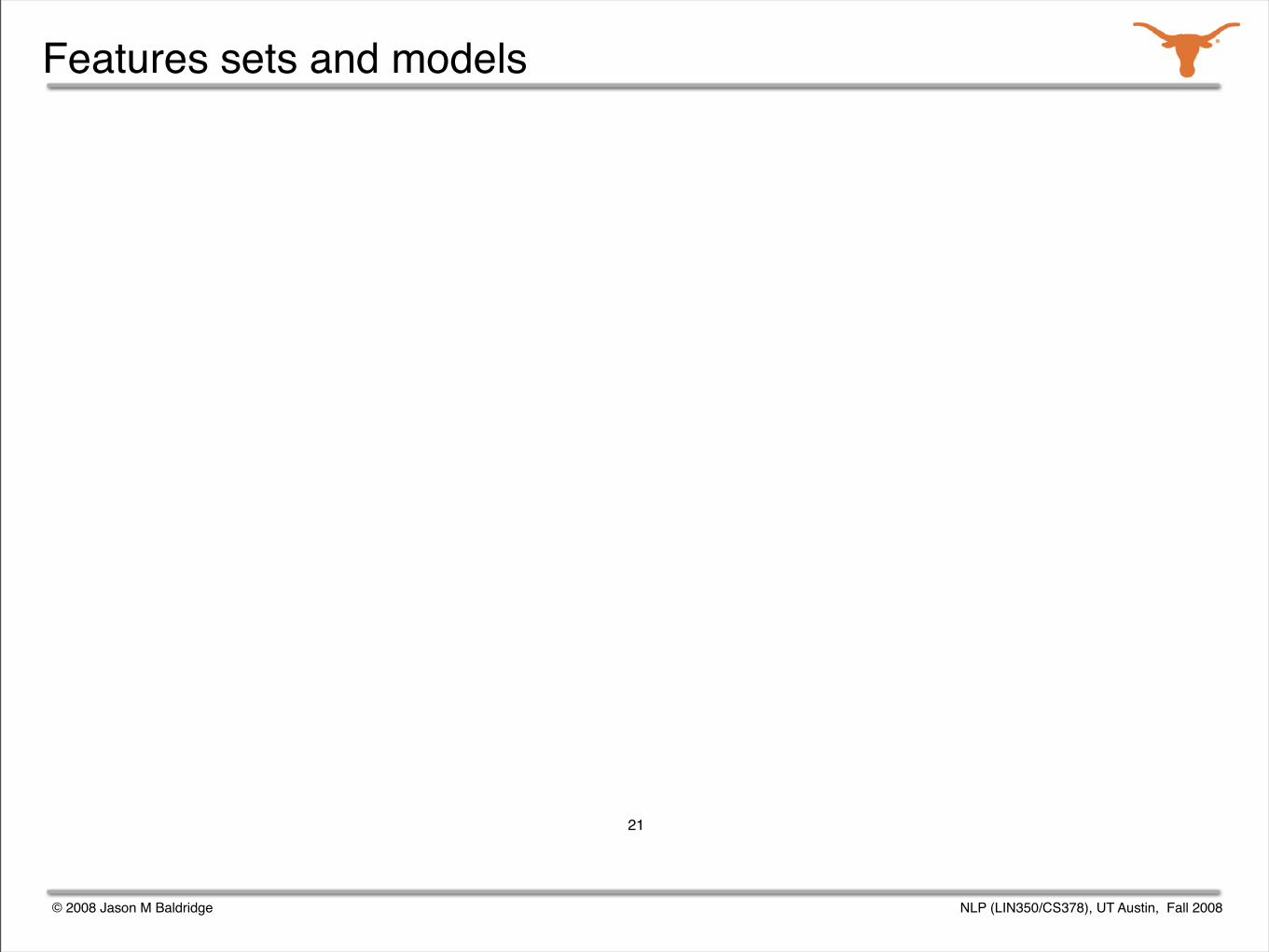
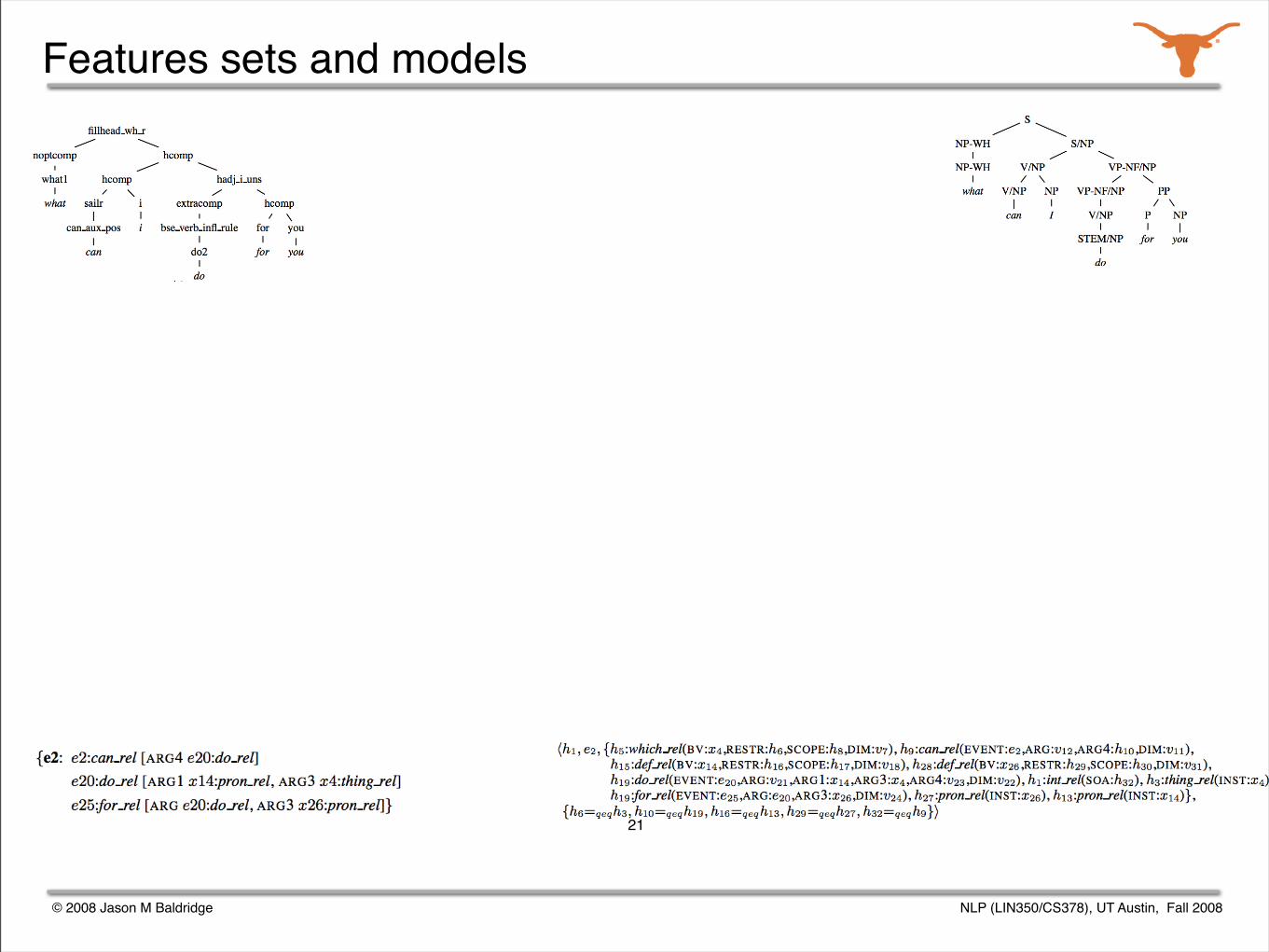
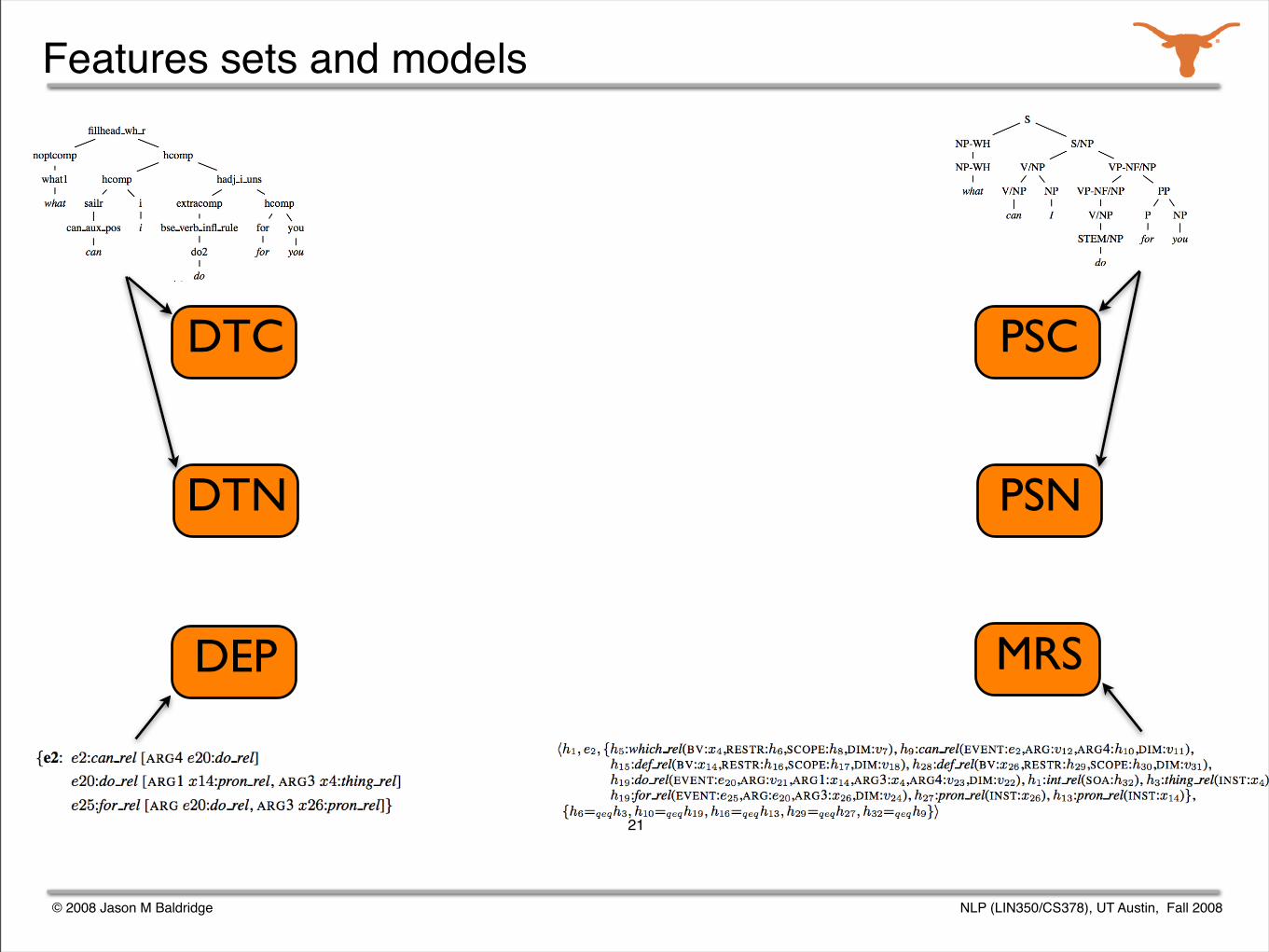
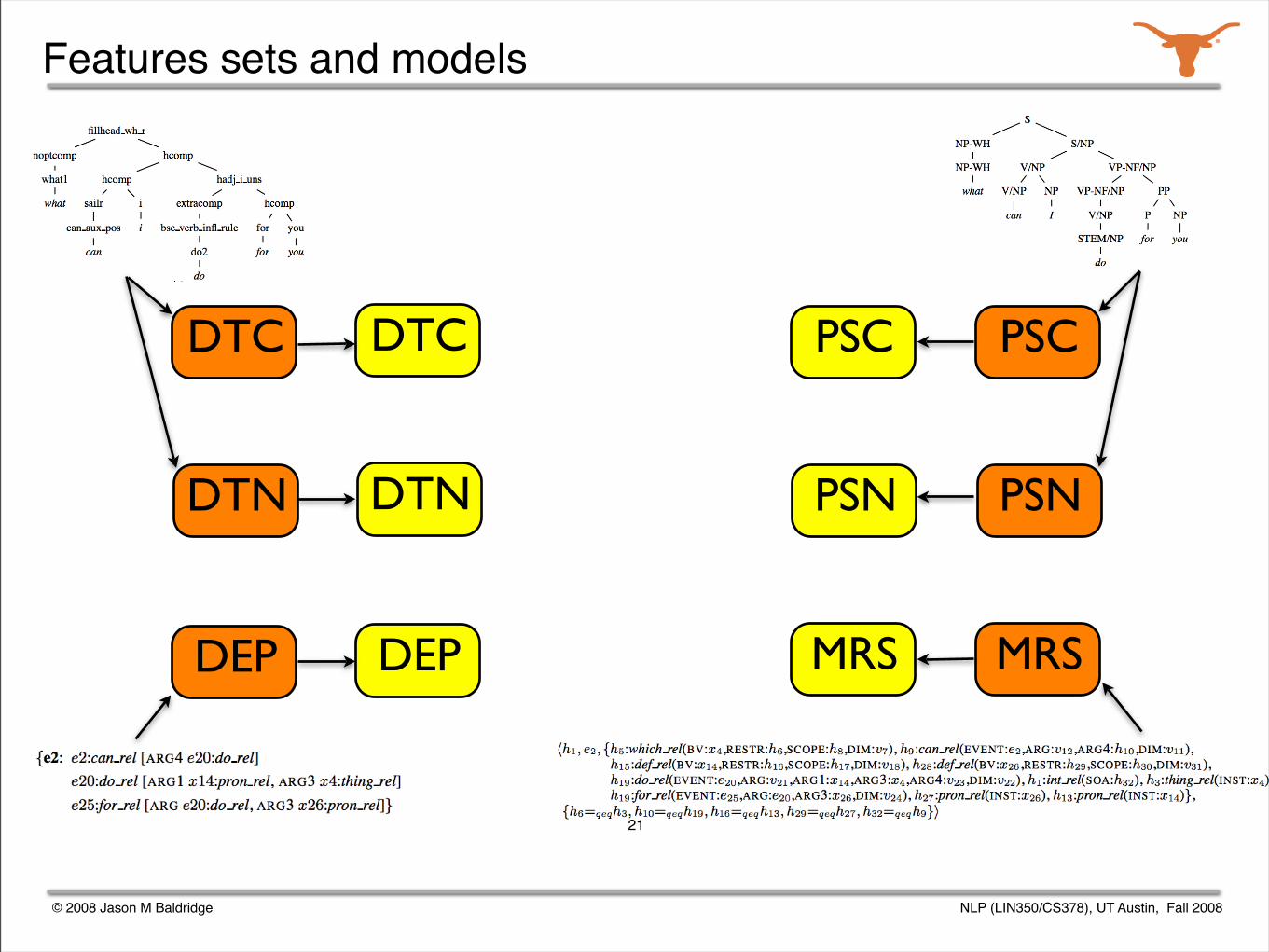
Starting point: parse selection models
Using these data structures, six feature sets were extracted.
A maximum entropy model was trained from each feature set.
The models were used in an ensemble.
20
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Features sets and models
21

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Features sets and models
What can I do for you?
21
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Features sets and models
21
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Features sets and models
DTC
DTN PSN
PSC
DEP MRS
21
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Features sets and models
DTC
DTN PSN
PSC
DEP MRS
DTN
DTC
DEP
PSC
MRS
PSN
21
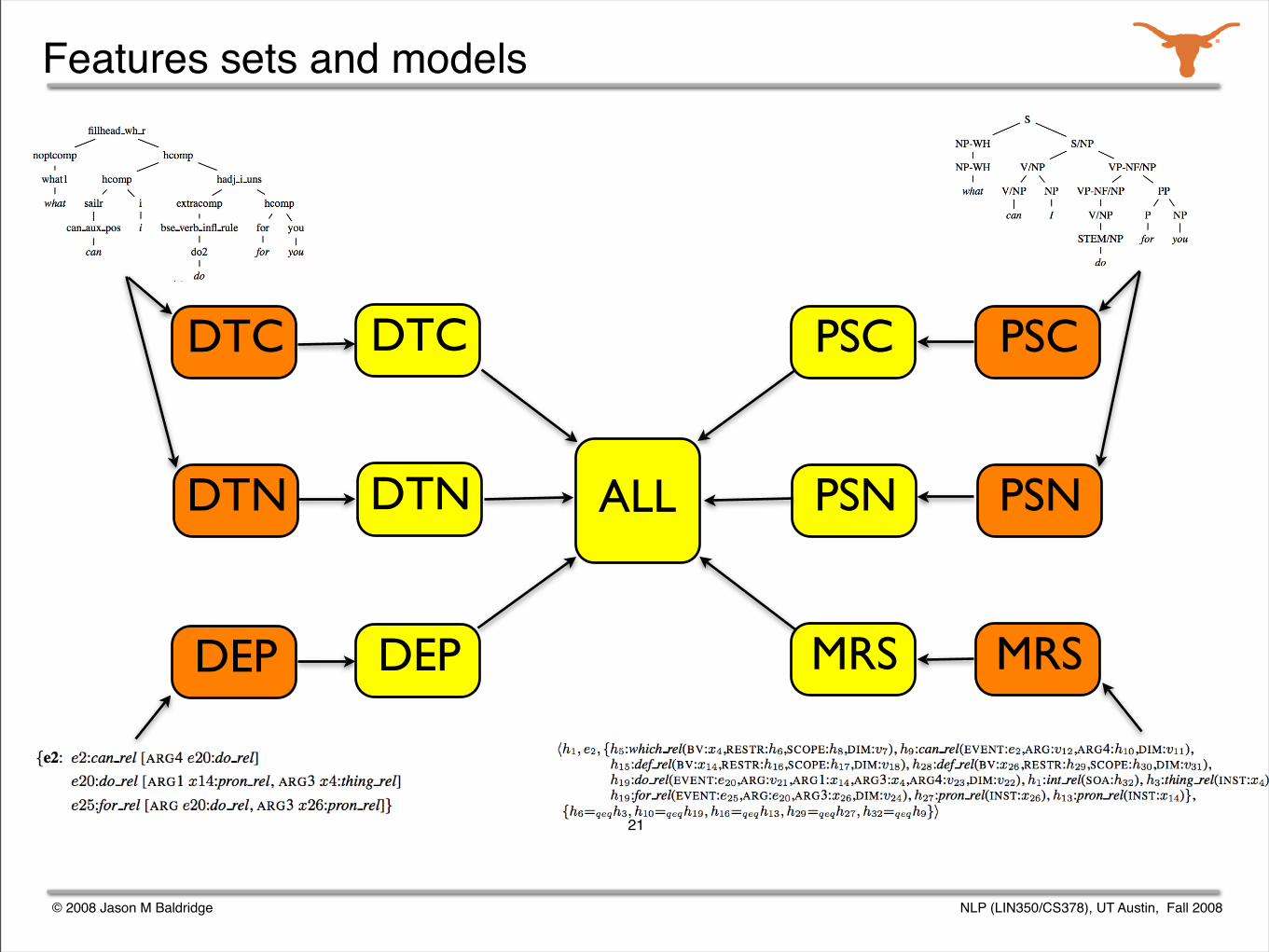
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Features sets and models
DTC
DTN PSN
PSC
DEP MRS
ALLDTN
DTC
DEP
PSC
MRS
PSN
21
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
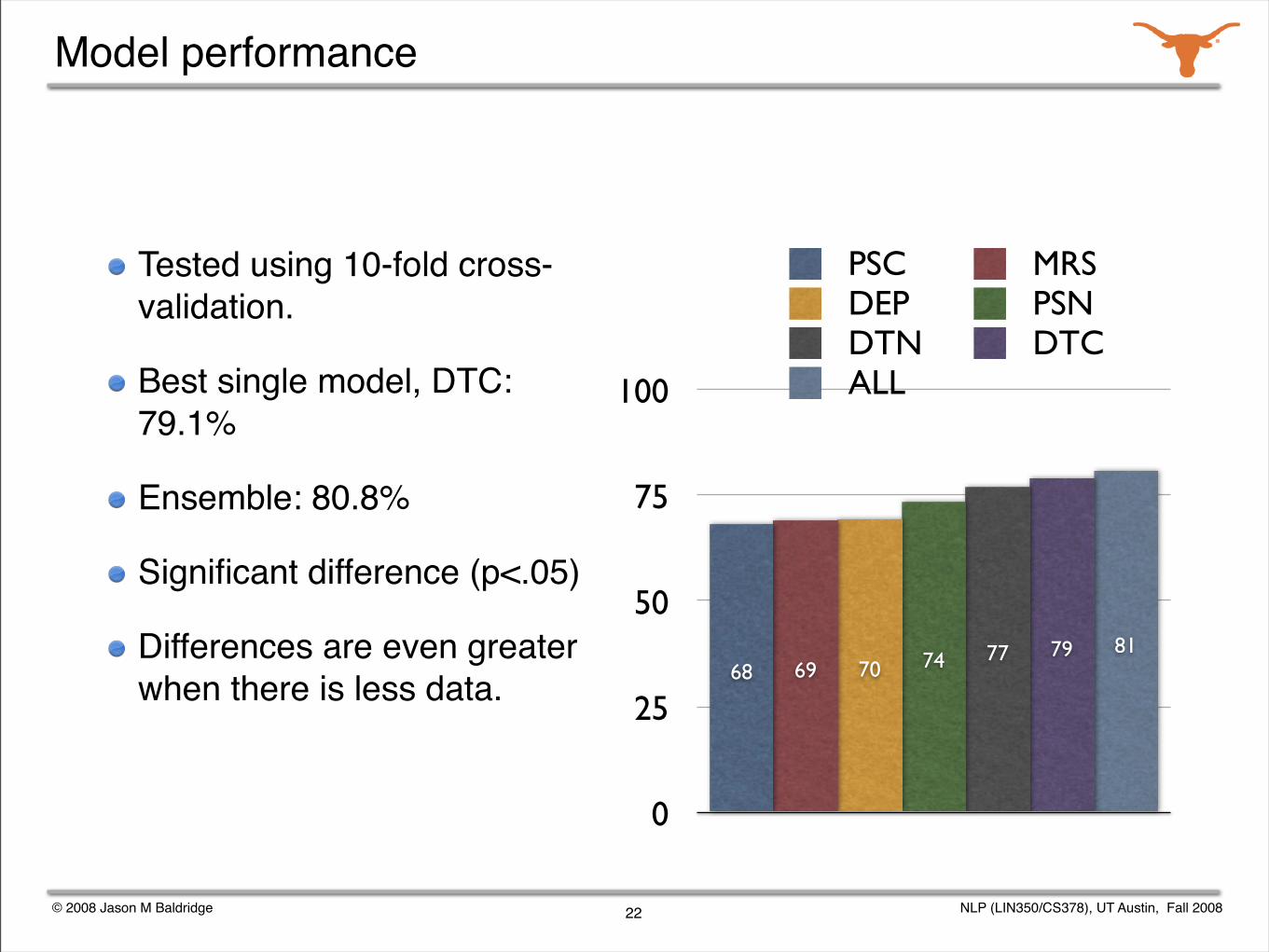
Model performance
Tested using 10-fold cross-validation.
Best single model, DTC: 79.1%
Ensemble: 80.8%
Significant difference (p<.05)
Differences are even greater when there is less data.
0
25
50
75
100
81797774706968
PSC MRSDEP PSNDTN DTCALL
22

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
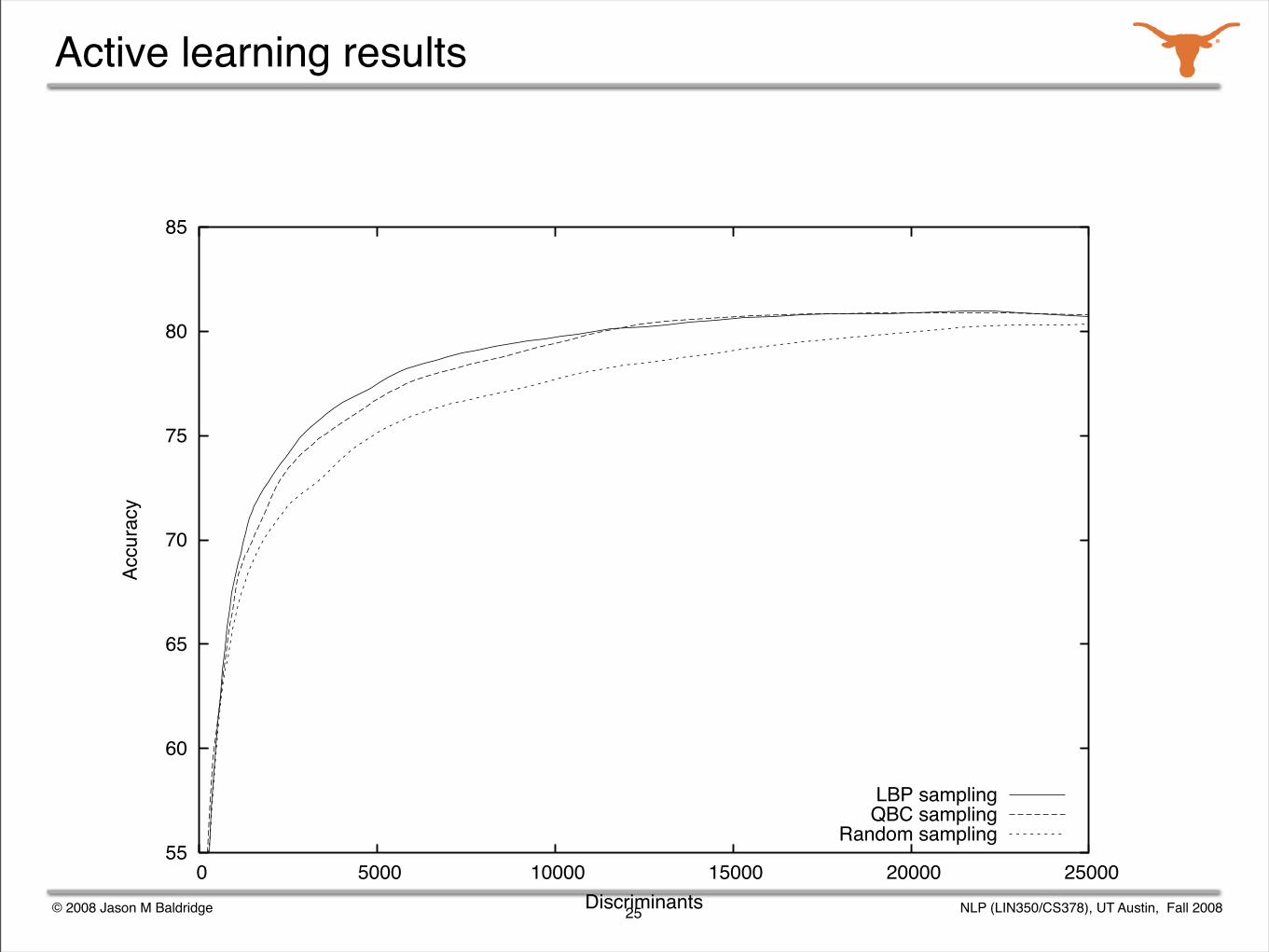
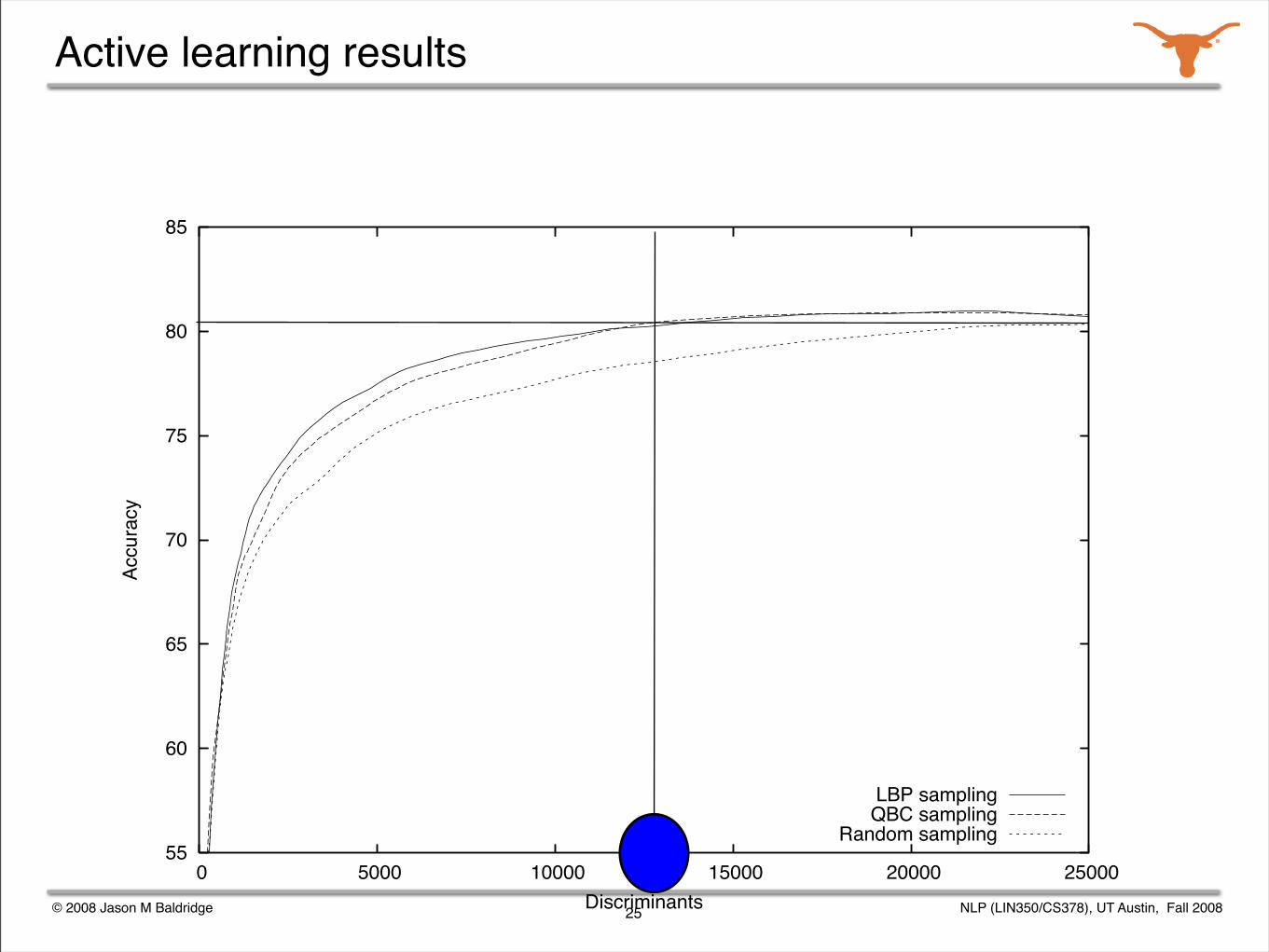
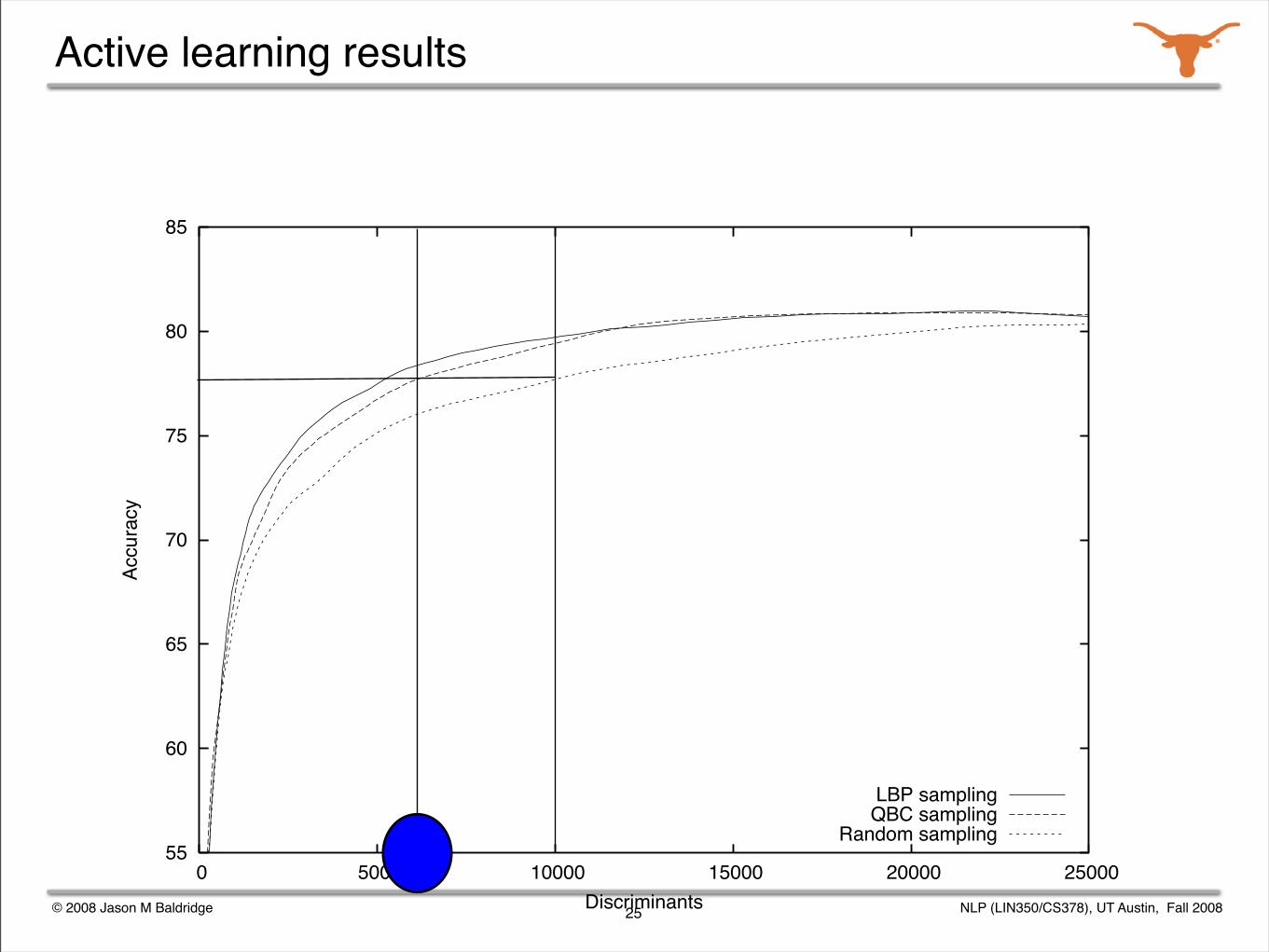
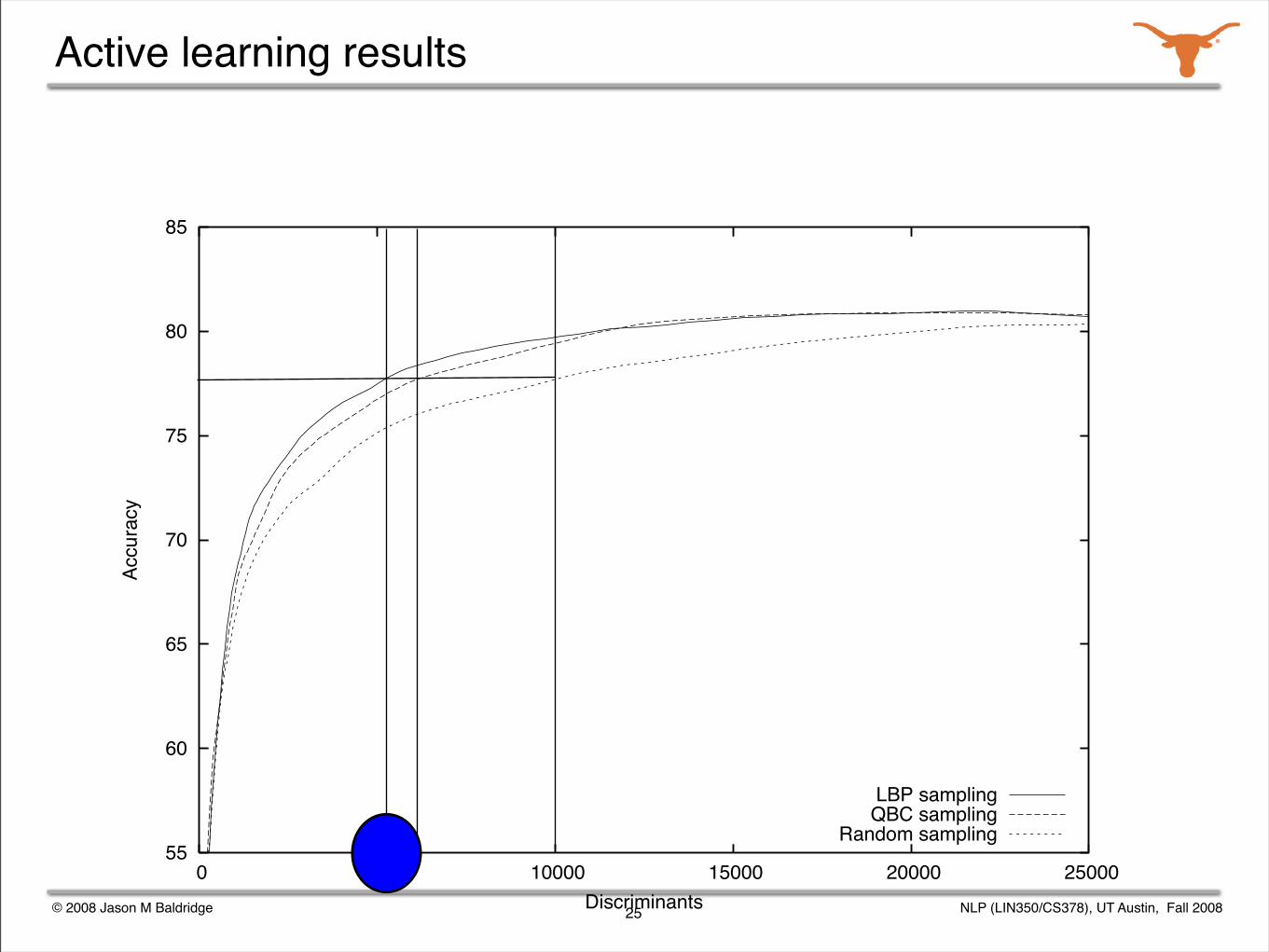
Active learning methods
Sample selection was used: consider batches of 500 sentences at a time and identify the most informative ones.
Training utility was determined with three different methods:
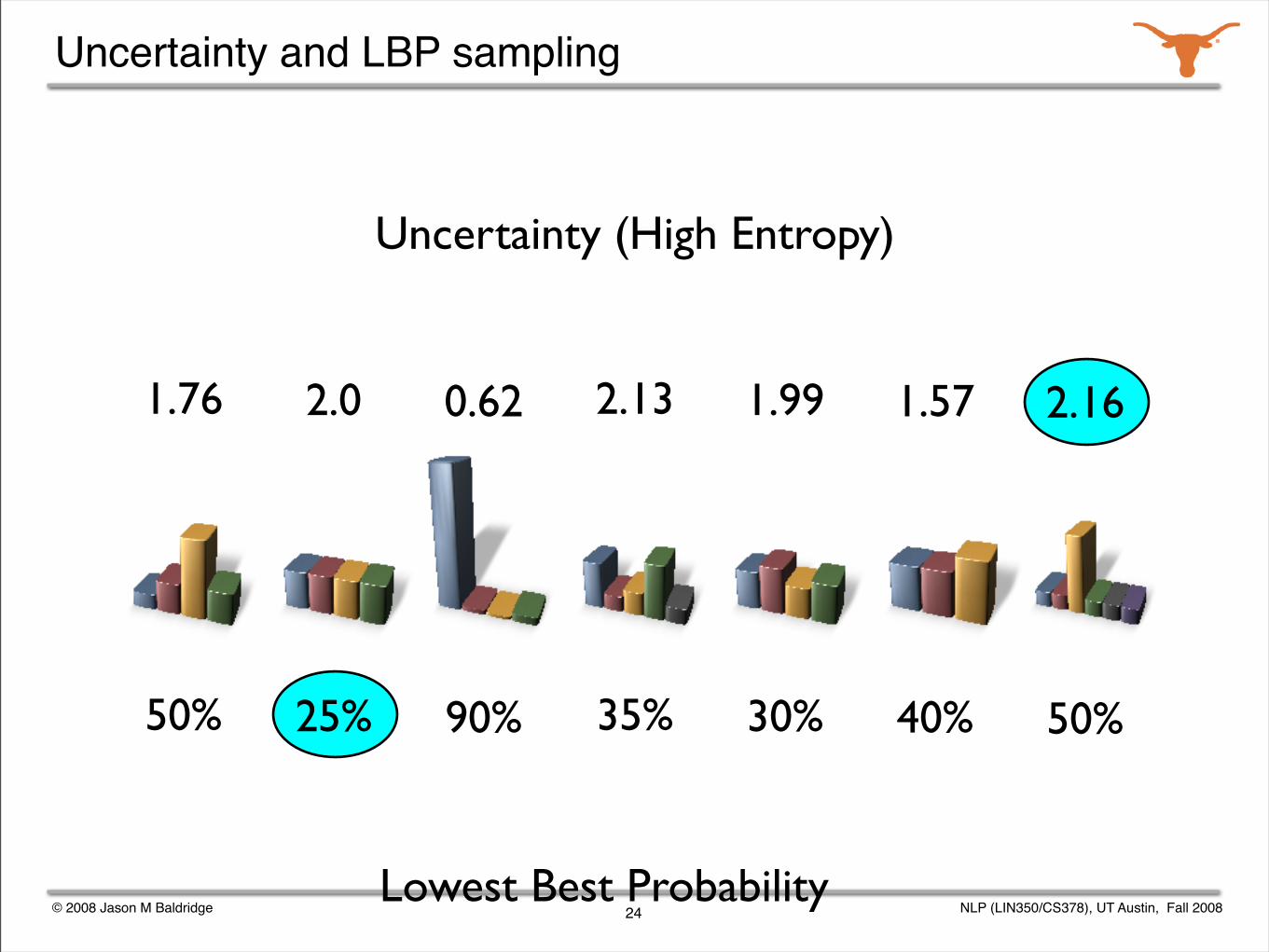
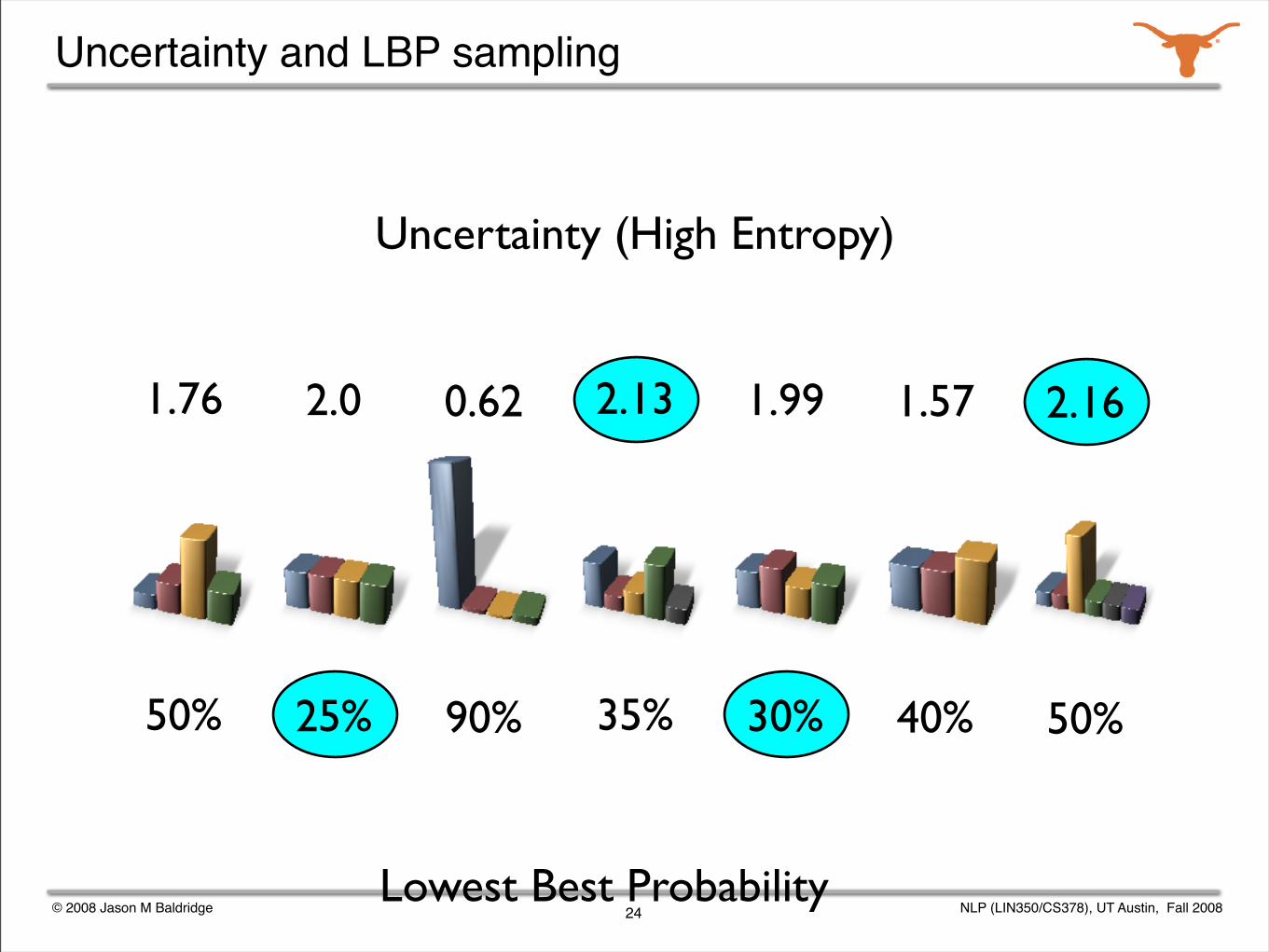
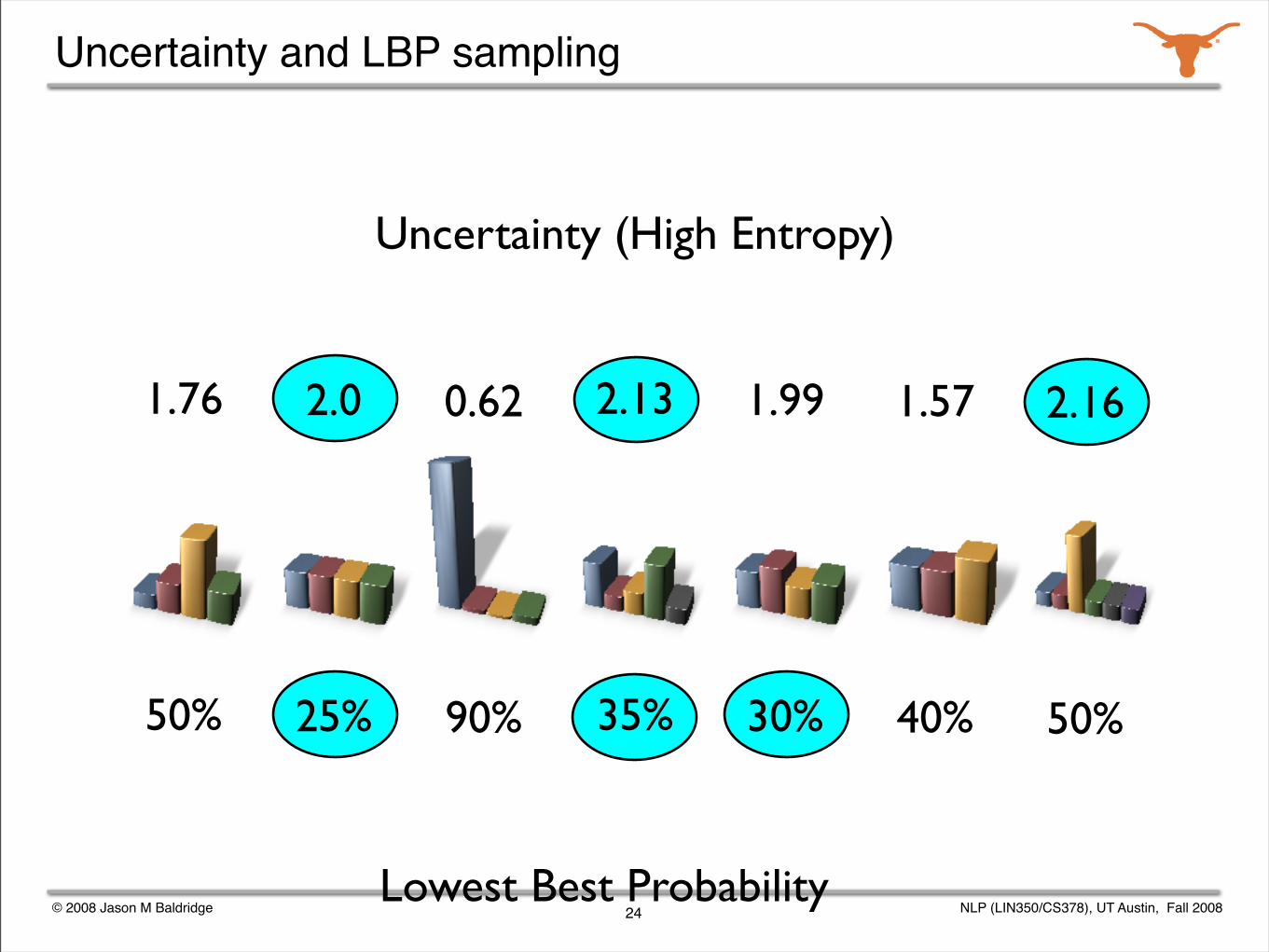
uncertainty sampling (entropy)
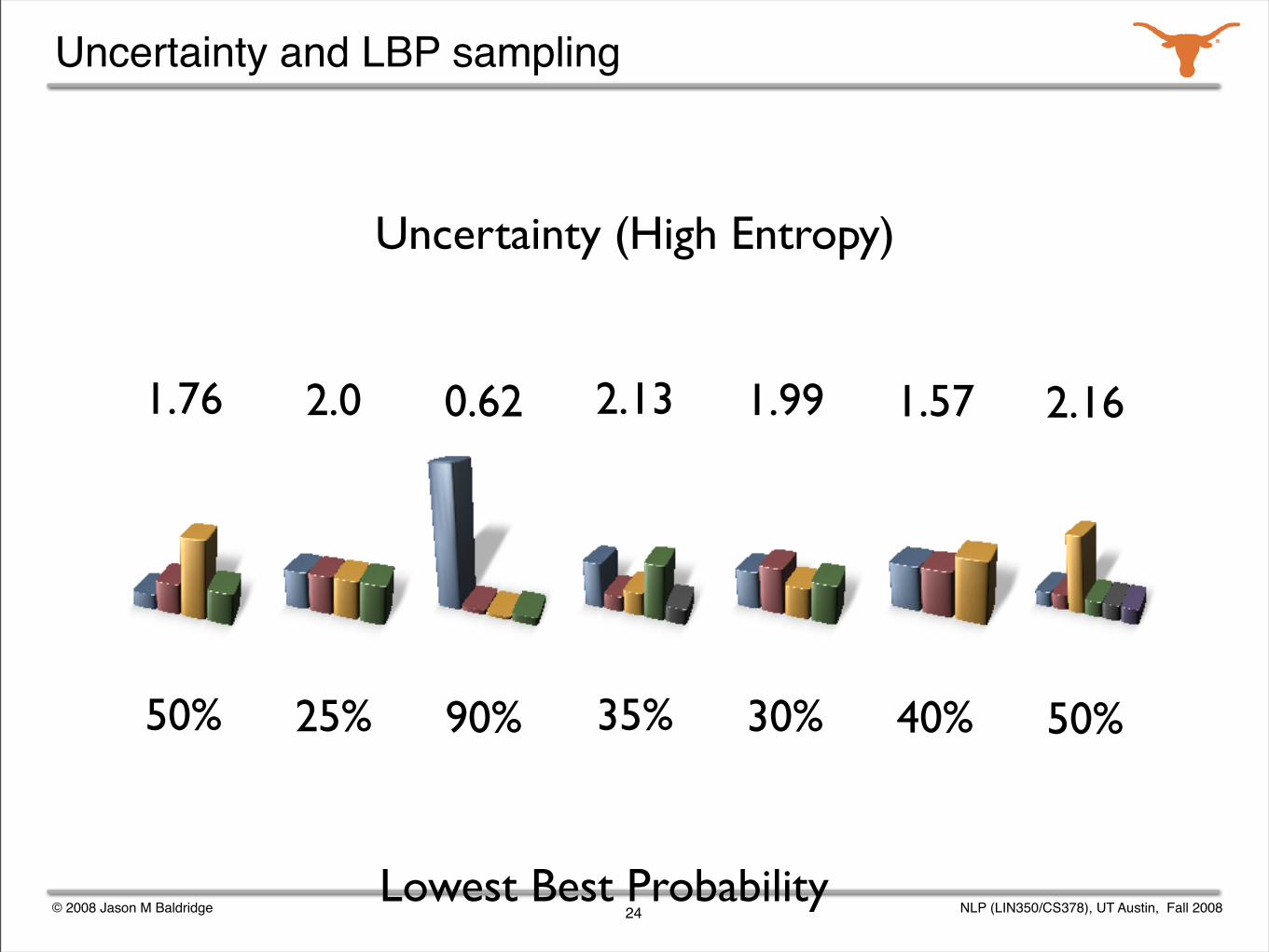
lowest best probability selection
query-by-committee
23
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Uncertainty and LBP sampling
24
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Uncertainty and LBP sampling
24
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Uncertainty and LBP sampling
24
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Uncertainty and LBP sampling
24
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Uncertainty and LBP sampling
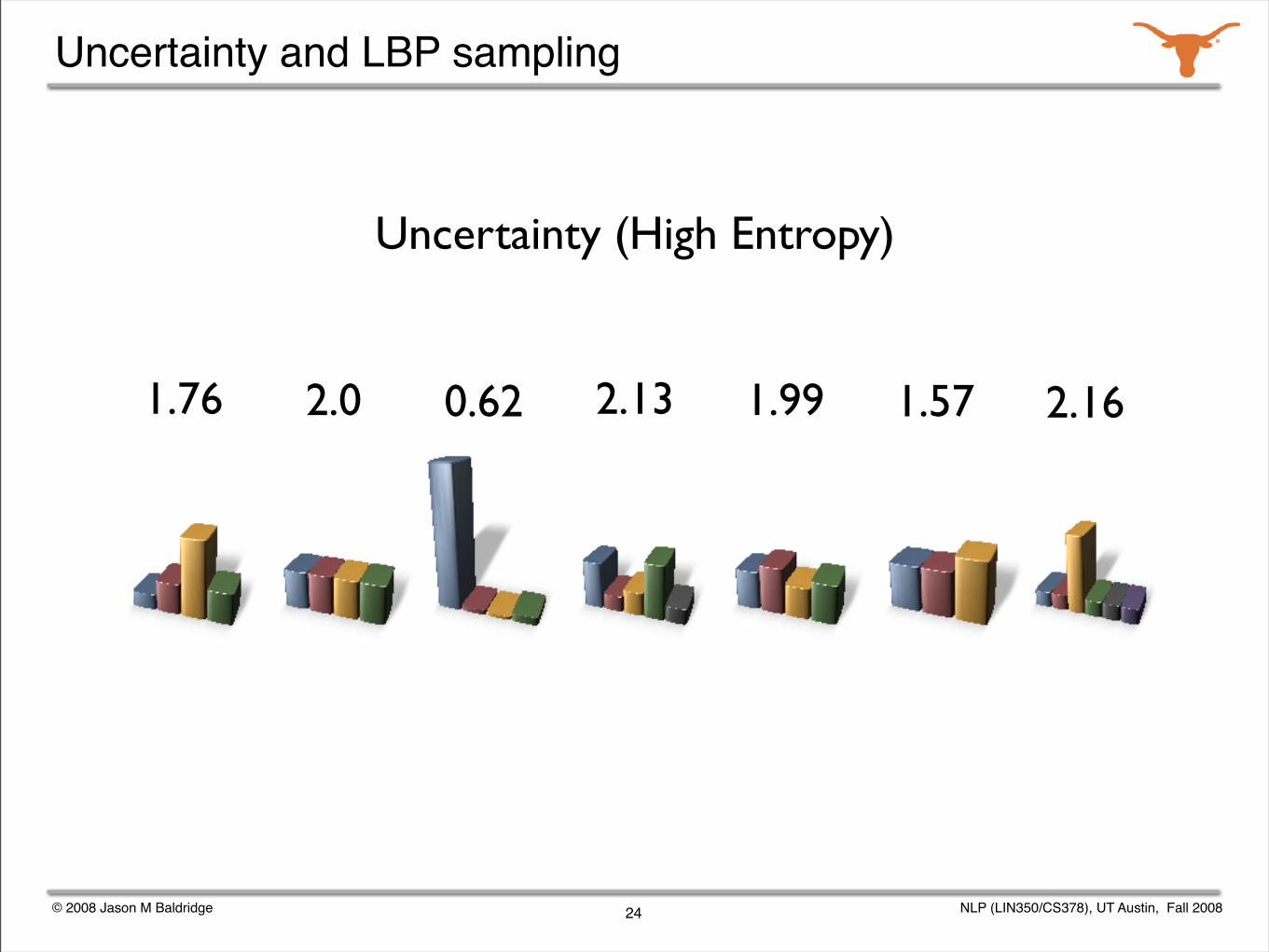
Uncertainty (High Entropy)
2.13 1.99 1.57 2.161.76 2.0 0.62
24
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Uncertainty and LBP sampling
Uncertainty (High Entropy)
Lowest Best Probability
2.13
35%
1.99
30%
1.57
40%
2.16
50%
1.76
50%
2.0
25%
0.62
90%
24
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Uncertainty and LBP sampling
Uncertainty (High Entropy)
Lowest Best Probability
2.13
35%
1.99
30%
1.57
40%
2.16
50%
1.76
50%
2.0
25%
0.62
90%
24
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Uncertainty and LBP sampling
Uncertainty (High Entropy)
Lowest Best Probability
2.13
35%
1.99
30%
1.57
40%
2.16
50%
1.76
50%
2.0
25%
0.62
90%
24
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Uncertainty and LBP sampling
Uncertainty (High Entropy)
Lowest Best Probability
2.13
35%
1.99
30%
1.57
40%
2.16
50%
1.76
50%
2.0
25%
0.62
90%
24
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
55
60
65
70
75
80
85
0 5000 10000 15000 20000 25000
Accura
cy
Discriminants
LBP samplingQBC sampling
Random sampling
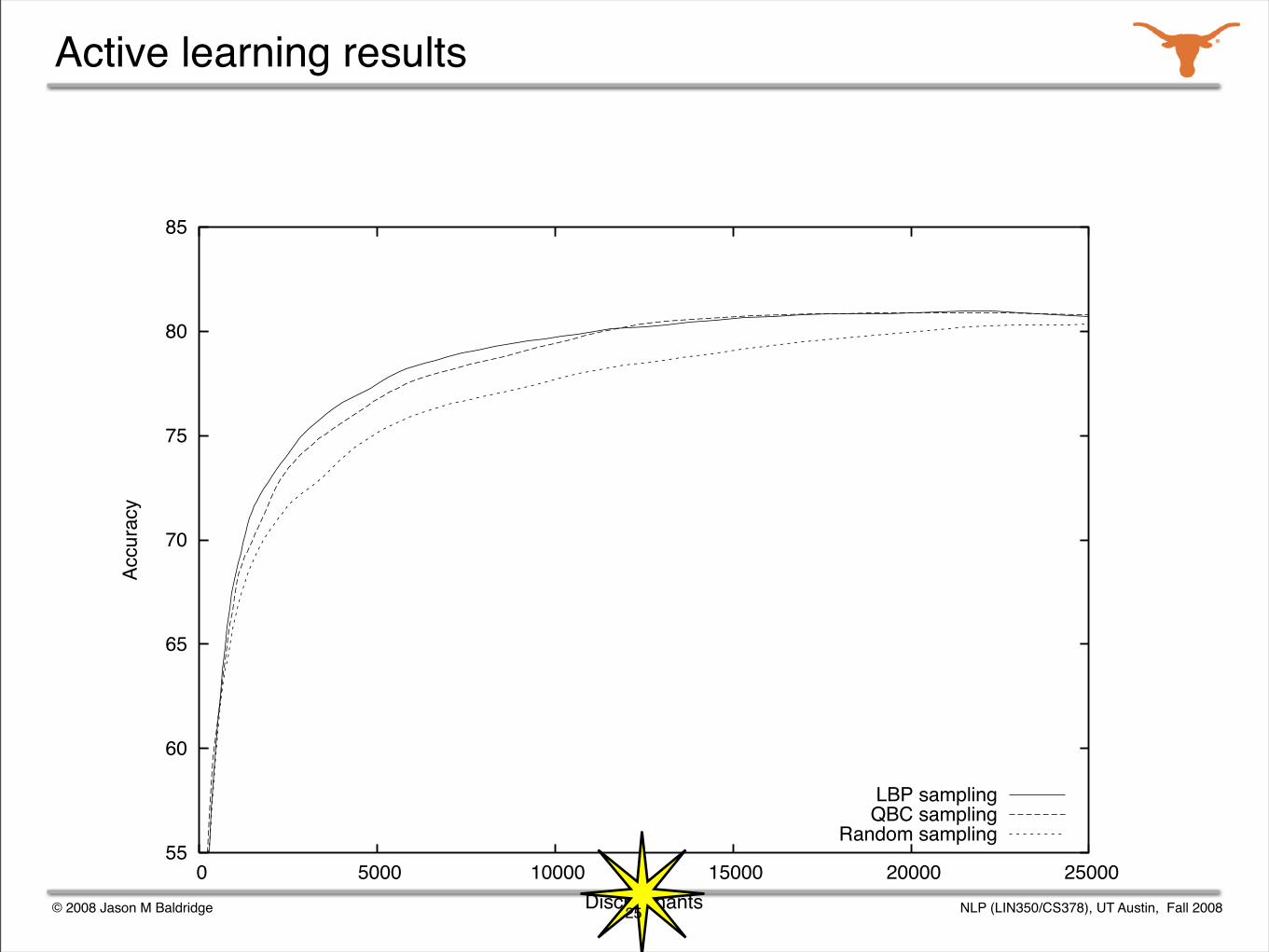
Active learning results
25
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
55
60
65
70
75
80
85
0 5000 10000 15000 20000 25000
Accura
cy
Discriminants
LBP samplingQBC sampling
Random sampling
Active learning results
25
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
55
60
65
70
75
80
85
0 5000 10000 15000 20000 25000
Accura
cy
Discriminants
LBP samplingQBC sampling
Random sampling
Active learning results
25
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
55
60
65
70
75
80
85
0 5000 10000 15000 20000 25000
Accura
cy
Discriminants
LBP samplingQBC sampling
Random sampling
Active learning results
25
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
55
60
65
70
75
80
85
0 5000 10000 15000 20000 25000
Accura
cy
Discriminants
LBP samplingQBC sampling
Random sampling
Active learning results
25
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
55
60
65
70
75
80
85
0 5000 10000 15000 20000 25000
Accura
cy
Discriminants
LBP samplingQBC sampling
Random sampling
Active learning results
25

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
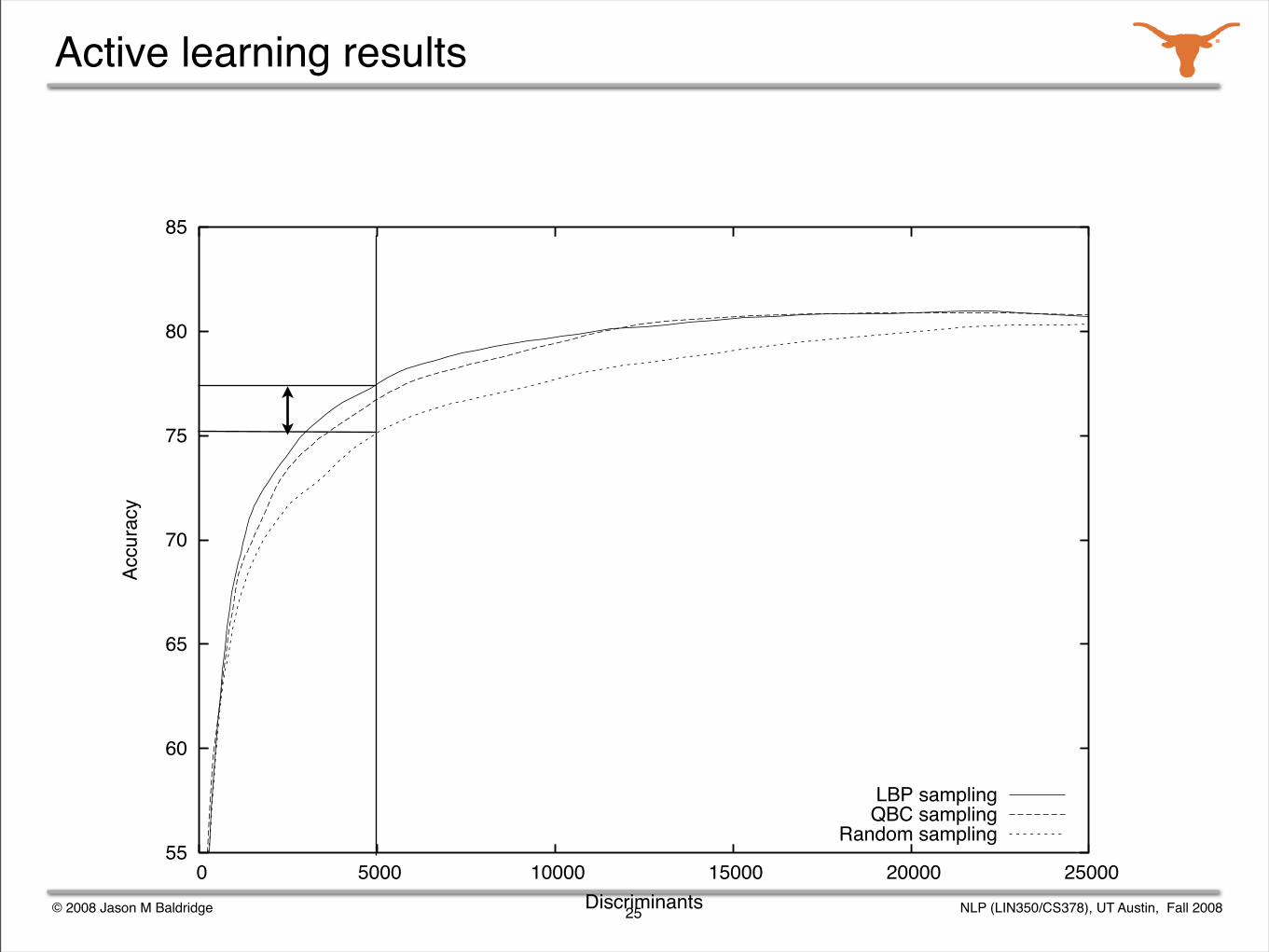
Buyer beware!
Not all examples take the same amount of effort to annotate.
This is especially true for parse selection: picking the best parse of two is far easier than picking the best of 1000.
A bigger tree will give the machine learner much more training information, so picking big trees would look like a good strategy if we utilize unit cost.
A lot of work on active learning assumes such a unit cost: this is likely to exaggerate the improvements.
Good active learning aims to maximize the training utility to cost ratio.
26

Bootstrapping through alignment

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Documentary linguistics
Documentation of a language involves many levels of analysis.
Linguist provides primary data and initial hypotheses (e.g. morphology, parts-of-speech, and more).
Encoding this knowledge in a corpus could be extremely advantageous.
But there are only so many linguists, and languages are dying rapidly.
Techniques which support more analysis with less effort thus merit investigation within the documentary context.
28
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
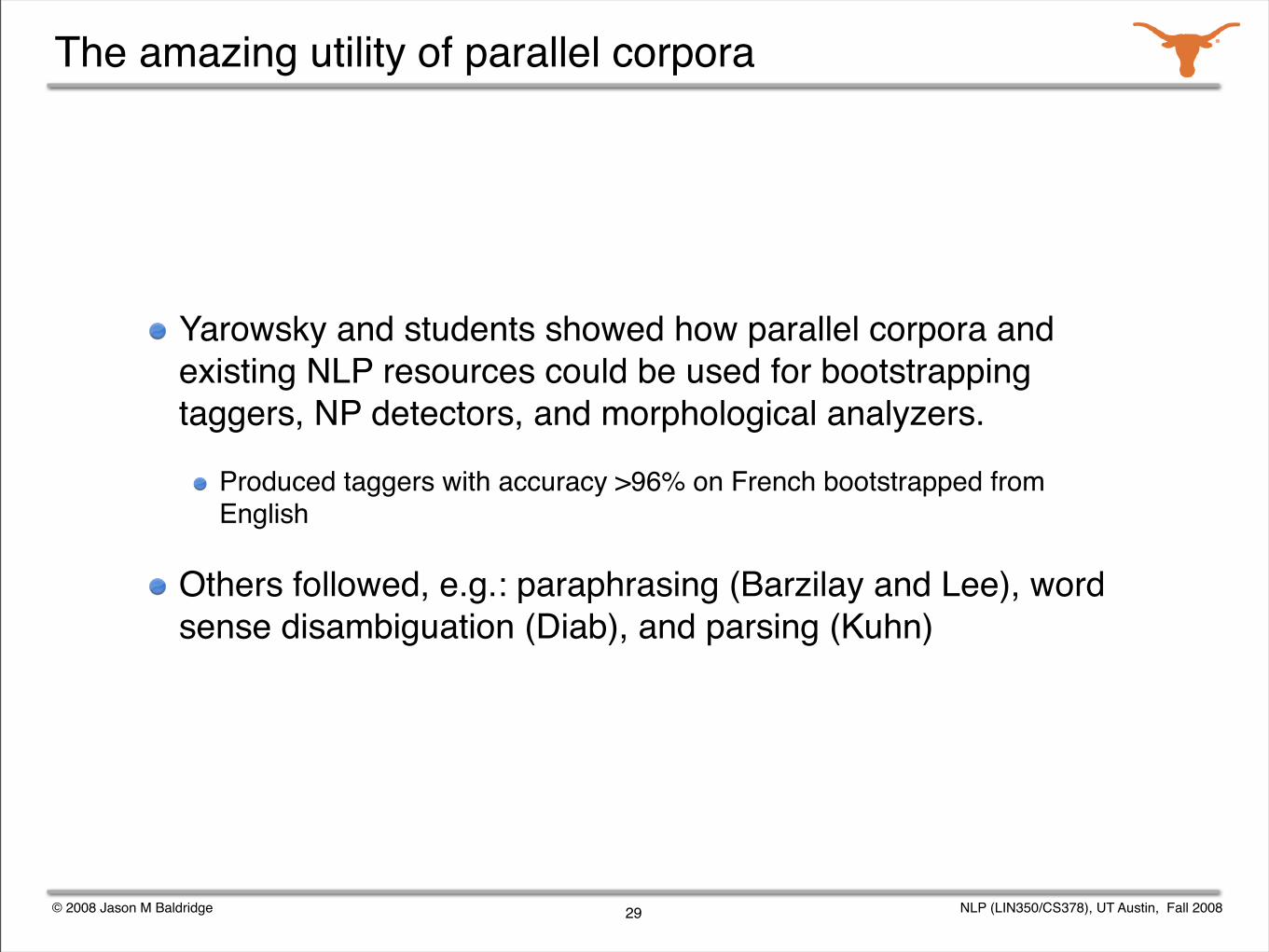
The amazing utility of parallel corpora
Yarowsky and students showed how parallel corpora and existing NLP resources could be used for bootstrapping taggers, NP detectors, and morphological analyzers.
Produced taggers with accuracy >96% on French bootstrapped from English
Others followed, e.g.: paraphrasing (Barzilay and Lee), word sense disambiguation (Diab), and parsing (Kuhn)
29

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
The Bible as a parallel corpus
The Bible has been translated into more languages than any other text.
Consistent sectioning makes it easy to produce sentence alignments.
An example:
30

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
The Bible as a parallel corpus
The Bible has been translated into more languages than any other text.
Consistent sectioning makes it easy to produce sentence alignments.
An example:
In the beginning God created the heavens and the earth
In the bigynnyng God made of nouyt heune and erthe
30

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
The Bible as a parallel corpus
The Bible has been translated into more languages than any other text.
Consistent sectioning makes it easy to produce sentence alignments.
An example:
In the beginning God created the heavens and the earth
In the bigynnyng God made of nouyt heune and erthe
P DT N NNP V DT V CC DT N
P DT N NNP V ? ? V CC N
30

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Bootstrapping a tagger for Middle English
Curran and Clark (maxent) tagger trained on Wall Street Journal
Middle English - Modern English word alignments created with Models 1 and 4 (using Giza++)
Modern English source text tagged with C&C.
Tags were transferred across alignments and used to train bigram tagger.
Bigram tagger retagged Middle English to fill in gaps (also evaluated)
31
© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
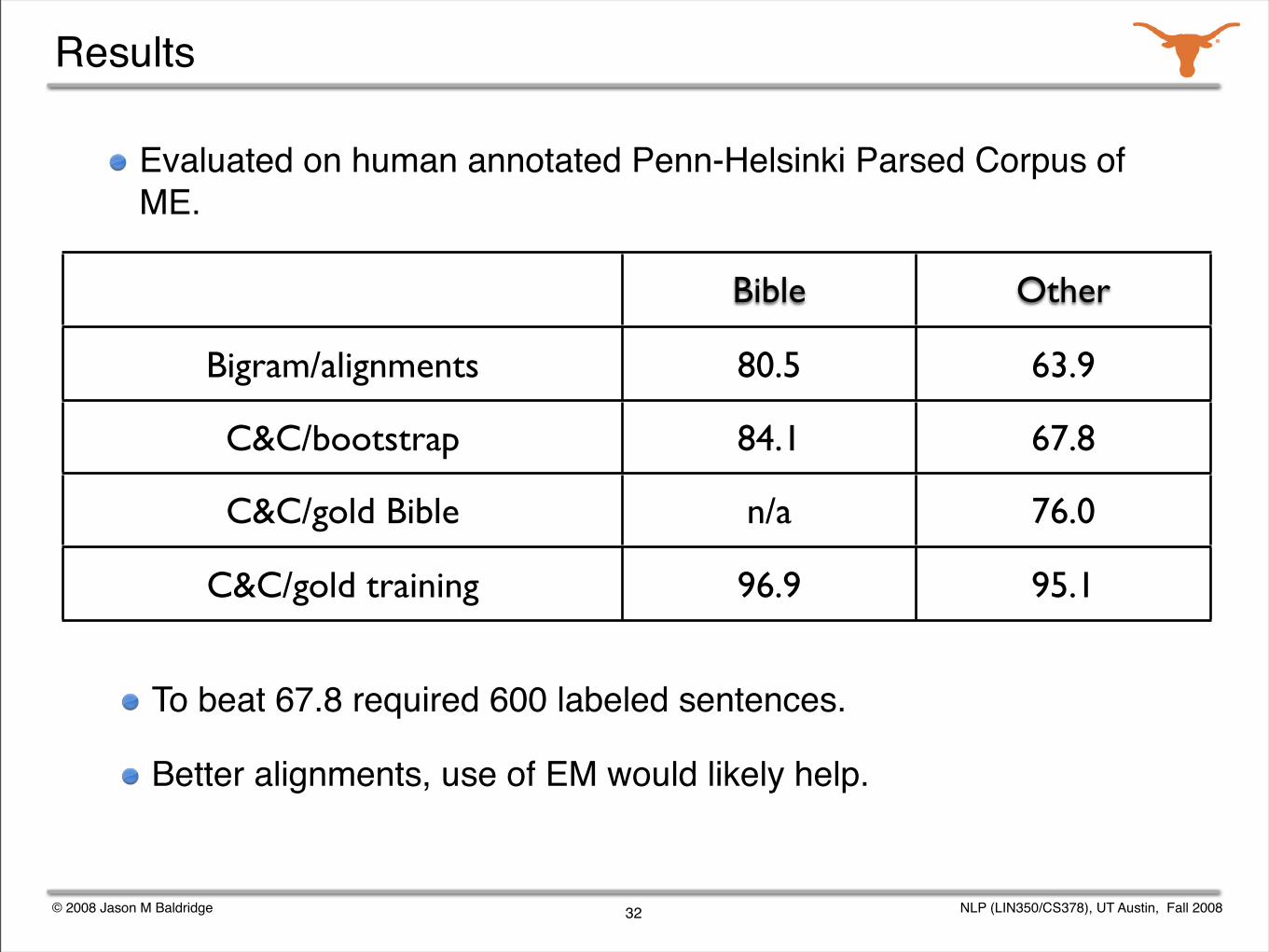
Results
Evaluated on human annotated Penn-Helsinki Parsed Corpus of ME.
Bible Other
Bigram/alignments 80.5 63.9
C&C/bootstrap 84.1 67.8
C&C/gold Bible n/a 76.0
C&C/gold training 96.9 95.1
32
To beat 67.8 required 600 labeled sentences.
Better alignments, use of EM would likely help.

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Caveats
Clear domain effects: double hit due to WSJ + Bible training material
Yarowsky study on French all used same domain
Spelling differences between the online Wycliffe Bible and the material in the Penn-Helsinki corpus
likely to occur in language documentation scenario
Tags for some target languages likely to be richer than source language
e.g. case, inflection, etc as in English -> Czech (Drabek & Yarowksy)
33

Semi-supervised tagging and supertagging

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
CCG
35
Grammatical formalism that extends earlier categorial grammars (developed since the 1930ʼs)
linguistically interesting
computationally attractive
Words are assigned lexical categories.
Categories can be combined through a small set of combinatory rules.

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200536
Application
Basic rules of combination
Forward application (>): X/Y Y ⇒ X
Backward application (<): Y X\Y ⇒ X
Example derivation

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200536
Application
Basic rules of combination
Forward application (>): X/Y Y ⇒ X
Backward application (<): Y X\Y ⇒ X
Example derivation
Ed
np
saw
(s\np)/np
Ann
np

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200536
Application
Basic rules of combination
Forward application (>): X/Y Y ⇒ X
Backward application (<): Y X\Y ⇒ X
Example derivation
Ed
np
saw
(s\np)/np
Ann
np>

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200536
Application
Basic rules of combination
Forward application (>): X/Y Y ⇒ X
Backward application (<): Y X\Y ⇒ X
Example derivation
Ed
np
saw
(s\np)/np
Ann
np>
s\np

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200536
Application
Basic rules of combination
Forward application (>): X/Y Y ⇒ X
Backward application (<): Y X\Y ⇒ X
Example derivation
Ed
np
saw
(s\np)/np
Ann
np>
s\np<

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200536
Application
Basic rules of combination
Forward application (>): X/Y Y ⇒ X
Backward application (<): Y X\Y ⇒ X
Example derivation
Ed
np
saw
(s\np)/np
Ann
np>
s\nps
<

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
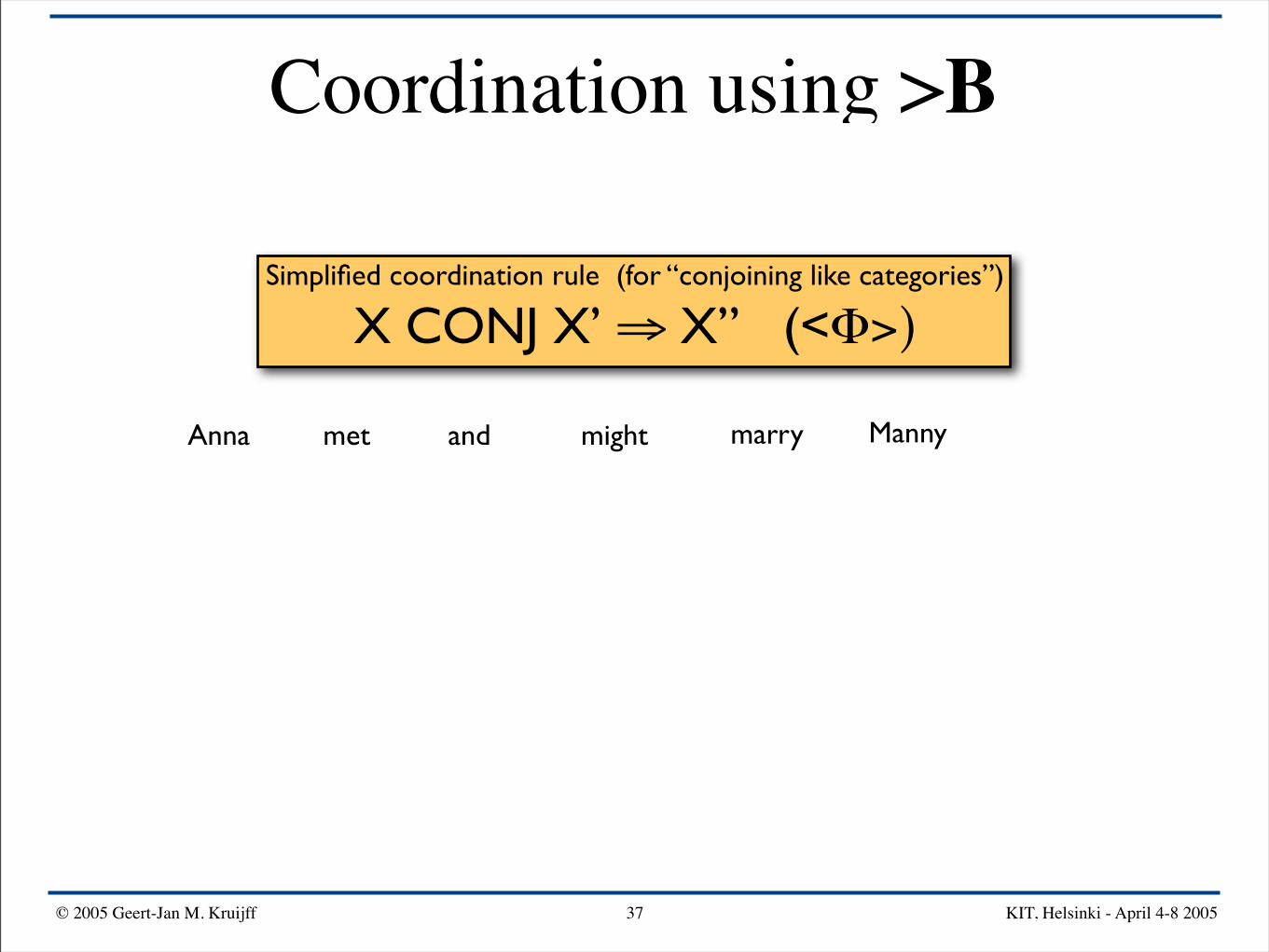
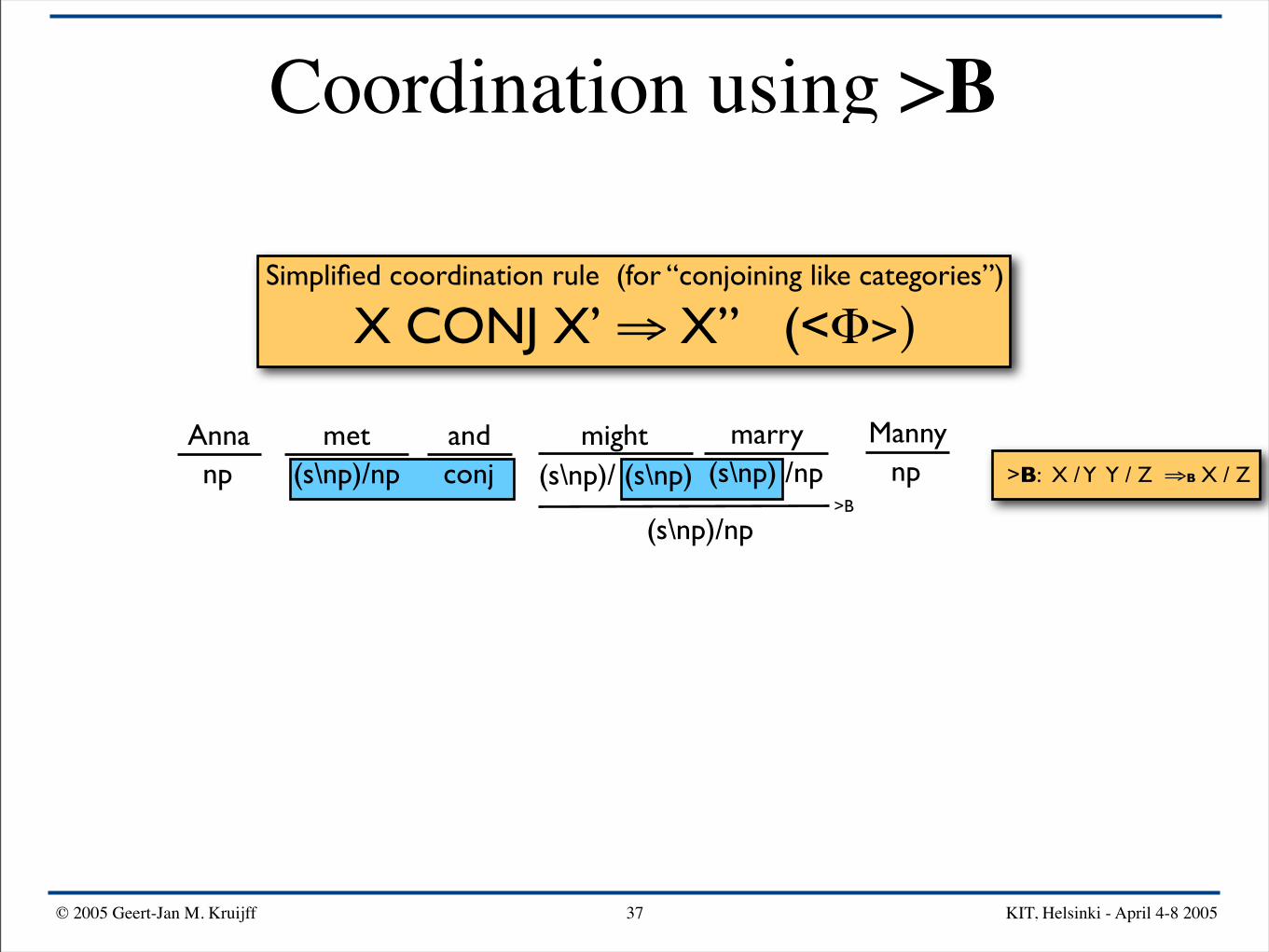
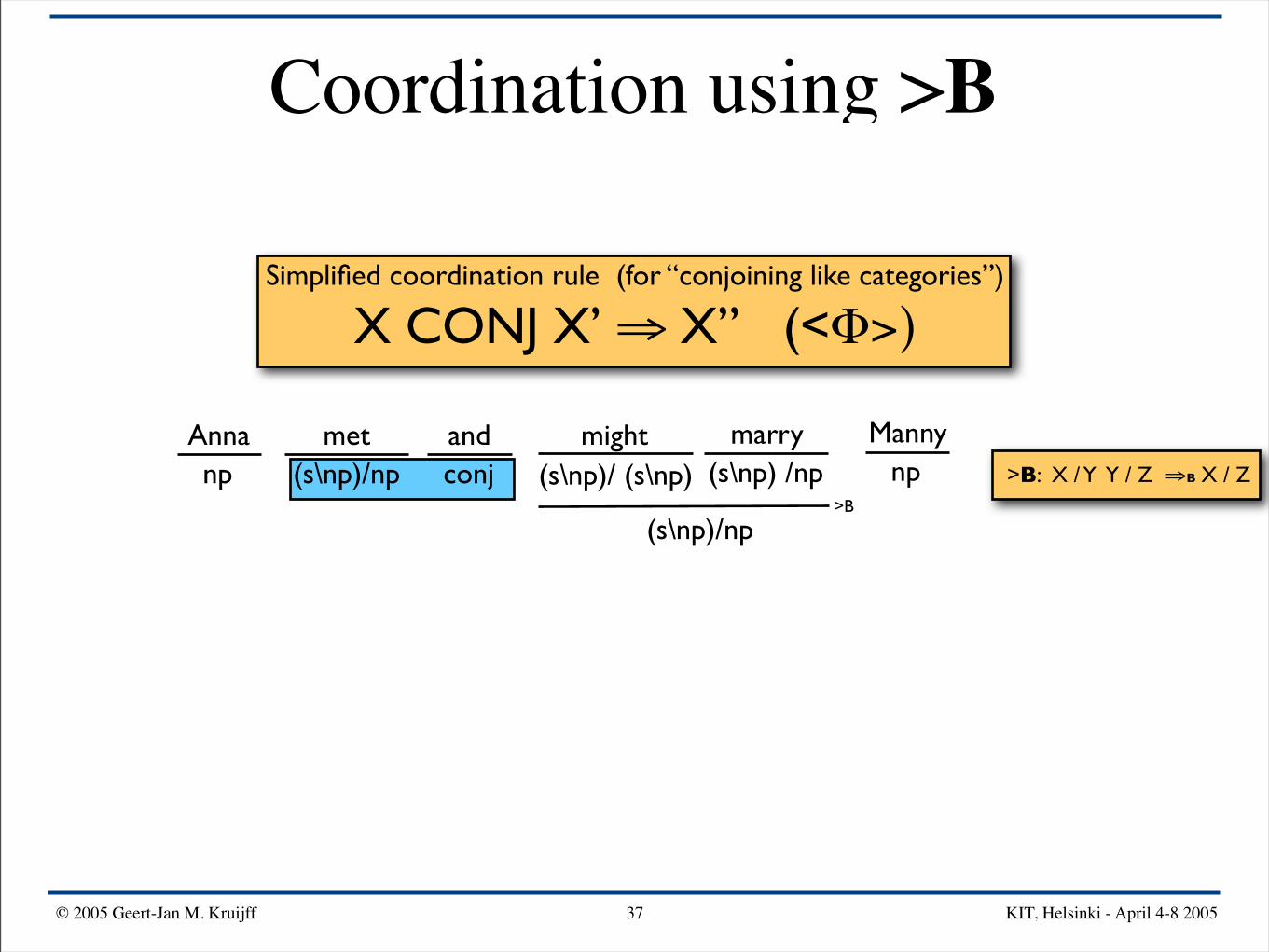
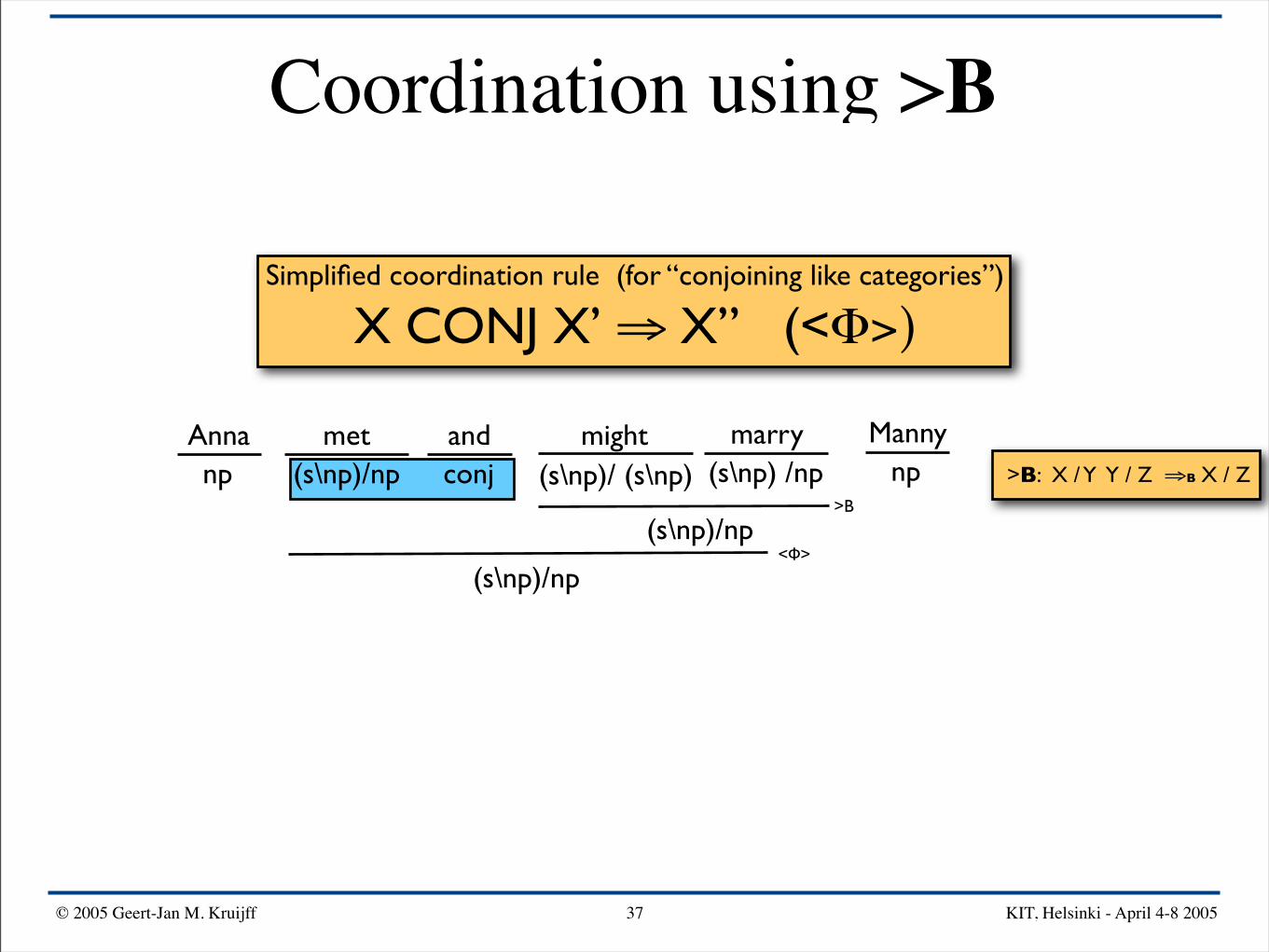
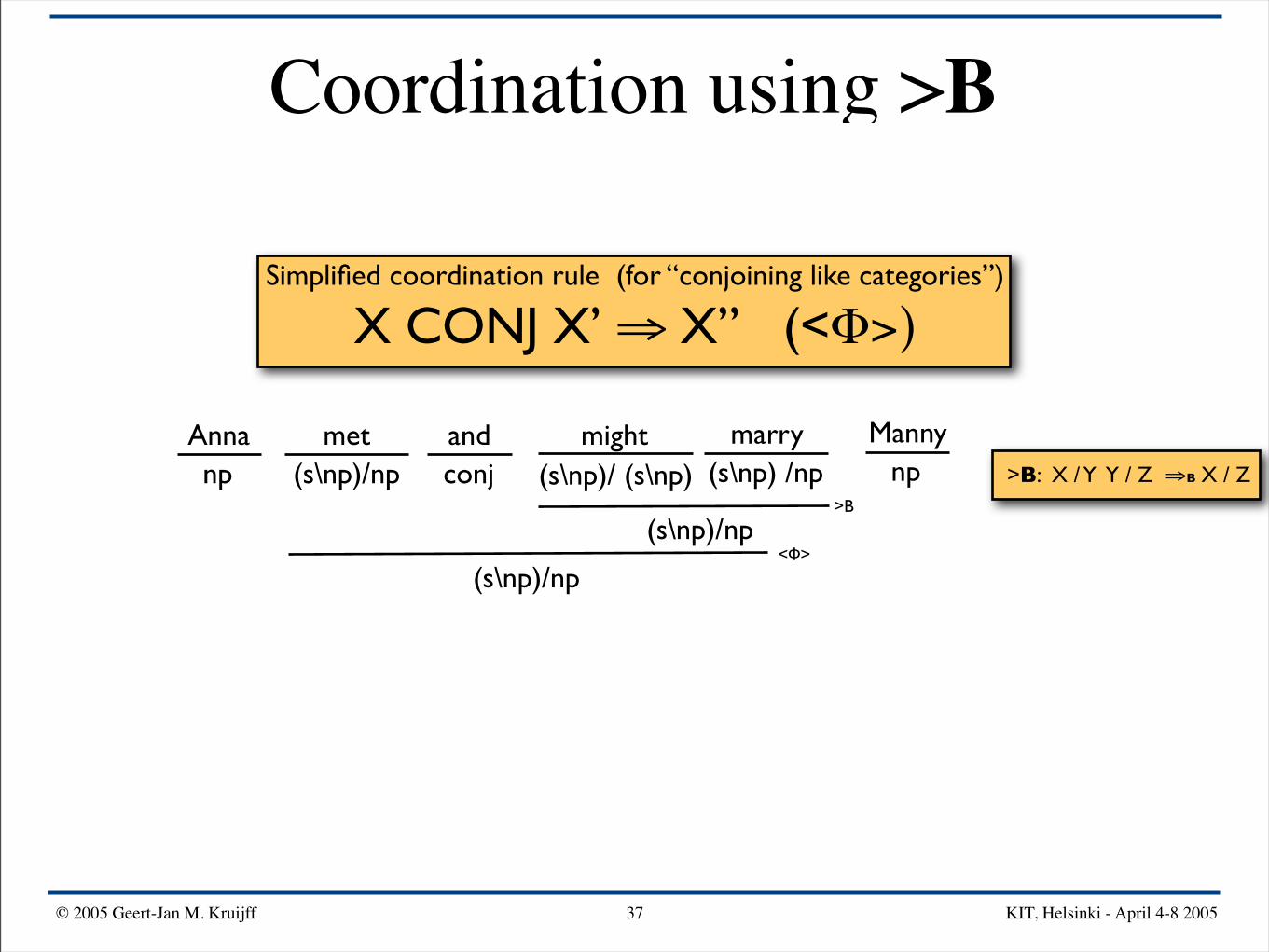
Coordination using >B

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Anna mightand Mannymarrymet
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
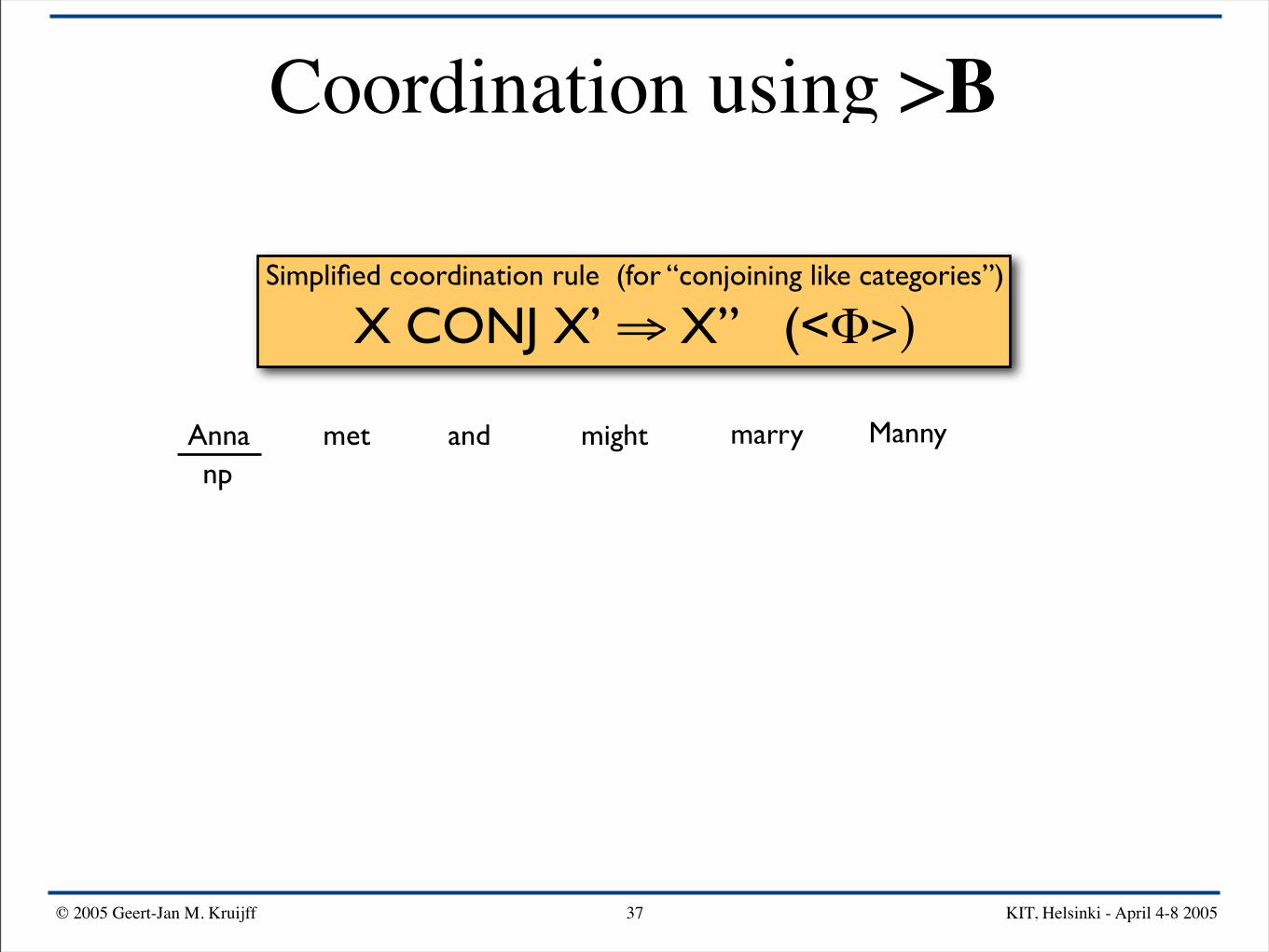
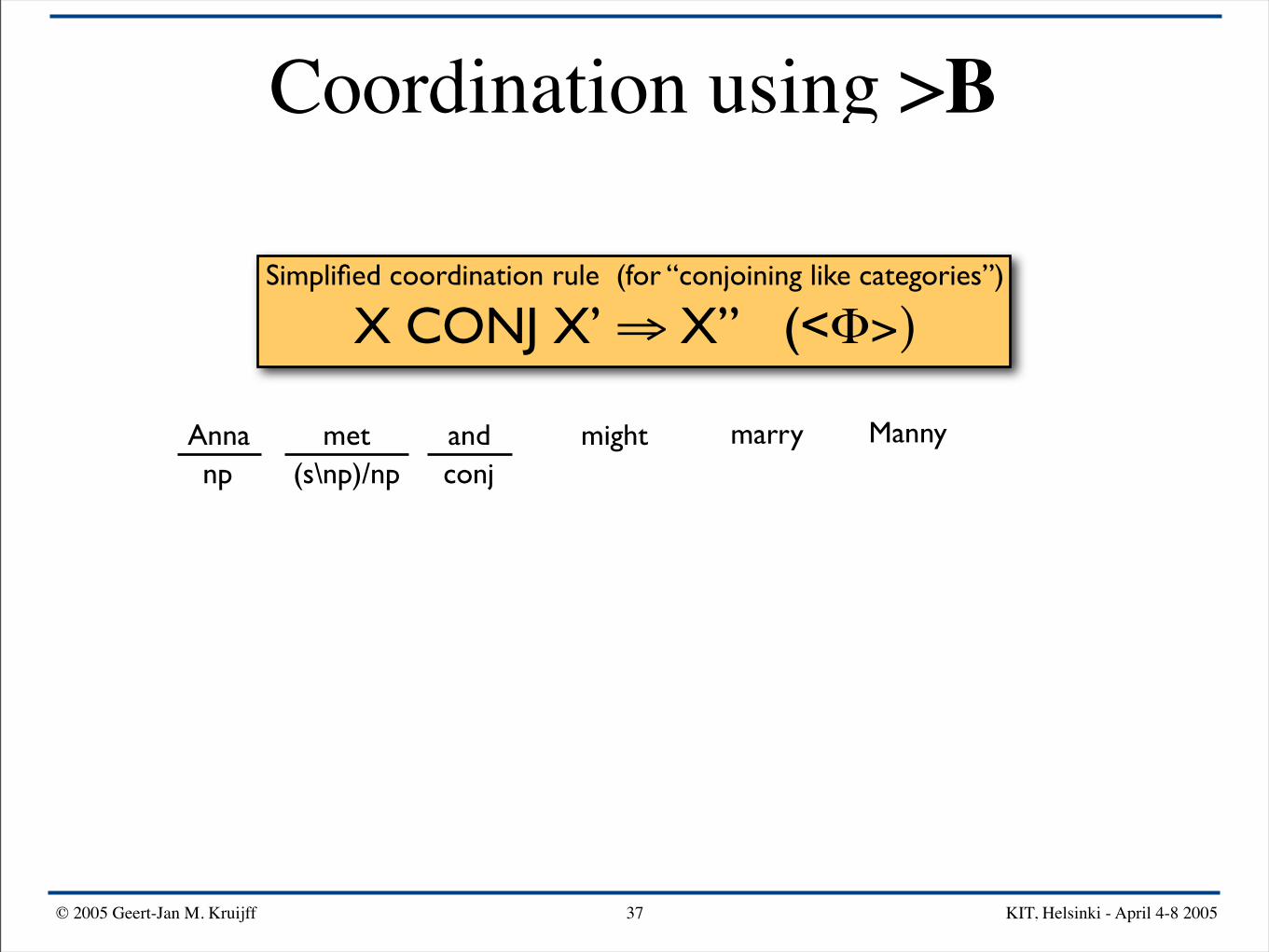
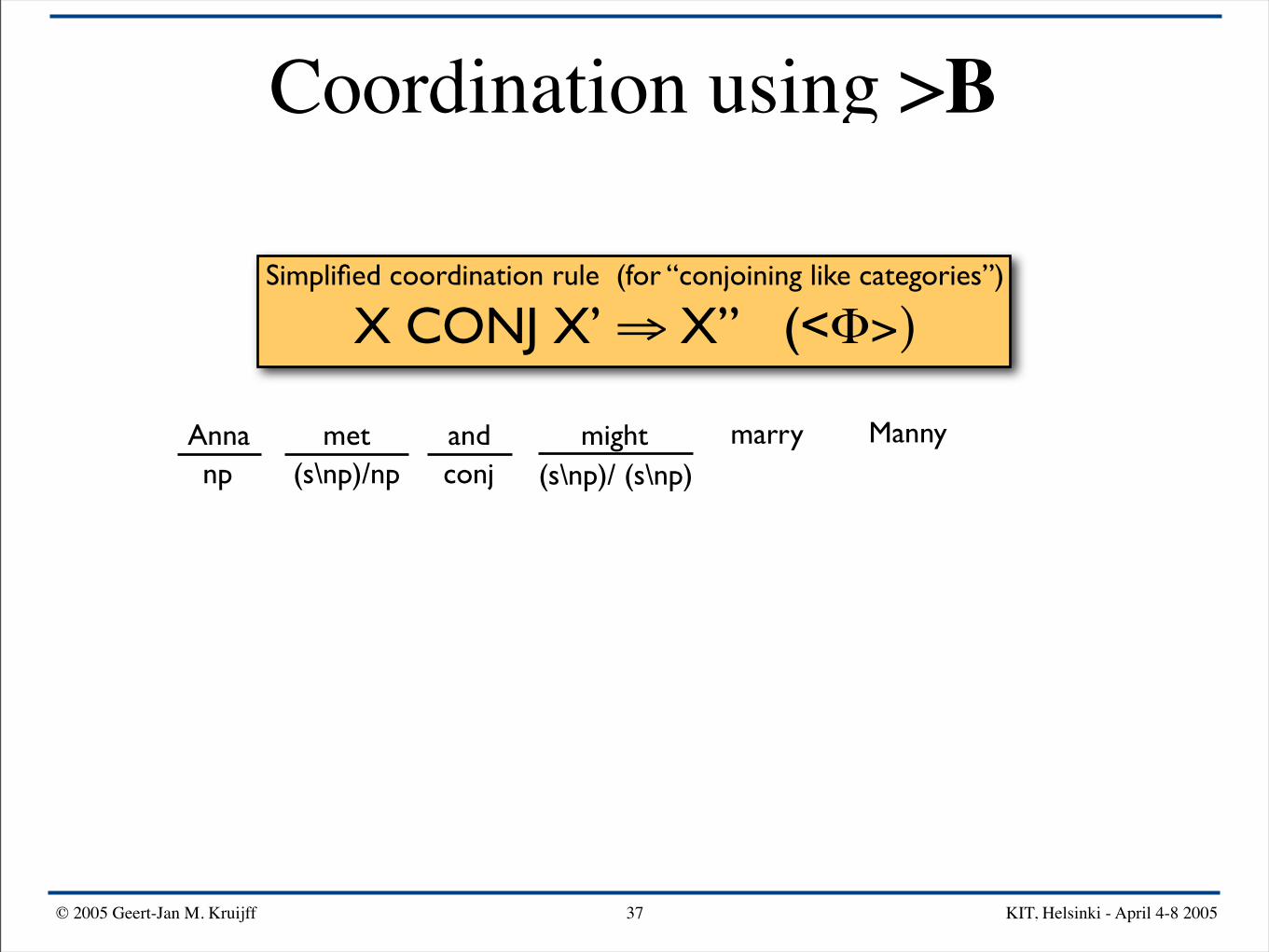
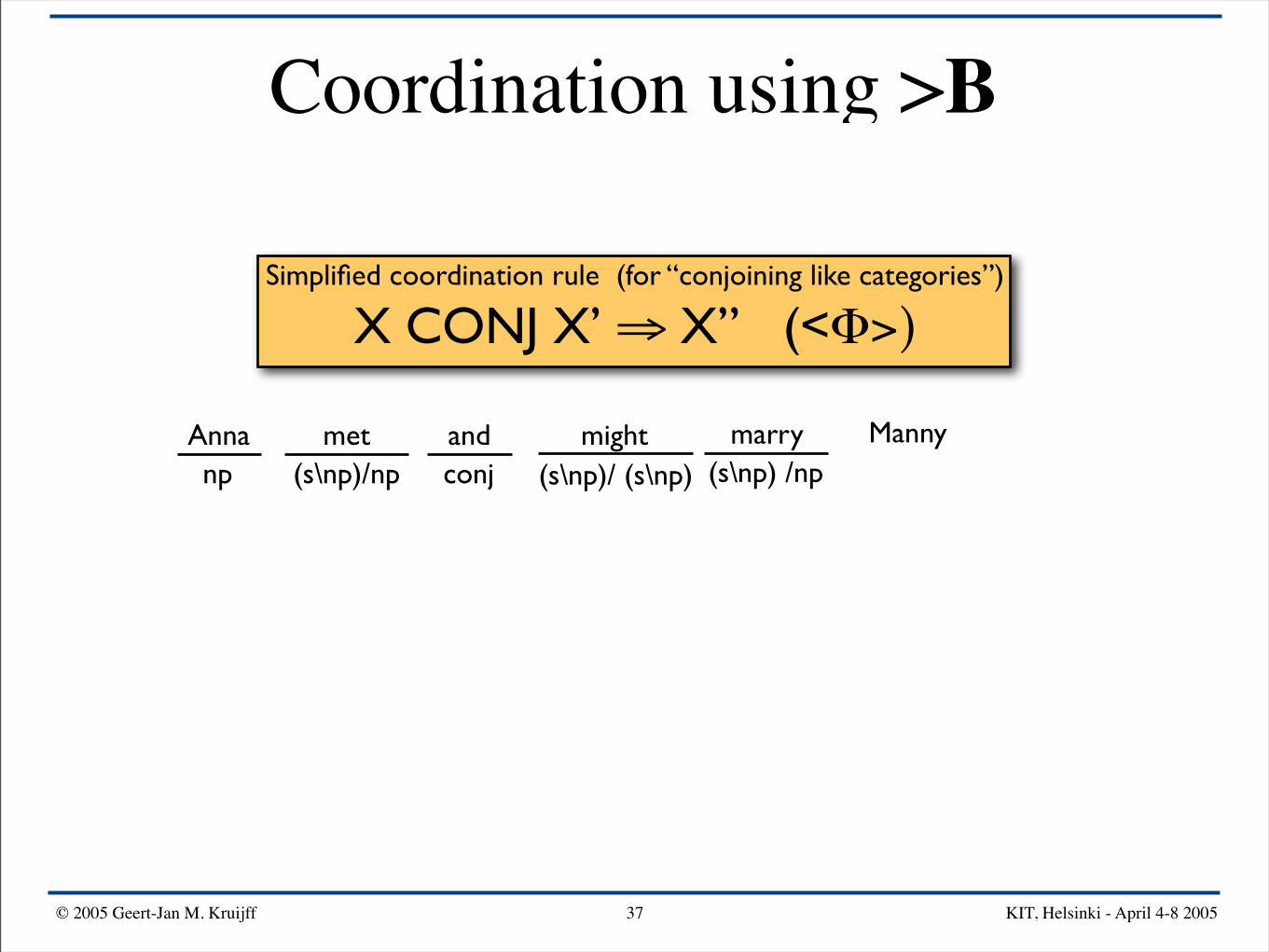
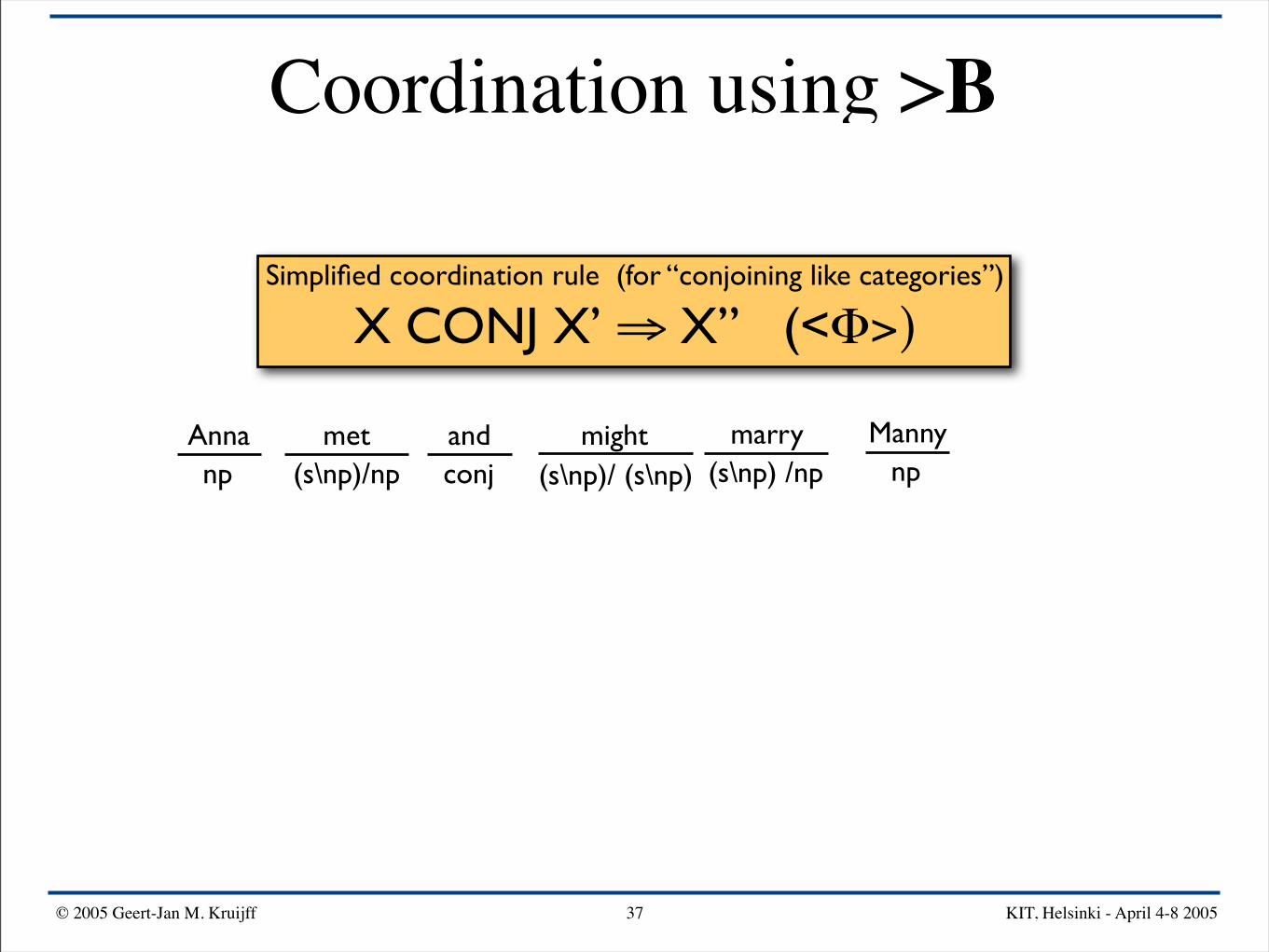
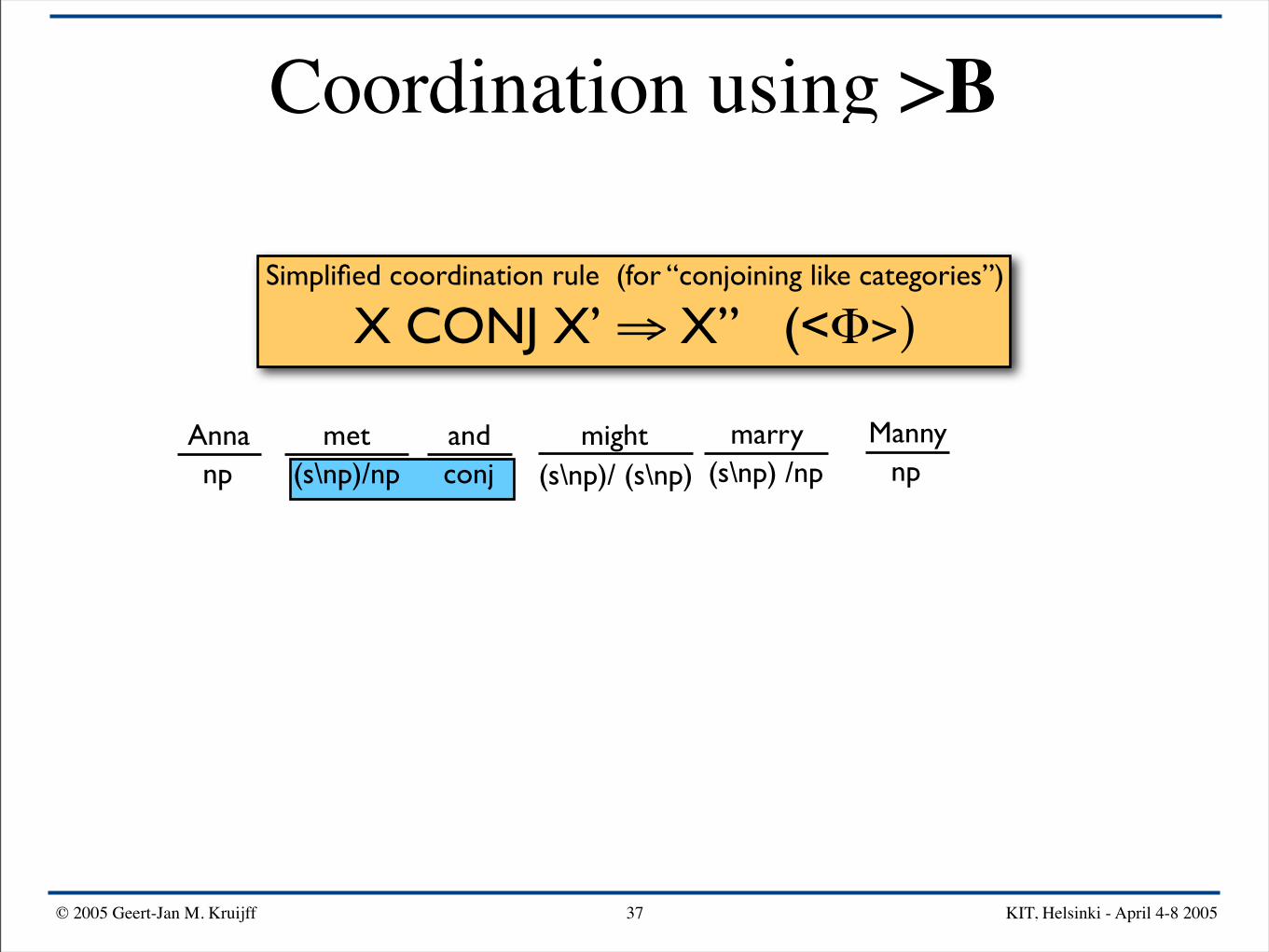
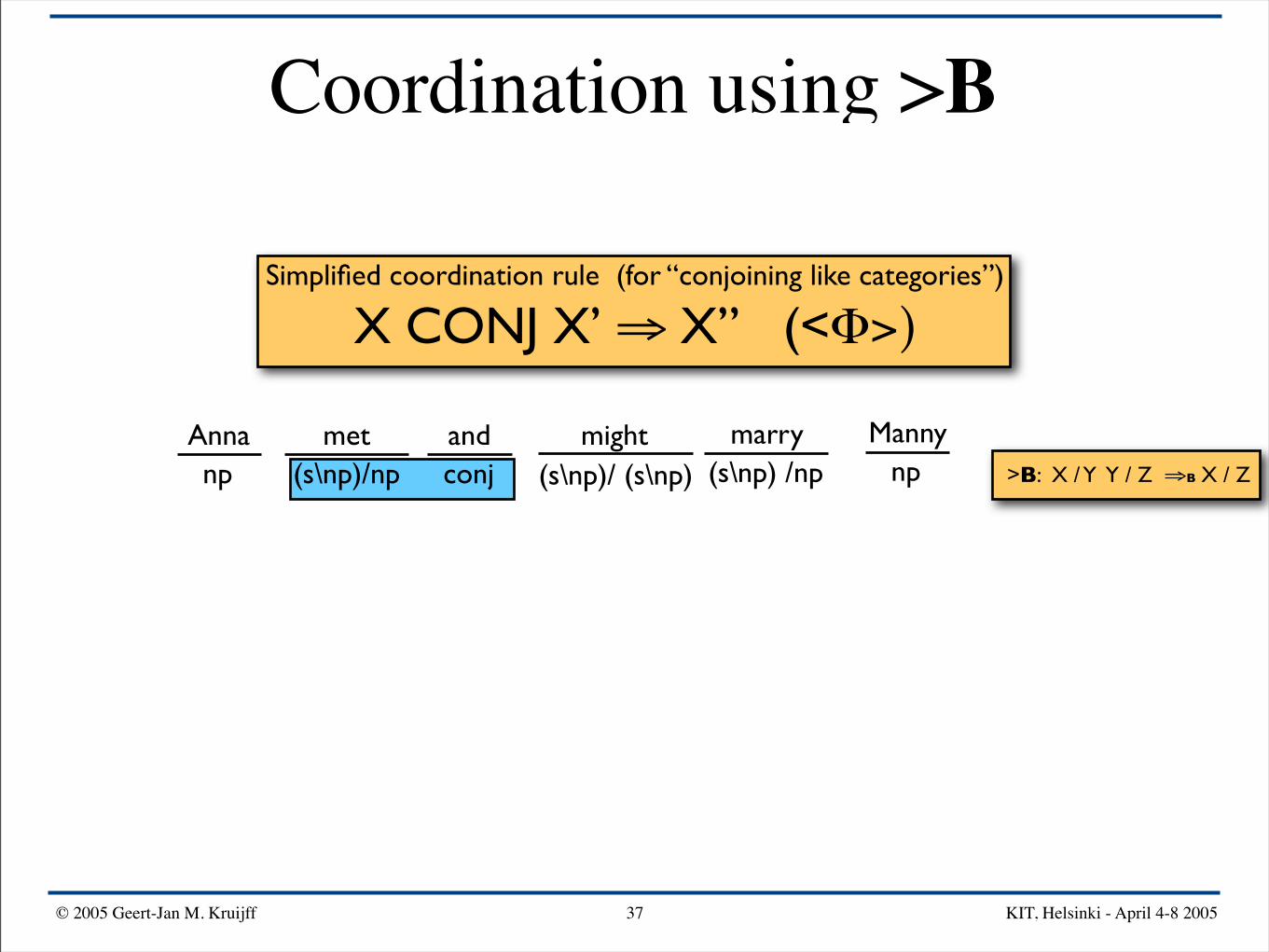
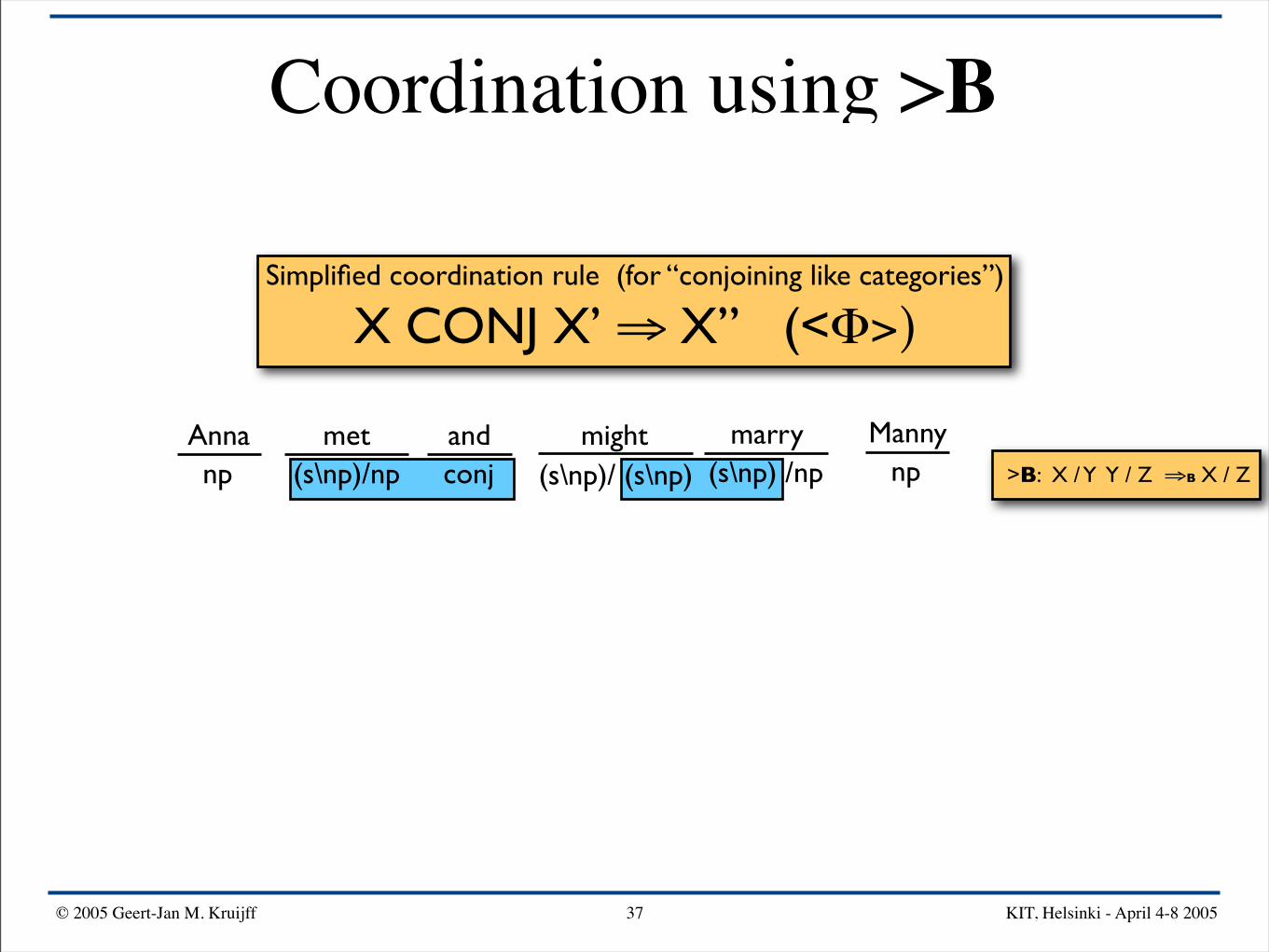
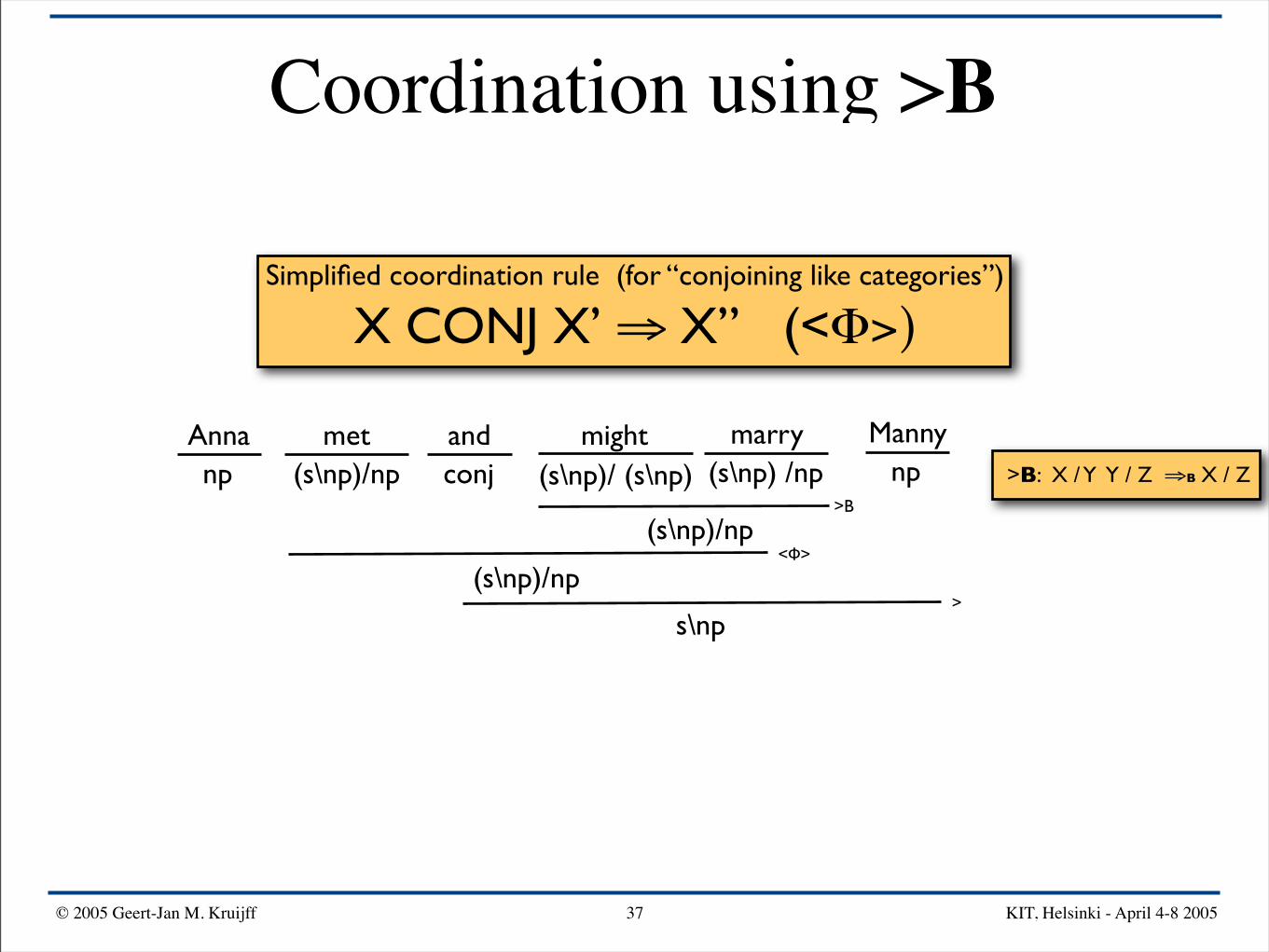
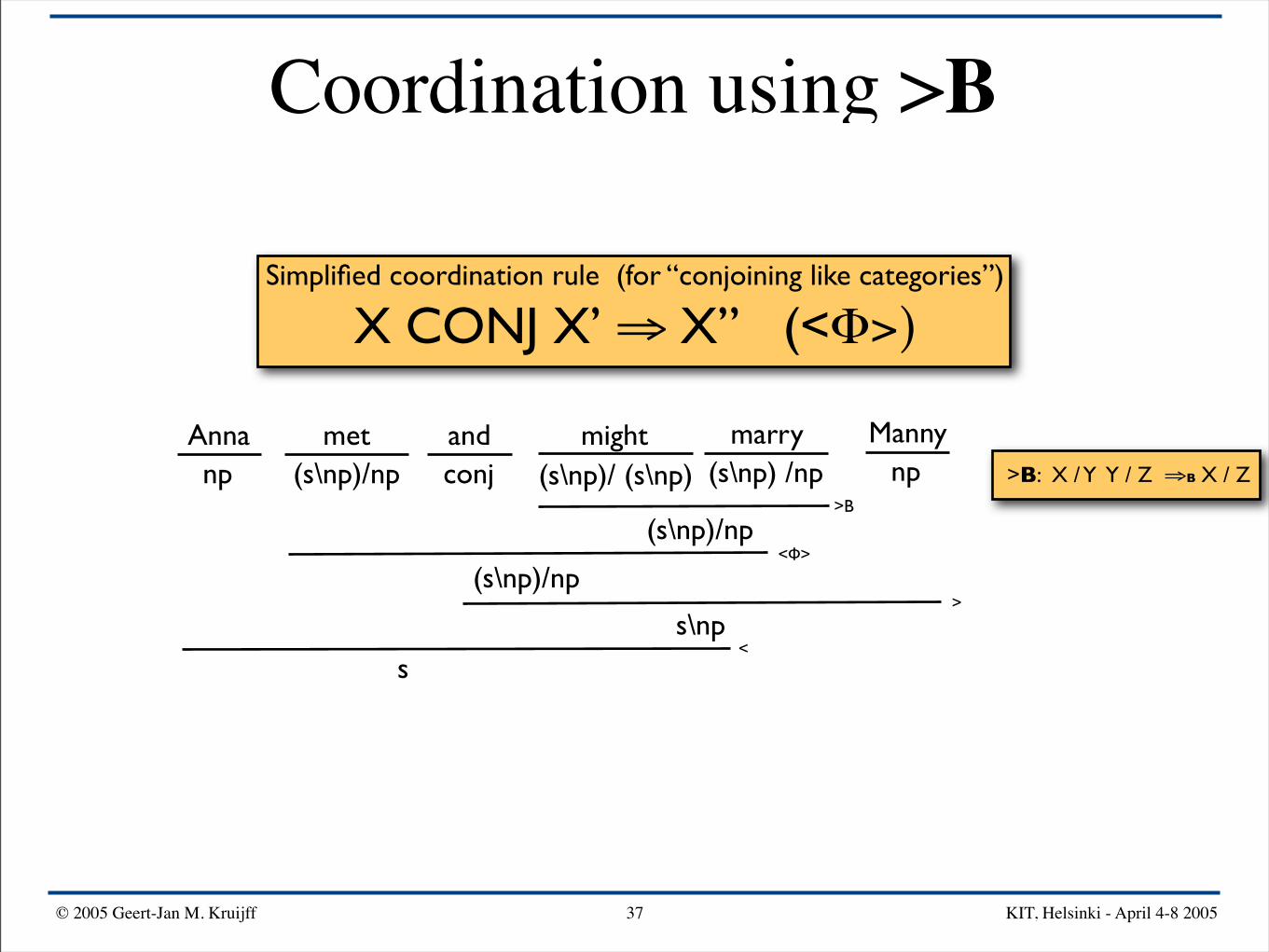
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymet
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp (s\np)/np
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp conj(s\np)/np
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp conj(s\np)/np (s\np)/ (s\np)
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp conj(s\np)/np (s\np) /np(s\np)/ (s\np)
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp npconj(s\np)/np (s\np) /np(s\np)/ (s\np)
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp npconj(s\np)/np (s\np) /np(s\np)/ (s\np)
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp npconj(s\np)/np (s\np) /np(s\np)/ (s\np) >B: X / Y Y / Z ⇒B X / Z
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp npconj(s\np)/np (s\np) /np(s\np)/ (s\np) >B: X / Y Y / Z ⇒B X / Z
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp npconj(s\np)/np (s\np) /np(s\np)/ (s\np) >B: X / Y Y / Z ⇒B X / Z
>B
(s\np)/np
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp npconj(s\np)/np (s\np) /np(s\np)/ (s\np) >B: X / Y Y / Z ⇒B X / Z
>B
(s\np)/np
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp npconj(s\np)/np (s\np) /np(s\np)/ (s\np) >B: X / Y Y / Z ⇒B X / Z
>B
(s\np)/np<Φ>
(s\np)/np
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp npconj(s\np)/np (s\np) /np(s\np)/ (s\np) >B: X / Y Y / Z ⇒B X / Z
>B
(s\np)/np<Φ>
(s\np)/np
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp npconj(s\np)/np (s\np) /np(s\np)/ (s\np) >B: X / Y Y / Z ⇒B X / Z
>B
(s\np)/np<Φ>
(s\np)/np
s\np>
© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200537
Coordination using >B
Simplified coordination rule (for “conjoining like categories”)
X CONJ X’ ⇒ X” (<Φ>)
Anna mightand Mannymarrymetnp npconj(s\np)/np (s\np) /np(s\np)/ (s\np) >B: X / Y Y / Z ⇒B X / Z
>B
(s\np)/np<Φ>
(s\np)/np
s\np>
s<

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200538
Example“type-raising changes order in which arguments can be saturated”
>T: X ⇒T Y/(Y\X) <T: X ⇒T Y\(Y/X)

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200538
Example“type-raising changes order in which arguments can be saturated”
Germany Brazil defeated
>T: X ⇒T Y/(Y\X) <T: X ⇒T Y\(Y/X)

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200538
Example“type-raising changes order in which arguments can be saturated”
Germany Brazil defeated np
>T: X ⇒T Y/(Y\X) <T: X ⇒T Y\(Y/X)

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200538
Example“type-raising changes order in which arguments can be saturated”
Germany Brazil defeated (s\np)/np np
>T: X ⇒T Y/(Y\X) <T: X ⇒T Y\(Y/X)

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200538
Example“type-raising changes order in which arguments can be saturated”
Germany Brazil defeated np (s\np)/np np
>T: X ⇒T Y/(Y\X) <T: X ⇒T Y\(Y/X)

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200538
Example“type-raising changes order in which arguments can be saturated”
Germany Brazil defeated np (s\np)/np np
>s\np
>T: X ⇒T Y/(Y\X) <T: X ⇒T Y\(Y/X)

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200538
Example“type-raising changes order in which arguments can be saturated”
Germany Brazil defeated np (s\np)/np np
>s\np
s<
>T: X ⇒T Y/(Y\X) <T: X ⇒T Y\(Y/X)

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200538
Example“type-raising changes order in which arguments can be saturated”
Germany Brazil defeated np (s\np)/np np
>s\np
Germany Brazil defeated np np (s\np)/np
s<
>T: X ⇒T Y/(Y\X) <T: X ⇒T Y\(Y/X)

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200538
Example“type-raising changes order in which arguments can be saturated”
Germany Brazil defeated np (s\np)/np np
>s\np
Germany Brazil defeated np np (s\np)/np
>Ts/(s\np)
s<
>T: X ⇒T Y/(Y\X) <T: X ⇒T Y\(Y/X)

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200538
Example“type-raising changes order in which arguments can be saturated”
Germany Brazil defeated np (s\np)/np np
>s\np
Germany Brazil defeated np np (s\np)/np
>Ts/(s\np)
>B
s/np
s<
>T: X ⇒T Y/(Y\X) <T: X ⇒T Y\(Y/X)

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200538
Example“type-raising changes order in which arguments can be saturated”
Germany Brazil defeated np (s\np)/np np
>s\np
Germany Brazil defeated np np (s\np)/np
>Ts/(s\np)
>B
s/np
s<
s>
>T: X ⇒T Y/(Y\X) <T: X ⇒T Y\(Y/X)

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200539
ExampleObject-extraction using T and B
Peripheral object extraction

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200539
ExampleObject-extraction using T and B
team that Brazil defeated n n\n/(s/np) np (s\np)/np
Peripheral object extraction

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200539
ExampleObject-extraction using T and B
team that Brazil defeated n n\n/(s/np) np (s\np)/np
>Ts/(s\np)
Peripheral object extraction

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200539
ExampleObject-extraction using T and B
team that Brazil defeated n n\n/(s/np) np (s\np)/np
>Ts/(s\np)
>Bs/np
Peripheral object extraction

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200539
ExampleObject-extraction using T and B
team that Brazil defeated n n\n/(s/np) np (s\np)/np
>Ts/(s\np)
>Bs/np
n\n>
Peripheral object extraction

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200539
ExampleObject-extraction using T and B
team that Brazil defeated n n\n/(s/np) np (s\np)/np
>Ts/(s\np)
>Bs/np
n\n>
n<
Peripheral object extraction

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200540
ExampleObject-extraction using T and B
team that Brazil defeated n n\n/(s/np) np (s\np)/np
I np
thought (s\np)/s
that s/s
>Ts/(s\np)
>Bs/s
>Ts/(s\np)
>Bs/np
>Bs/np
s/np>B
>n\n
n<
Object extraction is unboundedWe capture this using >B, passing up the argument

© 2005 Geert-Jan M. Kruijff KIT, Helsinki - April 4-8 200540
ExampleObject-extraction using T and B
team that Brazil defeated n n\n/(s/np) np (s\np)/np
I np
thought (s\np)/s
that s/s
>Ts/(s\np)
>Bs/s
>Ts/(s\np)
>Bs/np
>Bs/np
s/np>B
>n\n
n<
Object extraction is unboundedWe capture this using >B, passing up the argument
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
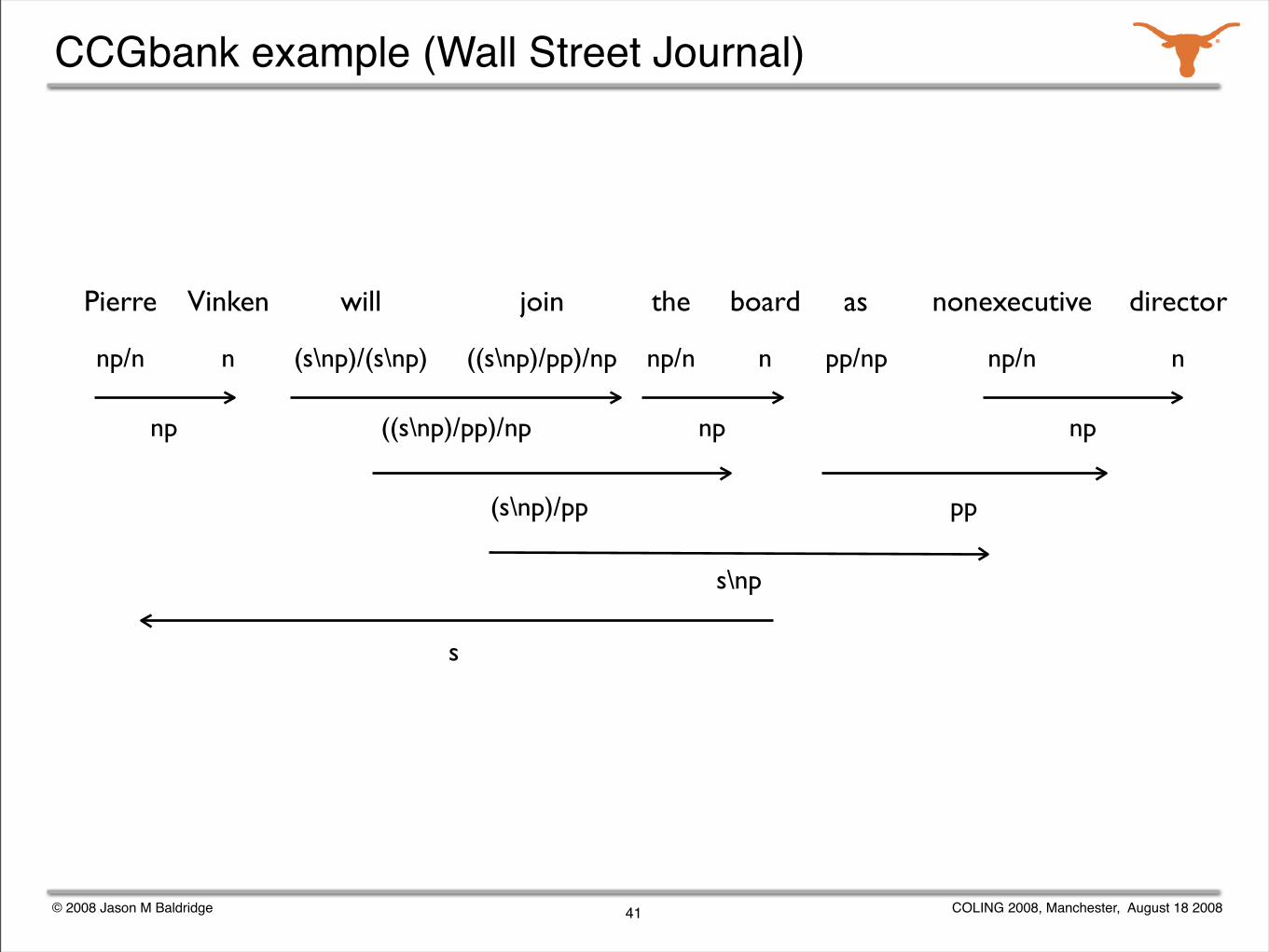
CCGbank example (Wall Street Journal)
Pierre Vinken will join the board as nonexecutive director
41
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
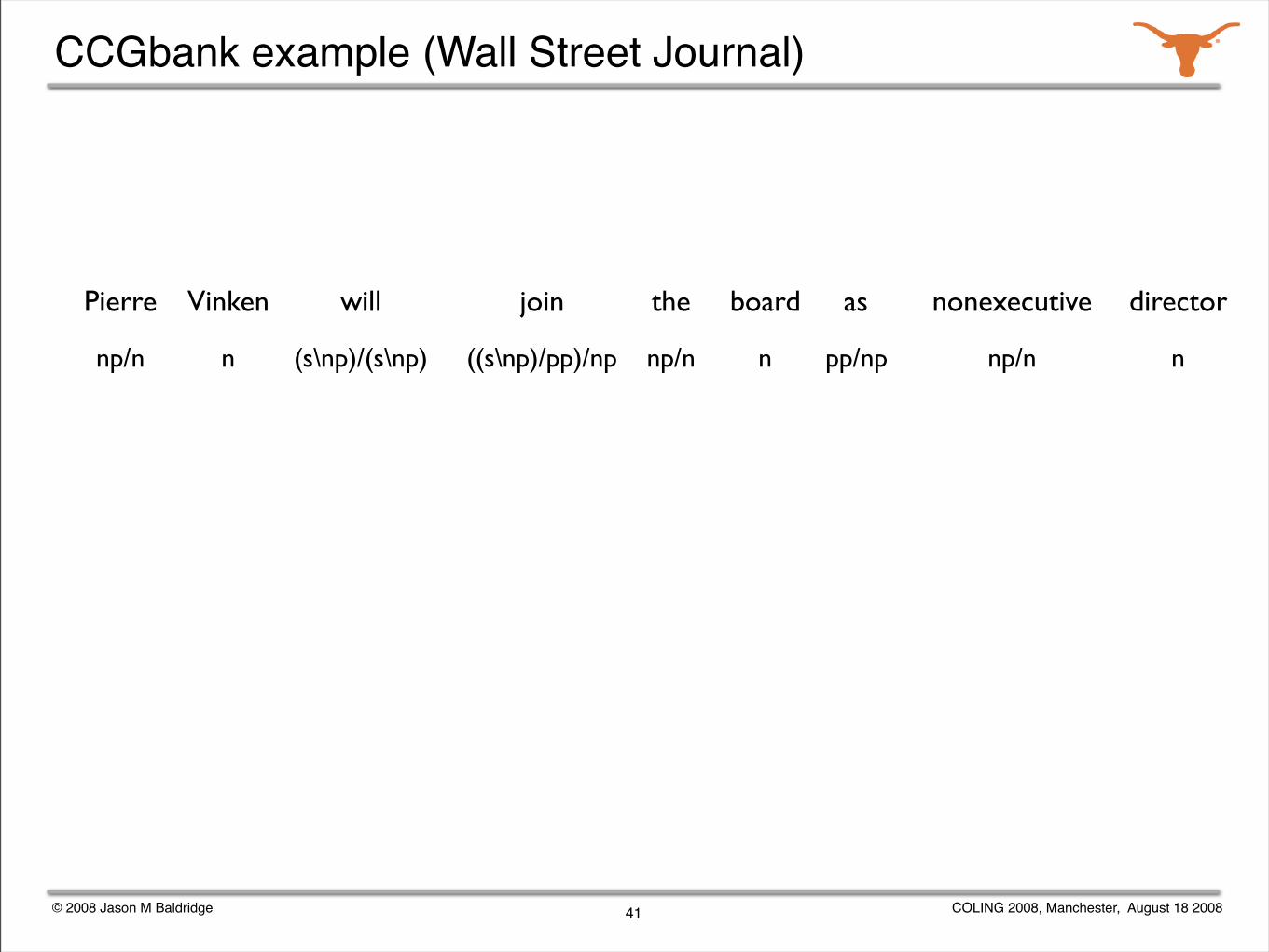
np/n n (s\np)/(s\np) ((s\np)/pp)/np np/n np/n npp/npn
CCGbank example (Wall Street Journal)
Pierre Vinken will join the board as nonexecutive director
41
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
np/n n (s\np)/(s\np) ((s\np)/pp)/np np/n np/n npp/npn
CCGbank example (Wall Street Journal)
Pierre Vinken will join the board as nonexecutive director
((s\np)/pp)/npnp np np
pp(s\np)/pp
s\np
s
41

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Big picture
Considerable progress has been made in using CCG grammars in computational applications:
CCGbank: statistical CCG parsers - StatCCG (Hockenmaier) C&C (Clark and Curran)
OpenCCG: domain-specific grammars for dialogue systems (Baldridge, Bierner, Kruijff, White, and others)
However, creating the grammars and resources for these parsing systems is considerably labor-intensive.
Can we work with new languages and domains with less effort?
42

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Big picture
CCG grammars are defined in terms of lexicons that map words to the categories.
Given an initial lexicon, we want to be able
to generalize it to unseen words
identify the correct category of those possible, for each word token
Standard supervised tagging models have worked well for learning from annotated instances. (Clark/Curran, Blunsom/Baldwin)
How well will weakly supervised supertagging models work?
43

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Big picture
HMMs can learn from lexicons alone and perform well given appropriate starting conditions (e.g., Goldberg, Adler and Elhadad)
Key idea: the properties of the CCG formalism itself can be used to constrain weakly supervised learning -- prior to considering any particular language, grammar or data set.
44

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
The importance of supertags
Originally developed in the context of Tree Adjoining Grammar for almost parsing. (Bangalore and Joshi)
Supertagging is the key to robust, fast parsing with CCG (Clark/Curran).
Supertags are also proving useful in other tasks (MT, generation, features in other models)
Supertags also happen to be categories -- the stuff that CCG grammars are made of. They are the grammar.
45

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Creating supertaggers
Supertaggers have so far used a great deal of supervision (supervised HMMs, MEMMs, CRFs).
There has been a great deal of work on using HMMs to learn POS taggers starting with a tag dictionary and using expectation-maximization.
Given a clean tag dictionary, accurate POS taggers can be created. (E.g. 95% versus 96% from supervised.)
46

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Creating supertaggers
A CCG lexicon is a tag dictionary -- just what is needed for using HMMs to bootstrapping supertaggers.
HMMs are also quite simple and efficient, which is important because of the number of labels being predicted: hundreds rather than tens.
But... the ambiguity is greater for supertagging, which means we have a less clear starting point for EM.
47

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Categories arenʼt just labels
Categories vary in the complexity/size of their internal structure; e.g., np/n vs ((s\np)/(s\np))/np
Categories project syntactic structure in full CCG derivations: they are inherently about syntactic context.
Idea: exploit these properties of categories for breaking symmetry in initializing HMM parameters.
48
(s\np)\np
(s\np)/np
(s/np)/np
VBZ vs
SOV: Turkish
SVO: English
VSO: Tagalog

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Lexical category distribution
Not all categories are equally likely, so we could define a distribution over lexical categories before considering any actual data.
Generally, smaller categories are preferable to big and complex ones.
49
buy := (sdcl\np)/np
buy := ((((sb\np)/pp)/pp)/(sadj\np))/np

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Lexical category distribution
Not all categories are equally likely, so we could define a distribution over lexical categories before considering any actual data.
Generally, smaller categories are preferable to big and complex ones.
49
buy := (sdcl\np)/np
buy := ((((sb\np)/pp)/pp)/(sadj\np))/np
Occurs 33 times in CCGbank.

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Lexical category distribution
Not all categories are equally likely, so we could define a distribution over lexical categories before considering any actual data.
Generally, smaller categories are preferable to big and complex ones.
49
buy := (sdcl\np)/np
buy := ((((sb\np)/pp)/pp)/(sadj\np))/np
Occurs 33 times in CCGbank.
Occurs once...

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Lexical category distribution
Not all categories are equally likely, so we could define a distribution over lexical categories before considering any actual data.
Generally, smaller categories are preferable to big and complex ones.
49
buy := (sdcl\np)/np
buy := ((((sb\np)/pp)/pp)/(sadj\np))/np
Occurs 33 times in CCGbank.
Occurs once...
(s\np)/(s\np)
((s\np)/pp)/np
np
s/s
(s\((s\np)\s)/(np\np)
((s\np)/(s/(np\s))/np
(((np/np)/np)/np)/np
(np/s)/((s\np)/np)versus And so on...

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
A simple distribution
Idea: first have a measure of the complexity of a category.
Then define a distribution that assigns a probability to a category which is inversely proportional to its complexity.
For example, given a lexicon L, let Prob(ci) = Λ(ci) = Λi such that:
50

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
A simple measure of complexity
What make a category complex?
having many arguments
having complex arguments
Count the number of tokens of subcategories in a category. E.g.:
51
((s\np)\(s\np))/np

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
A simple measure of complexity
What make a category complex?
having many arguments
having complex arguments
Count the number of tokens of subcategories in a category. E.g.:
51
((s\np)\(s\np))/np ((s\np)\(s\np))/np
(s\np)\(s\np)
s\np
np
s
11232
= 9
s np s np
s\np s\np
(s\np)\(s\np) np

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Category transition distribution
HMM transition distributions are of the form p(ti | ti-1).
POS tags are just labels and donʼt tell us anything about whether they are likely to occur next to one another.
Categories are not so uninformative. They project syntactic structure, so they say something about the categories that are likely to be found around them.
The fact that CCG is highly associative makes this even more effective.
52
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
np/n n (s\np)/(s\np) ((s\np)/pp)/np np/n np/n npp/npn
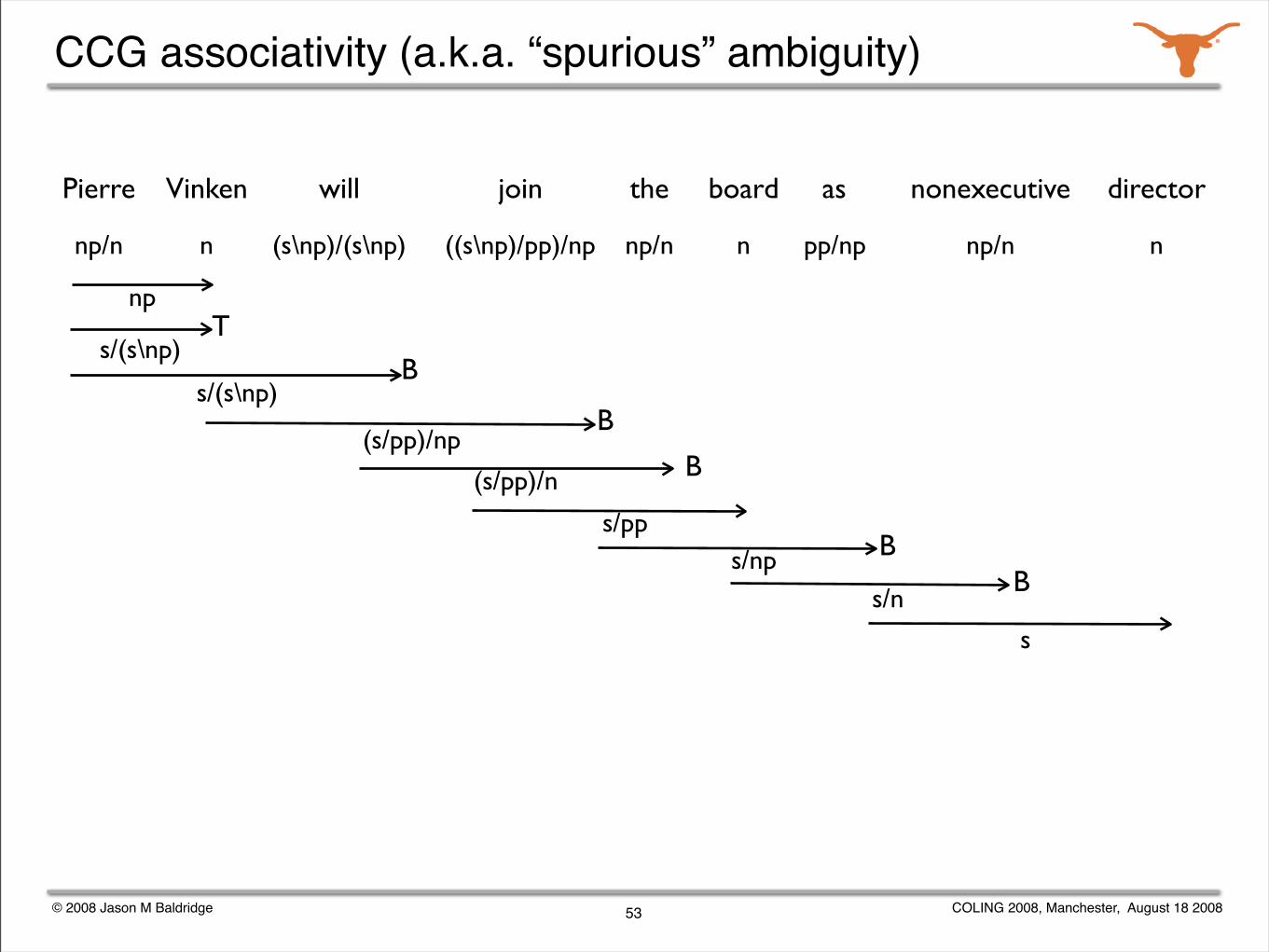
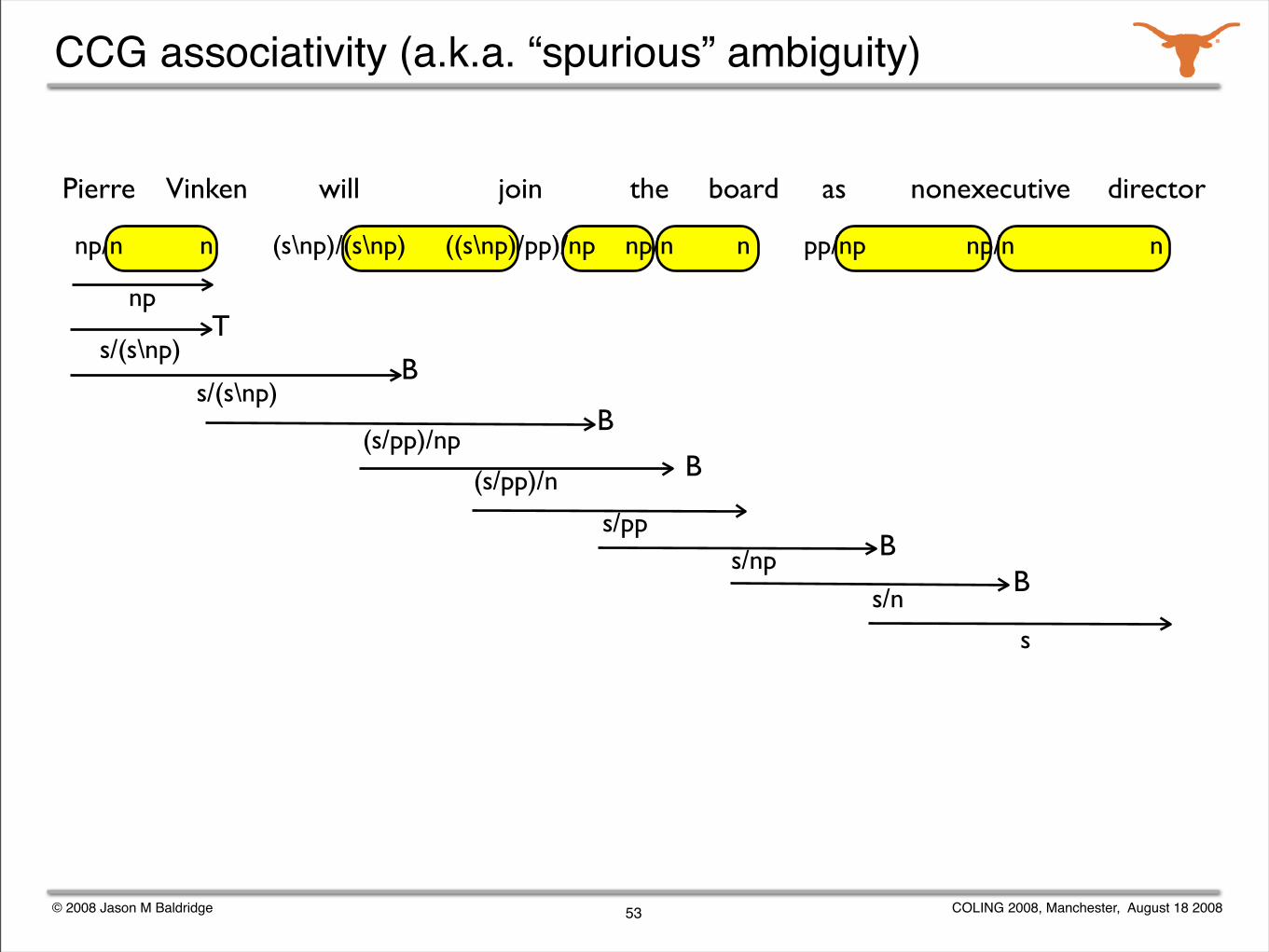
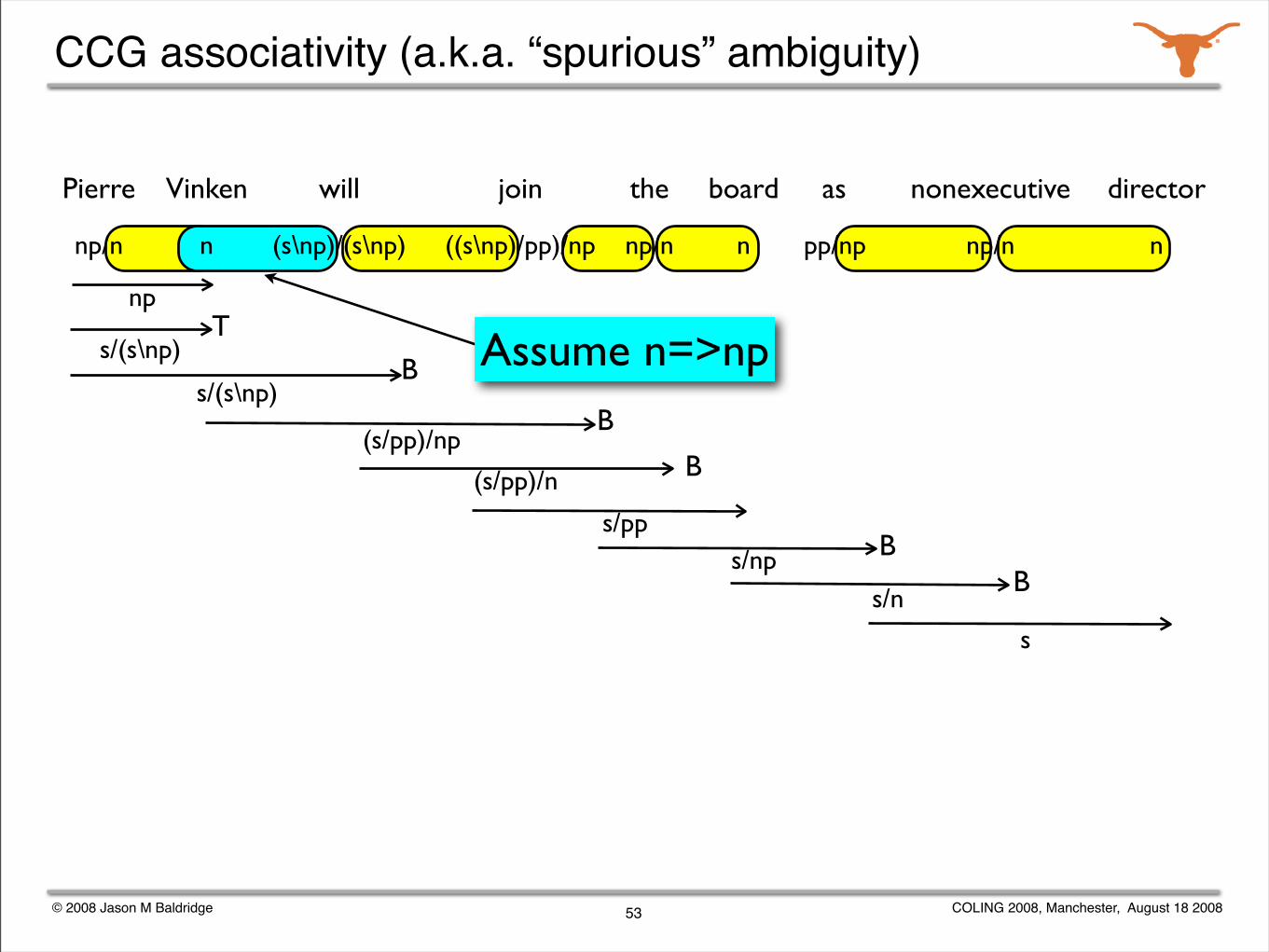
CCG associativity (a.k.a. “spurious” ambiguity)
Pierre Vinken will join the board as nonexecutive director
53
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
np/n n (s\np)/(s\np) ((s\np)/pp)/np np/n np/n npp/npn
CCG associativity (a.k.a. “spurious” ambiguity)
Pierre Vinken will join the board as nonexecutive director
(s/pp)/np
np
53
s/(s\np)T
s/(s\np)B
B
B(s/pp)/n
s/ppBs/np
Bs/n
s
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
np/n n (s\np)/(s\np) ((s\np)/pp)/np np/n np/n npp/npn
CCG associativity (a.k.a. “spurious” ambiguity)
Pierre Vinken will join the board as nonexecutive director
(s/pp)/np
np
53
s/(s\np)T
s/(s\np)B
B
B(s/pp)/n
s/ppBs/np
Bs/n
s
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
np/n n (s\np)/(s\np) ((s\np)/pp)/np np/n np/n npp/npn
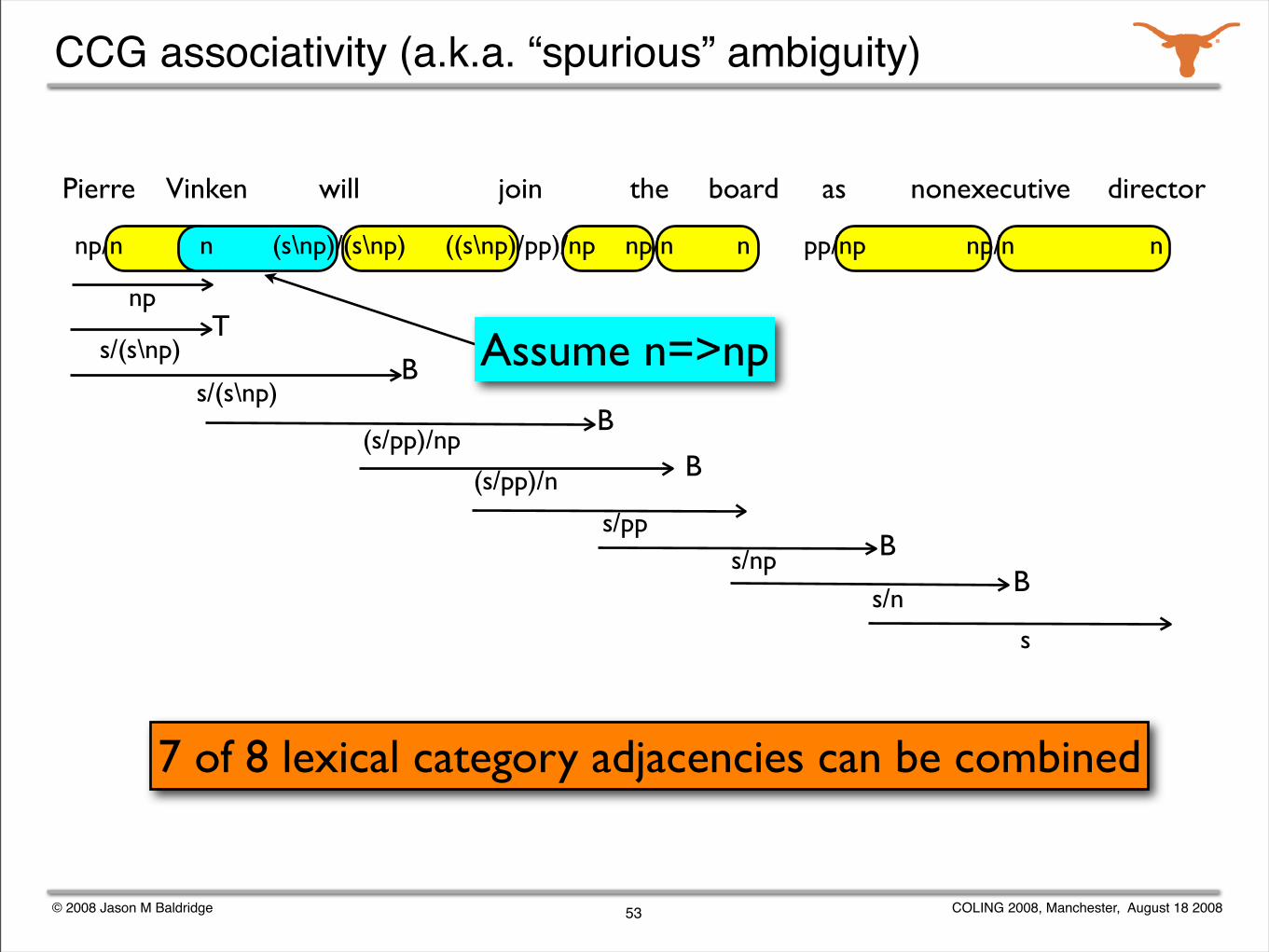
CCG associativity (a.k.a. “spurious” ambiguity)
Pierre Vinken will join the board as nonexecutive director
(s/pp)/np
np
53
s/(s\np)T
s/(s\np)B
B
B(s/pp)/n
s/ppBs/np
Bs/n
s
Assume n=>np
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
np/n n (s\np)/(s\np) ((s\np)/pp)/np np/n np/n npp/npn
CCG associativity (a.k.a. “spurious” ambiguity)
Pierre Vinken will join the board as nonexecutive director
(s/pp)/np
np
53
7 of 8 lexical category adjacencies can be combined
s/(s\np)T
s/(s\np)B
B
B(s/pp)/n
s/ppBs/np
Bs/n
s
Assume n=>np

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Exploiting category combination
Used by Bangalore and Joshi (1999) for TAG supertagging as hard constraints in a supervised HMM.
Supervised supertaggers: use features that say whether or not the previous and current category can combine.
Weak supervision: initialize the transition distributions to favor transitions for categories that can combine.
Similar to Grenager et al (2005), who used diagonal initialization to encourage an HMM to remain in the same state for field segmentation in IE.
54

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Defining what can combine
Define a function κ(i,j) → {0,1} which states whether a category i can combine via some CCG rule with a following category j.
e.g. κ(np/n,n) = 1, κ(s\np,s) = 0
Need some special handling for CCGbank:
CCGbank assumes a rule N => NP
also need to handle type-raising
<Bx only works for S-rooted categories
55

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
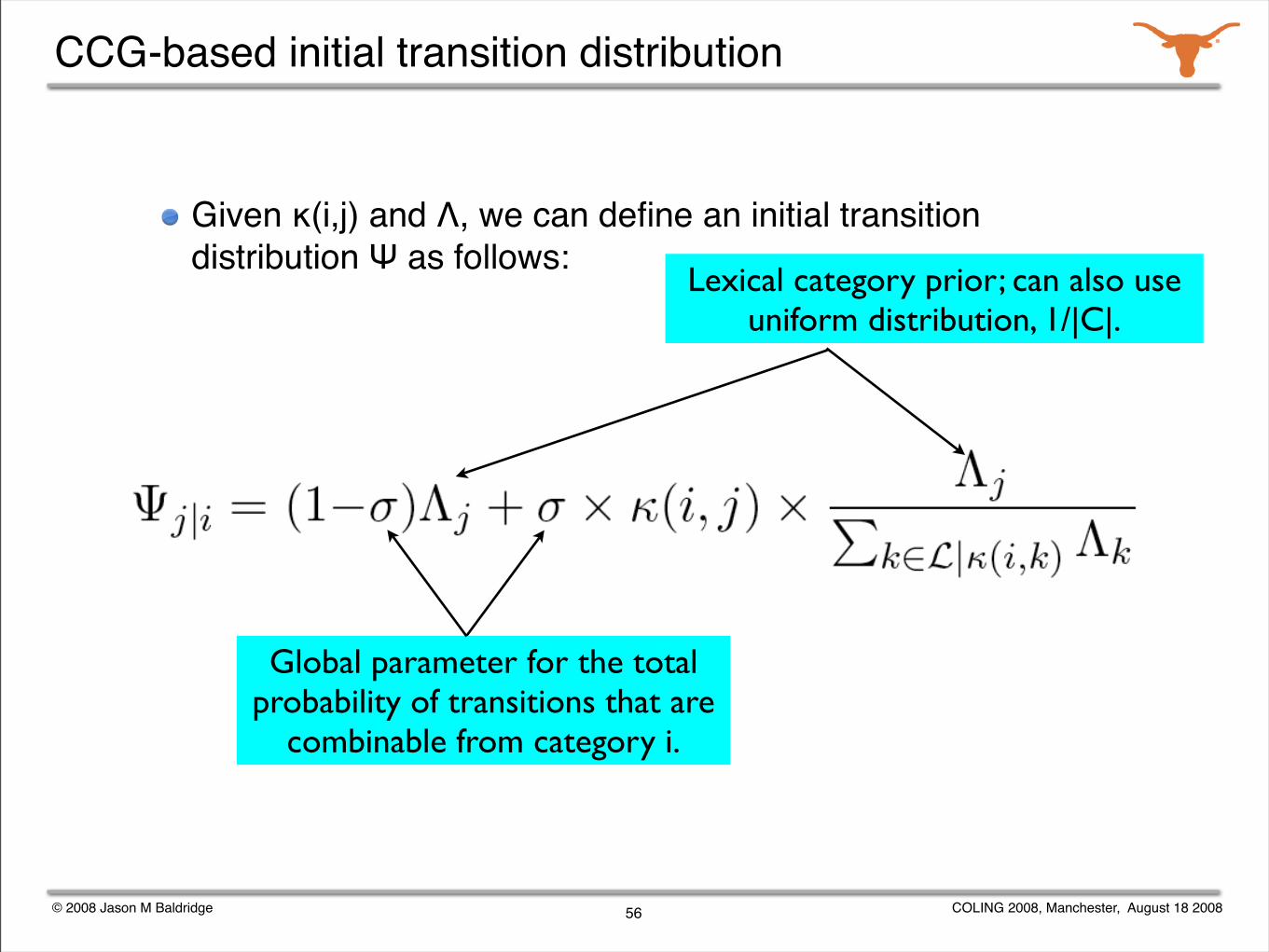
CCG-based initial transition distribution
Given κ(i,j) and Λ, we can define an initial transition distribution Ψ as follows:
56

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
CCG-based initial transition distribution
Given κ(i,j) and Λ, we can define an initial transition distribution Ψ as follows:
56
Global parameter for the total probability of transitions that are
combinable from category i.
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
CCG-based initial transition distribution
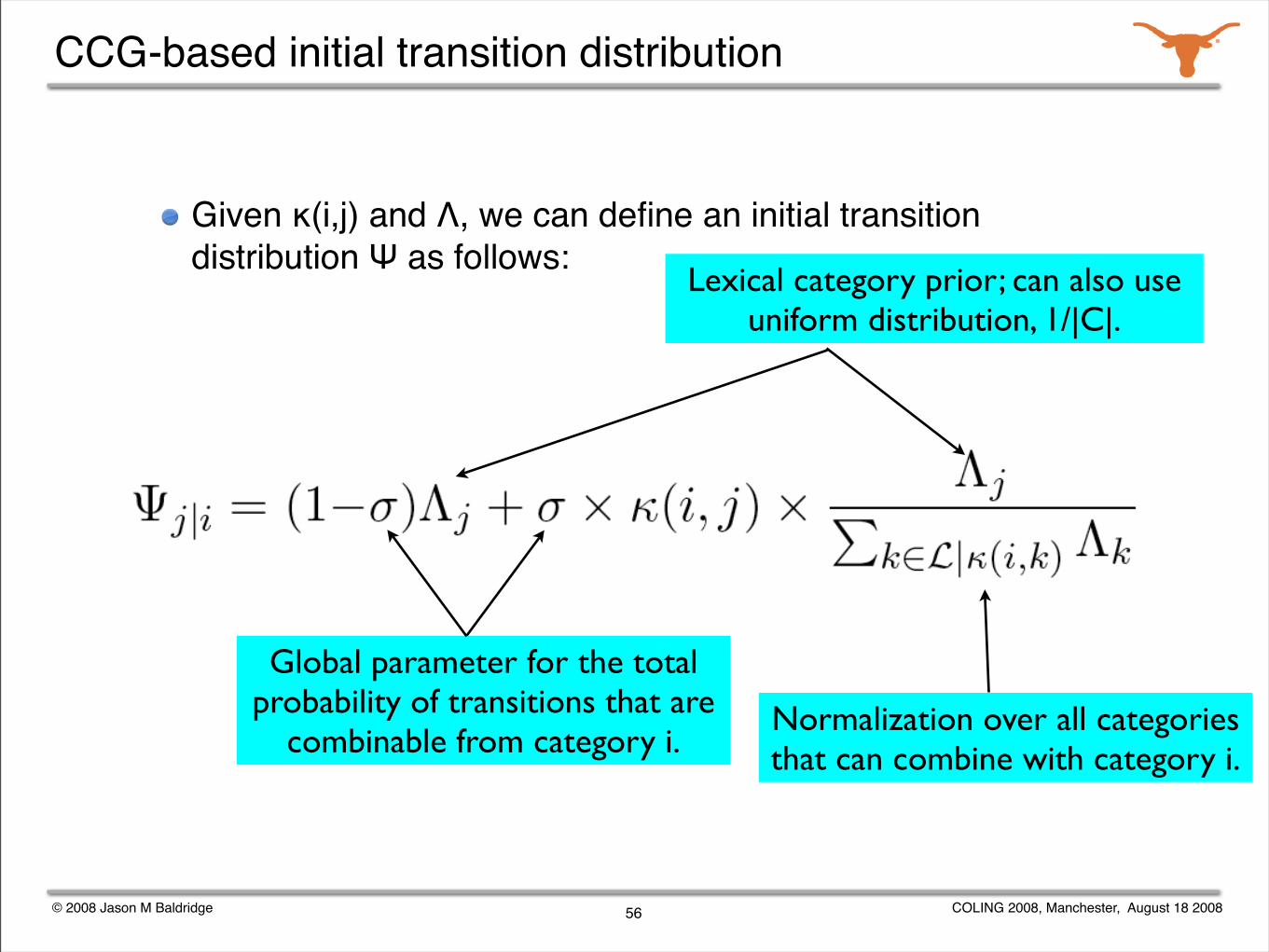
Given κ(i,j) and Λ, we can define an initial transition distribution Ψ as follows:
56
Global parameter for the total probability of transitions that are
combinable from category i.
Lexical category prior; can also use uniform distribution, 1/|C|.
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
CCG-based initial transition distribution
Given κ(i,j) and Λ, we can define an initial transition distribution Ψ as follows:
56
Global parameter for the total probability of transitions that are
combinable from category i.Normalization over all categories that can combine with category i.
Lexical category prior; can also use uniform distribution, 1/|C|.
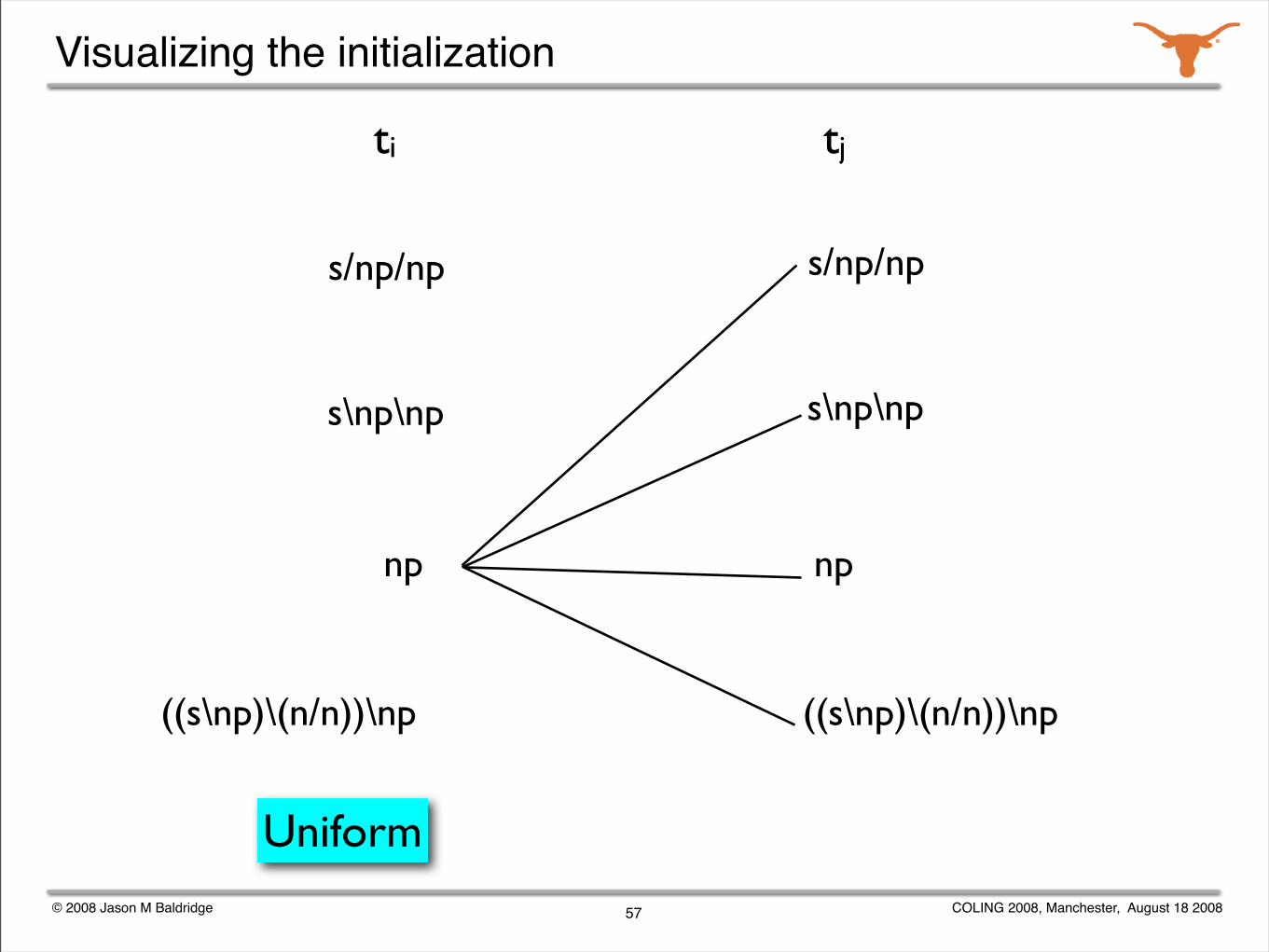
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Visualizing the initialization
57
((s\np)\(n/n))\np
s\np\np
np
s/np/np
Uniform
ti tj
((s\np)\(n/n))\np
s\np\np
np
s/np/np
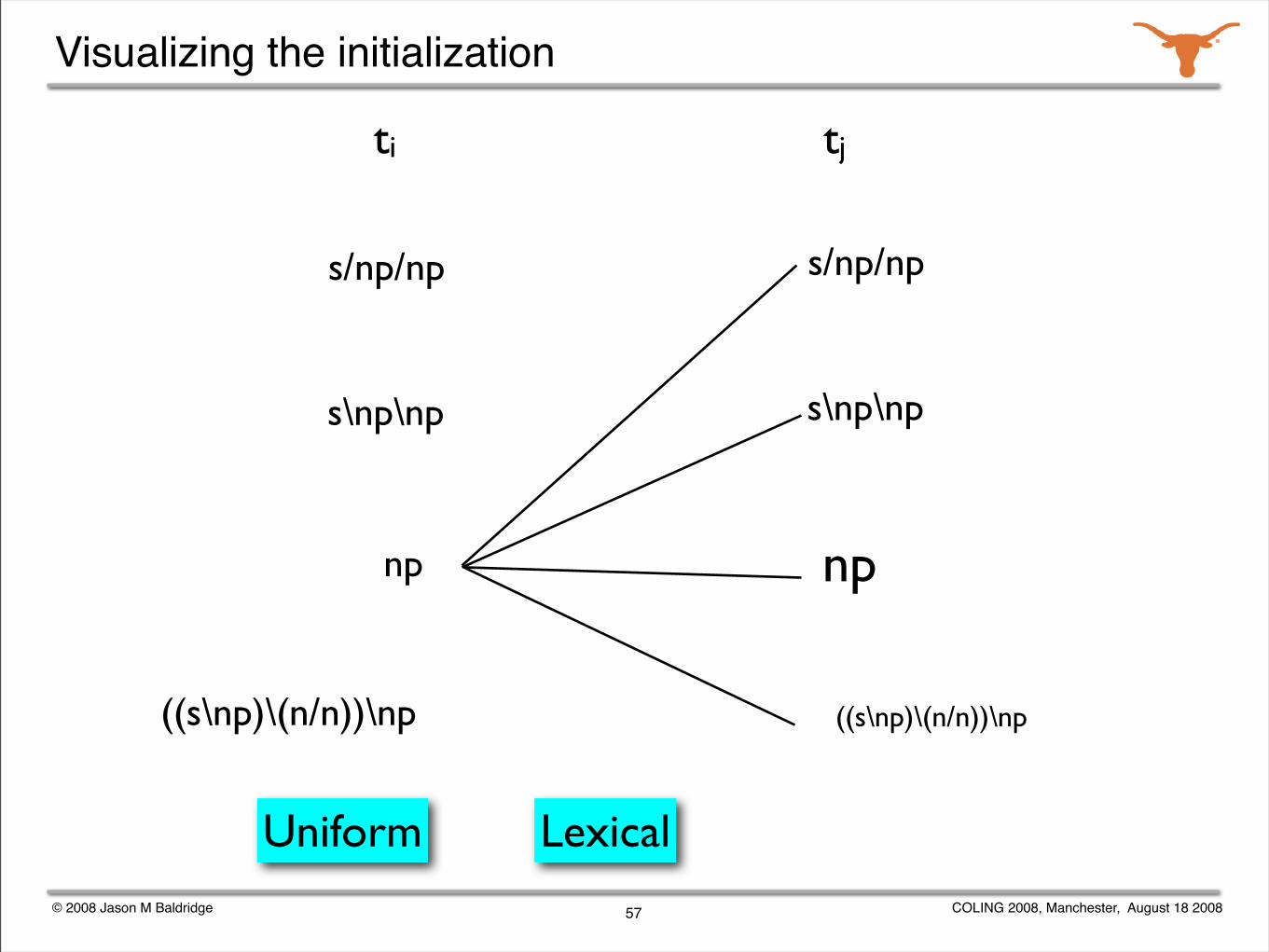
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Visualizing the initialization
57
((s\np)\(n/n))\np
s\np\np
np
s/np/np
Uniform Lexical
ti tj
((s\np)\(n/n))\np
s\np\np
np
s/np/np
((s\np)\(n/n))\np
np
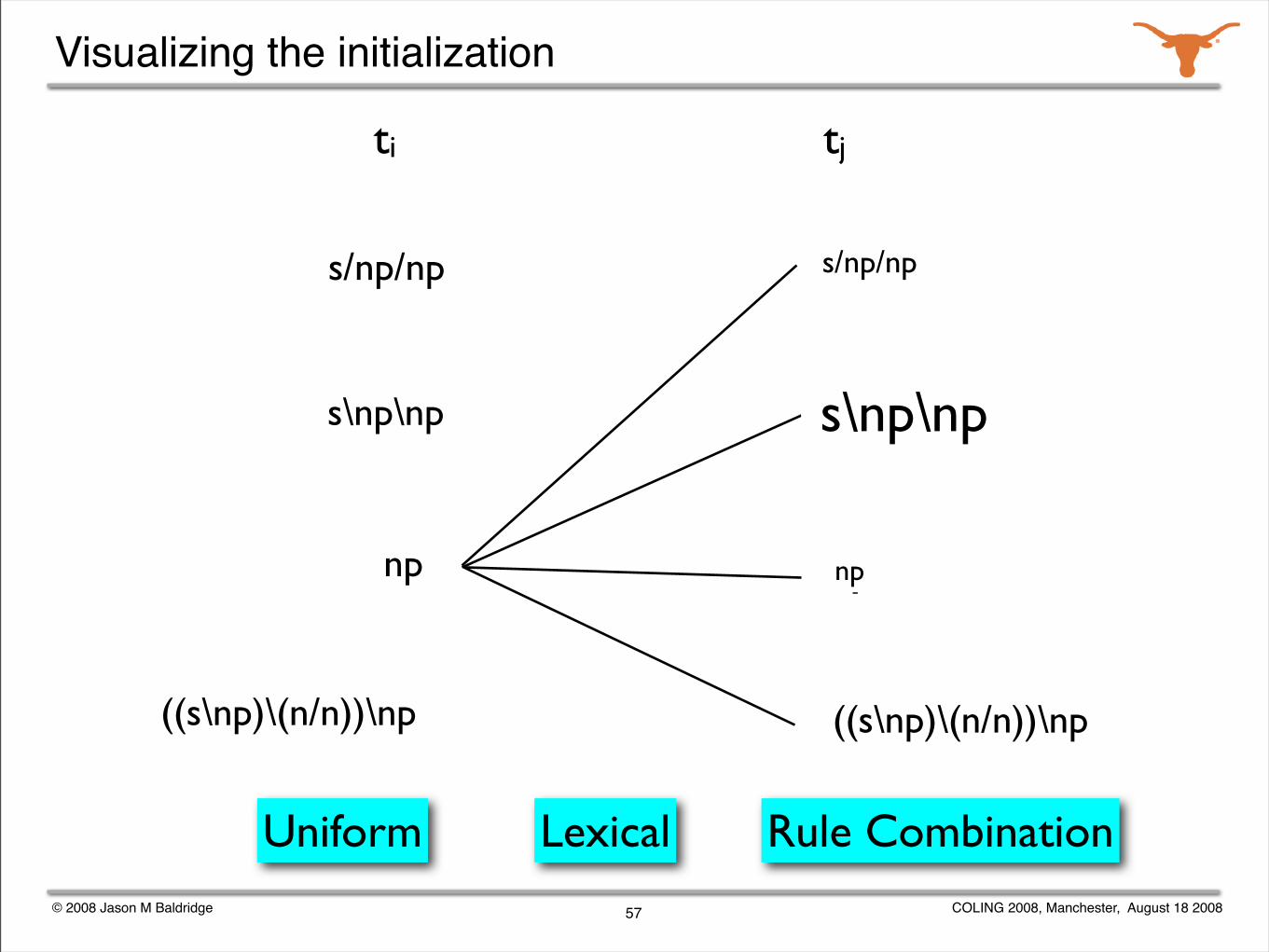
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Visualizing the initialization
57
((s\np)\(n/n))\np
s\np\np
np
s/np/np
Uniform Lexical Rule Combination
ti tj
((s\np)\(n/n))\np
s\np\np
np
s/np/np
((s\np)\(n/n))\np
s\np\np
np
s/np/np
((s\np)\(n/n))\np
np

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Model
First-order HMM
efficient: easily handles thousands of supertags
simple: easy to observe effects of initialization
Dirichlet prior on transitions (using variational Bayes EM).
Standard handling of emissions.
58
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
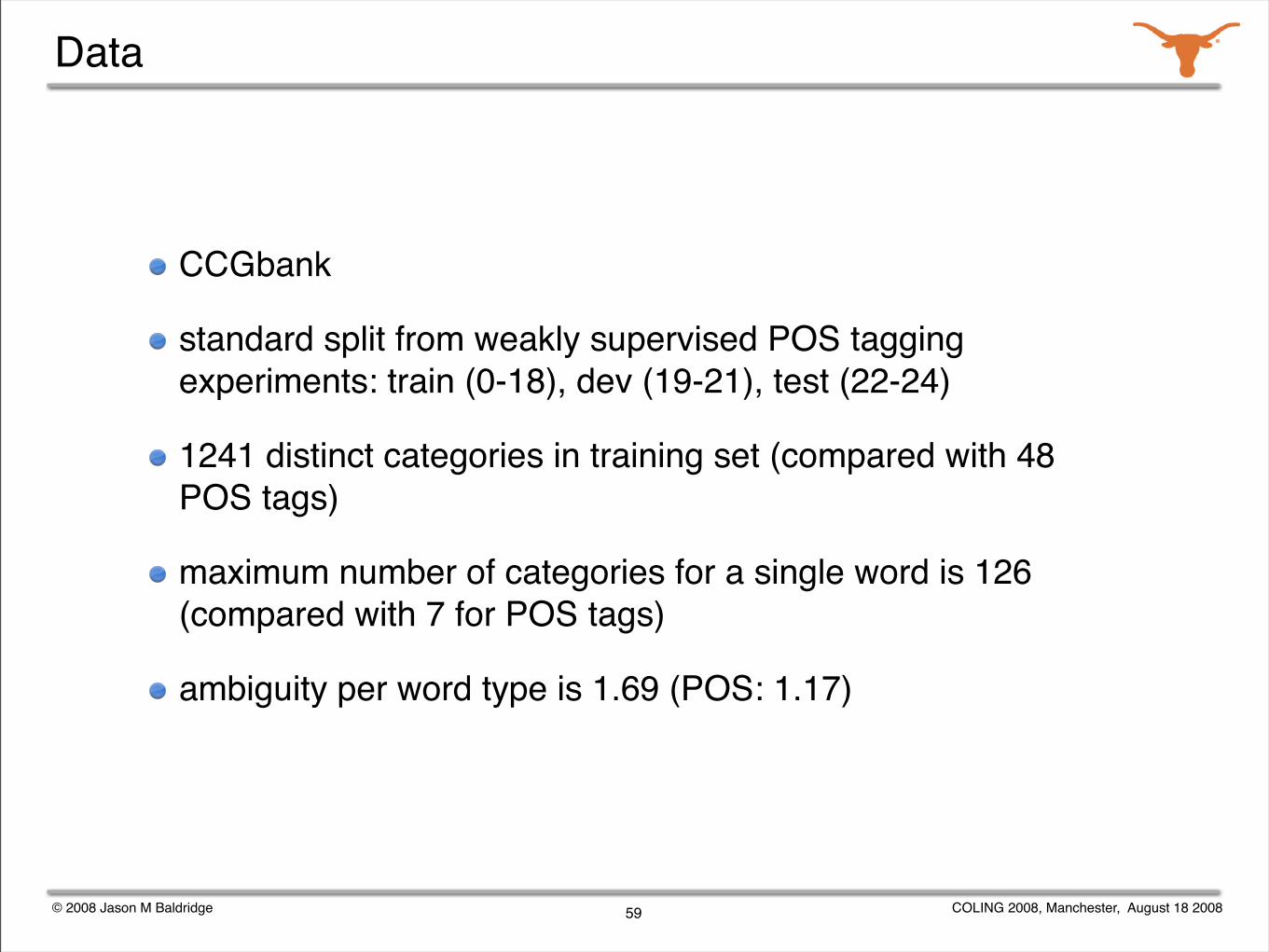
Data
CCGbank
standard split from weakly supervised POS tagging experiments: train (0-18), dev (19-21), test (22-24)
1241 distinct categories in training set (compared with 48 POS tags)
maximum number of categories for a single word is 126 (compared with 7 for POS tags)
ambiguity per word type is 1.69 (POS: 1.17)
59

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Supervised performance
Supervised HMM supertagging accuracy is 87.6%
C&C accuracy is 91.4%.
Interestingly, the HMM
does not use POS tags,
trains in seconds,
and doesnʼt need to employ a tag cutoff.
60

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Weak supervision in HMMs
Banko and Moore (2002) found that previous results on weakly supervised HMM taggers were highly influenced by having a clean tag dictionary that didnʼt contain very infrequent tags.
Tag cutoff: remove entries for a tag that appear with the word less than X% of the time.
This turns out to have an even greater impact with supertagging.
61

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
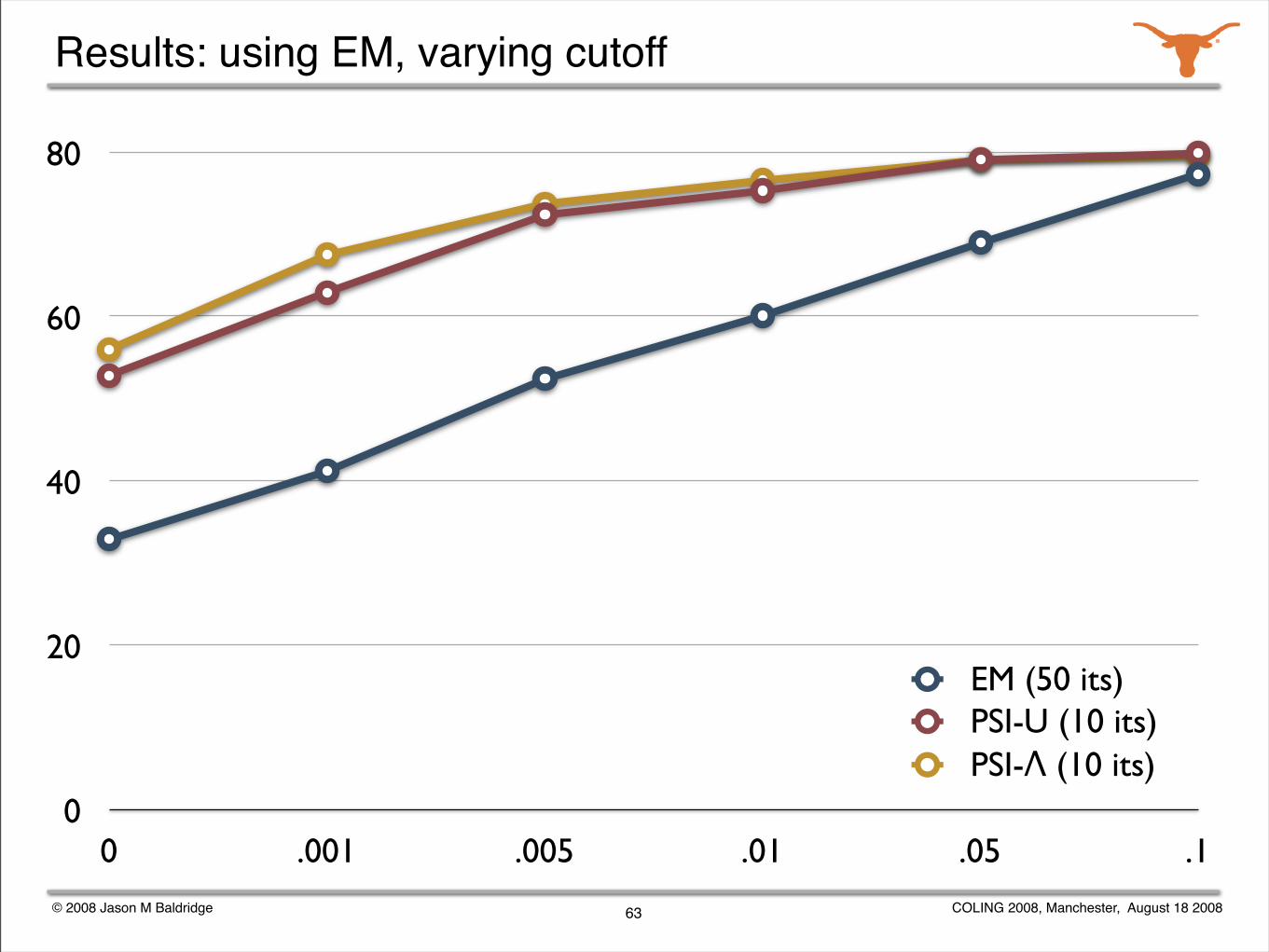
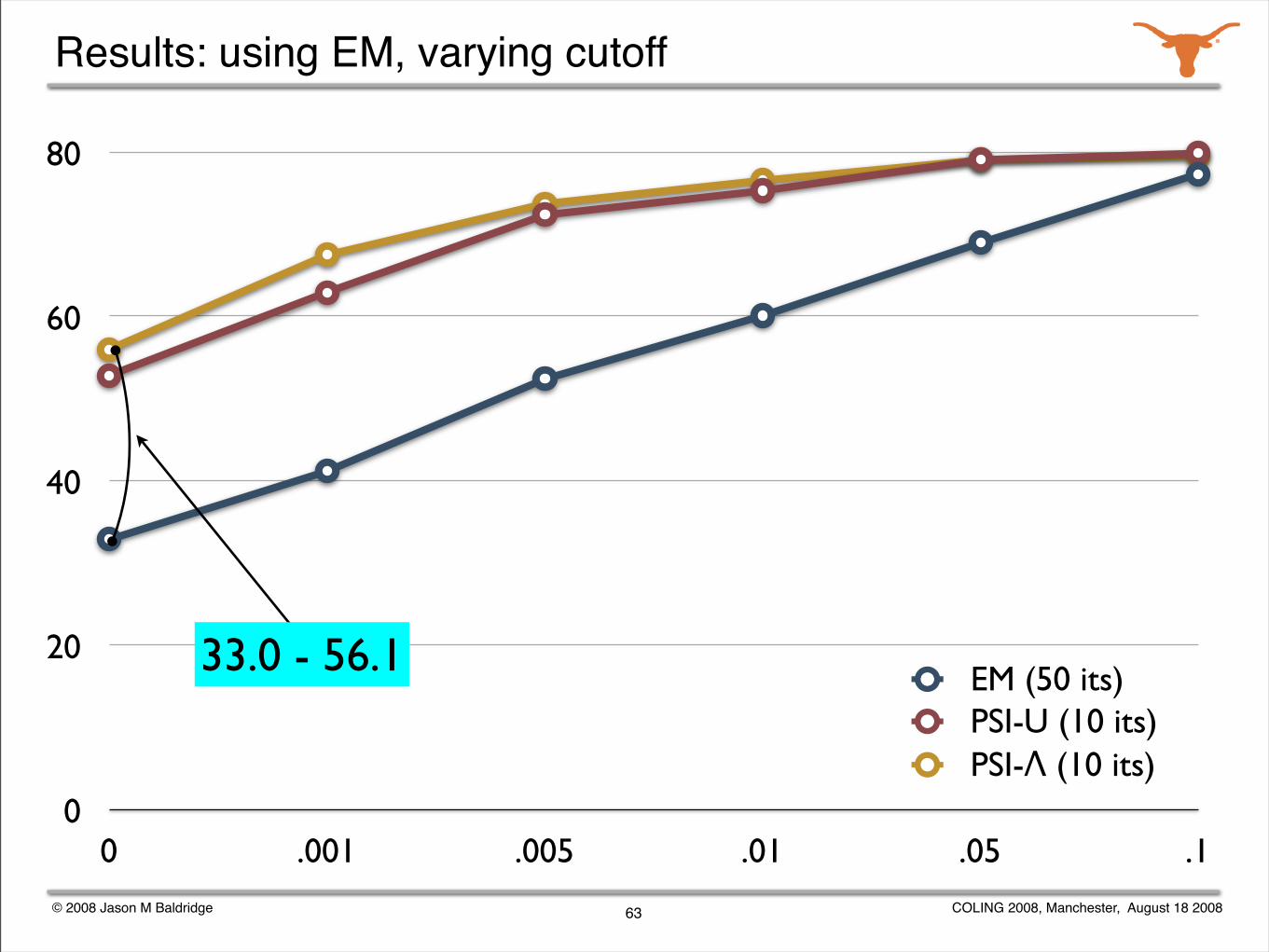
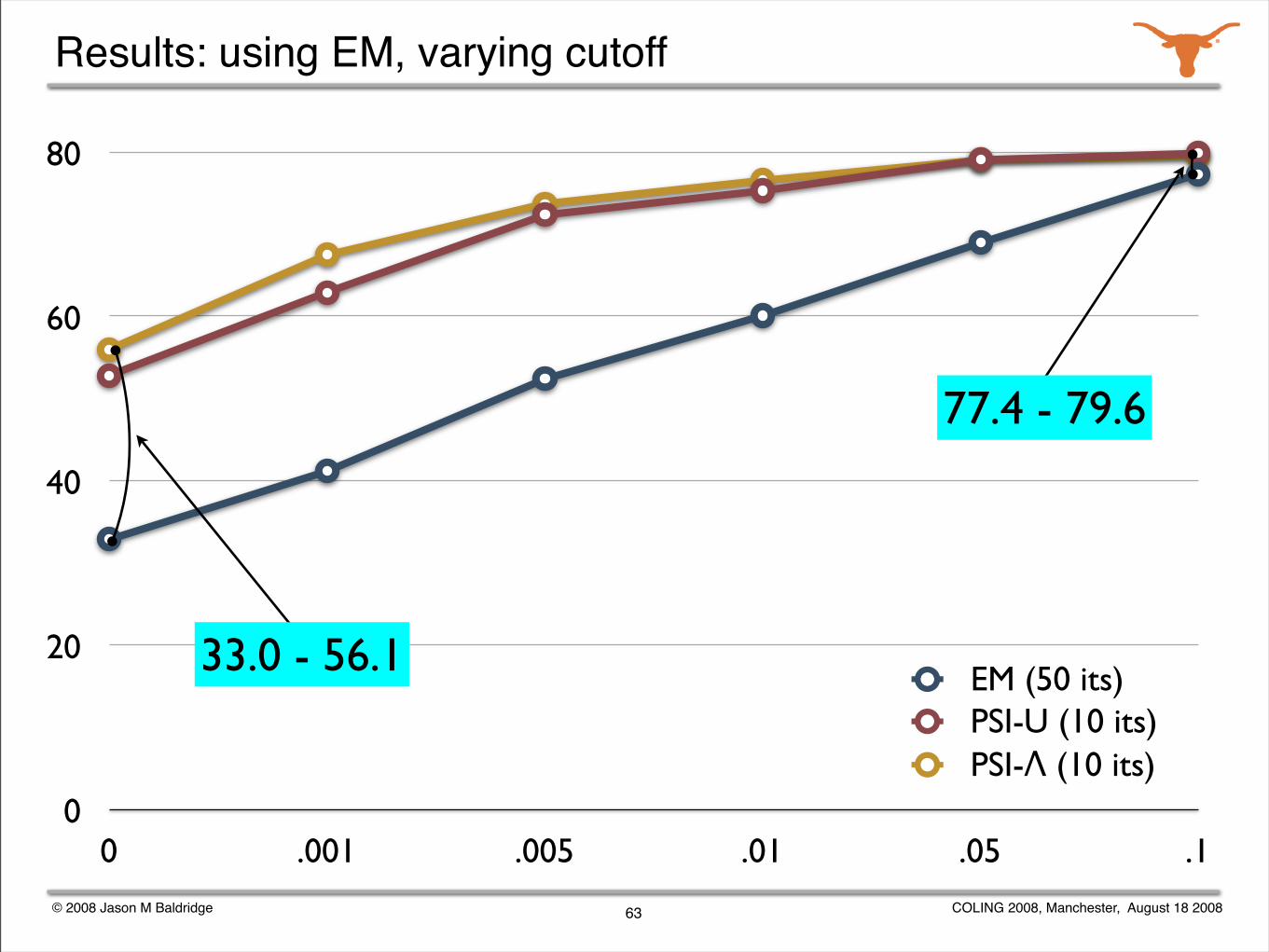
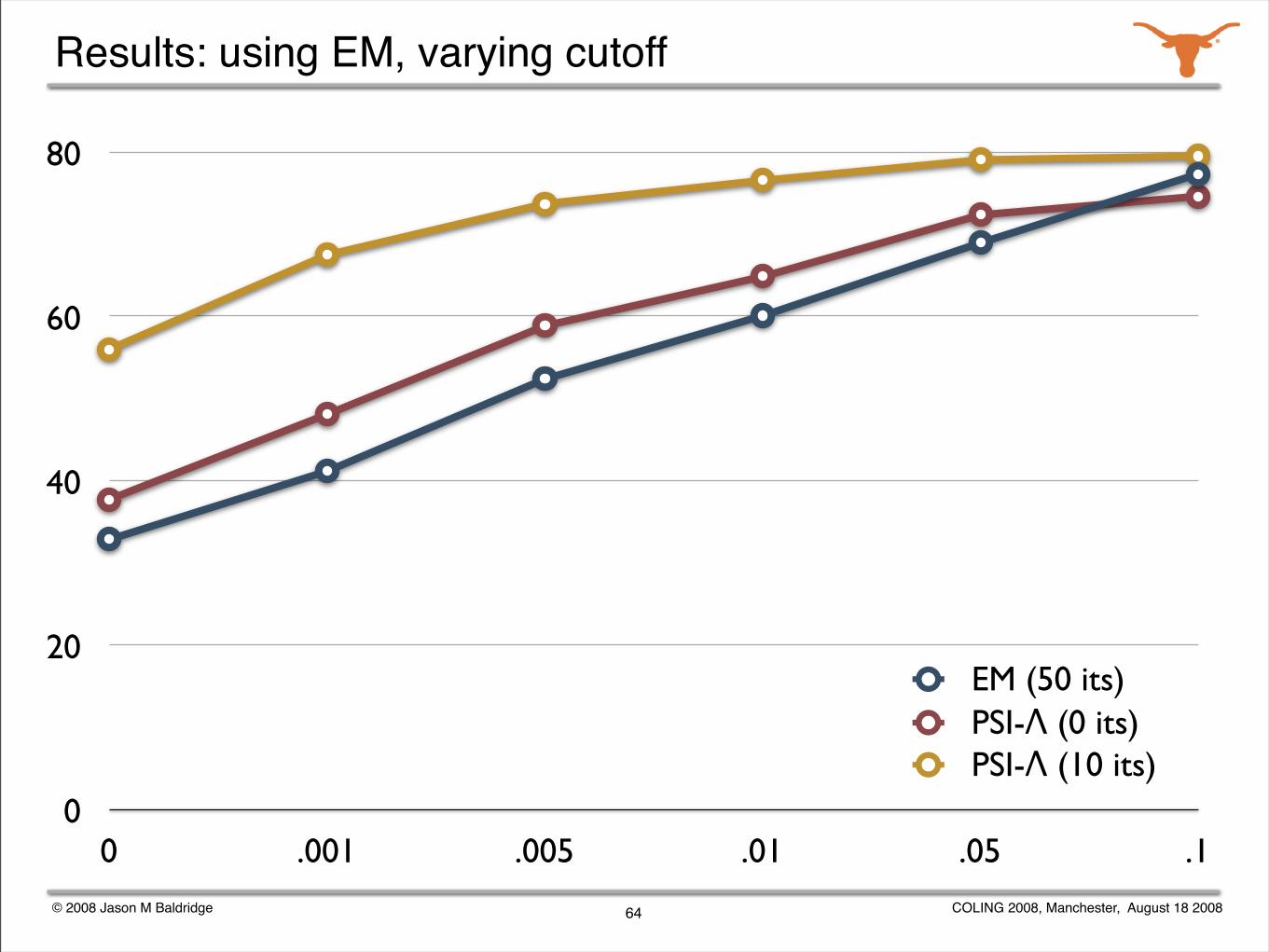
Experiments with weak supervision
Explore the effectiveness of weak supervision for supertagging while varying ambiguity using supertag frequency cutoffs.
Also, vary the initialization of the transition distributions:
uniform transitions
Ψ initialization with uniform lexical category distribution
Ψ initialization with Λ lexical category distribution
Evaluate only on ambiguous words.
62
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Results: using EM, varying cutoff
63
0
20
40
60
80
0 .001 .005 .01 .05 .1
EM (50 its)PSI-U (10 its)PSI-Λ (10 its)
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Results: using EM, varying cutoff
63
0
20
40
60
80
0 .001 .005 .01 .05 .1
EM (50 its)PSI-U (10 its)PSI-Λ (10 its)
33.0 - 56.1
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Results: using EM, varying cutoff
63
0
20
40
60
80
0 .001 .005 .01 .05 .1
EM (50 its)PSI-U (10 its)PSI-Λ (10 its)
33.0 - 56.1
77.4 - 79.6
© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Results: using EM, varying cutoff
64
0
20
40
60
80
0 .001 .005 .01 .05 .1
EM (50 its)PSI-Λ (0 its)PSI-Λ (10 its)

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Using a smaller dictionary
The previous experiments start with a relatively large lexicon induced from sections 0-18 of CCGbank.
Another option is to label a small number of sentences, and then bootstrap a tagger.
A big part of the goal here is to accurately identify the categories associated with unknown words.
65

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Simple co-training for POS taggers
Cotraining with generative and discriminative model (Clark, Curran and Osborne)
HMM tagger (TnT) and a Maxent tagger (C&C)
TnT tags for C&C, visa versa, etc, starting with 50 seed sentences
TnT: 81.3 -> 85.3
C&C: 73.2 -> 85.1
Same strategy works well for supertagging.
66
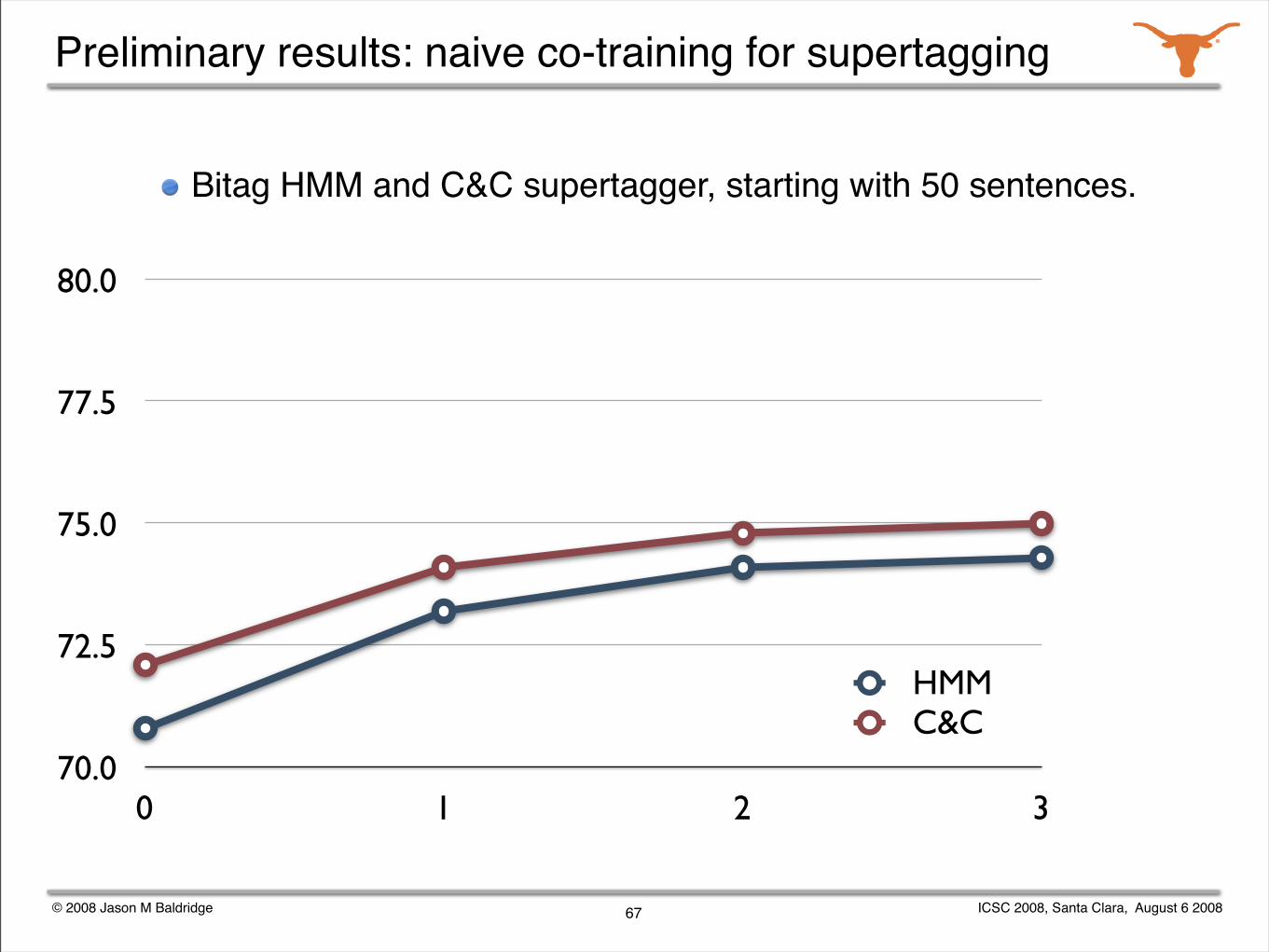
© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Preliminary results: naive co-training for supertagging
67
70.0
72.5
75.0
77.5
80.0
0 1 2 3
HMMC&C
Bitag HMM and C&C supertagger, starting with 50 sentences.

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Further goals/questions
Can re-estimation with EM on output from C&C help?
not clearly helping
Using multiple discriminative taggers?
promising initial results
EM seems to help here
Using asymmetric cotraining with large amounts of raw text labeled by discriminative taggers and used by HMM?
promising initial results with Gigaword
68

© 2008 Jason M Baldridge COLING 2008, Manchester, August 18 2008
Future work
Incorporate a parsing feedback loop
Incorporate formalism information as priors rather than initialization.
Prior over lexicons rather than categories
Bootstrap from smaller lexicons
identify novel entries consisting of seen word and seen category
predict unseen, but valid, categories
Better model: trigram, factorial HMM, etc.
69

Part II: CCG and
Dependency ParsingPreliminary work with Elias Ponvert
© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
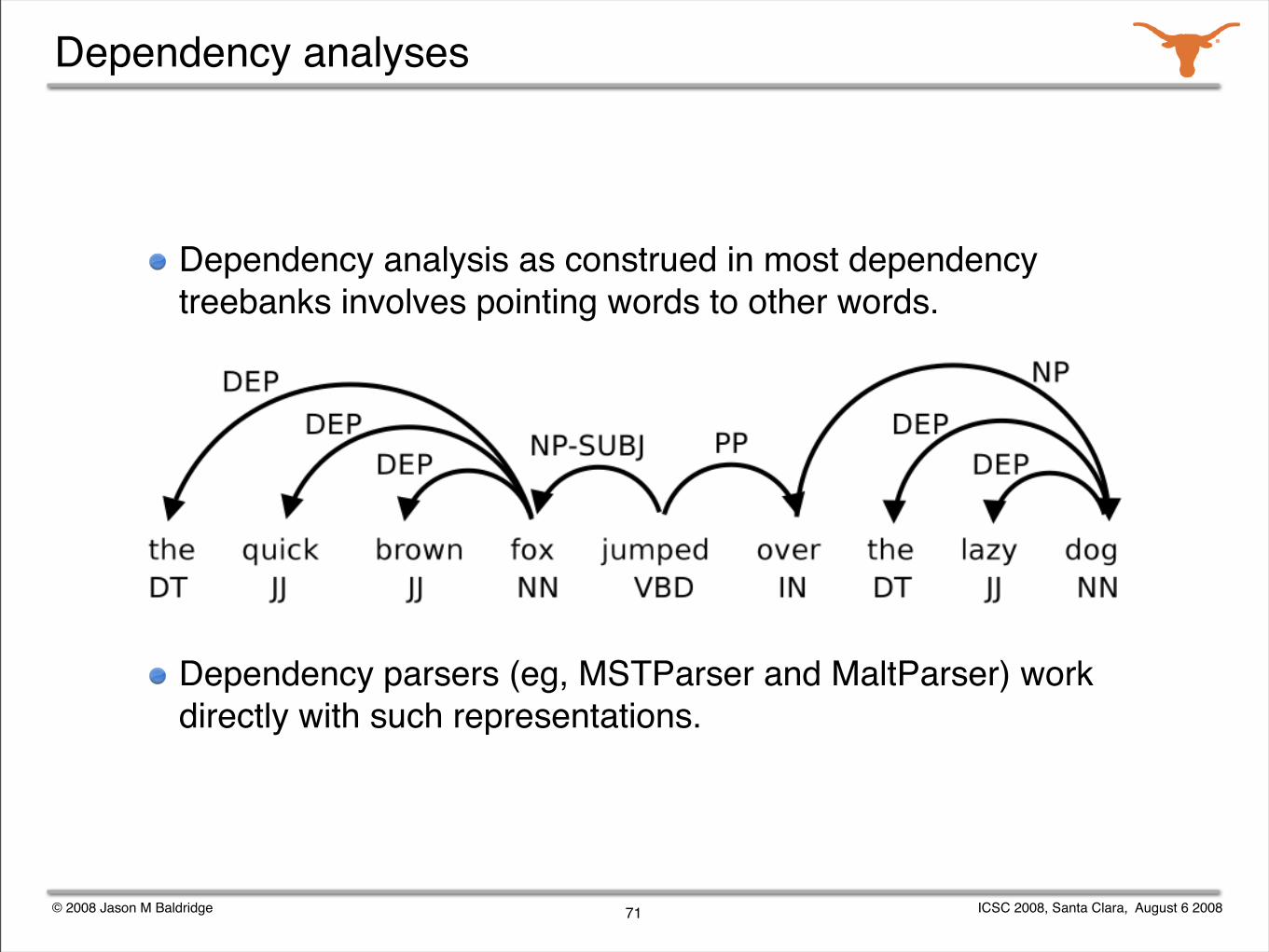
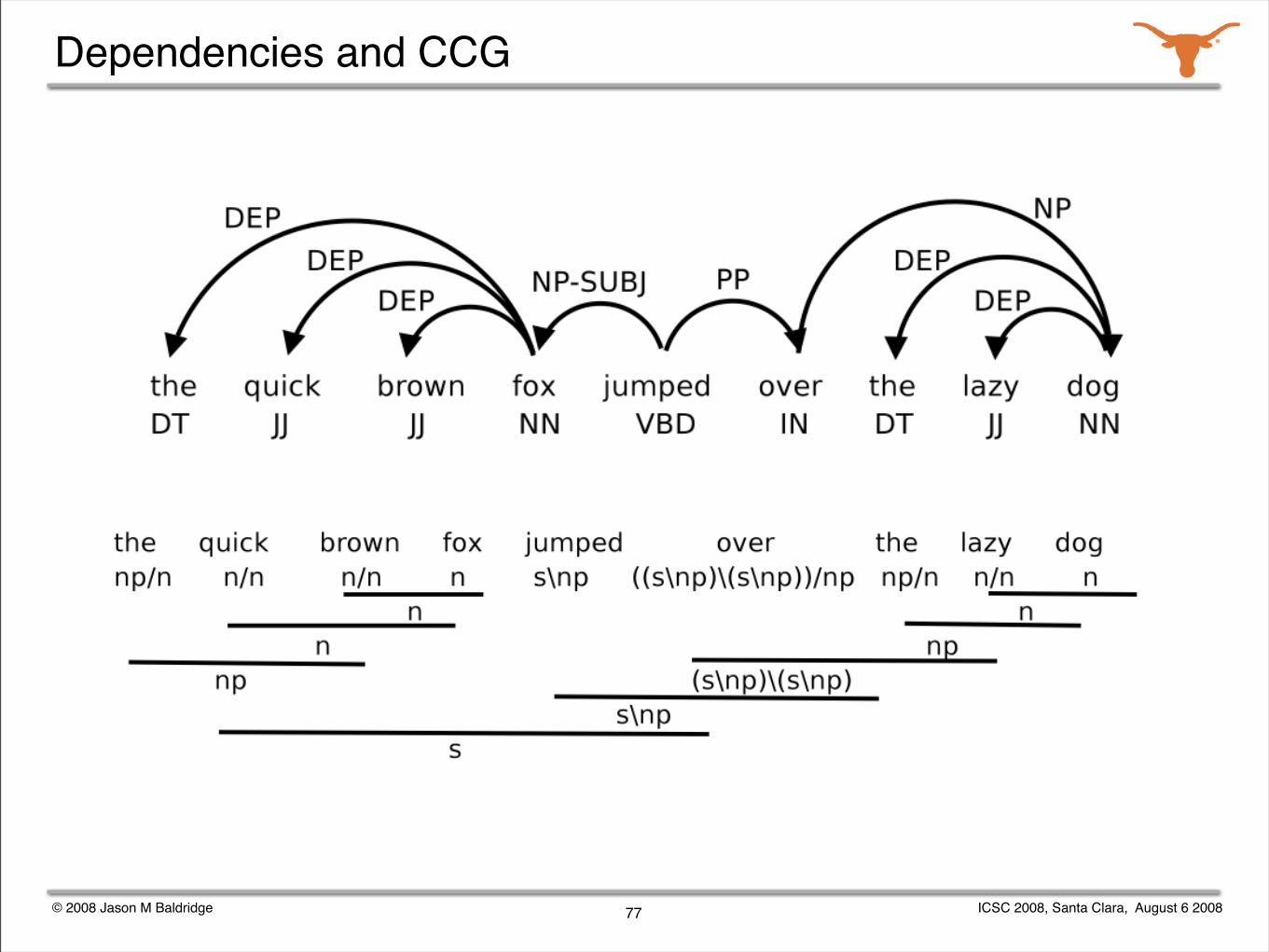
Dependency analyses
Dependency analysis as construed in most dependency treebanks involves pointing words to other words.
Dependency parsers (eg, MSTParser and MaltParser) work directly with such representations.
71

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Some things are missing...
Most dependency treebanks punt on questions of coordination and higher-order dependencies, such as
Coordination
Subject and object control
Relative clauses
Basically, non-local and multiple dependencies.
72

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Subcategorization
Dependency parsers do not attempt to use subcategorization in any explicit manner: parses are determined by the strength of linkage between words in combination with a search algorithm.
Subcategorization could potentially be exploited to improve dependency parsing.
It can also lead to a better shot at capturing the harder dependencies, if combined with a categorial syntax and its explicit handling of syntactic subcategorization.
73

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Where do the dependencies lie?
Dependency analyses fall somewhere in between the notion of syntactic analysis and semantic analysis.
Categorial grammar actually is a dependency formalism -- it just happens to be one that deals with linear order explicitly.
Idea: target dependency analyses as the logical forms output by a CCG.
74
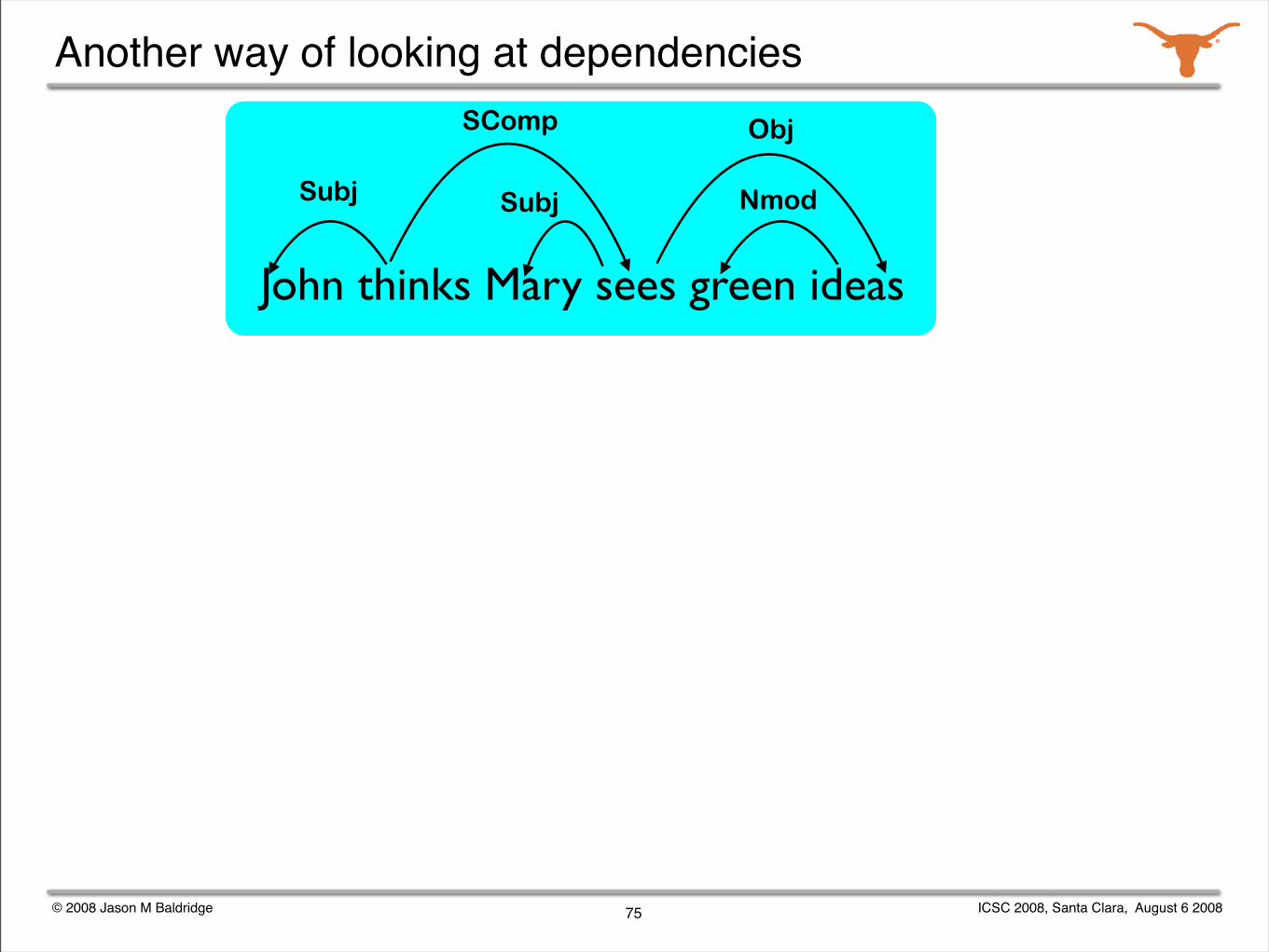
© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
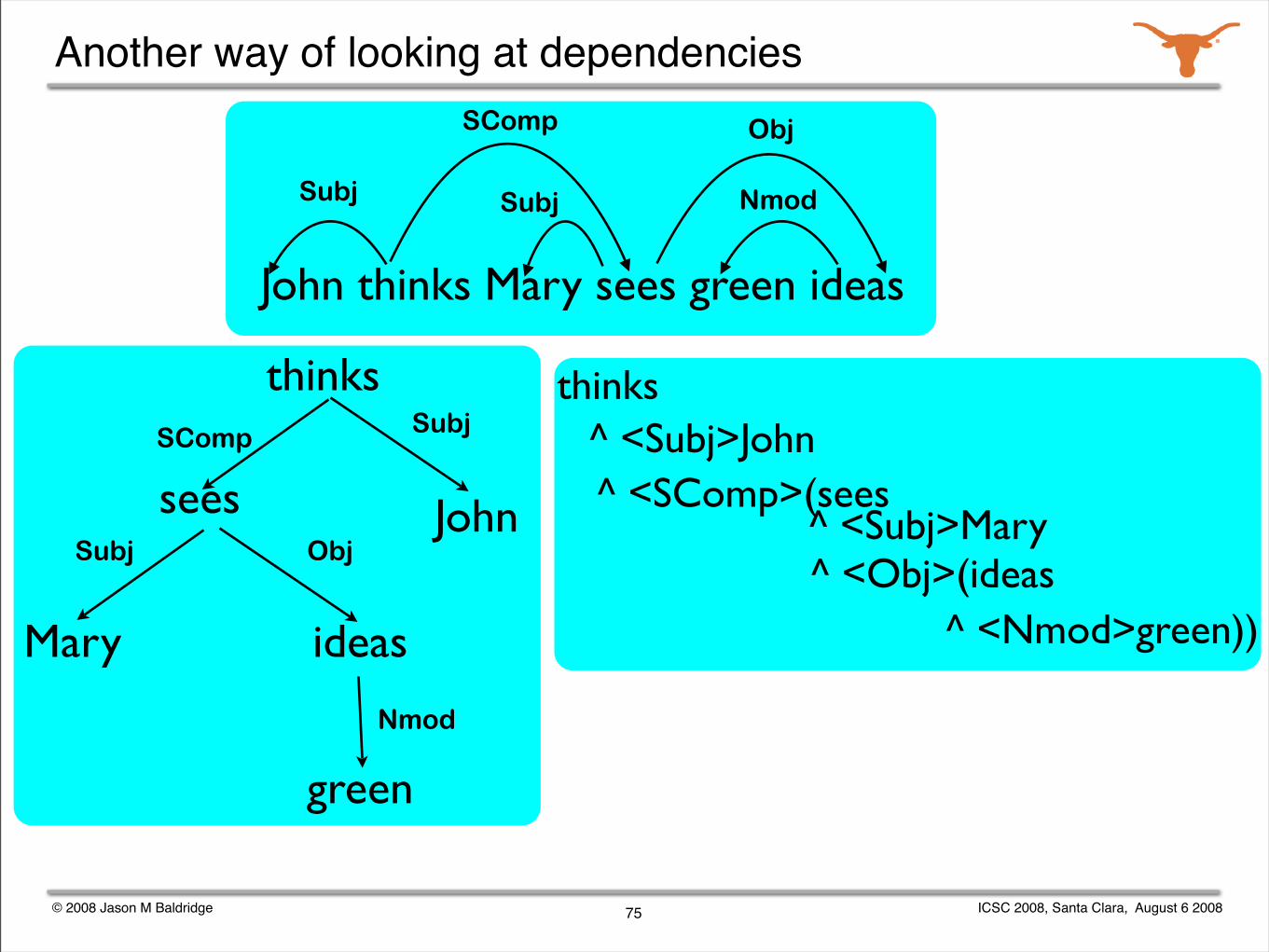
Another way of looking at dependencies
75
John thinks Mary sees green ideas
Subj Subj
SComp Obj
Nmod
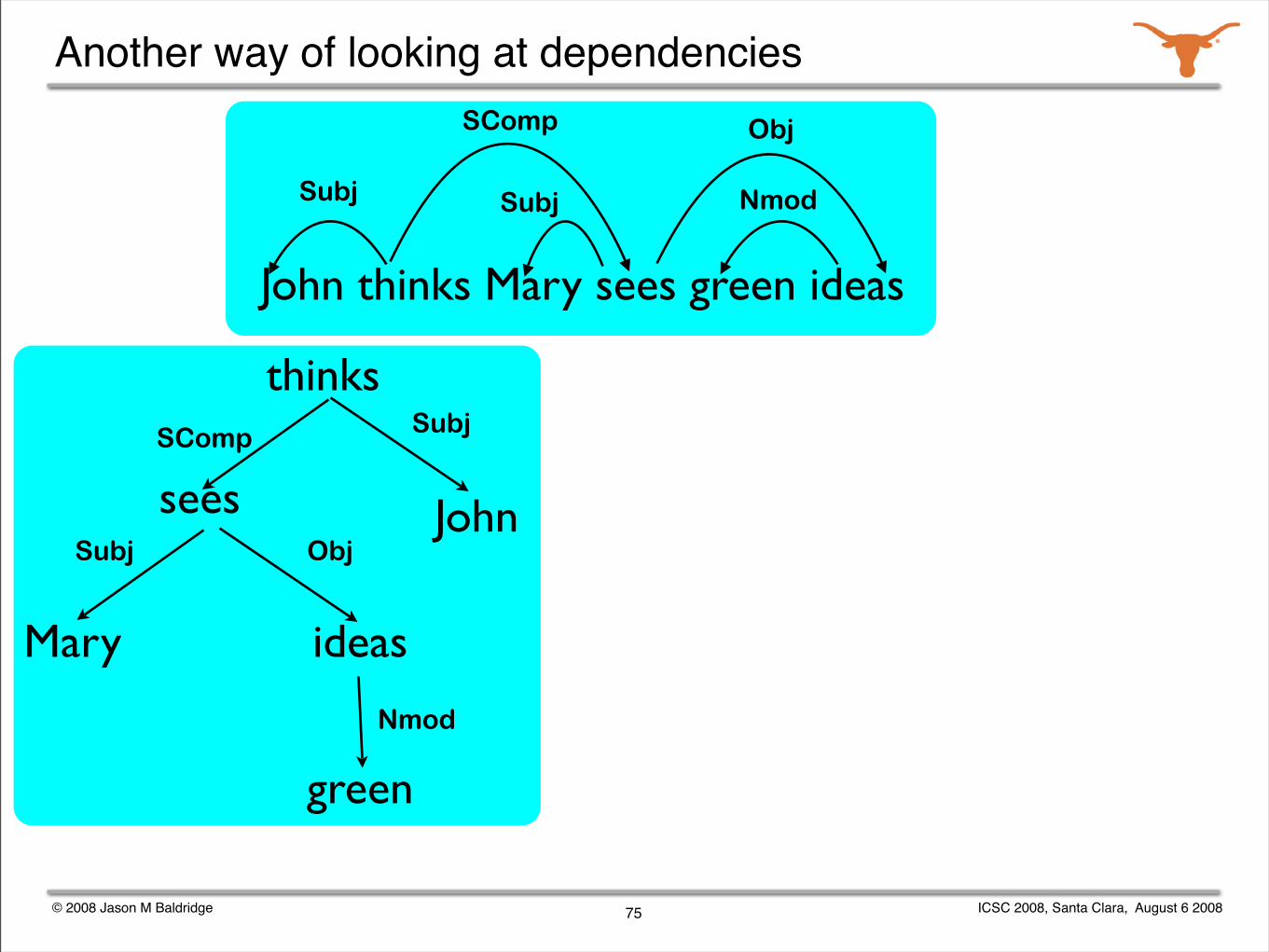
© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Another way of looking at dependencies
75
John thinks Mary sees green ideas
Subj Subj
SComp Obj
Nmod
thinks
sees
ideasMary
green
John
Subj
Subj Obj
SComp
Nmod
© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Another way of looking at dependencies
75
John thinks Mary sees green ideas
Subj Subj
SComp Obj
Nmod
thinks
sees
ideasMary
green
John
Subj
Subj Obj
SComp
Nmod
thinks
^ <SComp>(sees
^ <Obj>(ideas
^ <Subj>John
^ <Subj>Mary
^ <Nmod>green))
© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Another way of looking at dependencies
75
John thinks Mary sees green ideas
Subj Subj
SComp Obj
Nmod
thinks
sees
ideasMary
green
John
Subj
Subj Obj
SComp
Nmod
thinks
^ <SComp>(sees
^ <Obj>(ideas
^ <Subj>John
^ <Subj>Mary
^ <Nmod>green))
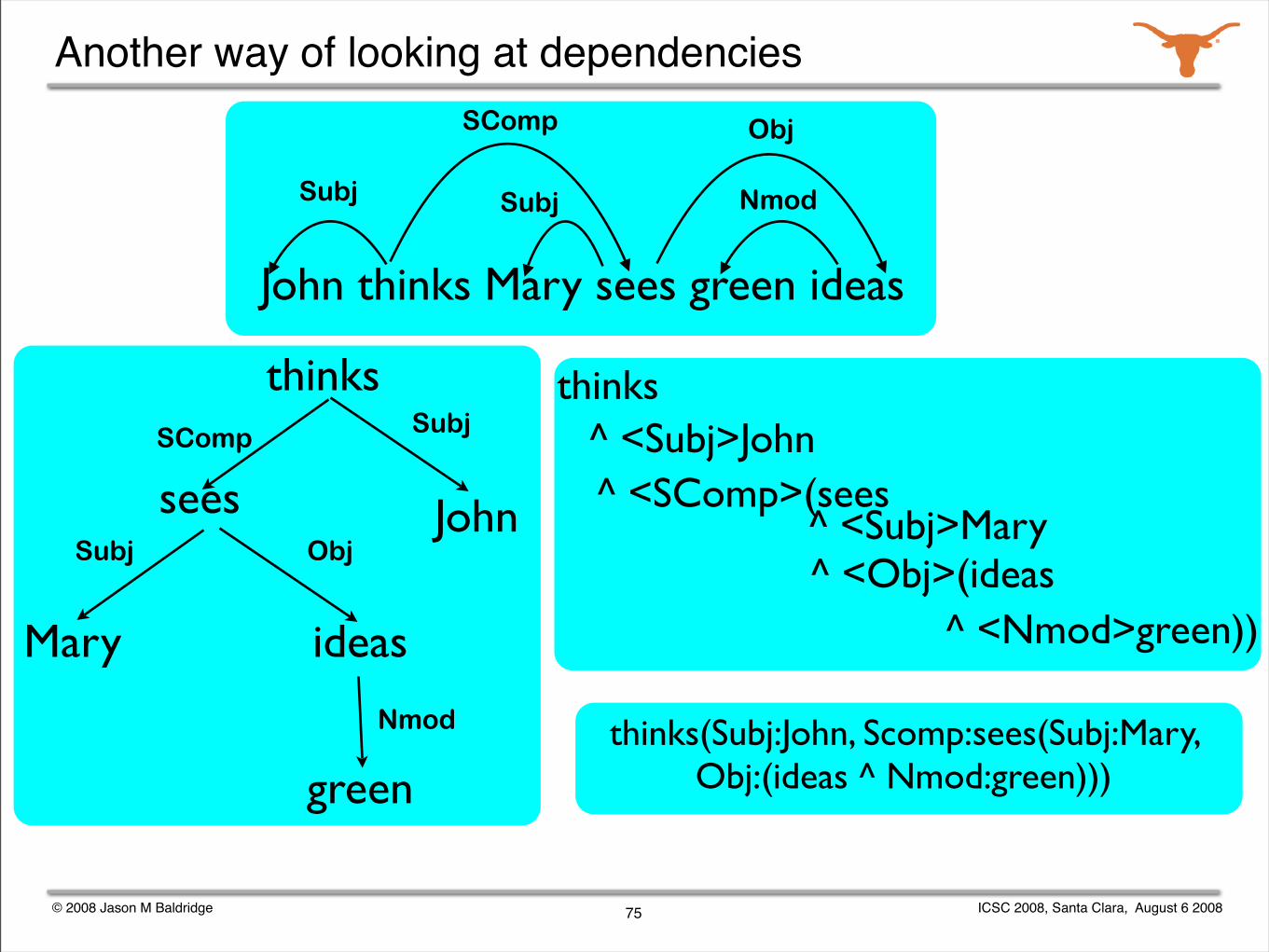
thinks(Subj:John, Scomp:sees(Subj:Mary, Obj:(ideas ^ Nmod:green)))

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
First try CCG
Construct a lexicon and use it.
76
thinks := (s\np)/s : λxλy.thinks(Subj:y,Scomp:x)sees := (s\np)/np : λxλy.sees(Subj:y,Obj:x)
green := np/np : λx.(x ^ Nmod: green)ideas := np : ideas
John := np : JohnMary := np : Mary

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
First try CCG
Construct a lexicon and use it.
76
thinks := (s\np)/s : λxλy.thinks(Subj:y,Scomp:x)sees := (s\np)/np : λxλy.sees(Subj:y,Obj:x)
green := np/np : λx.(x ^ Nmod: green)ideas := np : ideas
John := np : JohnMary := np : Mary
sees(s\np)/np
: λxλy.sees(Subj:y,Obj:x)
greennp/np : λx.(x^Nmod: green)
ideasnp : ideas
Marynp : Mary

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
First try CCG
Construct a lexicon and use it.
76
thinks := (s\np)/s : λxλy.thinks(Subj:y,Scomp:x)sees := (s\np)/np : λxλy.sees(Subj:y,Obj:x)
green := np/np : λx.(x ^ Nmod: green)ideas := np : ideas
John := np : JohnMary := np : Mary
np : (ideas^Nmod: green)
sees(s\np)/np
: λxλy.sees(Subj:y,Obj:x)
greennp/np : λx.(x^Nmod: green)
ideasnp : ideas
Marynp : Mary

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
First try CCG
Construct a lexicon and use it.
76
thinks := (s\np)/s : λxλy.thinks(Subj:y,Scomp:x)sees := (s\np)/np : λxλy.sees(Subj:y,Obj:x)
green := np/np : λx.(x ^ Nmod: green)ideas := np : ideas
John := np : JohnMary := np : Mary
np : (ideas^Nmod: green)
s\np : λy.sees(Subj:y,Obj:(ideas^Nmod: green))
sees(s\np)/np
: λxλy.sees(Subj:y,Obj:x)
greennp/np : λx.(x^Nmod: green)
ideasnp : ideas
Marynp : Mary

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
First try CCG
Construct a lexicon and use it.
76
thinks := (s\np)/s : λxλy.thinks(Subj:y,Scomp:x)sees := (s\np)/np : λxλy.sees(Subj:y,Obj:x)
green := np/np : λx.(x ^ Nmod: green)ideas := np : ideas
John := np : JohnMary := np : Mary
np : (ideas^Nmod: green)
s\np : λy.sees(Subj:y,Obj:(ideas^Nmod: green))
s : sees(Subj: Mary,Obj:(ideas ^ Nmod: green))
sees(s\np)/np
: λxλy.sees(Subj:y,Obj:x)
greennp/np : λx.(x^Nmod: green)
ideasnp : ideas
Marynp : Mary
© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Dependencies and CCG
77

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
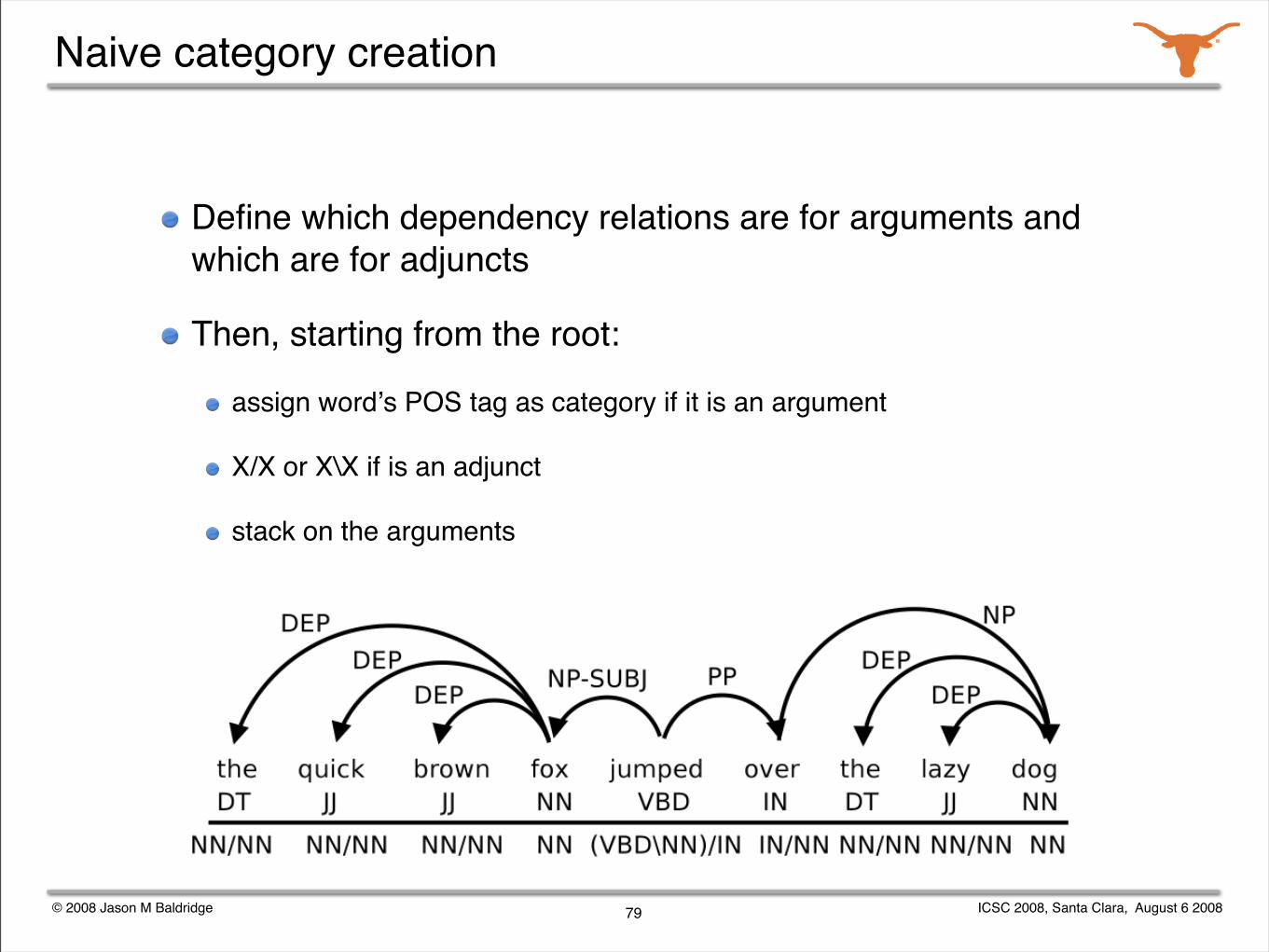
Naive category creation
Idea: use POS tags and links to create simple categories.
Similar to conversion from Penn Treebank (by Julia Hockenmaier) or METU Turkish dependency treebank (Ruken Cakici) in spirit.
...but: just model the word-word dependencies in the dependency treebank.
Donʼt worry about the deeper dependencies, such as coordination, control, and relativization.
The goal is not a standard CCG lexicon -- just something that could be useful for the original dependency parsing task.
...and which might lead to a proper CCG lexicon.
78
© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Naive category creation
Define which dependency relations are for arguments and which are for adjuncts
Then, starting from the root:
assign wordʼs POS tag as category if it is an argument
X/X or X\X if is an adjunct
stack on the arguments
79

CCG, unsupervised parsing, and word meaning
Preliminary thoughts with Katrin Erk

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Unsupervised parsing
We have still assumed we have corpora annotated with dependency structures.
They are available for many languages, but the dependencies which are annotated can vary quite a bit.
It is of course of interest to find ways to learn (some amount of) syntactic structure directly from text alone.
Extracting CCGs from such structures is possible as well, and could lead to more adequate analyses than are produced at present.
81

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Vector spaces for word meaning
Weʼd like to move beyond the atomic primitive view on word meaning (the meaning of life is lifeʼ).
Vector spaces using bags-of-words are a popular and interesting way to do this.
They can be made sensitive to syntactic structure as well, and in turn can be used to create models for selection preferences.
...but this requires having a parser (and whatever it took to train it or create the grammar for it)
It would thus be of interest to learn models of word meaning jointly with unsupervised parsing.
82

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Common cover link parsing (Seginer 2007)
Seginer 2007 presents a formalism and parser using common cover links for unsupervised parsing.
Builds structure from plain text (no POS tags).
Incremental, fast, and performs well on standard unsupervised parsing task.
83

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Common cover link parsing
Generalization on words is done through representations reminiscent of vector spaces.
During learning, structural adjacencies are used to define lexical entries.
Parsing actions are based on an implicit model of adjacency preferences that are similar to selectional preferences.
Frequent words act as stand-ins for less frequent ones based on implicit notion of structural similarity.
84

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Common cover link parsing
Representational limitations:
only projective structures
coordination is basically ignored
gets relative clauses wrong
Lexical entry representations use many heuristic cutoffs.
85

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Moving forward
Joint learning: define adjacency preferences directly as vector spaces.
parsing actions defined on standard similarity measures to determine link strength
structure-sensitive word meanings induced (and used)
Extraction and use of CCGs from CCLs
similar to extraction from dependency grammars
induce clusters over words (POS tags) and links (dependency relations)
adjacency preferences (= quasi-selectional preferences) could be used to learn higher-order category definitions (e.g., subject vs object control).
86

© 2008 Jason M Baldridge ICSC 2008, Santa Clara, August 6 2008
Wrap-up
It is possible to use properties of CCG itself to improve weakly supervised learning of supertaggers, which is a way to generalize smaller lexicons to larger ones.
CCG can be used for the standard dependency parsing paradigm (either directly or for features encoding subcategorization and directionality of arguments)
That it turn points to the possibility of bootstrapping CCGs from simpler link-based representations used in unsupervised parsing.
Supertagging (and bootstrapping for it) is likely to help in refining/generalizing any lexicons created in this manner.
87

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Conclusion
Lots can be done to improve classifiers by:
choosing better data to be annotated (active learning)
using resources more effectively (alignment transfer)
using the data we have more effectively (bootstrapping)
using linguistically informed/informative models and exploiting their expected behaviors (priors)
88

© 2008 Jason M Baldridge NLP (LIN350/CS378), UT Austin, Fall 2008
Conclusion (contʼd)
This is all enormously important because:
of the data bottleneck in machine learning
of the need for better linguistic models
we havenʼt even come near fully exploiting the massive amounts of (multilingual) text available on the internet, even with simple models (eg, bag-of-words)
Languages are dying: we need to speed up documentation
Robots and other applications need to learn and generalize their linguistic knowledge in realtime.
We can exploit the web more effectively, but need to do so in a resource-light manner.
89





























