Embed Size (px)
Citation preview

Pierre VermaakUCT

An attempt to automate the discovery of initial solution candidates.
Example-based learning Why?
◦ Track record on difficult problems◦ Very different to ∆2 – approaches ;
complimentary◦ Neat
In this talk, I’ll give a practical perspective

What is it?◦ Very broad field◦ Data mining◦ Machine learning
Well-known algorithms◦ Neural Networks◦ Tree inducers (J48, M5P)◦ Support Vector Machines◦ Nearest Neighbour
Same idea throughout ...

Attempt to map input to output◦ e.g. binary lens light curve -> model parameters
Uses example data set: “training set” ◦ e.g. many simulated curves and their model
parameters Adjusts learning model parameters to best
fit of training data: “training”◦ Usually some sort of iteration◦ Algorithm dependent
Evaluation◦ Usually performance measured on unseen data
set: “test set”.

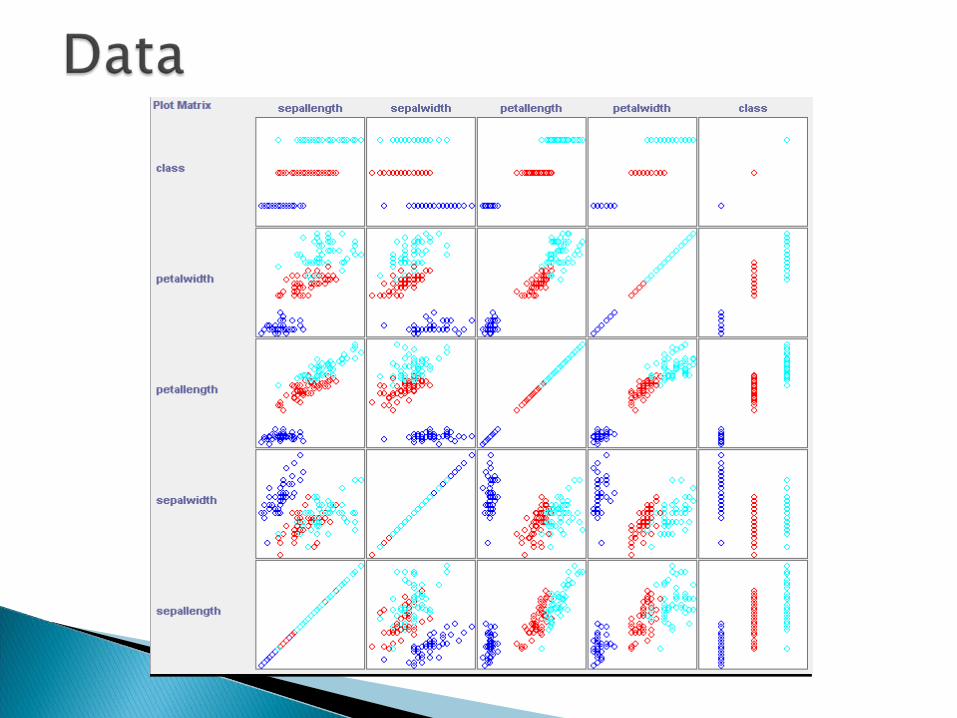
Famous data set by Fisher. Want to classify irises into three categories
based on petal and sepal width and length. 150 examples
sepallength (cm) sepalwidth (cm) petallength (cm) petalwidth (cm) class5 2 3.5 1 Iris-versicolor6 2.2 4 1 Iris-versicolor6.2 2.2 4.5 1.5 Iris-versicolor6 2.2 5 1.5 Iris-virginica4.5 2.3 1.3 0.3 Iris-setosa
sepallength (cm) sepalwidth (cm) petallength (cm) petalwidth (cm) class5 2 3.5 1 Iris-versicolor6 2.2 4 1 Iris-versicolor6.2 2.2 4.5 1.5 Iris-versicolor6 2.2 5 1.5 Iris-virginica4.5 2.3 1.3 0.3 Iris-setosa
Data SnippetData Snippet

“OneR”◦ Deduces a rule based on one input column
(“attribute”)
ResultsResults
RuleRule
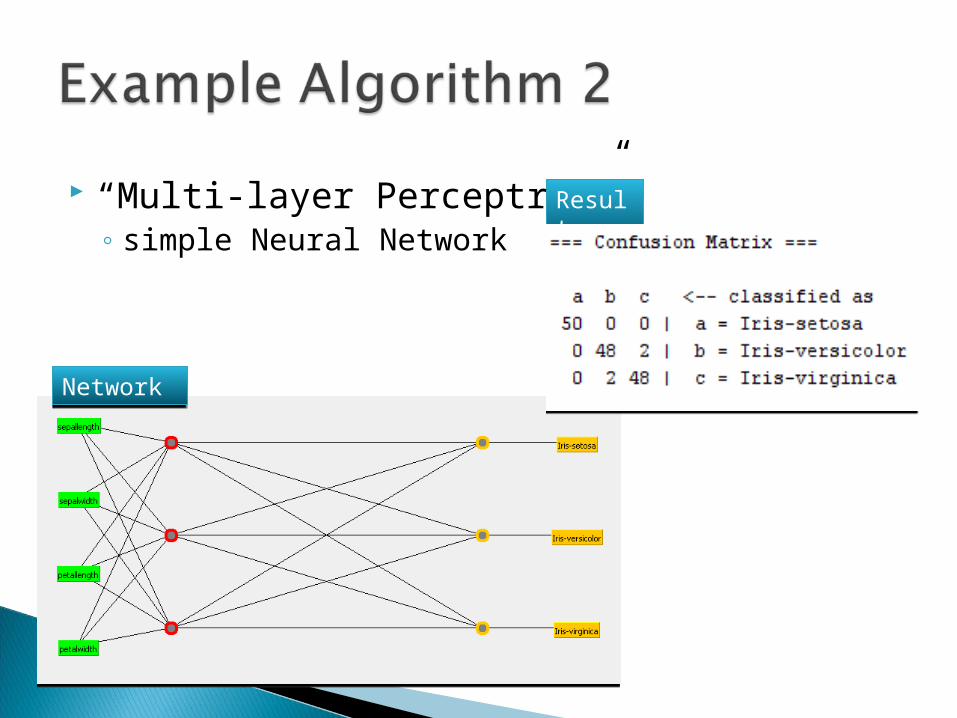
“Multi-layer Perceptron” ◦ simple Neural Network
ResultResult
NetworkNetwork

Neat examples ... Can it be used on the real problem? Issues
◦ Many ambiguities of binary model◦ No uniform input - not uniformly sampled◦ Noise◦ Complexity

Success/failure with a variety of approaches The approach I’d like to take DIY tools for the job
◦ Do try this at home.

“Raw” light curves are unsuitable Require uniform inputs for training
◦ And the same scheme needs to be applied to subsequent unseen curves
Interpolation – non-trivial◦ Which scheme? What biases are introduced?
Smoothing – non-trivial◦ Required for interpolation anyway◦ Also for derived features (extrema, slope)
Centering/Scaling – non-trivial◦ Algorithms performed much better with normalized light
curves◦ What to centre on? Peak? Which one?◦ What baseline? Real curves are truncated

How many example curves to use? Ranges of binary lens model parameters in
training set. Noise model for example curves. Choice of learning algorithm Pre-processing parameters etc.

Normalized Curves◦ Using truncation/centering/scaling and smoothing
Derived Features◦ Attempt to extract properties of a light curve◦ PCA◦ polynomial fits◦ extrema◦ etc.

Various schemes attempted Most successful
◦ Find time corresponding to peak brightness◦ Translate the curve in time to this this value◦ Discard all data fainter (by magnitude) than 20%
of the total magnitude range◦ Normalize the time axis (-0.5 to 05)

Required for interpolation of equally-spaced data points on the curve
Too much smoothing destroys features Too little smoothing turns noise into
features Final scheme was a fitted B-spline iteration.
◦ Fit a B-spline◦ Count extrema◦ Repeat until number of extrema in suitable range◦ Worked out to be surprisingly robust

Truncation◦ Slope-based ... Numerical derivatives too noisy◦ Fitting a simpler model (Gaussian, single-lens)◦ Brightness exceeds 3 standard deviations of wing
brightness Smoothing
◦ Moving window averaging – destroys small features
◦ Savitzky-Golay – only works on evenly-spaced points
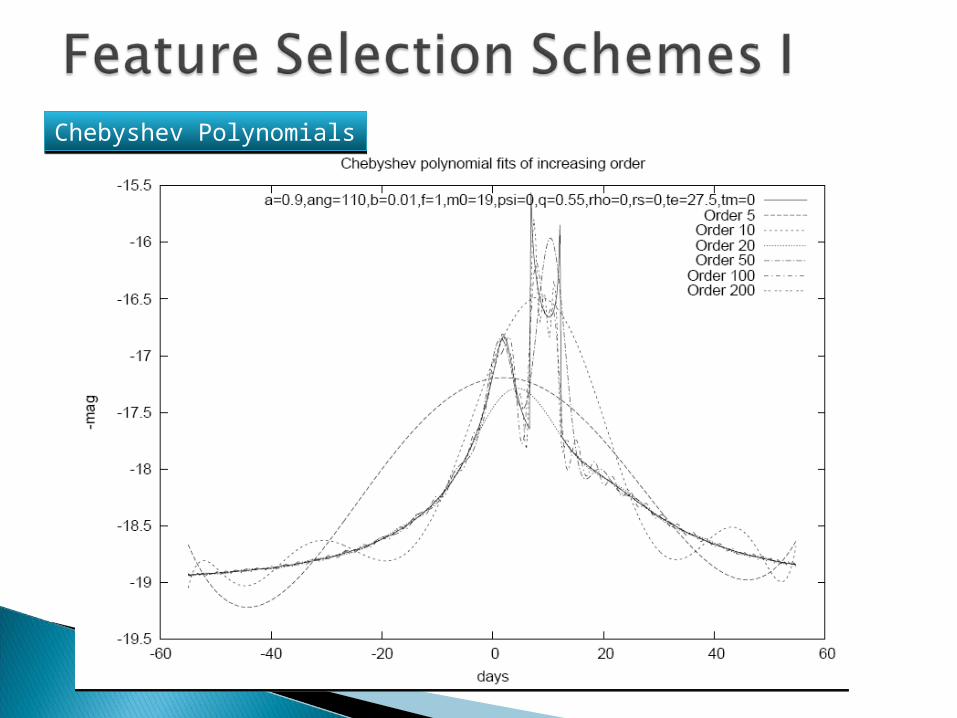
Chebyshev PolynomialsChebyshev Polynomials
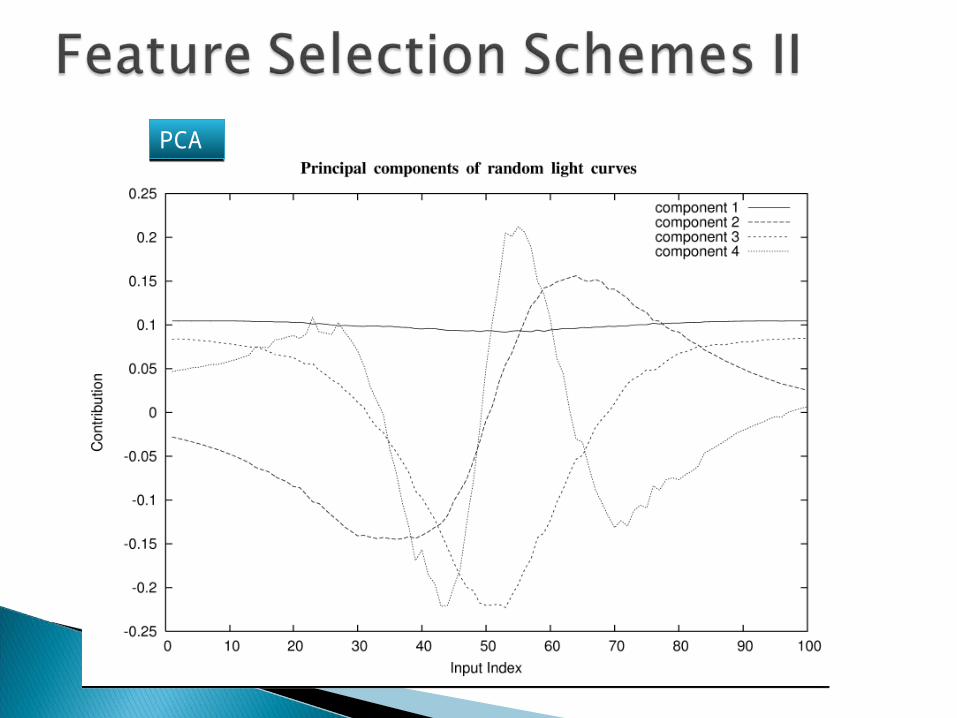
PCAPCA

Single lens fits Moments Derivatives Smoothed Curves Time and Magnitude of extrema
Features are then selected for usefulness using selection algos (brute-force, information-based, etc.)

Using simulated curvesUsing simulated curves
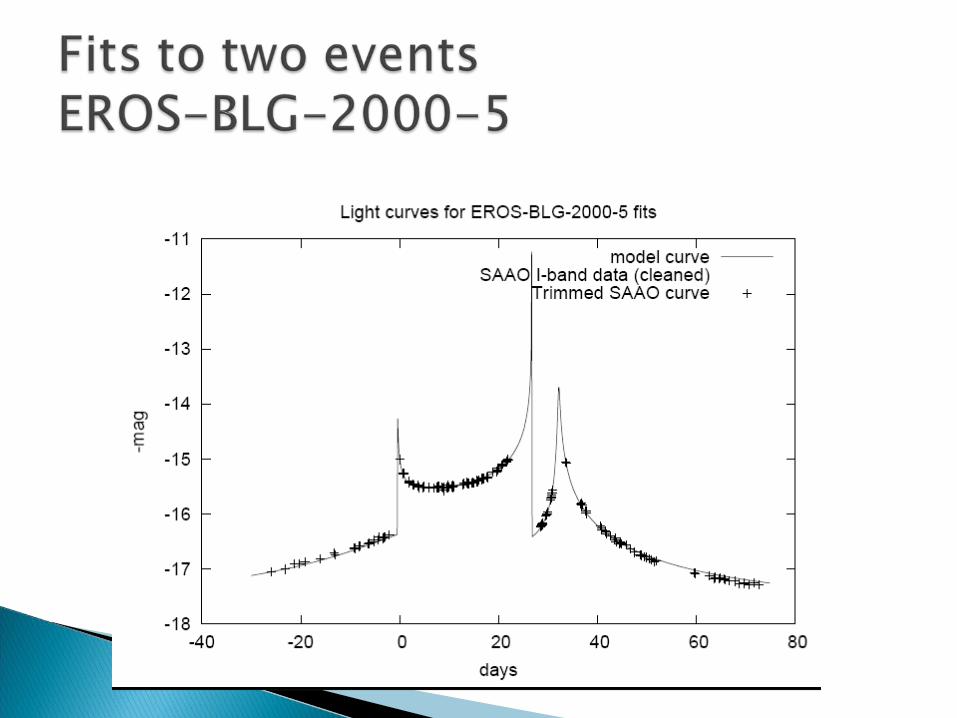
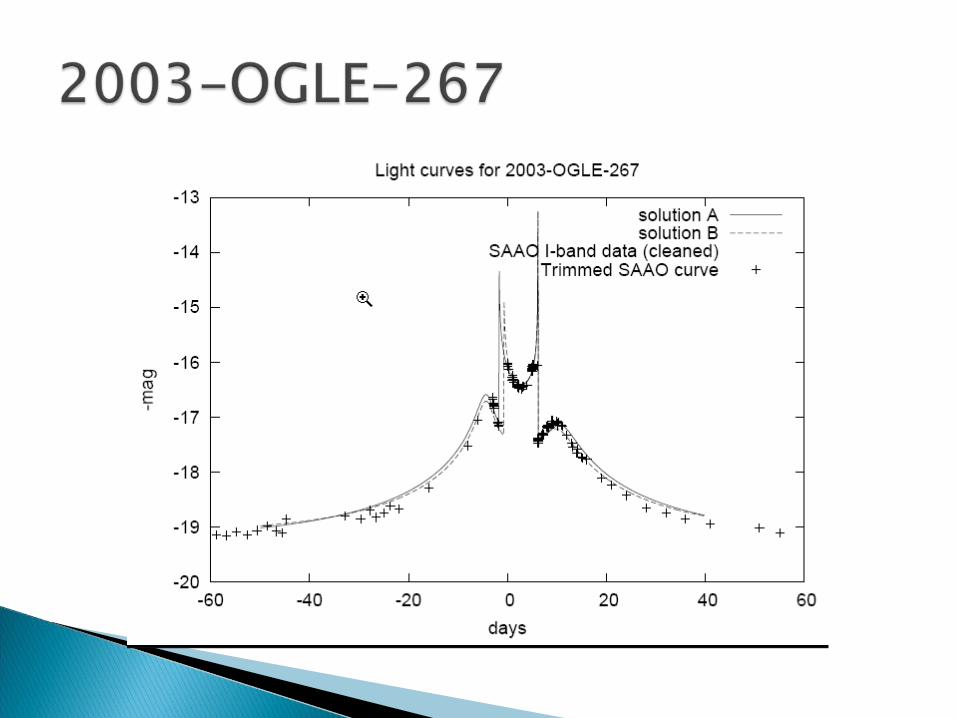

The pre-processed curves themselves performed slightly better than derived features.
A simple learning algorithm performed best (nearest neighbour)
It sort of works on real events, but not at Production strength and still with intervention.
Still required Genetic Algo fine-tuning. Not good at finding multiple solutions

Automation: Mimic a human expert Categorize curves instantly Use categorization to come up with joint
likelihood distribution in model parameter space.
I want multiple solutions and large regions of exclusion.

Still believe in feature selection Eliminate dodgy pre-processing
◦ Smoothing◦ Interpolation
Use fast fits of “basis” functions◦ Possibly use binary curves themselves for
comparison, but with a robust distance metric.◦ Use the quality of fits as main feature◦ Fit a single lens and characterize residuals

These algorithms are very powerful But no algorithm is any good against
impossible odds. So, alternative parameterizations, etc. are
extremely important to this approach, just like to traditional fitting.

Java◦ 60%-100% as fast as C++ nowadays◦ Cross-platform◦ Plugs into and out of everything (Python, legacy
COM, Matlab, etc.)◦ Oh, the tools! – Parallelisation, IDE’s, just
everything. “javalens” – my rather humble new Java code
◦ Asada’s method◦ Lots of abstraction, more like framework◦ Open Source◦ Search “javalens” on google code

R◦ Awesome, free and open source statistics environment◦ Can be called from Java
WEKA◦ Great data mining app, used extensively in my thesis◦ Dangerous! Can spend years playing with it.◦ Make sure you concentrate on the sensibility of your data◦ NOT the large variety of fitting algorithms
Netbeans◦ Just a great free, open source Java IDE◦ Code completion◦ Automatic refactoring tools
VI◦ No comment





























