Embed Size (px)
Citation preview

D. Koop, CIS 602-02, Fall 2015
Scalable Data Analysis (CIS 602-02)
Databases
Dr. David Koop
144 Introduction
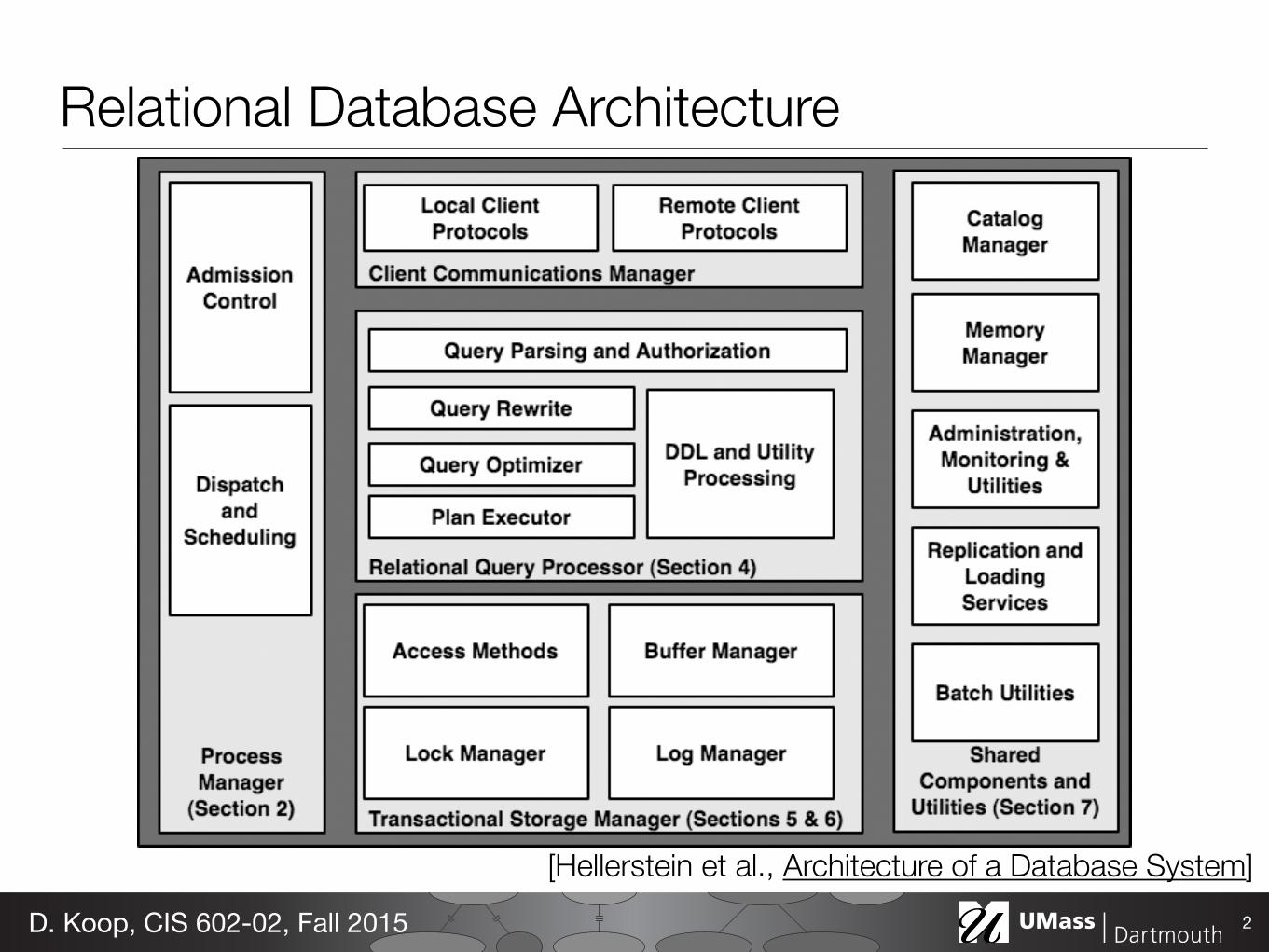
Fig. 1.1 Main components of a DBMS.
a well-understood point of reference for new extensions and revolutionsin database systems that may arise in the future. As a result, we focuson relational database systems throughout this paper.
At heart, a typical RDBMS has five main components, as illustratedin Figure 1.1. As an introduction to each of these components and theway they fit together, we step through the life of a query in a databasesystem. This also serves as an overview of the remaining sections of thepaper.
Consider a simple but typical database interaction at an airport, inwhich a gate agent clicks on a form to request the passenger list for aflight. This button click results in a single-query transaction that worksroughly as follows:
1. The personal computer at the airport gate (the “client”) callsan API that in turn communicates over a network to estab-lish a connection with the Client Communications Managerof a DBMS (top of Figure 1.1). In some cases, this connection
Relational Database Architecture
2D. Koop, CIS 602-02, Fall 2015
[Hellerstein et al., Architecture of a Database System]

Relational Databases: One size fits all?• Lots of work goes into relational database development:
- B-trees - Cost-based query optimizers - ACID (Atomicity, Consistency, Isolation, Durability) makes sure that
transactions are processed reliably • Vendors have stuck with this model since the 1980s • Having different systems leads to business problems:
- cost problem - compatibility problem - sales problem - marketing problem
3D. Koop, CIS 602-02, Fall 2015
[Stonebraker and Çetinetmel, 2005]

ACID Transactions• Atomicity: leave the database as is if some part of the transaction
fails (e.g. don't add/remove only part of the data) using rollbacks • Consistency: database moves from one valid state to another • Isolation: concurrent execution matches serial execution • Durability: endure hardware failures, make sure changes hit disk
4D. Koop, CIS 602-02, Fall 2015
www.percona.com
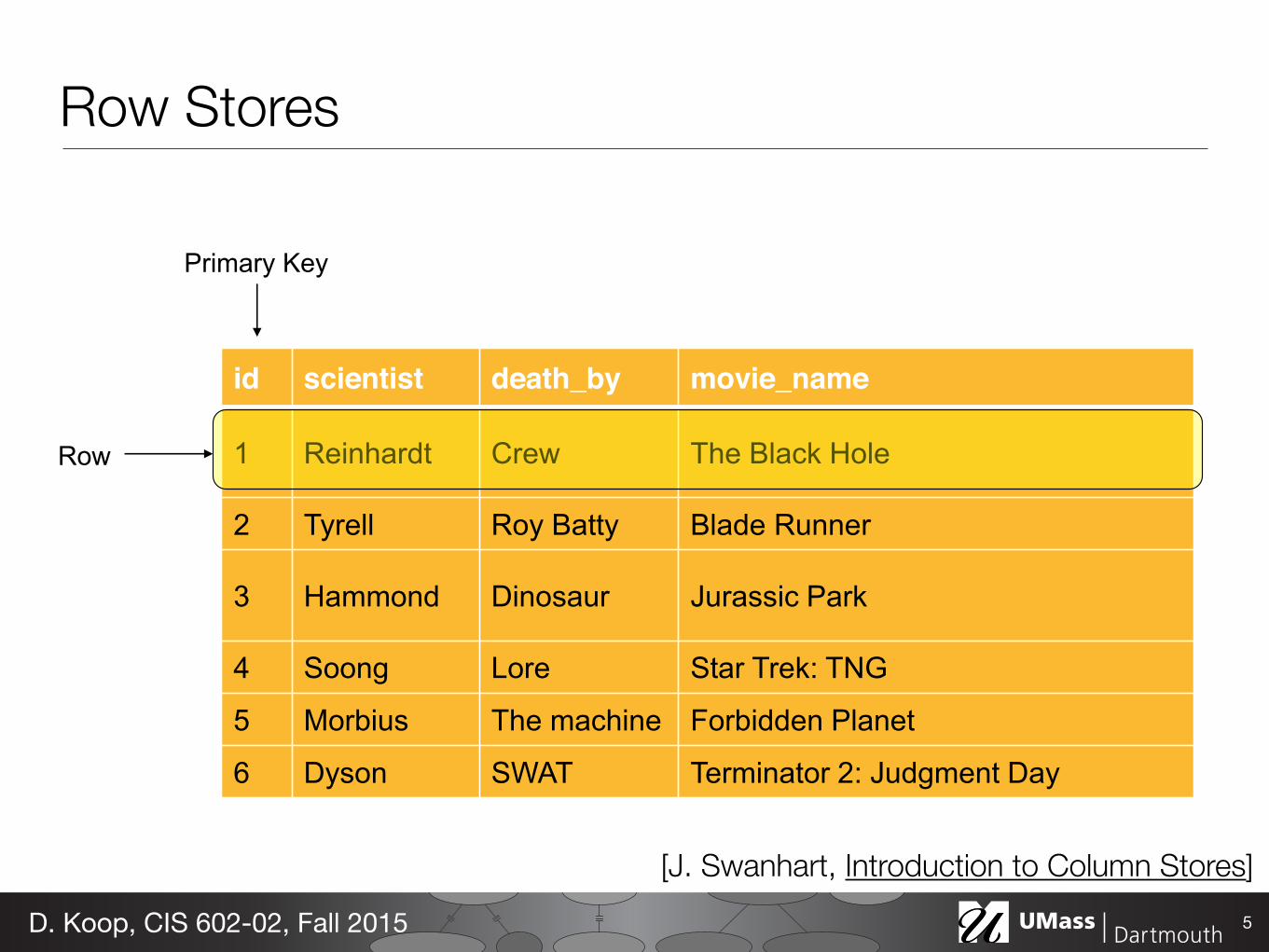
Typical Table
id scientist death_by movie_name
1 Reinhardt Crew The Black Hole
2 Tyrell Roy Batty Blade Runner
3 Hammond Dinosaur Jurassic Park
4 Soong Lore Star Trek: TNG
5 Morbius The machine Forbidden Planet
6 Dyson SWAT Terminator 2: Judgment Day
Primary Key
Row
Row Stores
5D. Koop, CIS 602-02, Fall 2015
[J. Swanhart, Introduction to Column Stores]

OLTP vs. OLAP• Online Transactional Processing (OLTP) often used in business
applications, data entry and retrieval transactions • OLTP Examples:
- Add customer's shopping cart to the database of orders - Find me all information about John Hammond's death
• OLTP is focused on the day-to-day operations while Online Analytical Processing (OLAP) is focused on analyzing that data for trends, etc.
• OLAP Examples: - Find the average amount spent by each customer - Find which year had the most movies with scientists dying
6D. Koop, CIS 602-02, Fall 2015

www.percona.com
Row stores can waste IO
6 15 on_hold 247 122 9 72 76 5 66
select sum(metric) as the_sum from fact
247
1. Storage engine gets a whole row from the table
2. SQL interface extracts only requested portion, adds it to “the_sum”
3. IF all rows scanned, send results to client, else GOTO 1
Inefficiency in Row Stores for OLAP
7D. Koop, CIS 602-02, Fall 2015
[J. Swanhart, Introduction to Column Stores]

www.percona.com
Simple column store on disk
Genre
ComedyHorrorHorrorDramaComedyDrama
id
123456
Title
Mrs. DoubtfireJawsThe FlySteel MagnoliasThe BirdcageErin Brokovitch
Person
Robin WilliamsRoy ScheiderJeff GoldblumDolly PartonNathan LaneJulia Roberts
row id = 1
row id = 6
Each column has a file or segment on disk
Column Stores
8D. Koop, CIS 602-02, Fall 2015
[J. Swanhart, Introduction to Column Stores]

Assignment 2• http://www.cis.umassd.edu/~dkoop/cis602/assignment2.html • Bikes and Weather • Bike sharing data and weather for Washington DC • Hypothesis might be that people are more likely to use the program
when the weather is "nicer" • Integrate data, visualize it, do regression • Use pandas, matplotlib, and scikit-learn libraries • Can generate a solution with relatively little code (~50 lines) but will
require experimentation to get there • Due Tuesday, October 20
9D. Koop, CIS 602-02, Fall 2015

Project Proposal• Due: Tuesday, October 27 • Types of projects
- Dataset Analysis - Technique Improvement
• Format (Shared): - Title - Name - Student ID
10D. Koop, CIS 602-02, Fall 2015

Project Proposal: Dataset Analysis• Description of dataset(s). Include the URL(s). If a dataset is not
available online, please describe how you have access to it. • Existing work. List papers or Web articles with existing analyses of
the dataset(s) or similar datasets. (at least 3) • Questions. List questions you would like to answer about the data.
(at least 3) Be specific. You are not obligated to answer every question you list here for the project.
• Techniques. List the techniques you plan to use to answer the questions. Be specific. "Visualize the data" is not specific. "Create a choropleth map showing each county colored by incidence of disease" is specific.
• Evaluation. How do you plan to check the validity of the answers to your questions?
11D. Koop, CIS 602-02, Fall 2015

Project Proposal: Technique Improvement• Description of the problem. Describe the problem at a high-level
first, then add any relevant details. • Existing work. List papers that address the problem or related
problems. (at least 3) • Ideas. What do you plan to investigate to solve the problem? • Evaluation. How do you plan to compare your work to the existing
solutions to show improvement? What tests do you plan to run?
12D. Koop, CIS 602-02, Fall 2015

Midterm• Main ideas of papers plus material covered during class • Topics:
- Python - Scientific Writing - Data Sources - Data Integration - Visualization - Statistics - Machine Learning - Clustering - Databases - Data Cubes
13D. Koop, CIS 602-02, Fall 2015

Midterm• Multiple Choice and/or Short Response • Types of questions:
- Difference between Frequentist and Bayesian analysis - Two cultures of statistical modeling - OLTP vs. OLAP - Types of operations on Data Cubes - Descriptive vs. Inferential Statistics - Mediated Integration vs. Data Warehouses - What are the advantages of dataspaces and pay-as-you-go
integration? - Types of data sources - Structure of data (item, attribute, dataset types, data types)
14D. Koop, CIS 602-02, Fall 2015

Midterm- What is the goal of a scientific research paper? - Why is Python used for data analysis? - What questions should you answer when critically reading a
research paper? - Why do scientific papers usually not cite blog posts? - Describe differences between "big data" or "small data" problems. - What makes data valuable? - Why is data cleaning important? Give an example of cleaning
data. - What is a mixed-initiative interface? Give examples of systems
that have such interfaces. Why are they useful? - Why do we use data visualization when trying to understand
datasets?15D. Koop, CIS 602-02, Fall 2015

Midterm- How does Voyager help users understand their data? - Why does having a lot of data help smooth over the Frequentist
vs. Bayesian debate? - What are the two major categories of clustering algorithms?
Which type is the BFR algorithm? How does BFR minimize execution time?
- Why have RDBMSs had few major architectural changes? Why have scientists started to question their utility in the past ten years?
- What is a polystore? How does this relate to federated databases?
16D. Koop, CIS 602-02, Fall 2015
face of slow disk writes, it is much less important in a mem-ory resident system. A single-threaded implementation may besufficient in some cases, particularly if it provides good per-formance. Though a way to take advantage of multiple proces-sor cores on the same hardware is needed, recent advances invirtual machine technology provide a way to make these coreslook like distinct processing nodes without imposing massiveperformance overheads [BDR97], which may make suchdesigns feasible.
• Transaction-less databases. Transactional support is notneeded in many systems. In particular, in distributed Internetapplications, eventual consistency is often favored over trans-actional consistency [Bre00, DHJ+07]. In other cases, light-weight forms of transactions, for example, where all reads arerequired to be done before any writes, may be acceptable[AMS+07, SMA+07].
In fact, there have been several proposals from inside the data-base community to build database systems with some or all of theabove characteristics [WSA97, SMA+07]. An open question,however, is how well these different configurations would per-form if they were actually built. This is the central question ofthis paper.
1.2 Measuring the Overheads of OLTPTo understand this question, we took a modern open source data-base system (Shore — see http://www.cs.wisc.edu/shore/) andbenchmarked it on a subset of the TPC-C benchmark. Our initialimplementation — running on a modern desktop machine — ranabout 640 transactions per second (TPS). We then modified it byremoving different features from the engine one at a time, pro-ducing new benchmarks each step of the way, until we were leftwith a tiny kernel of query processing code that could process12700 TPS. This kernel is a single-threaded, lock-free, mainmemory database system without recovery. During this decompo-sition, we identified four major components whose removal sub-stantially improved the throughput of the system:
Logging. Assembling log records and tracking down all changesin database structures slows performance. Logging may not benecessary if recoverability is not a requirement or if recoverabil-ity is provided through other means (e.g., other sites on the net-work).
Locking. Traditional two-phase locking poses a sizeable over-head since all accesses to database structures are governed by aseparate entity, the Lock Manager.
Latching. In a multi-threaded database, many data structureshave to be latched before they can be accessed. Removing thisfeature and going to a single-threaded approach has a noticeableperformance impact.
Buffer management. A main memory database system does notneed to access pages through a buffer pool, eliminating a level ofindirection on every record access.
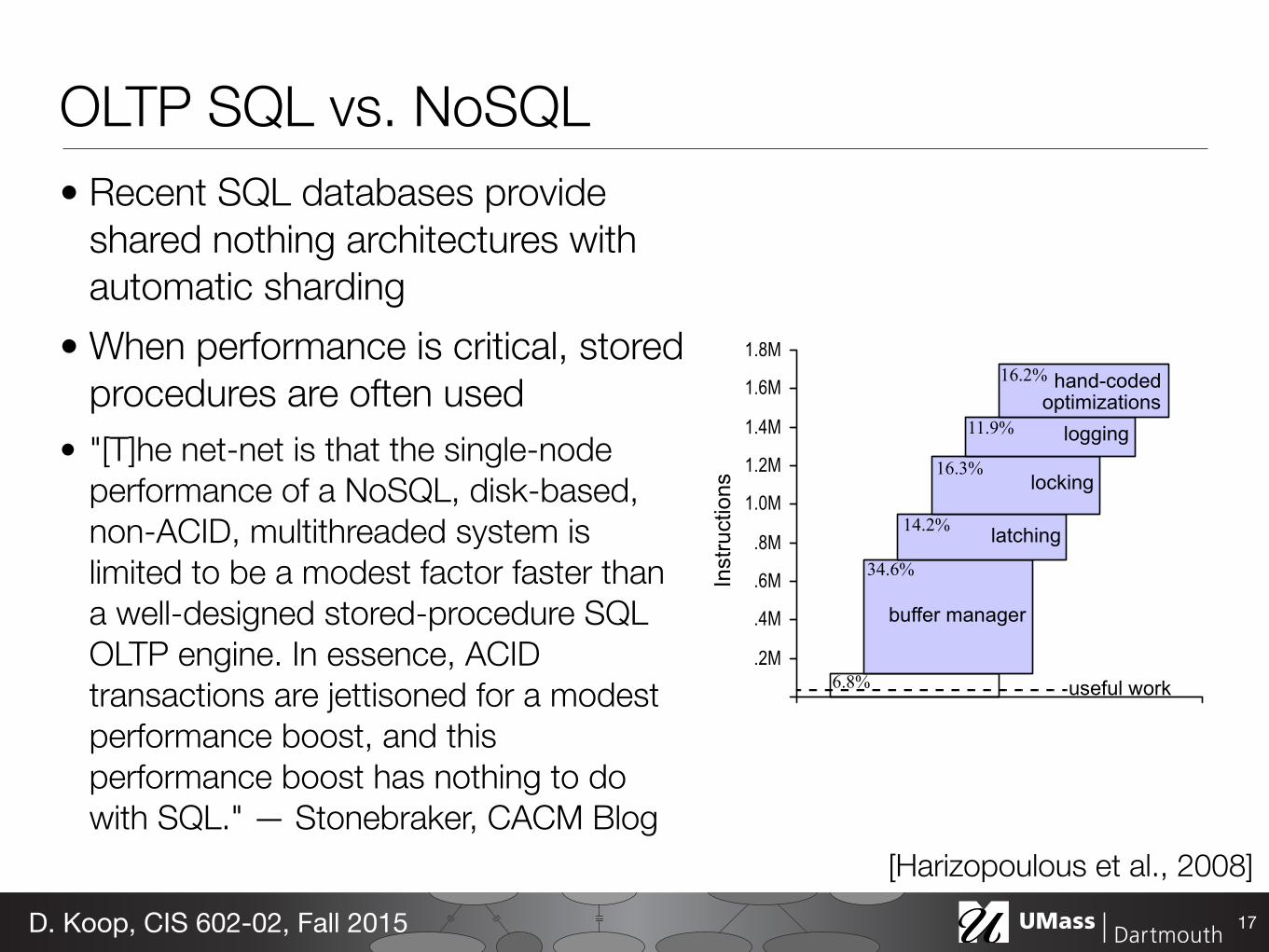
1.3 ResultsFigure 1 shows how each of these modifications affected the bot-tom line performance (in terms of CPU instructions per TPC-CNew Order transaction) of Shore. We can see that each of these
subsystems by itself accounts for between about 10% and 35% ofthe total runtime (1.73 million instructions, represented by thetotal height of the figure). Here, “hand coded optimizations” rep-resents a collection of optimizations we made to the code, whichprimarily improved the performance of the B-tree package. Theactual instructions to process the query, labelled “useful work”(measured through a minimal implementation we built on top of ahand-coded main-memory B-tree package) is only about 1/60th ofthat. The white box below “buffer manager” represents our ver-sion of Shore after we had removed everything from it — Shorestill runs the transactions, but it uses about 1/15th of the instruc-tions of the original system, or about 4 times the number ofinstructions in the useful work. The additional overheads in ourimplementation are due to call-stack depth in Shore and the factthat we could not completely strip out all references to transac-tions and the buffer manager.
1.4 Contributions and Paper OrganizationThe major contributions of this paper are to 1) dissect where timegoes inside of a modern database system, 2) to carefully measurethe performance of various stripped down variants of a moderndatabase system, and 3) to use these measurements to speculateon the performance of different data management systems — forexample, systems without transactions or logs — that one couldbuild.
The remainder of this paper is organized as follows. In Section 2we discuss OLTP features that may soon become (or are alreadybecoming) obsolete. In Section 3 we review the Shore DBMS, asit was the starting point of our exploration, and describe thedecomposition we performed. Section 4 contains our experimen-tation with Shore. Then, in Section 5, we use our measurementsto discuss implications on future OLTP engines and speculate onthe performance of some hypothetical data management systems.We present additional related work in Section 6 and conclude inSection 7.
.0M
.2M
.4M
.6M
.8M
1.0M
1.2M
1.4M
1.6M
1.8M
Figure 1. Breakdown of instruction count for various DBMS components for the New Order transaction from TPC-C. The top of the bar-graph is the original Shore performance with a
main memory resident database and no thread contention. The bottom dashed line is the useful work, measured by exe-
cuting the transaction on a no-overhead kernel.
buffer manager
latching
locking
logging
hand-codedoptimizations
useful work
Inst
ruct
ions
6.8%
34.6%
14.2%
16.3%
11.9%
16.2%
OLTP SQL vs. NoSQL• Recent SQL databases provide
shared nothing architectures with automatic sharding
• When performance is critical, stored procedures are often used
• "[T]he net-net is that the single-node performance of a NoSQL, disk-based, non-ACID, multithreaded system is limited to be a modest factor faster than a well-designed stored-procedure SQL OLTP engine. In essence, ACID transactions are jettisoned for a modest performance boost, and this performance boost has nothing to do with SQL." — Stonebraker, CACM Blog
17D. Koop, CIS 602-02, Fall 2015
[Harizopoulous et al., 2008]

Stonebraker: The End of an Architectural Era• "RDBMSs were designed for the business data processing market,
which is their sweet spot" • "They can be beaten handily in most any other market of significant
enough size to warrant the investment in a specialized engine" • Changes in markets (science), necessary features (scalability), and
technology (amount of memory) • RDBMS Overhead: Logging, Latching, and Locking • Relational model is not necessarily the answer • SQL is not necessarily the answer (more on this today)
18D. Koop, CIS 602-02, Fall 2015

One size fits all?• Specialized systems for specific types of data:
- Text data (e.g. search engines) - Data warehouses - Stream processing (e.g. sensors) - Scientific databases (e.g. arrays)
• Hardware changes: - Much more main memory (systems with 1TB) - Bandwidth between disk and memory has not increased as much
19D. Koop, CIS 602-02, Fall 2015

Polystore Systems• Federated databases:
- Middleware that presents a uniform interface to different databases
- Remember the mediator architecture for data integration? - Existing long ago but not used much in practice. Why?
• Changes in needs today: - Increase in disparate data (e.g. hospital patient data) - Performance concerns for different data types
20D. Koop, CIS 602-02, Fall 2015
[Duggan et al., 2015]
BigDAWGClients Streams AppsVisualizations
Array Island Relational Island Island X
Array DBMS RDBMS X RDBMS Y Streaming
Shim
CAST CAST CAST
Shim Shim Shim Shim Shim
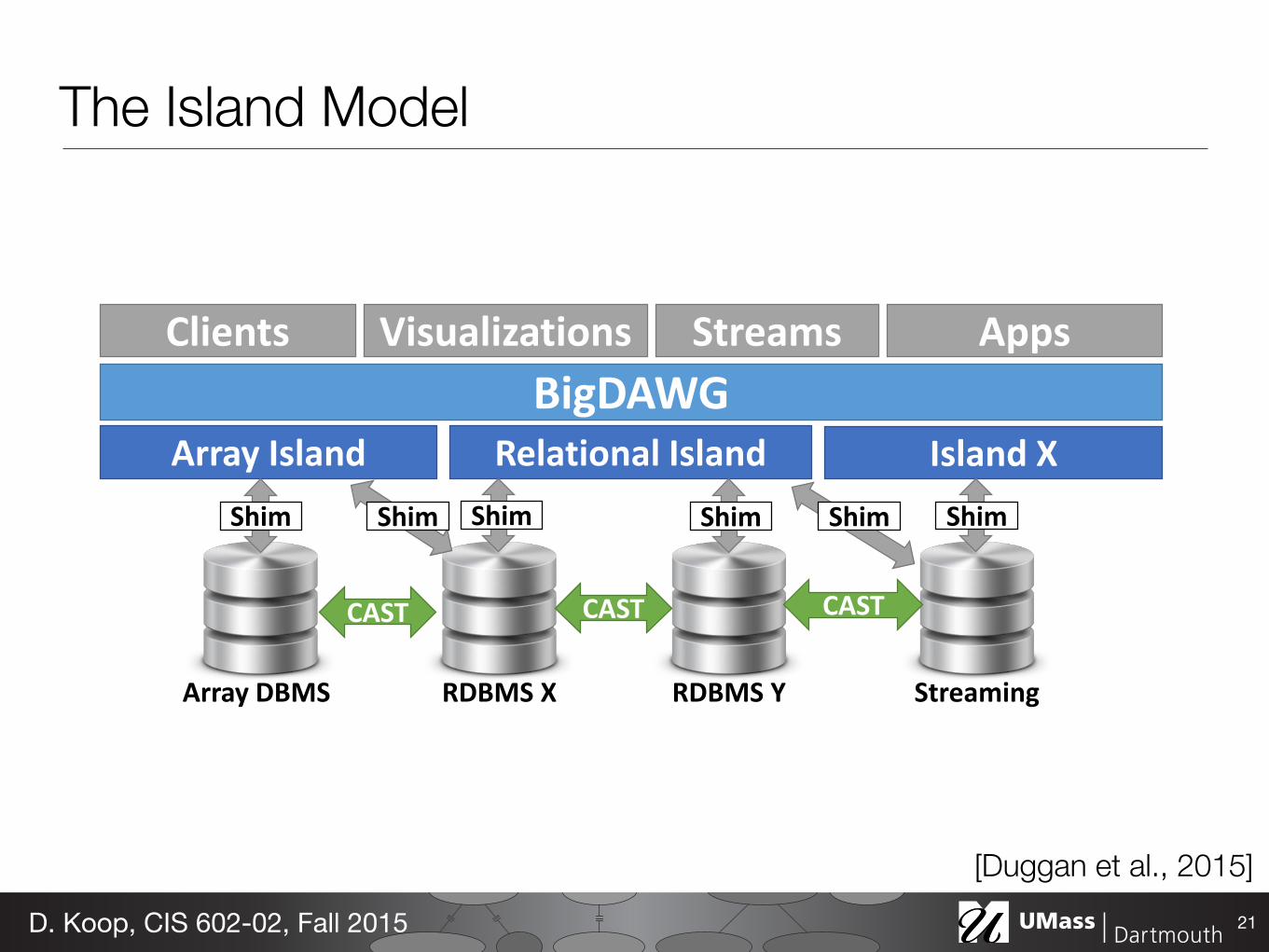
Figure 1: Polystore Architecture
his query in a SCOPE specification. A cross-island querywill have multiple scopes to indicate the expected behaviorof its subqueries. Likewise, a user may insert a CAST op-eration to denote when an object should be accessed witha given set of semantics.
For example, consider a cross-island operation, such asa join between an object in an array island and one in a ta-ble island. Obviously, we can CAST the array to the tableisland and do a relational join or we can do the converseand perform an array join. Since the each of these optionsproduces a different output, a user must specify the seman-tics he desires using SCOPE and CAST commands. If heelects relational semantics, his query might be:
RELATIONAL(SELECT *FROM R, CAST(A, relation)WHERE R.v = A.v);
Here, the user specifies that the query will execute in a re-lational scope. From the user’s perspective, the query willproduce output as if A were translated into a table, shippedto a relational engine, and executed there. Because A isan array, the CAST converts it into a table when it is ini-tially accessed. The user does not care whether the queryis executed in the array store or relational one provided hisprescribed island semantics are obeyed. Many queries mayhave implicit CASTS, and the polystore will insert theseoperations automatically as needed.
The full BigDAWG architecture is shown in Figure 1.This diagram shows multiple applications using a BigDAWGinstance with three islands. Each island speaks to one ormore engines through the use of shims. Objects can beCAST between engines, and only a subset of casts are shownfor clarity. Here, a user issues a query to BigDAWG, andhe specifies his commands using one or more island lan-guages. Within an island, the polystore calls the shimsneeded to translate the query into the language(s) of theparticipating storage engines. When the query uses multi-ple islands, data may be shuffled among them using CASToperations.
As a result, the BigDAWG query language consists ofthe above SCOPE-CAST facility for a collection of islandsover an overlapping set of storage engines. For simplicity,we leave the control of redundant copies of data objectsfor future work. In the rest of this paper we discuss ourapproach to query optimization and data placement.
3. QUERY OPTIMIZATIONIn this section, we first introduce our approach to op-
timizing single-island queries. After that, we outline amechanism for generating and managing the statistics neededfor query optimization and data placement within a poly-store. The section closes with a discussion of generalizingthe optimizer to multi-island query planning.
3.1 Single Island PlanningTraditional query optimization is simply not capable of
supporting cross-database queries. First, cost-based opti-mizers [19] require the planner to maintain a model foreach operation to estimate its resource needs. This essen-tially obligates the optimizer to understand all of the op-erations in all storage engines as well as how the variousshims work. Moreover, the primitives in each of the under-lying storage engines may not map neatly to the operatorsin the island language. For example, a distributed arraystore may implement matrix multiplication with a purpose-built set of scatter-gather operations whereas a relationalengine might categorize it as a group by aggregate. Rec-onciling these models would be non-trivial. Also, the opti-mizer would have to adapt whenever a new storage engineis added to the polystore. Lastly, conventional optimizersassume metadata about objects is available, such as theirdistribution of values. Local engines may or may not ex-pose such information. As a result, we propose a black boxapproach in this section, whereby no information about thelocal optimizer is assumed.
If our query optimizer cannot be made robust using thisapproach, then we will selectively add more sophisticatedknowledge of individual systems, recognizing that this maymake adding new storage engines to a polystore more chal-lenging. More detailed knowledge might include the sizesof operands, their data distribution, available access meth-ods, and explanations of query plans.
We first consider simple queries, ones which have com-parable performance on all of an island’s storage engines.We anticipate that many select-project-join queries will bein this category and we will examine in how to identifysuch queries in Section 3.2.Simple Queries For such queries we propose to minimizedata movement among storage engines, so as to avoid costlydata conversions and unnecessary network traffic. Rather,we should bring computation to the data whenever possi-ble. Hence, we divide any simple query optimization intostages. In Stage 1 we perform all possible local computa-tions that do not require any data movement. At the endof Stage 1, we are left with computations on collections ofobjects, where each one is located on a different storageengine. Since we have done all single-DBMS subqueries,we expect the number of remaining objects to be modest.In the next section we describe how to process this “re-mainder”.Complex Queries Now consider expensive operations, partsof the workload that have at least an order of magnitude
The Island Model
21D. Koop, CIS 602-02, Fall 2015
[Duggan et al., 2015]

The Island Model• When you're talking to a specific island, you should be able to
speak the native language - Data model - Query language - Shims to translate to storage dialects
• Computation done near the data • Cross-Island queries: query specified as multiple subqueries, one
for each island's semantics • Potentially move data from one store to another if speedup is
significant • Example query (A is an array from an array database):
- RELATIONAL(SELECT * FROM CAST(A, relation) WHERE v > 5)
22D. Koop, CIS 602-02, Fall 2015

BigDawg Guiding Tenets• One size does not fit all • Real-time decision support is crucial (e.g. Internet of Things with
streaming data) • Database interfaces are becoming diverse • Complex analytics are a must-have
23D. Koop, CIS 602-02, Fall 2015
[Elmore et al., 2015]

BigDawg Demo• Data: "Multiparameter Intelligent Monitoring in Intensive Care II"
- 26,000 intensive-care admissions at Boston hospital - Bedside measurements, patient metadata, medical notes, labe
results, and prescriptions filled • Interfaces:
- Browsing: top-level with drill-down - Exploratory Analysis: unguided data mining - Complex Analytics: regression, PCA - Text Analysis: complex keyword searches - Real-Time Monitoring: display bedside measurements with alerts
24D. Koop, CIS 602-02, Fall 2015
[Elmore et al., 2015]

Can OLTP and OLAP Co-exist?• Row vs. Column Store • Hierarchical Data? • Potential to support both types of queries efficiently?
25D. Koop, CIS 602-02, Fall 2015

D. Koop, CIS 602-02, Fall 2015
F1: A Distributed SQL Database That Scales
J. Shute, R. Vingralek, B. Samwel, B. Handy, C. Whipkey, E. Rollins, M. Oancea, K. Littlefield, D. Menestrina, S. Ellner, J. Cieslewicz, I. Rae, T. Stancescu, and H. Apte
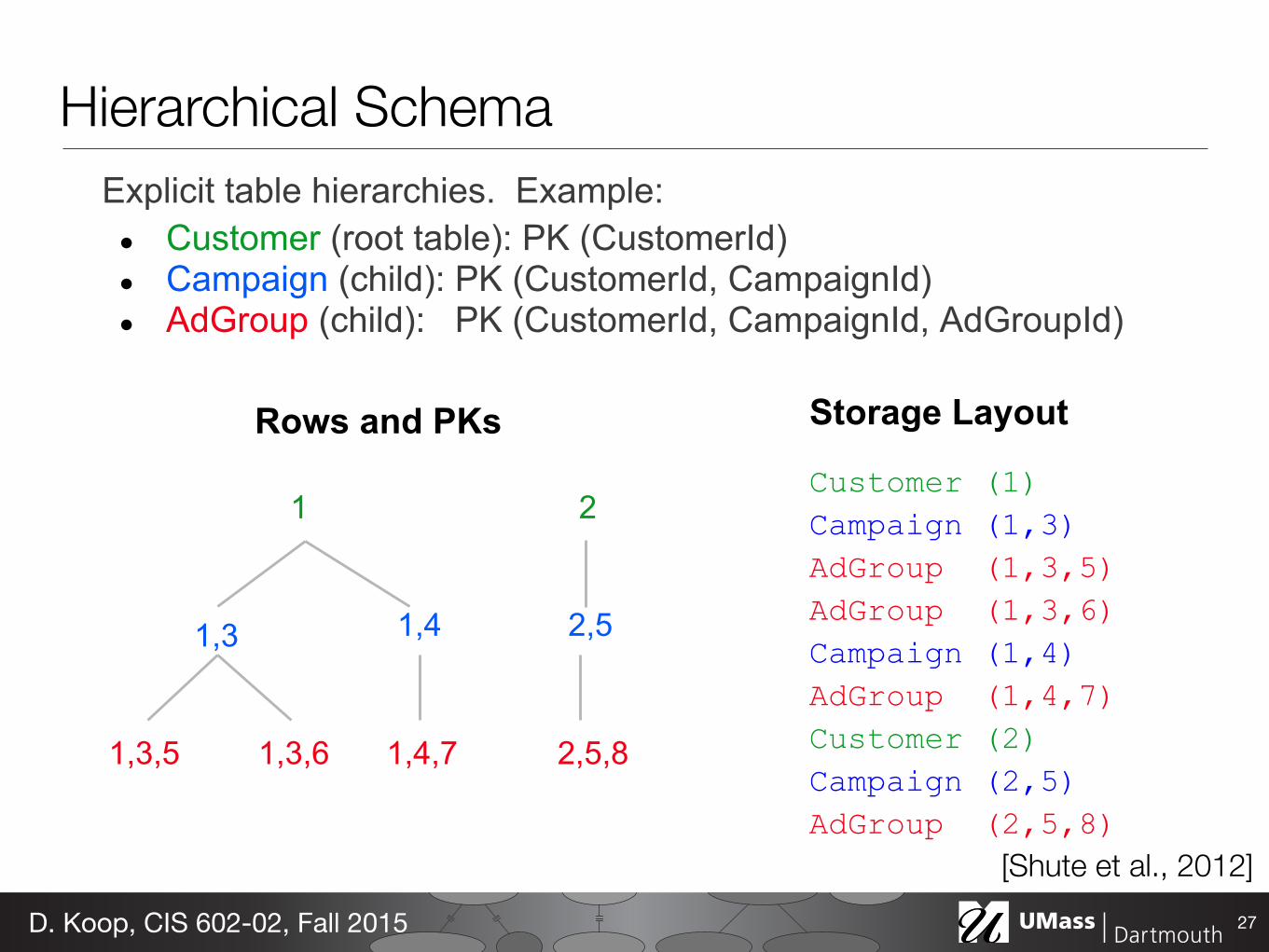
Hierarchical SchemaExplicit table hierarchies. Example:
● Customer (root table): PK (CustomerId)● Campaign (child): PK (CustomerId, CampaignId)● AdGroup (child): PK (CustomerId, CampaignId, AdGroupId)
Customer (1)Campaign (1,3)AdGroup (1,3,5)AdGroup (1,3,6)Campaign (1,4)AdGroup (1,4,7)Customer (2)Campaign (2,5)AdGroup (2,5,8)
1
1,3 1,4
1,4,71,3,61,3,5
2
2,5
2,5,8
Storage Layout
Rows and PKs
Hierarchical Schema
27D. Koop, CIS 602-02, Fall 2015
[Shute et al., 2012]

Clustered Storage
● Child rows under one root row form a cluster● Cluster stored on one machine (unless huge)● Transactions within one cluster are most efficient● Very efficient joins inside clusters (can merge with no sorting)
Customer (1)Campaign (1,3)AdGroup (1,3,5)AdGroup (1,3,6)Campaign (1,4)AdGroup (1,4,7)Customer (2)Campaign (2,5)AdGroup (2,5,8)
1
1,3 1,4
1,4,71,3,61,3,5
2
2,5
2,5,8
Storage Layout
Rows and PKs
Clustered Storage
28D. Koop, CIS 602-02, Fall 2015
[Shute et al., 2012]

F1 Notes• Schema changes: allow two different schemas • Transaction types: Snapshot, Pessimistic, Optimistic • Change History and application to caching • Disk latency or network latency?
29D. Koop, CIS 602-02, Fall 2015

Reminders• Next Class: Data Cubes • October 27: No class • October 29: Midterm Exam
30D. Koop, CIS 602-02, Fall 2015