Embed Size (px)
Citation preview

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Parameter-free Machine Learning through Coin Betting
Francesco Orabona
Boston UniversityBoston, MA USA
Geometric Analysis Approach to AI Workshop
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Motivation of my Recent Work: Parameter-free Algorithms
Most of the algorithms we know/use in machine learning have parameters
E.g. regularization parameter in LASSO, k in k -Nearest Neighbourhood,topology of the networks in deep learning
Most of the time, a large enough validation set can be used to tune theparameters
But, at what computational price? Are they really necessary?
Are you ignoring some computational/sample complexities?
When is the last time you needed to tune the learning rate to sort a vector?Or to invert a matrix?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Motivation of my Recent Work: Parameter-free Algorithms
Most of the algorithms we know/use in machine learning have parametersE.g. regularization parameter in LASSO, k in k -Nearest Neighbourhood,topology of the networks in deep learning
Most of the time, a large enough validation set can be used to tune theparameters
But, at what computational price? Are they really necessary?
Are you ignoring some computational/sample complexities?
When is the last time you needed to tune the learning rate to sort a vector?Or to invert a matrix?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Motivation of my Recent Work: Parameter-free Algorithms
Most of the algorithms we know/use in machine learning have parametersE.g. regularization parameter in LASSO, k in k -Nearest Neighbourhood,topology of the networks in deep learning
Most of the time, a large enough validation set can be used to tune theparameters
But, at what computational price? Are they really necessary?
Are you ignoring some computational/sample complexities?
When is the last time you needed to tune the learning rate to sort a vector?Or to invert a matrix?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Motivation of my Recent Work: Parameter-free Algorithms
Most of the algorithms we know/use in machine learning have parametersE.g. regularization parameter in LASSO, k in k -Nearest Neighbourhood,topology of the networks in deep learning
Most of the time, a large enough validation set can be used to tune theparameters
But, at what computational price? Are they really necessary?
Are you ignoring some computational/sample complexities?
When is the last time you needed to tune the learning rate to sort a vector?Or to invert a matrix?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Motivation of my Recent Work: Parameter-free Algorithms
Most of the algorithms we know/use in machine learning have parametersE.g. regularization parameter in LASSO, k in k -Nearest Neighbourhood,topology of the networks in deep learning
Most of the time, a large enough validation set can be used to tune theparameters
But, at what computational price? Are they really necessary?
Are you ignoring some computational/sample complexities?
When is the last time you needed to tune the learning rate to sort a vector?Or to invert a matrix?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Motivation of my Recent Work: Parameter-free Algorithms
Most of the algorithms we know/use in machine learning have parametersE.g. regularization parameter in LASSO, k in k -Nearest Neighbourhood,topology of the networks in deep learning
Most of the time, a large enough validation set can be used to tune theparameters
But, at what computational price? Are they really necessary?
Are you ignoring some computational/sample complexities?
When is the last time you needed to tune the learning rate to sort a vector?Or to invert a matrix?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
My Dream: Truly Automatic Machine Learning
No parameters to tune
No humans in the loop
Some guarantees
Sometimes this is possible
This talk is about a method to achieve this dream in many interesting cases
Not the only way nor the only parameter-free method I proposed
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
My Dream: Truly Automatic Machine Learning
No parameters to tune
No humans in the loop
Some guarantees
Sometimes this is possible
This talk is about a method to achieve this dream in many interesting cases
Not the only way nor the only parameter-free method I proposed
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Outline
1 Optimization of Non-smooth Convex Functions
2 Coin BettingBetting on a CoinFrom Betting to OptimizationCOCOB
3 Experiments
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Outline
1 Optimization of Non-smooth Convex Functions
2 Coin BettingBetting on a CoinFrom Betting to OptimizationCOCOB
3 Experiments
Francesco Orabona Parameter-free Machine Learning through Coin Betting
Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
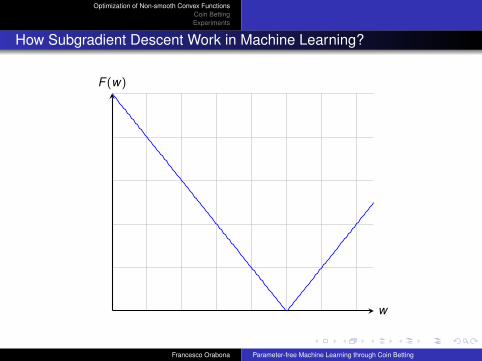
How Subgradient Descent Work in Machine Learning?
w
F (w)
Francesco Orabona Parameter-free Machine Learning through Coin Betting
Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
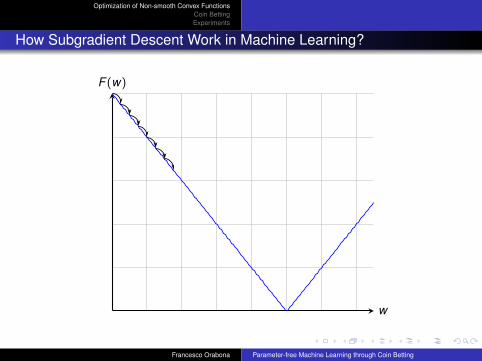
How Subgradient Descent Work in Machine Learning?
w
F (w)
Francesco Orabona Parameter-free Machine Learning through Coin Betting
Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
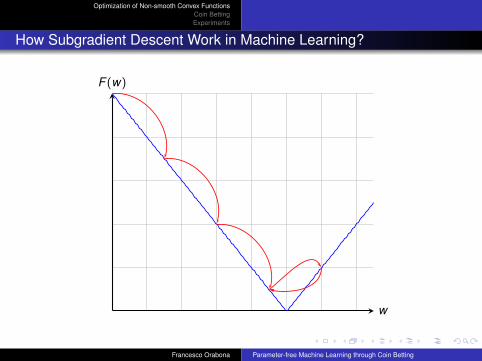
How Subgradient Descent Work in Machine Learning?
w
F (w)
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
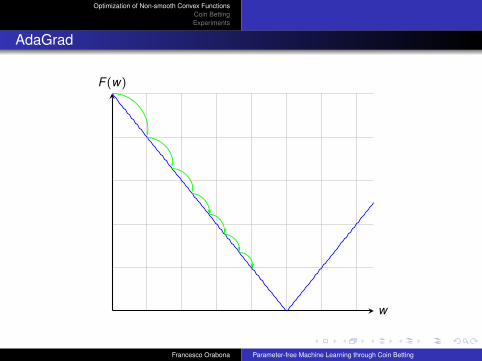
What About “Adaptive” Algorithms?
In the stochastic setting is even more challenging: the function at eachround is always the same only in expectation
What about AdaGrad?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
What About “Adaptive” Algorithms?
In the stochastic setting is even more challenging: the function at eachround is always the same only in expectation
What about AdaGrad?
Francesco Orabona Parameter-free Machine Learning through Coin Betting
Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
AdaGrad
w
F (w)
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
What the Theory Says?
Only strategy known: use a decreasing step size, O(η√
t
)Convergence after T iterations is O
(1√T
(‖w∗‖2
η+ η))
w∗ is the best solution
The optimal learning rate is with η = ‖w∗‖ that would give a rate ofO(
1√T‖w∗‖
)...but you don’t know w∗...
Why we cannot have an optimization algorithm that self-tunes its learning rate?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
What the Theory Says?
Only strategy known: use a decreasing step size, O(η√
t
)Convergence after T iterations is O
(1√T
(‖w∗‖2
η+ η))
w∗ is the best solution
The optimal learning rate is with η = ‖w∗‖ that would give a rate ofO(
1√T‖w∗‖
)
...but you don’t know w∗...
Why we cannot have an optimization algorithm that self-tunes its learning rate?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
What the Theory Says?
Only strategy known: use a decreasing step size, O(η√
t
)Convergence after T iterations is O
(1√T
(‖w∗‖2
η+ η))
w∗ is the best solution
The optimal learning rate is with η = ‖w∗‖ that would give a rate ofO(
1√T‖w∗‖
)...but you don’t know w∗...
Why we cannot have an optimization algorithm that self-tunes its learning rate?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
What the Theory Says?
Only strategy known: use a decreasing step size, O(η√
t
)Convergence after T iterations is O
(1√T
(‖w∗‖2
η+ η))
w∗ is the best solution
The optimal learning rate is with η = ‖w∗‖ that would give a rate ofO(
1√T‖w∗‖
)...but you don’t know w∗...
Why we cannot have an optimization algorithm that self-tunes its learning rate?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Parameter-free Optimization
[McMahan&Streeter, NIPS’12][McMahan&Abernethy, NIPS’13] suboptimal bound,1D
[Orabona, NIPS’13] suboptimal bound, Hilbert spaces
[McMahan&Orabona, COLT’14] optimal bound, Hilbert space
[Orabona, NIPS’14] data-dependent bound, analysis in RKHS, algorithm in VW
[Cutkosky&Boahen, NIPS’16, COLT’17] unbounded gradients
[van Erven&Koolen, NIPS’16] run multiple learning rates in parallel & aggregate
[Orabona&Pal, NIPS’16] coin-betting view
[Orabona&Tommasi, NIPS’17] coin-betting for deep learning
[Kotlowski, ALT’17] scale-free bound
[Foster et al., NIPS’17] run multiple learning rates in parallel & aggregate, works inBanach spaces
[Cutkosky&Orabona, COLT’18] coin-betting for Banach spaces
[Foster et al., COLT’18] parameter-free in Banach spaces, not data-dependent
Also, Learning with Experts algorithms: NormalHedge [Chaudhuri et al. NIPS’09],AdaNormalHedge [Luo&Schapire, NIPS’14, COLT’15], Squint [Koolen&Erven, COLT’15],etc.
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Parameter-free Optimization
[McMahan&Streeter, NIPS’12][McMahan&Abernethy, NIPS’13] suboptimal bound,1D
[Orabona, NIPS’13] suboptimal bound, Hilbert spaces
[McMahan&Orabona, COLT’14] optimal bound, Hilbert space
[Orabona, NIPS’14] data-dependent bound, analysis in RKHS, algorithm in VW
[Cutkosky&Boahen, NIPS’16, COLT’17] unbounded gradients
[van Erven&Koolen, NIPS’16] run multiple learning rates in parallel & aggregate
[Orabona&Pal, NIPS’16] coin-betting view
[Orabona&Tommasi, NIPS’17] coin-betting for deep learning
[Kotlowski, ALT’17] scale-free bound
[Foster et al., NIPS’17] run multiple learning rates in parallel & aggregate, works inBanach spaces
[Cutkosky&Orabona, COLT’18] coin-betting for Banach spaces
[Foster et al., COLT’18] parameter-free in Banach spaces, not data-dependent
Also, Learning with Experts algorithms: NormalHedge [Chaudhuri et al. NIPS’09],AdaNormalHedge [Luo&Schapire, NIPS’14, COLT’15], Squint [Koolen&Erven, COLT’15],etc.
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Outline
1 Optimization of Non-smooth Convex Functions
2 Coin BettingBetting on a CoinFrom Betting to OptimizationCOCOB
3 Experiments
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Betting on a Coin
Start with $1Bet wt money on head (wt > 0) or tails (wt < 0)
Cannot borrow money
Win or lose depending on the outcome of the coingt ∈ {−1, 1}Wealtht = Wealtht−1 + wtgt
Aim: Maximize gain on all sequences where the number of tails and head aredifferent
Francesco Orabona Parameter-free Machine Learning through Coin Betting
Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
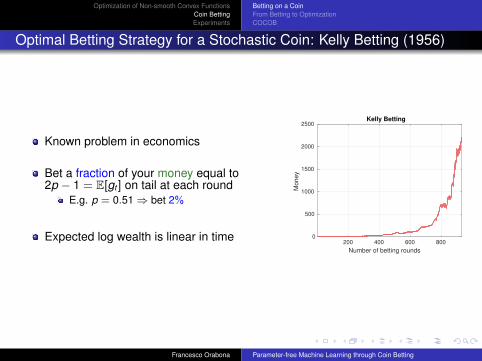
Optimal Betting Strategy for a Stochastic Coin: Kelly Betting (1956)
Known problem in economics
Bet a fraction of your money equal to2p − 1 = E[gt ] on tail at each round
E.g. p = 0.51⇒ bet 2%
Expected log wealth is linear in time200 400 600 800
Number of betting rounds
0
500
1000
1500
2000
2500
Mo
ne
y
Kelly Betting
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Non-Stochastic setting, but Knowing the Future
Non-stochastic setting, T rounds
Assume to bet a fixed fraction of money at each round
What is the optimal fraction?
The optimal signed fraction at each time step t is∑T
i=1 giT
Hence you bet∑T
i=1 giT ·Wealtht−1
Winnings are exponential
Winnings > exp
((∑T
t=1 gt)2
2T
)
[McMahan&Abernethy, NIPS’13; Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Non-Stochastic setting, but Knowing the Future
Non-stochastic setting, T rounds
Assume to bet a fixed fraction of money at each round
What is the optimal fraction?
The optimal signed fraction at each time step t is∑T
i=1 giT
Hence you bet∑T
i=1 giT ·Wealtht−1
Winnings are exponential
Winnings > exp
((∑T
t=1 gt)2
2T
)
[McMahan&Abernethy, NIPS’13; Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Worst case Optimal Betting Strategy: Krichevsky-Trofimov Bettor
What if we don’t know the future?
Estimate probability of head with Krichevsky-Trofimov (KT) estimator:12 +# of heads in t rounds
t+1
No stochastic assumptions: KT has optimal regret w.r.t. the log loss
Hence, on round t bet a fraction of your money equal to |∑t−1
i=1 gi |t , on the
side that appeared more often
Still exponential
Winnings of KT Bettor ≥ Winnings knowing the future2√
T
Not the only possible strategy, but the simplest one
Coin betting is solvable with a parameter-free optimal strategy, but what is theconnection with SGD?
[Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Worst case Optimal Betting Strategy: Krichevsky-Trofimov Bettor
What if we don’t know the future?Estimate probability of head with Krichevsky-Trofimov (KT) estimator:12 +# of heads in t rounds
t+1
No stochastic assumptions: KT has optimal regret w.r.t. the log loss
Hence, on round t bet a fraction of your money equal to |∑t−1
i=1 gi |t , on the
side that appeared more often
Still exponential
Winnings of KT Bettor ≥ Winnings knowing the future2√
T
Not the only possible strategy, but the simplest one
Coin betting is solvable with a parameter-free optimal strategy, but what is theconnection with SGD?
[Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Worst case Optimal Betting Strategy: Krichevsky-Trofimov Bettor
What if we don’t know the future?Estimate probability of head with Krichevsky-Trofimov (KT) estimator:12 +# of heads in t rounds
t+1
No stochastic assumptions: KT has optimal regret w.r.t. the log loss
Hence, on round t bet a fraction of your money equal to |∑t−1
i=1 gi |t , on the
side that appeared more often
Still exponential
Winnings of KT Bettor ≥ Winnings knowing the future2√
T
Not the only possible strategy, but the simplest one
Coin betting is solvable with a parameter-free optimal strategy, but what is theconnection with SGD?
[Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Worst case Optimal Betting Strategy: Krichevsky-Trofimov Bettor
What if we don’t know the future?Estimate probability of head with Krichevsky-Trofimov (KT) estimator:12 +# of heads in t rounds
t+1
No stochastic assumptions: KT has optimal regret w.r.t. the log loss
Hence, on round t bet a fraction of your money equal to |∑t−1
i=1 gi |t , on the
side that appeared more often
Still exponential
Winnings of KT Bettor ≥ Winnings knowing the future2√
T
Not the only possible strategy, but the simplest one
Coin betting is solvable with a parameter-free optimal strategy, but what is theconnection with SGD?
[Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Worst case Optimal Betting Strategy: Krichevsky-Trofimov Bettor
What if we don’t know the future?Estimate probability of head with Krichevsky-Trofimov (KT) estimator:12 +# of heads in t rounds
t+1
No stochastic assumptions: KT has optimal regret w.r.t. the log loss
Hence, on round t bet a fraction of your money equal to |∑t−1
i=1 gi |t , on the
side that appeared more often
Still exponential
Winnings of KT Bettor ≥ Winnings knowing the future2√
T
Not the only possible strategy, but the simplest one
Coin betting is solvable with a parameter-free optimal strategy, but what is theconnection with SGD?
[Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Worst case Optimal Betting Strategy: Krichevsky-Trofimov Bettor
What if we don’t know the future?Estimate probability of head with Krichevsky-Trofimov (KT) estimator:12 +# of heads in t rounds
t+1
No stochastic assumptions: KT has optimal regret w.r.t. the log loss
Hence, on round t bet a fraction of your money equal to |∑t−1
i=1 gi |t , on the
side that appeared more often
Still exponential
Winnings of KT Bettor ≥ Winnings knowing the future2√
T
Not the only possible strategy, but the simplest one
Coin betting is solvable with a parameter-free optimal strategy, but what is theconnection with SGD?
[Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
1D Optimization through Betting
Assume that there exists a function H(·) such that our betting strategy willguarantee that the wealth after T rounds will be at least H(
∑Tt=1 gt) for any
arbitrary sequence g1, · · · , gT
For KT H(∑T
t=1 gt ) = C exp((∑T
t=1 gt )2/T )/
√T )
We want to minimize F (w) = |w − 10|Let’s set a betting game: bet wt dollars on gt = −∂F (wt) ∈ {−1,+1}Claim: the average of the bets will converge to the minimum of F (w) at arate that depends on how good is our betting strategy!
F
(1T
T∑t=1
wt
)− F (w∗)
Jensen≤ 1
T
T∑t=1
F (wt)− F (w∗)Convexity≤ 1
T
(T∑
t=1
gtw∗ −T∑
t=1
gtwt
)Def. H≤ 1
T
(T∑
t=1
gtw∗ − H
(T∑
t=1
gt
))Max≤ 1
T maxv
vw∗ − H(v) Def H∗= H∗(w∗)
T
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
1D Optimization through Betting
Assume that there exists a function H(·) such that our betting strategy willguarantee that the wealth after T rounds will be at least H(
∑Tt=1 gt) for any
arbitrary sequence g1, · · · , gT
For KT H(∑T
t=1 gt ) = C exp((∑T
t=1 gt )2/T )/
√T )
We want to minimize F (w) = |w − 10|Let’s set a betting game: bet wt dollars on gt = −∂F (wt) ∈ {−1,+1}Claim: the average of the bets will converge to the minimum of F (w) at arate that depends on how good is our betting strategy!
F
(1T
T∑t=1
wt
)− F (w∗)
Jensen≤ 1
T
T∑t=1
F (wt)− F (w∗)Convexity≤ 1
T
(T∑
t=1
gtw∗ −T∑
t=1
gtwt
)Def. H≤ 1
T
(T∑
t=1
gtw∗ − H
(T∑
t=1
gt
))Max≤ 1
T maxv
vw∗ − H(v) Def H∗= H∗(w∗)
T
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
1D Optimization through Betting
Assume that there exists a function H(·) such that our betting strategy willguarantee that the wealth after T rounds will be at least H(
∑Tt=1 gt) for any
arbitrary sequence g1, · · · , gT
For KT H(∑T
t=1 gt ) = C exp((∑T
t=1 gt )2/T )/
√T )
We want to minimize F (w) = |w − 10|
Let’s set a betting game: bet wt dollars on gt = −∂F (wt) ∈ {−1,+1}Claim: the average of the bets will converge to the minimum of F (w) at arate that depends on how good is our betting strategy!
F
(1T
T∑t=1
wt
)− F (w∗)
Jensen≤ 1
T
T∑t=1
F (wt)− F (w∗)Convexity≤ 1
T
(T∑
t=1
gtw∗ −T∑
t=1
gtwt
)Def. H≤ 1
T
(T∑
t=1
gtw∗ − H
(T∑
t=1
gt
))Max≤ 1
T maxv
vw∗ − H(v) Def H∗= H∗(w∗)
T
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
1D Optimization through Betting
Assume that there exists a function H(·) such that our betting strategy willguarantee that the wealth after T rounds will be at least H(
∑Tt=1 gt) for any
arbitrary sequence g1, · · · , gT
For KT H(∑T
t=1 gt ) = C exp((∑T
t=1 gt )2/T )/
√T )
We want to minimize F (w) = |w − 10|Let’s set a betting game: bet wt dollars on gt = −∂F (wt) ∈ {−1,+1}
Claim: the average of the bets will converge to the minimum of F (w) at arate that depends on how good is our betting strategy!
F
(1T
T∑t=1
wt
)− F (w∗)
Jensen≤ 1
T
T∑t=1
F (wt)− F (w∗)Convexity≤ 1
T
(T∑
t=1
gtw∗ −T∑
t=1
gtwt
)Def. H≤ 1
T
(T∑
t=1
gtw∗ − H
(T∑
t=1
gt
))Max≤ 1
T maxv
vw∗ − H(v) Def H∗= H∗(w∗)
T
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
1D Optimization through Betting
Assume that there exists a function H(·) such that our betting strategy willguarantee that the wealth after T rounds will be at least H(
∑Tt=1 gt) for any
arbitrary sequence g1, · · · , gT
For KT H(∑T
t=1 gt ) = C exp((∑T
t=1 gt )2/T )/
√T )
We want to minimize F (w) = |w − 10|Let’s set a betting game: bet wt dollars on gt = −∂F (wt) ∈ {−1,+1}Claim: the average of the bets will converge to the minimum of F (w) at arate that depends on how good is our betting strategy!
F
(1T
T∑t=1
wt
)− F (w∗)
Jensen≤ 1
T
T∑t=1
F (wt)− F (w∗)Convexity≤ 1
T
(T∑
t=1
gtw∗ −T∑
t=1
gtwt
)Def. H≤ 1
T
(T∑
t=1
gtw∗ − H
(T∑
t=1
gt
))Max≤ 1
T maxv
vw∗ − H(v) Def H∗= H∗(w∗)
T
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
1D Optimization through Betting
Assume that there exists a function H(·) such that our betting strategy willguarantee that the wealth after T rounds will be at least H(
∑Tt=1 gt) for any
arbitrary sequence g1, · · · , gT
For KT H(∑T
t=1 gt ) = C exp((∑T
t=1 gt )2/T )/
√T )
We want to minimize F (w) = |w − 10|Let’s set a betting game: bet wt dollars on gt = −∂F (wt) ∈ {−1,+1}Claim: the average of the bets will converge to the minimum of F (w) at arate that depends on how good is our betting strategy!
F
(1T
T∑t=1
wt
)− F (w∗)
Jensen≤ 1
T
T∑t=1
F (wt)− F (w∗)
Convexity≤ 1
T
(T∑
t=1
gtw∗ −T∑
t=1
gtwt
)Def. H≤ 1
T
(T∑
t=1
gtw∗ − H
(T∑
t=1
gt
))Max≤ 1
T maxv
vw∗ − H(v) Def H∗= H∗(w∗)
T
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
1D Optimization through Betting
Assume that there exists a function H(·) such that our betting strategy willguarantee that the wealth after T rounds will be at least H(
∑Tt=1 gt) for any
arbitrary sequence g1, · · · , gT
For KT H(∑T
t=1 gt ) = C exp((∑T
t=1 gt )2/T )/
√T )
We want to minimize F (w) = |w − 10|Let’s set a betting game: bet wt dollars on gt = −∂F (wt) ∈ {−1,+1}Claim: the average of the bets will converge to the minimum of F (w) at arate that depends on how good is our betting strategy!
F
(1T
T∑t=1
wt
)− F (w∗)
Jensen≤ 1
T
T∑t=1
F (wt)− F (w∗)Convexity≤ 1
T
(T∑
t=1
gtw∗ −T∑
t=1
gtwt
)
Def. H≤ 1
T
(T∑
t=1
gtw∗ − H
(T∑
t=1
gt
))Max≤ 1
T maxv
vw∗ − H(v) Def H∗= H∗(w∗)
T
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
1D Optimization through Betting
Assume that there exists a function H(·) such that our betting strategy willguarantee that the wealth after T rounds will be at least H(
∑Tt=1 gt) for any
arbitrary sequence g1, · · · , gT
For KT H(∑T
t=1 gt ) = C exp((∑T
t=1 gt )2/T )/
√T )
We want to minimize F (w) = |w − 10|Let’s set a betting game: bet wt dollars on gt = −∂F (wt) ∈ {−1,+1}Claim: the average of the bets will converge to the minimum of F (w) at arate that depends on how good is our betting strategy!
F
(1T
T∑t=1
wt
)− F (w∗)
Jensen≤ 1
T
T∑t=1
F (wt)− F (w∗)Convexity≤ 1
T
(T∑
t=1
gtw∗ −T∑
t=1
gtwt
)Def. H≤ 1
T
(T∑
t=1
gtw∗ − H
(T∑
t=1
gt
))
Max≤ 1
T maxv
vw∗ − H(v) Def H∗= H∗(w∗)
T
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
1D Optimization through Betting
Assume that there exists a function H(·) such that our betting strategy willguarantee that the wealth after T rounds will be at least H(
∑Tt=1 gt) for any
arbitrary sequence g1, · · · , gT
For KT H(∑T
t=1 gt ) = C exp((∑T
t=1 gt )2/T )/
√T )
We want to minimize F (w) = |w − 10|Let’s set a betting game: bet wt dollars on gt = −∂F (wt) ∈ {−1,+1}Claim: the average of the bets will converge to the minimum of F (w) at arate that depends on how good is our betting strategy!
F
(1T
T∑t=1
wt
)− F (w∗)
Jensen≤ 1
T
T∑t=1
F (wt)− F (w∗)Convexity≤ 1
T
(T∑
t=1
gtw∗ −T∑
t=1
gtwt
)Def. H≤ 1
T
(T∑
t=1
gtw∗ − H
(T∑
t=1
gt
))Max≤ 1
T maxv
vw∗ − H(v)
Def H∗= H∗(w∗)
T
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
1D Optimization through Betting
Assume that there exists a function H(·) such that our betting strategy willguarantee that the wealth after T rounds will be at least H(
∑Tt=1 gt) for any
arbitrary sequence g1, · · · , gT
For KT H(∑T
t=1 gt ) = C exp((∑T
t=1 gt )2/T )/
√T )
We want to minimize F (w) = |w − 10|Let’s set a betting game: bet wt dollars on gt = −∂F (wt) ∈ {−1,+1}Claim: the average of the bets will converge to the minimum of F (w) at arate that depends on how good is our betting strategy!
F
(1T
T∑t=1
wt
)− F (w∗)
Jensen≤ 1
T
T∑t=1
F (wt)− F (w∗)Convexity≤ 1
T
(T∑
t=1
gtw∗ −T∑
t=1
gtwt
)Def. H≤ 1
T
(T∑
t=1
gtw∗ − H
(T∑
t=1
gt
))Max≤ 1
T maxv
vw∗ − H(v) Def H∗= H∗(w∗)
T
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
KT as an Optimization Algorithm
Assume ∂F (wt) ∈ {−1,+1}
wt =−
∑t−1i=1 ∂F (wi )
t Wealtht−1 =−
∑t−1i=1 ∂F (wi )
t (1−∑t−1
i=1 ∂F (wi) · wi)
Theorem (Informal)
KT betting in 1-d guarantees
F
(1T
T∑t=1
wt
)− F (w∗) ≤ C
|w∗|√
log(T )√T
[Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
KT as an Optimization Algorithm
Assume the function 1-Lipschitz
w t =−
∑t−1i=1 ∂F (w i )
t Wealtht−1 =−
∑t−1i=1 ∂F (w i )
t (1−∑t−1
i=1 〈∂F (w i),w i〉)
Theorem (Informal)
KT betting in Hilbert spaces guarantees
F
(1T
T∑t=1
w t
)− F (w∗) ≤ C
‖w∗‖√
log(T )√T
Proof idea:
“Worst” direction for gradient at time t is parallel to∑t−1
i=1 g i
“Worst” gradient have ‖gt‖ = 1
[Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
KT as an Optimization Algorithm
Assume the function 1-Lipschitz
w t =−
∑t−1i=1 ∂F (w i )
t Wealtht−1 =−
∑t−1i=1 ∂F (w i )
t (1−∑t−1
i=1 〈∂F (w i),w i〉)
Theorem (Informal)
KT betting in Hilbert spaces guarantees
F
(1T
T∑t=1
w t
)− F (w∗) ≤ min
ηC
(‖w∗‖2
η+ η)√
log(T )√
T
Compare it to Gradient Descent guarantee with learning rate η√t
F
(1T
T∑t=1
w t
)− F (w∗) ≤ C′
‖w∗‖2
η+ η
√T
[Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
KT as an Optimization Algorithm
Assume the function 1-Lipschitz
w t =−
∑t−1i=1 ∂F (w i )
t Wealtht−1 =−
∑t−1i=1 ∂F (w i )
t (1−∑t−1
i=1 〈∂F (w i),w i〉)
Theorem (Informal)
KT betting in Hilbert spaces guarantees
F
(1T
T∑t=1
w t
)− F (w∗) ≤ min
ηC
(‖w∗‖2
η+ η)√
log(T )√
T
Compare it to Gradient Descent guarantee with learning rate η√t
F
(1T
T∑t=1
w t
)− F (w∗) ≤ C′
‖w∗‖2
η+ η
√T
[Orabona&Pal, NIPS’16]
Francesco Orabona Parameter-free Machine Learning through Coin Betting
Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
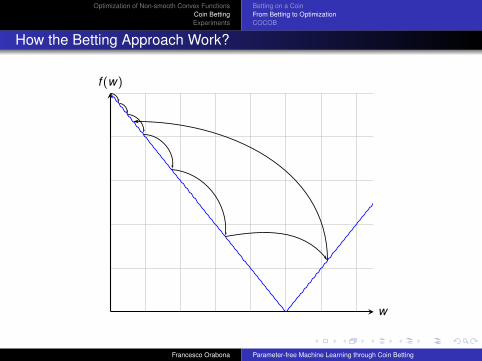
How the Betting Approach Work?
w
f (w)
Francesco Orabona Parameter-free Machine Learning through Coin Betting
Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
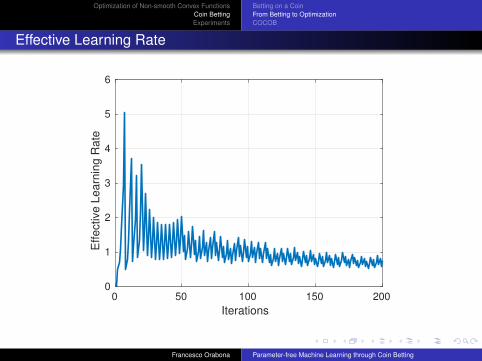
Effective Learning Rate
0 50 100 150 200
Iterations
0
1
2
3
4
5
6
Eff
ective
Le
arn
ing
Ra
te
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Improving KT: Continuous Coin Betting (COCOB)
We want per-coordinate learning rates
One coin for each coordinate
We want faster convergence with sparse gradients
KT strategy: w t =−
∑t−1i=1 ∂F (w i )
t Wealtht−1
COCOB strategy: w t = σ
(−
∑t−1i=1 ∂F (w i )
L(L+∑t−1
i=1 |∂F (w i )|)
)Wealtht−1
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Improving KT: Continuous Coin Betting (COCOB)
We want per-coordinate learning ratesOne coin for each coordinate
We want faster convergence with sparse gradients
KT strategy: w t =−
∑t−1i=1 ∂F (w i )
t Wealtht−1
COCOB strategy: w t = σ
(−
∑t−1i=1 ∂F (w i )
L(L+∑t−1
i=1 |∂F (w i )|)
)Wealtht−1
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Improving KT: Continuous Coin Betting (COCOB)
We want per-coordinate learning ratesOne coin for each coordinate
We want faster convergence with sparse gradients
KT strategy: w t =−
∑t−1i=1 ∂F (w i )
t Wealtht−1
COCOB strategy: w t = σ
(−
∑t−1i=1 ∂F (w i )
L(L+∑t−1
i=1 |∂F (w i )|)
)Wealtht−1
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
Improving KT: Continuous Coin Betting (COCOB)
We want per-coordinate learning ratesOne coin for each coordinate
We want faster convergence with sparse gradients
KT strategy: w t =−
∑t−1i=1 ∂F (w i )
t Wealtht−1
COCOB strategy: w t = σ
(−
∑t−1i=1 ∂F (w i )
L(L+∑t−1
i=1 |∂F (w i )|)
)Wealtht−1
Francesco Orabona Parameter-free Machine Learning through Coin Betting
Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
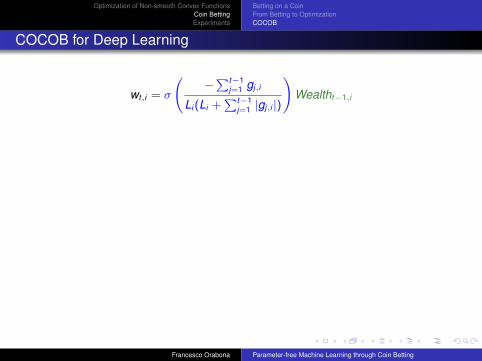
COCOB for Deep Learning
wt,i = σ
(−∑t−1
j=1 gj,i
Li(Li +∑t−1
j=1 |gj,i |)
)Wealtht−1,i
Estimate Li over time
Assures that the Wealth remains positive
Remove the sigmoid
Make sure first steps are small
Lt,i = max(Lt−1,i , |gt,i |)Wealtht−1,i = min(Wealtht−1,i , Lt,i)
wt,i =−∑t−1
j=1 gj,i
Lt,i max(Lt,i +∑t−1
j=1 |gj,i |, 100Lt,i)Wealtht−1,i
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
COCOB for Deep Learning
wt,i = σ
(−∑t−1
j=1 gj,i
Li(Li +∑t−1
j=1 |gj,i |)
)Wealtht−1,i
Estimate Li over time
Assures that the Wealth remains positive
Remove the sigmoid
Make sure first steps are small
Lt,i = max(Lt−1,i , |gt,i |)Wealtht−1,i = min(Wealtht−1,i , Lt,i)
wt,i =−∑t−1
j=1 gj,i
Lt,i max(Lt,i +∑t−1
j=1 |gj,i |, 100Lt,i)Wealtht−1,i
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
COCOB for Deep Learning
wt,i = σ
(−∑t−1
j=1 gj,i
Li(Li +∑t−1
j=1 |gj,i |)
)Wealtht−1,i
Estimate Li over time
Assures that the Wealth remains positive
Remove the sigmoid
Make sure first steps are small
Lt,i = max(Lt−1,i , |gt,i |)Wealtht−1,i = min(Wealtht−1,i , Lt,i)
wt,i =−∑t−1
j=1 gj,i
Lt,i max(Lt,i +∑t−1
j=1 |gj,i |, 100Lt,i)Wealtht−1,i
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
COCOB-Backprop: Coin-betting for Deep Learning
Require: w1 ∈ Rd (initial weights)Initialize: L0,i ← 0, G0,i ← 0, Reward0,i ← 0, θ0,i ← 0, i = 1, · · · , drepeat
Get a stochastic subgradient gtfor each i-th weight in the network do
Rewardt,i ← max(Rewardt−1,i − (wt,i − w1,i )gt,i , 0)Lt,i ← max(Lt−1,i , |gt,i |)Gt,i ← Gt−1,i + |gt,i |θt,i ← θt−1,i + gt,i
wt+1,i ← w1,i −θt,i
Lt,i max(Gt,i+Lt,i ,100Lt,i )
(Lt,i + Rewardt,i
)end for
until Stopping condition is met
Theorem (Informal)
Up to√
log T terms, the performance guarantee is the same one obtained byAdaGrad tuning the learning rate for each single weight.
[Tommasi&Orabona, NIPS’17; Cutkosky&Orabona, COLT’18]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Betting on a CoinFrom Betting to OptimizationCOCOB
And More!
All the results presented holds in the strict more difficult setting ofadversarial online learning
Learning in RKHS without regularization nor learning rates [Orabona,NIPS’14]
Learning With Expert Advice [Orabona&Pal, NIPS’16]
Sleeping Experts [Jun et al., AISTATS’17]
Online Learning with changing environments [Jun et al., AISTATS’17]
Coin-betting in Banach spaces, i.e. any norm [Cutkosky&Orabona,COLT’18]
Adaptation to the curvature: faster rates for strongly convex functions[Cutkosky&Orabona, COLT’18]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Outline
1 Optimization of Non-smooth Convex Functions
2 Coin BettingBetting on a CoinFrom Betting to OptimizationCOCOB
3 Experiments
Francesco Orabona Parameter-free Machine Learning through Coin Betting
Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
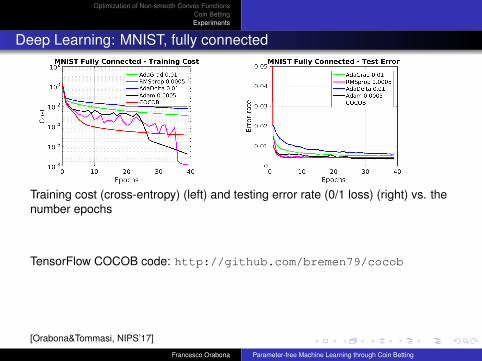
Deep Learning: MNIST, fully connected
Training cost (cross-entropy) (left) and testing error rate (0/1 loss) (right) vs. thenumber epochs
TensorFlow COCOB code: http://github.com/bremen79/cocob
[Orabona&Tommasi, NIPS’17]
Francesco Orabona Parameter-free Machine Learning through Coin Betting
Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
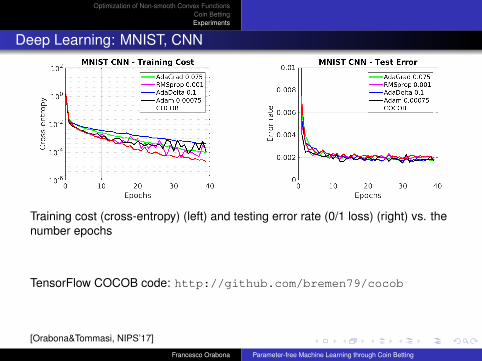
Deep Learning: MNIST, CNN
Training cost (cross-entropy) (left) and testing error rate (0/1 loss) (right) vs. thenumber epochs
TensorFlow COCOB code: http://github.com/bremen79/cocob
[Orabona&Tommasi, NIPS’17]
Francesco Orabona Parameter-free Machine Learning through Coin Betting
Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
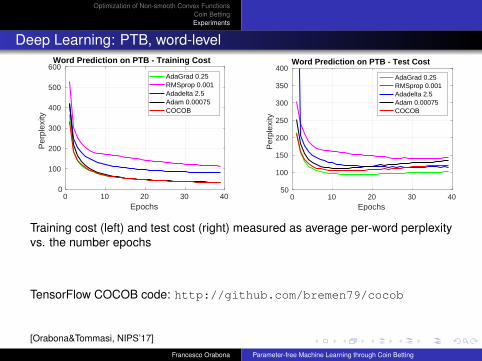
Deep Learning: PTB, word-level
0 10 20 30 40Epochs
0
100
200
300
400
500
600
Per
plex
ity
Word Prediction on PTB - Training Cost
AdaGrad 0.25RMSprop 0.001Adadelta 2.5Adam 0.00075COCOB
0 10 20 30 40Epochs
50
100
150
200
250
300
350
400
Per
plex
ity
Word Prediction on PTB - Test Cost
AdaGrad 0.25RMSprop 0.001Adadelta 2.5Adam 0.00075COCOB
Training cost (left) and test cost (right) measured as average per-word perplexityvs. the number epochs
TensorFlow COCOB code: http://github.com/bremen79/cocob
[Orabona&Tommasi, NIPS’17]
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Conclusions
Learning rates in SGD for quasi-convex Lipschitz functions areunnecessary
SGD, Learning with Experts, SVMs, etc. can be reduced to betting on acoin
Betting algorithms are easy to design, parameter-free, and (most of thetime) optimal
Future Work:
Beyond quasi-convex functions: convergence to critical point
Coin betting and Newton algorithms?
Francesco Orabona Parameter-free Machine Learning through Coin Betting

Optimization of Non-smooth Convex FunctionsCoin BettingExperiments
Thanks for your attention
http://francesco.orabona.com
Thanks to my collaborators: Ashok Cutkosky, Kwang-Sung Jun, David Pal,Brendan McMahan, Tatiana Tommasi, Rebecca Willett, Stephen Wright
Thanks to the support of Google and NSF
Francesco Orabona Parameter-free Machine Learning through Coin Betting





























