Embed Size (px)
Citation preview

Project Report Kerry Widder
Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture
Introduction:
Overview:This project explored the use of loop transformation techniques and loop vectorization using
subword parallel architectures to efficiently implement a portion of the H.264 video standard encoder. The focus was on the integer DCT-like 4x4 transform operation. This operation can be implemented using just add, subtract and shift operations (no multiplications), and was implemented on the PLX architecture. A significant improvement in efficiency was realized compared to a C-code implementation on an Intel® architecture platform.
Motivation:The processing of video images is a very computationally intensive task. The goal in such
processing is to maximize the perceived fidelity of the images. This task becomes more difficult as picture size or resolution increases. If the system processing the images can’t keep up with the quantity of computations, the result will be either loss of fidelity, loss of frames or other undesirable affects.
Several different approaches can be used to address this computation problem. One approach is to revise the algorithms used to process the video images to make the process more efficient (i.e., requiring fewer computations, or computations requiring less time to process). Another approach is to use a hardware platform that can process data faster (i.e., a processor with a higher clock rate, or wider data path, or faster memory, etc). A more holistic approach is to address all areas at the same time (i.e., use an architecture that is able to efficiently implement this type of algorithm).
One technique for increasing efficiency is subword parallelism. This technique essentially concatenates multiple data units into larger units and operates on these larger units. This results in the parallel computation of the same operation on multiple data units. This parallelism can be exploited to yield greater efficiency.
Prior Art:The H.264/AVC Video Coding Standard specifies an integer DCT-like 4x4 transform
designed to be computed using only additions, subtractions and shifts [1]. An additional advantage this transform has over the DCT transform is that the results only require an addition of 6 bits of dynamic range. Also, since it is an integer transform, there is no quantization error introduced by the encoding/decoding process.
An algorithm for implementing the H.264 transform was proposed by Malvar [2] that is applied first to the rows, then to the columns of the 4x4 image matrix. This type of formulation would seem to be a likely candidate for efficient implementation using subword parallel instructions.
A subword parallel implementation of a 4x4 matrix transpose operation was demonstrated by Lee [3] for the PLX architecture using only the ‘mix’ instruction. This implementation was given in the context of illustrating the use of subword parallelism in performing a DCT transform. The PLX architecture is under development by Lee and her group at Princeton. It is
ECE734 – Spring 2006 1 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
an Instruction Set Architecture (ISA) that is being designed to support subword parallelism (unlike most architectures that have added subword parallelism support as an enhancement to an existing architecture).
Problem Description:
H.264 Video encoding transform:The H.264 video standard specifies a transform for the residual data that has many
advantages over the DCT transform used with previous standards. This transform is similar, but with some significant improvements. It operates on a 4x4 block of data, uses integer arithmetic and only requires addition and shift operations (no multiplies). The dynamic range using these constraints is kept within a 16-bit word size. The lack of fractional numbers also reduces the chance of decoding errors.
The transform operates on the image data, X, with a transform matrix, C, and produces an output matrix, Y. The equation is
, where
resulting in a transformation:
This transformation can be implemented simply using the algorithm represented by the flow graph [2] in figure 1. These operations are applied to the rows of X, then to the columns of the intermediate result. This algorithm is implemented using C-code in the H.264 reference software, JM10.2 [4]. The residual 4x4 transform is located in function dct_luma() in module block.c. The portion of this function that does the transform operation was made into a standalone program that performs the transform on a fixed block of data. This result was used to check the validity of the PLX code functionality. The assembly code generated for this file was also compared with the PLX assembly code. (See Appendix A1 for a complete listing of the function.)
ECE734 – Spring 2006 2 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
Figure 1: Transform Algorithm Flow Graph.
PLX ISA:The PLX ISA was designed to support subword parallel operations, unlike other
architectures that have added this capability as an afterthought. It has 32 registers that are each either 32, 64, or 128 bits wide, depending on the data path specification of the particular PLX device. This large number of registers allows more data to be loaded into registers at any given time, thereby potentially reducing the time spent in slow accesses to RAM. The instruction set includes flexible subword parallel arithmetic operations, full data width loads from memory and pipelined operation, effectively allowing single cycle operation of most instructions. There are also some subword permutation instructions (e.g., mix, check, mux) which can be exploited to achieve efficient implementations of some algorithms.
The mix instruction has been demonstrated to be useful for efficiently performing matrix transpose operations on a 4x4 matrix [1]. This algorithm was coded as a macro for use in this project and is shown in figure 2 below. L1 – L4 are the input registers, and K1 – K4 contain the result. If registers are at a premium in a particular application, the macro can be called with Kn = Ln to minimize register usage. (Note: Rtemp1 – Rtemp4 must be defined elsewhere in the program.)
trans4x4 macro L1,L2,L3,L4,K1,K2,K3,K4mix.2.l Rtemp1,L1,L2mix.2.r Rtemp2,L1,L2mix.2.l Rtemp3,L3,L4mix.2.r Rtemp4,L3,L4mix.4.l K1,Rtemp1,Rtemp3mix.4.l K3,Rtemp2,Rtemp4mix.4.r K4,Rtemp1,Rtemp3mix.4.r K2,Rtemp2,Rtemp4endm
Figure 2: PLX Transpose Macro
ECE734 – Spring 2006 3 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
Approach:
The approach used to seek an efficient implementation of the transform involved several steps. The transform was analyzed to learn more details of how it worked and to get a bound on the dynamic range of the results. Then the reference encoder was analyzed to see how it could be modified using loop transformation techniques to achieve efficiency through parallel operations. These parallel operations were then realized using the PLX architecture, simulated, and the results were compared to the C-code realization in the reference encoder.
Transform Analysis:One important consideration in developing an implementation of an algorithm is the
dynamic range of the data for the operations to be performed. One way to determine this range would be to symbolically perform the two matrix multiplications and examine all the terms. Several of these terms follow:
Y11 = (X11+X21+X31+X41)+( X12+X22+X32+X42)+( X13+X23+X33+X43)+( X14+X24+X34+X44)
Y12 = 2*(X11+X21+X31+X41)+( X12+X22+X32+X42)-( X13+X23+X33+X43)-2*( X14+X24+X34+X44)
Y22 = 2*(2*X11+X21-X31-2*X41)+( 2* X12+X22-X32-2*X42)-( 2*X13+X23-X33-2*X43)-2*( 2*X14+X24-X34-2*X44)
In the case of Y11, it is just the sum of all sixteen X values, so its dynamic range would be 16 times that of the individual values (which are 9-bit prediction residuals [2]), or 13-bits. For Y12, the maximum range would occur if one half of the equation had all zero values. In this case, the result is essentially the sum of 12 values, so its dynamic range would be +/- 13-bits. For Y22, the range for each expression in the parentheses is +/- 3*9-bit. The maximum range occurs when the signs of these expressions in the first half are opposite those in the second half, resulting in a range of (2*3 + 3 –(-3) -2*(-3))*9-bit, or 18*9bit. Thus, for Y22, 14-bits plus one sign bit are required.
Instead of continuing this process, which is tedious, let us look at it a different way. We will do the matrix multiplication in two steps, only instead of writing down all the terms explicitly, we will just keep track of the multiplier on the range. For example, if the matrix multiply results in a term that could be four times the range of the starting value, then we will represent that term by the number 4. If there are some subtractions involved in calculating the term and it could be positive or negative, then we will represent this case by prefixing the number with a ~.
Several examples of how these numbers are derived will be instructive for understanding the process. If we multiply C by X, the first term in the result will be (X11+X21+X31+X41). This is the sum of four 9-bit values, so the range would increase by a factor of +4, therefore we represent this result as 4. The (2,2) term of this multiply operation would be ( 2* X12+X22-X32-2*X42). This is essentially the sum of three 9-bit values, so the range would increase by a factor of 3, but it could be +3 or -3, therefore we represent this result as ~3. The values obtained in this manner are shown below in two stages, first multiply C by X, then that result by CT.
ECE734 – Spring 2006 4 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
Thus, we see that the maximum possible increase in range is +/- 18 times, which means 9+5 bits, plus 1 sign bit, or a total of 15 bits required to prevent overflow. Thus, if 16-bit signed values are used in the algorithm, no overflow errors will result.
Software Algorithm Analysis:The reference encoder implements the transform algorithm in C. It does so with two loops.
One is executed four times to do the transform on each row of the matrix (the ‘horizontal’ transform), then the other is executed four times to do the transform on each column of the result (the ‘vertical’ transform). The ‘horizontal’ transform code snippet is shown below in figure 3. The temporary vector m5[], used to store intermediate results, is reused by each iteration of the loop. If the loop is to be ‘vectorized’, we must perform index localization on this variable. In figure 4, the result of index localization on this loop is seen. Now this loop can be vectorized for parallel execution.
// Horizontal transformfor (j=0; j < 4; j++) { m5[0] = img->m7[j][0]+img->m7[j][3]; m5[1] = img->m7[j][1]+img->m7[j][2]; m5[2] = img->m7[j][1]-img->m7[j][2]; m5[3] = img->m7[j][0]-img->m7[j][3]; m4[j][0] = m5[0] + m5[1]; m4[j][2] = m5[0] - m5[1]; m4[j][1] = m5[3]*2 + m5[2]; m4[j][3] = m5[3] - m5[2]*2; }
Figure 3: Original Transform Algorithm Code
ECE734 – Spring 2006 5 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
// Horizontal transform for (j=0; j < 4; j++) { m5[j ][ 0] = img->m7[j][0]+img->m7[j][3]; m5[j ][ 1] = img->m7[j][1]+img->m7[j][2]; m5[j ][ 2] = img->m7[j][1]-img->m7[j][2]; m5[j ][ 3] = img->m7[j][0]-img->m7[j][3]; m4[j][0] = m5[j ][ 0] + m5[j ][ 1]; m4[j][2] = m5[j ][ 0] - m5[j ][ 1]; m4[j][1] = m5j ][ 3]*2 + m5[j ][ 2]; m4[j][3] = m5[j ][ 3] - m5[j ][ 2]*2; }
Figure 4: Transform Algorithm Code after Index Localization
Subword Parallel Implementation in PLX:Subword parallel instructions provide a mechanism for performing loop operations in
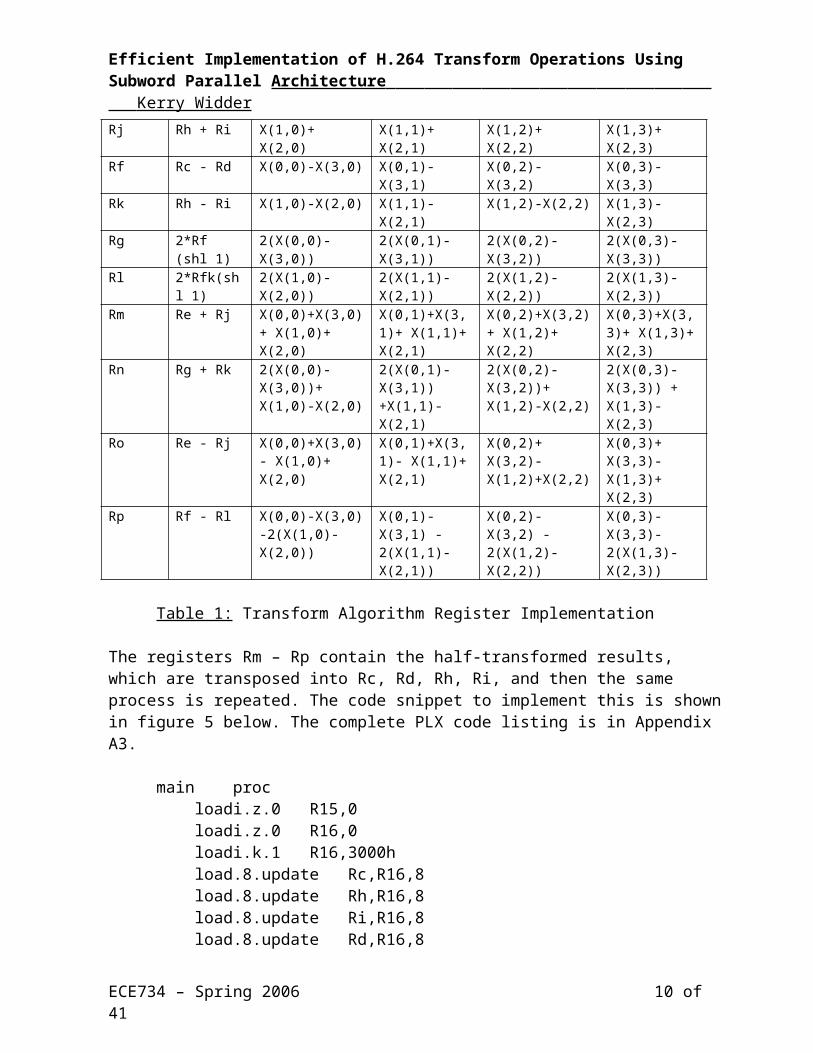
parallel. A 64-bit PLX architecture, with 64-bit registers, allows operations on 4 values in each register, since we need to use 16-bit values in the algorithm. The algorithm can be implemented in PLX by loading each row of the 4x4 matrix into a 64-bit register, then doing parallel arithmetic operations on the columns to perform the first half of the transform. Then, the mix instruction can be used to transpose the results, then repeat the transform process and finally do another transpose to get the values in the proper place.The implementation of the algorithm is shown in table 1 below, where the registers, their content and the operations on the registers are shown.
Register Operation Register valuesRc Load X(0,0) X(0,1) X(0,2) X(0,3)Rd Load X(3,0) X(3,1) X(3,2) X(3,3)Rh Load X(1,0) X(1,1) X(1,2) X(1,3)Ri Load X(2,0) X(2,1) X(2,2) X(2,3)Re Rc + Rd X(0,0)+X(3,0) X(0,1)+X(3,1) X(0,2)+ X(3,2) X(0,3)+ X(3,3)Rj Rh + Ri X(1,0)+ X(2,0) X(1,1)+ X(2,1) X(1,2)+ X(2,2) X(1,3)+ X(2,3)Rf Rc - Rd X(0,0)-X(3,0) X(0,1)-X(3,1) X(0,2)- X(3,2) X(0,3)-X(3,3)Rk Rh - Ri X(1,0)-X(2,0) X(1,1)-X(2,1) X(1,2)-X(2,2) X(1,3)- X(2,3)Rg 2*Rf (shl 1) 2(X(0,0)-X(3,0)) 2(X(0,1)-X(3,1)) 2(X(0,2)- X(3,2)) 2(X(0,3)-X(3,3))Rl 2*Rfk(shl 1) 2(X(1,0)- X(2,0)) 2(X(1,1)-X(2,1)) 2(X(1,2)-X(2,2)) 2(X(1,3)-X(2,3))Rm Re + Rj X(0,0)+X(3,0)+
X(1,0)+ X(2,0)X(0,1)+X(3,1)+ X(1,1)+ X(2,1)
X(0,2)+X(3,2)+ X(1,2)+ X(2,2)
X(0,3)+X(3,3)+ X(1,3)+ X(2,3)
Rn Rg + Rk 2(X(0,0)-X(3,0))+ X(1,0)-X(2,0)
2(X(0,1)-X(3,1)) +X(1,1)-X(2,1)
2(X(0,2)- X(3,2))+ X(1,2)-X(2,2)
2(X(0,3)-X(3,3)) + X(1,3)- X(2,3)
Ro Re - Rj X(0,0)+X(3,0)- X(1,0)+ X(2,0)
X(0,1)+X(3,1)- X(1,1)+ X(2,1)
X(0,2)+ X(3,2)-X(1,2)+X(2,2)
X(0,3)+ X(3,3)- X(1,3)+ X(2,3)
Rp Rf - Rl X(0,0)-X(3,0) -2(X(1,0)- X(2,0))
X(0,1)-X(3,1) -2(X(1,1)-X(2,1))
X(0,2)- X(3,2) -2(X(1,2)-X(2,2))
X(0,3)-X(3,3)- 2(X(1,3)-X(2,3))
Table 1: Transform Algorithm Register Implementation
ECE734 – Spring 2006 6 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
The registers Rm – Rp contain the half-transformed results, which are transposed into Rc, Rd, Rh, Ri, and then the same process is repeated. The code snippet to implement this is shown in figure 5 below. The complete PLX code listing is in Appendix A3.
main proc loadi.z.0 R15,0 loadi.z.0 R16,0 loadi.k.1 R16,3000h
load.8.update Rc,R16,8load.8.update Rh,R16,8load.8.update Ri,R16,8load.8.update Rd,R16,8
main_frame:padd.2.s Re,Rc,Rd padd.2.s Rj,Rh,Ri psub.2.s Rf,Rc,Rd psub.2.s Rk,Rh,Ri
pshifti.2.l Rg,Rf,1 pshifti.2.l Rl,Rk,1
padd.2.s Rm,Re,Rj padd.2.s Rn,Rk,Rg psub.2.s Ro,Re,Rj psub.2.s Rp,Rf,Rl
trans4x4 Rm,Rn,Ro,Rp,Rc,Rd,Rh,Ri addi R15,R15,1 cmpi.leu R15,1,P1,P2P1 jmp main_frame
Figure 5: Transform Algorithm PLX Code
Results:
The C-code comparison routine was compiled under Visual Studio with SSE2 enabled, although the compiler didn’t actually generate any SSE2 code. The assembly code generated by the compiler was analyzed and compared with the PLX code (see Appendix A2 for complete assembly listing). The cycle counts for the assembly instructions were obtained from the Intel manual[5].
The PLX code was compiled and simulated using the tools available from Lee’s group at Princeton. The image input data for the simulation was the 4x4 matrix X defined as:
ECE734 – Spring 2006 7 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
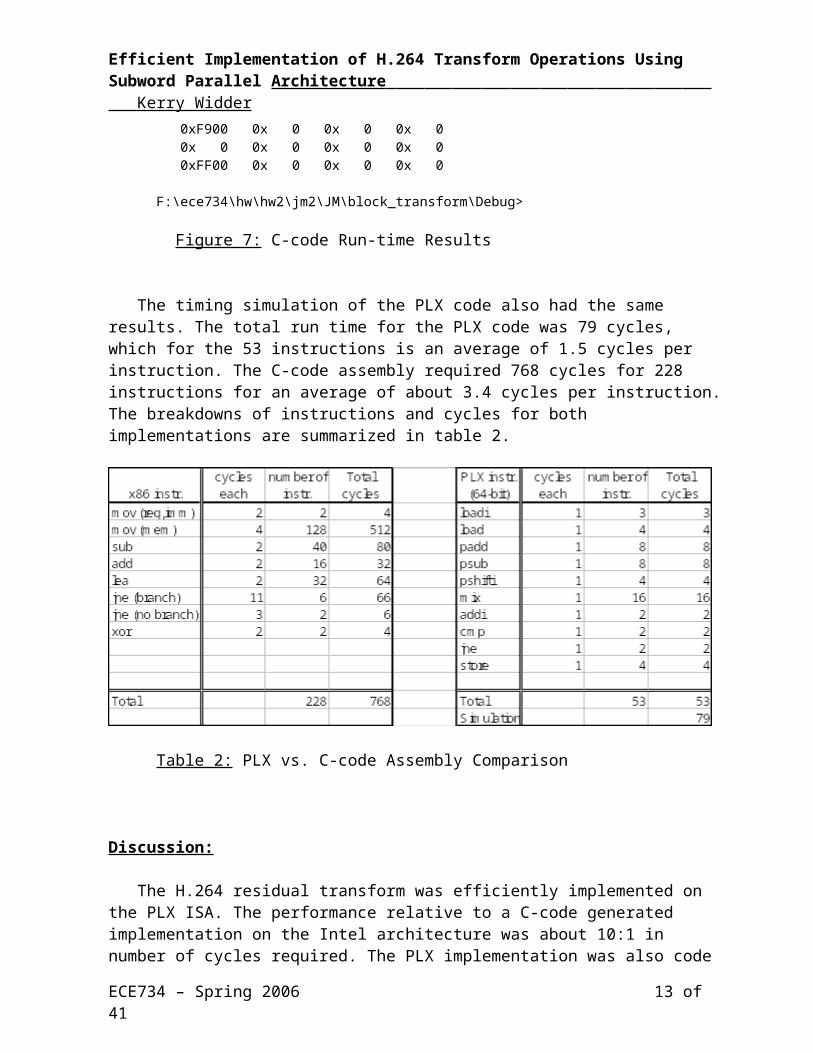
The functional simulation results agreed with the results obtained from the C-code. See figures 6 and 7 (with the PLX result values highlighted in gray). This shows the correctness of the PLX implementation. The full simulation results are in Appendix A4.
#58:0000006C(207FFFB0) P1 jmp 0000001Ch========(Skip)#59:00000070(0F860008) P0 store.8.update R1,R16,8======== --src1(R1)=0x0780FE400000FFC0 src2(R16)=0x0000000030000020#60:00000074(0F8E0008) P0 store.8.update R3,R16,8======== --src1(R3)=0xF900000000000000 src2(R16)=0x0000000030000028 --SRAMW:A=00000028 D=0780FE400000FFC0#61:00000078(0F920008) P0 store.8.update R4,R16,8======== --src1(R4)=0x0000000000000000 src2(R16)=0x0000000030000030 --SRAMW:A=00000030 D=F900000000000000#62:0000007C(0F8A0008) P0 store.8.update R2,R16,8======== --src1(R2)=0xFF00000000000000 src2(R16)=0x0000000030000038 --SRAMW:A=00000038 D=0000000000000000#63:00000080(0380FFFF) P0 trap FFFFh======== --SRAMW:A=00000040 D=FF00000000000000
Figure 6: PLX Code Functional Simulation Results
F:\ece734\hw\hw2\jm2\JM\block_transform\Debug>block_transformH.264 DCT-like transform, 4x4 matrix
Input matrix: 0x 0 0x 10 0x 20 0x 30 0x 40 0x 50 0x 60 0x 70 0x 80 0x 90 0x A0 0x B0 0x C0 0x D0 0x E0 0x F0
Output matrix: 0x 780 0xFE40 0x 0 0xFFC0 0xF900 0x 0 0x 0 0x 0 0x 0 0x 0 0x 0 0x 0 0xFF00 0x 0 0x 0 0x 0
F:\ece734\hw\hw2\jm2\JM\block_transform\Debug>
Figure 7: C-code Run-time Results
The timing simulation of the PLX code also had the same results. The total run time for the PLX code was 79 cycles, which for the 53 instructions is an average of 1.5 cycles per instruction.
ECE734 – Spring 2006 8 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
The C-code assembly required 768 cycles for 228 instructions for an average of about 3.4 cycles per instruction. The breakdowns of instructions and cycles for both implementations are summarized in table 2.
Table 2: PLX vs. C-code Assembly Comparison
Discussion:
The H.264 residual transform was efficiently implemented on the PLX ISA. The performance relative to a C-code generated implementation on the Intel architecture was about 10:1 in number of cycles required. The PLX implementation was also code efficient, requiring less than one fourth of the number of instructions. This implementation required the use of index localization, loop vectorization and subword parallel techniques to achieve this efficiency.
One key to efficiency is minimizing memory accesses. The C-code-generated assembly consisted of over half of the instructions being memory accesses, which accounted for about two-thirds of the execution time. Even in the PLX results, memory reads were slow, requiring 10 cycles to execute four reads.
This work could be extended in several areas. First, a better comparison to the Intel architecture’s capabilities could be obtained by comparing the PLX implementation to a hand-coded SSE2 implementation using the subword parallel features of the Intel architecture. Another area for further exploration would be the use of a 128-bit PLX architecture to see if the wider data path results in any significant improvement in performance for this algorithm. Finally, more pieces of the H.264 specification could be implemented on the PLX architecture.
ECE734 – Spring 2006 9 of 31
Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
Bibliography:
[1] T. Wiegand, G. J. Sullivan, G. Bjontegaard, and A. Luthra, “Overview of the H.264/AVC Video Coding Standard,” IEEE Transactions on Circuits and Systems for Video Technology, Vol. 13, No. 7, pp. 560-576, July 2003.
[2] H. Malvar, A. Hallapuro, M. Karczewicz, and L. Kerofsky: “Low-Complexity Transform and Quantization in H.264/AVC,” IEEE Transactions on Circuits and Systems for Video Technology, Vol. 13, No. 7, pp. 598-603, July 2003.
[3] R. Lee and A. M. Fiskiran, “PLX: An Instruction Set Architecture and Testbed for Multimedia Information Processing,” Journal of VLSI Signal Processing, Vol. 40, pp. 85–108, 2005
[4] K. Suhring, “H.264/AVC Reference Software,” Heinrich-Hertz Institut, Berlin, Germany.
[5] “386 DX Microprocessor Programmer’s Reference Manual,” Intel Corportation, Santa Clara, CA, 1990.
ECE734 – Spring 2006 10 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
Appendix A1 – C-code Transform Listing
// block_transform.cpp : Defines the entry point for the console application.#include "stdafx.h"int _tmain(int argc, _TCHAR* argv[]){static const __int16 A[4][4] = { { 00, 16, 32, 48}, { 64, 80, 96, 112}, { 128, 144, 160, 176}, { 192, 208, 224, 240}};#define BLOCK_SIZE 4
//testblock(); __int16 i,j, m4[4][4], m5[4];
for (j=0; j < BLOCK_SIZE; j++) { m5[0] = A[j][0]+A[j][3]; m5[1] = A[j][1]+A[j][2]; m5[2] = A[j][1]-A[j][2]; m5[3] = A[j][0]-A[j][3]; m4[j][0] = m5[0] + m5[1]; m4[j][2] = m5[0] - m5[1]; m4[j][1] = m5[3]*2 + m5[2]; m4[j][3] = m5[3] - m5[2]*2; } // Vertical transform for (i=0; i < BLOCK_SIZE; i++) { m5[0] = m4[0][i] + m4[3][i]; m5[1] = m4[1][i] + m4[2][i]; m5[2] = m4[1][i] - m4[2][i]; m5[3] = m4[0][i] - m4[3][i]; m4[0][i] = m5[0] + m5[1]; m4[2][i] = m5[0] - m5[1]; m4[1][i] = m5[3]*2 + m5[2]; m4[3][i] = m5[3] - m5[2]*2; }
// print output printf("H.264 DCT-like transform, 4x4 matrix\n\n"); printf("Input matrix:\n"); for (j=0; j < BLOCK_SIZE; j++) { printf(" 0x%4X 0x%4X 0x%4X 0x%4X\n", A[j][0], A[j][1], A[j][2], A[j][3]); } printf("\n\n"); printf("Output matrix:\n"); for (j=0; j < BLOCK_SIZE; j++) { printf(" 0x%4X 0x%4X 0x%4X 0x%4X\n", m4[j][0], m4[j][1], m4[j][2], m4[j][3]); }
return 0;}
ECE734 – Spring 2006 11 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
Appendix A2 – C-code Transform Assembly Listing
xor eax, eaxmov ebx, 4npad 9
$L10443:
; 24 : {; 25 : m5[0] = A[j][0]+A[j][3];
mov si, WORD PTR ?A@?1??main@@9@4QAY03$$CBFA[eax+6]mov cx, WORD PTR ?A@?1??main@@9@4QAY03$$CBFA[eax]
; 26 : m5[1] = A[j][1]+A[j][2];
mov di, WORD PTR ?A@?1??main@@9@4QAY03$$CBFA[eax+4]add eax, 8lea edx, DWORD PTR [ecx+esi]mov WORD PTR _m5$[esp+64], dxmov dx, WORD PTR ?A@?1??main@@9@4QAY03$$CBFA[eax-6]
; 27 : m5[2] = A[j][1]-A[j][2];; 28 : m5[3] = A[j][0]-A[j][3];
sub ecx, esimov WORD PTR _m5$[esp+70], cxlea ebp, DWORD PTR [edi+edx]sub edx, edimov WORD PTR _m5$[esp+68], dxmov WORD PTR _m5$[esp+66], bp
; 29 : ; 30 : m4[j][0] = m5[0] + m5[1];
mov edx, DWORD PTR _m5$[esp+66]mov ecx, DWORD PTR _m5$[esp+64]lea esi, DWORD PTR [edx+ecx]
; 31 : m4[j][2] = m5[0] - m5[1];
sub ecx, edx
; 32 : m4[j][1] = m5[3]*2 + m5[2];
mov edx, DWORD PTR _m5$[esp+68]mov WORD PTR _m4$[esp+eax+60], cxmov ecx, DWORD PTR _m5$[esp+70]mov WORD PTR _m4$[esp+eax+56], silea esi, DWORD PTR [edx+ecx*2]
; 33 : m4[j][3] = m5[3] - m5[2]*2;
add edx, edxsub ecx, edxsub ebx, 1mov WORD PTR _m4$[esp+eax+58], simov WORD PTR _m4$[esp+eax+62], cxjne SHORT $L10443
; 34 : }; 35 : ; 36 : // Vertical transform
ECE734 – Spring 2006 12 of 31
Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
; 37 : for (i=0; i < BLOCK_SIZE; i++)
lea eax, DWORD PTR _m4$[esp+80]mov ebx, 4npad 5
$L10446:
; 38 : { ; 39 : m5[0] = m4[0][i] + m4[3][i];
mov si, WORD PTR [eax+8]mov cx, WORD PTR [eax-16]
; 40 : m5[1] = m4[1][i] + m4[2][i];
mov di, WORD PTR [eax]add eax, 2lea edx, DWORD PTR [esi+ecx]mov WORD PTR _m5$[esp+64], dxmov dx, WORD PTR [eax-10]
; 41 : m5[2] = m4[1][i] - m4[2][i];; 42 : m5[3] = m4[0][i] - m4[3][i];
sub ecx, esimov WORD PTR _m5$[esp+70], cxlea ebp, DWORD PTR [edx+edi]sub edx, edimov WORD PTR _m5$[esp+68], dxmov WORD PTR _m5$[esp+66], bp
; 43 : ; 44 : m4[0][i] = m5[0] + m5[1];
mov edx, DWORD PTR _m5$[esp+66]mov ecx, DWORD PTR _m5$[esp+64]lea esi, DWORD PTR [edx+ecx]
; 45 : m4[2][i] = m5[0] - m5[1];
sub ecx, edx
; 46 : m4[1][i] = m5[3]*2 + m5[2];
mov edx, DWORD PTR _m5$[esp+68]mov WORD PTR [eax-2], cxmov ecx, DWORD PTR _m5$[esp+70]mov WORD PTR [eax-18], silea esi, DWORD PTR [edx+ecx*2]
; 47 : m4[3][i] = m5[3] - m5[2]*2;
add edx, edxsub ecx, edxsub ebx, 1mov WORD PTR [eax-10], simov WORD PTR [eax+6], cxjne SHORT $L10446
; 48 : }; 49 : ; 50 : // print output
ECE734 – Spring 2006 13 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
Appendix A3 – PLX Transform Listing
///////consts//#ifndef CPUDATAWIDTH #define CPUDATAWIDTH 64//64-bit//#endif#definestop trap 0FFFFh////////variables#define Rtemp1 R5#define Rtemp2 R6#define Rtemp3 R7#define Rtemp4 R8#define Rc R1#define Rd R2#define Rh R3#define Ri R4#define Re R5#define Rj R6#define Rf R7#define Rk R8#define Rg R9#define Rl R10#define Rm R11#define Rn R12#define Ro R13#define Rp R14////////
mov macro Rq,Rtori Rq,Rt,0endm
trans4x4 macro L1,L2,L3,L4,K1,K2,K3,K4mix.2.lRtemp1,L1,L2mix.2.rRtemp2,L1,L2mix.2.lRtemp3,L3,L4mix.2.rRtemp4,L3,L4mix.4.lK1,Rtemp1,Rtemp3mix.4.lK3,Rtemp2,Rtemp4mix.4.rK4,Rtemp1,Rtemp3mix.4.rK2,Rtemp2,Rtemp4endm
init_data macro Row,Offsetloadi.z.3 Row,Offsetloadi.k.2 Row,Offset+16loadi.k.1 Row,Offset+32loadi.k.0 Row,Offset+48endm
main proc loadi.z.0 R15,0 loadi.z.0 R16,0 loadi.k.1 R16,3000h
load.8.update Rc,R16,8load.8.update Rh,R16,8load.8.update Ri,R16,8
ECE734 – Spring 2006 14 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
load.8.update Rd,R16,8
main_frame:padd.2.s Re,Rc,Rd padd.2.s Rj,Rh,Ri psub.2.s Rf,Rc,Rd psub.2.s Rk,Rh,Ri
pshifti.2.l Rg,Rf,1 pshifti.2.l Rl,Rk,1
padd.2.s Rm,Re,Rj padd.2.s Rn,Rk,Rg psub.2.s Ro,Re,Rj psub.2.s Rp,Rf,Rl
trans4x4 Rm,Rn,Ro,Rp,Rc,Rd,Rh,Ri addi R15,R15,1 cmpi.leu R15,1,P1,P2 P1 jmp main_frame //store results
store.8.update Rc,R16,8 store.8.update Rh,R16,8 store.8.update Ri,R16,8 store.8.update Rd,R16,8
stopendpend
ECE734 – Spring 2006 15 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
Appendix A4 – PLX Transform Functional Simulation
#10:00000000(023C0000) P0 loadi.z.0 R15,0000h======== --src2(immu)=0x0000 --R15=0000000000000000#11:00000004(02400000) P0 loadi.z.0 R16,0000h======== --src2(immu)=0x0000 --R16=0000000000000000#12:00000008(02C13000) P0 loadi.k.1 R16,3000h======== --src1(R16)=0x0000000000000000 src2(immu)=0x3000 --R16=0000000030000000#13:0000000C(0B860008) P0 load.8.update R1,R16,8======== --src1(R16)=0x0000000030000000 --SRAMR:A=00000008 D=0000001000200030 --R1=0000001000200030#14:00000010(0B8E0008) P0 load.8.update R3,R16,8======== --src1(R16)=0x0000000030000008 --SRAMR:A=00000010 D=0040005000600070 --R3=0040005000600070#15:00000014(0B920008) P0 load.8.update R4,R16,8======== --src1(R16)=0x0000000030000010 --SRAMR:A=00000018 D=0080009000A000B0 --R4=0080009000A000B0#16:00000018(0B8A0008) P0 load.8.update R2,R16,8======== --src1(R16)=0x0000000030000018 --SRAMR:A=00000020 D=00C000D000E000F0 --R2=00C000D000E000F0#17:0000001C(18142209) P0 padd.2.s R5,R1,R2======== --src1(R1)=0x0000001000200030 src2(R2)=0x00C000D000E000F0 --R5=00C000E001000120#18:00000020(18186409) P0 padd.2.s R6,R3,R4======== --src1(R3)=0x0040005000600070 src2(R4)=0x0080009000A000B0 --R6=00C000E001000120#19:00000024(181C2219) P0 psub.2.s R7,R1,R2======== --src1(R1)=0x0000001000200030 src2(R2)=0x00C000D000E000F0 --R7=FF40FF40FF40FF40#20:00000028(18206419) P0 psub.2.s R8,R3,R4======== --src1(R3)=0x0040005000600070 src2(R4)=0x0080009000A000B0 --R8=FFC0FFC0FFC0FFC0#21:0000002C(19A4E101) P0 pshifti.2.l R9,R7,1======== --src1(R7)=0xFF40FF40FF40FF40 src2(immu)=0x0001 --R9=FE80FE80FE80FE80#22:00000030(19A90101) P0 pshifti.2.l R10,R8,1======== --src1(R8)=0xFFC0FFC0FFC0FFC0 src2(immu)=0x0001 --R10=FF80FF80FF80FF80#23:00000034(182CA609) P0 padd.2.s R11,R5,R6======== --src1(R5)=0x00C000E001000120 src2(R6)=0x00C000E001000120 --R11=018001C002000240#24:00000038(18310909) P0 padd.2.s R12,R8,R9======== --src1(R8)=0xFFC0FFC0FFC0FFC0 src2(R9)=0xFE80FE80FE80FE80 --R12=FE40FE40FE40FE40#25:0000003C(1834A619) P0 psub.2.s R13,R5,R6======== --src1(R5)=0x00C000E001000120 src2(R6)=0x00C000E001000120 --R13=0000000000000000#26:00000040(1838EA19) P0 psub.2.s R14,R7,R10======== --src1(R7)=0xFF40FF40FF40FF40 src2(R10)=0xFF80FF80FF80FF80 --R14=FFC0FFC0FFC0FFC0
ECE734 – Spring 2006 16 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
#27:00000044(19156C11) P0 mix.2.l R5,R11,R12======== --src1(R11)=0x018001C002000240 src2(R12)=0xFE40FE40FE40FE40 --R5=0180FE400200FE40#28:00000048(19196C15) P0 mix.2.r R6,R11,R12======== --src1(R11)=0x018001C002000240 src2(R12)=0xFE40FE40FE40FE40 --R6=01C0FE400240FE40#29:0000004C(191DAE11) P0 mix.2.l R7,R13,R14======== --src1(R13)=0x0000000000000000 src2(R14)=0xFFC0FFC0FFC0FFC0 --R7=0000FFC00000FFC0#30:00000050(1921AE15) P0 mix.2.r R8,R13,R14======== --src1(R13)=0x0000000000000000 src2(R14)=0xFFC0FFC0FFC0FFC0 --R8=0000FFC00000FFC0#31:00000054(1904A712) P0 mix.4.l R1,R5,R7======== --src1(R5)=0x0180FE400200FE40 src2(R7)=0x0000FFC00000FFC0 --R1=0180FE400000FFC0#32:00000058(190CC812) P0 mix.4.l R3,R6,R8======== --src1(R6)=0x01C0FE400240FE40 src2(R8)=0x0000FFC00000FFC0 --R3=01C0FE400000FFC0#33:0000005C(1910A716) P0 mix.4.r R4,R5,R7======== --src1(R5)=0x0180FE400200FE40 src2(R7)=0x0000FFC00000FFC0 --R4=0200FE400000FFC0#34:00000060(1908C816) P0 mix.4.r R2,R6,R8======== --src1(R6)=0x01C0FE400240FE40 src2(R8)=0x0000FFC00000FFC0 --R2=0240FE400000FFC0#35:00000064(103DE001) P0 addi R15,R15,1======== --src1(R15)=0x0000000000000000 src2(imms)=1 --R15=0000000000000001#36:00000068(04BC04A7) P0 cmpi.leu R15,1,P1,P2======== --src1(R15)=0x0000000000000001 src2(imms)=1 --P1=1 P2=0#37:0000006C(207FFFB0) P1 jmp 0000001Ch========#38:0000001C(18142209) P0 padd.2.s R5,R1,R2======== --src1(R1)=0x0180FE400000FFC0 src2(R2)=0x0240FE400000FFC0 --R5=03C0FC800000FF80#39:00000020(18186409) P0 padd.2.s R6,R3,R4======== --src1(R3)=0x01C0FE400000FFC0 src2(R4)=0x0200FE400000FFC0 --R6=03C0FC800000FF80#40:00000024(181C2219) P0 psub.2.s R7,R1,R2======== --src1(R1)=0x0180FE400000FFC0 src2(R2)=0x0240FE400000FFC0 --R7=FF40000000000000#41:00000028(18206419) P0 psub.2.s R8,R3,R4======== --src1(R3)=0x01C0FE400000FFC0 src2(R4)=0x0200FE400000FFC0 --R8=FFC0000000000000#42:0000002C(19A4E101) P0 pshifti.2.l R9,R7,1======== --src1(R7)=0xFF40000000000000 src2(immu)=0x0001 --R9=FE80000000000000#43:00000030(19A90101) P0 pshifti.2.l R10,R8,1======== --src1(R8)=0xFFC0000000000000 src2(immu)=0x0001 --R10=FF80000000000000#44:00000034(182CA609) P0 padd.2.s R11,R5,R6======== --src1(R5)=0x03C0FC800000FF80 src2(R6)=0x03C0FC800000FF80 --R11=0780F9000000FF00#45:00000038(18310909) P0 padd.2.s R12,R8,R9======== --src1(R8)=0xFFC0000000000000 src2(R9)=0xFE80000000000000 --R12=FE40000000000000#46:0000003C(1834A619) P0 psub.2.s R13,R5,R6======== --src1(R5)=0x03C0FC800000FF80 src2(R6)=0x03C0FC800000FF80
ECE734 – Spring 2006 17 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
--R13=0000000000000000#47:00000040(1838EA19) P0 psub.2.s R14,R7,R10======== --src1(R7)=0xFF40000000000000 src2(R10)=0xFF80000000000000 --R14=FFC0000000000000#48:00000044(19156C11) P0 mix.2.l R5,R11,R12======== --src1(R11)=0x0780F9000000FF00 src2(R12)=0xFE40000000000000 --R5=0780FE4000000000#49:00000048(19196C15) P0 mix.2.r R6,R11,R12======== --src1(R11)=0x0780F9000000FF00 src2(R12)=0xFE40000000000000 --R6=F9000000FF000000#50:0000004C(191DAE11) P0 mix.2.l R7,R13,R14======== --src1(R13)=0x0000000000000000 src2(R14)=0xFFC0000000000000 --R7=0000FFC000000000#51:00000050(1921AE15) P0 mix.2.r R8,R13,R14======== --src1(R13)=0x0000000000000000 src2(R14)=0xFFC0000000000000 --R8=0000000000000000#52:00000054(1904A712) P0 mix.4.l R1,R5,R7======== --src1(R5)=0x0780FE4000000000 src2(R7)=0x0000FFC000000000 --R1=0780FE400000FFC0#53:00000058(190CC812) P0 mix.4.l R3,R6,R8======== --src1(R6)=0xF9000000FF000000 src2(R8)=0x0000000000000000 --R3=F900000000000000#54:0000005C(1910A716) P0 mix.4.r R4,R5,R7======== --src1(R5)=0x0780FE4000000000 src2(R7)=0x0000FFC000000000 --R4=0000000000000000#55:00000060(1908C816) P0 mix.4.r R2,R6,R8======== --src1(R6)=0xF9000000FF000000 src2(R8)=0x0000000000000000 --R2=FF00000000000000#56:00000064(103DE001) P0 addi R15,R15,1======== --src1(R15)=0x0000000000000001 src2(imms)=1 --R15=0000000000000002#57:00000068(04BC04A7) P0 cmpi.leu R15,1,P1,P2======== --src1(R15)=0x0000000000000002 src2(imms)=1 --P1=0 P2=1#58:0000006C(207FFFB0) P1 jmp 0000001Ch========(Skip)#59:00000070(0F860008) P0 store.8.update R1,R16,8======== --src1(R1)=0x0780FE400000FFC0 src2(R16)=0x0000000030000020#60:00000074(0F8E0008) P0 store.8.update R3,R16,8======== --src1(R3)=0xF900000000000000 src2(R16)=0x0000000030000028 --SRAMW:A=00000028 D=0780FE400000FFC0#61:00000078(0F920008) P0 store.8.update R4,R16,8======== --src1(R4)=0x0000000000000000 src2(R16)=0x0000000030000030 --SRAMW:A=00000030 D=F900000000000000#62:0000007C(0F8A0008) P0 store.8.update R2,R16,8======== --src1(R2)=0xFF00000000000000 src2(R16)=0x0000000030000038 --SRAMW:A=00000038 D=0000000000000000#63:00000080(0380FFFF) P0 trap FFFFh======== --SRAMW:A=00000040 D=FF00000000000000
ECE734 – Spring 2006 18 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
Appendix A5 – PLX Transform Timing Simulation
--SDRAM Precharge --SDRAM MRS --SDRAM MRS --SDRAM Precharge --SDRAM AutoRefresh --SDRAM AutoRefresh --SDRAM MRS#239:00000000(00000000) P0 jmp 00000000h======== --src1(R0)=00000000000000000000000000000000 --src2(R0)=00000000000000000000000000000000QWVT=00000000 00000000 00000000 00000000 head=0 tail=0 Wn=06209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1f800000 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=0 src2fd=0 regwait=00000000#240:00000000(1F800000) P0 IDLE========QWVT=00000000 00000000 00000000 00000000 head=0 tail=0 Wn=06209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1f800000 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=0 src2fd=0 regwait=00000000#241:00000000(1F800000) P0 IDLE======== --src1(R0)=00000000000000000000000000000000 --src2(R0)=00000000000000000000000000000000QWVT=00000000 00000000 00000000 00000000 head=0 tail=0 Wn=06209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1f800000 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=0 src2fd=0 regwait=00000000#242:00000000(1F800000) P0 IDLE======== --src1(R0)=00000000000000000000000000000000 --src2(R0)=00000000000000000000000000000000QWVT=00000000 00000000 00000000 00000000 head=0 tail=0 Wn=06209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1f800000 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=0 src2fd=0 regwait=00000000#243:00000000(1F800000) P0 IDLE======== --src1(R0)=00000000000000000000000000000000 --src2(R0)=00000000000000000000000000000000QWVT=00000000 00000000 00000000 00000000 head=0 tail=0 Wn=06209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1f800000 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=0 src2fd=0 regwait=00000000#244:00000000(1F800000) P0 IDLE======== --src1(R0)=00000000000000000000000000000000 --src2(R0)=00000000000000000000000000000000QWVT=00000000 00000000 00000000 00000000 head=0 tail=0 Wn=06209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=023c0000 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=0 src2fd=0 regwait=00000000#245:00000000(023C0000) P0 loadi.z.0 R15,0000h======== --src1(R0)=00000000000000000000000000000000 --src2(imm)=00000000000000000000000000000000QWVT=00000000 00000000 00000000 00000000 head=0 tail=0 Wn=06209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=02400000 pause=0 skip=0 Rs1=16 Rs2=0 src1fd=0 src2fd=0 regwait=00008000 --R16 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd
ECE734 – Spring 2006 19 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
#246:00000004(02400000) P0 loadi.z.0 R16,0000h======== --src1(R0)=00000000000000000000000000000000 --src2(imm)=00000000000000000000000000000000QWVT=00000000 00000000 00000000 00000000 head=0 tail=0 Wn=06209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=02c13000 pause=0 skip=0 Rs1=16 Rs2=0 src1fd=1 src2fd=0 regwait=00018000 --R15 WD=00000000000000000000000000000000 --R16 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#247:00000008(02C13000) P0 loadi.k.1 R16,3000h======== --src1(R16)=00000000000000000000000000000000 --src2(imm)=00000000000000000000000000013000QWVT=00000000 00000000 00000000 00000000 head=0 tail=0 Wn=06209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0b860008 pause=0 skip=0 Rs1=16 Rs2=0 src1fd=1 src2fd=0 regwait=00010000 --R16 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#248:0000000C(0B860008) P0 load.8.update R1,R16,8======== --src1(R16)=00000000000000000000000030000000 --src2(imm)=00000000000000000000000000000008QWVT=00000001 00000000 00000000 00000000 head=1 tail=0 Wn=06209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0b8e0008 pause=0 skip=0 Rs1=16 Rs2=0 src1fd=2 src2fd=0 regwait=00010002 --R16 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#249:00000010(0B8E0008) P0 load.8.update R3,R16,8======== --src1(R16)=00000000000000000000000030000008 --src2(imm)=00000000000000000000000000000008QWVT=00000010 00000001 00000000 00000000 head=2 tail=1 Wn=06209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0b920008 pause=0 skip=0 Rs1=16 Rs2=0 src1fd=2 src2fd=0 regwait=0001000A --R16 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#250:00000014(0B920008) P0 load.8.update R4,R16,8======== --src1(R16)=00000000000000000000000030000010 --src2(imm)=00000000000000000000000000000008 --RAMR(top.sram):A=00000000h D=00000010002000300000000000000000QWVT=00000110 00000001 00000000 00000000 head=3 tail=1 Wn=16209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0b8a0008 pause=0 skip=0 Rs1=1 Rs2=2 src1fd=2 src2fd=0 regwait=0001001A --R16 WD=00000000000000000000000030000008 --R1 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd --R2 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#251:00000018(0B8A0008) P0 load.8.update R2,R16,8======== --src1(R16)=00000000000000000000000030000018 --src2(imm)=00000000000000000000000000000008QWVT=00001100 00000010 00000001 00000001 head=4 tail=2 Wn=16209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18142209 pause=1 skip=0 Rs1=1 Rs2=2 src1fd=8 src2fd=0 regwait=0001001E --R16 WD=00000000000000000000000030000010 --R1 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd --R2 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#252:0000001C(18142209) P0 padd.2.s R5,R1,R2========(pause) --RAMR(top.sram):A=00000010h D=0080009000a000b00040005000600070QWVT=00001100 00000010 00000001 00000001 head=4 tail=2 Wn=2
ECE734 – Spring 2006 20 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
6209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18142209 pause=1 skip=0 Rs1=1 Rs2=2 src1fd=8 src2fd=0 regwait=0000001E --R16 WD=00000000000000000000000030000020 --R1 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd --R2 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#253:0000001C(18142209) P0 padd.2.s R5,R1,R2========(pause)QWVT=00001000 00000100 00000011 00000011 head=4 tail=3 Wn=26209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18142209 pause=1 skip=0 Rs1=1 Rs2=2 src1fd=8 src2fd=0 regwait=0000001E --R16 WD=00000000000000000000000030000020 --R1 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd --R2 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#254:0000001C(18142209) P0 padd.2.s R5,R1,R2========(pause) --RAMR(top.sram):A=00000010h D=0080009000a000b00040005000600070QWVT=00001000 00000100 00000011 00000011 head=4 tail=3 Wn=36209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18142209 pause=1 skip=0 Rs1=1 Rs2=2 src1fd=8 src2fd=0 regwait=0000001E --R1 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd --R2 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#255:0000001C(18142209) P0 padd.2.s R5,R1,R2========(pause)QWVT=00000000 00001000 00000111 00000111 head=4 tail=4 Wn=36209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18142209 pause=1 skip=0 Rs1=1 Rs2=2 src1fd=8 src2fd=0 regwait=0000001E --R1 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd --R2 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#256:0000001C(18142209) P0 padd.2.s R5,R1,R2========(pause) --RAMR(top.sram):A=00000020h D=cdcdcdcdcdcdcdcd00c000d000e000f0QWVT=00000000 00001000 00000111 00000111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18142209 pause=1 skip=0 Rs1=1 Rs2=2 src1fd=8 src2fd=0 regwait=0000001E --R1 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd --R2 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#257:0000001C(18142209) P0 padd.2.s R5,R1,R2========(pause)QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18142209 pause=0 skip=0 Rs1=3 Rs2=4 src1fd=8 src2fd=11 regwait=0000001E --R3 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd --R4 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#258:0000001C(18142209) P0 padd.2.s R5,R1,R2======== --src1(R1)=00000010002000300000001000200030 --src2(R2)=CDCDCDCDCDCDCDCD00C000D000E000F0QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18186409 pause=0 skip=0 Rs1=1 Rs2=2 src1fd=9 src2fd=10 regwait=0000003E --R1 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd --R2 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#259:00000020(18186409) P0 padd.2.s R6,R3,R4======== --src1(R3)=0080009000A000B00040005000600070 --src2(R4)=0080009000A000B00080009000A000B0QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=4
ECE734 – Spring 2006 21 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
6209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=181c2219 pause=0 skip=0 Rs1=3 Rs2=4 src1fd=8 src2fd=11 regwait=0000007E --R5 WD=cdcdcdddcdedcdfd00c000e001000120 --R3 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd --R4 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#260:00000024(181C2219) P0 psub.2.s R7,R1,R2======== --src1(R1)=00000010002000300000001000200030 --src2(R2)=CDCDCDCDCDCDCDCD00C000D000E000F0QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18206419 pause=0 skip=0 Rs1=7 Rs2=0 src1fd=9 src2fd=10 regwait=000000DE --R6 WD=010001200140016000c000e001000120 --R7 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#261:00000028(18206419) P0 psub.2.s R8,R3,R4======== --src1(R3)=0080009000A000B00040005000600070 --src2(R4)=0080009000A000B00080009000A000B0QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=19a4e101 pause=0 skip=0 Rs1=8 Rs2=0 src1fd=7 src2fd=0 regwait=0000019E --R7 WD=3233324332533263ff40ff40ff40ff40 --R8 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#262:0000002C(19A4E101) P0 pshifti.2.l R9,R7,1======== --src1(R7)=3233324332533263FF40FF40FF40FF40 --src2(imm)=00000000000000000000000000000001QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=19a90101 pause=0 skip=0 Rs1=5 Rs2=6 src1fd=7 src2fd=0 regwait=0000031E --R8 WD=0000000000000000ffc0ffc0ffc0ffc0 --R5 RD=cdcdcdddcdedcdfd00c000e001000120 --R6 RD=010001200140016000c000e001000120#263:00000030(19A90101) P0 pshifti.2.l R10,R8,1======== --src1(R8)=0000000000000000FFC0FFC0FFC0FFC0 --src2(imm)=00000000000000000000000000000001QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=182ca609 pause=0 skip=0 Rs1=8 Rs2=9 src1fd=0 src2fd=0 regwait=0000061E --R9 WD=6466648664a664c6fe80fe80fe80fe80 --R8 RD=0000000000000000ffc0ffc0ffc0ffc0 --R9 RD=6466648664a664c6fe80fe80fe80fe80#264:00000034(182CA609) P0 padd.2.s R11,R5,R6======== --src1(R5)=CDCDCDDDCDEDCDFD00C000E001000120 --src2(R6)=010001200140016000C000E001000120QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18310909 pause=0 skip=0 Rs1=5 Rs2=6 src1fd=0 src2fd=0 regwait=00000C1E --R10 WD=0000000000000000ff80ff80ff80ff80 --R5 RD=cdcdcdddcdedcdfd00c000e001000120 --R6 RD=010001200140016000c000e001000120#265:00000038(18310909) P0 padd.2.s R12,R8,R9======== --src1(R8)=0000000000000000FFC0FFC0FFC0FFC0 --src2(R9)=6466648664A664C6FE80FE80FE80FE80
ECE734 – Spring 2006 22 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1834a619 pause=0 skip=0 Rs1=7 Rs2=10 src1fd=0 src2fd=0 regwait=0000181E --R11 WD=cecdcefdcf2dcf5d018001c002000240 --R7 RD=3233324332533263ff40ff40ff40ff40 --R10 RD=0000000000000000ff80ff80ff80ff80#266:0000003C(1834A619) P0 psub.2.s R13,R5,R6======== --src1(R5)=CDCDCDDDCDEDCDFD00C000E001000120 --src2(R6)=010001200140016000C000E001000120QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1838ea19 pause=0 skip=0 Rs1=11 Rs2=12 src1fd=0 src2fd=0 regwait=0000301E --R12 WD=6466648664a664c6fe40fe40fe40fe40 --R11 RD=cecdcefdcf2dcf5d018001c002000240 --R12 RD=6466648664a664c6fe40fe40fe40fe40#267:00000040(1838EA19) P0 psub.2.s R14,R7,R10======== --src1(R7)=3233324332533263FF40FF40FF40FF40 --src2(R10)=0000000000000000FF80FF80FF80FF80QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=19156c11 pause=0 skip=0 Rs1=11 Rs2=12 src1fd=0 src2fd=0 regwait=0000601E --R13 WD=cccdccbdccadcc9d0000000000000000 --R11 RD=cecdcefdcf2dcf5d018001c002000240 --R12 RD=6466648664a664c6fe40fe40fe40fe40#268:00000044(19156C11) P0 mix.2.l R5,R11,R12======== --src1(R11)=CECDCEFDCF2DCF5D018001C002000240 --src2(R12)=6466648664A664C6FE40FE40FE40FE40QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=19196c15 pause=0 skip=0 Rs1=13 Rs2=14 src1fd=0 src2fd=0 regwait=0000403E --R14 WD=3233324332533263ffc0ffc0ffc0ffc0 --R13 RD=cccdccbdccadcc9d0000000000000000 --R14 RD=3233324332533263ffc0ffc0ffc0ffc0#269:00000048(19196C15) P0 mix.2.r R6,R11,R12======== --src1(R11)=CECDCEFDCF2DCF5D018001C002000240 --src2(R12)=6466648664A664C6FE40FE40FE40FE40QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=191dae11 pause=0 skip=0 Rs1=13 Rs2=14 src1fd=0 src2fd=0 regwait=0000007E --R5 WD=cecd6466cf2d64a60180fe400200fe40 --R13 RD=cccdccbdccadcc9d0000000000000000 --R14 RD=3233324332533263ffc0ffc0ffc0ffc0#270:0000004C(191DAE11) P0 mix.2.l R7,R13,R14======== --src1(R13)=CCCDCCBDCCADCC9D0000000000000000 --src2(R14)=3233324332533263FFC0FFC0FFC0FFC0QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1921ae15 pause=0 skip=0 Rs1=5 Rs2=7 src1fd=0 src2fd=0 regwait=000000DE --R6 WD=cefd6486cf5d64c601c0fe400240fe40 --R5 RD=cecd6466cf2d64a60180fe400200fe40 --R7 RD=3233324332533263ff40ff40ff40ff40
ECE734 – Spring 2006 23 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
#271:00000050(1921AE15) P0 mix.2.r R8,R13,R14======== --src1(R13)=CCCDCCBDCCADCC9D0000000000000000 --src2(R14)=3233324332533263FFC0FFC0FFC0FFC0QWVT=00000000 00000000 00001111 00001111 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1904a712 pause=0 skip=0 Rs1=6 Rs2=8 src1fd=0 src2fd=7 regwait=0000019E --R7 WD=cccd3233ccad32530000ffc00000ffc0 --R6 RD=cefd6486cf5d64c601c0fe400240fe40 --R8 RD=0000000000000000ffc0ffc0ffc0ffc0#272:00000054(1904A712) P0 mix.4.l R1,R5,R7======== --src1(R5)=CECD6466CF2D64A60180FE400200FE40 --src2(R7)=CCCD3233CCAD32530000FFC00000FFC0QWVT=00000000 00000000 00001111 00001110 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=190cc812 pause=0 skip=0 Rs1=5 Rs2=7 src1fd=0 src2fd=7 regwait=0000011E --R8 WD=ccbd3243cc9d32630000ffc00000ffc0 --R5 RD=cecd6466cf2d64a60180fe400200fe40 --R7 RD=cccd3233ccad32530000ffc00000ffc0#273:00000058(190CC812) P0 mix.4.l R3,R6,R8======== --src1(R6)=CEFD6486CF5D64C601C0FE400240FE40 --src2(R8)=CCBD3243CC9D32630000FFC00000FFC0QWVT=00000000 00000000 00001111 00001100 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1910a716 pause=0 skip=0 Rs1=6 Rs2=8 src1fd=0 src2fd=0 regwait=0000001E --R1 WD=cecd6466cccd32330180fe400000ffc0 --R6 RD=cefd6486cf5d64c601c0fe400240fe40 --R8 RD=ccbd3243cc9d32630000ffc00000ffc0#274:0000005C(1910A716) P0 mix.4.r R4,R5,R7======== --src1(R5)=CECD6466CF2D64A60180FE400200FE40 --src2(R7)=CCCD3233CCAD32530000FFC00000FFC0QWVT=00000000 00000000 00001111 00001000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1908c816 pause=0 skip=0 Rs1=15 Rs2=0 src1fd=0 src2fd=0 regwait=0000001C --R3 WD=cefd6486ccbd324301c0fe400000ffc0 --R15 RD=00000000000000000000000000000000#275:00000060(1908C816) P0 mix.4.r R2,R6,R8======== --src1(R6)=CEFD6486CF5D64C601C0FE400240FE40 --src2(R8)=CCBD3243CC9D32630000FFC00000FFC0QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=103de001 pause=0 skip=0 Rs1=15 Rs2=0 src1fd=0 src2fd=0 regwait=00000014 --R4 WD=cf2d64a6ccad32530200fe400000ffc0 --R15 RD=00000000000000000000000000000000#276:00000064(103DE001) P0 addi R15,R15,1======== --src1(R15)=00000000000000000000000000000000 --src2(imm)=00000000000000000000000000000001QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=04bc04a7 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=1 src2fd=0 regwait=00008004 --R2 WD=cf5d64c6cc9d32630240fe400000ffc0#277:00000068(04BC04A7) P0 cmpi.leu R15,1,P1,P2========
ECE734 – Spring 2006 24 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
--src1(R15)=00000000000000000000000000000001 --src2(imm)=00000000000000000000000000000001QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=207fffb0 pause=1 skip=1 Rs1=0 Rs2=0 src1fd=0 src2fd=0 regwait=00008000 --R15 WD=00000000000000000000000000000001#278:0000006C(207FFFB0) P1 jmp 0000001Ch========(pause) --P1=1 P2=0QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=207fffb0 pause=0 skip=0 Rs1=16 Rs2=1 src1fd=0 src2fd=0 regwait=00000000 --R16 RD=00000000000000000000000030000020 --R1 RD=cecd6466cccd32330180fe400000ffc0#279:0000006C(207FFFB0) P1 jmp 0000001Ch======== --src1(imm)=0000000000000000000000000000001C --src2(imm)=00000000000000000000000000000070QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0f860008 pause=0 skip=0 Rs1=16 Rs2=3 src1fd=0 src2fd=0 regwait=00000000 --R16 RD=00000000000000000000000030000020 --R3 RD=cefd6486ccbd324301c0fe400000ffc0#280:00000070(1F800000) P0 IDLE========QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1f800000 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=0 src2fd=0 regwait=00000000#281:00000070(1F800000) P0 IDLE======== --src1(R0)=00000000000000000000000000000000 --src2(R0)=00000000000000000000000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1f800000 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=0 src2fd=0 regwait=00000000#282:00000070(1F800000) P0 IDLE======== --src1(R0)=00000000000000000000000000000000 --src2(R0)=00000000000000000000000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1f800000 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=0 src2fd=0 regwait=00000000#283:00000070(1F800000) P0 IDLE======== --src1(R0)=00000000000000000000000000000000 --src2(R0)=00000000000000000000000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1f800000 pause=0 skip=0 Rs1=1 Rs2=2 src1fd=0 src2fd=0 regwait=00000000 --R1 RD=cecd6466cccd32330180fe400000ffc0 --R2 RD=cf5d64c6cc9d32630240fe400000ffc0#284:00000070(1F800000) P0 IDLE======== --src1(R0)=00000000000000000000000000000000 --src2(R0)=00000000000000000000000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972
ECE734 – Spring 2006 25 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
--opd=18142209 pause=0 skip=0 Rs1=3 Rs2=4 src1fd=0 src2fd=0 regwait=00000000 --R3 RD=cefd6486ccbd324301c0fe400000ffc0 --R4 RD=cf2d64a6ccad32530200fe400000ffc0#285:0000001C(18142209) P0 padd.2.s R5,R1,R2======== --src1(R1)=CECD6466CCCD32330180FE400000FFC0 --src2(R2)=CF5D64C6CC9D32630240FE400000FFC0QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18186409 pause=0 skip=0 Rs1=1 Rs2=2 src1fd=0 src2fd=0 regwait=00000020 --R1 RD=cecd6466cccd32330180fe400000ffc0 --R2 RD=cf5d64c6cc9d32630240fe400000ffc0#286:00000020(18186409) P0 padd.2.s R6,R3,R4======== --src1(R3)=CEFD6486CCBD324301C0FE400000FFC0 --src2(R4)=CF2D64A6CCAD32530200FE400000FFC0QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=181c2219 pause=0 skip=0 Rs1=3 Rs2=4 src1fd=0 src2fd=0 regwait=00000060 --R5 WD=9e2ac92c996a649603c0fc800000ff80 --R3 RD=cefd6486ccbd324301c0fe400000ffc0 --R4 RD=cf2d64a6ccad32530200fe400000ffc0#287:00000024(181C2219) P0 psub.2.s R7,R1,R2======== --src1(R1)=CECD6466CCCD32330180FE400000FFC0 --src2(R2)=CF5D64C6CC9D32630240FE400000FFC0QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18206419 pause=0 skip=0 Rs1=7 Rs2=0 src1fd=0 src2fd=0 regwait=000000C0 --R6 WD=9e2ac92c996a649603c0fc800000ff80 --R7 RD=cccd3233ccad32530000ffc00000ffc0#288:00000028(18206419) P0 psub.2.s R8,R3,R4======== --src1(R3)=CEFD6486CCBD324301C0FE400000FFC0 --src2(R4)=CF2D64A6CCAD32530200FE400000FFC0QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=19a4e101 pause=0 skip=0 Rs1=8 Rs2=0 src1fd=7 src2fd=0 regwait=00000180 --R7 WD=ff70ffa00030ffd0ff40000000000000 --R8 RD=ccbd3243cc9d32630000ffc00000ffc0#289:0000002C(19A4E101) P0 pshifti.2.l R9,R7,1======== --src1(R7)=FF70FFA00030FFD0FF40000000000000 --src2(imm)=00000000000000000000000000000001QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=19a90101 pause=0 skip=0 Rs1=5 Rs2=6 src1fd=7 src2fd=0 regwait=00000300 --R8 WD=ffd0ffe00010fff0ffc0000000000000 --R5 RD=9e2ac92c996a649603c0fc800000ff80 --R6 RD=9e2ac92c996a649603c0fc800000ff80#290:00000030(19A90101) P0 pshifti.2.l R10,R8,1======== --src1(R8)=FFD0FFE00010FFF0FFC0000000000000 --src2(imm)=00000000000000000000000000000001QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972
ECE734 – Spring 2006 26 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
--opd=182ca609 pause=0 skip=0 Rs1=8 Rs2=9 src1fd=0 src2fd=0 regwait=00000600 --R9 WD=fee0ff400060ffa0fe80000000000000 --R8 RD=ffd0ffe00010fff0ffc0000000000000 --R9 RD=fee0ff400060ffa0fe80000000000000#291:00000034(182CA609) P0 padd.2.s R11,R5,R6======== --src1(R5)=9E2AC92C996A649603C0FC800000FF80 --src2(R6)=9E2AC92C996A649603C0FC800000FF80QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=18310909 pause=0 skip=0 Rs1=5 Rs2=6 src1fd=0 src2fd=0 regwait=00000C00 --R10 WD=ffa0ffc00020ffe0ff80000000000000 --R5 RD=9e2ac92c996a649603c0fc800000ff80 --R6 RD=9e2ac92c996a649603c0fc800000ff80#292:00000038(18310909) P0 padd.2.s R12,R8,R9======== --src1(R8)=FFD0FFE00010FFF0FFC0000000000000 --src2(R9)=FEE0FF400060FFA0FE80000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1834a619 pause=0 skip=0 Rs1=7 Rs2=10 src1fd=0 src2fd=0 regwait=00001800 --R11 WD=3c54925832d4c92c0780f9000000ff00 --R7 RD=ff70ffa00030ffd0ff40000000000000 --R10 RD=ffa0ffc00020ffe0ff80000000000000#293:0000003C(1834A619) P0 psub.2.s R13,R5,R6======== --src1(R5)=9E2AC92C996A649603C0FC800000FF80 --src2(R6)=9E2AC92C996A649603C0FC800000FF80QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1838ea19 pause=0 skip=0 Rs1=11 Rs2=12 src1fd=0 src2fd=0 regwait=00003000 --R12 WD=feb0ff200070ff90fe40000000000000 --R11 RD=3c54925832d4c92c0780f9000000ff00 --R12 RD=feb0ff200070ff90fe40000000000000#294:00000040(1838EA19) P0 psub.2.s R14,R7,R10======== --src1(R7)=FF70FFA00030FFD0FF40000000000000 --src2(R10)=FFA0FFC00020FFE0FF80000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=19156c11 pause=0 skip=0 Rs1=11 Rs2=12 src1fd=0 src2fd=0 regwait=00006000 --R13 WD=00000000000000000000000000000000 --R11 RD=3c54925832d4c92c0780f9000000ff00 --R12 RD=feb0ff200070ff90fe40000000000000#295:00000044(19156C11) P0 mix.2.l R5,R11,R12======== --src1(R11)=3C54925832D4C92C0780F9000000FF00 --src2(R12)=FEB0FF200070FF90FE40000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=19196c15 pause=0 skip=0 Rs1=13 Rs2=14 src1fd=0 src2fd=0 regwait=00004020 --R14 WD=ffd0ffe00010fff0ffc0000000000000 --R13 RD=00000000000000000000000000000000 --R14 RD=ffd0ffe00010fff0ffc0000000000000#296:00000048(19196C15) P0 mix.2.r R6,R11,R12======== --src1(R11)=3C54925832D4C92C0780F9000000FF00
ECE734 – Spring 2006 27 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
--src2(R12)=FEB0FF200070FF90FE40000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=191dae11 pause=0 skip=0 Rs1=13 Rs2=14 src1fd=0 src2fd=0 regwait=00000060 --R5 WD=3c54feb032d400700780fe4000000000 --R13 RD=00000000000000000000000000000000 --R14 RD=ffd0ffe00010fff0ffc0000000000000#297:0000004C(191DAE11) P0 mix.2.l R7,R13,R14======== --src1(R13)=00000000000000000000000000000000 --src2(R14)=FFD0FFE00010FFF0FFC0000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1921ae15 pause=0 skip=0 Rs1=5 Rs2=7 src1fd=0 src2fd=0 regwait=000000C0 --R6 WD=9258ff20c92cff90f9000000ff000000 --R5 RD=3c54feb032d400700780fe4000000000 --R7 RD=ff70ffa00030ffd0ff40000000000000#298:00000050(1921AE15) P0 mix.2.r R8,R13,R14======== --src1(R13)=00000000000000000000000000000000 --src2(R14)=FFD0FFE00010FFF0FFC0000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1904a712 pause=0 skip=0 Rs1=6 Rs2=8 src1fd=0 src2fd=7 regwait=00000180 --R7 WD=0000ffd0000000100000ffc000000000 --R6 RD=9258ff20c92cff90f9000000ff000000 --R8 RD=ffd0ffe00010fff0ffc0000000000000#299:00000054(1904A712) P0 mix.4.l R1,R5,R7======== --src1(R5)=3C54FEB032D400700780FE4000000000 --src2(R7)=0000FFD0000000100000FFC000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=190cc812 pause=0 skip=0 Rs1=5 Rs2=7 src1fd=0 src2fd=7 regwait=00000102 --R8 WD=0000ffe00000fff00000000000000000 --R5 RD=3c54feb032d400700780fe4000000000 --R7 RD=0000ffd0000000100000ffc000000000#300:00000058(190CC812) P0 mix.4.l R3,R6,R8======== --src1(R6)=9258FF20C92CFF90F9000000FF000000 --src2(R8)=0000FFE00000FFF00000000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1910a716 pause=0 skip=0 Rs1=6 Rs2=8 src1fd=0 src2fd=0 regwait=0000000A --R1 WD=3c54feb00000ffd00780fe400000ffc0 --R6 RD=9258ff20c92cff90f9000000ff000000 --R8 RD=0000ffe00000fff00000000000000000#301:0000005C(1910A716) P0 mix.4.r R4,R5,R7======== --src1(R5)=3C54FEB032D400700780FE4000000000 --src2(R7)=0000FFD0000000100000FFC000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=1908c816 pause=0 skip=0 Rs1=15 Rs2=0 src1fd=0 src2fd=0 regwait=00000018 --R3 WD=9258ff200000ffe0f900000000000000 --R15 RD=00000000000000000000000000000001
ECE734 – Spring 2006 28 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
#302:00000060(1908C816) P0 mix.4.r R2,R6,R8======== --src1(R6)=9258FF20C92CFF90F9000000FF000000 --src2(R8)=0000FFE00000FFF00000000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=103de001 pause=0 skip=0 Rs1=15 Rs2=0 src1fd=0 src2fd=0 regwait=00000014 --R4 WD=32d40070000000100000000000000000 --R15 RD=00000000000000000000000000000001#303:00000064(103DE001) P0 addi R15,R15,1======== --src1(R15)=00000000000000000000000000000001 --src2(imm)=00000000000000000000000000000001QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=04bc04a7 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=1 src2fd=0 regwait=00008004 --R2 WD=c92cff900000fff0ff00000000000000#304:00000068(04BC04A7) P0 cmpi.leu R15,1,P1,P2======== --src1(R15)=00000000000000000000000000000002 --src2(imm)=00000000000000000000000000000001QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=207fffb0 pause=1 skip=0 Rs1=0 Rs2=0 src1fd=0 src2fd=0 regwait=00008000 --R15 WD=00000000000000000000000000000002#305:0000006C(207FFFB0) P1 jmp 0000001Ch========(pause) --P1=0 P2=1QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=207fffb0 pause=0 skip=1 Rs1=16 Rs2=1 src1fd=0 src2fd=0 regwait=00000000 --R16 RD=00000000000000000000000030000020 --R1 RD=3c54feb00000ffd00780fe400000ffc0#306:0000006C(207FFFB0) P1 jmp 0000001Ch========(skip)QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0f860008 pause=0 skip=0 Rs1=16 Rs2=3 src1fd=0 src2fd=0 regwait=00000000 --R16 RD=00000000000000000000000030000020 --R3 RD=9258ff200000ffe0f900000000000000#307:00000070(0F860008) P0 store.8.update R1,R16,8======== --src1(R16)=00000000000000000000000030000020 --src2(R1)=3C54FEB00000FFD00780FE400000FFC0QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0f8e0008 pause=1 skip=0 Rs1=16 Rs2=3 src1fd=2 src2fd=0 regwait=00010000 --R16 RD=00000000000000000000000030000020 --R3 RD=9258ff200000ffe0f900000000000000#308:00000074(0F8E0008) P0 store.8.update R3,R16,8========(pause)QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0f8e0008 pause=1 skip=0 Rs1=16 Rs2=3 src1fd=5 src2fd=0 regwait=00010000 --R16 WD=00000000000000000000000030000028 --R16 RD=00000000000000000000000030000028 --R3 RD=9258ff200000ffe0f900000000000000
ECE734 – Spring 2006 29 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
#309:00000074(0F8E0008) P0 store.8.update R3,R16,8========(pause) --RAMW(top.sram):A=00000020h D=0780fe400000ffc0----------------QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0f8e0008 pause=0 skip=0 Rs1=16 Rs2=4 src1fd=7 src2fd=0 regwait=00000000 --R16 WD=00000000000000000000000030000028 --R16 RD=00000000000000000000000030000028 --R4 RD=32d40070000000100000000000000000#310:00000074(0F8E0008) P0 store.8.update R3,R16,8======== --src1(R16)=00000000000000000000000030000028 --src2(R3)=9258FF200000FFE0F900000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0f920008 pause=1 skip=0 Rs1=16 Rs2=4 src1fd=2 src2fd=0 regwait=00010000 --R16 RD=00000000000000000000000030000028 --R4 RD=32d40070000000100000000000000000#311:00000078(0F920008) P0 store.8.update R4,R16,8========(pause)QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0f920008 pause=1 skip=0 Rs1=16 Rs2=4 src1fd=5 src2fd=0 regwait=00010000 --R16 WD=00000000000000000000000030000030 --R16 RD=00000000000000000000000030000030 --R4 RD=32d40070000000100000000000000000#312:00000078(0F920008) P0 store.8.update R4,R16,8========(pause) --RAMW(top.sram):A=00000030h D=----------------f900000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0f920008 pause=0 skip=0 Rs1=16 Rs2=2 src1fd=7 src2fd=0 regwait=00000000 --R16 WD=00000000000000000000000030000030 --R16 RD=00000000000000000000000030000030 --R2 RD=c92cff900000fff0ff00000000000000#313:00000078(0F920008) P0 store.8.update R4,R16,8======== --src1(R16)=00000000000000000000000030000030 --src2(R4)=32D40070000000100000000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0f8a0008 pause=1 skip=0 Rs1=16 Rs2=2 src1fd=2 src2fd=0 regwait=00010000 --R16 RD=00000000000000000000000030000030 --R2 RD=c92cff900000fff0ff00000000000000#314:0000007C(0F8A0008) P0 store.8.update R2,R16,8========(pause)QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0f8a0008 pause=1 skip=0 Rs1=16 Rs2=2 src1fd=5 src2fd=0 regwait=00010000 --R16 WD=00000000000000000000000030000038 --R16 RD=00000000000000000000000030000038 --R2 RD=c92cff900000fff0ff00000000000000#315:0000007C(0F8A0008) P0 store.8.update R2,R16,8========(pause) --RAMW(top.sram):A=00000030h D=0000000000000000----------------QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972
ECE734 – Spring 2006 30 of 31

Efficient Implementation of H.264 Transform Operations Using Subword Parallel Architecture Kerry Widder
--opd=0f8a0008 pause=0 skip=0 Rs1=0 Rs2=0 src1fd=7 src2fd=0 regwait=00000000 --R16 WD=00000000000000000000000030000038#316:0000007C(0F8A0008) P0 store.8.update R2,R16,8======== --src1(R16)=00000000000000000000000030000038 --src2(R2)=C92CFF900000FFF0FF00000000000000QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=0380ffff pause=0 skip=0 Rs1=14 Rs2=19 src1fd=0 src2fd=0 regwait=00010000 --R14 RD=ffd0ffe00010fff0ffc0000000000000 --R19 RD=cdcdcdcdcdcdcdcdcdcdcdcdcdcdcdcd#317:00000080(0380FFFF) P0 trap FFFF======== --src1(imm)=0000000000000000000000000003FFFC --src2(imm)=C92CFF900000FFF0FF00000000000080QWVT=00000000 00000000 00001111 00000000 head=4 tail=4 Wn=46209972 6209972 6209972 6209972 6209972 6209972 6209972 6209972 --opd=cdcdcdcd pause=0 skip=1 Rs1=14 Rs2=19 src1fd=0 src2fd=0 regwait=00010000
ECE734 – Spring 2006 31 of 31





























