Embed Size (px)
Citation preview

Person Name Disambiguation by Bootstrapping
Presenter: Lijie Zhang
Advisor: Weining Zhang

Outlines
Introduction Motivation Two-stage Clustering Algorithm Experiments

People Name Disambiguation
Given a target name (query q ), search engine returns a set of web pages P={d1, d2, …, dn }
Task: cluster web pages P such that each cluster refers to a single person.
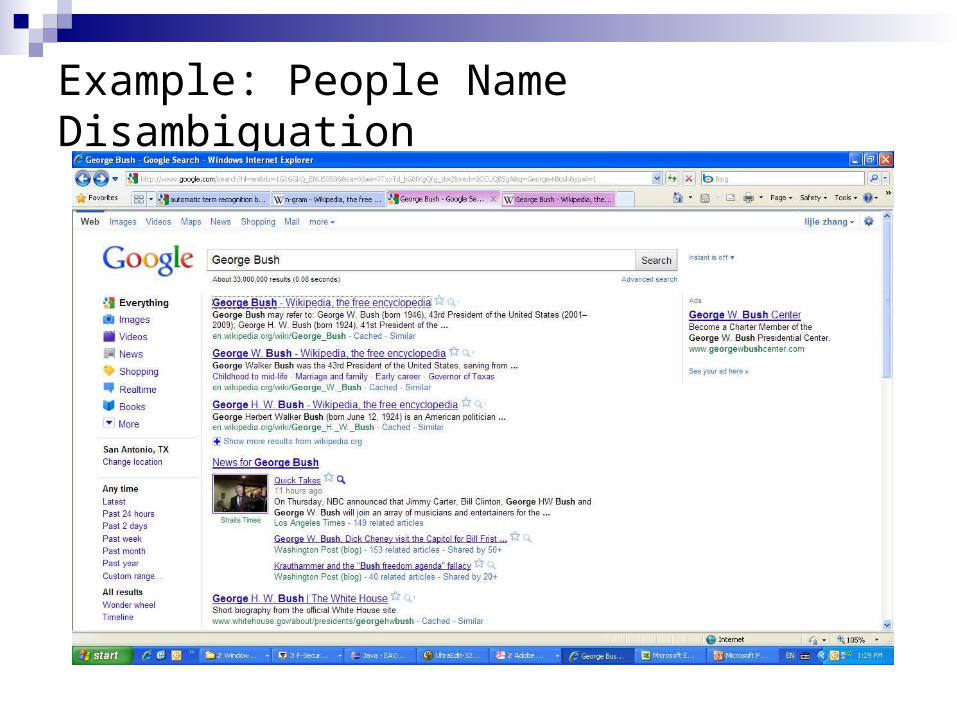
Example: People Name Disambiguation

People Name Disambiguation
A typical solution: Extract a set of features from each document returned by search
engine Cluster the documents based on some similarity metrics on sets
of features Two types of features
Strong features such as named entities (NEs), compound key words (CKWs), URLs
NE: Paul Allen, Microsoft (indicate the person Bill Gates) CKW: chief software architect (a concept strongly related to Bill
Gates) Very strong ability to distinguish between clusters.
Weak features: single words

People Name Disambiguation
Evaluation Metric: F measure Treat each cluster as if it were the result of a
query and each class as if it were the desired set of documents for a query
For class i and cluster j, Recall(i, j)= nij/ni, Precision(i, j)=nij/nj
F(i, j) = (2 * Recall(i, j) * Precision(i, j)) / ((Precision(i, j) + Recall(i, j))

Motivation
Problem of current systems: Using only strong features achieves high precision but low recall.
Proposed solution: two-stage clustering algorithm by bootstrapping to improve the recall value.1st stage: strong features2nd stage: weak features

Two-stage Clustering Algorithm
Input: one query string Output: a set of clusters
1. Preprocessing documents returned by search engine
2. First-stage clustering
3. Second-stage clustering

Preprocessing a Document
Covert HTML files to text files Remove HTML tagsKeep sentences
Extract text around query string Using a window size
Extract strong features (NEs, CKWs, URLs)

Extract Strong Features Use Stanford NER to identify NEs:
a set of sets of names including names of persons, organizations, and places
Compound Key Word (CKW) Features: a set of CKWs Extract compound words (CW): w1w2..wl
Score each CW: Determine CKW based on a threshold of scores.
Extract URLs from the original HTML files exclude URLs with high frequencies

Two-stage Clustering Algorithm
Input: one or more query strings Output: a set of clusters
1. Preprocessing documents returned by search engine
2.1st stage clustering
3. 2nd stage clustering

First stage clustering
1. Calculate the similarities between documents based on these features
2. Use standard hierarchical agglomerative clustering (HAC) algorithm for clustering

Document Similarities
Similarity for NE features and CKW features
avoids too small denominator values in the equation

Document Similarities
Similarity for URLs

Document Similarities
Similarity for NE:
Similarities for NE, CKW, and URL

First stage clustering
1. Calculate the similarities between documents based on these features
2. Use standard hierarchical agglomerative clustering (HAC) algorithm for clustering

HAC algorithm
Starts from one-in-one clustering, i.e. each document is a cluster
Iteratively merge the most similar cluster pairs, which similarity is above a threshold.
Cluster similarity:

Two-stage Clustering Algorithm
Input: one or more query strings Output: a set of clusters
1. Preprocessing documents returned by search engine
2.1st stage clustering
3. 2nd stage clustering

Second Stage Clustering
Goal: Cluster documents still in one-in-one clustering after the first stage clustering
Idea of bootstrapping algorithm: Given some seed instances, finds patterns useful to extract such
seed instances; Use these patterns to harvest new instances, and form the
harvested new instances new patterns are induced. Instances correspond to documents Patterns correspond to weak features: 1-gram, 2-gram in
experiment
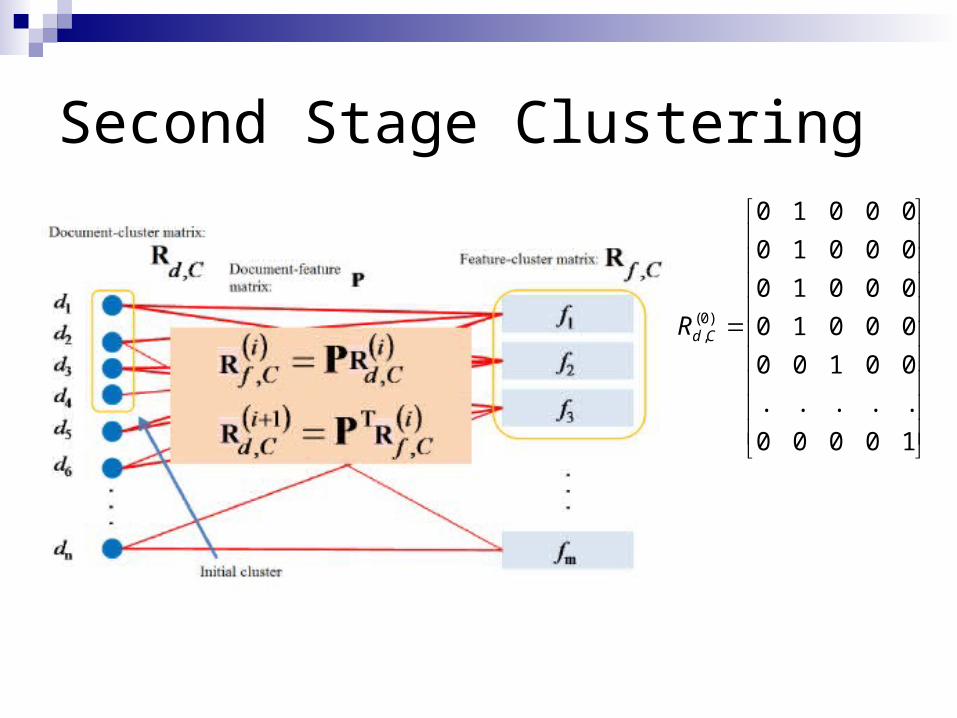
Second Stage Clustering
10000
.....
00100
00010
00010
00010
00010
)0(,CdR


Experiments Setup Dataset: WePS-2
30 names, each has 150 pages The same page can refer to two or more entities;
Evaluation Metrics [5] Multiplicity precision and recall between document e and e’
C(e) is predicted cluster of e, L(e) is the cluster assigned to e by the gold standard
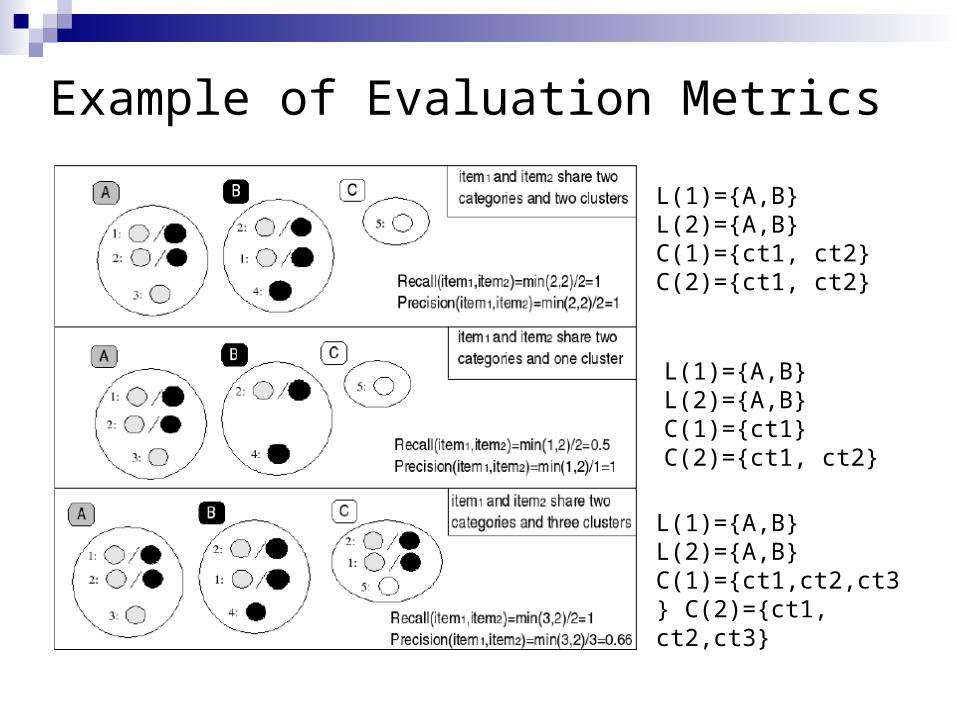
Example of Evaluation Metrics
L(1)={A,B} L(2)={A,B}C(1)={ct1, ct2} C(2)={ct1, ct2}
L(1)={A,B} L(2)={A,B}C(1)={ct1} C(2)={ct1, ct2}
L(1)={A,B} L(2)={A,B}C(1)={ct1,ct2,ct3} C(2)={ct1, ct2,ct3}

Experiments Setup
Evaluation Metrics Extended B-Cubed precision (BEP) and recall (BER)

Experiments Setup
Baselines:First stage clustering: all-in-one, one-in-one,
combined baseline (each doc belongs to one cluster from all-in-one and one from one-in-one).
Second stage clustering: TOPIC algorithm, CKW algorithm
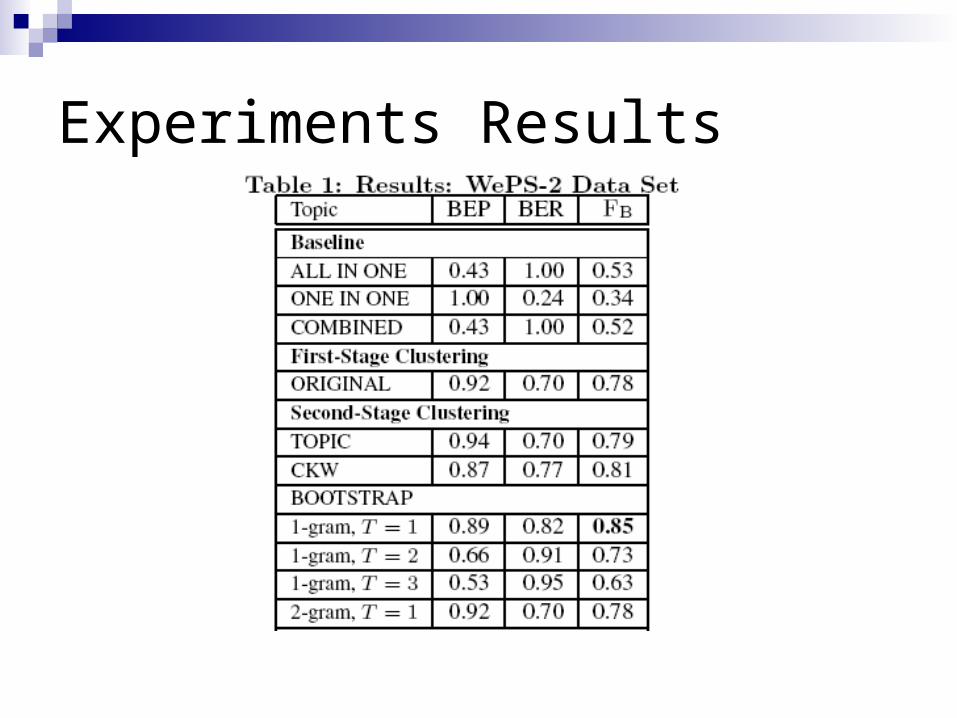
Experiments Results

References[1] A. Bagga and B. Baldwin. Entity-based cross-document coreferencing using the vector
space model. In Proceedings of COLING-ACL 1998, pages 79–85, 1998.[2] C. Niu, W. Li, and R. K. Srihari. Weakly supervised learning for cross-document
person name disambiguation supported by information extraction. In Proceedings of 42nd Annual Meeting of the Association for Computational Linguistics (ACL-2004), pages 598–605, 2004.
[3] X. Liu, Y. Gong, W. Xu, and S. Zhu. Document clustering with cluster refinement and model selection capabilities. In Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, pages 191–198, 2002.
[4] X. Wan, M. L. J. Gao, and B. Ding. Person resolution in person search results: WebHawk. In Proceedings of CIKM2005, pages 163–170, 2005.
[5] E. Amigo, J. Gonzalo, J. Artiles, and F. Verdejo. A comparison of extrinsic clustering evaluation metrics based on formal constraints. Information Retrieval, 12(4), 2009.
[6] Minoru Yoshida, Masaki Ikeda, Shingo Ono, Issei Sato, Hiroshi Nakagawa. Person Name Disambiguation by Bootstrapping. In Proceedings of SIGIR, 2010.




























