Embed Size (px)
Citation preview

Reversible watermarking
Wu Dan2008.9.10
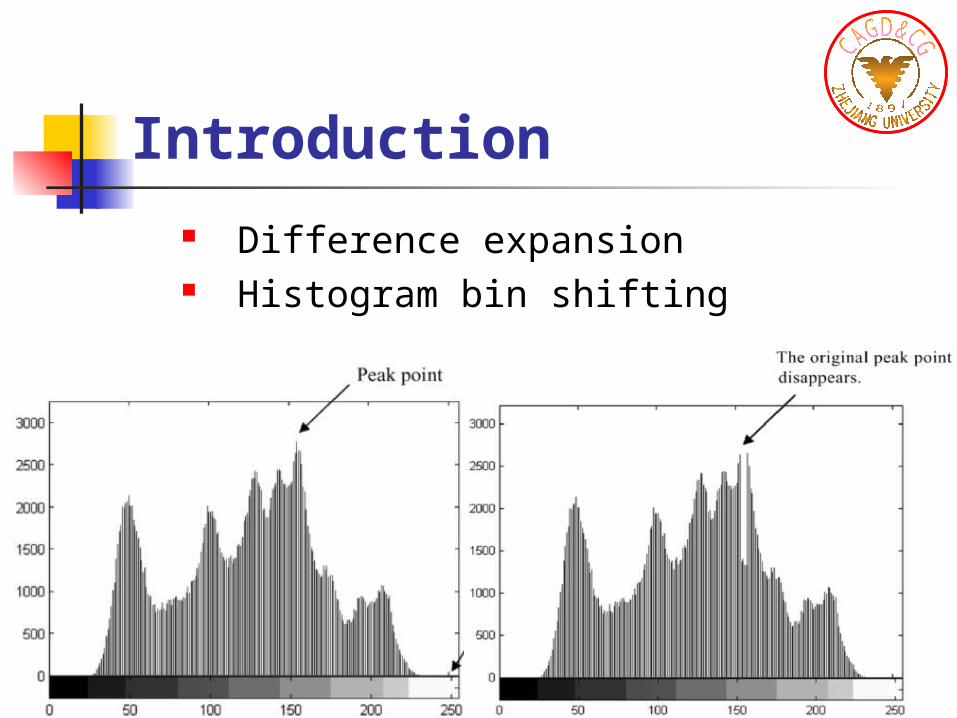
Introduction Difference expansion Histogram bin shifting

Expansion Embedding Techniques for Reversible Watermarking
Diljith M. Thodi and Jeffrey J. Rodríguez,
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 16, NO. 3, MARCH 2007

I alternative approaches
Histogram-Based selection of locations
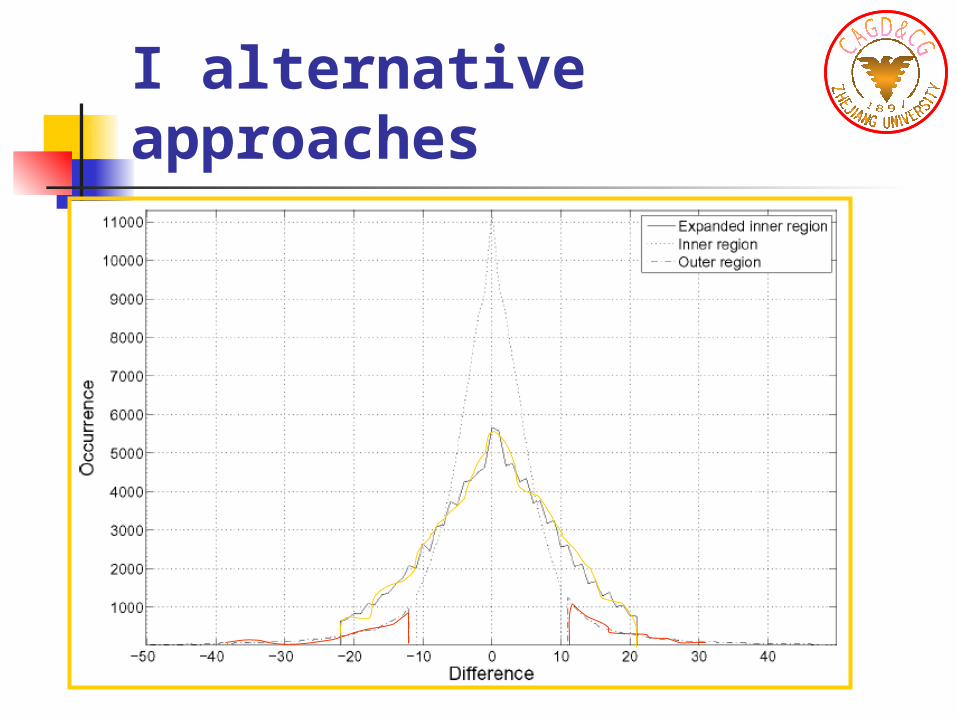
I alternative approaches
Histogram shifting

Histogram Shifting

I alternative approaches
Histogram shifting
Notation and functions

II Difference-expansion based algorithms
Difference expansion with histogram shifting and overflow map (DE-HS-OM)• Decompose the image into differences and i
nteger averages• Determine the changeable (C) and the expa
ndable locations (E) • 2D overflow map (M) is losslessly compresse
d

II Difference-expansion based algorithms
Difference expansion with histogram shifting and flag bits (DE-HS-FB)
Many of expandable differences are capable of undergoing multiple expansion/shifting.• Order of modifiability

Flag bits255
253
255
251
254
250
253
251
255
252
254
253
200
210
100
50
α β I=(255,253) l=254 h=2 Non-Embeddable -1 -1
I=(255,251) l=253 h=4 Non-Embeddable -1 -1
I=(254,250) l=252 h=4 Changeable 0 0
I=(253,251) l=252 h=2 Expandable 1 0
I=(255,252) l=253 h=3 Changeable 0 0
I=(254,253) l=253 h=1 Expandable 1 0
I=(200,210) l=205 h=(-10) Expandable 3 2
I=(100,50) l=75 h=50 Expandable 1 0
FB|LSB|Secret=01011|01|1001
Lossless compression=100100

III expansion embedding
PE (prediction error expansion) based reversible watermarking
PE DE
+HS+OMFBLM

III expansion embedding
D1: DE with location map (Tian’s method). D2: DE with histogram shifting and overflow map(DE-HS-OM). D3: DE with histogram shifting and flag bits (DE-HS-FB). P1: PE expansion with location map. P2: PE expansion with histogram shifting and overflowmap. P3: PE expansion with histogram shifting and flag bits.
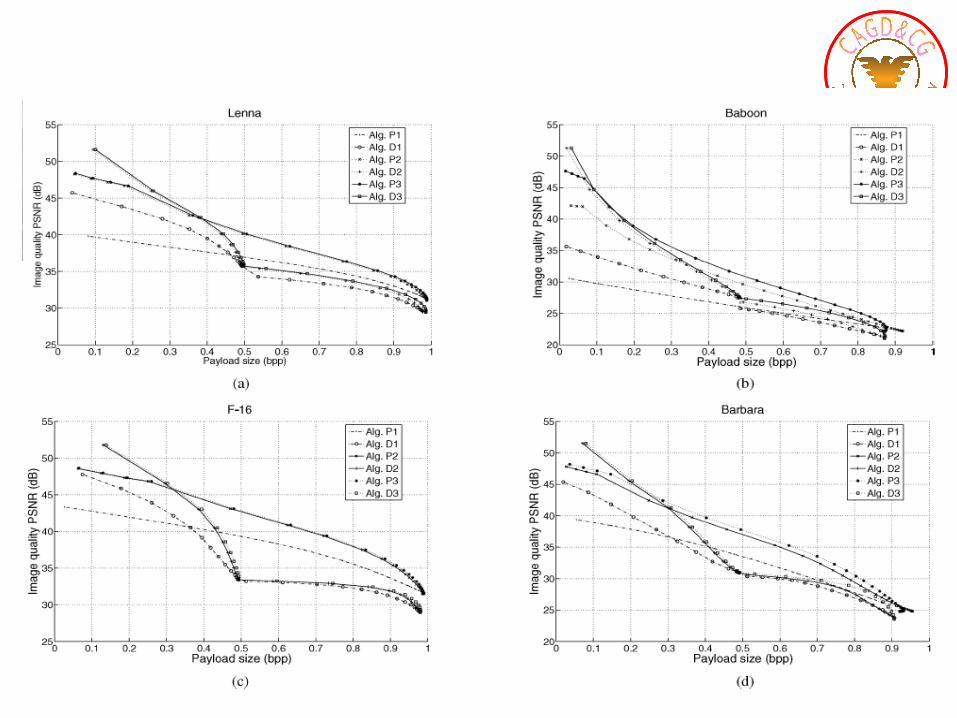

results
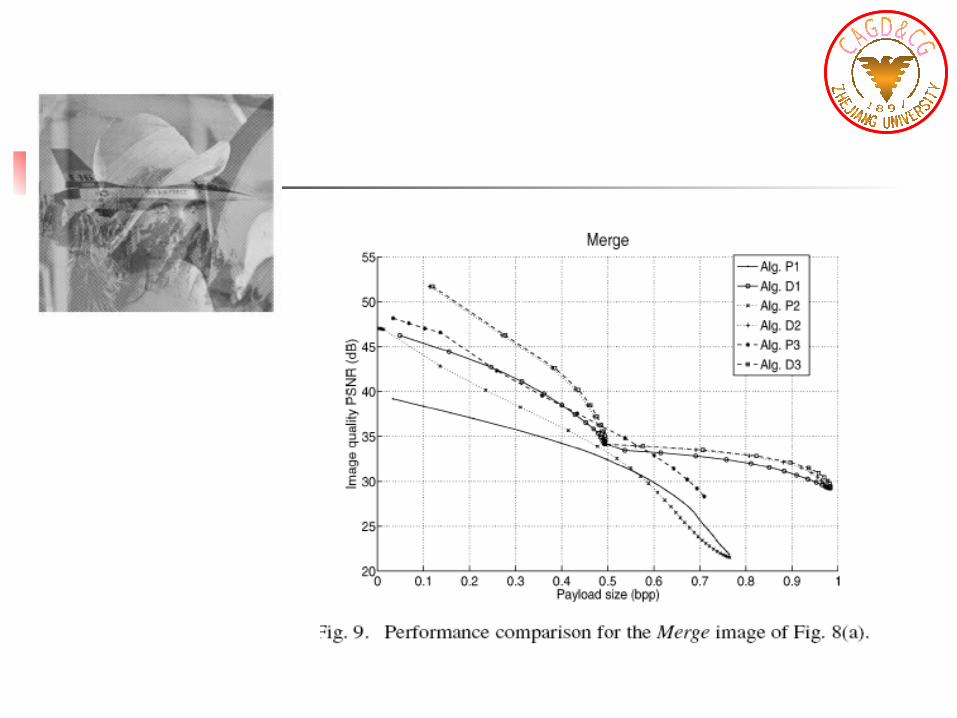

Adaptive lossless steganographic scheme with centralizeddifference expansion
Chih-Chiang Lee, Hsien-ChuWu, Chwei-Shyong Tsai, Yen-Ping Chu
Pattern Recognition 41 (2008,6)
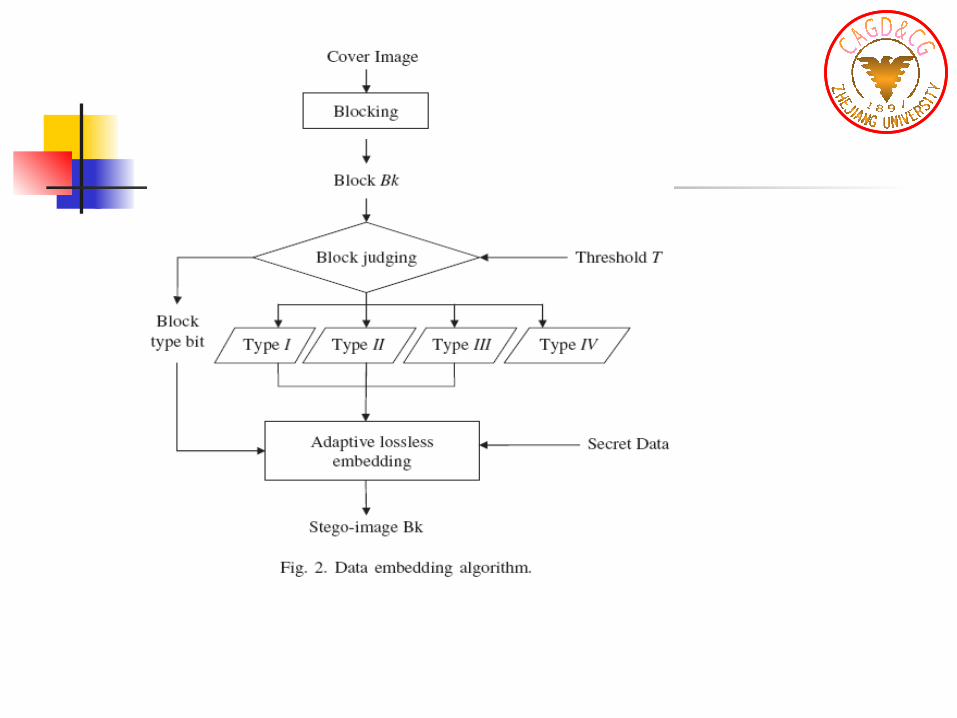

Centralized difference expansion
for each component of a block, we canobtain a series of pixel values v0, v1, v2, . . . , vk−1. Sorting these pixels in ascending order take the medium value vm as a reference value

Adaptive embedding procedure
I II III IV
I
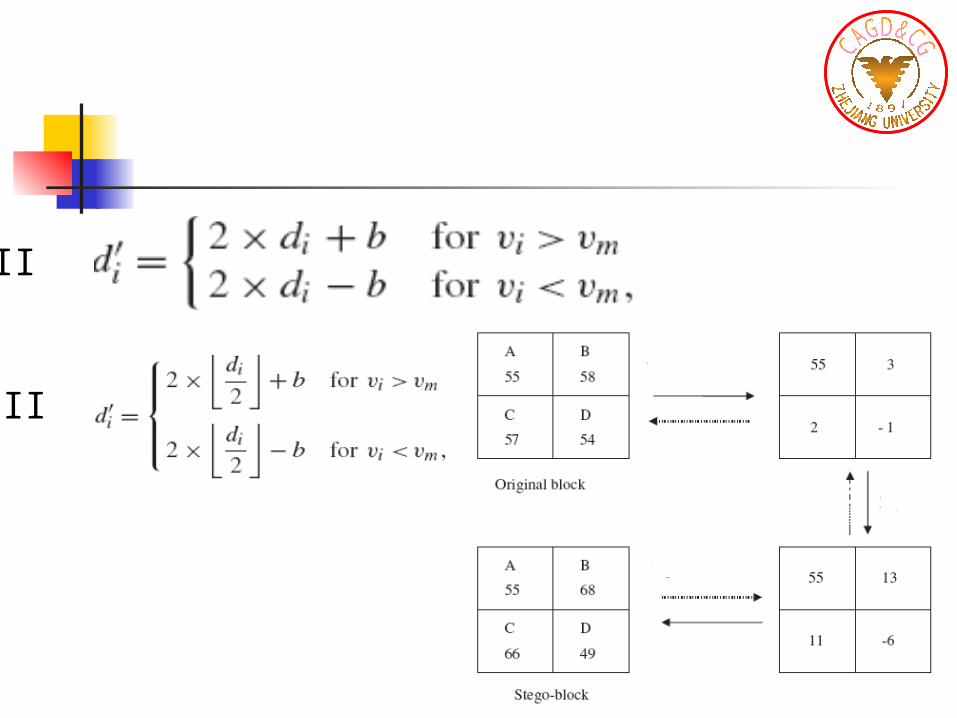
II
III

I II III IV 0 1 0
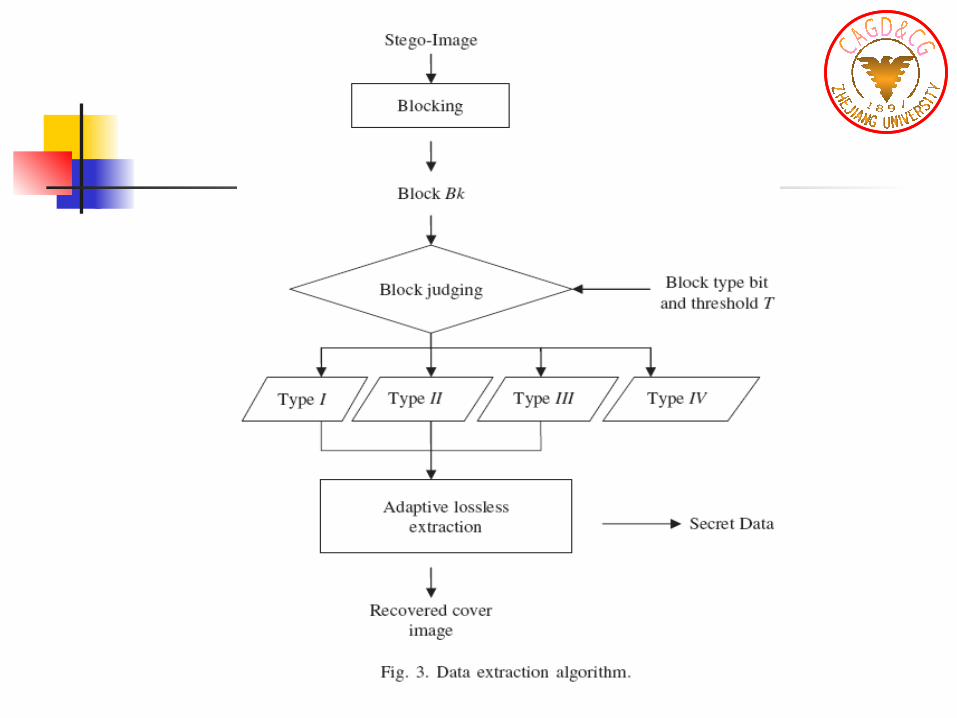

Adaptive extracting procedure

result

Circular Interpretation of bijective transformations in lossless watermarking for media asset management
Christophe De Vleeschouwer, Jean-François Delaigle, and Benoît Macq,
IEEE TRANSACTIONS ON MULTIMEDIA, MARCH 2003

I Reversible embedding Patchwork algorithm1. Each image block is equally divided
into two pseudo-random sets of pixels
2. Zones A and B have close average values before embedding.
3. After embedding, depending on the bit to embed, their luminance values are incremented or decremented.
I Reversible embedding


II extraction and inversion process
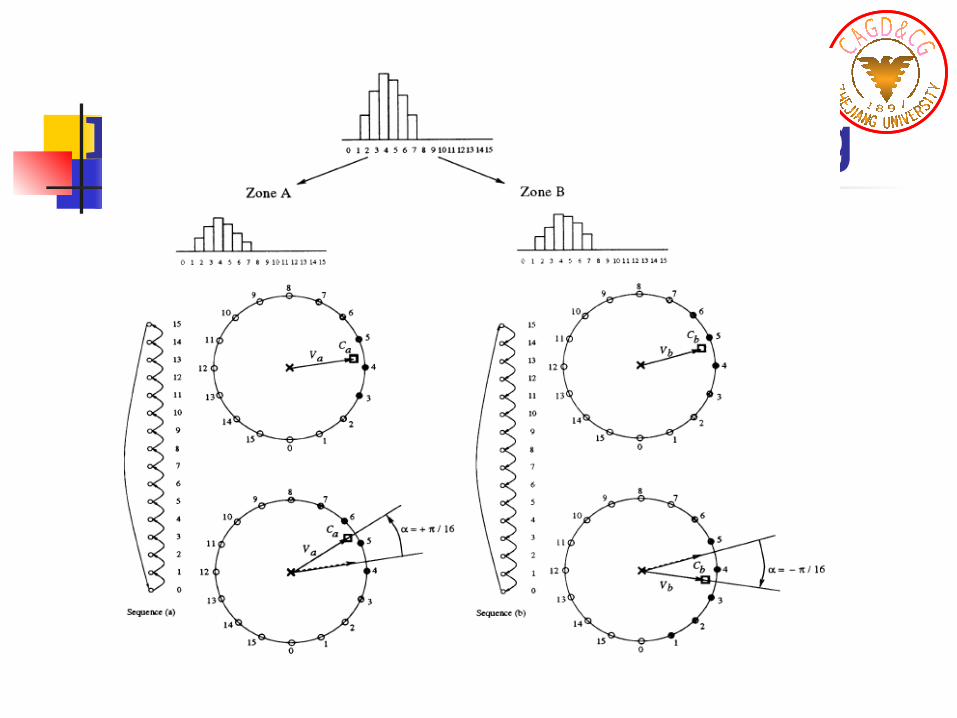
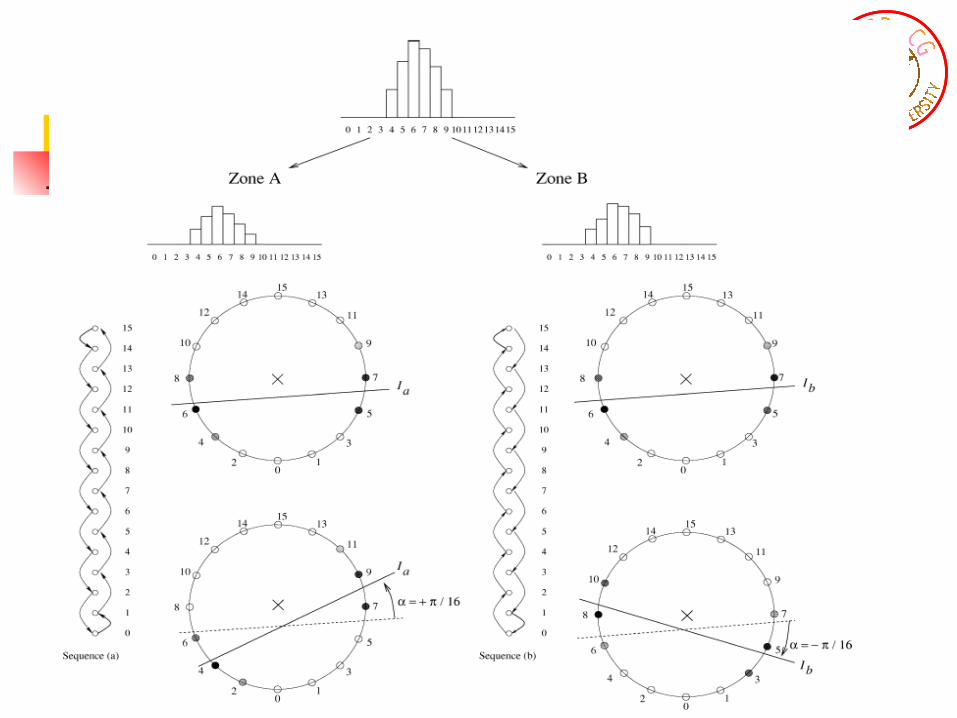
1. Partition the image into blocks and zones A and B.2. Zones A and B have close average values before e
mbedding.3. Histograms of each zone are mapped to the circle.
For both zones, the center of mass is computed.4. Let a be the angle between the vectors Ca and Cb , p
ointing from the circle center to each center of mass.
5. The sign of a provides the direction of rotation during the embedding process and enables bit retrieval and reversibility.
6. Once the embedded bit has been retrieved, the original block can be recovered.
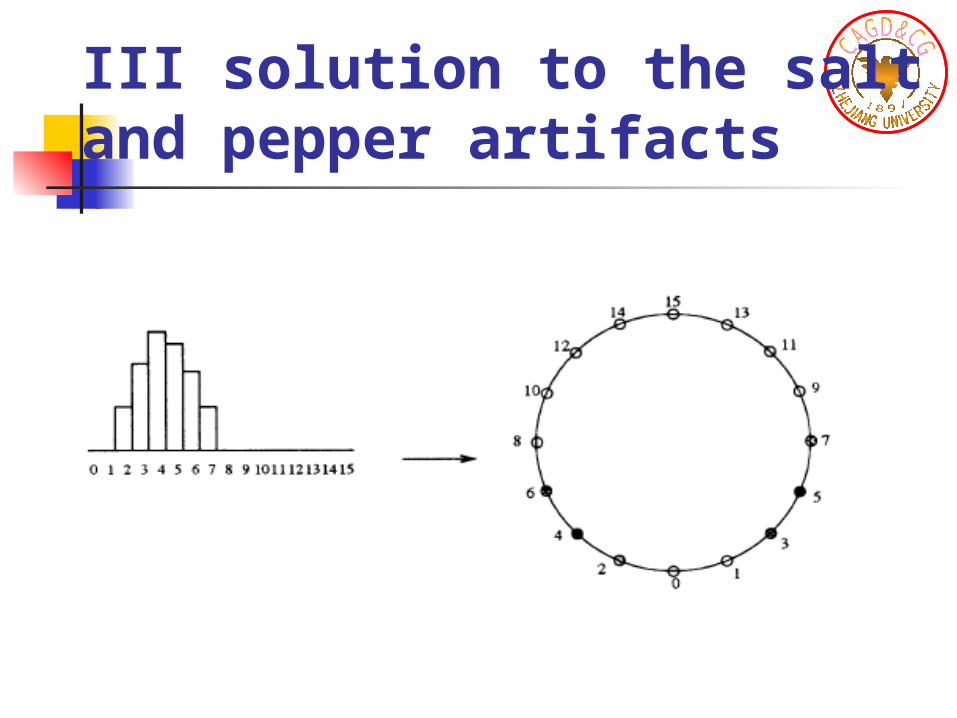
III solution to the salt and pepper artifacts




Robust Lossless Image Data Hiding Designed for Semi-Fragile Image Authentication
Zhicheng Ni, Yun-Qing Shi, Nirwan Ansari, and Wei SuIEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VI
DEO TECHNOLOGY,April 2008

I a novel robust lossless image data hiding algorithm
A Robust Statistical Quantity Used to Embed Data
1. Consider a given 8×8 image block, we split it into two sets A and B
2. For each block, we calculate the difference value , which is defined as the arithmetic average of differences of grayscale values of pixel pairs within the block.

Differentiating Bit-Embedding Schemes Based on Different Grayscale Distributions Within a Block of Pixels
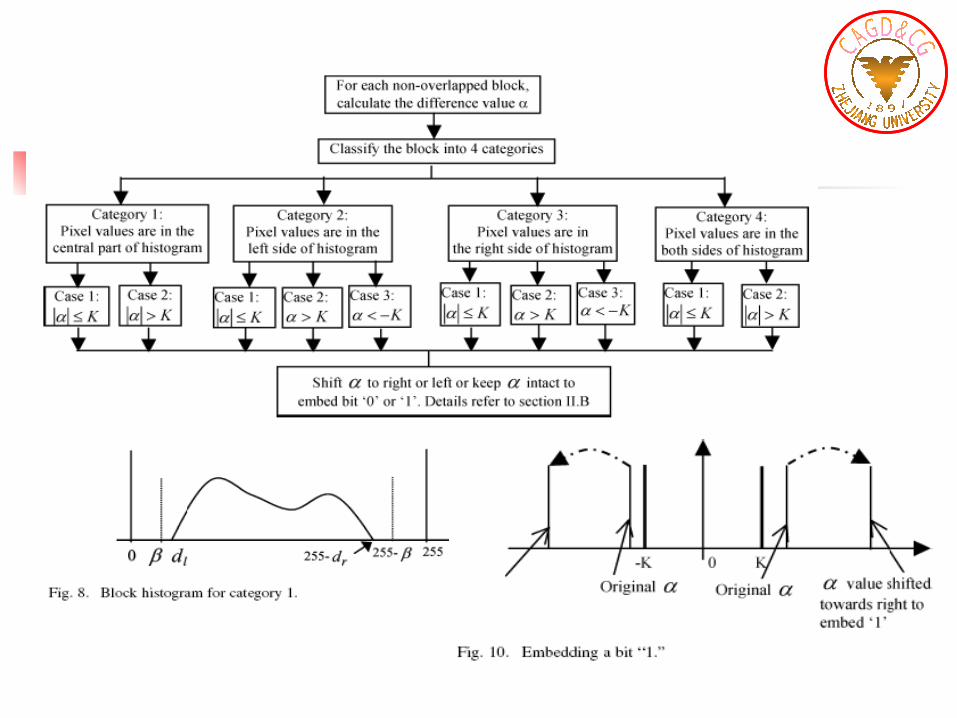
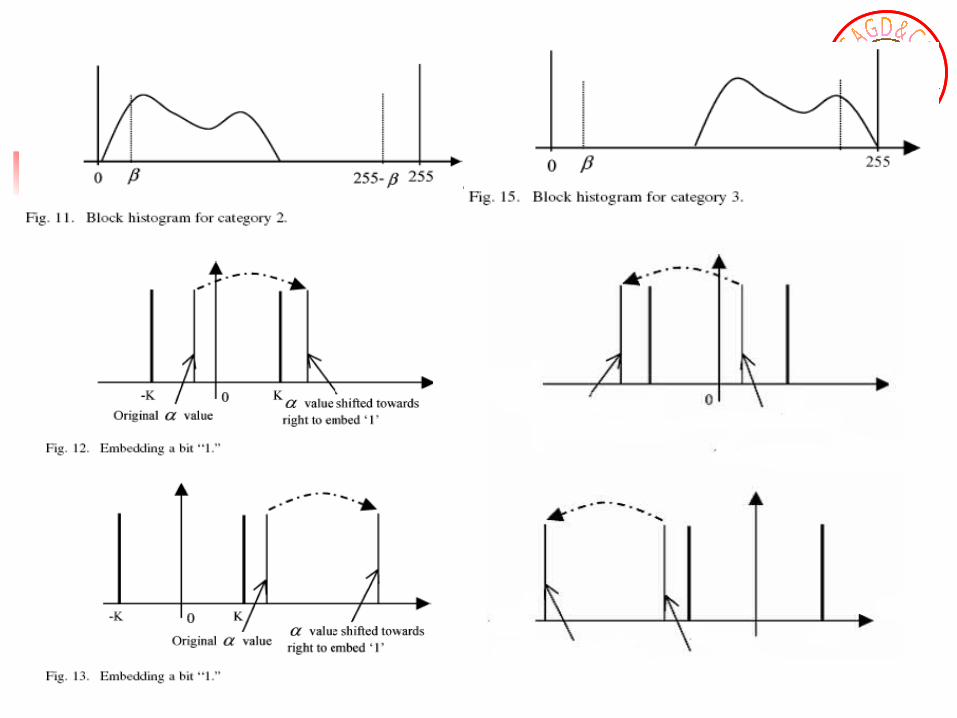
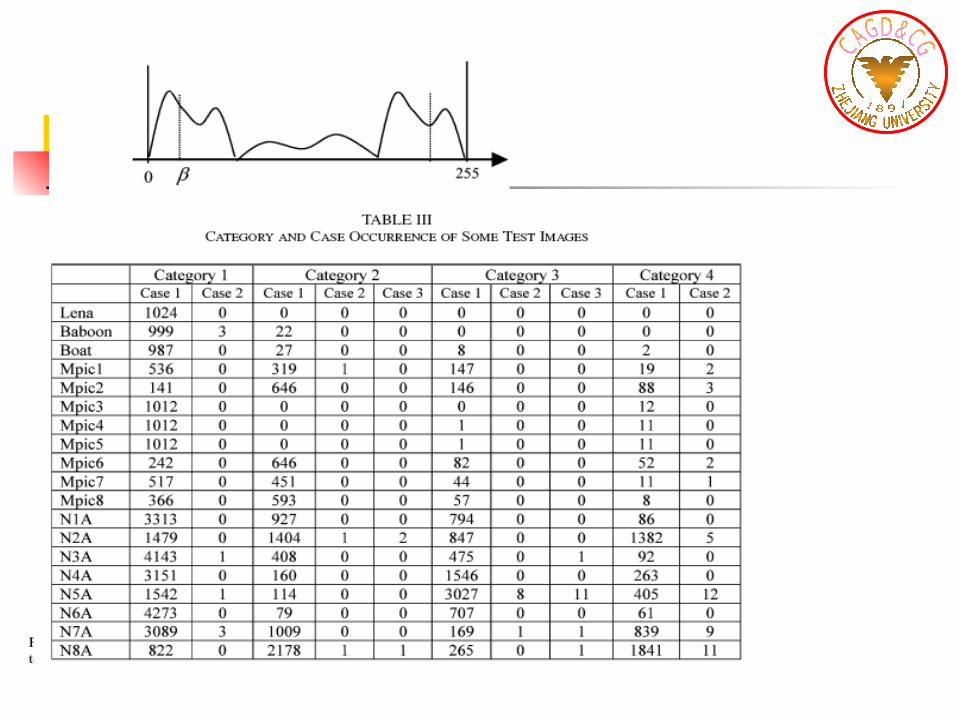
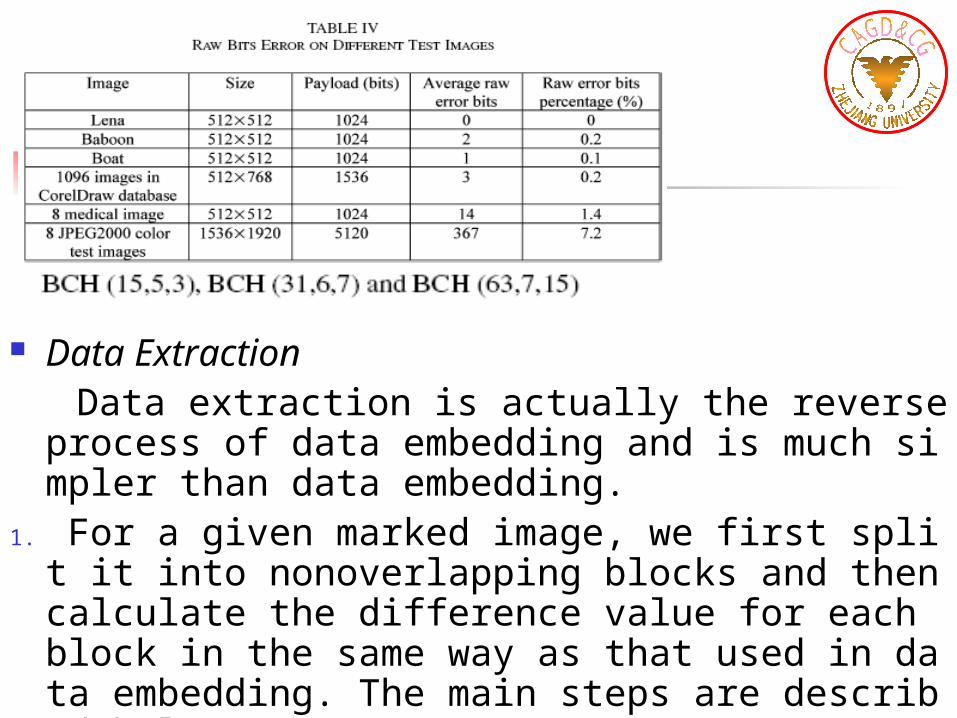
Data Extraction Data extraction is actually the reverse process of dat
a embedding and is much simpler than data embedding.
1. For a given marked image, we first split it into nonoverlapping blocks and then calculate the difference value for each block in the same way as that used in data embedding. The main steps are described below.

2. If the absolute difference value is larger than the threshold K, the grayscale value distribution of the block is then examined. If the block is identified as Case 3 in Category 2, Case 2 in Category 3, or Case 2 in Category 4,the bit “0” is extracted, and the block remains unchanged. Otherwise, bit “1” is extracted and the difference value is shifted back towards the zero point by adding or subtracting the quantity.
3. If the absolute value of the difference value is less than the threshold K, then bit “0” is extracted, and nothing to do on the pixel grayscale value of that block. Note that by combining this step and the above step in data extraction, it is obvious that all pixel grayscale values will be the same as in the original image.
4. After data extraction, the inverse permutation and the ECC decoding are applied, respectively, so as to obtain the original information bits correctly. In this way, we can extract the original information bits and recover the original image without any distortion.
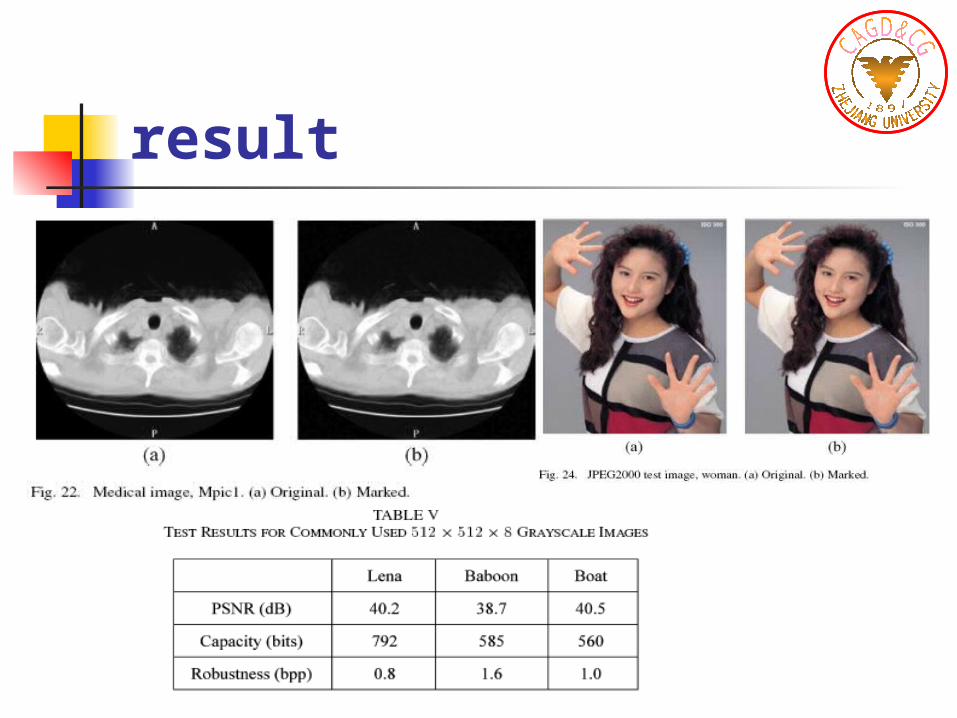
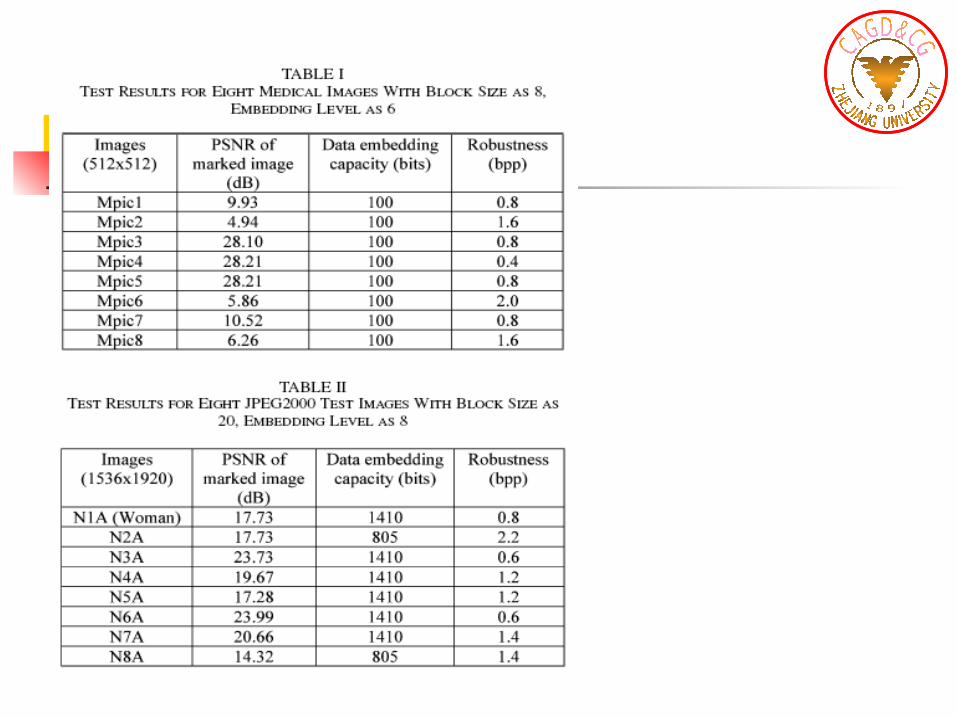
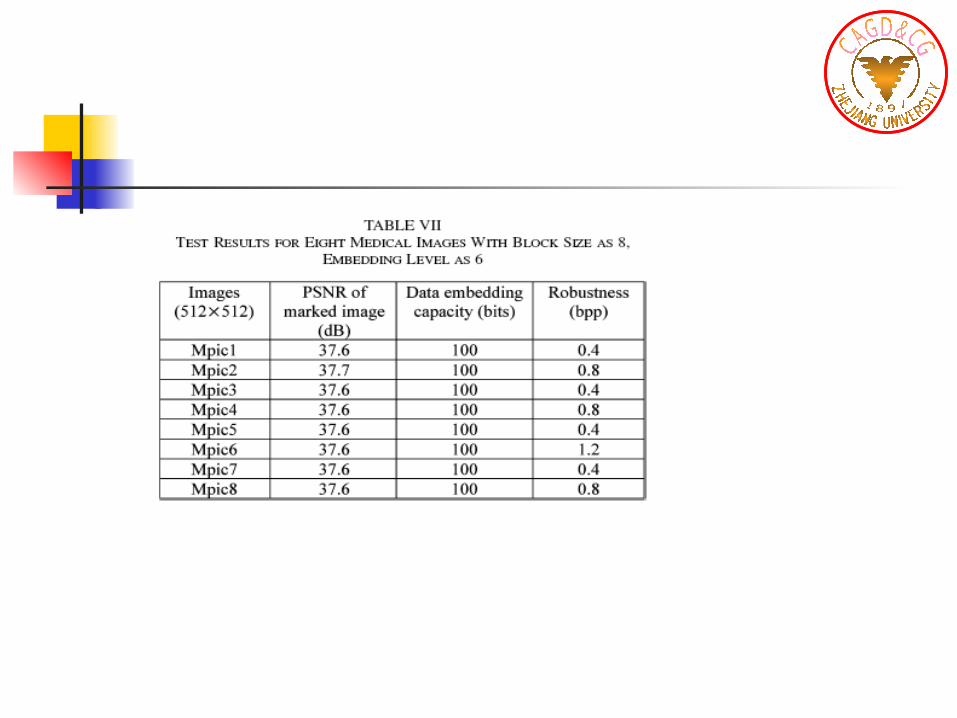
result














![Athena: Capacity Enhancement of Reversible Data …... Capacity Enhancement of Reversible Data ... a histogram-based scheme using pixel differences was proposed [2]. ... The histogram-based](https://img.pdfslide.us/doc/110x75/5ada54e37f8b9ae1768d0526/athena-capacity-enhancement-of-reversible-data-capacity-enhancement-of.jpg)














