Embed Size (px)
Citation preview

PBLCACHEPBLCACHE
Vault Boston 2015 - Luis Pabón - Red Hat
A cl ient side persistent block cache for the data center

ABOUT MEABOUT MEL U I S PA B Ó NL U I S PA B Ó NPrincipal Software Engineer,
Red Hat Storage
IRC, GitHub: lpabon
QUESTIONS:QUESTIONS:
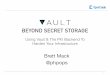
Storage
SSD
Compute Node
What are the benefits of client sidepersistent caching?How to effectively use the SSD?

MERCURY*MERCURY*
* S. Byan, et al ., Mercury: Host-side flash caching for the data center
Use in memorydata structuresto handle cachemisses asquickly aspossible
Writesequential ly tothe SSD
Cache must bepersistent sincewarming could betime consuming
Increase storagebackend availabil ityby reducing readrequests

M E R C U RY Q E M U I N T E G R AT I O NM E R C U RY Q E M U I N T E G R AT I O N

PBLCACHEPBLCACHE

P B L C AC H EP B L C AC H E
Persistent, block based, look aside cache for QEMUUser space library/applicationBased on ideas described in the Mercury paperRequires exclusive access to mutable objects
Persistent BLock Cache

G OA L : Q E M U S H A R E D C AC H EG OA L : Q E M U S H A R E D C AC H E

P B L C AC H E A R C H I T E C T U R EP B L C AC H E A R C H I T E C T U R E
PBL Application
Cache Map
Log
SSD

P B L A P P L I C AT I O NP B L A P P L I C AT I O N
Sets up the cache map and logDecides how to use the cache (writethrough, read-miss)Inserts, retrieves, or invalidates blocks from the cache
Cache map Log
Msg Queue
Pbl App
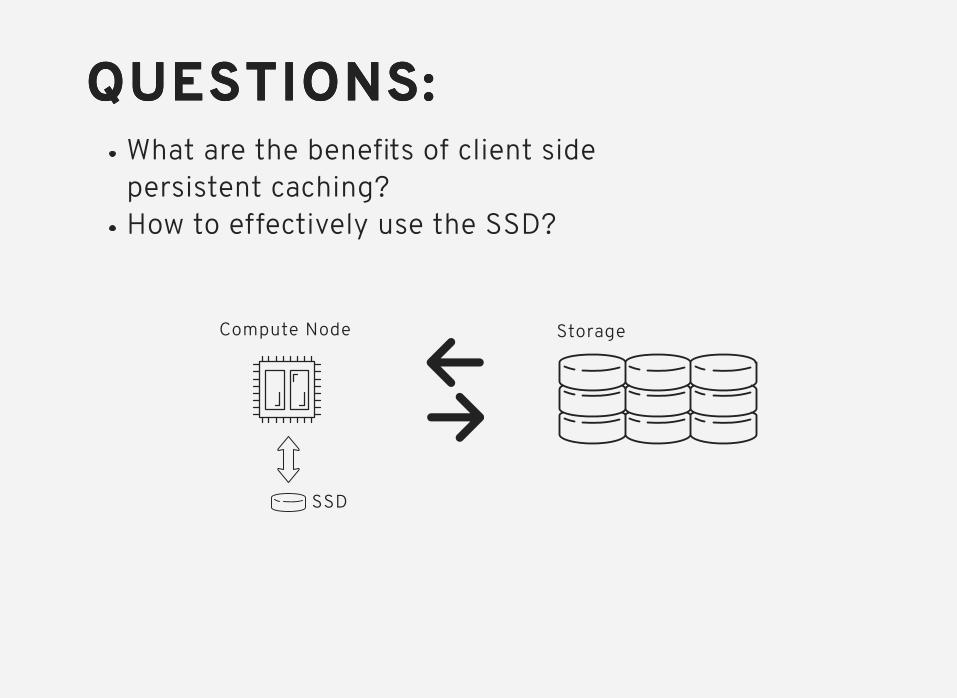
C AC H E M A PC AC H E M A P
Composed of two data structuresMaintains all block metadata
Address Map
BlockDescriptor
Array

A D D R E S S M A PA D D R E S S M A P
Address Map
BlockDescriptor
Array
Implemented using as a hash tableTranslates object blocks to Block Descriptor Array (BDA) indecesCache misses are determined extremely fast

B L O C K D E S C R I P TO R A R R AYB L O C K D E S C R I P TO R A R R AY
Address Map
BlockDescriptor
Array
Contains metadata for blocks stored in the logLength is equal to the maximum number of blocksstored in the log Handles CLOCK evictionsInvalidations are extremely fast
Insertions always append

C AC H E M A P I / O F L O WC AC H E M A P I / O F L O W
Block
Descr iptor
Array

C AC H E M A P I / O F L O WC AC H E M A P I / O F L O W
G et
In add re s s map
M is s H i t
S e t CLO CKbi t i n BD A
Read f rom log
N o Y es

C AC H E M A P I / O F L O WC AC H E M A P I / O F L O W
Inva l i da t e
F ree BDA index
De le t e f rom map

L O GL O G
Block location determined by BDACLOCK optimized with segment read-aheadSegment pool with buffered writesContiguous block support
Segments
SSD

L O G S E G M E N T S TAT E M AC H I N EL O G S E G M E N T S TAT E M AC H I N E

L O G R E A D I / O F L O WL O G R E A D I / O F L O W
Read
In a s egmen t?
Read f rom segmen t Read f rom SSD
Yes No

P E R S I S T E N T M E TA DATAP E R S I S T E N T M E TA DATA
Save address map to a file on application shutdownCache warm on application restartNot designed to be durableSystem crash will cause metadata file not to be created

PBLIO BENCHMARKPBLIO BENCHMARKPBL APPLICATIONPBL APPLICATION

P B L I OP B L I O
Benchmark toolUses an enterprise workload workload generator from NetApp*Cache setup as write throughCan be used with or without pblcacheDocumentation
https://github.com/pblcache/pblcache/wiki/Pblio
* S. Daniel et al ., A portable, open-source implementation of the SPC-1 workload
* https://github.com/lpabon/goioworkload

E N T E R P R I S E W O R K L OA DE N T E R P R I S E W O R K L OA D
Synthetic OLTP enterprise workload generatorTests for maximum number of IOPS before exceeding 30ms latencyDivides storage system into three logical storage units:
ASU1 - Data Store - 45% of total storage - RW ASU2 - User Store - 45% of total storage - RWASU3 - Log - 10% of total storage - Write Only
BSU - Business Scaling Units
1 BSU = 50 IOPS

S I M P L E E X A M P L ES I M P L E E X A M P L E
$ fallocate -l 45MiB file1$ fallocate -l 45MiB file2$ fallocate -l 10MiB file3$$ ./pblio -asu1=file1 \ -asu2=file2 \ -asu3=file3 \ -runlen=30 -bsu=2-----pblio-----Cache : NoneASU1 : 0.04 GBASU2 : 0.04 GBASU3 : 0.01 GBBSUs : 2Contexts: 1Run time: 30 s-----Avg IOPS:98.63 Avg Latency:0.2895 ms

R AW D E V I C E S E X A M P L ER AW D E V I C E S E X A M P L E
$ ./pblio -asu1=/dev/sdb,/dev/sdc,/dev/sdd,/dev/sde \ -asu2=/dev/sdf,/dev/sdg,/dev/sdh,/dev/sdi \ -asu3=/dev/sdj,/dev/sdk,/dev/sdl,/dev/sdm \ -runlen=30 -bsu=2

C AC H E E X A M P L EC AC H E E X A M P L E$ fallocate -l 10MiB mycache$ ./pblio -asu1=file1 -asu2=file2 -asu3=file3 \ -runlen=30 -bsu=2 -cache=mycache-----pblio-----Cache : mycache (New)C Size : 0.01 GBASU1 : 0.04 GBASU2 : 0.04 GBASU3 : 0.01 GBBSUs : 2Contexts: 1Run time: 30 s-----Avg IOPS:98.63 Avg Latency:0.2573 ms Read Hit Rate: 0.4457Invalidate Hit Rate: 0.6764Read hits: 1120Invalidate hits: 347Reads: 2513Insertions: 1906Evictions: 0Invalidations: 513== Log Information ==Ram Hit Rate: 1.0000Ram Hits: 1120Buffer Hit Rate: 0.0000Buffer Hits: 0Storage Hits: 0Wraps: 1Segments Skipped: 0Mean Read Latency: 0.00 usecMean Segment Read Latency: 4396.77 usecMean Write Latency: 1162.58 usec

-----pblio-----Cache : /dev/sdg (Loaded)C Size : 185.75 GBASU1 : 673.83 GBASU2 : 673.83 GBASU3 : 149.74 GBBSUs : 32Contexts: 1Run time: 600 s-----
Avg IOPS:1514.92 Avg Latency:112.1096 ms
Read Hit Rate: 0.7004Invalidate Hit Rate: 0.7905Read hits: 528539Invalidate hits: 120189Reads: 754593Insertions: 378093Evictions: 303616Invalidations: 152039== Log Information ==Ram Hit Rate: 0.0002Ram Hits: 75Buffer Hit Rate: 0.0000Buffer Hits: 0Storage Hits: 445638Wraps: 0Segments Skipped: 0Mean Read Latency: 850.89 usecMean Segment Read Latency: 2856.16 usecMean Write Latency: 6472.74 usec
L AT E N C Y OV E R 3 0 M SL AT E N C Y OV E R 3 0 M S

EVALUATIONEVALUATION

T E S T S E T U PT E S T S E T U P
Client using 180GB SAS SSD (about 10% of workload size)GlusterFS 6x2 Cluster100 files for each ASUpblio v0.1 compiled with go1.4.1
Each system has:
Fedora 20
6 Inte l Xeon E5-2620 @ 2GHz
64 GB RAM
5 300GB SAS Dr ives
10Gbit Network

C AC H E WA R M U P I S T I M EC AC H E WA R M U P I S T I M EC O M S U M I N GC O M S U M I N G
16 hours
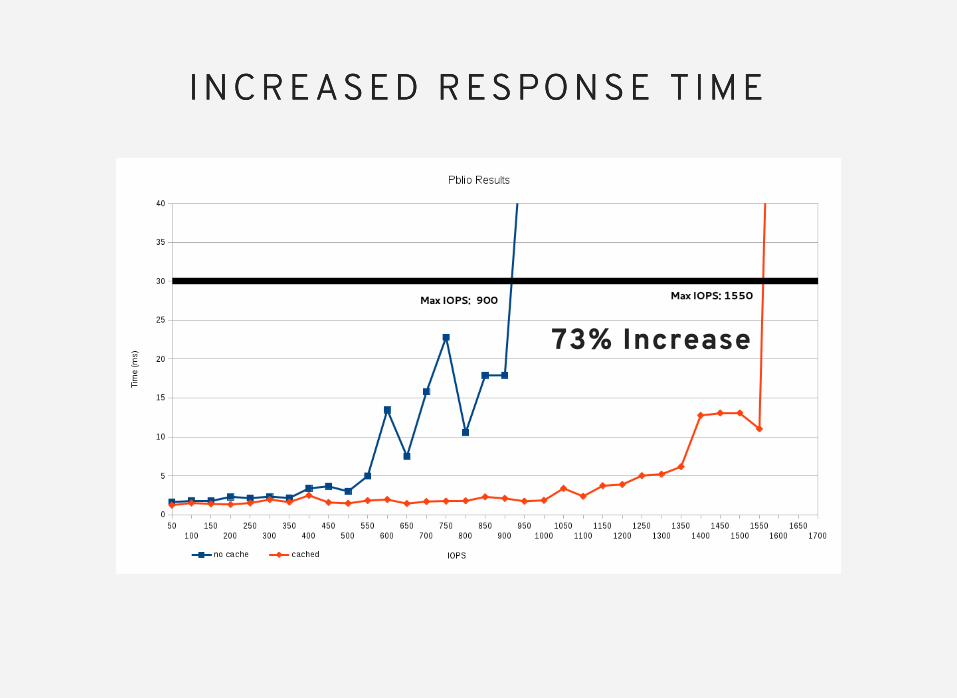
I N C R E A S E D R E S P O N S E T I M EI N C R E A S E D R E S P O N S E T I M E
73% Increase

S TO R AG E B AC K E N D I O P SS TO R AG E B AC K E N D I O P SR E D U C T I O NR E D U C T I O N
BSU = 31 or 1550 IOPS
~75% IOPS Reduction

CURRENT STATUSCURRENT STATUS

M I L E S TO N E SM I L E S TO N E S
1. Create Cache Map - COMPLETED2. Create Log - COMPLETED3. Create Benchmark application - COMPLETED4. Design pblcached architecture - IN PROGRESS

N E X T: Q E M U S H A R E D C AC H EN E X T: Q E M U S H A R E D C AC H E
Work with the community to bring this technology to QEMUPossible architecture:
Some conditions to think about:
VM migrationVolume deletionVM crash

F U T U R EF U T U R E
HyperconvergencePeer-cacheWritebackShared cache QoS using mClock*Possible integrations with Ceph and GlusterFS backends
* A. Gulati et al ., mClock: Handling Throughput Variabil ity for Hypervisor IO Scheduling

J O I N !J O I N !
Github:
IRC Freenode: #pblcache
Google Group:
Mail l ist :
https://github.com/pblcache/pblcache
https://groups.google.com/forum/#!forum/pblcache

FROM THIS...FROM THIS...

TO THISTO THIS