Embed Size (px)
Citation preview

Parallelization of Irregular Applications:
Hypergraph-based Models and Methods for
Partitioning and Load Balancing
Cevdet Aykanat
Bilkent University
Computer Engineering Department

2
P1
10 13 5 1 6 14 11 3 2 15 7 9 8 16 4
10 13 5 1 6 14 11 3 2 15 7 9 8 16 4
13
6
11
3
2
16
12
4
10
5
1
14
15
7
98
13
6
11
3
2
16
12
4
10
5
1
14
15
7
98
12
12
P4
P3
P2
“Partitioning” of irregular computations
• Partitioning of computation into smaller works
• Divide the work and data for efficient parallel computation
(applicable for data-parallelism)

Partitioning of irregular computations“Good Partitioning”
• Low computational imbalance
(computational load balancing)
• Low communication overhead
– Total message volume
– Total message count (latency)
– Maximum message volume and count per processor
(Communication load minimization and balancing)
3

4
Why graph models are not sufficient?
• Existing Graph Models– Standard graph model– Bipartite graph model– Multi-constraint / multi-objective graph partitioning– Skewed partitioning
• Flaws– Wrong cost metric for communication volume– Latency: number of messages also important– Minimize the maximum volume and/or message count
• Limitations– Standard Graph Model can only express symmetric dependencies– Symmetric = identical partitioning of input and output data– Multiple computation phases

5
Preliminaries: Graph Partitioning
P1 P2
v5
v3
1vv2 v6
v8 v9
v10v7
v4
3
5
3
3
2
3
3 3
34
1
1
2
1
1 2
11
2
2
2
1
1
1
2
1
• Partitioning constraint: maintaining balance on part weights
• Partitioning objective: minimizing cutsize

6
Preliminaries: Hypergraph Partitioning
18
17
16
15
14
13
12
11
10 91
8
7
6
5
4
3
215
14
13
1211
10
9
8
7
6
5
4
2
3
1
V1 V2
V3
• Partitioning constraint: maintaining balance on part weights
• Partitioning objective: minimizing cutsize

7
Irregular Computations – an example: Parallel Sparse Matrix Vector Multiply (y=Ax)
• Abounds in scientific computing– A concrete example is iterative methods
• SpMxV is applied repeatedly• efficient parallelization: load balance and small communication
cost
• Characterizes a wide range of applications with irregular computational dependency
• A fine-grain computation– guaranteeing efficiency will guarantee higher efficiency in
applications with coarser-grain computations

8
Sparse-matrix partitioning taxonomy for parallel y=Ax

9
Row-parallel y=Ax• Rows (and hence y) and x is partitioned
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
123456789
10111213141516
y4
y3
y2
y1P1
P2
P3
P4
x1 x2 x3 x4
P1 P2 P3 P4
1. Expand x vector (sends/receives)
2. Compute with diagonal blocks
3. Receive x and compute with off-diagonal blocks

10
Row-parallel y=Ax
Communication requirements
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
123456789
10111213141516
y4
y3
y2
y1P1
P2
P3
P4
x1 x2 x3 x4
P1 P2 P3 P4
Total message volume:#nonzero column segments in off diagonal blocks (13)
Total message number :#nonzero off diagonal blocks (9)
Per processor: above two metrics confined within a column stripe
We minimize total volume and number of messages and obtain balance on per processor basis

11
Column-parallel y=Ax• Columns (and hence x) and y is partitioned
1. Compute with off diagonal blocks; obtain partial y results, issue sends/receives
2. Compute with diagonal block
3. Receive partial results on y for nonzero off-diagonal blocks and add the partial results
y3
y2
y1 P1
P2
P3
P4
x1 x2 x3
P1 P2 P3 P4
10
123456789
1011121314151617181920212223242526
1 2 3 4 5 6 7 8 9 11
12
13
14
15
16
y4
x4

12
Row-column-parallel y=Ax• Matrix nonzeros, x, and y are partitioned
1. Expand x vector
2. Scalar multiply and add yi aijxj aikxk
3. Fold on y vector
(send and receive partial results)
1 2 3 4 5 6 7 8 9 10
1
2
3
4
5
6
7
8
9
10
1 1 1 1
11
1
1
1
2
2
2
22
2
2
2
2
2
3
44 4
4 4
4
4
4
4
3
3
3
3
33 3
3
P1 P1 P4 P4P1 P4 P3 P2P2 P3
P4
P4
P1
P1
P3
P3
P2
P2
P4
P2 Send partial y9
Send x5
and x7

13
Hypergraph Models for y = Ax

14
Hypergraph Model for row-parallel y = Ax 1D Rowwise Partitioning: Column-net Model
• Columns are nets; rows are vertices: Connect vi to nj if aij is nonzero
• Assign yi using vi, xj using nj (permutation policy)
• Respects row coherence, disturbs column coherence
• Symmetric partitioning: aii should be nonzero
• Partitioning constraint: computational load balancing
• Partitioning objective: minimizing total communication volume
• Comm. vol. = 2(x5)+2(x12)+1(x7)+1(x11) = 6 words

15
• Dual of column-net model: rows are nets; columns are vertices• Assign xj using vj, yi using ni (permutation policy)• Symmetric partitioning: nonzero diagonal entries• Respects column coherence, disturbs row coherence• Partitioning constraint: computational load balancing• Partitioning objective: minimizing total communication volume • Comm. vol. = 2(y5)+2(y12)+1(y6)+1(y10) = 6 words
1234 56 8 9101112 1314 1516
1
2
34
5
6
7
8
9
10
11
12
13
14
15
16
7
P1 P2 P3 P4 v16
v7
v4
v12
n16
n7
n4
v14
v11
v3v6
n14n11
n3
v10
v2 v8
v15
n15n8
n2
n10
n12
n6
n5
v13
v5
v1
v9
n13
n9n1
P1
P3
P2
P4
Hypergraph Model for column-parallel y = Ax 1D Columnwise Partitioning: Row-net Model

16
Hypergraph Model for row-column-parallel y = Ax: 2D Fine-Grain Partitioning: Row-column-net Model
• MN matrix A with nnz nonzeros: M row nets,
N column nets
nnz vertices.
• Vertex aij is connected to
nets ri and cj
1 2 3 4 5 6 7 8 9 10
1
2
3
4
5
6
7
8
9
10
1 1 1 1
11
1
1
1
2
2
2
22
2
2
2
2
2
3
44 4
4 4
4
4
4
4
3
3
3
3
33 3
3
a32r3 c2

17
2D Fine-Grain Partitioning
• One vertex for each nonzero
• Disturbs both row and column coherence
• Partitioning constraint: computational load balancing
• Partitioning objective: minimizing total communication volume
• Symmetric partitioning: nonzero diagonal entries
r5
r9
c1
c2
c3
c4
c5
c6
c7
c8
c9
c10
r1
r2
r3
r6
r8
r10
r4
r7
a15
a17
a19
a29
a31 a32
a33
a35
a41
a42
a43
a46
a47
a49
a51
a54
a56
a65
a66
a68
a72
a74
a77
a82
a92
a93
a95
a96
a97
a1010
a810
a101
a108
a104
a210
a110
a710
P1P2
P3P4
con-1 =2
con-1=1

18
Hypergraph Methods for y = Ax

19
Hypergraph Methods for y = Ax
2D Jagged 2D Checkerboard
• √K–by–√K virtual processor mesh
• 2-phase method: Each phase models either expand or fold communication
• Column-net and Row-net models are used

20
HP Methods for y = Ax: 2D Jagged Partitioning
• Phase 1: √K-way rowwise partitioning using column-net model
• Respects row coherence at processor-row level

21
• Phase 2: √K independent √K-way columnwise partitionings using row-net model
• Symmetric partitioning
• Column coherence for cols 2 and 5 are disturbed => P3 sends messages to both P1 and P2
HP Methods for y = Ax: 2D Jagged Partitioning

22
• Row coherence => fold comms confined to procs in the same row => max mssg count per proccessor = √K-1 in fold phase
• No column coherence => max mssg count per proc = K - √K in expand phase
HP Methods for y = Ax: 2D Jagged Partitioning

23
HP Methods for y = Ax: 2D Checkerboard Partitioning
• Phase 1: √K-way rowwise partitioning using column-net model
• Respects row coherence at processor-row level
• Same as phase 1 of jagged partitioning

24
• Phase 2: One √K-way √K-constraint columnwise partitioning using row-net model
• Respects column coherence at processor column level
• Symmetric partitioning
HP Methods for y = Ax: 2D Checkerboard Partitioning

25
• Row coherence => fold comms confined to procs in the same row => max mssg count per proccessor = √K-1 in fold phase
• Column coherence => expand comms confined to procs in the same column => max mssg count per proccessor = √K-1 in fold phase
HP Methods for y = Ax: 2D Checkerboard Partitioning

26
• Respects either row or column coherence at proc level• Single communication phase (either expand or fold)• Max mssg count per processor = K – 1 • Fast partitioning time• Determining the partitioning dimension
– Dense columns => rowwise partitioning– Dense rows => columnwise partitioning– Partition both rowwise and columnwise and choose the best
Comparison of Partitioning Schemes:1D Partitioning

27
• Do not respect row or column coherencies at processor level• Two communication phases (both expand and fold) • Better in load balancing• 2D Fine Grain:
– Disturbs both row and column coherencies at processor-row and processor-col level– Significant reductions in total volume wrt 1D and other 2D partitionings – Worse in total number of messages– Slow partitioning time
• 2D Checkerboard– Respect both row and column coherencies at processor-row and processor-col level– Restricts max mssg count per processor to 2(√K –1)– Good for architectures with high mssg latency – As fast as 1D partitioning schemes
• 2D Jagged:– Respect either row or column coherencies at processor-row or processor-col level– Restricts max mssg count per processor to K – 2√K –1 – Better communication volume and load balance wrt checkerboard– As fast as 1D partitioning schemes
Comparison of Partitioning Schemes:2D Partitioning

28
2-Phase Approach for Minimizing Multiple
Communication Hypergraph ModelCommunication-Cost Metrics:
• Communication Cost Metrics-- Total message volume
-- Total message count
-- Maximum message volume and count per processor
• 2-Phase Approach: 1D unsymmetric partitioning
-- Phase 1: Rowwise (colwise) partitioning using col-net (row-net) model
– minimize total mssg volume
– maintain computational load balance
-- Phase 2: Refine rowwise (colwise) partition using communication hypergraph model– encapsulate the remaining communication-cost metrics
– try to attain total mssg volume bound obtained in Phase 1

29
• Construct communication matrix Cx– Perform rowwise compression
• Compress row stripe Rk of A into a single row rk of Cx – Sparsity pattern of rk = Union of sparsity patterns of all rows in Rk
– Discard internal columns of Rk
– Nonzeros in rk: Subset of x-vector entries needed by processor Pk.– Nonzeros in column cj: The set of processors that need xj
• Construct row-net model H of comm matrix Cx
– Vertices (columns of Cx) represent expand communication tasks
– Nets (rows of Cx) represent processors – Partitioning constraint: balancing send volume loads of processors– Partitioning objective: minimizing total number of messages
Communication Hypergraph Model:Phase 2 for 1D rowwise partitioning

30
Communication Hypergraph Model
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
123456789
10111213141516
y4
y3
y2
y1P1
P2
P3
P4
x1 x2 x3 x4
P1 P2 P3 P4
Rowwise partition obtained in phase one Communication matrix
Communication hypergraphColwise permutation induced by comm HP

31
• Communication Cost Metrics– Total message volume and count
– Maximum message volume and count per processor
• Balancing on external nets of parts => minimizing max mssg count per processors
Communication hypergraph model showing incoming and outgoing messages of processor Pk
Communication Hypergraph Model

32
• Construct communication matrix Cy– Perform columnwise compression
• Compress kth column stripe of A into a single column ck of Cy – Sparsity pattern of ck = Union of sparsity patterns of all columns in kth
column stripe
– Discard internal rows of kth column stripe
– Nonzeros in ck: Subset of y-vector entries needed by processor Pk.– Nonzeros in row rj: The set of processors that need yj
• Construct column-net model of comm matrix Cy– Vertices (rows of Cy) represent fold communication tasks
– Nets (cols of Cy) represent processors – Partitioning constraint: balancing send volume loads of processors– Partitioning objective: minimizing total number of messages
Communication Hypergraph Model:Phase 2 for 1D columnwise partitioning

33
Communication Hypergraph ModelColwise partition obtained in Phase-1 Communication matrix Communication hypergraph
Colwise permutation induced by comm HP

34
Communication Hypergraph Modelfor 2D Fine-Grain Partitioning
• Phase 1: Obtain a fine-grain partition on nonzero elements• Phase 2: Obtain 2 communication matrices:
– Cx: rowwise compression– Cy: columnwise compression
• Phase 2: Construct two communication hypergraphs– Hx: column-net model of Cx– Hy: row-net model of Cy
• Phase 2 for unsymmetric partitioning– Partition Hx and Hy independently– Partitioning constraints: balancing expand and fold volume loads of
processors– Partitioning objectives: minimizing total number of messages in the expand
and fold phases

35
Communication Matrix Cx
Communication Matrix Cy
Rowwise compression
Columnwise compression
Fine-grain partitioned matrix obtained in Phase-1 Cx represents
which processor needs which x vector entry
Cy represents which processor contributes to which y entry
Communication Hypergraph Modelfor 2D Fine-Grain Partitioning

36
Phase-2 for unsymmetric partitioning
• Partition communication hypergraphs Hx and Hy
5
n1
n2 n3n410
8
21
7
P1P4
P3
P25
m1
m2
m3
m4
7 9
4P4
P1
P3
P2
Cut= 1+ 2+ 1+1= 5 Cut=5
HxHy

37
Number of messages regarding x
1 2 3 4 5 6 7 8 9 10
1
2
3
4
5
6
7
8
9
10
1 1 1 1
11
1
1
1
2
2
2
22
2
2
2
2
2
3
44 4
4 4
4
4
4
4
3
3
3
3
33 3
3
P1 P1 P4 P4P1 P4 P3 P2P2 P3
P4
P4
P1
P1
P3
P3
P2
P2
P4
P2
P1 P2
x1 and x2
P4 P1
x5
P4 P3
x5 and x7
P3 P2
x8
P2 P4
x10

38
Number of messages regarding y
1 2 3 4 5 6 7 8 9 10
1
2
3
4
5
6
7
8
9
10
1 1 1 1
11
1
1
1
2
2
2
22
2
2
2
2
2
3
44 4
4 4
4
4
4
4
3
3
3
3
33 3
3
P1 P1 P4 P4P1 P4 P3 P2P2 P3
P4
P4
P1
P1
P3
P3
P2
P2
P4
P2
P1 P4
partial y4
P3 P4
P2 P3
P4 P2
P3 P1
partial y4
partial y5
partial y7
partial y9

39
Communication Hypergraph Modelfor 2D Fine-Grain Partitioning
• Phase-2 for symmetric partitioning– Combine two hypergraphs Hx and Hy into a new one H by merging
corresponding vertices
– Both net nk and mk represent processor k
• Cut net nk : processor k sending message(s) in expand phase
• Cut net mk : processor k receiving message(s) in fold phase
– Fix both net nk and mk to part Vk
• H contains K fixed vertices
– Partition augmented hypergraph H• partitioning objective: minimizing total number of messages
• 2 partitioning constraints: balancing expand and fold volume loads of processors

40
Phase 2 for symmetric partitioning
• Partition augmented hypergraph H.
A portion of augmented hypergraph H
• Vertex v4 does not exist in Hx whereas it exists in Hy.
– All nonzeros of column 4 were assigned to processor 2 in fine-grain partitioning.
• Vertex v7 exists in both Hx and Hy.

41
SpMxV Context: Iterative Methods
• Used for solving linear systems Axb– Usually A is sparse
• Involves– Linear vector operations
• x = xy xi = xi yi
– Inner products = x,y = sum of xi yi
– Sparse matrix-vector multiplies (SpMxV)• y = Ax yi = Ai,x
• y = ATx yi = ATi,x
– Assuming 1D rowwise partitioning of A
while not converged do computations check convergence

42
Parallelizing Iterative Methods
• Avoid communicating vector entries for linear vector operations and inner products
• Nothing to do for inner products– Regular communication – Low communication volume
• partial sum values communicated
• Efficiently parallelize the SpMxV operations – in the light of previous discussion, are we done?– Preconditioning?

43
Preconditioning
• Iterative methods may converge slowly, or diverge
• Transform Axb to another system that is easier to solve
• Preconditioner is a matrix that helps in obtaining desired transformation

44
Preconditioning
• We consider parallelization of iterative methods that use approximate inverse preconditioners
• Approximate inverse is a matrix M such that AMI
• Instead of solving Axb, use right preconditioning and solve
AMyb and then set
x = My• Preconditioning cliché: “Preconditioning is art rather
than science”

45
Preconditioned Iterative Methods• Additional SpMxV operations with M
– never form matrix AM; perform successive SpMxVs
• Parallelizing a full step in these methods requires efficient SpMxV operations with A and M– partition A and M
• What have been done– a bipartite graph model with limited usage
• A blend of dependencies and interactions among matrices and vectors– partition A and M simultaneously

46
Preconditioned Iterative Methods
• Partition A and M simultaneously
• Figure out partitioning requirements through analyzing linear vector operations and inner products
– Reminder: never communicate vector entries for these operations
• Different methods have different partitioning requirements

47
Preconditioned BiCG-STAB
tsr
spxx
ttst
sAt
Mss
vrs
pAv
Mpp
vprp
ii
ii
iii
i
ii
i
i
i
ii
ii
ii
1
1
11
11
1
,,
ˆ
ˆ
ˆ
ˆ
p, r, v should be partitioned conformably
s should be with r and v
t should be with s
x should be with p and s

48
Preconditioned BiCG-STAB p, r, v, s, t, and, x should be partitioned conformably
• What remains?
sAt
Mss
pAv
Mppi
i
ˆ
ˆ
ˆ
ˆ
Columns of M and rows of A should be conformal
should be conformal
p
s
Rows of M and columns of A should be conformal
PAQT QMPT

49
Partitioning Requirements
• “and” means there is a synchronization
point between successive SpMxV’s– Load balance each SpMxV individually
BiCG-STAB PAQTQMPTPAMPT
TFQMR PAPT and PM1M2PT
GMRES PAPT and PMPT
CGNE PAQ and PMPT

50
Model for simultaneous partitioning
• We use the previously proposed models– define operators to build composite models
ci(A)
ri(M)
ri(A)
| ri(A) |
ci(M)
| ci(M) |

51
Combining Hypergraph Models× Net amalgamation:
× newer combine nets of individual hypergraphs
• Vertex amalgamation: – combine vertices of individual hypergraphs, and connect the
composite vertex to the nets of the individual vertices
• Vertex weighting: – define multiple weights; individual vertex weights are not added up
• Vertex insertion: – create a new vertex, di, to be connected to nets ni of individual
hypergraphs
• Pin addition: – connect a specific vertex to a net

52
Combining Guideline
1. Determine partitioning requirements
1. Decide on partitioning dimension for each matrix
• generate column-net model for the matrices to be partitioned rowwise
• generate row-net model for the matrices to be partitioned columnwise

53
Combining Guideline1. Apply vertex operations
i. to impose identical partition on two vertices amalgamate them
ii. if the application of matrices are interleaved with synchronization apply vertex weighting
2. Apply net operationsi. if a net ought to be permuted with a specific vertex
then establish a policy for that net. If it is not connected then apply pin addition
ii. if two nets ought to be permuted together independent of the existing vertices then apply vertex insertion

54
Combining Example
• BiCG-STAB requires PAMPT
– Reminder: rows of A and columns of M;
columns of A and rows of M
• A rowwise and M columnwise
ci(A)
ri(M)
ri(A)
| ri(A) |
ci(M)
| ci(M) |
ci(A)
ri(M)
ri(A)ci(M)
| ri(A) | + | ci(M) |
1
2 3i

55
Combining Example
ci(A)
ri(M)
diri(A)ci(M)
| ri(A) | + | ci(M) |, 0
0, ?
3ii
4ii
– PAMPT: Columns of A and rows of M should be conformable
– di vertices are different

56
Remarks on composite models• Operations on hypergraphs are defined to built
composite hypergraphs• Partitioning the composite hypergraphs
– balances computational loads of processors– minimizes the total communication volume
in a full step of the preconditioned iterative methods
• Can meet a broad spectrum of partitioning requirements: multi-phase, multi-physics applications
57
Parallelization of a sample application (other than SpMxV)
A Remapping Model for Image-Space Parallel Volume Rendering
• Volume Rendering– mapping a set of scalar or vectoral values defined in a
3D dataset to a 2D image on the screen.
– Surface-based rendering– Direct volume rendering (DVR)

58
Ray-Casting-Based DVR

59
Parallel Rendering: Object-space (OS) and Image-space (IS)
Parallelization

60
Screen Partitioning• Static
simplicity good load balancing high primitive replication
• Dynamic good load balancing– overhead of broadcasting pixel assignments– high primitive replication
• Adaptive good load balancing respects image-space coherency view-dependent preprocessing overhead

61
Adaptive Parallel DVR Pipeline

62
Screen Partitioning

63
View Independent Cell Clustering
Tetrahedral dataset Graph representation

64
View Independent Cell Clustering
Resulting 6 cell clusters6-way partitioned graph

65
Pixel Clustering

66
Cons and Pros of Cell and Pixel Clustering
Reduction in the 3D-2D interaction
Less preprocessing overhead
Estimation errors in workload calculations
Increase in data replication

67
Screen Partitioning Model
A sample visualization instance 15 cell clusters and eight pixel blocks
Interaction hypergraph

68
Screen Partitioning Model
3-way partition of Interaction hypergraph
Cell cluster (net)
Pixel block (vertex)

69
Two-Phase Remapping ModelCell cluster (net)
Pixel block (vertex)

70
Two-Phase Remapping ModelWeighted bipartite graph matching

71
One-Phase Remapping ModelHypergraph Partitioning with Fixed Vertices
3-way partitioning of a remapping hypergraph
Cell cluster (net)
Pixel block (free vertex)
Processor (fixed vertex)

72
Adaptive IS-Parallel DVR Algorithm

73
Example Rendering

74
Example Screen PartitioningsJagged partitioning Hypergraph partitioning

75
Rendering Load Imbalance
76
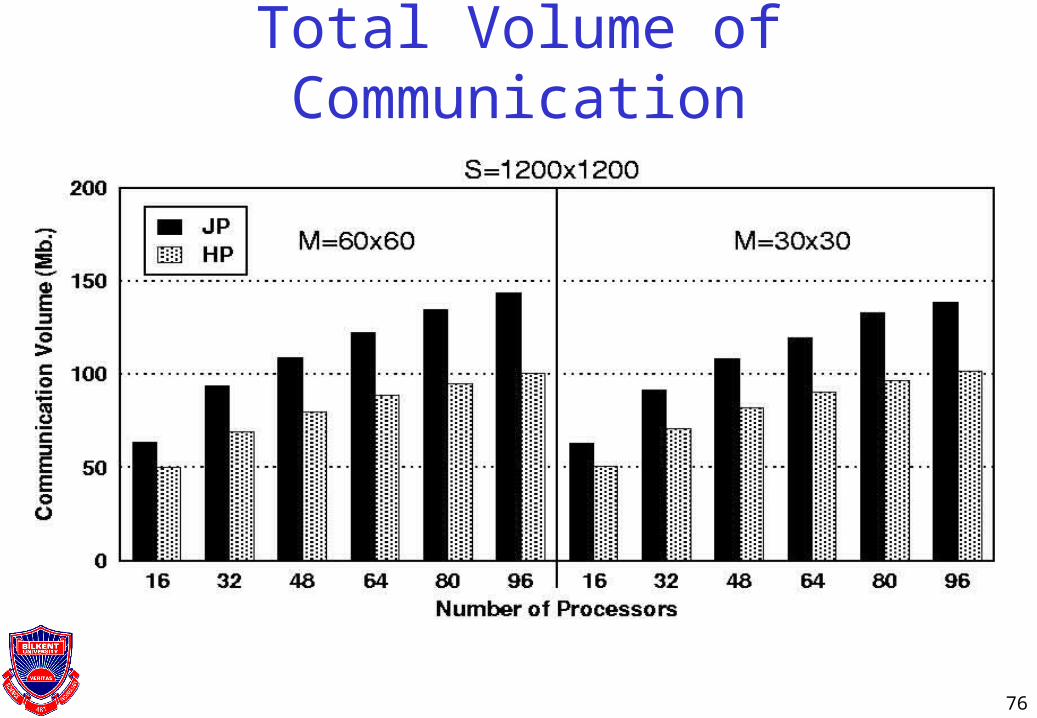
Total Volume of Communication

77
Speedups

78
Related works of our groupSparse matrix partitioning for parallel processing
• U.V. Çatalyürek, C. Aykanat, and B. Ucar, “On Two-Dimensional Sparse Matrix Partitioning: Models, Methods and a Recipe”, submitted to SIAM Journal on Scientific Computing.
• B. Ucar and C. Aykanat, “Revisiting Hypergraph Models for Sparse Matrix Partitioning,” SIAM Review, vol. 49(4), pp. 595–603, 2007.
• B. Uçar and C. Aykanat, “Partitioning Sparse Matrices for Parallel Preconditioned Iterative Methods,” SIAM Journal on Scientific Computing, vol. 29(4), pp. 1683–1709, 2007.
• B. Ucar and C. Aykanat, “Encapsulating Multiple Communication-Cost Metrics in Partitioning Sparse Rectangular Matrices for Parallel Matrix-Vector Multiplies," SIAM Journal on Scientific Computing, vol. 25(6), pp. 1837–1859, 2004.
• C. Aykanat, A. Pinar, and U.V. Catalyurek, “Permuting Sparse Rectangular Matrices into Block Diagonal Form," SIAM Journal on Scientific Computing, vol. 25(6), pp. 1860–1879, 2004.
• B.Ucar and C.Aykanat, "Minimizing Communication Cost in Fine-Grain Partitioning of Sparse Matrices,” Lecture Notes in Computer Science, vol. 2869, pp. 926–933, 2003.
• U.V. Çatalyürek and C. Aykanat, "Hypergraph-Partitioning-Based Decomposition for Parallel Sparse-Matrix Vector Multiplication," IEEE Transactions on Parallel and Distributed Systems, vol. 10, pp. 673–693, 1999.
• U.V. Catalyurek and C. Aykanat, "Decomposing Irregularly Sparse Matrices for Parallel Matrix-Vector Multiplication," Lecture Notes in Computer Science, vol. 1117, pp. 75–86, 1996.
• A. Pinar, C. Aykanat and M. Pinar, "Decomposing Linear Programs for Parallel Solution," Lecture Notes in Computer Science, vol. 1041, pp. 473–482, 1996.

79
Related works of our groupGraph and Hypergraph Models and Methods for other Parallel & Distributed Applications
• B.B. Cambazoğlu and C. Aykanat, “Hypergraph-Partioning-Based Remapping Models for Image-Space-Parallel Direct Volume Rendering of Unstructured Grids,” IEEE Transactions on Parallel and Distributed Systems, vol. 18(1), pp. 3–16, 2007.
• K. Kaya, B. Uçar and C. Aykanat, “Heuristics for Scheduling File-Sharing Tasks on Heterogeneous Systems with Distributed Repositories,” Journal of Parallel and Distributed Computing, vol. 67, pp. 271–285, 2007.
• B. Uçar, C. Aykanat, M. Pınar and T. Malas, “Parallel Image Restoration Using Surrogate Constraint Methods,” Journal of Parallel and Distributed Computing, vol. 67, pp. 186–204, 2007.
• C. Aykanat, B. B. Cambazoğlu, F. Findik, and T.M. Kurc, “Adaptive Decomposition and Remapping Algorithms for Object-Space-Parallel Direct Volume Rendering of Unstructured Grids,” Journal of Parallel and Distributed Computing, vol. 67, pp. 77–99, 2006.
• K. Kaya and C. Aykanat, “Iterative-Improvement-Based Heuristics for Adaptive Scheduling of Tasks Sharing Files on Heterogeneous Master-Slave Environments,” IEEE Transactions on Parallel and Distributed Systems, vol. 17(8), pp. 883–896, August 2006.
• B. Ucar, C. Aykanat, K. Kaya and M. İkinci, “Task Assignment in Heterogeneous Systems,” Journal of Parallel and Distributed Computing, vol. 66(1), pp. 32–46, 2006.
• M. Koyuturk and C. Aykanat, “Iterative-Improvement Based Declustering Heuristics for Multi-Disk Databases,” Information Systems, vol. 30, pp. 47–70, 2005.
• B.B. Cambazoglu, A. Turk and C. Aykanat, "Data-Parallel Web-Crawling Models,” Lecture Notes in Computer Science, vol. 3280, pp. 801–809, 2004.

80
Related works of our groupHypergraph Models and Methods for Sequential Applications
• E. Demir and C. Aykanat, “A Link-Based Storage Scheme for Efficient Aggregate Query Processing on Clustered Road Networks,” Information Systems, accepted for publication.
• E. Demir, C. Aykanat and B. B. Cambazoglu, “Clustering Spatial Networks for Aggregate Query Processing, a Hypergarph Approach,” Information Systems, vol. 33(1), pp. 1–17, 2008.
• M. Özdal and C. Aykanat, “Hypergraph Models and Algorithms for Data-Pattern Based Clustering," Data Mining and Knowledge Discovery, vol. 9, pp. 29–57, 2004.
Software Package / Tool Development
• C. Aykanat, B.B. Cambazoglu and B. Ucar, “Multi-level Direct K-way Hypergraph Partitioning with Multiple Constraints and Fixed vertices,” Journal of Parallel and Distributed Computing, vol. 68, pp 609–625, 2008.
• B. Ucar and C. Aykanat, “A Library for Parallel Sparse Matrix Vector Multiplies”, Tech. Rept. BU-CE-0506, Dept. of Computer Eng., Bilkent Univ., 2005.
• Ümit V. Çatalyürek and Cevdet Aykanat. PaToH: A multilevel hypergraph- partitioning tool, ver. 3.0.Tech. Rept. BU-CE-9915, Dept. of Computer Eng., Bilkent Univ., 1999.

81
Conclusion• Computational hypergraph models & methods for
1D & 2D sparse matrix partitioning for parallel SpMxV– All models encapsulate exact total message volume– 1D models: Good trade-off between comm overhead & partitioning time– 2D Fine-Grain: Lowest total mssg volume– 2D Jagged & Checkerboard: Restrict mssg latency
• Communication hypergraph models– Minimize mssg latency (number of messages)– Balance communication loads of processors
• Composite hypergraph models – Parallelization of preconditioned iterative methods– Partition two or more matrices together for efficient SpMxVs
• Extension and adaptation of these models & methods for the parallelization of other irregular applications
– e.g. Image-space parallelization of direct volume rendering





























