Embed Size (px)
Citation preview

Ronny Krashinsky
Erik Machnicki
Software Cache Coherent
Shared Memory under Split-C

Motivation
Shared address space parallel programming is conceptually simpler than message passing NOWs are more cost effective than SMPs However, NOWs are a more natural fit for message passing Two approaches to supporting a shared address space with distributed shared memory:
1.Simulate the hardware solution, using coherent replication2.Translate all accesses to shared variables into explicit messages

Split-C uses the second method (no caching) This makes the Split-C implementation much simpler The programmer labels variables as local or global Global accesses become function calls to the Split-C
library Disadvantage:
The demand on the programmer is much greater
The programmer must provide efficient distribution and access
The programmer must manage "caching"

Our Solution
• Add automatic coherent caching to Split-C
• SWCC-Split-C:
Software Cache Coherent Split-C
• (Almost) No changes to the Split-C programming language
• The programmer gets a shared memory system with automatic replication on a NOW
• The programmers task is simpler, not as much emphasis on placement
• Good for irregular applications

Next:
•Design
•Results
•Conclusion

Design Overview
• Fine-grained coherence at the level of blocks of memory
• Simple MSI invalidate protocol
• Directory structure tracks the state of blocks as they move
through the system
• Each block is associated with a home node
• NACKs and retries are used to achieve coherence
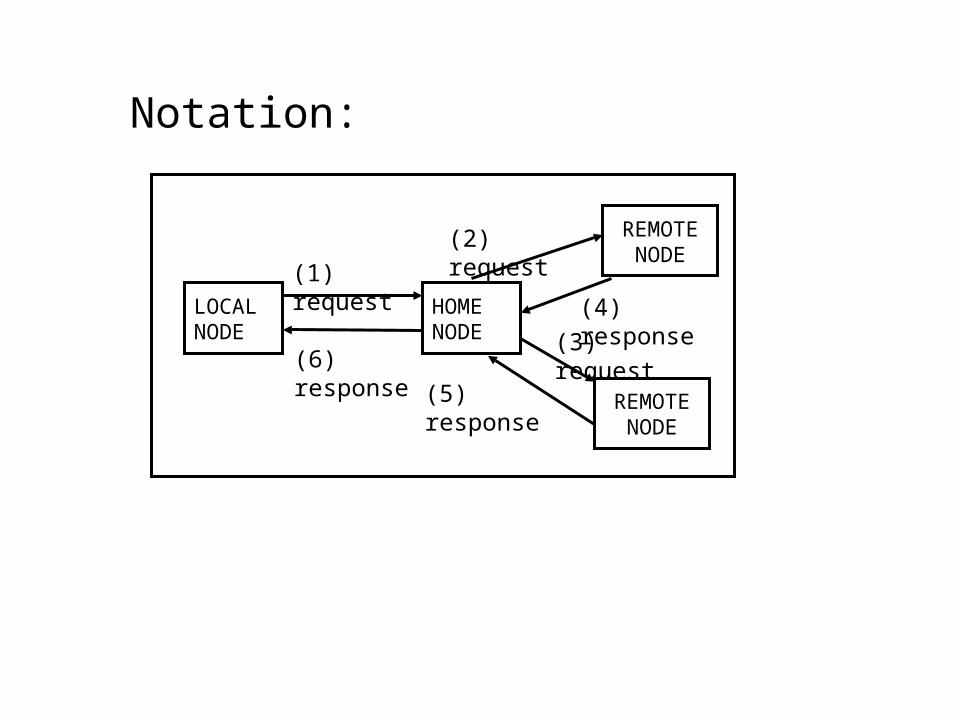
LOCAL NODE
HOME NODE
REMOTE NODE
REMOTE NODE
(1) request
(2) request
(3) request
(4) response
(5) response
(6) response
Notation:

Address Blocks:
• Split-C shared variable has Processor Number and Local Address (virtual memory address)
• SWCC: partition the entire address space into blocks
• Coherence is maintained at the level of blocks
• The upper bits of the Local Address part of a global variable determines its block address
• Addresses associated with directory structure and coherence protocols are block addresses

0x0000 0x0001 0x0002 … HASH_SIZE
012…
PROCS
DIR
ENTRY
DIR
ENTRY
DIR
ENTRY
BLOCK_ADDR (shifted &masked)
Proc Num
Directory Structure:• Hash table of pointers to linked lists of directory entries
• Lives in local memory (malloc’ed at beginning of program)

Directory Entry:•Block Addr
•State
•Data
•Linked list pointer
•user vector (maintained and used only by home node)
•Directory entry for every shared block which a program accesses
(not only at home node)
• At home node, the directory entry gets a copy of local memory

Directory Lookup (hit):• Calculate the directory hash table index • Load the address of the directory entry • Load the block addr field of the directory entry • Check that it matches the block addr of the global variable • Load the state of the directory entry • Check the state of the entry • Perform the memory access
Only user optimization:• Check that the node is the home node• Calculate the directory hash table index • Load the entry from the directory hash table • Check that the entry is NULL • Perform the memory access

Coherence Protocol:• 3 stable states: Modified, Shared, Invalid
• Also: Read-Busy, Write-Busy
• If data is available in appropriate state, no communication.
• Otherwise, Local node sends request to home node. Home node does necessary processing to reply with the data. May send invalidate or flush requests to remote nodes.
• Serialization at home node: NACKs and retries
• Messages via Active Messages
• Active Message deadlock rules?
• State transition diagrams (simplified) ...
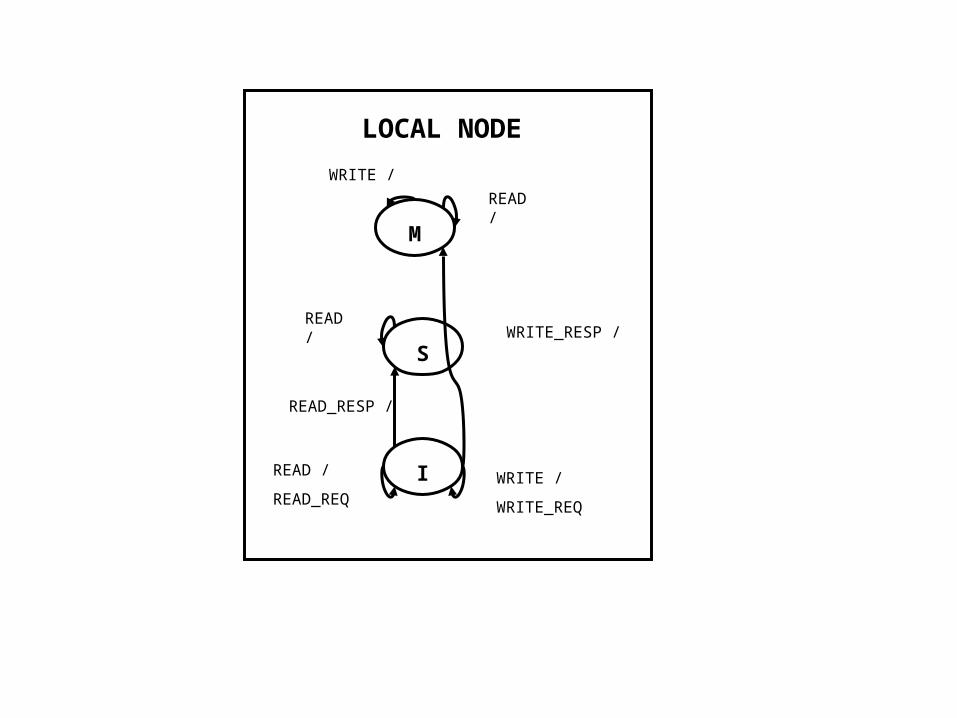
M
S
I
READ /
READ /
READ_REQ
LOCAL NODE
WRITE /
READ /
WRITE /
WRITE_REQ
READ_RESP /
WRITE_RESP /

M (self)
S
I
WRITE_REQ /
WRITE_RESP
HOME NODE
M (other)
WriteBusy
Read Busy
READ_REQ / FLUSH_REQ
FLUSH_RESP /
READ_RESP
READ OR
WRITE REQ /
NACK
READ_REQ /
READ_RESP
READ OR
WRITE REQ /
NACK WRITE_REQ /
N * INV_REQ
N * INV_RESP /
WRITE_RESP
FLUSH_X_RESP /
WRITE_RESPWRITE_REQ / FLUSH_X_REQ
READ_REQ /
READ_RESP
READ_REQ /
READ_RESP
WRITE_REQ /
WRITE_RESP

M
S
I
FLUSH_X_REQ /
FLUSH_X_RESP
FLUSH_REQ /
FLUSH_RESP
INV_REQ /
INV_RESP
REMOTE NODE

Other Design Points:• race conditions, write lock flag
• non-FIFO network, NACKs and Retries
• duplicate requests
• bulk transactions
• stores

Performance Results
• Micro-Benchmarks
• Matrix-Multiply
• EM3D

SC time (ns)
SWCC time (ns)
READ
PRIVATE ~10 ~10
SHARED
LOCAL 110(local state)
M (SELF) 470
M (OTHER) 95,000
S 350
I (not present) 160
REMOTE 31,000(local state)
M 260
S 300
I(home state)
M (SELF) 50,000
M (OTHER) 100,000
S 50,000
I (not present) 53,000
Read Micro-Benchmarks

SC time (ns)
SWCC time (ns)
WRITE
PRIVATE ~10 ~10
SHARED
LOCAL 110(local state)
M (SELF) 180
M (OTHER) 100,000
S (one reader) 88,000
I (not present) 180
REMOTE 31,000(local state)
M 370
S(other readers)
0 52,000
1 90,000
2 100,000
I(home state)
M (SELF) 54,000
M (OTHER) 105,000
S (one reader) 92,000
I (not present) 55,000
Write Micro-Benchmarks

Matrix Multiplication
•Naïve
•Blocked
•Optimized Blocked

Naïve MM, Scaling the Number of Processors
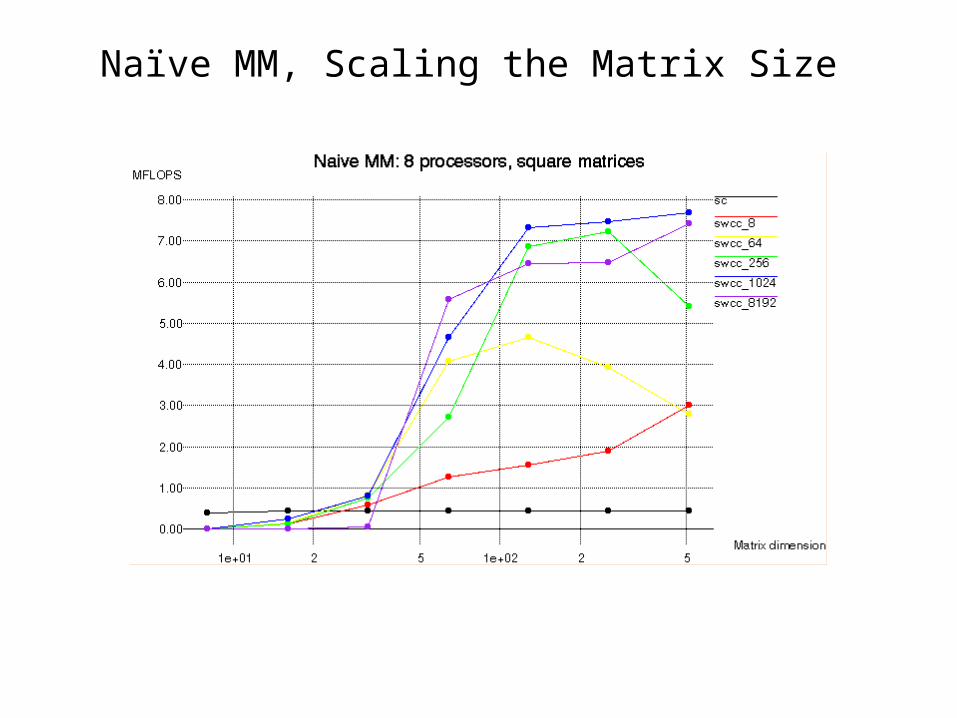
Naïve MM, Scaling the Matrix Size

MM: Fixed Size, Fixed Resources, Different Versions
Naive Basic Blocked Optimized Blocked
0 1 16 64 16 64 1284 Block Size
1
10
100
MFLOPS

EM3D:• H nodes and E nodes depend on each other
• Each iteration the values of H nodes are updated based on the values of the E nodes it depends on and vice-versa.
• parameters:
• number of nodes
• degree of nodes
• remote probability
• distance span
• number of iterations

EM3D: Scaling Remote Dependency Percentage

EM3D: Scaling Number of Processors

Conclusions•Automatic coherent caching can make the programmer's life easier
• Initial data placement is less important
• For some applications it is even more difficult to predict access patterns or do “caching” in the user program, e.g. Barnes Hut or Ray-Tracing
• Cache coherence is also useful in exploiting spatial locality
• Sometimes caching isn’t useful and just provides extra overhead. Potentially the user or compiler could decide to use caching on a per-variable basis.





























