Embed Size (px)
DESCRIPTION
Search and Access Technologies for Large Scale Web Archives. Joseph JaJa, Sangchul Song, and Mike Smorul Institute for Advanced Computer Studies Department of Electrical and Computer Engineering University of Maryland. In Collaboration with the Library of Congress and the Internet Archive. - PowerPoint PPT Presentation
Citation preview

Search and Access Technologies for Large Scale
Web ArchivesJoseph JaJa, Sangchul Song, and Mike Smorul
Institute for Advanced Computer StudiesDepartment of Electrical and Computer EngineeringUniversity of MarylandIn Collaboration with the Library of Congress and the Internet Archive

• Web – Main publication/communication medium today, but it is an ephemeral medium.
• Web Archiving:– Capture, annotate, and store important web
contents within their contextual and temporal characteristics;
– Preserve to enable search and access in the long term;
– Unprecedented scale and heterogeneity.
Web Archiving
NDIIPP Partners Meeting 2June 24, 2009

• Discovery of relevant contents based on unstructured queries involving temporal specifications
• Presentation of pertinent summary information in ranked order according to the temporal context
• Scalable search and access performance
Goals
NDIIPP Partners Meeting 3June 24, 2009

Existing Access Methods
• Chronological Listing Based on URLs– Used by the Wayback Machine of the Internet
Archive, arguably the leader in web archiving.
• Directory Organization– Typically for domain specific contents, which are
organized according to some hierarchical structure.
• Full Text Search– Similar to current web search engines
(NutchWax/WERA)NDIIPP Partners Meeting 4June 24, 2009

Limitations of Current Technologies
• Chronological Listing– Users are expected to provide URLs.
• Hierarchical Listing– Not scalable. Users explore hierarchical
structures, with possibly large numbers of entries.
• Full Text Search (NutchWax/WERA)– Ranking of returned results does not take
temporal context into consideration.– A listing similar to current web search engines.– Lack in performance and scalability.
NDIIPP Partners Meeting 5June 24, 2009

Issue #1: Scalability and Performance
• For any search time span, the ENTIRE history has to be examined. (Multiple distributed indices can be maintained instead. However, all the indices still need to be searched).
NDIIPP Partners Meeting
time
Inverted index
a
…
z
search time span
6June 24, 2009

Example: Search All, and then Filter
“Find web pages that contain ‘September 11th’ before 2001”
Search all, and then Filter Very inefficient!!
September 11 attacks - Wikipedia, the free encyclopediaThe September 11 attacks (often referred to as nine-eleven, written 9/11) were a series of coordinated suicide attacks by al-Qaeda upon the United States on … en.wikipedia.org/wiki/September_11,_2001_attacks
September 11 Digital ArchiveUses electronic media to collect, preserve, and present the history of the September 11, 2001 attacks in New York, Virginia, and Pennsylvania and the public … 911digitalarchive.org/
9/11 Tributes, September 11 Tributes and Memorials to the Victims …Tributes of 9/11 - September 11th 9/11 memorials. For the Victims their Families and the many Heroes of September 11th. 2001. 9/11 World Trade Center, ... www.jontzen.com/tribute.htm - 132k
National Commission on Terrorist Attacks Upon the United StatesCommission chartered to prepare a full and complete account of the circumstances surrounding the September 11, 2001 terrorist ttacks, … www.9-11commission.gov/ - 8k
… and 4 million other pages pertaining to the September 11th Attack …
September 11 attacks - Wikipedia, the free encyclopediaThe September 11 attacks (often referred to as nine-eleven, written 9/11) were a series of coordinated suicide attacks by al-Qaeda upon the United States on … en.wikipedia.org/wiki/September_11,_2001_attacks
September 11 Digital ArchiveUses electronic media to collect, preserve, and present the history of the September 11, 2001 attacks in New York, Virginia, and Pennsylvania and the public … 911digitalarchive.org/
9/11 Tributes, September 11 Tributes and Memorials to the Victims …Tributes of 9/11 - September 11th 9/11 memorials. For the Victims their Families and the many Heroes of September 11th. 2001. 9/11 World Trade Center, ... www.jontzen.com/tribute.htm - 132k
National Commission on Terrorist Attacks Upon the United StatesCommission chartered to prepare a full and complete account of the circumstances surrounding the September 11, 2001 terrorist ttacks, … www.9-11commission.gov/ - 8k
… and 4 million other pages pertaining to the September 11th Attack …
Ethiopian calendar - Wikipedia, the free encyclopediaThus the first day of the Ethiopian year, 1 Mäskäräm, for years between 1901 and 2099 (inclusive), is usually September 11 (Gregorian), ...en.wikipedia.org/wiki/Ethiopian_calendar - 43k
APOD: September 11, 1997 - Mars Global Surveyor: AerobrakingSeptember 11, 1997 See Explanation. Clicking on the picture will download the highest resolution version available. Mars Global Surveyor: Aerobraking … apod.nasa.gov/apod/ap970911.html - 5k
… and only 630 other pages that are irrelevant to the September 11th Attack
Ethiopian calendar - Wikipedia, the free encyclopediaThus the first day of the Ethiopian year, 1 Mäskäräm, for years between 1901 and 2099 (inclusive), is usually September 11 (Gregorian), ...en.wikipedia.org/wiki/Ethiopian_calendar - 43k
APOD: September 11, 1997 - Mars Global Surveyor: AerobrakingSeptember 11, 1997 See Explanation. Clicking on the picture will download the highest resolution version available. Mars Global Surveyor: Aerobraking … apod.nasa.gov/apod/ap970911.html - 5k
… and only 630 other pages that are irrelevant to the September 11th Attack
4 Million+ pages4 Million+ pages
600+ pages600+ pages

Issue #2: Time-independent Ranking
• Regardless of the search time span, the current ranking schemes always consider the ENTIRE history.
• Meaning and popularity of a term changes over time, and a ranking scheme should be dependent not only on the search terms but also the search time span.
NDIIPP Partners Meeting
timesearch time span
8June 24, 2009

Issue #3: Ineffective Search Result Delivery
• Search results are usually delivered as a list of URLs, sorted by the relevance ranks.
• No other grouping / sorting options available.
NDIIPP Partners Meeting 9June 24, 2009

• Ranking that depends on the time span specified by the user.
• Flexible and intuitive presentations of the returned results, ordered according to user’s specification.
• First Step toward Scalable and efficient ‘full text + temporal’ search.
Core Technologies Developed
NDIIPP Partners Meeting 10June 24, 2009

Scalable & Efficient Temporal Searches
NDIIPP Partners Meeting
time
time-window
Inverted Index 1
a
…
z
Inverted Index 2
a
…
z
Inverted Index 3
a
…
z
Inverted Index 4
a
…
z
Inverted Index 5
a
…
z
t1 t2 t3t4
search time span
For a given search time span, only these two indices are involved.
11June 24, 2009
Inverted index
a
…
z

Index Distribution and Parallel Search
NDIIPP Partners Meeting
Search ServerSearch Server
Inverted Index 1-4
a
…
z
Search ServerSearch Server
Inverted Index 5-8
a
…
z
Search ServerSearch Server
Inverted Index 9-12
a
…
z
Search ServerSearch Server
Inverted Index 13-16
a
…
z
Search ClusterSearch Cluster
ADAPT Web Archive Search Web Server
Request Broker
Result Aggregator
Web Interface
Web Interface
12June 24, 2009

Time-dependent Ranking
NDIIPP Partners Meeting
time
time-window
Inverted Index 1
a
…
z
Inverted Index 2
a
…
z
Inverted Index 3
a
…
z
Inverted Index 4
a
…
z
Inverted Index 5
a
…
z
t1 t2t3 t4
search time span
For a given search time span and terms, rankings depend on term popularity during this time span only (rather than the entire time span)
13June 24, 2009

Search Result Delivery
NDIIPP Partners Meeting
Grouped by TimeGrouped by Time Grouped by
URLGrouped by URL
Sorted by RelevanceSorted by Relevance
Sorted by TimeSorted by Time
14June 24, 2009

• Collaboration with the Library of Congress and the Internet Archive.
• US 108th Congress Web Archive:– 16 monthly crawls between December 2003
and March 2005.– Web sites of Representatives, Senators,
Delegates, and Committees of the 108th US Congress (2003-2004).
– Number of sites: 582– Number of records: 27 Millions– Total size around 2TB
• Archived in the Library of Congress
Collection Used
NDIIPP Partners Meeting 15June 24, 2009

P
ADAPT Web Archive Server
INTERNETINTERNET
UMIACSUMIACS
Search/ReturnRanked URLs Retrieve Web
Documents
Search ClusterSearch Cluster Storage ClusterStorage ClusterProcessing/Indexing
Cluster (Hadoop)Processing/Indexing
Cluster (Hadoop)
WARCs
WARCsWARCs
Library of Congress
Internet Archive
Inverted Indices
StorageContainers

Demo
NDIIPP Partners Meeting 17June 24, 2009
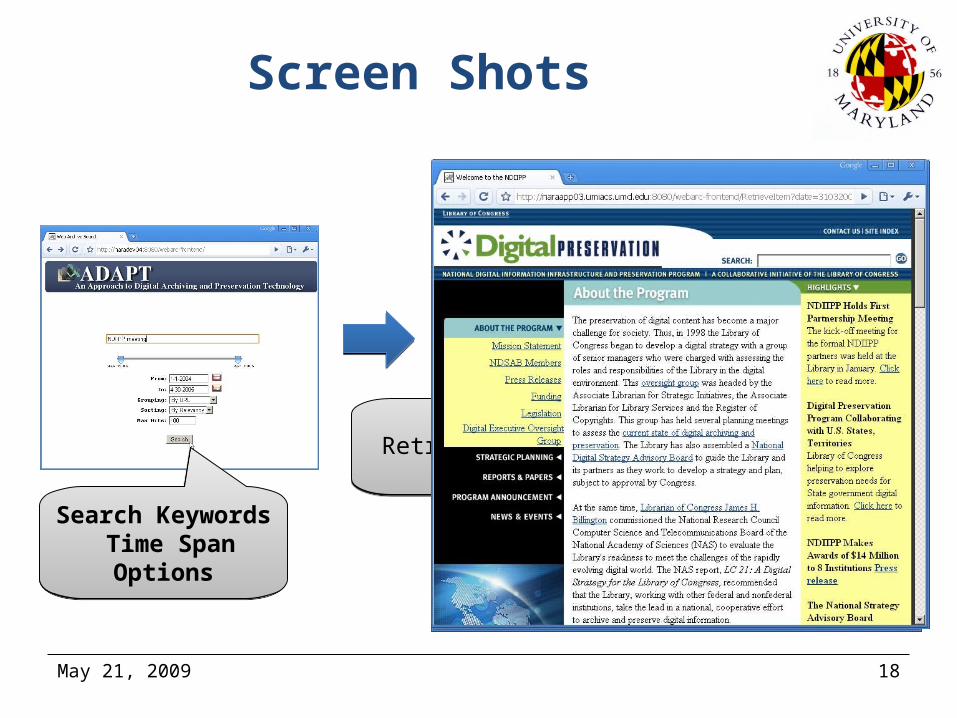
Screen Shots
May 21, 2009 18
Group by TimeGroup by Time
Search Keywords Time Span
Options
Search Keywords Time Span
Options
Collapse ResultsCollapse Results
Sort by TimeSort by TimeUngroupUngroupSort by RelevanceSort by Relevance
Retrieve PageRetrieve PageFollow LinkFollow Link





























