Embed Size (px)
Citation preview

A
PROJECT REPORT ON
TIME TABLE GENERATOR
Submitted in partial fulfillment of the requirement of
UTTARAKHAND TECHNICAL UNIVERSITY, DEHRADUN
For the degree of
B.Tech
In
INFORMATION TECHNOLOGY
Submitted by Under the Guidance of
ANISHA VERMA(07070103014) Ms. ENA JAIN
HARSHITA RAI( 98070103123) ASSISTANT PROFESSOR
ANKITA ASWAL(07070104017) DEPARTMENT OF IT
DIVYA SHARMA(07070106019)
DEPARTMENT OF INFORMATION TECHNOLOGY
DEHRADUN INSTITUTE OF TECHNOLOGY
Dehradun
MAY 2011

A
Project report on
“TIME TABLE GENERATOR”
Submitted in partial fulfillment of the requirement of Uttarakhand Technical University, Dehradun for the degree of B.Tech.
In
Information Technology
Submitted by: - Under the Supervision of:-
Anisha Verma (07070103014) Ms. Ena Jain
Harshita Rai (98070103123 Assistant Professor
Ankita Aswal (07070104017) Department Of IT
Divya Sharma(07070106019)
Information Technology Department
DEHRADUN INSTITUTE OF TECHNOLOGY DEHRADUN
(UTTARAKHAND)
MAY 2011

ACKNOWLEDGEMENT
It is a great pleasure to have the opportunity to extend our heartiest felt gratitude to everybody who helped us throughout the course of this project.
It is distinct pleasure to express our deep sense of gratitude and indebtedness to our learned supervisor Ms. Ena Jain, Assistant Professor ,for their invaluable guidance, encouragement and patient reviews. With their continuous inspiration only, it becomes possible to complete this Project.
We would also like to take this opportunity to present our sincere regards to our teachers Mr. G. P Saroha(HOD), Mr. Vivudh Fore for their support and encouragement.
We would also like to thank all the faculty members of the Department for their support and encouragement.
ANISHA VERMA(07070103014)HARSHITA RAI(98070103123)ANKITA ASWAL(07070104017)DIVYA SHARMA(07070106019)

CERTIFICATE
This is to certify that Project Report entitled “TIME TABLE GENERATOR”
which is submitted by following students in partial fulfillment of the
requirement for the award of degree B.Tech. In Computer Science and
Engineering to Uttarakhand Technical University, Dehradun is a record of the
candidate’s own work carried out by them under my supervision. The matter
embodied in this report is original and has not been submitted for the award of
any other degree.
ANISHA VERMA 07070103014
HARSHITA RAI 98070103123
ANKITA ASWAL 07070104017
DIVYA SHARMA 07070106019
HOD: Supervisor/Guide:
Prof. G.P. Saroha Ms. ENA JAIN
Deptt. Of IT Deptt. Of CSE/IT
Dehradun Institute of Technology Dehradun Institute of Technology
Dehradun Dehradun

Table of Contents
1. ABSTRACT
2. INTRODUCTION
2.1 Brief Overview2.2 Objective of the Project
3. SYSTEM FEATURES
3.1 Feature & Scope of Old and New System3.2 Benefit of Proposed System3.3 Team Structure3.4 Hardware & Software Requirements
4. FEASIBILITY STUDY
4.1 Economic Feasibility
4.2 Technical Feasibility
4.3 Operational Feasibility
5. SYSTEM ANALYSIS & DATA FLOW DIAGRAMS
5.1 Existing System
5.2 Proposed System
5.3 Data Flow Diagram
6. SYSTEM DESIGN

6.1 System Flow Chart
6.2 Database Design
7. GRAPHICAL USER INTERFACE
8. SYSTEM TESTING
9. IMPLEMENTATION & TESTING
10. CONCLUSION
11. REFERENCES
12.APPENDIX

ABSTRACT
The project called Time Table Generator is a software for generating conflict free time
tables. This project is aimed at developing a Time Table Generator for Colleges. Colleges are
supposed to make time tables for each semester which used to be a very tedious and pain
staking job. Each teacher and Student is eligible for viewing his own timetable once they are
finalized for a given semester but they can not edit them.
This timetable generator is a semi automatic time table scheduling software. The manual
method of generating time table is very cumbersome and requires a lot of time and not even
completely removes all the conflicts . this project will be generating time tables that will
ensure the conlict free allocation of subjects assigned to various faculties.
This project will be suitable from the security point of view as well. The project differentiates
between users on the basis of their designation. Only the administrator will be having the
authority to create the timetable and faculties and students will only be viewing the time
table. We provide another facility to export the generated time table to ms excel from where
it can be printed.

SYSTEM FEATURES
FEATURE AND SCOPE OF OLD AND NEW SYSTEM
The manual method of generating time table is very cumbersome and requires a lot of time
and not even completely removes all the conflicts. This was about the old system. The new
system will be generating time tables semi-automatically that will ensure the conflict free
allocation of subjects assigned to various faculties.
The system includes the administrative login as well as the student login. Through the student
login we can only view the timetable which has been generated, whereas through the
administrative login, the faculty and the administrative block can login where the various
functions can be performed.
The faculty members are given a provision to register themselves and view the timetable. If
required, they can request for changing the lecture timings also.
The work of the administrative block is to keep a track of all the registered faculty members,
assign them the subjects, and generate the timetable for various sections of students.they also
accept the requests made by the faculty members and make changes as per the requirements
so that still there is no conflict in the timetable generated.
Since all the timetables are generated manually in the college, the college can use this project
to generate the timetable semi-automatically, by reducing the chances of conflicts of any
kind.

BENEFITS OF PROPOSED SYSTEM
The first and foremost benefit of the proposed system is that it is useful for the college
administrative authorities
The generation of the timetable will be fast.
The timetable will be accurate.
The system will provide error-free timetable without any conflicts.
The resources can be used else-where since the time table will be generated within
few seconds.
The faculty members have the provision of sending request for changing the time
table according to the timing that best suits them.
The proposed system is extensible; i.e. it can be extended to generate the time table
for as many branches as required.

FEASIBILITY STUDY
Feasibility studies aim to objectively and rationally uncover the strengths and weaknesses of
the existing business or proposed venture, opportunities and threats as presented by the
environment, the resources required to carry through, and ultimately the prospects for
success. In its simplest term, the two criteria to judge feasibility are cost required and value to
be attained. As such, a well-designed feasibility study should provide a historical background
of the business or project, description of the product or service, accounting statements, details
of the operations and management, marketing research and policies, financial data, legal
requirements and tax obligations. Generally, feasibility studies precede technical
development and project implementation.
Five common factors (TELOS)
Technology and system feasibility
The assessment is based on an outline design of system requirements in terms of Input,
Processes, Output, Fields, Programs, and Procedures. This can be quantified in terms of
volumes of data, trends, frequency of updating, etc. in order to estimate whether the new
system will perform adequately or not. Technological feasibility is carried out to determine
whether the company has the capability, in terms of software, hardware, personnel and
expertise, to handle the completion of the project when writing a feasibility report, the
following should be taken to consideration:
A brief description of the business
The part of the business being examined

The human and economic factor
The possible solutions to the problems
At this level, the concern is whether the proposal is both technically and legally feasible
(assuming moderate cost).
Economic feasibility
Economic analysis is the most frequently used method for evaluating the effectiveness of a
new system. More commonly known as cost/benefit analysis, the procedure is to determine
the benefits and savings that are expected from a candidate system and compare them with
costs. If benefits outweigh costs, then the decision is made to design and implement the
system. An entrepreneur must accurately weigh the cost versus benefits before taking an
action.
Cost-based study: It is important to identify cost and benefit factors, which can be
categorized as follows: 1. Development costs; and 2. Operating costs. This is an analysis of
the costs to be incurred in the system and the benefits derivable out of the system.
Time-based study: This is an analysis of the time required to achieve a return on investments.
The future value of a project is also a factor.
Legal feasibility
Determines whether the proposed system conflicts with legal requirements, e.g. a data
processing system must comply with the local Data Protection Acts.
Operational feasibility
Operational feasibility is a measure of how well a proposed system solves the problems, and
takes advantage of the opportunities identified during scope definition and how it satisfies the
requirements identified in the requirements analysis phase of system development.
Schedule feasibility
A project will fail if it takes too long to be completed before it is useful. Typically this means
estimating how long the system will take to develop, and if it can be completed in a given

time period using some methods like payback period. Schedule feasibility is a measure of
how reasonable the project timetable is. Given our technical expertise, are the project
deadlines reasonable? Some projects are initiated with specific deadlines. You need to
determine whether the deadlines are mandatory or desirable.
Other feasibility factors
Market and real estate feasibility
Market Feasibility Study typically involves testing geographic locations for a real estate
development project, and usually involves parcels of real estate land. Developers often
conduct market studies to determine the best location within a jurisdiction, and to test
alternative land uses for given parcels. Jurisdictions often require developers to complete
feasibility studies before they will approve a permit application for retail, commercial,
industrial, manufacturing, housing, office or mixed-use project. Market Feasibility takes into
account the importance of the business in the selected area.
Resource feasibility
This involves questions such as how much time is available to build the new system, when it
can be built, whether it interferes with normal business operations, type and amount of
resources required, dependencies,
Cultural feasibility
In this stage, the project's alternatives are evaluated for their impact on the local and general
culture. For example, environmental factors need to be considered and these factors are to be
well known. Further an enterprise's own culture can clash with the results of the project.
Financial feasibility
In case of a new project,financial viability can be judged on the following parameters:
Total estimated cost of the project
Financing of the project in terms of its capital structure, debt equity ratio and promoter's
share of total cost

Existing investment by the promoter in any other business
Projected cash flow and profitability
ECONOMIC FEASIBILITY STUDY
Feasibility studies are crucial during the early development of any project and form a vital
component in the business development process. Accounting and Advisory feasibility studies
enable organizations to assess the viability, cost and benefits of projects before financial
resources are allocated. They also provide independent project assessment and enhance
project credibility.
Built on the information provided in the feasibility study, a business case is used to convince
the audience that a particular project should be implemented. It is often a prerequisite for any
funding approval. The business case will detail the reasons why a particular project should be
prioritized higher than others. It will also sum up the strengths, weaknesses and validity of
assumptions as well as assessing the financial and non-financial costs and benefits underlying
preferred options.
For any system if the expected benefits equal or exceed the expected costs, the system can be
judged to be economically feasible. In economic feasibility, cost benefit analysis is done in
which expected costs and benefits are evaluated. Economic analysis is used for evaluating the
effectiveness of the proposed system.
In economic feasibility, the most important is cost-benefit analysis. As the name suggests, it
is an analysis of the costs to be incurred in the system and benefits derivable out of the
system. Click on the link below which will get you to the page that explains what cost benefit
analysis is and how you can perform a cost benefit analysis.
A Deloitte feasibility study can help your organization to:
Define the business requirements that must be met by the selected project and include the
critical success factors for the project
Detail alternative approaches that will meet business requirements, including comparative
cost/benefit and risk analyses

Recommend the best approach for preparing a business case or moving through the
implementation process
Our feasibility studies and business cases can help you answer crucial questions such as:
Have the alternatives been carefully, thoroughly and objectively examined?
What are the consequences of each choice on all relevant areas?
What are the results of any cost/benefit studies?
What are the costs and consequences of no action?
What are the impacts on the various interest groups?
What are the timelines for decisions?
Are the consequences displayed to make comparisons easier?
Cost Benefit Analysis:
Developing an IT application is an investment. Since after developing that application it
provides the organization with profits. Profits can be monetary or in the form of an improved
working environment. However, it carries risks, because in some cases an estimate can be
wrong. And the project might not actually turn out to be beneficial.
Cost benefit analysis helps to give management a picture of the costs, benefits and risks. It
usually involves comparing alternate investments.
Cost benefit determines the benefits and savings that are expected from the system and
compares them with the expected costs.
The cost of an information system involves the development cost and maintenance cost. The
development costs are one time investment whereas maintenance costs are recurring. The
development cost is basically the costs incurred during the various stages of the system
development.
Each phase of the life cycle has a cost. Some examples are :
Personnel
Equipment

Supplies
Overheads
Consultants' fees
Cost and Benefit Categories
In performing Cost benefit analysis (CBA) it is important to identify cost and benefit factors.
Cost and benefits can be categorized into the following categories.
There are several cost factors/elements. These are hardware, personnel, facility, operating,
and supply costs.
In a broad sense the costs can be divided into two types
1. Development costs-
Development costs that are incurred during the development of the system are one time
investment.
Wages
Equipment
2. Operating costs,
e.g. , Wages
Supplies
Overheads
Another classification of the costs can be:
Hardware/software costs:
It includes the cost of purchasing or leasing of computers and it's peripherals. Software costs
involves required software costs.
Personnel costs:

It is the money, spent on the people involved in the development of the system. These
expenditures include salaries, other benefits such as health insurance, conveyance allowance,
etc.
Facility costs:
Expenses incurred during the preparation of the physical site where the system will be
operational. These can be wiring, flooring, acoustics, lighting, and air conditioning.
Operating costs:
Operating costs are the expenses required for the day to day running of the system. This
includes the maintenance of the system. That can be in the form of maintaining the hardware
or application programs or money paid to professionals responsible for running or
maintaining the system.
Supply costs:
These are variable costs that vary proportionately with the amount of use of paper, ribbons,
disks, and the like. These should be estimated and included in the overall cost ofthe system.
Benefits
We can define benefit as
Profit or Benefit = Income - Costs
Benefits can be accrued by :
- Increasing income, or
- Decreasing costs, or
- both
The system will provide some benefits also. Benefits can be tangible or intangible, direct or
indirect. In cost benefit analysis, the first task is to identify each benefit and assign a
monetary value to it.
The two main benefits are improved performance and minimized processing costs.

Further costs and benefits can be categorized as
Tangible or Intangible Costs and Benefits
Tangible cost and benefits can be measured. Hardware costs, salaries for professionals, software cost are all tangible costs. They are identified and measured.. The purchase of hardware or software, personnel training, and employee salaries are example of tangible costs. Costs whose value cannot be measured are referred as intangible costs. The cost of breakdown of an online system during banking hours will cause the bank lose deposits.
Benefits are also tangible or intangible. For example, more customer satisfaction, improved company status, etc are all intangible benefits. Whereas improved response time, producing error free output such as producing reports are all tangible benefits. Both tangible and intangible costs and benefits should be considered in the evaluation process.
Direct or Indirect Costs and Benefits
From the cost accounting point of view, the costs are treated as either direct or indirect. Direct costs are having rupee value associated with it. Direct benefits are also attributable to a given project. For example, if the proposed system that can handle more transactions say 25% more than the present system then it is direct benefit.
Indirect costs result from the operations that are not directly associated with the system. Insurance, maintenance, heat, light, air conditioning are all indirect costs.
Fixed or Variable Costs and Benefits
Some costs and benefits are fixed. Fixed costs don't change. Depreciation of hardware, Insurance, etc are all fixed costs. Variable costs are incurred on regular basis. Recurring period may be weekly or monthly depending upon the system. They are proportional to the work volume and continue as long as system is in operation.
Fixed benefits don't change. Variable benefits are realized on a regular basis.
TECHNICAL FEASIBILITY
A feasibility study is an important phase in the development of business related
services. The need for evaluation is great especially in large high-risk information
service development projects. A feasibility study focuses in the study of the
challenges, technical problems and solution models of information service
realisation, analyses the potential solutions to the problems against the
requirements, evaluates their ability to meet the goals and describes and
rationalises the recommended solution.

The term “technical feasibility” establishes that the product or service can operate
in the desired manner. Technical feasibility means “achievable”. This has to be
proven without building the system. The proof is defining a comprehensive
number of technical options that are feasible within known and demanded
resources and requirements. These options should cover all technical sub-areas.
The goal of a feasibility study is to outline and clarify the things and factors
connected to the technical realisation of a information service system. It is good to
outline, recognise and possibly solve these things before the actual design and
realisation. Other goals for feasibility studies are:
• Produce sufficient information:
• Is the development project technically feasible?
• Produce base data for the requirement definition phase. E.g. what technical
requirements does the production of the service place on the clients’
current technology i.e. help direct research and development investments
to right things.
• What are the realisation alternatives?
• Is there a recommended realisation alternative?
Evaluation answers:
The evaluation of technical feasibility tries to answer whether the desired
information service is feasible and what are the technical matters connected to the
feasibility:
• Technical feasibility from the organisation viewpoint.
• How practical is the technical solution?
• The availability of technical resources and know-how?
The evaluation backs the selection of the most suitable technical alternative.
The feasibility study is a critical document defining the original system concepts,
goals, requirements and alternatives. The study also forms the framework for the
system development project and creates a baseline for further studies.
The evaluation process can be utilised at different stages of an information service
development project:
• At the beginning of an information service development project: evaluation of

the technical feasibility of the desired information service and the
implementation alternatives based on the available information. Usually a
more concise evaluation.
• At the beginning of an information service development project alongside
requirement definition (and partly after): Produces data for requirement
definition and utilises the data produced by the requirement definition process.
A more demanding and in-depth evaluation process.
The evaluation of the technical feasibility of an information system produces
information and answers e.g. the following points:
• Definitions of feasible alternatives for information service system design and
development.
• Identifies, raises and clarifies issues connected to the technical implementation
of an information system.
• Produces data for requirement definition i.e. complements and utilises the
information service requirement definition.
The feasibility evaluation studies the information system from different
viewpoints:
• Technical feasibility
• Financial feasibility
• Operational feasibility
The other modules connected to the ”Technical feasibility” module are thus:
• Markets and foresight (technology foresight, mega-trends)
• Risk analyses (reliability, technical risks (?))
• Revenue and finance (economical profitability and project feasibility)
In technical feasibility the following issues are taken into consideration.
Whether the required technology is available or not
Whether the required resources are available -
- Manpower- programmers, testers & debuggers
- Software and hardware

Once the technical feasibility is established, it is important to consider the monetary factors
also. Since it might happen that developing a particular system may be technically possible
but it may require huge investments and benefits may be less. For evaluating this, economic
feasibility of the proposed system is carried out.
OPERATIONAL FEASIBILITY
Not only must an application make economic and technical sense, it must also make
operational sense. The basic question that you are trying to answer is “Is it possible to
maintain and support this application once it is in production?” Building an application is
decidedly different than operating it, therefore you need to determine whether or not you can
effectively operate and support it. TABLE below summarizes critical issues which you
should consider.
Issues to consider when determining the operational feasibility of a project.
Operations Issues Support Issues
What tools are
needed to support
operations?
What skills will
operators need to be
trained in?
What processes
need to be created
and/or updated?
What
documentation does
operations need?
What
documenta
tion will
users be
given?
What
training
will users
be given?
How will
change
requests be
managed?

Very often you will need to improve the existing operations, maintenance, and support
infrastructure to support the operation of the new application that you intend to develop. To
determine what the impact will be you will need to understand both the current operations
and support infrastructure of your organization and the operations and support characteristics
of your new application. If the existing operations and support infrastructure can handle your
application, albeit with the appropriate training of the affected staff, then your project is
operationally feasible.
The operational feasibility parameters are:
Does this project require some investment in tools, skill levels, hiring, infrastructures?
Do we have the right mix of team to take up this project?
Is there any time zone advantage?
Did we anticipate any operational risk …like staffing, people leaving the company in the
middle of the project?
Identify the anticipated impact on customer satisfaction, retention, and loyalty?
Based on this the operational feasibility of the project is checked and the score is generated.

SYSTEM ANALYSIS AND DATA FLOW DIAGRAMS
EXISTING SYSTEM:
every college or institution requires time tables and the manual generation of time table is
quite a cumbersome task and requires lot of sharp observation and time. Thus far, the time
tables are generated manually, so, this project is aimed at developing a system that will
generate a time table semi automatically which will be conflict free and thus replace the
existing system of manual time table generation with a time table generator.
Their must have been other time table generators too but this project that we have completed
is quite customised for use in our institution specially.

PROPOSED SYSTEM:
INTRODUCTION TO THE PROPOSED SYSTEM:
Time Table generator is revolutionary software which helps in reducing human efforts in generating time table. It not only helps in managing time schedule but also helps in allocating the classes and laboratories. It makes the work of time table generation error free and accurate.
It is a powerful software tool not only for the management but also for students. It gives benefit to: administrator, the head of concerned department, faculty and students. It is an organizational based software which helps in maintain the time management in the organization and helps faculty and students.
ABOUT THE TECHNOLOGY USED
ASP.NET is a web application framework developed and marketed by Microsoft to allow
programmers to build dynamic web sites, web applications and web services. It was first
released in January 2002 with version 1.0 of the .NET Framework, and is the successor to
Microsoft's Active Server Pages (ASP) technology. ASP.NET is built on the Common
Language Runtime (CLR), allowing programmers to write ASP.NET code using any
supported .NET language. The ASP.NET SOAP extension framework allows ASP.NET
components to process SOAP messages.
Characteristics
PAGES

ASP.NET web pages or webpage, known officially as "web forms", are the main building
block for application development. Web forms are contained in files with an ".aspx"
extension; these files typically contain static (X)HTML markup, as well as markup defining
server-side Web Controls and User Controls where the developers place all the required static
and dynamic content for the web page. Additionally, dynamic code which runs on the server
can be placed in a page within a block <% -- dynamic code -- %>, which is similar
to other web development technologies such as PHP, JSP, and ASP. With ASP.NET
Framework 2.0, Microsoft introduced a new code-behind model which allows static text to
remain on the .aspx page, while dynamic code remains in an .aspx.vb or .aspx.cs file
(depending on the programming language used).
CODE BEHIND MODEL
Microsoft recommends dealing with dynamic program code by using the code-behind model,
which places this code in a separate file or in a specially designated script tag. Code-behind
files typically have names like MyPage.aspx.cs or MyPage.aspx.vb while the page file is
MyPage.aspx (same filename as the page file (ASPX), but with the final extension denoting
the page language). This practice is automatic in Microsoft Visual Studio and other IDEs.
When using this style of programming, the developer writes code to respond to different
events, like the page being loaded, or a control being clicked, rather than a procedural walk
through of the document.
ASP.NET's code-behind model marks a departure from Classic ASP in that it encourages
developers to build applications with separation of presentation and content in mind. In
theory, this would allow a web designer, for example, to focus on the design markup with
less potential for disturbing the programming code that drives it. This is similar to the
separation of the controller from the view in Model–View–Controller (MVC) frameworks.
DIRECTIVES
A directive is special instructions on how ASP.NET should process the pages. The most
common directive is <%@ Page %> which can specify many things, such as which
programming language is used for the server-side code.
USER CONTROLS

User controls are encapsulations of sections of pages which are registered and used as
controls in ASP.NET. User controls are created as ASCX markup files. These files usually
contain static (X)HTML markup, as well as markup defining server-side web controls. These
are the locations where the developer can place the required static and dynamic content. A
user control is compiled when its containing page is requested and is stored in memory for
subsequent requests. User controls have their own events which are handled during the life of
ASP.NET requests. An event bubbling mechanism provides the ability to pass an event fired
by a user control up to its containing page. Unlike an ASP.NET page, a user control cannot
be requested independently; one of its containing pages is requested instead.
CUSTOM CONTROLS
Programmers can also build custom controls for ASP.NET applications. Unlike user controls,
these controls do not have an ASCX markup file, having all their code compiled into a
dynamic link library (DLL) file. Such custom controls can be used across multiple web
applications and Visual Studio projects
RENDERING TECHNIQUE
ASP.NET uses a visited composites rendering technique. During compilation, the template
(.aspx) file is compiled into initialization code which builds a control tree (the composite)
representing the original template. Literal text goes into instances of the Literal control class,
and server controls are represented by instances of a specific control class. The initialization
code is combined with user-written code (usually by the assembly of multiple partial classes)
and results in a class specific for the page. The page doubles as the root of the control tree.
Actual requests for the page are processed through a number of steps. First, during the
initialization steps, an instance of the page class is created and the initialization code is
executed. This produces the initial control tree which is now typically manipulated by the
methods of the page in the following steps. As each node in the tree is a control represented
as an instance of a class, the code may change the tree structure as well as manipulate the
properties/methods of the individual nodes. Finally, during the rendering step a visitor is used
to visit every node in the tree, asking each node to render itself using the methods of the
visitor. The resulting HTML output is sent to the client.

After the request has been processed, the instance of the page class is discarded and with it
the entire control tree. This is a source of confusion among novice ASP.NET programmers
who rely on class instance members that are lost with every page request/response cycle.
STATE MANAGEMENT
ASP.NET applications are hosted by a web server and are accessed using the stateless HTTP
protocol. As such, if an application uses stateful interaction, it has to implement state
management on its own. ASP.NET provides various functions for state management.
Conceptually, Microsoft treats "state" as GUI state. Problems may arise if an application
needs to keep track of "data state"; for example, a finite state machine which may be in a
transient state between requests (lazy evaluation) or which takes a long time to initialize.
State management in ASP.NET pages with authentication can make Web scraping difficult or
impossible.
APPLICATION STATE
Application state is held by a collection of shared user-defined variables. These are set and
initialized when the Application_OnStart event fires on the loading of the first instance of
the application and are available until the last instance exits. Application state variables are
accessed using the Applications collection, which provides a wrapper for the application
state. Application state variables are identified by name.
SESSION STATE
Server-side session state is held by a collection of user-defined session variables that are
persistent during a user session. These variables, accessed using the Session collection, are
unique to each session instance. The variables can be set to be automatically destroyed after a
defined time of inactivity even if the session does not end. Client-side user session is
maintained by either a cookie or by encoding the session ID in the URL itself.
ASP.NET supports three modes of persistence for server-side session variables.
In-Process Mode

The session variables are maintained within the ASP.NET process. This is the fastest way;
however, in this mode the variables are destroyed when the ASP.NET process is recycled or
shut down.
ASPState Mode
ASP.NET runs a separate Windows service that maintains the state variables. Because state
management happens outside the ASP.NET process, and because the ASP.NET engine
accesses data using .NET Remoting, ASPState is slower than In-Process. This mode allows an
ASP.NET application to be load-balanced and scaled across multiple servers. Because the
state management service runs independently of ASP.NET, the session variables can persist
across ASP.NET process shutdowns. However, since session state server runs as one
instance, it is still one point of failure for session state. The session-state service cannot be
load-balanced, and there are restrictions on types that can be stored in a session variable.
SqlServer Mode
State variables are stored in a database, allowing session variables to be persisted across
ASP.NET process shutdowns. The main advantage of this mode is that it allows the
application to balance load on a server cluster, sharing sessions between servers. This is the
slowest method of session state management in ASP.NET.
VIEW STATE
View state refers to the page-level state management mechanism, utilized by the HTML
pages emitted by ASP.NET applications to maintain the state of the web form controls and
widgets. The state of the controls is encoded and sent to the server at every form submission
in a hidden field known as __VIEWSTATE. The server sends back the variable so that when the
page is re-rendered, the controls render at their last state. At the server side, the application
may change the viewstate, if the processing requires a change of state of any control. The
states of individual controls are decoded at the server, and are available for use in ASP.NET
pages using the ViewState collection.
The main use for this is to preserve form information across postbacks. View state is turned
on by default and normally serializes the data in every control on the page regardless of
whether it is actually used during a postback. This behavior can (and should) be modified,
however, as View state can be disabled on a per-control, per-page, or server-wide basis.

Developers need to be wary of storing sensitive or private information in the View state of a
page or control, as the base64 string containing the view state data can easily be de-serialized.
By default, View state does not encrypt the __VIEWSTATE value. Encryption can be enabled
on a server-wide (and server-specific) basis, allowing for a certain level of security to be
maintained.
SERVER SIDE CACHING
ASP.NET offers a "Cache" object that is shared across the application and can also be used to
store various objects. The "Cache" object holds the data only for a specified amount of time
and is automatically cleaned after the session time-limit elapses.
OTHER:
Other means of state management that are supported by ASP.NET are cookies, caching, and
using the query string.
TEMPLATE ENGINE
When first released, ASP.NET lacked a template engine. Because the .NET Framework is
object-oriented and allows for inheritance, many developers would define a new base class
that inherits from "System.Web.UI.Page", write methods there that render HTML, and then
make the pages in their application inherit from this new class. While this allows for common
elements to be reused across a site, it adds complexity and mixes source code with markup.
Furthermore, this method can only be visually tested by running the application - not while
designing it. Other developers have used include files and other tricks to avoid having to
implement the same navigation and other elements in every page.
ASP.NET 2.0 introduced the concept of "master pages", which allow for template-based page
development. A web application can have one or more master pages, which, beginning with
ASP.NET 2.0, can be nested. Master templates have place-holder controls, called
ContentPlaceHolders to denote where the dynamic content goes, as well as HTML and
JavaScript shared across child pages.

Child pages use those ContentPlaceHolder controls, which must be mapped to the place-
holder of the master page that the content page is populating. The rest of the page is defined
by the shared parts of the master page, much like a mail merge in a word processor. All
markup and server controls in the content page must be placed within the
ContentPlaceHolder control.
When a request is made for a content page, ASP.NET merges the output of the content page
with the output of the master page, and sends the output to the user.
The master page remains fully accessible to the content page. This means that the content
page may still manipulate headers, change title, configure caching etc. If the master page
exposes public properties or methods (e.g. for setting copyright notices) the content page can
use these as well.
DIRECTORY STRUCTURE
In general, the ASP.NET directory structure can be determined by the developer's
preferences. Apart from a few reserved directory names, the site can span any number of
directories. The structure is typically reflected directly in the URLs. Although ASP.NET
provides means for intercepting the request at any point during processing, the developer is
not forced to funnel requests through a central application or front controller.
The special directory names (from ASP.NET 2.0 on) are:
App_Code
This is the "raw code" directory. The ASP.NET server automatically compiles files (and
subdirectories) in this folder into an assembly which is accessible in the code of every page
of the site. App_Code will typically be used for data access abstraction code, model code and
business code. Also any site-specific http handlers and modules and web service
implementation go in this directory. As an alternative to using App_Code the developer may
opt to provide a separate assembly with precompiled code.
App_Data
default directory for databases, such as Access mdb files and SQL Server mdf files. This
directory is usually the only one with write access for the application.
App_LocalResources
E.g. a file called CheckOut.aspx.fr-FR.resx holds localized resources for the French version of
the CheckOut.aspx page. When the UI culture is set to French, ASP.NET will automatically
find and use this file for localization.
App_GlobalResources
Holds resx files with localized resources available to every page of the site. This is where the
ASP.NET developer will typically store localized messages etc. which are used on more than
one page.
App_Themes
Adds a folder that holds files related to themes which is a new ASP.NET feature that helps
ensure a consistent appearance throughout a Web site and makes it easier to change the
Web site’s appearance when necessary.
App_WebReferences
holds discovery files and WSDL files for references to web services to be consumed in the
site.
Bin
Contains compiled code (.dll files) for controls, components, or other code that you want to
reference in your application. Any classes represented by code in the Bin folder are
automatically referenced in your application.
PERFORMANCE
ASP.NET aims for performance benefits over other script-based technologies (including
Classic ASP) by compiling the server-side code to one or more DLL files on the web
server . This compilation happens automatically the first time a page is requested (which
means the developer need not perform a separate compilation step for pages). This feature
provides the ease of development offered by scripting languages with the performance
benefits of a compiled binary. However, the compilation might cause a noticeable but short
delay to the web user when the newly-edited page is first requested from the web server, but
will not again unless the page requested is updated further.

The ASPX and other resource files are placed in a virtual host on an Internet Information
Services server (or other compatible ASP.NET servers; see Other implementations, below).
The first time a client requests a page, the .NET Framework parses and compiles the file(s)
into a .NET assembly and sends the response; subsequent requests are served from the DLL
files. By default ASP.NET will compile the entire site in batches of 1000 files upon first
request. If the compilation delay is causing problems, the batch size or the compilation
strategy may be tweaked.
Developers can also choose to pre-compile their "codebehind" files before deployment, using
MS Visual Studio, eliminating the need for just-in-time compilation in a production
environment. This also eliminates the need of having the source code on the web server.
EXTENSION
Microsoft has released some extension frameworks that plug into ASP.NET and extend its
functionality. Some of them are:
ASP.NET AJAX
An extension with both client-side as well as server-side components for writing ASP.NET
pages that incorporate AJAX functionality.
ASP.NET MVC Framework
An extension to author ASP.NET pages using the MVC architecture.
ASP.NET compared with ASP classic
ASP.NET simplifies developers' transition from Windows application development to web
development by offering the ability to build pages composed of controls similar to a
Windows user interface. A web control, such as a button or label, functions in very much the
same way as its Windows counterpart: code can assign its properties and respond to its
events. Controls know how to render themselves: whereas Windows controls draw
themselves to the screen, web controls produce segments of HTML and JavaScript which
form parts of the resulting page sent to the end-user's browser.

ASP.NET encourages the programmer to develop applications using an event-driven GUI
model, rather than in conventional web-scripting environments like ASP and PHP. The
framework combines existing technologies such as JavaScript with internal components like
"ViewState" to bring persistent (inter-request) state to the inherently stateless web
environment.
Other differences compared to ASP classic are:
Compiled code means applications run faster with more design-time errors trapped at the
development stage.
Significantly improved run-time error handling, making use of exception handling using try-
catch blocks.
Similar metaphors to Microsoft Windows applications such as controls and events.
An extensive set of controls and class libraries allows the rapid building of applications, plus
user-defined controls allow commonly-used web template, such as menus. Layout of these
controls on a page is easier because most of it can be done visually in most editors.
ASP.NET uses the multi-language abilities of the .NET Common Language Runtime, allowing
web pages to be coded in VB.NET, C#, J#, Delphi.NET, Chrome, etc.
Ability to cache the whole page or just parts of it to improve performance.
Ability to use the code-behind development model to separate business logic from
presentation.
Ability to use true object-oriented design for programming pages and controls
If an ASP.NET application leaks memory, the ASP.NET runtime unloads the AppDomain
hosting the erring application and reloads the application in a new AppDomain.
Session state in ASP.NET can be saved in a Microsoft SQL Server database or in a separate
process running on the same machine as the web server or on a different machine. That way
session values are not lost when the web server is reset or the ASP.NET worker process is
recycled.
Versions of ASP.NET prior to 2.0 were criticized for their lack of standards compliance. The
generated HTML and JavaScript sent to the client browser would not always validate against
W3C/ECMA standards. In addition, the framework's browser detection feature sometimes
incorrectly identified web browsers other than Microsoft's own Internet Explorer as
"downlevel" and returned HTML/JavaScript to these clients with some of the features
removed, or sometimes crippled or broken. However, in version 2.0, all controls generate
valid HTML 4.0, XHTML 1.0 (the default) or XHTML 1.1 output, depending on the site

configuration. Detection of standards-compliant web browsers is more robust and support
for Cascading Style Sheets is more extensive.
Web Server Controls: these are controls introduced by ASP.NET for providing the UI for the
web form. These controls are state managed controls and are WYSIWYG controls.
FRAMEWORKS
It is not essential to use the standard webforms development model when developing with
ASP.NET. Noteworthy frameworks designed for the platform include:
Base One Foundation Component Library (BFC) is a RAD framework for building .NET
database and distributed computing applications.
DotNetNuke is an open-source solution which comprises both a web application framework
and a content management system which allows for advanced extensibility through
modules, skins, and providers.
Castle Monorail , an open-source MVC framework with an execution model similar to Ruby
on Rails. The framework is commonly used with Castle ActiveRecord, an ORM layer built on
NHibernate.
Spring.NET, a port of the Spring framework for Java.
Skaffold.NET, A simple framework for .NET applications, used in enterprise applications.
Survey™ Project is an open-source web based survey and form engine framework written in
ASP.NET and C#.
C #
C# is a multi-paradigm programming language encompassing imperative, declarative,
functional, generic, object-oriented (class-based), and component-oriented programming
disciplines. It was developed by Microsoft within the .NET initiative and later approved as a
standard by Ecma (ECMA-334) and ISO (ISO/IEC 23270). C# is one of the programming
languages designed for the Common Language Infrastructure.
C# is intended to be a simple, modern, general-purpose, object-oriented programming
language. Its development team is led by Anders Hejlsberg. The most recent version is C#
4.0, which was released on April 12, 2010.

DESIGN GOALS
The ECMA standard lists these design goals for C#
C# language is intended to be a simple, modern, general-purpose, object-oriented
programming language.
The language, and implementations thereof, should provide support for software
engineering principles such as strong type checking, array bounds checking, detection
of attempts to use uninitialized variables, and automatic garbage collection. Software
robustness, durability, and programmer productivity are important.
The language is intended for use in developing software components suitable for
deployment in distributed environments.
Source code portability is very important, as is programmer portability, especially for
those programmers already familiar with C and C++.
Support for internationalization is very important.
C# is intended to be suitable for writing applications for both hosted and embedded
systems, ranging from the very large that use sophisticated operating systems, down
to the very small having dedicated functions.
Although C# applications are intended to be economical with regard to memory and
processing power requirements, the language was not intended to compete directly on
performance and size with C or assembly language.
NAME
The name "C sharp" was inspired by musical notation where a sharp indicates that the written
note should be made a semitone higher in pitch. This is similar to the language name of C++,
where "++" indicates that a variable should be incremented by 1.
Due to technical limitations of display (standard fonts, browsers, etc.) and the fact that the
sharp symbol (U+266F ♯ (HTML: ♯ )) is not present on the standard keyboard, the
number sign (U+0023 # NUMBER SIGN (HTML: # )) was chosen to represent the sharp
symbol in the written name of the programming language.This convention is reflected in the

ECMA-334 C# Language Specification. However, when it is practical to do so (for example,
in advertising or in box art), Microsoft uses the intended musical symbol.
The "sharp" suffix has been used by a number of other .NET languages that are variants of
existing languages, including J# (a .NET language also designed by Microsoft which is
derived from Java 1.1), A# (from Ada), and the functional F#. The original implementation of
Eiffel for .NET was called Eiffel#, a name since retired since the full Eiffel language is now
supported. The suffix has also been used for libraries, such as Gtk# (a .NET wrapper for
GTK+ and other GNOME libraries), Cocoa# (a wrapper for Cocoa) and Qt#
FEATURES
By design, C# is the programming language that most directly reflects the underlying
Common Language Infrastructure (CLI). Most of its intrinsic types correspond to value-types
implemented by the CLI framework. However, the language specification does not state the
code generation requirements of the compiler: that is, it does not state that a C# compiler
must target a Common Language Runtime, or generate Common Intermediate Language
(CIL), or generate any other specific format. Theoretically, a C# compiler could generate
machine code like traditional compilers of C++ or Fortran.
Some notable distinguishing features of C# are:
There are no global variables or functions. All methods and members must be
declared within classes. Static members of public classes can substitute for global
variables and functions.
Local variables cannot shadow variables of the enclosing block, unlike C and C++.
Variable shadowing is often considered confusing by C++ texts.
C# supports a strict Boolean datatype, bool. Statements that take conditions, such as
while and if, require an expression of a type that implements the true operator, such as
the boolean type. While C++ also has a boolean type, it can be freely converted to and
from integers, and expressions such as if(a) require only that a is convertible to bool,
allowing a to be an int, or a pointer. C# disallows this "integer meaning true or false"
approach, on the grounds that forcing programmers to use expressions that return

exactly bool can prevent certain types of common programming mistakes in C or C++
such as if (a = b) (use of assignment = instead of equality ==).
In C#, memory address pointers can only be used within blocks specifically marked as
unsafe, and programs with unsafe code need appropriate permissions to run. Most
object access is done through safe object references, which always either point to a
"live" object or have the well-defined null value; it is impossible to obtain a reference
to a "dead" object (one which has been garbage collected), or to a random block of
memory. An unsafe pointer can point to an instance of a value-type, array, string, or a
block of memory allocated on a stack. Code that is not marked as unsafe can still store
and manipulate pointers through the System.IntPtr type, but it cannot dereference
them.
Managed memory cannot be explicitly freed; instead, it is automatically garbage
collected. Garbage collection addresses the problem of memory leaks by freeing the
programmer of responsibility for releasing memory which is no longer needed.
In addition to the try...catch construct to handle exceptions, C# has a try...finally
construct to guarantee execution of the code in the finally block.
Multiple inheritance is not supported, although a class can implement any number of
interfaces. This was a design decision by the language's lead architect to avoid
complication and simplify architectural requirements throughout CLI.
C# is more type safe than C++. The only implicit conversions by default are those
which are considered safe, such as widening of integers. This is enforced at compile-
time, during JIT, and, in some cases, at runtime. There are no implicit conversions
between booleans and integers, nor between enumeration members and integers
(except for literal 0, which can be implicitly converted to any enumerated type). Any
user-defined conversion must be explicitly marked as explicit or implicit, unlike C++
copy constructors and conversion operators, which are both implicit by default.
Starting with version 4.0, C# supports a "dynamic" data type that enforces type
checking at runtime only.
Enumeration members are placed in their own scope.
C# provides properties as syntactic sugar for a common pattern in which a pair of
methods, accessor (getter) and mutator (setter) encapsulate operations on a single
attribute of a class.
Full type reflection and discovery is available.
C# currently (as of version 4.0) has 77 reserved words.

Checked exceptions are not present in C# (in contrast to Java). This has been a
conscious decision based on the issues of scalability and versionability




GRAPHICAL USER INTERFACE
graphical user interface (GUI, sometimes pronounced gooey,) is a type of user interface
that allows users to interact with electronic devices with images rather than text commands.
GUIs can be used in computers, hand-held devices such as MP3 players, portable media
players or gaming devices, household appliances and office equipment . A GUI represents the
information and actions available to a user through graphical icons and visual indicators such
as secondary notation, as opposed to text-based interfaces, typed command labels or text
navigation. The actions are usually performed through direct manipulation of the graphical
elements.
Next ,we have presented the snap shots of all the pages that are encountered while using the software for generating time table.
Home page Login page New student login page Welcome page for admin only Page for changing password Show/delete user login page Add subject page Show all faculty list

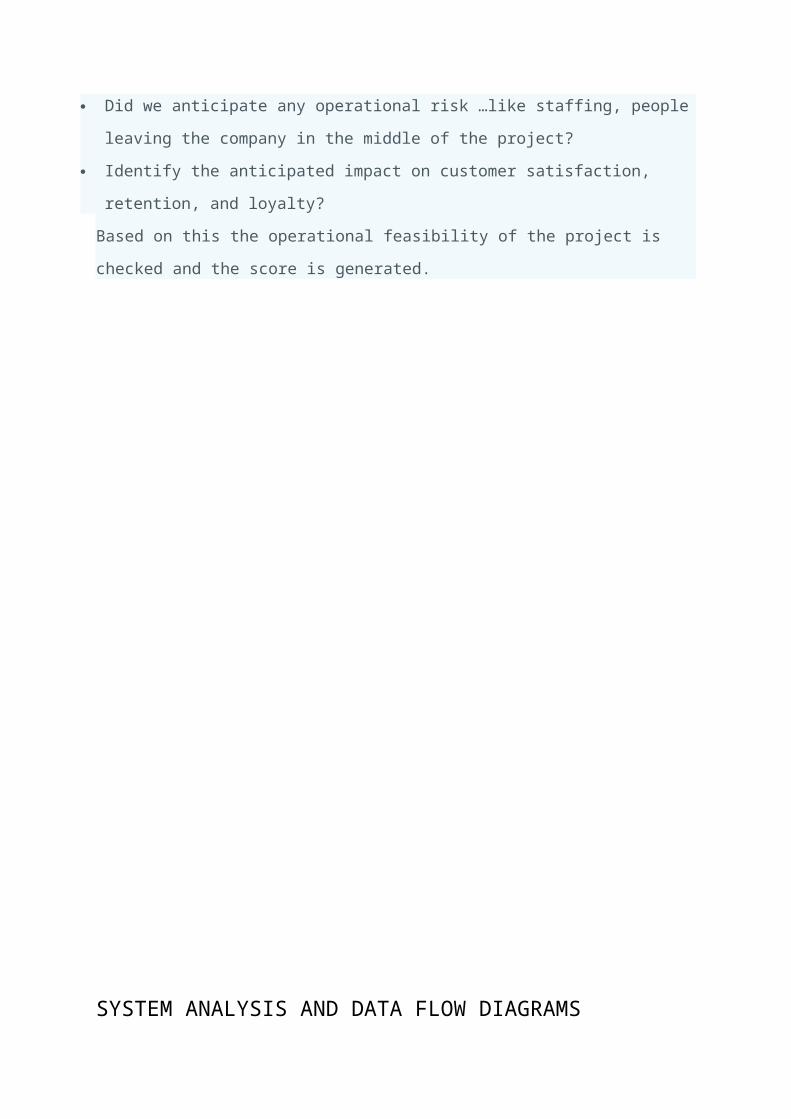
HOME PAGE:
LOGIN PAGE

NEW STUDENT LOGIN PAGE

WELCOME PAGE FOR ADMIN ONLY
PASSWORD CHANGE PAGE
CREATE NEW USER LOGIN PAGE

SHOW/DELETE USER LOGIN PAGE
ADD NEW SUBJECT PAGE

SHOW ALL FACULTY LIST PAGE
ASSIGN SUBJECTS TO FACULTY PAGE

SHOW/DELETE ASSIGNED SUBJECT
ADD LECTURE TIMINGS PAGE

SHOW/DELETE LECTURE TIMINGS PAGE
SHOW SEMESTER WISE SUBJECT LIST

GENERATE TIME TABLE PAGE
SYSTEM TESTING

Software testing is any activity aimed at evaluating an attribute or capability of a program or
system and determining that it meets its required results. Although crucial to software quality
and widely deployed by programmers and testers, software testing still remains an art, due to
limited understanding of the principles of software. The difficulty in software testing stems
from the complexity of software: we can not completely test a program with moderate
complexity. Testing is more than just debugging. The purpose of testing can be quality
assurance, verification and validation, or reliability estimation. Testing can be used as a
generic metric as well. Correctness testing and reliability testing are two major areas of
testing. Software testing is a trade-off between budget, time and quality.
Software Testing is the process of executing a program or system with the intent of finding
errors. [Myers79] Or, it involves any activity aimed at evaluating an attribute or capability of
a program or system and determining that it meets its required results. Software is not unlike
other physical processes where inputs are received and outputs are produced. Where software
differs is in the manner in which it fails. Most physical systems fail in a fixed (and reasonably
small) set of ways. By contrast, software can fail in many bizarre ways. Detecting all of the
different failure modes for software is generally infeasible.
Unlike most physical systems, most of the defects in software are design errors, not
manufacturing defects. Software does not suffer from corrosion, wear-and-tear -- generally it
will not change until upgrades, or until obsolescence. So once the software is shipped, the
design defects -- or bugs -- will be buried in and remain latent until activation.
Software bugs will almost always exist in any software module with moderate size: not
because programmers are careless or irresponsible, but because the complexity of software is
generally intractable -- and humans have only limited ability to manage complexity. It is also
true that for any complex systems, design defects can never be completely ruled out.
Discovering the design defects in software, is equally difficult, for the same reason of
complexity. Because software and any digital systems are not continuous, testing boundary
values are not sufficient to guarantee correctness. All the possible values need to be tested
and verified, but complete testing is infeasible. Exhaustively testing a simple program to add
only two integer inputs of 32-bits (yielding 2^64 distinct test cases) would take hundreds of
years, even if tests were performed at a rate of thousands per second. Obviously, for a
realistic software module, the complexity can be far beyond the example mentioned here. If

inputs from the real world are involved, the problem will get worse, because timing and
unpredictable environmental effects and human interactions are all possible input parameters
under consideration.
A further complication has to do with the dynamic nature of programs. If a failure occurs
during preliminary testing and the code is changed, the software may now work for a test
case that it didn't work for previously. But its behavior on pre-error test cases that it passed
before can no longer be guaranteed. To account for this possibility, testing should be
restarted. The expense of doing this is often prohibitive.
An interesting analogy parallels the difficulty in software testing with the pesticide, known as
the Pesticide Paradox [Beizer90]: Every method you use to prevent or find bugs leaves a
residue of subtler bugs against which those methods are ineffectual. But this alone will not
guarantee to make the software better, because the Complexity Barrier principle states:
Software complexity(and therefore that of bugs) grows to the limits of our ability to manage
that complexity. By eliminating the (previous) easy bugs you allowed another escalation of
features and complexity, but his time you have subtler bugs to face, just to retain the
reliability you had before. Society seems to be unwilling to limit complexity because we all
want that extra bell, whistle, and feature interaction. Thus, our users always push us to the
complexity barrier and how close we can approach that barrier is largely determined by the
strength of the techniques we can wield against ever more complex and subtle bugs.
[Beizer90]
Regardless of the limitations, testing is an integral part in software development. It is broadly
deployed in every phase in the software development cycle. Typically, more than 50%
percent of the development time is spent in testing. Testing is usually performed for the
following purposes:
To improve quality.
As computers and software are used in critical applications, the outcome of a bug can be
severe. Bugs can cause huge losses. Bugs in critical systems have caused airplane crashes,
allowed space shuttle missions to go awry, halted trading on the stock market, and worse.
Bugs can kill. Bugs can cause disasters. The so-called year 2000 (Y2K) bug has given birth to
a cottage industry of consultants and programming tools dedicated to making sure the modern

world doesn't come to a screeching halt on the first day of the next century. [Bugs] In a
computerized embedded world, the quality and reliability of software is a matter of life and
death.
Quality means the conformance to the specified design requirement. Being correct, the
minimum requirement of quality, means performing as required under specified
circumstances. Debugging, a narrow view of software testing, is performed heavily to find
out design defects by the programmer. The imperfection of human nature makes it almost
impossible to make a moderately complex program correct the first time. Finding the
problems and get them fixed [Kaner93], is the purpose of debugging in programming phase.
For Verification & Validation (V&V)
Just as topic Verification and Validation indicated, another important purpose of testing is
verification and validation (V&V). Testing can serve as metrics. It is heavily used as a tool in
the V&V process. Testers can make claims based on interpretations of the testing results,
which either the product works under certain situations, or it does not work. We can also
compare the quality among different products under the same specification, based on results
from the same test.
We can not test quality directly, but we can test related factors to make quality visible.
Quality has three sets of factors -- functionality, engineering, and adaptability. These three
sets of factors can be thought of as dimensions in the software quality space. Each dimension
may be broken down into its component factors and considerations at successively lower
levels of detail. Table 1 illustrates some of the most frequently cited quality considerations.
Functionality (exterior
quality)
Engineering (interior
quality)
Adaptability (future
quality)
Correctness Efficiency Flexibility
Reliability Testability Reusability
Usability Documentation Maintainability

Integrity Structure
Table 1. Typical Software Quality Factors [Hetzel88]
Good testing provides measures for all relevant factors. The importance of any particular
factor varies from application to application. Any system where human lives are at stake must
place extreme emphasis on reliability and integrity. In the typical business system usability
and maintainability are the key factors, while for a one-time scientific program neither may
be significant. Our testing, to be fully effective, must be geared to measuring each relevant
factor and thus forcing quality to become tangible and visible. [Hetzel88]
Tests with the purpose of validating the product works are named clean tests, or positive
tests. The drawbacks are that it can only validate that the software works for the specified test
cases. A finite number of tests can not validate that the software works for all situations. On
the contrary, only one failed test is sufficient enough to show that the software does not work.
Dirty tests, or negative tests, refers to the tests aiming at breaking the software, or showing
that it does not work. A piece of software must have sufficient exception handling
capabilities to survive a significant level of dirty tests.
A testable design is a design that can be easily validated, falsified and maintained. Because
testing is a rigorous effort and requires significant time and cost, design for testability is also
an important design rule for software development.
For reliability estimation [Kaner93] [Lyu95]
Software reliability has important relations with many aspects of software, including the
structure, and the amount of testing it has been subjected to. Based on an operational profile
(an estimate of the relative frequency of use of various inputs to the program [Lyu95]),
testing can serve as a statistical sampling method to gain failure data for reliability
estimation.
Software testing is not mature. It still remains an art, because we still cannot make it a
science. We are still using the same testing techniques invented 20-30 years ago, some of
which are crafted methods or heuristics rather than good engineering methods. Software

testing can be costly, but not testing software is even more expensive, especially in places
that human lives are at stake. Solving the software-testing problem is no easier than solving
the Turing halting problem. We can never be sure that a piece of software is correct. We can
never be sure that the specifications are correct. No verification system can verify every
correct program. We can never be certain that a verification system is correct either.
Black-box testing
The black-box approach is a testing method in which test data are derived from the specified
functional requirements without regard to the final program structure. [Perry90] It is also
termed data-driven, input/output driven [Myers79], or requirements-based [Hetzel88] testing.
Because only the functionality of the software module is of concern, black-box testing also
mainly refers to functional testing -- a testing method emphasized on executing the functions
and examination of their input and output data. [Howden87] The tester treats the software
under test as a black box -- only the inputs, outputs and specification are visible, and the
functionality is determined by observing the outputs to corresponding inputs. In testing,
various inputs are exercised and the outputs are compared against specification to validate the
correctness. All test cases are derived from the specification. No implementation details of
the code are considered.
It is obvious that the more we have covered in the input space, the more problems we will
find and therefore we will be more confident about the quality of the software. Ideally we
would be tempted to exhaustively test the input space. But as stated above, exhaustively
testing the combinations of valid inputs will be impossible for most of the programs, let alone
considering invalid inputs, timing, sequence, and resource variables. Combinatorial explosion
is the major roadblock in functional testing. To make things worse, we can never be sure
whether the specification is either correct or complete. Due to limitations of the language
used in the specifications (usually natural language), ambiguity is often inevitable. Even if we
use some type of formal or restricted language, we may still fail to write down all the possible
cases in the specification. Sometimes, the specification itself becomes an intractable problem:
it is not possible to specify precisely every situation that can be encountered using limited
words. And people can seldom specify clearly what they want -- they usually can tell whether

a prototype is, or is not, what they want after they have been finished. Specification problems
contributes approximately 30 percent of all bugs in software.
The research in black-box testing mainly focuses on how to maximize the effectiveness of
testing with minimum cost, usually the number of test cases. It is not possible to exhaust the
input space, but it is possible to exhaustively test a subset of the input space. Partitioning is
one of the common techniques. If we have partitioned the input space and assume all the
input values in a partition is equivalent, then we only need to test one representative value in
each partition to sufficiently cover the whole input space. Domain testing [Beizer95]
partitions the input domain into regions, and consider the input values in each domain an
equivalent class. Domains can be exhaustively tested and covered by selecting a
representative value(s) in each domain. Boundary values are of special interest. Experience
shows that test cases that explore boundary conditions have a higher payoff than test cases
that do not. Boundary value analysis [Myers79] requires one or more boundary values
selected as representative test cases. The difficulties with domain testing are that incorrect
domain definitions in the specification can not be efficiently discovered.
Good partitioning requires knowledge of the software structure. A good testing plan will not
only contain black-box testing, but also white-box approaches, and combinations of the two.
White-box testing
Contrary to black-box testing, software is viewed as a white-box, or glass-box in white-box
testing, as the structure and flow of the software under test are visible to the tester. Testing
plans are made according to the details of the software implementation, such as programming
language, logic, and styles. Test cases are derived from the program structure. White-box
testing is also called glass-box testing, logic-driven testing [Myers79] or design-based testing
[Hetzel88].
There are many techniques available in white-box testing, because the problem of
intractability is eased by specific knowledge and attention on the structure of the software
under test. The intention of exhausting some aspect of the software is still strong in white-box
testing, and some degree of exhaustion can be achieved, such as executing each line of code
at least once (statement coverage), traverse every branch statements (branch coverage), or

cover all the possible combinations of true and false condition predicates (Multiple condition
coverage)
Control-flow testing, loop testing, and data-flow testing, all maps the corresponding flow
structure of the software into a directed graph. Test cases are carefully selected based on the
criterion that all the nodes or paths are covered or traversed at least once. By doing so we
may discover unnecessary "dead" code -- code that is of no use, or never get executed at all,
which can not be discovered by functional testing.
In mutation testing, the original program code is perturbed and many mutated programs are
created, each contains one fault. Each faulty version of the program is called a mutant. Test
data are selected based on the effectiveness of failing the mutants. The more mutants a test
case can kill, the better the test case is considered. The problem with mutation testing is that
it is too computationally expensive to use. The boundary between black-box approach and
white-box approach is not clear-cut. Many testing strategies mentioned above, may not be
safely classified into black-box testing or white-box testing. It is also true for transaction-flow
testing, syntax testing, finite-state testing, and many other testing strategies not discussed in
this text. One reason is that all the above techniques will need some knowledge of the
specification of the software under test. Another reason is that the idea of specification itself
is broad -- it may contain any requirement including the structure, programming language,
and programming style as part of the specification content.
We may be reluctant to consider random testing as a testing technique. The test case selection
is simple and straightforward: they are randomly chosen. Study in [Duran84] indicates that
random testing is more cost effective for many programs. Some very subtle errors can be
discovered with low cost. And it is also not inferior in coverage than other carefully designed
testing techniques. One can also obtain reliability estimate using random testing results based
on operational profiles. Effectively combining random testing with other testing techniques
may yield more powerful and cost-effective testing strategies.
Performance testing:
Not all software systems have specifications on performance explicitly. But every system will
have implicit performance requirements. The software should not take infinite time or infinite

resource to execute. "Performance bugs" sometimes are used to refer to those design
problems in software that cause the system performance to degrade.
Performance has always been a great concern and a driving force of computer evolution.
Performance evaluation of a software system usually includes: resource usage, throughput,
stimulus-response time and queue lengths detailing the average or maximum number of tasks
waiting to be serviced by selected resources. Typical resources that need to be considered
include network bandwidth requirements, CPU cycles, disk space, disk access operations, and
memory usage [Smith90]. The goal of performance testing can be performance bottleneck
identification, performance comparison and evaluation, etc. The typical method of doing
performance testing is using a benchmark -- a program, workload or trace designed to be
representative of the typical system usage. [Vokolos98]
Reliability testing
Software reliability refers to the probability of failure-free operation of a system. It is related
to many aspects of software, including the testing process. Directly estimating software
reliability by quantifying its related factors can be difficult. Testing is an effective sampling
method to measure software reliability. Guided by the operational profile, software testing
(usually black-box testing) can be used to obtain failure data, and an estimation model can be
further used to analyze the data to estimate the present reliability and predict future
reliability. Therefore, based on the estimation, the developers can decide whether to release
the software, and the users can decide whether to adopt and use the software. Risk of using
software can also be assessed based on reliability information. [Hamlet94] advocates that the
primary goal of testing should be to measure the dependability of tested software.
There is agreement on the intuitive meaning of dependable software: it does not fail in
unexpected or catastrophic ways. Robustness testing and stress testing are variances of
reliability testing based on this simple criterion.
The robustness of a software component is the degree to which it can function correctly in the
presence of exceptional inputs or stressful environmental conditions. Robustness testing
differs with correctness testing in the sense that the functional correctness of the software is
not of concern. It only watches for robustness problems such as machine crashes, process
hangs or abnormal termination. The oracle is relatively simple, therefore robustness testing

can be made more portable and scalable than correctness testing. This research has drawn
more and more interests recently, most of which uses commercial operating systems as their
target.
Stress testing, or load testing, is often used to test the whole system rather than the software
alone. In such tests the software or system are exercised with or beyond the specified limits.
Typical stress includes resource exhaustion, bursts of activities, and sustained high loads.

IMPLEMENTATION AND MAINTENANCE
IMPLEMENTATION
Implementation is the carrying out, execution, or practice of a plan, a method, or any design
for doing something. As such, implementation is the action that must follow any preliminary
thinking in order for something to actually happen. In an information technology context,
implementation encompasses all the processes involved in getting new software or hardware
operating properly in its environment, including installation, configuration, running, testing,
and making necessary changes. An implementation is a realization of a technical
specification or algorithm as a program, software component, or other computer system
through programming and deployment. Many implementations may exist for a given
specification or standard. For example, web browsers contain implementations of World
Wide Web Consortium-recommended specifications, and software development tools contain
implementations of programming languages. Implementation includes the following phases:
Writing Computer Software (Coding) this means actually writing the code. This is
primarily done by the programmers.
Testing software this involves using test data scenario to verify that each component
and the whole system work under normal and abnormal circumstances.
Converting from old system to new system- this includes not only installing the new
system in organizational sites but also dealing with documentation.
Training users and others- this may include a variety of human and computer-assisted
sessions as well as tools to explain the purpose and use of the system.
There are other implementation techniques also like Direct Installation (in this the old system
is turned off and the new system replaces the old system. This type of a system is a bit risky
because users are at the mercy of new system) and Phased Installation (Under this, new
system is brought on-line in functional components; different parts of the old and new system
are in cooperation until the whole new system is installed).
After a thorough testing of the different aspects of the system as described in earlier section,
the system is to be put to actual use by using live data by user staff after sufficient training for
the use of the software has been provided to staff members. We have used parallel installation
technique in the implementation of the new system.
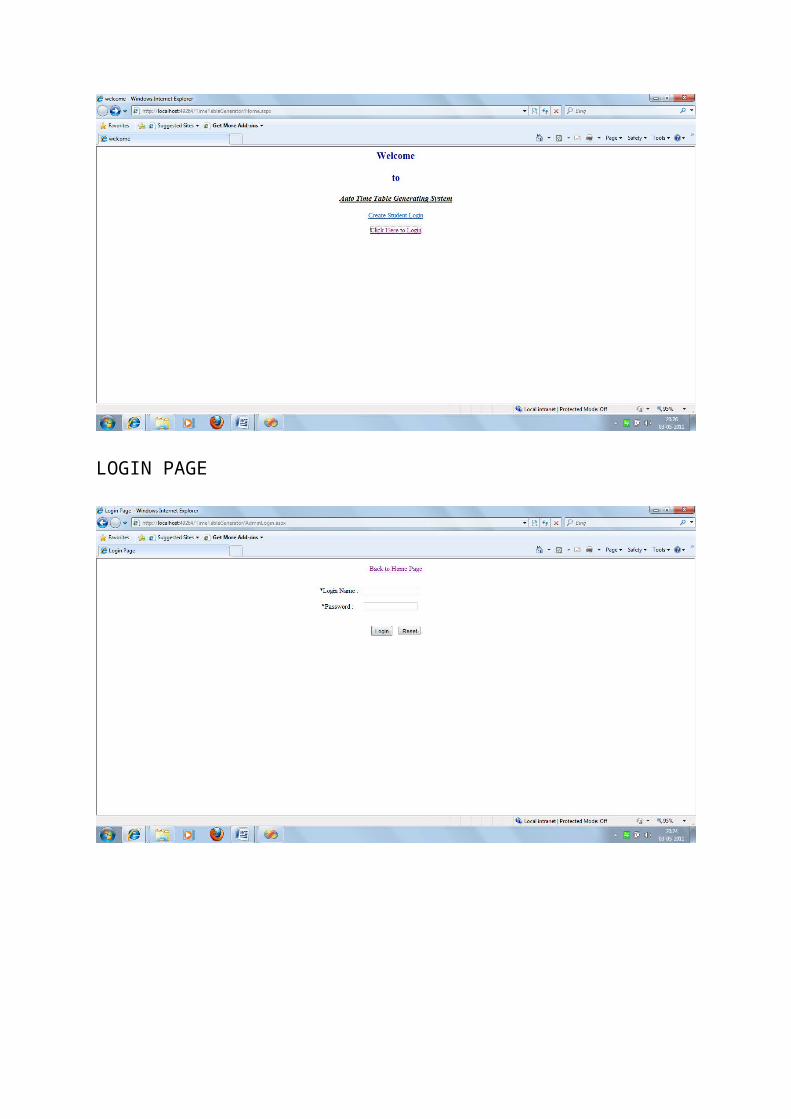
USER TRANING:
The type of necessary training varies by type of system and expertise of users. The list of
potential points we have taken in mind while estimating the amount of user training needed
are as follows:
Use of system
General computer concepts
Information system concepts
System management
System installation
As the end users in our case are computer literates, therefore we don’t have to give them any
computer fundamentals training (eg. How to operate computer system).
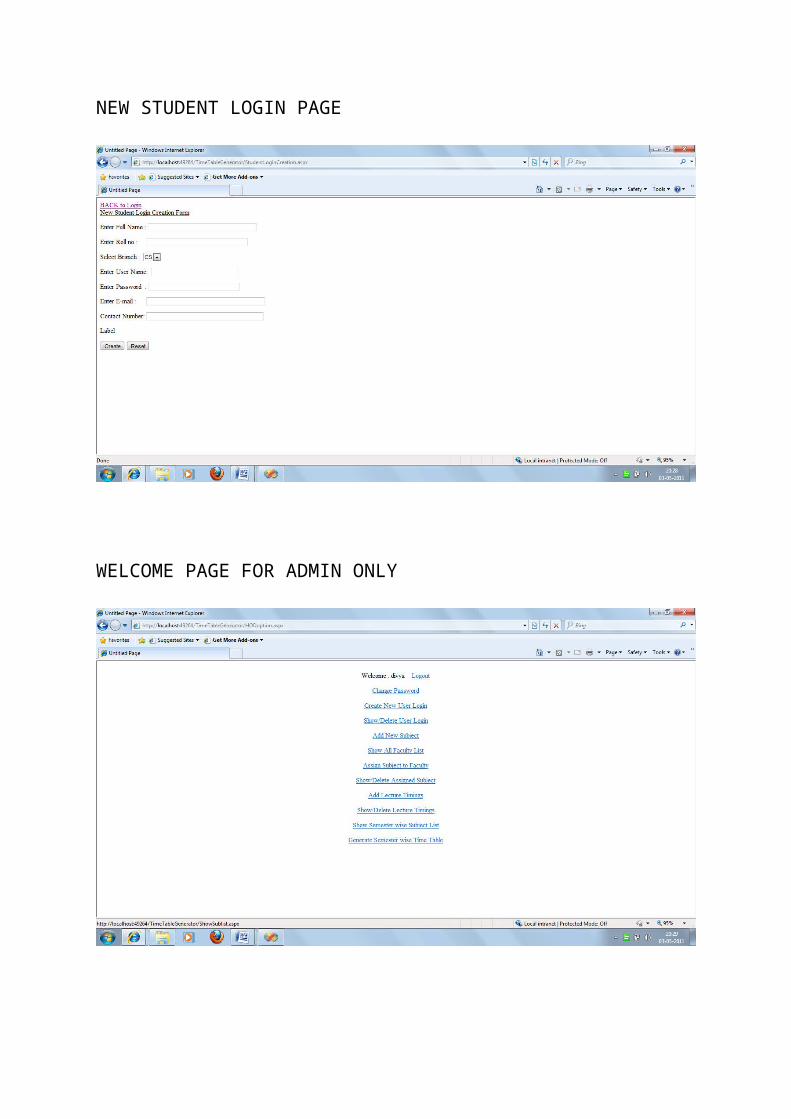
MAINTENANCE
Software maintenance in software engineering is the modification of a software product after
delivery to correct faults, to improve performance or other attributes.
A common perception of maintenance is that it is merely fixing bugs. However, studies and
surveys over the years have indicated that the majority, over 80%, of the maintenance effort
is used for non-corrective actions (Pigosky 1997). This perception is perpetuated by users
submitting problem reports that in reality are functionality enhancements to the system.
Software maintenance and evolution of systems was first addressed by Meir M. Lehman in
1969. Over a period of twenty years, his research led to the formulation of eight Laws of
Evolution (Lehman 1997). Key findings of his research include that maintenance is really
evolutionary developments and that maintenance decisions are aided by understanding what
happens to systems (and software) over time. Lehman demonstrated that systems continue to
evolve over time. As they evolve, they grow more complex unless some action such as code
refactoring is taken to reduce the complexity.
The key software maintenance issues are both managerial and technical. Key management
issues are: alignment with customer priorities, staffing, which organization does maintenance,
estimating costs. Key technical issues are: limited understanding, impact analysis, testing,
and maintainability measurement. Best and Worst Practices in Software Maintenance
Because maintenance of aging legacy software is very labour intensive it is quite important to
explore the best and most cost effective methods available for dealing with the millions of
applications that currently exist. The sets of best and worst practices are not the same. Just as
practice that has the most positive impact on maintenance productivity is the use of trained
maintenance experts, while the factor that has the greatest negative impact is the presence
error-prone modules in application being maintained.
The software maintenance is categorized into four classes:
Adaptive – dealing with changes and adapting in the software environment
Perfective – accommodating with new or changed user requirements which concern
functional enhancements to the software
Corrective – dealing with errors found and fixing it
Preventive – concerns activities aiming on increasing software maintainability and
prevent problems in the future
SOFTWARE MAINTENANCE PLANNING
The integral part of software is the maintenance part which requires accurate maintenance
plan to be prepared during software development and should specify how users will request
modifications or report problems and the estimation of resources such as cost should be
included in the budget and a new decision should address to develop a new system and its
quality objectives. The software maintenance which can last for 5–6 years after the
development calls for an effective planning which addresses the scope of software
maintenance, the tailoring of the post delivery process, the designation of who will provide
maintenance, an estimate of the life-cycle costs .
SOFTWARE MAINTENANCE PROCESSES
This section describes the six software maintenance processes as:
1. The implementation processes contains software preparation and transition activities,
such as the conception and creation of the maintenance plan, the preparation for
handling problems identified during development, and the follow-up on product
configuration management.
2. The problem and modification analysis process, which is executed once the
application has become the responsibility of the maintenance group. The maintenance
programmer must analyze each request, confirm it (by reproducing the situation) and
check its validity, investigate it and propose a solution, document the request and the
solution proposal, and, finally, obtain all the required authorizations to apply the
modifications.
3. The process considering the implementation of the modification itself.
4. The process acceptance of the modification, by confirming the modified work with
the individual who submitted the request in order to make sure the modification
provided a solution.
5. The migration process (platform migration, for example) is exceptional, and is not
part of daily maintenance tasks. If the software must be ported to another platform
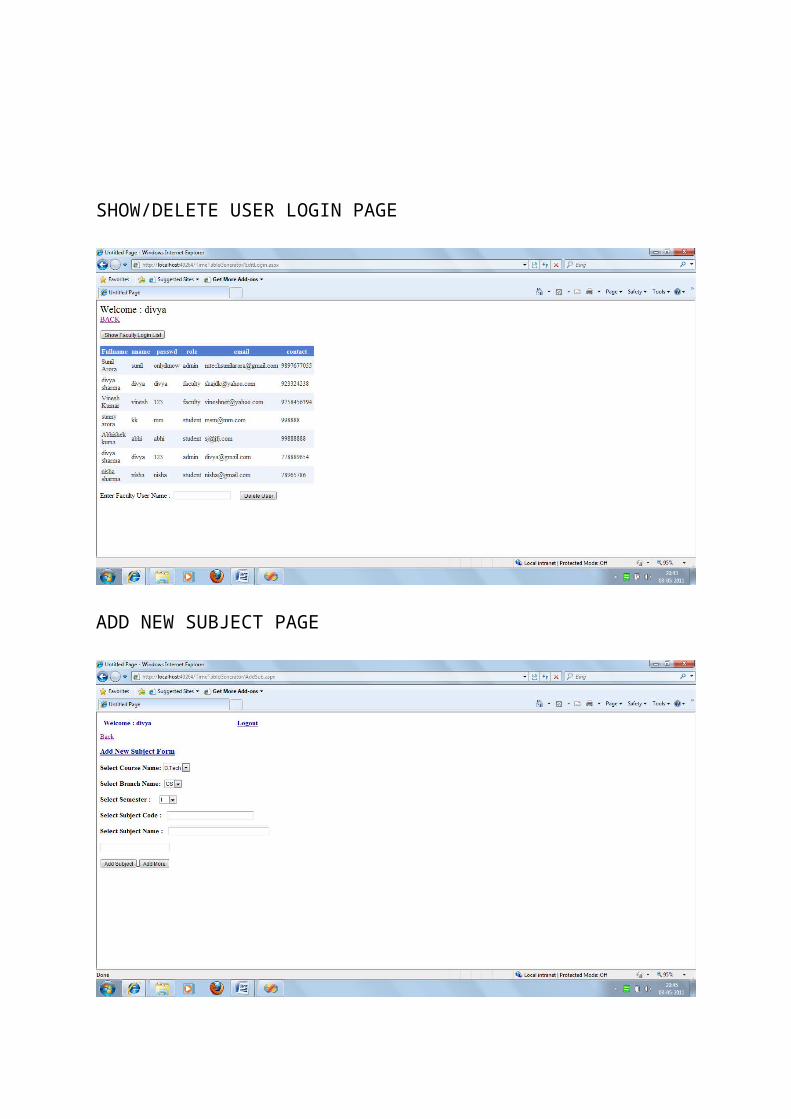
without any change in functionality, this process will be used and a maintenance
project team is likely to be assigned to this task.
6. Finally, the last maintenance process, also an event which does not occur on a daily
basis, is the retirement of a piece of software.
There are a number of processes, activities and practices that are unique to maintainers, for
example:
Transition: a controlled and coordinated sequence of activities during which a system
is transferred progressively from the developer to the maintainer;
Service Level Agreements (SLAs) and specialized (domain-specific) maintenance
contracts negotiated by maintainers;
Modification Request and Problem Report Help Desk: a problem-handling process
used by maintainers to prioritize, documents and route the requests they receive;
Modification Request acceptance/rejection: modification request work over a certain
size/effort/complexity may be rejected by maintainers and rerouted to a developer.
CATEGORIES OF MAINTENANCE IN ISO/IEC 14764
E.B. Swanson initially identified three categories of maintenance: corrective, adaptive, and
perfective. These have since been updated and ISO/IEC 14764 presents:
Corrective maintenance: Reactive modification of a software product performed after
delivery to correct discovered problems.
Adaptive maintenance: Modification of a software product performed after delivery to
keep a software product usable in a changed or changing environment.
Perfective maintenance: Modification of a software product after delivery to improve
performance or maintainability.
Preventive maintenance: Modification of a software product after delivery to detect
and correct latent faults in the software product before they become effective faults.
There is also a notion of pre-delivery/pre-release maintenance which is all the good things
you do to lower the total cost of ownership of the software. Things like compliance with
coding standards that includes software maintainability goals. The management of coupling
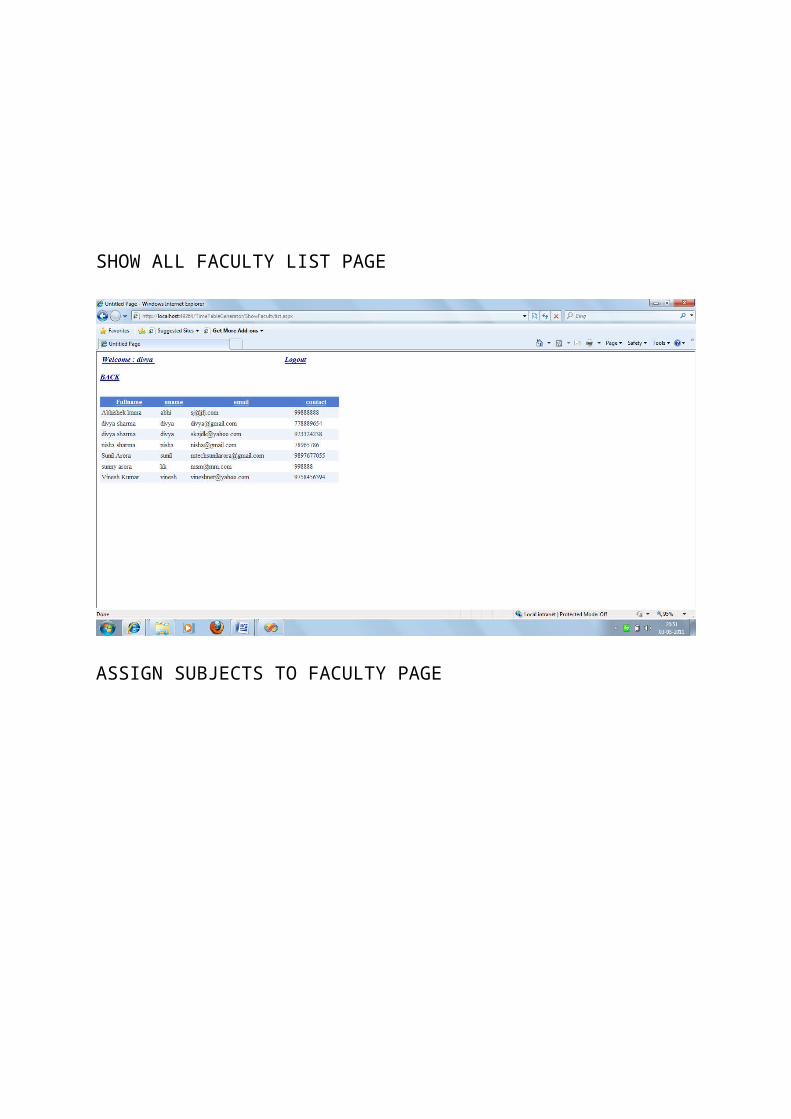
and cohesion of the software. The attainment of software supportability goals (SAE JA1004,
JA1005 and JA1006 for example). Note also that some academic institutions are carrying out
research to quantify the cost to ongoing software maintenance due to the lack of resources
such as design documents and system/software comprehension training and resources
(multiply costs by approx. 1.5-2.0 where there is no design data available.).








![[MS-RPL]: Report Page Layout (RPL) Binary Stream Format€¦ · MS-RPL] —. stream report. report page. report report report](https://img.pdfslide.us/doc/110x75/5fd9f7a7a90b7c34145fa364/ms-rpl-report-page-layout-rpl-binary-stream-format-ms-rpl-a-stream-report.jpg)




















