Embed Size (px)
Citation preview

1
Storage-Aware Caching:Revisiting Caching for Heterogeneous Storage
Systems(Fast’02)
Brian ForneyAndrea Arpaci-Dusseau Remzi Arpaci-Dusseau
Wisconsin Network DisksUniversity of Wisconsin at Madison
Presented by Enhua Tan
July 1, 2005
2
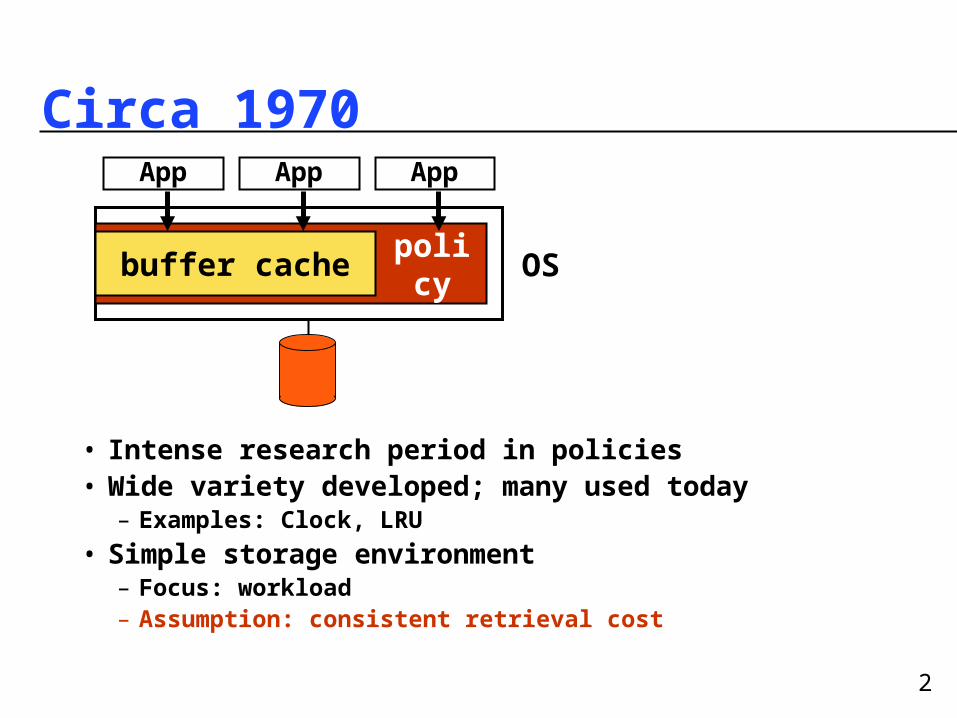
Circa 1970
OSpolic
y
• Intense research period in policies• Wide variety developed; many used today– Examples: Clock, LRU
• Simple storage environment– Focus: workload– Assumption: consistent retrieval cost
buffer cache
App AppApp
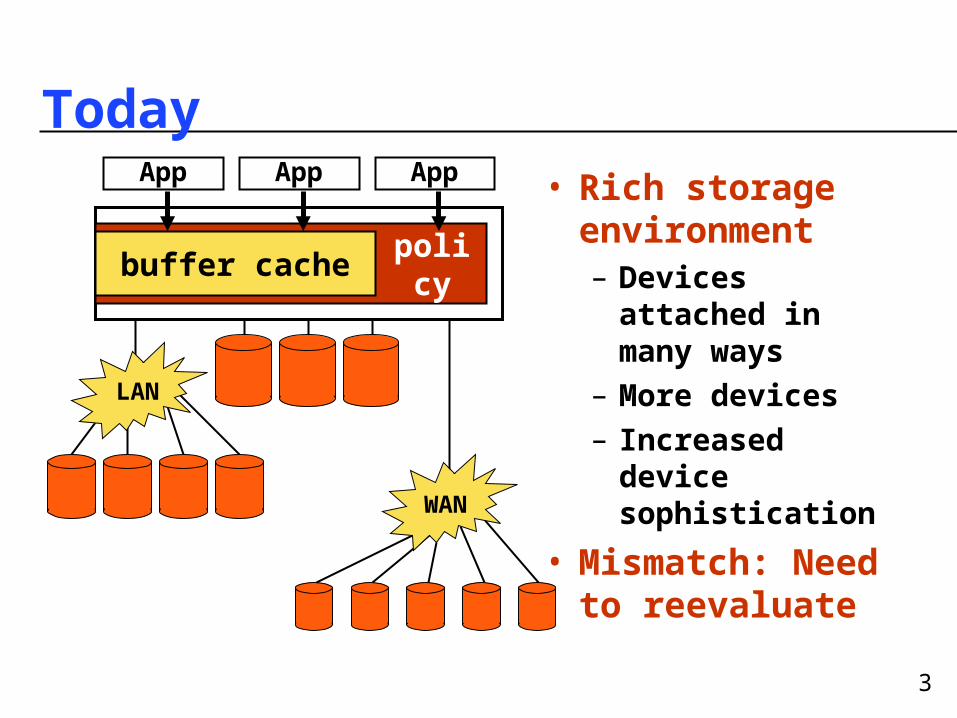
3
Today• Rich storage
environment– Devices attached
in many ways– More devices– Increased device
sophistication
• Mismatch: Need to reevaluate
LAN
WAN
policy
buffer cache
App AppApp

4
Problem illustration• Uniform workload• Two disks• LRU policy
• Slow disk is bottleneck• Problem: Policy is oblivious– Does not filter well
fast slow

5
General solution
• Integrate workload and device performance– Balance work across devices–Work: cumulative delay
• Cannot throw out:– Existing non-cost aware policy research– Existing caching software

6
Existing cost-aware algorithm
• LANDLORD– Cost-aware, based on LRU / FIFO– Same as web caching algorithm– Integration problems with modern OSes

7
LANDLORD (LRU version)
• Each object associates with a cost L– Initially set to H: the retrieval cost
divided by the size of the object– Evict the object with lowest L; and
decrementing all remaining pages by this L
– Upon reference, L restored to H
• When all H values are the same, equal to strict LRU

8
Solution Overview• Generic partitioning framework– Old idea– One-to-one mapping: device partition– Each partition has cost-oblivious policy– Adjust partition sizes
• Advantages– Aggregates performance information– Easily and quickly adapts to workload and
device performance changes– Integrates well with existing software
• Key: How to pick the partition sizes

9
Outline
• Motivation
• Solution overview
• Taxonomy
• Dynamic partitioning algorithm
• Evaluation
• Summary

10
Partitioning algorithms
• Static– Pro: Simple– Con: Wasteful – cannot balance work for all
workloads
• Dynamic– Adapts to workload
• Hotspots• Access pattern changes
– Handles device performance faults
• Used dynamic

11
Algorithm: Overview
1. Observe: Determine per-device cumulative delay
2. Act: Repartition cache
3. Save & reset: Clear last W requests
Observe
Act
Save & reset

12
Algorithm: Observe
• Want accurate system balance view
• Record per-device cumulative delay for last W (window size) completed disk requests– At client– Includes network time (and the remote
disk service time)

13
Algorithm: Act• Categorize each partition
– Page consumers• Cumulative delay above threshold possible bottleneck
– Page suppliers• Cumulative delay below mean lose pages without
decreasing performance
– Neither
• Always have page suppliers if there are page consumers
Page consumer Page supplier Neither
Page consumer Page supplierNeither
Before
After

14
Page consumers• How many pages? Depends on state:
– Warming• Cumulative delay increasing• Aggressively add pages: reduce queuing
– Cooling• Cumulative delay decreasing• Do nothing; naturally decreases
– Warm• Cumulative delay constant• Conservatively add pages

15
Three parameters
• W: window size– W = 1000 provides sufficient smoothing and
feedback
• T: threshold– T = 5, can detect changes in relative wait time
that need correction
• I: base increment amount– Should be small for exponential correction– 0.2% of the cache works well

16
Dynamic partitioning
• Eager– Immediately change partition sizes– Pro: Matches observation– Con: Some pages temporarily unused
• Lazy– Change partition sizes on demand– Pro: Easier to implement– Con: May cause over correction

17
Partitioned-Clock algorithm
• Each page has a use bit like the Clock algorithm
• Also has the partition number that it belongs
• Victim will be selected with the matched partition number for replacement
• A separate clock hand for each partition helps

18
Lazy Clock
• When searching for a replacement– Only those pages belonging to the
victim’s partition should have their use bits cleared
• Uses inverse lottery scheduling to pick victims among partitions– Each partition is given a number of
tickets in inverse proportion to its desired size

19
Outline
• Motivation
• Solution overview
• Taxonomy
• Dynamic partitioning algorithm
• Evaluation
• Summary
20
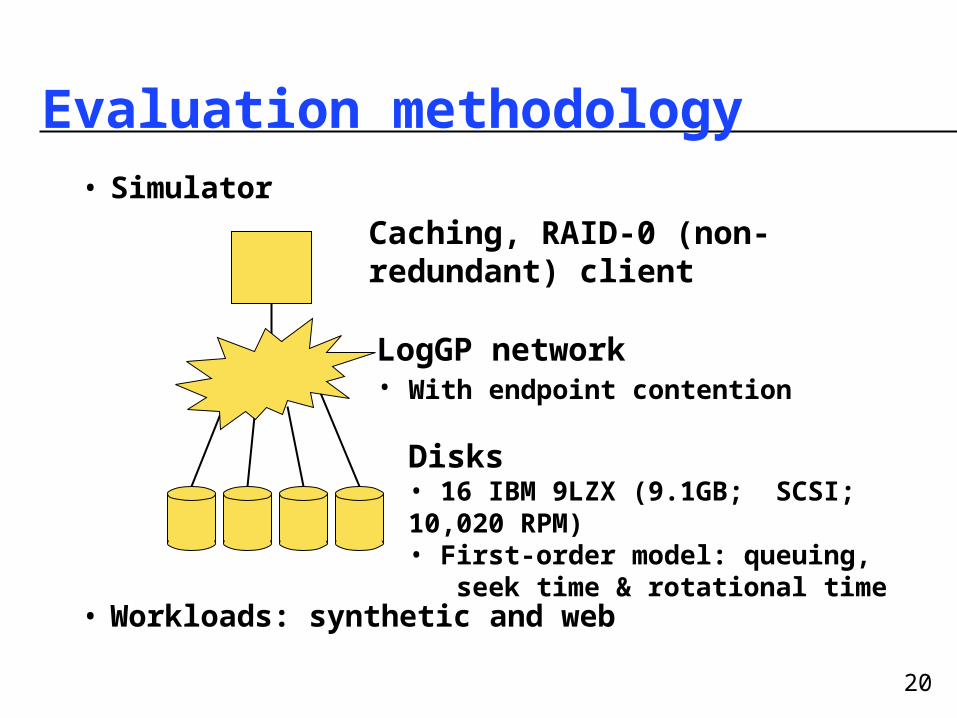
Evaluation methodology• Simulator
• Workloads: synthetic and web
Caching, RAID-0 (non-redundant) client
LogGP network• With endpoint contention
Disks• 16 IBM 9LZX (9.1GB; SCSI; 10,020 RPM)• First-order model: queuing, seek time & rotational time
21
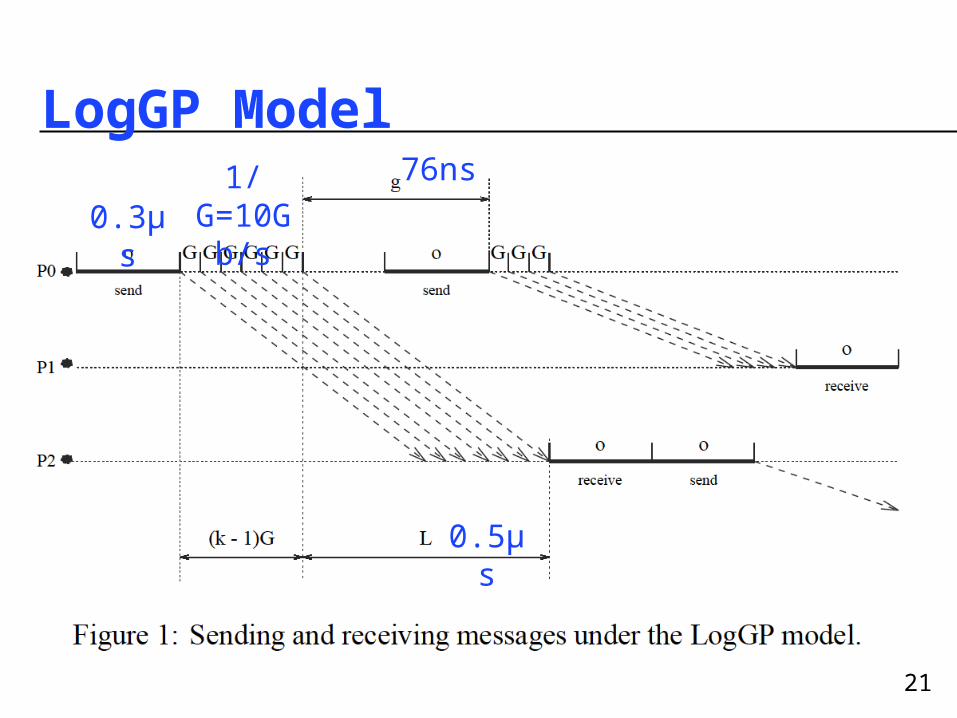
LogGP Model
0.5μs
0.3μs
76ns1/G=10Gb/s

22
Evaluation methodology• Introduced performance heterogeneity– Disk aging• Used current technology trends
– Seek and rotation: 10% decrease/year– Bandwidth: 40% increase/year
• Scenarios– Single disk degradation: Single disk, multiple
ages– Incremental upgrades: Multiple disks, two ages
– Fault injection• Understand dynamic device performance
change and device sharing effects

23
Evaluated policies
• Cost-oblivious: LRU, Clock
• Storage-aware: Eager LRU, Lazy LRU; Lazy Clock, Eager Clock
• Comparison: LANDLORD
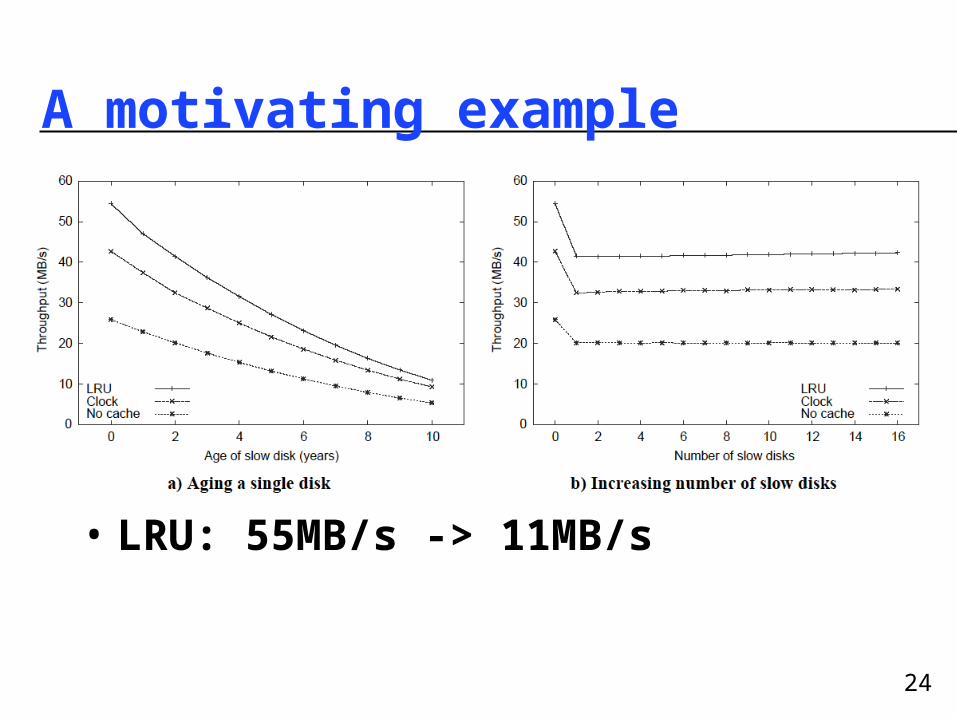
24
A motivating example
• LRU: 55MB/s -> 11MB/s
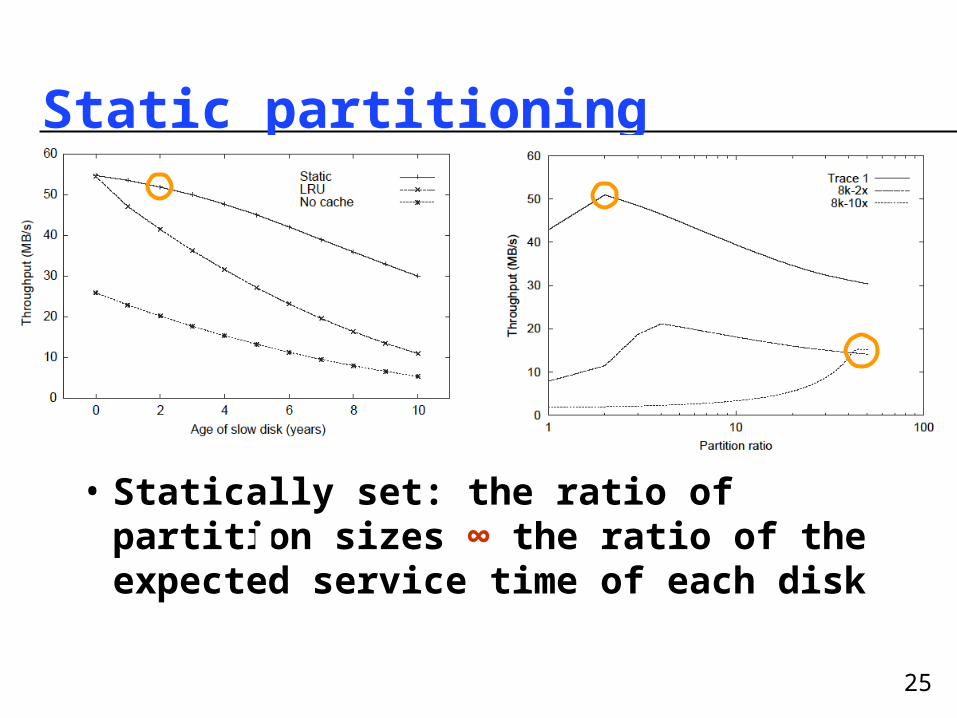
25
Static partitioning
• Statically set: the ratio of partition sizes ∞ the ratio of the expected service time of each disk
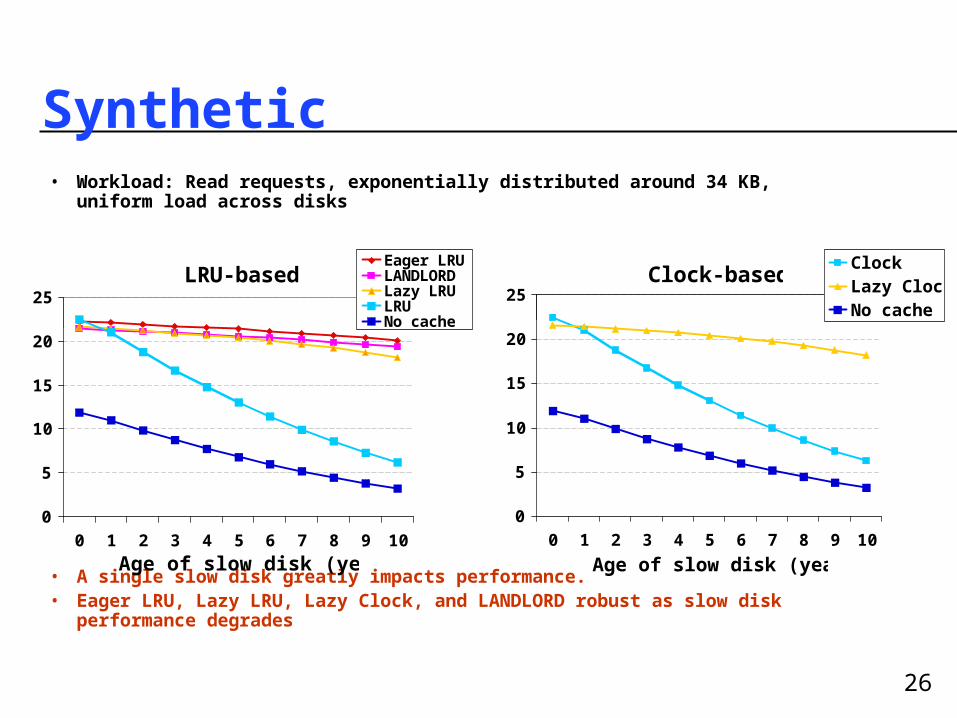
26
Synthetic• Workload: Read requests, exponentially distributed around 34 KB,
uniform load across disks
• A single slow disk greatly impacts performance.• Eager LRU, Lazy LRU, Lazy Clock, and LANDLORD robust as slow disk
performance degrades
LRU-based
0
5
10
15
20
25
0 1 2 3 4 5 6 7 8 9 10
Age of slow disk (years)
Th
rou
gh
pu
t (M
B/s
)
Eager LRULANDLORDLazy LRULRUNo cache
Clock-based
0
5
10
15
20
25
0 1 2 3 4 5 6 7 8 9 10
Age of slow disk (years)
Th
rou
gh
pu
t (M
B/s
)
ClockLazy ClockNo cache
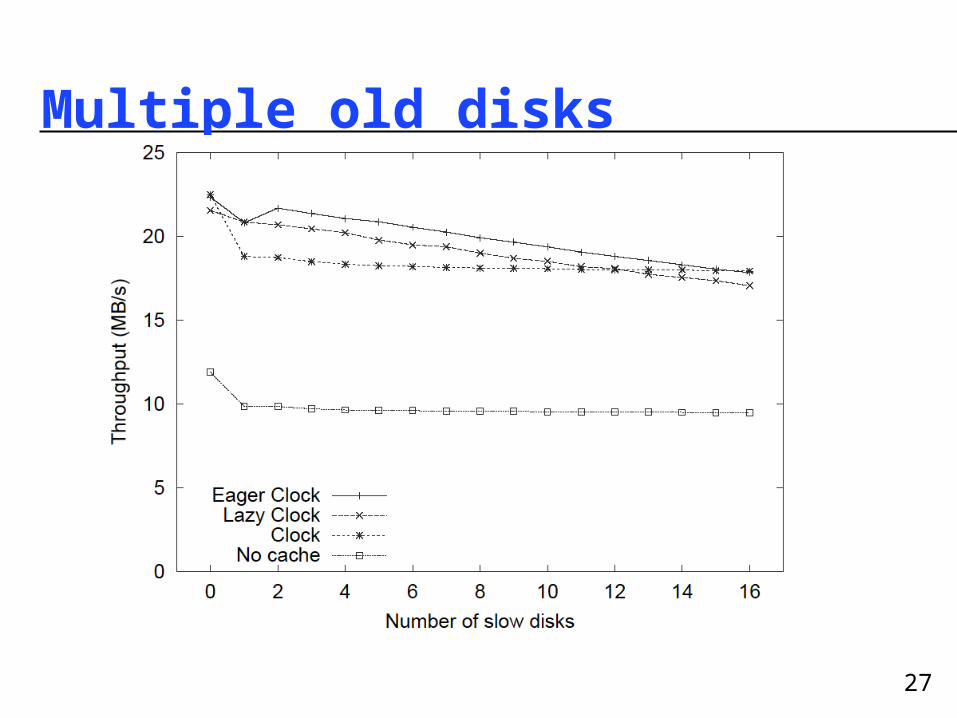
27
Multiple old disks
28
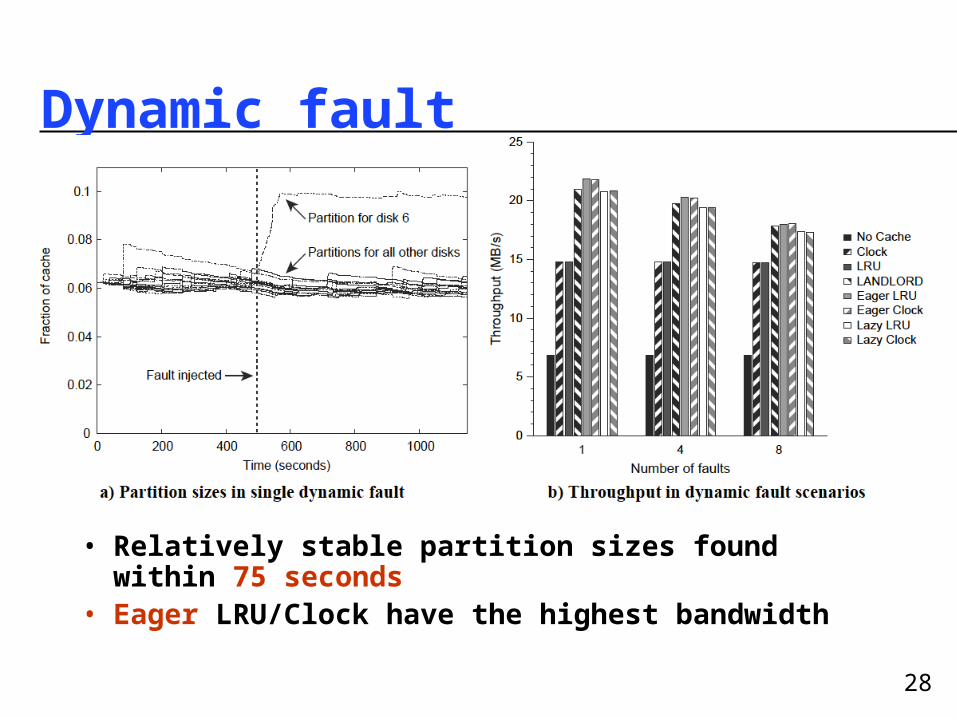
Dynamic fault
• Relatively stable partition sizes found within 75 seconds
• Eager LRU/Clock have the highest bandwidth
29
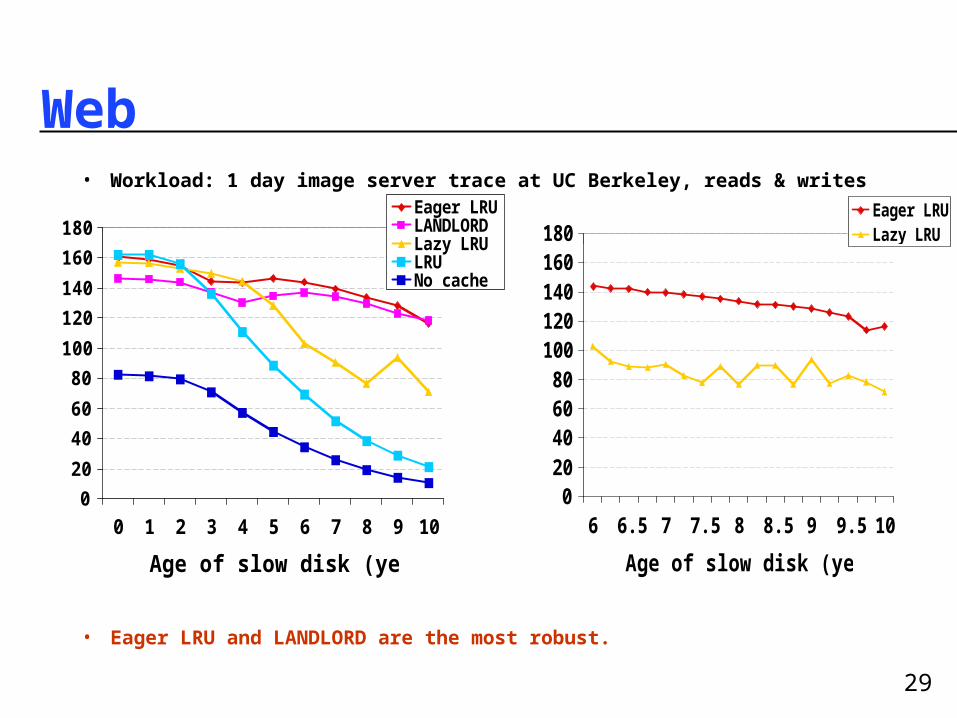
Web• Workload: 1 day image server trace at UC Berkeley, reads & writes
• Eager LRU and LANDLORD are the most robust.
020406080
100120140160180
6 6.5 7 7.5 8 8.5 9 9.5 10
Age of slow disk (years)
Thro
ughp
ut (
MB
/s)
Eager LRULazy LRU
0
20
40
60
80
100
120
140
160
180
0 1 2 3 4 5 6 7 8 9 10
Age of slow disk (years)
Th
rou
gh
pu
t (M
B/s
)
Eager LRULANDLORDLazy LRULRUNo cache
30
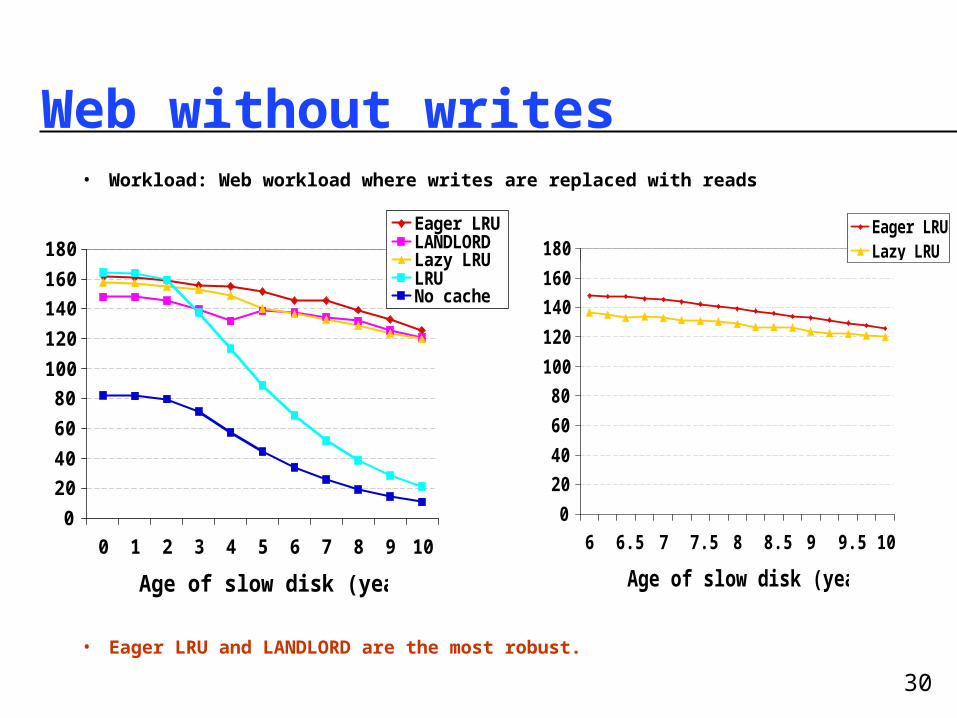
Web without writes• Workload: Web workload where writes are replaced with reads
• Eager LRU and LANDLORD are the most robust.
0
20
40
60
80
100
120
140
160
180
6 6.5 7 7.5 8 8.5 9 9.5 10
Age of slow disk (years)
Thro
ughp
ut (
MB
/s)
Eager LRULazy LRU
0
20
40
60
80
100
120
140
160
180
0 1 2 3 4 5 6 7 8 9 10
Age of slow disk (years)
Th
rou
gh
pu
t (M
B/s
)
Eager LRULANDLORDLazy LRULRUNo cache

31
Summary• Problem: Mismatch between storage
environment and cache policy– Current buffer cache policies lack device
information
• Policies need to include storage environment information
• Solution: Generic partitioning framework– Aggregates performance information– Adapts quickly– Allows for use of existing policies

32
Limitations• Assumptions
– Linear relationship between cache size and hit rate• Doesn’t hold for workload with little locality
– Rely on proper values for three parameters: window size, base increment amount, and threshold
• Outperform dramatically when a disk is quite slow (4~10 years old)– But is that a realistic problem with technology
advancing? Should the disk be replaced rather than using more cache space to mask the lag?
• Break transparency:– Clients need to know there exist 16 network disks?

33
Future work
• Implementation in Linux
• Cost-benefit algorithm
• Study of integration with prefetching and layout

34
Follow-ups
• 10 citations found in Google Scholar, most are before 2003
• Papers in the field of Web, Cluster, and Storage system

35
WiND project
• Wisconsin Network Disks
• Building manageabledistributed storage
• Focus: Local-areanetworked storage
• Issues similar in wide-area





























