Embed Size (px)
Citation preview

Platform based design5KK70
MPSoC Platforms
With special emphasis on the Cell
Bart Mesman and Henk Corporaal

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 2
The Software Crisis

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 3
The first SW crisis
Time Frame: ’60s and ’70s• Problem: Assembly Language Programming
– Computers could handle larger more complex programs
• Needed to get Abstraction and Portability without losing Performance
• Solution:– High-level languages for von-Neumann machines
FORTRAN and C

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 4
The second SW crisis
Time Frame: ’80s and ’90s• Problem: Inability to build and maintain complex
and robust applications requiring multi-million lines of code developed by hundreds of programmers– Computers could handle larger more complex
programs
• Needed to get Composability and Maintainability– High-performance was not an issue: left for Moore’s
Law

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 5
Solution
• Object Oriented Programming– C++, C# and Java
• Also…– Better tools
• Component libraries, Purify
– Better software engineering methodology• Design patterns, specification, testing, code
reviews

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 6
Today: Programmers are Oblivious to Processors
• Solid boundary between Hardware and Software• Programmers don’t have to know anything about the
processor– High level languages abstract away the processors
• Ex: Java bytecode is machine independent
– Moore’s law does not require the programmers to know anything about the processors to get good speedups
• Programs are oblivious of the processor -> work on all processors– A program written in ’70 using C still works and is much faster
today
• This abstraction provides a lot of freedom for the programmers

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 7
The third crisis: Powered by PlayStation

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 8
Contents
• Hammer your head against 4 walls– Or: Why Multi-Processor
• Cell Architecture
• Programming and porting– plus case-study

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 9
Moore’s Law

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 10
Single Processor SPECint Performance

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 11
What’s stopping them?
• General-purpose uni-cores have stopped historic performance scaling– Power consumption– Wire delays– DRAM access latency– Diminishing returns of more instruction-level
parallelism

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 12
Power density

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 13
Power Efficiency (Watts/Spec)

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 14
1 clock cycle wire range

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 15
Global wiring delay becomes dominant over gate delay
Gate delay vs. wire delay
0
50
100
150
200
250
300
350
400
0.5 0.35 0.25 0.18 0.13 0.1
technology (micron)
ps
wire delay (ps/mm)
gate delay (ps)

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 16
Memory
µProc:55%/year
CPU
DRAM:7%/yearDRAM
1
10
100
1000
1980
1985
1990
1995
2000
Processor-MemoryPerformance Gap:(grows 50% / year)
Performance
Time
“Moore’s Law”
[Patterson]
2005

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 17
Now what?
• Latest research drained
• Tried every trick in the book
So: We’re fresh out of ideas
Multi-processor is all that’s left!

04/18/23 ECA - 5KK73 H. Corporaal and B. Mesman 18
Low power through parallelism• Sequential Processor
– Switching capacitance C– Frequency f– Voltage V– P = fCV2
• Parallel Processor (two times the number of units)– Switching capacitance 2C– Frequency f/2– Voltage V’ < V– P = f/2 2C V’2 = fCV’2

04/18/23 ECA - 5KK73 H. Corporaal and B. Mesman 19
Architecture methods
Powerful Instructions (1)
MD-technique• Multiple data operands per operation• SIMD: Single Instruction Multiple Data
Vector instruction:
for (i=0, i++, i<64) c[i] = a[i] + 5*b[i];
c = a + 5*b
Assembly:
set vl,64ldv v1,0(r2)mulvi v2,v1,5ldv v1,0(r1)addv v3,v1,v2stv v3,0(r3)

04/18/23 ECA - 5KK73 H. Corporaal and B. Mesman 20
Architecture methods
Powerful Instructions (1)
• Sub-word parallelism– SIMD on restricted scale:– Used for Multi-media instructions– Motivation: use a powerful 64-bit alu
as 4 x 16-bit alus
• Examples– MMX, SUN-VIS, HP MAX-2, AMD-
K7/Athlon 3Dnow, Trimedia II
– Example: i=1..4|ai-bi| * * * *

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 21
MPSoC Issues
• Homogeneous vs Heterogeneous• Shared memory vs local memory• Topology• Communication (Bus vs. Network)• Granularity (many small vs few large)• Mapping
– Automatic vs manual parallelization– TLP vs DLP– Parallel vs Pipelined

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 22
Multi-core

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 23
Communication models: Shared Memory
Process P1 Process P2
SharedMemory
• Coherence problem• Memory consistency issue• Synchronization problem
(read, write)(read, write)
04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 24
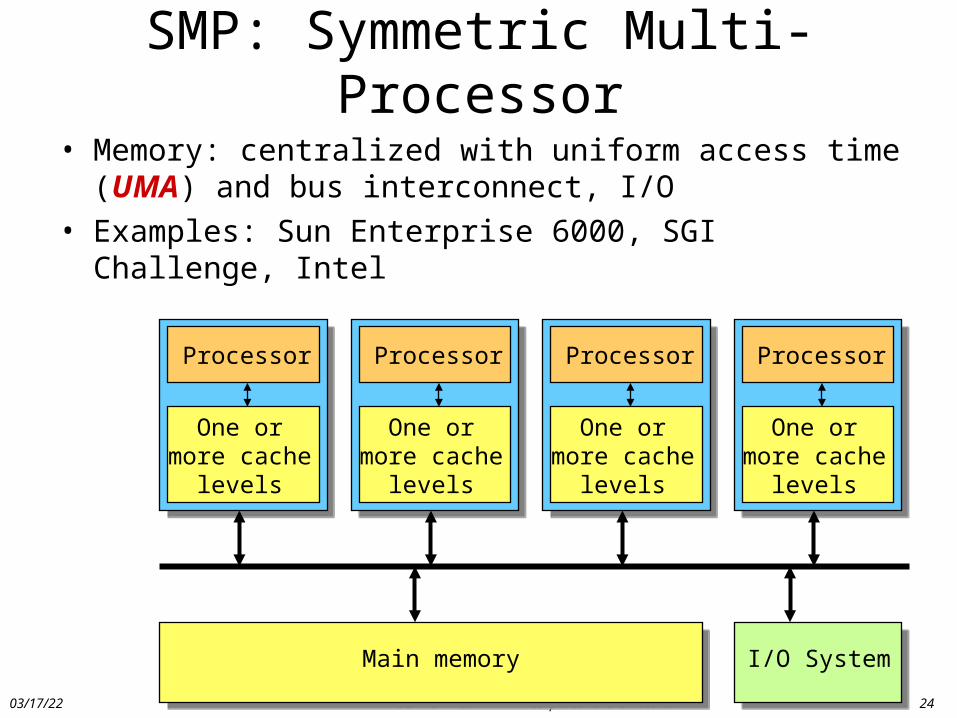
SMP: Symmetric Multi-Processor
• Memory: centralized with uniform access time (UMA) and bus interconnect, I/O
• Examples: Sun Enterprise 6000, SGI Challenge, Intel
Main memory I/O System
One ormore cache
levels
Processor
One ormore cache
levels
Processor
One ormore cache
levels
Processor
One ormore cache
levels
Processor

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 25
DSM: Distributed Shared Memory
• Nonuniform access time (NUMA) and scalable interconnect (distributed memory)
Interconnection NetworkInterconnection Network
Cache
Processor
Memory
Cache
Processor
Memory
Cache
Processor
Memory
Cache
Processor
Memory
Main memory I/O System

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 26
Communication models: Message Passing
• Communication primitives– e.g., send, receive library calls
Process P1 Process P2
receive
receive send
sendFiFO

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 27
Message passing communication
Interconnection NetworkInterconnection Network
Networkinterface
Networkinterface
Networkinterface
Networkinterface
Cache
Processor
Memory
DMA
Cache
Processor
Memory
DMA
Cache
Processor
Memory
DMA
Cache
Processor
Memory
DMA

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 28
Communication Models: Comparison
• Shared-Memory– Compatibility with well-understood (language)
mechanisms– Ease of programming for complex or dynamic
communications patterns– Shared-memory applications; sharing of large data
structures– Efficient for small items– Supports hardware caching
• Messaging Passing– Simpler hardware– Explicit communication– Scalable!

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 29
Three fundamental issues for shared memory multiprocessors• Coherence,
about: Do I see the most recent data?
• Consistency, about: When do I see a written value?– e.g. do different processors see writes at the same time
(w.r.t. other memory accesses)?
• SynchronizationHow to synchronize processes?– how to protect access to shared data?

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 30
Coherence problem, in Multi-Proc system
CPU-1
a'
b'
b
a
cache
memory
550
100
200
200
CPU-2
a''
b''
cache
100
200

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 31
Potential HW Coherency Solutions• Snooping Solution (Snoopy Bus):
– Send all requests for data to all processors (or local caches)– Processors snoop to see if they have a copy and respond
accordingly – Requires broadcast, since caching information is at processors– Works well with bus (natural broadcast medium)– Dominates for small scale machines (most of the market)
• Directory-Based Schemes– Keep track of what is being shared in one centralized place– Distributed memory => distributed directory for scalability
(avoids bottlenecks)– Send point-to-point requests to processors via network– Scales better than Snooping– Actually existed BEFORE Snooping-based schemes

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 32
Example Snooping protocol
• 3 states for each cache line: – invalid, shared, modified (exclusive)
• FSM per cache, receives requests from both processor and bus
Main memory I/O System
Cache
Processor
Cache
Processor
Cache
Processor
Cache
Processor

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 33
Cache coherence protocolWrite invalidate protocol for write-back cache• Showing state transitions for each block in the cache

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 34
Synchronization problem• Computer system of bank has credit process (P_c)
and debit process (P_d)
/* Process P_c */ /* Process P_d */shared int balance shared int balanceprivate int amount private int amount
balance += amount balance -= amount
lw $t0,balance lw $t2,balancelw $t1,amount lw $t3,amountadd $t0,$t0,t1 sub $t2,$t2,$t3sw $t0,balance sw $t2,balance

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 35
Issues for Synchronization
• Hardware support: – Un-interruptable instruction to fetch-and-
update memory (atomic operation)
• User level synchronization operation(s) using this primitive;
• For large scale MPs, synchronization can be a bottleneck; techniques to reduce contention and latency of synchronization

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 36
Cell

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 37
What can it do?

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 38
Cell/B.E. - the history
• Sony/Toshiba/IBM consortium– Austin, TX – March 2001– Initial investment: $400,000,000
• Official name: STI Cell Broadband Engine – Also goes by Cell BE, STI Cell, Cell
• In production for:– PlayStation 3 from Sony – Mercury’s blades

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 39
Cell blade

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 40
Cell/B.E. – the architecture1 x PPE 64-bit PowerPC
L1: 32 KB I$ + 32 KB D$L2: 512 KB
8 x SPE cores:Local store: 256 KB 128 x 128 bit vector registers
Hybrid memory model: PPE: Rd/Wr SPEs: Asynchronous DMA
• EIB: 205 GB/s sustained aggregate bandwidth• Processor-to-memory bandwidth: 25.6 GB/s• Processor-to-processor: 20 GB/s in each direction

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 41
Cell chip

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 42
SPE

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 43
SPE

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 44
SPE pipeline

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 45
Communication

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 46
8 parallel transactions

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 47
C++ on Cell
1
234
Send the code of the function to be run on SPE
Send address to fetch the dataDMA data in LS from the main memoryRun the code on the SPE
56
DMA data out of LS to the main memorySignal the PPE that the SPE has finished the function

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 49
Porting C++
1
2
3
4
Detect & isolate kernels to be ported
Replace kernels with C++ stubs
Implement the data transfers and move kernels on SPEs
Iteratively optimize SPE code

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 50
Performance estimation
• Based on Amdhal’s law
… where – K i
fr = the fraction of the execution time for kernel Ki
– K ispeed-up = the speed-up of kernel Ki compared with
the sequential version

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 51
Performance estimation
• Based on Amdhal’s law:– Sequential use of kernels:
– Parallel use of kernels: ?

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 52
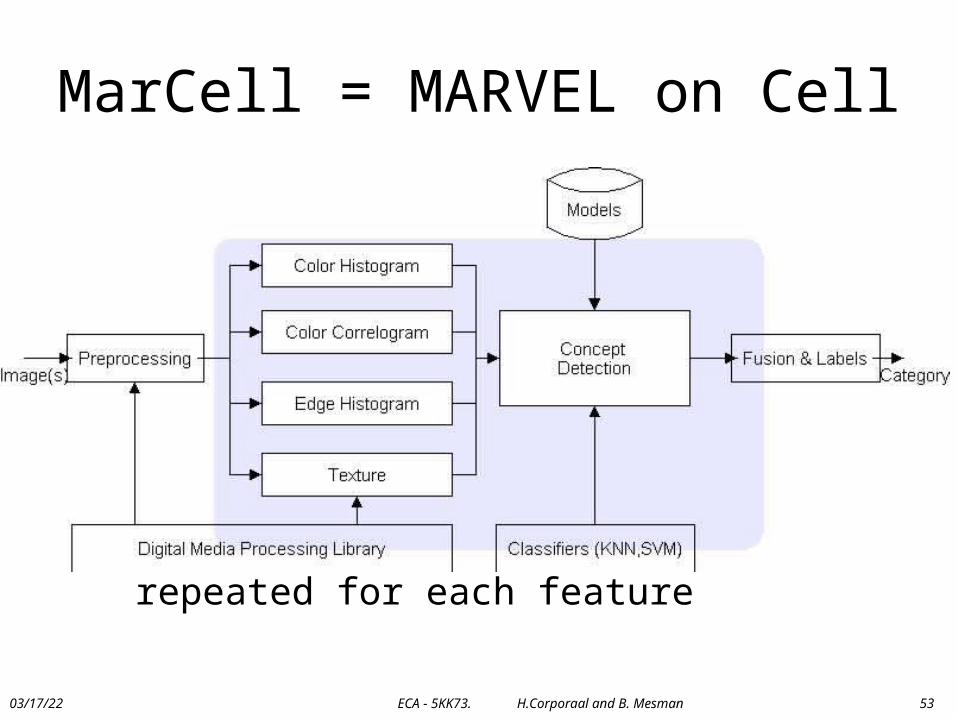
MARVEL case-study
• Multimedia content retrieval and analysis
For each picture, we extract thevalues for the features of interest:
ColorHistogram, ColorCorrelogram,Texture, EdgeHistogram
Compares the image features with the model features and generates an overall confidence score
http://www.research.ibm.com/marvel
04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 53
MarCell = MARVEL on Cell
• Identified 5 kernels to port on the SPEs:– 4 feature extraction algorithms
• ColorHistogram (CHExtract)• ColorCorrelogram(CCExtract)• Texture (TXExtract)• EdgeHistogram (EHExtract)
– 1 common concept detection, repeated for each feature

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 54
MarCell – kernels speed-up
Kernel SPE[ms]Speed-up vs. PPE
Speed-up vs.
Desktop
Speed-up vs. Laptop
Overall contribution
AppStart 7.17 0.95 0.67 0.83 8 %
CHExtract 0.82 52.22 21.00 30.17 8 %
CCExtract 5.87 55.44 21.26 22.45 54 %
TXExtract 2.01 15.56 7.08 8.04 6 %
EHExtract 2.48 91.05 18.79 30.85 28 %
CDetect 0.41 7.15 3.75 4.88 2 %

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 55
MarCell – kernels execution times

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 56
Task parallelism – setup

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 57
Task parallelism – results*
*reported on PS3
0.31.0 0.8
10.3
14.4
0
2
4
6
8
10
12
14
16
PPE Desktop Laptop SPU Seq SPU Par
Sp
ee
d-u
p [r
ela
tive
to th
e D
esk
top
exe
cutio
n ti
me
]

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 58
Data parallelism – setup
• Data parallel requires all SPEs to execute the same kernel in SPMD fashion
• Requires SPE reconfiguration:– Thread re-creation – Overlays

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 59
Data parallelism – results* [1/2]
Data-parallel execution of the feature extraction kernels
0.00
2.00
4.00
6.00
8.00
10.00
12.00
1 2 3 4 5 6Number of SPEs
Sp
eed
-up
CH_Extract
CC_Extract
TX_Extract
EH_Extract
*reported on PS3
► Kernels do scale when run alone

04/18/23 ECA - 5KK73. H.Corporaal and B. Mesman 60
Conclusions
• Multi-processors inevitable• Huge performance increase, but…• Hell to program
– Got to be an architecture expert– Portability?





























