Embed Size (px)
Citation preview

Neutrino: Revisiting Memory Caching for Iterative Data Analytics
Erci Xu*, Mohit Saxena†, and Lawrence Chiu†
*Ohio State University, †IBM Research [email protected],{msaxena,lchiu}@us.ibm.com
AbstractIn-memory analytics frameworks such as Apache Spark arerapidly gaining popularity as they provide order of magni-tude performance speedup over disk-based systems for iterativeworkloads. For example, Spark uses the Resilient DistributedDataset (RDD) abstraction to cache data in memory and itera-tively compute on it in a distributed cluster.
In this paper, we make the case that existing abtractionssuch as RDD are coarse-grained and only allow discrete cachelevels to be used for caching data. This results in inefficientmemory utilization and lower than optimal performance. Inaddition, relying on the programmer to enforce caching deci-sions for an RDD makes it infeasible for the system to adaptto runtime changes. To overcome these challenges, we proposeNeutrino that employs fine-grained memory caching of RDDpartitions and adapts to the use of different in-memory cachelevels based on runtime characteristics of the cluster. First, itextracts a data flow graph to capture the data access dependen-cies between RDDs across different stages of a Spark applica-tion without relying on cache enforcement decisions from theprogrammer. Second, it uses a dynamic-programming based al-gorithm to guide caching decisions across the cluster and adap-tively convert or discard the RDD partitions from the differentcache levels.
We have implemented a prototype of Neutrino as an exten-sion to Spark and use four different machine-learning work-loads for performance evaluation. Neutrino improves the aver-age job execution time by up to 70% over the use of Spark’snative memory cache levels.
1 IntroductionTraditional disk-based big data frameworks, for exam-ple Apache Hadoop, scale out the computation acrossmultiple nodes in a distributed cluster. However, theyfall short for the needs of the recently emerging iterativeworkloads such as clustering, inference and regressionalgorithms for machine learning [3]. These workloadsrequire data to be cached in memory across different it-erations.
Apache Spark [8, 5] is one of the most popular sys-tems that is custom designed for serving iterative queries
and use the Resilient Distributed Dataset (RDD) abstrac-tion to cache data in memory. As a result, memory effi-ciency becomes critical to the overall performance [7, 4].A Spark job is composed of Transformations (e.g. map,flatMap); and Actions (e.g. count, reduce). A RDDis typically created by loading data in an Action fromHDFS wherein each HDFS block on disk represents aRDD partition in memory. The programmer can man-ually prescribe the system to cache the loaded RDD ina given cache level across different actions. Otherwise,the RDD is discarded from memory after the action iscompleted. Table 1 shows the different cache levels andtheir tradeoffs. These cache levels store all partitions of aRDD in serialized (compact) or deserialized (fast) mem-ory cache levels. Alternatively, the RDD can be storedoutside the Spark JVM heap (off heap) in memory andon disk.
In this paper, we find that coarse-grained cache man-agement using RDD abstraction and discrete cache levelsresults in inefficient memory utilization and lower per-formance. First, all partitions of a RDD are stored in thesame cache level across all worker nodes regardless ofruntime characteristics such as the memory required forthe RDD partition and free memory on a worker node.Second, the system relies on the application programmerto enforce caching decisions for a RDD using persist andunpersist interfaces exposed to the programmer. Thismakes it infeasible for moving a RDD or its partitionsfrom one caching level to another.
In this paper, we address these challenges by designingNeutrino- a new distributed memory management sys-tem - implemented as an extension to Spark. Neutrinoeliminates the need for the programmer to manually es-timate the memory needs of serialized or deserializedcache levels; and enforce caching decisions based oncluster configuration. Instead, the programmer now sim-ply uses a new adaptive cache level supported by Neu-trino. Neutrino automatically extracts a data flow graphthat tracks the access dependency of different RDDs used
1
020406080
100120140
10 20 30 40 50
SizeinM
emory(GB)
DataSize(GB) Serialized Deserialized
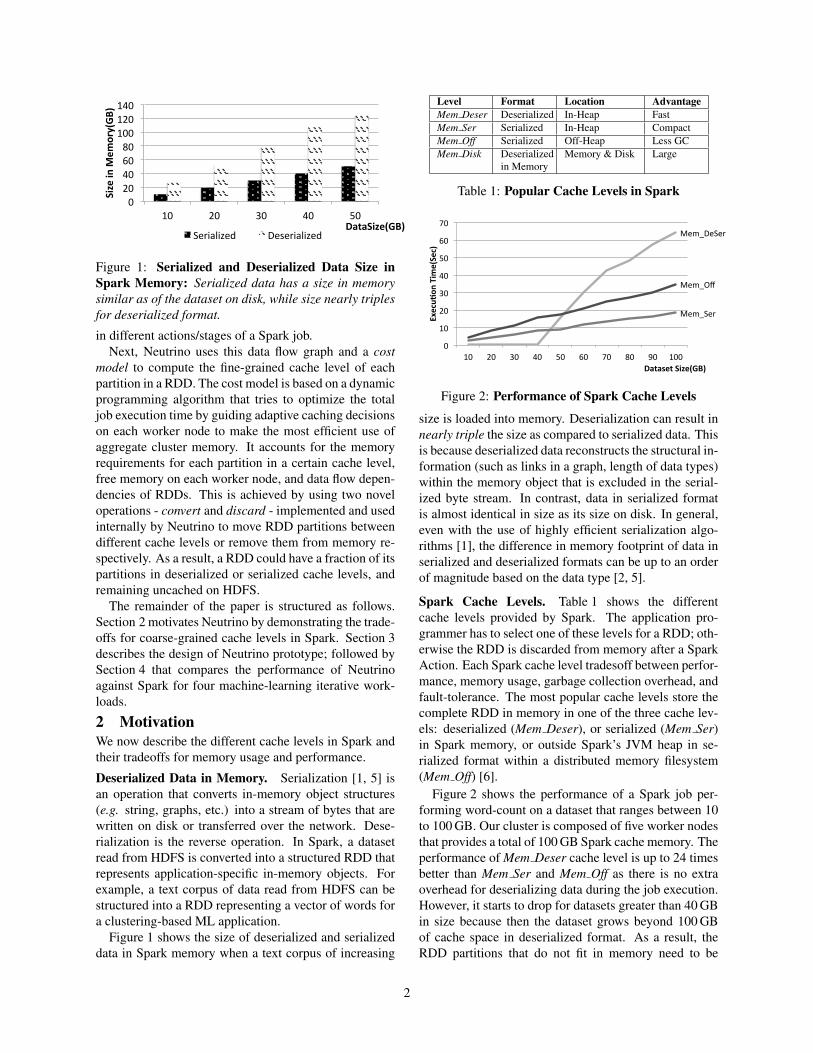
Figure 1: Serialized and Deserialized Data Size inSpark Memory: Serialized data has a size in memorysimilar as of the dataset on disk, while size nearly triplesfor deserialized format.
in different actions/stages of a Spark job.Next, Neutrino uses this data flow graph and a cost
model to compute the fine-grained cache level of eachpartition in a RDD. The cost model is based on a dynamicprogramming algorithm that tries to optimize the totaljob execution time by guiding adaptive caching decisionson each worker node to make the most efficient use ofaggregate cluster memory. It accounts for the memoryrequirements for each partition in a certain cache level,free memory on each worker node, and data flow depen-dencies of RDDs. This is achieved by using two noveloperations - convert and discard - implemented and usedinternally by Neutrino to move RDD partitions betweendifferent cache levels or remove them from memory re-spectively. As a result, a RDD could have a fraction of itspartitions in deserialized or serialized cache levels, andremaining uncached on HDFS.
The remainder of the paper is structured as follows.Section 2 motivates Neutrino by demonstrating the trade-offs for coarse-grained cache levels in Spark. Section 3describes the design of Neutrino prototype; followed bySection 4 that compares the performance of Neutrinoagainst Spark for four machine-learning iterative work-loads.
2 MotivationWe now describe the different cache levels in Spark andtheir tradeoffs for memory usage and performance.
Deserialized Data in Memory. Serialization [1, 5] isan operation that converts in-memory object structures(e.g. string, graphs, etc.) into a stream of bytes that arewritten on disk or transferred over the network. Dese-rialization is the reverse operation. In Spark, a datasetread from HDFS is converted into a structured RDD thatrepresents application-specific in-memory objects. Forexample, a text corpus of data read from HDFS can bestructured into a RDD representing a vector of words fora clustering-based ML application.
Figure 1 shows the size of deserialized and serializeddata in Spark memory when a text corpus of increasing
Level Format Location AdvantageMem Deser Deserialized In-Heap FastMem Ser Serialized In-Heap CompactMem Off Serialized Off-Heap Less GCMem Disk Deserialized
in MemoryMemory & Disk Large
Table 1: Popular Cache Levels in Spark
Mem_DeSer
Mem_Ser
Mem_Off
0
10
20
30
40
50
60
70
10 20 30 40 50 60 70 80 90 100
Execu&
onTim
e(Sec)
DatasetSize(GB)
Figure 2: Performance of Spark Cache Levels
size is loaded into memory. Deserialization can result innearly triple the size as compared to serialized data. Thisis because deserialized data reconstructs the structural in-formation (such as links in a graph, length of data types)within the memory object that is excluded in the serial-ized byte stream. In contrast, data in serialized formatis almost identical in size as its size on disk. In general,even with the use of highly efficient serialization algo-rithms [1], the difference in memory footprint of data inserialized and deserialized formats can be up to an orderof magnitude based on the data type [2, 5].
Spark Cache Levels. Table 1 shows the differentcache levels provided by Spark. The application pro-grammer has to select one of these levels for a RDD; oth-erwise the RDD is discarded from memory after a SparkAction. Each Spark cache level tradesoff between perfor-mance, memory usage, garbage collection overhead, andfault-tolerance. The most popular cache levels store thecomplete RDD in memory in one of the three cache lev-els: deserialized (Mem Deser), or serialized (Mem Ser)in Spark memory, or outside Spark’s JVM heap in se-rialized format within a distributed memory filesystem(Mem Off) [6].
Figure 2 shows the performance of a Spark job per-forming word-count on a dataset that ranges between 10to 100 GB. Our cluster is composed of five worker nodesthat provides a total of 100 GB Spark cache memory. Theperformance of Mem Deser cache level is up to 24 timesbetter than Mem Ser and Mem Off as there is no extraoverhead for deserializing data during the job execution.However, it starts to drop for datasets greater than 40 GBin size because then the dataset grows beyond 100 GBof cache space in deserialized format. As a result, theRDD partitions that do not fit in memory need to be
2

Figure 3: Neutrino Architecture: Different componentsof the Neutrino architecture implemented as extensionsto Spark.
read from HDFS when accessed. In contrast, job exe-cution times grow almost linearly for both Mem Ser andMem Off as they store all data in memory in serializedformat. Mem Ser is faster than Mem Off because it doesnot incur extra memory copies for moving data to mem-ory outside Spark’s heap. We also observe that Mem Serresults in unused memory in the cluster for dataset sizesbetween 50-90 GB.
These results show that the programmer can not eas-ily select the most suitable cache level as it is difficult tostatically account for different data types and free mem-ory at runtime in the cluster. Second, a coarse-grainedselection of a cache level for a RDD may be inflexibleto make the most effective use of free cluster memory.We now show how Neutrino addresses these challengesusing adaptive caching by extracting a data flow graphto capture the access dependencies and using a runtimecost model to guide fine-grained conversion of RDD par-titions between different cache levels.
3 System DesignIn this section, we describe the design principles forNeutrino and how we have implemented a prototype foradaptive caching for managing memory in Spark.
Figure 3 shows the three main components ofNeutrino architecture: adaptive caching implementedwithin the Spark Executors running on each workernode (Section 3.1), generation of the data flow graph(Section 3.2), and the runtime cost model implementedas a (dynamic cache scheduling) algorithm at the SparkMaster to trigger convert and discard operations of adap-tive caching on the different executors (Section 3.3).
3.1 Adaptive Caching in NeutrinoNeutrino provides programmers a new cache level Adap-
tive that enables to provide fine-grained cache manage-ment by moving RDD partitions between cache levels atruntime.
The Spark master directs the executors on differentworker nodes to apply a coarse-grained cache level to allpartitions of a RDD. The Spark block manager in eachexecutor applies the same cache level directive to all par-titions read from HDFS. We extend the partition struc-ture to add an extra attribute that defines its cache level inNeutrino. As a result, when the Spark master distributesthe executors in Neutrino to work on a given partition,it also assigns a cache level when loading that partitioninto memory.
At runtime, adaptive caching can move a partitionacross different cache levels or remove it from memorycompletely based on the inputs from the DP Schedulingalgorithm. We enable the executor to perform this us-ing three operations on a partition: cache, discard, andconvert. The cache operation places the partition in thegiven cache level similar to Spark.
Spark identifies each partition by a global identifierand can asynchronously discard a partition. As a result,the memory is actually not freed immediately after is-suing the asynchronous discard. We integrate this APIin the Neutrino adaptive caching as it does not blockthe discard operation. The Neutrino adaptive cachingverifies the completion of the asynchronous discard bychecking the free capacity of the executor in the cacheand convert operations. This ensures that the space forthe discarded partition is not reused before it is actuallydiscarded. As discard is asynchronous, its overhead is al-ways overlapped by a cache or convert operation for thenext job.
In Spark, a RDD partition can not be transformed be-tween different cache levels, instead a RDD needs to bediscarded from memory and then cached again in anotherlevel. Neutrino also provides a mechanism to convertRDD partitions between different cache levels. We cur-rently support conversion from deserialized to serializedcache levels and vice versa. The conversion requires ex-tra computation to (de)-serialize a RDD partition. Asa result, we perform conversion only on-demand whena RDD partition is used and cached for the executingjob. A convert from deserialized to serialized cache levelfrees up space to be reused for loading more partitionsin memory or converting another partition to the deseri-alized level. A convert from serialized to deserializedcache level improves performance for computing overthe partition by making use of the un-utilized memoryin the cluster.
3.2 Data Flow GenerationAs shown in Figure 3, Neutrino first extracts the dataflow graph which is the order in which the different
3

Figure 4: K-Nearest Neighbor (KNN) ApplicationRDDs are accessed in a Spark job. We can extract a dataflow graph using different approaches, e.g. static analy-sis of the program, or by actually executing the programon a smaller dataset. We use the second approach to ex-tract the RDD access order by executing the program ona smaller dataset.
A Spark application is split into different jobs and thedata flow graph captures the access order of RDDs indifferent jobs’ execution. We retrieve the access order byinstrumenting the getOrCompute API in the master node.This API is used whenever a RDD is loaded from HDFSor computed using another RDD. The access order is re-trieved as a table of key-value pairs where each key rep-resents a job id and the value is the list of RDDs that areused in this job. The order of RDD access across jobs isdependent on how Transformations and Actions are ap-plied in a Spark program. For example, in the K-NearestNeighbor (KNN) Application (see Figure 4), the testingand training RDDs are loaded from HDFS datasets, andtestVec and trainVec vector RDDs are created from themin the map Transformations. KNNjoin represents a se-ries of Actions applied iteratively on these testVec andtrainVec RDDs. Each iteration represents an action orstage. The dataflow graph generated by Neutrino repre-sents all four RDDs used in the first stage, and followingiterative stages only include the vectorized RDDs. Thedataflow graph captures the RDD access order, hence itcan be generated on a relatively small dataset and usedfor different iterations or job executions.
3.3 Dynamic Cache Scheduling at RuntimeNeutrino extends the Spark master to maintain runtimeinformation and guide adaptive caching decisions at theexecutors. We maintain a partitionStatus map at the mas-ter node that records the status of each partition. It in-cludes the blockId of the partition as the key, and a valuethat is a combination of the serialized/deserialized sizesof the partition, location of the partition, current cachelevel, and the pending action on the partition. Eachrecord in partitionStatus map is 48 bytes, and it takesno more than 512 MB of memory space for a very largepetabyte dataset.
Figure 5 shows how the Neutrino master generates
Figure 5: Neutrino KNN Execution Flow
Figure 6: Dynamic Cache Scheduling Algorithm
the caching decisions for a Spark K-Nearest Neighborapplication (see Figure 4 with two RDDs created fromthe training and testing datasets. The two datasets aremapped into vectors and the compute tasks are createdbased on the location of the dataset partitions. Beforethe tasks are scheduled on the different worker nodes,Neutrino master uses the Dynamic Cache scheduling al-gorithm to generate the decisions for adaptive caching totrigger the cache, convert or discard operations for se-lecting the cache level of each RDD partition. For exam-ple, without the Dynamic Cache Scheduling generatingcaching decisions in Figure 5, the vectorized datasets asRDDs will be cached in a cache level, which might over-flow the memory if deserialized or leave memory under-utilized if serialized.
Figure 6 shows the Dynamic Cache Scheduling algo-rithm. It computes the minimum time to execute a Sparkapplication for a given data flow graph (rdd seq) and par-tition status map (pMap). rdd seq[i] is the list of RDDs
4

Figure 7: System Comparison: Neutrino vs. Spark
used in the ith stage/action of the data flow graph. pMaprepresents the cache level and location of each partitionin the system. The dy sched algorithm uses dynamicprogramming to compute the minimum execution timeat the ith stage by exploring all possible combinations ofavailable operations (convert, cache, discard) applied tothe different partitions at stages i and later. It does notexplore infeasible combinations such as caching with in-sufficient memory or convert non-cached partitions. Thefunctions Accessing and Executing compute the time toread data from the given cache level (partition map) inthe ith stage, and the time to apply the selected oper-ations at the end of ith stage respectively (also shownas Executing Cache Decisions in Figure 5). To limit thenumber of possible combinations to explore in each stageand use memory fairly across different executors in thecluster, we apply the cache operations at the granularityof a configurable fraction of a RDD. For example, wecan apply a cache operation such as convert 25% of thepartitions of a RDD from deserialized to serialized cachelevel to save memory space uniformly across all workernodes.
4 EvaluationWe compare Neutrino against Spark’s native cachinglevels: Mem Ser and Mem Deser. The experimentswere performed on a cluster of six worker nodes, eachequipped with Intel i5-2400 3.1 GHz CPU, one 500 GBdisk, 8 GB DRAM out of which Spark uses 6 GB mem-ory. We use HDFS v2.6.3 with a block size of 128 MBand Spark v1.5.0 with four MLlib workloads: K-Means,KNN, Latent Dirichlet Allocation (LDA), and LogisticRegression. These workloads cover the three differentpopular categories of ML workloads including inference,nearest neighbor, and regression; and iteratively queryone or multiple RDDs.
Figure 7 shows the average job execution time forSpark Mem Ser and Mem Deser cache levels relativeto Neutrino. We evaluate three scenarios with differentdataset size: (1) deserialized dataset size < cluster mem-ory, (2) deserialized dataset size = cluster memory, and(3) serialized dataset size = cluster memory.
Neutrino outperforms Spark cache levels in most sce-
narios for all three workloads. In Scenario 1, Neutrinois about 45-60% faster than Spark Mem Ser because itdeserializes all partitions and makes more efficient useof unused cluster memory than Mem Ser. Neutrino is upto 7% slower than Spark Mem Deser because of the ex-tra computation overhead for dynamic cache schedulingand additional cache or convert operations. The discardoperation is asynchronous and its overhead gets over-lapped with the job computation time. In Scenario 2,Neutrino is about 16-35% and 5-66% faster than SparkMem Ser and Mem Deser cache levels respectively. Thisis because Spark Mem Deser starts missing the memorycache and has to recompute partitions from HDFS. Incontrast, Neutrino always hits in the memory and keepsRDD partitions in both formats. Spark Mem Ser hasan overhead for deserializing data during job execution.In Scenario 3, Neutrino serializes all RDD partitions inmemory and is almost identical in performance to SparkMem Ser. The performance gap between Neutrino andSpark Mem Deser increases to 46-70% because of morefrequent cache misses in Spark Mem Deser.
5 Conclusions and Future DirectionsIn this paper, we take a fresh look on a very pressing areaof memory caching for iterative data analytics. We makea case for fine-grained caching with a new dynamic cachescheduling algorithm. The results look promising and weplan to build upon current work. In future, we will con-tinue to work in two main directions: (1) improve dataflow generation process to track dependencies for itera-tive workloads that can result in non-deterministic execu-tion flows, and (2) improve the pruning technique to re-duce the exploration space and provide stronger fairnessguarantees for the dynamic cache scheduling algorithm.References[1] Kyro: Java serialization and cloning. https://github.com/
EsotericSoftware/kryo, 2016.
[2] Project Tungsten: Bringing spark closer to bare metal. https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html, 2016.
[3] Spark MLlib. http://spark.apache.org/docs/latest/mllib-guide.html, 2016.
[4] ANANTHANARAYANAN, G., GHODSI, A., WANG, A., BORTHAKUR, D.,KANDULA, S., SHENKER, S., AND STOICA, I. Pacman: Coordinated mem-ory caching for parallel jobs. In NSDI (2012).
[5] ARMBRUST, M., DAS, T., DAVIDSON, A., GHODSI, A., OR, A., ROSEN,J., STOICA, I., WENDELL, P., XIN, R., AND ZAHARIA, M. Scaling sparkin the real world: Performance and usability. PVLDB (2015).
[6] LI, H., GHODSI, A., ZAHARIA, M., SHENKER, S., AND STOICA, I.Tachyon: Reliable, memory speed storage for cluster computing frame-works. In SOCC (2014).
[7] PU, Q., LI, H., ZAHARIA, M., GHODSI, A., AND STOICA, I. Fairride:Near-optimal, fair cache sharing. In NSDI (2016).
[8] ZAHARIA, M., CHOWDHURY, M., DAS, T., DAVE, A., MA, J., MC-CAULY, M., FRANKLIN, M. J., SHENKER, S., AND STOICA, I. Resilientdistributed datasets: A fault-tolerant abstraction for in-memory cluster com-puting. In NSDI (2012).
5