Embed Size (px)
Citation preview

Michael M. Richter 1 -
Machine Learning
Michael M. Richter
Evolutionary Algorithms
Email: [email protected]

Michael M. Richter 2 -
Part 1
General

Michael M. Richter3 -
To find the peak by throwing dices? That's not,
what an Evolution-Strategist is doing!
Strategic rules are based on a predictable order
of the world (linearity, continuity, symmetry...).
The Evolution Strategy presumes the universal
behavior of the world called sufficient strong
causality.
An ordinary hill is the visualization of strong
causality. In the mathematical abstraction this is
continuity. The theory of the Evolution-Strategy
derives the central law of progress as the leading
idea for optimization.
.
Evolution

Michael M. RichterCallgary 2010
Coping with Complexity
• Complex problem have many different possibilities for
solutions incorporated.
• This applies in particular for dynamic situations where
e.g. planning is involved.
• In such cases an exhaustive search is impossible.
• But which possibilities should be taken?
• A solution is (motivated by evolution)
– Make a stochastic selection !
• But how to know how good it is?
– Semisupervised means you get an opinion about this.
4 -

Michael M. RichterCallgary 2010
5 -
Biology (1): Chromosome
• All living organisms consist of cells. In each cell there is the same set
of chromosomes (or genomes). Chromosomes are strings of DNA
and serve as a model for the whole organism. A chromosome
consists of genes, blocks of DNA. Each gene encodes a particular
protein. Basically, it can be said that each gene encodes a trait, for
example color of eyes. Possible settings for a trait (e.g. blue, brown)
are called alleles. Each gene has its own position in the chromosome.
This position is called locus.
• The complete set of genetic material (all chromosomes) is called
genome. Particular set of genes in genome is called genotype. The
genotype is with later development after birth base for the organism's
phenotype, its physical and mental characteristics, such as eye color,
intelligence etc.

Michael M. RichterCallgary 2010
6 -
Biology (2): Reproduction
• During reproduction, recombination (or crossover) first
occurs. Genes from parents combine to form a whole new
chromosome. The newly created offspring can then be
mutated. Mutation means that the elements of DNA are a
bit changed. This changes are mainly caused by errors in
copying genes from parents.
• The fitness of an organism is measured by success of the
organism in its life (survival).
• Genetic algorithms are inspired by Darwin's theory of
evolution. Solution to a problem solved by genetic
algorithms uses an evolutionary process (it is evolved).
Michael M. Richter7 -
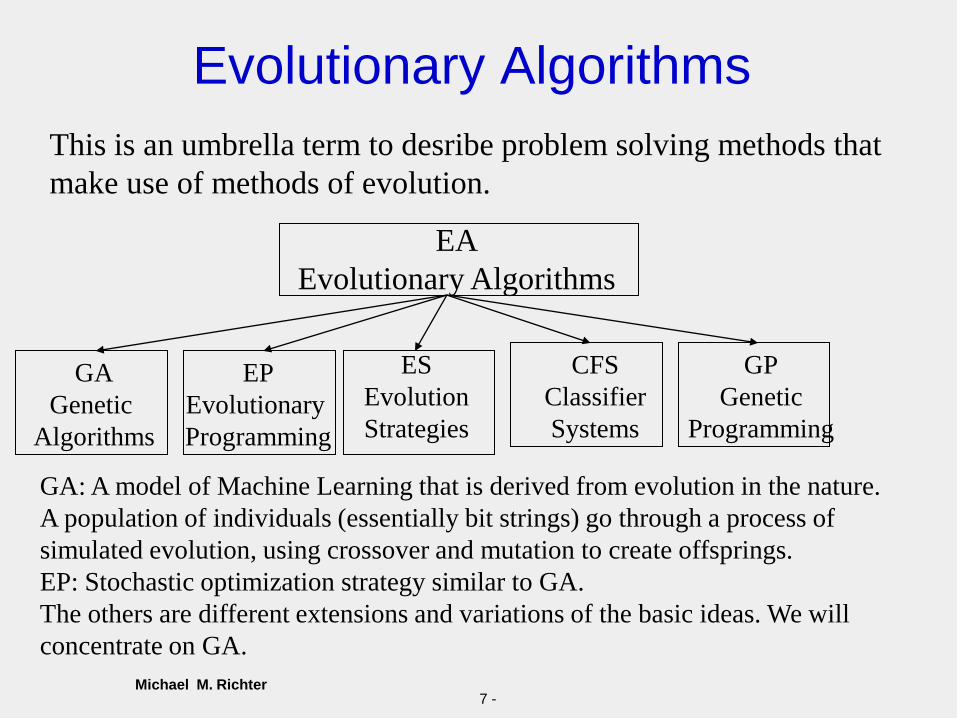
Evolutionary Algorithms
This is an umbrella term to desribe problem solving methods that
make use of methods of evolution.
EA
Evolutionary Algorithms
GA
Genetic
Algorithms
EP
Evolutionary
Programming
ES
Evolution
Strategies
CFS
Classifier
Systems
GP
Genetic
Programming
GA: A model of Machine Learning that is derived from evolution in the nature.
A population of individuals (essentially bit strings) go through a process of
simulated evolution, using crossover and mutation to create offsprings.
EP: Stochastic optimization strategy similar to GA.
The others are different extensions and variations of the basic ideas. We will
concentrate on GA.

Michael M. RichterCallgary 2010
What is Changed in Evolutionary
Algorithms?
• We want to solve a problem
• For this, we have solutions (may be of bad quality) or
solution candidates
• These form the population
• They are up to change or improvement
• Therefore they form the population that will change
through evolution
8 -

Michael M. RichterCallgary 2010
9 -
Learning and Optimization
• Often there is no clear borderline between learning and
optimization: Their target is to improve something.
• An optimization problem consists typically of a set F of
functions f: S(f) IR that share some properties; the
functions f are often cost or win functions which one
wants to minimize or maximize.
• Such an f is called an objective function
• The actual set of solutions are the genomes that form
the population.
• This population is the set subject to evolution and
improvement

Michael M. RichterCallgary 2010
10 -
Evolutionary Algorithms
• Suppose we want to maximize a (reward) function
f: {0,1}n IR
• The most simple evolutionary algorithm:
– 1) Chose x {0,1}n uniformly at random
– 2) Create y by flipping independently each bit in x with
probability 1/n
– 3) If f(x) f(y) then x:= y
– 4) Goto 2)
– There is no stopping criterion and one is interested in the first
time when f is optimal, i.e.
fI(x) = max{f(y) | y {0,1}n

Michael M. RichterCallgary 2010
11 -
More General (1)
• As an example we keep the Travelling Salesman Problem (TSP) in
mind: Given a set of n cities c1, ...,cn and a cost function f for the cost
of the travel in that order. For any permutation p f(p) will measure the
cost concerning this travel; the set of all such permutations will be
called S(f).
• In general:
– F is a set of (reward/cost) functions
– S(f) is the set of search points or individuals p („solutiion candidates“)
– Each f F is a mapping S(f) IRn;
– f(p) is the fitness of p;
– For each p there is a probability Prob(p) assigned to be picked;
– A starting population of individuals is generated randomly;

Michael M. RichterCallgary 2010
12 -
More General (2)
– For each population some individuals are chosen, based on the fitness
function;
– Genetic operators G produce from the chosen individuals new ones;
– Selection operators, again based on the fitness function, select those
individuals that will survive and become members of the next
generation;
– A stopping criterion decides when to stop, the individuals of the last
generation are presented as a solution.
• Such an algorithm often produces good results but can never
guarantee optimality.
• The results depend to a large degree on fitness function and the
genetic operators.

Michael M. Richter 13 -
Part 2
Genetic Algorithms

Michael M. Richter14 -
Genetic Algorithms (1)
Genetic algorithms belong to the class of stochastic search
methods.
Most stochastic search methods operate on a single or solution to
the problem at hand.
Genetic algorithms operate on a population of solutions.
First step: Encode solutions to your problem, i.e. find a genetic
representation consisting of “genomes” (or “chromosomes”).
The genetic algorithm creates an population of genomes and
creates new individuals in the population.
It picks the “best” to proceed.

Michael M. RichterCallgary 2010
Genetic Algorithms (2)
• Generation of new individuals:
– Done by genetic operators that operate on a set of randomly
selected „parents“
• How to judge the quality of an individual?
– This is done by a „quality function“ that is called fitness function.
– The fitness function is given by the user who has some expert
knowledge.
– Therefore the fitness function may be misleading
15 -

Michael M. RichterCallgary 2010
16 -
Genetic Algorithms (3)
The three most important aspects of using genetic algorithms are:
(1) definition of the objective function(s),
(2) definition and implementation of the genetic representation,
and
(3) definition and implementation of the genetic operators.
Once these three have been defined, the generic genetic algorithm
should work fairly well. Beyond that you can try many
different variations to improve performance, find multiple
optima (species - if they exist), or parallelize the algorithms.

Michael M. RichterCallgary 2010
Two Types
• One distinguishes two types of genetic algorithms:
• Generational GA (massive parallel):
Entire populations replaced with each iteration.
• Often here parallelism has to be simulated sequentially,
• Steady-state GA (mainly sequential):
A few members replaced each generation.
17 -

Michael M. RichterCallgary 2010
Chromosomes
• Chromosomes could be:
– Bit strings (0101 ... 1100)
– Real numbers (43.2 -33.1 ... 0.0 89.2)
– Permutations of elements (E11 E3 E7 ... E1 E15)
– Lists of rules (R1, R2, R3 ... R22, R23)
– Program elements (genetic programming)
– ... any data structure” ...
18 -

Michael M. RichterCallgary 2010
19 -
Genetic Operators (1)
• We suppose that the set I of individuals consists of vectors (x1,x2,...,xk,...xn) of length n with entries of some data structure (which is often {0,1}).
• Mutation operators:– Simple mutation operators pick some k and y with a certain probability,
the result of the mutation is (x1,x2,...,xk,...xn) where xk = y.
– Multivariate mutation performs this at several places.
• Cross-over operators have two arguments (the parents):– (x1,x2,...,xk,...xn), (y1,y2,...,yk,...yn) ;
– The result are two children (x1,x2,...,xk,yk+1,...xn), (y1,y2,...,yk, xk+1,...xn); again k is picked with some probability.

Michael M. RichterCallgary 2010
Mutation
• Mutation causes movement in the search space
(local or global)
• Restores lost information to the population
• Example;
– Before: (1 0 1 1 0 1 1 0)
– After: (0 1 1 0 0 1 1 0)
– Before: (1.38 -69.4, 326.44 0.1)
– After: (1.38 -67.5, 326.44 0.1)
20 -

Michael M. RichterCallgary 2010
Crossover
– It greatly accelerates search early in evolution of a population
– It leads to effective combination of schemata (sub solutions on
different chromosomes)
• Example:
– P1 (0 1 1 0 1 0 0 0) (0 1 0 0 1 0 0 0) C1
– P2 (1 1 0 1 1 0 1 0) (1 1 1 1 1 0 1 0) C2
21 -

Michael M. Richter22 -
•We present three methods for selecting the crossover operation.
•The first method uses probability based on the fitness of the
solution.
•If
•f(Sj) is the fitness of the solution Sj
•and S(f(Snj(t)│1≤ j≤ M) is the total sum of all the members of
the population,
then the probability that the solution Si will be copied to the next
generation is
f(Sj) / S(f(Sj(t)│1≤ j≤ M) .
• The technique is to choose the most likely ones.
Selecting the Crossover Operation (1)

Michael M. Richter23 -
Selecting the Crossover Operation (2)
• The second method for selecting the solution is tournament
selection.
•Typically the genetic program chooses two solutions at random.
•The solution with the higher fitness will win.
•This method simulates biological mating patterns in which
two members of the same sex compete to mate with a third one
of a different sex.
• The third method is done by rank.
In rank selection, selection is based on the rank,
(not the numerical value) of the fitness values of the solutions
of the population.

Michael M. RichterCallgary 2010
Selecting for Survival:
Roulette Wheel Selection
• Imagine a roulette wheel where all chromosomes in the
populationare placed , every has its place that is big
according to its fitness function.
• Then a marble is thrown there and selects the
chromosome. Chromosome with bigger fitness will be
selected more times.
• Disadvantage:
– This selection will have problems when the fitness differs very
much. For example, if the best chromosome fitness is 90% of all
the roulette wheel then the other chromosomes will have very few
chances to be selected.
24 -

Michael M. RichterCallgary 2010
Rank Selection
• Rank selection first ranks the population and then every
chromosome receives fitness from this ranking. The worst
will have fitness 1, second worst 2 etc. and the best will
have fitness N (number of chromosomes in population).
• Then all the chromosomes have a chance to be selected.
• Disadvantage:
– The method can lead to slower convergence, because the best
chromosomes do not differ so much from other ones.
25 -

Michael M. RichterCallgary 2010
Steady-State Selection
• The main idea of this selection is that a big part of
chromosomes should survive to next generation.
• GA then works in a following way:
• In every generation are selected a few (good - with high
fitness) chromosomes for creating a new offspring. Then
some (bad - with low fitness) chromosomes are removed
and the new offspring is placed in their place. The rest of
population survives to new generation.
26 -

Michael M. RichterCallgary 2010
Elitism
• When creating new population by crossover and
mutation, there is a big chance, that one will loose the
best chromosome.
• Elitism first copies the best chromosome (or a few best
chromosomes) to new population. The rest is done in
classical way. Elitism can very rapidly increase
performance of GA, because it prevents losing the best
found solution.
27 -

Michael M. Richter28 -
Examples: Arrays (1)
These are some sample tree mutation operators:

Michael M. Richter29 -
Arrays (2)

Michael M. Richter30 -
ListsThese are some sample list mutation operators.
Notice that lists may be fixed or have variable length.
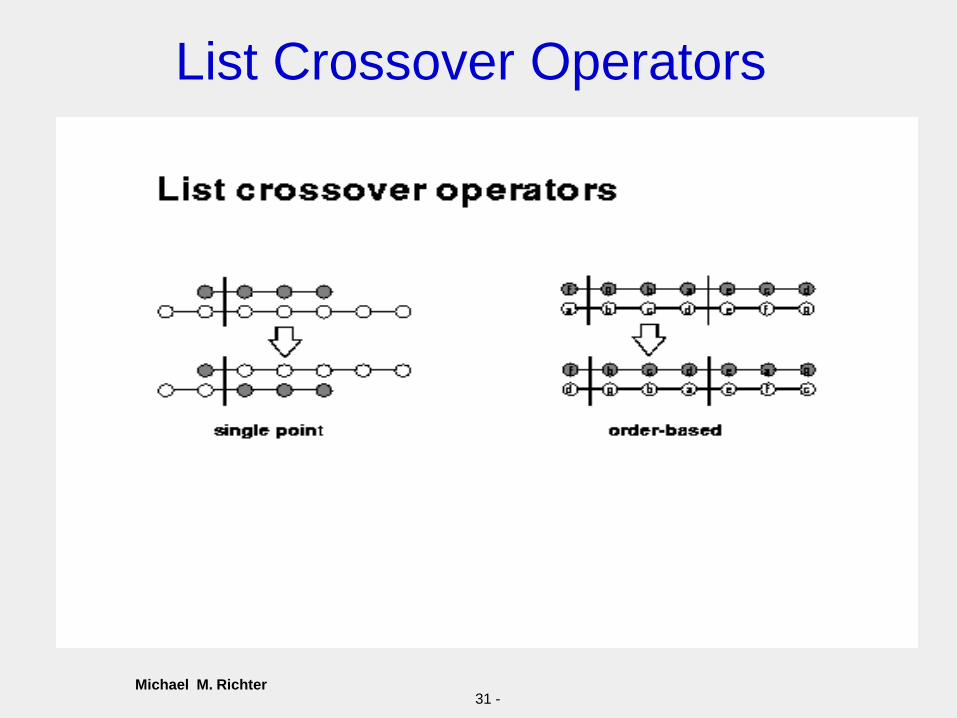
Michael M. Richter31 -
List Crossover Operators

Michael M. Richter32 -
Trees
These are some sample tree mutation operators:
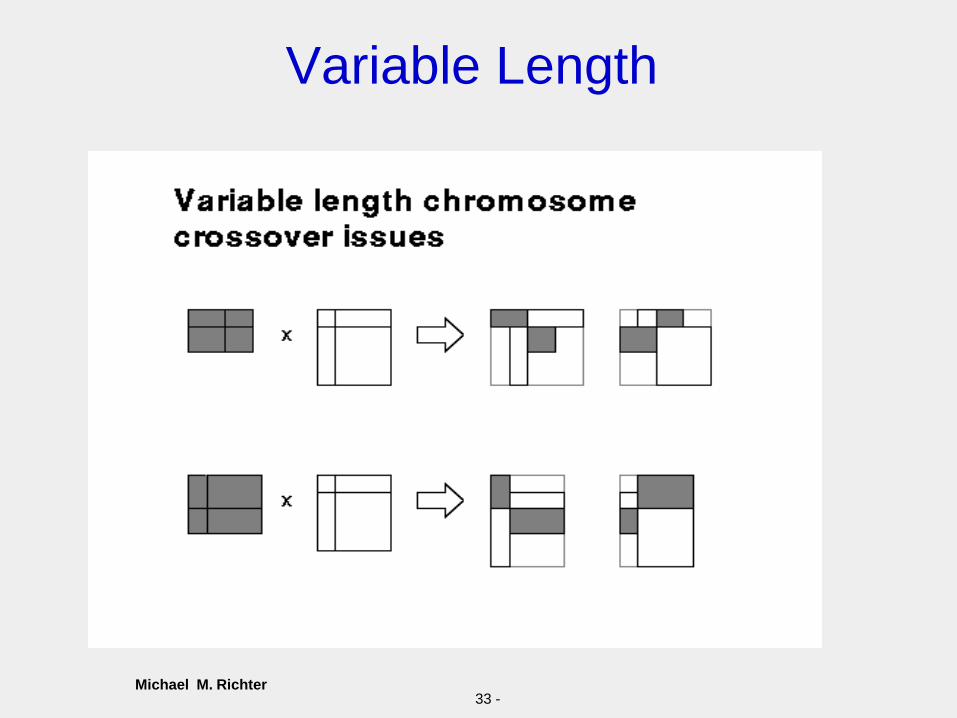
Michael M. Richter33 -
Variable Length

Michael M. RichterCallgary 2010
34 -
Fitness Function (1)
• The most difficult and most important concept of genetic programming is the fitness function. The fitness function determines how well a program is able to solve the problem. It varies greatly from one type of program to the next.
• For example, if one were to create a genetic program to set the time of a clock, the fitness function would simply be the amount of time that the clock is wrong.
• Unfortunately, few problems have such an easy fitness function; most cases require a slight modification of the problem in order to find the fitness.

Michael M. RichterCallgary 2010
Fitness Function (2)
• The fitness function decides which individuals survive.
• Stronger individuals, that is those chromosomes with
fitness values closer to the optimal solution will have a
greater chance to survive across epochs and to
reproduce than weaker individuals which will tend to
perish.
• In other words, the algorithm will tend to keep inputs that
are close to the optimal in the set of inputs being
considered and discard those that under-perform the rest.
• The fitness function can also be used to select genetic
operators.
35 -

Michael M. RichterCallgary 2010
Fitness Function (3)
• The problem is that often one does not know what
„optimal“ or „close to optimal“ means.
• Therefore the fitness function is only a guess of what is
good.
• One often has candidates, coming from experiences or
expert knowledge, as for example in chess.
• However, it may happen that the function is misleading
and e.g. resulting in loosing a game.
• In such a situation one has to carefully analyzing the
function and improving it or replacing it by another one.
36 -

Michael M. RichterCallgary 2010
37 -
Example: Water Sprinkler System (1)
• Consider a program to control the flow of water through
a system of water sprinklers. The fitness function is the
correct amount of water evenly distributed over the
surface.
• Unfortunately, there is no one variable encompassing
this measurement. Thus, the problem must be modified
to find a numerical fitness.
• One possible solution is placing water-collecting
measuring devices at certain intervals on the surface.
The fitness could then be the standard deviation in
water level from all the measuring devices.

Michael M. RichterCallgary 2010
38 -
Water Sprinkler System (2)
• Another possible fitness measure could be the
difference between the lowest measured water
level and the ideal amount of water.
• However, this number would not account in any
way the water marks at other measuring devices,
which may not be at the ideal mark.

Michael M. RichterCallgary 2010
39 -
A Basic Genetic Algorithm (1)
• [Start] Generate a random population of n chromosomes
• (suitable solutions for the problem)
• 2. [Fitness] Evaluate the fitness f(x) of each chromosome x in the
population
• 3. [New population] Create a new population by repeating following
steps until the new population is complete
• 1. [Selection] Select two parent chromosomes from a population
according to their fitness (the better fitness, the bigger chance to be selected)
• 2. [Crossover] With a crossover probability cross over the parents to
form new offspring (children). If no crossover was performed, offspring is the
exact copy of parents.
• 3. [Mutation] With a mutation probability mutate new offspring at each
locus (position in chromosome).
• 4. [Accepting] Place new offspring in the new population
•

Michael M. RichterCallgary 2010
40 -
A Basic Genetic Algorithm (2)
• 4. [Replace] Use new generated population for a further run of the
algorithm
• 5. [Test] If the end condition is satisfied, stop, and return the best
solution in current population
• 6. [Loop] Go to step 2
• The outline of the Basic GA is very general. There are
many parameters and settings that can be implemented
differently in various problems.
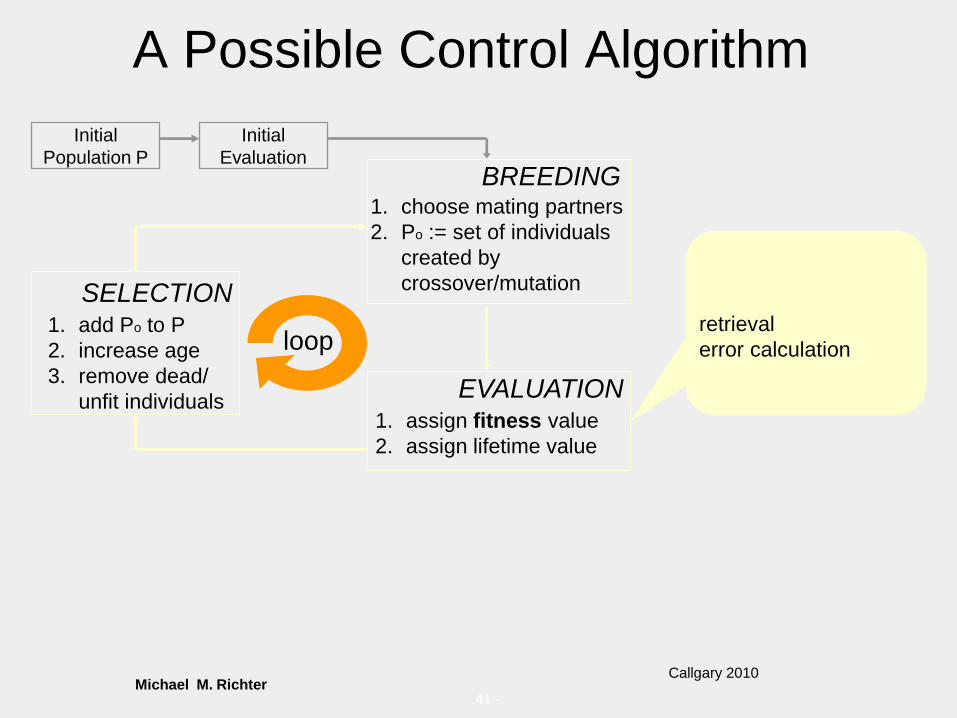
Michael M. RichterCallgary 2010
41 -
A Possible Control Algorithm
Initial
Population P
Initial
EvaluationBREEDING
1. choose mating partners
2. Po := set of individuals
created by
crossover/mutation
EVALUATION1. assign fitness value
2. assign lifetime value
SELECTION1. add Po to P
2. increase age
3. remove dead/
unfit individuals
loopretrieval
error calculation

Michael M. RichterCallgary 2010
Main Parameters (1)
• Crossover rate
Crossover rate generally should be high, about 80%-95%.
(However for some problems crossover rate about 60% is
the best.)
• Mutation rate
On the other side, mutation rate should be very low. Best
rates reported are about 0.5%-1%.
• Population size
A very big population size usually does not improve
performance of GA (in meaning of speed of finding
solution). Good population size is about 20-30.
•
42 -

Michael M. RichterCallgary 2010
Main Parameters (2)
• Selection
• Random selection can be used, but sometimes rank
selection can be better. There are also some more
sophisticated methods, which changes parameters of
selection during run of GA.
• Encoding
Encoding depends on the problem and also on the size
of instance of the problem
• Crossover and mutation type
Operators depend on encoding and on the problem.
43 -

Michael M. RichterCallgary 2010
Main Parameters (3)
• Crossover and Mutation Probability
• If crossover probability is 100%, then all offspring is made
by crossover. If it is 0%, whole new generation is made
from exact copies of chromosomes from old population
(but this does not mean that the new generation is the
same!).
• If mutation probability is 100%, whole chromosome is
changed, if it is 0%, nothing is changed.
Mutation is made to prevent falling GA into local extreme,
but it should not occur very often, because then GA will in
fact change to random search.
•
44 -

Michael M. RichterCallgary 2010
Recommendations• Crossover rate
Crossover rate generally should be high, about 80%-95%.
(However some results show that for some problems
crossover rate about 60% is the best.)
• Mutation rate
On the other side, mutation rate should be very low. Best
rates reported are about 0.5%-1%.
• Population size
Very big population size usually does not improve
performance of GA (in meaning of speed of finding
solution). Good population size is about 20-30, however
sometimes sizes 50-100 are reported as best.
45 -

Michael M. RichterCallgary 2010
Discussion
• Advantage of GAs is in their parallelism. GA is travelling
in a search space with more individuals (and with
genotype rather than phenotype) so they are less likely to
get stuck in a local extreme like some other methods.
• They are also easy to implement. Once you have some
GA, you just have to write new chromosome (just one
object) to solve another problem. With the same encoding
you just change the fitness function and it is all.On the
other hand, choosing encoding and fitness function can
be difficult.
• Disadvantage of GAs is in their computational time.
46 -

Michael M. Richter
Part 3
Applications
Calgary
2010

Michael M. RichterCallgary 2010
How to Start a Project (1)
• Before you can use a genetic algorithm to solve a
problem, a way must be found of encoding any potential
solution to the problem. This could be as a string of real
numbers or, as is more typically the case, a binary bit
string, i.e. as a chromosome. A typical chromosome may
look like this:
• 10010101110101001010011101101110111111101
• How do we do this? First we need to represent all the
different characters available to the solution. This will
represent a gene. Each chromosome will be made up of
several genes.
48 -

Michael M. RichterCallgary 2010
How to Start a Project (2)
• Test each chromosome to see how good it is at solving
the problem at hand and assign a fitness score
accordingly. The fitness score is a measure of how good
that chromosome is at solving the problem to hand.
• Select two members from the current population. The
chance of being selected is proportional to the
chromosomes fitness. Random selection can be used .
• Dependent on the crossover rate crossover the bits from
each chosen chromosome at a randomly chosen point.
• Step through the chosen chromosomes bits and flip
dependent on the mutation rate.
• Repeat the steps.
49 -

Michael M. RichterCallgary 2010
Some Past Applications (1)
• Engineering Design
• Getting the most out of a range of materials to optimize
the structural and operational design of buildings,
factories, machines, etc. is a rapidly expanding
application of GAs. These are being created for such
uses as optimizing the design of heat exchangers, robot
gripping arms, satellite booms, building trusses,
flywheels, turbines, and just about any other computer-
assisted engineering design application.
50 -

Michael M. RichterCallgary 2010
Some Past Applications (2)
• Robotics
• Robotics involves human designers and engineers trying
out all sorts of things in order to create useful machines
that can do work for humans. GAs can be programmed to
search for a range of optimal designs and components for
each specific use, or to return results for entirely new
types of robots that can perform multiple tasks and have
more general application.
51 -

Michael M. RichterCallgary 2010
Some Past Applications (3)
• Optimized Telecommunications Routing
• GAs are being developed that will allow for dynamic and
anticipatory routing of circuits for telecommunication
networks. These could take notice of your system's
instability and anticipate your re-routing needs. Other GAs
are being developed to optimize placement and routing of
cell towers for best coverage and ease of switching.
•
52 -

Michael M. RichterCallgary 2010
Some Past Applications (4)
• Encryption and Code Breaking
• GAs can be used both to create encrytion for sensitive
data as well as to break those codes. Every time
someone adds more complexity to their encryption
algorithms, someone else comes up with a GA that can
break the code. It is hoped that one day soon we will have
quantum computers that will be able to generate
completely indecipherable codes.
53 -

Michael M. RichterCallgary 2010
54 -
Other Application Areas
• Developmental biology is the study of the process by which
organisms grow and develop. Modern developmental biology studies
the genetic control of cell growth, differentiation and morphogenesis,
which is the process that gives rise to tissues, organs, and anatomy.
• Simulated reality (not the same as virtual reality!) is the idea that
reality could be simulated by computers to a degree indistinguishable
from 'true' reality. It could contain conscious minds which may or may
not know that they are living inside a simulation. In its strongest form,
it claims we actually are living in such a simulation.

Michael M. RichterCallgary 2010
A Tool Example: DTREG (1)
• Continuous and categorical target variables
• Automatic handling of categorical predictor variables
• A large library of functions that you can select for
inclusion in the model
• Mathematical and logical (AND, OR, NOT, etc.) function
generation
• Choice of many fitness functions
• Both static linking functions and evolving genes
• Fixed and random constants
55 -

Michael M. RichterCallgary 2010
A Tool Example: DTREG (2)
• Nonlinear regression to optimize constants
• Parsimony pressure to optimize the size of functions
• Automatic algebraic simplification of the combined
function
• Several forms of validation including cross-validation
• Computation of the relative importance of predictor
variables
• Automatic generation of C or C++ source code for the
functions
• Multi-CPU execution for multiple target categories and
cross-validation
56 -

Michael M. RichterCallgary 2010
57 -
E-Commerce Application• We want to sell certain products. • There are two forms of product descriptions:
– The first one is the description of the seller. This describes all available products; they are called cases here, denoted by c.
– The second one is the description of the customer. They are called queries here, denoted by q.
– Queries are descriptions of possible products. These may not be available or not even exist.
• Cases and queries are represented as attribute value vectors, e.g. q = (q1,...,qn), c = (c1,...,cn)
• The task is to find for each query a case that is maximally useful for the query.
• For this purpose we introduce utility functions.

Michael M. Richter58 -
Utility Functions
n
i
iiii cquwCQu1
),(),(
• Utility functions have the same structure as queries and cases.
• For each index i the utility of ci for qi is denoted by ui(qi, ci)
(the so-called local utility).
• The importance of element i is denoted by a weight wi.
We assume for the total utility a weighted sum:
• If all the domains are finite then the utility function can be
represented as a finite matrix.

Michael M. RichterCallgary 2010
59 -
Example
• Suppose we are selling cars. Some attributes are:
– A1: Color; domain = {red, green, white, metallic,…}, finite
– A2: Number of seats; domain = {2,4,6}, finite
– A3: Maximum speed; domain = [ 130, 320], numeric
– …
• For a fixed class of customers the local utilities as well as
the weights (for the importance of the attribute) reflect the
taste of the customer.
• There are two forms of the utility:
– One that reflects the true tast of the customer
– One that is the estimated tast of the customer

Michael M. RichterCallgary 2010
60 -
Learning Utilities Functions (1)
• Because the taste of the customer is partially unknown
one wants to know more about it.
• Direct queries to the customer to give an explicit and
precise description of the taste will fail.
• The „data mining way out“ is to learn the taste by
observing the customer.
• This can be done by looking at the sales records
• This gives rise to a partial order of the cases (the
preference relation) according to the utility value.

Michael M. RichterCallgary 2010
61 -
Learning Utility Functions (2)
• The customers are going to make decisions, e.g. which product to buy; the decisions are the cases here.
• A utility function measures the degree of utility of the cases for the query. The utility of the user is not known and has to be approximated by formal utility functions.
• In this approach we apply genetic algorithms for learning.
• The individuals are the estimated utility functions; a population is a set of such functions.
• The fitness function is given by user feedback who evaluate the utility functions.
• The genetic operators produce new utility functions.

Michael M. RichterCallgary 2010
62 -
Learning Utility Functions (3)
• Learning has two aspects:
• Learning weights: To the weight vectors mutation and
cross-over operators can be applied directly.
• Learning local utilities: We distinguish two cases:
– The domains of the attributes are finite: We represent the
function as a matrix (i.e. in principle as a vector) and proceed
as before.
– The domains are real numbers: We approximate the function
by a piecewise linear function which can again be represented
as a vector.

Michael M. RichterCallgary 2010
63 -
Error (1)• A training example for a given utility u and a query q is of
the form
TEu(q): = (q,u(q,c1)), …. (q,u(cn)), where the ci are cases.
• Training data are of the form TDu = (TEu(q1),.., TEu(qm)) for several queries.
• A given set of training data TD introduces a error function ETD : estimated utilities: u IR that measures the error.
• The task is now to minimize the error function.
• That means: We want an optimal estimated utility uop
where ETD(uop) = emin is minimal.
• Attention: There may be local minima that are not global minima!

Michael M. Richter64 -
Error (2)
• We assume that in the training examples (((q,u(q,c1)), …. (q,u(cn))) and select two examples (q,u(q,ci)) and (q,u(q,cj)) such that
u(q,cj) u(q,ci)
• This ranking from the customer is now compared with the ranking from the estimated utlity ur:
• We choose some function ef0(ci, cj) that gives some penalty if the ranking
with respect to u and ur differ more than a certain threshold. This penalty function can be choosen in different ways.
• For the total error of a training set (((q,u(q,c1)), …. (q,u(cn))) we take the sum over the set of pairs.
• In addition, we introduce a position parameter q that allows to increase the influence of wrong case rankings among more useful cases.
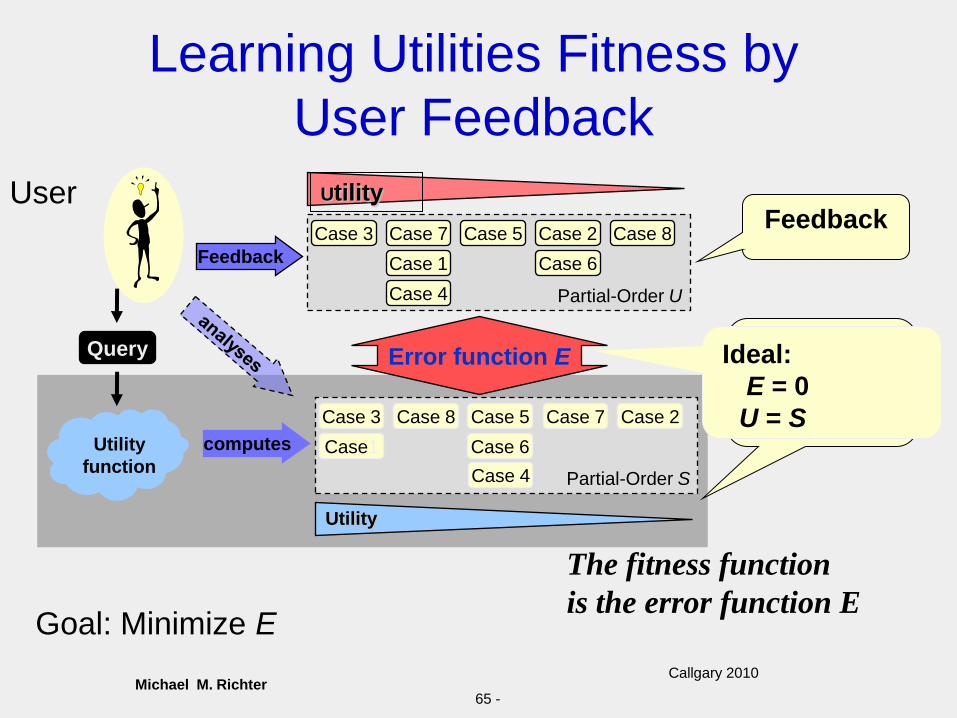
Michael M. RichterCallgary 2010
65 -
Learning Utilities Fitness by
User Feedback
Query
computes
Case 3
Partial-Order S
Case 8
Case1
Case 4
Case 6
Case 5 Case 7 Case 2
Utility
Utility
function
Feedback
Partial-Order U
Case 7
Case 1
Case 4
Case 6
Case 5 Case 2 Case 8
Utility
Case 3
Goal: Minimize E
Ideal:
E = 0
U = S
Error function E
UserFeedback
The fitness function
is the error function E

Michael M. RichterCallgary 2010
66 -
Learning Utilities
• Mathematical formulation of the retrieval error by an
error function
uinitial uopt
emin
einitial
ETD(u)
U
u(q,c1) u(q,c2) u(q,c3) ... u(q,cn)
Example
Computed utilities
q c1 c2 c3 ... cn
Michael M. RichterCallgary 2010
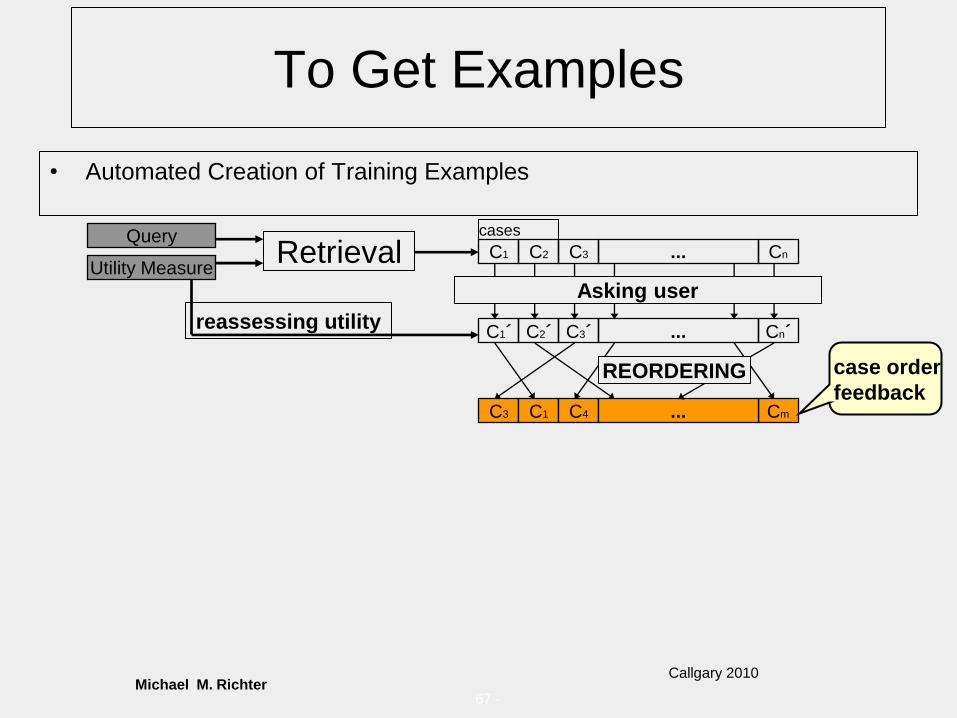
67 -
To Get Examples
• Automated Creation of Training Examples
Utility Measure
QueryRetrieval
C1´ C2´ C3´ Cn´...
Asking user
C3 C1 C4 Cm...
REORDERING
reassessing utility
case order
feedback
C1 C2 C3 Cn...
cases

Michael M. RichterCallgary 2010
68 -
The Genetic Algorithm
• Advantages:
• Also suitable for learning local utilities
• Disadvantage:
– Less efficient learning
• Approach:
– Coding of utilities as genomes
– Definition of Crossover and Mutation operators
– Evolutionary process with respect to fittest utility
„Evolution“ of optimal utilities
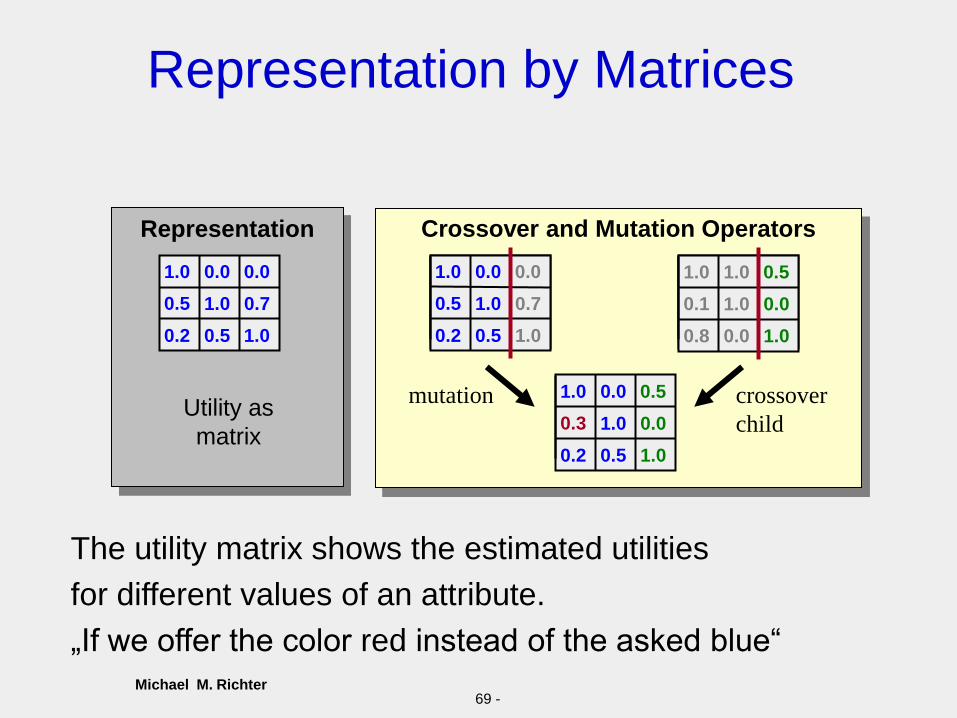
Michael M. Richter69 -
Representation by Matrices
Crossover and Mutation Operators
0.0
0.7
1.0
1.0
0.5 1.0
0.2 0.5
0.0 0.5
0.0
1.0
1.0
0.1 1.0
0.8 0.0
1.00.0
0.7
1.0
1.0
0.5 1.0
0.2 0.5
0.0
Representation
Utility as
matrix
0.5
0.0
1.0
1.0
0.3 1.0
0.2 0.5
0.0
0.0
0.7
1.0
1.0
0.5 1.0
0.2 0.5
0.0 0.5
0.0
1.0
1.0
0.1 1.0
0.8 0.0
1.0
mutation crossover
child
The utility matrix shows the estimated utilities
for different values of an attribute.
„If we offer the color red instead of the asked blue“
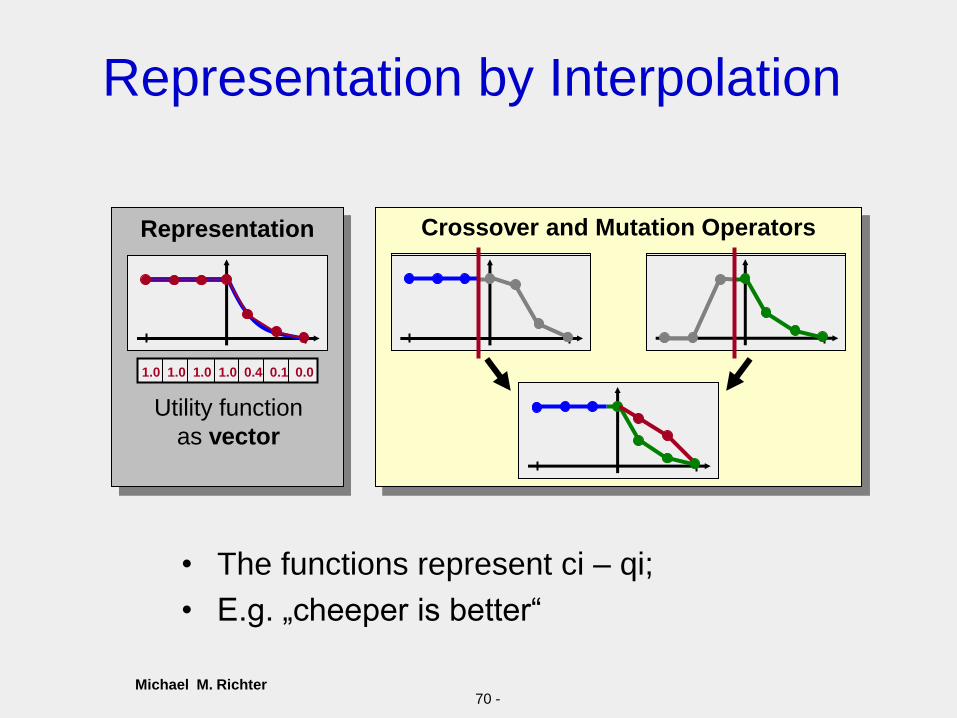
Michael M. Richter70 -
Crossover and Mutation Operators
Representation by Interpolation
Representation
Utility function
as vector
1.0 1.0 1.0 1.0 0.4 0.1 0.0
• The functions represent ci – qi;
• E.g. „cheeper is better“

Michael M. Richter 71 -
Part 4
Genetic Programming

Michael M. Richter72 -
What is Genetic Programming (GP)? (1)
• Genetic programming (GP) is an automated method
for creating a working computer program from a high-
level problem statement of a problem.
• Genetic programming starts from a high-level
statement of “what needs to be done” and automatically
creates a computer program to solve the problem.

Michael M. RichterCallgary 2010
73 -
What is Genetic Programming (GP)? (2)
• One of the central challenges of computer science is to get a computer
to do what needs to be done, without telling it how to do it.
• Genetic programming addresses this challenge by providing a method
for automatically creating a working computer program from a high-
level problem statement of the problem.
• Genetic programming achieves this goal of automatic programming
(also sometimes called program synthesis or program induction) by
genetically breeding a population of computer programs using the
selection and mutations.
• The operations include reproduction, crossover, mutation, and
architecture-altering operations patterned after gene duplication and
gene deletion in nature.

Michael M. RichterCallgary 2010
74 -
Preparatory Steps of Genetic Programming
• The five major preparatory steps for the basic version of genetic
programming require the human user to specify branch
(1) the set of terminals (e.g., the independent variables of the problem,
zero-argument functions, and random constants) for each of the to-be-
evolved program,
• (2) the set of primitive functions for each branch of the to-be-evolved
program,
• (3) the fitness measure (for explicitly or implicitly measuring the fitness of
individuals in the population),
• (4) certain parameters for controlling the run, and
• (5) the termination criterion and method for designating the result of the
run.

Michael M. RichterCallgary 2010
75 -
Flowchart (Executional Steps) of
Genetic Programming
• Genetic programming is problem-independent in the sense that the
flowchart specifying the basic sequence of executional steps is not
modified for each new run or each new problem.
• There is usually no discretionary human intervention or interaction
during a run of genetic programming (although a human user may
exercise judgment as to whether to terminate a run).

Michael M. RichterCallgary 2010
76 -
Creation of Initial Population of
Computer Programs
• Genetic programming starts with a primordial ooze of thousands of
randomly-generated computer programs. The set of functions that
may appear at the internal points of a program tree may include
ordinary arithmetic functions and conditional operators.
• The set of terminals appearing at the external points typically include
the program's external inputs (such as the independent variables X
and Y) and random constants (such as 3.2 and 0.4).
• The randomly created programs typically have different sizes and
shapes.

Michael M. RichterCallgary 2010
77 -
Main Generational Loop of Genetic
Programming (1)• The main generational loop of a run of genetic programming
consists of the fitness evaluation, selection, and the genetic
operations. Each individual program in the population is
evaluated to determine how fit it is at solving the problem at
hand. Programs are then probabilistically selected from the
population based on their fitness to participate in the various
genetic operations, with reselection allowed. While a more fit
program has a better chance of being selected, even individuals
known to be unfit are allocated some trials in a mathematically
principled way. That is, genetic programming is not a purely
greedy hill-climbing algorithm.
• The individuals in the initial random population and the offspring
produced by each genetic operation are all syntactically valid
executable programs.
• After many generations, a program may emerge that solves, or
approximately solves, the problem at hand.
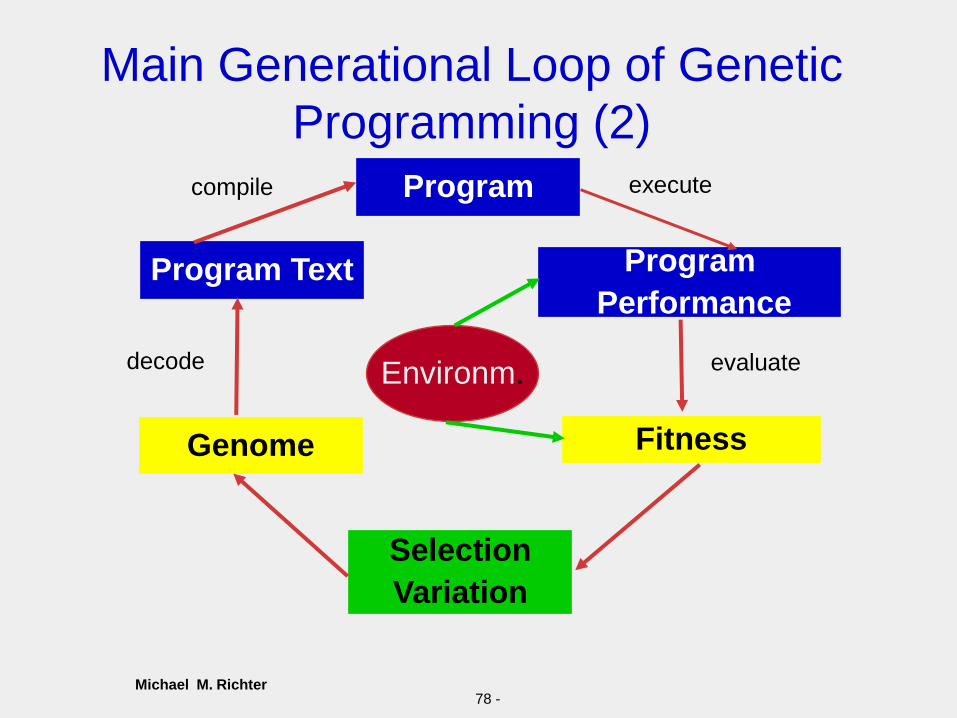
Michael M. Richter78 -
Main Generational Loop of Genetic
Programming (2)
Program
Program
PerformanceProgram Text
compile execute
Genome Fitness
decode evaluate
Selection
Variation
Environm.

Michael M. RichterCallgary 2010
Example (1)
• Objective:
• Find a computer program with one input (independent
variable X) whose output equals the given data
• Terminal set:
• T = {X, Random-Constants}
• Function set:
• F = {+, -, *, %}
79 -

Michael M. RichterCallgary 2010
Example (2)
• Fitness:
• The sum of the absolute value of the differences
between the candidate program’s output and the
given data (computed over numerous values of the
independent variable x from –1.0 to +1.0)
• Parameters:
• Population size M = 4
• Termination:
• An individual emerges whose sum of absolute errors
is less than 0.1
80 -

Michael M. RichterCallgary 2010
Fitness Function
• There are different ways to define it.
• They are all connected with the correctness of the
program.
• One example is to maximize the number of correctly
solved test cases.
81 -

Michael M. RichterCallgary 2010
82 -
Mutation Operation
• In the mutation operation, a single parental program is
probabilistically selected from the population based on
fitness.
A mutation point is randomly chosen, the subtree rooted at
that point is deleted, and a new subtree is grown there
using the same random growth process that was used to
generate the initial population. This mutation operation is
typically performed sparingly (with a low probability of,
say, 1% during each generation of the run).

Michael M. RichterCallgary 2010
83 -
Crossover Operation
In the crossover, or sexual recombination operation, two parental programs are
probabilistically selected from the population based on fitness. The two
parents participating in crossover are usually of different sizes and shapes.
A crossover point is randomly chosen in the first parent and a crossover point is
randomly chosen in the second parent.
Then the subtree rooted at the crossover point of the first, or receiving, parent is
deleted and replaced by the subtree from the second, or contributing, parent.
Crossover is the predominant operation in genetic programming (and genetic
algorithm) work and is performed with a high probability (say, 85% to 90%).

Michael M. RichterCallgary 2010
84 -
Reproduction Operation
The reproduction operation copies a single individual,
probabilistically selected based on fitness, into the next
generation of the population.

Michael M. Richter85 -
Example (1)

Michael M. Richter86 -
Example (2)

Michael M. Richter87 -
Example (3)
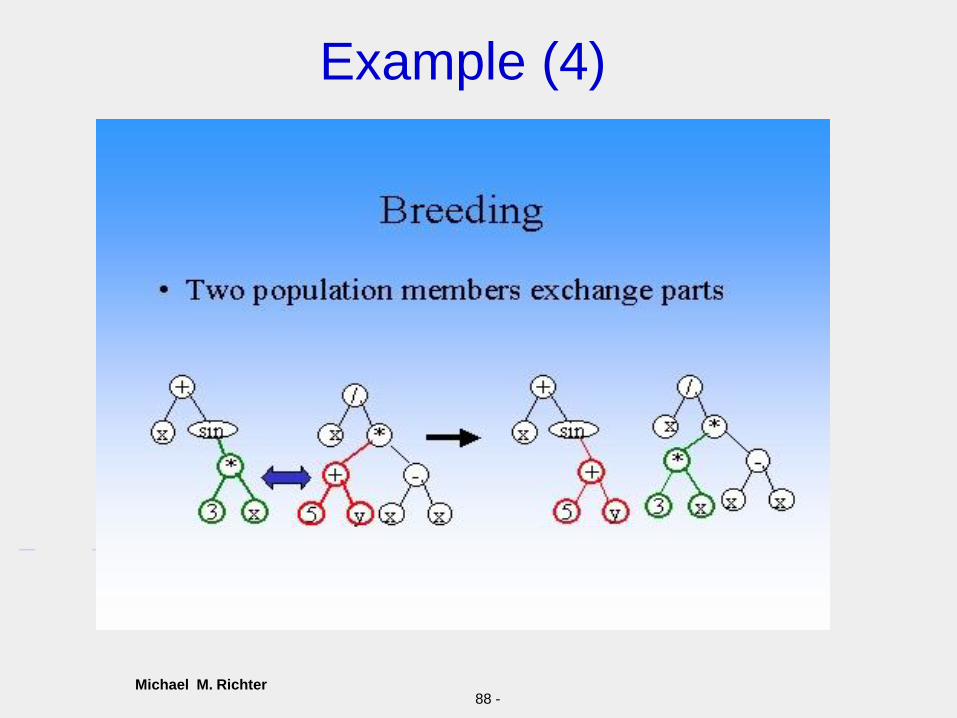
Michael M. Richter88 -
Example (4)

Michael M. Richter89 -
Example (5)
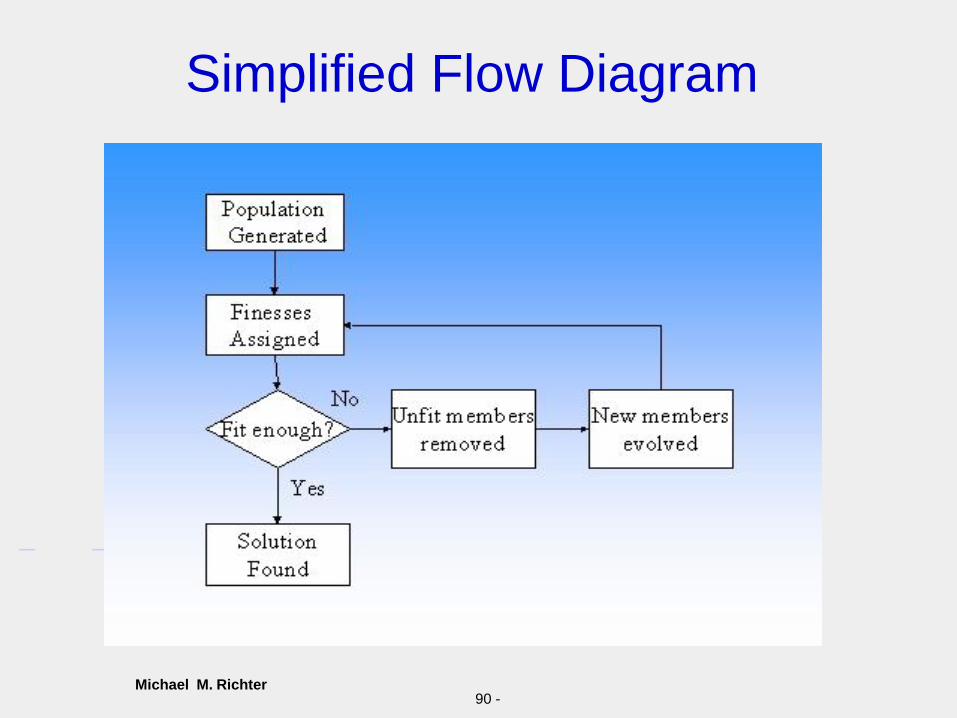
Michael M. Richter90 -
Simplified Flow Diagram

Michael M. RichterCallgary 2010
A C Program
91 -
int foo (int time)
{
int temp1, temp2;
if (time > 10)
temp1 = 3;
else
temp1 = 4;
temp2 = temp1 + 1 + 2;
return (temp2);
}
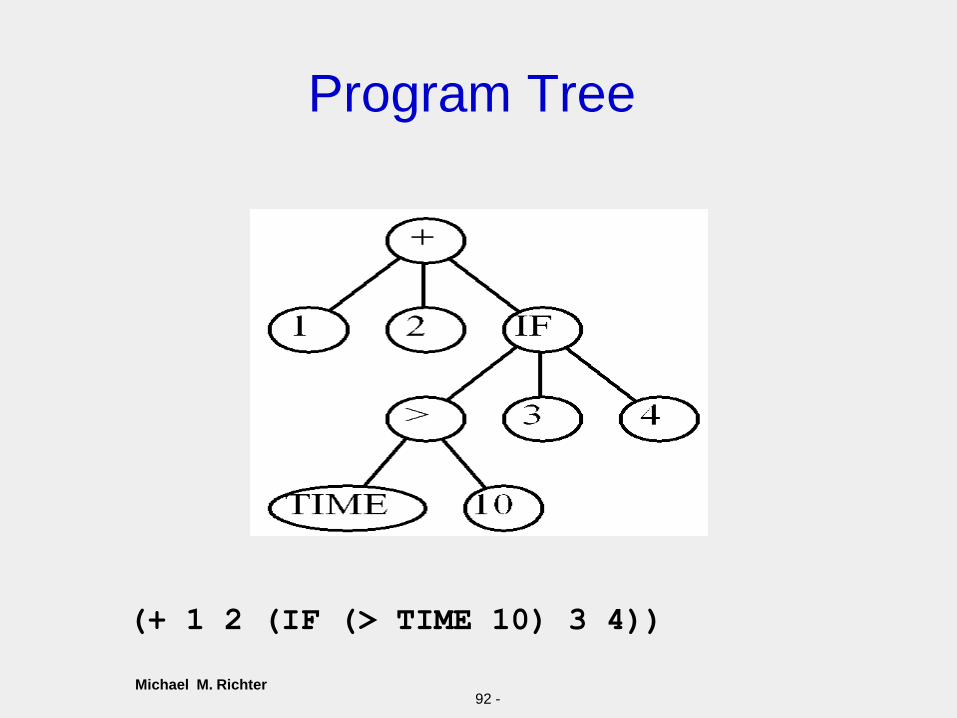
Michael M. Richter
Program Tree
92 -
(+ 1 2 (IF (> TIME 10) 3 4))

Michael M. RichterCallgary 2010
93 -
Summary
• General principles, evaluation and background
• Genetic algorithms
• Genetic operators
• Fitness function
• User feedback, applications to e-commerce
• Genetic Programming

Michael M. RichterCallgary 2010
94 -
Additional References
• David Goldberg (2002): The Design of Innovation: Lessons from and for
Competent Genetic Algorithms, Addison-Wesley, Reading, MA.
• T. Bäck: Evolutionary Algorithms in Theory and Practice. Oxford University
Press 1996
• C. Jacob: Illustrating Evolutionary Computation with Mathematica. Morgan
Kaufmann 2001
• www. genetic-programming.com
• John Koza (1992): Genetic Programming: On the Programming of
Computers by Means of Natural Selection
• Z. Michalewicz (1999): Genetic Algorithms + Data Structures = Evolution
Programs, Springer-Verlag.
• Melanie Mitchell: (1996), An Introduction to Genetic Algorithms, MIT Press,
Cambridge, MA.

Michael M. RichterCallgary 2010
95 -
Links (1)
• A very complete FAQ is available, called The Hitchhiker's Guide to
Evolutionary Computation.
• GA Source Code is a collection of implementations, including GAs, GPs and
other EC programs. The index is now an html document. In addition to
storing code on our archive, we will also now store links directly to the
author's code when available.
• ENCORE (The EvolutioNary COmputation REpository network) is a
repository of information on evolutionary computation available through FTP
access. It was created by the same people who wrote the Hitchhiker's Guide
(see above), and is intended as an appendix to the Guide. The information in
ENCORE is considered to be introductory in nature.
• * The Flying Circus is another resource for EC-related material. It includes an
application-oriented bibliography, pointers to fielded applications, and tutorial
materials.
• GEATbx: Genetic and Evolutionary Algorithm Toolbox for use with Matlab.
http://www.geatbx.com/.

Michael M. RichterCallgary 2010
96 -
Links (2)
• EVONET The European Network of Excellence in Evolutionary Computing is
a European Commission funded network established to co-ordinate and
facilitate co-operation between academics doing research in Evolutionary
Computing, and also to transfer such expertise to Industry. It is co-ordinated
by Napier University, UK, and involves the leading figures in Evolutionary
Algorithms Research in Europe. They also publish a quarterly newsletter
called EvoNews.
• The USENET news group can be reached under comp.ai.genetic.
• Information and links pertaining to the area of genetic programming are
maintained by John Koza at www.genetic-programming.org.
• MIT Press maintains a collection of abstracts of papers published in
Evolutionary Computation Journal. Information on ordering the journal can
also be found at this site.





























