Embed Size (px)
Citation preview

Inhalt
• Parts of Speech
• POS-Tagging-Probleme: OOV, Ambiguitaten
• Regelbasierte Tagger
• Markov-Tagger
• Transformationsbasiertes Tagging
• Evaluierung
1

Parts of Speech
Deutsch: STTS (Stuttgart-Tubingen Tagset; Schiller et al., 1995)Label Wortart Beispiel
Nomen
NN Substantiv Tisch
NE Eigennamen Hans, Hamburg
TRUNC Kompositions-Erstglied An- und Abreise
Verben
VVFIN Finites Verb, voll du gehst
VVIMP Imperativ, voll komm!
VVINF Infinitiv, voll gehen
VVIZU Infinitiv mit zu, voll anzukommen
VVPP Partizip Perfekt, voll gegangen
VAFIN Finites Verb, aux wir werden
VAIMP Imperativ, aux sei ruhig!
VAINF Infinitiv, aux sein, werden
VAPP Partizip Perfekt, aux gewesen
VMFIN Finites Verb, modal wollte
VMINF Infinitiv, modal wollen
VMPP Partizip Perfekt, modal er hat gekonnt
2
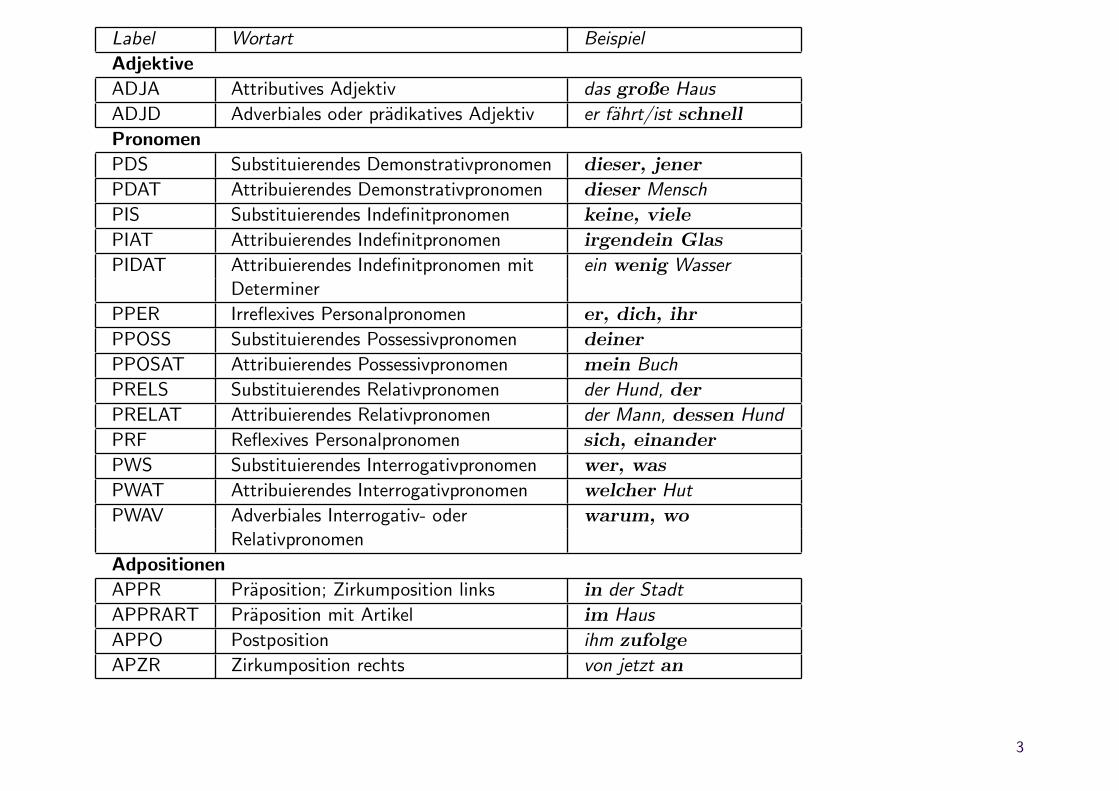
Label Wortart Beispiel
Adjektive
ADJA Attributives Adjektiv das große Haus
ADJD Adverbiales oder pradikatives Adjektiv er fahrt/ist schnell
Pronomen
PDS Substituierendes Demonstrativpronomen dieser, jener
PDAT Attribuierendes Demonstrativpronomen dieser Mensch
PIS Substituierendes Indefinitpronomen keine, viele
PIAT Attribuierendes Indefinitpronomen irgendein Glas
PIDAT Attribuierendes Indefinitpronomen mit ein wenig WasserDeterminer
PPER Irreflexives Personalpronomen er, dich, ihr
PPOSS Substituierendes Possessivpronomen deiner
PPOSAT Attribuierendes Possessivpronomen mein Buch
PRELS Substituierendes Relativpronomen der Hund, der
PRELAT Attribuierendes Relativpronomen der Mann, dessen Hund
PRF Reflexives Personalpronomen sich, einander
PWS Substituierendes Interrogativpronomen wer, was
PWAT Attribuierendes Interrogativpronomen welcher Hut
PWAV Adverbiales Interrogativ- oder warum, wo
Relativpronomen
Adpositionen
APPR Praposition; Zirkumposition links in der Stadt
APPRART Praposition mit Artikel im Haus
APPO Postposition ihm zufolge
APZR Zirkumposition rechts von jetzt an
3
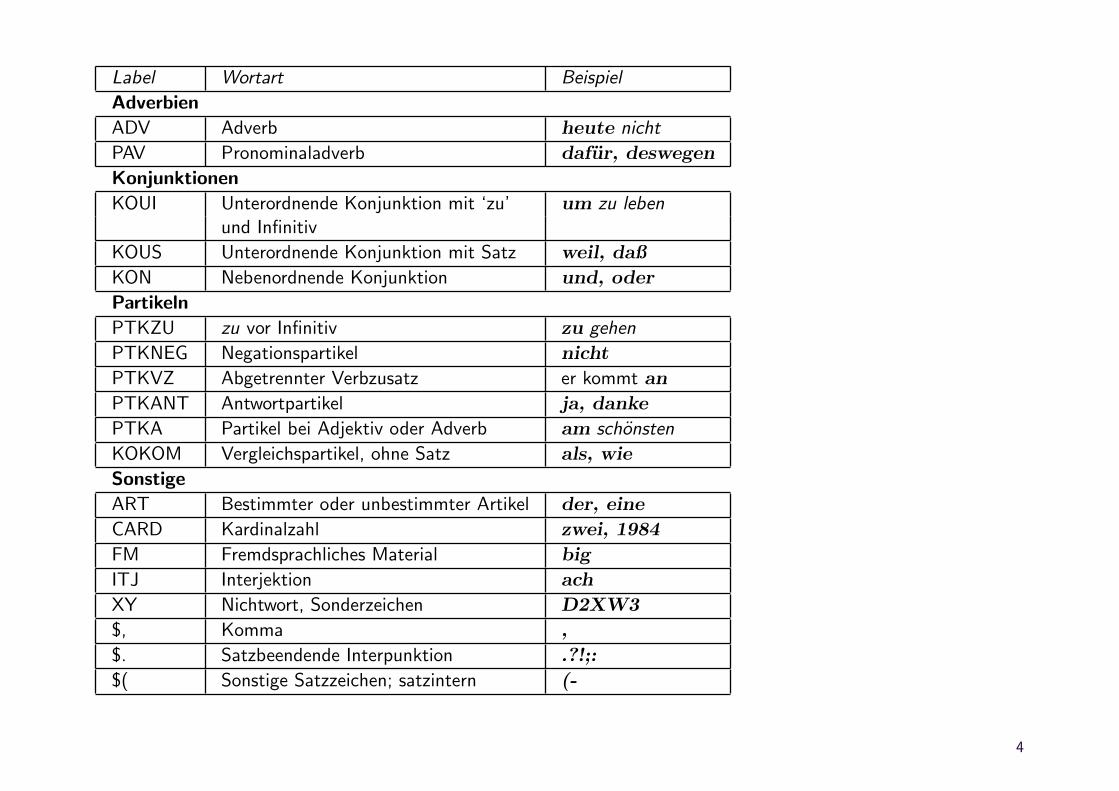
Label Wortart Beispiel
Adverbien
ADV Adverb heute nicht
PAV Pronominaladverb dafur, deswegen
Konjunktionen
KOUI Unterordnende Konjunktion mit ‘zu’ um zu lebenund Infinitiv
KOUS Unterordnende Konjunktion mit Satz weil, daß
KON Nebenordnende Konjunktion und, oder
Partikeln
PTKZU zu vor Infinitiv zu gehen
PTKNEG Negationspartikel nicht
PTKVZ Abgetrennter Verbzusatz er kommt an
PTKANT Antwortpartikel ja, danke
PTKA Partikel bei Adjektiv oder Adverb am schonsten
KOKOM Vergleichspartikel, ohne Satz als, wie
Sonstige
ART Bestimmter oder unbestimmter Artikel der, eine
CARD Kardinalzahl zwei, 1984
FM Fremdsprachliches Material big
ITJ Interjektion ach
XY Nichtwort, Sonderzeichen D2XW3
$, Komma ,
$. Satzbeendende Interpunktion .?!;:
$( Sonstige Satzzeichen; satzintern (-
4

Englische Tagsets• Penn Tagset (Marcus et al., 1993): 45 tags
• . . .
• C7 Tagset (Leech et al., 1994): 146 tags
5

Probleme
Probleme beim reinen Lexikon-Lookup• Out of Vocabulary-Falle (OOV): POS fur Worter, die nicht im Lexikon
stehen, unbekannt
• Ambiguitaten: Wort kann verschiedene POS-Labels tragen– Sucht: NN vs. VVFIN
– ab: ADP vs. PTKVZ
– als: KOKOM vs. KOUS
– am: APPRART vs. PTKA
– Anfangs: NN vs. ADV
Losungen• Einbeziehen des Wortkontexts
• Einbeziehen POS-relevanter Worteigenschaften (z.B. String-Suffixe)
6

Tagger-Uberblick
• Regelbasierte Verfahren: ENGTWOL (Voutilainen, 1995)
• Statistische Verfahren: Jelinek (1985), Tree Tagger (Schmidt, 1995), Reichel(2005)
• Transformationsbasierte Verfahren: Brill (1995)
7

Regelbasierte Verfahren
ENGTWOL (Voutilainen, 1995)• 2 Schritte:
1. Lexikon-Lookup −→ POS-Kandidaten
2. falls mehrere: Auswahl des richtigen Labels (Disambiguierung) anhand vonRegeln
• Lexikon-Eintrage: Wortform, POS, morpholog.+syntakt. Features(Subkategorisierungsrahmen usw.)
show::V::IMPERATIVE VFIN SVO SVOOshow::V::PRESENT –SG3 VFIN SVO SVOOshow::N::NOMINATIVE SG
8

• Disambiguierung von that in it isn’t that oddthat::ADVthat::PRON DEM SGthat::DET DEM SGthat::CS
Adverbial-That Regel:
Given Input “that”if
(+1 A|ADV|QUANT); %if next word is adj, adv or quantifier(+2 SENT-LIM); %and following which is a sentence boundary(NOT -1 SVOC/A); %and previous word is not verb allowing adjs as object complements
then eliminate non-ADV tagselse eliminate ADV tag
• Nachteile:– zeitaufwendiges Adjustieren der Regeln
– mangelnde Generaliserungsfahigkeit
– keine Ubertragbarkeit auf andere Sprachen
9

Statistische VerfahrenStatistische Sprachmodelle: N-Gramme• Statistisches Modell: Vorhersage von Ereigniswahrscheinlichkeiten
• Wahrscheinlichkeit (Likelihood) einer Wortfolge w1 . . . wn (gemaßKettenregel):
P (w1 . . . wn) = P (w1)P (w2|w1)P (w3|w1w2) . . . P (wn|w1 . . . wn−1)
= P (w1)n∏
k=2
P (wk|w1 . . . wk−1)
• Anzahl von langen Wortvorgeschichten zu gering, als daß man darausverlaßliche Wahrscheinlichkeiten ableiten konnte −→ vereinfachendeMarkov-Annahme: Lange der Wortvorgeschichte begrenzt auf m (z.B. =2:Trigramme)
P (w1 . . . wn) = P (w1)P (w2|w1)n∏
k=3
P (wk|wk−m . . . wk−1)
10

• Trigrammwahrscheinlichkeit: P (wk|wk−2wk−1) = #(wk−2wk−1wk)
#(wk−2wk−1)
• Smoothing: Anpassung der beobachteten Haufigkeiten, damit auchungesehene n-Gramme eine Wahrscheinlichkeit großer 0 erhalten;Discounting, Good-Turing-Verfahren usw.
11

• lineare Interpolation: gewichtete Kombination verschiedener statistischerModelle
P (w1 . . . wn) =n∏
k=1
Phybrid (wk) =n∏
k=1
∑i
λiPi(wk)
P (w1 . . . wn) ist die Likelihood der Wortfolge w1 bis wn, die sichzusammensetzt aus dem Produkt der Wahrscheinlichkeiten der betrachtetenEinzelereignisse (Auftreten von Wort wk). Zur Ermittlung derWahrscheinlichkeiten fur wk kann man verschiedene Modelle heranziehen(beispielsweise mit variierender Lange der Wortvorgeschichte) und die durchsie vorhergesagten Wahrscheinlichkeiten zu Phybrid kombinieren. Pi(wk) ist
hierbei die Wahrscheinlichkeit von wk im Modell Mi. Sei M1 ein Unigramm-,M2 ein Bigramm- und M3 ein Trigramm-Modell zur Vorhersage derWahrscheinlichkeit von wk, dann ergibt sich oben eingesetzt:
Phybrid(wk) = λ1P1(wk) + λ2P2(wk|wk−1) + λ3P3(wk|wk−2wk−1)
Die Gewichte λi werden mit Hilfe des EM-Algorithmus(expectation+maximization) ermittelt, ihre Summe ergibt 1.
12

• Satz von Bayes
P (X|Y ) =P (Y |X)P (X)
P (Y )
Wird eingesetzt, wenn P (X|Y ) nicht geschatzt werden kann, beispielsweisewegen zu geringer Haufigkeit von Y.
Einfache Form eines Markov-Taggers (Jelinek, 1985)• Schatzung der wahrscheinlichsten Tag-Sequenz G, gegeben die Wort-Sequenz
word W
G = arg maxG
[P (G|W )
]= arg max
G
[P (G)P (W |G)
P (W )
](Bayes)
= arg maxG
[P (G)P (W |G)
](P(W) konstant)
P (G)P (W |G) =T∏
t=1
P (wt|w1g1 . . . wt−1gt−1gt)P (gt|w1g1 . . . wt−1gt−1) (Kettenr.)
13

• Vereinfachende Annahmen– Die Wahrscheinlichkeit des Worts wt hangt nur von seinem tag gt ab.
– Die Wahrscheinlichkeit des tags gt hangt von einer begrenztentag-Vorgeschichte ab (Markov-Annahme)
G = arg maxg1...gT
[ T∏t=1
P (gt|g-historyt)P (wt|gt)]
• Tagging-Problem als Hidden-Markov-Modell (HMM) formalisiert (sieheTafelbild)
• Bestandteile eines HMM (mit konkreten Entsprechungen):– Menge von Zustanden Q = {qi}; an jedem Zustand wird ein POS-Label
angetragen
– Ubergangswahrscheinlichkeiten A = {aij}: von Zustand i zu Zustand j;
entspricht P (POS j|POS-history), Ubergangswahrscheinlichkeiten abhangigvon den POS-Labels der n vorangehenden Zustande (bei einer history derLange n).
– Emissionswahrscheinlichkeiten (observation likelihoods) B = {bjot}: furBeobachtung ot; entspricht P (wt|POSt) fur alle POS j
14

• Ermittlung von T mit Hilfe des Viterbi-Algorithmus:– Aufbau einer Trellis: Zustand-Zeitpunkt-Gitter; ein Knoten entspricht
einem POS-tag zu einem bestimmten Zeitpunkt, also zum Index desjeweiligen Worts im zu taggenden Text1
– Ziel: finde fur beobachtete Wortfolge denjenigen Pfad durch die Trellis, indem das Produkt aus Emissions- und Ubergangswahrscheinlichkeiten
maximiert wird −→ max[P (G)P (W |G)
]−→ max
[P (G|W )
]. Die damit
verbundene Tag-Sequenz g1 . . . gT ist der Output des Taggers.
– in jedem Knoten kj(t) der Trellis fur tag j und Zeitpunkt t wird folgendesnotiert: a) die Wahrscheinlichkeit δj(t) des bis hierhin wahrscheinlichstenPfads, und b) der Vorgangerknoten auf diesem Pfad
1Indizes: uber Zustande (tags): 1 ≤ i, j ≤ N ; uber Zeitpunkte: 1 ≤ t ≤ T bei einem POS-Inventar der GroßeN und einem zu taggenden Text der Lange T
15

– Ermittlung der δj(t)’s:∗ Initialisierung:
δj(1) = bjo1
∗ Induktion2
δj(t) = maxi
[δi(t− 1)aijbjot
]
2Induktion (informell): Fortfuhrung eines fur n gultigen Sachverhalts mit n + 1.
16

Bei der Initialisierung zum Zeitpunkt t = 1 werden die δ’s fur jeden POSj gleich den bedingten Wahrscheinlichkeiten P(erstes Wort im zutaggenden Text | POS j) gesetzt. Im Zuge der Induktion wird fur jedenKnoten kjt der Trellis fur POS j zum Zeitpunkt t die Wahrscheinlichkeitδj(t) des wahrscheinlichsten Pfads hin zu diesem Knoten ermittelt. Dieseergibt sich durch Multiplikation von (Emissionswahrscheinlichkeit des t-tenWorts im zu taggenden Text, gegeben POS j) mit dem Maximum unterden Produkten (Wahrscheinlichkeiten der Pfade zu den Knoten zumZeitpunkt t− 1) x (Ubergangswahrscheinlichkeiten zwischen den Knotender Ebene t− 1 und kjt). Der Vorganger von kjt im wahrscheinlichstenPfad wird ebenfalls am Knoten vermerkt, damit der Pfad dann nachZeitpunkt T , also nach dem letzten Wort, ausgelesen werden kann.
17

Tree Tagger (Schmidt, 1995)
• P (wt|gt) mittels Lexikon, das Vollformen und Suffixe enthalt
• P (gt|g-historyt) mittels Entscheidungsbaum, der fur g-history einen Vektormit den Wahrscheinlichkeiten der POS-tags ausgibt; g-history ist als Pfad imBaum reprasentiert
• Reduzierung des OOV-Problems, aber sprachabhangig
18

Reichel (2005)
• Vergleiche auch: TnT-Tagger (Brants, 2000)
• Generalisierung des Grundmodells mittels linearer Interpolation
• ersetze P (gt|g-historyt) durch∑
j ujP (gt|g-historytj)
• ersetze P (wt|gt) durch P (wt)P (gt)
∑k vkP (gt|w-representationtk)
T = arg maxg1...gT
[ T∏t=1
1P (gt)
∑j
ujP (gt|g-historytj)∑
k
vkP (gt|w-representationtk)]
19

Word-Reprasentation: String-Suffixe• Motivation
– in vielen Sprachen ist POS-Information Suffix-Morphemen,Flektionsendungen, und finalen Kompositumgliedern kodiert(Gelegenheit/NN, Umgehungsstraße/NN, partly/ADV)
– Nutzung dieser Einheiten reduziert das OOV-Problem
• Desideratum: ermittle linguistisch sinntragende String-Suffixe ohnelinguistisches Wissen −→ Sprachunabhangigkeit
Ermittlung der String-Suffixe mittels Weighted Backward SuccessorVariety (SV)• SV eines Strings: Anzahl verschiedener Characters, die ihm in einem Lexikon
folgen konnen
• Backward SV: SV’s werden von gespiegelten Strings ermittelt (Suffixe)
• Weighting: SV’s werden gewichtet in Abhangigkeit der mittleren SV an derentsprechenden String-Position, um Positions-Effekte zu eliminieren
20
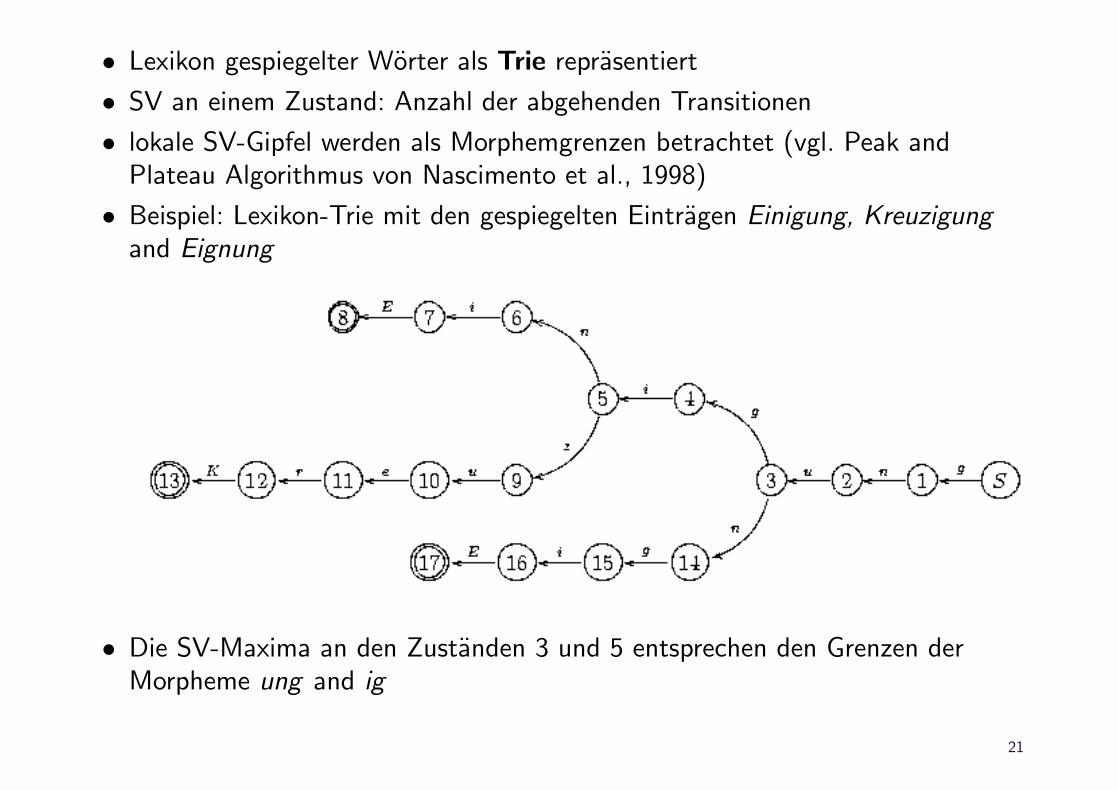
• Lexikon gespiegelter Worter als Trie reprasentiert
• SV an einem Zustand: Anzahl der abgehenden Transitionen
• lokale SV-Gipfel werden als Morphemgrenzen betrachtet (vgl. Peak andPlateau Algorithmus von Nascimento et al., 1998)
• Beispiel: Lexikon-Trie mit den gespiegelten Eintragen Einigung, Kreuzigungand Eignung
• Die SV-Maxima an den Zustanden 3 und 5 entsprechen den Grenzen derMorpheme ung and ig
21

Transformationsbasiertes Tagging
Brill Tagger (Brill, 1995)• regelbasierter Tagger
• Regeln werden automatisch anhand der Trainingsdaten gewonnen(uberwachtes Lernen)
• Lernalgorithmus:1. weise jedem Wort den wahrscheinlichsten POS-tag zu
2. iterate until Verbesserung < Schwelle– wahle aus einer Menge von Transformationenregeln diejenige aus, die
zum besten Tagging-Ergebnis fuhrt
– fuge diese Regel hinten an die Liste bisher ausgewahlter Regeln trl an
– tagge das Corpus unter Anwendung dieser Regel neu
• Beispiel fur Transformationsregel: NN → VB if (vorangehender tag gleichTO)expected to/TO race/NN −→ expected to race/VB
22

• Transformationsregeln ergeben sich durch Einsetzen aller moglichen POS-tagsin folgende Templates:
tag a −→ tag b, ifvorangehendes (folgendes) Wort ist mit tag z gelabelt.das zweite vorangehende (folgende) Wort ist mit tag z gelabelt.eines der zwei (drei) vorangehenden (folgenden) Worter ist mit tag zgelabelt.vorangehendes Wort ist mit tag z gelabelt, und das folgende mit tag w.das vorangehende (folgende) Wort ist mit tag z gelabelt, und das zweitevorangehende (folgende) Wort mit tag w.
• Lernalgorithmus sehr zeitaufwendig, wenn fur jedes Template zur Belegungvon a, b, z, w alle POS-Kombinationen zugelassen werden
• Tagging:1. weise jedem Wort den wahrscheinlichsten POS-tag zu
2. foreach Regel tr in trl : tagge den Text unter Anwendung von tr neu
23

Evaluierung
• anhand eines Testcorpus
• Gold-Standard: Vergleich des Tagger-Outputs mit manuell gesetzten tags;Relativierung durch Inter-Tagger-Agreement < 100 %
• Baseline: Vergleich des Outputs mit Output eines Baseline-Taggers,beispielsweise einem Unigramm-Tagger (ohne POS-History)
• Vergleichbarkeit von Taggern bei beliebiger Tagset-Große:3 Kappa-Statistik
κ =Pt(C)− Pz(C)
1− Pz(C)
C: Wort korrekt getaggt, Pt(C): Anteil der vom Tagger korrekt klassifiziertenWorter, Pz(C): zu erwartender Anteil zufallig korrekt klassifizierter Worter =
1
|Tagset|3Bei einem Tagset der Große 1 ist die Performanz des Taggers, der nur diesen einen Tag vorhersagt, 100 %.
24






























