Embed Size (px)
DESCRIPTION
MOLAR: MO dular L inux and A daptive R untime support. Project Team David Bernholdt 1 , Christian Engelmann 1 , Stephen L. Scott 1 , Jeffrey Vetter 1 Arthur B. Maccabe 2 , Patrick G. Bridges 2 Frank Mueller 3 Ponnuswany Sadayappan 4 Chokchai Leangsuksun 5 1 Oak Ridge National Laboratory - PowerPoint PPT Presentation
Citation preview

1
MOLAR: MOdular Linux and Adaptive Runtime support
Project Team
David Bernholdt1, Christian Engelmann1, Stephen L. Scott1, Jeffrey Vetter1
Arthur B. Maccabe2, Patrick G. Bridges2
Frank Mueller3
Ponnuswany Sadayappan4
Chokchai Leangsuksun5
1Oak Ridge National Laboratory2University of New Mexico
3North Carolina State University4Ohio State University
5Louisiana Tech University
Briefing at: Scalable Systems Software meeting
Argonne National Laboratory - August 26, 2004

2
Research Plan
Create a modular and configurable Linux system that allows customized changes based on the requirements of the applications, runtime systems, and cluster management software.
Build runtime systems that leverage the OS modularity and configurability to improve efficiency, reliability, scalability, ease-of-use, and provide support to legacy and promising programming models.
Advance computer RAS management systems to work cooperatively with the OS/R to identify and preemptively resolve system issues.
Explore the use of advanced monitoring and adaptation to improve application performance and predictability of system interruptions.
3
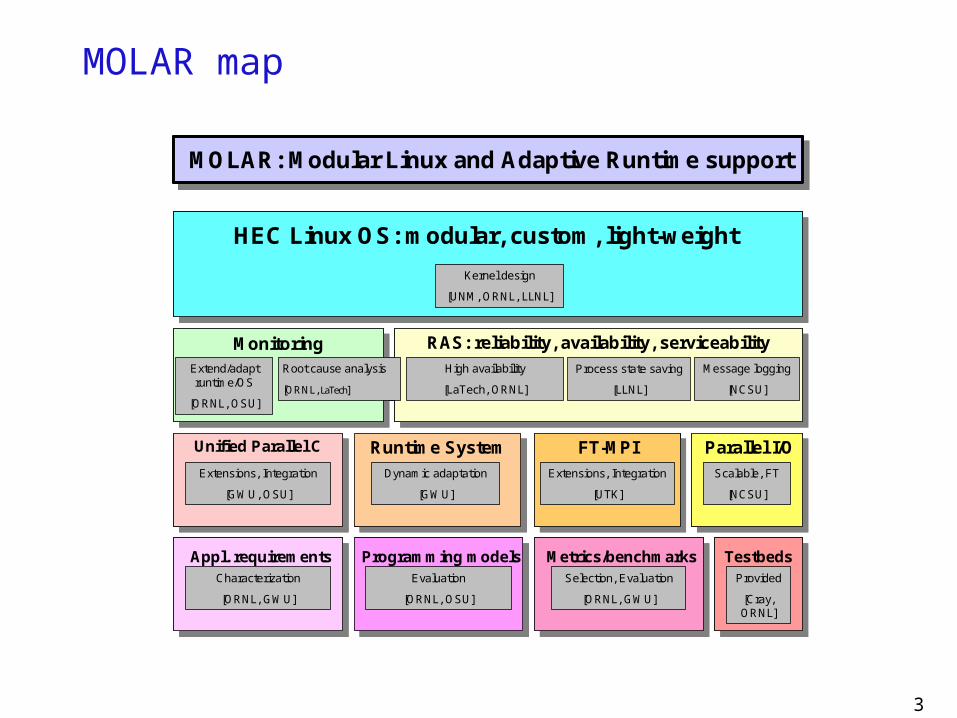
MOLAR map
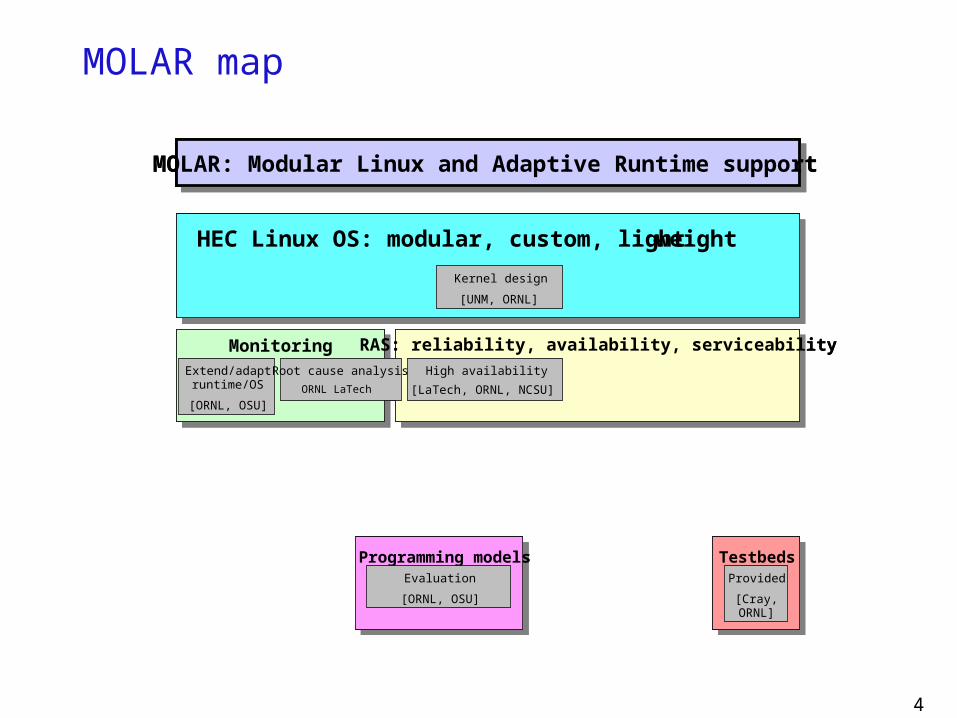
MOLAR: Modular Linux and Adaptive Runtime support
HEC Linux OS: modular, custom, light-weight
Monitoring RAS: reliability, availability, serviceabilityHigh availability
[LaTech, ORNL]
Process state saving
[LLNL]
Message logging
[NCSU]
Extend/adaptruntime/OS
[ORNL, OSU]
Root cause analysis
[ORNL, LaTech]
Kernel design
[UNM, ORNL, LLNL]
Unified Parallel C
Appl. requirements
Runtime System FT-MPIExtensions, Integration
[GWU, OSU]
Extensions, Integration
[UTK]
Dynamic adaptation
[GWU]
Programming models Metrics/benchmarks TestbedsSelection, Evaluation
[ORNL, GWU]
Evaluation
[ORNL, OSU]
Characterization
[ORNL, GWU]
Provided
[Cray,ORNL]
Parallel I/OScalable, FT
[NCSU]
MOLAR: Modular Linux and Adaptive Runtime support
HEC Linux OS: modular, custom, light-weight
Monitoring RAS: reliability, availability, serviceabilityHigh availability
[LaTech, ORNL]
Process state saving
[LLNL]
Message logging
[NCSU]
Extend/adaptruntime/OS
[ORNL, OSU]
Root cause analysis
[ORNL, LaTech]
Kernel design
[UNM, ORNL, LLNL]
Unified Parallel C
Appl. requirements
Runtime System FT-MPIExtensions, Integration
[GWU, OSU]
Extensions, Integration
[UTK]
Dynamic adaptation
[GWU]
Programming models Metrics/benchmarks TestbedsSelection, Evaluation
[ORNL, GWU]
Evaluation
[ORNL, OSU]
Characterization
[ORNL, GWU]
Provided
[Cray,ORNL]
Parallel I/OScalable, FT
[NCSU]
4
MOLAR map
MOLAR: Modular Linux and Adaptive Runtime support
HEC Linux OS: modular, custom, light -weight
Monitoring RAS: reliability, availability, serviceability
High availability
[LaTech, ORNL]
Process state saving
[LLNL]
Message logging
[NCSU]
Extend/adaptruntime/OS
[ORNL, OSU]
Root cause analysis
[ORNL, LaTech]
Kernel design
[UNM, ORNL, LLNL]
Programming models TestbedsEvaluation
[ORNL, OSU]
Provided
[Cray,ORNL]
MOLAR: Modular Linux and Adaptive Runtime support
HEC Linux OS: modular, custom, light -weight
Monitoring RAS: reliability, availability, serviceability
High availabilityExtend/adaptruntime/OS
[ORNL, OSU]
Kernel design
[UNM, ORNL]
Programming models TestbedsEvaluation
[ORNL, OSU]
Provided
[Cray,ORNL]
Root cause analysis
ORNL LaTech [LaTech, ORNL, NCSU]

5
RAS for Scientific and Engineering Applications
High mean time between interrupts (MTBI) for hardware, system software, and storage devices.
High mean time between errors/failures that affect users.
Recovery is automatic w/o human intervention. Minimal work loss due to recovery process.
Computation – Storage – Network

6
Case for RAS in HEC
Today’s systems need to reboot to recover. Entire system often down for any maintenance or repair. Compute nodes sit idle if their head (service) node is down. Availability and MTBI typically decreases as system grows. The “hidden” costs of failures
researchers’ lost work-in-progress researchers on hold additional system staff checkpoint & restart time
Why do we accept such significant system outages due to failures, maintenance or repair?
With the expected investment into HEC we simply cannot afford low availability!
We need to drastically increase the availability of HEC computing resources now!

7
High-availability in Industry
Industry has shown for years that 99.999% (five nines) high-availability is feasible for computing services.
Used in corporate web servers, distributed data bases, business accounting and stock exchange services.
OS-level high-availability has not been a priority in the past. Implementation involves complex algorithms. Development and distribution licensing issues exist. Most solutions are proprietary and do not perform well. HA-OSCAR first freely available open source HA cluster
implementation.
If we don’t step-up and do it as an Open Source proof-of-concept implementation and set the standard no one will.
8
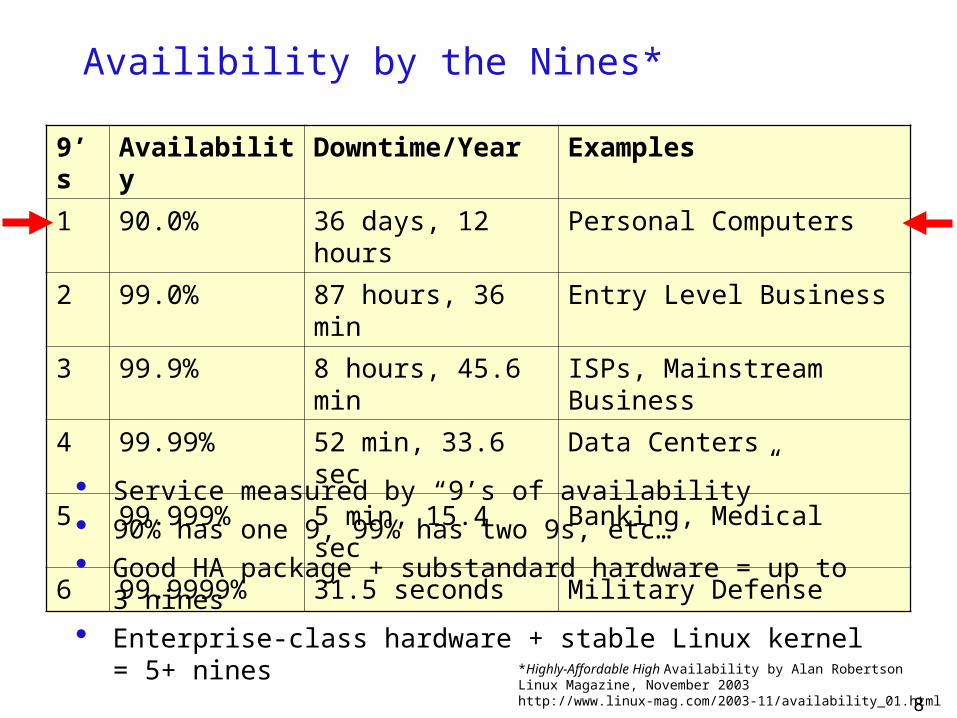
Availibility by the Nines*
9’s Availability Downtime/Year Examples
1 90.0% 36 days, 12 hours Personal Computers
2 99.0% 87 hours, 36 min Entry Level Business
3 99.9% 8 hours, 45.6 min ISPs, Mainstream Business
4 99.99% 52 min, 33.6 sec Data Centers
5 99.999% 5 min, 15.4 sec Banking, Medical
6 99.9999% 31.5 seconds Military Defense
*Highly-Affordable High Availability by Alan RobertsonLinux Magazine, November 2003http://www.linux-mag.com/2003-11/availability_01.html
Service measured by “9’s of availability” 90% has one 9, 99% has two 9s, etc… Good HA package + substandard hardware = up to 3 nines Enterprise-class hardware + stable Linux kernel = 5+ nines
9
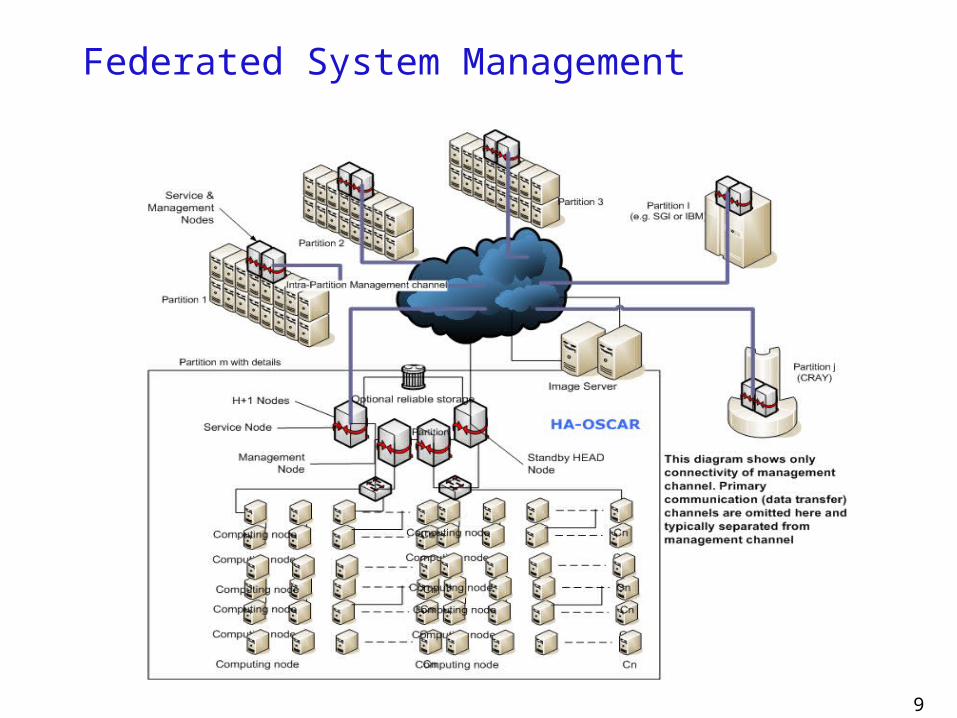
Federated System Management

10
High-availability Methods
Active/Hot-Standby: Single head node. Idle standby head node(s). Backup to shared storage.
Service interruption for the time of the fail-over. Rollback to backup. Simple checkpoint/restart.
Service interruption for the time of restore-over.
Active/Active: Many active head nodes. Work load distribution. Symmetric replication between head nodes. Continuous service.
Always up-to-date. Complex distributed control
algorithms. No restore-over necessary

11
High-availability Technology
Active/Hot-Standby: HA-OSCAR with active/ hot-standby head node. Cluster system software. No support for multiple
active/active head nodes. No middleware support. No support for compute
nodes.
Active/Active: HARNESS with symmetric distributed virtual machine. Heterogeneous adaptable distributed middleware. No system level support.
System-level data replication and distributed control service needed for active/active head node solution.
Reconfigurable framework similar to HARNESS needed to adapt to system properties and application needs.
12
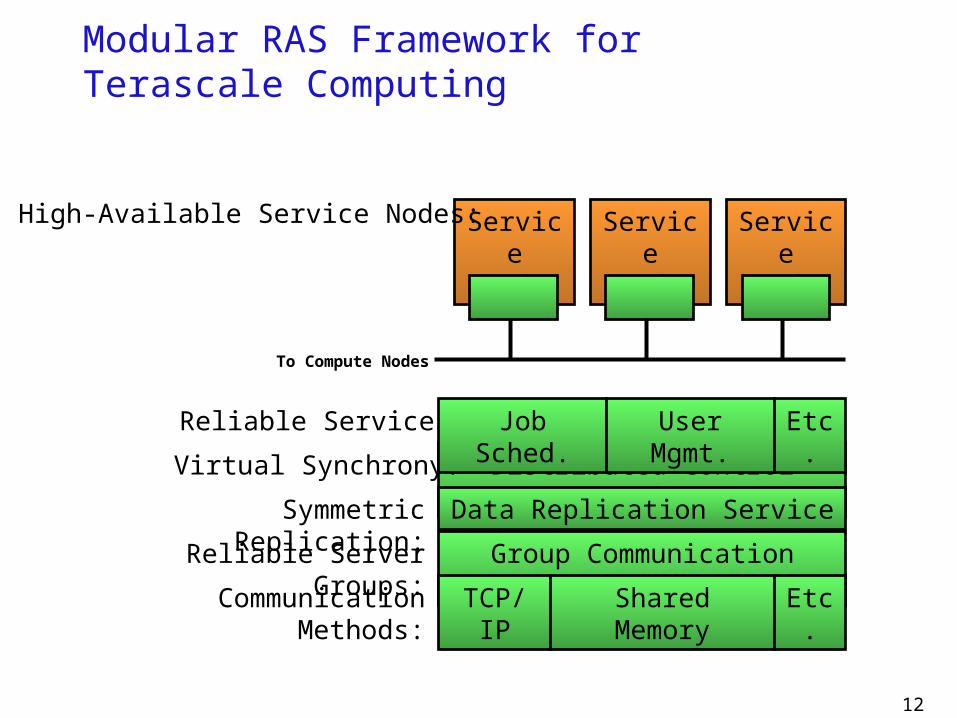
Modular RAS Framework forTerascale Computing
Distributed Control Service
Data Replication Service
Group Communication ServiceReliable Server Groups:
Virtual Synchrony:
Symmetric Replication:
Communication Methods: TCP/IP Shared Memory Etc.
Reliable Services: Job Sched. User Mgmt. Etc.
ServiceNode
ServiceNode
ServiceNode
High-Available Service Nodes:
To Compute Nodes