Embed Size (px)
Citation preview

Hindawi Publishing CorporationVLSI DesignVolume 2013 Article ID 936181 16 pageshttpdxdoiorg1011552013936181
Research ArticleFramework for Simulation of Heterogeneous MpSoC forDesign Space Exploration
Bisrat Tafesse and Venkatesan Muthukumar
Department of Electrical and Computer Engineering University of Nevada Las Vegas 4505 Maryland Pkwy Las VegasNV 89154 USA
Correspondence should be addressed to Venkatesan Muthukumar venkatesanmuthukumarunlvedu
Received 8 October 2012 Revised 29 January 2013 Accepted 14 April 2013
Academic Editor Paul Bogdan
Copyright copy 2013 B Tafesse and V Muthukumar This is an open access article distributed under the Creative CommonsAttribution License which permits unrestricted use distribution and reproduction in any medium provided the original work isproperly cited
Due to the ever-growing requirements in high performance data computation multiprocessor systems have been proposedto solve the bottlenecks in uniprocessor systems Developing efficient multiprocessor systems requires effective exploration ofdesign choices like application scheduling mapping and architecture design Also fault tolerance in multiprocessors needs tobe addressed With the advent of nanometer-process technology for chip manufacturing realization of multiprocessors on SoC(MpSoC) is an active field of research Developing efficient low power fault-tolerant task scheduling and mapping techniquesfor MpSoCs require optimized algorithms that consider the various scenarios inherent in multiprocessor environments Thereforethere exists a need to develop a simulation framework to explore and evaluate new algorithms on multiprocessor systems Thiswork proposes a modular framework for the exploration and evaluation of various design algorithms forMpSoC systemThis workalso proposes new multiprocessor task scheduling and mapping algorithms for MpSoCs These algorithms are evaluated usingthe developed simulation framework The paper also proposes a dynamic fault-tolerant (FT) scheduling and mapping algorithmfor robust application processing The proposed algorithms consider optimizing the power as one of the design constraints Theframework for a heterogeneous multiprocessor simulation was developed using SystemCC++ language Various design variationswere implemented and evaluated using standard task graphs Performance evaluation metrics are evaluated and discussed forvarious design scenarios
1 Introduction
Current uniprocessor systems guarantee high processor uti-lization however they fall short in meeting critical realtime demands that require (1) high data throughput (2) fastprocessing time (3) low energy and power consumptionsand (4) fault tolerance Present-day applications that runon embedded or uniprocessor systems such as multimediadigital signal processing image processing andwireless com-munication require an ever-growing amount of resourcesand speed for data processing and storage which can nolonger be satisfied by uniprocessor systems [1] The increas-ing performance demand dictates the need for concurrenttask processing on multiprocessor systems MultiprocessorSoC (MpSoC) systems have emerged as a viable alternate
to address the bottlenecks of uniprocessor systems In aneffort to improve the processing performancemultiprocessorsystems incorporate a number of processors or processingelements (PEs) A typical MpSoC system is composed of thefollowing major components
(1) multiple processing elements (PEs) that perform thetask execution
(2) multiple memory elements (MEs) that are used fordata storage and
(3) a communication network that interconnects theprocessors and memories in a manner defined by thetopology
Heterogeneity in MpSoCs [2] is described as the variationof the functionality and flexibility of the processor or the
2 VLSI Design
memory element Heterogeneous processors in MpSoCs canbe programmable or dedicated (nonprogrammable) proces-sors Also memory elements can be heterogeneous withrespect to their memory type size access mode and clockcycles To transfer the data to and from the processingand memory elements the network component may includebusses switches crossbars and routers
Present-day MpSoC architectures employ most of theabove discussed components [3] In fact to effectively meettodayrsquos complex design requirements modern multiproces-sor systems are real time preemptive and heterogeneous [4]For data exchange memory elements inMpSoCs often followeither distributed memory architecture (message passing) ora global shared memory architecture [5ndash7]
An efficient MpSoC is based upon several key designchoices also known as design space exploration networktopology selection good routing policy efficient applicationscheduling mapping and the overall framework implemen-tation A formal categorization of MpSoC design issuespresented in [8] is summarized below Design methodolo-gies in multiprocessor systems (MpSoC and NoC) havebeen classified as follows (1) application characterizationscheduling andmapping (2) processing memory switchingand communication architecture modeling developmentand analysis and (3) simulation synthesis and emulationframework
Major design features that need to be addressed formultiprocessors are task scheduling mapping and faulttoleranceThis work concentrates on developing a simulationframework formultiprocessors on a single chip (MpSoC) thatsimplifies design space exploration by offering comprehen-sive simulation supportThe simulation framework allows theuser to optimize the system design by evaluating multipledesign choices in scheduling mapping and fault tolerancefor the given design constraints TILE andTORUS topologieswhich are common layouts inmultiprocessing environmentsare supported in this framework
Using the developed MpSoC simulation frameworkwe propose and evaluate (1) an efficient strategy for taskscheduling called the performance driven scheduling (PDS)algorithmbased on SimulatedAnnealing heuristic that deter-mines an optimal schedule for a given application (2) a newmapping policy called Homogenous Workload Distribution(HWD) which maps tasks to processors by consideringprocessors runtime status and (3) finally in an effort toimplement a robust system a simple fault-tolerant (FT) algo-rithm that reconfigures task execution sequence of the systemin the event of processor failure Heterogeneity in processorarchitecture is a key design feature in multiprocessor systemsand therefore is modeled in this framework Even thoughmany earlier multiprocessor designs solve the scheduling andmapping problem together our framework considers themindividually for fault-tolerance
In summary the research presented in this paperaddresses the following issues and solutions
(1) Develop a comprehensive MpSoC framework imple-mented using C++ and SystemC programminglanguages for effective exploration of design choices
like application scheduling mapping and architec-ture design
(2) The developed system can also evaluate MpSoCsystem architecture design choices differing in thenumber and type of processing elements (PEs) andtopology
(3) The paper proposes a heuristic scheduling algorithmbased on Simulated Annealing
(4) Also a mapping algorithm that distributes the work-load among the available PE is proposed
(5) Finally a centralized fault-tolerant scheme to handlefaults in PEs is proposed
This paper is organized as follows Section 2 briefly sum-marizes previousworks in the field ofmultiprocessor systemsSection 3 provides definitions and terminologies used in thiswork Section 4 presents the framework description as wellas the proposed algorithms and their implementation intask scheduling mapping and fault tolerance techniquesSection 5 discusses the experimental setup for simulationand evaluations Section 6 discusses the detailed simulationresults and the analysis of the algorithms on benchmarksFinally Section 7 summarizes the conclusions
2 MpSoC Design Literature Review
Extensive work has been done in the field of MpSoC- andNoC-based systems Earlier research targeted a variety ofsolutions including processor architecture router designrouting and switching algorithms scheduling mapping faulttolerance and application execution in multiprocessors toaddress the performance and area demands The readerscan refer to [8ndash10] for an extensive enumeration of NoCresearch problems and proposed solutions In this sectionwe concentrate on the earlier proposed scheduling mappingand fault-tolerant algorithms It has been shown that earlierscheduling algorithms like FCFS and Least Laxity [7] fail toqualify as acceptable choices of scheduling because they areunable to meet deadline (hard deadlines) requirements forreal-time applications Thai [7] proposed Earliest EffectiveDeadline First (EEDF) scheduling algorithm This workdemonstrated that increasing the number of processors toimprove the scheduling success increased the size of thearchitecture which makes task scheduling more difficultStuijk et al [11] proposed dynamic scheduling and routingstrategies to increase resource utilization by exploiting allthe scheduling freedom on the multiprocessors This workconsidered application dynamism to schedule applications onmultiprocessors both for regular and irregular tiled topologyHu and Marculescu [12] propose an algorithm based on listscheduling where mapping is performed to optimize energyconsumption and performance Varatkar and Marculescu[13] propose an ILP-based scheduling algorithm that min-imizes interprocess communication in NoCs Zhang et al[14] propose approximate algorithms for powerminimizationof EDF and RM schedules using voltage and frequencyscaling Also other researchers [15ndash17] have used dynamic
VLSI Design 3
voltage scaling in conjunction with scheduling for low powerrequirements
Finding an optimal solution in scheduling and mappingproblem domain for set of real-time tasks has been shownto be NP-hard problem [11] Carvalho et al [18] proposeda ldquocongestion-awarerdquo mapping heuristic to dynamically maptasks on heterogeneous MpSoCs This heuristic approachinitially assigns master-tasks to selected processors and theslave-tasks are allocated on congestion minimizing mannerto reduce the communication traffic Sesame project [4]proposed a multiprocessor model that maps applicationstogether with the communication channels on the architec-ture This model tries to minimize an objective functionwhich considers power consumption application execu-tion time and total cost of the architectural design Manyresearchers have discussed static and dynamic task allocationfor deterministic and non-deterministic tasks extensively [5]Static mapping has also been shown non-efficient strategybecause it does not take application dynamism into accountthat is a core design issues in multiprocessor systems Ahnet al [19] suggests that real-time applications should behavedeterministically even in unpredictable environments sothat the tasks can be processed in real-time Ostler andChatha [20] propose an ILP formulation for applicationmapping on network processors Harmanani and Farah[21] propose an efficient mapping and routing algorithmthat minimizes blocking and increases bandwidth based onsimulated annealing Also mapping algorithms to minimizecommunication cost energy bandwidth and latency eitherindividually [22ndash24] or as a multi-objective criteria [25 26]have been proposed
Task migration as opposed to dynamic mapping has beenproposed in [4] to overcome performance bottlenecks Taskmigration may result in performance improvement in sharedmemory systems butmay not be feasible when considered fordistributed memory architectures due to the high volume ofinter-processor data communication [5]
Previous research in [5 6 27] has demonstrated reliabilityissues regarding application processing data routing andcommunication link failure Zhu andQin [28] demonstrateda system level design framework for a tiled architecture toconstruct a reliable computing platform from potentiallyunreliable chip resources This work proposed a fault modelwhere faults may have transient and permanent behaviourTransient errors are monitored by a dedicated built-inchecker processor that effectively corrects the fault at run-time Nurmi et al [6] demonstrated error tolerance methodsthrough time space and data redundancy This is however aclassic and costly approach with respect to system resourcesand bandwidth though thework demonstrated redundancy isone potential approach to address faulty scenarios Holsmarket al [29] proposed a fault tolerant deadlock free algorithm(APSRA) for heterogeneous multiprocessors APSRA storesrouting information in memory to monitor faulty routsand allow re-configurability dynamically Pirretti et al [30]and Bertozzi et al [31] propose NoC routing algorithmsthat can route tasks around the fault and sustain networkfunctionality Also research on router design to improvereliability [32] buffer flow control [33] and error correction
techniques [34 35] for NoC have been proposed Koibuchiet al [36] proposed a lightweight fault-tolerant mechanismcalled default backup path (DBP) The approach proposed asolution for non-faulty routers and healthy PEs They designNoC routers with special buffers and switch matrix elementsto re-route packets through special paths Also Bogdanet al [37] propose an on-chip stochastic communicationparadigm based on probabilistic broadcasting scheme thattakes advantage of the large bandwidth available on the chipIn their method messagespackets are diffused across thenetwork using spreaders and are guaranteed to be receivedby destination tilesprocessors
A number of EDA research groups are studying differentaspects of MpSoC design some of which include the fol-lowing (1) Polis [18] is a framework based on both micro-controllers and ASICs for software and hardware imple-mentation (2) Metropolis [18] is an extension of Polis thatproposed a unified modeling and structure for simulatingcomputationmodels (3) Ptolemy [18] is a flexible frameworkfor simulating and prototyping heterogeneous systems (4)Thiele et al [1] proposed a simulation based on distributedoperation layer (DOL) which considers concurrency scal-ability mapping optimization and performance analysisin an effort to yield faster simulation time (5) NetChipxpipes xpipes compiler and SUNMAP NetChip is a NoCsynthesis environment primarily composed of two toolsnamely SUNMAP [38] and the xpipes compiler [39] (6)NNSENostrumNoCSimulationEnvironmentNNSE [40] isa SystemC-based NoC simulation environment initially usedfor theNostrumNoC (7) ARTSModeling Framework ARTS[41] is a system-level framework to model networked multi-processor systems on chip (MpSoC) and evaluate the cross-layer causality between the application the operating system(OS) and the platform architecture (8) StepNP a System-Level Exploration Platform for Network Processors StepNP[42] is a System-Level Exploration Platform for NetworkProcessing built in SystemC It enables the creation of multi-processor architectures with models of interconnects (func-tional channels NoCs) processors (simple RISC) memoriesand coprocessors (9) Genko et al [43] present a flexible emu-lation environment implemented on an FPGA that is suitableto explore evaluate and compare a wide range of NoCsolutions with a very limited effort (10) Coppola et al [44]proposes an efficient open-source research and developmentframework (On-Chip Communication Network (OCCN))for the specification modeling and simulation of on-chipcommunication architectures (11) Zeferino and Susin [45]present SoCIN a scalable network based on a parametricrouter architecture to be used in the synthesis of customizedlow cost NoCs The architecture of SoCIN and its router aredescribed and some synthesis results are presented
The following papers presented are the closest worksrelated to the proposed algorithms discussed in this paperOrsila et al [46] investigated the use of Simulated Annealing-based mapping algorithm to optimize energy and perfor-mance on heterogeneous multiprocessor architecture Inspecific the cost function considered for SA optimization
4 VLSI Design
includes processor area frequency of operation and switch-ing activity factor The work compares the performance oftheir SA-mapping algorithms for different heterogeneousarchitectures In another similar work [47] proposed bythe same author the SA-mapping algorithm is adoptedto optimize usage of on-chip memory buffers Their workemploys a B-level scheduler after the mapping process toschedule tasks on each processor
The proposed framework discussed in this paper employsSA-based scheduling and workload balanced mapping algo-rithms Our algorithms also optimize scheduling andmapping cost functions that include processor utilizationthroughput buffer utilization and port traffic along withprocessor power In addition our algorithms also considertask deadline constraints Both scheduling and mappingalgorithms adopted in ourwork perform global optimization
Paterna et al [48] propose two workload allocationmapping algorithms for energy minimization The algo-rithms are based on integer linear programming and a two-stage-heuristic mapping algorithm based on linear program-ming and bin packing policies Teodorescu and Torrellas[49] and Lide et al [50 51] explore workload-based map-ping algorithms for independent tasks and dependent tasksrespectively The work by Zhang et al is based on ILPoptimization for execution time and energy minimizationOur proposed mapping algorithm varies from the above-specified workload constrained algorithms by consideringthe buffer size usage and execution time of the tasks in thebuffer
Works by Ababei and Katti [52] and Derin et al [53]have used remapping strategies forNoC fault tolerance In thesolution proposed by Ababei and Katti [52] fault tolerancein NoCs is achieved by adaptive remapping They considersingle and multiple processor (PE) failures The remappingalgorithm optimizes the remap energy and communicationcosts They perform comparisons with a SA-based remapperOrsila et al [46] propose an online remapping strategycalled local nonidentical multiprocessor scheduling heuristic(LNMS) based on integer linear programming (ILP) TheILP minimizing cost functions include communication andexecution time The proposed NoC fault-tolerant algorithmemploys rescheduling and remapping strategies to optimizeprocessor performance and communication cost Also taskdeadline constraints are considered during the reschedulingand remapping
With the current design trends moving towards mul-tiprocessor systems for high performance and embeddedsystem applications the need to develop comprehensivedesign space exploration techniques has gained importanceMany research contributions in development of hardwaremodules and memory synchronization to optimize powerperformance and area for multiprocessor systems are beingdeveloped However algorithmic development for multipro-cessor systems like multiprocessor scheduling and mappinghas yielded significant results Therefore a comprehensiveand generic framework for a multi-processor system isrequired to evaluate the algorithmic contributionsThis workaddresses the above requirement in developing a compre-hensive MpSoC evaluation framework for evaluating many
scheduling mapping and fault-tolerant algorithms Also theframework is developed on generic modeling or represen-tation of applications (task graphs) architecture processorstopologies communication costs and so forth resulting in acomprehensive design exploration environment
The main contributions of this work can be summarizedas follows
(1) We propose a unique scheduling algorithm forMpSoC system called performance driven schedulingalgorithm that is based on Simulated Annealing andoptimizes an array of performance metrics such astask execution time processor utilization processorthroughput buffer utilization and port traffic andpower The proposed algorithm performance is com-pared to that of the classical earliest deadline firstscheduling algorithm
(2) This paper proposes a mapping algorithm that suc-ceeded the scheduling algorithm called the homo-geneous workload distribution algorithm that dis-tributes tasks evenly to the available processors in aneffort to balance the dynamic workload throughoutthe processors The proposed algorithm performanceis compared with other classical mapping algorithm
(3) Also a fault-tolerant scheme that is effective duringPE failure is proposed in this paper The proposedfault-tolerant (FT) scheme performs an updatedscheduling and mapping of the tasks assigning to thefailed PE when the PE fault is detected The uniquecontribution of this work is the fact that it addressesthe pending and executing tasks in the faulty PEsThe latency overhead of the proposed FT algorithmis evaluated by experimentation
3 Definitions and Theory
Simulation Model The simulation model consists of threesubmodels (Figure 1) (1) application (2) architecture and (3)topologyThe applicationmodel represents the application tobe executed on the given MpSoC architecture and connectedby the topology specified
Application Model (Task Graphs) A task graph is a directedacyclic graph (DAG) that represents an application A taskgraph is denoted as TG such that TG = (119881 119864) where 119881 is aset of nodes and 119864 is a set of edges A node in 119881 representsa task such that 119881 = 119879
1 1198792 1198793 119879
119873 and an edge in
119864 represents the communication dependency between thetasks such that 119864 = 119862
1 1198622 1198623 119862
119870 A weighted edge
if specified denotes the communication cost incurred totransfer data from a source task to destination task Eachtask can exist in a processor in one of the following statesideal pending ready active running or complete The taskgraph is derived by parsing the high-level description of anapplication
Architecture Model The architecture of the MpSoC sys-tem consists of the processors hardware components
VLSI Design 5
pending readyactive running
TG =
Processormemoryarchitecture type
power clock-rateinterrupt memory
NG =
PE
PE
PE
PE
PE
PE
PE
PEM
M
M
PE PEPE
PE
PE
PE PE
PE
PE
PE PE
PE
PE
PE
⟩
complete⟩
NG ⟨
⟨
processor type topology⟩
Task ⟨119879119868119863
Task status ⟨ideal
TtypeTrelease timeTexec timeTdeadline Tadress TDlist
(V E) V = T1 T2 T3 middot middot middot T9E = C1 C2 C3 middot middot middot CK
T1
T2T3
T4
T5T6 T7
T8
T9
ARCH = P1 P2 P3 middot middot middot PNM1 M2 M3 middot middot middot MK
(V E)V = Pi Mi E = C1 middot middot middot CL
Figure 1 Simulation model containing application architecture and topology
memory and interconnects as defined by the topologymodel The MpSoC architecture is represented as a set1198751 1198752 1198753 119875
119873119872111987221198723 119872
119870 where119875
1 1198752 119875
119899
are a set of 119873 processors and 11987211198722 119872
119870are a set
of 119870 memory units Each processor 119875119894or memory 119872
119894is
defined by the following characteristics type powertaskexecutiontask clock rate preempt overhead and also by a setof tasks 119879
119886 119879119887 119879119888 119879
119911 each processor can execute along
with their respective execution times and power costs Theimplemented heterogeneousMpSoC consists of processors ofthe same architecture but can execute various set of tasks
Topology Model (Topology Graph) Topology describes thephysical layout of hardware components in a system Thetopology model is represented as a topology graph (NG) thatconsists of the set of processors topology type ⟨tile torus⟩and communication cost This communication cost is thesame communication cost (119864) as defined in the applicationmodel
Scheduling Scheduling is the process of assigning an execu-tion start time instance to all tasks in an application such thattasks are executed within their respective deadline For anapplication 119860 = 119879
1 1198792sdot sdot sdot 119879119873 where 119879
119894is a task instance in
the application task scheduling denoted as 120572(119879119894) is defined
as an assignment of execution start time (119905119894) for the task 119879
119894in
the time domain such that
120572 (119879119894) = 119905119894 119905
119894+ 119890119894le 119889119894 (1)
where 119890119894is the worst-case execution time of the task on a
specific processor 119889119894is the deadline of the task119879
119894 and 119905
119894is the
execution start time of task 119879119894 Scheduling of an application
119860 is denoted as
120572 (119860) = 120572 (1198791) 120572 (119879
2) 120572 (119879
3) sdot sdot sdot 120572 (119879
119873) (2)
If there exists a precedence operation between any two taskssuch that the execution of a task 119879
119894should occur before the
execution of task 119879119895 represented as 119879
119894lt 119879119895 then
119905119894+ 119890119894le 119905119895le 119889119894 119905
119895+ 119890119895le 119889119895 (3)
where 119905119894is the start time of task 119879
119895 and 119890
119895and 119889
119895are the
execution time and deadline of task 119879119895 respectively
Performance Index (PI) PI is the cumulative cost functionused to determine the optimal schedule by using the Sim-ulated Annealing technique PI quantifies the performanceof the system taking into consideration the averaged valuesof processor execution time (ETIME) utilization (UTL)throughput (THR) buffer utilizationusage (BFR) port traf-fic (PRT) and power (PWR) PI is evaluated by a costfunction that is expressed as
COST = 1205721(
1
ETIME) + 1205722(
1
UTL) + 1205723(
1
THR)
+ 1205724(
1
BFR) + 1205725(PRT) + 120572
6(PWR)
(4)
where 1205721sim 1205726are normalizing constants
6 VLSI Design
The Simulated Annealing procedure compares the per-formance of successive design choices based on the PIExecution time processor utilization processor throughputand buffer utilization are maximized so that their costis computed reciprocally however power and port trafficare minimized so that the nonreciprocal values are takenThe coefficient values in the cost equation are set accordingto the desired performance goals of the system
Optimization of Scheduling Algorithm The problem of deter-mining optimal scheduling is to determine the optimal starttime and execution time of all tasks in the application
minimize(119873
sum
119894=1
(119905119894+ 119890119894))
minimize(119873
sum
119894=1
COST (120572 (119879119894))) 119905
119899+ 119890119899le DL
(5)
where 119890119894is the worst-case execution time of each task 119879
119894
DL is the deadline of the application and 119905119899and 119890119899are the
start time and worst-case execution time of the last taskrespectively in the application COST (120572(119879
119894)) is the cost
function of scheduling the tasks
Mapping Mapping is the process of assigning each task in anapplication to a processor such that the processor executes thetask and satisfies the task deadline as well as other constraints(power throughput completion time) if any
For an application 119860 = 1198791 1198792sdot sdot sdot 119879119873 where 119879
119894is a
task instance in the application mapping a task denoted as119872(119879119894) is defined as an assignment of the processor 119875
119895 =
1198751 1198752 119875
119872 = 119875 for the task 119879
119894
119872(119879119894) = 119875
119895 (6)
Application mapping is defined as mapping of all tasks 119879119894 in
the application 119860 to processors and is denoted as
119872(119860) = 119872 (1198791) 119872 (119879
2) sdot sdot sdot119872 (119879
119873) (7)
Optimization of the Mapping Algorithm The problem indetermining optimummapping is to determine the optimumallocation of all tasks in the application on the processorssuch that the total execution time of all tasks is minimizedOther factors for optimum mapping include maximizingprocessor execution time throughput minimizing inter-processor communication delay and balancing workloadhomogenously on the processors in order to improve utiliza-tion
minimize(119873
sum
119894=1
(119888119894)) 119888
119894= COST (119872 (119879
119894)) (8)
where 119888119894is the cost function for optimal mapping of the tasks
on the processor
Power Modeling In this research scheduling and mappingalgorithms model heterogeneous processor execution andpower requirements as follows
(1) Switch power is consumed whenever a task is routedfrom input port to output port
(2) Processor power is modeled with respect to idle-mode (also includes pending ready active and com-plete) and execution-mode (running) power both ofwhich are functions of the task execution time 119890
119894 We
also assume that for the idle model Δ120578 = 0
120578119894(119879119894) = Δ120578 lowast 119890
119894 (9)
whereΔ120578 is the unit power consumed per unit time oftask processingThe total power rating for a processor119875119895would be expressed as
120578119895= Δ120578 lowast
119899
sum
119894=1
(119890119894) (10)
where 119899 is the number of tasks executed by theprocessor
(3) Whenever a task 119879119896is executed on processor 119875
119897
the execution time 119890119896and the power consumed by
processor 120578119896are updated as
120578119897(119879119896) = Δ120578 lowast 119890
119896
120578119897= Δ120578 lowast
119899
sum
119894=1
(119890119896)
(11)
(4) Whenever a task is transferred between switchesthe communication delay is updated on the TotalTask Communication Delay parameter (T) and isexpressed as
T = 119899 lowast v lowast Δ119862 (12)
where 119899 is number of switch hopes task-size (v) is thesize of the task defined as a function of its executiontime in time-units and Δ119862 is a time constant that isrequired to transfer single time-unit task for one hop
(5) For each task 119879119894 the Task Slack Time 119878
119894and Average
Slack Time 119878 are calculated as
119878119894= 119889119894minus [119905119894+ 119890119894]
119878 =
sum
119873
119894=1(119878119894)
119873
(13)
where 119889119894is the deadline 119905
119894is the release time and119873
is the total number of tasks processed
Fault-Tolerant System A fault-tolerant system describes arobust system that is capable of sustaining application pro-cessing in the event of component failure A fault-tolerantalgorithm is a process that performs scheduling andmappingon a set of unprocessed tasks for the available processors
Let an application119860with a set of tasks119860 = 1198791 1198792sdot sdot sdot 119879119873
be scheduled denoted by 120572(119860) and mapped on the set
VLSI Design 7
of processors 119875 = 1198751 1198752 119875
119872 denoted as 119872(119860) A
fault is defined as a nonrecurring permanent failure of aprocessor at time instance 119905
119891during the execution of a
task 119879119891 The application after the occurrence of the fault is
expressed as 119860119891such that 119860
119891sub 119860 which has a list of tasks
119860119891= 119879119892 119879ℎsdot sdot sdot 119879119899 that are not dispatched to processors
by the mapper when the processor failure occurs The set ofprocessors after the failure119865 is denoted by 119875
119891= 1198751 1198752sdot sdot sdot 119875119871
and 119875 notin 119875119891 where 119875
119891is the failed processor The proposed
fault-tolerant MpSoC framework determines the updatedscheduling 120572(119860
119891) and updated mapping119872(119860
119891) for a set of
unprocessed tasks in the application subset 119860119891 such that
119905119899+ 119890119899le DL (14)
where 119905119899and 119890
119899are the start time and execution time
respectively of the last scheduled task in 119860119891
Optimization of Fault-Tolerant Strategy Due to the dynamicmapping methodology adopted in the framework only thetasks dispatched to the failed processormdashwhich includes thetask that was executing on the failed processor and thetasks dispatched by the mapper to the failed processormdashwillneed to be rescheduled along with the tasks that were notdispatched by the mapper
Let us consider an application 119860119891with a list of 119899 tasks
119860119891
= 119879119892 119879ℎsdot sdot sdot 119879119899 that have not been dispatched to
processors at the occurrence of the fault Also let the tasks119879119887= 119879119903sdot sdot sdot 119879119905 be the list of tasks in the buffer of the failed
processor 119875119891and let 119879
119901be the task that was being executed
during failure by the failed processor The task list 119879FT of thefault tolerant algorithm at time 119905
119891is represented as
119879FT = 119860119891+ 119879119887+ 119879119891 (15)
It is also assumed that all the tasks that are being executedby the nonfailed processor complete the execution of thetasks even after the time of failure 119905
119891 Thus the FT algorithm
performs the updated scheduling (119879FT) and updated map-ping
119872(119879FT) on the task set 119879FT which satisfies the deadlineconstraint DL of the application 119860
4 Framework Modeling and Implementation
The proposed framework adopts a ldquobottom-uprdquo modulardesign methodology that gives the benefit of componentreusability Behavioral componentmodels were designed andstored in hardware and software librariesThe frameworkwasimplemented in SystemC 22C++ and compiled with g++-43 under Linux The framework is divided into three majorcomponents input or user interface module core MpSoCsimulation module and the output or performance evalua-tion module The hardware modules such as the processorswitch dispatcher unit and multiplexer were implementedin SystemC the software modules such as input parserscheduler and task interface classes were implemented inC++
Input Module Such userrsquos data as the number of processorstopology task graph processor types buffer size switching
Software libraries
Settings
Task interface
Other IPs
Main GUI
TG parser
Scheduler
Mapper
Dispatcher
Switch
Processor
Multiplexer
ARCH setup
Performance evaluation
PE
PE
PE
PE
PE PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
Hardware libraries
Figure 2 Framework modeling
technology fault-tolerant mode and schedulingmappingspecifications are read either by using a command lineinterface or else from a GUI interface
Core Simulation Module The core simulation module isdepicted in Figure 2 which shows the softwarehardwarelibraries and control flow between the modules The sim-ulation module consists of two components the softwareand hardware libraries Software libraries include softwarecomponents of the framework for instance the input parserscheduler data store and task interface Hardware librariesinclude hardware components implemented in SystemCsuch as the processor the mapper the dispatcher andmultiplexersThe processors are implemented as behaviouralprocessors capable of computing the various tasks in thetask graphs The communication cost for a task is depen-dent on the size and thus the execution duration of thetask (Section 3) Thus communication latency is modelledas a function of task size Heterogeneity is modelled byvarying the task processing cost (processing timetask andpowertask) All processors are capable of executing allpossible operations but with different costs Processor failureis permanent once it occurs and only single processorfailure is considered Due to the modular implementationof the simulation module architecture topology routingscheduling and mapping methods can be easily changedin MpSoCs to conduct extensive evaluation of design spaceexploration
Output Module The simulation terminates by evaluating thesystem performance module which retrieves the various
8 VLSI Design
for each task in ATG do
set the longest-path-maximum-delay deadline
setDeadline()
initial solution
taskrandom mapToPE()
while simulation temp gt cooling threshold
do
for temperature length
for task sub iteration length
while each task is assigned a release time
generates the RTW w Comm cost
genRTL()
rand task from RTL
t sch = sel rand(RTL)
generate release time window
t schgenRTW()
set rel time
t schrel time = sel rand(RTW)
init and run systemC simulation
sc start(time)
calculating objective function value
calcObjFunc()
accepts or rejects a solution
probFunc()
for each task in ATG do
calculate workload of processors
taskcalc HWDcost()
new mapping solution
taskHWD mapToPE()
calculate new simulation temperature
calc simulation temp()
Algorithm 1 Pseudocode for the performance driven (PD) scheduling and HWDmapping algorithms
performance variables from the individual processors suchas the total execution time power throughput port trafficnumber of tasks processed and buffer usageThese values aredisplayed on the output GUI and stored in the result log file
41 Performance Driven Scheduling Algorithm This workalso proposes an efficient offline and performance drivenscheduling algorithm based on the Simulate Annealing tech-nique The performance index (PI) determined by a costfunction is used to determine the optimal schedule Theperformance index is a cumulative factor of (1) processor exe-cution time (2) processor utilization (3) processor through-put (4) processor power (5) processor port traffic and (6)processor buffer utilization The problem of determining theoptimal schedule is defined as determining the schedulewith maximal performance index The Simulated Annealingalgorithm performs (1) random scheduling and mappingof tasks (2) simulation and (3) capturing averaging andnormalizing performance variables finally it calculates theperformance index These steps are repeated several times inan effort to increase the PI During the iterations if a better
PI is found the state is saved and the simulation repeats untilthe temperature reaches the threshold value
For the problem being considered the normalizing coef-ficients used to calculate the PI were set to 120572
1= 300 120572
2=
500 1205723= 250 120572
4= 125 120572
5= 120 and 120572
6= 50000
These coefficients were determined after conducting sev-eral runs on all benchmarks Execution time utilizationthroughput and power factors are key performance indicesTherefore they are given significant weights (a higher valueof coefficient) during normalization Port traffic and powerindices are minimized consequently their respective costfunction is computed reciprocally The pseudocode for theperformance driven scheduling (PDS) and HWD mappingalgorithms is given in Algorithm 1
42 Multiprocessor Task Mapping Strategy Multiprocessorenvironments grant the freedom for dynamic task mappingThus themultiprocessormapping algorithm needs to specifythe locationwhere a particular task should be processed Taskmapping in heterogeneous systems is accomplished in twosteps (1) binding and (2) placement First the task binding
VLSI Design 9
procedure attempts to find which particular assignment oftasks would lead to effective lower power and faster executiontimeDuring task placement themapper considers allocatingany two tasks that exchange data more frequently as closeto each other as possible Placement of communicating tasksto adjacent or nearby processors reduces the communicationlatency switch traffic and power dissipation
Static mapping assigns a particular task to a predeter-mined processing element offline regardless of the dynamicstate of the system components This however does not sat-isfy the MpSoCs requirement because processing tasks on aheterogeneous architecture introduces workload irregularityon system resources (PEs) Irregular workload distributionis a design issue that degrades the utilization of system Toovercome this problem tasks should bemapped dynamicallybased on the dynamic workload on the processors Thenumber of tasks in the processorsrsquo local memory measuresthe processor workload
The dynamic mapper in the proposed framework per-forms the task allocation as per the configured policy Inorder to take heterogeneity of processors into considerationadditional power cost and execution latency cost have beenintroduced This emphasizes the fact that processing a par-ticular task on different types of processors incurs differentcost (power consumption and execution time) Efficient andoptimized heterogeneous mapping algorithms are tailored tominimize this additional cost
In the framework various task allocation heuristics wereimplemented Given a scheduled task the task mappingfollows one of the below policies
(1) Next Available Mapping (NXT AVLB) In the NextAvailable Mapping policy a scheduled task 119879
119894is
mapped on processor 119875119894 followed by the mapping of
the next scheduled task119879119894+1
on processor119875119895 provided
119875119894and 119875
119895are neighbors to each other as defined by
the topology This policy assigns tasks on successiveprocessor sequentially but does not consider theheterogeneity of the tasks nor the processorworkload
(2) Homogenous Workload Distribution Mapping(HWD) HWD considers the workload on eachprocessor and maps a scheduled task on a processorthat has the minimum workload
(3) Random mapping (RANDOM) rRandom task allo-cation is used by the PD algorithm to distribute theworkload randomly throughout the available proces-sors
HWD Mapping Approach Minimizing the idle time ofeach processor or maximizing processing time improvesprocessor utilization To reduce idle time tasks shouldbe distributed evenly throughout the available processorsThe proposed Homogenous Workload Distribution (HWD)algorithm is tailored to distribute tasks evenly to the availableprocessors in an effort to balance the dynamic workloadthroughout the processors The algorithm is a two-stepprocess (1) probing individual processor buffers throughdedicated snooping channels that connects each processor
to the mapper and (2) mapping each scheduled task ona processor that has the lowest workload Workload is ameasure of the number of tasks and its respective executiontime in the processor bufferThus a processor having the leastnumber of tasks and respective execution time in its bufferhas the lowest workload therefore themapper will assign thenext scheduled task to this processor
HWD Mapping Algorithm Let 1198751 1198752sdot sdot sdot 119875119872 be a set of
processors let 1198711 1198712sdot sdot sdot 119871119872 be the dynamic task workloads
defined by number of tasks on respective processor buffersand let119873 be the number of processors Let 119879
1 1198792sdot sdot sdot 119879119873 be a
set of119872 tasks and the symbol ldquorarr rdquo denotes ldquomappingrdquoThen
A task 119879119896⟨119879release-time 119879exec-time 119879deadline⟩ 997888rarr 119875
119894
iff 119871119894lt 119871119895
forall [119871119894 119871119895] isin 119871
1 1198712sdot sdot sdot 119871119873
(16)
where 119875119894isin 1198751 1198752sdot sdot sdot 119875119872 and 119879
119896isin 1198791 1198792sdot sdot sdot 119879119873 such that
(119890119896+ 119905119896le 119889119896)
This approach has three advantages (1) it minimizesthe chance for buffer overflow (2) the task waiting time inprocessor buffer is reduced and (3) utilization is increasedbecause idle processors will be assigned scheduled tasks
43 Fault-Tolerant Methodology System designs often haveflaws that cannot be identified at design time It is almostimpossible to anticipate all faulty scenarios beforehandbecause processor failure may occur due to unexpectedruntime errors Real-time systems are critically affected if nomeans of fault tolerance scheme is implemented Failure toemploy fault detection and recovery strategies is often unaf-fordable in critical mission systems because the error maylead to possible data discrepancies and deadline violation
Processor failure introduces inevitable overall perfor-mance degradation due to (1) the reduced computing powerof the system and (2) the overhead involved in applying thefault recovery schemes Recovery procedures involve trackingthe task execution history and reconfiguring the systemby using the available processors This enables applicationprocessing to resume when the execution was terminatedDuring processor failure application processing is temporar-ily suspended and error recovery procedures are appliedbefore application processing is resumed
Fault-TolerantModelFaultmodeling can have several dimen-sions that define the fault occurring time the fault durationlocation of failure and so forth The proposed frameworkadopts the following fault modeling parameters
(1) It is assumed that the processor failure is permanentThus fault duration time 119905FD is infinite (119905FD = infin)During failure the address of the failed processor iscompletely removed from the mapper address table
(2) The location specifies where the failure occurred Fortile and torus topology location is represented in two-dimensional coordinate addresses
(3) During task processing any processors may fail atany time instance Consequently time of failure ismodeled as a random time instance
10 VLSI Design
In the event of failure the following procedures areexecuted
(1) Themapper removes the failed processor ID from theaddress table
(2) Tasks that are scheduled or mapped but not dis-patched have to be rescheduled and remapped Therespective new task release time and task address bothhave to be done again This is because the executioninstance of a task depends on the finish time ofits predecessor task which may possibly have beensuspended in the failed processor
(3) Tasks that are already dispatched to the failed proces-sor can be either (1) in the processorrsquos buffer or (2)in the middle of execution when the failure occurredThese tasks have to be migrated back to the mapperand their respective rescheduling and remapping haveto be done The scheduler can perform task schedul-ing concurrently when the nonfaulty processors areexecuting their respective tasks
(4) Tasks that are dispatched to other nonfailed proces-sors are not affected
Due to the dynamic property of the mapper and the fault-tolerant implementation the cost incurred during the eventof processor failure is minimal overhead incurred is only25 of the total execution time of the task The only penaltyincurred during processor failure is the cost due to taskmigration and the respective rerescheduling and remappingprocedures
5 Experimental Setup
The heterogeneous MpSoC framework developed in thiswork was developed using C++ and SystemC programminglanguage The architectural components such as processingelements (PEs) memory elements routers and networkinterfaces are developed using SystemC language and providecycle accurate simulations The processing elements areimplemented as a simple 32-bit processor that performssimple logic and arithmetic operations The heterogeneousPE structure in our MpSoC is implemented by altering thetype of operation and the execution times of the tasks eachPE can execute The routers implementations consist of aswitching matrix with input port buffers The tasks and datawithin PEs are transmitted using a data-serializing moduleof the PE A typical data transmitted within PEs consists oftask commands task data (if any) and the destination PEIDs (addresses) The data is propagated through the MpSoCsystem using the119883119884 routing algorithm
The scheduling and mapping algorithm are implementedusing C++ language and are interfaced with the SystemCarchitecture implementations The application in this workis considered as a task graph Each task graph consists ofprocessor operations their execution time communicationcost and deadline The application as a whole also has adeadline The scheduling algorithm parses the application(task graph) and assigns start times for the tasks on the
processors based on the set of optimization goals describedin the proposed performance driven scheduling algorithmThe scheduled tasks aremapped to their respective processorsin the MpSoC system based on the proposed homogenousworkload-mapping algorithm The tasksrsquo information com-prising of the task operations task data destination PEs(pathaddress of successor PEs) are assembled and forwardedto the initial PE by the dispatcher module The performanceevaluation module or the monitor module records cycleaccurate timing signals in the architecture during tasksexecution and communication
During the simulation of fault-tolerant scenario themonitor module triggers a PE failure event at a predefinedtime instance The dispatcher is informed of the PE failureand based on the mapper table and the current processingtask and the tasks in the buffer of the failed PE are determinedAn updated task graph is constructed and scheduling andmapping on the remaining unexecuted tasks are performedTasks currently executing on the PEs are undisturbed Thereassigned tasks are inserted in the PE buffers to satisfy thedeadlines
The implemented MpSoC system has been evaluatedextensively by modifying the architecture and topology Thesystemwas evaluated using a set of synthetic task graphs with50ndash3000 tasksThe architectural modifications for evaluatingthe MpSoC include change in type of PEs in the systemmesh and torus topology variations and the number of PEsin the system (9 16 32) The MpSoC system has been usedto evaluate the proposed scheduling mapping and fault-tolerant algorithms and compared with respective classicalalgorithms The performance of the proposed algorithmsalong with variation in architecture and topology have beenevaluated and presented The performance metrics consid-ered in this work include processor throughput processorutilization processor execution timetask and powertaskbuffers utilization and port utilization Detailed summary ofthe results and its significance are shown in Section 6
6 Simulation Results and Analysis
For evaluation of the proposed framework to explore designfeatures variations in scheduling mapping and fault tolerantalgorithms have been considered The application modeladapted is similar to the standard task graph (STG) [50 51]and E3S benchmark suite [54] which contains random set ofbenchmarks and application-specific benchmarks The sim-ulation was conducted with many STG benchmarks havingtask sizes 50 through 3000 The task graph is characterizedby the number of tasks dependencies of tasks task size(code size) communication cost (latency for interprocessortransfer) and application deadline The processor architec-ture model is derived from the E3S benchmark where eachprocessor is characterized by the type tasks it can executetask execution time task size (code size) and task powerTheprocessor also has general characteristics like type overheadcost (preemptive cost) task powertime and clock rate
The simulation results presented in this paper follow thefollowing legend 119883119884 plusmn 119885 where 119883 denotes 119877 or 119879 for
VLSI Design 11
Table 1 PE comparison
No of PEs AVG ETIMEPETASK (120583sec)
AVGUTLPE
AVGPWRPE(120583watts)
AVGPDPPE
PE no 9 498 048 18125 90748PE no 16 281 040 9834 27698PE no 25 189 035 6359 12006
Table 2 Comparison of task execution times processor utilizationand throughput of EDF-SA and PDS scheduling algorithms
ETIME (120583s) UTL THR (Bns) Std SA CostRAND-50
EDF-SA 20426 046 003 016PDS 22003 055 003 019
SPARSE-96EDF-SA 61651 044 002 015PDS 63789 049 002 017
RAND-100EDF-SA 41867 047 003 017PDS 43217 060 003 021
RAND-300EDF-SA 129945 049 003 017PDS 129695 056 003 019
FPPP-334EDF-SA 223836 042 002 015PDS 233736 047 002 016
RAND-500EDF-SA 143279 048 002 016PDS 212533 066 003 023
RAND-1000EDF-SA 416373 052 003 018PDS 432458 058 003 020
torus or tile topology 119884 denotes 119864 or 119878 for EDF-SA or PDscheduling algorithm + or minus for presence or absence of faulttolerance algorithm and 119885 denotes the number of PEs in theMpSoC system Performance evaluations on architecture andtopological variations were performed but are not included inthis paper Only performance results related to the proposedalgorithms are presented
61 Simulation Scenarios To demonstrate the capabilities ofthe proposed framework and the algorithms we performedseveral simulations on task graph sets and evaluated theireffectiveness over the following design abstractions
(i) Architectural architecture-based evaluation empha-sizes the effect of different PEs in the MpSoC frame-work Current implementation of our frameworkconsists of processors of the same architecture thatcan execute various tasks that is each processor hasa different set of tasks they can execute The MpSoC
Table 3 Comparison of HWD and next available and randommapping algorithms (simulation TS-9)
Mapping Random HWD NXT AVLBLAVG ETIME 141746 139467 13825AVG UTL 048 059 059AVG THR 002 002 002AVG PRT 108 107 108AVG PWR 599503 579969 57005AVG BFR 5 4 6
architecture was modified by changing the number ofPEs the types of PEs and topology It is importantto consider the effect of topology in architectureevaluation because the topology of the MpSoC alsodictates the performance of the individual PEs Theeffect of such architecture changes is measured interms of average execution timePEtask (ETIME) in120583sec average PE utilization (UTL) powertask of PEs(PWR) in 120583-Watts and power delay product (PDP)which are shown in Table 1
(ii) Scheduling evaluation of scheduling algorithms overvarious MpSoC architectures was conducted Per-formance of earliest deadline first based simulatedannealing (EDF-SA) and the new performance driven(PD) algorithms are compared (Table 2) Perfor-mance metrics for evaluating scheduling algorithmsare the same as that of architecture evaluations Alsothe standardized SA costs are shown
(iii) Mapping evaluation of mapping algorithms overvarious MpSoC architectures was conducted usingperformance driven scheduling policy Performanceof the proposed HWD Next Available (NA) andrandom mapping algorithms is compared as shownin Table 3
(iv) Fault Tolerant-evaluation and comparison of fault-tolerant (FT) and nonfault-tolerant (NFT) imple-mentation over various MpSoC architectures wereconducted and results for two test cases are shownin Tables 4 and 5
62 Simulation Results and Explanation Table 1 shows theaverage performance metrics obtained for various architec-tural variations possible in the developedMpSoC frameworkThe architectural variations include the type of topology(tile or torus) scheduling algorithm (EDF-SA or PDS)mapping algorithm (HWD) fault-tolerant scheme (NFT orFT) and the number of PEs Table 2 specifically compares theperformance of the EDF-SA and PDS scheduling algorithmComparison results on total execution time (ECT) in 120583secaverage processor utilization and average throughput inbytes120583sec are presented Other metrics that have less signif-icance have been omitted Also comparisons between EDF-SA and PDS algorithms for processor utilization throughputand buffer usage evaluations across various architectural
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

2 VLSI Design
memory element Heterogeneous processors in MpSoCs canbe programmable or dedicated (nonprogrammable) proces-sors Also memory elements can be heterogeneous withrespect to their memory type size access mode and clockcycles To transfer the data to and from the processingand memory elements the network component may includebusses switches crossbars and routers
Present-day MpSoC architectures employ most of theabove discussed components [3] In fact to effectively meettodayrsquos complex design requirements modern multiproces-sor systems are real time preemptive and heterogeneous [4]For data exchange memory elements inMpSoCs often followeither distributed memory architecture (message passing) ora global shared memory architecture [5ndash7]
An efficient MpSoC is based upon several key designchoices also known as design space exploration networktopology selection good routing policy efficient applicationscheduling mapping and the overall framework implemen-tation A formal categorization of MpSoC design issuespresented in [8] is summarized below Design methodolo-gies in multiprocessor systems (MpSoC and NoC) havebeen classified as follows (1) application characterizationscheduling andmapping (2) processing memory switchingand communication architecture modeling developmentand analysis and (3) simulation synthesis and emulationframework
Major design features that need to be addressed formultiprocessors are task scheduling mapping and faulttoleranceThis work concentrates on developing a simulationframework formultiprocessors on a single chip (MpSoC) thatsimplifies design space exploration by offering comprehen-sive simulation supportThe simulation framework allows theuser to optimize the system design by evaluating multipledesign choices in scheduling mapping and fault tolerancefor the given design constraints TILE andTORUS topologieswhich are common layouts inmultiprocessing environmentsare supported in this framework
Using the developed MpSoC simulation frameworkwe propose and evaluate (1) an efficient strategy for taskscheduling called the performance driven scheduling (PDS)algorithmbased on SimulatedAnnealing heuristic that deter-mines an optimal schedule for a given application (2) a newmapping policy called Homogenous Workload Distribution(HWD) which maps tasks to processors by consideringprocessors runtime status and (3) finally in an effort toimplement a robust system a simple fault-tolerant (FT) algo-rithm that reconfigures task execution sequence of the systemin the event of processor failure Heterogeneity in processorarchitecture is a key design feature in multiprocessor systemsand therefore is modeled in this framework Even thoughmany earlier multiprocessor designs solve the scheduling andmapping problem together our framework considers themindividually for fault-tolerance
In summary the research presented in this paperaddresses the following issues and solutions
(1) Develop a comprehensive MpSoC framework imple-mented using C++ and SystemC programminglanguages for effective exploration of design choices
like application scheduling mapping and architec-ture design
(2) The developed system can also evaluate MpSoCsystem architecture design choices differing in thenumber and type of processing elements (PEs) andtopology
(3) The paper proposes a heuristic scheduling algorithmbased on Simulated Annealing
(4) Also a mapping algorithm that distributes the work-load among the available PE is proposed
(5) Finally a centralized fault-tolerant scheme to handlefaults in PEs is proposed
This paper is organized as follows Section 2 briefly sum-marizes previousworks in the field ofmultiprocessor systemsSection 3 provides definitions and terminologies used in thiswork Section 4 presents the framework description as wellas the proposed algorithms and their implementation intask scheduling mapping and fault tolerance techniquesSection 5 discusses the experimental setup for simulationand evaluations Section 6 discusses the detailed simulationresults and the analysis of the algorithms on benchmarksFinally Section 7 summarizes the conclusions
2 MpSoC Design Literature Review
Extensive work has been done in the field of MpSoC- andNoC-based systems Earlier research targeted a variety ofsolutions including processor architecture router designrouting and switching algorithms scheduling mapping faulttolerance and application execution in multiprocessors toaddress the performance and area demands The readerscan refer to [8ndash10] for an extensive enumeration of NoCresearch problems and proposed solutions In this sectionwe concentrate on the earlier proposed scheduling mappingand fault-tolerant algorithms It has been shown that earlierscheduling algorithms like FCFS and Least Laxity [7] fail toqualify as acceptable choices of scheduling because they areunable to meet deadline (hard deadlines) requirements forreal-time applications Thai [7] proposed Earliest EffectiveDeadline First (EEDF) scheduling algorithm This workdemonstrated that increasing the number of processors toimprove the scheduling success increased the size of thearchitecture which makes task scheduling more difficultStuijk et al [11] proposed dynamic scheduling and routingstrategies to increase resource utilization by exploiting allthe scheduling freedom on the multiprocessors This workconsidered application dynamism to schedule applications onmultiprocessors both for regular and irregular tiled topologyHu and Marculescu [12] propose an algorithm based on listscheduling where mapping is performed to optimize energyconsumption and performance Varatkar and Marculescu[13] propose an ILP-based scheduling algorithm that min-imizes interprocess communication in NoCs Zhang et al[14] propose approximate algorithms for powerminimizationof EDF and RM schedules using voltage and frequencyscaling Also other researchers [15ndash17] have used dynamic
VLSI Design 3
voltage scaling in conjunction with scheduling for low powerrequirements
Finding an optimal solution in scheduling and mappingproblem domain for set of real-time tasks has been shownto be NP-hard problem [11] Carvalho et al [18] proposeda ldquocongestion-awarerdquo mapping heuristic to dynamically maptasks on heterogeneous MpSoCs This heuristic approachinitially assigns master-tasks to selected processors and theslave-tasks are allocated on congestion minimizing mannerto reduce the communication traffic Sesame project [4]proposed a multiprocessor model that maps applicationstogether with the communication channels on the architec-ture This model tries to minimize an objective functionwhich considers power consumption application execu-tion time and total cost of the architectural design Manyresearchers have discussed static and dynamic task allocationfor deterministic and non-deterministic tasks extensively [5]Static mapping has also been shown non-efficient strategybecause it does not take application dynamism into accountthat is a core design issues in multiprocessor systems Ahnet al [19] suggests that real-time applications should behavedeterministically even in unpredictable environments sothat the tasks can be processed in real-time Ostler andChatha [20] propose an ILP formulation for applicationmapping on network processors Harmanani and Farah[21] propose an efficient mapping and routing algorithmthat minimizes blocking and increases bandwidth based onsimulated annealing Also mapping algorithms to minimizecommunication cost energy bandwidth and latency eitherindividually [22ndash24] or as a multi-objective criteria [25 26]have been proposed
Task migration as opposed to dynamic mapping has beenproposed in [4] to overcome performance bottlenecks Taskmigration may result in performance improvement in sharedmemory systems butmay not be feasible when considered fordistributed memory architectures due to the high volume ofinter-processor data communication [5]
Previous research in [5 6 27] has demonstrated reliabilityissues regarding application processing data routing andcommunication link failure Zhu andQin [28] demonstrateda system level design framework for a tiled architecture toconstruct a reliable computing platform from potentiallyunreliable chip resources This work proposed a fault modelwhere faults may have transient and permanent behaviourTransient errors are monitored by a dedicated built-inchecker processor that effectively corrects the fault at run-time Nurmi et al [6] demonstrated error tolerance methodsthrough time space and data redundancy This is however aclassic and costly approach with respect to system resourcesand bandwidth though thework demonstrated redundancy isone potential approach to address faulty scenarios Holsmarket al [29] proposed a fault tolerant deadlock free algorithm(APSRA) for heterogeneous multiprocessors APSRA storesrouting information in memory to monitor faulty routsand allow re-configurability dynamically Pirretti et al [30]and Bertozzi et al [31] propose NoC routing algorithmsthat can route tasks around the fault and sustain networkfunctionality Also research on router design to improvereliability [32] buffer flow control [33] and error correction
techniques [34 35] for NoC have been proposed Koibuchiet al [36] proposed a lightweight fault-tolerant mechanismcalled default backup path (DBP) The approach proposed asolution for non-faulty routers and healthy PEs They designNoC routers with special buffers and switch matrix elementsto re-route packets through special paths Also Bogdanet al [37] propose an on-chip stochastic communicationparadigm based on probabilistic broadcasting scheme thattakes advantage of the large bandwidth available on the chipIn their method messagespackets are diffused across thenetwork using spreaders and are guaranteed to be receivedby destination tilesprocessors
A number of EDA research groups are studying differentaspects of MpSoC design some of which include the fol-lowing (1) Polis [18] is a framework based on both micro-controllers and ASICs for software and hardware imple-mentation (2) Metropolis [18] is an extension of Polis thatproposed a unified modeling and structure for simulatingcomputationmodels (3) Ptolemy [18] is a flexible frameworkfor simulating and prototyping heterogeneous systems (4)Thiele et al [1] proposed a simulation based on distributedoperation layer (DOL) which considers concurrency scal-ability mapping optimization and performance analysisin an effort to yield faster simulation time (5) NetChipxpipes xpipes compiler and SUNMAP NetChip is a NoCsynthesis environment primarily composed of two toolsnamely SUNMAP [38] and the xpipes compiler [39] (6)NNSENostrumNoCSimulationEnvironmentNNSE [40] isa SystemC-based NoC simulation environment initially usedfor theNostrumNoC (7) ARTSModeling Framework ARTS[41] is a system-level framework to model networked multi-processor systems on chip (MpSoC) and evaluate the cross-layer causality between the application the operating system(OS) and the platform architecture (8) StepNP a System-Level Exploration Platform for Network Processors StepNP[42] is a System-Level Exploration Platform for NetworkProcessing built in SystemC It enables the creation of multi-processor architectures with models of interconnects (func-tional channels NoCs) processors (simple RISC) memoriesand coprocessors (9) Genko et al [43] present a flexible emu-lation environment implemented on an FPGA that is suitableto explore evaluate and compare a wide range of NoCsolutions with a very limited effort (10) Coppola et al [44]proposes an efficient open-source research and developmentframework (On-Chip Communication Network (OCCN))for the specification modeling and simulation of on-chipcommunication architectures (11) Zeferino and Susin [45]present SoCIN a scalable network based on a parametricrouter architecture to be used in the synthesis of customizedlow cost NoCs The architecture of SoCIN and its router aredescribed and some synthesis results are presented
The following papers presented are the closest worksrelated to the proposed algorithms discussed in this paperOrsila et al [46] investigated the use of Simulated Annealing-based mapping algorithm to optimize energy and perfor-mance on heterogeneous multiprocessor architecture Inspecific the cost function considered for SA optimization
4 VLSI Design
includes processor area frequency of operation and switch-ing activity factor The work compares the performance oftheir SA-mapping algorithms for different heterogeneousarchitectures In another similar work [47] proposed bythe same author the SA-mapping algorithm is adoptedto optimize usage of on-chip memory buffers Their workemploys a B-level scheduler after the mapping process toschedule tasks on each processor
The proposed framework discussed in this paper employsSA-based scheduling and workload balanced mapping algo-rithms Our algorithms also optimize scheduling andmapping cost functions that include processor utilizationthroughput buffer utilization and port traffic along withprocessor power In addition our algorithms also considertask deadline constraints Both scheduling and mappingalgorithms adopted in ourwork perform global optimization
Paterna et al [48] propose two workload allocationmapping algorithms for energy minimization The algo-rithms are based on integer linear programming and a two-stage-heuristic mapping algorithm based on linear program-ming and bin packing policies Teodorescu and Torrellas[49] and Lide et al [50 51] explore workload-based map-ping algorithms for independent tasks and dependent tasksrespectively The work by Zhang et al is based on ILPoptimization for execution time and energy minimizationOur proposed mapping algorithm varies from the above-specified workload constrained algorithms by consideringthe buffer size usage and execution time of the tasks in thebuffer
Works by Ababei and Katti [52] and Derin et al [53]have used remapping strategies forNoC fault tolerance In thesolution proposed by Ababei and Katti [52] fault tolerancein NoCs is achieved by adaptive remapping They considersingle and multiple processor (PE) failures The remappingalgorithm optimizes the remap energy and communicationcosts They perform comparisons with a SA-based remapperOrsila et al [46] propose an online remapping strategycalled local nonidentical multiprocessor scheduling heuristic(LNMS) based on integer linear programming (ILP) TheILP minimizing cost functions include communication andexecution time The proposed NoC fault-tolerant algorithmemploys rescheduling and remapping strategies to optimizeprocessor performance and communication cost Also taskdeadline constraints are considered during the reschedulingand remapping
With the current design trends moving towards mul-tiprocessor systems for high performance and embeddedsystem applications the need to develop comprehensivedesign space exploration techniques has gained importanceMany research contributions in development of hardwaremodules and memory synchronization to optimize powerperformance and area for multiprocessor systems are beingdeveloped However algorithmic development for multipro-cessor systems like multiprocessor scheduling and mappinghas yielded significant results Therefore a comprehensiveand generic framework for a multi-processor system isrequired to evaluate the algorithmic contributionsThis workaddresses the above requirement in developing a compre-hensive MpSoC evaluation framework for evaluating many
scheduling mapping and fault-tolerant algorithms Also theframework is developed on generic modeling or represen-tation of applications (task graphs) architecture processorstopologies communication costs and so forth resulting in acomprehensive design exploration environment
The main contributions of this work can be summarizedas follows
(1) We propose a unique scheduling algorithm forMpSoC system called performance driven schedulingalgorithm that is based on Simulated Annealing andoptimizes an array of performance metrics such astask execution time processor utilization processorthroughput buffer utilization and port traffic andpower The proposed algorithm performance is com-pared to that of the classical earliest deadline firstscheduling algorithm
(2) This paper proposes a mapping algorithm that suc-ceeded the scheduling algorithm called the homo-geneous workload distribution algorithm that dis-tributes tasks evenly to the available processors in aneffort to balance the dynamic workload throughoutthe processors The proposed algorithm performanceis compared with other classical mapping algorithm
(3) Also a fault-tolerant scheme that is effective duringPE failure is proposed in this paper The proposedfault-tolerant (FT) scheme performs an updatedscheduling and mapping of the tasks assigning to thefailed PE when the PE fault is detected The uniquecontribution of this work is the fact that it addressesthe pending and executing tasks in the faulty PEsThe latency overhead of the proposed FT algorithmis evaluated by experimentation
3 Definitions and Theory
Simulation Model The simulation model consists of threesubmodels (Figure 1) (1) application (2) architecture and (3)topologyThe applicationmodel represents the application tobe executed on the given MpSoC architecture and connectedby the topology specified
Application Model (Task Graphs) A task graph is a directedacyclic graph (DAG) that represents an application A taskgraph is denoted as TG such that TG = (119881 119864) where 119881 is aset of nodes and 119864 is a set of edges A node in 119881 representsa task such that 119881 = 119879
1 1198792 1198793 119879
119873 and an edge in
119864 represents the communication dependency between thetasks such that 119864 = 119862
1 1198622 1198623 119862
119870 A weighted edge
if specified denotes the communication cost incurred totransfer data from a source task to destination task Eachtask can exist in a processor in one of the following statesideal pending ready active running or complete The taskgraph is derived by parsing the high-level description of anapplication
Architecture Model The architecture of the MpSoC sys-tem consists of the processors hardware components
VLSI Design 5
pending readyactive running
TG =
Processormemoryarchitecture type
power clock-rateinterrupt memory
NG =
PE
PE
PE
PE
PE
PE
PE
PEM
M
M
PE PEPE
PE
PE
PE PE
PE
PE
PE PE
PE
PE
PE
⟩
complete⟩
NG ⟨
⟨
processor type topology⟩
Task ⟨119879119868119863
Task status ⟨ideal
TtypeTrelease timeTexec timeTdeadline Tadress TDlist
(V E) V = T1 T2 T3 middot middot middot T9E = C1 C2 C3 middot middot middot CK
T1
T2T3
T4
T5T6 T7
T8
T9
ARCH = P1 P2 P3 middot middot middot PNM1 M2 M3 middot middot middot MK
(V E)V = Pi Mi E = C1 middot middot middot CL
Figure 1 Simulation model containing application architecture and topology
memory and interconnects as defined by the topologymodel The MpSoC architecture is represented as a set1198751 1198752 1198753 119875
119873119872111987221198723 119872
119870 where119875
1 1198752 119875
119899
are a set of 119873 processors and 11987211198722 119872
119870are a set
of 119870 memory units Each processor 119875119894or memory 119872
119894is
defined by the following characteristics type powertaskexecutiontask clock rate preempt overhead and also by a setof tasks 119879
119886 119879119887 119879119888 119879
119911 each processor can execute along
with their respective execution times and power costs Theimplemented heterogeneousMpSoC consists of processors ofthe same architecture but can execute various set of tasks
Topology Model (Topology Graph) Topology describes thephysical layout of hardware components in a system Thetopology model is represented as a topology graph (NG) thatconsists of the set of processors topology type ⟨tile torus⟩and communication cost This communication cost is thesame communication cost (119864) as defined in the applicationmodel
Scheduling Scheduling is the process of assigning an execu-tion start time instance to all tasks in an application such thattasks are executed within their respective deadline For anapplication 119860 = 119879
1 1198792sdot sdot sdot 119879119873 where 119879
119894is a task instance in
the application task scheduling denoted as 120572(119879119894) is defined
as an assignment of execution start time (119905119894) for the task 119879
119894in
the time domain such that
120572 (119879119894) = 119905119894 119905
119894+ 119890119894le 119889119894 (1)
where 119890119894is the worst-case execution time of the task on a
specific processor 119889119894is the deadline of the task119879
119894 and 119905
119894is the
execution start time of task 119879119894 Scheduling of an application
119860 is denoted as
120572 (119860) = 120572 (1198791) 120572 (119879
2) 120572 (119879
3) sdot sdot sdot 120572 (119879
119873) (2)
If there exists a precedence operation between any two taskssuch that the execution of a task 119879
119894should occur before the
execution of task 119879119895 represented as 119879
119894lt 119879119895 then
119905119894+ 119890119894le 119905119895le 119889119894 119905
119895+ 119890119895le 119889119895 (3)
where 119905119894is the start time of task 119879
119895 and 119890
119895and 119889
119895are the
execution time and deadline of task 119879119895 respectively
Performance Index (PI) PI is the cumulative cost functionused to determine the optimal schedule by using the Sim-ulated Annealing technique PI quantifies the performanceof the system taking into consideration the averaged valuesof processor execution time (ETIME) utilization (UTL)throughput (THR) buffer utilizationusage (BFR) port traf-fic (PRT) and power (PWR) PI is evaluated by a costfunction that is expressed as
COST = 1205721(
1
ETIME) + 1205722(
1
UTL) + 1205723(
1
THR)
+ 1205724(
1
BFR) + 1205725(PRT) + 120572
6(PWR)
(4)
where 1205721sim 1205726are normalizing constants
6 VLSI Design
The Simulated Annealing procedure compares the per-formance of successive design choices based on the PIExecution time processor utilization processor throughputand buffer utilization are maximized so that their costis computed reciprocally however power and port trafficare minimized so that the nonreciprocal values are takenThe coefficient values in the cost equation are set accordingto the desired performance goals of the system
Optimization of Scheduling Algorithm The problem of deter-mining optimal scheduling is to determine the optimal starttime and execution time of all tasks in the application
minimize(119873
sum
119894=1
(119905119894+ 119890119894))
minimize(119873
sum
119894=1
COST (120572 (119879119894))) 119905
119899+ 119890119899le DL
(5)
where 119890119894is the worst-case execution time of each task 119879
119894
DL is the deadline of the application and 119905119899and 119890119899are the
start time and worst-case execution time of the last taskrespectively in the application COST (120572(119879
119894)) is the cost
function of scheduling the tasks
Mapping Mapping is the process of assigning each task in anapplication to a processor such that the processor executes thetask and satisfies the task deadline as well as other constraints(power throughput completion time) if any
For an application 119860 = 1198791 1198792sdot sdot sdot 119879119873 where 119879
119894is a
task instance in the application mapping a task denoted as119872(119879119894) is defined as an assignment of the processor 119875
119895 =
1198751 1198752 119875
119872 = 119875 for the task 119879
119894
119872(119879119894) = 119875
119895 (6)
Application mapping is defined as mapping of all tasks 119879119894 in
the application 119860 to processors and is denoted as
119872(119860) = 119872 (1198791) 119872 (119879
2) sdot sdot sdot119872 (119879
119873) (7)
Optimization of the Mapping Algorithm The problem indetermining optimummapping is to determine the optimumallocation of all tasks in the application on the processorssuch that the total execution time of all tasks is minimizedOther factors for optimum mapping include maximizingprocessor execution time throughput minimizing inter-processor communication delay and balancing workloadhomogenously on the processors in order to improve utiliza-tion
minimize(119873
sum
119894=1
(119888119894)) 119888
119894= COST (119872 (119879
119894)) (8)
where 119888119894is the cost function for optimal mapping of the tasks
on the processor
Power Modeling In this research scheduling and mappingalgorithms model heterogeneous processor execution andpower requirements as follows
(1) Switch power is consumed whenever a task is routedfrom input port to output port
(2) Processor power is modeled with respect to idle-mode (also includes pending ready active and com-plete) and execution-mode (running) power both ofwhich are functions of the task execution time 119890
119894 We
also assume that for the idle model Δ120578 = 0
120578119894(119879119894) = Δ120578 lowast 119890
119894 (9)
whereΔ120578 is the unit power consumed per unit time oftask processingThe total power rating for a processor119875119895would be expressed as
120578119895= Δ120578 lowast
119899
sum
119894=1
(119890119894) (10)
where 119899 is the number of tasks executed by theprocessor
(3) Whenever a task 119879119896is executed on processor 119875
119897
the execution time 119890119896and the power consumed by
processor 120578119896are updated as
120578119897(119879119896) = Δ120578 lowast 119890
119896
120578119897= Δ120578 lowast
119899
sum
119894=1
(119890119896)
(11)
(4) Whenever a task is transferred between switchesthe communication delay is updated on the TotalTask Communication Delay parameter (T) and isexpressed as
T = 119899 lowast v lowast Δ119862 (12)
where 119899 is number of switch hopes task-size (v) is thesize of the task defined as a function of its executiontime in time-units and Δ119862 is a time constant that isrequired to transfer single time-unit task for one hop
(5) For each task 119879119894 the Task Slack Time 119878
119894and Average
Slack Time 119878 are calculated as
119878119894= 119889119894minus [119905119894+ 119890119894]
119878 =
sum
119873
119894=1(119878119894)
119873
(13)
where 119889119894is the deadline 119905
119894is the release time and119873
is the total number of tasks processed
Fault-Tolerant System A fault-tolerant system describes arobust system that is capable of sustaining application pro-cessing in the event of component failure A fault-tolerantalgorithm is a process that performs scheduling andmappingon a set of unprocessed tasks for the available processors
Let an application119860with a set of tasks119860 = 1198791 1198792sdot sdot sdot 119879119873
be scheduled denoted by 120572(119860) and mapped on the set
VLSI Design 7
of processors 119875 = 1198751 1198752 119875
119872 denoted as 119872(119860) A
fault is defined as a nonrecurring permanent failure of aprocessor at time instance 119905
119891during the execution of a
task 119879119891 The application after the occurrence of the fault is
expressed as 119860119891such that 119860
119891sub 119860 which has a list of tasks
119860119891= 119879119892 119879ℎsdot sdot sdot 119879119899 that are not dispatched to processors
by the mapper when the processor failure occurs The set ofprocessors after the failure119865 is denoted by 119875
119891= 1198751 1198752sdot sdot sdot 119875119871
and 119875 notin 119875119891 where 119875
119891is the failed processor The proposed
fault-tolerant MpSoC framework determines the updatedscheduling 120572(119860
119891) and updated mapping119872(119860
119891) for a set of
unprocessed tasks in the application subset 119860119891 such that
119905119899+ 119890119899le DL (14)
where 119905119899and 119890
119899are the start time and execution time
respectively of the last scheduled task in 119860119891
Optimization of Fault-Tolerant Strategy Due to the dynamicmapping methodology adopted in the framework only thetasks dispatched to the failed processormdashwhich includes thetask that was executing on the failed processor and thetasks dispatched by the mapper to the failed processormdashwillneed to be rescheduled along with the tasks that were notdispatched by the mapper
Let us consider an application 119860119891with a list of 119899 tasks
119860119891
= 119879119892 119879ℎsdot sdot sdot 119879119899 that have not been dispatched to
processors at the occurrence of the fault Also let the tasks119879119887= 119879119903sdot sdot sdot 119879119905 be the list of tasks in the buffer of the failed
processor 119875119891and let 119879
119901be the task that was being executed
during failure by the failed processor The task list 119879FT of thefault tolerant algorithm at time 119905
119891is represented as
119879FT = 119860119891+ 119879119887+ 119879119891 (15)
It is also assumed that all the tasks that are being executedby the nonfailed processor complete the execution of thetasks even after the time of failure 119905
119891 Thus the FT algorithm
performs the updated scheduling (119879FT) and updated map-ping
119872(119879FT) on the task set 119879FT which satisfies the deadlineconstraint DL of the application 119860
4 Framework Modeling and Implementation
The proposed framework adopts a ldquobottom-uprdquo modulardesign methodology that gives the benefit of componentreusability Behavioral componentmodels were designed andstored in hardware and software librariesThe frameworkwasimplemented in SystemC 22C++ and compiled with g++-43 under Linux The framework is divided into three majorcomponents input or user interface module core MpSoCsimulation module and the output or performance evalua-tion module The hardware modules such as the processorswitch dispatcher unit and multiplexer were implementedin SystemC the software modules such as input parserscheduler and task interface classes were implemented inC++
Input Module Such userrsquos data as the number of processorstopology task graph processor types buffer size switching
Software libraries
Settings
Task interface
Other IPs
Main GUI
TG parser
Scheduler
Mapper
Dispatcher
Switch
Processor
Multiplexer
ARCH setup
Performance evaluation
PE
PE
PE
PE
PE PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
Hardware libraries
Figure 2 Framework modeling
technology fault-tolerant mode and schedulingmappingspecifications are read either by using a command lineinterface or else from a GUI interface
Core Simulation Module The core simulation module isdepicted in Figure 2 which shows the softwarehardwarelibraries and control flow between the modules The sim-ulation module consists of two components the softwareand hardware libraries Software libraries include softwarecomponents of the framework for instance the input parserscheduler data store and task interface Hardware librariesinclude hardware components implemented in SystemCsuch as the processor the mapper the dispatcher andmultiplexersThe processors are implemented as behaviouralprocessors capable of computing the various tasks in thetask graphs The communication cost for a task is depen-dent on the size and thus the execution duration of thetask (Section 3) Thus communication latency is modelledas a function of task size Heterogeneity is modelled byvarying the task processing cost (processing timetask andpowertask) All processors are capable of executing allpossible operations but with different costs Processor failureis permanent once it occurs and only single processorfailure is considered Due to the modular implementationof the simulation module architecture topology routingscheduling and mapping methods can be easily changedin MpSoCs to conduct extensive evaluation of design spaceexploration
Output Module The simulation terminates by evaluating thesystem performance module which retrieves the various
8 VLSI Design
for each task in ATG do
set the longest-path-maximum-delay deadline
setDeadline()
initial solution
taskrandom mapToPE()
while simulation temp gt cooling threshold
do
for temperature length
for task sub iteration length
while each task is assigned a release time
generates the RTW w Comm cost
genRTL()
rand task from RTL
t sch = sel rand(RTL)
generate release time window
t schgenRTW()
set rel time
t schrel time = sel rand(RTW)
init and run systemC simulation
sc start(time)
calculating objective function value
calcObjFunc()
accepts or rejects a solution
probFunc()
for each task in ATG do
calculate workload of processors
taskcalc HWDcost()
new mapping solution
taskHWD mapToPE()
calculate new simulation temperature
calc simulation temp()
Algorithm 1 Pseudocode for the performance driven (PD) scheduling and HWDmapping algorithms
performance variables from the individual processors suchas the total execution time power throughput port trafficnumber of tasks processed and buffer usageThese values aredisplayed on the output GUI and stored in the result log file
41 Performance Driven Scheduling Algorithm This workalso proposes an efficient offline and performance drivenscheduling algorithm based on the Simulate Annealing tech-nique The performance index (PI) determined by a costfunction is used to determine the optimal schedule Theperformance index is a cumulative factor of (1) processor exe-cution time (2) processor utilization (3) processor through-put (4) processor power (5) processor port traffic and (6)processor buffer utilization The problem of determining theoptimal schedule is defined as determining the schedulewith maximal performance index The Simulated Annealingalgorithm performs (1) random scheduling and mappingof tasks (2) simulation and (3) capturing averaging andnormalizing performance variables finally it calculates theperformance index These steps are repeated several times inan effort to increase the PI During the iterations if a better
PI is found the state is saved and the simulation repeats untilthe temperature reaches the threshold value
For the problem being considered the normalizing coef-ficients used to calculate the PI were set to 120572
1= 300 120572
2=
500 1205723= 250 120572
4= 125 120572
5= 120 and 120572
6= 50000
These coefficients were determined after conducting sev-eral runs on all benchmarks Execution time utilizationthroughput and power factors are key performance indicesTherefore they are given significant weights (a higher valueof coefficient) during normalization Port traffic and powerindices are minimized consequently their respective costfunction is computed reciprocally The pseudocode for theperformance driven scheduling (PDS) and HWD mappingalgorithms is given in Algorithm 1
42 Multiprocessor Task Mapping Strategy Multiprocessorenvironments grant the freedom for dynamic task mappingThus themultiprocessormapping algorithm needs to specifythe locationwhere a particular task should be processed Taskmapping in heterogeneous systems is accomplished in twosteps (1) binding and (2) placement First the task binding
VLSI Design 9
procedure attempts to find which particular assignment oftasks would lead to effective lower power and faster executiontimeDuring task placement themapper considers allocatingany two tasks that exchange data more frequently as closeto each other as possible Placement of communicating tasksto adjacent or nearby processors reduces the communicationlatency switch traffic and power dissipation
Static mapping assigns a particular task to a predeter-mined processing element offline regardless of the dynamicstate of the system components This however does not sat-isfy the MpSoCs requirement because processing tasks on aheterogeneous architecture introduces workload irregularityon system resources (PEs) Irregular workload distributionis a design issue that degrades the utilization of system Toovercome this problem tasks should bemapped dynamicallybased on the dynamic workload on the processors Thenumber of tasks in the processorsrsquo local memory measuresthe processor workload
The dynamic mapper in the proposed framework per-forms the task allocation as per the configured policy Inorder to take heterogeneity of processors into considerationadditional power cost and execution latency cost have beenintroduced This emphasizes the fact that processing a par-ticular task on different types of processors incurs differentcost (power consumption and execution time) Efficient andoptimized heterogeneous mapping algorithms are tailored tominimize this additional cost
In the framework various task allocation heuristics wereimplemented Given a scheduled task the task mappingfollows one of the below policies
(1) Next Available Mapping (NXT AVLB) In the NextAvailable Mapping policy a scheduled task 119879
119894is
mapped on processor 119875119894 followed by the mapping of
the next scheduled task119879119894+1
on processor119875119895 provided
119875119894and 119875
119895are neighbors to each other as defined by
the topology This policy assigns tasks on successiveprocessor sequentially but does not consider theheterogeneity of the tasks nor the processorworkload
(2) Homogenous Workload Distribution Mapping(HWD) HWD considers the workload on eachprocessor and maps a scheduled task on a processorthat has the minimum workload
(3) Random mapping (RANDOM) rRandom task allo-cation is used by the PD algorithm to distribute theworkload randomly throughout the available proces-sors
HWD Mapping Approach Minimizing the idle time ofeach processor or maximizing processing time improvesprocessor utilization To reduce idle time tasks shouldbe distributed evenly throughout the available processorsThe proposed Homogenous Workload Distribution (HWD)algorithm is tailored to distribute tasks evenly to the availableprocessors in an effort to balance the dynamic workloadthroughout the processors The algorithm is a two-stepprocess (1) probing individual processor buffers throughdedicated snooping channels that connects each processor
to the mapper and (2) mapping each scheduled task ona processor that has the lowest workload Workload is ameasure of the number of tasks and its respective executiontime in the processor bufferThus a processor having the leastnumber of tasks and respective execution time in its bufferhas the lowest workload therefore themapper will assign thenext scheduled task to this processor
HWD Mapping Algorithm Let 1198751 1198752sdot sdot sdot 119875119872 be a set of
processors let 1198711 1198712sdot sdot sdot 119871119872 be the dynamic task workloads
defined by number of tasks on respective processor buffersand let119873 be the number of processors Let 119879
1 1198792sdot sdot sdot 119879119873 be a
set of119872 tasks and the symbol ldquorarr rdquo denotes ldquomappingrdquoThen
A task 119879119896⟨119879release-time 119879exec-time 119879deadline⟩ 997888rarr 119875
119894
iff 119871119894lt 119871119895
forall [119871119894 119871119895] isin 119871
1 1198712sdot sdot sdot 119871119873
(16)
where 119875119894isin 1198751 1198752sdot sdot sdot 119875119872 and 119879
119896isin 1198791 1198792sdot sdot sdot 119879119873 such that
(119890119896+ 119905119896le 119889119896)
This approach has three advantages (1) it minimizesthe chance for buffer overflow (2) the task waiting time inprocessor buffer is reduced and (3) utilization is increasedbecause idle processors will be assigned scheduled tasks
43 Fault-Tolerant Methodology System designs often haveflaws that cannot be identified at design time It is almostimpossible to anticipate all faulty scenarios beforehandbecause processor failure may occur due to unexpectedruntime errors Real-time systems are critically affected if nomeans of fault tolerance scheme is implemented Failure toemploy fault detection and recovery strategies is often unaf-fordable in critical mission systems because the error maylead to possible data discrepancies and deadline violation
Processor failure introduces inevitable overall perfor-mance degradation due to (1) the reduced computing powerof the system and (2) the overhead involved in applying thefault recovery schemes Recovery procedures involve trackingthe task execution history and reconfiguring the systemby using the available processors This enables applicationprocessing to resume when the execution was terminatedDuring processor failure application processing is temporar-ily suspended and error recovery procedures are appliedbefore application processing is resumed
Fault-TolerantModelFaultmodeling can have several dimen-sions that define the fault occurring time the fault durationlocation of failure and so forth The proposed frameworkadopts the following fault modeling parameters
(1) It is assumed that the processor failure is permanentThus fault duration time 119905FD is infinite (119905FD = infin)During failure the address of the failed processor iscompletely removed from the mapper address table
(2) The location specifies where the failure occurred Fortile and torus topology location is represented in two-dimensional coordinate addresses
(3) During task processing any processors may fail atany time instance Consequently time of failure ismodeled as a random time instance
10 VLSI Design
In the event of failure the following procedures areexecuted
(1) Themapper removes the failed processor ID from theaddress table
(2) Tasks that are scheduled or mapped but not dis-patched have to be rescheduled and remapped Therespective new task release time and task address bothhave to be done again This is because the executioninstance of a task depends on the finish time ofits predecessor task which may possibly have beensuspended in the failed processor
(3) Tasks that are already dispatched to the failed proces-sor can be either (1) in the processorrsquos buffer or (2)in the middle of execution when the failure occurredThese tasks have to be migrated back to the mapperand their respective rescheduling and remapping haveto be done The scheduler can perform task schedul-ing concurrently when the nonfaulty processors areexecuting their respective tasks
(4) Tasks that are dispatched to other nonfailed proces-sors are not affected
Due to the dynamic property of the mapper and the fault-tolerant implementation the cost incurred during the eventof processor failure is minimal overhead incurred is only25 of the total execution time of the task The only penaltyincurred during processor failure is the cost due to taskmigration and the respective rerescheduling and remappingprocedures
5 Experimental Setup
The heterogeneous MpSoC framework developed in thiswork was developed using C++ and SystemC programminglanguage The architectural components such as processingelements (PEs) memory elements routers and networkinterfaces are developed using SystemC language and providecycle accurate simulations The processing elements areimplemented as a simple 32-bit processor that performssimple logic and arithmetic operations The heterogeneousPE structure in our MpSoC is implemented by altering thetype of operation and the execution times of the tasks eachPE can execute The routers implementations consist of aswitching matrix with input port buffers The tasks and datawithin PEs are transmitted using a data-serializing moduleof the PE A typical data transmitted within PEs consists oftask commands task data (if any) and the destination PEIDs (addresses) The data is propagated through the MpSoCsystem using the119883119884 routing algorithm
The scheduling and mapping algorithm are implementedusing C++ language and are interfaced with the SystemCarchitecture implementations The application in this workis considered as a task graph Each task graph consists ofprocessor operations their execution time communicationcost and deadline The application as a whole also has adeadline The scheduling algorithm parses the application(task graph) and assigns start times for the tasks on the
processors based on the set of optimization goals describedin the proposed performance driven scheduling algorithmThe scheduled tasks aremapped to their respective processorsin the MpSoC system based on the proposed homogenousworkload-mapping algorithm The tasksrsquo information com-prising of the task operations task data destination PEs(pathaddress of successor PEs) are assembled and forwardedto the initial PE by the dispatcher module The performanceevaluation module or the monitor module records cycleaccurate timing signals in the architecture during tasksexecution and communication
During the simulation of fault-tolerant scenario themonitor module triggers a PE failure event at a predefinedtime instance The dispatcher is informed of the PE failureand based on the mapper table and the current processingtask and the tasks in the buffer of the failed PE are determinedAn updated task graph is constructed and scheduling andmapping on the remaining unexecuted tasks are performedTasks currently executing on the PEs are undisturbed Thereassigned tasks are inserted in the PE buffers to satisfy thedeadlines
The implemented MpSoC system has been evaluatedextensively by modifying the architecture and topology Thesystemwas evaluated using a set of synthetic task graphs with50ndash3000 tasksThe architectural modifications for evaluatingthe MpSoC include change in type of PEs in the systemmesh and torus topology variations and the number of PEsin the system (9 16 32) The MpSoC system has been usedto evaluate the proposed scheduling mapping and fault-tolerant algorithms and compared with respective classicalalgorithms The performance of the proposed algorithmsalong with variation in architecture and topology have beenevaluated and presented The performance metrics consid-ered in this work include processor throughput processorutilization processor execution timetask and powertaskbuffers utilization and port utilization Detailed summary ofthe results and its significance are shown in Section 6
6 Simulation Results and Analysis
For evaluation of the proposed framework to explore designfeatures variations in scheduling mapping and fault tolerantalgorithms have been considered The application modeladapted is similar to the standard task graph (STG) [50 51]and E3S benchmark suite [54] which contains random set ofbenchmarks and application-specific benchmarks The sim-ulation was conducted with many STG benchmarks havingtask sizes 50 through 3000 The task graph is characterizedby the number of tasks dependencies of tasks task size(code size) communication cost (latency for interprocessortransfer) and application deadline The processor architec-ture model is derived from the E3S benchmark where eachprocessor is characterized by the type tasks it can executetask execution time task size (code size) and task powerTheprocessor also has general characteristics like type overheadcost (preemptive cost) task powertime and clock rate
The simulation results presented in this paper follow thefollowing legend 119883119884 plusmn 119885 where 119883 denotes 119877 or 119879 for
VLSI Design 11
Table 1 PE comparison
No of PEs AVG ETIMEPETASK (120583sec)
AVGUTLPE
AVGPWRPE(120583watts)
AVGPDPPE
PE no 9 498 048 18125 90748PE no 16 281 040 9834 27698PE no 25 189 035 6359 12006
Table 2 Comparison of task execution times processor utilizationand throughput of EDF-SA and PDS scheduling algorithms
ETIME (120583s) UTL THR (Bns) Std SA CostRAND-50
EDF-SA 20426 046 003 016PDS 22003 055 003 019
SPARSE-96EDF-SA 61651 044 002 015PDS 63789 049 002 017
RAND-100EDF-SA 41867 047 003 017PDS 43217 060 003 021
RAND-300EDF-SA 129945 049 003 017PDS 129695 056 003 019
FPPP-334EDF-SA 223836 042 002 015PDS 233736 047 002 016
RAND-500EDF-SA 143279 048 002 016PDS 212533 066 003 023
RAND-1000EDF-SA 416373 052 003 018PDS 432458 058 003 020
torus or tile topology 119884 denotes 119864 or 119878 for EDF-SA or PDscheduling algorithm + or minus for presence or absence of faulttolerance algorithm and 119885 denotes the number of PEs in theMpSoC system Performance evaluations on architecture andtopological variations were performed but are not included inthis paper Only performance results related to the proposedalgorithms are presented
61 Simulation Scenarios To demonstrate the capabilities ofthe proposed framework and the algorithms we performedseveral simulations on task graph sets and evaluated theireffectiveness over the following design abstractions
(i) Architectural architecture-based evaluation empha-sizes the effect of different PEs in the MpSoC frame-work Current implementation of our frameworkconsists of processors of the same architecture thatcan execute various tasks that is each processor hasa different set of tasks they can execute The MpSoC
Table 3 Comparison of HWD and next available and randommapping algorithms (simulation TS-9)
Mapping Random HWD NXT AVLBLAVG ETIME 141746 139467 13825AVG UTL 048 059 059AVG THR 002 002 002AVG PRT 108 107 108AVG PWR 599503 579969 57005AVG BFR 5 4 6
architecture was modified by changing the number ofPEs the types of PEs and topology It is importantto consider the effect of topology in architectureevaluation because the topology of the MpSoC alsodictates the performance of the individual PEs Theeffect of such architecture changes is measured interms of average execution timePEtask (ETIME) in120583sec average PE utilization (UTL) powertask of PEs(PWR) in 120583-Watts and power delay product (PDP)which are shown in Table 1
(ii) Scheduling evaluation of scheduling algorithms overvarious MpSoC architectures was conducted Per-formance of earliest deadline first based simulatedannealing (EDF-SA) and the new performance driven(PD) algorithms are compared (Table 2) Perfor-mance metrics for evaluating scheduling algorithmsare the same as that of architecture evaluations Alsothe standardized SA costs are shown
(iii) Mapping evaluation of mapping algorithms overvarious MpSoC architectures was conducted usingperformance driven scheduling policy Performanceof the proposed HWD Next Available (NA) andrandom mapping algorithms is compared as shownin Table 3
(iv) Fault Tolerant-evaluation and comparison of fault-tolerant (FT) and nonfault-tolerant (NFT) imple-mentation over various MpSoC architectures wereconducted and results for two test cases are shownin Tables 4 and 5
62 Simulation Results and Explanation Table 1 shows theaverage performance metrics obtained for various architec-tural variations possible in the developedMpSoC frameworkThe architectural variations include the type of topology(tile or torus) scheduling algorithm (EDF-SA or PDS)mapping algorithm (HWD) fault-tolerant scheme (NFT orFT) and the number of PEs Table 2 specifically compares theperformance of the EDF-SA and PDS scheduling algorithmComparison results on total execution time (ECT) in 120583secaverage processor utilization and average throughput inbytes120583sec are presented Other metrics that have less signif-icance have been omitted Also comparisons between EDF-SA and PDS algorithms for processor utilization throughputand buffer usage evaluations across various architectural
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

VLSI Design 3
voltage scaling in conjunction with scheduling for low powerrequirements
Finding an optimal solution in scheduling and mappingproblem domain for set of real-time tasks has been shownto be NP-hard problem [11] Carvalho et al [18] proposeda ldquocongestion-awarerdquo mapping heuristic to dynamically maptasks on heterogeneous MpSoCs This heuristic approachinitially assigns master-tasks to selected processors and theslave-tasks are allocated on congestion minimizing mannerto reduce the communication traffic Sesame project [4]proposed a multiprocessor model that maps applicationstogether with the communication channels on the architec-ture This model tries to minimize an objective functionwhich considers power consumption application execu-tion time and total cost of the architectural design Manyresearchers have discussed static and dynamic task allocationfor deterministic and non-deterministic tasks extensively [5]Static mapping has also been shown non-efficient strategybecause it does not take application dynamism into accountthat is a core design issues in multiprocessor systems Ahnet al [19] suggests that real-time applications should behavedeterministically even in unpredictable environments sothat the tasks can be processed in real-time Ostler andChatha [20] propose an ILP formulation for applicationmapping on network processors Harmanani and Farah[21] propose an efficient mapping and routing algorithmthat minimizes blocking and increases bandwidth based onsimulated annealing Also mapping algorithms to minimizecommunication cost energy bandwidth and latency eitherindividually [22ndash24] or as a multi-objective criteria [25 26]have been proposed
Task migration as opposed to dynamic mapping has beenproposed in [4] to overcome performance bottlenecks Taskmigration may result in performance improvement in sharedmemory systems butmay not be feasible when considered fordistributed memory architectures due to the high volume ofinter-processor data communication [5]
Previous research in [5 6 27] has demonstrated reliabilityissues regarding application processing data routing andcommunication link failure Zhu andQin [28] demonstrateda system level design framework for a tiled architecture toconstruct a reliable computing platform from potentiallyunreliable chip resources This work proposed a fault modelwhere faults may have transient and permanent behaviourTransient errors are monitored by a dedicated built-inchecker processor that effectively corrects the fault at run-time Nurmi et al [6] demonstrated error tolerance methodsthrough time space and data redundancy This is however aclassic and costly approach with respect to system resourcesand bandwidth though thework demonstrated redundancy isone potential approach to address faulty scenarios Holsmarket al [29] proposed a fault tolerant deadlock free algorithm(APSRA) for heterogeneous multiprocessors APSRA storesrouting information in memory to monitor faulty routsand allow re-configurability dynamically Pirretti et al [30]and Bertozzi et al [31] propose NoC routing algorithmsthat can route tasks around the fault and sustain networkfunctionality Also research on router design to improvereliability [32] buffer flow control [33] and error correction
techniques [34 35] for NoC have been proposed Koibuchiet al [36] proposed a lightweight fault-tolerant mechanismcalled default backup path (DBP) The approach proposed asolution for non-faulty routers and healthy PEs They designNoC routers with special buffers and switch matrix elementsto re-route packets through special paths Also Bogdanet al [37] propose an on-chip stochastic communicationparadigm based on probabilistic broadcasting scheme thattakes advantage of the large bandwidth available on the chipIn their method messagespackets are diffused across thenetwork using spreaders and are guaranteed to be receivedby destination tilesprocessors
A number of EDA research groups are studying differentaspects of MpSoC design some of which include the fol-lowing (1) Polis [18] is a framework based on both micro-controllers and ASICs for software and hardware imple-mentation (2) Metropolis [18] is an extension of Polis thatproposed a unified modeling and structure for simulatingcomputationmodels (3) Ptolemy [18] is a flexible frameworkfor simulating and prototyping heterogeneous systems (4)Thiele et al [1] proposed a simulation based on distributedoperation layer (DOL) which considers concurrency scal-ability mapping optimization and performance analysisin an effort to yield faster simulation time (5) NetChipxpipes xpipes compiler and SUNMAP NetChip is a NoCsynthesis environment primarily composed of two toolsnamely SUNMAP [38] and the xpipes compiler [39] (6)NNSENostrumNoCSimulationEnvironmentNNSE [40] isa SystemC-based NoC simulation environment initially usedfor theNostrumNoC (7) ARTSModeling Framework ARTS[41] is a system-level framework to model networked multi-processor systems on chip (MpSoC) and evaluate the cross-layer causality between the application the operating system(OS) and the platform architecture (8) StepNP a System-Level Exploration Platform for Network Processors StepNP[42] is a System-Level Exploration Platform for NetworkProcessing built in SystemC It enables the creation of multi-processor architectures with models of interconnects (func-tional channels NoCs) processors (simple RISC) memoriesand coprocessors (9) Genko et al [43] present a flexible emu-lation environment implemented on an FPGA that is suitableto explore evaluate and compare a wide range of NoCsolutions with a very limited effort (10) Coppola et al [44]proposes an efficient open-source research and developmentframework (On-Chip Communication Network (OCCN))for the specification modeling and simulation of on-chipcommunication architectures (11) Zeferino and Susin [45]present SoCIN a scalable network based on a parametricrouter architecture to be used in the synthesis of customizedlow cost NoCs The architecture of SoCIN and its router aredescribed and some synthesis results are presented
The following papers presented are the closest worksrelated to the proposed algorithms discussed in this paperOrsila et al [46] investigated the use of Simulated Annealing-based mapping algorithm to optimize energy and perfor-mance on heterogeneous multiprocessor architecture Inspecific the cost function considered for SA optimization
4 VLSI Design
includes processor area frequency of operation and switch-ing activity factor The work compares the performance oftheir SA-mapping algorithms for different heterogeneousarchitectures In another similar work [47] proposed bythe same author the SA-mapping algorithm is adoptedto optimize usage of on-chip memory buffers Their workemploys a B-level scheduler after the mapping process toschedule tasks on each processor
The proposed framework discussed in this paper employsSA-based scheduling and workload balanced mapping algo-rithms Our algorithms also optimize scheduling andmapping cost functions that include processor utilizationthroughput buffer utilization and port traffic along withprocessor power In addition our algorithms also considertask deadline constraints Both scheduling and mappingalgorithms adopted in ourwork perform global optimization
Paterna et al [48] propose two workload allocationmapping algorithms for energy minimization The algo-rithms are based on integer linear programming and a two-stage-heuristic mapping algorithm based on linear program-ming and bin packing policies Teodorescu and Torrellas[49] and Lide et al [50 51] explore workload-based map-ping algorithms for independent tasks and dependent tasksrespectively The work by Zhang et al is based on ILPoptimization for execution time and energy minimizationOur proposed mapping algorithm varies from the above-specified workload constrained algorithms by consideringthe buffer size usage and execution time of the tasks in thebuffer
Works by Ababei and Katti [52] and Derin et al [53]have used remapping strategies forNoC fault tolerance In thesolution proposed by Ababei and Katti [52] fault tolerancein NoCs is achieved by adaptive remapping They considersingle and multiple processor (PE) failures The remappingalgorithm optimizes the remap energy and communicationcosts They perform comparisons with a SA-based remapperOrsila et al [46] propose an online remapping strategycalled local nonidentical multiprocessor scheduling heuristic(LNMS) based on integer linear programming (ILP) TheILP minimizing cost functions include communication andexecution time The proposed NoC fault-tolerant algorithmemploys rescheduling and remapping strategies to optimizeprocessor performance and communication cost Also taskdeadline constraints are considered during the reschedulingand remapping
With the current design trends moving towards mul-tiprocessor systems for high performance and embeddedsystem applications the need to develop comprehensivedesign space exploration techniques has gained importanceMany research contributions in development of hardwaremodules and memory synchronization to optimize powerperformance and area for multiprocessor systems are beingdeveloped However algorithmic development for multipro-cessor systems like multiprocessor scheduling and mappinghas yielded significant results Therefore a comprehensiveand generic framework for a multi-processor system isrequired to evaluate the algorithmic contributionsThis workaddresses the above requirement in developing a compre-hensive MpSoC evaluation framework for evaluating many
scheduling mapping and fault-tolerant algorithms Also theframework is developed on generic modeling or represen-tation of applications (task graphs) architecture processorstopologies communication costs and so forth resulting in acomprehensive design exploration environment
The main contributions of this work can be summarizedas follows
(1) We propose a unique scheduling algorithm forMpSoC system called performance driven schedulingalgorithm that is based on Simulated Annealing andoptimizes an array of performance metrics such astask execution time processor utilization processorthroughput buffer utilization and port traffic andpower The proposed algorithm performance is com-pared to that of the classical earliest deadline firstscheduling algorithm
(2) This paper proposes a mapping algorithm that suc-ceeded the scheduling algorithm called the homo-geneous workload distribution algorithm that dis-tributes tasks evenly to the available processors in aneffort to balance the dynamic workload throughoutthe processors The proposed algorithm performanceis compared with other classical mapping algorithm
(3) Also a fault-tolerant scheme that is effective duringPE failure is proposed in this paper The proposedfault-tolerant (FT) scheme performs an updatedscheduling and mapping of the tasks assigning to thefailed PE when the PE fault is detected The uniquecontribution of this work is the fact that it addressesthe pending and executing tasks in the faulty PEsThe latency overhead of the proposed FT algorithmis evaluated by experimentation
3 Definitions and Theory
Simulation Model The simulation model consists of threesubmodels (Figure 1) (1) application (2) architecture and (3)topologyThe applicationmodel represents the application tobe executed on the given MpSoC architecture and connectedby the topology specified
Application Model (Task Graphs) A task graph is a directedacyclic graph (DAG) that represents an application A taskgraph is denoted as TG such that TG = (119881 119864) where 119881 is aset of nodes and 119864 is a set of edges A node in 119881 representsa task such that 119881 = 119879
1 1198792 1198793 119879
119873 and an edge in
119864 represents the communication dependency between thetasks such that 119864 = 119862
1 1198622 1198623 119862
119870 A weighted edge
if specified denotes the communication cost incurred totransfer data from a source task to destination task Eachtask can exist in a processor in one of the following statesideal pending ready active running or complete The taskgraph is derived by parsing the high-level description of anapplication
Architecture Model The architecture of the MpSoC sys-tem consists of the processors hardware components
VLSI Design 5
pending readyactive running
TG =
Processormemoryarchitecture type
power clock-rateinterrupt memory
NG =
PE
PE
PE
PE
PE
PE
PE
PEM
M
M
PE PEPE
PE
PE
PE PE
PE
PE
PE PE
PE
PE
PE
⟩
complete⟩
NG ⟨
⟨
processor type topology⟩
Task ⟨119879119868119863
Task status ⟨ideal
TtypeTrelease timeTexec timeTdeadline Tadress TDlist
(V E) V = T1 T2 T3 middot middot middot T9E = C1 C2 C3 middot middot middot CK
T1
T2T3
T4
T5T6 T7
T8
T9
ARCH = P1 P2 P3 middot middot middot PNM1 M2 M3 middot middot middot MK
(V E)V = Pi Mi E = C1 middot middot middot CL
Figure 1 Simulation model containing application architecture and topology
memory and interconnects as defined by the topologymodel The MpSoC architecture is represented as a set1198751 1198752 1198753 119875
119873119872111987221198723 119872
119870 where119875
1 1198752 119875
119899
are a set of 119873 processors and 11987211198722 119872
119870are a set
of 119870 memory units Each processor 119875119894or memory 119872
119894is
defined by the following characteristics type powertaskexecutiontask clock rate preempt overhead and also by a setof tasks 119879
119886 119879119887 119879119888 119879
119911 each processor can execute along
with their respective execution times and power costs Theimplemented heterogeneousMpSoC consists of processors ofthe same architecture but can execute various set of tasks
Topology Model (Topology Graph) Topology describes thephysical layout of hardware components in a system Thetopology model is represented as a topology graph (NG) thatconsists of the set of processors topology type ⟨tile torus⟩and communication cost This communication cost is thesame communication cost (119864) as defined in the applicationmodel
Scheduling Scheduling is the process of assigning an execu-tion start time instance to all tasks in an application such thattasks are executed within their respective deadline For anapplication 119860 = 119879
1 1198792sdot sdot sdot 119879119873 where 119879
119894is a task instance in
the application task scheduling denoted as 120572(119879119894) is defined
as an assignment of execution start time (119905119894) for the task 119879
119894in
the time domain such that
120572 (119879119894) = 119905119894 119905
119894+ 119890119894le 119889119894 (1)
where 119890119894is the worst-case execution time of the task on a
specific processor 119889119894is the deadline of the task119879
119894 and 119905
119894is the
execution start time of task 119879119894 Scheduling of an application
119860 is denoted as
120572 (119860) = 120572 (1198791) 120572 (119879
2) 120572 (119879
3) sdot sdot sdot 120572 (119879
119873) (2)
If there exists a precedence operation between any two taskssuch that the execution of a task 119879
119894should occur before the
execution of task 119879119895 represented as 119879
119894lt 119879119895 then
119905119894+ 119890119894le 119905119895le 119889119894 119905
119895+ 119890119895le 119889119895 (3)
where 119905119894is the start time of task 119879
119895 and 119890
119895and 119889
119895are the
execution time and deadline of task 119879119895 respectively
Performance Index (PI) PI is the cumulative cost functionused to determine the optimal schedule by using the Sim-ulated Annealing technique PI quantifies the performanceof the system taking into consideration the averaged valuesof processor execution time (ETIME) utilization (UTL)throughput (THR) buffer utilizationusage (BFR) port traf-fic (PRT) and power (PWR) PI is evaluated by a costfunction that is expressed as
COST = 1205721(
1
ETIME) + 1205722(
1
UTL) + 1205723(
1
THR)
+ 1205724(
1
BFR) + 1205725(PRT) + 120572
6(PWR)
(4)
where 1205721sim 1205726are normalizing constants
6 VLSI Design
The Simulated Annealing procedure compares the per-formance of successive design choices based on the PIExecution time processor utilization processor throughputand buffer utilization are maximized so that their costis computed reciprocally however power and port trafficare minimized so that the nonreciprocal values are takenThe coefficient values in the cost equation are set accordingto the desired performance goals of the system
Optimization of Scheduling Algorithm The problem of deter-mining optimal scheduling is to determine the optimal starttime and execution time of all tasks in the application
minimize(119873
sum
119894=1
(119905119894+ 119890119894))
minimize(119873
sum
119894=1
COST (120572 (119879119894))) 119905
119899+ 119890119899le DL
(5)
where 119890119894is the worst-case execution time of each task 119879
119894
DL is the deadline of the application and 119905119899and 119890119899are the
start time and worst-case execution time of the last taskrespectively in the application COST (120572(119879
119894)) is the cost
function of scheduling the tasks
Mapping Mapping is the process of assigning each task in anapplication to a processor such that the processor executes thetask and satisfies the task deadline as well as other constraints(power throughput completion time) if any
For an application 119860 = 1198791 1198792sdot sdot sdot 119879119873 where 119879
119894is a
task instance in the application mapping a task denoted as119872(119879119894) is defined as an assignment of the processor 119875
119895 =
1198751 1198752 119875
119872 = 119875 for the task 119879
119894
119872(119879119894) = 119875
119895 (6)
Application mapping is defined as mapping of all tasks 119879119894 in
the application 119860 to processors and is denoted as
119872(119860) = 119872 (1198791) 119872 (119879
2) sdot sdot sdot119872 (119879
119873) (7)
Optimization of the Mapping Algorithm The problem indetermining optimummapping is to determine the optimumallocation of all tasks in the application on the processorssuch that the total execution time of all tasks is minimizedOther factors for optimum mapping include maximizingprocessor execution time throughput minimizing inter-processor communication delay and balancing workloadhomogenously on the processors in order to improve utiliza-tion
minimize(119873
sum
119894=1
(119888119894)) 119888
119894= COST (119872 (119879
119894)) (8)
where 119888119894is the cost function for optimal mapping of the tasks
on the processor
Power Modeling In this research scheduling and mappingalgorithms model heterogeneous processor execution andpower requirements as follows
(1) Switch power is consumed whenever a task is routedfrom input port to output port
(2) Processor power is modeled with respect to idle-mode (also includes pending ready active and com-plete) and execution-mode (running) power both ofwhich are functions of the task execution time 119890
119894 We
also assume that for the idle model Δ120578 = 0
120578119894(119879119894) = Δ120578 lowast 119890
119894 (9)
whereΔ120578 is the unit power consumed per unit time oftask processingThe total power rating for a processor119875119895would be expressed as
120578119895= Δ120578 lowast
119899
sum
119894=1
(119890119894) (10)
where 119899 is the number of tasks executed by theprocessor
(3) Whenever a task 119879119896is executed on processor 119875
119897
the execution time 119890119896and the power consumed by
processor 120578119896are updated as
120578119897(119879119896) = Δ120578 lowast 119890
119896
120578119897= Δ120578 lowast
119899
sum
119894=1
(119890119896)
(11)
(4) Whenever a task is transferred between switchesthe communication delay is updated on the TotalTask Communication Delay parameter (T) and isexpressed as
T = 119899 lowast v lowast Δ119862 (12)
where 119899 is number of switch hopes task-size (v) is thesize of the task defined as a function of its executiontime in time-units and Δ119862 is a time constant that isrequired to transfer single time-unit task for one hop
(5) For each task 119879119894 the Task Slack Time 119878
119894and Average
Slack Time 119878 are calculated as
119878119894= 119889119894minus [119905119894+ 119890119894]
119878 =
sum
119873
119894=1(119878119894)
119873
(13)
where 119889119894is the deadline 119905
119894is the release time and119873
is the total number of tasks processed
Fault-Tolerant System A fault-tolerant system describes arobust system that is capable of sustaining application pro-cessing in the event of component failure A fault-tolerantalgorithm is a process that performs scheduling andmappingon a set of unprocessed tasks for the available processors
Let an application119860with a set of tasks119860 = 1198791 1198792sdot sdot sdot 119879119873
be scheduled denoted by 120572(119860) and mapped on the set
VLSI Design 7
of processors 119875 = 1198751 1198752 119875
119872 denoted as 119872(119860) A
fault is defined as a nonrecurring permanent failure of aprocessor at time instance 119905
119891during the execution of a
task 119879119891 The application after the occurrence of the fault is
expressed as 119860119891such that 119860
119891sub 119860 which has a list of tasks
119860119891= 119879119892 119879ℎsdot sdot sdot 119879119899 that are not dispatched to processors
by the mapper when the processor failure occurs The set ofprocessors after the failure119865 is denoted by 119875
119891= 1198751 1198752sdot sdot sdot 119875119871
and 119875 notin 119875119891 where 119875
119891is the failed processor The proposed
fault-tolerant MpSoC framework determines the updatedscheduling 120572(119860
119891) and updated mapping119872(119860
119891) for a set of
unprocessed tasks in the application subset 119860119891 such that
119905119899+ 119890119899le DL (14)
where 119905119899and 119890
119899are the start time and execution time
respectively of the last scheduled task in 119860119891
Optimization of Fault-Tolerant Strategy Due to the dynamicmapping methodology adopted in the framework only thetasks dispatched to the failed processormdashwhich includes thetask that was executing on the failed processor and thetasks dispatched by the mapper to the failed processormdashwillneed to be rescheduled along with the tasks that were notdispatched by the mapper
Let us consider an application 119860119891with a list of 119899 tasks
119860119891
= 119879119892 119879ℎsdot sdot sdot 119879119899 that have not been dispatched to
processors at the occurrence of the fault Also let the tasks119879119887= 119879119903sdot sdot sdot 119879119905 be the list of tasks in the buffer of the failed
processor 119875119891and let 119879
119901be the task that was being executed
during failure by the failed processor The task list 119879FT of thefault tolerant algorithm at time 119905
119891is represented as
119879FT = 119860119891+ 119879119887+ 119879119891 (15)
It is also assumed that all the tasks that are being executedby the nonfailed processor complete the execution of thetasks even after the time of failure 119905
119891 Thus the FT algorithm
performs the updated scheduling (119879FT) and updated map-ping
119872(119879FT) on the task set 119879FT which satisfies the deadlineconstraint DL of the application 119860
4 Framework Modeling and Implementation
The proposed framework adopts a ldquobottom-uprdquo modulardesign methodology that gives the benefit of componentreusability Behavioral componentmodels were designed andstored in hardware and software librariesThe frameworkwasimplemented in SystemC 22C++ and compiled with g++-43 under Linux The framework is divided into three majorcomponents input or user interface module core MpSoCsimulation module and the output or performance evalua-tion module The hardware modules such as the processorswitch dispatcher unit and multiplexer were implementedin SystemC the software modules such as input parserscheduler and task interface classes were implemented inC++
Input Module Such userrsquos data as the number of processorstopology task graph processor types buffer size switching
Software libraries
Settings
Task interface
Other IPs
Main GUI
TG parser
Scheduler
Mapper
Dispatcher
Switch
Processor
Multiplexer
ARCH setup
Performance evaluation
PE
PE
PE
PE
PE PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
Hardware libraries
Figure 2 Framework modeling
technology fault-tolerant mode and schedulingmappingspecifications are read either by using a command lineinterface or else from a GUI interface
Core Simulation Module The core simulation module isdepicted in Figure 2 which shows the softwarehardwarelibraries and control flow between the modules The sim-ulation module consists of two components the softwareand hardware libraries Software libraries include softwarecomponents of the framework for instance the input parserscheduler data store and task interface Hardware librariesinclude hardware components implemented in SystemCsuch as the processor the mapper the dispatcher andmultiplexersThe processors are implemented as behaviouralprocessors capable of computing the various tasks in thetask graphs The communication cost for a task is depen-dent on the size and thus the execution duration of thetask (Section 3) Thus communication latency is modelledas a function of task size Heterogeneity is modelled byvarying the task processing cost (processing timetask andpowertask) All processors are capable of executing allpossible operations but with different costs Processor failureis permanent once it occurs and only single processorfailure is considered Due to the modular implementationof the simulation module architecture topology routingscheduling and mapping methods can be easily changedin MpSoCs to conduct extensive evaluation of design spaceexploration
Output Module The simulation terminates by evaluating thesystem performance module which retrieves the various
8 VLSI Design
for each task in ATG do
set the longest-path-maximum-delay deadline
setDeadline()
initial solution
taskrandom mapToPE()
while simulation temp gt cooling threshold
do
for temperature length
for task sub iteration length
while each task is assigned a release time
generates the RTW w Comm cost
genRTL()
rand task from RTL
t sch = sel rand(RTL)
generate release time window
t schgenRTW()
set rel time
t schrel time = sel rand(RTW)
init and run systemC simulation
sc start(time)
calculating objective function value
calcObjFunc()
accepts or rejects a solution
probFunc()
for each task in ATG do
calculate workload of processors
taskcalc HWDcost()
new mapping solution
taskHWD mapToPE()
calculate new simulation temperature
calc simulation temp()
Algorithm 1 Pseudocode for the performance driven (PD) scheduling and HWDmapping algorithms
performance variables from the individual processors suchas the total execution time power throughput port trafficnumber of tasks processed and buffer usageThese values aredisplayed on the output GUI and stored in the result log file
41 Performance Driven Scheduling Algorithm This workalso proposes an efficient offline and performance drivenscheduling algorithm based on the Simulate Annealing tech-nique The performance index (PI) determined by a costfunction is used to determine the optimal schedule Theperformance index is a cumulative factor of (1) processor exe-cution time (2) processor utilization (3) processor through-put (4) processor power (5) processor port traffic and (6)processor buffer utilization The problem of determining theoptimal schedule is defined as determining the schedulewith maximal performance index The Simulated Annealingalgorithm performs (1) random scheduling and mappingof tasks (2) simulation and (3) capturing averaging andnormalizing performance variables finally it calculates theperformance index These steps are repeated several times inan effort to increase the PI During the iterations if a better
PI is found the state is saved and the simulation repeats untilthe temperature reaches the threshold value
For the problem being considered the normalizing coef-ficients used to calculate the PI were set to 120572
1= 300 120572
2=
500 1205723= 250 120572
4= 125 120572
5= 120 and 120572
6= 50000
These coefficients were determined after conducting sev-eral runs on all benchmarks Execution time utilizationthroughput and power factors are key performance indicesTherefore they are given significant weights (a higher valueof coefficient) during normalization Port traffic and powerindices are minimized consequently their respective costfunction is computed reciprocally The pseudocode for theperformance driven scheduling (PDS) and HWD mappingalgorithms is given in Algorithm 1
42 Multiprocessor Task Mapping Strategy Multiprocessorenvironments grant the freedom for dynamic task mappingThus themultiprocessormapping algorithm needs to specifythe locationwhere a particular task should be processed Taskmapping in heterogeneous systems is accomplished in twosteps (1) binding and (2) placement First the task binding
VLSI Design 9
procedure attempts to find which particular assignment oftasks would lead to effective lower power and faster executiontimeDuring task placement themapper considers allocatingany two tasks that exchange data more frequently as closeto each other as possible Placement of communicating tasksto adjacent or nearby processors reduces the communicationlatency switch traffic and power dissipation
Static mapping assigns a particular task to a predeter-mined processing element offline regardless of the dynamicstate of the system components This however does not sat-isfy the MpSoCs requirement because processing tasks on aheterogeneous architecture introduces workload irregularityon system resources (PEs) Irregular workload distributionis a design issue that degrades the utilization of system Toovercome this problem tasks should bemapped dynamicallybased on the dynamic workload on the processors Thenumber of tasks in the processorsrsquo local memory measuresthe processor workload
The dynamic mapper in the proposed framework per-forms the task allocation as per the configured policy Inorder to take heterogeneity of processors into considerationadditional power cost and execution latency cost have beenintroduced This emphasizes the fact that processing a par-ticular task on different types of processors incurs differentcost (power consumption and execution time) Efficient andoptimized heterogeneous mapping algorithms are tailored tominimize this additional cost
In the framework various task allocation heuristics wereimplemented Given a scheduled task the task mappingfollows one of the below policies
(1) Next Available Mapping (NXT AVLB) In the NextAvailable Mapping policy a scheduled task 119879
119894is
mapped on processor 119875119894 followed by the mapping of
the next scheduled task119879119894+1
on processor119875119895 provided
119875119894and 119875
119895are neighbors to each other as defined by
the topology This policy assigns tasks on successiveprocessor sequentially but does not consider theheterogeneity of the tasks nor the processorworkload
(2) Homogenous Workload Distribution Mapping(HWD) HWD considers the workload on eachprocessor and maps a scheduled task on a processorthat has the minimum workload
(3) Random mapping (RANDOM) rRandom task allo-cation is used by the PD algorithm to distribute theworkload randomly throughout the available proces-sors
HWD Mapping Approach Minimizing the idle time ofeach processor or maximizing processing time improvesprocessor utilization To reduce idle time tasks shouldbe distributed evenly throughout the available processorsThe proposed Homogenous Workload Distribution (HWD)algorithm is tailored to distribute tasks evenly to the availableprocessors in an effort to balance the dynamic workloadthroughout the processors The algorithm is a two-stepprocess (1) probing individual processor buffers throughdedicated snooping channels that connects each processor
to the mapper and (2) mapping each scheduled task ona processor that has the lowest workload Workload is ameasure of the number of tasks and its respective executiontime in the processor bufferThus a processor having the leastnumber of tasks and respective execution time in its bufferhas the lowest workload therefore themapper will assign thenext scheduled task to this processor
HWD Mapping Algorithm Let 1198751 1198752sdot sdot sdot 119875119872 be a set of
processors let 1198711 1198712sdot sdot sdot 119871119872 be the dynamic task workloads
defined by number of tasks on respective processor buffersand let119873 be the number of processors Let 119879
1 1198792sdot sdot sdot 119879119873 be a
set of119872 tasks and the symbol ldquorarr rdquo denotes ldquomappingrdquoThen
A task 119879119896⟨119879release-time 119879exec-time 119879deadline⟩ 997888rarr 119875
119894
iff 119871119894lt 119871119895
forall [119871119894 119871119895] isin 119871
1 1198712sdot sdot sdot 119871119873
(16)
where 119875119894isin 1198751 1198752sdot sdot sdot 119875119872 and 119879
119896isin 1198791 1198792sdot sdot sdot 119879119873 such that
(119890119896+ 119905119896le 119889119896)
This approach has three advantages (1) it minimizesthe chance for buffer overflow (2) the task waiting time inprocessor buffer is reduced and (3) utilization is increasedbecause idle processors will be assigned scheduled tasks
43 Fault-Tolerant Methodology System designs often haveflaws that cannot be identified at design time It is almostimpossible to anticipate all faulty scenarios beforehandbecause processor failure may occur due to unexpectedruntime errors Real-time systems are critically affected if nomeans of fault tolerance scheme is implemented Failure toemploy fault detection and recovery strategies is often unaf-fordable in critical mission systems because the error maylead to possible data discrepancies and deadline violation
Processor failure introduces inevitable overall perfor-mance degradation due to (1) the reduced computing powerof the system and (2) the overhead involved in applying thefault recovery schemes Recovery procedures involve trackingthe task execution history and reconfiguring the systemby using the available processors This enables applicationprocessing to resume when the execution was terminatedDuring processor failure application processing is temporar-ily suspended and error recovery procedures are appliedbefore application processing is resumed
Fault-TolerantModelFaultmodeling can have several dimen-sions that define the fault occurring time the fault durationlocation of failure and so forth The proposed frameworkadopts the following fault modeling parameters
(1) It is assumed that the processor failure is permanentThus fault duration time 119905FD is infinite (119905FD = infin)During failure the address of the failed processor iscompletely removed from the mapper address table
(2) The location specifies where the failure occurred Fortile and torus topology location is represented in two-dimensional coordinate addresses
(3) During task processing any processors may fail atany time instance Consequently time of failure ismodeled as a random time instance
10 VLSI Design
In the event of failure the following procedures areexecuted
(1) Themapper removes the failed processor ID from theaddress table
(2) Tasks that are scheduled or mapped but not dis-patched have to be rescheduled and remapped Therespective new task release time and task address bothhave to be done again This is because the executioninstance of a task depends on the finish time ofits predecessor task which may possibly have beensuspended in the failed processor
(3) Tasks that are already dispatched to the failed proces-sor can be either (1) in the processorrsquos buffer or (2)in the middle of execution when the failure occurredThese tasks have to be migrated back to the mapperand their respective rescheduling and remapping haveto be done The scheduler can perform task schedul-ing concurrently when the nonfaulty processors areexecuting their respective tasks
(4) Tasks that are dispatched to other nonfailed proces-sors are not affected
Due to the dynamic property of the mapper and the fault-tolerant implementation the cost incurred during the eventof processor failure is minimal overhead incurred is only25 of the total execution time of the task The only penaltyincurred during processor failure is the cost due to taskmigration and the respective rerescheduling and remappingprocedures
5 Experimental Setup
The heterogeneous MpSoC framework developed in thiswork was developed using C++ and SystemC programminglanguage The architectural components such as processingelements (PEs) memory elements routers and networkinterfaces are developed using SystemC language and providecycle accurate simulations The processing elements areimplemented as a simple 32-bit processor that performssimple logic and arithmetic operations The heterogeneousPE structure in our MpSoC is implemented by altering thetype of operation and the execution times of the tasks eachPE can execute The routers implementations consist of aswitching matrix with input port buffers The tasks and datawithin PEs are transmitted using a data-serializing moduleof the PE A typical data transmitted within PEs consists oftask commands task data (if any) and the destination PEIDs (addresses) The data is propagated through the MpSoCsystem using the119883119884 routing algorithm
The scheduling and mapping algorithm are implementedusing C++ language and are interfaced with the SystemCarchitecture implementations The application in this workis considered as a task graph Each task graph consists ofprocessor operations their execution time communicationcost and deadline The application as a whole also has adeadline The scheduling algorithm parses the application(task graph) and assigns start times for the tasks on the
processors based on the set of optimization goals describedin the proposed performance driven scheduling algorithmThe scheduled tasks aremapped to their respective processorsin the MpSoC system based on the proposed homogenousworkload-mapping algorithm The tasksrsquo information com-prising of the task operations task data destination PEs(pathaddress of successor PEs) are assembled and forwardedto the initial PE by the dispatcher module The performanceevaluation module or the monitor module records cycleaccurate timing signals in the architecture during tasksexecution and communication
During the simulation of fault-tolerant scenario themonitor module triggers a PE failure event at a predefinedtime instance The dispatcher is informed of the PE failureand based on the mapper table and the current processingtask and the tasks in the buffer of the failed PE are determinedAn updated task graph is constructed and scheduling andmapping on the remaining unexecuted tasks are performedTasks currently executing on the PEs are undisturbed Thereassigned tasks are inserted in the PE buffers to satisfy thedeadlines
The implemented MpSoC system has been evaluatedextensively by modifying the architecture and topology Thesystemwas evaluated using a set of synthetic task graphs with50ndash3000 tasksThe architectural modifications for evaluatingthe MpSoC include change in type of PEs in the systemmesh and torus topology variations and the number of PEsin the system (9 16 32) The MpSoC system has been usedto evaluate the proposed scheduling mapping and fault-tolerant algorithms and compared with respective classicalalgorithms The performance of the proposed algorithmsalong with variation in architecture and topology have beenevaluated and presented The performance metrics consid-ered in this work include processor throughput processorutilization processor execution timetask and powertaskbuffers utilization and port utilization Detailed summary ofthe results and its significance are shown in Section 6
6 Simulation Results and Analysis
For evaluation of the proposed framework to explore designfeatures variations in scheduling mapping and fault tolerantalgorithms have been considered The application modeladapted is similar to the standard task graph (STG) [50 51]and E3S benchmark suite [54] which contains random set ofbenchmarks and application-specific benchmarks The sim-ulation was conducted with many STG benchmarks havingtask sizes 50 through 3000 The task graph is characterizedby the number of tasks dependencies of tasks task size(code size) communication cost (latency for interprocessortransfer) and application deadline The processor architec-ture model is derived from the E3S benchmark where eachprocessor is characterized by the type tasks it can executetask execution time task size (code size) and task powerTheprocessor also has general characteristics like type overheadcost (preemptive cost) task powertime and clock rate
The simulation results presented in this paper follow thefollowing legend 119883119884 plusmn 119885 where 119883 denotes 119877 or 119879 for
VLSI Design 11
Table 1 PE comparison
No of PEs AVG ETIMEPETASK (120583sec)
AVGUTLPE
AVGPWRPE(120583watts)
AVGPDPPE
PE no 9 498 048 18125 90748PE no 16 281 040 9834 27698PE no 25 189 035 6359 12006
Table 2 Comparison of task execution times processor utilizationand throughput of EDF-SA and PDS scheduling algorithms
ETIME (120583s) UTL THR (Bns) Std SA CostRAND-50
EDF-SA 20426 046 003 016PDS 22003 055 003 019
SPARSE-96EDF-SA 61651 044 002 015PDS 63789 049 002 017
RAND-100EDF-SA 41867 047 003 017PDS 43217 060 003 021
RAND-300EDF-SA 129945 049 003 017PDS 129695 056 003 019
FPPP-334EDF-SA 223836 042 002 015PDS 233736 047 002 016
RAND-500EDF-SA 143279 048 002 016PDS 212533 066 003 023
RAND-1000EDF-SA 416373 052 003 018PDS 432458 058 003 020
torus or tile topology 119884 denotes 119864 or 119878 for EDF-SA or PDscheduling algorithm + or minus for presence or absence of faulttolerance algorithm and 119885 denotes the number of PEs in theMpSoC system Performance evaluations on architecture andtopological variations were performed but are not included inthis paper Only performance results related to the proposedalgorithms are presented
61 Simulation Scenarios To demonstrate the capabilities ofthe proposed framework and the algorithms we performedseveral simulations on task graph sets and evaluated theireffectiveness over the following design abstractions
(i) Architectural architecture-based evaluation empha-sizes the effect of different PEs in the MpSoC frame-work Current implementation of our frameworkconsists of processors of the same architecture thatcan execute various tasks that is each processor hasa different set of tasks they can execute The MpSoC
Table 3 Comparison of HWD and next available and randommapping algorithms (simulation TS-9)
Mapping Random HWD NXT AVLBLAVG ETIME 141746 139467 13825AVG UTL 048 059 059AVG THR 002 002 002AVG PRT 108 107 108AVG PWR 599503 579969 57005AVG BFR 5 4 6
architecture was modified by changing the number ofPEs the types of PEs and topology It is importantto consider the effect of topology in architectureevaluation because the topology of the MpSoC alsodictates the performance of the individual PEs Theeffect of such architecture changes is measured interms of average execution timePEtask (ETIME) in120583sec average PE utilization (UTL) powertask of PEs(PWR) in 120583-Watts and power delay product (PDP)which are shown in Table 1
(ii) Scheduling evaluation of scheduling algorithms overvarious MpSoC architectures was conducted Per-formance of earliest deadline first based simulatedannealing (EDF-SA) and the new performance driven(PD) algorithms are compared (Table 2) Perfor-mance metrics for evaluating scheduling algorithmsare the same as that of architecture evaluations Alsothe standardized SA costs are shown
(iii) Mapping evaluation of mapping algorithms overvarious MpSoC architectures was conducted usingperformance driven scheduling policy Performanceof the proposed HWD Next Available (NA) andrandom mapping algorithms is compared as shownin Table 3
(iv) Fault Tolerant-evaluation and comparison of fault-tolerant (FT) and nonfault-tolerant (NFT) imple-mentation over various MpSoC architectures wereconducted and results for two test cases are shownin Tables 4 and 5
62 Simulation Results and Explanation Table 1 shows theaverage performance metrics obtained for various architec-tural variations possible in the developedMpSoC frameworkThe architectural variations include the type of topology(tile or torus) scheduling algorithm (EDF-SA or PDS)mapping algorithm (HWD) fault-tolerant scheme (NFT orFT) and the number of PEs Table 2 specifically compares theperformance of the EDF-SA and PDS scheduling algorithmComparison results on total execution time (ECT) in 120583secaverage processor utilization and average throughput inbytes120583sec are presented Other metrics that have less signif-icance have been omitted Also comparisons between EDF-SA and PDS algorithms for processor utilization throughputand buffer usage evaluations across various architectural
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

4 VLSI Design
includes processor area frequency of operation and switch-ing activity factor The work compares the performance oftheir SA-mapping algorithms for different heterogeneousarchitectures In another similar work [47] proposed bythe same author the SA-mapping algorithm is adoptedto optimize usage of on-chip memory buffers Their workemploys a B-level scheduler after the mapping process toschedule tasks on each processor
The proposed framework discussed in this paper employsSA-based scheduling and workload balanced mapping algo-rithms Our algorithms also optimize scheduling andmapping cost functions that include processor utilizationthroughput buffer utilization and port traffic along withprocessor power In addition our algorithms also considertask deadline constraints Both scheduling and mappingalgorithms adopted in ourwork perform global optimization
Paterna et al [48] propose two workload allocationmapping algorithms for energy minimization The algo-rithms are based on integer linear programming and a two-stage-heuristic mapping algorithm based on linear program-ming and bin packing policies Teodorescu and Torrellas[49] and Lide et al [50 51] explore workload-based map-ping algorithms for independent tasks and dependent tasksrespectively The work by Zhang et al is based on ILPoptimization for execution time and energy minimizationOur proposed mapping algorithm varies from the above-specified workload constrained algorithms by consideringthe buffer size usage and execution time of the tasks in thebuffer
Works by Ababei and Katti [52] and Derin et al [53]have used remapping strategies forNoC fault tolerance In thesolution proposed by Ababei and Katti [52] fault tolerancein NoCs is achieved by adaptive remapping They considersingle and multiple processor (PE) failures The remappingalgorithm optimizes the remap energy and communicationcosts They perform comparisons with a SA-based remapperOrsila et al [46] propose an online remapping strategycalled local nonidentical multiprocessor scheduling heuristic(LNMS) based on integer linear programming (ILP) TheILP minimizing cost functions include communication andexecution time The proposed NoC fault-tolerant algorithmemploys rescheduling and remapping strategies to optimizeprocessor performance and communication cost Also taskdeadline constraints are considered during the reschedulingand remapping
With the current design trends moving towards mul-tiprocessor systems for high performance and embeddedsystem applications the need to develop comprehensivedesign space exploration techniques has gained importanceMany research contributions in development of hardwaremodules and memory synchronization to optimize powerperformance and area for multiprocessor systems are beingdeveloped However algorithmic development for multipro-cessor systems like multiprocessor scheduling and mappinghas yielded significant results Therefore a comprehensiveand generic framework for a multi-processor system isrequired to evaluate the algorithmic contributionsThis workaddresses the above requirement in developing a compre-hensive MpSoC evaluation framework for evaluating many
scheduling mapping and fault-tolerant algorithms Also theframework is developed on generic modeling or represen-tation of applications (task graphs) architecture processorstopologies communication costs and so forth resulting in acomprehensive design exploration environment
The main contributions of this work can be summarizedas follows
(1) We propose a unique scheduling algorithm forMpSoC system called performance driven schedulingalgorithm that is based on Simulated Annealing andoptimizes an array of performance metrics such astask execution time processor utilization processorthroughput buffer utilization and port traffic andpower The proposed algorithm performance is com-pared to that of the classical earliest deadline firstscheduling algorithm
(2) This paper proposes a mapping algorithm that suc-ceeded the scheduling algorithm called the homo-geneous workload distribution algorithm that dis-tributes tasks evenly to the available processors in aneffort to balance the dynamic workload throughoutthe processors The proposed algorithm performanceis compared with other classical mapping algorithm
(3) Also a fault-tolerant scheme that is effective duringPE failure is proposed in this paper The proposedfault-tolerant (FT) scheme performs an updatedscheduling and mapping of the tasks assigning to thefailed PE when the PE fault is detected The uniquecontribution of this work is the fact that it addressesthe pending and executing tasks in the faulty PEsThe latency overhead of the proposed FT algorithmis evaluated by experimentation
3 Definitions and Theory
Simulation Model The simulation model consists of threesubmodels (Figure 1) (1) application (2) architecture and (3)topologyThe applicationmodel represents the application tobe executed on the given MpSoC architecture and connectedby the topology specified
Application Model (Task Graphs) A task graph is a directedacyclic graph (DAG) that represents an application A taskgraph is denoted as TG such that TG = (119881 119864) where 119881 is aset of nodes and 119864 is a set of edges A node in 119881 representsa task such that 119881 = 119879
1 1198792 1198793 119879
119873 and an edge in
119864 represents the communication dependency between thetasks such that 119864 = 119862
1 1198622 1198623 119862
119870 A weighted edge
if specified denotes the communication cost incurred totransfer data from a source task to destination task Eachtask can exist in a processor in one of the following statesideal pending ready active running or complete The taskgraph is derived by parsing the high-level description of anapplication
Architecture Model The architecture of the MpSoC sys-tem consists of the processors hardware components
VLSI Design 5
pending readyactive running
TG =
Processormemoryarchitecture type
power clock-rateinterrupt memory
NG =
PE
PE
PE
PE
PE
PE
PE
PEM
M
M
PE PEPE
PE
PE
PE PE
PE
PE
PE PE
PE
PE
PE
⟩
complete⟩
NG ⟨
⟨
processor type topology⟩
Task ⟨119879119868119863
Task status ⟨ideal
TtypeTrelease timeTexec timeTdeadline Tadress TDlist
(V E) V = T1 T2 T3 middot middot middot T9E = C1 C2 C3 middot middot middot CK
T1
T2T3
T4
T5T6 T7
T8
T9
ARCH = P1 P2 P3 middot middot middot PNM1 M2 M3 middot middot middot MK
(V E)V = Pi Mi E = C1 middot middot middot CL
Figure 1 Simulation model containing application architecture and topology
memory and interconnects as defined by the topologymodel The MpSoC architecture is represented as a set1198751 1198752 1198753 119875
119873119872111987221198723 119872
119870 where119875
1 1198752 119875
119899
are a set of 119873 processors and 11987211198722 119872
119870are a set
of 119870 memory units Each processor 119875119894or memory 119872
119894is
defined by the following characteristics type powertaskexecutiontask clock rate preempt overhead and also by a setof tasks 119879
119886 119879119887 119879119888 119879
119911 each processor can execute along
with their respective execution times and power costs Theimplemented heterogeneousMpSoC consists of processors ofthe same architecture but can execute various set of tasks
Topology Model (Topology Graph) Topology describes thephysical layout of hardware components in a system Thetopology model is represented as a topology graph (NG) thatconsists of the set of processors topology type ⟨tile torus⟩and communication cost This communication cost is thesame communication cost (119864) as defined in the applicationmodel
Scheduling Scheduling is the process of assigning an execu-tion start time instance to all tasks in an application such thattasks are executed within their respective deadline For anapplication 119860 = 119879
1 1198792sdot sdot sdot 119879119873 where 119879
119894is a task instance in
the application task scheduling denoted as 120572(119879119894) is defined
as an assignment of execution start time (119905119894) for the task 119879
119894in
the time domain such that
120572 (119879119894) = 119905119894 119905
119894+ 119890119894le 119889119894 (1)
where 119890119894is the worst-case execution time of the task on a
specific processor 119889119894is the deadline of the task119879
119894 and 119905
119894is the
execution start time of task 119879119894 Scheduling of an application
119860 is denoted as
120572 (119860) = 120572 (1198791) 120572 (119879
2) 120572 (119879
3) sdot sdot sdot 120572 (119879
119873) (2)
If there exists a precedence operation between any two taskssuch that the execution of a task 119879
119894should occur before the
execution of task 119879119895 represented as 119879
119894lt 119879119895 then
119905119894+ 119890119894le 119905119895le 119889119894 119905
119895+ 119890119895le 119889119895 (3)
where 119905119894is the start time of task 119879
119895 and 119890
119895and 119889
119895are the
execution time and deadline of task 119879119895 respectively
Performance Index (PI) PI is the cumulative cost functionused to determine the optimal schedule by using the Sim-ulated Annealing technique PI quantifies the performanceof the system taking into consideration the averaged valuesof processor execution time (ETIME) utilization (UTL)throughput (THR) buffer utilizationusage (BFR) port traf-fic (PRT) and power (PWR) PI is evaluated by a costfunction that is expressed as
COST = 1205721(
1
ETIME) + 1205722(
1
UTL) + 1205723(
1
THR)
+ 1205724(
1
BFR) + 1205725(PRT) + 120572
6(PWR)
(4)
where 1205721sim 1205726are normalizing constants
6 VLSI Design
The Simulated Annealing procedure compares the per-formance of successive design choices based on the PIExecution time processor utilization processor throughputand buffer utilization are maximized so that their costis computed reciprocally however power and port trafficare minimized so that the nonreciprocal values are takenThe coefficient values in the cost equation are set accordingto the desired performance goals of the system
Optimization of Scheduling Algorithm The problem of deter-mining optimal scheduling is to determine the optimal starttime and execution time of all tasks in the application
minimize(119873
sum
119894=1
(119905119894+ 119890119894))
minimize(119873
sum
119894=1
COST (120572 (119879119894))) 119905
119899+ 119890119899le DL
(5)
where 119890119894is the worst-case execution time of each task 119879
119894
DL is the deadline of the application and 119905119899and 119890119899are the
start time and worst-case execution time of the last taskrespectively in the application COST (120572(119879
119894)) is the cost
function of scheduling the tasks
Mapping Mapping is the process of assigning each task in anapplication to a processor such that the processor executes thetask and satisfies the task deadline as well as other constraints(power throughput completion time) if any
For an application 119860 = 1198791 1198792sdot sdot sdot 119879119873 where 119879
119894is a
task instance in the application mapping a task denoted as119872(119879119894) is defined as an assignment of the processor 119875
119895 =
1198751 1198752 119875
119872 = 119875 for the task 119879
119894
119872(119879119894) = 119875
119895 (6)
Application mapping is defined as mapping of all tasks 119879119894 in
the application 119860 to processors and is denoted as
119872(119860) = 119872 (1198791) 119872 (119879
2) sdot sdot sdot119872 (119879
119873) (7)
Optimization of the Mapping Algorithm The problem indetermining optimummapping is to determine the optimumallocation of all tasks in the application on the processorssuch that the total execution time of all tasks is minimizedOther factors for optimum mapping include maximizingprocessor execution time throughput minimizing inter-processor communication delay and balancing workloadhomogenously on the processors in order to improve utiliza-tion
minimize(119873
sum
119894=1
(119888119894)) 119888
119894= COST (119872 (119879
119894)) (8)
where 119888119894is the cost function for optimal mapping of the tasks
on the processor
Power Modeling In this research scheduling and mappingalgorithms model heterogeneous processor execution andpower requirements as follows
(1) Switch power is consumed whenever a task is routedfrom input port to output port
(2) Processor power is modeled with respect to idle-mode (also includes pending ready active and com-plete) and execution-mode (running) power both ofwhich are functions of the task execution time 119890
119894 We
also assume that for the idle model Δ120578 = 0
120578119894(119879119894) = Δ120578 lowast 119890
119894 (9)
whereΔ120578 is the unit power consumed per unit time oftask processingThe total power rating for a processor119875119895would be expressed as
120578119895= Δ120578 lowast
119899
sum
119894=1
(119890119894) (10)
where 119899 is the number of tasks executed by theprocessor
(3) Whenever a task 119879119896is executed on processor 119875
119897
the execution time 119890119896and the power consumed by
processor 120578119896are updated as
120578119897(119879119896) = Δ120578 lowast 119890
119896
120578119897= Δ120578 lowast
119899
sum
119894=1
(119890119896)
(11)
(4) Whenever a task is transferred between switchesthe communication delay is updated on the TotalTask Communication Delay parameter (T) and isexpressed as
T = 119899 lowast v lowast Δ119862 (12)
where 119899 is number of switch hopes task-size (v) is thesize of the task defined as a function of its executiontime in time-units and Δ119862 is a time constant that isrequired to transfer single time-unit task for one hop
(5) For each task 119879119894 the Task Slack Time 119878
119894and Average
Slack Time 119878 are calculated as
119878119894= 119889119894minus [119905119894+ 119890119894]
119878 =
sum
119873
119894=1(119878119894)
119873
(13)
where 119889119894is the deadline 119905
119894is the release time and119873
is the total number of tasks processed
Fault-Tolerant System A fault-tolerant system describes arobust system that is capable of sustaining application pro-cessing in the event of component failure A fault-tolerantalgorithm is a process that performs scheduling andmappingon a set of unprocessed tasks for the available processors
Let an application119860with a set of tasks119860 = 1198791 1198792sdot sdot sdot 119879119873
be scheduled denoted by 120572(119860) and mapped on the set
VLSI Design 7
of processors 119875 = 1198751 1198752 119875
119872 denoted as 119872(119860) A
fault is defined as a nonrecurring permanent failure of aprocessor at time instance 119905
119891during the execution of a
task 119879119891 The application after the occurrence of the fault is
expressed as 119860119891such that 119860
119891sub 119860 which has a list of tasks
119860119891= 119879119892 119879ℎsdot sdot sdot 119879119899 that are not dispatched to processors
by the mapper when the processor failure occurs The set ofprocessors after the failure119865 is denoted by 119875
119891= 1198751 1198752sdot sdot sdot 119875119871
and 119875 notin 119875119891 where 119875
119891is the failed processor The proposed
fault-tolerant MpSoC framework determines the updatedscheduling 120572(119860
119891) and updated mapping119872(119860
119891) for a set of
unprocessed tasks in the application subset 119860119891 such that
119905119899+ 119890119899le DL (14)
where 119905119899and 119890
119899are the start time and execution time
respectively of the last scheduled task in 119860119891
Optimization of Fault-Tolerant Strategy Due to the dynamicmapping methodology adopted in the framework only thetasks dispatched to the failed processormdashwhich includes thetask that was executing on the failed processor and thetasks dispatched by the mapper to the failed processormdashwillneed to be rescheduled along with the tasks that were notdispatched by the mapper
Let us consider an application 119860119891with a list of 119899 tasks
119860119891
= 119879119892 119879ℎsdot sdot sdot 119879119899 that have not been dispatched to
processors at the occurrence of the fault Also let the tasks119879119887= 119879119903sdot sdot sdot 119879119905 be the list of tasks in the buffer of the failed
processor 119875119891and let 119879
119901be the task that was being executed
during failure by the failed processor The task list 119879FT of thefault tolerant algorithm at time 119905
119891is represented as
119879FT = 119860119891+ 119879119887+ 119879119891 (15)
It is also assumed that all the tasks that are being executedby the nonfailed processor complete the execution of thetasks even after the time of failure 119905
119891 Thus the FT algorithm
performs the updated scheduling (119879FT) and updated map-ping
119872(119879FT) on the task set 119879FT which satisfies the deadlineconstraint DL of the application 119860
4 Framework Modeling and Implementation
The proposed framework adopts a ldquobottom-uprdquo modulardesign methodology that gives the benefit of componentreusability Behavioral componentmodels were designed andstored in hardware and software librariesThe frameworkwasimplemented in SystemC 22C++ and compiled with g++-43 under Linux The framework is divided into three majorcomponents input or user interface module core MpSoCsimulation module and the output or performance evalua-tion module The hardware modules such as the processorswitch dispatcher unit and multiplexer were implementedin SystemC the software modules such as input parserscheduler and task interface classes were implemented inC++
Input Module Such userrsquos data as the number of processorstopology task graph processor types buffer size switching
Software libraries
Settings
Task interface
Other IPs
Main GUI
TG parser
Scheduler
Mapper
Dispatcher
Switch
Processor
Multiplexer
ARCH setup
Performance evaluation
PE
PE
PE
PE
PE PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
Hardware libraries
Figure 2 Framework modeling
technology fault-tolerant mode and schedulingmappingspecifications are read either by using a command lineinterface or else from a GUI interface
Core Simulation Module The core simulation module isdepicted in Figure 2 which shows the softwarehardwarelibraries and control flow between the modules The sim-ulation module consists of two components the softwareand hardware libraries Software libraries include softwarecomponents of the framework for instance the input parserscheduler data store and task interface Hardware librariesinclude hardware components implemented in SystemCsuch as the processor the mapper the dispatcher andmultiplexersThe processors are implemented as behaviouralprocessors capable of computing the various tasks in thetask graphs The communication cost for a task is depen-dent on the size and thus the execution duration of thetask (Section 3) Thus communication latency is modelledas a function of task size Heterogeneity is modelled byvarying the task processing cost (processing timetask andpowertask) All processors are capable of executing allpossible operations but with different costs Processor failureis permanent once it occurs and only single processorfailure is considered Due to the modular implementationof the simulation module architecture topology routingscheduling and mapping methods can be easily changedin MpSoCs to conduct extensive evaluation of design spaceexploration
Output Module The simulation terminates by evaluating thesystem performance module which retrieves the various
8 VLSI Design
for each task in ATG do
set the longest-path-maximum-delay deadline
setDeadline()
initial solution
taskrandom mapToPE()
while simulation temp gt cooling threshold
do
for temperature length
for task sub iteration length
while each task is assigned a release time
generates the RTW w Comm cost
genRTL()
rand task from RTL
t sch = sel rand(RTL)
generate release time window
t schgenRTW()
set rel time
t schrel time = sel rand(RTW)
init and run systemC simulation
sc start(time)
calculating objective function value
calcObjFunc()
accepts or rejects a solution
probFunc()
for each task in ATG do
calculate workload of processors
taskcalc HWDcost()
new mapping solution
taskHWD mapToPE()
calculate new simulation temperature
calc simulation temp()
Algorithm 1 Pseudocode for the performance driven (PD) scheduling and HWDmapping algorithms
performance variables from the individual processors suchas the total execution time power throughput port trafficnumber of tasks processed and buffer usageThese values aredisplayed on the output GUI and stored in the result log file
41 Performance Driven Scheduling Algorithm This workalso proposes an efficient offline and performance drivenscheduling algorithm based on the Simulate Annealing tech-nique The performance index (PI) determined by a costfunction is used to determine the optimal schedule Theperformance index is a cumulative factor of (1) processor exe-cution time (2) processor utilization (3) processor through-put (4) processor power (5) processor port traffic and (6)processor buffer utilization The problem of determining theoptimal schedule is defined as determining the schedulewith maximal performance index The Simulated Annealingalgorithm performs (1) random scheduling and mappingof tasks (2) simulation and (3) capturing averaging andnormalizing performance variables finally it calculates theperformance index These steps are repeated several times inan effort to increase the PI During the iterations if a better
PI is found the state is saved and the simulation repeats untilthe temperature reaches the threshold value
For the problem being considered the normalizing coef-ficients used to calculate the PI were set to 120572
1= 300 120572
2=
500 1205723= 250 120572
4= 125 120572
5= 120 and 120572
6= 50000
These coefficients were determined after conducting sev-eral runs on all benchmarks Execution time utilizationthroughput and power factors are key performance indicesTherefore they are given significant weights (a higher valueof coefficient) during normalization Port traffic and powerindices are minimized consequently their respective costfunction is computed reciprocally The pseudocode for theperformance driven scheduling (PDS) and HWD mappingalgorithms is given in Algorithm 1
42 Multiprocessor Task Mapping Strategy Multiprocessorenvironments grant the freedom for dynamic task mappingThus themultiprocessormapping algorithm needs to specifythe locationwhere a particular task should be processed Taskmapping in heterogeneous systems is accomplished in twosteps (1) binding and (2) placement First the task binding
VLSI Design 9
procedure attempts to find which particular assignment oftasks would lead to effective lower power and faster executiontimeDuring task placement themapper considers allocatingany two tasks that exchange data more frequently as closeto each other as possible Placement of communicating tasksto adjacent or nearby processors reduces the communicationlatency switch traffic and power dissipation
Static mapping assigns a particular task to a predeter-mined processing element offline regardless of the dynamicstate of the system components This however does not sat-isfy the MpSoCs requirement because processing tasks on aheterogeneous architecture introduces workload irregularityon system resources (PEs) Irregular workload distributionis a design issue that degrades the utilization of system Toovercome this problem tasks should bemapped dynamicallybased on the dynamic workload on the processors Thenumber of tasks in the processorsrsquo local memory measuresthe processor workload
The dynamic mapper in the proposed framework per-forms the task allocation as per the configured policy Inorder to take heterogeneity of processors into considerationadditional power cost and execution latency cost have beenintroduced This emphasizes the fact that processing a par-ticular task on different types of processors incurs differentcost (power consumption and execution time) Efficient andoptimized heterogeneous mapping algorithms are tailored tominimize this additional cost
In the framework various task allocation heuristics wereimplemented Given a scheduled task the task mappingfollows one of the below policies
(1) Next Available Mapping (NXT AVLB) In the NextAvailable Mapping policy a scheduled task 119879
119894is
mapped on processor 119875119894 followed by the mapping of
the next scheduled task119879119894+1
on processor119875119895 provided
119875119894and 119875
119895are neighbors to each other as defined by
the topology This policy assigns tasks on successiveprocessor sequentially but does not consider theheterogeneity of the tasks nor the processorworkload
(2) Homogenous Workload Distribution Mapping(HWD) HWD considers the workload on eachprocessor and maps a scheduled task on a processorthat has the minimum workload
(3) Random mapping (RANDOM) rRandom task allo-cation is used by the PD algorithm to distribute theworkload randomly throughout the available proces-sors
HWD Mapping Approach Minimizing the idle time ofeach processor or maximizing processing time improvesprocessor utilization To reduce idle time tasks shouldbe distributed evenly throughout the available processorsThe proposed Homogenous Workload Distribution (HWD)algorithm is tailored to distribute tasks evenly to the availableprocessors in an effort to balance the dynamic workloadthroughout the processors The algorithm is a two-stepprocess (1) probing individual processor buffers throughdedicated snooping channels that connects each processor
to the mapper and (2) mapping each scheduled task ona processor that has the lowest workload Workload is ameasure of the number of tasks and its respective executiontime in the processor bufferThus a processor having the leastnumber of tasks and respective execution time in its bufferhas the lowest workload therefore themapper will assign thenext scheduled task to this processor
HWD Mapping Algorithm Let 1198751 1198752sdot sdot sdot 119875119872 be a set of
processors let 1198711 1198712sdot sdot sdot 119871119872 be the dynamic task workloads
defined by number of tasks on respective processor buffersand let119873 be the number of processors Let 119879
1 1198792sdot sdot sdot 119879119873 be a
set of119872 tasks and the symbol ldquorarr rdquo denotes ldquomappingrdquoThen
A task 119879119896⟨119879release-time 119879exec-time 119879deadline⟩ 997888rarr 119875
119894
iff 119871119894lt 119871119895
forall [119871119894 119871119895] isin 119871
1 1198712sdot sdot sdot 119871119873
(16)
where 119875119894isin 1198751 1198752sdot sdot sdot 119875119872 and 119879
119896isin 1198791 1198792sdot sdot sdot 119879119873 such that
(119890119896+ 119905119896le 119889119896)
This approach has three advantages (1) it minimizesthe chance for buffer overflow (2) the task waiting time inprocessor buffer is reduced and (3) utilization is increasedbecause idle processors will be assigned scheduled tasks
43 Fault-Tolerant Methodology System designs often haveflaws that cannot be identified at design time It is almostimpossible to anticipate all faulty scenarios beforehandbecause processor failure may occur due to unexpectedruntime errors Real-time systems are critically affected if nomeans of fault tolerance scheme is implemented Failure toemploy fault detection and recovery strategies is often unaf-fordable in critical mission systems because the error maylead to possible data discrepancies and deadline violation
Processor failure introduces inevitable overall perfor-mance degradation due to (1) the reduced computing powerof the system and (2) the overhead involved in applying thefault recovery schemes Recovery procedures involve trackingthe task execution history and reconfiguring the systemby using the available processors This enables applicationprocessing to resume when the execution was terminatedDuring processor failure application processing is temporar-ily suspended and error recovery procedures are appliedbefore application processing is resumed
Fault-TolerantModelFaultmodeling can have several dimen-sions that define the fault occurring time the fault durationlocation of failure and so forth The proposed frameworkadopts the following fault modeling parameters
(1) It is assumed that the processor failure is permanentThus fault duration time 119905FD is infinite (119905FD = infin)During failure the address of the failed processor iscompletely removed from the mapper address table
(2) The location specifies where the failure occurred Fortile and torus topology location is represented in two-dimensional coordinate addresses
(3) During task processing any processors may fail atany time instance Consequently time of failure ismodeled as a random time instance
10 VLSI Design
In the event of failure the following procedures areexecuted
(1) Themapper removes the failed processor ID from theaddress table
(2) Tasks that are scheduled or mapped but not dis-patched have to be rescheduled and remapped Therespective new task release time and task address bothhave to be done again This is because the executioninstance of a task depends on the finish time ofits predecessor task which may possibly have beensuspended in the failed processor
(3) Tasks that are already dispatched to the failed proces-sor can be either (1) in the processorrsquos buffer or (2)in the middle of execution when the failure occurredThese tasks have to be migrated back to the mapperand their respective rescheduling and remapping haveto be done The scheduler can perform task schedul-ing concurrently when the nonfaulty processors areexecuting their respective tasks
(4) Tasks that are dispatched to other nonfailed proces-sors are not affected
Due to the dynamic property of the mapper and the fault-tolerant implementation the cost incurred during the eventof processor failure is minimal overhead incurred is only25 of the total execution time of the task The only penaltyincurred during processor failure is the cost due to taskmigration and the respective rerescheduling and remappingprocedures
5 Experimental Setup
The heterogeneous MpSoC framework developed in thiswork was developed using C++ and SystemC programminglanguage The architectural components such as processingelements (PEs) memory elements routers and networkinterfaces are developed using SystemC language and providecycle accurate simulations The processing elements areimplemented as a simple 32-bit processor that performssimple logic and arithmetic operations The heterogeneousPE structure in our MpSoC is implemented by altering thetype of operation and the execution times of the tasks eachPE can execute The routers implementations consist of aswitching matrix with input port buffers The tasks and datawithin PEs are transmitted using a data-serializing moduleof the PE A typical data transmitted within PEs consists oftask commands task data (if any) and the destination PEIDs (addresses) The data is propagated through the MpSoCsystem using the119883119884 routing algorithm
The scheduling and mapping algorithm are implementedusing C++ language and are interfaced with the SystemCarchitecture implementations The application in this workis considered as a task graph Each task graph consists ofprocessor operations their execution time communicationcost and deadline The application as a whole also has adeadline The scheduling algorithm parses the application(task graph) and assigns start times for the tasks on the
processors based on the set of optimization goals describedin the proposed performance driven scheduling algorithmThe scheduled tasks aremapped to their respective processorsin the MpSoC system based on the proposed homogenousworkload-mapping algorithm The tasksrsquo information com-prising of the task operations task data destination PEs(pathaddress of successor PEs) are assembled and forwardedto the initial PE by the dispatcher module The performanceevaluation module or the monitor module records cycleaccurate timing signals in the architecture during tasksexecution and communication
During the simulation of fault-tolerant scenario themonitor module triggers a PE failure event at a predefinedtime instance The dispatcher is informed of the PE failureand based on the mapper table and the current processingtask and the tasks in the buffer of the failed PE are determinedAn updated task graph is constructed and scheduling andmapping on the remaining unexecuted tasks are performedTasks currently executing on the PEs are undisturbed Thereassigned tasks are inserted in the PE buffers to satisfy thedeadlines
The implemented MpSoC system has been evaluatedextensively by modifying the architecture and topology Thesystemwas evaluated using a set of synthetic task graphs with50ndash3000 tasksThe architectural modifications for evaluatingthe MpSoC include change in type of PEs in the systemmesh and torus topology variations and the number of PEsin the system (9 16 32) The MpSoC system has been usedto evaluate the proposed scheduling mapping and fault-tolerant algorithms and compared with respective classicalalgorithms The performance of the proposed algorithmsalong with variation in architecture and topology have beenevaluated and presented The performance metrics consid-ered in this work include processor throughput processorutilization processor execution timetask and powertaskbuffers utilization and port utilization Detailed summary ofthe results and its significance are shown in Section 6
6 Simulation Results and Analysis
For evaluation of the proposed framework to explore designfeatures variations in scheduling mapping and fault tolerantalgorithms have been considered The application modeladapted is similar to the standard task graph (STG) [50 51]and E3S benchmark suite [54] which contains random set ofbenchmarks and application-specific benchmarks The sim-ulation was conducted with many STG benchmarks havingtask sizes 50 through 3000 The task graph is characterizedby the number of tasks dependencies of tasks task size(code size) communication cost (latency for interprocessortransfer) and application deadline The processor architec-ture model is derived from the E3S benchmark where eachprocessor is characterized by the type tasks it can executetask execution time task size (code size) and task powerTheprocessor also has general characteristics like type overheadcost (preemptive cost) task powertime and clock rate
The simulation results presented in this paper follow thefollowing legend 119883119884 plusmn 119885 where 119883 denotes 119877 or 119879 for
VLSI Design 11
Table 1 PE comparison
No of PEs AVG ETIMEPETASK (120583sec)
AVGUTLPE
AVGPWRPE(120583watts)
AVGPDPPE
PE no 9 498 048 18125 90748PE no 16 281 040 9834 27698PE no 25 189 035 6359 12006
Table 2 Comparison of task execution times processor utilizationand throughput of EDF-SA and PDS scheduling algorithms
ETIME (120583s) UTL THR (Bns) Std SA CostRAND-50
EDF-SA 20426 046 003 016PDS 22003 055 003 019
SPARSE-96EDF-SA 61651 044 002 015PDS 63789 049 002 017
RAND-100EDF-SA 41867 047 003 017PDS 43217 060 003 021
RAND-300EDF-SA 129945 049 003 017PDS 129695 056 003 019
FPPP-334EDF-SA 223836 042 002 015PDS 233736 047 002 016
RAND-500EDF-SA 143279 048 002 016PDS 212533 066 003 023
RAND-1000EDF-SA 416373 052 003 018PDS 432458 058 003 020
torus or tile topology 119884 denotes 119864 or 119878 for EDF-SA or PDscheduling algorithm + or minus for presence or absence of faulttolerance algorithm and 119885 denotes the number of PEs in theMpSoC system Performance evaluations on architecture andtopological variations were performed but are not included inthis paper Only performance results related to the proposedalgorithms are presented
61 Simulation Scenarios To demonstrate the capabilities ofthe proposed framework and the algorithms we performedseveral simulations on task graph sets and evaluated theireffectiveness over the following design abstractions
(i) Architectural architecture-based evaluation empha-sizes the effect of different PEs in the MpSoC frame-work Current implementation of our frameworkconsists of processors of the same architecture thatcan execute various tasks that is each processor hasa different set of tasks they can execute The MpSoC
Table 3 Comparison of HWD and next available and randommapping algorithms (simulation TS-9)
Mapping Random HWD NXT AVLBLAVG ETIME 141746 139467 13825AVG UTL 048 059 059AVG THR 002 002 002AVG PRT 108 107 108AVG PWR 599503 579969 57005AVG BFR 5 4 6
architecture was modified by changing the number ofPEs the types of PEs and topology It is importantto consider the effect of topology in architectureevaluation because the topology of the MpSoC alsodictates the performance of the individual PEs Theeffect of such architecture changes is measured interms of average execution timePEtask (ETIME) in120583sec average PE utilization (UTL) powertask of PEs(PWR) in 120583-Watts and power delay product (PDP)which are shown in Table 1
(ii) Scheduling evaluation of scheduling algorithms overvarious MpSoC architectures was conducted Per-formance of earliest deadline first based simulatedannealing (EDF-SA) and the new performance driven(PD) algorithms are compared (Table 2) Perfor-mance metrics for evaluating scheduling algorithmsare the same as that of architecture evaluations Alsothe standardized SA costs are shown
(iii) Mapping evaluation of mapping algorithms overvarious MpSoC architectures was conducted usingperformance driven scheduling policy Performanceof the proposed HWD Next Available (NA) andrandom mapping algorithms is compared as shownin Table 3
(iv) Fault Tolerant-evaluation and comparison of fault-tolerant (FT) and nonfault-tolerant (NFT) imple-mentation over various MpSoC architectures wereconducted and results for two test cases are shownin Tables 4 and 5
62 Simulation Results and Explanation Table 1 shows theaverage performance metrics obtained for various architec-tural variations possible in the developedMpSoC frameworkThe architectural variations include the type of topology(tile or torus) scheduling algorithm (EDF-SA or PDS)mapping algorithm (HWD) fault-tolerant scheme (NFT orFT) and the number of PEs Table 2 specifically compares theperformance of the EDF-SA and PDS scheduling algorithmComparison results on total execution time (ECT) in 120583secaverage processor utilization and average throughput inbytes120583sec are presented Other metrics that have less signif-icance have been omitted Also comparisons between EDF-SA and PDS algorithms for processor utilization throughputand buffer usage evaluations across various architectural
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

VLSI Design 5
pending readyactive running
TG =
Processormemoryarchitecture type
power clock-rateinterrupt memory
NG =
PE
PE
PE
PE
PE
PE
PE
PEM
M
M
PE PEPE
PE
PE
PE PE
PE
PE
PE PE
PE
PE
PE
⟩
complete⟩
NG ⟨
⟨
processor type topology⟩
Task ⟨119879119868119863
Task status ⟨ideal
TtypeTrelease timeTexec timeTdeadline Tadress TDlist
(V E) V = T1 T2 T3 middot middot middot T9E = C1 C2 C3 middot middot middot CK
T1
T2T3
T4
T5T6 T7
T8
T9
ARCH = P1 P2 P3 middot middot middot PNM1 M2 M3 middot middot middot MK
(V E)V = Pi Mi E = C1 middot middot middot CL
Figure 1 Simulation model containing application architecture and topology
memory and interconnects as defined by the topologymodel The MpSoC architecture is represented as a set1198751 1198752 1198753 119875
119873119872111987221198723 119872
119870 where119875
1 1198752 119875
119899
are a set of 119873 processors and 11987211198722 119872
119870are a set
of 119870 memory units Each processor 119875119894or memory 119872
119894is
defined by the following characteristics type powertaskexecutiontask clock rate preempt overhead and also by a setof tasks 119879
119886 119879119887 119879119888 119879
119911 each processor can execute along
with their respective execution times and power costs Theimplemented heterogeneousMpSoC consists of processors ofthe same architecture but can execute various set of tasks
Topology Model (Topology Graph) Topology describes thephysical layout of hardware components in a system Thetopology model is represented as a topology graph (NG) thatconsists of the set of processors topology type ⟨tile torus⟩and communication cost This communication cost is thesame communication cost (119864) as defined in the applicationmodel
Scheduling Scheduling is the process of assigning an execu-tion start time instance to all tasks in an application such thattasks are executed within their respective deadline For anapplication 119860 = 119879
1 1198792sdot sdot sdot 119879119873 where 119879
119894is a task instance in
the application task scheduling denoted as 120572(119879119894) is defined
as an assignment of execution start time (119905119894) for the task 119879
119894in
the time domain such that
120572 (119879119894) = 119905119894 119905
119894+ 119890119894le 119889119894 (1)
where 119890119894is the worst-case execution time of the task on a
specific processor 119889119894is the deadline of the task119879
119894 and 119905
119894is the
execution start time of task 119879119894 Scheduling of an application
119860 is denoted as
120572 (119860) = 120572 (1198791) 120572 (119879
2) 120572 (119879
3) sdot sdot sdot 120572 (119879
119873) (2)
If there exists a precedence operation between any two taskssuch that the execution of a task 119879
119894should occur before the
execution of task 119879119895 represented as 119879
119894lt 119879119895 then
119905119894+ 119890119894le 119905119895le 119889119894 119905
119895+ 119890119895le 119889119895 (3)
where 119905119894is the start time of task 119879
119895 and 119890
119895and 119889
119895are the
execution time and deadline of task 119879119895 respectively
Performance Index (PI) PI is the cumulative cost functionused to determine the optimal schedule by using the Sim-ulated Annealing technique PI quantifies the performanceof the system taking into consideration the averaged valuesof processor execution time (ETIME) utilization (UTL)throughput (THR) buffer utilizationusage (BFR) port traf-fic (PRT) and power (PWR) PI is evaluated by a costfunction that is expressed as
COST = 1205721(
1
ETIME) + 1205722(
1
UTL) + 1205723(
1
THR)
+ 1205724(
1
BFR) + 1205725(PRT) + 120572
6(PWR)
(4)
where 1205721sim 1205726are normalizing constants
6 VLSI Design
The Simulated Annealing procedure compares the per-formance of successive design choices based on the PIExecution time processor utilization processor throughputand buffer utilization are maximized so that their costis computed reciprocally however power and port trafficare minimized so that the nonreciprocal values are takenThe coefficient values in the cost equation are set accordingto the desired performance goals of the system
Optimization of Scheduling Algorithm The problem of deter-mining optimal scheduling is to determine the optimal starttime and execution time of all tasks in the application
minimize(119873
sum
119894=1
(119905119894+ 119890119894))
minimize(119873
sum
119894=1
COST (120572 (119879119894))) 119905
119899+ 119890119899le DL
(5)
where 119890119894is the worst-case execution time of each task 119879
119894
DL is the deadline of the application and 119905119899and 119890119899are the
start time and worst-case execution time of the last taskrespectively in the application COST (120572(119879
119894)) is the cost
function of scheduling the tasks
Mapping Mapping is the process of assigning each task in anapplication to a processor such that the processor executes thetask and satisfies the task deadline as well as other constraints(power throughput completion time) if any
For an application 119860 = 1198791 1198792sdot sdot sdot 119879119873 where 119879
119894is a
task instance in the application mapping a task denoted as119872(119879119894) is defined as an assignment of the processor 119875
119895 =
1198751 1198752 119875
119872 = 119875 for the task 119879
119894
119872(119879119894) = 119875
119895 (6)
Application mapping is defined as mapping of all tasks 119879119894 in
the application 119860 to processors and is denoted as
119872(119860) = 119872 (1198791) 119872 (119879
2) sdot sdot sdot119872 (119879
119873) (7)
Optimization of the Mapping Algorithm The problem indetermining optimummapping is to determine the optimumallocation of all tasks in the application on the processorssuch that the total execution time of all tasks is minimizedOther factors for optimum mapping include maximizingprocessor execution time throughput minimizing inter-processor communication delay and balancing workloadhomogenously on the processors in order to improve utiliza-tion
minimize(119873
sum
119894=1
(119888119894)) 119888
119894= COST (119872 (119879
119894)) (8)
where 119888119894is the cost function for optimal mapping of the tasks
on the processor
Power Modeling In this research scheduling and mappingalgorithms model heterogeneous processor execution andpower requirements as follows
(1) Switch power is consumed whenever a task is routedfrom input port to output port
(2) Processor power is modeled with respect to idle-mode (also includes pending ready active and com-plete) and execution-mode (running) power both ofwhich are functions of the task execution time 119890
119894 We
also assume that for the idle model Δ120578 = 0
120578119894(119879119894) = Δ120578 lowast 119890
119894 (9)
whereΔ120578 is the unit power consumed per unit time oftask processingThe total power rating for a processor119875119895would be expressed as
120578119895= Δ120578 lowast
119899
sum
119894=1
(119890119894) (10)
where 119899 is the number of tasks executed by theprocessor
(3) Whenever a task 119879119896is executed on processor 119875
119897
the execution time 119890119896and the power consumed by
processor 120578119896are updated as
120578119897(119879119896) = Δ120578 lowast 119890
119896
120578119897= Δ120578 lowast
119899
sum
119894=1
(119890119896)
(11)
(4) Whenever a task is transferred between switchesthe communication delay is updated on the TotalTask Communication Delay parameter (T) and isexpressed as
T = 119899 lowast v lowast Δ119862 (12)
where 119899 is number of switch hopes task-size (v) is thesize of the task defined as a function of its executiontime in time-units and Δ119862 is a time constant that isrequired to transfer single time-unit task for one hop
(5) For each task 119879119894 the Task Slack Time 119878
119894and Average
Slack Time 119878 are calculated as
119878119894= 119889119894minus [119905119894+ 119890119894]
119878 =
sum
119873
119894=1(119878119894)
119873
(13)
where 119889119894is the deadline 119905
119894is the release time and119873
is the total number of tasks processed
Fault-Tolerant System A fault-tolerant system describes arobust system that is capable of sustaining application pro-cessing in the event of component failure A fault-tolerantalgorithm is a process that performs scheduling andmappingon a set of unprocessed tasks for the available processors
Let an application119860with a set of tasks119860 = 1198791 1198792sdot sdot sdot 119879119873
be scheduled denoted by 120572(119860) and mapped on the set
VLSI Design 7
of processors 119875 = 1198751 1198752 119875
119872 denoted as 119872(119860) A
fault is defined as a nonrecurring permanent failure of aprocessor at time instance 119905
119891during the execution of a
task 119879119891 The application after the occurrence of the fault is
expressed as 119860119891such that 119860
119891sub 119860 which has a list of tasks
119860119891= 119879119892 119879ℎsdot sdot sdot 119879119899 that are not dispatched to processors
by the mapper when the processor failure occurs The set ofprocessors after the failure119865 is denoted by 119875
119891= 1198751 1198752sdot sdot sdot 119875119871
and 119875 notin 119875119891 where 119875
119891is the failed processor The proposed
fault-tolerant MpSoC framework determines the updatedscheduling 120572(119860
119891) and updated mapping119872(119860
119891) for a set of
unprocessed tasks in the application subset 119860119891 such that
119905119899+ 119890119899le DL (14)
where 119905119899and 119890
119899are the start time and execution time
respectively of the last scheduled task in 119860119891
Optimization of Fault-Tolerant Strategy Due to the dynamicmapping methodology adopted in the framework only thetasks dispatched to the failed processormdashwhich includes thetask that was executing on the failed processor and thetasks dispatched by the mapper to the failed processormdashwillneed to be rescheduled along with the tasks that were notdispatched by the mapper
Let us consider an application 119860119891with a list of 119899 tasks
119860119891
= 119879119892 119879ℎsdot sdot sdot 119879119899 that have not been dispatched to
processors at the occurrence of the fault Also let the tasks119879119887= 119879119903sdot sdot sdot 119879119905 be the list of tasks in the buffer of the failed
processor 119875119891and let 119879
119901be the task that was being executed
during failure by the failed processor The task list 119879FT of thefault tolerant algorithm at time 119905
119891is represented as
119879FT = 119860119891+ 119879119887+ 119879119891 (15)
It is also assumed that all the tasks that are being executedby the nonfailed processor complete the execution of thetasks even after the time of failure 119905
119891 Thus the FT algorithm
performs the updated scheduling (119879FT) and updated map-ping
119872(119879FT) on the task set 119879FT which satisfies the deadlineconstraint DL of the application 119860
4 Framework Modeling and Implementation
The proposed framework adopts a ldquobottom-uprdquo modulardesign methodology that gives the benefit of componentreusability Behavioral componentmodels were designed andstored in hardware and software librariesThe frameworkwasimplemented in SystemC 22C++ and compiled with g++-43 under Linux The framework is divided into three majorcomponents input or user interface module core MpSoCsimulation module and the output or performance evalua-tion module The hardware modules such as the processorswitch dispatcher unit and multiplexer were implementedin SystemC the software modules such as input parserscheduler and task interface classes were implemented inC++
Input Module Such userrsquos data as the number of processorstopology task graph processor types buffer size switching
Software libraries
Settings
Task interface
Other IPs
Main GUI
TG parser
Scheduler
Mapper
Dispatcher
Switch
Processor
Multiplexer
ARCH setup
Performance evaluation
PE
PE
PE
PE
PE PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
Hardware libraries
Figure 2 Framework modeling
technology fault-tolerant mode and schedulingmappingspecifications are read either by using a command lineinterface or else from a GUI interface
Core Simulation Module The core simulation module isdepicted in Figure 2 which shows the softwarehardwarelibraries and control flow between the modules The sim-ulation module consists of two components the softwareand hardware libraries Software libraries include softwarecomponents of the framework for instance the input parserscheduler data store and task interface Hardware librariesinclude hardware components implemented in SystemCsuch as the processor the mapper the dispatcher andmultiplexersThe processors are implemented as behaviouralprocessors capable of computing the various tasks in thetask graphs The communication cost for a task is depen-dent on the size and thus the execution duration of thetask (Section 3) Thus communication latency is modelledas a function of task size Heterogeneity is modelled byvarying the task processing cost (processing timetask andpowertask) All processors are capable of executing allpossible operations but with different costs Processor failureis permanent once it occurs and only single processorfailure is considered Due to the modular implementationof the simulation module architecture topology routingscheduling and mapping methods can be easily changedin MpSoCs to conduct extensive evaluation of design spaceexploration
Output Module The simulation terminates by evaluating thesystem performance module which retrieves the various
8 VLSI Design
for each task in ATG do
set the longest-path-maximum-delay deadline
setDeadline()
initial solution
taskrandom mapToPE()
while simulation temp gt cooling threshold
do
for temperature length
for task sub iteration length
while each task is assigned a release time
generates the RTW w Comm cost
genRTL()
rand task from RTL
t sch = sel rand(RTL)
generate release time window
t schgenRTW()
set rel time
t schrel time = sel rand(RTW)
init and run systemC simulation
sc start(time)
calculating objective function value
calcObjFunc()
accepts or rejects a solution
probFunc()
for each task in ATG do
calculate workload of processors
taskcalc HWDcost()
new mapping solution
taskHWD mapToPE()
calculate new simulation temperature
calc simulation temp()
Algorithm 1 Pseudocode for the performance driven (PD) scheduling and HWDmapping algorithms
performance variables from the individual processors suchas the total execution time power throughput port trafficnumber of tasks processed and buffer usageThese values aredisplayed on the output GUI and stored in the result log file
41 Performance Driven Scheduling Algorithm This workalso proposes an efficient offline and performance drivenscheduling algorithm based on the Simulate Annealing tech-nique The performance index (PI) determined by a costfunction is used to determine the optimal schedule Theperformance index is a cumulative factor of (1) processor exe-cution time (2) processor utilization (3) processor through-put (4) processor power (5) processor port traffic and (6)processor buffer utilization The problem of determining theoptimal schedule is defined as determining the schedulewith maximal performance index The Simulated Annealingalgorithm performs (1) random scheduling and mappingof tasks (2) simulation and (3) capturing averaging andnormalizing performance variables finally it calculates theperformance index These steps are repeated several times inan effort to increase the PI During the iterations if a better
PI is found the state is saved and the simulation repeats untilthe temperature reaches the threshold value
For the problem being considered the normalizing coef-ficients used to calculate the PI were set to 120572
1= 300 120572
2=
500 1205723= 250 120572
4= 125 120572
5= 120 and 120572
6= 50000
These coefficients were determined after conducting sev-eral runs on all benchmarks Execution time utilizationthroughput and power factors are key performance indicesTherefore they are given significant weights (a higher valueof coefficient) during normalization Port traffic and powerindices are minimized consequently their respective costfunction is computed reciprocally The pseudocode for theperformance driven scheduling (PDS) and HWD mappingalgorithms is given in Algorithm 1
42 Multiprocessor Task Mapping Strategy Multiprocessorenvironments grant the freedom for dynamic task mappingThus themultiprocessormapping algorithm needs to specifythe locationwhere a particular task should be processed Taskmapping in heterogeneous systems is accomplished in twosteps (1) binding and (2) placement First the task binding
VLSI Design 9
procedure attempts to find which particular assignment oftasks would lead to effective lower power and faster executiontimeDuring task placement themapper considers allocatingany two tasks that exchange data more frequently as closeto each other as possible Placement of communicating tasksto adjacent or nearby processors reduces the communicationlatency switch traffic and power dissipation
Static mapping assigns a particular task to a predeter-mined processing element offline regardless of the dynamicstate of the system components This however does not sat-isfy the MpSoCs requirement because processing tasks on aheterogeneous architecture introduces workload irregularityon system resources (PEs) Irregular workload distributionis a design issue that degrades the utilization of system Toovercome this problem tasks should bemapped dynamicallybased on the dynamic workload on the processors Thenumber of tasks in the processorsrsquo local memory measuresthe processor workload
The dynamic mapper in the proposed framework per-forms the task allocation as per the configured policy Inorder to take heterogeneity of processors into considerationadditional power cost and execution latency cost have beenintroduced This emphasizes the fact that processing a par-ticular task on different types of processors incurs differentcost (power consumption and execution time) Efficient andoptimized heterogeneous mapping algorithms are tailored tominimize this additional cost
In the framework various task allocation heuristics wereimplemented Given a scheduled task the task mappingfollows one of the below policies
(1) Next Available Mapping (NXT AVLB) In the NextAvailable Mapping policy a scheduled task 119879
119894is
mapped on processor 119875119894 followed by the mapping of
the next scheduled task119879119894+1
on processor119875119895 provided
119875119894and 119875
119895are neighbors to each other as defined by
the topology This policy assigns tasks on successiveprocessor sequentially but does not consider theheterogeneity of the tasks nor the processorworkload
(2) Homogenous Workload Distribution Mapping(HWD) HWD considers the workload on eachprocessor and maps a scheduled task on a processorthat has the minimum workload
(3) Random mapping (RANDOM) rRandom task allo-cation is used by the PD algorithm to distribute theworkload randomly throughout the available proces-sors
HWD Mapping Approach Minimizing the idle time ofeach processor or maximizing processing time improvesprocessor utilization To reduce idle time tasks shouldbe distributed evenly throughout the available processorsThe proposed Homogenous Workload Distribution (HWD)algorithm is tailored to distribute tasks evenly to the availableprocessors in an effort to balance the dynamic workloadthroughout the processors The algorithm is a two-stepprocess (1) probing individual processor buffers throughdedicated snooping channels that connects each processor
to the mapper and (2) mapping each scheduled task ona processor that has the lowest workload Workload is ameasure of the number of tasks and its respective executiontime in the processor bufferThus a processor having the leastnumber of tasks and respective execution time in its bufferhas the lowest workload therefore themapper will assign thenext scheduled task to this processor
HWD Mapping Algorithm Let 1198751 1198752sdot sdot sdot 119875119872 be a set of
processors let 1198711 1198712sdot sdot sdot 119871119872 be the dynamic task workloads
defined by number of tasks on respective processor buffersand let119873 be the number of processors Let 119879
1 1198792sdot sdot sdot 119879119873 be a
set of119872 tasks and the symbol ldquorarr rdquo denotes ldquomappingrdquoThen
A task 119879119896⟨119879release-time 119879exec-time 119879deadline⟩ 997888rarr 119875
119894
iff 119871119894lt 119871119895
forall [119871119894 119871119895] isin 119871
1 1198712sdot sdot sdot 119871119873
(16)
where 119875119894isin 1198751 1198752sdot sdot sdot 119875119872 and 119879
119896isin 1198791 1198792sdot sdot sdot 119879119873 such that
(119890119896+ 119905119896le 119889119896)
This approach has three advantages (1) it minimizesthe chance for buffer overflow (2) the task waiting time inprocessor buffer is reduced and (3) utilization is increasedbecause idle processors will be assigned scheduled tasks
43 Fault-Tolerant Methodology System designs often haveflaws that cannot be identified at design time It is almostimpossible to anticipate all faulty scenarios beforehandbecause processor failure may occur due to unexpectedruntime errors Real-time systems are critically affected if nomeans of fault tolerance scheme is implemented Failure toemploy fault detection and recovery strategies is often unaf-fordable in critical mission systems because the error maylead to possible data discrepancies and deadline violation
Processor failure introduces inevitable overall perfor-mance degradation due to (1) the reduced computing powerof the system and (2) the overhead involved in applying thefault recovery schemes Recovery procedures involve trackingthe task execution history and reconfiguring the systemby using the available processors This enables applicationprocessing to resume when the execution was terminatedDuring processor failure application processing is temporar-ily suspended and error recovery procedures are appliedbefore application processing is resumed
Fault-TolerantModelFaultmodeling can have several dimen-sions that define the fault occurring time the fault durationlocation of failure and so forth The proposed frameworkadopts the following fault modeling parameters
(1) It is assumed that the processor failure is permanentThus fault duration time 119905FD is infinite (119905FD = infin)During failure the address of the failed processor iscompletely removed from the mapper address table
(2) The location specifies where the failure occurred Fortile and torus topology location is represented in two-dimensional coordinate addresses
(3) During task processing any processors may fail atany time instance Consequently time of failure ismodeled as a random time instance
10 VLSI Design
In the event of failure the following procedures areexecuted
(1) Themapper removes the failed processor ID from theaddress table
(2) Tasks that are scheduled or mapped but not dis-patched have to be rescheduled and remapped Therespective new task release time and task address bothhave to be done again This is because the executioninstance of a task depends on the finish time ofits predecessor task which may possibly have beensuspended in the failed processor
(3) Tasks that are already dispatched to the failed proces-sor can be either (1) in the processorrsquos buffer or (2)in the middle of execution when the failure occurredThese tasks have to be migrated back to the mapperand their respective rescheduling and remapping haveto be done The scheduler can perform task schedul-ing concurrently when the nonfaulty processors areexecuting their respective tasks
(4) Tasks that are dispatched to other nonfailed proces-sors are not affected
Due to the dynamic property of the mapper and the fault-tolerant implementation the cost incurred during the eventof processor failure is minimal overhead incurred is only25 of the total execution time of the task The only penaltyincurred during processor failure is the cost due to taskmigration and the respective rerescheduling and remappingprocedures
5 Experimental Setup
The heterogeneous MpSoC framework developed in thiswork was developed using C++ and SystemC programminglanguage The architectural components such as processingelements (PEs) memory elements routers and networkinterfaces are developed using SystemC language and providecycle accurate simulations The processing elements areimplemented as a simple 32-bit processor that performssimple logic and arithmetic operations The heterogeneousPE structure in our MpSoC is implemented by altering thetype of operation and the execution times of the tasks eachPE can execute The routers implementations consist of aswitching matrix with input port buffers The tasks and datawithin PEs are transmitted using a data-serializing moduleof the PE A typical data transmitted within PEs consists oftask commands task data (if any) and the destination PEIDs (addresses) The data is propagated through the MpSoCsystem using the119883119884 routing algorithm
The scheduling and mapping algorithm are implementedusing C++ language and are interfaced with the SystemCarchitecture implementations The application in this workis considered as a task graph Each task graph consists ofprocessor operations their execution time communicationcost and deadline The application as a whole also has adeadline The scheduling algorithm parses the application(task graph) and assigns start times for the tasks on the
processors based on the set of optimization goals describedin the proposed performance driven scheduling algorithmThe scheduled tasks aremapped to their respective processorsin the MpSoC system based on the proposed homogenousworkload-mapping algorithm The tasksrsquo information com-prising of the task operations task data destination PEs(pathaddress of successor PEs) are assembled and forwardedto the initial PE by the dispatcher module The performanceevaluation module or the monitor module records cycleaccurate timing signals in the architecture during tasksexecution and communication
During the simulation of fault-tolerant scenario themonitor module triggers a PE failure event at a predefinedtime instance The dispatcher is informed of the PE failureand based on the mapper table and the current processingtask and the tasks in the buffer of the failed PE are determinedAn updated task graph is constructed and scheduling andmapping on the remaining unexecuted tasks are performedTasks currently executing on the PEs are undisturbed Thereassigned tasks are inserted in the PE buffers to satisfy thedeadlines
The implemented MpSoC system has been evaluatedextensively by modifying the architecture and topology Thesystemwas evaluated using a set of synthetic task graphs with50ndash3000 tasksThe architectural modifications for evaluatingthe MpSoC include change in type of PEs in the systemmesh and torus topology variations and the number of PEsin the system (9 16 32) The MpSoC system has been usedto evaluate the proposed scheduling mapping and fault-tolerant algorithms and compared with respective classicalalgorithms The performance of the proposed algorithmsalong with variation in architecture and topology have beenevaluated and presented The performance metrics consid-ered in this work include processor throughput processorutilization processor execution timetask and powertaskbuffers utilization and port utilization Detailed summary ofthe results and its significance are shown in Section 6
6 Simulation Results and Analysis
For evaluation of the proposed framework to explore designfeatures variations in scheduling mapping and fault tolerantalgorithms have been considered The application modeladapted is similar to the standard task graph (STG) [50 51]and E3S benchmark suite [54] which contains random set ofbenchmarks and application-specific benchmarks The sim-ulation was conducted with many STG benchmarks havingtask sizes 50 through 3000 The task graph is characterizedby the number of tasks dependencies of tasks task size(code size) communication cost (latency for interprocessortransfer) and application deadline The processor architec-ture model is derived from the E3S benchmark where eachprocessor is characterized by the type tasks it can executetask execution time task size (code size) and task powerTheprocessor also has general characteristics like type overheadcost (preemptive cost) task powertime and clock rate
The simulation results presented in this paper follow thefollowing legend 119883119884 plusmn 119885 where 119883 denotes 119877 or 119879 for
VLSI Design 11
Table 1 PE comparison
No of PEs AVG ETIMEPETASK (120583sec)
AVGUTLPE
AVGPWRPE(120583watts)
AVGPDPPE
PE no 9 498 048 18125 90748PE no 16 281 040 9834 27698PE no 25 189 035 6359 12006
Table 2 Comparison of task execution times processor utilizationand throughput of EDF-SA and PDS scheduling algorithms
ETIME (120583s) UTL THR (Bns) Std SA CostRAND-50
EDF-SA 20426 046 003 016PDS 22003 055 003 019
SPARSE-96EDF-SA 61651 044 002 015PDS 63789 049 002 017
RAND-100EDF-SA 41867 047 003 017PDS 43217 060 003 021
RAND-300EDF-SA 129945 049 003 017PDS 129695 056 003 019
FPPP-334EDF-SA 223836 042 002 015PDS 233736 047 002 016
RAND-500EDF-SA 143279 048 002 016PDS 212533 066 003 023
RAND-1000EDF-SA 416373 052 003 018PDS 432458 058 003 020
torus or tile topology 119884 denotes 119864 or 119878 for EDF-SA or PDscheduling algorithm + or minus for presence or absence of faulttolerance algorithm and 119885 denotes the number of PEs in theMpSoC system Performance evaluations on architecture andtopological variations were performed but are not included inthis paper Only performance results related to the proposedalgorithms are presented
61 Simulation Scenarios To demonstrate the capabilities ofthe proposed framework and the algorithms we performedseveral simulations on task graph sets and evaluated theireffectiveness over the following design abstractions
(i) Architectural architecture-based evaluation empha-sizes the effect of different PEs in the MpSoC frame-work Current implementation of our frameworkconsists of processors of the same architecture thatcan execute various tasks that is each processor hasa different set of tasks they can execute The MpSoC
Table 3 Comparison of HWD and next available and randommapping algorithms (simulation TS-9)
Mapping Random HWD NXT AVLBLAVG ETIME 141746 139467 13825AVG UTL 048 059 059AVG THR 002 002 002AVG PRT 108 107 108AVG PWR 599503 579969 57005AVG BFR 5 4 6
architecture was modified by changing the number ofPEs the types of PEs and topology It is importantto consider the effect of topology in architectureevaluation because the topology of the MpSoC alsodictates the performance of the individual PEs Theeffect of such architecture changes is measured interms of average execution timePEtask (ETIME) in120583sec average PE utilization (UTL) powertask of PEs(PWR) in 120583-Watts and power delay product (PDP)which are shown in Table 1
(ii) Scheduling evaluation of scheduling algorithms overvarious MpSoC architectures was conducted Per-formance of earliest deadline first based simulatedannealing (EDF-SA) and the new performance driven(PD) algorithms are compared (Table 2) Perfor-mance metrics for evaluating scheduling algorithmsare the same as that of architecture evaluations Alsothe standardized SA costs are shown
(iii) Mapping evaluation of mapping algorithms overvarious MpSoC architectures was conducted usingperformance driven scheduling policy Performanceof the proposed HWD Next Available (NA) andrandom mapping algorithms is compared as shownin Table 3
(iv) Fault Tolerant-evaluation and comparison of fault-tolerant (FT) and nonfault-tolerant (NFT) imple-mentation over various MpSoC architectures wereconducted and results for two test cases are shownin Tables 4 and 5
62 Simulation Results and Explanation Table 1 shows theaverage performance metrics obtained for various architec-tural variations possible in the developedMpSoC frameworkThe architectural variations include the type of topology(tile or torus) scheduling algorithm (EDF-SA or PDS)mapping algorithm (HWD) fault-tolerant scheme (NFT orFT) and the number of PEs Table 2 specifically compares theperformance of the EDF-SA and PDS scheduling algorithmComparison results on total execution time (ECT) in 120583secaverage processor utilization and average throughput inbytes120583sec are presented Other metrics that have less signif-icance have been omitted Also comparisons between EDF-SA and PDS algorithms for processor utilization throughputand buffer usage evaluations across various architectural
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

6 VLSI Design
The Simulated Annealing procedure compares the per-formance of successive design choices based on the PIExecution time processor utilization processor throughputand buffer utilization are maximized so that their costis computed reciprocally however power and port trafficare minimized so that the nonreciprocal values are takenThe coefficient values in the cost equation are set accordingto the desired performance goals of the system
Optimization of Scheduling Algorithm The problem of deter-mining optimal scheduling is to determine the optimal starttime and execution time of all tasks in the application
minimize(119873
sum
119894=1
(119905119894+ 119890119894))
minimize(119873
sum
119894=1
COST (120572 (119879119894))) 119905
119899+ 119890119899le DL
(5)
where 119890119894is the worst-case execution time of each task 119879
119894
DL is the deadline of the application and 119905119899and 119890119899are the
start time and worst-case execution time of the last taskrespectively in the application COST (120572(119879
119894)) is the cost
function of scheduling the tasks
Mapping Mapping is the process of assigning each task in anapplication to a processor such that the processor executes thetask and satisfies the task deadline as well as other constraints(power throughput completion time) if any
For an application 119860 = 1198791 1198792sdot sdot sdot 119879119873 where 119879
119894is a
task instance in the application mapping a task denoted as119872(119879119894) is defined as an assignment of the processor 119875
119895 =
1198751 1198752 119875
119872 = 119875 for the task 119879
119894
119872(119879119894) = 119875
119895 (6)
Application mapping is defined as mapping of all tasks 119879119894 in
the application 119860 to processors and is denoted as
119872(119860) = 119872 (1198791) 119872 (119879
2) sdot sdot sdot119872 (119879
119873) (7)
Optimization of the Mapping Algorithm The problem indetermining optimummapping is to determine the optimumallocation of all tasks in the application on the processorssuch that the total execution time of all tasks is minimizedOther factors for optimum mapping include maximizingprocessor execution time throughput minimizing inter-processor communication delay and balancing workloadhomogenously on the processors in order to improve utiliza-tion
minimize(119873
sum
119894=1
(119888119894)) 119888
119894= COST (119872 (119879
119894)) (8)
where 119888119894is the cost function for optimal mapping of the tasks
on the processor
Power Modeling In this research scheduling and mappingalgorithms model heterogeneous processor execution andpower requirements as follows
(1) Switch power is consumed whenever a task is routedfrom input port to output port
(2) Processor power is modeled with respect to idle-mode (also includes pending ready active and com-plete) and execution-mode (running) power both ofwhich are functions of the task execution time 119890
119894 We
also assume that for the idle model Δ120578 = 0
120578119894(119879119894) = Δ120578 lowast 119890
119894 (9)
whereΔ120578 is the unit power consumed per unit time oftask processingThe total power rating for a processor119875119895would be expressed as
120578119895= Δ120578 lowast
119899
sum
119894=1
(119890119894) (10)
where 119899 is the number of tasks executed by theprocessor
(3) Whenever a task 119879119896is executed on processor 119875
119897
the execution time 119890119896and the power consumed by
processor 120578119896are updated as
120578119897(119879119896) = Δ120578 lowast 119890
119896
120578119897= Δ120578 lowast
119899
sum
119894=1
(119890119896)
(11)
(4) Whenever a task is transferred between switchesthe communication delay is updated on the TotalTask Communication Delay parameter (T) and isexpressed as
T = 119899 lowast v lowast Δ119862 (12)
where 119899 is number of switch hopes task-size (v) is thesize of the task defined as a function of its executiontime in time-units and Δ119862 is a time constant that isrequired to transfer single time-unit task for one hop
(5) For each task 119879119894 the Task Slack Time 119878
119894and Average
Slack Time 119878 are calculated as
119878119894= 119889119894minus [119905119894+ 119890119894]
119878 =
sum
119873
119894=1(119878119894)
119873
(13)
where 119889119894is the deadline 119905
119894is the release time and119873
is the total number of tasks processed
Fault-Tolerant System A fault-tolerant system describes arobust system that is capable of sustaining application pro-cessing in the event of component failure A fault-tolerantalgorithm is a process that performs scheduling andmappingon a set of unprocessed tasks for the available processors
Let an application119860with a set of tasks119860 = 1198791 1198792sdot sdot sdot 119879119873
be scheduled denoted by 120572(119860) and mapped on the set
VLSI Design 7
of processors 119875 = 1198751 1198752 119875
119872 denoted as 119872(119860) A
fault is defined as a nonrecurring permanent failure of aprocessor at time instance 119905
119891during the execution of a
task 119879119891 The application after the occurrence of the fault is
expressed as 119860119891such that 119860
119891sub 119860 which has a list of tasks
119860119891= 119879119892 119879ℎsdot sdot sdot 119879119899 that are not dispatched to processors
by the mapper when the processor failure occurs The set ofprocessors after the failure119865 is denoted by 119875
119891= 1198751 1198752sdot sdot sdot 119875119871
and 119875 notin 119875119891 where 119875
119891is the failed processor The proposed
fault-tolerant MpSoC framework determines the updatedscheduling 120572(119860
119891) and updated mapping119872(119860
119891) for a set of
unprocessed tasks in the application subset 119860119891 such that
119905119899+ 119890119899le DL (14)
where 119905119899and 119890
119899are the start time and execution time
respectively of the last scheduled task in 119860119891
Optimization of Fault-Tolerant Strategy Due to the dynamicmapping methodology adopted in the framework only thetasks dispatched to the failed processormdashwhich includes thetask that was executing on the failed processor and thetasks dispatched by the mapper to the failed processormdashwillneed to be rescheduled along with the tasks that were notdispatched by the mapper
Let us consider an application 119860119891with a list of 119899 tasks
119860119891
= 119879119892 119879ℎsdot sdot sdot 119879119899 that have not been dispatched to
processors at the occurrence of the fault Also let the tasks119879119887= 119879119903sdot sdot sdot 119879119905 be the list of tasks in the buffer of the failed
processor 119875119891and let 119879
119901be the task that was being executed
during failure by the failed processor The task list 119879FT of thefault tolerant algorithm at time 119905
119891is represented as
119879FT = 119860119891+ 119879119887+ 119879119891 (15)
It is also assumed that all the tasks that are being executedby the nonfailed processor complete the execution of thetasks even after the time of failure 119905
119891 Thus the FT algorithm
performs the updated scheduling (119879FT) and updated map-ping
119872(119879FT) on the task set 119879FT which satisfies the deadlineconstraint DL of the application 119860
4 Framework Modeling and Implementation
The proposed framework adopts a ldquobottom-uprdquo modulardesign methodology that gives the benefit of componentreusability Behavioral componentmodels were designed andstored in hardware and software librariesThe frameworkwasimplemented in SystemC 22C++ and compiled with g++-43 under Linux The framework is divided into three majorcomponents input or user interface module core MpSoCsimulation module and the output or performance evalua-tion module The hardware modules such as the processorswitch dispatcher unit and multiplexer were implementedin SystemC the software modules such as input parserscheduler and task interface classes were implemented inC++
Input Module Such userrsquos data as the number of processorstopology task graph processor types buffer size switching
Software libraries
Settings
Task interface
Other IPs
Main GUI
TG parser
Scheduler
Mapper
Dispatcher
Switch
Processor
Multiplexer
ARCH setup
Performance evaluation
PE
PE
PE
PE
PE PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
Hardware libraries
Figure 2 Framework modeling
technology fault-tolerant mode and schedulingmappingspecifications are read either by using a command lineinterface or else from a GUI interface
Core Simulation Module The core simulation module isdepicted in Figure 2 which shows the softwarehardwarelibraries and control flow between the modules The sim-ulation module consists of two components the softwareand hardware libraries Software libraries include softwarecomponents of the framework for instance the input parserscheduler data store and task interface Hardware librariesinclude hardware components implemented in SystemCsuch as the processor the mapper the dispatcher andmultiplexersThe processors are implemented as behaviouralprocessors capable of computing the various tasks in thetask graphs The communication cost for a task is depen-dent on the size and thus the execution duration of thetask (Section 3) Thus communication latency is modelledas a function of task size Heterogeneity is modelled byvarying the task processing cost (processing timetask andpowertask) All processors are capable of executing allpossible operations but with different costs Processor failureis permanent once it occurs and only single processorfailure is considered Due to the modular implementationof the simulation module architecture topology routingscheduling and mapping methods can be easily changedin MpSoCs to conduct extensive evaluation of design spaceexploration
Output Module The simulation terminates by evaluating thesystem performance module which retrieves the various
8 VLSI Design
for each task in ATG do
set the longest-path-maximum-delay deadline
setDeadline()
initial solution
taskrandom mapToPE()
while simulation temp gt cooling threshold
do
for temperature length
for task sub iteration length
while each task is assigned a release time
generates the RTW w Comm cost
genRTL()
rand task from RTL
t sch = sel rand(RTL)
generate release time window
t schgenRTW()
set rel time
t schrel time = sel rand(RTW)
init and run systemC simulation
sc start(time)
calculating objective function value
calcObjFunc()
accepts or rejects a solution
probFunc()
for each task in ATG do
calculate workload of processors
taskcalc HWDcost()
new mapping solution
taskHWD mapToPE()
calculate new simulation temperature
calc simulation temp()
Algorithm 1 Pseudocode for the performance driven (PD) scheduling and HWDmapping algorithms
performance variables from the individual processors suchas the total execution time power throughput port trafficnumber of tasks processed and buffer usageThese values aredisplayed on the output GUI and stored in the result log file
41 Performance Driven Scheduling Algorithm This workalso proposes an efficient offline and performance drivenscheduling algorithm based on the Simulate Annealing tech-nique The performance index (PI) determined by a costfunction is used to determine the optimal schedule Theperformance index is a cumulative factor of (1) processor exe-cution time (2) processor utilization (3) processor through-put (4) processor power (5) processor port traffic and (6)processor buffer utilization The problem of determining theoptimal schedule is defined as determining the schedulewith maximal performance index The Simulated Annealingalgorithm performs (1) random scheduling and mappingof tasks (2) simulation and (3) capturing averaging andnormalizing performance variables finally it calculates theperformance index These steps are repeated several times inan effort to increase the PI During the iterations if a better
PI is found the state is saved and the simulation repeats untilthe temperature reaches the threshold value
For the problem being considered the normalizing coef-ficients used to calculate the PI were set to 120572
1= 300 120572
2=
500 1205723= 250 120572
4= 125 120572
5= 120 and 120572
6= 50000
These coefficients were determined after conducting sev-eral runs on all benchmarks Execution time utilizationthroughput and power factors are key performance indicesTherefore they are given significant weights (a higher valueof coefficient) during normalization Port traffic and powerindices are minimized consequently their respective costfunction is computed reciprocally The pseudocode for theperformance driven scheduling (PDS) and HWD mappingalgorithms is given in Algorithm 1
42 Multiprocessor Task Mapping Strategy Multiprocessorenvironments grant the freedom for dynamic task mappingThus themultiprocessormapping algorithm needs to specifythe locationwhere a particular task should be processed Taskmapping in heterogeneous systems is accomplished in twosteps (1) binding and (2) placement First the task binding
VLSI Design 9
procedure attempts to find which particular assignment oftasks would lead to effective lower power and faster executiontimeDuring task placement themapper considers allocatingany two tasks that exchange data more frequently as closeto each other as possible Placement of communicating tasksto adjacent or nearby processors reduces the communicationlatency switch traffic and power dissipation
Static mapping assigns a particular task to a predeter-mined processing element offline regardless of the dynamicstate of the system components This however does not sat-isfy the MpSoCs requirement because processing tasks on aheterogeneous architecture introduces workload irregularityon system resources (PEs) Irregular workload distributionis a design issue that degrades the utilization of system Toovercome this problem tasks should bemapped dynamicallybased on the dynamic workload on the processors Thenumber of tasks in the processorsrsquo local memory measuresthe processor workload
The dynamic mapper in the proposed framework per-forms the task allocation as per the configured policy Inorder to take heterogeneity of processors into considerationadditional power cost and execution latency cost have beenintroduced This emphasizes the fact that processing a par-ticular task on different types of processors incurs differentcost (power consumption and execution time) Efficient andoptimized heterogeneous mapping algorithms are tailored tominimize this additional cost
In the framework various task allocation heuristics wereimplemented Given a scheduled task the task mappingfollows one of the below policies
(1) Next Available Mapping (NXT AVLB) In the NextAvailable Mapping policy a scheduled task 119879
119894is
mapped on processor 119875119894 followed by the mapping of
the next scheduled task119879119894+1
on processor119875119895 provided
119875119894and 119875
119895are neighbors to each other as defined by
the topology This policy assigns tasks on successiveprocessor sequentially but does not consider theheterogeneity of the tasks nor the processorworkload
(2) Homogenous Workload Distribution Mapping(HWD) HWD considers the workload on eachprocessor and maps a scheduled task on a processorthat has the minimum workload
(3) Random mapping (RANDOM) rRandom task allo-cation is used by the PD algorithm to distribute theworkload randomly throughout the available proces-sors
HWD Mapping Approach Minimizing the idle time ofeach processor or maximizing processing time improvesprocessor utilization To reduce idle time tasks shouldbe distributed evenly throughout the available processorsThe proposed Homogenous Workload Distribution (HWD)algorithm is tailored to distribute tasks evenly to the availableprocessors in an effort to balance the dynamic workloadthroughout the processors The algorithm is a two-stepprocess (1) probing individual processor buffers throughdedicated snooping channels that connects each processor
to the mapper and (2) mapping each scheduled task ona processor that has the lowest workload Workload is ameasure of the number of tasks and its respective executiontime in the processor bufferThus a processor having the leastnumber of tasks and respective execution time in its bufferhas the lowest workload therefore themapper will assign thenext scheduled task to this processor
HWD Mapping Algorithm Let 1198751 1198752sdot sdot sdot 119875119872 be a set of
processors let 1198711 1198712sdot sdot sdot 119871119872 be the dynamic task workloads
defined by number of tasks on respective processor buffersand let119873 be the number of processors Let 119879
1 1198792sdot sdot sdot 119879119873 be a
set of119872 tasks and the symbol ldquorarr rdquo denotes ldquomappingrdquoThen
A task 119879119896⟨119879release-time 119879exec-time 119879deadline⟩ 997888rarr 119875
119894
iff 119871119894lt 119871119895
forall [119871119894 119871119895] isin 119871
1 1198712sdot sdot sdot 119871119873
(16)
where 119875119894isin 1198751 1198752sdot sdot sdot 119875119872 and 119879
119896isin 1198791 1198792sdot sdot sdot 119879119873 such that
(119890119896+ 119905119896le 119889119896)
This approach has three advantages (1) it minimizesthe chance for buffer overflow (2) the task waiting time inprocessor buffer is reduced and (3) utilization is increasedbecause idle processors will be assigned scheduled tasks
43 Fault-Tolerant Methodology System designs often haveflaws that cannot be identified at design time It is almostimpossible to anticipate all faulty scenarios beforehandbecause processor failure may occur due to unexpectedruntime errors Real-time systems are critically affected if nomeans of fault tolerance scheme is implemented Failure toemploy fault detection and recovery strategies is often unaf-fordable in critical mission systems because the error maylead to possible data discrepancies and deadline violation
Processor failure introduces inevitable overall perfor-mance degradation due to (1) the reduced computing powerof the system and (2) the overhead involved in applying thefault recovery schemes Recovery procedures involve trackingthe task execution history and reconfiguring the systemby using the available processors This enables applicationprocessing to resume when the execution was terminatedDuring processor failure application processing is temporar-ily suspended and error recovery procedures are appliedbefore application processing is resumed
Fault-TolerantModelFaultmodeling can have several dimen-sions that define the fault occurring time the fault durationlocation of failure and so forth The proposed frameworkadopts the following fault modeling parameters
(1) It is assumed that the processor failure is permanentThus fault duration time 119905FD is infinite (119905FD = infin)During failure the address of the failed processor iscompletely removed from the mapper address table
(2) The location specifies where the failure occurred Fortile and torus topology location is represented in two-dimensional coordinate addresses
(3) During task processing any processors may fail atany time instance Consequently time of failure ismodeled as a random time instance
10 VLSI Design
In the event of failure the following procedures areexecuted
(1) Themapper removes the failed processor ID from theaddress table
(2) Tasks that are scheduled or mapped but not dis-patched have to be rescheduled and remapped Therespective new task release time and task address bothhave to be done again This is because the executioninstance of a task depends on the finish time ofits predecessor task which may possibly have beensuspended in the failed processor
(3) Tasks that are already dispatched to the failed proces-sor can be either (1) in the processorrsquos buffer or (2)in the middle of execution when the failure occurredThese tasks have to be migrated back to the mapperand their respective rescheduling and remapping haveto be done The scheduler can perform task schedul-ing concurrently when the nonfaulty processors areexecuting their respective tasks
(4) Tasks that are dispatched to other nonfailed proces-sors are not affected
Due to the dynamic property of the mapper and the fault-tolerant implementation the cost incurred during the eventof processor failure is minimal overhead incurred is only25 of the total execution time of the task The only penaltyincurred during processor failure is the cost due to taskmigration and the respective rerescheduling and remappingprocedures
5 Experimental Setup
The heterogeneous MpSoC framework developed in thiswork was developed using C++ and SystemC programminglanguage The architectural components such as processingelements (PEs) memory elements routers and networkinterfaces are developed using SystemC language and providecycle accurate simulations The processing elements areimplemented as a simple 32-bit processor that performssimple logic and arithmetic operations The heterogeneousPE structure in our MpSoC is implemented by altering thetype of operation and the execution times of the tasks eachPE can execute The routers implementations consist of aswitching matrix with input port buffers The tasks and datawithin PEs are transmitted using a data-serializing moduleof the PE A typical data transmitted within PEs consists oftask commands task data (if any) and the destination PEIDs (addresses) The data is propagated through the MpSoCsystem using the119883119884 routing algorithm
The scheduling and mapping algorithm are implementedusing C++ language and are interfaced with the SystemCarchitecture implementations The application in this workis considered as a task graph Each task graph consists ofprocessor operations their execution time communicationcost and deadline The application as a whole also has adeadline The scheduling algorithm parses the application(task graph) and assigns start times for the tasks on the
processors based on the set of optimization goals describedin the proposed performance driven scheduling algorithmThe scheduled tasks aremapped to their respective processorsin the MpSoC system based on the proposed homogenousworkload-mapping algorithm The tasksrsquo information com-prising of the task operations task data destination PEs(pathaddress of successor PEs) are assembled and forwardedto the initial PE by the dispatcher module The performanceevaluation module or the monitor module records cycleaccurate timing signals in the architecture during tasksexecution and communication
During the simulation of fault-tolerant scenario themonitor module triggers a PE failure event at a predefinedtime instance The dispatcher is informed of the PE failureand based on the mapper table and the current processingtask and the tasks in the buffer of the failed PE are determinedAn updated task graph is constructed and scheduling andmapping on the remaining unexecuted tasks are performedTasks currently executing on the PEs are undisturbed Thereassigned tasks are inserted in the PE buffers to satisfy thedeadlines
The implemented MpSoC system has been evaluatedextensively by modifying the architecture and topology Thesystemwas evaluated using a set of synthetic task graphs with50ndash3000 tasksThe architectural modifications for evaluatingthe MpSoC include change in type of PEs in the systemmesh and torus topology variations and the number of PEsin the system (9 16 32) The MpSoC system has been usedto evaluate the proposed scheduling mapping and fault-tolerant algorithms and compared with respective classicalalgorithms The performance of the proposed algorithmsalong with variation in architecture and topology have beenevaluated and presented The performance metrics consid-ered in this work include processor throughput processorutilization processor execution timetask and powertaskbuffers utilization and port utilization Detailed summary ofthe results and its significance are shown in Section 6
6 Simulation Results and Analysis
For evaluation of the proposed framework to explore designfeatures variations in scheduling mapping and fault tolerantalgorithms have been considered The application modeladapted is similar to the standard task graph (STG) [50 51]and E3S benchmark suite [54] which contains random set ofbenchmarks and application-specific benchmarks The sim-ulation was conducted with many STG benchmarks havingtask sizes 50 through 3000 The task graph is characterizedby the number of tasks dependencies of tasks task size(code size) communication cost (latency for interprocessortransfer) and application deadline The processor architec-ture model is derived from the E3S benchmark where eachprocessor is characterized by the type tasks it can executetask execution time task size (code size) and task powerTheprocessor also has general characteristics like type overheadcost (preemptive cost) task powertime and clock rate
The simulation results presented in this paper follow thefollowing legend 119883119884 plusmn 119885 where 119883 denotes 119877 or 119879 for
VLSI Design 11
Table 1 PE comparison
No of PEs AVG ETIMEPETASK (120583sec)
AVGUTLPE
AVGPWRPE(120583watts)
AVGPDPPE
PE no 9 498 048 18125 90748PE no 16 281 040 9834 27698PE no 25 189 035 6359 12006
Table 2 Comparison of task execution times processor utilizationand throughput of EDF-SA and PDS scheduling algorithms
ETIME (120583s) UTL THR (Bns) Std SA CostRAND-50
EDF-SA 20426 046 003 016PDS 22003 055 003 019
SPARSE-96EDF-SA 61651 044 002 015PDS 63789 049 002 017
RAND-100EDF-SA 41867 047 003 017PDS 43217 060 003 021
RAND-300EDF-SA 129945 049 003 017PDS 129695 056 003 019
FPPP-334EDF-SA 223836 042 002 015PDS 233736 047 002 016
RAND-500EDF-SA 143279 048 002 016PDS 212533 066 003 023
RAND-1000EDF-SA 416373 052 003 018PDS 432458 058 003 020
torus or tile topology 119884 denotes 119864 or 119878 for EDF-SA or PDscheduling algorithm + or minus for presence or absence of faulttolerance algorithm and 119885 denotes the number of PEs in theMpSoC system Performance evaluations on architecture andtopological variations were performed but are not included inthis paper Only performance results related to the proposedalgorithms are presented
61 Simulation Scenarios To demonstrate the capabilities ofthe proposed framework and the algorithms we performedseveral simulations on task graph sets and evaluated theireffectiveness over the following design abstractions
(i) Architectural architecture-based evaluation empha-sizes the effect of different PEs in the MpSoC frame-work Current implementation of our frameworkconsists of processors of the same architecture thatcan execute various tasks that is each processor hasa different set of tasks they can execute The MpSoC
Table 3 Comparison of HWD and next available and randommapping algorithms (simulation TS-9)
Mapping Random HWD NXT AVLBLAVG ETIME 141746 139467 13825AVG UTL 048 059 059AVG THR 002 002 002AVG PRT 108 107 108AVG PWR 599503 579969 57005AVG BFR 5 4 6
architecture was modified by changing the number ofPEs the types of PEs and topology It is importantto consider the effect of topology in architectureevaluation because the topology of the MpSoC alsodictates the performance of the individual PEs Theeffect of such architecture changes is measured interms of average execution timePEtask (ETIME) in120583sec average PE utilization (UTL) powertask of PEs(PWR) in 120583-Watts and power delay product (PDP)which are shown in Table 1
(ii) Scheduling evaluation of scheduling algorithms overvarious MpSoC architectures was conducted Per-formance of earliest deadline first based simulatedannealing (EDF-SA) and the new performance driven(PD) algorithms are compared (Table 2) Perfor-mance metrics for evaluating scheduling algorithmsare the same as that of architecture evaluations Alsothe standardized SA costs are shown
(iii) Mapping evaluation of mapping algorithms overvarious MpSoC architectures was conducted usingperformance driven scheduling policy Performanceof the proposed HWD Next Available (NA) andrandom mapping algorithms is compared as shownin Table 3
(iv) Fault Tolerant-evaluation and comparison of fault-tolerant (FT) and nonfault-tolerant (NFT) imple-mentation over various MpSoC architectures wereconducted and results for two test cases are shownin Tables 4 and 5
62 Simulation Results and Explanation Table 1 shows theaverage performance metrics obtained for various architec-tural variations possible in the developedMpSoC frameworkThe architectural variations include the type of topology(tile or torus) scheduling algorithm (EDF-SA or PDS)mapping algorithm (HWD) fault-tolerant scheme (NFT orFT) and the number of PEs Table 2 specifically compares theperformance of the EDF-SA and PDS scheduling algorithmComparison results on total execution time (ECT) in 120583secaverage processor utilization and average throughput inbytes120583sec are presented Other metrics that have less signif-icance have been omitted Also comparisons between EDF-SA and PDS algorithms for processor utilization throughputand buffer usage evaluations across various architectural
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

VLSI Design 7
of processors 119875 = 1198751 1198752 119875
119872 denoted as 119872(119860) A
fault is defined as a nonrecurring permanent failure of aprocessor at time instance 119905
119891during the execution of a
task 119879119891 The application after the occurrence of the fault is
expressed as 119860119891such that 119860
119891sub 119860 which has a list of tasks
119860119891= 119879119892 119879ℎsdot sdot sdot 119879119899 that are not dispatched to processors
by the mapper when the processor failure occurs The set ofprocessors after the failure119865 is denoted by 119875
119891= 1198751 1198752sdot sdot sdot 119875119871
and 119875 notin 119875119891 where 119875
119891is the failed processor The proposed
fault-tolerant MpSoC framework determines the updatedscheduling 120572(119860
119891) and updated mapping119872(119860
119891) for a set of
unprocessed tasks in the application subset 119860119891 such that
119905119899+ 119890119899le DL (14)
where 119905119899and 119890
119899are the start time and execution time
respectively of the last scheduled task in 119860119891
Optimization of Fault-Tolerant Strategy Due to the dynamicmapping methodology adopted in the framework only thetasks dispatched to the failed processormdashwhich includes thetask that was executing on the failed processor and thetasks dispatched by the mapper to the failed processormdashwillneed to be rescheduled along with the tasks that were notdispatched by the mapper
Let us consider an application 119860119891with a list of 119899 tasks
119860119891
= 119879119892 119879ℎsdot sdot sdot 119879119899 that have not been dispatched to
processors at the occurrence of the fault Also let the tasks119879119887= 119879119903sdot sdot sdot 119879119905 be the list of tasks in the buffer of the failed
processor 119875119891and let 119879
119901be the task that was being executed
during failure by the failed processor The task list 119879FT of thefault tolerant algorithm at time 119905
119891is represented as
119879FT = 119860119891+ 119879119887+ 119879119891 (15)
It is also assumed that all the tasks that are being executedby the nonfailed processor complete the execution of thetasks even after the time of failure 119905
119891 Thus the FT algorithm
performs the updated scheduling (119879FT) and updated map-ping
119872(119879FT) on the task set 119879FT which satisfies the deadlineconstraint DL of the application 119860
4 Framework Modeling and Implementation
The proposed framework adopts a ldquobottom-uprdquo modulardesign methodology that gives the benefit of componentreusability Behavioral componentmodels were designed andstored in hardware and software librariesThe frameworkwasimplemented in SystemC 22C++ and compiled with g++-43 under Linux The framework is divided into three majorcomponents input or user interface module core MpSoCsimulation module and the output or performance evalua-tion module The hardware modules such as the processorswitch dispatcher unit and multiplexer were implementedin SystemC the software modules such as input parserscheduler and task interface classes were implemented inC++
Input Module Such userrsquos data as the number of processorstopology task graph processor types buffer size switching
Software libraries
Settings
Task interface
Other IPs
Main GUI
TG parser
Scheduler
Mapper
Dispatcher
Switch
Processor
Multiplexer
ARCH setup
Performance evaluation
PE
PE
PE
PE
PE PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
PE PE PE PE
Hardware libraries
Figure 2 Framework modeling
technology fault-tolerant mode and schedulingmappingspecifications are read either by using a command lineinterface or else from a GUI interface
Core Simulation Module The core simulation module isdepicted in Figure 2 which shows the softwarehardwarelibraries and control flow between the modules The sim-ulation module consists of two components the softwareand hardware libraries Software libraries include softwarecomponents of the framework for instance the input parserscheduler data store and task interface Hardware librariesinclude hardware components implemented in SystemCsuch as the processor the mapper the dispatcher andmultiplexersThe processors are implemented as behaviouralprocessors capable of computing the various tasks in thetask graphs The communication cost for a task is depen-dent on the size and thus the execution duration of thetask (Section 3) Thus communication latency is modelledas a function of task size Heterogeneity is modelled byvarying the task processing cost (processing timetask andpowertask) All processors are capable of executing allpossible operations but with different costs Processor failureis permanent once it occurs and only single processorfailure is considered Due to the modular implementationof the simulation module architecture topology routingscheduling and mapping methods can be easily changedin MpSoCs to conduct extensive evaluation of design spaceexploration
Output Module The simulation terminates by evaluating thesystem performance module which retrieves the various
8 VLSI Design
for each task in ATG do
set the longest-path-maximum-delay deadline
setDeadline()
initial solution
taskrandom mapToPE()
while simulation temp gt cooling threshold
do
for temperature length
for task sub iteration length
while each task is assigned a release time
generates the RTW w Comm cost
genRTL()
rand task from RTL
t sch = sel rand(RTL)
generate release time window
t schgenRTW()
set rel time
t schrel time = sel rand(RTW)
init and run systemC simulation
sc start(time)
calculating objective function value
calcObjFunc()
accepts or rejects a solution
probFunc()
for each task in ATG do
calculate workload of processors
taskcalc HWDcost()
new mapping solution
taskHWD mapToPE()
calculate new simulation temperature
calc simulation temp()
Algorithm 1 Pseudocode for the performance driven (PD) scheduling and HWDmapping algorithms
performance variables from the individual processors suchas the total execution time power throughput port trafficnumber of tasks processed and buffer usageThese values aredisplayed on the output GUI and stored in the result log file
41 Performance Driven Scheduling Algorithm This workalso proposes an efficient offline and performance drivenscheduling algorithm based on the Simulate Annealing tech-nique The performance index (PI) determined by a costfunction is used to determine the optimal schedule Theperformance index is a cumulative factor of (1) processor exe-cution time (2) processor utilization (3) processor through-put (4) processor power (5) processor port traffic and (6)processor buffer utilization The problem of determining theoptimal schedule is defined as determining the schedulewith maximal performance index The Simulated Annealingalgorithm performs (1) random scheduling and mappingof tasks (2) simulation and (3) capturing averaging andnormalizing performance variables finally it calculates theperformance index These steps are repeated several times inan effort to increase the PI During the iterations if a better
PI is found the state is saved and the simulation repeats untilthe temperature reaches the threshold value
For the problem being considered the normalizing coef-ficients used to calculate the PI were set to 120572
1= 300 120572
2=
500 1205723= 250 120572
4= 125 120572
5= 120 and 120572
6= 50000
These coefficients were determined after conducting sev-eral runs on all benchmarks Execution time utilizationthroughput and power factors are key performance indicesTherefore they are given significant weights (a higher valueof coefficient) during normalization Port traffic and powerindices are minimized consequently their respective costfunction is computed reciprocally The pseudocode for theperformance driven scheduling (PDS) and HWD mappingalgorithms is given in Algorithm 1
42 Multiprocessor Task Mapping Strategy Multiprocessorenvironments grant the freedom for dynamic task mappingThus themultiprocessormapping algorithm needs to specifythe locationwhere a particular task should be processed Taskmapping in heterogeneous systems is accomplished in twosteps (1) binding and (2) placement First the task binding
VLSI Design 9
procedure attempts to find which particular assignment oftasks would lead to effective lower power and faster executiontimeDuring task placement themapper considers allocatingany two tasks that exchange data more frequently as closeto each other as possible Placement of communicating tasksto adjacent or nearby processors reduces the communicationlatency switch traffic and power dissipation
Static mapping assigns a particular task to a predeter-mined processing element offline regardless of the dynamicstate of the system components This however does not sat-isfy the MpSoCs requirement because processing tasks on aheterogeneous architecture introduces workload irregularityon system resources (PEs) Irregular workload distributionis a design issue that degrades the utilization of system Toovercome this problem tasks should bemapped dynamicallybased on the dynamic workload on the processors Thenumber of tasks in the processorsrsquo local memory measuresthe processor workload
The dynamic mapper in the proposed framework per-forms the task allocation as per the configured policy Inorder to take heterogeneity of processors into considerationadditional power cost and execution latency cost have beenintroduced This emphasizes the fact that processing a par-ticular task on different types of processors incurs differentcost (power consumption and execution time) Efficient andoptimized heterogeneous mapping algorithms are tailored tominimize this additional cost
In the framework various task allocation heuristics wereimplemented Given a scheduled task the task mappingfollows one of the below policies
(1) Next Available Mapping (NXT AVLB) In the NextAvailable Mapping policy a scheduled task 119879
119894is
mapped on processor 119875119894 followed by the mapping of
the next scheduled task119879119894+1
on processor119875119895 provided
119875119894and 119875
119895are neighbors to each other as defined by
the topology This policy assigns tasks on successiveprocessor sequentially but does not consider theheterogeneity of the tasks nor the processorworkload
(2) Homogenous Workload Distribution Mapping(HWD) HWD considers the workload on eachprocessor and maps a scheduled task on a processorthat has the minimum workload
(3) Random mapping (RANDOM) rRandom task allo-cation is used by the PD algorithm to distribute theworkload randomly throughout the available proces-sors
HWD Mapping Approach Minimizing the idle time ofeach processor or maximizing processing time improvesprocessor utilization To reduce idle time tasks shouldbe distributed evenly throughout the available processorsThe proposed Homogenous Workload Distribution (HWD)algorithm is tailored to distribute tasks evenly to the availableprocessors in an effort to balance the dynamic workloadthroughout the processors The algorithm is a two-stepprocess (1) probing individual processor buffers throughdedicated snooping channels that connects each processor
to the mapper and (2) mapping each scheduled task ona processor that has the lowest workload Workload is ameasure of the number of tasks and its respective executiontime in the processor bufferThus a processor having the leastnumber of tasks and respective execution time in its bufferhas the lowest workload therefore themapper will assign thenext scheduled task to this processor
HWD Mapping Algorithm Let 1198751 1198752sdot sdot sdot 119875119872 be a set of
processors let 1198711 1198712sdot sdot sdot 119871119872 be the dynamic task workloads
defined by number of tasks on respective processor buffersand let119873 be the number of processors Let 119879
1 1198792sdot sdot sdot 119879119873 be a
set of119872 tasks and the symbol ldquorarr rdquo denotes ldquomappingrdquoThen
A task 119879119896⟨119879release-time 119879exec-time 119879deadline⟩ 997888rarr 119875
119894
iff 119871119894lt 119871119895
forall [119871119894 119871119895] isin 119871
1 1198712sdot sdot sdot 119871119873
(16)
where 119875119894isin 1198751 1198752sdot sdot sdot 119875119872 and 119879
119896isin 1198791 1198792sdot sdot sdot 119879119873 such that
(119890119896+ 119905119896le 119889119896)
This approach has three advantages (1) it minimizesthe chance for buffer overflow (2) the task waiting time inprocessor buffer is reduced and (3) utilization is increasedbecause idle processors will be assigned scheduled tasks
43 Fault-Tolerant Methodology System designs often haveflaws that cannot be identified at design time It is almostimpossible to anticipate all faulty scenarios beforehandbecause processor failure may occur due to unexpectedruntime errors Real-time systems are critically affected if nomeans of fault tolerance scheme is implemented Failure toemploy fault detection and recovery strategies is often unaf-fordable in critical mission systems because the error maylead to possible data discrepancies and deadline violation
Processor failure introduces inevitable overall perfor-mance degradation due to (1) the reduced computing powerof the system and (2) the overhead involved in applying thefault recovery schemes Recovery procedures involve trackingthe task execution history and reconfiguring the systemby using the available processors This enables applicationprocessing to resume when the execution was terminatedDuring processor failure application processing is temporar-ily suspended and error recovery procedures are appliedbefore application processing is resumed
Fault-TolerantModelFaultmodeling can have several dimen-sions that define the fault occurring time the fault durationlocation of failure and so forth The proposed frameworkadopts the following fault modeling parameters
(1) It is assumed that the processor failure is permanentThus fault duration time 119905FD is infinite (119905FD = infin)During failure the address of the failed processor iscompletely removed from the mapper address table
(2) The location specifies where the failure occurred Fortile and torus topology location is represented in two-dimensional coordinate addresses
(3) During task processing any processors may fail atany time instance Consequently time of failure ismodeled as a random time instance
10 VLSI Design
In the event of failure the following procedures areexecuted
(1) Themapper removes the failed processor ID from theaddress table
(2) Tasks that are scheduled or mapped but not dis-patched have to be rescheduled and remapped Therespective new task release time and task address bothhave to be done again This is because the executioninstance of a task depends on the finish time ofits predecessor task which may possibly have beensuspended in the failed processor
(3) Tasks that are already dispatched to the failed proces-sor can be either (1) in the processorrsquos buffer or (2)in the middle of execution when the failure occurredThese tasks have to be migrated back to the mapperand their respective rescheduling and remapping haveto be done The scheduler can perform task schedul-ing concurrently when the nonfaulty processors areexecuting their respective tasks
(4) Tasks that are dispatched to other nonfailed proces-sors are not affected
Due to the dynamic property of the mapper and the fault-tolerant implementation the cost incurred during the eventof processor failure is minimal overhead incurred is only25 of the total execution time of the task The only penaltyincurred during processor failure is the cost due to taskmigration and the respective rerescheduling and remappingprocedures
5 Experimental Setup
The heterogeneous MpSoC framework developed in thiswork was developed using C++ and SystemC programminglanguage The architectural components such as processingelements (PEs) memory elements routers and networkinterfaces are developed using SystemC language and providecycle accurate simulations The processing elements areimplemented as a simple 32-bit processor that performssimple logic and arithmetic operations The heterogeneousPE structure in our MpSoC is implemented by altering thetype of operation and the execution times of the tasks eachPE can execute The routers implementations consist of aswitching matrix with input port buffers The tasks and datawithin PEs are transmitted using a data-serializing moduleof the PE A typical data transmitted within PEs consists oftask commands task data (if any) and the destination PEIDs (addresses) The data is propagated through the MpSoCsystem using the119883119884 routing algorithm
The scheduling and mapping algorithm are implementedusing C++ language and are interfaced with the SystemCarchitecture implementations The application in this workis considered as a task graph Each task graph consists ofprocessor operations their execution time communicationcost and deadline The application as a whole also has adeadline The scheduling algorithm parses the application(task graph) and assigns start times for the tasks on the
processors based on the set of optimization goals describedin the proposed performance driven scheduling algorithmThe scheduled tasks aremapped to their respective processorsin the MpSoC system based on the proposed homogenousworkload-mapping algorithm The tasksrsquo information com-prising of the task operations task data destination PEs(pathaddress of successor PEs) are assembled and forwardedto the initial PE by the dispatcher module The performanceevaluation module or the monitor module records cycleaccurate timing signals in the architecture during tasksexecution and communication
During the simulation of fault-tolerant scenario themonitor module triggers a PE failure event at a predefinedtime instance The dispatcher is informed of the PE failureand based on the mapper table and the current processingtask and the tasks in the buffer of the failed PE are determinedAn updated task graph is constructed and scheduling andmapping on the remaining unexecuted tasks are performedTasks currently executing on the PEs are undisturbed Thereassigned tasks are inserted in the PE buffers to satisfy thedeadlines
The implemented MpSoC system has been evaluatedextensively by modifying the architecture and topology Thesystemwas evaluated using a set of synthetic task graphs with50ndash3000 tasksThe architectural modifications for evaluatingthe MpSoC include change in type of PEs in the systemmesh and torus topology variations and the number of PEsin the system (9 16 32) The MpSoC system has been usedto evaluate the proposed scheduling mapping and fault-tolerant algorithms and compared with respective classicalalgorithms The performance of the proposed algorithmsalong with variation in architecture and topology have beenevaluated and presented The performance metrics consid-ered in this work include processor throughput processorutilization processor execution timetask and powertaskbuffers utilization and port utilization Detailed summary ofthe results and its significance are shown in Section 6
6 Simulation Results and Analysis
For evaluation of the proposed framework to explore designfeatures variations in scheduling mapping and fault tolerantalgorithms have been considered The application modeladapted is similar to the standard task graph (STG) [50 51]and E3S benchmark suite [54] which contains random set ofbenchmarks and application-specific benchmarks The sim-ulation was conducted with many STG benchmarks havingtask sizes 50 through 3000 The task graph is characterizedby the number of tasks dependencies of tasks task size(code size) communication cost (latency for interprocessortransfer) and application deadline The processor architec-ture model is derived from the E3S benchmark where eachprocessor is characterized by the type tasks it can executetask execution time task size (code size) and task powerTheprocessor also has general characteristics like type overheadcost (preemptive cost) task powertime and clock rate
The simulation results presented in this paper follow thefollowing legend 119883119884 plusmn 119885 where 119883 denotes 119877 or 119879 for
VLSI Design 11
Table 1 PE comparison
No of PEs AVG ETIMEPETASK (120583sec)
AVGUTLPE
AVGPWRPE(120583watts)
AVGPDPPE
PE no 9 498 048 18125 90748PE no 16 281 040 9834 27698PE no 25 189 035 6359 12006
Table 2 Comparison of task execution times processor utilizationand throughput of EDF-SA and PDS scheduling algorithms
ETIME (120583s) UTL THR (Bns) Std SA CostRAND-50
EDF-SA 20426 046 003 016PDS 22003 055 003 019
SPARSE-96EDF-SA 61651 044 002 015PDS 63789 049 002 017
RAND-100EDF-SA 41867 047 003 017PDS 43217 060 003 021
RAND-300EDF-SA 129945 049 003 017PDS 129695 056 003 019
FPPP-334EDF-SA 223836 042 002 015PDS 233736 047 002 016
RAND-500EDF-SA 143279 048 002 016PDS 212533 066 003 023
RAND-1000EDF-SA 416373 052 003 018PDS 432458 058 003 020
torus or tile topology 119884 denotes 119864 or 119878 for EDF-SA or PDscheduling algorithm + or minus for presence or absence of faulttolerance algorithm and 119885 denotes the number of PEs in theMpSoC system Performance evaluations on architecture andtopological variations were performed but are not included inthis paper Only performance results related to the proposedalgorithms are presented
61 Simulation Scenarios To demonstrate the capabilities ofthe proposed framework and the algorithms we performedseveral simulations on task graph sets and evaluated theireffectiveness over the following design abstractions
(i) Architectural architecture-based evaluation empha-sizes the effect of different PEs in the MpSoC frame-work Current implementation of our frameworkconsists of processors of the same architecture thatcan execute various tasks that is each processor hasa different set of tasks they can execute The MpSoC
Table 3 Comparison of HWD and next available and randommapping algorithms (simulation TS-9)
Mapping Random HWD NXT AVLBLAVG ETIME 141746 139467 13825AVG UTL 048 059 059AVG THR 002 002 002AVG PRT 108 107 108AVG PWR 599503 579969 57005AVG BFR 5 4 6
architecture was modified by changing the number ofPEs the types of PEs and topology It is importantto consider the effect of topology in architectureevaluation because the topology of the MpSoC alsodictates the performance of the individual PEs Theeffect of such architecture changes is measured interms of average execution timePEtask (ETIME) in120583sec average PE utilization (UTL) powertask of PEs(PWR) in 120583-Watts and power delay product (PDP)which are shown in Table 1
(ii) Scheduling evaluation of scheduling algorithms overvarious MpSoC architectures was conducted Per-formance of earliest deadline first based simulatedannealing (EDF-SA) and the new performance driven(PD) algorithms are compared (Table 2) Perfor-mance metrics for evaluating scheduling algorithmsare the same as that of architecture evaluations Alsothe standardized SA costs are shown
(iii) Mapping evaluation of mapping algorithms overvarious MpSoC architectures was conducted usingperformance driven scheduling policy Performanceof the proposed HWD Next Available (NA) andrandom mapping algorithms is compared as shownin Table 3
(iv) Fault Tolerant-evaluation and comparison of fault-tolerant (FT) and nonfault-tolerant (NFT) imple-mentation over various MpSoC architectures wereconducted and results for two test cases are shownin Tables 4 and 5
62 Simulation Results and Explanation Table 1 shows theaverage performance metrics obtained for various architec-tural variations possible in the developedMpSoC frameworkThe architectural variations include the type of topology(tile or torus) scheduling algorithm (EDF-SA or PDS)mapping algorithm (HWD) fault-tolerant scheme (NFT orFT) and the number of PEs Table 2 specifically compares theperformance of the EDF-SA and PDS scheduling algorithmComparison results on total execution time (ECT) in 120583secaverage processor utilization and average throughput inbytes120583sec are presented Other metrics that have less signif-icance have been omitted Also comparisons between EDF-SA and PDS algorithms for processor utilization throughputand buffer usage evaluations across various architectural
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

8 VLSI Design
for each task in ATG do
set the longest-path-maximum-delay deadline
setDeadline()
initial solution
taskrandom mapToPE()
while simulation temp gt cooling threshold
do
for temperature length
for task sub iteration length
while each task is assigned a release time
generates the RTW w Comm cost
genRTL()
rand task from RTL
t sch = sel rand(RTL)
generate release time window
t schgenRTW()
set rel time
t schrel time = sel rand(RTW)
init and run systemC simulation
sc start(time)
calculating objective function value
calcObjFunc()
accepts or rejects a solution
probFunc()
for each task in ATG do
calculate workload of processors
taskcalc HWDcost()
new mapping solution
taskHWD mapToPE()
calculate new simulation temperature
calc simulation temp()
Algorithm 1 Pseudocode for the performance driven (PD) scheduling and HWDmapping algorithms
performance variables from the individual processors suchas the total execution time power throughput port trafficnumber of tasks processed and buffer usageThese values aredisplayed on the output GUI and stored in the result log file
41 Performance Driven Scheduling Algorithm This workalso proposes an efficient offline and performance drivenscheduling algorithm based on the Simulate Annealing tech-nique The performance index (PI) determined by a costfunction is used to determine the optimal schedule Theperformance index is a cumulative factor of (1) processor exe-cution time (2) processor utilization (3) processor through-put (4) processor power (5) processor port traffic and (6)processor buffer utilization The problem of determining theoptimal schedule is defined as determining the schedulewith maximal performance index The Simulated Annealingalgorithm performs (1) random scheduling and mappingof tasks (2) simulation and (3) capturing averaging andnormalizing performance variables finally it calculates theperformance index These steps are repeated several times inan effort to increase the PI During the iterations if a better
PI is found the state is saved and the simulation repeats untilthe temperature reaches the threshold value
For the problem being considered the normalizing coef-ficients used to calculate the PI were set to 120572
1= 300 120572
2=
500 1205723= 250 120572
4= 125 120572
5= 120 and 120572
6= 50000
These coefficients were determined after conducting sev-eral runs on all benchmarks Execution time utilizationthroughput and power factors are key performance indicesTherefore they are given significant weights (a higher valueof coefficient) during normalization Port traffic and powerindices are minimized consequently their respective costfunction is computed reciprocally The pseudocode for theperformance driven scheduling (PDS) and HWD mappingalgorithms is given in Algorithm 1
42 Multiprocessor Task Mapping Strategy Multiprocessorenvironments grant the freedom for dynamic task mappingThus themultiprocessormapping algorithm needs to specifythe locationwhere a particular task should be processed Taskmapping in heterogeneous systems is accomplished in twosteps (1) binding and (2) placement First the task binding
VLSI Design 9
procedure attempts to find which particular assignment oftasks would lead to effective lower power and faster executiontimeDuring task placement themapper considers allocatingany two tasks that exchange data more frequently as closeto each other as possible Placement of communicating tasksto adjacent or nearby processors reduces the communicationlatency switch traffic and power dissipation
Static mapping assigns a particular task to a predeter-mined processing element offline regardless of the dynamicstate of the system components This however does not sat-isfy the MpSoCs requirement because processing tasks on aheterogeneous architecture introduces workload irregularityon system resources (PEs) Irregular workload distributionis a design issue that degrades the utilization of system Toovercome this problem tasks should bemapped dynamicallybased on the dynamic workload on the processors Thenumber of tasks in the processorsrsquo local memory measuresthe processor workload
The dynamic mapper in the proposed framework per-forms the task allocation as per the configured policy Inorder to take heterogeneity of processors into considerationadditional power cost and execution latency cost have beenintroduced This emphasizes the fact that processing a par-ticular task on different types of processors incurs differentcost (power consumption and execution time) Efficient andoptimized heterogeneous mapping algorithms are tailored tominimize this additional cost
In the framework various task allocation heuristics wereimplemented Given a scheduled task the task mappingfollows one of the below policies
(1) Next Available Mapping (NXT AVLB) In the NextAvailable Mapping policy a scheduled task 119879
119894is
mapped on processor 119875119894 followed by the mapping of
the next scheduled task119879119894+1
on processor119875119895 provided
119875119894and 119875
119895are neighbors to each other as defined by
the topology This policy assigns tasks on successiveprocessor sequentially but does not consider theheterogeneity of the tasks nor the processorworkload
(2) Homogenous Workload Distribution Mapping(HWD) HWD considers the workload on eachprocessor and maps a scheduled task on a processorthat has the minimum workload
(3) Random mapping (RANDOM) rRandom task allo-cation is used by the PD algorithm to distribute theworkload randomly throughout the available proces-sors
HWD Mapping Approach Minimizing the idle time ofeach processor or maximizing processing time improvesprocessor utilization To reduce idle time tasks shouldbe distributed evenly throughout the available processorsThe proposed Homogenous Workload Distribution (HWD)algorithm is tailored to distribute tasks evenly to the availableprocessors in an effort to balance the dynamic workloadthroughout the processors The algorithm is a two-stepprocess (1) probing individual processor buffers throughdedicated snooping channels that connects each processor
to the mapper and (2) mapping each scheduled task ona processor that has the lowest workload Workload is ameasure of the number of tasks and its respective executiontime in the processor bufferThus a processor having the leastnumber of tasks and respective execution time in its bufferhas the lowest workload therefore themapper will assign thenext scheduled task to this processor
HWD Mapping Algorithm Let 1198751 1198752sdot sdot sdot 119875119872 be a set of
processors let 1198711 1198712sdot sdot sdot 119871119872 be the dynamic task workloads
defined by number of tasks on respective processor buffersand let119873 be the number of processors Let 119879
1 1198792sdot sdot sdot 119879119873 be a
set of119872 tasks and the symbol ldquorarr rdquo denotes ldquomappingrdquoThen
A task 119879119896⟨119879release-time 119879exec-time 119879deadline⟩ 997888rarr 119875
119894
iff 119871119894lt 119871119895
forall [119871119894 119871119895] isin 119871
1 1198712sdot sdot sdot 119871119873
(16)
where 119875119894isin 1198751 1198752sdot sdot sdot 119875119872 and 119879
119896isin 1198791 1198792sdot sdot sdot 119879119873 such that
(119890119896+ 119905119896le 119889119896)
This approach has three advantages (1) it minimizesthe chance for buffer overflow (2) the task waiting time inprocessor buffer is reduced and (3) utilization is increasedbecause idle processors will be assigned scheduled tasks
43 Fault-Tolerant Methodology System designs often haveflaws that cannot be identified at design time It is almostimpossible to anticipate all faulty scenarios beforehandbecause processor failure may occur due to unexpectedruntime errors Real-time systems are critically affected if nomeans of fault tolerance scheme is implemented Failure toemploy fault detection and recovery strategies is often unaf-fordable in critical mission systems because the error maylead to possible data discrepancies and deadline violation
Processor failure introduces inevitable overall perfor-mance degradation due to (1) the reduced computing powerof the system and (2) the overhead involved in applying thefault recovery schemes Recovery procedures involve trackingthe task execution history and reconfiguring the systemby using the available processors This enables applicationprocessing to resume when the execution was terminatedDuring processor failure application processing is temporar-ily suspended and error recovery procedures are appliedbefore application processing is resumed
Fault-TolerantModelFaultmodeling can have several dimen-sions that define the fault occurring time the fault durationlocation of failure and so forth The proposed frameworkadopts the following fault modeling parameters
(1) It is assumed that the processor failure is permanentThus fault duration time 119905FD is infinite (119905FD = infin)During failure the address of the failed processor iscompletely removed from the mapper address table
(2) The location specifies where the failure occurred Fortile and torus topology location is represented in two-dimensional coordinate addresses
(3) During task processing any processors may fail atany time instance Consequently time of failure ismodeled as a random time instance
10 VLSI Design
In the event of failure the following procedures areexecuted
(1) Themapper removes the failed processor ID from theaddress table
(2) Tasks that are scheduled or mapped but not dis-patched have to be rescheduled and remapped Therespective new task release time and task address bothhave to be done again This is because the executioninstance of a task depends on the finish time ofits predecessor task which may possibly have beensuspended in the failed processor
(3) Tasks that are already dispatched to the failed proces-sor can be either (1) in the processorrsquos buffer or (2)in the middle of execution when the failure occurredThese tasks have to be migrated back to the mapperand their respective rescheduling and remapping haveto be done The scheduler can perform task schedul-ing concurrently when the nonfaulty processors areexecuting their respective tasks
(4) Tasks that are dispatched to other nonfailed proces-sors are not affected
Due to the dynamic property of the mapper and the fault-tolerant implementation the cost incurred during the eventof processor failure is minimal overhead incurred is only25 of the total execution time of the task The only penaltyincurred during processor failure is the cost due to taskmigration and the respective rerescheduling and remappingprocedures
5 Experimental Setup
The heterogeneous MpSoC framework developed in thiswork was developed using C++ and SystemC programminglanguage The architectural components such as processingelements (PEs) memory elements routers and networkinterfaces are developed using SystemC language and providecycle accurate simulations The processing elements areimplemented as a simple 32-bit processor that performssimple logic and arithmetic operations The heterogeneousPE structure in our MpSoC is implemented by altering thetype of operation and the execution times of the tasks eachPE can execute The routers implementations consist of aswitching matrix with input port buffers The tasks and datawithin PEs are transmitted using a data-serializing moduleof the PE A typical data transmitted within PEs consists oftask commands task data (if any) and the destination PEIDs (addresses) The data is propagated through the MpSoCsystem using the119883119884 routing algorithm
The scheduling and mapping algorithm are implementedusing C++ language and are interfaced with the SystemCarchitecture implementations The application in this workis considered as a task graph Each task graph consists ofprocessor operations their execution time communicationcost and deadline The application as a whole also has adeadline The scheduling algorithm parses the application(task graph) and assigns start times for the tasks on the
processors based on the set of optimization goals describedin the proposed performance driven scheduling algorithmThe scheduled tasks aremapped to their respective processorsin the MpSoC system based on the proposed homogenousworkload-mapping algorithm The tasksrsquo information com-prising of the task operations task data destination PEs(pathaddress of successor PEs) are assembled and forwardedto the initial PE by the dispatcher module The performanceevaluation module or the monitor module records cycleaccurate timing signals in the architecture during tasksexecution and communication
During the simulation of fault-tolerant scenario themonitor module triggers a PE failure event at a predefinedtime instance The dispatcher is informed of the PE failureand based on the mapper table and the current processingtask and the tasks in the buffer of the failed PE are determinedAn updated task graph is constructed and scheduling andmapping on the remaining unexecuted tasks are performedTasks currently executing on the PEs are undisturbed Thereassigned tasks are inserted in the PE buffers to satisfy thedeadlines
The implemented MpSoC system has been evaluatedextensively by modifying the architecture and topology Thesystemwas evaluated using a set of synthetic task graphs with50ndash3000 tasksThe architectural modifications for evaluatingthe MpSoC include change in type of PEs in the systemmesh and torus topology variations and the number of PEsin the system (9 16 32) The MpSoC system has been usedto evaluate the proposed scheduling mapping and fault-tolerant algorithms and compared with respective classicalalgorithms The performance of the proposed algorithmsalong with variation in architecture and topology have beenevaluated and presented The performance metrics consid-ered in this work include processor throughput processorutilization processor execution timetask and powertaskbuffers utilization and port utilization Detailed summary ofthe results and its significance are shown in Section 6
6 Simulation Results and Analysis
For evaluation of the proposed framework to explore designfeatures variations in scheduling mapping and fault tolerantalgorithms have been considered The application modeladapted is similar to the standard task graph (STG) [50 51]and E3S benchmark suite [54] which contains random set ofbenchmarks and application-specific benchmarks The sim-ulation was conducted with many STG benchmarks havingtask sizes 50 through 3000 The task graph is characterizedby the number of tasks dependencies of tasks task size(code size) communication cost (latency for interprocessortransfer) and application deadline The processor architec-ture model is derived from the E3S benchmark where eachprocessor is characterized by the type tasks it can executetask execution time task size (code size) and task powerTheprocessor also has general characteristics like type overheadcost (preemptive cost) task powertime and clock rate
The simulation results presented in this paper follow thefollowing legend 119883119884 plusmn 119885 where 119883 denotes 119877 or 119879 for
VLSI Design 11
Table 1 PE comparison
No of PEs AVG ETIMEPETASK (120583sec)
AVGUTLPE
AVGPWRPE(120583watts)
AVGPDPPE
PE no 9 498 048 18125 90748PE no 16 281 040 9834 27698PE no 25 189 035 6359 12006
Table 2 Comparison of task execution times processor utilizationand throughput of EDF-SA and PDS scheduling algorithms
ETIME (120583s) UTL THR (Bns) Std SA CostRAND-50
EDF-SA 20426 046 003 016PDS 22003 055 003 019
SPARSE-96EDF-SA 61651 044 002 015PDS 63789 049 002 017
RAND-100EDF-SA 41867 047 003 017PDS 43217 060 003 021
RAND-300EDF-SA 129945 049 003 017PDS 129695 056 003 019
FPPP-334EDF-SA 223836 042 002 015PDS 233736 047 002 016
RAND-500EDF-SA 143279 048 002 016PDS 212533 066 003 023
RAND-1000EDF-SA 416373 052 003 018PDS 432458 058 003 020
torus or tile topology 119884 denotes 119864 or 119878 for EDF-SA or PDscheduling algorithm + or minus for presence or absence of faulttolerance algorithm and 119885 denotes the number of PEs in theMpSoC system Performance evaluations on architecture andtopological variations were performed but are not included inthis paper Only performance results related to the proposedalgorithms are presented
61 Simulation Scenarios To demonstrate the capabilities ofthe proposed framework and the algorithms we performedseveral simulations on task graph sets and evaluated theireffectiveness over the following design abstractions
(i) Architectural architecture-based evaluation empha-sizes the effect of different PEs in the MpSoC frame-work Current implementation of our frameworkconsists of processors of the same architecture thatcan execute various tasks that is each processor hasa different set of tasks they can execute The MpSoC
Table 3 Comparison of HWD and next available and randommapping algorithms (simulation TS-9)
Mapping Random HWD NXT AVLBLAVG ETIME 141746 139467 13825AVG UTL 048 059 059AVG THR 002 002 002AVG PRT 108 107 108AVG PWR 599503 579969 57005AVG BFR 5 4 6
architecture was modified by changing the number ofPEs the types of PEs and topology It is importantto consider the effect of topology in architectureevaluation because the topology of the MpSoC alsodictates the performance of the individual PEs Theeffect of such architecture changes is measured interms of average execution timePEtask (ETIME) in120583sec average PE utilization (UTL) powertask of PEs(PWR) in 120583-Watts and power delay product (PDP)which are shown in Table 1
(ii) Scheduling evaluation of scheduling algorithms overvarious MpSoC architectures was conducted Per-formance of earliest deadline first based simulatedannealing (EDF-SA) and the new performance driven(PD) algorithms are compared (Table 2) Perfor-mance metrics for evaluating scheduling algorithmsare the same as that of architecture evaluations Alsothe standardized SA costs are shown
(iii) Mapping evaluation of mapping algorithms overvarious MpSoC architectures was conducted usingperformance driven scheduling policy Performanceof the proposed HWD Next Available (NA) andrandom mapping algorithms is compared as shownin Table 3
(iv) Fault Tolerant-evaluation and comparison of fault-tolerant (FT) and nonfault-tolerant (NFT) imple-mentation over various MpSoC architectures wereconducted and results for two test cases are shownin Tables 4 and 5
62 Simulation Results and Explanation Table 1 shows theaverage performance metrics obtained for various architec-tural variations possible in the developedMpSoC frameworkThe architectural variations include the type of topology(tile or torus) scheduling algorithm (EDF-SA or PDS)mapping algorithm (HWD) fault-tolerant scheme (NFT orFT) and the number of PEs Table 2 specifically compares theperformance of the EDF-SA and PDS scheduling algorithmComparison results on total execution time (ECT) in 120583secaverage processor utilization and average throughput inbytes120583sec are presented Other metrics that have less signif-icance have been omitted Also comparisons between EDF-SA and PDS algorithms for processor utilization throughputand buffer usage evaluations across various architectural
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

VLSI Design 9
procedure attempts to find which particular assignment oftasks would lead to effective lower power and faster executiontimeDuring task placement themapper considers allocatingany two tasks that exchange data more frequently as closeto each other as possible Placement of communicating tasksto adjacent or nearby processors reduces the communicationlatency switch traffic and power dissipation
Static mapping assigns a particular task to a predeter-mined processing element offline regardless of the dynamicstate of the system components This however does not sat-isfy the MpSoCs requirement because processing tasks on aheterogeneous architecture introduces workload irregularityon system resources (PEs) Irregular workload distributionis a design issue that degrades the utilization of system Toovercome this problem tasks should bemapped dynamicallybased on the dynamic workload on the processors Thenumber of tasks in the processorsrsquo local memory measuresthe processor workload
The dynamic mapper in the proposed framework per-forms the task allocation as per the configured policy Inorder to take heterogeneity of processors into considerationadditional power cost and execution latency cost have beenintroduced This emphasizes the fact that processing a par-ticular task on different types of processors incurs differentcost (power consumption and execution time) Efficient andoptimized heterogeneous mapping algorithms are tailored tominimize this additional cost
In the framework various task allocation heuristics wereimplemented Given a scheduled task the task mappingfollows one of the below policies
(1) Next Available Mapping (NXT AVLB) In the NextAvailable Mapping policy a scheduled task 119879
119894is
mapped on processor 119875119894 followed by the mapping of
the next scheduled task119879119894+1
on processor119875119895 provided
119875119894and 119875
119895are neighbors to each other as defined by
the topology This policy assigns tasks on successiveprocessor sequentially but does not consider theheterogeneity of the tasks nor the processorworkload
(2) Homogenous Workload Distribution Mapping(HWD) HWD considers the workload on eachprocessor and maps a scheduled task on a processorthat has the minimum workload
(3) Random mapping (RANDOM) rRandom task allo-cation is used by the PD algorithm to distribute theworkload randomly throughout the available proces-sors
HWD Mapping Approach Minimizing the idle time ofeach processor or maximizing processing time improvesprocessor utilization To reduce idle time tasks shouldbe distributed evenly throughout the available processorsThe proposed Homogenous Workload Distribution (HWD)algorithm is tailored to distribute tasks evenly to the availableprocessors in an effort to balance the dynamic workloadthroughout the processors The algorithm is a two-stepprocess (1) probing individual processor buffers throughdedicated snooping channels that connects each processor
to the mapper and (2) mapping each scheduled task ona processor that has the lowest workload Workload is ameasure of the number of tasks and its respective executiontime in the processor bufferThus a processor having the leastnumber of tasks and respective execution time in its bufferhas the lowest workload therefore themapper will assign thenext scheduled task to this processor
HWD Mapping Algorithm Let 1198751 1198752sdot sdot sdot 119875119872 be a set of
processors let 1198711 1198712sdot sdot sdot 119871119872 be the dynamic task workloads
defined by number of tasks on respective processor buffersand let119873 be the number of processors Let 119879
1 1198792sdot sdot sdot 119879119873 be a
set of119872 tasks and the symbol ldquorarr rdquo denotes ldquomappingrdquoThen
A task 119879119896⟨119879release-time 119879exec-time 119879deadline⟩ 997888rarr 119875
119894
iff 119871119894lt 119871119895
forall [119871119894 119871119895] isin 119871
1 1198712sdot sdot sdot 119871119873
(16)
where 119875119894isin 1198751 1198752sdot sdot sdot 119875119872 and 119879
119896isin 1198791 1198792sdot sdot sdot 119879119873 such that
(119890119896+ 119905119896le 119889119896)
This approach has three advantages (1) it minimizesthe chance for buffer overflow (2) the task waiting time inprocessor buffer is reduced and (3) utilization is increasedbecause idle processors will be assigned scheduled tasks
43 Fault-Tolerant Methodology System designs often haveflaws that cannot be identified at design time It is almostimpossible to anticipate all faulty scenarios beforehandbecause processor failure may occur due to unexpectedruntime errors Real-time systems are critically affected if nomeans of fault tolerance scheme is implemented Failure toemploy fault detection and recovery strategies is often unaf-fordable in critical mission systems because the error maylead to possible data discrepancies and deadline violation
Processor failure introduces inevitable overall perfor-mance degradation due to (1) the reduced computing powerof the system and (2) the overhead involved in applying thefault recovery schemes Recovery procedures involve trackingthe task execution history and reconfiguring the systemby using the available processors This enables applicationprocessing to resume when the execution was terminatedDuring processor failure application processing is temporar-ily suspended and error recovery procedures are appliedbefore application processing is resumed
Fault-TolerantModelFaultmodeling can have several dimen-sions that define the fault occurring time the fault durationlocation of failure and so forth The proposed frameworkadopts the following fault modeling parameters
(1) It is assumed that the processor failure is permanentThus fault duration time 119905FD is infinite (119905FD = infin)During failure the address of the failed processor iscompletely removed from the mapper address table
(2) The location specifies where the failure occurred Fortile and torus topology location is represented in two-dimensional coordinate addresses
(3) During task processing any processors may fail atany time instance Consequently time of failure ismodeled as a random time instance
10 VLSI Design
In the event of failure the following procedures areexecuted
(1) Themapper removes the failed processor ID from theaddress table
(2) Tasks that are scheduled or mapped but not dis-patched have to be rescheduled and remapped Therespective new task release time and task address bothhave to be done again This is because the executioninstance of a task depends on the finish time ofits predecessor task which may possibly have beensuspended in the failed processor
(3) Tasks that are already dispatched to the failed proces-sor can be either (1) in the processorrsquos buffer or (2)in the middle of execution when the failure occurredThese tasks have to be migrated back to the mapperand their respective rescheduling and remapping haveto be done The scheduler can perform task schedul-ing concurrently when the nonfaulty processors areexecuting their respective tasks
(4) Tasks that are dispatched to other nonfailed proces-sors are not affected
Due to the dynamic property of the mapper and the fault-tolerant implementation the cost incurred during the eventof processor failure is minimal overhead incurred is only25 of the total execution time of the task The only penaltyincurred during processor failure is the cost due to taskmigration and the respective rerescheduling and remappingprocedures
5 Experimental Setup
The heterogeneous MpSoC framework developed in thiswork was developed using C++ and SystemC programminglanguage The architectural components such as processingelements (PEs) memory elements routers and networkinterfaces are developed using SystemC language and providecycle accurate simulations The processing elements areimplemented as a simple 32-bit processor that performssimple logic and arithmetic operations The heterogeneousPE structure in our MpSoC is implemented by altering thetype of operation and the execution times of the tasks eachPE can execute The routers implementations consist of aswitching matrix with input port buffers The tasks and datawithin PEs are transmitted using a data-serializing moduleof the PE A typical data transmitted within PEs consists oftask commands task data (if any) and the destination PEIDs (addresses) The data is propagated through the MpSoCsystem using the119883119884 routing algorithm
The scheduling and mapping algorithm are implementedusing C++ language and are interfaced with the SystemCarchitecture implementations The application in this workis considered as a task graph Each task graph consists ofprocessor operations their execution time communicationcost and deadline The application as a whole also has adeadline The scheduling algorithm parses the application(task graph) and assigns start times for the tasks on the
processors based on the set of optimization goals describedin the proposed performance driven scheduling algorithmThe scheduled tasks aremapped to their respective processorsin the MpSoC system based on the proposed homogenousworkload-mapping algorithm The tasksrsquo information com-prising of the task operations task data destination PEs(pathaddress of successor PEs) are assembled and forwardedto the initial PE by the dispatcher module The performanceevaluation module or the monitor module records cycleaccurate timing signals in the architecture during tasksexecution and communication
During the simulation of fault-tolerant scenario themonitor module triggers a PE failure event at a predefinedtime instance The dispatcher is informed of the PE failureand based on the mapper table and the current processingtask and the tasks in the buffer of the failed PE are determinedAn updated task graph is constructed and scheduling andmapping on the remaining unexecuted tasks are performedTasks currently executing on the PEs are undisturbed Thereassigned tasks are inserted in the PE buffers to satisfy thedeadlines
The implemented MpSoC system has been evaluatedextensively by modifying the architecture and topology Thesystemwas evaluated using a set of synthetic task graphs with50ndash3000 tasksThe architectural modifications for evaluatingthe MpSoC include change in type of PEs in the systemmesh and torus topology variations and the number of PEsin the system (9 16 32) The MpSoC system has been usedto evaluate the proposed scheduling mapping and fault-tolerant algorithms and compared with respective classicalalgorithms The performance of the proposed algorithmsalong with variation in architecture and topology have beenevaluated and presented The performance metrics consid-ered in this work include processor throughput processorutilization processor execution timetask and powertaskbuffers utilization and port utilization Detailed summary ofthe results and its significance are shown in Section 6
6 Simulation Results and Analysis
For evaluation of the proposed framework to explore designfeatures variations in scheduling mapping and fault tolerantalgorithms have been considered The application modeladapted is similar to the standard task graph (STG) [50 51]and E3S benchmark suite [54] which contains random set ofbenchmarks and application-specific benchmarks The sim-ulation was conducted with many STG benchmarks havingtask sizes 50 through 3000 The task graph is characterizedby the number of tasks dependencies of tasks task size(code size) communication cost (latency for interprocessortransfer) and application deadline The processor architec-ture model is derived from the E3S benchmark where eachprocessor is characterized by the type tasks it can executetask execution time task size (code size) and task powerTheprocessor also has general characteristics like type overheadcost (preemptive cost) task powertime and clock rate
The simulation results presented in this paper follow thefollowing legend 119883119884 plusmn 119885 where 119883 denotes 119877 or 119879 for
VLSI Design 11
Table 1 PE comparison
No of PEs AVG ETIMEPETASK (120583sec)
AVGUTLPE
AVGPWRPE(120583watts)
AVGPDPPE
PE no 9 498 048 18125 90748PE no 16 281 040 9834 27698PE no 25 189 035 6359 12006
Table 2 Comparison of task execution times processor utilizationand throughput of EDF-SA and PDS scheduling algorithms
ETIME (120583s) UTL THR (Bns) Std SA CostRAND-50
EDF-SA 20426 046 003 016PDS 22003 055 003 019
SPARSE-96EDF-SA 61651 044 002 015PDS 63789 049 002 017
RAND-100EDF-SA 41867 047 003 017PDS 43217 060 003 021
RAND-300EDF-SA 129945 049 003 017PDS 129695 056 003 019
FPPP-334EDF-SA 223836 042 002 015PDS 233736 047 002 016
RAND-500EDF-SA 143279 048 002 016PDS 212533 066 003 023
RAND-1000EDF-SA 416373 052 003 018PDS 432458 058 003 020
torus or tile topology 119884 denotes 119864 or 119878 for EDF-SA or PDscheduling algorithm + or minus for presence or absence of faulttolerance algorithm and 119885 denotes the number of PEs in theMpSoC system Performance evaluations on architecture andtopological variations were performed but are not included inthis paper Only performance results related to the proposedalgorithms are presented
61 Simulation Scenarios To demonstrate the capabilities ofthe proposed framework and the algorithms we performedseveral simulations on task graph sets and evaluated theireffectiveness over the following design abstractions
(i) Architectural architecture-based evaluation empha-sizes the effect of different PEs in the MpSoC frame-work Current implementation of our frameworkconsists of processors of the same architecture thatcan execute various tasks that is each processor hasa different set of tasks they can execute The MpSoC
Table 3 Comparison of HWD and next available and randommapping algorithms (simulation TS-9)
Mapping Random HWD NXT AVLBLAVG ETIME 141746 139467 13825AVG UTL 048 059 059AVG THR 002 002 002AVG PRT 108 107 108AVG PWR 599503 579969 57005AVG BFR 5 4 6
architecture was modified by changing the number ofPEs the types of PEs and topology It is importantto consider the effect of topology in architectureevaluation because the topology of the MpSoC alsodictates the performance of the individual PEs Theeffect of such architecture changes is measured interms of average execution timePEtask (ETIME) in120583sec average PE utilization (UTL) powertask of PEs(PWR) in 120583-Watts and power delay product (PDP)which are shown in Table 1
(ii) Scheduling evaluation of scheduling algorithms overvarious MpSoC architectures was conducted Per-formance of earliest deadline first based simulatedannealing (EDF-SA) and the new performance driven(PD) algorithms are compared (Table 2) Perfor-mance metrics for evaluating scheduling algorithmsare the same as that of architecture evaluations Alsothe standardized SA costs are shown
(iii) Mapping evaluation of mapping algorithms overvarious MpSoC architectures was conducted usingperformance driven scheduling policy Performanceof the proposed HWD Next Available (NA) andrandom mapping algorithms is compared as shownin Table 3
(iv) Fault Tolerant-evaluation and comparison of fault-tolerant (FT) and nonfault-tolerant (NFT) imple-mentation over various MpSoC architectures wereconducted and results for two test cases are shownin Tables 4 and 5
62 Simulation Results and Explanation Table 1 shows theaverage performance metrics obtained for various architec-tural variations possible in the developedMpSoC frameworkThe architectural variations include the type of topology(tile or torus) scheduling algorithm (EDF-SA or PDS)mapping algorithm (HWD) fault-tolerant scheme (NFT orFT) and the number of PEs Table 2 specifically compares theperformance of the EDF-SA and PDS scheduling algorithmComparison results on total execution time (ECT) in 120583secaverage processor utilization and average throughput inbytes120583sec are presented Other metrics that have less signif-icance have been omitted Also comparisons between EDF-SA and PDS algorithms for processor utilization throughputand buffer usage evaluations across various architectural
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

10 VLSI Design
In the event of failure the following procedures areexecuted
(1) Themapper removes the failed processor ID from theaddress table
(2) Tasks that are scheduled or mapped but not dis-patched have to be rescheduled and remapped Therespective new task release time and task address bothhave to be done again This is because the executioninstance of a task depends on the finish time ofits predecessor task which may possibly have beensuspended in the failed processor
(3) Tasks that are already dispatched to the failed proces-sor can be either (1) in the processorrsquos buffer or (2)in the middle of execution when the failure occurredThese tasks have to be migrated back to the mapperand their respective rescheduling and remapping haveto be done The scheduler can perform task schedul-ing concurrently when the nonfaulty processors areexecuting their respective tasks
(4) Tasks that are dispatched to other nonfailed proces-sors are not affected
Due to the dynamic property of the mapper and the fault-tolerant implementation the cost incurred during the eventof processor failure is minimal overhead incurred is only25 of the total execution time of the task The only penaltyincurred during processor failure is the cost due to taskmigration and the respective rerescheduling and remappingprocedures
5 Experimental Setup
The heterogeneous MpSoC framework developed in thiswork was developed using C++ and SystemC programminglanguage The architectural components such as processingelements (PEs) memory elements routers and networkinterfaces are developed using SystemC language and providecycle accurate simulations The processing elements areimplemented as a simple 32-bit processor that performssimple logic and arithmetic operations The heterogeneousPE structure in our MpSoC is implemented by altering thetype of operation and the execution times of the tasks eachPE can execute The routers implementations consist of aswitching matrix with input port buffers The tasks and datawithin PEs are transmitted using a data-serializing moduleof the PE A typical data transmitted within PEs consists oftask commands task data (if any) and the destination PEIDs (addresses) The data is propagated through the MpSoCsystem using the119883119884 routing algorithm
The scheduling and mapping algorithm are implementedusing C++ language and are interfaced with the SystemCarchitecture implementations The application in this workis considered as a task graph Each task graph consists ofprocessor operations their execution time communicationcost and deadline The application as a whole also has adeadline The scheduling algorithm parses the application(task graph) and assigns start times for the tasks on the
processors based on the set of optimization goals describedin the proposed performance driven scheduling algorithmThe scheduled tasks aremapped to their respective processorsin the MpSoC system based on the proposed homogenousworkload-mapping algorithm The tasksrsquo information com-prising of the task operations task data destination PEs(pathaddress of successor PEs) are assembled and forwardedto the initial PE by the dispatcher module The performanceevaluation module or the monitor module records cycleaccurate timing signals in the architecture during tasksexecution and communication
During the simulation of fault-tolerant scenario themonitor module triggers a PE failure event at a predefinedtime instance The dispatcher is informed of the PE failureand based on the mapper table and the current processingtask and the tasks in the buffer of the failed PE are determinedAn updated task graph is constructed and scheduling andmapping on the remaining unexecuted tasks are performedTasks currently executing on the PEs are undisturbed Thereassigned tasks are inserted in the PE buffers to satisfy thedeadlines
The implemented MpSoC system has been evaluatedextensively by modifying the architecture and topology Thesystemwas evaluated using a set of synthetic task graphs with50ndash3000 tasksThe architectural modifications for evaluatingthe MpSoC include change in type of PEs in the systemmesh and torus topology variations and the number of PEsin the system (9 16 32) The MpSoC system has been usedto evaluate the proposed scheduling mapping and fault-tolerant algorithms and compared with respective classicalalgorithms The performance of the proposed algorithmsalong with variation in architecture and topology have beenevaluated and presented The performance metrics consid-ered in this work include processor throughput processorutilization processor execution timetask and powertaskbuffers utilization and port utilization Detailed summary ofthe results and its significance are shown in Section 6
6 Simulation Results and Analysis
For evaluation of the proposed framework to explore designfeatures variations in scheduling mapping and fault tolerantalgorithms have been considered The application modeladapted is similar to the standard task graph (STG) [50 51]and E3S benchmark suite [54] which contains random set ofbenchmarks and application-specific benchmarks The sim-ulation was conducted with many STG benchmarks havingtask sizes 50 through 3000 The task graph is characterizedby the number of tasks dependencies of tasks task size(code size) communication cost (latency for interprocessortransfer) and application deadline The processor architec-ture model is derived from the E3S benchmark where eachprocessor is characterized by the type tasks it can executetask execution time task size (code size) and task powerTheprocessor also has general characteristics like type overheadcost (preemptive cost) task powertime and clock rate
The simulation results presented in this paper follow thefollowing legend 119883119884 plusmn 119885 where 119883 denotes 119877 or 119879 for
VLSI Design 11
Table 1 PE comparison
No of PEs AVG ETIMEPETASK (120583sec)
AVGUTLPE
AVGPWRPE(120583watts)
AVGPDPPE
PE no 9 498 048 18125 90748PE no 16 281 040 9834 27698PE no 25 189 035 6359 12006
Table 2 Comparison of task execution times processor utilizationand throughput of EDF-SA and PDS scheduling algorithms
ETIME (120583s) UTL THR (Bns) Std SA CostRAND-50
EDF-SA 20426 046 003 016PDS 22003 055 003 019
SPARSE-96EDF-SA 61651 044 002 015PDS 63789 049 002 017
RAND-100EDF-SA 41867 047 003 017PDS 43217 060 003 021
RAND-300EDF-SA 129945 049 003 017PDS 129695 056 003 019
FPPP-334EDF-SA 223836 042 002 015PDS 233736 047 002 016
RAND-500EDF-SA 143279 048 002 016PDS 212533 066 003 023
RAND-1000EDF-SA 416373 052 003 018PDS 432458 058 003 020
torus or tile topology 119884 denotes 119864 or 119878 for EDF-SA or PDscheduling algorithm + or minus for presence or absence of faulttolerance algorithm and 119885 denotes the number of PEs in theMpSoC system Performance evaluations on architecture andtopological variations were performed but are not included inthis paper Only performance results related to the proposedalgorithms are presented
61 Simulation Scenarios To demonstrate the capabilities ofthe proposed framework and the algorithms we performedseveral simulations on task graph sets and evaluated theireffectiveness over the following design abstractions
(i) Architectural architecture-based evaluation empha-sizes the effect of different PEs in the MpSoC frame-work Current implementation of our frameworkconsists of processors of the same architecture thatcan execute various tasks that is each processor hasa different set of tasks they can execute The MpSoC
Table 3 Comparison of HWD and next available and randommapping algorithms (simulation TS-9)
Mapping Random HWD NXT AVLBLAVG ETIME 141746 139467 13825AVG UTL 048 059 059AVG THR 002 002 002AVG PRT 108 107 108AVG PWR 599503 579969 57005AVG BFR 5 4 6
architecture was modified by changing the number ofPEs the types of PEs and topology It is importantto consider the effect of topology in architectureevaluation because the topology of the MpSoC alsodictates the performance of the individual PEs Theeffect of such architecture changes is measured interms of average execution timePEtask (ETIME) in120583sec average PE utilization (UTL) powertask of PEs(PWR) in 120583-Watts and power delay product (PDP)which are shown in Table 1
(ii) Scheduling evaluation of scheduling algorithms overvarious MpSoC architectures was conducted Per-formance of earliest deadline first based simulatedannealing (EDF-SA) and the new performance driven(PD) algorithms are compared (Table 2) Perfor-mance metrics for evaluating scheduling algorithmsare the same as that of architecture evaluations Alsothe standardized SA costs are shown
(iii) Mapping evaluation of mapping algorithms overvarious MpSoC architectures was conducted usingperformance driven scheduling policy Performanceof the proposed HWD Next Available (NA) andrandom mapping algorithms is compared as shownin Table 3
(iv) Fault Tolerant-evaluation and comparison of fault-tolerant (FT) and nonfault-tolerant (NFT) imple-mentation over various MpSoC architectures wereconducted and results for two test cases are shownin Tables 4 and 5
62 Simulation Results and Explanation Table 1 shows theaverage performance metrics obtained for various architec-tural variations possible in the developedMpSoC frameworkThe architectural variations include the type of topology(tile or torus) scheduling algorithm (EDF-SA or PDS)mapping algorithm (HWD) fault-tolerant scheme (NFT orFT) and the number of PEs Table 2 specifically compares theperformance of the EDF-SA and PDS scheduling algorithmComparison results on total execution time (ECT) in 120583secaverage processor utilization and average throughput inbytes120583sec are presented Other metrics that have less signif-icance have been omitted Also comparisons between EDF-SA and PDS algorithms for processor utilization throughputand buffer usage evaluations across various architectural
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of
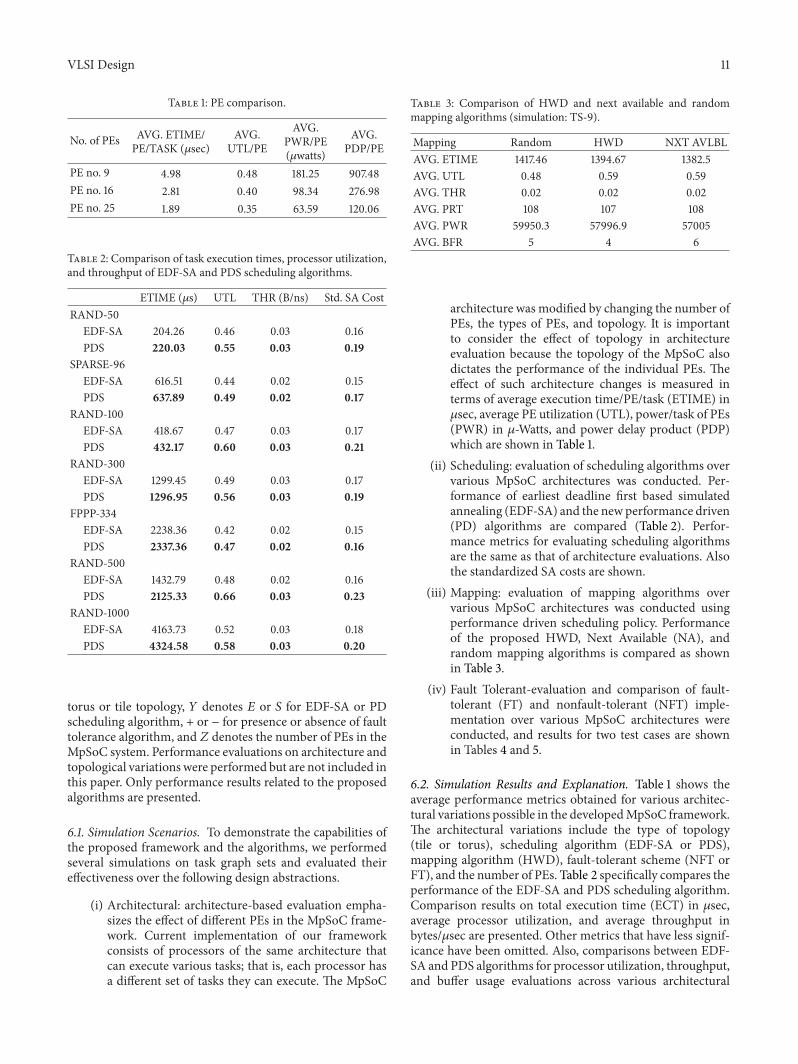
VLSI Design 11
Table 1 PE comparison
No of PEs AVG ETIMEPETASK (120583sec)
AVGUTLPE
AVGPWRPE(120583watts)
AVGPDPPE
PE no 9 498 048 18125 90748PE no 16 281 040 9834 27698PE no 25 189 035 6359 12006
Table 2 Comparison of task execution times processor utilizationand throughput of EDF-SA and PDS scheduling algorithms
ETIME (120583s) UTL THR (Bns) Std SA CostRAND-50
EDF-SA 20426 046 003 016PDS 22003 055 003 019
SPARSE-96EDF-SA 61651 044 002 015PDS 63789 049 002 017
RAND-100EDF-SA 41867 047 003 017PDS 43217 060 003 021
RAND-300EDF-SA 129945 049 003 017PDS 129695 056 003 019
FPPP-334EDF-SA 223836 042 002 015PDS 233736 047 002 016
RAND-500EDF-SA 143279 048 002 016PDS 212533 066 003 023
RAND-1000EDF-SA 416373 052 003 018PDS 432458 058 003 020
torus or tile topology 119884 denotes 119864 or 119878 for EDF-SA or PDscheduling algorithm + or minus for presence or absence of faulttolerance algorithm and 119885 denotes the number of PEs in theMpSoC system Performance evaluations on architecture andtopological variations were performed but are not included inthis paper Only performance results related to the proposedalgorithms are presented
61 Simulation Scenarios To demonstrate the capabilities ofthe proposed framework and the algorithms we performedseveral simulations on task graph sets and evaluated theireffectiveness over the following design abstractions
(i) Architectural architecture-based evaluation empha-sizes the effect of different PEs in the MpSoC frame-work Current implementation of our frameworkconsists of processors of the same architecture thatcan execute various tasks that is each processor hasa different set of tasks they can execute The MpSoC
Table 3 Comparison of HWD and next available and randommapping algorithms (simulation TS-9)
Mapping Random HWD NXT AVLBLAVG ETIME 141746 139467 13825AVG UTL 048 059 059AVG THR 002 002 002AVG PRT 108 107 108AVG PWR 599503 579969 57005AVG BFR 5 4 6
architecture was modified by changing the number ofPEs the types of PEs and topology It is importantto consider the effect of topology in architectureevaluation because the topology of the MpSoC alsodictates the performance of the individual PEs Theeffect of such architecture changes is measured interms of average execution timePEtask (ETIME) in120583sec average PE utilization (UTL) powertask of PEs(PWR) in 120583-Watts and power delay product (PDP)which are shown in Table 1
(ii) Scheduling evaluation of scheduling algorithms overvarious MpSoC architectures was conducted Per-formance of earliest deadline first based simulatedannealing (EDF-SA) and the new performance driven(PD) algorithms are compared (Table 2) Perfor-mance metrics for evaluating scheduling algorithmsare the same as that of architecture evaluations Alsothe standardized SA costs are shown
(iii) Mapping evaluation of mapping algorithms overvarious MpSoC architectures was conducted usingperformance driven scheduling policy Performanceof the proposed HWD Next Available (NA) andrandom mapping algorithms is compared as shownin Table 3
(iv) Fault Tolerant-evaluation and comparison of fault-tolerant (FT) and nonfault-tolerant (NFT) imple-mentation over various MpSoC architectures wereconducted and results for two test cases are shownin Tables 4 and 5
62 Simulation Results and Explanation Table 1 shows theaverage performance metrics obtained for various architec-tural variations possible in the developedMpSoC frameworkThe architectural variations include the type of topology(tile or torus) scheduling algorithm (EDF-SA or PDS)mapping algorithm (HWD) fault-tolerant scheme (NFT orFT) and the number of PEs Table 2 specifically compares theperformance of the EDF-SA and PDS scheduling algorithmComparison results on total execution time (ECT) in 120583secaverage processor utilization and average throughput inbytes120583sec are presented Other metrics that have less signif-icance have been omitted Also comparisons between EDF-SA and PDS algorithms for processor utilization throughputand buffer usage evaluations across various architectural
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of
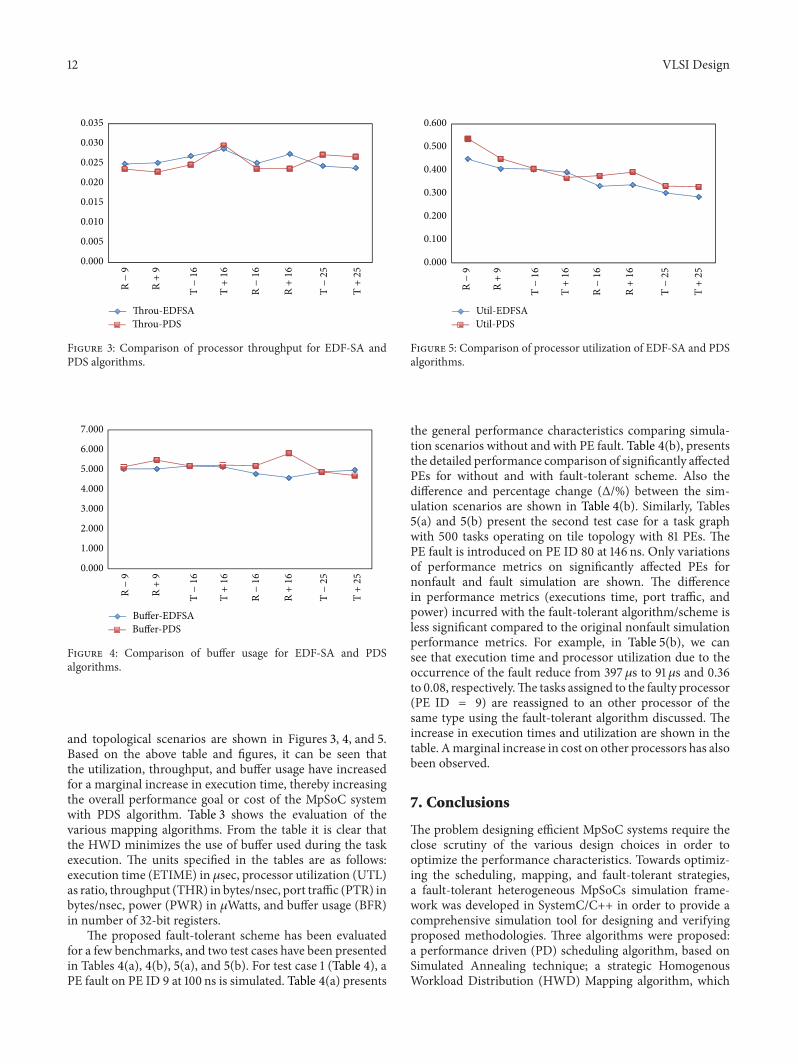
12 VLSI Design
0000
0005
0010
0015
0020
0025
0030
0035
Throu-EDFSAThrou-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25Figure 3 Comparison of processor throughput for EDF-SA andPDS algorithms
0000
1000
2000
3000
4000
5000
6000
7000
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Buffer-EDFSABuffer-PDS
Figure 4 Comparison of buffer usage for EDF-SA and PDSalgorithms
and topological scenarios are shown in Figures 3 4 and 5Based on the above table and figures it can be seen thatthe utilization throughput and buffer usage have increasedfor a marginal increase in execution time thereby increasingthe overall performance goal or cost of the MpSoC systemwith PDS algorithm Table 3 shows the evaluation of thevarious mapping algorithms From the table it is clear thatthe HWD minimizes the use of buffer used during the taskexecution The units specified in the tables are as followsexecution time (ETIME) in 120583sec processor utilization (UTL)as ratio throughput (THR) in bytesnsec port traffic (PTR) inbytesnsec power (PWR) in 120583Watts and buffer usage (BFR)in number of 32-bit registers
The proposed fault-tolerant scheme has been evaluatedfor a few benchmarks and two test cases have been presentedin Tables 4(a) 4(b) 5(a) and 5(b) For test case 1 (Table 4) aPE fault on PE ID 9 at 100 ns is simulated Table 4(a) presents
0000
0100
0200
0300
0400
0500
0600
Util-EDFSAUtil-PDS
R minus
9
R +
9
T minus
16
T +
16
R minus
16
R +
16
T minus
25
T +
25
Figure 5 Comparison of processor utilization of EDF-SA and PDSalgorithms
the general performance characteristics comparing simula-tion scenarios without and with PE fault Table 4(b) presentsthe detailed performance comparison of significantly affectedPEs for without and with fault-tolerant scheme Also thedifference and percentage change (Δ) between the sim-ulation scenarios are shown in Table 4(b) Similarly Tables5(a) and 5(b) present the second test case for a task graphwith 500 tasks operating on tile topology with 81 PEs ThePE fault is introduced on PE ID 80 at 146 ns Only variationsof performance metrics on significantly affected PEs fornonfault and fault simulation are shown The differencein performance metrics (executions time port traffic andpower) incurred with the fault-tolerant algorithmscheme isless significant compared to the original nonfault simulationperformance metrics For example in Table 5(b) we cansee that execution time and processor utilization due to theoccurrence of the fault reduce from 397120583s to 91 120583s and 036to 008 respectivelyThe tasks assigned to the faulty processor(PE ID = 9) are reassigned to an other processor of thesame type using the fault-tolerant algorithm discussed Theincrease in execution times and utilization are shown in thetable Amarginal increase in cost on other processors has alsobeen observed
7 Conclusions
The problem designing efficient MpSoC systems require theclose scrutiny of the various design choices in order tooptimize the performance characteristics Towards optimiz-ing the scheduling mapping and fault-tolerant strategiesa fault-tolerant heterogeneous MpSoCs simulation frame-work was developed in SystemCC++ in order to provide acomprehensive simulation tool for designing and verifyingproposed methodologies Three algorithms were proposeda performance driven (PD) scheduling algorithm based onSimulated Annealing technique a strategic HomogenousWorkload Distribution (HWD) Mapping algorithm which
VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

VLSI Design 13
Table 4 Test case no 1 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE types
RAND 0000 500 81 8
Schedule Mapping Topology Fault mode
EDF-SA HWD TILE ON
Fault PE ID 80 146 120583sec
WO fault Wfault DIFF
AVG ETIME 63559 63826 minus267
AVG UTL 025 025 000
AVG THR 002 002 000
AVG PRT 15400 15400 000
AVG PWR 2606700 2612900 minus6200
AVG BFR 479 490 minus011
MAX EXCT 86540 87568 minus1028
TOTAL EXCT 5148300 5169896 minus21596
TOTAL PWR 211141790 211641310 minus499520
TOTAL BFR 38800 39700 minus900
(b)
PE ID ETIME UTL THR PRT PWR BFR
1 597864664(Δ48848)
024026(Δ0028)
002002(Δ00)
12461300(Δ544)
287849307437(Δ195887)
95(Δminus4minus44)
2 693274774(Δ54548)
02803(Δ0028)
002002(Δ00)
12561290(Δ343)
339391361041(Δ21656)
56(Δ120)
13 538660329(Δ646912)
021024(Δ00312)
002002(Δ0minus4)
12081282(Δ746)
227019259439(Δ324214)
84(Δminus4minus50)
30 434647851(Δ439110)
017019(Δ00210)
003003(Δ0minus2)
12011275(Δ746)
155633169416(Δ137839)
84(Δminus4minus50)
36 53660382(Δ678213)
021024(Δ00312)
002002(Δ0minus4)
11121211(Δ999)
200438235667(Δ3522918)
44(Δ00)
50 68988017(Δ111916)
027032(Δ00416)
002002(Δ00)
10481101(Δ535)
330685367479(Δ3679411)
76(Δminus1minus14)
56 634270519(Δ709911)
025028(Δ00311)
002002(Δ0minus3)
10311050(Δ192)
223309258826(Δ3551716)
74(Δminus3minus43)
64 735880451(Δ68719)
029032(Δ0039)
002002(Δ0minus1)
9991116(Δ11712)
312089334909(Δ22827)
38(Δ5167)
72 807287568(Δ68488)
032035(Δ0038)
001001(Δ00)
881965(Δ8410)
348916371501(Δ225856)
74(Δminus3minus43)
80lowast 7721492(Δminus6228minus81)
031006(Δminus025minus81)
002001(Δ0minus14)
883290(Δminus593minus67)
3076396858(Δminus239059minus78)
32(Δminus1minus33)
considers dynamic processor workload and a fault-tolerant(FT) methodology to deliver a robust application processingsystem
Extensive simulation and evaluation of the frameworkas well as of the proposed and classical algorithms were
conducted using task graph benchmarks Simulation resultson all performance indices for different scenarios wereevaluated and discussed For the scheduling space the PDheuristic has shown better overall performance than EDFspecifically for small number of processors Fault-tolerant
14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

14 VLSI Design
Table 5 Test case no 2 for fault-tolerant simulation
(a)
Benchmark No of tasks No of PEs PE typesRAND 0000 100 36 6Scheduding Mapping Topology Fault modeEDF-SA HWD TILE ONFault PE ID 9 100120583sec
WO fault Wfault DIFFAVG ETIME 42316 42737 minus421
AVG UTL 038 039 000AVG THR 002 002 000AVG PRT 4100 4100 000AVG PWR 1855370 1873640 minus18270
AVG BFR 531 494 036
MAX EXCT 52060 53370 minus1310
TOTAL EXCT 1523360 1538516 minus15156
TOTAL PWR 66793279 67450941 minus657662
TOTAL BFR 19100 17800 1300
(b)
PE ID ETIME UTL THR PRT PWR BFR
3 37984254(Δ45612)
034038(Δ00412)
002002(Δ0minus1)
353367(Δ144)
173652193091(Δ1943911)
36(Δ3100)
5 441250974(Δ685416)
04046(Δ00615)
002002(Δ0minus4)
317324(Δ72)
205143243016(Δ3787318)
64(Δminus2minus33)
lowast9 397491(Δminus3064minus77)
036008(Δminus028minus77)
002002(Δ0minus3)
323180(Δminus143minus44)
157887299326(Δminus1279544minus81)
68(Δ233)
19 356840777(Δ509714)
032037(Δ00414)
002002(Δ0minus2)
278320(Δ4215)
156068171429(Δ1536110)
43(Δminus1minus25)
22 266232947(Δ632724)
02403(Δ00623)
003003(Δ0minus9)
269283(Δ145)
895162112699(Δ23182826)
93(Δminus6minus67)
23 354645578(Δ1011829)
032041(Δ00928)
002002(Δ0minus3)
270300(Δ3011)
12774174336(Δ4659636)
64(Δminus2minus33)
29 4625337(Δ71716)
042048(Δ00615)
002002(Δ0minus3)
224256(Δ3214)
200694237312(Δ3661818)
27(Δ5250)
evaluations showed that throughput buffers utilization exe-cution timetask and powertask factors are not significantlyaffected even after processor failure occurs A fault-tolerantscheme showed a small decrease in processor utilization Tiletopology showed better utilization and throughput howevertorus topology showed significantly better performance withrespect to execution timetask and powertask A number ofprocessor comparisons showed a proportional decrease inutilization execution time and power when the number ofprocessors was increased However throughput and bufferutilization remained almost identical Executing highly het-erogeneous tasks resulted in higher power and latency costs
Finally the proposed HWD algorithm evenly distributed theexecution workload among the processors which improvesthe processor overall performance specifically processor andbuffer utilization
The proposed algorithms on the MpSoC frameworkare currently evaluated only with synthetic task graphsWe would like to evaluate the algorithms for applicationbenchmarksThe PE implemented is a basic 32-bit behavioralprocessor We would like to implement industry standardprocessor like ARM or OpenRISC processors as our PEsAlso during scheduling communication cost values arederived from the execution time of the tasks Futurework that
VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

VLSI Design 15
considers actual communication cost needs to be exploredWork related to router and buffer failures will also beconsidered
References
[1] L Thiele I Bacivarov W Haid and K Huang ldquoMappingapplications to tiled multiprocessor embedded systemsrdquo inProceedings of the 7th International Conference on Application ofConcurrency to System Design (ACSD rsquo07) pp 29ndash40 July 2007
[2] C Neeb and N Wehn ldquoDesigning efficient irregular networksfor heterogeneous systems-on-chiprdquo Journal of Systems Archi-tecture vol 54 no 3-4 pp 384ndash396 2008
[3] S Manolache P Eles and Z Peng Real-Time Applications withStochastic Task Execution Times Analysis and OptimizationSpringer 1st edition 2007
[4] W Wolf High-Performance Embedded Computing Elsevier20072007
[5] A A Jerraya and W Wolf Multiprocessor Systems-on-ChipsMorgan Kaufmann Series in Systems on Silicon 2005
[6] J Nurmi H Tenhunen J Isoaho and A Jantsch Interconnect-Centric Design for Advanced SoC and NoC Kluwer Academic2004
[7] N D Thai ldquoReal-time scheduling in distributed systemsrdquo inProceedings of the IEEE International Conference on ParallelComputing in Electrical Engineering (PARELEC rsquo02) pp 165ndash170 2002
[8] R Marculescu U Y Ogras L S Peh N E Jerger and YHoskote ldquoOutstanding research problems in NoC design sys-tem microarchitecture and circuit perspectivesrdquo IEEE Trans-actions on Computer-Aided Design of Integrated Circuits andSystems vol 28 no 1 pp 3ndash21 2009
[9] G DeMicheli and L BeniniNetworks on Chips Technology andTools Systems on Silicon Academic Press 2006
[10] R Marculescu and P Bogdan ldquoThe Chip is the network towarda science of network-on-chip designrdquo Foundations and Trendsin Electronic Design Automation vol 2 no 4 pp 371ndash461 2007
[11] S Stuijk T BastenMGeilen AHGhamarian andBTheelenldquoResource-efficient routing and scheduling of time-constrainednetwork-on-chip communicationrdquo in Proceedings of the 9thEUROMICRO Conference on Digital System Design Architec-tures Methods and Tools (DSD rsquo06) pp 45ndash52 September 2006
[12] J Hu and R Marculescu ldquoCommunication and task schedulingof application-specific networks-on-chiprdquo Proceedings of theIEEE vol 152 no 5 pp 643ndash651 2005
[13] G Varatkar and R Marculescu ldquoCommunication-aware taskscheduling and voltage selection for total systems energyminimizationrdquo in International Conference on Computer AidedDesign (ICCAD rsquo03) pp 510ndash517 San Jose Calif USA Novem-ber 2003
[14] S Zhang K S Chatha and G Konjevod ldquoApproximationalgorithms for powerminimization of earliest deadline first andrate monotonic schedulesrdquo in Proceedings of the InternationalSymposium on Low Power Electronics and Design (ISLPED rsquo07)pp 225ndash230 August 2007
[15] F Gruian ldquoHard real-time scheduling for low-energy usingstochastic data and DVS processorsrdquo in Proceedings of the Inter-national Symposium on Low Electronics and Design (ISLPEDrsquo01) pp 46ndash51 August 2001
[16] M T Schmitz B M Al-Hashimi and P Eles ldquoIterative sched-ule optimization for voltage scalable distributed embedded
systemsrdquo Journal ACM Transactions on Embedded ComputingSystems vol 3 no 1 pp 182ndash217 2004
[17] D Shin and J Kim ldquoPower-aware communication optimizationfor networks-on-chips with voltage scalable linksrdquo in Interna-tional Conference on HardwareSoftware Codesign and SystemSynthesis (CODES+ISSS rsquo04) pp 170ndash175 September 2004
[18] E Carvalho N Calazans and F Moraes ldquoHeuristics fordynamic task mapping in NoC-based heterogeneous MPSoCsrdquoin Proceedings of the 18th IEEEIFIP International Workshop onRapid System Prototyping (RSP rsquo07) pp 34ndash40 May 2007
[19] H J AhnMH ChoM J Jung Y H Kim JM Kim and C HLee ldquoUbiFOS a small real-time operating system for embeddedsystemsrdquo ETRI Journal vol 29 no 3 pp 259ndash269 2007
[20] C Ostler and K S Chatha ldquoAn ILP formulation for system-level application mapping on network processor architecturesrdquoin Proceedings of the Design Automation and Test in EuropeConference and Exhibition (DATE rsquo07) pp 99ndash104 April 2007
[21] H M Harmanani and R Farah ldquoA method for efficient map-ping and reliable routing for NoC architectures with minimumbandwidth and areardquo in Proceedings of the Joint IEEE North-East Workshop on Circuits and Systems and TAISA Conference(NEWCAS-TAISA rsquo08) pp 29ndash32 June 2008
[22] J Hu and R Marculescu ldquoEnergy- and performance-awaremapping for regular NoC architecturesrdquo IEEE Transactions onComputer-Aided Design of Integrated Circuits and Systems vol24 no 4 pp 551ndash562 2005
[23] S Murali and G DeMicheli ldquoBandwidth-constrainedmappingof cores onto NoC architecturesrdquo in Proceedings of the DesignAutomation and Test in Europe Conference and Exhibition(DATE rsquo04) pp 896ndash901 February 2004
[24] P Poplavko T Basten M Bekooij J Van Meerbergen andB Mesman ldquoTask-level timing models for guaranteed per-formance in multiprocessor networks-on-chiprdquo in Proceedingsof the International Conference on Compilers Architectureand Synthesis for Embedded Systems (CASES rsquo03) pp 63ndash72November 2003
[25] G Ascia V Catania and M Palesi ldquoMulti-objective map-ping for mesh-based NoC architecturesrdquo in Proceedings ofthe 2nd IEEEACMIFIP International Conference on Hard-wareSoftware Codesign and System Synthesis (CODES+ISSSrsquo04) pp 182ndash187 September 2004
[26] K Srinivasan and K S Chatha ldquoA technique for low energymapping and routing in network-on-chip architecturesrdquo inProceedings of the International Symposium on Low PowerElectronics and Design pp 387ndash392 August 2005
[27] P Brucker Scheduling Algorithms 5th edition 2006[28] X Zhu andWQin ldquoPrototyping a fault-tolerantmultiprocessor
SoC with run-time fault recoveryrdquo in Proceedings of the 43rdAnnual Design Automation Conference (DAC rsquo06) pp 53ndash562006
[29] R Holsmark M Palesi and S Kumar ldquoDeadlock free routingalgorithms for mesh topology NoC systems with regionsrdquo inProceedings of the 9th EUROMICRO Conference on DigitalSystem Design Architectures Methods and Tools (DSD rsquo06) pp696ndash703 September 2006
[30] M Pirretti G M Link R R Brooks N Vijaykrishnan MKandemir and M J Irwin ldquoFault tolerant algorithms fornetwork-on-chip interconnectrdquo in Proceedings of the IEEEComputer Society Annual Symposium on VLSI Emerging Trendsin VLSI Systems Design pp 46ndash51 February 2004
16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

16 VLSI Design
[31] D Bertozzi L Benini and G De Micheli ldquoError con-trol schemes for on-chip communication links the energy-reliability tradeoffrdquo IEEE Transactions on Computer-AidedDesign of Integrated Circuits and Systems vol 24 no 6 pp 818ndash831 2005
[32] F Angiolini D Atienza SMurali L Benins andGDeMichelildquoReliability support for on-chip memories using Networks-on-Chiprdquo in Proceedings of the 24th International Conference onComputer Design (ICCD rsquo06) pp 389ndash396 October 2006
[33] V Puente J A Gregorio F Vallejo and R Beivide ldquoImmuneta cheap and robust fault-tolerant packet routing mechanismrdquoin Proceedings of the 31st Annual International Symposium onComputer Architecture pp 198ndash209 June 2004
[34] A Pullini F Angiolini D Bertozzi and L Benini ldquoFaulttolerance overhead in network-on-chip flow control schemesrdquoin proceedings of the 18th Symposium on Integrated Circuits andSystems Design (SBCCI rsquo05) pp 224ndash229 September 2005
[35] P Beerel and M E Roncken ldquoLow power and energy efficientasynchronous designrdquo Journal of Low Power Electronics vol 3no 3 pp 234ndash253 2007
[36] M Koibuchi H Matsutani H Amano and T M PinkstonldquoA lightweight fault-tolerant mechanism for network-on-chiprdquoin Proceedings of the 2nd IEEE International Symposium onNetworks-on-Chip (NOCS rsquo08) pp 13ndash22 April 2008
[37] P Bogdan T Dumitras and R Marculescu ldquoStochastic com-munication a new paradigm for fault-tolerant Networks-on-chiprdquo VLSI Design vol 2007 Article ID 95348 17 pages 2007
[38] S Murali and G De Micheli ldquoSUNMAP a tool for automatictopology selection and generation for NoCsrdquo in Proceedings ofthe 41st Design Automation Conference (DAC rsquo04) pp 914ndash919June 2004
[39] A Jalabert S Murali L Benini and G De Micheli ldquoXpipes-compiler a tool for instantiating application specific networkson chiprdquo in Proceedings of the Design Automation and Test inEurope Conference and Exhibition (DATE rsquo04) pp 884ndash889February 2004
[40] Z Lu R Thid M Millberg E Nilsson and A JantschldquoNNSE nostrumnetwork-on-chip simulation environmentrdquo inProceedings of the Swedish System-on-Chip Conference (SSoCCrsquo03) April 2005
[41] S Mahadevan M Storgaard J Madsen and K Virk ldquoARTSa system-level framework for modeling MPSoC componentsand analysis of their causalityrdquo in Proceedings of the 13th IEEEInternational Symposium on Modeling Analysis and Simulationof Computer and Telecommunications Systems (MASCOTS rsquo05)pp 480ndash483 September 2005
[42] P G Paulin C Pilkington and E Bensoudane ldquoStepNPa system-level exploration platform for network processorsrdquoIEEEDesign andTest of Computers vol 19 no 6 pp 17ndash26 2002
[43] N Genko D Atienza G De Micheli J M Mendias R Her-mida and F Catthoor ldquoA complete network-on-chip emulationframeworkrdquo in Proceedings of the Design Automation and Testin Europe (DATE rsquo05) pp 246ndash251 March 2005
[44] MCoppola S CurabaMDGrammatikakis GMaruccia andF Papariello ldquoOCCN a network-on-chip modeling and simu-lation frameworkrdquo in Proceedings of the Design Automation andTest in Europe Conference and Exhibition DATE 04 vol 3 pp174ndash179 February 2004
[45] C A Zeferino and A A Susin ldquoSoCIN a parametric and scal-able Network-on-Chiprdquo in Proceedings of the 16th Symposiumon Integrated Circuits and Systems Design pp 169ndash174 2003
[46] H Orsila E SalminenMHannikainen and T DHamalainenldquoEvaluation of heterogeneous multiprocessor architectures byenergy and performance optimizationrdquo in Proceedings of theInternational Symposium on System-on-Chip (SOC rsquo08) pp 1ndash6 November 2008
[47] H Orsila T Kangas E Salminen T D Hamalainen and MHannikainen ldquoAutomatedmemory-aware application distribu-tion for Multi-processor System-on-Chipsrdquo Journal of SystemsArchitecture vol 53 no 11 pp 795ndash815 2007
[48] F Paterna L Benini A Acquaviva F Papariello and G DesolildquoVariability-tolerant workload allocation for MPSoC energyminimization under real-time constraintsrdquo in Proceedings of theIEEEACMIFIP 7th Workshop on Embedded Systems for Real-Time Multimedia (ESTIMedia rsquo09) pp 134ndash142 October 2009
[49] R Teodorescu and J Torrellas ldquoVariation-aware applicationscheduling and power management for chip multiprocessorsrdquoACM SIGARCH Computer Architecture News vol 36 no 3 pp363ndash374 2008
[50] Z Lide L S Bai R P Dick S Li and R Joseph ldquoProcessvariation characterization of chip-levelmultiprocessorsrdquo inPro-ceedings of the 46th ACMIEEE Design Automation Conference(DAC rsquo09) pp 694ndash697 New York NY USA July 2009
[51] ldquoEmbedded System Synthesis Benchmarks Suite (E3S)rdquo httpziyangeecsumichedusimdickrpe3s
[52] C Ababei and R Katti ldquoAchieving network on chip fault toler-ance by adaptive remappingrdquo in Proceedings of the 23rd IEEEInternational Parallel and Distributed Processing Symposium(IPDPS rsquo09) pp 23ndash29 May 2009
[53] O Derin D Kabakci and L Fiorin ldquoOnline task remappingstrategies for fault-tolerant network-on-chip multiprocessorsrdquoin Proceedings of the 5th ACMIEEE International Symposiumon Networks-on-Chip (NOCS rsquo11) pp 129ndash136 May 2011
[54] ldquoStandard Task Graph (STG)rdquo httpwwwkasaharaelecwasedaacjpschedule
International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of

International Journal of
AerospaceEngineeringHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
RoboticsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Active and Passive Electronic Components
Control Scienceand Engineering
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
RotatingMachinery
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporation httpwwwhindawicom
Journal ofEngineeringVolume 2014
Submit your manuscripts athttpwwwhindawicom
VLSI Design
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Shock and Vibration
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Civil EngineeringAdvances in
Acoustics and VibrationAdvances in
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Electrical and Computer Engineering
Journal of
Advances inOptoElectronics
Hindawi Publishing Corporation httpwwwhindawicom
Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
SensorsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Modelling amp Simulation in EngineeringHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Chemical EngineeringInternational Journal of Antennas and
Propagation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Navigation and Observation
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
DistributedSensor Networks
International Journal of





























