Embed Size (px)
Citation preview

Proteogenomics:Refining and Improving
Genome Annotation
Samuel H Payne
J Craig Venter Institute

State of Genome Annotation
• Most prokaryotic genomes are auto-annotated.• Sequence and function are inferred with
comparative genomics; validation is sparse.• Difficulties with novel or HGT genes• Mature protein features
localization PTM, cleavage
Salzberg 2007

Diversity or Confusion

Proteomics
• Input: protein sample • Output: list of peptides

Proteogenomics
• Definition: using proteomics data to do genome annotation
• Goals: Find all coding regions of the genome,
annotated and unannotated Submit improved annotation to NCBI Identify “mature protein” features

Proteogenomics Protocol
• Data sources Yersinia pestis - Pieper et al., 2008, 2009 Bacillus anthracis – PRC/NIAID

Correcting Errors
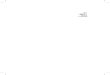
• Unannotated genes Both known and totally novel
Correcting Errors
• Unannotated genes Both known and totally novel

Correcting Errors
• Start site assignment

Exceptions to Rules
• Multi-ORF genes: self splicing, frame shift

Exceptions to Rules
• Non-canonical start codons infC – ATT (Sacerdot 1982, Payne 2010) in
enterobacteria; ATA in Shewanella (Gupta 2007) Deinococcus (Baudet 2009) suggests new non-
standard starts

Overlaps/Wrong Frames

Pseudo?genes
• Expression of ABC transporter n-terminus. Missing critical motif elements.
• 5 peptides (with splicing) map to a transposable element gene. Sequence alignment to an Arabidopsis Ulp1 Castellana 2008
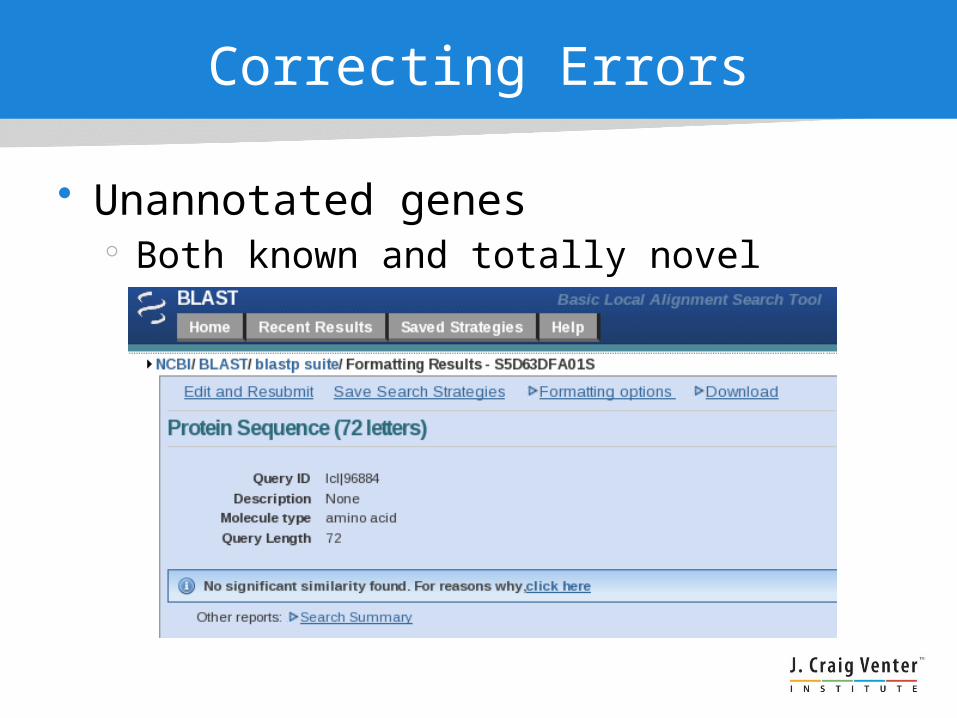
Signal Peptide
• N-terminal motif, target protein for export• 1983 Perlman & Halvorson
Early basic residue, hydrophobic patch, AxB motif– A = [I,V,L,A,G,S], B = [A,G,S]
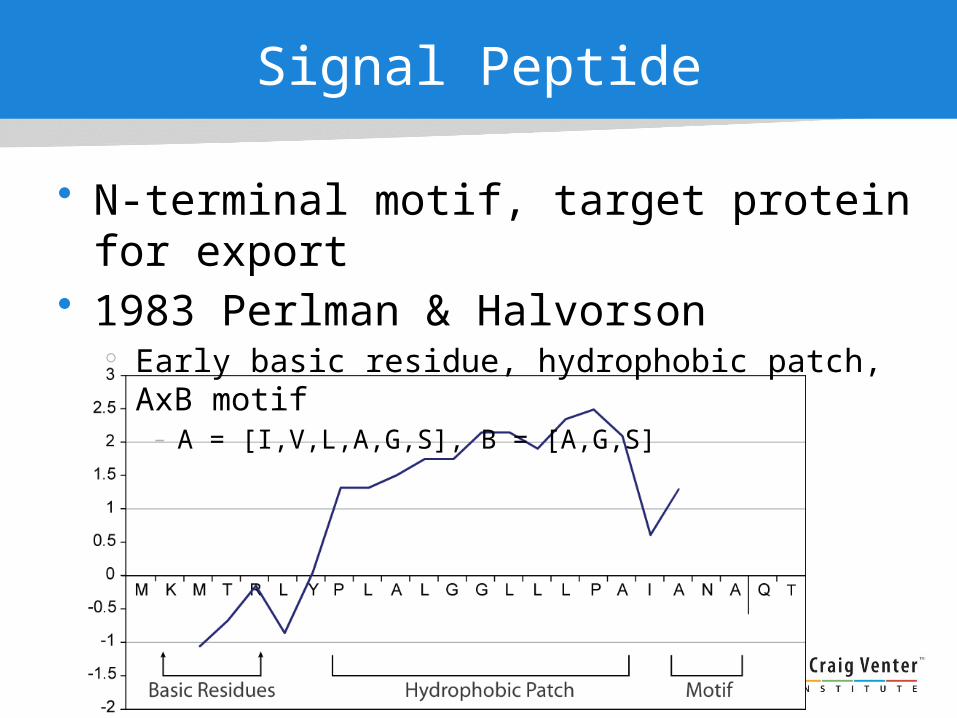
Profile of an Exported Protein
Early basic residue, hydrophobic patch, motif

Future
• Rinse and repeat• 30 proteomes in 3 years• Stable, robust pipeline for general use
Hosted at TeraGrid
Novel New Start
Y. pestis 4 5
B. anthracis 4 6
D. radiodurans 225 117
D. vulgaris 55 89
L. interrogans 20 23

When Gene Predictors Fail
• Are GC extremes difficult? 50% (Y. pestis) – 4 missed 30’s (B. anthracis, L.interrogans) 4, 20 60’s (D. vulgaris, D. radiodurans) 55, 225

Are They Strange?
• Relative GC – does it fail on genes with different GC from others?
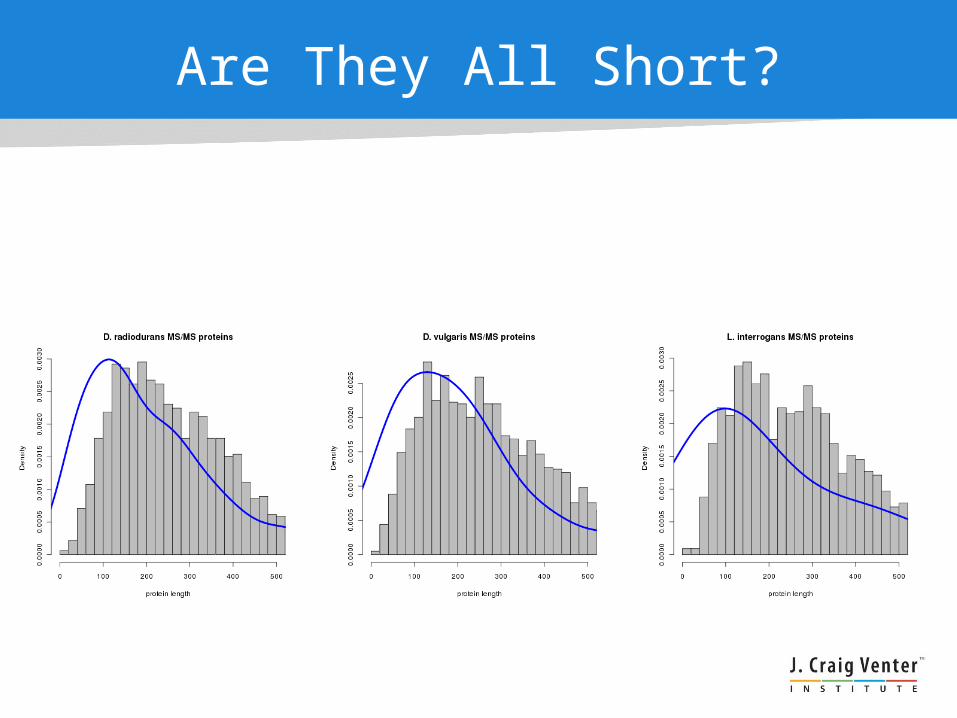
Are They All Short?
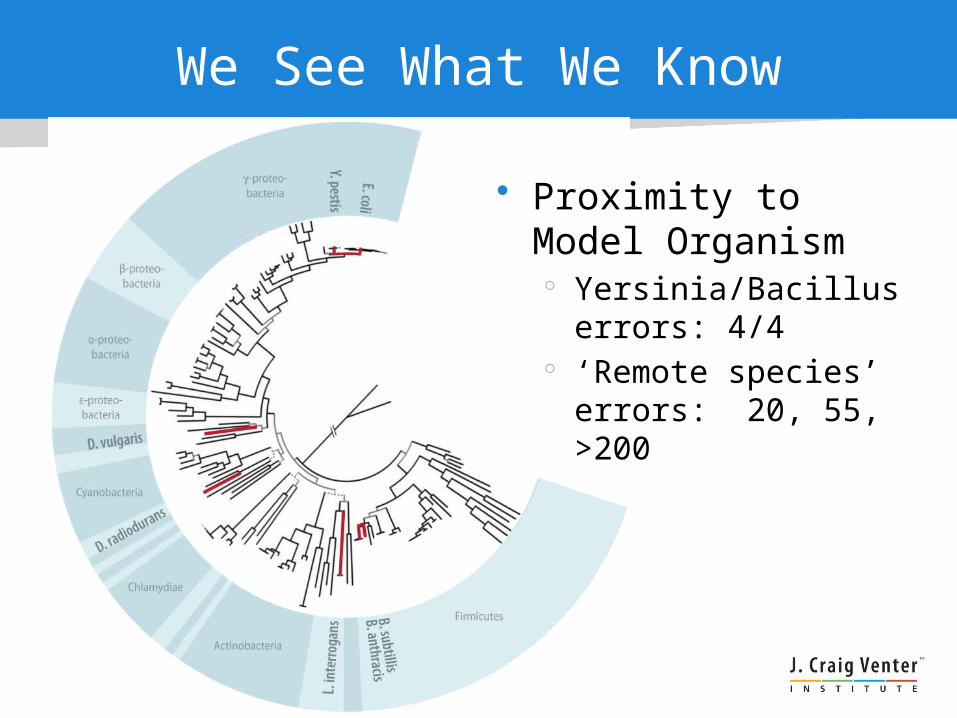
We See What We Know
• Proximity to Model Organism
Yersinia/Bacillus errors: 4/4
‘Remote species’ errors: 20, 55, >200

We See What We Know
• Hypothetical vs. Named Compare novel genes to observed proteome Hypergeometric where Null probability is from
the observed proteome
Hypothetical Named p-value
B. anthracis 3 1 0.018
L. interrogans 12 8 0.018
D. radiodurans 31 8 10-10
D. vulgaris 39 16 10-14

Expressed Protein Resource
• Protein Sequences >30 M sequences nr, uniprot JCVI metagenomics JGI genomes
• 40,000 clusters• Cross referenced with
proteomics, for validated proteins

Acknowledgements
• Eli Venter• Shih-Ting Huang, Rembert Pieper• Granger Sutton• Dick Smith, PNNL
• NSF