Embed Size (px)
Citation preview

© Springer-Verlag 1988
Nucleotide sequences of cDNAs encoding four complete nuclear-encoded plastid ribosomal proteins
J. Stephen Gantt
Department of Botany and the Plant Molecular Genetics Institute, University of Minnesota, 220 Biological Sciences Center, St. Paul, MN 55108, USA
Summary. The nucleotide sequences of four pea nuclear- encoded plastid ribosomal protein cDNAs have been determined. These cDNAs were shown to encode the complete precursor proteins. The transit sequences of the encoded proteins are similar to the transit sequences of other imported proteins being rich in serine and/or threonine and lacking aspartic and glutamic acid. The transit sequences do not, however, have any apparent amino acid sequence similarity with one another or with the transit sequences of other imported proteins. The derived amino acid sequences of the plastid ribosomal proteins were compared to the amino acid sequences of other ribosomal proteins. Significant amino acid se- quence similarity was found between Escherichia coli ribosomal proteins L9 and L24 and two of the nuclear- encoded pea plastid ribosomal proteins.
Key words: Chloroplast ribosomal proteins - Transit peptides - Pisum sativum
Introduction
The plastid genome contains approximately 100 pro- tein-encoding genes, 30-32 tRNA genes and four rRNA genes (Ohyama et al. 1986; Shinozaki et al. 1986). These genes are transcribed by plastid-specific RNA polymerase and the mRNAs are translated by 70S ribosomes located inside the plastid. These plastid specific ribosomes are structurally and functionally more similar to those found in eubacteria than to those found in the eukaryotic cytosol. Many structural sim- ilarities exist among the components of plastid and
eubacterial ribosomes including strong sequence sim- ilarities of the ribosomal proteins (e.g. Bartsch et al. 1982; Subramanian et al. 1983) and 16S and 23S rRNAs (Schwarz and Kossel 1980; Edwards and Kossel 1981).
The plastid ribosome of higher plants is composed of 50-60 different ribosomal proteins (Eneas-Filho et al. 1981 ; Capel and Bourque 1982; Gantt and Key 1986). The deduced protein sequence from 19 open reading frames in the plastid genome bear remarkable resem- blance to bacterial ribosomal proteins, leading to the conclusion that 19 of the plastid ribosomal proteins are encoded in the plastomes of the higher plant Nicotiana tabacum and the bryophyte Marchantia (Shinozaki et al. 1986; Ohyama et al. 1986). The remaining 30-40 plastid ribosomal proteins are assumed to be encoded in the nuclear genome. The nuclear-encoded plastid ribosomal protein mRNAs, like the mRNAs of other nuclear-encoded plastid proteins, are translated in the cytosol by 80S ribosomes and post-translationally transported into the plastid (Schmidt et al. 1984; Gantt and Key 1986). The dual genetic origin of the plastid ribosome raises intriguing questions about the mechan- isms which regulate and coordinate the expression of genes located in the nucleus and the plastid. Addi- tionally, the split location of the plastid ribosomal protein genes raises questions concerning their evolu- tion.
To begin to address these questions, cDNA clones encoding six nuclear-encoded plastid ribosomal proteins have been isolated (Gantt and Key 1986). These proteins are synthesized as higher molecular weight precursors from poly(A+)RNA and are proteolytically processed to their mature sizes upon their in vitro translocation into the plastid. In this report, the nucleotide sequences of four cDNAs that encode the entire precursor pro- teins are examined.

520
Methods and materials
Molecular cloning and DNA sequencing. The isolation and characterization of the four nuclear-encoded plastid ribosomal protein cDNAs from a pea Xgtl 1 library have been described (Gantt and Key 1986). The eDNAs were subcloned into the vectors pUC18 and pSP65 (Promega Biotec, Inc.) according to procedures described in Maniatis et al. (1982). The cDNAs were sequenced by the chemical sequencing technique (Maxam and Gilbert 1980; Nagao et al. 1985).
Hybrid-selection of mRNA, in vitro transcription and cell-free translation. RNA was isolated from 10-14 day old pea (Pisum sativum, vat. Little Marvel) seedlings (Gantt and Key 1985). Hybrid-selection of complementary RNA was carried out as described previously (Gantt and Key 1986). cDNAs cloned into pSP65 were transcribed in vitro according to Krieg and Melton (1984). The in vitro synthesized and the hybrid-selected RNAs were translated in a wheat germ cell-free system con- taining 2 mCi/ml [35S]methionine (Gantt and Key 1985).
DNA isolation and Southern analysis. Pea genomic DNA was isolated from etiolated pea seedlings according to Bendich et al. (1980). The DNA was digested with restriction endo- nucleases, subjected to electrophoresis through 0.8% agarose gels, and blotted to nitrocellulose filters as described in Mania- tis et al. (1982). cDNA inserts were labeled with [a-32p]dATP as described by Feinberg and Vogelstein (1983) and hybridized overnight to nitrocellulose filter blots. Hybridization buffer contained 50% formamide, 750 mM NaC1, 75 mM trisodium citrate, 5x Denhardt's solution, 50 mM sidum phosphate (pH 6.8), 0.1% SDS and 0.1 mg/ml salmon sperm DNA at 42 °C. The filters were washed as previously described (Gantt and Key 1987).
DNA and protein sequence analysis, cDNA sequences were analyzed using the programs developed by Intelligenetics, Inc. amino acid sequence comparison were determined by the DFASTP program (Lipman and Pearson 1985).
Nomenclature. Results reported here show that pea plastid ribosomal proteins originally named PsCL12 and PsCL13 (Gantt and Key 1986) have amino acid sequence similarity, and are probably homologous, with E. coli ribosomal proteins L24 and Lg, respectively. Therefore, these two pea plastid ribosomal proteins have been renamed, following the system used by Tanaka et al. (1986), CL24 and CL9 in order to minimize confusion in the literature. Since no sequence similarity could be found between pea plastid ribosomal proteins PsCL18 and PsCL25 (Ps, Pisum sativum; C, chloroplast; Gantt and Key 1986) and any of the published bacterial ribosomal protein sequences, these names have not been changed. These protein designations conform with a proposed nomenclature system for the eukaryotic cytosolic ribosomal proteins (J. R. Warner, personal communica- tion).
Results and discussion
Characterization o f the eDNA clones
Gantt and Key (1986) isolated six cDNA clones derived from pea poly(A+)RNA and showed that they encode six different plastid ribosomal proteins. These cDNAs
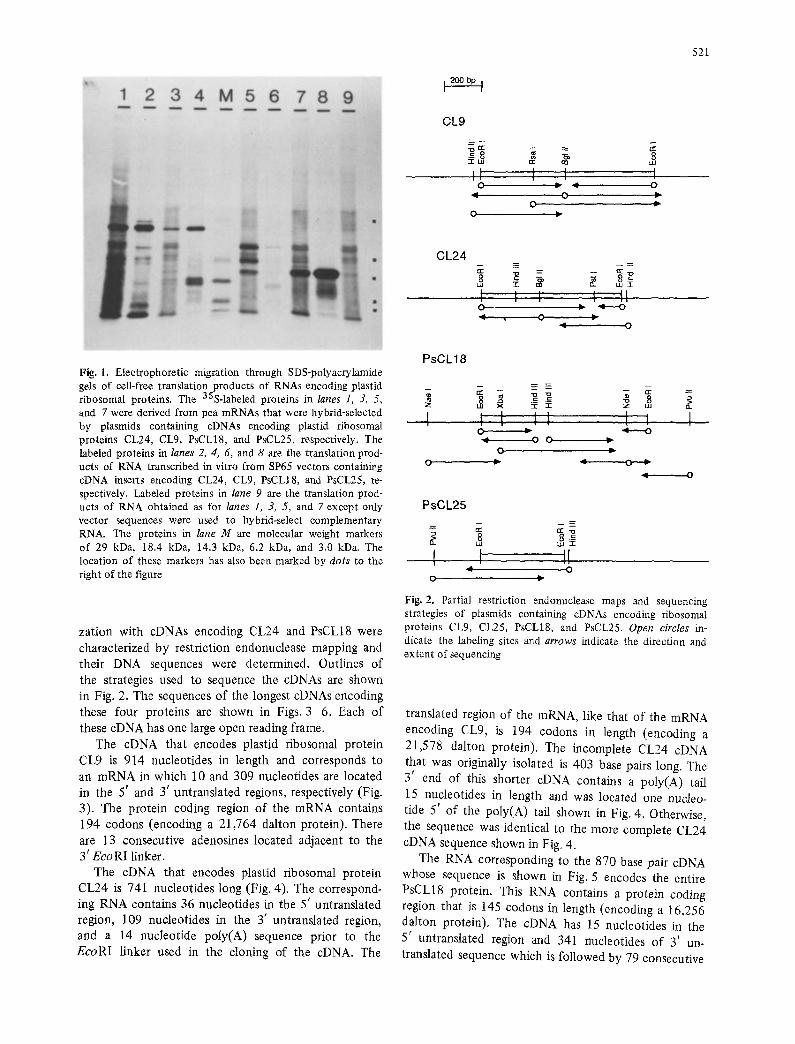
were subcloned into the vector SP65 which contains an SP6 RNA polymerase promoter. To test whether these cDNAs encoded the entire precursor protein, SP6 transcripts were synthesized in vitro and the RNAs were translated in a wheat germ cell-free system. The electrophoretic mobilities of these proteins through SDS-polyacrylamide gels were compared with those of the cell-free translation products derived from pea mRNAs that were hybrid-selected by the cloned cDNAs. Electrophoretic co-migration of the proteins synthesized in vitro from RNA transcribed by SP6 RNA polymerase and from the hybrid-selected RNAs would show that the cloned cDNA encodes the entire precursor protein. By this criterion, two of the original six cDNAs encoded the entire precursor protein (CL9 and PsCL25). Sub- sequently, CL24 and PsCL18 cDNAs were used to rescreen the recombinant cDNA library and those cDNAs whose size closely matched the estimated size of CL24 and PsCL18 mRNA were analyzed as described above. Results of these experiments are shown in Fig. 1. For each cDNA the high molecular weight protein synthesized from hybrid-selected mRNA comigrates with a specific protein synthesized from the correspond- ing SP6 transcript. The relatively low abundance of the nuclear-encoded plastid ribosomal protein mRNAs makes their hybrid-selection difficult and leads to the high background o f common polypeptides seen in lanes 1, 3, 5, 7 and 9. Several specific protein products are synthesized when RNA that was hybrid-selected by PsCL18 cDNA is translated in vitro (lane 5). Two- dimensional polyacrylamide gel electrophoresis of these translation products (not shown) resolves four proteins including mature PsCL18 (Gantt and Key 1986). Schmidt et al. (1984) have also observed pre- cursor, intermediate, and mature forms of plastid ribosomal proteins among the cell-free translation products of Chlamydomonas reinhardtii poly(A+)RNA. The low molecular weight proteins seen in lanes 2, 4, 6 and 8, which are the cell-free translation products of in vitro transcribed cDNA, may result from premature transcription or translation termination, internal transla- tion initiation, or protein or RNA degradation. In vitro transcription of PsCL18 cDNA repeatedly yielded little RNA (lane 6) although it is clear that one of the translation products co-migrates with the largest of the specific cell-free translation products of the hybrid- selected RNA (lane 5).
Nucleotide sequence analysis o f cDNAs encoding plastid ribosomal proteins CL9, CL24, PsCL18, and PsCL25
Four cDNAs isolated by Gantt and Key (1986) and two additional cDNAs that were isolated by hybridi-
} 200 bp ]
CL9
t l ,,1 I 0 ,,, ,11.- .e
C 0
0 ,,, ID-
8 IJA
I 0
521
Fig. 1. Electrophoretic migration through SDS-polyacrylamide gels of cell-free translation products of RNAs encoding plastid ribosomal proteins. The 35S-labeled proteins in lanes 1, 3, 5, and 7 were derived from pea mRNAs that were hybrid-selected by plasmids containing cDNAs encoding plastid ribosomal proteins CL24, CL9, PsCL18, and PsCL25, respectively. The labeled proteins in lanes 2, 4, 6, and 8 are the translation prod- ucts of RNA transcribed in vitro from SP65 vectors containing cDNA inserts encoding CL24, CL9, PsCL18, and PsCL25, re- spectively. Labeled proteins in lane 9 are the translation prod- ucts of RNA obtained as for lanes 1, 3, 5, and 7 except only vector sequences were used to hybrid-select complementary RNA. The proteins in lane M are molecular weight markers of 29 kDa, 18.4 kDa, 14.3 kDa, 6.2 kDa, and 3.0 kDa. The location of these markers has also been marked by dots to the right of the figure
zation with cDNAs encoding CL24 and PsCL18 were characterized by restriction endonuclease mapping and their DNA sequences were determined. Outlines of the strategies used to sequence the cDNAs are shown in Fig. 2. The sequences of the longest cDNAs encoding these four proteins are shown in Figs. 3 - 6 . Each of these cDNA has one large open reading frame.
The cDNA that encodes plastid ribosomal protein CL9 is 914 nucleotides in length and corresponds to an mRNA in which 10 and 309 nucleotides are located in the 5' and 3' untranslated regions, respectively (Fig. 3). The protein coding region of the mRNA contains 194 codons (encoding a 21,764 dalton protein). There are 13 consecutive adenosines located adjacent to the 3' Eco RI linker.
The cDNA that encodes plastid ribosomal protein CL24 is 741 nucleotides long (Fig. 4). The correspond- ing RNA contains 36 nucleotides in the 5' untranslated region, 109 nucleotides in the 3' untranslated region, and a 14 nucteotide poly(A) sequence prior to the E c o R I linker used in the cloning of the cDNA. The
CL24 cc
-1-
I t 0 - - -
m ~ 7
I: , I", II -'- ~ 0
0
PsCL18
C
0 O
C
0 .....
z
i i I
PsCL25
= ~ - =
..... I l ..... I I .......... 0
0
Fig. 2. Partial restriction endonuclease maps and sequencing strategies of plasmids containing cDNAs encoding ribosomal proteins CL9, CL25, PsCL18, and PsCL25. Open circles in- dicate the labeling sites and arrows indicate the direction and extent of sequencing
translated region of the mRNA, like that of the mRNA encoding CL9, is 194 codons in length (encoding a 21,578 dalton protein). The incomplete CL24 cDNA that was originally isolated is 403 base pairs long. The 3' end of this shorter cDNA contains a poly(A) tail 15 nucleotides in length and was located one nucleo- tide 5' of the poly(A) tail shown in Fig. 4. Otherwise, the sequence was identical to the more complete CL24 cDNA sequence shown in Fig. 4.
The RNA corresponding to the 870 base pair cDNA whose sequence is shown in Fig. 5 encodes the entire PsCL18 protein. This RNA contains a protein coding region that is 145 codons in length (encoding a 16,256 dalton protein). The cDNA has 15 nucleotides in the 5' untranslated region and 341 nucleotides of 3' un- translated sequence which is followed by 79 consecutive

522
-I0 I 30 CAAAACAACA ATG GCA TCA TCA ACG TTA TCT TCT CTC TCC TCG ACC CCG TTG CAA CAC AGT
Met Ala $er Ser Thr Leu $er Ser Leu Ser Set Thr Pro Leu Gin His Set
60 90 120 TTC GCC GAC AAC TTG AAA ACT TGT TCT CAA TTT CCG AAC AAA AGT TCG GGT TTT ATG GTT TTC GCT CAA Phe Ala Ala Asn Leu Lys Thr Cys Set Gtn Phe Pro Asn Lys Ser Ser Gly Phe Met Val Phe Ala Gin
150 180 AAG AAA ACA AAG AAA ACT CGA AAG ATT ATA CTG AAG GAA GAT ATT GTT AAT GTT GGA AAG AAA GGG GAA Lys Lys Thr Lys Lys Thr Arg Lys lle lle Leu Lys Glu Asp Ire Vat Asn Val Gly Lys Lys Gly Glu
210 240 CTT CTT GAT GTG AGG GTT GGG TTT TIC AGA AAT TTC CTC TTT CCA AGT GGC AAG GCT CAG CTT GTA ACT Leu Leu Asp Vat Arg Vat Gty Phe Phe Arg Asn Phe Leu Phe Pro Ser Gty Lys Ata Gin Leu Val Thr
270 300 CCT GGT GTA CTC AAG GAA ATG AAG ATA GAA GAA GAA AGA AIT GAG GCT GAG AAA CGA CGG GTA ITA GAA Pro Gly Val Leu Lys Glu Met Lys Ire Glu Glu Glu Arg lEe Glu Ata Glu Lys Arg Arg Val Leu Glu
330 360 390 GAG GCA CAG CAA CTT GCT CTA TTT TTT GAA ACT TIT GGG GCT TIC AAG GTA AAG CGG AAA GGT GGT AAA GLu Ala Gtn Gin Leu Ala Leu Phe Phe Glu Thr Phe Gly Ala Phe Lys Vat Lys Arg Lys Gly Gly Lys
420 450 GGA AAA CAG ATA TIT GGA AGT GTT ACG GCT CAA GAT CTT GTG GAC ATA ATA AAG GCA CAA CTT CAA AGG Gly Lys Gin l l e Phe Gly Ser Val Thr Ala Gin Asp Leu Val Asp l l e l l e Lys Ata Gin Leu Gin Arg
480 510 GAG GIG GAC AAG AGA ATT GTT AAT CTT CCA GAG ATC AGG GAA ACA GGA GAA TAT ATT GCA GAA TTA AAA GIu Val Asp Lys Arg lle Val Asn Leu Pro GLu lle Arg Glu Thr Gly Glu Tyr lle Ala Glu Leu Lys
540 570 600 CTT CAT CCA GAT GTT ACA GCT AAA GTG AGG GIG AAT GTT ATA GCT AAC TAA GCAGCCCT AAATTGTTTC Leu His Pro Asp Vat Thr Ala Lys Val Arg Val Asn Vat l l e Ala Asn - - -
630 660 AAAGTTCCAT ATGCTAAATG CACACATGGG AGTGTCACCA ACTTGCATAA CTTCAAGGTG CATAACAACC ATCTTATGAA
690 720 750 CTATGATGAG AAATGTTCAG ACTTAGTTCA AGCTCGACGT AGTAGTCTCG TGACTTTGGC CGAAGGCCGG ACGAGGAGGA
780 810 840 TGTGGAGATT GTTTCTTATT TTAACATTTT GTTTTTTGGT ATCTCCTCCT TGAATGTGTA TTCAATTTTC AGGACAATGT
870 900 TTGTAATGTT CTTATTTATG ATGGTAAAAG AGATATTTTT GTCAGTTCAA AAAAAAAAAA A
Fig. 3. Complete nucleic acid sequence and derived amino acid sequence of the cDNA encoding pea plastid ribosomal protein CL9. The underlined amino acid indicates the approximate location of the mature protein's amino terminus
adenosines (Fig. 5). The original incomplete cDNA clone identified as encoding PsCL18 was 528 base pairs long and contained 26 consecutive adenosines at its 3' end. The nucleotide sequences of the 2 clones are exactly the same in the overlapping region which ex- tends from nucleotides 39 to 553 (not including the 3' poly(A) sequence); the 870 base pair cDNA shown in Fig. 5 encodes an RNA that contains an additional 202 nucleotides of 3' untranslated sequence.
The sequence of the 439 base pair cDNA that encodes PsCL25 is shown in Fig. 6. The mRNA sequence pre- dicted from the cDNA sequence has 7 nucleotides of 5' untranslated sequence and 108 nucleotides in the 3' untranslated region which is followed by a 12 nuc-
leotide poly(A) sequence. The protein coding region of the mRNA consists of 104 codons (encoding an 11,256 dalton protein).
Each of the cDNAs has an A at position - 3 and a G at +4 around the proposed initiator methionine codon. This matches the plant consensus sequence surrounding the AUG initiation codon (Lutcke et al. 1987). It is likely that the poly(A) sequences at the 3' ends of the cDNAs are added post-transcriptionally and are not encoded in the genomic DNA, although experiments to establish this have yet to be carried out. Two cDNAs were isolated and sequenced for both CL24 and PsCL18. In both of these pairs of cDNAs, the location of the 3' poly(A) sequences were not

523
-30 -20 -10 I 30 GCAAAA AAGAACAAGA GGTTACATAC AACAACAACA ATG GTA GCT ATG GCT ATG GCT TCT CTT CAG AGT TCC
Met Val Ala Met Ala Met Ala Set Leu Gin Ser Ser
60 90 ATG TCC TCA CTC TCC CTC TCC TCC AAC TCT TTC TTA GGC CAA CCT CTC TCT CCC ATC ACT CTC TCC CCT Met Ser Ser Leu Ser Leu Ser Ser Asn Ser Phe Leu Gly Gin Pro Leu Ser Pro I l e Thr Leu Ser Pro
120 150 TTT CTT CAG GGT AAG CCA ACA GAG AAG AAA TGT CTT ATT GTA ATG AAG CTT AAA CGA TGG GAG CGA AAG Phe Leu Gin Gly Lys Pro Thr Glu Lys Lys Cys Leu lle Val Met Lys Leu Lys Arg Trp Glu Arg Lys
180 210 240 GAA TGT AAA CCA AAC AGC CTT CCC GTA TTA CAC AAA TTG CAT GTT AAA GTT GGA GAT ACA GTG AAA GTC Glu Cys Lys Pro Asn $er Leu Pro Val Leu His Lys Leu His Val Lys Vat Gly Asp Thr Vat Lys Val
270 300 ATA TCG GGA CAT GAA AAG GGT CAA ATA GGG GAG ATT ACT AAG ATC TTC AAA CAC AAC AGC AGT GTC ATT lle Ser Gly His Gtu Lys Gly Gin lle Gly Glu lle Thr Lys lle Phe Lys His Asn Ser Ser Vat lle
330 360 GTT AAA GAC ATA AAC TTG AAG ACA AAG CAT GTG AAA AGT AAC CAA GAG GGA GAA CCC GGA CAA ATA AAT Val Lys Asp lle Asn Leu Lys Thr Lys His Vat Lys Ser Asn Gin Glu Gly Gtu Pro Gly Gin lle Asn
390 420 450 AAG GTC GAA GCT CCT ATC CAC AGT TCA AAT GIG ATG CTT TAC TCC AAA GAA AAG GAT GTA ACA AGC CGC Lys val Glu Ala Pro Ire His Ser Ser Asn Val Met Leu Tyr Ser Lys Glu Lys Asp Val Thr Ser Arg
480 510 GTA GGT CAT AAA GTT CTT GAA AAT GGT AAA AGA GTT CGC TAC CTG ATA AAA ACT GGA GAG ATA ATT GAT Val Gly His Lys Val keu Glu Asn Gly Lys Arg Val Arg Tyr Leu lle Lys Thr Gly Glu lle lle Asp
540 570 AGT GAA GAA AAT TGG AAG AAA CTG AAG GAA GCT AAT AAG AAA ACT GCA GAA GTT GCT GCT ACC TAG TTT Ser Glu Glu Asn Trp Lys Lys Leu Lys Glu Ala Asn Lys Lys Thr Ala Glu Va[ Ala Ala Thr ---
600 630 660 TACTGTATTA CTTCATGTAT TCAGCAGTTA TGTAACTCTA TGTACTTGTA TTTTTTTGCT CATTTTATTT TAAGTGTATA
690 TTATGTTATT ATTTTTGTTG C~TAAAAAAA AAAAAAA
Fig. 4. Complete nucleic acid sequence and derived amino acid sequence of the eDNA encoding pea plastid ribosomal protein CL24. The underlined amino acid indicates the approximate location of the mature protein's amino terminus. The underlined nucleotide at position 690 is the last nucleotide prior to a poly(A) tail (A1s) in another eDNA clone encoding CL24
identical. This most likely represents differences in the site of polyadenylation rather than different genetic loci encoding the same proteins since there were no differences in the overlapping nucleotide sequences of the cDNAs. Plant transcripts with multiple 3' ends have been previously described (Hernandez-Lucas et al. 1986;Dean et al. 1985).
Heidecker and Messing (1986), examining 47 dif- ferent plant mRNAs, have described a conserved nu- cleotide sequence (AAUAA) located 15-35 nucleotides preceding the poly(A) sequence in approximately 90% of the mRNAs that were examined. Joshi (1987) has reached similar conclusions. However, as determined from the eDNA sequences, AAUAA is not found in the 3' untranslated region of any of the nuclear-encoded ribosomal protein mRNAs. This suggests that either this consensus sequence is not necessary for mRNA polyadenylation or that there are alternative mechan-
isms or signals that lead to poly(A) addition. Further- more, among the plastid ribosomal protein cDNAs, no significant amount of sequence similarity can be found in the region 15-35 nucleotides preseding the poly(A) sequences.
Southern analysis o f the pea ribosomal protein genes
Pea genomic DNA was digested with restriction endo- nucleases and subjected to agarose gel electrophoresis. The location of genomic DNA sequences complementary to the nuclear-encoded plastid ribosomal protein cDNAs was determined by Southern blot analysis. The data pres- ented in Fig. 7 suggest that each of the pea nuclear- encoded plastid ribosomal protein genes are present as one or a few copies in the pea genome. The presence of several linked genes has not been ruled out.

524
-10 1 30 AAAAA ACCAAACACT ATG GCA CTT CTC TGC TTC AAT TCC TTC ACA ACC ACC CCT GTT ACC TCT
Met ALa Leu Leu Cys Phe Asn Ser Phe Thr Thr Thr Pro VaL Thr Ser
60 90 TCT TCC TCC CTT TTC CCT CAT CCC ACA GCA AAC CCT ATT TCT AGA GTA CGA ATC GGT CTG CCC ACC AAC Ser Ser Ser Leu Phe Pro His Pro Thr Ala Asn Pro lle Ser Arg Vat Arg lle Gly Leu Pro Thr Asn
120 150 180 TGT TTG AAG GGA TTT CGA ATC TTG ACA CCC ATT GTT CAG AAA CCG AGA AAA AAT TCA ATT TTT ATT GCA Cys Leu Lys Gly Phe Arg lle Leu Thr Pro lle Vat Gin Lys Pro Arg Lys Asn Ser lle Phe lle Ala
210 240 TCC GCT GCT GCT GGT GCG GAT TCT AAT GTT GCA GAT GGA GTA GAA GAA AGT GAG AGC AAG AAA GAG AGT Ser Ata Ala Ala Gly Ala Asp Ser Asn Val Ala Asp Gly Val Glu Glu Ser Glu Ser Lys Lys Glu Ser
270 300 GAT GTT GTT TCT GTA GAT AAG CTT CCA TTA GAA TCA AAA TTG AAG GAG AGG GAA GAG CGG ATG TTG AAG Asp Val Va[ Ser Vat Asp Lys Leu Pro Leu Glu Ser Lys Leu L ys Glu Arg Gtu Glu Arg Met Leu Lys
330 360 390 ATG AAG CTT GCC AAG AAG ATA AGG TTG AAG AGA AAG AGG CTT GTT CAA AAG AGG AGG TTG AGG AAG AAG Met Lys Leu Ala Lys Lys lle Arg Leu Lys Arg Lys Arg Leu Val Gin Lys Arg Arg Leu Arg Lys Lys
420 450 GGG AAT TGG CCA CCT TCC AAG ATG AAG AAA TTG GAA GGT GTT TAA TATCT GTTTGCAGGT TTCATTCTGA Gly Asn Trp Pro Pro Ser Lys Met Lys Lys Leu Glu Gly Val ---
480 510 540 TTTTCTATTG TTCGACTCTG CCCTTGTTGT CAACATTTTT TCTGGTGTAT TTTGACAATT TTGTTCATTT TCAATCAAGA
570 600 TTTTTAGTT~ ATATATTGTA TATGCCTTCT GTTTGGTTAA GGTTGAAATA GGGGGTTTGA TTTGAAATCT ATGTAGCATC
630 660 690 AACACTTCTT ATTAAAGGGT GTTCGGTGTT CTGACACTTC CGCAGCACCA ACATAGGAAA ATACATTCAT GTATCCAGTG
720 750 780 TTCAACAAGC GTTAGTGTCC GACACTTATG CAGCACCAAC ATATGGAAAT ACATTCAACT CTTCAATTTT TTCAAAAAAA
810 840 AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AA
F~. 5. Complete nucleic acid sequence and derived amino acid sequence of the cDNA encoding pea plastid ribosomal protein PsCLIS. The underlined amino acid indicates the approximate location of the mature protein's amino terminus. The underlined nucleotide at position 553 is the last nucleotide prior to a poly(A) tail (A26) in another cDNA clone that encodes PsCL18
Chloroplast ribosomal protein sequence analysis
The amino acid composition of each nuclear-encoded plastid ribosomal protein can be determined from its derived amino acid sequence (shown in Figs. 3-6) . In general, ribosomal proteins have very high isoelectric points and, as expected, for each of the ribosomal proteins whose sequence is reported here, the number of lysine and arginine residues exceeds the number of aspartic and glutamic acid residues. CL9, CL24, and PsCL25 each have about the same electrophoretic mobility at pH 5.5 in urea-4% potyacrylamide gels (Gantt and Key 1986), reflecting the fact that at this pH they have about the same net charge (ranging from +9 to +14). PsCL18 contains 32 lysine and arginine residues and 13 aspartic and glutamic acid residues giving it a net charge of +19 at pH 5.5. Its mobility at pH 5.5 in urea-4% polyacrylamide gels is greater
than that of CL9, CL25, or PsCL25. The molecular weights of the ribosomal proteins as determined by their electrophoretic mobilities though SDS polyacryl- amide gels are larger, by 20 to 40%, than expected from the sequence data. This anomalous migration probably results from their high net positive charge.
Most nuclear-encoded plastid proteins have a transit peptide that is located at the amino terminus of the precursor polypeptide (Schmidt and Mishkind 1986). This sequence is proteolytically removed upon entry of the protein into the plastid. Stromal proteins are therefore thought to be composed of two domains, the transit peptide and the mature protein. It has been demonstrated that the transit sequence is sufficient to signal the transport of proteins into chloroplasts (Schreier et al. 1985; Van den Broeck et al. 1985). This raises the question of what signal in the transit sequence determines the protein's final intracellular

525
I 30 60 TAGAAAA ATG GCG TCA GIG TCG AGC ATA TTT GGG TGT GGT GTA TCG ATG GCA CCA AAT TCT TCA CTG
Met Ata Set Vat Ser Ser I re Phe Gty Cys Gty Vat Ser Met Ata Pro Asn $er Set Leu
90 120 GCA ATT CGA ACT GAA AGA AGA AGT GCG TGT GGA GGA TTG TTG ATT GAG TGT TCA TCA AGG Ala lle Arg Thr Glu Arg Arg Ser Ala Cys Gly Gly Leu Leu lle Glu Cys Ser Ser Arg
150 180 CCA CAG AAG AAA TCA ACT GCA CAT CAC ATG AAG ACG AGG CCG AGA AAA TCA CGA CTG TCC GAT AGG AAT Pro Gin Lys Lys Ser Thr Ala His His Met Lys Thr Arg Pro Arg Lys Ser Arg Leu Ser Asp Arg Asn
210 240 ACT GTG TAT GCT CCG TTG CCT CCG CTA CCT CCT GAT TTT ACG ATT GTG ATT CCT GCT GAT Thr Val Tyr Ala Pro Leu Pro Pro Leu Pro Pro Asp Phe Thr lle Vat lle Pro Ala Asp
300 330 GTT GAT TTT ACT CCT CCG CCT CCC ACT CCT TCT GAT TGA TTCGGTACTT TTTTTGTATG Vat Asp Phe Thr Pro Pro Pro Pro Thr Pro Ser Asp ---
360 390 TTGATGTGTT GTTGTTGTTC TCTTTTGTTG GATTTTGAAT TGTATTGTTA AGATATACTA TTGTATTATT TCAGTTTTGT
420 TTGTCAAAAA AAAAAAA
F~.6. Complete nucleic acid sequence and derwed ammoac~ sequenceofthecDNA encodingpeaplastidribosomalprotein PsCL25. TheundeHmedaminoacidindicatestheapproxim~elocationofthe matureprotein'saminoterminus
AGA AAC AAA Arg Asn Lys
CGG AAG CCG Arg Lys Pro
270 GCA TCG ACG Ata Ser Thr
Fig. 7. Southern analysis of pea genomic DNA cut with BamHI (B), EcoRI (E), or HindIII (H). The DNAs in 1, 2, 3, and 4 were probed with 32p-labeled cDNAs encoding plastid ribosomal pro- teins CL24, CL9, PsCL18 and PsCL25, respectively. The sizes of the molecular weight markers are given in kilobase pairs
location. Karlin-Neumann and Tobin (1986) have shown that particular amino acid sequences are present in the transit peptides of both the small subunit of ribulose bisphosphate carboxylase/oxygenase and the light harvesting chlorophyll a/b binding protein of several plant species. They speculate that these se- quences are important for the transport of these pro- teins across the plastid envelope membranes. These conserved amino acid sequence domains have been found in the transit peptides of other imported pro- teins (e.g. Quigley et al. 1988).
The sites of proteolytic cleavage of the precursor proteins, defining the transit peptide and the mature protein, have been estimated on the basis of the shift in electrophoretic mobility after in vitro transport
of the precursor protein into chloroplasts (Gantt and Key 1986). This estimation has been done despite their anomalous electrophoretic migration in SDS polyacrylamide gels. The amino acid composition of the amino termini of the precursor proteins is not particularly basic. Thus, the difference between the migration of the precursor and mature proteins should be related to the molecular weight of the transit peptide. The approximate locations of the cleavage sites are underlined in Figs. 3-6 .
The amino acid composition of the postulated ribosomal protein transit peptides are similar to other transit peptides (Schmidt and Mishkind 1986). They contain a relatively high abundance of serine and/or threonine and lack acidic amino acids. One other char-

526
acteristic shared by the transit sequences of the plastid ribosomal proteins is an initial long stretch of amino acids devoid of acidic or basic amino acids. The length of the amino terminal uncharged regions varies from 20 amino acids in PsCL25 to 39 amino acids in CL24. This is striking since the remaining portions of these proteins are composed of 27 to 39% charged amino acids.
Although there are similarities in the amino acid composition of the proposed transit peptides, there is little amino acid sequence similarity among the four plastid ribosomal proteins or among the plastid ribo- somal proteins and previously sequenced nuclear- encoded plastid proteins. The sequences previously proposed to be important for protein transport into plastids (Karlin-Neuman and Tobin 1986) are, with a single exception in the proposed transit peptide of CL24, not found. The sequence PFLQGK found near the putative cleavage site of CL24 precursor protein is similar to conserved domain II (P-F-G-K) identified by Karlin-Neuman and Tobin (1986). Reiss et al. (1987) have demonstrated that deletion of a segment con- taining domain II in the transit sequence of pea small subunit of ribulose bisphosphate carboxylase has little effect on the in vitro transport of the protein. Other investigators (e.g. Tyagi et al. 1987; Vierling et al. 1988) have also reported little sequence similarity among several recently determined transit peptides and the proposed transit peptide framework (Karlin- Neuman and Tobin 1986).
Comparisons of nuclear-encoded plastid ribosomal protein sequences with E. coli ribosomal proteins
The sequences of plastid ribosomal RNA and plastid- encoded ribosomal proteins are similar to ribosomal RNA and ribosomal protein sequences of E. coli even though E. coli and the photosynthetic endosymbiont that evolved into present day higher plant chloroplasts diverged more than 1.5 billion years ago (Ochman and Wilson 1987). The sequence similarities that exist between plastid and bacterial ribosomal proteins have led to the identification of 19 plastid ribosomal pro- tein gene sequences in the plastid genomes of tobacco and liverwort (Shinozaki et al. 1986; Ohyama et al. 1986). The degree of sequence similarity among these proteins range from about 20% to 60%. The amino acid sequence of a nuclear-encoded spinach plastid ribosomal protein has been reported (Bartsch et al. 1982). This protein has sequence (40-50% identity) and immunological similarities with E. coli ribosomal protein L12.
No sequence similarities were found between PsCL18 and PsCL25 and any of the E. coli ribosomal proteins
using the DFASTP program developed by Lipman and Pearson (1985) or the IFIND program developed by Intelligenetics, Inc. The distribution of charged amino acids in each of these proteins is somewhat unusual. Of the last 41 amino acids in PsCL18, 19 are arginine or lysine and there is only a single acidic amino acid. The carboxyl terminal 36 amino acids of PsCL25 contains 4 aspartic acid residues as the only charged amino acids. These characteristics, a highly basic, highly charged carboxyl third of the PsCL18 protein and the carboxyl third of the PsCL25 protein containing just a few acidic amino acid residues, were used to search for E. coli ribosomal proteins with similar features. While all of the E. coli ribosomal proteins have been sequenced (compiled in Giri et al. 1984) and were examined, none have the characteristics found in the carboxyl-terminal regions of PsCL18 or PsCL25.
The amino acid sequences of pea CL24 and CL9 have significant similarity with both Bacillus stearo- thermophilus and E. coli ribosomal proteins L24 and L9, respectively. When compared to the bacterial ribo- somal proteins, both CL24 and CL9 have long amino terminal extensions (Fig. 8). This is not unexpected since this region is most likely the transit peptide.
Comparisons of the amino acid sequences of CL9 with E. coli and B. stearothermophilus ribosomal pro- tein L9 are shown in Fig. 8. Of the 150 overlapping positions, 49 amino acids are identical in the two se- quences (33%) and 65 of the remaining non-identical overlapping residues (43%) are known to often replace one another in evolutionarily related proteins. Com- parison of CL9's amino acid sequence with the B. stearothermophilus L9 sequence shows that 33% of the amino acids are identical and 34% are conservative changes. Comparison of the two eubacterial L9 pro- teins reveals that 40% of the sequence is identical and 38% of the amino acids in the sequences are con- servative substitutions (not shown). The identical matches between the amino acid sequences of the plastid and eubacterial ribosomal proteins are scattered throughout the entire length of the overlapping region and limited to a maximum of 5 continuous identities. Little is known of the function of L9 in the ribosome although it appears to be a RNA binding protein (Giri et al. 1984).
The amino acid sequence of CL24 matches that of E. coli L24 in 35 of the 105 overlapping positions (33%, Fig. 8). Evolutionarily conservative amino acid substitutions have occurred in 48 of the remaining amino acids (46%). The amino acid sequence of CL24 is somewhat more similar to the B. stearothermophilus L24 sequence, with 44% identical residues and 35% of the positions having conservative substitutions. A comparison between the two eubacterial L24 proteins shows that their sequences are 46% identical with 40%

Ec L9
Ps L9
Bs L9
Ec L9
Ps L9
Bs L9
Ec L9
Ps L9
Bs L9
10 20 30 MQVILLDKVANLGSLGDQVNVKAGYARNFLVPQG
• .:1 .... :.:. :. ..:..:. :::1 : :
MA$~TL~L~STPLQH~FAANLKT~QFPNK~SG~MVFAQKKTKTKRKIILKED~VNVGKKGELLDVRVGFFRNFLFPSG
MKVIFLKDVKGKGKKGEIKNVADG-YANFLFKQG
40 50 60 70 80 90 100 110 KA•PATKKNIEFFEARRAELEAKLAE•LAAANARAEKINALET•TIASKAGDEGKLFG$IGTRDIADA•TAADG•E•AKS :: .: . . . . . . ::. ::..:.. : . . . . . . . . . :.: .... ::: .... 1..: ..:. ::.:.
KAQLVTPGVLKEMKIEEERIEAEKRRVLEEAQQ•A•FFETFGAFKVKRKGGKGKQ•FGSVTAPDLVDIIKAQ•QREVDKR : .::. :: ....... :. . :..1..: .: . . . . . :.:.: ..:::.: ........ :1 ..:::
LA•EATPANLKALEAQKQK.EQRQAAE•ANAKK•KEQLEKL•TVT•PAKAGEGGRLFG•IT•KQIAE•LQAQHGLKLDKR
120 130 140 EVRLPNGVLRTHGEEVS-FQVH-EVFAKVIVNVVAE
.... :.1:. .: • ::.1 .: ::: :::.:.
IVNLPE--IRETGEYIAELKLHPDVTAKVRVNVIAN • .:.. ::. : . .::::.:::...:.:...
KIELADA-IRALGYTNVPVKLHPEVTATLKVHVTEQK
527
Ec L24
Ps L24
Bs L24
10 AAKIRRDDEVI
.. .'."
MVAMAMASLQSSMSSLSLSSNS FLGQPLSPI TLSPFLQGKPTEKKCL I VMKLKRWERKECKPNSLPVLHKL HVKVGDTVK
MHVKKGDKVQ
Ec L24
Ps L24
Bs L24
20 30 40 50 60 70 80 V•TGKDK•KRGKVKNVL••SGKV•VEGINLVKKHQK•VPA•NQPGGIVEKEAAIQVSNVAIFNAATGKADRVGFR-FEDG :..:..::. : .......... :::..:::. :: : ...... :: : . ::.:. ::: . . . . . . . . ::: . .:.:
VISGHEKGQIGEITKIFKHNSSVIVKDINLKTKHVK•NQE.GEPGQINKVEAPIHSSNVMLYSKEKDVTSRVGHKVLENG ::::..::. : : : .... :::...:. .::.:..:. . .: : . ::::: :.:: . . . . . . :.:o:... :
VISGKDKGKQGVILAAFPKKNRV•VEGVN•VKKHAKP•QA•NPQGGI•EKEAPIHVSKVMPLDPKTGEPTRIGYKIVD•G
Ec L24
Ps L24
Bs L24
90 100 KKVRFFKSNSETIK :.:: ..... :.:
KRVRYLIKTGEIIDSEENWKKLKEANKKTAEVAAT
KKVRYAKKSGEILDK
Fig. 8. Amino acid alignments of pea (Ps) plastid ribosomal proteins CL9 and CL24 with ribosomal protein sequences from E. coli (Ec) and B. stearothermophilus (Bs). E. coli ribosomal protein sequences L9 and L24 were determined by Schnier et al. (1986) and Wittman-Liebold (1979), respectively. The sequences of B. stearothermophilus ribosomal proteins homologous to E. eoli ribosomal proteins L24 and L9 were determined by Kimura et al. (1980) and Kimura et al. (1985), respectively. Colons (:) indicate amino acid identity and periods (.) indicate a commonly occurring amino acid replacement
of the residues having conservative substitutions (not shown). As with the sequence comparison of CL9 with E. coil and B. stearothermophilus L9, there are no stretches of amino acid sequence identity between the plastid ribosomal protein and the bacterial pro- teins that are longer than 5 residues. E. eoli L24 is found in the spc operon and is thought to initiate the assembly of 50S subunits by organizing the tertiary structure of the RNA (Egebjerg et al. 1987). Whether this property has been retained by the CL24 is an in- teresting and open question.
Gantt and Key (1986) determined that the proteins encoded by the cDNAs whose sequences are reported here are localized to the plastid ribosome and specifical- ly to the large ribosomal subunit. This fact, together
with the protein sequence similarities between CL9 and CL24 and eubacterial L9 and L24, strongly sug- gests that the plastid ribosomal proteins and the bac- terial ribosomal proteins have common ancestral genes and are therefore homologous.
The relationship of plastid ribosomal proteins PsCL18 and PsCL25 to other ribosomal proteins is not clear. It is somewhat perplexing that PsCL18 and PsCL25 apparently do not have sequence similarity with any of the E. coli ribosomal proteins since so many of the characteristics of the E. coli ribosomes are shared by the plastid ribosomes. It would be interesting to de- termine if photosynthetic bacteria such as Cyanobacteria or Prochloron have ribosomal proteins similar to PsCL18 and PsCL25 since these organisms are thought to be

528
more closely related to the endosymbiont that evolved
into chloroplasts of higher plants than are E. coli or
B. stearothermophilus. Alternatively, it is possible
that PsCL18 and PsCL25 are encoded by genes that
evolved from duplicated cytosolic ribosomal protein
genes rather than from genes originally encoded by
the prokaryotic endosymbiont. The evolution of a
nuclear gene to one encoding a plastid protein is exem-
plified by a eukaryotic-like heat shock protein that
is localized to the chloroplast during heat stress (Vier-
ling et al. 1988).
Acknowledgements. The author thanks Dr. Joe L. Key, in whose laboratory this work was initiated, and Dr. Jocelyn Shaw, Dr. John Larkin and Mr. Mike Thompson for critical review of the manuscript. This work was supported by USPHS Grant GM 30317 (to J. L. Key), USPHS Fellowship GM 09187 (to J. S. G.) and by the University of Minnesota Graduate School.
References
Bartsch M, Kimura M, Subramanian A-R (1982) Proc Natl Acad Sci USA 79:6871-6975
Bendich AJ, Anderson RS, Ward BL (1980) Plant DNA: long, pure and simple. In: Leaver CJ (ed) Genome organization and expression in plants. Plenum Press, New York London
Capel MS, Bourque DP (1982) J BiN Chem 257:7746-7755 Dean C, Van den Elzen P, Tamaki S, Dunsmuir P, Bedbrook J
(1985) EMBO J 4:3055-3061 Edwards K, Kossel H (1981) Nucleic Acids Res 9:2853-2869 Egebjerg J, Leffers H, Christensen A, Andersen H, Garrett RA
(1987) J Mol Biol 197:125-136 Eneas-Filho J, Hartley MR, Mache R (1981) Mol Gen Genet
184:484-488 Feinberg AP, Vogelstein 13 (1983) Anal Biochem 132:6-13 Gantt JS, Key JL (1985) J Biol Chem 260:6175-6181 Gantt JS, Key JL (1986) Mol Gen Genet 202:186-193 Gantt JS, Key JL (1987) Eur J Biochem 166:119-125 Giri L, Hill WE, Wittmann HG, Wittmann-Liebold B (1984)
Adv Prot Chem 36:1-78 Heidecker G, Messing J (1986) Annu Rev Plant Physiol 37:439-
466 Hernandez-Lucas C, Royo J, Paz-Ares J, Ponz F, Garcia-Olme-
do F, Carbonero P (1986) FEBS Lett 200:103-106 Joshi CP (1987) Nucleic Acids Res 15:9627-9640 Karlin-Neumann GA, Tobin EM (1986) EMBO J 5 : 9 - 13 Kimura M, Dijk J, Heiland I (1980) FEBS Lett 121:323-326
Kimura M, Kimura J, Ashman K (1985) Eur J Biochem 150: 491-497
Krieg PA, Melton DA (1984) Nucleic Acids Res 12:7057-7070 Lipman VJ, Pearson WR (1985) Science 227:1435-1441 Lutcke HA, Chow KC, Mickel FS, Moss KA, Kern HF, Scheele
GA (1987) EMBO J 6:43-48 Maniatis T, Fritsch EF, Sambrook J (1982) Molecular cloning:
a laboratory manual. Cold Spring Harbor Laboratory, Cold Spring Harbor, New York
Maxam AM, Gilbert W (1980) Methods Enzymol 65:499-569 Nagao RT, Czarnecka E, Gurley WB, Schoffl F, Key JL (1985)
Mol Cell Biol 5:3417-3428 Ochman H, Wilson AC (1987) J Mol Evol 26:74-86 Ohyama K, Fukuzawa H, Kohchi T, Shirai H, Sano T, Sano S,
Umeso K, Shiki Y, Takeuchi M, Chang Z, Aota S, Inokuehi H, Ozeki H (1986) Nature 322:572-574
Quigley F, Martin WF, Cerff R (1988) Proc Natl Acad Sci USA 85:2672-2676
Reiss B, Wasmann CC, Bohnert HJ (1987) Mol Gen Genet 209: 116-121
Schmidt RJ, Myers AM, Gillham NW, Boynton JE (1984) J Cell Biol 98:2011-2018
Schmidt GW, Mishind ML (1986) Annu Rev Biochem 55:879- 912
Schnier J, Kitakawa M, Isono K (1986) Mol Gen Genet 204: 126-132
Schreier PH, Seftor EA, Schell J, Bohnert HJ (1985) EMBO J 4:25-32
Schwarz Z, Kossel H (1980) Nature 283:739-742 Shinozaki K, Ohme M, Tanaka M, Wakasugi T, Hayashida N,
Matsubayashi T, Zaita N, Chunwongse J, Obokata J, Yama- guchi-Shinozaki K, Ohto C, Torazawa K, Meng BY, Sugita N, Deno H, Kamogashira T, Yamada K, Kusuda J, Takaiwa F, Kata A, Tohdoh N, Shimada H, Sugiura M (1986) EMBO J 5:2043-2049
Subramanian AR, Steinmetz A, Bogorad L (1983) Nucleic Acids Res 11:5277-5286
Tanaka M, Wakasugi T, Sugita M, Shinozaki K, Sugiura M (1986) Proc Natl Acad Sei USA 83:6030-6034
Tyagi A, Hermans J, Steppuhn J, Hansson CH, Vater F, Herr- mann RG (1987) Mol Gen Genet 207:288-293
Van den Broeck G, Timko MP, Kausch AP, Cashmore AR, Van Montagu M, Herrera-Estrella L (1985) Nature 313: 358-363
Vierling E, Nagao RT, DeRocher AE, Harris LM (1988) EMBO J 7:575-581
Wittmann-Liebold B (1979) FEBS Lett 108:75-80
Communicated by B. B. Sears
Received May 11, 1988 / July 28, 1988





























