Embed Size (px)
Citation preview

Distributed RDF data store on HBase.
Project By:
• Anuj Shetye
• Vinay Boddula

Project Overview
Introduction
Motivation
HBase
Our work
Evaluation
Related work.
Future work and conclusion.

Introduction
As RDF datasets goes on increasing, therefore size of RDF
is much larger than traditional graph
Cardinality of vertex and edges is much larger.
Therefore large data stores are required for following reasons
Fast and efficient querying .
Scalability issues.

Motivation
Research has been done to map RDF dataset onto relational databases
example: Virtuoso, Jena SDB.
But dataset is stored centrally i.e. on one server.
Examples: Jena SDB map RDF triple in relational database.
– Scalability
Some try to store RDF data as a large graph but on single node example Jena TDB– Scalability

HBase.
Hbase is an open source distributed sorted map datastore.
modelled on google big table.

Contd...Hbase is a
No SQL datbase.High Scalability , Highly Fault Tolerant.Fast Read/WriteDynamic DatabaseHadoop and other apps integrated.Column family oriented data layout.Max datasize : ~1 PB.Read/write limits millions of queries per second.
Who uses Hbase/BigtableAdobe, Facebook, Twitter, Yahoo, Gmail, Google maps etc.
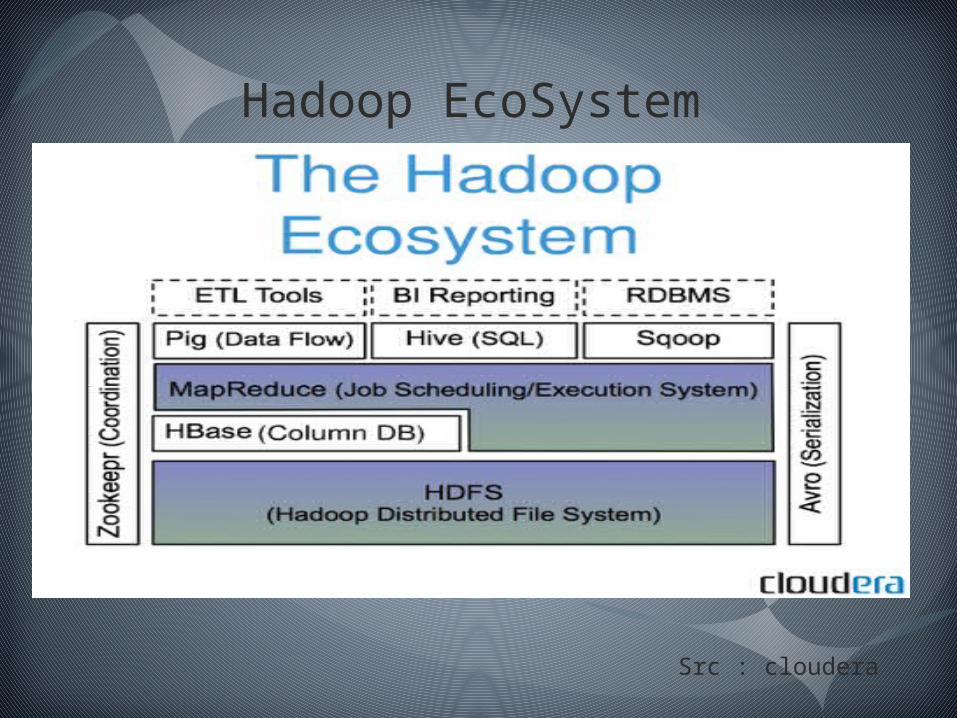
Hadoop EcoSystem
Src : cloudera

Our Project
Our project to create a distributed data storage capability for RDF schema using Hbase .
We developed a system which takes the Ntriple file of an RDF graph as an input and stores the triples in Hbase as a Key value pair using Map reduce jobs.
The schema is simple
we create column families of each predicates
subjects as Row keys
objects as the values

Mapper
MR Job
MR job
MR Job
Hbase Data store
System Architecture
I/p File

Data Model
Row key Data
Anuj hasAdvisor : {‘Dr. Miller’} workedFor: {‘UGA’}
Vinay hasAdvisor : {‘Dr.Ramaswamy’} hasPapers : {‘Paper 1’,’Paper 2’} workedFor: {‘IBM’ , ‘UGA’}
Logical view as ‘Records’

Data Model contd..
Row Key
Column key
Timestamp
value
Anuj hasAdvisor
T1 Dr. Miller
Vinay hasAdvisor
T2 Dr.Ramaswamy
Row Key
Column key
Timestamp
value
Vinay hasPaper T2 Paper1
Vinay hasPaper T1 Paper2
Physical Model
hasAdvisor Column family
hasPaper Column family

Row Key Column key
Timestamp
value
Anuj workedFor T1 ‘UGA’
Vinay workedFor T3 ‘UGA’
Vinay workedFor T2 ‘IBM’
workedFor Column family

Two major issues can be solved using Hbase
Data insertionData updation
Versioning possible (Timestamps).
Bulk loading of data. Two types
complete bulk load (hbase File Formatter, our approach )Incremental bulk load

Evaluations
We talk about it during the demo

Related Work.
CumulusRDF: Linked Data Management on Nested Key-Value Stores appeared in SSWS 2011 works on distributed key value indexing on data stores they used Casandra as the data store.
Apache Casandra is currently capable of storing rdf data and has an adapter to store data in a distributed management system.

Future Work and Conclusion
Our future work lies in developing an efficient interface for sparql as querying with SQL like HIVE is slower in Hbase.
The testing of the system was done on single node, therefore testing it on multiple nodes would be an ultimate test of efficiency .

Questions ??





























