Embed Size (px)
Citation preview

PacketShader as a Future Internet Platform
AsiaFI Summer School
2011.8.11.
Sue Moon
in collaboration with:
Joongi Kim, Seonggu Huh, Sangjin Han, Keon Jang, KyoungSoo Park ‡
Advanced Networking Lab, CS, KAIST ‡ Networked and Distributed Computing Systems Lab, EE, KAIST

Network Systems
Routers are the last bastion of niche super computers Cisco CRS-1 4-slot 320Gbps chassis = $15K on ebay Cisco’s CRS-3 Multishelf System = 322Tbps =$15K x 10^3 + 𝑎
Cost = special-purpose ASIC chips + TCAMs + S/W suites
Why?
People want Huge Freaking Routers!
Why do people go for large routers? Managment O/H Routing protocol scalability
Hurdles for innovation Special-purpose ASICs, network processors Proprietary S/W (Cisco’s IOS, Juniper’s JunOS, Huawei’s ???) Cost
2

Recent Trends
New functions keep added
Firewalls / IDS / IPS
Monitoring and measurement
VPN gears
VoIP
Traffic engineering
Switches with minimum L3 functions at the network edge
3
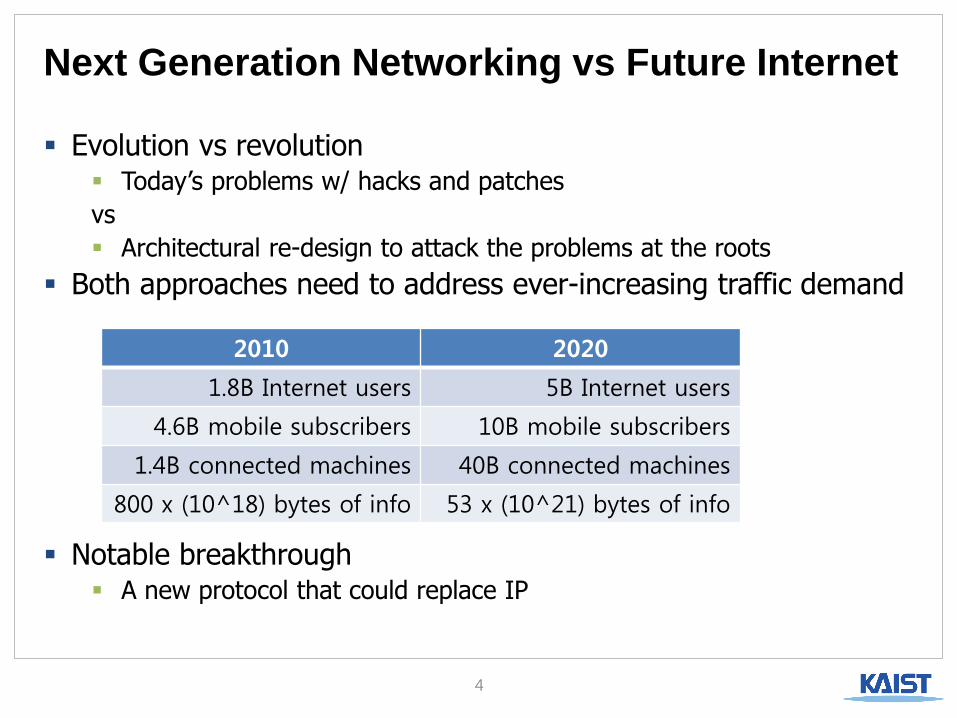
Next Generation Networking vs Future Internet
Evolution vs revolution Today’s problems w/ hacks and patches
vs
Architectural re-design to attack the problems at the roots
Both approaches need to address ever-increasing traffic demand
Notable breakthrough A new protocol that could replace IP
4
2010 2020
1.8B Internet users 5B Internet users
4.6B mobile subscribers 10B mobile subscribers
1.4B connected machines 40B connected machines
800 x (10^18) bytes of info 53 x (10^21) bytes of info

Challenges Ahead
Design and demonstrate “overarching architecture”
Routing + security + mobility
NSF Future Internet Architecture (FIA) projects
• XIA
• NDN
• Mobility First
• Nebula
NSF GENI projects
• Testbed building – Mostly OpenFlow driven
Need a platform to play with
Fast but cost-effective
Software routers!
5

Positioning of 10+ Gbps Routers
Commercial competitor?
Core routers with 100+ Tbps capacity? No.
Edge routers with 100+ Gbps capacity with complex features? Maybe
Experimental platforms?
• NetFGPA
• ServerSwitch
• RouteBricks
• ATCA-based boxes
6

7
PacketShader: A GPU-Accelerated Software Router
High-performance
Our prototype: 40 Gbps on a single box

Software Router
Despite its name, not limited to IP routing
You can implement whatever you want on it.
Driven by software
Flexible
Friendly development environments
Based on commodity hardware
Cheap
Fast evolution
8
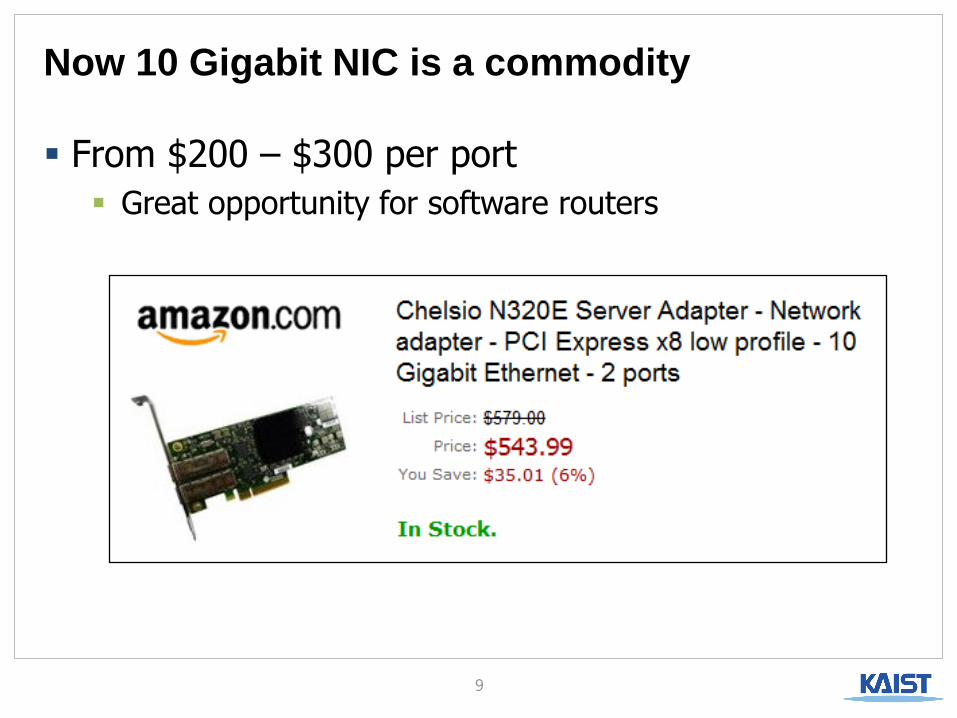
Now 10 Gigabit NIC is a commodity
From $200 – $300 per port
Great opportunity for software routers
9
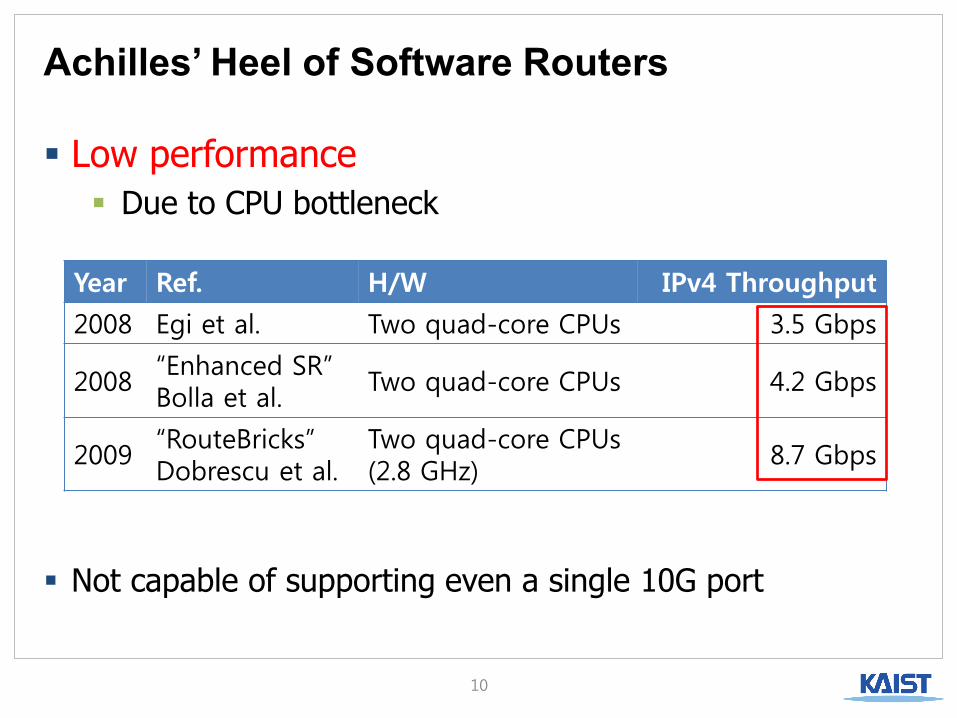
Achilles’ Heel of Software Routers
Low performance
Due to CPU bottleneck
10
Year Ref. H/W IPv4 Throughput
2008 Egi et al. Two quad-core CPUs 3.5 Gbps
2008 “Enhanced SR” Bolla et al.
Two quad-core CPUs 4.2 Gbps
2009 “RouteBricks” Dobrescu et al.
Two quad-core CPUs (2.8 GHz)
8.7 Gbps
Not capable of supporting even a single 10G port

What is PacketShader?
A high-speed software router
Presented at SIGCOMM 2010
40 Gbps on a single box
Main ideas
Optimizing packet I/O
Utilizing GPU for packet processing
Four applications
IPv4, IPv6 forwarding, OpenFlow switch, IPsec gateway
11

WHAT IS GPU?
12

GPU = Graphics Processing Unit
The heart of graphics cards
Mainly used for real-time 3D game rendering
Massively-parallel processing capacity
13
(Ubisoft’s AVARTAR, from http://ubi.com)

CPU vs. GPU
14
CPU: Small # of super-fast cores
GPU: Large # of small cores
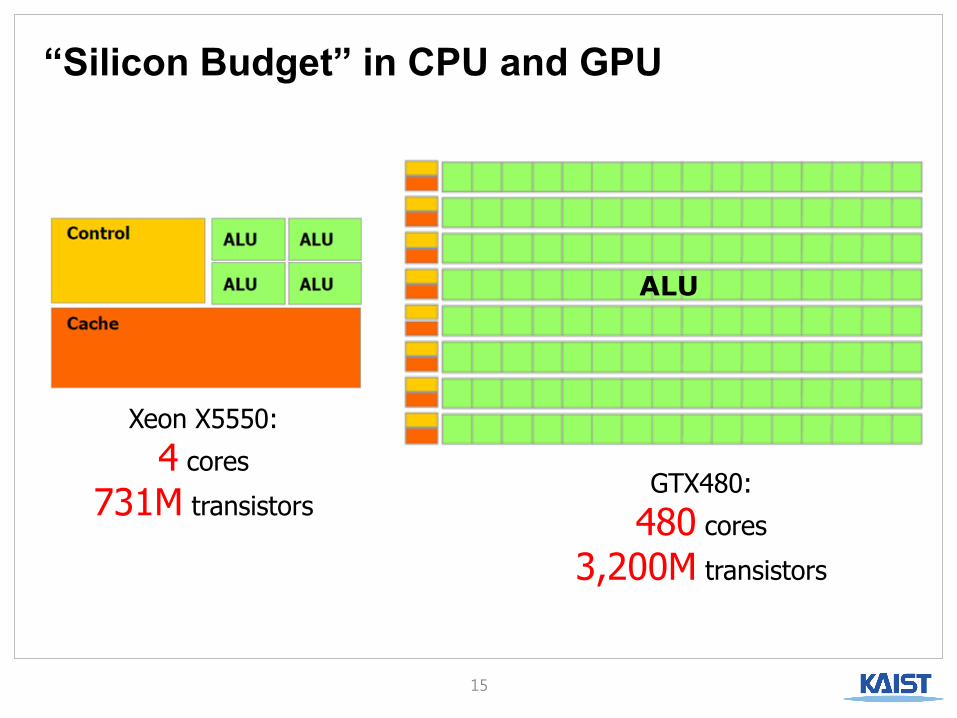
“Silicon Budget” in CPU and GPU
15
Xeon X5550:
4 cores
731M transistors GTX480:
480 cores
3,200M transistors
ALU

CPU BOTTLENECK
16

Per-Packet CPU Cycles for 10G
17
1,200 600
1,200 1,600 Cycles needed
Packet I/O IPv4 lookup
= 1,800 cycles
= 2,800
Your budget
1,400 cycles
10G, min-sized packets, dual quad-core 2.66GHz CPUs
5,400 1,200 … = 6,600
Packet I/O IPv6 lookup
Packet I/O Encryption and hashing
IPv4
IPv6
IPsec
+
+
+
(in x86, cycle numbers are from RouteBricks [Dobrescu09] and ours)
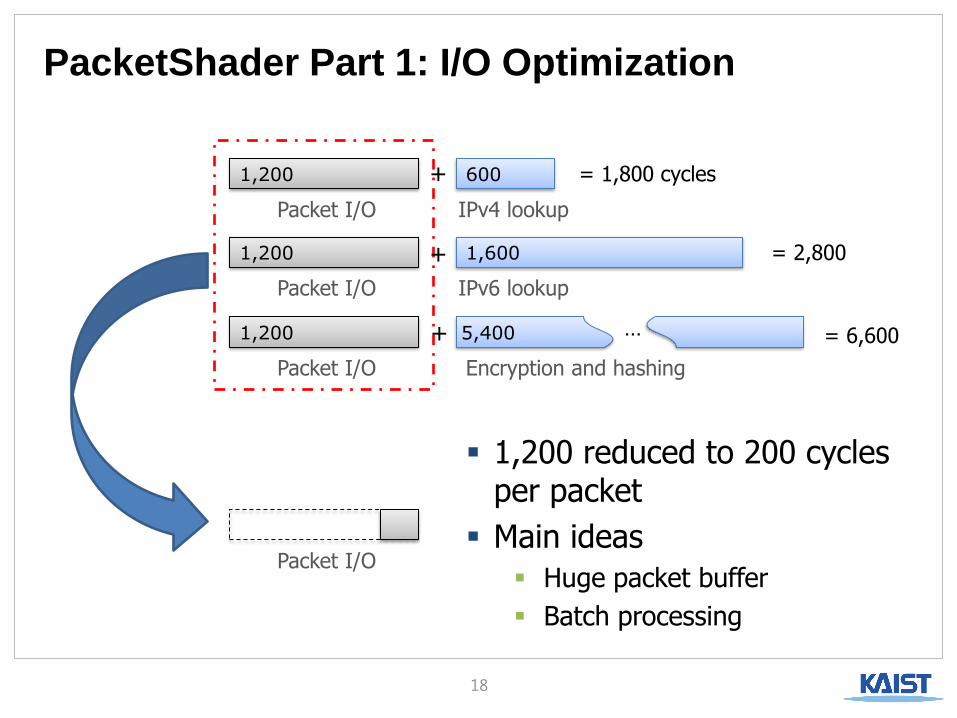
PacketShader Part 1: I/O Optimization
18
Packet I/O
Packet I/O
Packet I/O
Packet I/O
1,200 reduced to 200 cycles per packet
Main ideas
Huge packet buffer
Batch processing
600
1,600
IPv4 lookup
= 1,800 cycles
= 2,800
5,400 … = 6,600
IPv6 lookup
Encryption and hashing
+
+
+
1,200
1,200
1,200
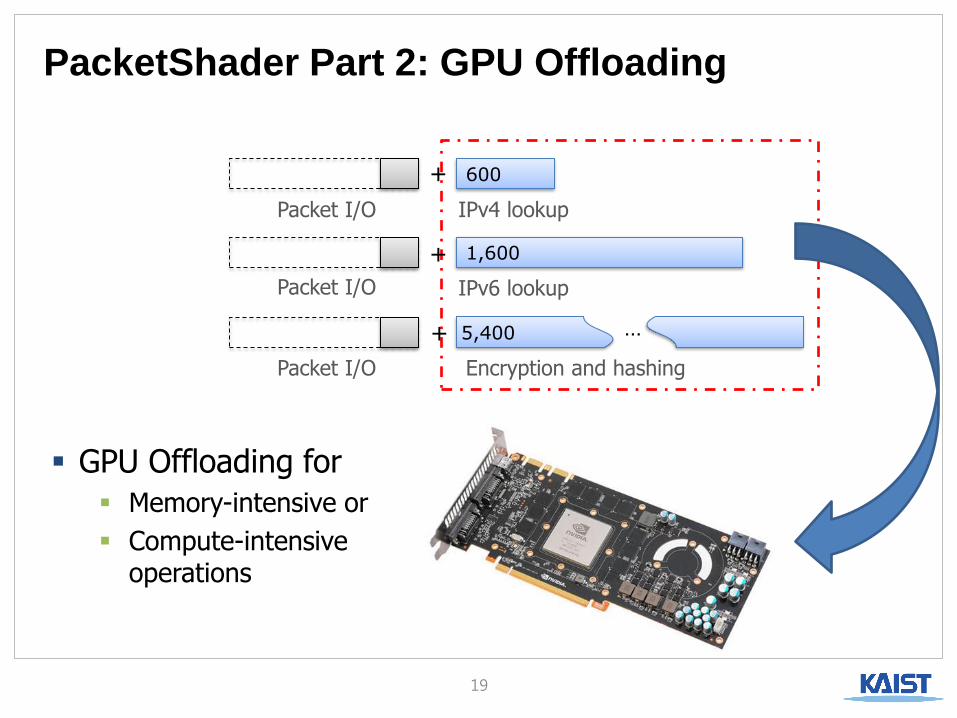
PacketShader Part 2: GPU Offloading
19
Packet I/O
Packet I/O
Packet I/O
GPU Offloading for
Memory-intensive or
Compute-intensive operations
600
1,600
IPv4 lookup
5,400 …
IPv6 lookup
Encryption and hashing
+
+
+

OPTIMIZING PACKET I/O ENGINE
20

User-space Packet Processing
Packet processing in kernel is bad
Kernel has higher scheduling priority; overloaded kernel may starve user-level processes.
Some CPU extensions such as MMX and SSE are not available.
Buggy kernel code causes irreversible damage to the system.
21
Processing in user-space is good
• Rich, friendly development and debugging environment
• Seamless integration with 3rd party libraries such as CUDA or OpenSSL
• Easy to develop virtualized data plane.
But packet processing in user-space is known to be 3x times slower!
Our solution: (1) batching + (2) better core-queue mapping

Inefficiencies of Linux Network Stack
CPU cycle breakdown in packet RX
Software prefetch
Huge packet buffer
Compact metadata
Batch processing
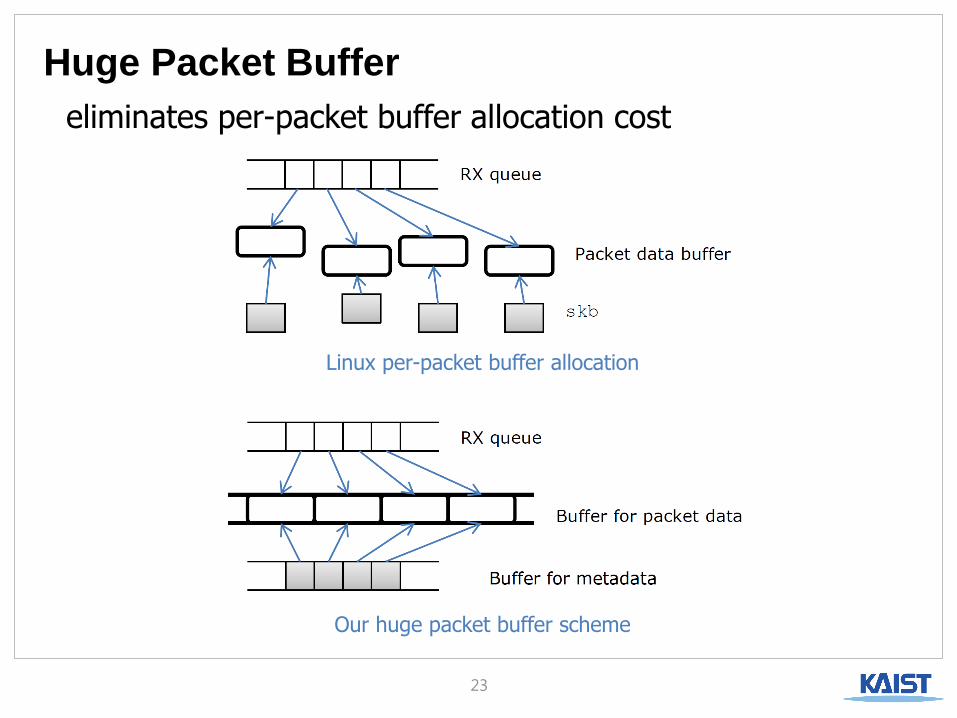
Huge Packet Buffer
23
eliminates per-packet buffer allocation cost
Linux per-packet buffer allocation
Our huge packet buffer scheme

GPU FOR PACKET PROCESSING
24

Advantages of GPU for Packet Processing
1. Raw computation power
2. Memory access latency
3. Memory bandwidth
Comparison between
Intel X5550 CPU
NVIDIA GTX480 GPU
25

(1/3) Raw Computation Power
Compute-intensive operations in software routers
Hashing, encryption, pattern matching, network coding, compression, etc.
GPU can help!
26
CPU: 43×109 = 2.66 (GHz) × 4 (# of cores) ×
4 (4-way superscalar)
GPU: 672×109 = 1.4 (GHz) ×
480 (# of cores)
Instructions/sec
<
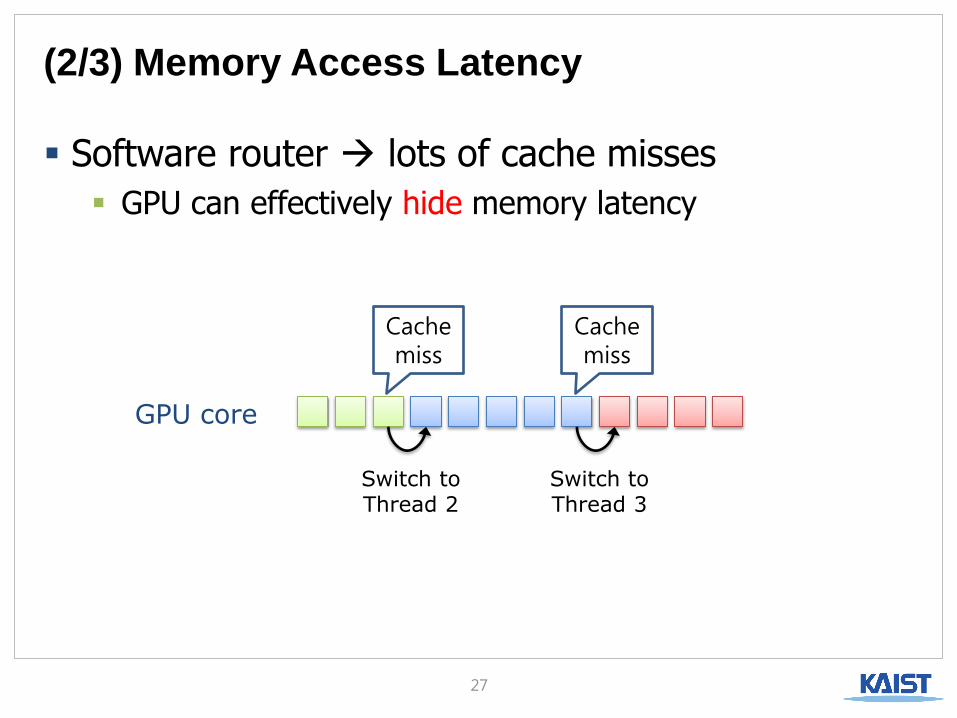
(2/3) Memory Access Latency
Software router lots of cache misses
GPU can effectively hide memory latency
27
GPU core
Cache miss
Cache miss
Switch to Thread 2
Switch to Thread 3

(3/3) Memory Bandwidth
28
CPU’s memory bandwidth (theoretical): 32 GB/s
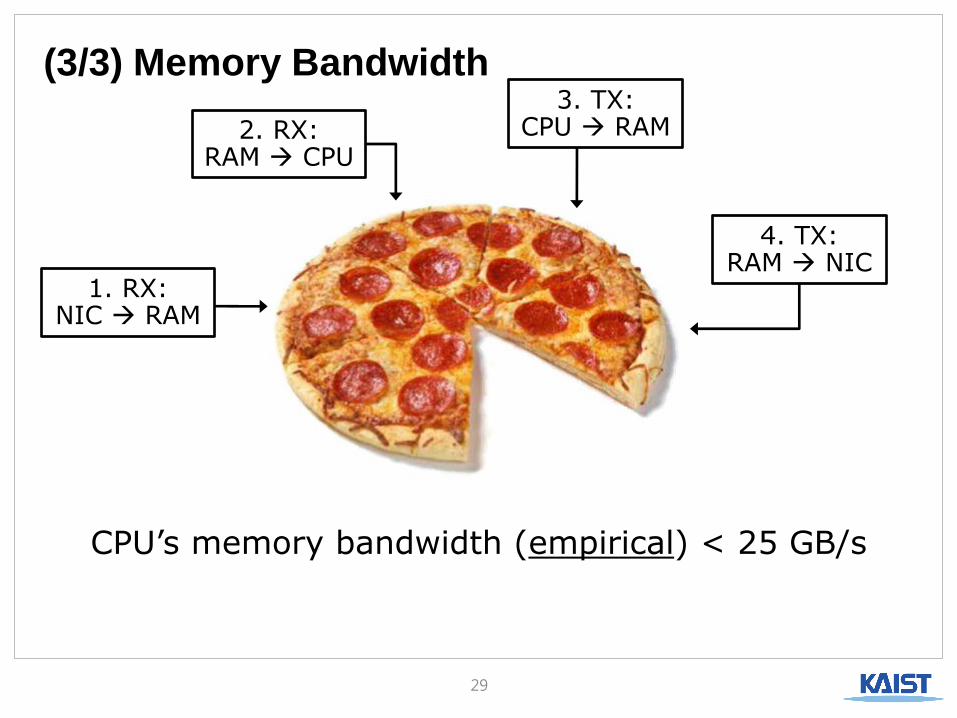
(3/3) Memory Bandwidth
29
CPU’s memory bandwidth (empirical) < 25 GB/s
4. TX: RAM NIC
3. TX: CPU RAM 2. RX:
RAM CPU
1. RX: NIC RAM

(3/3) Memory Bandwidth
30
Your budget for packet processing can be less 10 GB/s

(3/3) Memory Bandwidth
31
Your budget for packet processing can be less 10 GB/s
GPU’s memory bandwidth: 174GB/s

PACKETSHADER DESIGN
32
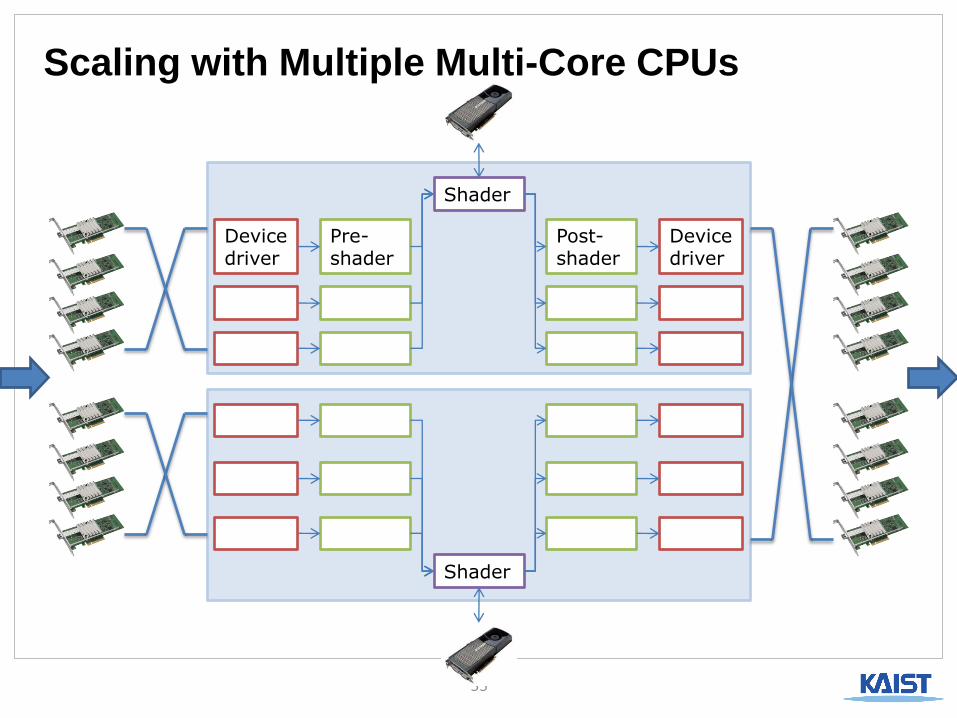
33
Device driver
Pre-shader
Shader
Post-shader
Device driver
Shader
Scaling with Multiple Multi-Core CPUs
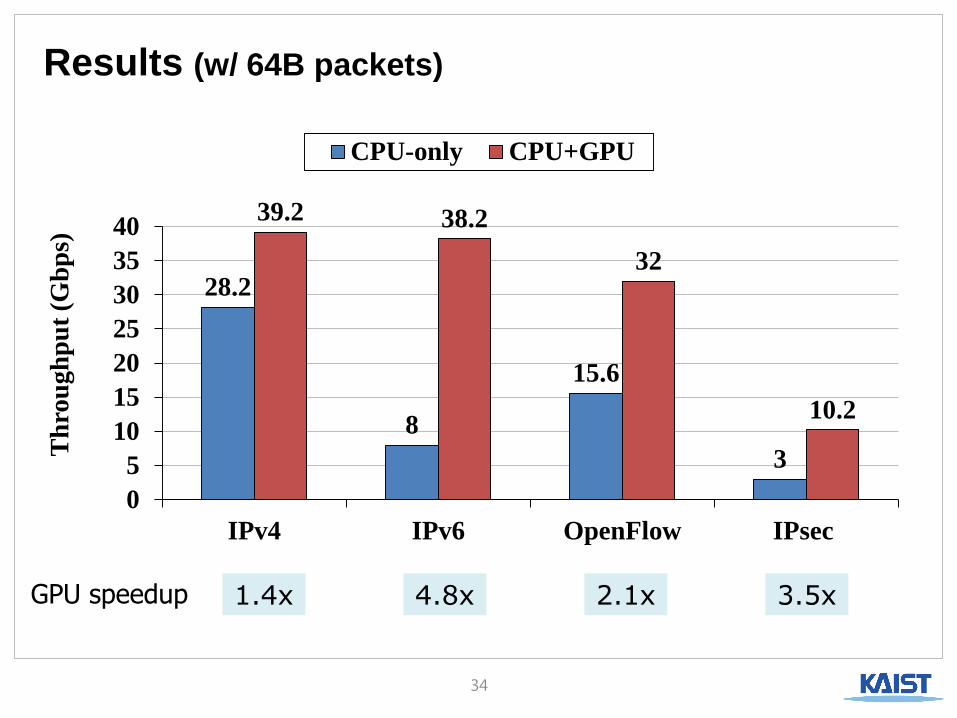
Results (w/ 64B packets)
34
28.2
8
15.6
3
39.2 38.2
32
10.2
0
5
10
15
20
25
30
35
40
IPv4 IPv6 OpenFlow IPsec
Th
rou
gh
pu
t (G
bp
s)
CPU-only CPU+GPU
1.4x 4.8x 2.1x 3.5x GPU speedup
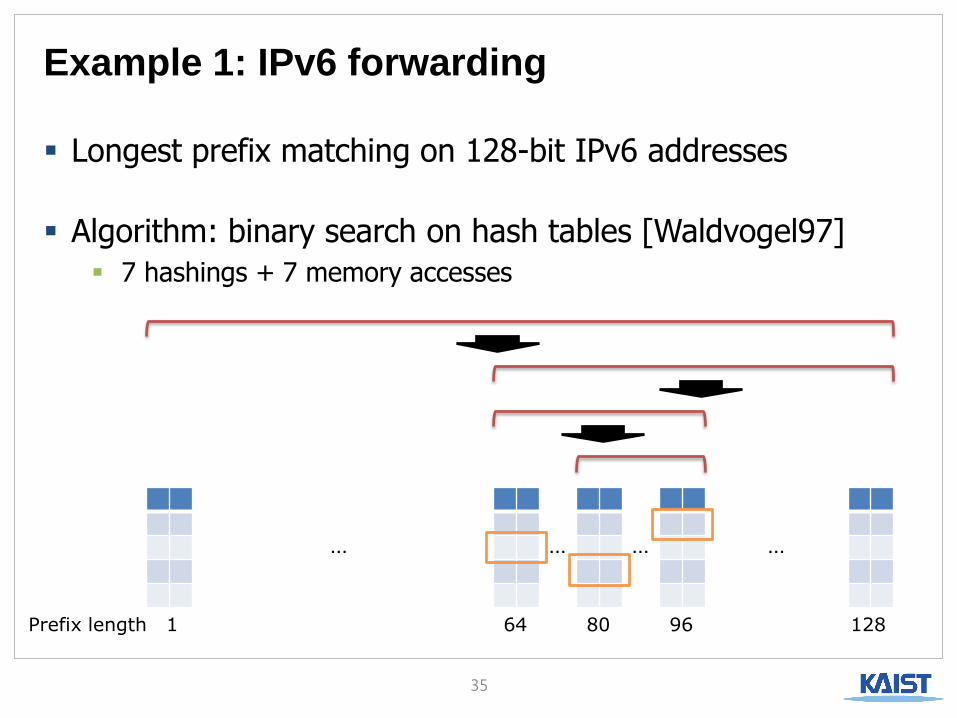
Example 1: IPv6 forwarding
Longest prefix matching on 128-bit IPv6 addresses
Algorithm: binary search on hash tables [Waldvogel97]
7 hashings + 7 memory accesses
35
… … … …
Prefix length 1 64 128 96 80
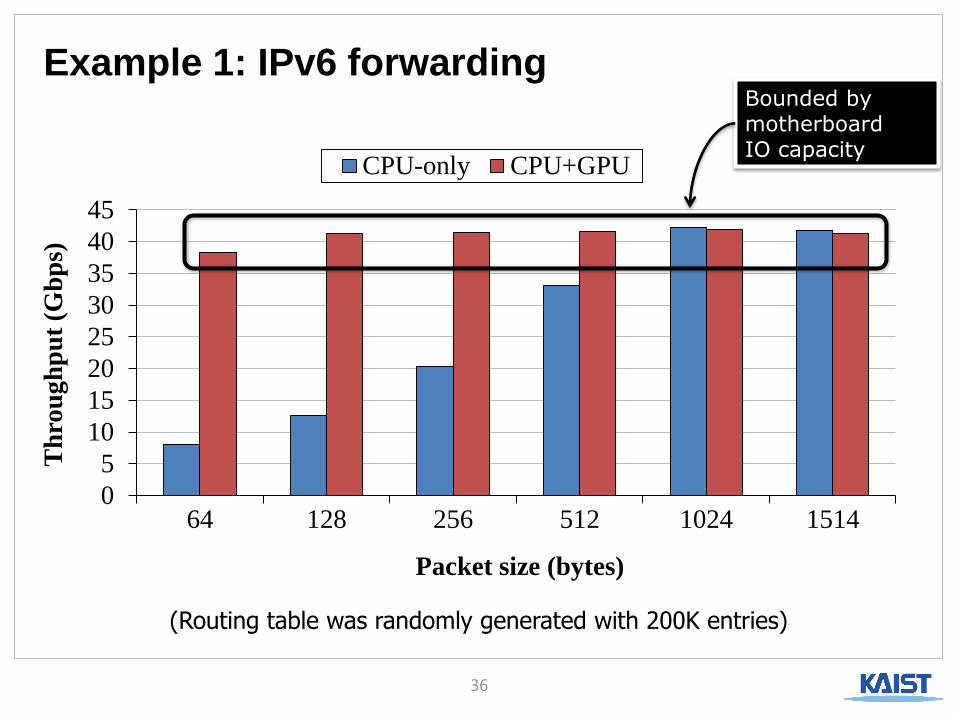
Example 1: IPv6 forwarding
(Routing table was randomly generated with 200K entries)
36
0
5
10
15
20
25
30
35
40
45
64 128 256 512 1024 1514
Th
rou
gh
pu
t (G
bp
s)
Packet size (bytes)
CPU-only CPU+GPU
Bounded by motherboard IO capacity
37
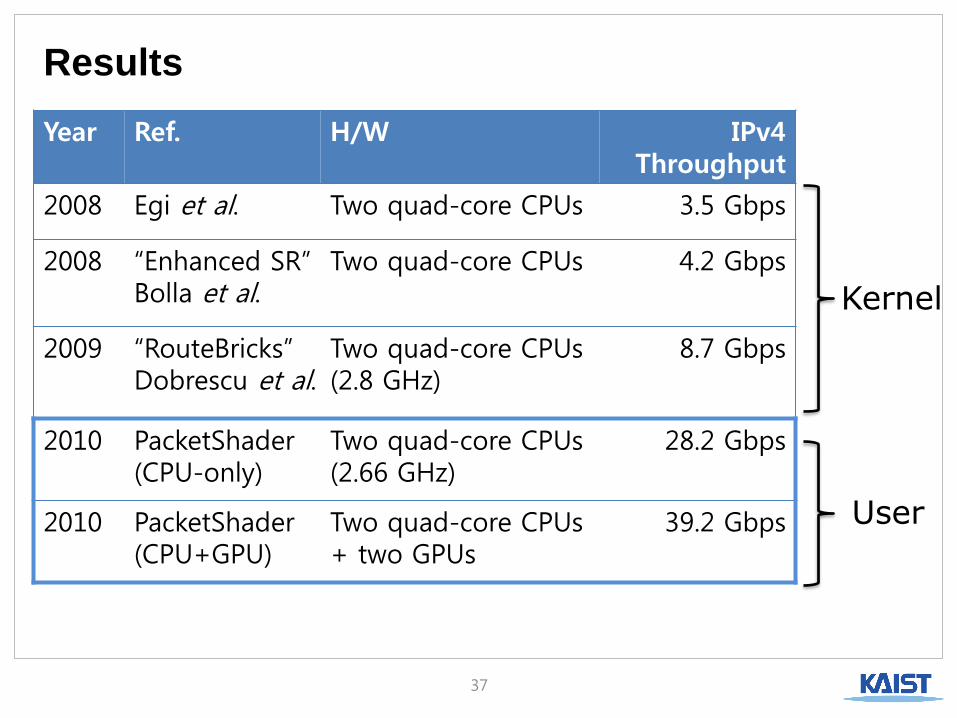
Year Ref. H/W IPv4 Throughput
2008 Egi et al. Two quad-core CPUs 3.5 Gbps
2008 “Enhanced SR” Bolla et al.
Two quad-core CPUs 4.2 Gbps
2009 “RouteBricks” Dobrescu et al.
Two quad-core CPUs (2.8 GHz)
8.7 Gbps
2010 PacketShader (CPU-only)
Two quad-core CPUs (2.66 GHz)
28.2 Gbps
2010 PacketShader (CPU+GPU)
Two quad-core CPUs + two GPUs
39.2 Gbps
Kernel
User
Results

PacketShader 1.0
GPU
a great opportunity for fast packet processing
PacketShader
Optimized packet I/O + GPU acceleration
scalable with
• # of multi-core CPUs, GPUs, and high-speed NICs
Current Prototype
Supports IPv4, IPv6, OpenFlow, and IPsec
40 Gbps performance on a single PC
38

Next Steps?
39

PacketShader 2.0
Control plane integration
Dynamic routing protocols with Quagga or XORP
Opportunistic offloading
CPU at low load
GPU at high load
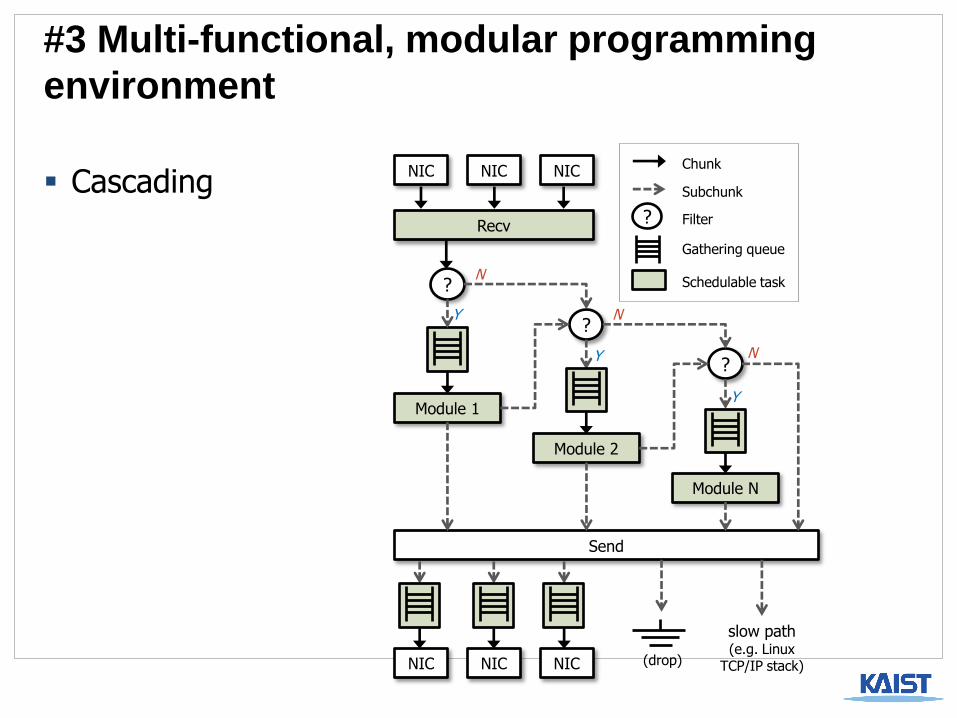
Multi-functional, modular programming environment
Integration with Click? [Kohler99]
40
#3 Multi-functional, modular programming
environment
NIC
Recv
Send
?
Module 1
?
Module 2
?
Module N
NIC NIC
NIC NIC NIC
slow path (e.g. Linux
TCP/IP stack) (drop)
?
Chunk
Subchunk
Filter
Gathering queue
Schedulable task
Y
N
N
N Y
Y
Cascading

Batching, batching, batching!
The IO engine (modified NIC driver) uses continuous huge packet buffers called “chunks”.
The user-level process pipelines multiple chunks.
The GPU processes multiple chunks in parallel.
Hardware-aware optimizations
No NUMA node crossing
Minimized cache conflicts among multi-cores
Factors behind PacketShader 1.0 Performance

Remaining Challenges
100+ Gbps speed
Stateful processing
Intrusion detection systems / firewalls
43

Review of I/O Capacity for 100+ Gbps
QuickPath Interconnect (QPI)
CPU socket-to-socket link for remote memory
IOH-to-IOH link for I/O traffic
CPU-to-IOH for CPU to peripheral connections
Today’s QPI link
12.8 GB/s or 102.4 Gbps
Sandy Bridge
On recall at the moment
Expected to boost performance to 60 Gbps w/o modification

Review of Memory B/W for 100+ Gbps
For 100Gbps forwarding we need 400 Gbps in memory bandwidth + bookkeeping
Current configuration
triple-channel DDR3 1,333 MHz
32 GB/s per core (theoretical) and 17.9GB/s (empirical)
On NUMA system
More nodes
Careful placement...

Future Work
Consider other architectures
AMD’s APU
Tilera’s tiled many-core chips
Inte’s MIC
Become a platform for all new FIA architectures
Advantage over NetFPGA, ServerSwitch, ATCA solutions
46

QUESTIONS?
THANK YOU!
For more details
https://shader.kaist.edu/
47