Embed Size (px)
Citation preview

‘‘Ring’’ in the Solo Child Singing Voice
*DavidM. Howard, †JenevoraWilliams, and ‡,§Christian T. Herbst, *York, yGuildford, UK, and zOlomouc, Czech Republic, andxVienna, Austria
Summary: Objectives/Hypothesis. Listeners often describe the voices of solo child singers as being ‘‘pure’’ or
AccepFrom t
York, YoUniversitogy, BioaAddre
tronics, Adavid.howJourna0892-1� 201http://d
‘‘clear’’; these terms would suggest that the voice is not only pleasant but also clearly audible. The audibility or claritycould be attributed to the presence of high-frequency partials in the sound: a ‘‘brightness’’ or ‘‘ring.’’ This article aims toinvestigate spectrally the acoustic nature of this ring phenomenon in children’s solo voices, and in particular, relating itto their ‘‘nonring’’ production. Additionally, this is set in the context of establishing to what extent, if any, the spectralcharacteristics of ring are shared with those of the singer’s formant cluster associated with professional adult operasingers in the 2.5–3.5 kHz region.Methods. A group of child solo singers, acknowledged as outstanding by a singing teacher who specializes in teach-ing professional child singers, were recorded in a major UK concert hall performing Come unto him, all ye that labour,from the aria He shall feed his flock from The Messiah by GF Handel. Their singing was accompanied by a recording ofa piano played through in-ear headphones. Sound pressure recordings were made from well within the critical distancein the hall. The singers were observed to produce notes with and without ring, and these recordings were analyzed in thefrequency domain to investigate their spectra.Results. The results indicate that there is evidence to suggest that ring in child solo singers is carried in two areas of theoutput spectrum: first in the singer’s formant cluster region, centered around 4 kHz, which is more than 1000 Hz higherthan what is observed in adults; and second in the region around 7.5–11 kHz where a significant strengthening of har-monic presence is observed. A perceptual test has been carried out demonstrating that 94% of 62 listeners label a syn-thesized version of the calculated overall average ring spectrum for all subjects as having ring when compared witha synthesized version of the calculated overall average nonring spectrum.Conclusions. The notion of ring in the child solo voice manifests itself not only with spectral features in commonwiththe projection peak found in adult singers but also in a higher frequency region. It is suggested that the formant cluster ataround 4 kHz is the children’s equivalent of the singers’ formant cluster; the frequency is higher than in the adult, mostlikely due to the smaller dimensions of the epilaryngeal tube. The frequency cluster observed as a strong peak at about7.5–11 kHz, when added to the children’s singers’ formant cluster, may be the key to cueing the notion of ring in thechild solo voice.Key Words: Child voice–Singing–Soloist–Ring–Singer’s formant–Singer’s formant cluster.
INTRODUCTION
At the start of a Service of Lessons and Carols at Christmas,pioneered by the King’s College Cambridge, UK and broadcastworldwide, a lone boy chorister sings the first verse of ‘‘Once inroyal David’s city.’’1, p100 Listeners have described children’svoices as having ‘‘lightness and clarity’’ and ‘‘beauty oftone,’’2 a ‘‘clean white tone,’’3 and as being ‘‘clearer,’’ ‘‘purer,’’‘‘echoey,’’ and ‘‘non fuzzy.’’4 Day5 lists epithets that have beenused to characterize children’s singing including, ‘‘pure,’’‘‘sweet,’’ ‘‘other worldly,’’ ‘‘ethereal,’’ and ‘‘impersonal.’’ Ingeneral, listeners seem able to pick out child solo singers whoexhibit a ring-like sound easily and by mutual assent, and theterm ‘‘ring’’ is often used in common parlance to describe it.In the solo performance context, such a sound tends to projectwell in a large reverberant building. The concept of ring isnot restricted to solo child singers; it is also heard in the outputs
ted for publication September 4, 2013.he *Department of Electronics, York Centre for Singing Science, University ofrk, UK; ySinging teaching, Guildford, UK; zDepartment of Biophysics, Palackyy Olomouc, Olomouc, Czech Republic; and the xDepartment of Cognitive Biol-coustics Laboratory, University of Vienna, Vienna, Austria.ss correspondence and reprint requests to David M. Howard, Department of Elec-udio Laboratory, University of York, Heslington, York, YO10 5DD, UK. E-mail:[email protected]
l of Voice, Vol. 28, No. 2, pp. 161-169997/$36.004 The Voice Foundationx.doi.org/10.1016/j.jvoice.2013.09.001
from trained adult singers6, p47, 7, 8, p55 and Titze9, p41 describesa ‘‘ringing’’ voice quality as a ‘‘brilliant sound—has ping in it.’’
Because ‘‘ring’’ appears perceptually to have features incommon with the projection of the sung sound, it has beenacoustically linked10 to the singer’s formant7,9,11 or singer’sformant cluster12 that is associated with how a singer can beheard above an orchestra13 and ‘‘projecting or focusing thevoice.’’14, p71 Child singers are also able to project their singingvoices; a trained solo voice can be heard clearly in a large build-ing or over accompaniment such as an organ or orchestra. Thevocal quality linked with this projected sound is often referredto, in adult’s voices, as ‘‘ping’’ or ‘‘ring’’3,15 or, in the Bel Cantotradition, ‘‘squillo’’ or ‘‘twang.’’16
The adult listener has a response to the solo voice of the childsinger that is reflected in many cultures. The reason for thiscould be linked to the potential for perceived vulnerability inthe young singer, which in the performance is combined withan advanced level of artistry. Or it could be that there is anelement of the acoustic output of a child’s voice that is partic-ularly emotive for the adult listener? Emotional triggers in thesinging voice tend to be sounds that have similarities withprimal emotive vocal gestures such as crying, wailing, calling,giggling, or sighing.17–19 Scheiner et al20 reported a significantincrease in the overall frequency range of the vocal output frompositive (surprise, interest, contentment, joy) to negative (pain,unease, anger) emotional nonverbal vocalizations (cry, coo,
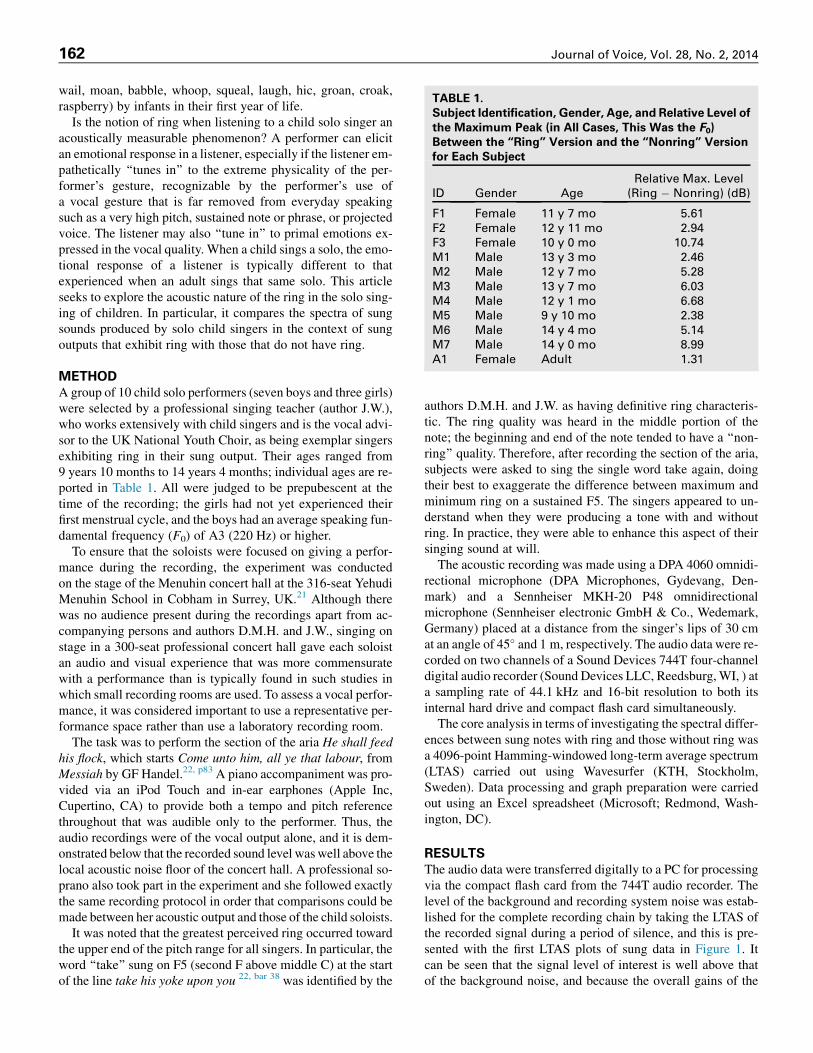
TABLE 1.
Subject Identification, Gender, Age, and Relative Level of
the Maximum Peak (in All Cases, This Was the F0)Between the ‘‘Ring’’ Version and the ‘‘Nonring’’ Version
for Each Subject
ID Gender AgeRelative Max. Level
(Ring � Nonring) (dB)
F1 Female 11 y 7 mo 5.61F2 Female 12 y 11 mo 2.94F3 Female 10 y 0 mo 10.74M1 Male 13 y 3 mo 2.46M2 Male 12 y 7 mo 5.28M3 Male 13 y 7 mo 6.03M4 Male 12 y 1 mo 6.68M5 Male 9 y 10 mo 2.38M6 Male 14 y 4 mo 5.14M7 Male 14 y 0 mo 8.99A1 Female Adult 1.31
Journal of Voice, Vol. 28, No. 2, 2014162
wail, moan, babble, whoop, squeal, laugh, hic, groan, croak,raspberry) by infants in their first year of life.
Is the notion of ring when listening to a child solo singer anacoustically measurable phenomenon? A performer can elicitan emotional response in a listener, especially if the listener em-pathetically ‘‘tunes in’’ to the extreme physicality of the per-former’s gesture, recognizable by the performer’s use ofa vocal gesture that is far removed from everyday speakingsuch as a very high pitch, sustained note or phrase, or projectedvoice. The listener may also ‘‘tune in’’ to primal emotions ex-pressed in the vocal quality. When a child sings a solo, the emo-tional response of a listener is typically different to thatexperienced when an adult sings that same solo. This articleseeks to explore the acoustic nature of the ring in the solo sing-ing of children. In particular, it compares the spectra of sungsounds produced by solo child singers in the context of sungoutputs that exhibit ring with those that do not have ring.
METHOD
A group of 10 child solo performers (seven boys and three girls)were selected by a professional singing teacher (author J.W.),who works extensively with child singers and is the vocal advi-sor to the UK National Youth Choir, as being exemplar singersexhibiting ring in their sung output. Their ages ranged from9 years 10 months to 14 years 4 months; individual ages are re-ported in Table 1. All were judged to be prepubescent at thetime of the recording; the girls had not yet experienced theirfirst menstrual cycle, and the boys had an average speaking fun-damental frequency (F0) of A3 (220 Hz) or higher.
To ensure that the soloists were focused on giving a perfor-mance during the recording, the experiment was conductedon the stage of the Menuhin concert hall at the 316-seat YehudiMenuhin School in Cobham in Surrey, UK.21 Although therewas no audience present during the recordings apart from ac-companying persons and authors D.M.H. and J.W., singing onstage in a 300-seat professional concert hall gave each soloistan audio and visual experience that was more commensuratewith a performance than is typically found in such studies inwhich small recording rooms are used. To assess a vocal perfor-mance, it was considered important to use a representative per-formance space rather than use a laboratory recording room.
The task was to perform the section of the aria He shall feedhis flock, which starts Come unto him, all ye that labour, fromMessiah by GF Handel.22, p83 A piano accompaniment was pro-vided via an iPod Touch and in-ear earphones (Apple Inc,Cupertino, CA) to provide both a tempo and pitch referencethroughout that was audible only to the performer. Thus, theaudio recordings were of the vocal output alone, and it is dem-onstrated below that the recorded sound level was well above thelocal acoustic noise floor of the concert hall. A professional so-prano also took part in the experiment and she followed exactlythe same recording protocol in order that comparisons could bemade between her acoustic output and those of the child soloists.
It was noted that the greatest perceived ring occurred towardthe upper end of the pitch range for all singers. In particular, theword ‘‘take’’ sung on F5 (second F above middle C) at the startof the line take his yoke upon you 22, bar 38 was identified by the
authors D.M.H. and J.W. as having definitive ring characteris-tic. The ring quality was heard in the middle portion of thenote; the beginning and end of the note tended to have a ‘‘non-ring’’ quality. Therefore, after recording the section of the aria,subjects were asked to sing the single word take again, doingtheir best to exaggerate the difference between maximum andminimum ring on a sustained F5. The singers appeared to un-derstand when they were producing a tone with and withoutring. In practice, they were able to enhance this aspect of theirsinging sound at will.The acoustic recording was made using a DPA 4060 omnidi-
rectional microphone (DPA Microphones, Gydevang, Den-mark) and a Sennheiser MKH-20 P48 omnidirectionalmicrophone (Sennheiser electronic GmbH & Co., Wedemark,Germany) placed at a distance from the singer’s lips of 30 cmat an angle of 45� and 1 m, respectively. The audio data were re-corded on two channels of a Sound Devices 744T four-channeldigital audio recorder (Sound Devices LLC, Reedsburg,WI, ) ata sampling rate of 44.1 kHz and 16-bit resolution to both itsinternal hard drive and compact flash card simultaneously.The core analysis in terms of investigating the spectral differ-
ences between sung notes with ring and those without ring wasa 4096-point Hamming-windowed long-term average spectrum(LTAS) carried out using Wavesurfer (KTH, Stockholm,Sweden). Data processing and graph preparation were carriedout using an Excel spreadsheet (Microsoft; Redmond, Wash-ington, DC).
RESULTS
The audio data were transferred digitally to a PC for processingvia the compact flash card from the 744T audio recorder. Thelevel of the background and recording system noise was estab-lished for the complete recording chain by taking the LTAS ofthe recorded signal during a period of silence, and this is pre-sented with the first LTAS plots of sung data in Figure 1. Itcan be seen that the signal level of interest is well above thatof the background noise, and because the overall gains of the
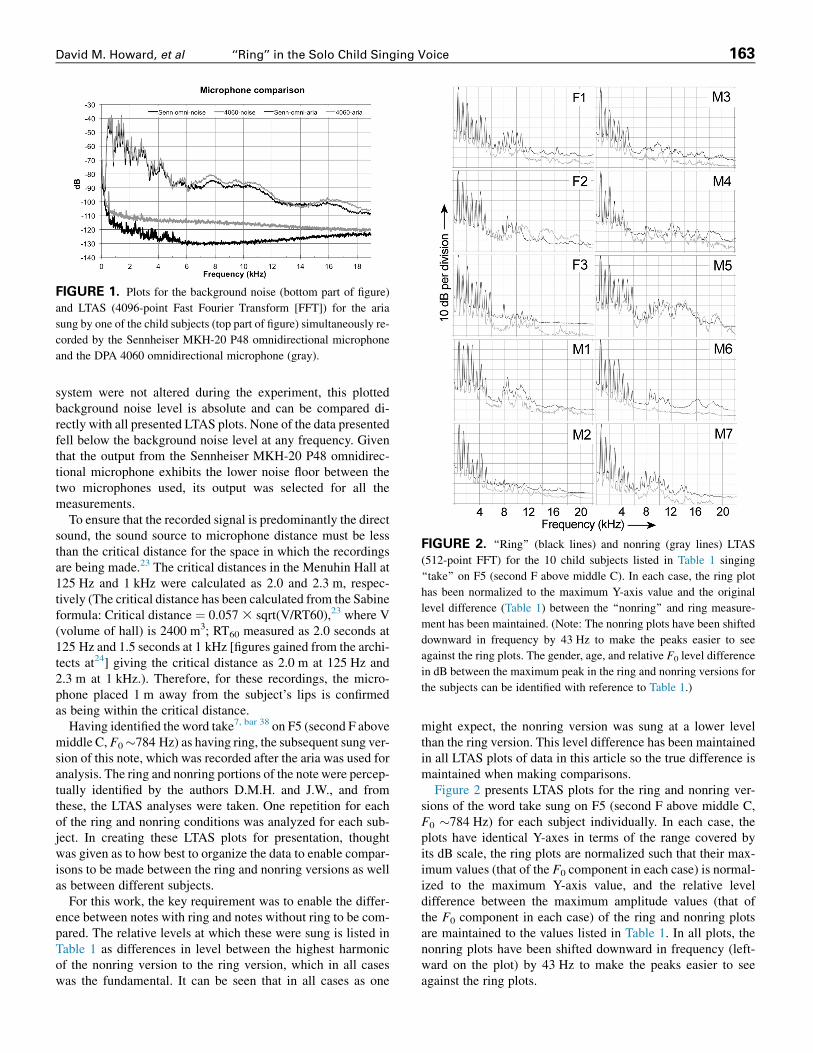
FIGURE 1. Plots for the background noise (bottom part of figure)
and LTAS (4096-point Fast Fourier Transform [FFT]) for the aria
sung by one of the child subjects (top part of figure) simultaneously re-
corded by the Sennheiser MKH-20 P48 omnidirectional microphone
and the DPA 4060 omnidirectional microphone (gray).
FIGURE 2. ‘‘Ring’’ (black lines) and nonring (gray lines) LTAS
(512-point FFT) for the 10 child subjects listed in Table 1 singing
‘‘take’’ on F5 (second F above middle C). In each case, the ring plot
has been normalized to the maximum Y-axis value and the original
level difference (Table 1) between the ‘‘nonring’’ and ring measure-
ment has been maintained. (Note: The nonring plots have been shifted
downward in frequency by 43 Hz to make the peaks easier to see
against the ring plots. The gender, age, and relative F0 level difference
in dB between the maximum peak in the ring and nonring versions for
the subjects can be identified with reference to Table 1.)
David M. Howard, et al ‘‘Ring’’ in the Solo Child Singing Voice 163
system were not altered during the experiment, this plottedbackground noise level is absolute and can be compared di-rectly with all presented LTAS plots. None of the data presentedfell below the background noise level at any frequency. Giventhat the output from the Sennheiser MKH-20 P48 omnidirec-tional microphone exhibits the lower noise floor between thetwo microphones used, its output was selected for all themeasurements.
To ensure that the recorded signal is predominantly the directsound, the sound source to microphone distance must be lessthan the critical distance for the space in which the recordingsare being made.23 The critical distances in the Menuhin Hall at125 Hz and 1 kHz were calculated as 2.0 and 2.3 m, respec-tively (The critical distance has been calculated from the Sabineformula: Critical distance ¼ 0.0573 sqrt(V/RT60),23 where V(volume of hall) is 2400 m3; RT60 measured as 2.0 seconds at125 Hz and 1.5 seconds at 1 kHz [figures gained from the archi-tects at24] giving the critical distance as 2.0 m at 125 Hz and2.3 m at 1 kHz.). Therefore, for these recordings, the micro-phone placed 1 m away from the subject’s lips is confirmedas being within the critical distance.
Having identified the word take7, bar 38 on F5 (second F abovemiddle C, F0�784 Hz) as having ring, the subsequent sung ver-sion of this note, which was recorded after the aria was used foranalysis. The ring and nonring portions of the note were percep-tually identified by the authors D.M.H. and J.W., and fromthese, the LTAS analyses were taken. One repetition for eachof the ring and nonring conditions was analyzed for each sub-ject. In creating these LTAS plots for presentation, thoughtwas given as to how best to organize the data to enable compar-isons to be made between the ring and nonring versions as wellas between different subjects.
For this work, the key requirement was to enable the differ-ence between notes with ring and notes without ring to be com-pared. The relative levels at which these were sung is listed inTable 1 as differences in level between the highest harmonicof the nonring version to the ring version, which in all caseswas the fundamental. It can be seen that in all cases as one
might expect, the nonring version was sung at a lower levelthan the ring version. This level difference has been maintainedin all LTAS plots of data in this article so the true difference ismaintained when making comparisons.
Figure 2 presents LTAS plots for the ring and nonring ver-sions of the word take sung on F5 (second F above middle C,F0 �784 Hz) for each subject individually. In each case, theplots have identical Y-axes in terms of the range covered byits dB scale, the ring plots are normalized such that their max-imum values (that of the F0 component in each case) is normal-ized to the maximum Y-axis value, and the relative leveldifference between the maximum amplitude values (that ofthe F0 component in each case) of the ring and nonring plotsare maintained to the values listed in Table 1. In all plots, thenonring plots have been shifted downward in frequency (left-ward on the plot) by 43 Hz to make the peaks easier to seeagainst the ring plots.
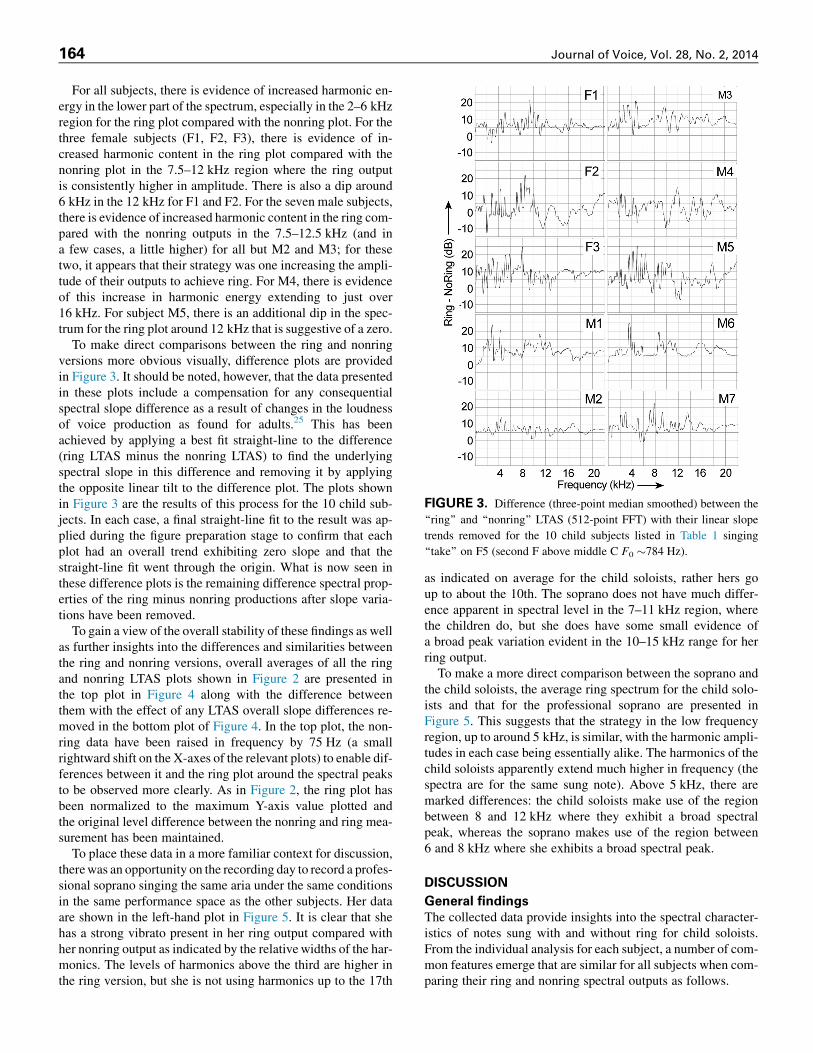
FIGURE 3. Difference (three-point median smoothed) between the
‘‘ring’’ and ‘‘nonring’’ LTAS (512-point FFT) with their linear slope
trends removed for the 10 child subjects listed in Table 1 singing
‘‘take’’ on F5 (second F above middle C F0 �784 Hz).
Journal of Voice, Vol. 28, No. 2, 2014164
For all subjects, there is evidence of increased harmonic en-ergy in the lower part of the spectrum, especially in the 2–6 kHzregion for the ring plot compared with the nonring plot. For thethree female subjects (F1, F2, F3), there is evidence of in-creased harmonic content in the ring plot compared with thenonring plot in the 7.5–12 kHz region where the ring outputis consistently higher in amplitude. There is also a dip around6 kHz in the 12 kHz for F1 and F2. For the seven male subjects,there is evidence of increased harmonic content in the ring com-pared with the nonring outputs in the 7.5–12.5 kHz (and ina few cases, a little higher) for all but M2 and M3; for thesetwo, it appears that their strategy was one increasing the ampli-tude of their outputs to achieve ring. For M4, there is evidenceof this increase in harmonic energy extending to just over16 kHz. For subject M5, there is an additional dip in the spec-trum for the ring plot around 12 kHz that is suggestive of a zero.
To make direct comparisons between the ring and nonringversions more obvious visually, difference plots are providedin Figure 3. It should be noted, however, that the data presentedin these plots include a compensation for any consequentialspectral slope difference as a result of changes in the loudnessof voice production as found for adults.25 This has beenachieved by applying a best fit straight-line to the difference(ring LTAS minus the nonring LTAS) to find the underlyingspectral slope in this difference and removing it by applyingthe opposite linear tilt to the difference plot. The plots shownin Figure 3 are the results of this process for the 10 child sub-jects. In each case, a final straight-line fit to the result was ap-plied during the figure preparation stage to confirm that eachplot had an overall trend exhibiting zero slope and that thestraight-line fit went through the origin. What is now seen inthese difference plots is the remaining difference spectral prop-erties of the ring minus nonring productions after slope varia-tions have been removed.
To gain a view of the overall stability of these findings as wellas further insights into the differences and similarities betweenthe ring and nonring versions, overall averages of all the ringand nonring LTAS plots shown in Figure 2 are presented inthe top plot in Figure 4 along with the difference betweenthem with the effect of any LTAS overall slope differences re-moved in the bottom plot of Figure 4. In the top plot, the non-ring data have been raised in frequency by 75 Hz (a smallrightward shift on the X-axes of the relevant plots) to enable dif-ferences between it and the ring plot around the spectral peaksto be observed more clearly. As in Figure 2, the ring plot hasbeen normalized to the maximum Y-axis value plotted andthe original level difference between the nonring and ring mea-surement has been maintained.
To place these data in a more familiar context for discussion,therewas an opportunity on the recording day to record a profes-sional soprano singing the same aria under the same conditionsin the same performance space as the other subjects. Her dataare shown in the left-hand plot in Figure 5. It is clear that shehas a strong vibrato present in her ring output compared withher nonring output as indicated by the relativewidths of the har-monics. The levels of harmonics above the third are higher inthe ring version, but she is not using harmonics up to the 17th
as indicated on average for the child soloists, rather hers goup to about the 10th. The soprano does not have much differ-ence apparent in spectral level in the 7–11 kHz region, wherethe children do, but she does have some small evidence ofa broad peak variation evident in the 10–15 kHz range for herring output.To make a more direct comparison between the soprano and
the child soloists, the average ring spectrum for the child solo-ists and that for the professional soprano are presented inFigure 5. This suggests that the strategy in the low frequencyregion, up to around 5 kHz, is similar, with the harmonic ampli-tudes in each case being essentially alike. The harmonics of thechild soloists apparently extend much higher in frequency (thespectra are for the same sung note). Above 5 kHz, there aremarked differences: the child soloists make use of the regionbetween 8 and 12 kHz where they exhibit a broad spectralpeak, whereas the soprano makes use of the region between6 and 8 kHz where she exhibits a broad spectral peak.
DISCUSSION
General findings
The collected data provide insights into the spectral character-istics of notes sung with and without ring for child soloists.From the individual analysis for each subject, a number of com-mon features emerge that are similar for all subjects when com-paring their ring and nonring spectral outputs as follows.
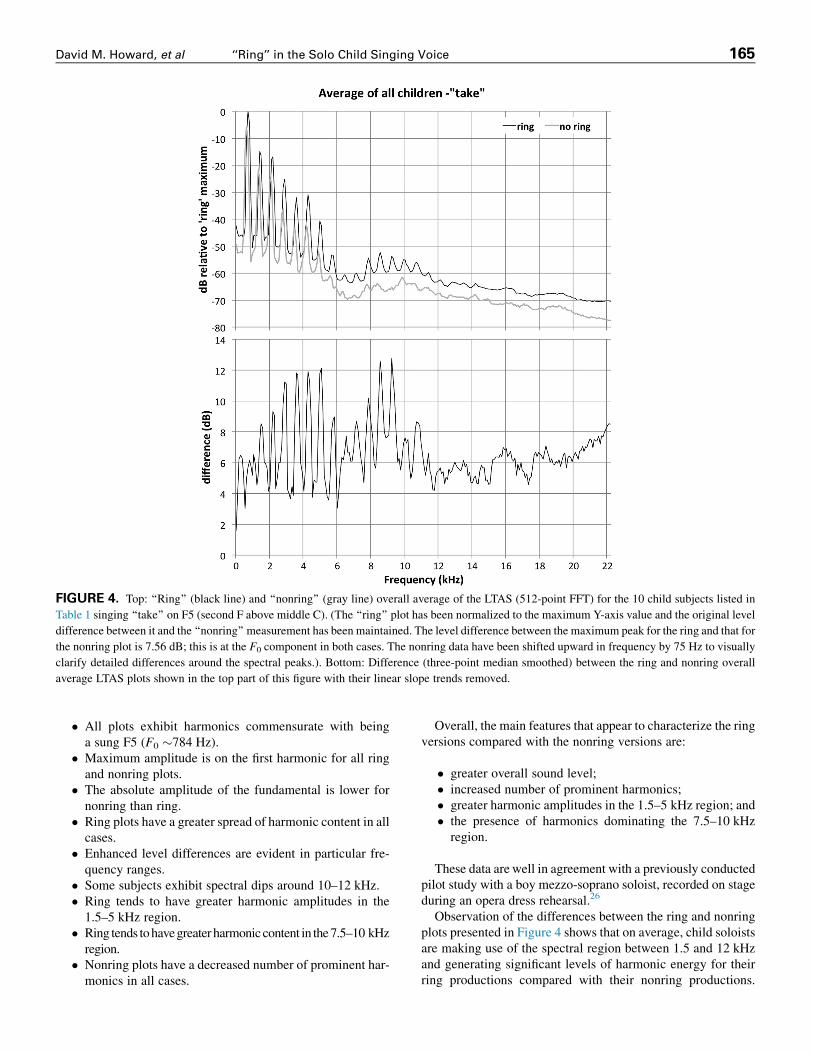
FIGURE 4. Top: ‘‘Ring’’ (black line) and ‘‘nonring’’ (gray line) overall average of the LTAS (512-point FFT) for the 10 child subjects listed in
Table 1 singing ‘‘take’’ on F5 (second F above middle C). (The ‘‘ring’’ plot has been normalized to the maximum Y-axis value and the original level
difference between it and the ‘‘nonring’’ measurement has been maintained. The level difference between the maximum peak for the ring and that for
the nonring plot is 7.56 dB; this is at the F0 component in both cases. The nonring data have been shifted upward in frequency by 75 Hz to visually
clarify detailed differences around the spectral peaks.). Bottom: Difference (three-point median smoothed) between the ring and nonring overall
average LTAS plots shown in the top part of this figure with their linear slope trends removed.
David M. Howard, et al ‘‘Ring’’ in the Solo Child Singing Voice 165
� All plots exhibit harmonics commensurate with beinga sung F5 (F0 �784 Hz).
� Maximum amplitude is on the first harmonic for all ringand nonring plots.
� The absolute amplitude of the fundamental is lower fornonring than ring.
� Ring plots have a greater spread of harmonic content in allcases.
� Enhanced level differences are evident in particular fre-quency ranges.
� Some subjects exhibit spectral dips around 10–12 kHz.� Ring tends to have greater harmonic amplitudes in the
1.5–5 kHz region.� Ring tends tohavegreaterharmoniccontent in the7.5–10 kHz
region.� Nonring plots have a decreased number of prominent har-
monics in all cases.
Overall, the main features that appear to characterize the ringversions compared with the nonring versions are:
� greater overall sound level;� increased number of prominent harmonics;� greater harmonic amplitudes in the 1.5–5 kHz region; and� the presence of harmonics dominating the 7.5–10 kHz
region.
These data are well in agreement with a previously conductedpilot study with a boy mezzo-soprano soloist, recorded on stageduring an opera dress rehearsal.26
Observation of the differences between the ring and nonringplots presented in Figure 4 shows that on average, child soloistsare making use of the spectral region between 1.5 and 12 kHzand generating significant levels of harmonic energy for theirring productions compared with their nonring productions.

FIGURE 5. Top left: ‘‘Ring’’ (black line) and ‘‘nonring’’ (gray line)
for LTAS (512-point FFT) of a professional soprano (A1 in Table 1)
singing ‘‘take’’ on F5 (second F above middle C). (The ring plot has
been normalized to the maximum Y-axis value and the original level
difference [Table 1] between the nonring and ring measurement has
been maintained.) Bottom left: Difference between the ring and nonr-
ing LTAS (512-point FFT) plots shown in the top left of this figure for
the professional soprano (subject A1) with their linear slope trends re-
moved. Top right: Ring plots for LTAS (512-point FFT) of a profes-
sional soprano as in the top left plot (black line) and that for the
average of all the children subjects (gray line) singing take on F5 (sec-
ond F above middle C). (Both plots have been normalized to the max-
imum Y-axis value.) Bottom right: Difference (three-point median
smoothed) between the professional soprano (subject A1) and average
for all children ring LTAS (512-point FFT) plots shown in the bottom
right of this figure with their linear slope trends removed.
Journal of Voice, Vol. 28, No. 2, 2014166
Accounting for the level difference in Figure 4 between themaximum peak for the ring and that for the nonring plot (mea-sured as 7.56 dB), it can be seen that there is not a great deal ofrelative amplitude variation between the first three harmonics.Above the third harmonic although the harmonics in the ringdominate its spectrum up to at least the 17th harmonic, whereasharmonics above the third in the nonring plot are very muchweaker, and they cease to be at all prominent above the seventh.
Perceptual relevance
Perceptually, this offers a possible explanation for the notion ofring in terms of those harmonics that are resolved separately bythe hearing system and those that are not. The nature of the crit-ical bands in hearing which relate to the bandwidth of the audi-tory filters at different center frequencies indicate that for a noteof any pitch, the first five to seven harmonics are resolved whilethose above are not.23,ch.3 This suggests that essentially all theharmonics in the nonring sounds would be resolved; the onlyharmonics that would not be resolved would be the sixth andseventh, but this effect would be small because their amplitudesare low. In contrast, the majority of the harmonics (say 10 or 11of the 17) in the ring sounds would not be resolved. The conse-quence of having significant nonresolved harmonics manifestsitself in terms of our perception of timbre, for which, descrip-tivewords are generally applied. Helmholtz27 offers four timbre‘rules’ that provide a useful insight into this process. His thirdrule is relevant to the nonring sound, where he describes
‘‘musical tones as being accompanied by a moderately loudseries of the lower partial tones up to about the sixth partial’’(see the average nonring spectrum in Figure 4), as being more‘‘harmonious and musical.’’ His fourth rule is relevant to thering sound, which indicates that when partials higher than thesixth are very distinct (see the average ring spectrum inFigure 3), the ‘‘quality of the tone is cutting or rough.’’27, p119
To test whether listeners would use the term ring for thesesounds, a perceptual test was carried out. Two sounds were syn-thesized using Pure Data [www.puredata.info] that have the av-erage harmonic content associated with the no ring (first sound)and ring (second sound) plots in the upper part of Figure 4. Theyboth had the same F0 value (708 Hz) and vibrato settings(rate¼ 6 Hz, depth¼ 117 Hz). The two sounds were equalizedin length and their onsets and offsets were linear ramped toavoid clicks.The test was carried out online and the following two ques-
tions were asked.
1. Can you hear the difference between these two sounds?2. If one of these sounds were described as having ring,
which would it be?
The first stimulus was ‘‘no ring’’ and the second was ring.Sixty-four listeners (34 females and 30 males) took part inthe test. One female and one male listener could not hear a dif-ference (question 1), perhaps due to hearing loss or to local lis-tening conditions, and therefore, they were unable to answerquestion 2 and they have not been included in the results. Ofthe remaining 62, 58 described the second stimulus as havingring and four described the first stimulus as having ring. Thissuggests that the averaged ring/no ring spectra carry sufficientacoustic information for a ring/no ring difference to be per-ceived and that the majority of listeners (94% in this case)can ascribe ring percept to the measured averaged ring spec-trum (the second stimulus). The results from this listeningtest provide clear evidence to suggest that the use of the termring in the context of this style of children’s solo singing is rea-sonable and typically acceptable to listeners.
Physiological considerations
The clear differences between the ring and the nonring voiceproduction seen in all singers suggests that the ring voice qual-ity is not created by pure chance, but that such a modification ofthe voice timbre constitutes a systematic phenomenon, overwhich the singers had sufficient physiological control. Thevoice timbre in singing can either be controlled in the vocaltract or at the voice source. In the following section, the possibleinfluence of both these components on the ring voice quality isdiscussed.The data considered in this study consist of sustained phona-
tion sung at a F0 of�710 Hz at the vowel /e/ or /ae/ (dependingon the openness of the vowel as chosen by the individualsinger). Due to the high F0, no data about formant centerfrequencies can be calculated from the acoustic signal. How-ever, when consulting the results presented by Peterson andBarney,28 the first formant for spoken /e/ and /ae/ vowels, as

David M. Howard, et al ‘‘Ring’’ in the Solo Child Singing Voice 167
pronounced by children, is to be found around 690 and1010 Hz, respectively. Considering that in all phones analyzedin this study, the first harmonic is the strongest component ofthe spectrum, it can be assumed that the first formant was atleast in the vicinity of the first harmonic in all samples, follow-ing a general strategy that is used by classically trained sopra-nos.29 Whether such a tuning of the first formant to the firstharmonic played a role in producing the ring versus the nonringquality can neither be supported nor rejected, based on the col-lected data.
In adults, the singers’ formant cluster is to be found in the re-gion of 2500–3200 Hz, depending on voice category,30 and it isclear from both experimental data and modeling approachesthat the second formant is well below the singers’ formant clus-ter, with the second formant’s skirt having only a small influ-ence on it. To verify whether the same would be true inchildren, the vocal tract and its formants can be modeled asa quarter-resonance resonator31 as a rough approximation. Insuch a model, the nth formant is calculated as
Fn ¼ ð2n� 1Þc=ð4LÞ; (1)
where, Fn is the frequency of the nth formant; L is the tubelength in meters; and c is the speed of sound (340 m/s).
Assuming a vocal tract length of 130 mm for 11- to 12-year-old children,32 the first formant is to be found around 700 Hz fora uniform vocal tract, with consecutive formants spaced at ap-proximately 1400 Hz intervals above it. In such a model, thesecond formant (around 2100 Hz) is well below the frequencymaximum around 3.5 kHz as found in our data, which is consis-tent with the data presented by Peterson and Barney28 for chil-dren’s vowel /e/. It can, therefore, be safely assumed that thesecond formant had only a small influence on the ring produc-tions in the present study and that any such influence wouldhave been similar for all subjects, given that the vowels were es-sentially the same. The third formant, on the other hand, mightwell have contributed to the energy maximum found around3.5 kHz. Confirmation of these predictions awaits suitably de-tailed articulatory synthesis investigations33 based on magneticresonance imaging (MRI) of appropriate singers’ vocal tracts.
In adults, a spectral peak in the region of 8–9 kHz has beeninterpreted as a second singers’ formant.34 This notion hasbeen derived by modeling the epilaryngeal tube as a quarter-wave resonator (Equation 1). At an estimated epilaryngealtube length of 3 cm, the first resonance frequency would befound around 2.85 kHz, that is, in the region of a tenor’ssingers’ formant (Ref. 30; Figure 9). The second resonance insuch a model would be found at�8.5 kHz, which might explainan energy peak seen in LTAS of adult singers at approximatelythis frequency.31 When adapting this model to the smaller vocaltract geometry of children, both the energy peaks seen in thebottom panel of Figure 4 might be explained thus. The observedsecond peak was around 9.3 kHz and substituting this value intoEquation 1 suggests an epilarynx tube length of 2.74 cm, anda first resonance of that tube at 3.1 kHz. Considering the spec-tral region around 3.1 kHz in the bottom panel of Figure 4, thisvalue seems plausible. It is hypothesized that the increase of
acoustic energy around 3.1 and 9.3 kHz in the ring condition(as compared with the nonring condition) is facilitated by a nar-rowing of the epilarynx tube in relation to the lower part of thepharyx.12
Based on these considerations, we propose that the ring, asfound in classical singing of children, is a linearly scaled ver-sion of the adults’ singers’ formant cluster. The higher centerfrequencies of the two main spectral peaks are most likelycaused by the smaller geometry of the children’s vocal tracts.Naturally, such a hypothesis needs to be backed up by furtherempirical data (eg, MRI recordings), and articulatory modeling.
The data presented in Figure 2 indicate that the ring voicequality has a flatter spectral slope and a larger number of acous-tically relevant harmonics (17 harmonics in the averaged LTASin Figure 4) above the noise floor, when compared with thenonring quality (seven harmonics in the averaged LTAS).This suggests that the singers modified their voice source char-acteristics when changing from nonring to ring. In human voiceproduction, most of the acoustic energy during a glottal cycle iscreated at the instant of glottal closure.13,14 The abruptness ofthe cessation of glottal airflow (caused by glottal closure) isrelated to the amount of high-frequency energy in the soundsource35,36 (see Ref. 37, for a more detailed discussion). Asinger has three possibilities to increase the amount of high-frequency energy components in the sound source:
(1) nonlinear interactions between the vocal tract and thesound source by changing the geometry of the epilarynxtube38;
(2) changing the degree of glottal adduction along the di-mension ‘‘breathy’’-‘‘flow’’-‘‘pressed’’39,40; and
(3) raising subglottal pressure, thus increasing the closedquotient and the maximum flow declination rate.37,41
The ring voice quality is less often heard in untrained singers,suggesting that the degree of vocal training is essential. Barlowand Howard42 showed that voice training has a tangible effecton sound source properties in child and adolescent singers. Inthis context, it is well conceivable that lengthened glottal closedphase and greater rate of vocal fold closure is the cause for theincreased number of high-frequency harmonics seen in the ringvoice quality in our subjects. Further research including directand indirect observation of glottal configuration in singing ringand nonring qualities is needed to test this hypothesis.
CONCLUSIONS
In conclusion, the data collected in this study provide reason tohypothesize that (a) the ring appears spectrally as a frequency-shifted version of the adult singers’ formant cluster, with peaksbetween 3–5 kHz and 8–10 kHz; (b) the higher formants, start-ing with F3, contribute to the ring, just as in the adult singers’formant cluster; (c) a larger degree of vocal fold adductionfacilitates the presence of high-frequency partials in the voicesource at frequencies of up to 12 kHz and beyond. Further stud-ies are necessary to investigate these notions in other singingstyles.

Journal of Voice, Vol. 28, No. 2, 2014168
It is clear from the presented evidence, as noted elsewhere,43
that the high-frequency region of the spectrum is both audibleand potentially of great importance in voice production, partic-ularly in the context of its use with respect to the singer’s for-mant cluster to communicate with listeners in the spectralregion where the ear has its widest dynamic range. One of thewonders of listening to child soloists such as these is how is itthat from their vocal output alone, perhaps via the radio, TV,or CD, listeners can be so affected by the experience. Bloodand Zatorre44 note that when listeners experience a particularlyintense, euphoric response to music, they describe it as produc-ing ‘‘shivers-down-the-spine’’ or ‘‘chills.’’ Other terms thathave been used include ‘‘goose bumps,’’45 ‘‘crying,’’ ‘‘lump inthe throat,’’ ‘‘goose pimples’,’’ ‘‘racing heart,’’ and ‘‘pit-of-stomach sensationa.’’46, p210 These and other responses, whichare often grouped under the term ‘‘tingling feelings’’47 or the‘‘tingle factor,’’48 have yet to be fully explored and analyzed.
Acknowledgments
The authors thank the singers who took part, their parentsfor allowing them to participate, the staff at and the acousticdesigners of the Menuhin Hall for their help and support, andthe referees for their insightful comments and advice. Thisresearch has been co-financed by the European Social Fundand the state budget of the Czech Republic, project no. CZ.1.07/2.3.00/30.0004 ‘‘POST-UP’’ (author CTH).
REFERENCES1. Gauntlett HJ, Alexander CF. Once in Royal David’s city. In: Jacques R,
Willcocks D, eds. Carols for Choirs 1. Oxford, UK: Oxford University
Press; 1961:100.
2. Laurence F. Children’s singing. In: Potter J, ed. The Cambridge Companion
to Singing. Cambridge, UK: Cambridge University Press; 2001:221–230.
3. Phillips P. The golden age regained. Early Music. 1980;8:4.
4. Laurence F. Children’s singing. In: Chapman J, ed. Singing and Teaching
Singing. San Diego, CA: Plural Publishing; 2013:221–230.
5. Day T. English cathedral choirs in the twentieth century. In: Potter J, ed. The
Cambridge Companion to Singing. Cambridge, UK: Cambridge University
Press; 2001:123–132.
6. Nair G. Voice-Tradition and Technology: A State-of-the-Art Studio. San
Diego, CA: Singular Publishing Group; 1999.
7. Brown O, Fraterrigo N, Gates L, Potter C, Reed W, Reynolds E, Teaney D.
The laryngograph in singing. II. The ‘‘ring’’ in the professional voice.
J Acoust Soc Am. 1980;67(suppl 1):S98–S99.
8. Howard DM, Murphy DT. Voice Science, Acoustics and Recording. San
Diego, CA: Plural press; 2008.
9. Titze IR. Fascinations with the Human Voice. Denver, CO: National Center
for Voice and Speech; 2010.
10. Hollien H. The puzzle of the singer’s formant. In: Bless DM, Abbs JH, eds.
Vocal Fold Physiology. San Diego, CA: College-Hill Press; 1983:368–380.
11. Bartholomew WT. A physical definition of good voice quality in the male
voice. J Acoust Soc Am. 1934;9:25–33.
12. Sundberg J. Articulatory interpretation of the ‘‘singing formant’’. J Acoust
Soc Am. 1974;55:838–844.
13. Sundberg J. The Science of Singing. Dekalb, IL: Northern Illinois Univer-
sity Press; 1987.
14. Sundberg J. Perception of singing. In: Deutsch D, ed. The Psychology of
Music. 3rd Ed. New York, NY: Academic Press; 2012.
15. Smith B, Sataloff RT.Choral Pedagogy. 3rd ed. San Diego, CA: Plural Pub-
lishing; 2006.
16. Chapman J. Singing and Teaching Singing. San Diego, CA: Plural Publish-
ing; 2013.
17. Davis PJ, Zhang SP, Bandler R. Midbrain and medullary regulation of
vocalization. In: Fletcher N, Davis P, eds. Controlling Complexity and
Chaos. San Diego, CA: Singular Publishing Corporation; 1996:121–136.
18. Lieberman P, Harris M, Wolff P, Russell L. Newborn infant cry and nonhu-
man primate vocalizations. J Speech Hear Res. 1971;14:41–53.
19. Lieberman P. Uniquely Human: The Evolution of Speech, Thought, and
Selfless Behavior. Cambridge MA: Harvard University Press; 1991.
20. Scheiner E, Hammerschmidt K, Jurgens U, Zwirner P. Acoustic analyses of
developmental changes and emotional expression in the preverbal vocaliza-
tions of infants. J Voice. 2002;16:509–529.
21. Available at: http://www.yehudimenuhinschool.co.uk/index.php?dept¼11.
Accessed September 2, 2013.
22. Handel GF. In: Shaw W, ed.Messiah. London, UK: Novello and Co; 1958:
83–85.
23. Howard DM, Angus JAS. Acoustic and Psychoacoustics. 4th ed. Oxford,
UK: Focal Press; 2009.
24. Available at: http://www.soundspacedesign.co.uk. Accessed September
2, 2013.
25. Ternstr€omS,BohmanM,S€oderstenM.Loud speechovernoise: some spectral
attributes, with gender differences. J Acoust Soc Am. 2006;119:1648–1665.
26. Herbst CT. Der Knabensolist in der Oper - Ein akustisches Portrait. L.O.G.
O.S Interdisziplin€ar. 2006;15:166–174. [In German].
27. Helmholtz H. On the Sensations of Tone, 2nd Edition of the 1885 Transla-
tion by AJ Ellis of the 4th Edition of 1877. New York, NY: Dover; 1954.
28. Peterson GE, Barney HL. Control methods used in study of the vowels.
J Acoust Soc Am. 1952;24:175–184.
29. Sundberg J. Formant technique in a professional female singer. Acustica.
1975;32:89–96.
30. Sundberg J. Level and center frequency of the singer’s formant. J Voice.
2001;15:176–186.
31. Titze IR. Principles of Voice Production. 2nd printing. National Center for
Voice and Speech. Englewood Cliffs, NJ: Prentice-Hall. 2000.
32. FitchWT, Giedd J. Morphology and development of the human vocal tract:
a study using magnetic resonance imaging. J Acoust Soc Am. 1999;
106(3 Pt 1):1511–1522.
33. Mullen J, Murphy DT, Howard DM. Real-time dynamic articulations in the
2D waveguide mesh vocal tract model. IEEE Trans Speech Audio Process.
2007;15:577–585.
34. Titze IR, Jin SM. Is there evidence of a second singer’s formant? J Singing.
2003;59:329–331.
35. Miller DG, Schutte HK. Characteristic Patterns of Sub- and Supraglottal
Pressure Variations Within the Glottal Cycle, in Transcripts of the XIIIth
Symposium: Care of the Professional Voice. New York, NY: The Voice
Foundation; 1984.
36. Schutte HK, Miller DG. Resonanzspiele der Gesangsstimme in ihren Bezie-
hungen zu supra- und subglottalen Druckverl€aufen: Konsequenzen f€ur dieStimmbildungstheorie.FoliaPhoniatr (Basel). 1988;40:65–73. [InGerman].
37. Herbst CT, Howard DM, Svec JG. The sound source in singing—basic prin-
ciples andmuscular adjustments for fine-tuning vocal timbre. In:Welch GF,
Howard DM, Nix J, eds. The Oxford Handbook of Singing. Oxford, UK:
Oxford University Press; in press.
38. Titze IR. Nonlinear source-filter coupling in phonation: theory. J Acoust
Soc Am. 2008;123:2733–2749.
39. Herbst CT, Ternstr€om S, �Svec JG. Investigation of four distinct glottal con-
figurations in classical singing—a pilot study. J Acoust Soc Am. 2009;125:
EL104–EL109.
40. Herbst CT, Howard DM, Schl€omicher-Thier J. Using electroglottographic
real-time feedback to control posterior glottal adduction during phonation.
J Voice. 2010;24:72–85.
41. Sundberg J, Fahlstedt E, Morell A. Effects on the glottal voice source of vo-
cal loudness variation in untrained female and male voices. J Acoust Soc
Am. 2005;117:879–885.
42. Barlow C, Howard DM. Electrolaryngographically derived voice source
changes of child and adolescent singers. Logoped Phoniatr Vocol. 2005;
30(3–4):147–157.
43. Monson BB, Lotto AJ, Ternstr€om S. Detection of high-frequency energy
changes in sustained vowels produced by singers. J Acoust Soc Am.
2011;129:2263–2268.

David M. Howard, et al ‘‘Ring’’ in the Solo Child Singing Voice 169
44. Blood AJ, Zatorre RJ. Intensely pleasurable responses to music correlate
with activity in brain regions implicated in reward and emotion. Proc
Natl Acad Sci USA. 2001; 98:11818–11823.
45. de Abreu MJA. Goose bumps all over: breath, media, and tremor. Social
Text. 2008;26:59–78.
46. Sloboda J. Exploring the Musical Mind. Oxford, UK: Oxford University
Press; 2005.
47. Clift SM, Hancox G. The perceived benefits of singing: findings from pre-
liminary surveys with a university college choral society. J R Soc Promot
Health. 2001;121:248–256.
48. Bule, E. They Call it the Tingle Factor: Choral Singing has Huge Benefits
on Both Curricular and Social Levels for Young People; Times Educational
Supplement Scotland, TESS. 2008. Available at: http://www.tes.co.uk/
article.aspx?storycode¼2647058. Accessed September 2, 2013.





























