Embed Size (px)
Citation preview

Processor Architectures and Program Mapping
TU/e 5kk10Henk Corporaal
Jef van Meerbergen
Bart Mesman
Exploiting DLPSIMD architectures
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
2
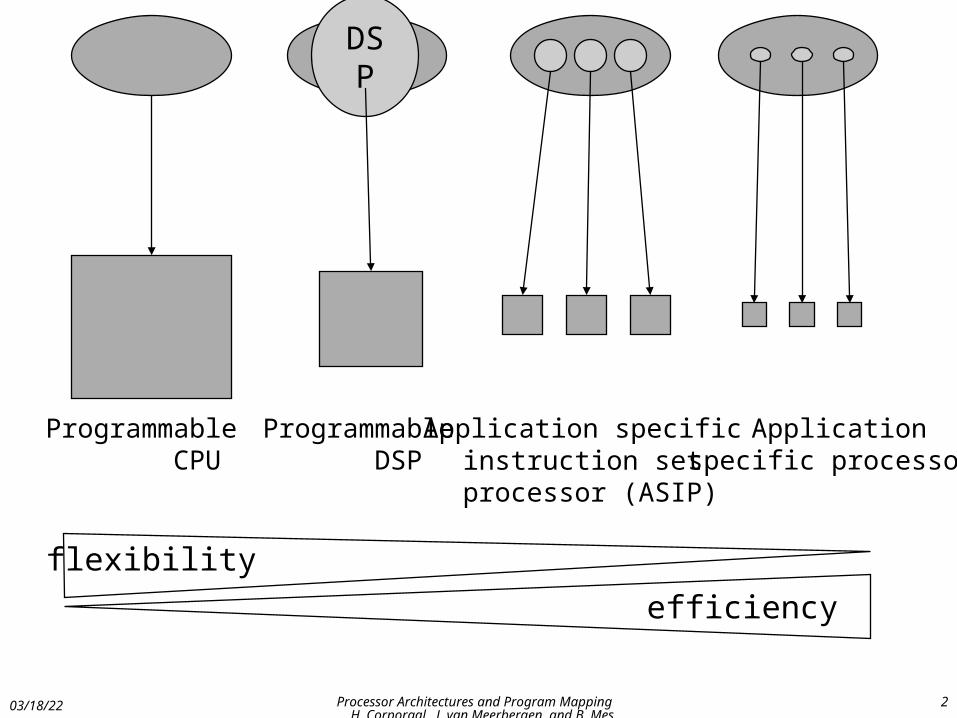
flexibility
efficiency
DSP
Programmable CPU
Programmable DSP
Application specific instruction set
processor (ASIP)
Applicationspecific processor
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
3
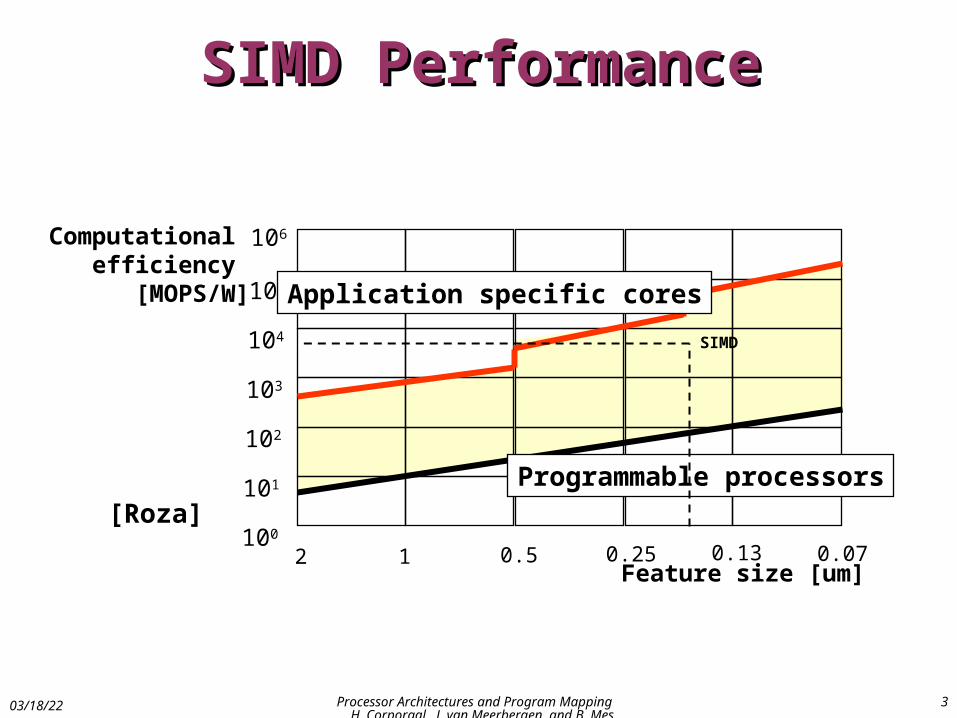
SIMD PerformanceSIMD Performance
106
105
104
103
102
101
100
2 1 0.5 0.25 0.13 0.07
Computational efficiency [MOPS/W]
Feature size [um]
Application specific cores
Programmable processors[Roza]
SIMD

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
4
What are we talking about?
ILP = Instruction Level Parallelism =
ability to perform multiple operations (or instructions),from a single instruction stream,
in parallel
VLIW = Very Long Instruction Word architecture
operation 1 operation 2 operation 3 operation 4
Instruction format:
operation 5

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
5
SIMD: Topics Overview• Enhance performance: architecture methods
• Data Level Parallelism
– Application area– Subword parallelism
• Locally connected SIMDs
– Xetal
• Fully connected SIMDs
– Imagine
• Communication in SIMD processors– RCSIMD
– DCSIMD

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
6
Enhance performance: 3 architecture methods
• (Super)-pipelining
• Powerful instructions– MD-technique
• multiple data operands per operation
– MO-technique• multiple operations per instruction
• Multiple instruction issue

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
7
Characteristics of Media Applications• Poorly matched to conventional architectures
– Caches
– Instruction-Level Parallelism
– Few arithmetic units
• Well-matched to modern VLSI technology
– Lots (100’s - 1000’s) of ALUs fit on a single chip
Communication bandwidth is the scarce resource

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
8
Architecture methods
Powerful Instructions (1)
MD-technique• Multiple data operands per operation• SIMD: Single Instruction Multiple Data
Vector instruction:
for (i=0, i++, i<64) c[i] = a[i] + 5*b[i];
c = a + 5*b
Assembly:
set vl,64ldv v1,0(r2)mulvi v2,v1,5ldv v1,0(r1)addv v3,v1,v2stv v3,0(r3)
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
9
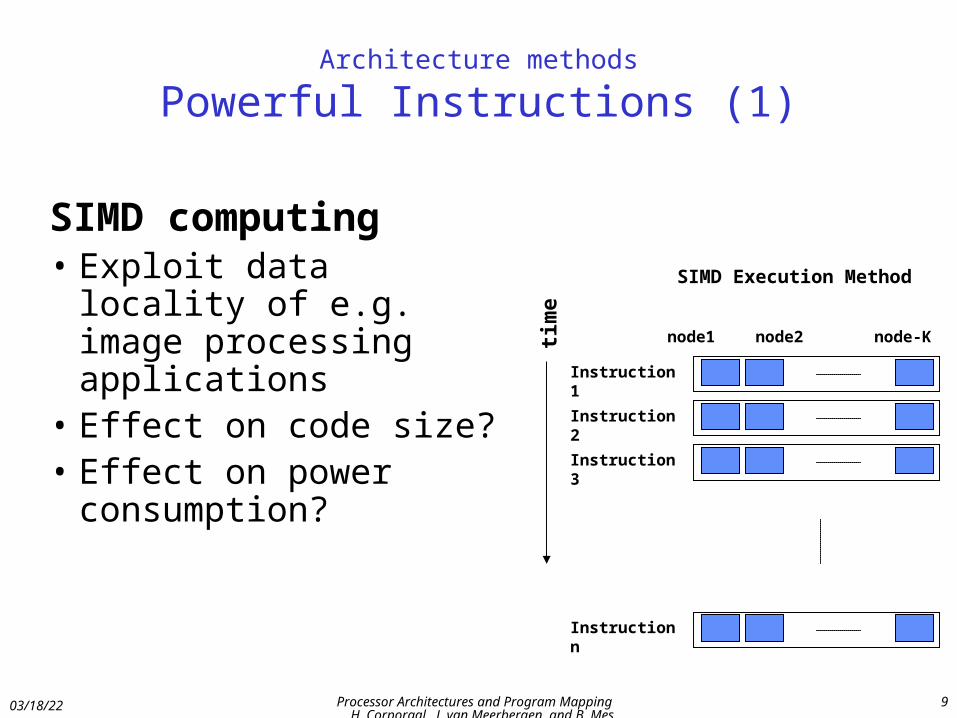
Architecture methods
Powerful Instructions (1)
SIMD computing• Exploit data locality of
e.g. image processing applications
• Effect on code size?• Effect on power
consumption?
SIMD Execution Method
tim
e
Instruction 1
Instruction 2
Instruction 3
Instruction n
node1 node2 node-K
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
10
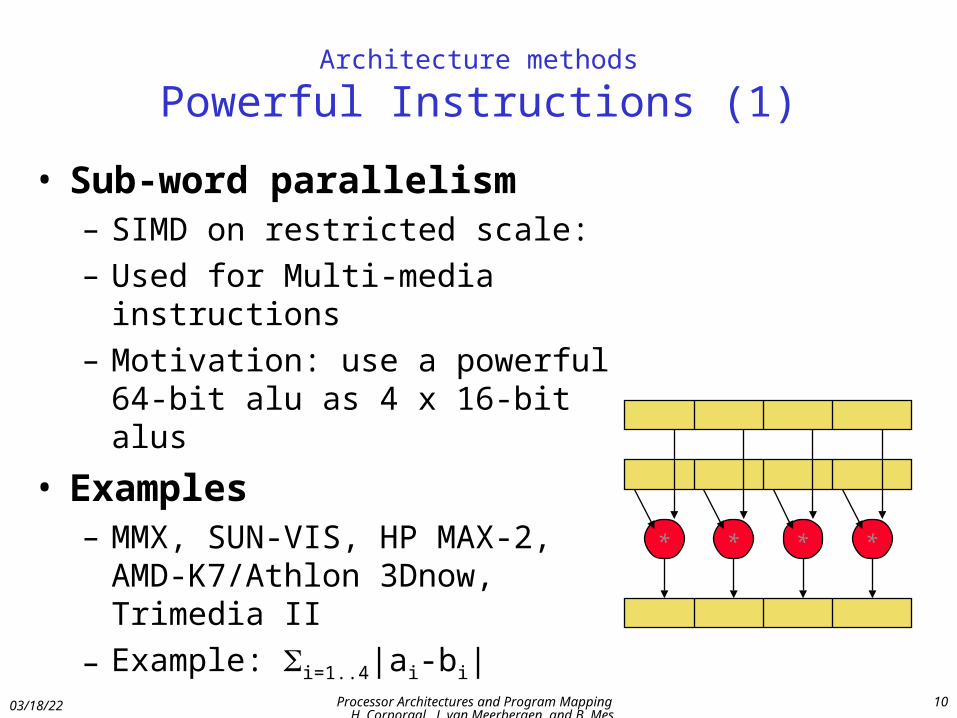
Architecture methods
Powerful Instructions (1)
• Sub-word parallelism– SIMD on restricted scale:
– Used for Multi-media instructions
– Motivation: use a powerful 64-bit alu as 4 x 16-bit alus
• Examples– MMX, SUN-VIS, HP MAX-2, AMD-
K7/Athlon 3Dnow, Trimedia II
– Example: i=1..4|ai-bi| * * * *
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
11
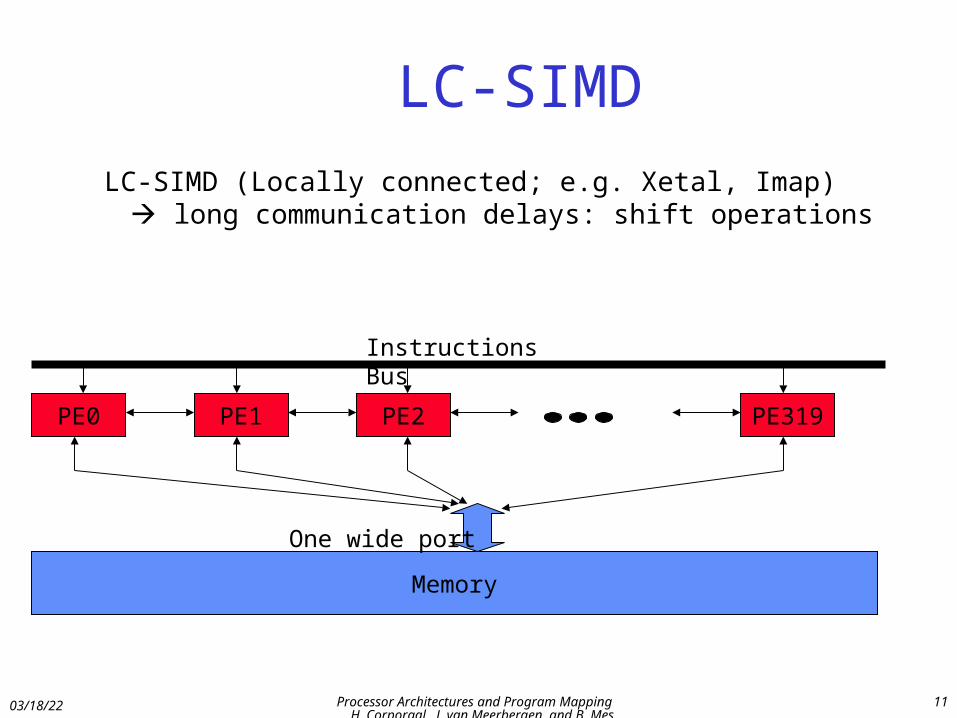
LC-SIMD
LC-SIMD (Locally connected; e.g. Xetal, Imap) long communication delays: shift operations
PE1 PE2 PE319PE0
Instructions Bus
Memory
One wide port
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
12
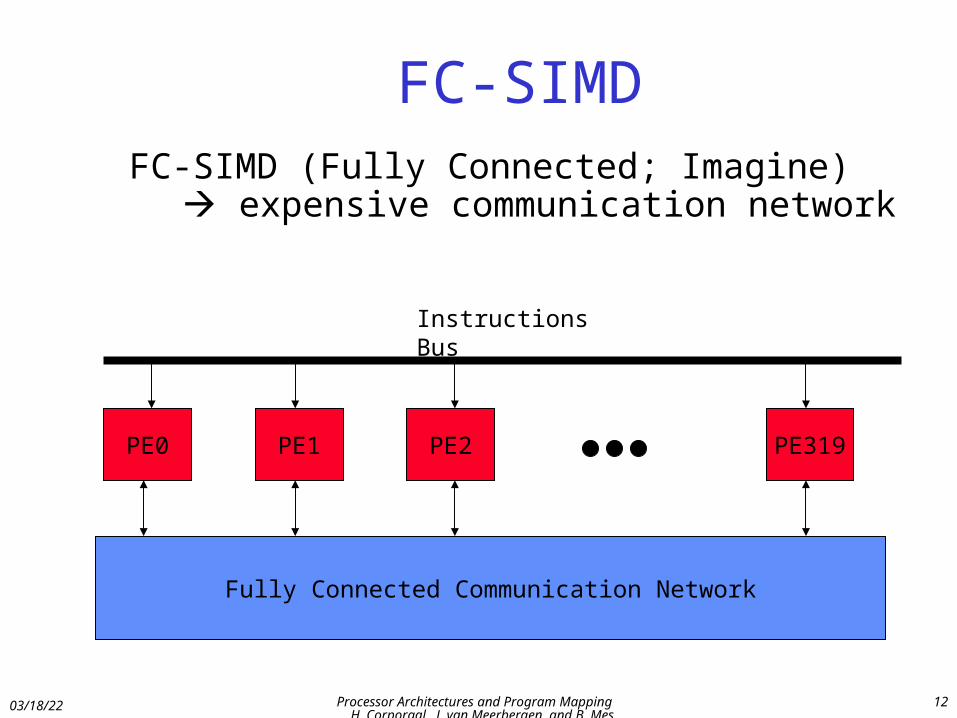
FC-SIMDFC-SIMD (Fully Connected; Imagine)
expensive communication network
PE1 PE2 PE319PE0
Instructions Bus
Fully Connected Communication Network

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
13
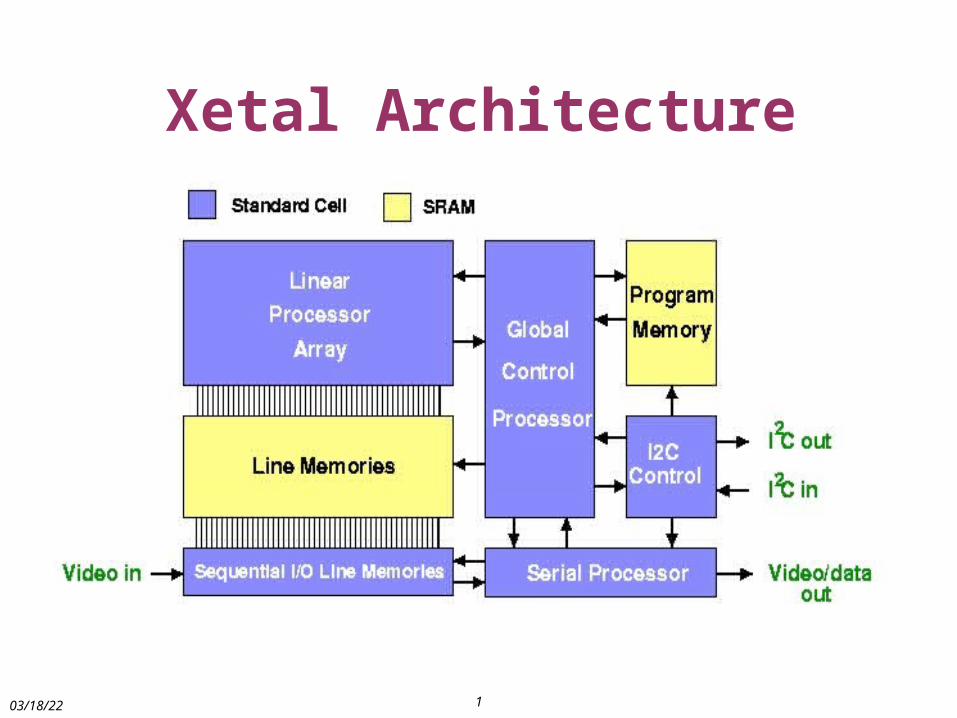
LC: Xetal Objectives
High-degree of system integration
CMOS imaging + DSP
low cost camera systems
Low power consumption
mobile & remote sensing
Flexibility
programmable DSP and control functions
04/18/23 1
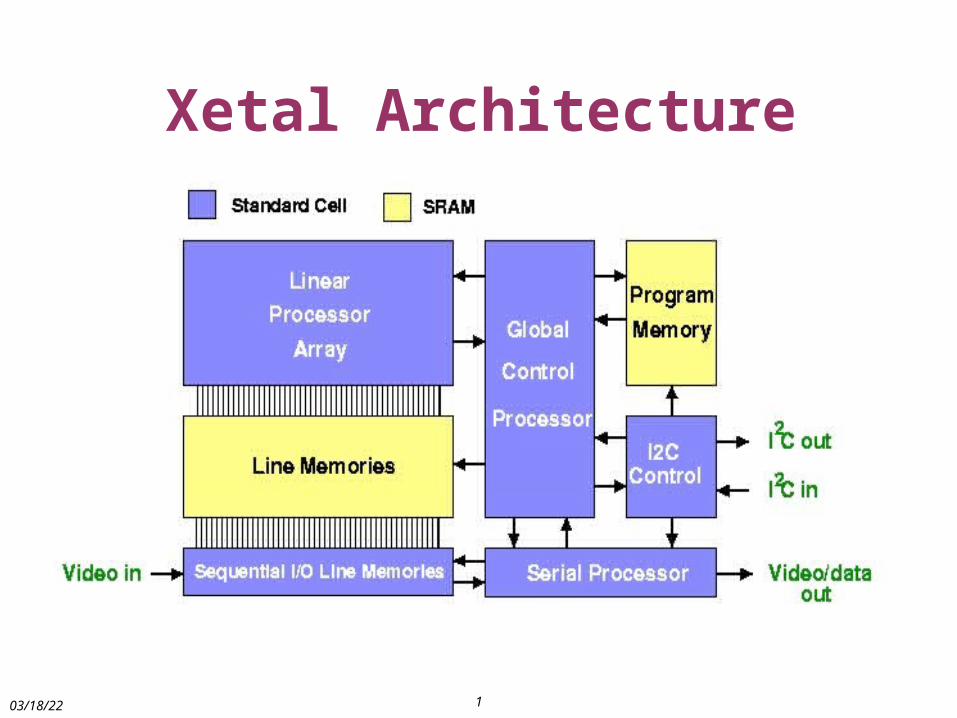
Xetal Architecture
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
15
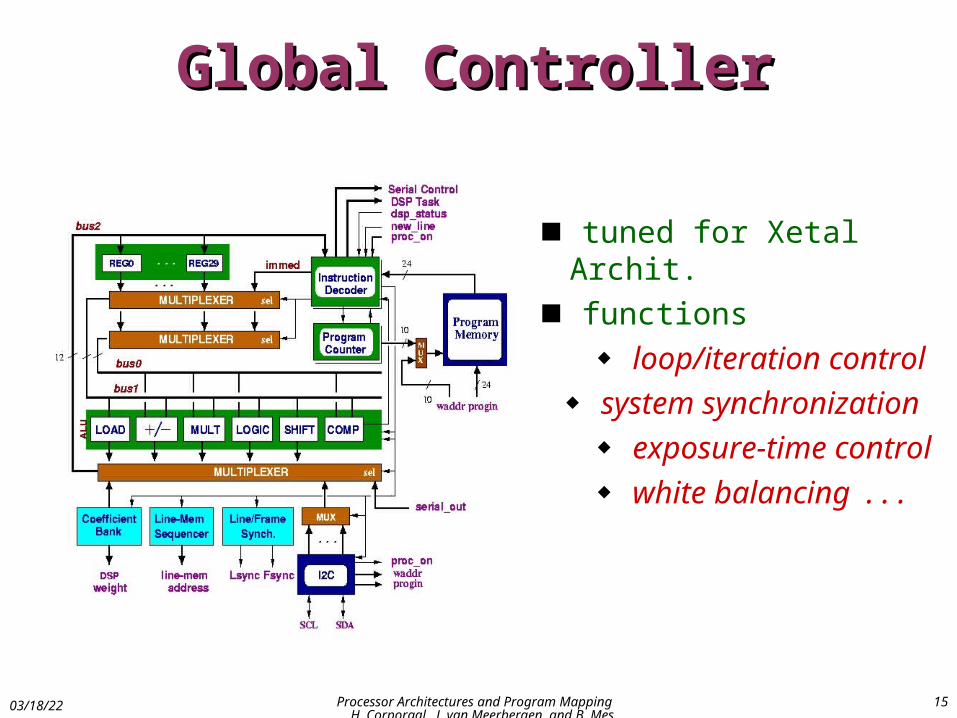
Global ControllerGlobal Controller
tuned for Xetal Archit.
functions
loop/iteration control
system synchronization
exposure-time control
white balancing . . .
04/18/23 1
Xetal Architecture
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
17
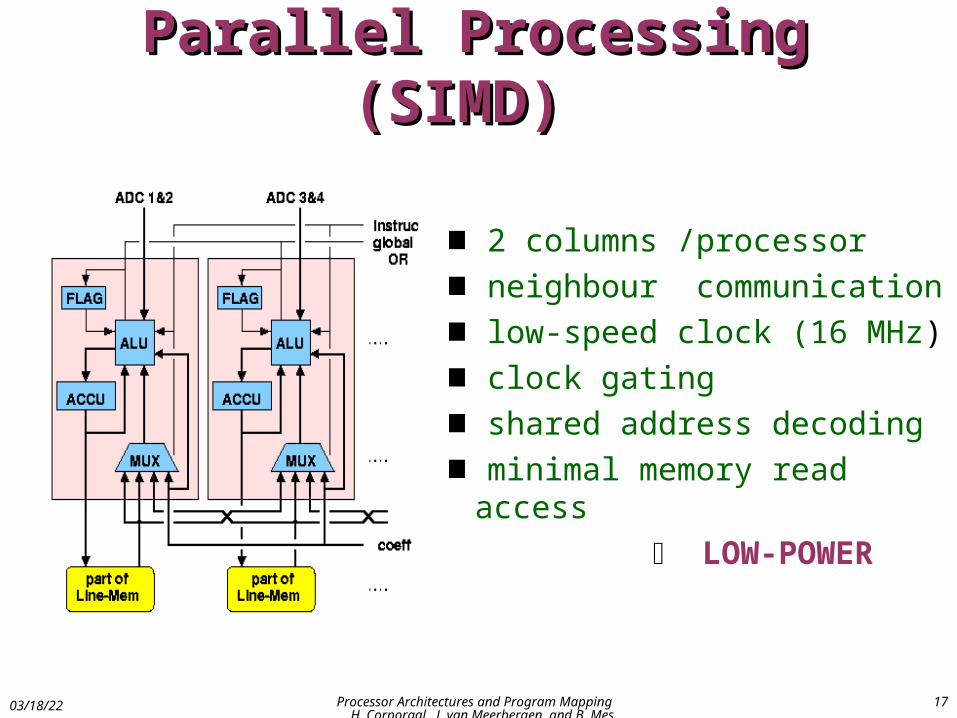
Parallel Processing (SIMD) Parallel Processing (SIMD)
2 columns /processor
neighbour communication
low-speed clock (16 MHz)
clock gating
shared address decoding
minimal memory read access
LOW-POWER
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
18
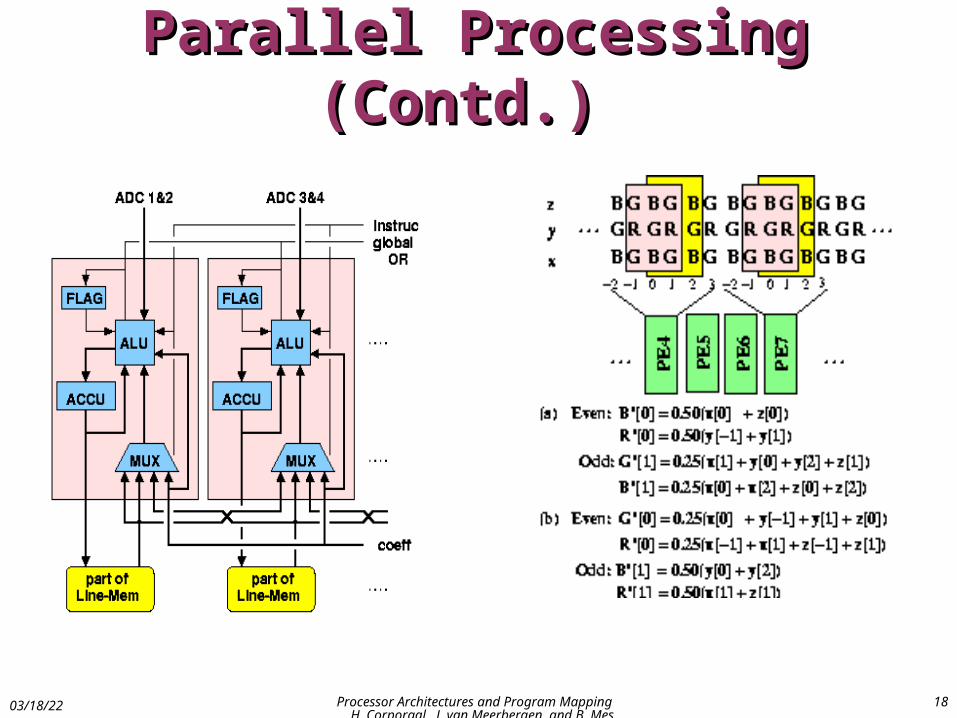
Parallel Processing (Contd.) Parallel Processing (Contd.)
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
19
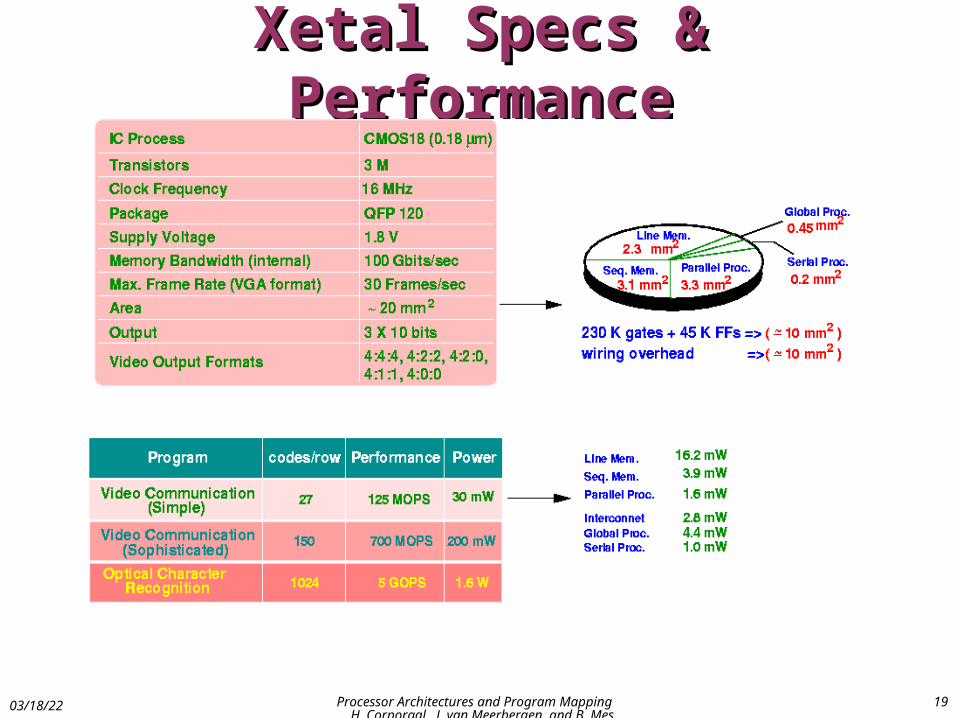
Xetal Specs & PerformanceXetal Specs & Performance

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
20
Simulation Results(1-input)Simulation Results(1-input)

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
21
Simulation Results(1-output)Simulation Results(1-output)
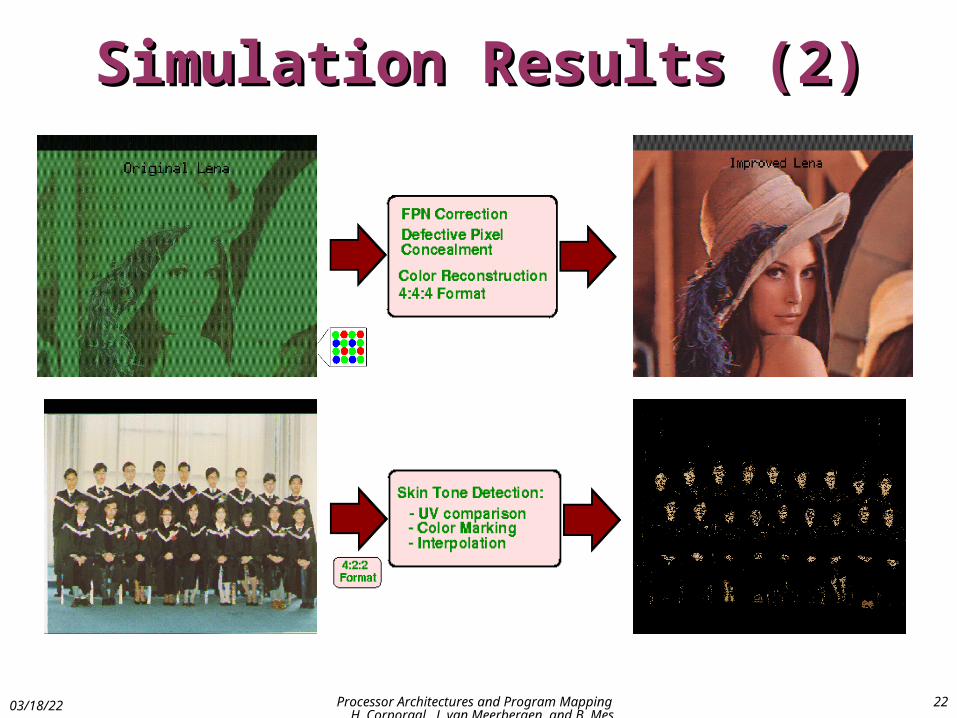
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
22
Simulation Results (2)Simulation Results (2)

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
23
Imagine
• Combining DLP (SIMD) and ILP (VLIW)– toplevel SIMD– per PE: VLIW
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
24
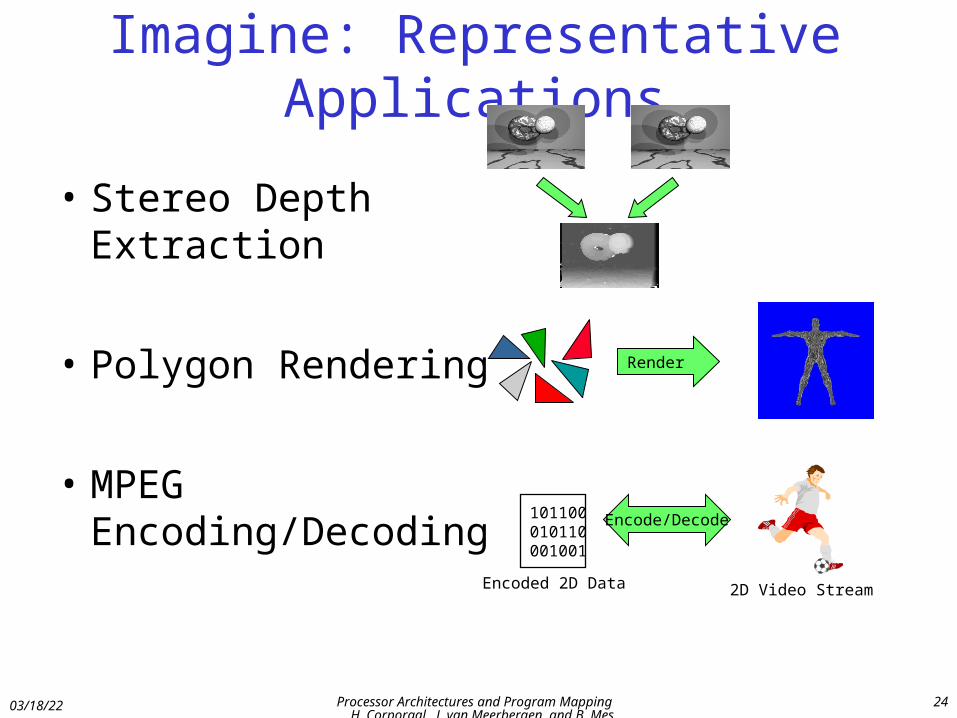
• Stereo Depth Extraction
• Polygon Rendering
• MPEG Encoding/Decoding
Encoded 2D Data 2D Video Stream
Encode/Decode
Imagine: Representative Applications
Render
101100010110001001
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
25
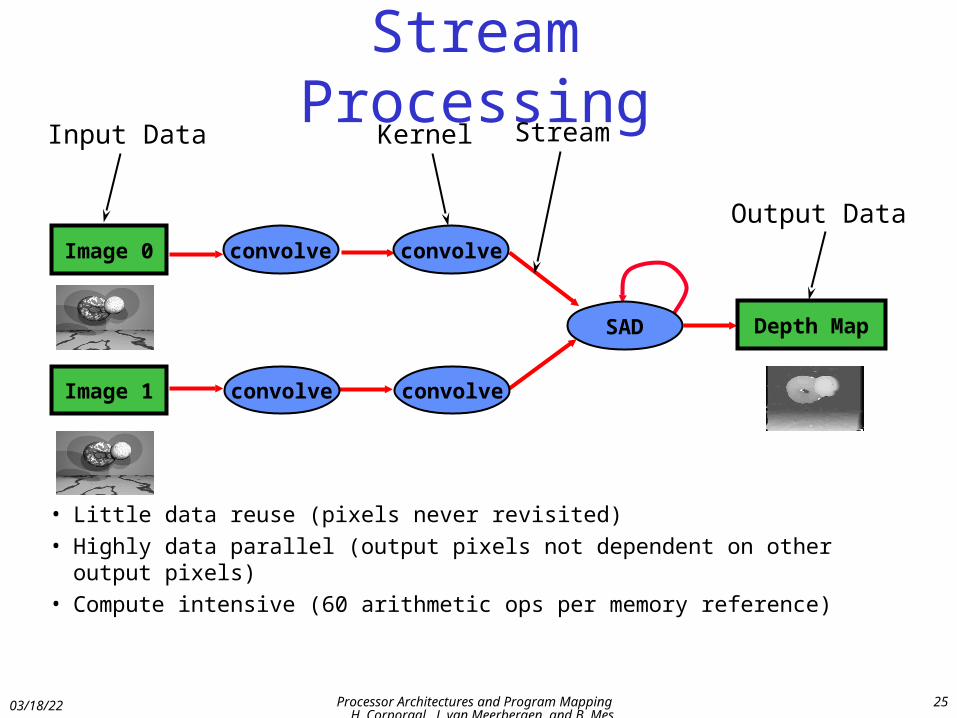
Stream Processing
• Little data reuse (pixels never revisited)• Highly data parallel (output pixels not dependent on other output pixels)• Compute intensive (60 arithmetic ops per memory reference)
SAD
Kernel StreamInput Data
Output Data
Image 1 convolve convolve
Image 0 convolve convolve
Depth Map
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
26
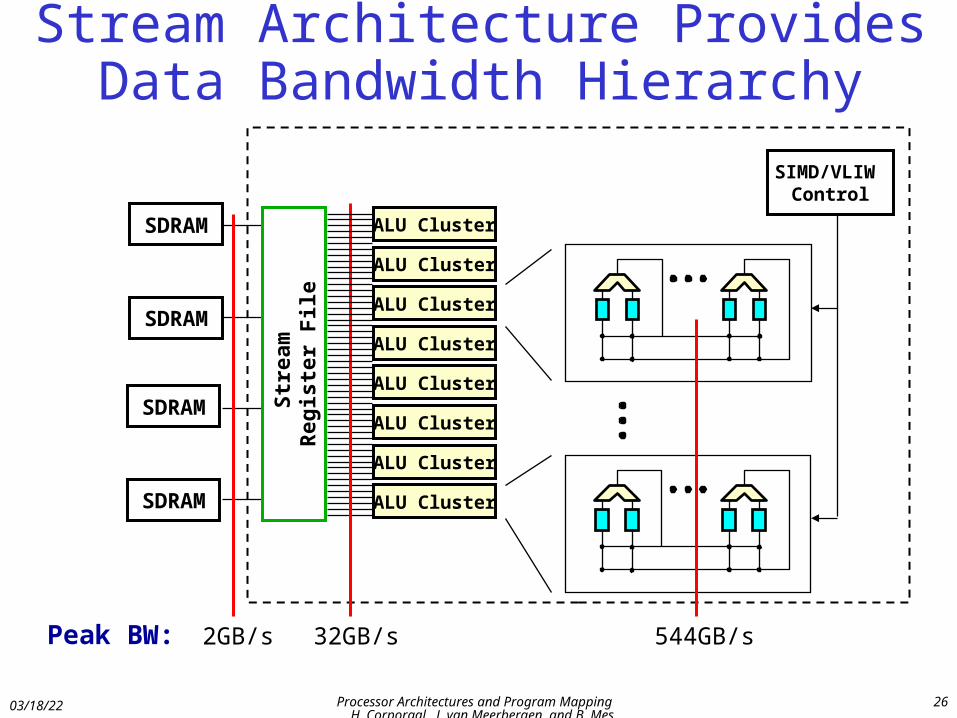
Stream Architecture Provides Data Bandwidth Hierarchy
2GB/s 32GB/s
SDRAM
SDRAM
SDRAM
SDRAM
Str
eam
R
egis
ter
File
ALU Cluster
ALU Cluster
ALU Cluster
544GB/s
ALU Cluster
ALU Cluster
ALU Cluster
ALU Cluster
ALU Cluster
SIMD/VLIW Control
Peak BW:
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
27
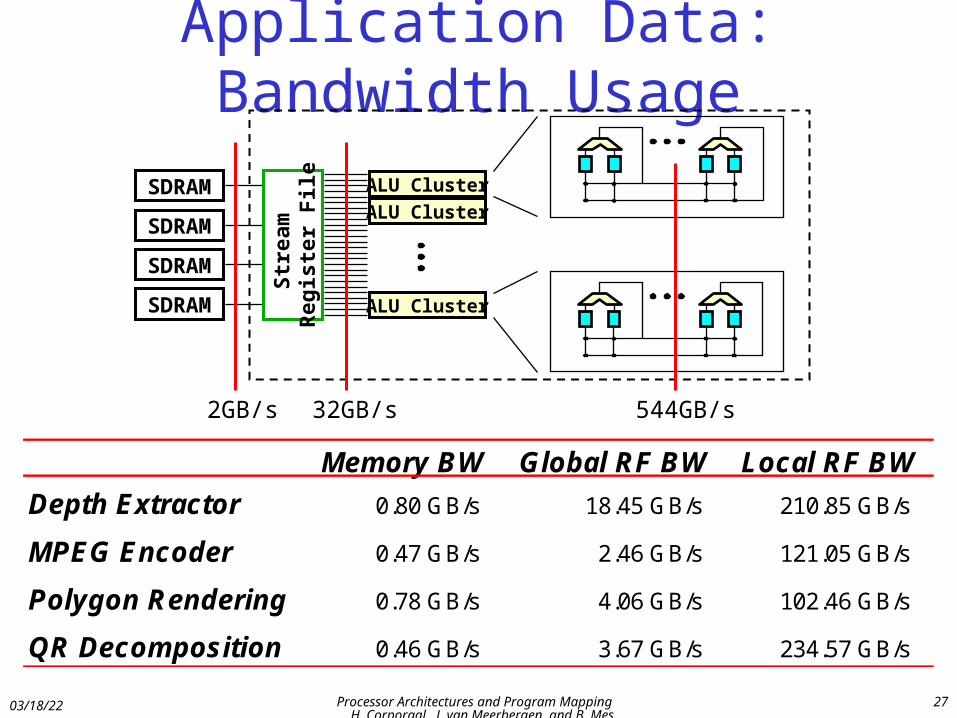
Application Data: Bandwidth Usage
2GB/s 32GB/s
SDRAM
SDRAM
SDRAM
SDRAMS
trea
m
Reg
iste
r F
ile
ALU Cluster
ALU Cluster
ALU Cluster
544GB/s
Memory BW Global RF BW Local RF BW
Depth Extractor 0.80 GB/s 18.45 GB/s 210.85 GB/s
MPEG Encoder 0.47 GB/s 2.46 GB/s 121.05 GB/s
Polygon Rendering 0.78 GB/s 4.06 GB/s 102.46 GB/s
QR Decomposition 0.46 GB/s 3.67 GB/s 234.57 GB/s
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
28
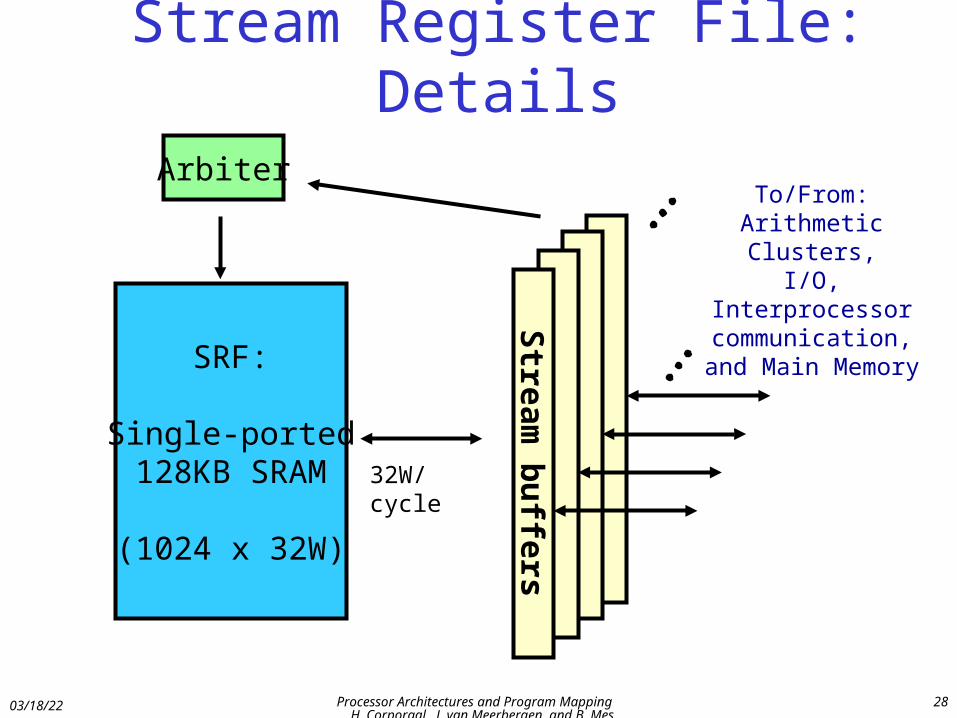
Stream Register File: Details
SRF:
Single-ported128KB SRAM
(1024 x 32W)
Stream
bu
ffers
32W/cycle
ArbiterTo/From:
Arithmetic Clusters,I/O,
Interprocessorcommunication,
and Main Memory
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
29
CU
Inte
rclu
ster
N
etw
ork+
From SRF
To SRF
+ * /
Cross Point
Local Register File
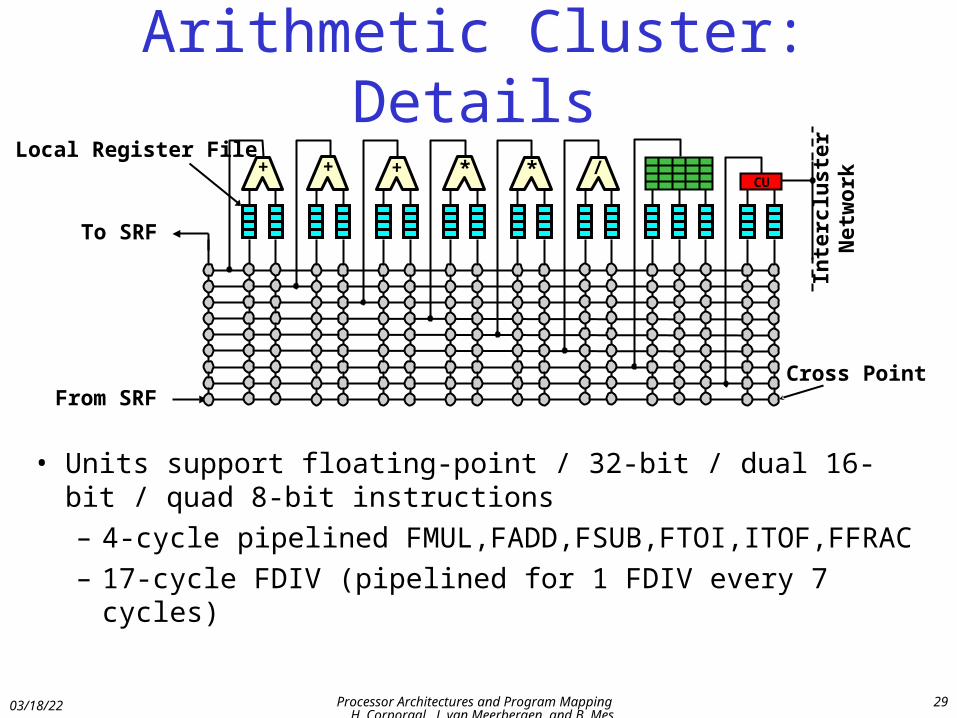
Arithmetic Cluster: Details
• Units support floating-point / 32-bit / dual 16-bit / quad 8-bit instructions
– 4-cycle pipelined FMUL,FADD,FSUB,FTOI,ITOF,FFRAC
– 17-cycle FDIV (pipelined for 1 FDIV every 7 cycles)
+ *
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
30
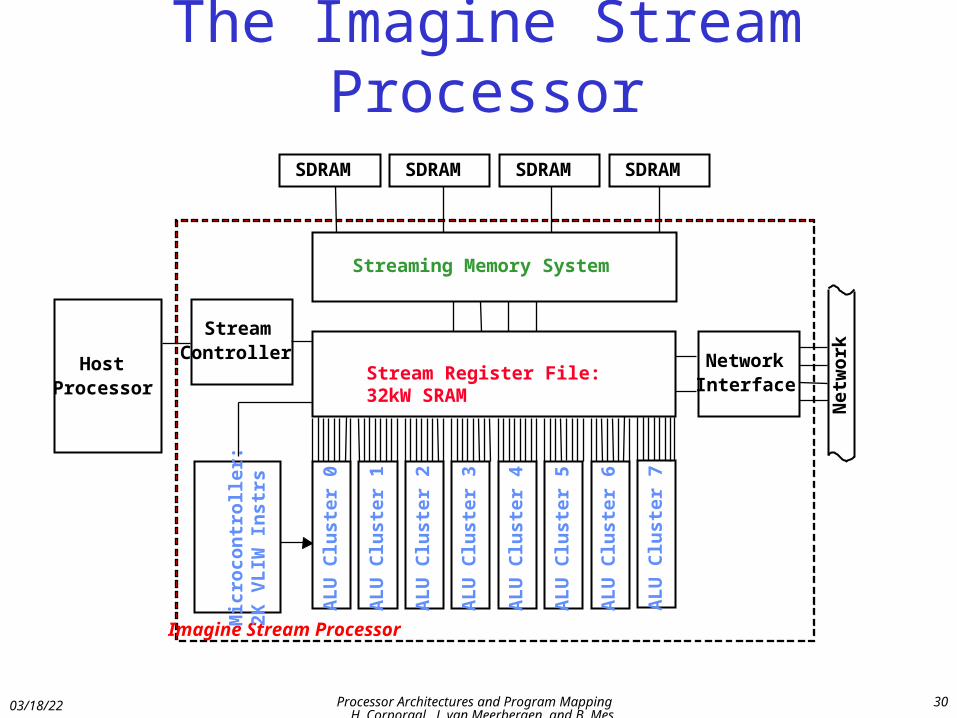
The Imagine Stream Processor
Stream Register File:32kW SRAM
NetworkInterface
StreamController
Imagine Stream Processor
HostProcessor
Net
wor
k
AL
U C
lust
er 0
AL
U C
lust
er 1
AL
U C
lust
er 2
AL
U C
lust
er 3
AL
U C
lust
er 4
AL
U C
lust
er 5
AL
U C
lust
er 6
AL
U C
lust
er 7
SDRAMSDRAM SDRAMSDRAM
Streaming Memory System
Mic
roco
ntr
oll
er:
2K V
LIW
In
strs
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
31
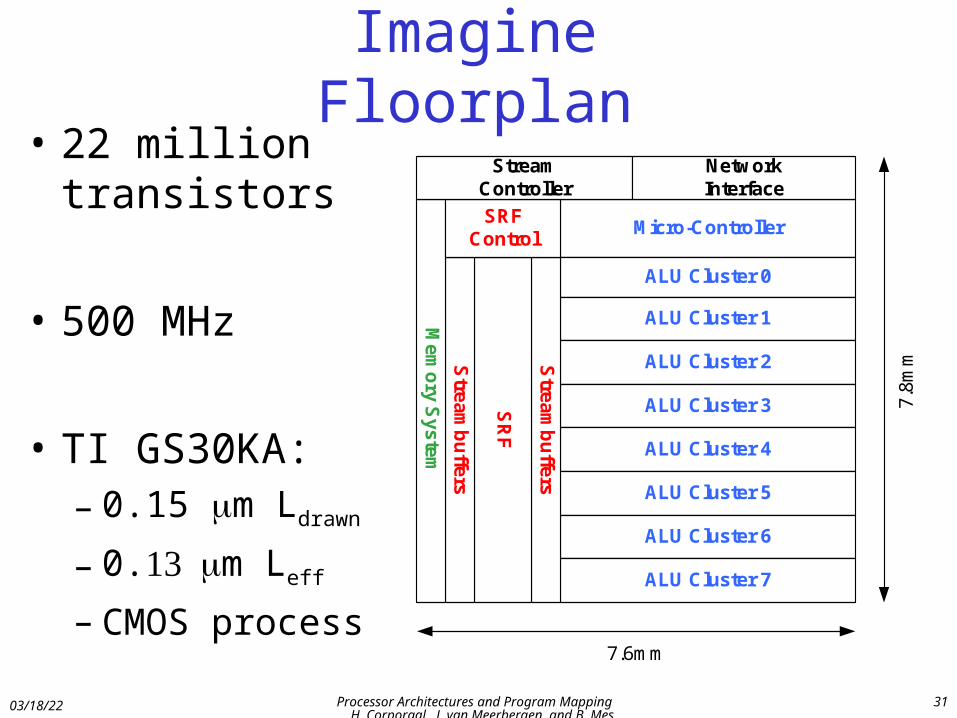
Imagine Floorplan• 22 million
transistors
• 500 MHz
• TI GS30KA:– 0.15 m Ldrawn
– 0.m Leff
– CMOS process
Micro-Controller
ALU Cluster 0
ALU Cluster 1
ALU Cluster 2
ALU Cluster 3
ALU Cluster 4
ALU Cluster 5
ALU Cluster 6
ALU Cluster 7
Stre
am
bu
ffers
SR
F
Stre
am
bu
ffers
Me
mo
ry S
ys
tem
SRFControl
StreamController
NetworkInterface
7.8
mm
7.6mm
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
32
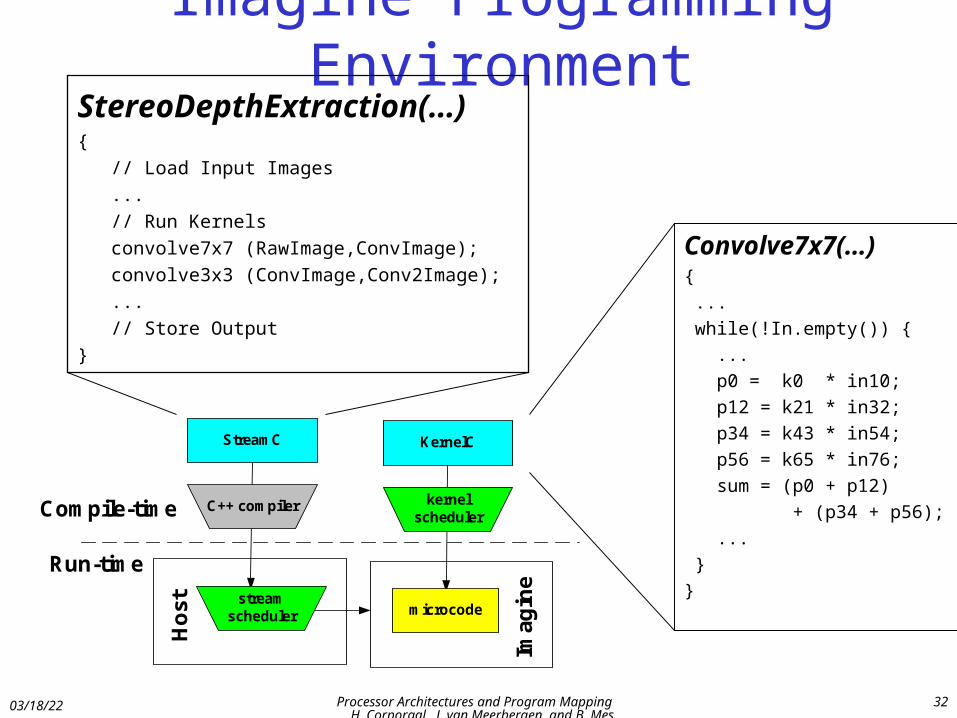
Imagine Programming Environment
StreamC
C++ compiler
KernelC
kernelscheduler
microcode
Ho
st
Imag
ine
streamscheduler
Run-time
Compile-time
StereoDepthExtraction(…) {
// Load Input Images
...
// Run Kernels
convolve7x7 (RawImage,ConvImage);
convolve3x3 (ConvImage,Conv2Image);
...
// Store Output
}
Convolve7x7(…){
...
while(!In.empty()) {
...
p0 = k0 * in10;
p12 = k21 * in32;
p34 = k43 * in54;
p56 = k65 * in76;
sum = (p0 + p12)
+ (p34 + p56);
...
}
}

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
33
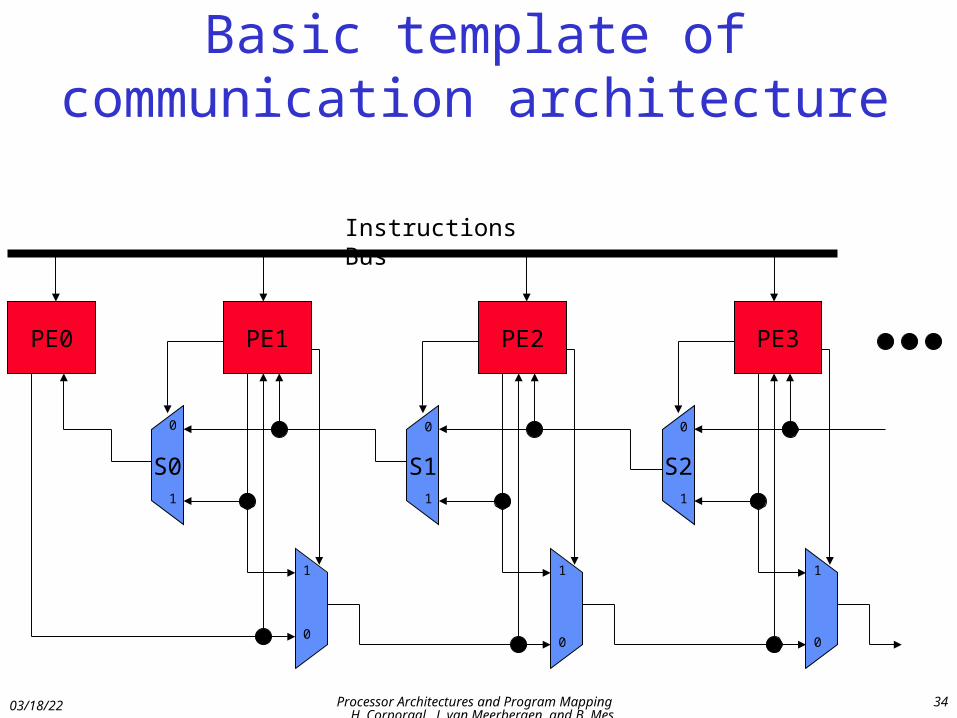
RC-SIMD
• Imagine support full interconnect between PEs
• Do we need this expensive interconnect?
• Alternative: RC-SIMD
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
34
Basic template of communication architecture
S0
PE1
S1
PE2
S2
PE3PE0
1
1
11
11
0 0
00
0
0
Instructions Bus
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
35
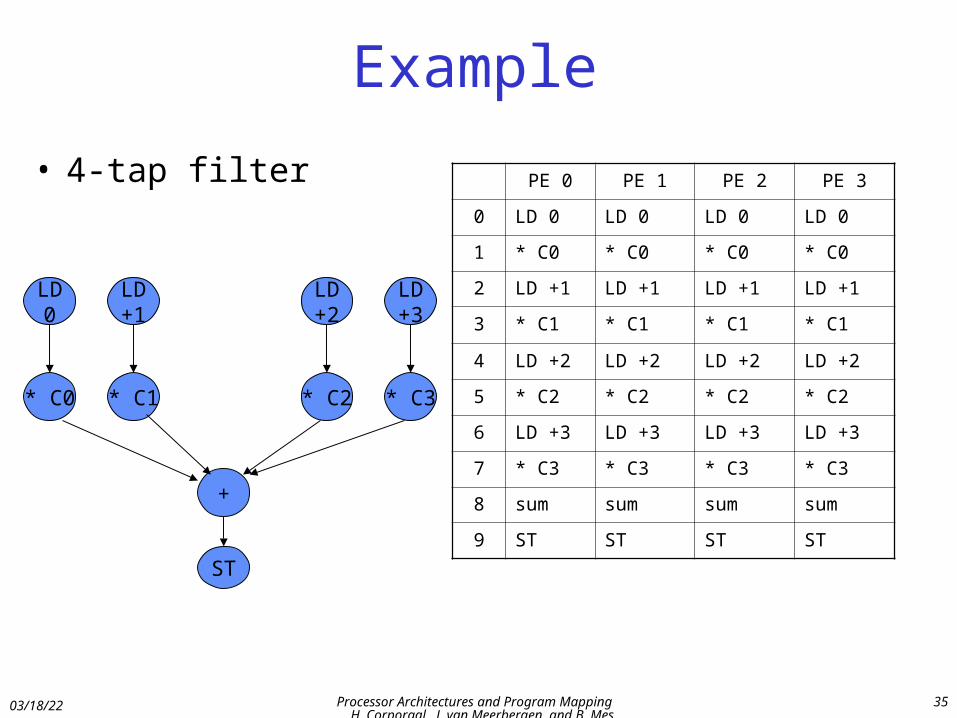
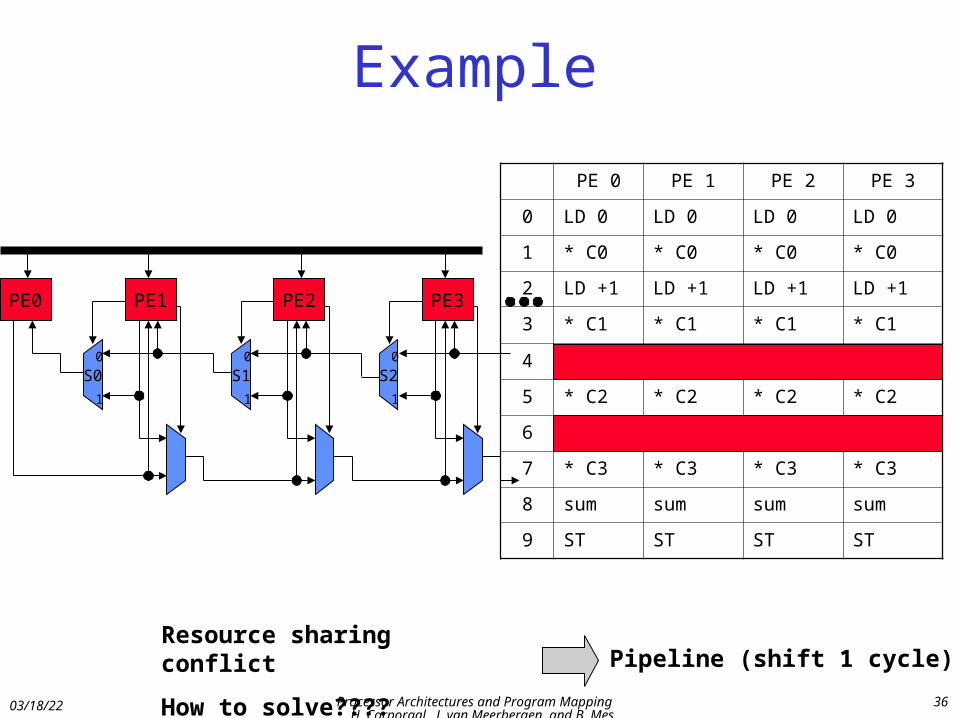
Example
• 4-tap filter
LD0
* C0
LD+1
* C1
LD+2
* C2
LD+3
* C3
+
ST
PE 0 PE 1 PE 2 PE 3
0 LD 0 LD 0 LD 0 LD 0
1 * C0 * C0 * C0 * C0
2 LD +1 LD +1 LD +1 LD +1
3 * C1 * C1 * C1 * C1
4 LD +2 LD +2 LD +2 LD +2
5 * C2 * C2 * C2 * C2
6 LD +3 LD +3 LD +3 LD +3
7 * C3 * C3 * C3 * C3
8 sum sum sum sum
9 ST ST ST ST
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
36
Example
PE 0 PE 1 PE 2 PE 3
0 LD 0 LD 0 LD 0 LD 0
1 * C0 * C0 * C0 * C0
2 LD +1 LD +1 LD +1 LD +1
3 * C1 * C1 * C1 * C1
4 LD +2 LD +2 LD +2 LD +2
5 * C2 * C2 * C2 * C2
6 LD +3 LD +3 LD +3 LD +3
7 * C3 * C3 * C3 * C3
8 sum sum sum sum
9 ST ST ST ST
Resource sharing conflict
How to solve????
Pipeline (shift 1 cycle)
PE1
S1
PE2 PE3PE0
1
0
S21
0
S01
0
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
37
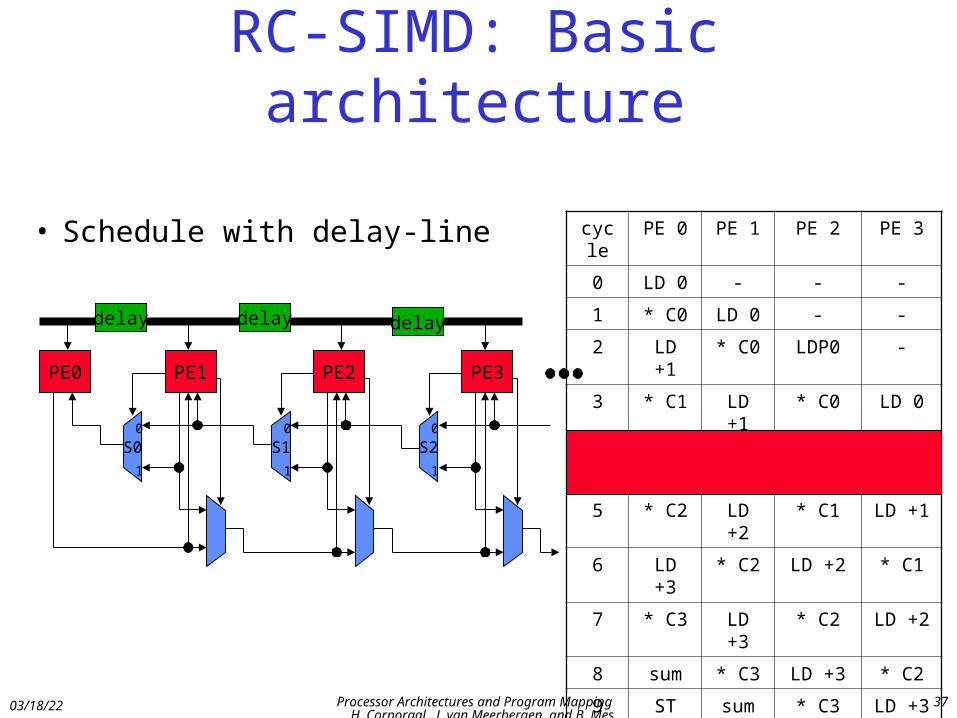
RC-SIMD: Basic architecture
cycle PE 0 PE 1 PE 2 PE 3
0 LD 0 - - -
1 * C0 LD 0 - -
2 LD +1 * C0 LDP0 -
3 * C1 LD +1 * C0 LD 0
4 LD +2 * C1 LD +1 * C0
5 * C2 LD +2 * C1 LD +1
6 LD +3 * C2 LD +2 * C1
7 * C3 LD +3 * C2 LD +2
8 sum * C3 LD +3 * C2
9 ST sum * C3 LD +3
10 - ST sum * C3
11 - - ST sum
12 - - - ST
• Schedule with delay-line
PE1
S1
PE2 PE3PE0
1
0
delay delay delay
S21
0
S01
0
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
38
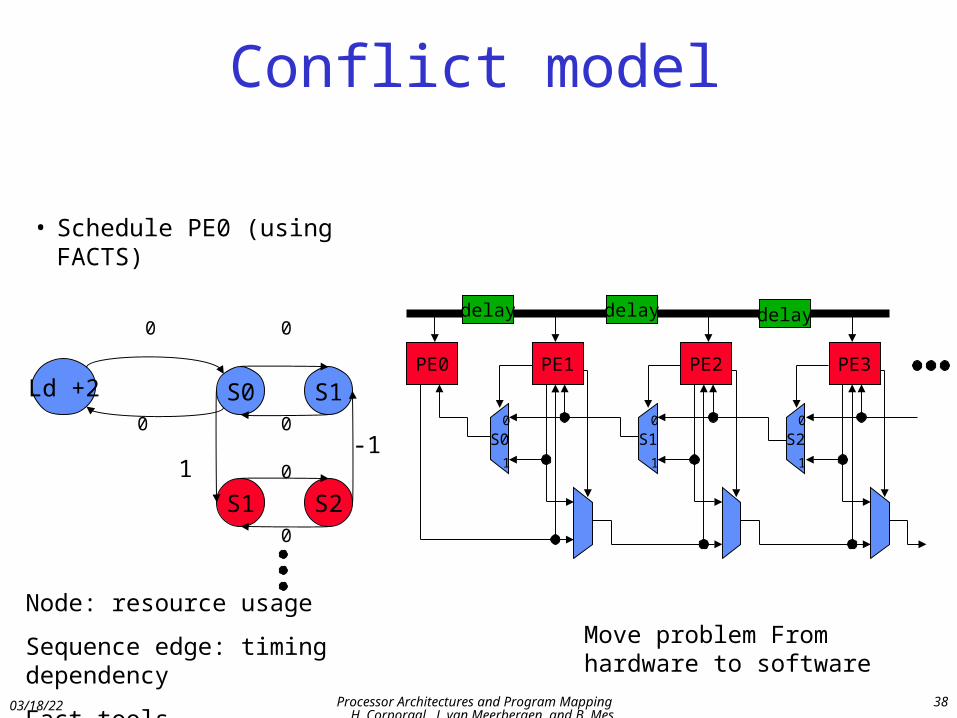
Conflict model
Ld +2 S0 S1
S1 S2
1-1
00
0 0
0
0
• Schedule PE0 (using FACTS)
Node: resource usage
Sequence edge: timing dependency
Fact tools
Move problem From hardware to software
PE1
S1
PE2 PE3PE0
1
0
delay delay delay
S21
0
S01
0
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
39
Basic architecture
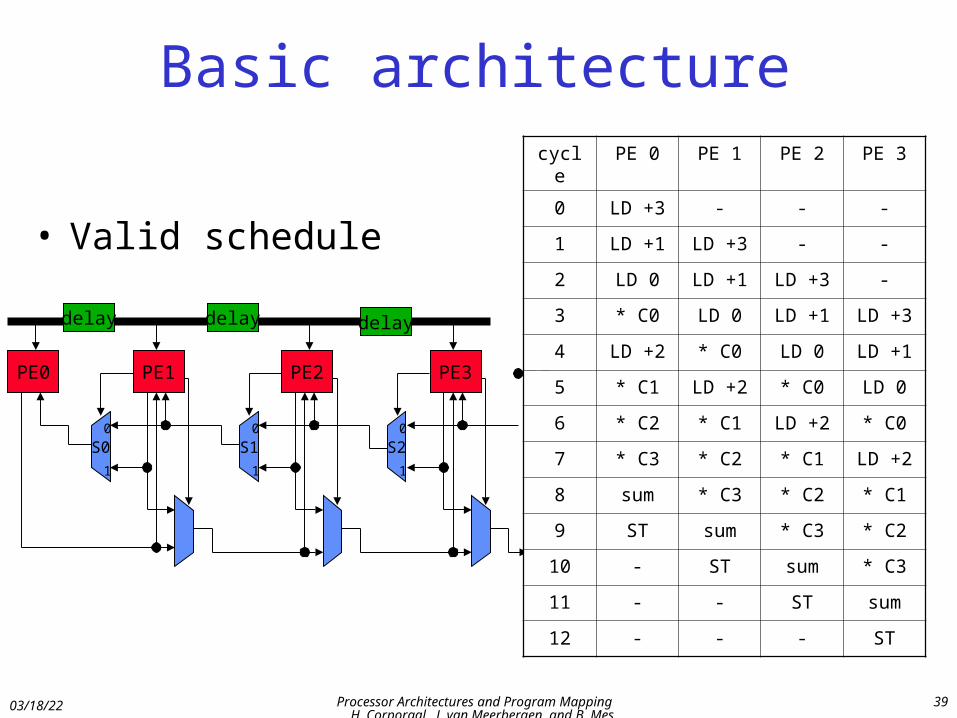
• Valid schedule
PE1
S1
PE2 PE3PE0
1
0
delay delay delay
S21
0
S01
0
cycle PE 0 PE 1 PE 2 PE 3
0 LD +3 - - -
1 LD +1 LD +3 - -
2 LD 0 LD +1 LD +3 -
3 * C0 LD 0 LD +1 LD +3
4 LD +2 * C0 LD 0 LD +1
5 * C1 LD +2 * C0 LD 0
6 * C2 * C1 LD +2 * C0
7 * C3 * C2 * C1 LD +2
8 sum * C3 * C2 * C1
9 ST sum * C3 * C2
10 - ST sum * C3
11 - - ST sum
12 - - - ST
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
40
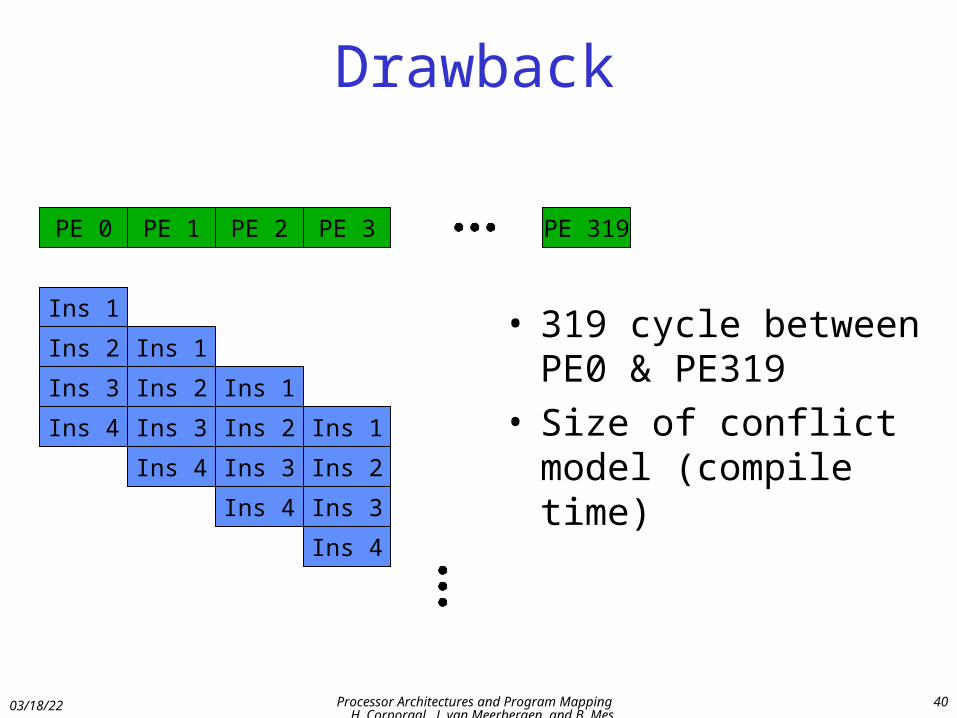
Drawback
Ins 1
Ins 2 Ins 1
Ins 2 Ins 1
Ins 2 Ins 1
Ins 2
Ins 3
Ins 4 Ins 3
Ins 4 Ins 3
Ins 4 Ins 3
Ins 4
• 319 cycle between PE0 & PE319
• Size of conflict model (compile time)
PE 0 PE 1 PE 2 PE 3 PE 319

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
41
Update Architecture
Ins 1
Ins 2 Ins 1
Ins 2 Ins 1
Ins 2 Ins 1
Ins 2
Ins 3
Ins 4 Ins 3
Ins 4 Ins 3
Ins 4 Ins 3
Ins 4
Ins 1
Ins 2 Ins 1
Ins 2 Ins 1
Ins 2 Ins 1
Ins 2
Ins 3
Ins 4 Ins 3
Ins 4 Ins 3
Ins 4 Ins 3
Ins 4
Cycle 1
Cycle 2
Cycle 3
Cycle 4
Cycle 5
Cycle 6
Cycle 7
PE 0 PE 1 PE 2 PE 3 PE 4 PE 5 PE 5 PE 6
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
42
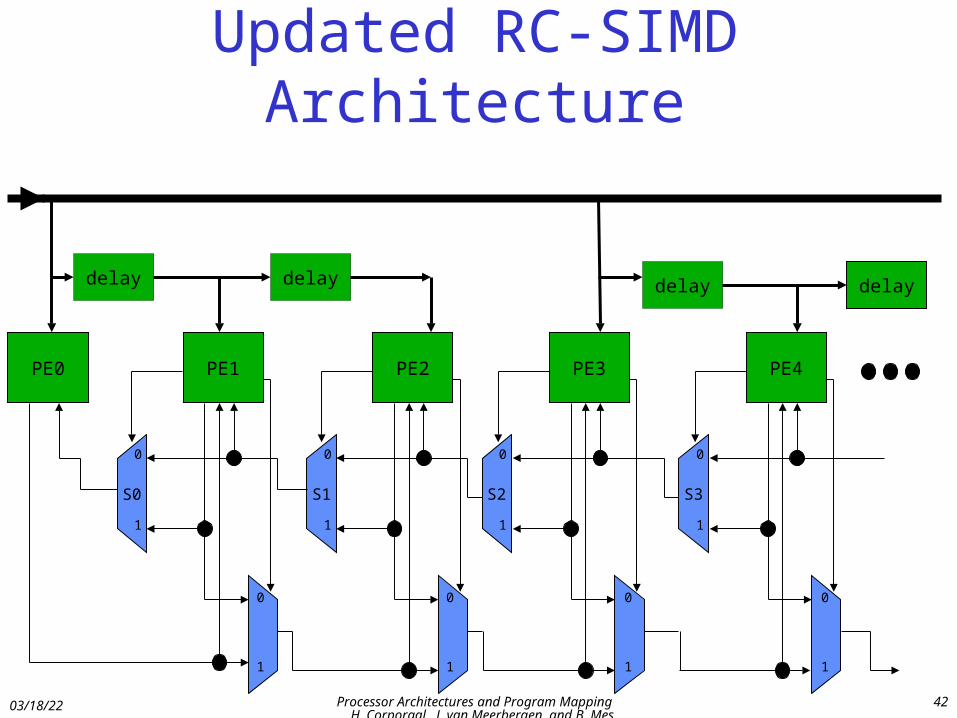
Updated RC-SIMD Architecture
PE1
S1
PE2 PE3PE0
1
0
delay delay
S2
1
0
S0
1
0
0
1
0
1
0
1
PE4
S3
1
0
0
1
delay delay
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
43
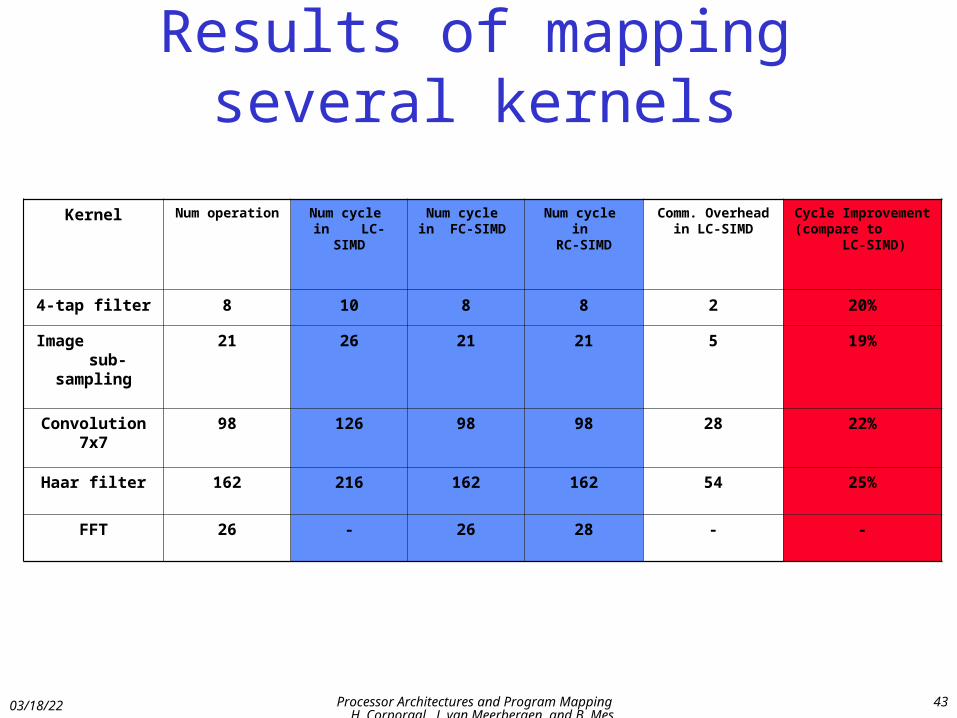
Results of mapping several kernels
Kernel Num operation Num cycle in LC-SIMD
Num cycle in FC-SIMD
Num cycle in RC-SIMD
Comm. Overhead in LC-SIMD
Cycle Improvement (compare to LC-
SIMD)
4-tap filter 8 10 8 8 2 20%
Image sub-sampling
21 26 21 21 5 19%
Convolution 7x7
98 126 98 98 28 22%
Haar filter 162 216 162 162 54 25%
FFT 26 - 26 28 - -
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
44
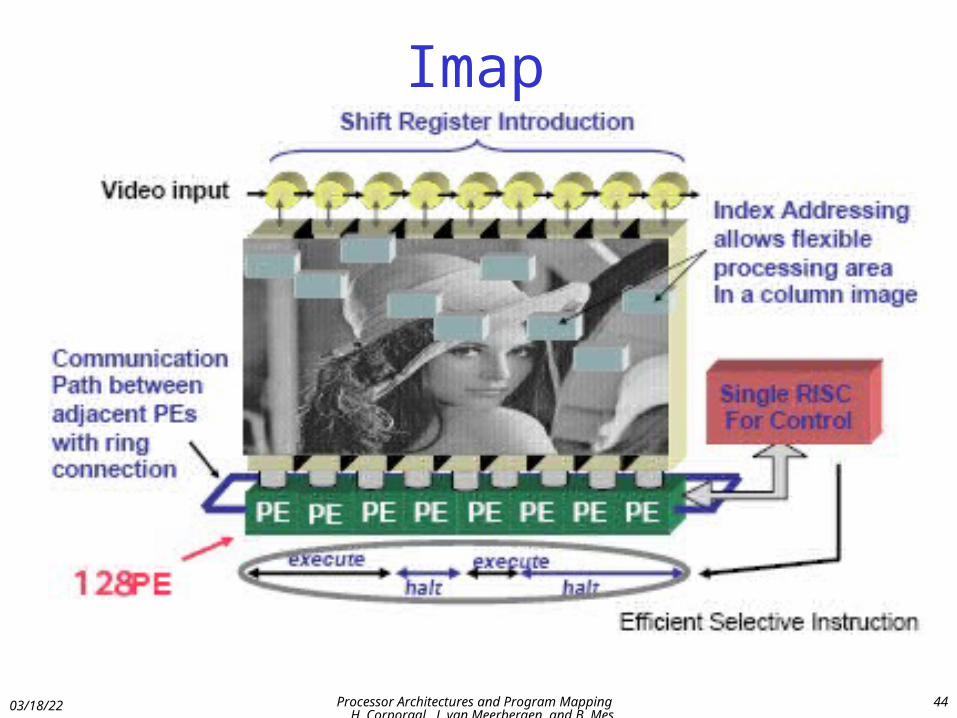
Imap
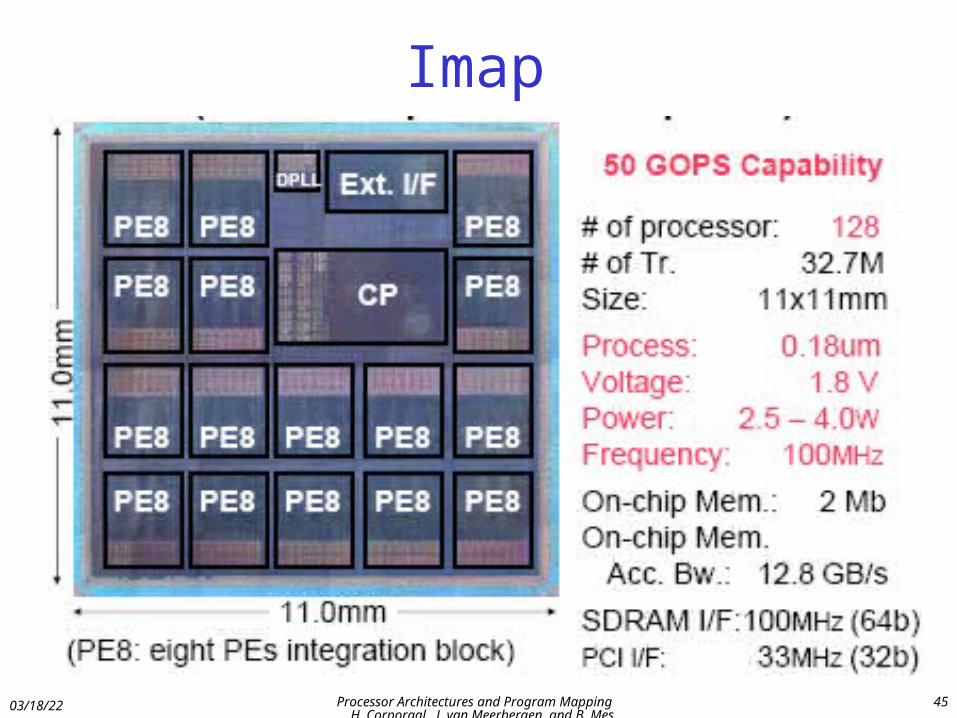
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
45
Imap

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
46
Difficult SIMD Applications
• Algorithms need Dynamic communication:– lens distortion– bucket processing– Mirroring,…
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
47
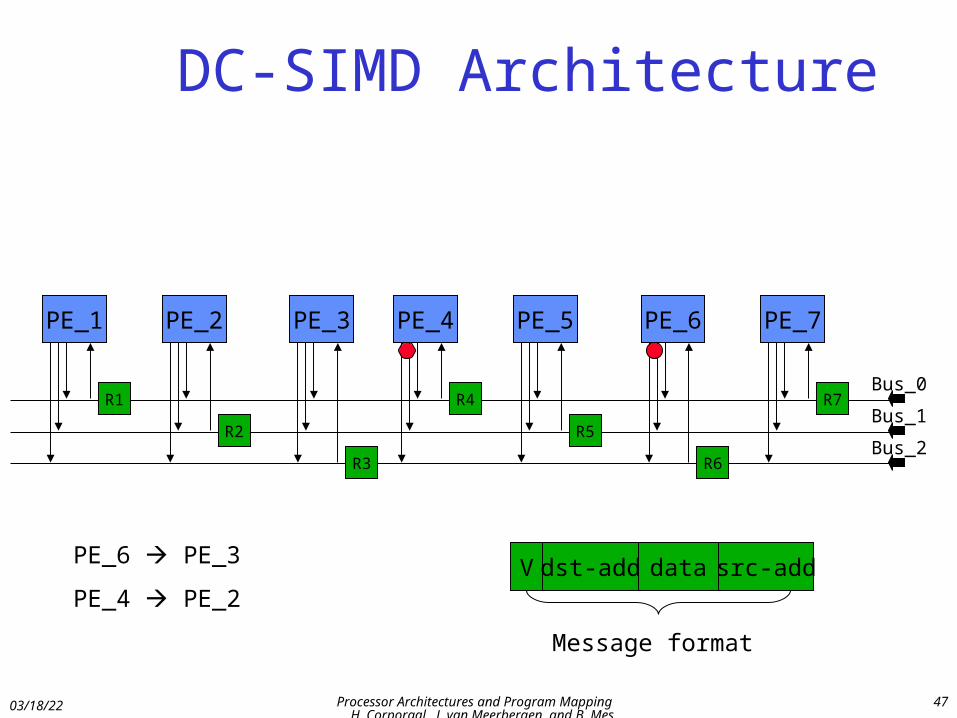
DC-SIMD Architecture
PE_1
Bus_0
Bus_1
Bus_2
PE_2 PE_3
R3
R2
R1
PE_4 PE_5 PE_6
R6
R5
R4
PE_7
R7
PE_6 PE_3
PE_4 PE_2V dst-add data src-add
Message format
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
48
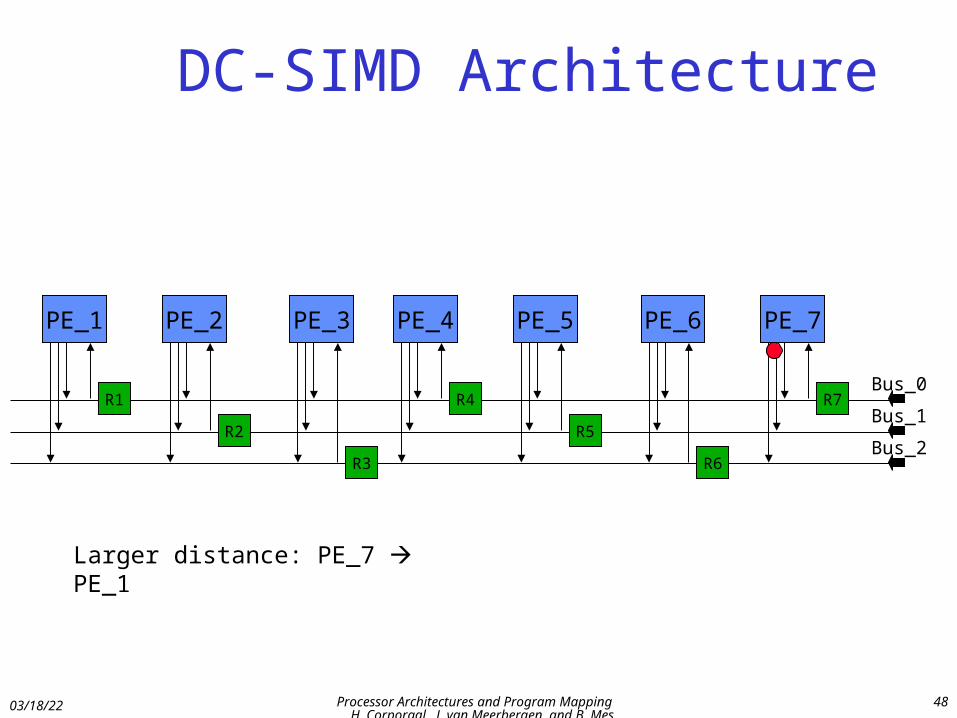
DC-SIMD Architecture
PE_1
Bus_0
Bus_1
Bus_2
PE_2 PE_3
R3
R2
R1
PE_4 PE_5 PE_6
R6
R5
R4
PE_7
R7
Larger distance: PE_7 PE_1
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
49
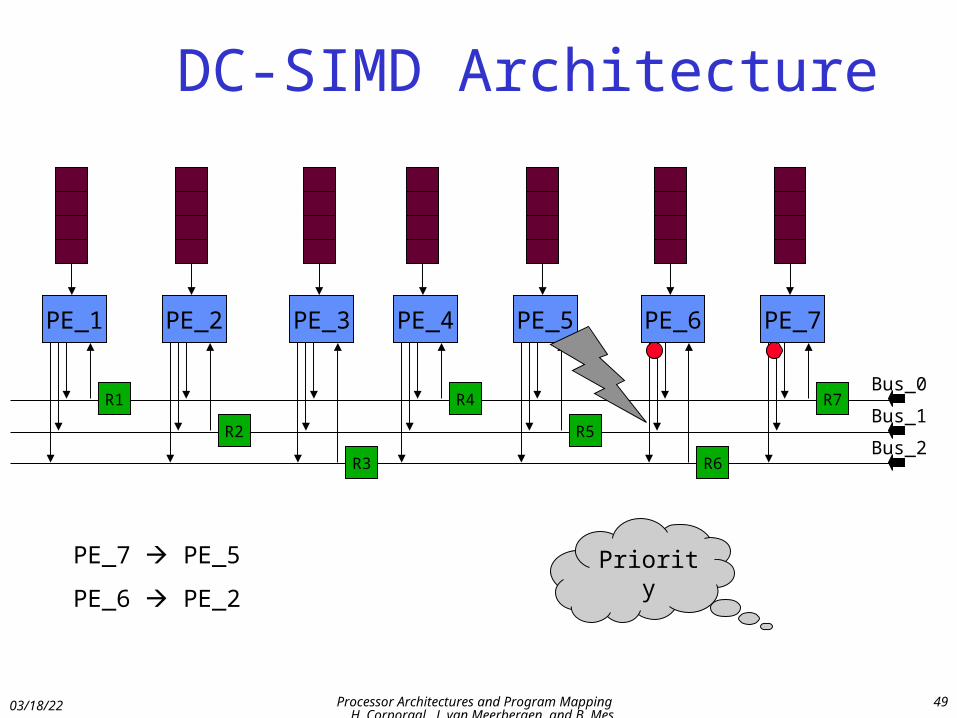
DC-SIMD Architecture
PE_1
Bus_0
Bus_1
Bus_2
PE_2 PE_3
R3
R2
R1
PE_4 PE_5 PE_6
R6
R5
R4
PE_7
R7
PE_7 PE_5
PE_6 PE_2
Priority
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
50
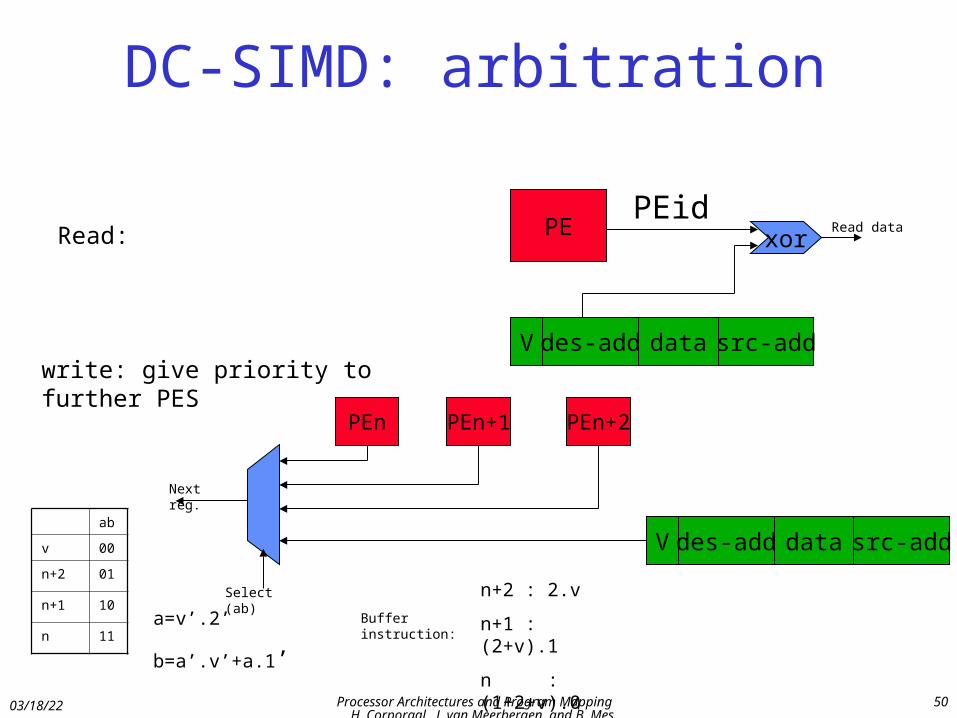
DC-SIMD: arbitration
PE
V des-add data src-add
xorRead data
write: give priority to further PES
Read:
PEn PEn+1 PEn+2
V des-add data src-add
Next reg.
Select (ab)
ab
v 00
n+2 01
n+1 10
n 11a=v’.2’
b=a’.v’+a.1’
n+2 : 2.v
n+1 : (2+v).1
n : (1+2+v).0
Buffer instruction:
PEid
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
51
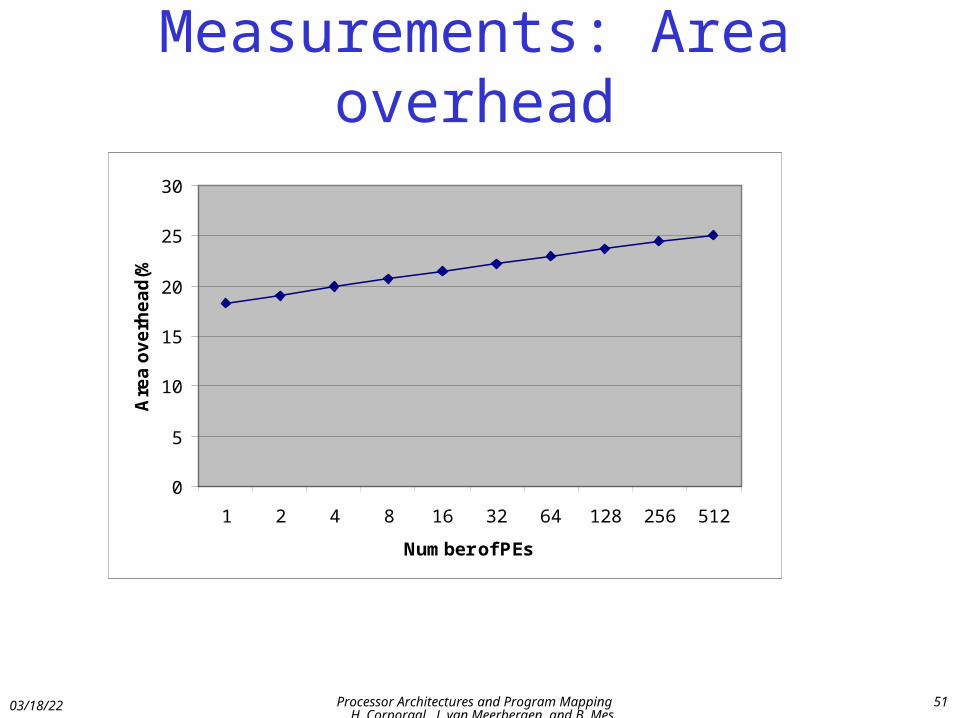
Measurements: Area overhead
0
5
10
15
20
25
30
1 2 4 8 16 32 64 128 256 512
Number of PEs
Are
a o
ve
rhe
ad
(%)
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
52
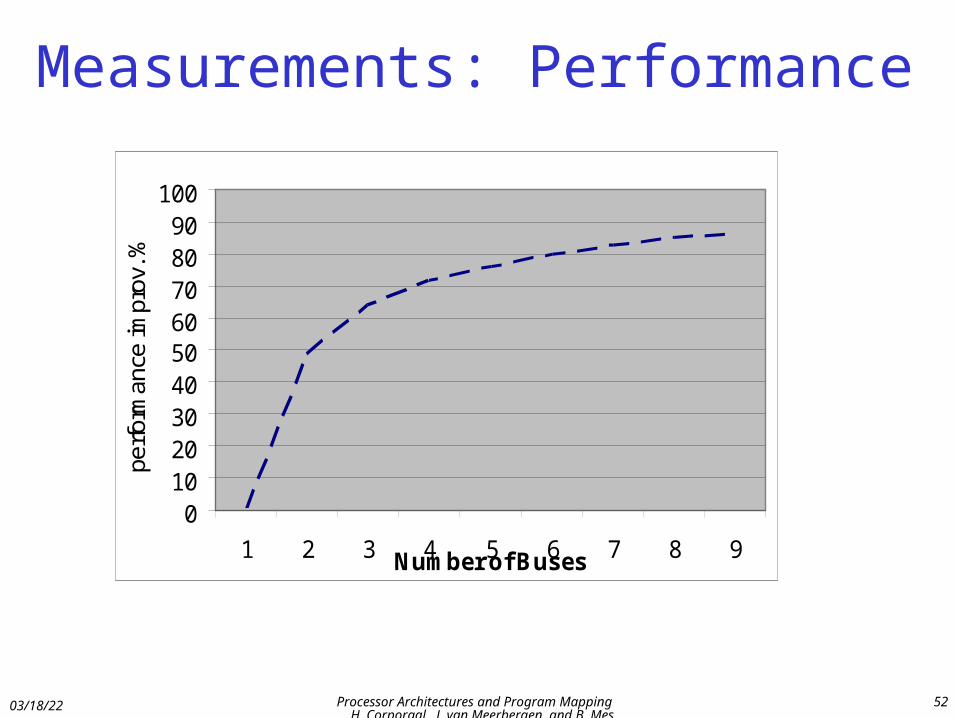
Measurements: Performance
0102030405060708090
100
1 2 3 4 5 6 7 8 9Number of Buses
perfo
rman
ce im
prov
. %
04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
53
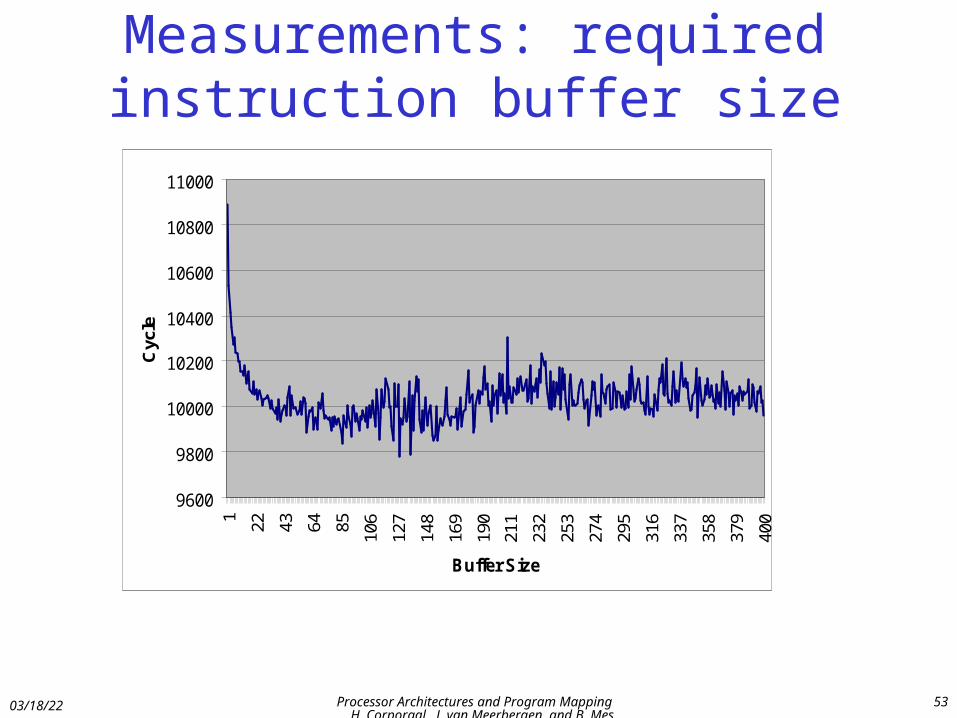
Measurements: required instruction buffer size
9600
9800
10000
10200
10400
10600
10800
11000
1
22 43 64 85
106
127
148
169
190
211
232
253
274
295
316
337
358
379
400
Buffer Size
Cyc
le

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
54
In PS3: CELL architecture

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
55
CELL Highlights• Observed clock speed
– – > 4 GHz
• Peak performance (single precision)– – > 256 GFlops
• Peak performance (double precision)– – >26 GFlops
• Area 221 mm2• Technology 90nm SOI• Total # of transistors 234M

04/18/23 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
56
Conclusions• SIMD nicely matches
– Image applications: data-level parallelism– VLSI efficiency: copy-paste of simple elements
• So – Very efficient architecture for image processing– Low power! Also by trading off clock vs peroformance
• But – Programmer is burdened with vector thinking– Vectorizing compilers are not good at recognizing opportunities for vector
executions– Need for a “control” processor for control code and if-then-else
• Communication is a problem:– Dimensioned for peak BW requirements -> RCSIMD– Unable to perform indirect PE addressing-> DCSIMD





























