Embed Size (px)
Citation preview

Record Counting in Historical
Handwritten Documents with
Convolutional Neural Networks
Samuele Capobianco
Artificial Intelligence Lab
Prof. Simone Marinai

Outline
1. Counting Records
Proposed Solution
2. Synthetic Document Generation
Generator Tool
3. Experiments
Results
4. Conclusion
Future works
2

Counting Records

Historical Handwritten Documents
Historical handwritten structured documents
• Census, birth records, other public or private collections
• Reconstruct genealogies, perform demographic research
• Structured documents with records
4

Understanding Handwritten Structured Documents
• Automatic transcription is a complex task
• Split in sub-task
• counting record for each page
• automatic record segmentation
• Produce ground-truth is expensive
5

Record Counting for Handwritten Documents
• Count the number of records for each page
• Provide valuable information for document collections
• Produce ground-truth is easier then segmentation task
6

Proposed Solution
Problem:
• High variability on document structure
• A collection has been produced by several writers
• Labeled collections are not large
7

Proposed Solution
Solution:
• Emulate a document production process with a generator
tool
• Generate synthetic dataset for training a prediction model
• Fine-tuning the best model on real ”smaller” document
collection
8

Synthetic Document Generation

Flowchart
Generation of synthetic handwritten documents
• Given a document collection
• Define the page structure
• Extract realistic background from the collection
• Generate synthetic dataset adding data augmentation10

Tool Features
• Define the page structure:
• static header
• record structure with flexible guidelines
• Modeling the writer behaviour
• different fonts
• different orientations and dimensions
• random text line positioning
• Modeling the document background
• pre-printed or empty page structure
• random noise
• extract the background from real samples
• Data augmentation
• random rotation
• salt-pepper noise11

Examples
12

Experiments
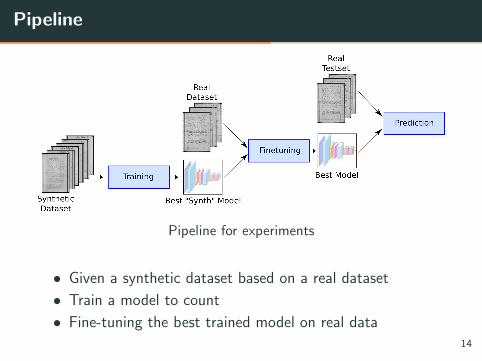
Pipeline
Pipeline for experiments
• Given a synthetic dataset based on a real dataset
• Train a model to count
• Fine-tuning the best trained model on real data14

The Five Centuries of Marriages Dataset
Some example from a real collection
• Marriage license books
• 200 labeled images with 5, 6 or 7 records for page
• Records with three columns (body, name and tax)
• RGB images, large dimension15

Deep ConvNet to count records
Model architecture
• One output neuron for regression task
• Resize the image to 256 × 366 pixels
• Input values: grayscale or black-white values
• Weight initialization using ”xavier” method
16

Measures and Testing Approach
• Measures for performance
• Accuracy
• Error:
N∑i=1|bpi+ 1
2c−ri |
N∑i=1
ri
• Score:|N∑i=1
ri−N∑i=1
pi |
N∑i=1
ri
• Cross-validation: 5 folds
• The train/test splits for segmenting/counting task
(train:150, valid:10, test:40)
17

Training on Synthetic Data
Table 1: Results with five fold cross-validation
Folds Accuracy Error Score
1 0.927 0.013 0.015
2 0.927 0.013 0.001
3 0.825 0.030 0.025
4 0.875 0.021 0.013
5 0.789 0.036 0.030
Average 0.869 0.023 0.015
• Using input images with black-white values
18

Benchmark comparison
Table 2: Results on benchmark split
Folds Accuracy Error Score
Training 0.833 0.029 0.016
Validation 0.600 0.070 0.025
Test 0.900 0.017 0.016
• Training on ”synthetic” data, the ”real” train-set used
only for validation
• Comparison with the previous results1
1Francisco Alvaro et al. “Structure detection and segmentation of
documents using 2D stochastic context-free grammars”. In:
Neurocomputing 150 (2015).
19

Finetuning the model
Table 3: Results on benchmark split
Folds Accuracy Error Score
Training 1.000 0.000 0.001
Validation 0.800 0.035 0.001
Test 1.000 0.000 0.002
• Fine-tuning the best model on ”real” trainset
• Data augmentation for the small ”real” trainset
• Improve the results
20

Conclusion

Future works
• Add features to generator tool
• Extend this CNN architecture
• Moving forwards the segmentation task
22

Conclusion
• Training a CNN on large synthetic structured documents
address the record counting task on real dataset
• Fine-tuning the trained model on ”real” few data
improves the results
• Better results using input images with binary values
23

Questions?
24

Examples
(a) Network 1 (b) Network 2
(c) Network 3 (d) Network 4
The average and standard deviation of critical parameters: Region
R4
25




![Arabic Handwritten Characters Recognition using Convolutional Neural … · 2018-05-25 · achieve a recognition rate of 73.4% with feature set 3 for Arabic letters. Kef et al. [24]](https://img.pdfslide.us/doc/110x75/5f521b2a51c66066ce5aff4c/arabic-handwritten-characters-recognition-using-convolutional-neural-2018-05-25.jpg)
























