Embed Size (px)
Citation preview

Near-Duplicate Detection by Instance-level Constrained
Clustering
Hui Yang, Jamie Callan
Language Technologies Institute
School of Computer Science
Carnegie Mellon University

Introduction
Near-Duplicate Detection• To identify and organize “nearly-identical”
documents• Different definition of “similarity” from other fields
– Database: Almost-identical documents • Finger-prints based approaches• Only allow small changes to the texts• Sensitive to text positions
– Information Retrieval: Relevant documents• Bag-of-word approaches • Measure overlap of the vocabulary• Focus more on semantic similarity while near-
duplicates more on syntactic (surface text) similarity• Cannot identify near-duplicates when they only share
a small amount of text

Near-Duplicate Detection in eRulemaking
• U.S. regulatory agencies receive and deal with large amount of public comments everyday– By law, they need to read each of them
• Many of them are “Form Letters”– Generate comments based on form letters
provided by online special interest groups• http://www.moveon.org• http://www.getactive.com
• Need to automate the duplicate detection process and save human effort

Editing Styles
• Block Added: Add one or more paragraphs (<200 words) to a document;
• Block Deleted: Remove one or more paragraphs (<200 words) from a document;
• Key Block: Contains at least one paragraph from a document;
• Minor Change: A few words altered within a paragraph (<5% or 15 word change in a paragraph) ;
• Minor Change & Block Edit: A combination of minor change and block edit;
• Block Reordering: Reorder the same set of paragraphs;• Repeated: Repeat the entire document several times in
another document;• Bag-of-word similar: >80% word overlap (not in above
categories); and• Exact: 100% word overlap.

“Key Block” Problem
D o c um e nt ID : 0 3 -2 3 -2 0 0 4 -2 4 5 5 2 8dive rge nc e 0 .3 0 0 6 4 1G iven tha t you have no com punction abou t d ropp ing bom bs on ch ild ren i tcom es a s no surpr ise tha t you cou ld care less abou t ch i ld ren in our ow ncoun try tha t a re ef fected by m ercury po ison ing . Y ou know w hy the M adH atter w as m ad? B ecause in those days m ercury w as used by ha tters to"f ix" ha ts and hence m any ha tters w ere "m ad" ( dem en ted , qu ick tem pered ,etc). G iven the regress ive po licies you l ike to pu t in to p lace, m aybe you 'da lso l ike to go back to u s ing m ercury to cure venerea l d isease? W hy don 'tyou chew on an o ld therm om eter fo r a w h ile and see w ha t inges t ingm ercury w il l do fo r you . N o? Y ou 're too good fo r tha t? W ell , a ren 't ourci t izens , ch i ld ren and adu lts a l ike, good enough to l ive hea lthy l ives?
T h e E P A s h o u ld req u i re p o w er p lan ts to cu t m ercu ry p o l lu t io n b y 9 0 % b y2 0 0 8 . T h es e red u ct io n s are co n s i s ten t w i th n at io n al s tan d ard s fo r o th erp o l lu tan ts an d ach iev ab le th ro u g h av ai lab le p o l lu t io n -co n t ro l t ech n o lo g y
D oc um e nt ID : 03-23-2004-043280dive rge nc e 0 .046286
S to p th e m a d n ess! ! ! ! ! ! !
T h e E P A sh o uld r e quir e p o we r p la n t s t o c ut m e r c ur y p o llut io n by9 0 % by 2 0 0 8 . T h e se r e duc t io n s a r e c o n sist e n t wit h n a t io n a lst a n da r ds f o r o t h e r p o llut a n t s a n d a c h ie v a ble t h r o ugh a v a ila blep o llut io n - c o n t r o l t e c h n o lo gy .

Need More Flexible Framework
• Need to use additional knowledge from the document collection
• Instance-level Constrained Clustering– A semi-supervised clustering approach
to incorporate additional knowledge• Document attributes • Content structure • Pair-wise relationships

Instance-level Constrained Clustering
• Instance-level Constraints– Pair-wise – Easy to generate– Cannot generate class labels – Weaker condition than semi-supervised
classification
• Types of Constraints– Must-links, cannot-links, family-links

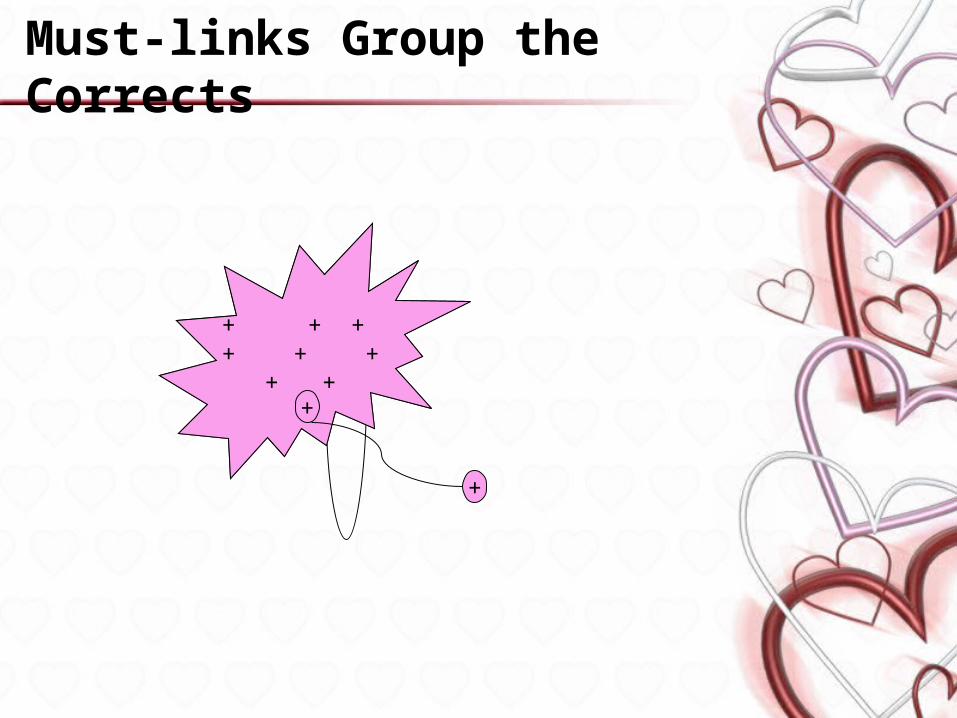
Must-links
• Two instances must be in the same cluster
• Created when
– complete containment of the reference copy (key block),
– word overlap > 95% (minor change).

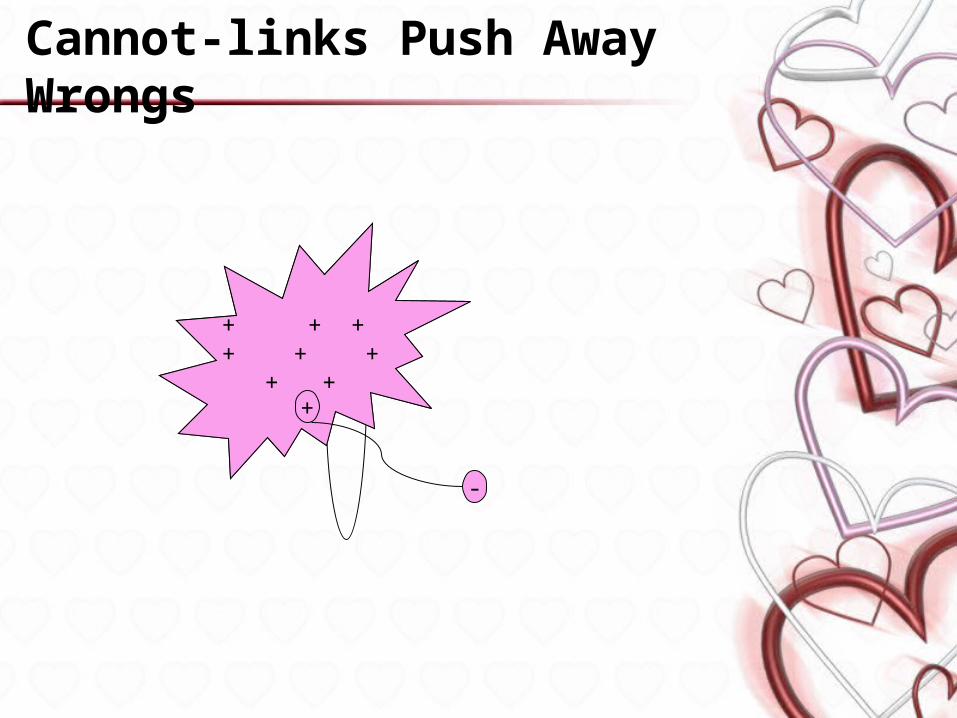
Cannot-links
• Two instances cannot be in the same cluster
• Created when two documents – cite different docket identification
numbers• People submitted comments to
wrong place

Family-links
• Two instances are likely to be in the same cluster
• Created when two documents have – the same email relayer, – similar file sizes, or
– the same footer block.
Must-links Group the Corrects
+ + + + + +
+ + ++
+ + + + + +
+ +
+
+
Cannot-links Push Away Wrongs
+ + + + + +
+ + -+
+ + + + + +
+ +
-
+

Family-links Attract the Similars
+ + + + + +
+ +
+
+
+ + + + + +
+ +
+
+

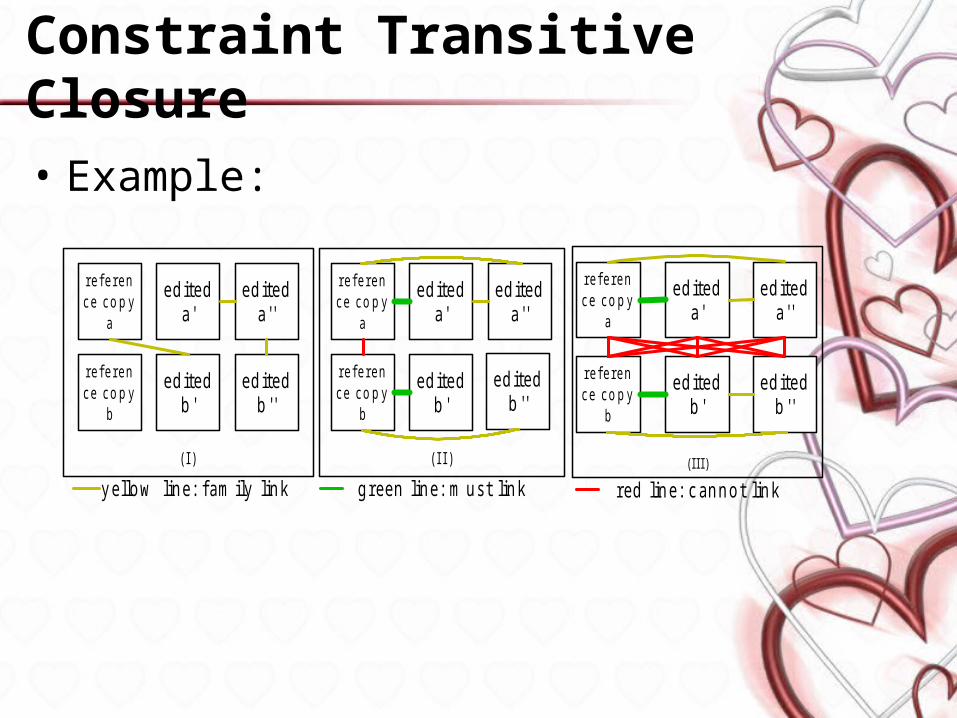
Constraint Transitive Closure
• An initial set of constraints are created for pairs of documents
• Taking transitive closure over the constraints– Must-link transitive closure:
da=m db , db=m dc => da=m dc
– Cannot-link transitive closure: da=c db , db=m dc => da=c dc
– Family-link transitive closure: da=f db , db=m dc => da=f dc da=f db , db=c dc => da=c dc da=f db , db=f dc => da=f dc
( =m, =c and =f indicate must-link, cannot-link and family-link respectively.)
Constraint Transitive Closure
• Example:
r e f e r e nc e c o p y
a
ed iteda '
ed iteda ' '
r e f e r e nc e c o p y
b
ed itedb '
ed itedb ' '
r e f e r e nc e c o p y
a
ed iteda '
ed iteda ' '
r e f e r e nc e c o p y
b
ed itedb '
ed itedb ' '
r e f e r e nc e c o p y
a
ed iteda '
ed iteda ' '
r e f e r e nc e c o p y
b
ed itedb '
ed itedb ' '
( I ) ( I I ) (III)
g r een lin e : m u s t lin k r ed lin e : c an n o t lin ky e llo w lin e : f am ily lin k
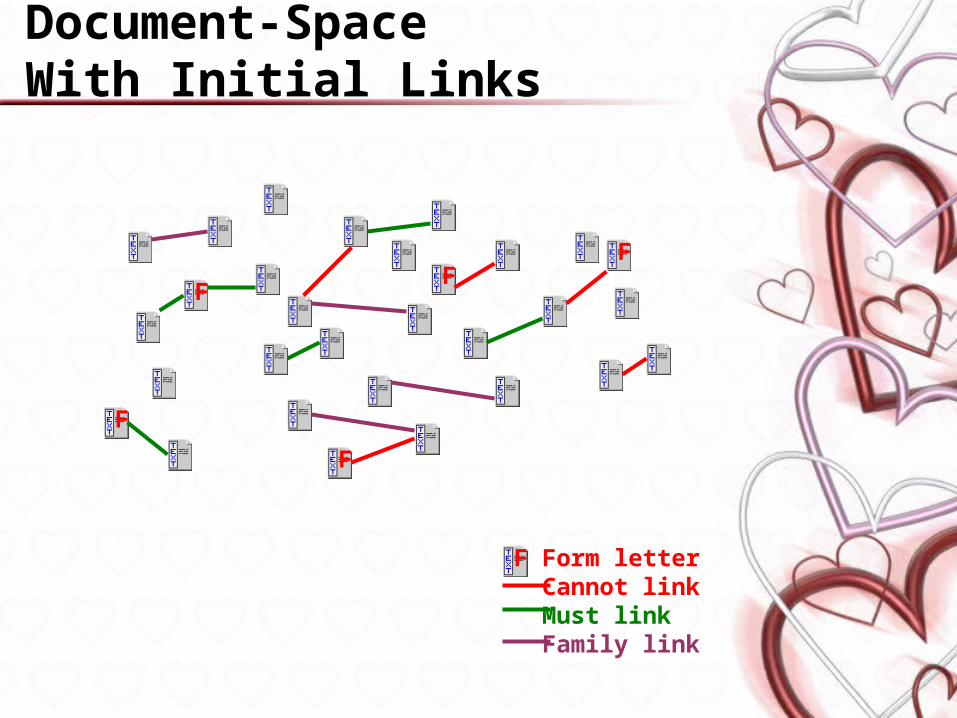
Document-Space With Initial Links
F
F
F
F
F
F
Form letterCannot linkMust linkFamily link
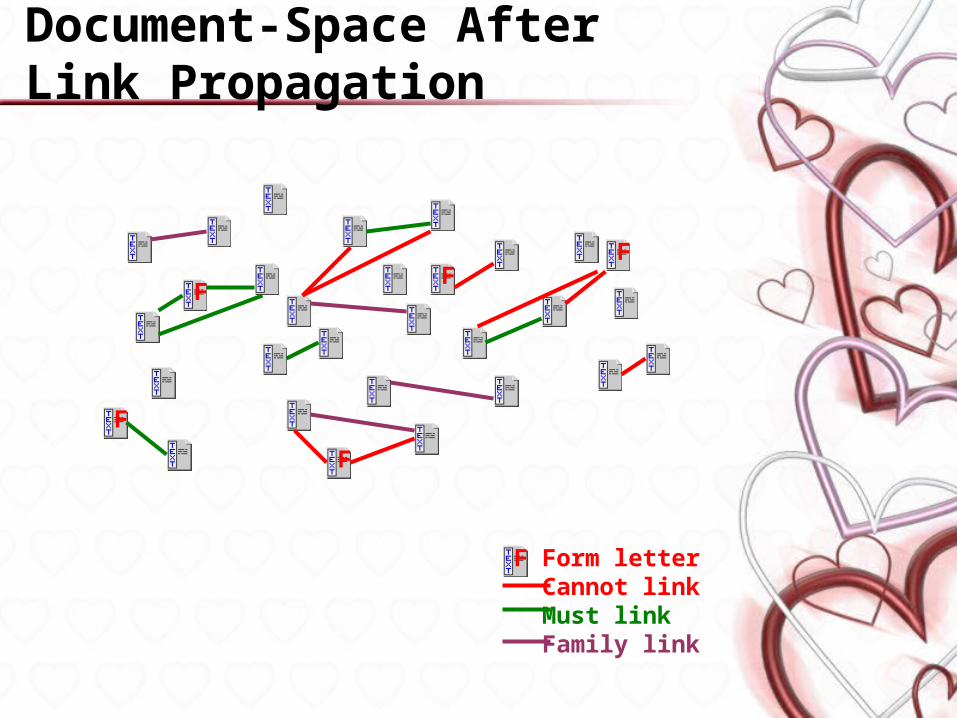
Document-Space After Link Propagation
F
F
F
F
F
F
Form letterCannot linkMust linkFamily link

Incorporating the Constraints
• When forming clusters, – if two documents have a must-link, they
must be put into same group, even if their text similarity is low
– if two documents have a cannot-link, they cannot be put into same group, even if their text similarity is high
– if two documents have a family-link, increase their text similarity score, so that their chance of being in the same group increases.

Redundancy-based Reference Copy Detection
• Apply hash function to the document string (all words in a document concatenated together)– NIST’s security hash function: SHA1 – For each document, there is a unique hash value for it
• Sort the <document id, hash-value> tuples by the hash value– Same hash values stay together
• Linear scan to the sorted list– Same hash value indicates exact duplicates
• The reference copies are selected as the one with the earliest timestamp in an exact duplicate group size bigger than 5

Evaluation
• Assessors (from coding lab in University of Pittsburgh) manually organized documents into near-duplicate clusters
• Compare human-human agreement to human-computer agreement
Dataset From Docket Size Sample(s) Sample Size
Mercury
Environmental Protection Agency
USEPA-OAR-
2002-0056
536,975 emails
NTF NTF2
1000 1000
DOT
Department of Transportation
USDOT-2003-16128
103,355 emails
DOT 1000

Experimental Results
Macro Average Micro Average
NTF NTF2 DOT NTF NTF2 DOT
Coder A / Coder B
0.93 0.90 0.95 0.99 0.95 0.96
Coder A / DURIAN
0.92 0.80 0.86 0.93 0.90 0.88
Coder B / DURIAN
0.90 0.82 0.94 0.91 0.91 0.98
-Comparing with human-human intercoder agreement -Metric: AC1
-A modified version of Kappa

Experimental Results
NTF NTF2 DOTFull 0.96 0.96 0.96DSC 0.81 0.80 0.70I-Match 0.69 0.70 0.65DURIAN 0.98 0.98 0.97
-Comparing with other duplicate detection Algorithms
-Metric: F1
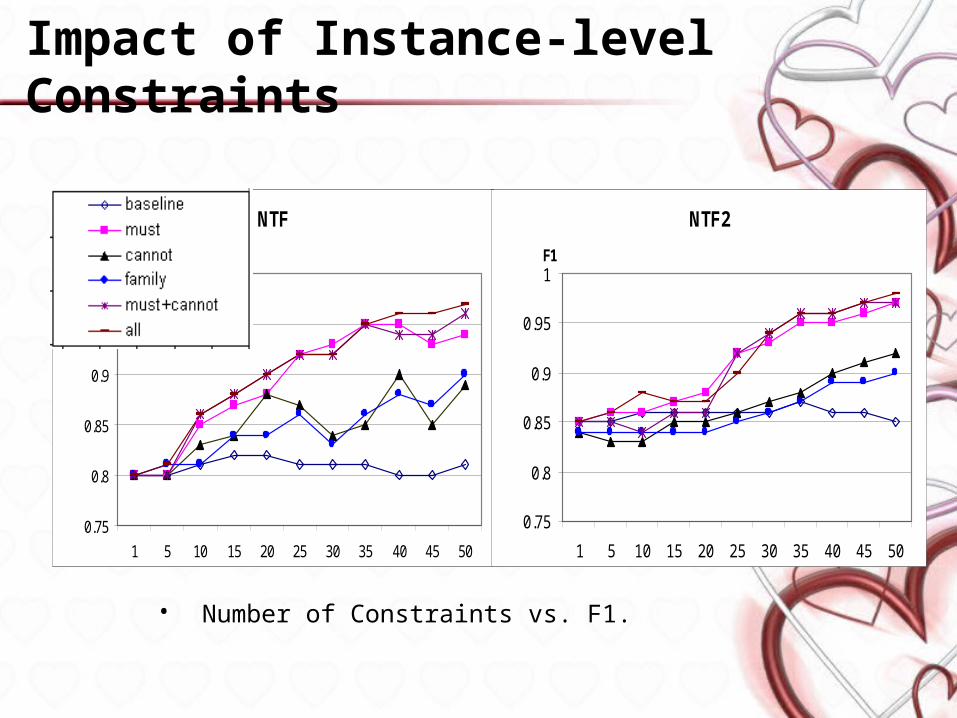
Impact of Instance-level Constraints
• Number of Constraints vs. F1.
NTF
0.75
0.8
0.85
0.9
0.95
1
1 5 10 15 20 25 30 35 40 45 50
F1
NTF2
0.75
0.8
0.85
0.9
0.95
1
1 5 10 15 20 25 30 35 40 45 50
F1
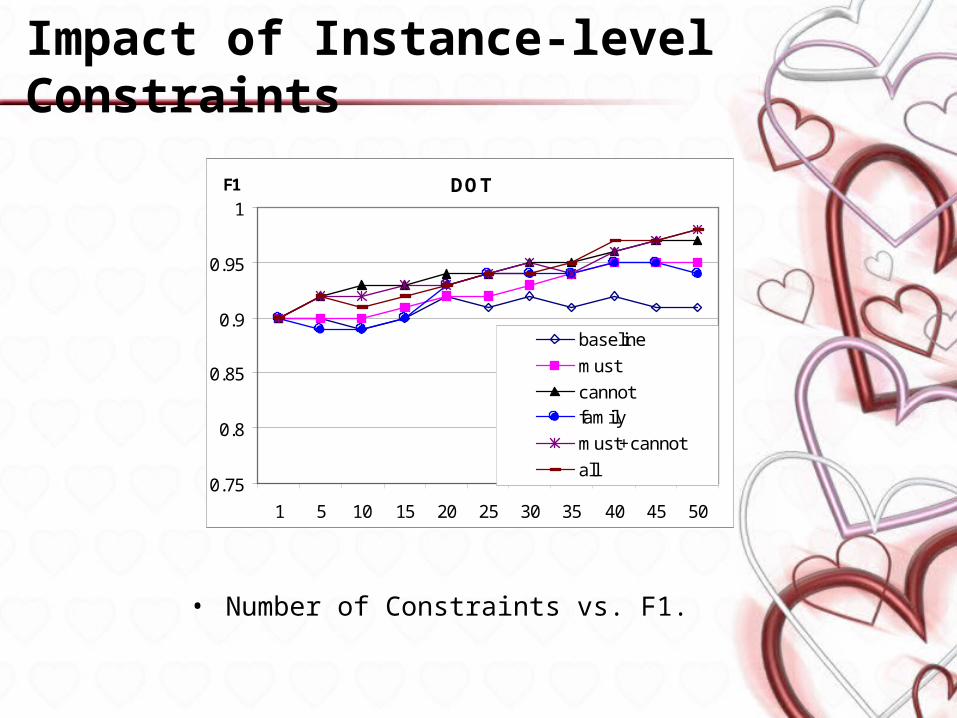
Impact of Instance-level Constraints
• Number of Constraints vs. F1.
DOT
0.75
0.8
0.85
0.9
0.95
1
1 5 10 15 20 25 30 35 40 45 50
F1
baseline
must
cannotfamily
must+cannot
all


Conclusion
• Near-duplicate detection on large public comment datasets is practical
• Instance-based constrained clustering/semi-supervised clustering– Efficient
– Greater control over the clustering
– Encourages use of other forms of evidence
– Easily applied to other datasets

Thank You!
Questions?















![Callan Book 1 [Stage 1]](https://img.pdfslide.us/doc/110x75/544744d2b1af9f800a8b4c46/callan-book-1-stage-1-558445bb7681f.jpg)




![Callan Book 2 [Stage 3]](https://img.pdfslide.us/doc/110x75/55cf8f7c550346703b9ce040/callan-book-2-stage-3-564765e022b75.jpg)







