Embed Size (px)
Citation preview

1
Qual Presentation
Daniel Khashabi

2
Outline My own line of research Papers:
Fast Dropout training, ICML, 2013 Distributional Semantics Beyond Words: Supervised Learning
of Analogy and Paraphrase, TACL, 2013.

3
Current Line of Research Conventional approach to a classification problem:
Problems: Never use the label information
Lose the structure in the output Limited to the classes in the training set Hard to leverage unsupervised data

4
Current Line of Research For example take the relation extraction problem:
Conventional Approach: Given sentence s and mentions e1 and e2, find their relation: Output:
“Bill Gates, CEO of Microsoft ….”
Manager
{𝑠 ,𝑒1 ,𝑒2 }→𝑟
𝑟 ∈𝑅={𝑅1 ,... ,𝑅𝑑}

5
Current Line of Research Let’s change the problem a little:
Create a claim about the relation:
“Bill Gates, CEO of Microsoft ….”
R = Manager
Text=“Bill Gates, CEO of Microsoft ….”
Claim=“Bill Gates is manager of Microsoft”
True

6
Current Line of Research Creating data is very easy!
What we do: Use knowledge bases to find entities that are related Find sentences that contain these entities Create claims about the relation inside the original sentence Ask Turker’s to label it
Much easier than extracting labels and labelling
7
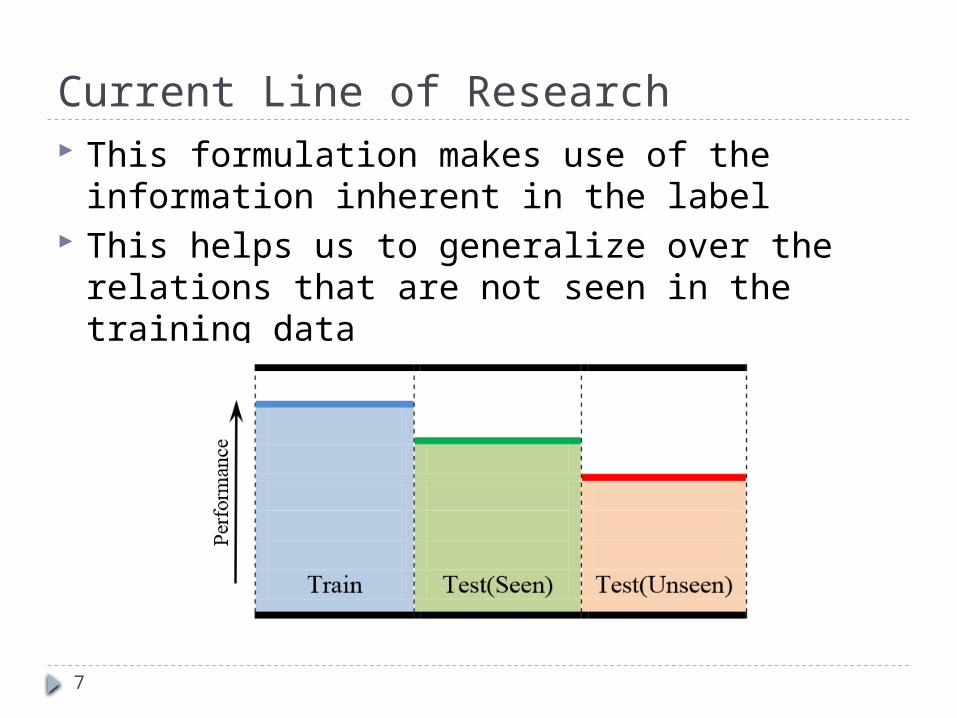
Current Line of Research This formulation makes use of the information inherent in
the label This helps us to generalize over the relations that are not
seen in the training data

8
Outline My own line of research Papers:
Fast Dropout training, ICML, 2013 Distributional Semantics Beyond Words: Supervised Learning
of Analogy and Paraphrase, TACL, 2013.

9
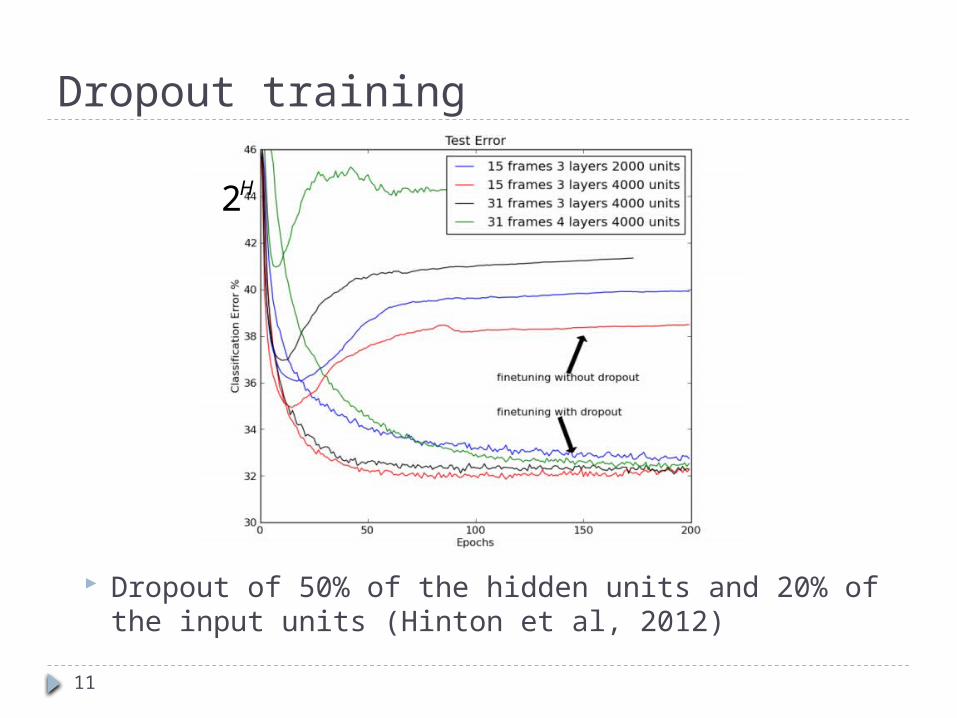
Dropout training Proposed by (Hinton et al, 2012)
Each time decide whether to delete one hidden unit with some probability p

10
Dropout training Model averaging effect
Among models, with shared parameters Only a few get trained Much stronger than the known regularizer
What about the input space? Do the same thing!
2H
11
Dropout training Model averaging effect
Among models, with shared parameters Only a few get trained Much stronger than the known regularizer
What about the input space? Do the same thing!
Dropout of 50% of the hidden units and 20% of the input units (Hinton et al, 2012)
2H

12
Outline Can we explicitly show that dropout acts as a regularizer?
Very easy to show for linear regression What about others?
Dropout needs sampling Can be slow!
Can we convert the sampling based update into a deterministic form? Find expected form of updates

13
Linear Regression Reminder:
Consider the standard linear regression
With regularization:
Closed form solution:
Tg w x
2* ( ) ( )arg min T i i
w i
w w x y
2( ) ( ) 2( ) T i ii
i i
L w w x y w
1T Tw X X I X y
~ ( )i iz Bernoulli p i iz p E
(1 )i i iz p p Var

14
Dropout Linear Regression Consider the standard linear regression
LR with dropout:
How to find the parameter?
Tg w x~ ( )i i ix z Bernoulli p
1( ,..., )z mD diag z z
Tzw D x
2( ) ( )( ) T i iz
i
L w w D x y

15
Fast Dropout for Linear Regression We had:
Instead of sampling, minimize the expected loss
Fixed x and y:
2
1
, ~ ( , )m
Tz i i i S S
i
w D x w x z S S N
S
2
1
(1 )m
i i i ii
w x p p
2( ) ( )( ) T i iz
i
L w w D x y
2Tzw D x y
E
1
m
i i ii
w x z
ETzw D x E
1
m
i i ii
w x p
2S T
zw D x Var 2
1
m
i i ii
w x z
Var

16
Fast Dropout for Linear Regression We had:
Instead of sampling minimize the expected loss:
Expected loss:
2
1
, ~ ( , )m
Tz i i i S S
i
w D x w x z S S N
2( ) ( )( ) T i iz
i
L w w D x y
2
2 2
~ ( , )S S
Tz S N
w D x y S y
E E
( )2( ) ( ) 2( ) ( )ii i
S Si
L w L w y E
2 2( ) ( ) 2 ( ), i i jS i i i i
i i j
y c w c x
2 2S Sy

17
Fast Dropout for Linear Regression Expected loss:
Data-dependent regulizer Closed form could be found:
( )2( ) ( ) 2( ) ( )ii i
S Si
L w L w y E
2 2( ) ( ) 2 ( ), i i jS i i i i
i i j
y c w c x
1( )T T Tw X X diag X X X y

18
Some definitions Dropout each input dimension randomly: Probit:
Logistic function / sigmoid :
2 /21( )
2
xtx e dt
1( )
1 zz
e

19
Some definitions useful equalities Useful equalities
We can find the following expectation in closed form:
2
2 2( ) ( ; , ) ( )x N x s dx
s
( ) ( )8
x x
2
2( ) ( ; , ) ( )
8 1x N x s dx
s
2~ ( , )( )
S NS
E

20
Logistic Regression Consider the standard LR
The standard gradient update rule is
For the parameter vector
1( 1| ) ( )
1T
T
w xP Y X x w x
e
( ( ))Tj jw y w x x
log ( ( ))Tw y w x x

21
Dropout on a Logistic Regression Dropout each input dimension randomly:
For the parameter vector
Notation:
~ ( )i i ix z Bernoulli p 1( ,..., )z mD diag z z
log ( ( )) ( ( ))T Tz zw y w x x w y w D x D x
-th dimension of ix i x( ) -th training instancejx j
( ) -th dimension of -th instancejix i j
1 i m 1 j n

22
Fast Dropout training Instead of using we use its expectation: w
; ~ ( )i iavg z z Bernoulli pw w E
2
1
, ~ ( , )m
Tz i i i S S
i
w D x w x z S S N
1 1
m mT
S z i i i i i ii i
w D x w x z w x p
E E
2 22
1 1
(1 )m m
TS z i i i i i i i
i i
w D x w x z w x p p
Var Var
; ~ ( ) ( ( ))i i
Tz z Bernoulli p z zy w D x D x E

23
Fast Dropout training Approx:
By knowing:
How to approximate?
Option 1:
Option 2:
Have closed forms but poor approximations
; ~ ( ) ( ( ))i i
Tavg z z Bernoulli p z zw y w D x D x E
2, ~ ( , )Tz S Sw D x S S N
( ( ))S z zy S D xE E
( ( ))S z zy S D x E E
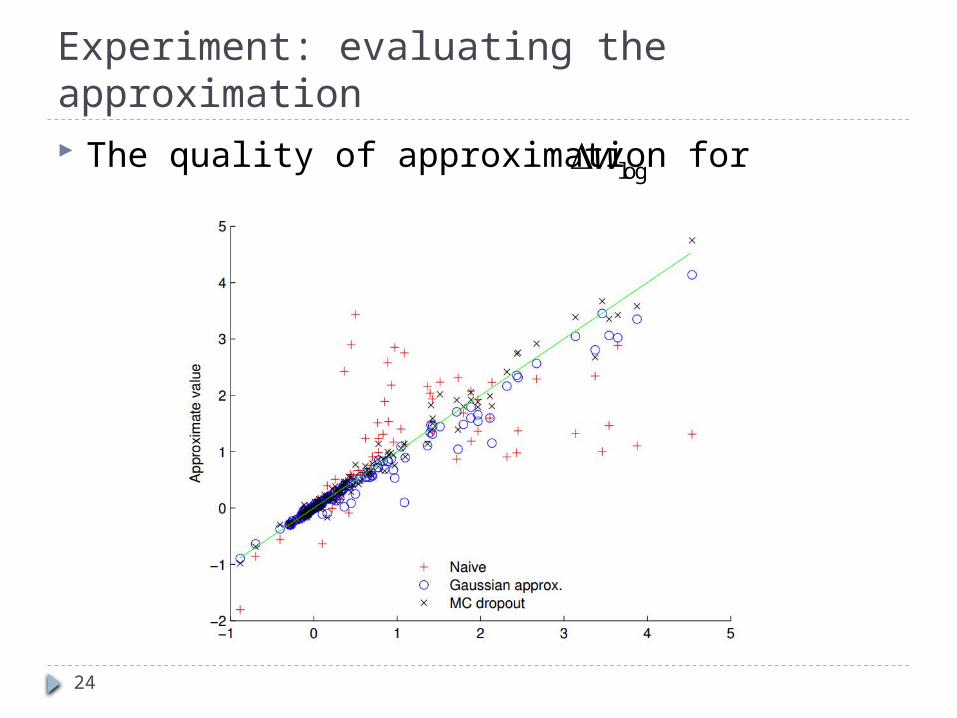
24
Experiment: evaluating the approximation The quality of approximation for logw
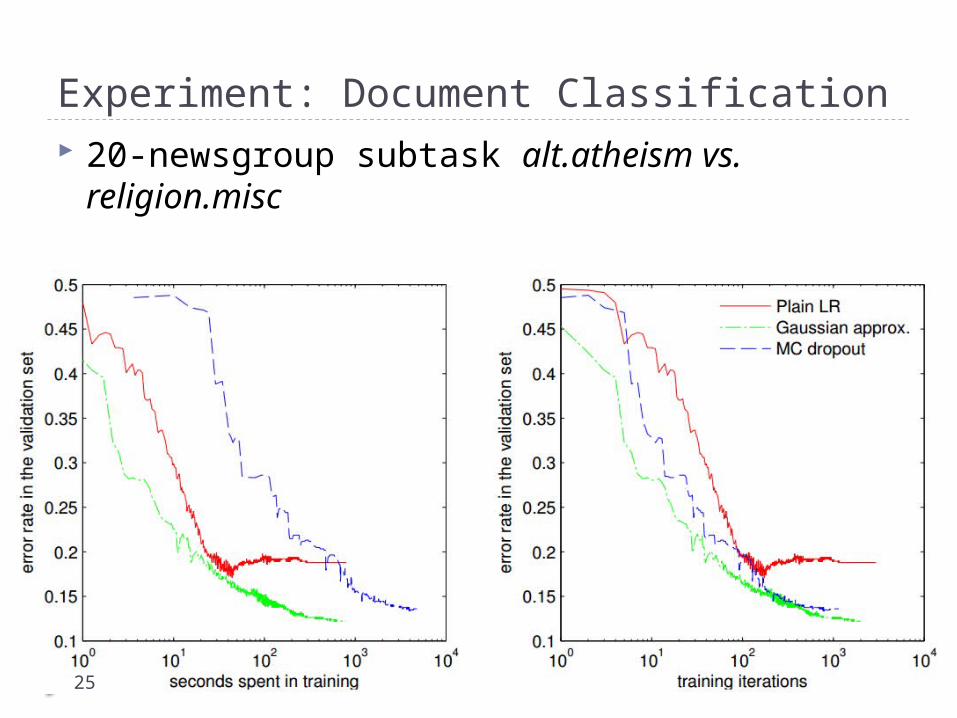
25
Experiment: Document Classification 20-newsgroup subtask alt.atheism vs. religion.misc

26
Experiment: Document Classification(2)

27
Fast Dropout training Approx:
By knowing:
; ~ ( ) ( ( ))i i
Tavg z z Bernoulli p z zw y w D x D x E
2, ~ ( , )Tz S Sw D x S S N
, ; ~ ( ) ( ( ))i i
Tavg i z z Bernoulli p z i iw y w D x z x E
( 1)i ip z x
| 1 ( ( ))i i
Ti i z z zp x y w D x
E
| 1 ( )i i
Ti i z z zp x y w D x
E
| 1 ( ) ?i i
Tz z zw D x E
| 1 ( ( ))i i
Tz z zy w D x E

28
Fast Dropout training We want to:
Previously:
which could be
found in closed form.
| 1 ( ) ?i i
Tz z zw D x E
2, ~ ( , ), ~ ( )Tz S S i iw D x S S N z Bern p
| 1i iz z
| 1 ( ) ( )i i i
Tz z z S iw D x S E E
S i i i i iw x z w x E
2S i i i i iw x z w x Var
2~ ( , )i ii S SS N T
z i i i i iw D x w x z w z
iS (1 )S i i iw x p 2
iS 2 2( ) (1 )S i i i iw x p p

29
Fast Dropout training We want to:
Previously:
deviates (approximately) from with and
Has closed form!
| 1 ( ) ?i i
Tz z zw D x E
2, ~ ( , )Tz S Sw D x S S N
2( ) (1 )i i i iw x p p
iS S 2
2
2 2
22 ( , )
( )S
S
NS
E
2| 1 ~ ( , )i i
Ti i z i i i i i i S Sz z w D x w x z w z S N
(1 ),i i iw x piS S 2 2 2
iS S
| 1 ( )i i
Tz z zw D x E 2( , )
( )S SN
S
E 2( , )( )
S
S
NS
E