Embed Size (px)
Citation preview

Relation Extraction
Pierre Bourreau
LSI-UPC
PLN-PTM

Plan
Relation Extraction description
Sampling templates
Reducing deep analysis errors…
Conclusion

Relation Extraction Description Finding relations between entities into a text Filling pre-defined templates slots
One-value-per-field Multi-value
Depend on analysis: Chunking Tokenization Sentence Parsing…

Plan
Relation Extraction description
Sampling templates (Cox, Nicolson, Finkel, Manning)
Reducing deep analysis errors…
Conclusion

First Example: Sampling Templates Example: workshop announcement PASCAL corpus Relations to extract:
dates of events Workshop conferences names, acronyms and
URL Domain knowledge:
Constraints on dates Constraints on names

PASCAL Corpus: semi-structured corpus <[email protected]> Type: cmu.andrew.academic.bio Topic: "MHC Class II: A Target for Specific Immunomodulation of the Immune Response" Dates: 3-May-95 Time: <stime>3:30 PM</stime> Place: <location>Mellon Institute Conference Room</location> PostedBy: Helena R. Frey on 26-Apr-95 at 11:09 from andrew.cmu.edu Abstract:
Seminar: Departments of Biological Sciences Carnegie Mellon and University of Pittsburgh Name: <speaker>Dr. Jeffrey D. Hermes</speaker> Affiliation: Department of Autoimmune Diseases Research & Biophysical Chemistry Merck Research Laboratories Title: "MHC Class II: A Target for Specific Immunomodulation of the Immune Response" Host/e-mail: Robert Murphy, [email protected] Date: Wednesday, May 3, 1995 Time: <stime>3:30 p.m.</stime> Place: <location>Mellon Institute Conference Room</location> Sponsor: MERCK RESEARCH LABORATORIES
Schedule for 1995 follows: (as of 4/26/95) Biological Sciences Seminars 1994-1995 Date Speaker Host April 26 Helen Salz Javier L~pez May 3 Jefferey Hermes Bob Murphy MERCK RESEARCH LABORATORIES

PASCAL Corpus: semi-structured corpus <[email protected]> Type: cmu.andrew.org.heinz.great-lake Topic: Re: PresentationCC: Dates: 25-Oct-93 Time: <stime>12:30</stime> PostedBy: Richard Florida on 21-Oct-93 at 17:00 from andrew.cmu.edu Abstract:
Folks:
<paragraph> <sentence>Our client has requested that the presentation be postponed until Monday during regular class-time</sentence>. <sentence>He has been asked to make a presentaion for the Governor of Michigan and Premier of Ontario tommorrow morning in Canada, and was afraid he could not catch a plane in time to make our presentation</sentence>. <sentence>After consulting with Rafael and a sub group of project managers, it was decided that Monday was the best feasible presentation alternative</sentence>. <sentence>Greg has been able to secure Room 2503 in Hamburg Hall for our presentation Monday during regular class-time</sentence>. </paragraph>
<paragraph><sentence>We will meet tommmorow in <location>2110</location> at <stime>12:30</stime> (lunch provided) to finalize presentation and briefing book</sentence>. <sentence>Also, the client has faxed a list of reactions and questions for discussion which we should review</sentence>. <sentence>Thanks very much for your hard work and understanding</sentence>. <sentence>Look forward to seeing you tommorrow</sentence>.</paragraph>
Richard

Idea
Sampling Templates: Generate all available templates Give a probability to each of them
Relational model: Constraints on dates: order
1. submission dates 2. acceptance dates 3. workshop dates / camera ready dates
Constraints on names. Slots: name, acronym, URL URL is generated from acronyms

Baselines
CRF Cliques: max=2 Viterbi algorithm Token => GATE tokenization
CMM Idem Window of the four previous tokens

Templates sampling
Tokens p(Li|Li-1) or p(Li|Li-1,…, Li-4) on 100 of documents
Template: Each slot holds one/no filler value -> date templates:
SUB_DATE ACC_DATE WORK_DATE CAMREADY_DATE

Templates sampling
Tokens p(Li|Li-1) or p(Li|Li-1,…, Li-4) on 100 of documents
Template: Each slot holds one/no filler value -> name templates:
CONF_NAME CONF_ACRO CONF_URL WORK_NAME WORK_ACRO WORK_URL

Templates sampling
D a distribution of these templates, over the training set. => LOCAL MODEL (PL)

Templates scoring: Date Model PA/P: Probability of present/absent fields. Set
with training data Po: Ordering probability. We give penalty to
constraints violations.
PPA/PA/P* P* Poo = P = Prelrel

Templates scoring: Name Model Name->Acronym: independent module
(likelihood score – Chang 2002): Pnam->acr
Acronym->URL: empirical probability from training: Pacr->url
Pb: Pb: missing entry give advantage to incomplete templates. PA/P: pondering templates (in training, most
values are filled) PPrelrel= Pnam->acr *Pacr->url *PA/P
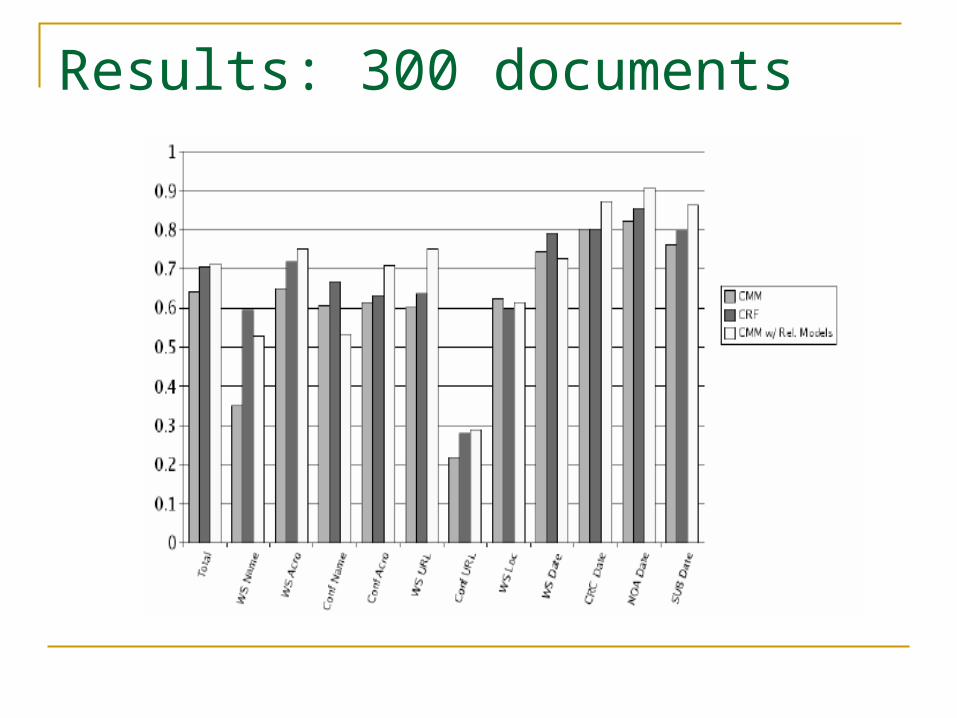
Results: 300 documents

Results
No results over CRF CRF accepts variation (ex: name)
=> lower recall
Rel. Model does not improve CRF (not on graph) Low-window of CRF => less info in distribution.
Substantial improvement over CMM (5%)

Plan
Relation Extraction description
Sampling templates
Reducing deep analysis errors (Zao, Grishman)
Conclusion

Problematic
Use different syntactic analysis for the task: Tokenization Chunking Sentence Parsing …
The more info they give, the less accurate they are.
=>combine them to correct errors

ACE task… remember
Entities: PERPERson – ORGORGanisation – FACFACility –
GGeoPPoliticEEntity - LOCLOCation – WEAWEApon – VEHVEHicle Mentions:
NAM NAM (proper), NOM , NOM (nominal), PRO , PRO (pronoun) Relations:Relations:
EMP-ORG, PHYS, GPE-AFF, PER-SOC, DISC, EMP-ORG, PHYS, GPE-AFF, PER-SOC, DISC, ART, OtherART, Other

Kernel, SVM … nice properties Kernel:
Function replacing scalar vector products Enables us to translate problems into a higher-
dimension space for solution Sum, product generates kernels.
SVM: SVM can pick up features for best separation

The relational model
R=(arg1, arg2, seq, link, path) arg1, arg2: the two entities to compare seq=(t1, …, tn): sequence of tokens intervening link=(t1, …, tm): idem seq but just with important words path: a dependency path…
T=(word, pos, base) pos: Part Of Speech tagging base: morphological base
E=(tk, type, subtype, mtype) type: according to ACE type subtype: refining mtype: the way it is mentioned
DT=(T, dseq) dseq=(arc1, …, arcn)
ARC=(w, dw, label, e) w: current token dw: token connected to w label: role label of this arc e: direction of the arc

The relational model: examplearg1=((“areas”, “NNS”, “area”,
dseq), “LOC”, “region”, “NOM”)
arg1.dseq=((OBJ, areas, in, 1), (OBJ, areas, controlled, 1))
path=((OBJ, areas, controlled, 1), (SBJ, controlled, troops, 0))

Kernels
1. Argument kernel: Matches two tokens,
comparing each fix arguments (word, pos, type…)
2. Bigram kernel: Matches token on a
window of size 1
3. Link sequence kernel: Relations often occur in
a short context.

Kernels (2)
4. Dependency path kernel: How similar are two paths?
5. Local dependency kernel: Idem as path but more
informative. Helpful if dependency path
does not exist.

Results: adding info into SVM The more information
we give, the better the result.
Link Sequence Kernel boosts results.

Results: SVM or KNN
SVM behaves globally better
Polynomial extension has no consequence on KNN.
Training problem in the last three.
… good results over ACE official task… secret, no comparison available

Conclusion
Really simple method Nice properties of Kernel/SVMs This method is generic!!! (tested on
annotated text)
Looks like SVM can process better, for this task.
… but hard to compare the two methods as goals are different.

References
[1] Template Sampling for Leveraging Domain Knowledge in Information Extraction. Cox, Nicolson, Finkel, Manning, Langley. Stanford University.
[2] Extracting Relations with Integrated Information Using Kernel Methods. Zao, Grishman. New York University. 2005





























