Embed Size (px)
Citation preview

HAL Id: dumas-01679194https://dumas.ccsd.cnrs.fr/dumas-01679194
Submitted on 9 Jan 2018
HAL is a multi-disciplinary open accessarchive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come fromteaching and research institutions in France orabroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, estdestinée au dépôt et à la diffusion de documentsscientifiques de niveau recherche, publiés ou non,émanant des établissements d’enseignement et derecherche français ou étrangers, des laboratoirespublics ou privés.
Mise en place d’un portail collaboratif pour la gestion dela connaissance dans le cadre de la gestion d’un cloud
privé chez EDFWandifa Gassama
To cite this version:Wandifa Gassama. Mise en place d’un portail collaboratif pour la gestion de la connaissance dansle cadre de la gestion d’un cloud privé chez EDF. Recherche d’information [cs.IR]. 2015. �dumas-01679194�

CONSERVATOIRE NATIONAL DES ARTS ET METIERS
PARIS
_______
MEMOIRE
présenté en vue d'obtenir
le DIPLOME d'INGENIEUR CNAM
SPECIALITE : Informatique
OPTION : Architecture et Intégration des Systèmes Logiciels
par
M. Wandifa GASSAMA
______
Mise en place d’un portail collaboratif pour la gestion de la
connaissance dans le cadre de la gestion d’un Cloud privé chez EDF
Soutenu le 24/03/2015
_______
JURY
PRESIDENT : M. Yves LALOUM
MEMBRES : M. Yann POLLET
M. Jean-Michel DOUIN
M. Jérémy LADET
M. Bertrand GOUMY

Table des matières
Remerciements ....................................................................................................................................... 1
Glossaire .................................................................................................................................................. 2
1. Introduction ..................................................................................................................................... 8
2. Présentation d’EDF ........................................................................................................................ 10
2.1. La société ............................................................................................................................... 10
2.2. Un acteur majeur de l’énergie européen .............................................................................. 11
2.3. L’organisation ........................................................................................................................ 11
2.4. Les Services ............................................................................................................................ 13
2.5. La prestation chez EDF pour le Service PFC........................................................................... 13
3. Présentation du Service PFC .......................................................................................................... 14
3.1. Le rôle du Service .................................................................................................................. 14
3.2. Objectif de la mission ............................................................................................................ 15
3.3. Rôle de l’opérateur PFC dans la mission exercée .................................................................. 17
3.4. Indentification des différents acteurs ................................................................................... 18
4. Analyse du besoin .......................................................................................................................... 18
4.1. Modélisation des processus métiers existants ...................................................................... 18
4.1.1. Interaction avec le Pilote d’Exploitation ....................................................................... 18
4.1.2. Interaction avec l’Infogérant Orange Business Service (OBS) ....................................... 22
4.1.3. Interaction avec l’Intégrateur Telindus ......................................................................... 24
4.1.4. Interaction avec les autres Services EDF ....................................................................... 24
4.1.5. Schéma des processus métiers ...................................................................................... 27
4.2. Motivation du Projet ............................................................................................................. 29
5. Présentation des référentiels de gestion de connaissances existants .......................................... 30
5.1. Les messageries électroniques du Service PFC ..................................................................... 31
5.2. La Base Lotus Notes PFC ........................................................................................................ 31
5.3. La Base Lotus Notes RD&E..................................................................................................... 31
5.4. PRODIS ................................................................................................................................... 31
5.5. SCOPE GS ............................................................................................................................... 32
5.6. Les problèmes liés à l’existant ............................................................................................... 32
6. Concept sur la gestion des connaissances collectives ................................................................... 33
6.1. Les enjeux .............................................................................................................................. 33
6.2. Le Knowledge Management .................................................................................................. 34
6.2.1. Définition ....................................................................................................................... 34
6.2.2. Qu’est-ce que la connaissance ? ................................................................................... 34

6.2.3. Les modèles du Knowledge Management .................................................................... 36
6.2.4. Les méthodes de capitalisation de connaissances du KM ............................................. 38
6.2.5. Les outils pour la mise en œuvre du Knowledge Management .................................... 42
6.2.6. Les communautés de pratiques et les communautés d’intérêt .................................... 50
6.2.7. Cartographie des connaissances ................................................................................... 50
6.3. Gestion des connaissances dans une démarche ITIL ............................................................ 51
6.3.1. Présentation d’ITIL ......................................................................................................... 51
6.3.2. Les recommandations d’ITIL sur la gestion des connaissances ..................................... 52
6.4. Le Web sémantique ............................................................................................................... 54
6.4.1. URI/IRI............................................................................................................................ 55
6.4.2. XML ................................................................................................................................ 55
6.4.3. RDF................................................................................................................................. 57
6.4.4. SPARQL .......................................................................................................................... 59
6.4.5. RDFS ............................................................................................................................... 59
6.4.6. OWL ............................................................................................................................... 59
6.4.7. Les applications du Web Sémantique ........................................................................... 59
7. Lancement du projet ..................................................................................................................... 60
7.1. Estimation de la charge de travail ......................................................................................... 60
7.2. Planning prévisionnel ............................................................................................................ 64
7.3. Estimation du retour sur investissement .............................................................................. 65
7.4. Analyse de risques ................................................................................................................. 67
7.4.1. Les risques techniques et technologiques ..................................................................... 68
7.4.2. Les risques au niveau des délais .................................................................................... 68
7.4.3. Les risques économiques ............................................................................................... 68
7.4.4. Les risques d’écarts par rapport aux objectifs initiaux .................................................. 69
7.4.5. Les risques juridiques .................................................................................................... 69
7.4.6. Les risques humains ...................................................................................................... 69
7.4.7. Matrice des risques ....................................................................................................... 70
8. Comment gérer les documents et le contenu du Service PFC ...................................................... 71
8.1. Rôle des GED et CMS ............................................................................................................. 71
8.2. Apport d’une solution de GED par rapport au système actuel ............................................. 72
8.3. Solution de gestion documentaire et de contenu pour le service PFC ................................. 73
9. Comment capitaliser les connaissances du Service PFC ............................................................... 73
9.1. Apport d’une solution de gestion de contenu par rapport au système actuel ..................... 74
9.2. Solution de capitalisation des connaissances pour le service PFC ........................................ 74
10. Architecture de la solution ........................................................................................................ 75

10.1. Diagramme UML de cas d’utilisation du système ............................................................. 75
10.2. Exemples d’utilisation de la solution ................................................................................. 77
10.3. Sécurité .............................................................................................................................. 81
10.3.1. Accès aux données ........................................................................................................ 81
10.3.2. Préservation des données ............................................................................................. 82
11. Choix technologique de la solution ........................................................................................... 83
11.1. Etudes comparatives des différents outils du Marché ...................................................... 83
11.1.1. Choisir un moteur Wiki .................................................................................................. 84
11.1.2. Choisir une solution de GED .......................................................................................... 87
11.1.3. Choisir un portail d’entreprise ...................................................................................... 89
11.2. Les contraintes .................................................................................................................. 89
11.2.1. Economique ................................................................................................................... 90
11.2.2. Technologique ............................................................................................................... 90
11.2.3. Contraintes de l’infrastructure actuelle ........................................................................ 91
11.3. Choix définitif : la suite logicielle Alfresco ......................................................................... 91
11.3.1. Motivation du choix....................................................................................................... 91
11.3.2. Architecture technique de la suite Alfresco .................................................................. 92
12. Mise en place du portail collaboratif au sein du Service PFC .................................................... 97
12.1. Installation et configuration .............................................................................................. 97
12.1.1. Choix du système d’exploitation de la machine cible ................................................... 97
12.1.2. Choix de la configuration du matériel de la machine cible ........................................... 97
12.1.3. Les prérequis à l’installation .......................................................................................... 98
12.1.4. Paramètres d’installation .............................................................................................. 99
12.1.5. Configuration complémentaire suite à l’installation ................................................... 100
12.1.6. Installation d’un module de monitoring ...................................................................... 104
12.2. Transfert des données du système existant vers la nouvelle solution ........................... 105
12.3. Premier retour des utilisateurs avant la personnalisation de la solution ....................... 107
12.4. Personnalisation de la solution ....................................................................................... 109
12.4.1. Personnalisation du Wiki : création de modèles de fiches ......................................... 109
12.4.2. Nommage des nouveaux articles ................................................................................ 111
12.4.3. Rapprocher le Wiki intégré d’Alfresco de MediaWiki ................................................. 111
12.4.4. Choix des Sites de collaboration .................................................................................. 112
12.4.5. La fonctionnalité discussion pour les remarques des utilisateurs .............................. 115
12.4.6. Personnalisation de l’interface utilisateur .................................................................. 115
12.4.7. Personnalisation de l’espace documentaire ............................................................... 117
12.4.8. Gestion des documents obsolètes .............................................................................. 119

12.5. Mise en place du processus de mise à jour et de maintenance ...................................... 120
12.6. Conduite du changement ................................................................................................ 121
12.7. Perspectives d’évolutions fonctionnelles et métiers de la solution ................................ 123
13. Bilan et synthèse ..................................................................................................................... 124
13.1. Les résultats obtenus ....................................................................................................... 124
13.2. Analyse de la démarche du projet ................................................................................... 126
13.3. Analyse des difficultés rencontrées................................................................................. 127
14. Conclusion ............................................................................................................................... 129
Liste des figures ................................................................................................................................... 131
Liste des tableaux ................................................................................................................................ 132
Bibliographie et Webographie ............................................................................................................ 133
Annexes ............................................................................................................................................... 136
Procédure d’installation de la suite logicielle Alfresco ................................................................... 136
Procédure de mise à jour de la suite logicielle Alfresco .................................................................. 141
Fichiers de configuration de la suite Alfresco ................................................................................. 142
Procédure pour gérer les documents obsolètes ............................................................................. 148
Créer un nouveau thème pour le portail Alfresco Share ................................................................ 151
Tableau des rôles utilisateur dans Alfresco Share ........................................................................... 153

1
Remerciements
Ce travail revêt une importance particulière pour moi puisqu’il s’agit de l’aboutissement
de sept années d’étude au CNAM. Je remercie donc tous les intervenants du CNAM pour la
qualité de la formation.
Je tenais à remercier M. Jérémie LADET le Pilote Opérationnel du Service PFC et M.
Bertrand GOUMY le responsable de la cellule Pilotage du Service PFC sans qui ce travail
n’aurait pas été possible. Je remercie aussi l’ensemble du Service PFC pour leur participation
et leur patience.
Je remercie également mon tuteur au CNAM M. Yves LALOUM pour son temps et son aide
à la rédaction de ce mémoire. Je remercie aussi tous les membres du Jury pour l’évaluation de
mon travail.
Je remercie mes parents et ma famille pour leur soutien et leurs encouragements pour
que j’aille jusqu’au bout de cette formation.
Enfin, je remercie toutes les personnes que je n’ai pas citées qui m’ont aidé à la réalisation
de ce travail.

2
Glossaire
EDF : « Electricité de France » est une grande entreprise française de production d’énergie électrique.
RTE : « Réseau de Transport d’Electricité » est une entreprise chargée du transport de l’électricité.
ERDF : « Electricité Réseau Distribution en France » est une entreprise chargée de la distribution d’électricité.
GDF : « Gaz De France » est entreprise de production et distribution de Gaz.
CEA : « Commissariat de l’Energie Atomique » est un organisme de recherche sur l’énergie nucléaire.
PE : « Pilote d’exploitation ». Il s’agit, chez EDF, de la personne responsable d’un Serveur.
POA : « Pilote Opérationnel d’Application » chez EDF.
POS : « Pilote Opérationnel de Service » qui est le responsable d’un Service chez EDF.
SI : Acronyme de « Système d’Information »
IT : Acronyme de « Information Technology » qui signifie « Technologie de l’Information »
DSP-IT : « Direction des Services Partagés Informatique et Télécom » chez EDF.
CSP-IT-O : « Centre des Services Partagés Informatique et Télécom Opérateur » chez EDF.
Datacenter : Il s’agit d’un département chez EDF. Le mot peut aussi faire référence à des grands centres de données qui sont de grands entrepôts dans lesquels sont regroupés de nombreux équipements informatiques (serveurs, systèmes de sauvegarde, etc…).
SRT : Département Réseau et Télécom chez EDF.
ESC : Groupe « Exploitation des Solutions Cloud » chez EDF.
EEI : Groupe « Expertise Ingénierie Informatique » chez EDF.
GAA : Groupe « Gestion des Assets et des Appro » chez EDF.
CONSER : Service chez EDF proposant de la virtualisation personnalisée de serveurs.
PFC : « Plateformes Convergées ». Il s’agit d’un Service chez EDF proposant un Cloud Privé de type IaaS.
OGC : Désigne « Outils de Gestion Centralisée » chez EDF. Le terme signifie aussi « Office of Government Commerce » qui est l’organisme qui distribue les livres ITIL.
VCE : Société regroupant VMware, Cisco et EMC et commercialisant des solutions de virtualisation telles que les Vblock.
Vblock : Solution packagée de virtualisation proposée par la société VCE.

3
Telindus : Intégrateur ayant remporté l’appel d’offre pour proposer la solution PFC. Il est en charge de la maintenance de l’évolution matérielle et logicielle des Vblock. C’est l’intermédiaire entre EDF et le fournisseur VCE.
OBS : « Orange Business Service » est un infogérant ayant la charge de l’exploitation de l’infrastructure PFC.
VM : « Virtual Machine » ou « Machine Virtuelle ». Il s’agit d’une machine informatique simulée sur une autre machine informatique à l’aide d’un outil de virtualisation tel que VMware ou Virtual Box.
vApp : « Virtual Appliance » qui, sous VMware vCloud Director, représente un ensemble de VM interconnectées entre elle pour former une Appliance.
Cloud Computing : Service informatique en ligne permettant de mettre à disposition des utilisateurs soit des applications (pour le SaaS ou « Software As A Service »), soit des plateformes (pour le PaaS ou « Plateforme As A Service »), soit des Infrastructures (pour le IaaS ou « Infrastructure As A Service »). Le Cloud Computing a pour caractéristiques principales la mutualisation des ressources, l’élasticité, la non-localité des données, le Self-Service et le « Pay As You Go » (payer ce que vous utilisez).
IaaS : « Infrastructure As A Service ». Il s’agit d’un service de Cloud Computing proposant aux utilisateurs une infrastructure informatique leur permettant de créer des machines virtuelles x86.
Cloud privé : Service de Cloud Computing mis en place directement dans l’infrastructure de l’entreprise qui l’exploite.
VMware : Editeur de logiciels spécialisé dans le développement de solutions de virtualisation.
vCenter : Logiciel de virtualisation mis au point par VMware permettant de centraliser la gestion de serveurs de virtualisation ESX.
ESX : Serveur de virtualisation VMware pouvant héberger plusieurs machines virtuelles.
vCloud Director : Portail VMware d’administration d’un Cloud IaaS.
vCO : « vCenter Orchestrator » : Il s’agit d’un outil de VMware vCenter permettant de réaliser des Workflows dans le but d’automatiser certaines tâches sur l’environnement virtuel comme par exemple le déploiement d’une machine virtuelle personnalisée pour un utilisateur.
vCOps : « vCenter Operations Manager » est un logiciel de surveillance d’une infrastructure virtuelle VMware.
SCOPE GP : Outil de gestion du parc informatique chez EDF.
SCOPE GS : Outil de gestion des demandes et des incidents chez EDF.
Fisher : Outil de facturation chez EDF.
PRODIS : Intranet permettant de télécharger des outils EDF.
RD&E : « Référentiel Développement et Exploitation » est une Base Lotus Notes chez EDF.

4
V2V : « Virtual To Virtual » ou « Virtuel à Virtuel » est une technique qui consiste à migrer une machine virtuelle d’un environnement à un autre.
P2V : « Physical To Virtual » ou « Physique à Virtuel » est une technique de virtualisation d’une machine physique. La machine est donc déplacée vers un environnement virtuel.
vCPU : « Virtual Central Processor Unit » ou « Unité Centrale de Traitement Virtuelle ». Il s’agit d’un microprocesseur alloué sur une machine virtuelle par la machine hôte.
RAM : « Random Access Memory » ou « Mémoire à accès aléatoire ». Il s’agit de la mémoire non persistante d’un système informatique permettant de stocker temporairement des données lors d’un traitement.
AVAMAR : Système de sauvegarde informatique mis au point par la société EMC.
Active Directory (AD) : Système d’annuaire de Microsoft pour les réseaux informatiques reposant sur une architecture Windows.
DNS : « Domain Name System » ou « Système de Nom de Domaine » est un service permettant d’associer une adresse IP à un nom de domaine (plus facile à utiliser) sur un réseau TCP/IP.
VLAN : « Virtual Local Area Network » ou « Réseau Local Virtuel » est un réseau informatique logique indépendant qui peut être créé sans tenir compte des limites du ou des réseaux physiques dans lesquels se trouvent les machines. Cela permet de simplifier la gestion des réseaux.
VPN : « Virtual Private Network » ou « Réseau Privé Virtuel » est un réseau informatique sécurisé dans une zone isolée et protégée par un pare-feu permettant de relier des machines en passant par un réseau non sécurisé comme Internet. Il est généralement accessible en ouvrant un canal sécurisé (appelé aussi « tunnel ») entre la machine source et la machine cible. Ce système est très utile pour le travail à distance.
ZHB : « Zone d’Hébergement de Base » correspondant chez EDF à une zone réseau non sécurisée.
ZSA : « Zone Sécurisée d’Administration » correspondant chez EDF à une zone sécurisée derrière un pare-feu et accessible uniquement en ouvrant un canal VPN.
AMP : « Administration Management Pod » est la couche de base d’un Vblock qui permet de gérer le matériel avec des outils permettant d’administrer les lames Cisco UCS (« Cisco Unified Computing System » sont des serveurs informatiques physiques enfichables correspondant, dans le cas des Vblock, à un ESX), les équipements du réseau CISCO et le stockage EMC.
IMP : « Infrastructure Management Pod » est un ensemble de plusieurs VM comportant les briques de base VMware au sein d’un Vblock permettant de faire fonctionner l’infrastructure virtuelle PFC. C’est une personnalisation du Vblock par EDF.
SQL : « Structured Query Language » ou « Langage de Requête Structurée ». Il s’agit d’un langage informatique de haut niveau qui permet d’interroger des bases de données relationnelles.

5
HTML : « Hypertext Markup Language » est un langage informatique de haut niveau à balise. Il permet de donner une description du contenu d’une page Web interprétable par un navigateur Web.
CSS : « Cascading Style Sheet » ou « Feuilles de Style en Cascade » est un langage informatique de haut niveau qui permet de décrire la présentation des documents de type HTLM. Il permet, par exemple, de modifier la présentation d’une page Web.
PHP : « PHP : Hypertext Preprocessor » est un langage informatique de haut niveau permettant de développer des sites Web dynamiques. Les pages de ces sites Web apparaissent dynamiquement selon le choix des utilisateurs.
ASP : « Application Server Pages » est une suite logicielle développée par Microsoft permettant de réaliser des sites Web dynamiques.
XML : « eXtensible Markup Language » ou « Langage à Balisage Extensible » est un langage informatique de haut niveau à balise.
RDF : « Resource Description Framework » est une syntaxe qui permet de décrire de manière formelle les ressources Web.
SPARQL : « Simple Protocole and RDF Query Language » est un langage permettant de formuler des requêtes sur des graphes RDF.
RDFS : « Resource Description Framework Schema » est un langage de description de vocabulaire du Web Sémantique.
OWL : « Web Ontology Language » est un langage informatique basé sur RDF permettant de décrire des ontologies.
GNU : « GNU is not UNIX » est un projet de système d’exploitation libre créé par Richard Stallman en 1983.
GNU GPL : « GNU General Public License » ou « Licence Publique Générale GNU » est une licence qui décrit les conditions de distribution des logiciels libres du projet GNU.
GNU LGPL : « GNU Lesser General Public License » ou « Licence Publique Générale Limitée GNU » est une licence rédigée par la « Free Software Fondation » créé par Richard Stallman permettant de distribuer des logiciels partiellement libres.
BSD License : « Berkeley Software Distribution License » est une licence pour distribuer des logiciels libres.
MCD : « Modèle Conceptuel de Données ».
MLDR : « Modèle Logique de Données Relationnelles ».
SGBD : « Système de Gestion de Bases de Données ».
SGBDR : « Système de Gestion de Bases de Données Relationnelles ».
MySQL : SGBDR libre sous licence GNU GPL développé par Oracle.
SQL Server : SGBDR propriétaire développé par Microsoft.
PostgreSQL : SGBDR libre sous licence BSD.

6
Adobe Flash : Logiciel développé par la société Adobe permettant de créer des animations basées sur le langage ActionScript qui peuvent s’intégrer aux pages Web. Il permet aussi l’intégration de vidéo dans les pages Web.
KM : « Knowledge Management » ou « Gestion des connaissances ».
DIKW : Modèle « Data Information Knowledge Wisdom » ou « Donnée Information Connaissance Sagesse »
SECI : Modèle Socialisation, Externalisation, Combinaison et Internalisation mis au point par le professeur Nonaka.
OID : Modèle Système Opérant, Système d’Information et Système de Décision.
AIK : Modèle Actor, Information, Knowledge (Acteur, Information, Connaissance).
Ontologie : Concept utilisé pour représenter les connaissances sous formes d’objets.
MASK : « Method for Analysing and Structuring Knowledge » ou « Méthode d’analyse et de structuration des connaissances » mis au point par Jean-Louis ERMINE au CEA.
REX : Méthode « Retour d’Expérience » mise au point au CEA.
MEREX : Méthode « Mise en Règle de l’Expérience ».
KADS : Méthode « Knowledge Analysis and Design System/Support ».
KALAM : Méthode « Knowledge And Learning in Action Mapping ».
KOD : Méthode « Knowledge Oriented Design ».
OCSIMA : Méthode « Objectifs, Connaissances, Support Informatique, Management Approprié ».
COP : « Community Of Practice » ou Communauté de Pratique.
CoINS : « Community Of Interest Network » ou « Réseau de Communauté d’Intérêt ».
GED : « Gestion Electronique Documentaire ».
Wiki : Outil Web de gestion de contenu collaboratif.
CMS : « Content Management System » ou « Système de Gestion de Contenu ».
ECM : « Entreprise Content Management » ou « Gestion de contenu d’entreprise ».
HTTP : « Hypertext Transfert Protocol » est un protocole de communication Client-Serveur.
HTTPS : HTTP Secure est la version sécurisée du protocole HTTP avec une couche de chiffrement SSL.
SSL : « Secure Sockets Layer » est un protocole sécurisant les échanges de données sur un réseau.
FTP : « File Transfert Protocol » est un protocole de transfert de fichiers sur un réseau.
SMTP : « Simple Mail Transfert Protocol » est un protocole de transfert de courrier électronique.

7
POP3 : « Post Office Protocol version 3 » est un protocole de récupération du courrier électronique avec suppression des messages du serveur.
IMAP4 : « Internet Message Access Protocol version 4 » est un protocole de récupération du courrier électronique avec possibilité de conserver les messages sur le serveur.
CIFS : « Common Internet File System » est un protocole de partage de ressources sur un réseau local de type Windows. Il a aussi pour nom SMB (Server Message Block).
WebDAV : « Web-based Distributed Authoring and Versioning » est une extension du protocole HTTP simplifiant la gestion de fichiers sur des serveurs distants.
LDAP : « Lightweight Directory Access Protocol » est un protocole permettant d’interagir avec les services d’annuaire comme Active Directory.
NTLM : « NT LAN Manager » est un protocole d’identification Microsoft utilisé, par exemple, lors d’une connexion distante sur un serveur avec l’outil « Connexion Bureau à distance ».
PRINCE2 : « PRojects IN Controlled Environments » est une méthode de gestion de projets.
ITIL : « Information Technology Infrastructure Library » ou « Bibliothèque pour l'infrastructure des technologies de l'information » est un ensemble d’ouvrage regroupant des bonnes pratiques sur le management des systèmes d’information.
SKMS : « Service Knowledge Management System » est un système de gestion de connaissances selon ITIL.
ROI : Acronyme de « Return On Invest » qui signifie « Retour Sur Investissement ».
BPMN : « Business Process Modeling Notation » est une notation pour modéliser les processus métier.
UML : « Unified Modeling Language » ou « Langage de Modélisation Unifié » est un langage de modélisation informatique à base de pictogrammes utilisé en développement logiciel.
MOA : Acronyme de « Maîtrise d’Ouvrage ».
MOE : Acronyme de « Maîtrise d’Œuvre ».
PDF : « Portable Document Format » est format de documents textes portables inventé par la société Adobe.
DOC : Format de fichiers du logiciel de traitement de textes Microsoft Word.
DOCX : Format de fichiers du logiciel de traitement de textes Microsoft Word avec une avec la prise en charge de la norme OpenXML à partir de Microsoft Office 2007.
B2C : « Business to Consumers » correspond à une communication entre entreprise et consommateur.
B2B : « Business to Business » correspond à une communication entre entreprises.
B2E : « Business to Employee » correspond à une communication entre entreprise et employé.
RAID : « Redundant Array of Independent Disks » est un système de répartition des données sur plusieurs disques pour la tolérance de panne.

8
1. Introduction
Depuis maintenant quelques années, les entreprises ont pris conscience qu’il était
nécessaire de gérer les connaissances qu’elles généraient et d’essayer de les conserver. En
effet, pendant longtemps la priorité des entreprises reposait sur la production et l’homme
restait un facteur secondaire [1, p. 6]. Ce n’est qu’au début des années 1980 que cette prise
de conscience de l’importance de l’homme au sein de l’entreprise a commencé à apparaître.
En effet, il s’est avéré que les entreprises perdaient des connaissances au rythme des départs
des personnes qu’elles employaient car ce sont elles qui détenaient vraiment les
connaissances. Beaucoup de personnes se sont donc interrogées afin de savoir s’il n’était pas
possible de conserver les connaissances sous une forme exploitable mais aussi de capitaliser
sur ces connaissances afin d’améliorer les performances de l’entreprise.
EDF est une très grande entreprise et un acteur majeur de l’énergie en France. Elle a donc
un Système d’Information très complexe. Dans un tel contexte, les Services des différentes
entités de la DSI doivent pouvoir gérer et capitaliser leurs connaissances et aussi favoriser le
travail collaboratif. Chez EDF, il existe bien sûr, comme dans tous les grands groupes, un
système de gestion de contenu et une messagerie électronique mais ces derniers sont
insuffisants car ils ont pour principal défaut qu’ils ciblent toute l’entreprise. Ce système est
donc trop rigide pour répondre précisément aux besoins de chaque service qui génère des
connaissances qui lui sont spécifiques. Le problème concerne également un nouveau Service
chez EDF qui a pour rôle de gérer un Cloud privé.
Comment gérer la connaissance collective d’un Service et améliorer le travail collaboratif
et la qualité de service ? C’est précisément la question à laquelle ce travail va tenter de
répondre.
Dans un premier temps, nous présenterons l’organisation dans laquelle se déroule le
projet afin de bien situer le contexte. Puis nous aborderons l’analyse du besoin qui décrira en
détail les attentes du Client par rapport à ce projet.
Ensuite, nous présenterons un état de l’art de ce qui se fait dans le domaine de la gestion
de la connaissance et des contenus en réalisant une étude approfondie du Knowledge
Management avec ses modèles, ces méthodes et ses outils en passant par une description des
Ontologies et une présentation de le Web Sémantique.

9
Ces éléments nous permettrons ensuite de décrire comment le projet sera organisé. Nous
proposerons une estimation de la charge de travail, le planning prévisionnel du projet, le calcul
du ROI et l’analyse de risques.
Une fois que les bases du projet auront été fixées nous pourrons commencer à proposer
des solutions permettant de répondre à la problématique. Grâce à la formalisation des
solutions nous aurons la possibilité de proposer des outils qui permettent de les mettre en
œuvre et comme ces derniers sont nombreux, il y aura une étude comparative afin de
déterminer lesquels sont les plus adaptés.
Nous aborderons ensuite les questions sur l’installation de la solution, sa configuration,
sa personnalisation, sa prise en main par les utilisateurs, sa mise à jour, le transfert des
données existantes vers le nouveau système. Nous décrirons également l’aspect concernant
la conduite du changement et les perspectives d’avenir de la solution
Nous terminerons par la présentation du bilan de ce projet.

10
2. Présentation d’EDF
2.1. La société
Electricité de France est une société anonyme du CAC 40 qui a été créée le 8 avril 1946
par Marcel PAUL assisté par Maurice THOREZ tous les deux appartenant au Parti communiste
français (PCF) [2]. L’origine de sa création était de regrouper les 1450 entreprises de
production et distribution d’énergie en France qui existaient dans les années 30. C’était donc
un grand défi mais cela avait pour but de simplifier la situation devenue difficile à gérer. Suite
à cette gigantesque fusion, l’entreprise formait le groupe EDF GDF.
En France, dans les années 70, les autorités publiques ont fait le choix de s’orienter vers
l’énergie nucléaire et c’est donc la principale méthode de fabrication d’électricité utilisée par
EDF. A noter que c’est la société Areva qui est chargée de la construction des Centrales
Nucléaires.
Figure 1 : Répartition des méthodes de production d’électricité en 2013 inspirée de [3]
En 2000, Afin qu’EDF n’ait pas le monopole de la fabrication d’énergie, le groupe EDF a
fait l’objet d’une dérégulation et a été divisé en plusieurs entités qui sont EDF pour la
production d’électricité, RTE (Réseau de Transport d’Electricité) pour son transport, ERDF
(Electricité Réseau Distribution en France) pour sa distribution et GDF pour la production de
75%
9%
6%8%2%
Répartition de la production en 2013
Nucléaire Thermique fossile hors gaz
Cycle combiné gaz et cogénération Hydrolique
Autres énergies renouvelables

11
l’énergie au Gaz. Aujourd’hui GDF s’est séparé du groupe EDF et fait partie du groupe GDF
SUEZ.
Le 25 novembre 2009, Henri PROGLIO succède à Pierre GADONNEIX à la tête du groupe
[4] et le 21 novembre 2014, il est remplacé par Jean-Bernard LEVY ancien PDG de Thales.
Etant donné la complexité de la fabrication et distribution d’énergie électrique, car elle
ne peut pas être stockée facilement, il a fallu mettre en place une organisation spécifique
pouvant répondre à cette complexité. EDF est donc divisée en 7 régions en France formant
ensemble le réseau national. Il s’agit en fait d’un réseau maillé qui est interconnecté avec le
réseau Européen.
2.2. Un acteur majeur de l’énergie européen
EDF ne produit pas uniquement de l’électricité pour la France mais elle dispose également
de contrats avec les autres pays européens avec lesquels son réseau est interconnecté. EDF
exporte donc une grande partie de son électricité à d’autres pays européens qui n’en
produisent pas assez. EDF est une multinationale et un acteur majeur de l’énergie en France
et en Europe, c’est aussi une société spécialisée dans l’utilisation de l’énergie nucléaire avec
environ 58 centrales nucléaires en fonctionnement [2]. Elle fait donc office de référence dans
le domaine avec une production d’énergie de qualité et les autres sociétés d’électricité dans
le monde n’hésitent pas à la consulter pour avoir des conseils, ce qui fut le cas pour la société
de production d’électricité japonaise Tepco lors de l’accident nucléaire de Fukushima le 11
mars 2011.
Ce statut d’acteur majeur de l’énergie peut même être élargi au monde puisqu’EDF est le
premier producteur et fournisseur d’électricité [5] avec 39.1 millions de clients dans le monde
et une production de 653.9 TWh provenant à 74.5% du Nucléaire [3]. En 2013, le chiffre
d’affaire d’EDF s’élève à 75.6 Milliards d’euros [3]. En 2012, 46.2% de son chiffre d’affaire de
71.7 Milliards d’euros était réalisé en dehors de France [2].
2.3. L’organisation
EDF est une très grande entreprise française dont l’effectif total était de 158467 employés
en 2013 [3]. Ici, le propos de ce travail ne concerne qu’une seule direction d’EDF : la Direction
des Service Partagé de l’IT (DSP-IT) chargée principalement de la gestion des technologies de
l’information. Même si cette direction travaille pour les autres, il ne serait pas judicieux de
12
présenter en détail toute l’organisation de la société EDF car cela dépasse le cadre de ce
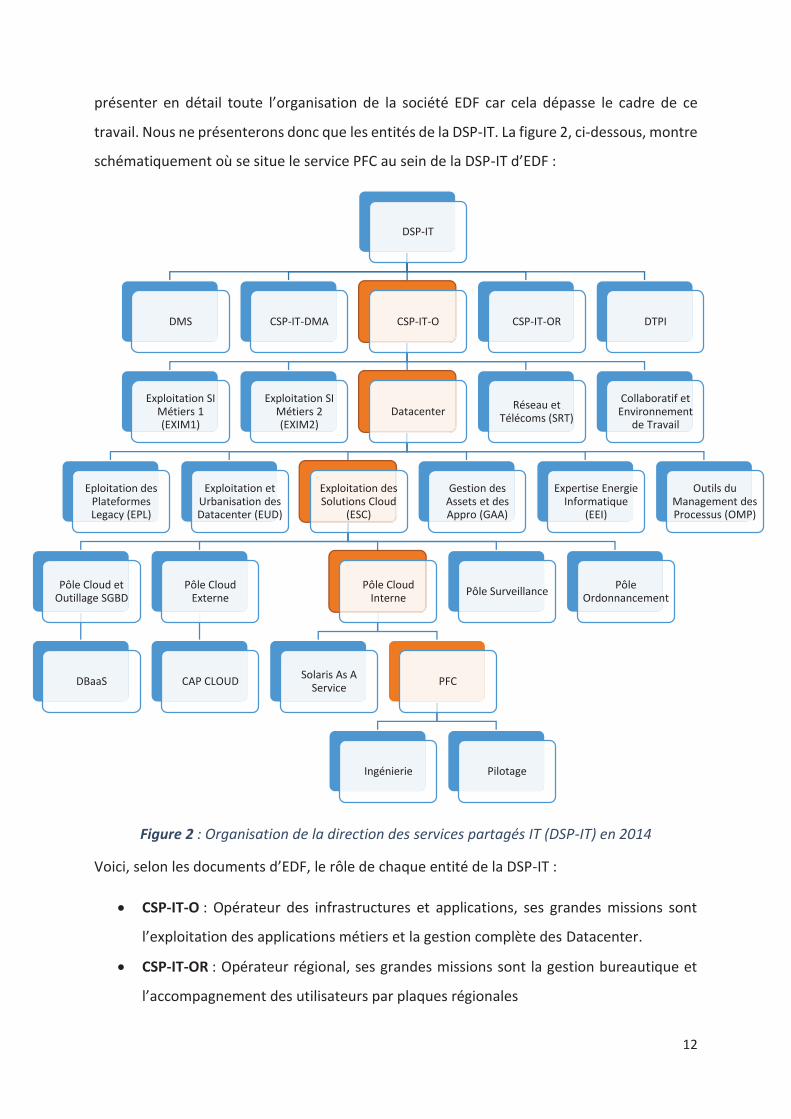
travail. Nous ne présenterons donc que les entités de la DSP-IT. La figure 2, ci-dessous, montre
schématiquement où se situe le service PFC au sein de la DSP-IT d’EDF :
Figure 2 : Organisation de la direction des services partagés IT (DSP-IT) en 2014
Voici, selon les documents d’EDF, le rôle de chaque entité de la DSP-IT :
CSP-IT-O : Opérateur des infrastructures et applications, ses grandes missions sont
l’exploitation des applications métiers et la gestion complète des Datacenter.
CSP-IT-OR : Opérateur régional, ses grandes missions sont la gestion bureautique et
l’accompagnement des utilisateurs par plaques régionales
DSP-IT
DMS CSP-IT-DMA CSP-IT-O
Exploitation SI Métiers 1 (EXIM1)
Exploitation SI Métiers 2 (EXIM2)
Datacenter
Eploitation des Plateformes Legacy (EPL)
Exploitation et Urbanisation des Datacenter (EUD)
Exploitation des Solutions Cloud
(ESC)
Pôle Cloud et Outillage SGBD
DBaaS
Pôle Cloud Externe
CAP CLOUD
Pôle Cloud Interne
Solaris As A Service PFC
Ingénierie Pilotage
Pôle Surveillance Pôle Ordonnancement
Gestion des Assets et des Appro (GAA)
Expertise Energie Informatique
(EEI)
Outils du Management des Processus (OMP)
Réseau et Télécoms (SRT)
Collaboratif et Environnement
de Travail
CSP-IT-OR DTPI

13
CSP-IT-DMA : Développement et Maintenance Applicative, ses grandes missions sont
l’accompagnement des projets métiers et l’expertise sur les grands middlewares et
SGBD
DTPI : Direction Technique, établit la stratégie et la feuille de route IT et la politique
industrielle
DMS : Management des services, gestion ITIL et de la communication
La DSP-IT ne représente qu’une des directions d’EDF. Il en existe, bien entendu d’autres
qui couvrent le Commerce, le Nucléaire, l’Optimisation trading et les Ressources Humaines.
2.4. Les Services
Chez EDF, comme expliqué plus haut, la DSP-IT est subdivisée en branches, elles-mêmes
subdivisées en départements qui sont subdivisés en groupes puis en pôles. Chaque pôle
dispose de plusieurs Services ce qui implique un nombre important de ces derniers dans la
DSP-IT. Pour résumer, un Service est la plus petite entité prise en compte officiellement chez
EDF. Cependant, il est possible que ces Services comportent des cellules comme c’est le cas
pour PFC.
2.5. La prestation chez EDF pour le Service PFC
De nombreux prestataires externes sont amenés à travailler pour EDF. Cette prestation
peut être de deux types différents. Il s’agit soit d’un contrat d’infogérance où les prestataires
forment une entité indépendante d’EDF qui peut travailler à distance, soit d’une prestation
d’appui qui permet au Client d’avoir un soutien pour la gestion d’un Service ou d’un pôle ou
pour une expertise dans un domaine précis.
Dans le Service PFC, il s’agit du deuxième type de prestation qui est utilisé au sein même
de l’équipe. Il y a deux prestataires pour l’appui au pilotage et deux autres pour l’expertise
côté Ingénierie. La société ayant remporté l’appel d’offre pour cette prestation est l’Entreprise
de Services Numérique Open créée en 1989.
En 2012, Open avait un chiffre d’affaire de 242 millions d’euros et comptait 3150
collaborateurs dont 2900 en France. Aujourd’hui, il y a environ 200 prestataires salariés chez
Open qui travaillent en mission chez EDF.

14
Le Service PFC travaille aussi avec des Infogérants extérieurs, c’est le cas notamment avec
Orange Business Service (OBS). Les autres Infogérants qui sont des Exploitants Systèmes pour
les Pilotes d’Exploitation sont considérés comme des Clients du Service PFC.
3. Présentation du Service PFC
3.1. Le rôle du Service
Le Service PFC appartient au groupe ESC (Exploitation des solutions Cloud) dans le
département Datacenter du CSP-IT-O (Centre des Services Partagés Informatique et Télécom
Opérateur) de la DSP-IT (Direction des Services Partagés IT). Le Service est divisé en deux
cellules qui sont l’Ingénierie en charge du support niveau 3 et de l’évolution de la solution et
le Pilotage qui s’occupe du support niveau 2 et du pilotage de l’infogérant OBS qui exploite la
solution.
Avant l’ouverture du Service PFC, les Pilotes d’Exploitation (PE) pouvaient se retrouver
dans plusieurs cas pour approvisionner leurs serveurs informatiques1. Soit le nouveau serveur
n’était pas éligible à la virtualisation et dans ce cas il leur était possible d’obtenir une
dérogation pour la mise en place d’un serveur physique, soit leur serveur l’était et il devait
passer par le Service CONSER. Dans ce dernier cas, l’approvisionnement du serveur pouvait
prendre plusieurs semaines et coûtait relativement cher.
La mise en place des PFC avait donc deux objectifs principaux :
Réduire le temps d’approvisionnement des serveurs
Réduire les coûts des ressources informatiques pour les clients de la DSP
Pour arriver à ces objectifs, et créer ce nouveau Service PFC, EDF a donc effectué un appel
d’offre, avant la phase projet, auquel ont répondu, avec succès, l’intégrateur Telindus pour
proposer le matériel et le logiciel et l’infogérant Orange Business Service (OBS) pour
l’exploitation de la solution. Telindus a proposé d’utiliser les Vblock qui sont des armoires
serveurs spécialisées dans la virtualisation vendues par VCE. Le Vblock regroupe donc les
technologies Cisco pour le réseau, VMware pour le logiciel de virtualisation et EMC pour le
stockage et un système de sauvegarde indépendant appelé AVAMAR. A partir de ce moment,
il était possible pour EDF de commencer la phase projet qui a duré six mois et qui consistait à
1 Machine informatique physique ou virtuelle permettant de rendre des services à des clients

15
mettre en place ce nouveau Service PFC qui offre aux clients un Cloud privé de type IaaS. Le
Service a donc pu ouvrir le 06 janvier 2014 et c’est donc à cette date que la mission a débuté.
La solution PFC est aussi en concurrence avec le service proposé par CONSER et la solution
qui sera proposée par le projet CAP CLOUD. Pour le moment ce dernier n’est pas terminé,
donc le choix des PE se portera soit sur PFC, soit sur CONSER. Pour approvisionner un serveur
sur PFC, la machine doit répondre aux critères d’éligibilité maximum suivants :
6 vCPU
24 Go2 de RAM
250 Go d’espace disque
Un serveur dépassant un de ces critères devra donc être approvisionné sur CONSER. Dans
le cas contraire, le PE pourra utiliser PFC qui a pour avantage un temps très court de mise à
disposition du serveur, de l’ordre de 10 minutes en moyenne, qui fait défaut à CONSER.
3.2. Objectif de la mission
La mission a pour principal objectif de rendre un service d’approvisionnement de serveur
via un Cloud Privé de type IaaS aux Clients de manière efficace grâce à une équipe de Pilotes,
de Coordinateurs et d’ingénieurs.
Afin d’atteindre cet objectif, EDF a décidé de répartir le travail sur deux cellules :
La cellule Pilotage :
D’une part, elle se charge de rendre le service PFC par :
La gestion des incidents, des demandes, des changements et de la capacité via les
processus ITIL
Le suivi de la qualité du service et la mise à disposition d’un reporting
La communication externe vers les Clients
Le pilotage budgétaire
Le pilotage de chantiers avec l’infogérant OBS ou la cellule Ingénierie
2 Gigaoctet est une unité de mesure en informatique représentant une quantité de données. Un octet correspond à 8 bits (« Binary Digit » ou « Chiffre Binaire » qui est la plus petite unité de mesure, il peut avoir pour valeur « 0 » ou « 1 »). Dans le système d’exploitation Microsoft Windows et dans les outils du Service PFC, 1 Kilooctet (Ko) correspond à 210 octets c’est-à-dire 1024 octets, 1 Megaoctet (Mo) à 1024 Ko et 1 Go à 1024 Mo.

16
Le support niveau 1 et 2 sur le portail vCloud Director et la solution d’orchestration
(vCO)
L’animation des cellules de crise et la coordination des acteurs
D’autre part, elle gère les contrats avec :
Une prestation spécifique « iESI² » de gestion de l’infrastructure (OBS)
Une prestation d’accompagnement du fournisseur Telindus
Une prestation d’expertise interne
Un suivi du marché avec le fournisseur Telindus
La cellule Ingénierie :
D’une part, elle assure la pérennité du Service PFC en :
Elaborant la feuille de route du Service
Intégrant les évolutions fonctionnelles et techniques
Entretenant un réseau IT interne et externe
Prospectant des technologies Cloud Computing connexes au service PFC
Effectuant le support niveau 3 sur la solution d’orchestration et le portail vCloud
Director
Effectuant des audits et recommandations d’optimisations associées
Intégrant les Template livrés par EEI
D’autre part, elle prend en charge la MCO de l’architecture, du portail et de l’orchestrateur
par :
Le développement et le maintien des Workflows nécessaires au bon fonctionnement
du service vCO
La rédaction et la mise à jour de la documentation de configuration et d’architecture
L’ensemble du Service est géré par un Pilote Opérationnel de Service (POS). Il a, entre
autres, pour rôle de répartir les tâches auprès des responsables de chaque cellule, de gérer la
communication avec les autres services, d’établir la facturation et il est garant de la qualité de
service.

17
3.3. Rôle de l’opérateur PFC dans la mission exercée
J’occupe actuellement le poste d’opérateur PFC en tant qu’ingénieur de production au
sein de la cellule Pilotage du Service PFC.
La figure 3 présente la hiérarchie du pôle PFC :
Figure 3 : Ma place au sein du Service PFC d’EDF
Selon la fiche de poste d’EDF, les attentes vis-à-vis de cette fonction sont les suivantes :
Appui fonctionnel auprès du responsable de la cellule Pilotage :
Suivi du service via les processus ITIL
Gestion des accès aux différents portails (vCloud, vCOps, Avamar…)
L’analyse des architectures informatiques candidates au service et à la
virtualisation en général
Capacity planning du parc
Appui organisationnel auprès du responsable de la cellule Pilotage :
Aide au pilotage de la prestation d’infogérance du service
Suivi des chantiers (migration, patch, évolution, déploiement des solutions
réalisées par l'ingénierie...)
Gestion des incidents avec tous les acteurs concernés (Infogérants,
fournisseurs et équipes internes)
Communication sur les incidents et leur résolution auprès des équipes
impactées
Appui administratif auprès du responsable de la cellule Pilotage :
Gestion de la base de connaissances
Responsable du Pôle et du Service
PFC (POS)
Responsable de la cellule Pilotage
Chef de projet Ingénieur de production
Responsable de la cellule Ingénierie
Expert 1 Expert 2

18
Production et analyse des statistiques mensuelles sur les incidents, le taux de
disponibilité des applications, la volumétrie et la qualité de la production
Elaboration des tableaux de bords de mesures de l’efficacité, réalisation du
suivi de la performance et du reporting
3.4. Indentification des différents acteurs
Le Service PFC interagit avec plusieurs acteurs extérieurs dont les principaux sont : les
Pilotes d’Exploitation, l’Infogérant OBS, l’intégrateur Telindus et les autres Services EDF. En
interne, il y a également beaucoup d’échange entre la cellule Pilotage et Ingénierie.
4. Analyse du besoin
4.1. Modélisation des processus métiers existants
4.1.1. Interaction avec le Pilote d’Exploitation
Le Pilote d’Exploitation peut contacter la cellule Pilotage du Service PFC pour un incident
ou une demande.
4.1.1.1. Gestion des incidents
Il peut rencontrer les types d’incidents suivants :
Problème d’accès au portail vCloud Director
Problème d’approvisionnement d’un serveur
Problème de suppression d’un serveur
Problème d’accès au serveur
Problème Réseau (exemple : résolution DNS non fonctionnelle)
Problème d’inventaire (non présence du serveur dans SCOPE GP ou Fisher)
Problème de sauvegarde ou restauration AVAMAR remonté par son exploitant
système
Dans ce cas, le problème est analysé dans un premier temps par la cellule Pilotage qui
tente de le résoudre. Si la cellule Pilotage ne parvient pas à résoudre le problème, l’incident
est transféré à l’entité adéquate. Voici, dans la plupart des cas, comment les incidents sont
traités ou redirigés :

19
Problème d’accès au portail vCloud Director PFC
Les problèmes d’accès au portail sont habituellement liés à un problème de compte dans
l’Active Directory ADAM. L’intervenant de la cellule Pilotage va donc vérifier le compte de la
ou des personnes qui ne parviennent pas à se connecter. S’il s’agit de l’absence d’un compte,
ce dernier est ajouté par l’intervenant de la cellule Pilotage. S’il s’agit d’un problème Active
Directory général, l’incident est réorienté vers l’équipe en charge de l’AD ADAM. S’il s’agit d’un
problème de profil VPN pour la connexion sécurisée à la machine située en ZSA (Zone
Sécurisée d’Administration) qui héberge le portail vCloud, le PE est invité à se rapprocher de
son correspondant informatique pour créer son profil VPN ou, si le profil existe déjà, une
demande d’ouverture de flux est faite aux équipes Réseau par la cellule Pilotage.
Problème d’approvisionnement de serveurs sur PFC
Pour les problèmes d’approvisionnement, il peut s’agir soit d’un non-respect de la
procédure, auquel cas, le PE est invité à consulter la documentation, soit d’un problème du
Workflow vCenter Orchestrator (vCO) de création des VM PFC. Dans ce dernier cas, l’incident
est redirigé vers la cellule Ingénierie pour analyse par un expert. Dans la plupart des cas d’un
problème général de Workflow, les services vCO sont redémarrés par l’intervenant de la
cellule Ingénierie et le PE est invité, par l’intervenant de la cellule Pilotage, à relancer un
approvisionnement de son serveur.
Problèmes de suppression de serveurs sur PFC
Les problèmes de suppression surviennent habituellement quand le PE tente l’opération
lorsque la vApp ou la VM qu’elle contient sont allumées. L’intervenant de la cellule Pilotage
répond au PE en l’informant qu’il faut qu’il demande l’arrêt de la vApp et de la VM à son
infogérant système. La cellule Pilotage pourra exceptionnellement éteindre la vApp et la VM
à la demande du PE pour des contraintes de temps. Dans de rares cas, le problème peut être
dû à un dysfonctionnement du Workflow vCO de suppression.
Problèmes d’accès aux serveurs sur PFC
Les problèmes d’accès au serveur peuvent être divers et variés. En général, l’intervenant
de la cellule Pilotage s’assure qu’il n’y a pas de problème VMware au niveau de la VM. S’il y a
une anomalie, il corrige le problème ou le redirige vers la cellule Ingénierie pour correction ce

20
qui résout le problème. S’il n’y a pas de problème VMware ou que ce dernier est résolu mais
que le PE rencontre toujours des difficultés, il peut s’agir d’un problème Système. Dans ce cas,
l’incident est redirigé vers les équipes EEI et notamment le Support Serveurs.
Problèmes Réseau
Les problèmes Réseau regroupent les problèmes de configuration des VLAN sur PFC qui
sont redirigés vers l’infogérant OBS, les problèmes Active Directory qui sont redirigés vers les
équipes ADAM et les problèmes de flux VPN traités par les équipes Réseaux. Dans chacun des
cas, c’est l’intervenant de la cellule Pilotage qui doit rediriger l’incident vers l’entité concernée.
Problème d’inventaire ou de facturation
L’inventaire du parc informatique EDF est géré par les équipes GAA. En principe, le serveur
doit être ajouté dans l’outil de gestion de parc (SCOPE GP). Le lendemain de son ajout dans
SCOPE GP, la machine apparaît dans Fisher qui est l’outil de facturation et la fiche du serveur
peut être complétée par l’intervenant de la cellule Pilotage. Cette démarche est nécessaire
pour que le PE puisse demander l’installation de l’outillage à son Infogérant Système. En cas
de problème, soit la machine n’a pas été ajoutée dans SCOPE GP, soit elle ne l’a pas été dans
Fisher. Dans ces deux cas l’intervenant de la cellule Pilotage doit contacter la cellule GAA pour
qu’elle vérifie si la machine est présente dans la Base de données SCOPE GP et l’ajoute le cas
échéant. Si le problème provient plutôt de Fisher, il faut contacter son POA pour qu’il
demande à ses équipes d’analyser le problème.
Problème de sauvegarde de serveurs sur PFC
Les incidents AVAMAR sont redirigés vers la cellule Ingénierie PFC par un intervenant de
la cellule Pilotage. Si la cellule Ingénierie ne parvient pas à résoudre l’incident, l’intervenant
de la cellule Pilotage doit ouvrir un incident auprès d’OBS afin qu’ils ouvrent un « Case » chez
Telindus qui doit analyser le dysfonctionnement.
4.1.1.2. Gestion des demandes
Il peut y avoir les types de demandes suivantes :
Information générale sur le Service PFC
Liste des critères d’éligibilité d’un serveur au Service PFC
Sauvegarde des serveurs (lié à la classe de service du serveur)

21
Gestion des Bascules de CONSER vers PFC
Changement de classe de service d’un serveur
Approvisionnement d’un serveur
Suppression d’un serveur
Documentation sur le portail vCloud Director
Demande de mise à jour de la documentation
Ajout ou modification d’une interface réseau au serveur
Ajout d’une nouvelle entité à l’infrastructure PFC
Ajout d’une nouvelle souche à l’infrastructure PFC
La plupart des informations demandées se trouvent soit dans la documentation, soit dans
la FAQ PFC, soit dans la Base RD&E. Cependant, certaines demandes nécessitent l’intervention
de plusieurs acteurs. C’est le cas pour le changement de la classe de service d’un serveur,
l’ajout ou la modification d’une interface réseau, la gestion des Bascules, l’ajout d’une
nouvelle entité à l’infrastructure PFC, l’ajout d’une nouvelle Souche à l’infrastructure PFC et
la mise à jour de la documentation. Voici les demandes les plus courantes nécessitant
l’intervention de plusieurs acteurs :
Changement de la classe de service d’un Serveur PFC
Lors d’une demande de changement de la classe de service d’un serveur pour que ce
dernier soit sauvegardé, il faut que l’intervenant de la cellule Pilotage obtienne de la part du
PE une plage horaire pendant laquelle le serveur peut être éteint. En effet, l’opération ne peut
se faire que si la vApp et la VM du serveur sont éteintes. Une fois cette plage horaire fixée,
l’intervenant de la cellule Pilotage prend contact avec l’Infogérant OBS pour qu’il réalise le
geste technique.
Ajout ou modification d’une interface réseau d’un serveur sur PFC
L’ajout ou la modification d’une interface réseau sont réalisés directement par
l’intervenant de la cellule Pilotage sur le portail vCloud Director. Cette opération doit
également être réalisée lorsque la VM est éteinte donc il est nécessaire de fixer une plage
horaire d’arrêt du serveur avec le PE pour effectuer l’opération.

22
Ajout d’une nouvelle entité à l’infrastructure PFC
L’ajout d’une nouvelle entité (Plateau d’Exploitation ou Infogérant/Exploitant Système) à
l’infrastructure PFC demande la réalisation de plusieurs actions techniques sur l’Active
Directory, dans le portail vCloud Director, dans le Client du système de sauvegarde AVAMAR,
dans les Templates des Souches PFC via des commandes REST et dans le Workflow vCO. Les
cinq premières actions peuvent être prises en charge par l’intervenant de la cellule Pilotage et
la dernière action doit être effectuée par un intervenant de la cellule Ingénierie. Les gestes
techniques sont décrits dans des procédures présentes dans la Base PFC.
Ajout d’un Template d’une nouvelle Souche à l’infrastructure PFC
Les Templates des Souches PFC contiennent les systèmes d’exploitation et le « bundle
système » (ensemble d’outils logiciels) de base des serveurs virtuels EDF Linux et Windows.
Ces Templates sont gérés par les équipes EEI. Suite au Projet PFC, la plupart des Souches
étaient présentes. Cependant, il peut arriver qu’une entité demande une nouvelle Souche.
Dans ce cas, si les équipes qui gèrent cette Souche (en général le demandeur) sont d’accord
pour gérer cette Souche sur PFC, alors la Souche peut être ajoutée. Une fois cet accord obtenu,
la cellule Ingénierie doit mettre à disposition du demandeur une VM de test pour mettre au
point le Template avant sa mise en production. Cet ajout n’est justifié que si un nombre
important de VM sont approvisionnées par la suite en utilisant ce Template. A noter que lors
de l’approvisionnement d’une machine PFC, le Workflow vCO copie le Template qui est en fait
une VM éteinte et le personnalise en fonction des choix de configuration qu’a effectués le PE
pour son nouveau serveur (nombre de vCPU, quantité de RAM, espace disque, etc…).
4.1.2. Interaction avec l’Infogérant Orange Business Service (OBS)
L’infogérant OBS est garant du bon fonctionnement de l’infrastructure PFC excepté pour
le Workflow vCO qui reste à la charge de la cellule Ingénierie PFC. Pour fonctionner
l’infrastructure utilise de nombreuses VM d’infrastructure qui forment ce qu’EDF nomme
l’IMP (Infrastructure Management Pod). OBS doit s’assurer que les VM d’infrastructure
fonctionnent correctement et que le Service est opérationnel.
OBS doit également réaliser les actions suivantes :

23
Mise à jour des systèmes d’exploitation sur les VM d’infrastructure si demandé
(exemple : installation du SP1 pour les VM disposant de Windows Serveur 2008 R2)
Changement de la classe de service de certaines VM sur demande de la cellule Pilotage
PFC
Contrôle quotidien du bon déroulement des sauvegardes AVAMAR et relance le cas
échéant
Réalisation des Bascules de CONSER vers PFC selon un planning déterminé à l’avance
par la cellule Pilotage PFC
Gestion des incidents liés à l’infrastructure (exemple : problème d’accès à la VM du
vCenter ou au portail du vCenter)
Support Niveau 1 et 2 auprès des utilisateurs
Maintien de la documentation d’exploitation notamment le DEX
Chaque semaine, OBS rend compte de son activité lors d’un Comité Hebdomadaire
Opérationnel (CHO). Le CHO regroupe un intervenant de la cellule Pilotage PFC, un
responsable côté OBS et éventuellement le POS du Service PFC.
Excepté pour le CHO, les échanges entre le Service PFC et OBS se font par mail ou via
l’outil SCOPE GS qui permet de créer des demandes ou d’affecter des incidents. Cela permet
de laisser un historique nécessaire pour le processus de facturation de l’infogérant.
Les demandes qui peuvent être faites à l’Infogérant OBS sont les suivantes :
Opération exceptionnelle sur une VM PFC (exemple : installation d’un Patch système
sur une VM d’infrastructure, changement de la classe de service d’une VM)
Mise à jour de la documentation d’exploitation (exemple : mise à jour du DEX)
Vérification du bon fonctionnement des éléments de l’infrastructure PFC (exemple :
vérification de la sauvegarde d’une VM ayant fait l’objet d’une restauration complète)
Les incidents affectés à OBS sont de types suivants :
Problème de service d’une VM de l’infrastructure (exemple : le vCenter ou le vCO ne
répondent plus)
Problème de sauvegarde
Problème divers suite à une Bascule

24
Problème de configuration réseau ou de VLAN (exemple : une VM n’est plus joignable)
Problème d’accès lié à l’utilisation d’un compte de service ou de son mot de passe
4.1.3. Interaction avec l’Intégrateur Telindus
Telindus est l’intégrateur qui a proposé la solution sur laquelle repose le Service PFC. Il
s’agit de l’utilisation des machines de type Vblock commercialisées par VCE. C’est aussi lui qui
a proposé le système de sauvegarde AVAMAR. Une fois la solution en place, il est en charge
des points suivants :
Mise à jour matériel des Vblock et du système AVAMAR
Mise à jour du firmware et de l’AMP (Administration Management Pod)
Gestion des incidents matériels sur les Vblock et le système AVAMAR
Gestion des incidents logiciels sur les Vblock et le système AVAMAR
Accompagnement du Service PFC pour l’installation des nouveaux Vblock
Telindus est aussi un intermédiaire entre le service PFC et le constructeur VCE qui fournit
le matériel. C’est principalement la cellule Ingénierie qui communique avec l’intégrateur
Telindus, généralement lors de l’arrivée d’un nouveau Vblock ou lors d’un incident matériel
ou logiciel (AMP) provoquant un arrêt ou une dégradation du service PFC. L’infogérant OBS
peut aussi solliciter Telindus pour des demandes ou des incidents.
4.1.4. Interaction avec les autres Services EDF
Le Service PFC est souvent en relation avec d’autres Services EDF. Les Services avec
lesquels nous avons le plus de contacts sont les équipes Réseau (SRT), EEI, CONSER et GAA.
Les échanges avec SRT
Les échanges avec SRT concernent généralement les points suivants :
La mise à jour du cahier de Brassage des serveurs : Afin que les PE disposent de tous
les services réseau pour leurs serveurs comme, par exemple, la possibilité de passer
du domaine natif (ADAM) à un domaine national (ATLAS), il est nécessaire que
l’inventaire Réseau du parc soit à jour. Pour cela, l’intervenant de la cellule Pilotage
PFC doit remplir des formulaires de demande de « brassages3 » et « débrassages4 » qui
3 Mise à disposition de connexions réseau 4 Restitution de connexions réseau

25
sont adressés à l’infogérant en charge de l’application des mises à jour. La demande
est réalisée via l’outil SCOPE GS afin de garder un historique qui servira pour que
l’infogérant puisse effectuer sa facturation auprès d’EDF.
Les demandes d’ouverture de flux pour les profils VPN devant avoir accès à la ZSA PFC :
Lorsqu’une nouvelle entité est ajoutée à l’infrastructure PFC ou qu’il y a une
modification dans l’infrastructure PFC, la cellule PFC doit effectuer une demande de
modification du filtrage Réseau de certains profils VPN. Cette demande sert aux
membres de l’entité en question pour ouvrir des canaux VPN sécurisés pour avoir
accès aux outils de l’infrastructure PFC. Elle est, en général, réalisée par un intervenant
de la cellule Pilotage PFC qui l’envoie au SN1 (Support Niveau 1) de l’équipe Sécurité
Réseau via l’outil SCOPE GS. Cette demande fait d’abord l’objet d’une validation par le
SN3 (Support Niveau 3) des équipes Réseau puis, elle est traitée par le SN1.
Les VLAN PFC : il faut parfois contacter les équipes Réseau pour résoudre des
problèmes avec les VLAN PFC qui contiennent des « Pool » (réservoir) d’adresses IP
des VM PFC et qui représentent l’interface des serveurs avec l’extérieur.
La solution de Plan de Reprise d’Activité (PRA) : La mise en place d’une solution de PRA
nécessite l’intervention de la cellule ingénierie qui doit régulièrement communiquer
avec les équipes Réseau pour, par exemple, la reconstruction de la VM dans le RIB
(réseau en ZHB, c’est-à-dire hors ZSA et donc accessible sans profil VPN)
Les échanges avec EEI
Les échanges avec EEI concernent principalement les Templates PFC dont ils ont la charge.
En effet, les Template contiennent les Souches serveurs qui sont les systèmes d’exploitation
accompagnés du « bundle » système de base. Ces Souches sont exclusivement maintenues
par les équipes EEI. En cas d’une demande d’informations ou d’un problème avec un Template
en provenance d’un PE, l’intervenant de la cellule Pilotage le réoriente vers les équipes EEI.
Les cas les plus fréquemment rencontrés sont les suivants :
Demande d’information sur un Template (exemple : compatibilité d’un Template ou
possibilité pour la mise à disposition d’un nouveau Template)
Problème d’accès au système (le mot de passe du compte d’administration local ne
fonctionne pas)

26
Un outil du « bundle » système ne fonctionne pas correctement
Les autres types d’échanges avec EEI concernent les problèmes systèmes en général.
L’équipe en charge de ce type d’incident est le Support Serveurs. Le Service PFC peut, à de
rares occasions, être impliqué dans les échanges entre le Support Serveurs et le PE pour des
situations de crise mais cela reste exceptionnel.
Les échanges avec CONSER
Le Service CONSER comme PFC propose l’approvisionnement de serveurs sur un
environnement VMware. De nombreux serveurs éligibles aux PFC doivent migrer de la
plateforme CONSER à l’une des plateformes PFC (Virtual to Virtual ou V2V). Ces opérations de
migration appelées Bascules sont gérées côté PFC par le responsable de la cellule Pilotage qui
surveille ce travail qui est réalisé par l’infogérant OBS. Dans ce contexte, Il peut arriver qu’il y
ait des échanges entre PFC et CONSER mais c’est assez rare. D’autre part, comme le Service
CONSER est beaucoup plus ancien que le Service PFC, de nombreux concepts sont repris sur
PFC et un intervenant de la cellule Pilotage PFC peut les contacter pour leur demander des
informations et l’inverse est également possible.
Les échanges avec GAA Gestion de Parc
Comme expliqué plus haut dans ce document, GAA est souvent contacté par un
intervenant de la cellule Pilotage PFC pour la mise à jour de SCOPE GP. Cette mise à jour est
indispensable pour que les nouveaux serveurs PFC apparaissent dans l’outil de facturation
Fisher et que le PE puisse demander à son infogérant système d’installer l’outillage. Les
demandes peuvent être d’une des catégories suivantes :
Ajout d’une nouvelle VM dans SCOPE GP
Mise en Stock d’une VM dans SCOPE GP suite à une suppression de serveur
Vérification d’une machine qui a été ajoutée dans SCOPE GP mais qui n’apparaît pas
ou dont la fiche n’est pas correctement renseignée dans Fisher

27
4.1.5. Schéma des processus métiers5
Gestion des demandes :
5 C’est la notation BPMN (Business Process Modeling Notation) qui a été utilisée pour cette modélisation. Voir [36, p. 198] pour plus d’informations.
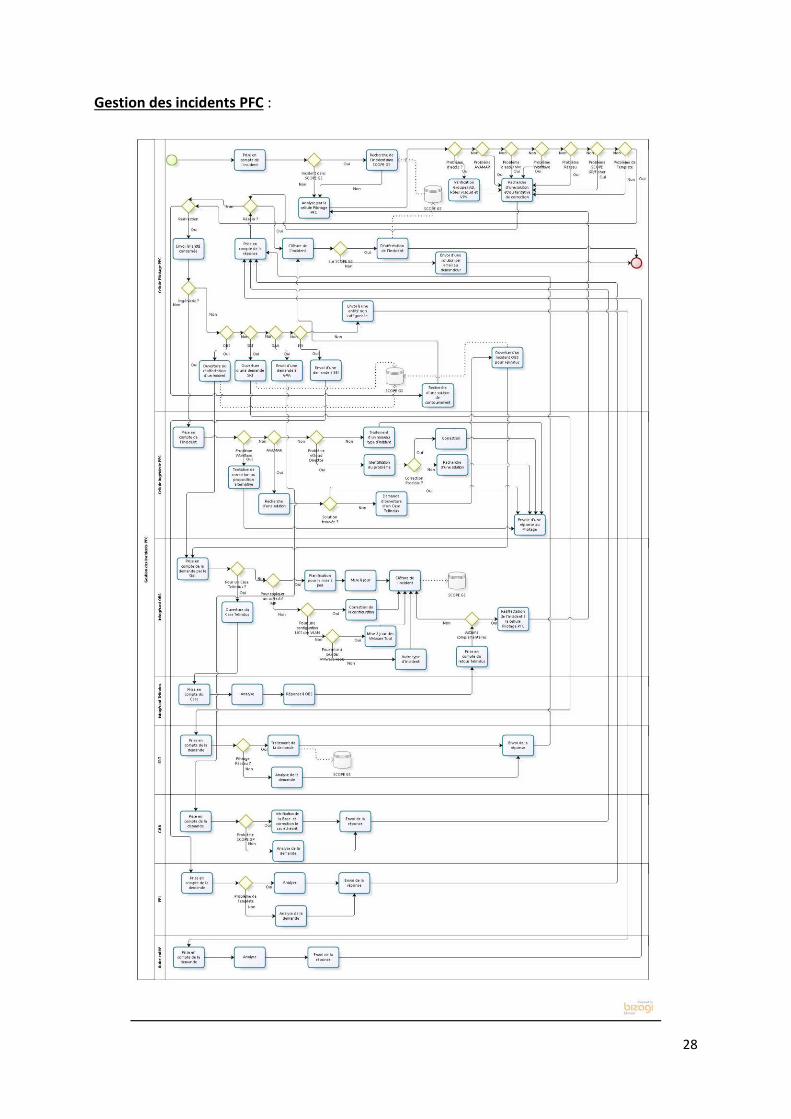
28
Gestion des incidents PFC :

29
4.2. Motivation du Projet
Comme le montre la modélisation des processus métiers du Service PFC, ces derniers sont
relativement complexes. Le système de gestion des connaissances actuel permet bien
d’enregistrer le traitement des incidents et des demandes ainsi que les documents mais
semble, cependant, insuffisant. En effet, il apparaît ici que la gestion de la connaissance se fait
au fil de l’eau et de manière un peu anarchique. Dans ces circonstances, il sera compliqué,
voire impossible, de réutiliser ces connaissances car elles seront trop difficiles à retrouver. La
solution est de mettre en place un système de gestion des connaissances adapté au Service
PFC en utilisant les outils du Knowledge Management (KM). Souvent, la mise en place du KM
reste une activité secondaire mais qu’il est indispensable de réaliser et c’est le cas pour le
Service PFC chez EDF. Cependant, il convient de rester prudent car ce type de projet peut
facilement échouer [1, p. 52]. En effet, le principal risque serait que les gens n’utilisent pas le
système parce qu’il est inadapté, non convivial, trop compliqué à utiliser, trop lourd ou qu’il
fait « doublon » avec le système existant.
Selon Jean Yves PRAX, il est très difficile de calculer de manière juste le Retour sur
Investissement de la mise en place du KM [1, p. 12]. En effet, d’après lui, les bénéfices qui se
traduisent généralement en temps gagné dans le traitement des processus métiers sont très
variables d’une situation à l’autre. Cela s’explique par le fait que l’efficacité du KM dépend
d’une combinaison de facteurs et qu’il n’est pas possible d’isoler le KM des autres facteurs.
Bien qu’il ne soit pas évident de constater les avantages immédiatement, il est sûr qu’il y a un
gain sur le long terme et ce dernier peut même être très important. Selon Alphonse CARLIER,
le KM permet d’améliorer les performances, l’efficacité, le partage et ainsi favorise
l’innovation [6, p. 108]. Dans notre cas, voici les avantages que pourront apporter la mise en
place du KM :
Les demandes seront plus rapides à traiter puisque les informations nécessaires pour
y répondre seront plus faciles à trouver
Certaines demandes pourront être évitées car les PE pourront accéder aux
informations plus facilement sans avoir besoin de solliciter le Service PFC
Les incidents pourront être résolus plus rapidement. En effet, le classement des
incidents et des solutions proposées correspondantes permettra de résoudre les

30
nouveaux incidents du même type bien plus rapidement et simplement en se référant
aux anciens incidents traités et enregistrés
Les outils du Service PFC, très utiles à la cellule Ingénierie, seront plus faciles à trouver.
Cela fera gagner du temps et donc améliora la réactivité du Service
Les échanges entre les membres de l’équipe PFC seront améliorés notamment pour la
mise à jour de la documentation et des procédures
Certaines procédures de la cellule Pilotage PFC seront simplifiées notamment celle qui
consiste au classement des incidents et des demandes
Le Reporting sera, lui aussi, simplifié
Les objectifs du projet sont donc d’améliorer la qualité de service en mettant en place un
système de partage des connaissances participatif et un système de stockage des documents
et des outils formant une Base de connaissances adaptée au Service PFC accessible à travers
un portail collaboratif.
Le système partage des connaissances participatif permettra d’avoir un accès plus rapide
aux connaissances aussi bien pour les membres de l’équipe PFC que pour les Pilotes
d’Exploitation ainsi que par toute personne de l’entreprise intéressée par le Service PFC et
souhaitant obtenir des informations rapidement. Ce système regroupera les cinq référentiels
de gestion de connaissances d’EDF décrits dans la section suivante et permettra de répondre
plus rapidement à certaines demandes et même d’en éviter. Le système permettra aussi de
capitaliser sur les incidents et de conserver des retours d’expérience (REX). En effet, il servira
à enregistrer les incidents par catégorie accompagnés de la solution à ce dernier qui a été
proposée au Client, cela permettra de mieux gérer les incidents futurs avec un système de
mise à jour et de recherche efficace.
Le système de stockage des documents et des outils servira, d’une part, pour la cellule
Ingénierie qui souhaite disposer d’un espace de stockage plus efficace pour les différents
outils nécessaires à l’utilisation et à l’administration de la plateforme PFC. Et, d’autre part, elle
servira à stocker des documents critiques pour les deux cellules du Service PFC.
5. Présentation des référentiels de gestion de connaissances existants
Il existe actuellement cinq sources d’informations principales pour le Service PFC, il s’agit
de la Base Lotus Notes PFC, des messageries électroniques du Services PFC, de la Base RD&E,

31
du référentiel PRODIS et de l’outil SCOPE GS. Chacune de ces sources a un rôle spécifique
décrit en détail dans les sections suivantes.
5.1. Les messageries électroniques du Service PFC
Les acteurs du Service PFC communiquent énormément en interne ou vers l’extérieur
avec les Clients, les infogérants, les intégrateurs, les fournisseurs et les autres Services d’EDF
via la messagerie électronique. Chaque acteur du Service PFC dispose bien entendu de sa
propre boîte aux lettres électronique mais pour les échanges importants nous préférons
utiliser les boîtes aux lettres électroniques génériques (un acteur recevant sur sa boite aux
lettres personnelle un mail destiné à tous les membres de la cellule ou de l’équipe le redirigera
vers la boîte aux lettres générique de sa cellule). Le Service PFC dispose d’une boîte aux lettres
générique par cellule et chacune d’elle peut contenir des informations importantes sur le
traitement d’une demande ou d’un incident qui ne figure nulle part ailleurs.
5.2. La Base Lotus Notes PFC
Elle sert exclusivement au Service PFC. Elle contient des informations communes à tout le
Service comme le suivi de la prestation, des informations spécifiques aux cellules Pilotage et
Ingénierie, des fiches décrivant des procédures particulières, des documents de toutes sortes
(contrats, PTE, procédures,…) et des informations concernant le Projet PFC. Cette Base n’est
accessible totalement que par les membres de l’équipe.
5.3. La Base Lotus Notes RD&E
Il s’agit également d’une Base Lotus Notes mais qui contient, entre autres, des
informations sur plusieurs Services chez EDF. En général, toutes personnes ayant besoin
d’informations sur un Service peut s’y connecter. La Base contient, bien sûr, des informations
sur le Service PFC et notamment la Frequently Asked Questions6 (FAQ) qui est en quelque
sorte l’ensemble des premières informations mises à disposition du PE avant la prise de
contact avec notre Service.
5.4. PRODIS
Il s’agit d’un intranet qui contient l’ensemble des logiciels, des outils et des procédures
du SI EDF. Il existe une entrée dans PRODIS pour PFC où sont présents le guide utilisateur du
6 Questions Fréquemment Posées par les utilisateurs du Service

32
portail vCloud Director pour les PE et la Procédure Technique d’Exploitation du système de
sauvegarde des serveurs PFC AVAMAR pour les infogérants système (une des fiches de la Base
RD&E contient les liens PRODIS vers ces documents). Les PE, les infogérants systèmes ainsi
que l’équipe PFC ont accès à ce référentiel.
5.5. SCOPE GS
EDF a mis en place un système de gestion des incidents et des demandes assez élaboré.
Ce système repose sur le logiciel HP OpenView ServiceCenter et est appelé SCOPE GS (Gestion
de Service). Comme pour tous les Services d’EDF, les incidents et les demandes concernant le
Service PFC passent par cet outil pour une meilleure traçabilité (la facturation des infogérants
se base d’ailleurs sur ce système). Chaque incident représente une entrée et les demandes
sont subdivisées en articles.
Ce système contient donc de nombreuses informations sur le traitement des incidents et
des demandes PFC qui n’ont pas été formulés par mail.
5.6. Les problèmes liés à l’existant
Le fait qu’il y ait cinq référentiels de gestion des connaissances différents n’est pas optimal
et nuit donc aux performances du Service PFC. En effet, non seulement cela pose problème
lors de la recherche d’une information précise qui peut s’avérer longue car il est difficile de
déterminer où chercher mais, en plus, c’est une source d’erreur car la même information est
souvent copiée dans plusieurs référentiels (des fois dans des versions différentes) et à long
terme une erreur est inévitable. Il s’agit d’un problème de « versionning » des documents.
A cela s’ajoute les informations sur les incidents et les demandes traitées qui peuvent être
présentes dans la boîte aux lettres générique Lotus Notes de la cellule Pilotage ou dans l’outil
de gestion des incidents et des demandes SCOPE GS. Cette organisation ne permet pas de
capitaliser facilement les connaissances acquises lors du traitement de ces demandes et
incidents qui deviennent difficiles à retrouver et à réutiliser.
Cette situation montre donc clairement les limites du système existant.

33
6. Concept sur la gestion des connaissances collectives
6.1. Les enjeux
Dès le moment de leur création, les entreprises commencent à accumuler des
connaissances. L’ensemble de ces connaissances augmente rapidement avec le temps.
Cependant, contrairement à ce qui pourrait être supposé, les entreprises peuvent perdre ces
connaissances. En effet, ce n’est pas l’entreprise en tant que telle qui crée ses connaissances
mais plutôt les personnes qui y travaillent. Certes, les entreprises peuvent essayer
d’enregistrer ces connaissances sur des supports papiers ou numériques, cependant ce n’est
pas suffisant car cela sous-entend que les connaissances peuvent toutes être stockées et
réutilisées indépendamment des personnes qui en sont à l’origine.
Cette difficulté de conservation des connaissances vient du fait qu’il en existe de plusieurs
types dont certaines, comme le savoir-faire ne peuvent pas être enregistrées facilement et
nécessitent d’être transmises d’une personne à une autre différemment que par le biais de
documents (par l’apprentissage par exemple). Les connaissances peuvent donc être perdues
lors du départ d’un collaborateur. D’autre part, même lorsque personne ne quitte l’entreprise,
il arrive souvent que les connaissances ne circulent pas de manière optimale voir pas du tout
à cause, par exemple, d’un mauvais système communication ou de rétention d’informations.
L’enjeu de la gestion des connaissances est d’essayer de maintenir toutes ces
connaissances au sein de l’entreprise et de faire en sorte qu’elles circulent de manière
optimale entre les différents acteurs. Cela permet ainsi :
De capitaliser et de pouvoir réutiliser facilement les connaissances déjà acquises. Cela
augmente donc la réactivité des individus par rapport à un problème donné.
De favoriser la communication et le travail collaboratif
De mieux former les nouvelles recrues
De mieux gérer le départ d’un collaborateur
De favoriser l’innovation
D’améliorer la qualité de service
L’ensemble de ces effets bénéfiques fait baisser les coûts de fonctionnement global. En
effet, les personnes ont accès plus rapidement aux connaissances et vont donc passer moins
de temps à résoudre des incidents et des problèmes connus. Ils pourront trouver plus

34
facilement une solution à un problème grâce au travail collaboratif et à l’échange
d’informations. L’innovation sera favorisée car les collaborateurs auront une meilleure vision
de l’ensemble des connaissances et pourront plus facilement suggérer des améliorations ou
des corrections.
6.2. Le Knowledge Management
Depuis très longtemps, l’homme a créé, manipulé et transmis des connaissances à ses
semblables [6, p. 19]. Ces connaissances sont à la base de toutes les civilisations. Le Knowledge
Management est une discipline qui a été inventée dans le but de gérer au mieux ces
connaissances.
Le Knowledge Management est un sujet complexe et très dense qui a fortement intéressé
les entreprises ces dernières années. Pour le présenter, il faut dans un premier temps en
donner une définition. Puis, il faut aborder la définition de la connaissance. Ensuite, il faut
décrire ses modèles et ses méthodes. Pour finir, il convient de montrer les catégories d’outils
qui existent pour mettre en pratique cette discipline.
6.2.1. Définition
Selon Jean-Yves PRAX, il existe de nombreuses définitions du Knowledge Management [1,
p. 17]. De son point de vue, voici les principales définitions :
Définition utilitaire : Le Knowledge Management doit réunir les conditions pour que
l’information nécessaire soit apportée au bon moment sans pour autant que celui qui
en a besoin soit obligé d’en faire la demande [1, p. 18]
Définition fonctionnelle : Le Knowledge Management sert à manager le cycle de vie
des connaissances ayant pour origine une idée [1, p. 19].
Définition opérationnelle : Le Knowledge Management doit permettre de combiner
les savoirs et savoir-faire dans les processus, les produits et les organisations afin de
créer de la valeur [1, p. 19]
Définition économique : Le Knowledge Management doit permettre la valorisation du
capital intellectuel de l’entreprise [1, p. 19]
6.2.2. Qu’est-ce que la connaissance ?
Pour comprendre ce qu’est la connaissance, il faut définir ce que Jean-Yves PRAX appelle
la pyramide de la sagesse [1, p. 65]. Il s’agit de la représentation la plus courante du modèle

35
DIKW (Data, Information, Knowledge, Wisdom) [7, p. 8]. Cette pyramide est construite avec à
sa base les données, au centre les informations et au sommet les connaissances et la sagesse
comme le montre la figure 4.
Figure 4 : Pyramide de la sagesse inspirée du schéma de [1, p. 66]
La donnée est la mesure qualitative ou quantitative d’un fait brute isolée d’un instrument
de mesure réel ou abstrait [1, p. 66]. La donnée est considérée comme objective car elle n’a
pas été soumise à interprétation mais cela dépend en fait de l’objectivité de l’instrument de
mesure qui augmente avec son degré de normalisation [1, p. 66].
L’information est un agrégat de donnée agencées de manière particulière pour
transmettre un message [1, p. 67]. Comme la sélection et l’organisation des données
objectives dépendent essentiellement du transmetteur, elle est subjective car elle donne une
interprétation des données [1, p. 67]. Cependant, pour que le message soit correctement
transmis, il faut que les entités qui communiquent partagent le même langage ou plus
précisément, la même « unité sémantique » [1, p. 68]. Selon Jean-Yves PRAX, il existe cinq
types d’informations :
Physique : regroupement des données d’un fait précis comme la description d’une
situation ou d’un état
Pragmatique : priorise la qualité de l’information comme dans une procédure
Rationnelle : met en avant la logique et la réflexion comme dans une théorie
scientifique
Paradigmatique : essaie de formaliser un lieu commun admis de tous mais qu’il n’est
pas possible de prouver
Sagesse
Connaissances
Informations
Données

36
Expressive : tend à provoquer une réaction émotionnelle chez le récepteur du
message comme dans un roman
La connaissance c’est l’appropriation des informations par un individu donné. C’est la
transformation des informations par une personne par rapport à la représentation qu’il a de
la réalité, de son environnement et de ses croyances [1, p. 68]. Cette connaissance peut aussi
évoluer au cours du temps. Ainsi, plusieurs personnes ne percevront pas le message d’une
information de la même façon et ce qu’ils ont perçu évoluera au cours du temps. Donc pour
qu’une personne transmette une connaissance à une autre personne, il est nécessaire que ces
deux personnes partagent la même « unité d’action » qui correspond à une forme de
socialisation [1, p. 69].
L’acquisition des connaissances a pour objectif ultime la sagesse. D’un point de vu
philosophique, elle peut être décrite comme un état vers lequel les civilisations, les groupes
d’individus et les individus veulent tendre [8]. C’est un peu comme une quête vers un savoir
absolu qui ne pourra jamais être atteint mais qui fait progresser à chaque fois que nous
tentons de nous en approcher. Mais la sagesse peut aussi être définie comme la mobilisation
des connaissances dans le but d’une action future et correspond à une « unité d’intention »
[1, p. 96].
6.2.3. Les modèles du Knowledge Management
Les modèles servent à représenter de manière restreinte la réalité qui nous entoure. Il n’y
a donc pas de modèle parfait. Ces modèles aident beaucoup pour la mise en pratique rapide.
Pour qu’un modèle soit efficace, il ne doit être ni trop précis, ni pas assez. Les modèles du KM
cherchent, pour la plupart, à expliquer le cycle de vie des connaissances c’est-à-dire décrire
comment les connaissances sont acquises, échangées, transmises et manipulées.
6.2.3.1. Le modèle SECI ou matrice Nonaka
Le modèle SECI (Socialisation Externalisation Combinaisons Internalisation) aussi appelé
matrice de Nonaka a été inventé par les professeurs japonais Nonaka et Takeuchi. Elle tente
d’expliquer comment s’effectue les échanges entre, d’une part, les connaissances tacites et
explicites et, d’autre part, entre les connaissances individuelles et collectives. Elle a inspiré la
méthode agile SCRUM qui a, depuis, fait ses preuves, ce qui dans un sens accrédite sa validité.

37
Les connaissances tacites représentent celles qui ne sont pas possibles à formaliser. Il
peut s’agir, par exemple du savoir-faire d’un individu. Les connaissances explicites par contre
peuvent être formalisées sous forme de documents comme, par exemple, des procédures.
La figure 5 montre une représentation de la matrice de Nonaka :
Figure 5 : Matrice de Nonaka inspirée de [9, p. 62], de [1, p. 93] et de [6, p. 29]
Ce modèle peut être vu comme une représentation du cycle de vie de la connaissance ou
encore du cercle vertueux de la connaissance d’une organisation. En effet, d’une certaine
façon, il explique comment les connaissances évoluent dans l’organisation lors des différents
échanges entre connaissances tacites et explicites au niveau individuel et collectif.
6.2.3.2. Le modèle d’Huber
Le modèle de George P. Huber met l’accent sur le rôle de l’apprentissage pour
l’acquisition, la manipulation et la diffusion de la connaissance au sein d’une organisation [6,
Tacite
Taci
te
Externalisation (Intégration des savoir-faire par l’apprentissage
en appliquant des connaissances formalisées)
Combinaison
(Création de nouvelles
connaissances en
combinant des
connaissances formelles
existantes)
Internalisation (Formalisation des savoir-faire d’un
individu)
Explicite
Explicite
Tacite Explicite Ex
plic
ite
Tacite
Connaissances individuelles Connaissances collectives
Socialisation
(Partage des expériences entre
individus)

38
p. 33]. Le modèle insiste aussi sur le fait que l’acquisition des connaissances par un individu
pourra se propager à toute l’organisation.
6.2.3.3. Le modèle de Boisot
Ce modèle a été inventé par Max Boisot en 1995 [6, p. 33]. L’idée de ce dernier repose
sur l’apprentissage collectif. Il y aurait donc un rôle important du social dans l’acquisition des
connaissances. Il y a trois éléments fondamentaux sur lesquels repose le modèle qui sont
l’espace épistémologique, l’utilité et la culture [6, p. 34].
6.2.3.4. Le modèle de K.E. Sveiby
Ce modèle inventé en 2001 essaie d’expliquer le mode de transformation des
connaissances à travers trois structures qui sont la structure interne, la structure externe et
les compétences [6, p. 34].
6.2.4. Les méthodes de capitalisation de connaissances du KM
6.2.4.1. La méthode MASK
Il s’agit d’une méthode inventée par Jean-Louis ERMINE et ses équipes dans le cadre de
ses travaux de capitalisation de connaissances pour le Commissariat de l’Energie Atomique
(CEA). MASK signifie « Method for Analysing and Structuring Knowledge » ou « Méthode
d’analyse et de structuration des connaissances ». Il s’agit de la dernière version de la
méthode initiale MKSM (Methodology for Knowledge System Management) mise au point en
1992. Cette méthode comporte quatre phases principales qui forment un cycle. Ces phases
sont représentées dans la figure 6.
Figure 6 : Le cycle de la méthode MASK inspiré des travaux de Jean-Louis ERMINE
1. Analyse stratégique
2. Capitalisation
3. Transfert
4. Inovation

39
La méthode MASK se sert de la théorie du macroscope de la connaissance pour structurer
le patrimoine des connaissances d’une organisation [10, p. 57]. Cette théorie se définie, d’une
part, par une hypothèse « sémiotique » qui dit que la connaissance est un ensemble de signes
composés d’information, de sens et d’un contexte et, d’autre part, par une hypothèse
« systémique » qui dit que la connaissance est un système global avec une structure, une
fonction et une évolution [10, p. 57]. La figure 7 donne une représentation visuelle de cette
théorie du macroscope de la connaissance.
Figure 7 : Macroscope de la connaissance inspiré de la figure de [10, p. 58]
La méthode MASK repose sur les fondements théoriques du modèle AIK. Le modèle AIK
(système d’Acteurs, système d’Information et système de connaissances K) est une évolution
du modèle des organisations OID (système Opérant, système d’Information et système de
Décision) qui prend en compte le patrimoine des connaissances. La figure 8 monte une
représentation simplifiée de ces deux modèles.
Information
Contexte Sens
Données
Datation Traitements
Domaine
Activité Historique Tâches Lignés
Réseaux sémantiques
40
Figure 8 : Evolution du modèle OID vers le modèle AIK pour la gestion des connaissances inspirée de [10, p. 64]
Le résultat de l’application de la méthode MASK est un livre des connaissances qui donne
accès à une synthèse structurée des connaissances de l’organisation sur un domaine
particulier [11, p. 154]. Ce livre des connaissances7 peut comporter les éléments suivants [11,
p. 176] :
Des modèles de connaissances
Des références documentaires
Des fiches
Des plans et des graphiques
Des images et des vidéos
6.2.4.2. La méthode CommonKADS
KADS signifie « Knowledge Analysis and Design System/Support ». Elle consiste à
effectuer l’analyse et la modélisation des connaissances en mettant l’accent sur le cycle de vie
7 Pour plus de détails voir [37] et [38]
Système de
Décision
Système d’Information
Système Opérant
Modèle OID
Biens et
services
Système d’Information
Réseau d’Acteurs
Système de Connaissances
Expression
Appropriation
Modèle AIK
Compétence Cognition
Valeur Résultat

41
des connaissances et l’interaction système-utilisateur [1, p. 257]. Elle a été inventée en 1985
par Anne Brooking du South Bank Polytechnic, Joost Breuker et Bob Wielinga de l’Université
d’Amsterdam sous le nom de projet ESPRIT. Elle a subit de nombreuse modification pour
devenir l’approche CommonKADS. Cette méthode est beaucoup utilisée en intelligence
artificielle.
6.2.4.3. La méthode REX
REX signifie Retour d’EXpérience. Elle a également été inventée au CEA. Cette méthode
consiste, comme son nom l’indique, à mettre en place une démarche qui permet de conserver
les connaissances relatives à une expérience données. Il existe deux types de REX, celui qui
concerne l’exploitation et celui qui concerne les projets [1, p. 204].
Dans le cadre le cadre de l’exploitation, il s’agit de décrire les différentes étapes d’un
processus métier donné. Il y aura donc la procédure standard, les événements programmés
et la procédure non standard [1, p. 204]
Dans le cadre des projets, il s’agit de regrouper toutes les informations qui expliqueraient
pourquoi le projet est un succès ou un échec. C’est d’ailleurs dans le deuxième cas que cette
méthode est le plus important car elle permet de tirer les leçons du passé et d’éviter de
reproduire ces erreurs.
Les grandes lignes de la démarche REX sont les suivantes [12] :
L’analyse du besoin
La construction des éléments de connaissance par les interviews des experts et
l’analyse du fond documentaire
La mise en place d’une procédure pour alimenter le système avec les éléments de
connaissance (exemple : des modèles de fiches)
La mise en place d’un processus d’évaluation, d’exploitation et d’évolution du système
La prise en compte des connaissances structurées non modélisables
Création d’une carte des connaissances
6.2.4.4. La méthode MEREX
MEREX signifie « Mise En Règle de l’EXpérience ». Cette méthode a été créée en 1995 par
Jean-Claude CORBEL pour améliorer l’ingénierie de la conception des véhicules pour la société
Renault [1, p. 230]. Cette méthode est très proche de la méthode REX en capitalisant les

42
connaissances en partant des demandes des clients à la différence qu’elle impose certaines
contraintes sur la formulation de l’expérience [1, p. 230] :
L’expérience doit pouvoir tenir sur une feuille au format A4
Les détails doivent être capitalisés
Il est nécessaire transcrire les faits sous une forme simple et précise
Elle doit être accessible à tout le monde
6.2.4.5. La méthode KALAM
KALAM est l’acronyme de « Knowledge And Learning in Action Mapping ». Il s’agit d’une
méthode de capitalisation des connaissances inventée par Jean-Yves PRAX. Elle donne les
mêmes préconisations que la méthode MASK de Jean-Louis ERMINE.
6.2.4.6. La méthode KOD
KOD signifie « Knowledge Oriented Design ». Elle a été inventée en 1988 par Claude
VOGEL lors de son travail en intelligence artificielle. Elle consiste à faire de la capitalisation par
la modélisation des expertises en se basant sur des modèles pratiques, cognitifs et
informatiques d’une part et des paradigmes de représentation, d’action et d’interprétation
d’autre part [1, p. 259].
6.2.4.7. La méthode OCSIMA
OCSIMA signifie « Objectifs, Connaissances, Support Informatique, Management
Approprié ». Cette méthode préconise que la direction de l’entreprise ou de l’organisation
doit déterminer les objectifs de gestion des connaissances à atteindre [6, p. 34]. Il s’agit d’une
méthode qui préconise l’utilisation d’un ensemble de documents pour décrire la recherche, la
gestion des thésaurus et la capitalisation des connaissances.
6.2.5. Les outils pour la mise en œuvre du Knowledge Management
6.2.5.1. Les Wiki
Il s’agit de sites Web permettant aux utilisateurs de créer des articles et de discuter sur
chaque point de ces articles pour en améliorer le contenu le cas échéant. L’objectif principal
de ces outils est de favoriser le partage des connaissances afin d’obtenir le meilleur contenu
possible pour chaque article. Il permet ainsi d’avoir une plateforme collaborative centralisée
[6, p. 127].

43
Un Wiki peut être ouvert, c’est-à-dire accessible à tous les utilisateurs en lecture et en
écriture ; semi-ouvert pour ne donner accès en écriture qu’aux personnes autorisées mais
laisser un accès en lecture à tous ; fermé auquel cas seules les personnes habilitées ont un
accès au site. Le choix du type de Wiki dépend de l’usage qui veut en être fait mais il a été
inventé dans l’idée de partager et donc d’être ouvert à tous ses utilisateurs. Un des exemples
les plus célèbres de Wiki est l’encyclopédie libre « Wikipédia ».
Un Wiki peut être une excellente solution pour mettre à disposition des informations
auprès d’utilisateurs et leur permettre de s’exprimer sur le contenu. Il peut aussi être utilisé
pour créer une base de connaissances sur les incidents afin de capitaliser et d’être plus réactif
sur la gestion des incidents futurs.
Le moteur Wiki est le système logiciel au cœur des Wiki. Ces moteurs peuvent être de
plusieurs natures :
Les Wiki traditionnels :
Les Wiki traditionnels permettent de créer de nouveaux articles sur différents sujets et de
modifier leur contenu. Si le Wiki est ouvert, les utilisateurs peuvent modifier des articles dont
ils ne sont pas les auteurs et discuter ces modifications avec les auteurs et d’autres personnes.
C’est avec cette démarche que l’aspect collaboratif prend tout son sens.
Les données des articles sont stockées soit dans des bases de données classiques soit dans
des fichiers selon les cas et les besoins. Les Wiki traditionnels sont donc très proches de sites
Web dynamiques classiques. Un bon exemple de Wiki traditionnels est « Wikipédia ».
Les Wiki sémantiques :
Les Wiki sémantiques8 vont gérer les données des articles différemment en utilisant une
approche orientée sur la gestion des connaissances. En effet, dans ce type de Wiki, les
données sont structurées en objets de la connaissance qui sont interconnectés comme c’est
le cas dans une ontologie informatique. Cela permet de donner une structure sémantique aux
articles qui est absente des Wiki traditionnels.
Ces Wiki ont de nombreux avantages car ils permettent de donner un sens à chaque
élément « article » et facilitent donc les recherches sur un thème particulier. Effectivement,
8 Voir [39] pour plus de détails

44
les recherches, ici, se font non pas sur du texte brute mais plutôt sur des objets de la
connaissance (élément « article ») connectés à d’autres objets de la connaissance. De plus
cette structure est beaucoup plus adaptée pour l’échange entre les applications du Web.
Les Wiki sémantiques ne sont pas incompatibles avec les Wiki traditionnels mais
simplement complémentaires. Il peut s’agir d’un simple module à installer au sein d’un Wiki
classique comme c’est le cas par exemple avec « MediaWiki » et « Semantic MediaWiki ».
6.2.5.2. Les Bases de données
Une base de données est une structure permettant de regrouper des données de manière
structurée rendues accessibles rapidement via des requêtes. Elle peut contenir des données
reliées entre elles auquel cas c’est une base de données relationnelles.
Il existe plusieurs méthodes pour modéliser des bases de données relationnelles. Merise
est une de ces méthodes très connue et utilisée en France. Elle consiste à définir un système
d’information pour cadrer le domaine représenté par les données. Puis à réaliser un
dictionnaire de données à partir des éléments qui sont la source de ces données. Et ensuite,
à créer un modèle conceptuel de données (MCD) ou modèle Entité-Relation qui regroupe les
données en différentes entités reliées entre elles par des relations. Ce MCD permet de créer
un modèle logique de données relationnelles (MLDR) qui peut être traduit en langage
informatique.
Les bases de données peuvent être créées et manipulées à l’aide de Système de Gestion
de Bases de Données (SGBD) comme par exemple Oracle, MySQL, SQL Server, PostgreSQL ou
IBM DB2. Ces systèmes utilisent tous le SQL (« Structured Qurey Language » ou « Langage de
Requête Structurée »).
Les bases de données permettent donc de stocker des données structurées et
représentent donc des outils importants pour la gestion des connaissances.
6.2.5.3. Les Bases de données sémantiques
Les bases de données sémantiques sont le fruit des travaux sur le Web Sémantiques. Elles
permettent de stocker des données RDF (première couche du standard Web Sémantique [13,
p. 28]) qui est une forme non supportée par les bases de données classiques [6, p. 133]. En

45
effet, elles insistent sur l’aspect sémantique des données non pris en compte dans les bases
de données ordinaires.
6.2.5.4. Les Bases de connaissances ou Ontologies informatiques
Le terme d’ontologie a été emprunté de la philosophie où il s’agit d’un domaine qui tente
de s’interroger sur les questions existentielles [13, p. 84]. Une ontologie en informatique est
un concept utilisé pour représenter les connaissances. Il est surtout utilisé en informatique en
intelligence artificielle et dans les Bases de connaissances. Plus précisément, dans les Bases
de connaissances, elles permettent de représenter les connaissances sous forme d’objets
reliés entre eux et soumis aux règles précises qui régissent le domaine qui est représenté. Elles
sont au cœur des systèmes de Web Sémantique [13, p. 84].
Une base de connaissances est en fait une ontologie [6, p. 128]. Elles sont souvent
utilisées pour représenter un domaine d’expertise particulier. La figure 9 représente une
Ontologie simple.
Figure 9 : Ontologie simple inspirée de [6, p. 129]
Chaîne de
Caractères
abcd 1234
P@ssw0rd
Nombre Mot
Entier Décimal
Z est plus grand que Y
Si X est plus grand
que Z et que Z est
plus grand que Y
alors X est plus
grand que Y
X est plus grand que Y
X est plus grand que Z
Si X est plus grand que Y alors X est supérieur à
Y X est
supérieur à Y

46
6.2.5.5. Les MindMap
Les MindMap sont des outils permettant de représenter les connaissances sous forme
d’objets liés entre eux de manière à former une « carte heuristique » [6, p. 127]. La figure 10
est une copie d’écran d’un exemple de représentation des connaissances avec l’outil
WikiMindMap lors d’une recherche sur le mot « Informatique ».
Figure 10 : Recherche du mot « Informatique » sur l’outil WikiMindMap9
Chacun des nœuds terminaux de ce graphe est en fait un lien hypertexte qui renvoie
directement sur l’article correspondant de l’encyclopédie en ligne libre Wikipédia. Cette
représentation facilite beaucoup la navigation dans les connaissances existantes d’un
domaine donné.
6.2.5.6. La gestion documentaire et de contenu
L’objectif de la gestion documentaire est de trouver un moyen efficace de stocker et de
classer une grande quantité de documents. Il doit être possible de stocker aussi bien les
documents définitifs que les documents en cours de création. Le système doit permettre de
retrouver le document rapidement et gérer les différentes versions de ce dernier. Enfin, il doit
être possible de travailler à plusieurs sur le même document et d’y ajouter des commentaires.
9 L’outil WikiMindMap est accessible à l’adresse URL « http://www.wikimindmap.org »

47
6.2.5.7. La messagerie électronique
La messagerie électronique est une des applications les plus importantes d’Internet et
c’est très certainement une des plus utilisées aussi bien par les particuliers que par les
entreprises du monde entier.
Il s’agit d’un système de courrier passant par les réseaux informatiques. Un individu ou
groupe d’individus peuvent donc envoyer, à partir d’une adresse électronique, vers une ou
plusieurs adresses électroniques un message comportant du texte qui peut être accompagné
d’une ou plusieurs pièces jointes. Ces dernières peuvent être n’importe quel type de fichiers
à condition qu’il ne dépasse pas les limites imposées par le système de messagerie utilisé. En
général, les logiciels de messagerie électronique utilisent le protocole SMTP (Simple Mail
Transfert Protocol) pour envoyer le courrier électronique vers les serveurs de messagerie et
les protocoles POP3 (Post Office Protocol version 3) ou IMAP4 (Internet Message Access
Protocol version 4) pour relever le courrier électronique.
De prime abord, la messagerie électronique peut être vue comme un simple moyen de
communication asynchrone mais, dans les entreprises, les collaborateurs travaillant en équipe
utilisent souvent des boites aux lettres génériques communes à toute l’équipe qui permettent
de stocker tous les échanges qui ont eu lieu. L’accumulation de ces courriers électroniques ou
e-mail peut être considéré comme une gigantesque base de connaissances. En effet, les
échanges peuvent, par exemple, concerner le traitement d’une demande ou la gestion d’un
incident et de ce fait contenir des informations qui ne sont disponibles nulle part ailleurs dans
le système d’information de l’entreprise.
Comme base de connaissances, ce système souffre cependant d’un problème majeur de
classement lorsque le nombre d’e-mail devient important. Ce qui fait qu’il devient difficile de
retrouver les informations.
6.2.5.8. Les forums
Les forums constituent une autre application d’Internet. Il s’agit de sites Web dynamiques
(créés, par exemple, avec la technologie PHP/MySQL ou ASP/SQL Server) permettant
d’échanger sur des sujets divers et variés.

48
En général, le forum traite d’une thématique particulière qui peut être un sujet particulier
(par exemple la gestion des connaissances), une technologie, un produit ou un service. Il est
structuré et peut être divisé en plusieurs sections et sous-sections.
Selon les règles établies par l’administrateur du site, les utilisateurs anonymes peuvent
avoir le droit de consulter le site et les utilisateurs membres peuvent créer de nouveau sujet
de conversation.
Lors de l’ouverture du sujet, l’utilisateur crée un message appelé « post » via un éditeur
qui génère automatiquement un code HTML qui contient du texte pouvant être accompagné
de liens hypertextes, d’image, de son et de fichiers de toutes sortes. Les autres utilisateurs
peuvent répondre à ce « post » avec un message de même nature.
Les forums constituent donc un moyen efficace d’échanger des connaissances entre
différents individus.
6.2.5.9. Les blogs
Les blogs sont aussi une des applications d’Internet. Il s’agit, en fait, de site Web dont la
création a été simplifiée pour rendre cette technologie accessible au plus grand nombre.
En effet, la création de site web nécessite généralement d’avoir des connaissances en
développement web et il faut connaitre des langages tels que HTML et CSS pour concevoir un
site Web statiques. Pour les sites Web dynamiques, il faut en plus connaître les langages PHP
ou ASP avec SQL et un système de gestion de bases de données comme MySQL ou SQL
Serveur. Cela se complique encore si le site Web doit comporter des animations Adobe Flash.
Certains acteurs du Web ont donc décidé d’offrir des plateformes permettant de créer des
sites Web un peu comme un document dans un logiciel de traitement de texte.
Les blogs permettent donc à un grand nombre de personnes ayant accès à Internet de
s’exprimer sur des sujets en créant des pages correspondant à des articles et, selon les règles
du blog, d’autoriser ou non les lecteurs à ajouter des commentaires.
Les blogs sont donc plus centrés sur la diffusion des connaissances que sur les échanges
entre individus.

49
6.2.5.10. Les portails d’entreprise
Les portails d’entreprise appelés aussi portails collaboratifs ou plateformes collaboratives
sont des suites logicielles informatiques qui regroupent plusieurs outils pour réaliser des
tâches diverses et variées en mettant l’accent sur la communication des individus. Cela
permet, par exemple, à plusieurs individus de travailler sur les différentes tâches d’un projet
en échangeant des informations. Le principal objectif de ces solutions est de faciliter le travail
collaboratif.
Ces portails collaboratifs proposent généralement un point d’accès unique à plusieurs
outils intégrés qui forme une suite logicielle contrairement à des outils individuels installés
séparément. Ils permettent de gérer les droits attribués à chaque utilisateur ou groupe
d’utilisateurs pour les données enregistrées dans la solution. Ils offrent aussi souvent aux
utilisateurs des possibilités étendues de personnalisation de leur espace de travail.
Il existe plusieurs façons de classer ces portails [14, p. 8] :
Par type d’utilisateurs avec les portails B2C (Business to Consumers) pour des
communications entre l’entreprise et le consommateur, B2B (Business to Business)
pour les échanges entre entreprise et B2E (Business to Employee) pour une interaction
avec les salariés de l’entreprise.
Par type de fonctionnalités des portails avec les portails verticaux d’une part qui se
centrent sur un domaine particulier de l’entreprise et les portails horizontaux d’autre
part qui ciblent plutôt un gamme très large d’utilisateurs avec des informations très
variées en provenance de sources différentes.
Par niveau de maturité [14, p. 9] où il est possible de classer les portails par rapport à
une échelle de valeur, d’innovation et d’intégration. Voici le classement obtenu avec
cette méthode :
1. Les portails d’information
2. Les portails collaboratifs
3. Les portails d’intégration des applications de l’entreprise
4. Les portails de gestion des situations de travail

50
Ces plateformes sont donc très utiles pour la gestion de la connaissance qui nécessite
l’emploi de nombreux outils complémentaires et en particulier pour les communautés de
pratiques.
6.2.6. Les communautés de pratiques et les communautés d’intérêt
Comme expliqué dans les sections précédentes, les individus jouent un rôle fondamental
dans la gestion des connaissances qui est bien plus important que celui des outils
technologiques. La communauté de pratiques est un concept mis en avant par
l’anthropologue Jean LAVE et Etienne WENGER en 1991, puis amélioré par WENGER en 1998,
qui donne une vision de la gestion des connaissances centrée sur l’humain alors qu’elle était
jusqu’à cette époque essentiellement centrée sur les technologies.
Une communauté de pratiques est un groupe d’individus composé d’au moins deux
personnes qui partagent un domaine d’intérêt commun [1, p. 342] et qui, pour atteindre leurs
objectifs, interagissent ensemble afin d’améliorer leur pratique [10, p. 56].
Dans les communautés d’intérêt, les individus échangent juste des informations sur des
idées, des croyances ou une cause [1, p. 346] sans forcément vouloir atteindre un objectif.
6.2.7. Cartographie des connaissances
La cartographie est la science qui permet de concevoir des cartes. Pour pouvoir mettre en
place un portail collaboratif afin de gérer la connaissance collective, il convient avant tout
d’identifier les connaissances qui vont être manipulées par les acteurs de la connaissance.
Pour cela, la méthode consiste à réaliser une carte des connaissances qui permettra d’avoir
une vue d’ensemble des connaissances qui apparaîtront classées et ordonnées.
Il existe plusieurs méthodes pour cartographier les connaissances. Voici les trois
démarches que nous avons sélectionnées pour présenter cela :
Utiliser la modélisation des processus métiers pour en extraire les procédures et
modes de fonctionnement d’une organisation. En effet, cela peut être très utile pour
concevoir un système de capitalisation sur les incidents. Il s’agit, ici, des connaissances
tacites qui sont difficiles à transcrire dans un document (exemple : le savoir-faire)
Réaliser un inventaire de tous les documents qui sont utiles pour l’organisation et
tenter d’en faire une classification par ordre d’importance. Ce fond documentaire

51
représente, en général, les connaissances explicites qui ont été traduites sous forme
écrite.
Organiser des interviews des personnes, qui vont alimenter la Base de connaissances
et qui vont la consulter, afin d’identifier d’autres connaissances tacites.
Ces trois démarches ne sont pas individuelles mais plutôt complémentaires. Elles
constituent la première étape pour cartographier les connaissances.
Cependant, ce n’est pas suffisant. En effet, les personnes n’ont pas la même vision d’un
élément de connaissance et c’est normal car cela vient du fait que la connaissance est une
représentation personnelle que nous nous faisons de la réalité. Il faut donc discuter des
connaissances identifiées et déterminer lesquelles représentent le mieux ce dont
l’organisation a besoin. Cette confrontation des connaissances représente la deuxième étape
de cette cartographie des connaissances.
Une fois que tous les acteurs de la connaissance seront d’accord sur les connaissances qui
auront été identifiées, il faudra les modéliser. Un outil intéressant pour réaliser ce travail est
probablement le MindMap qui permet de représenter assez simplement sous forme d’arbre
l’ensemble des connaissances identifiées.
6.3. Gestion des connaissances dans une démarche ITIL
6.3.1. Présentation d’ITIL
ITIL signifie « Information Technologie Infrastructure Library » ou « Bibliothèque pour
l’Infrastructure des Technologies de l’Information ». C’est un référentiel mis au point en 1988
par l’Office of Government Commerce (OGC) une entité gouvernementale britannique. Il s’agit
d’un rassemblement de « bonnes pratiques » pour la fourniture de services informatiques à
des organisations d’affaire. Dans l’édition 2011 de sa version 3, le référentiel ITIL comporte les
cinq livres suivants :
Stratégie des services
Conception des services
Transition des services
Exploitation des services
Amélioration continue des services

52
Les livres qui nous intéressent particulièrement pour ce travail sont celui sur la transition
des services qui aborde la gestion des connaissances et celui sur l’exploitation des services qui
traite de la gestion des incidents, des problèmes et des configurations.
ITIL est, en quelque sorte, la réponse de l’évolution de l’informatique d’une culture projet
à une culture de services [15, p. 32]. En effet, le but principal aujourd’hui n’est plus d’offrir de
nouvelles fonctionnalités aux Clients en fonction des évolutions technologiques mais plutôt
de leur fournir les services informatiques demandés au niveau de qualité souhaité [15, p. 32].
La culture de services doit permettre d’aligner les services informatiques sur les besoins
des Clients, d’en améliorer la qualité et d’en maîtriser les coûts [15, p. 32].
ITIL définit un service comme « un moyen de fournir de la valeur aux clients en facilitant
les résultats qu’il souhaitent obtenir sans qu’il ait à porter toute la responsabilité des coûts ou
des risques » [15, p. 32].
6.3.2. Les recommandations d’ITIL sur la gestion des connaissances
Pour gérer les connaissances, ITIL a défini un processus de gestion de connaissances. Il
préconise de recueillir toutes les requêtes des Clients en un point d’entrée unique appelé le
« Service Desk » (le Centre de Service). Ces requêtes doivent ensuite être transmises à la
bonne personne, sous le format le mieux adapté à ses besoins et au bon moment afin de
permettre à l’organisation d’améliorer ses prises de décision [6, p. 80].
L’objectif étant, d’une part, de bénéficier d’informations fiables pendant tout le cycle de
vie des services informatiques [6, p. 80] et, d’autre part, de capitaliser sur les cas déjà
rencontrés par la mise en œuvre d’un système de gestion de connaissances SKMS ou Service
Knowledge Management System [15, p. 300].
ITIL donne une représentation de l’évolution des données à la sagesse qui ressemble
fortement à la pyramide de la sagesse. Cette représentation est donnée dans la figure 11.

53
Figure 11 : Flux de la donnée à la sagesse (inspiré d’ITIL Transition des services d’OGC10)
Le processus de gestion des connaissances comporte quatre activités qui consistent à
établir une stratégie de gestion de connaissances, puis vérifier le bon transfert de ces
connaissances, pour ensuite gérer l’information, et enfin vérifier que la base de connaissances
est bien utilisée [15, p. 302].
La figure 12 montre à quoi doit ressembler le système de gestion de connaissances
(SKMS11) selon ITIL.
10 Référentiel ITIL 2007, livre Service Transition figure 4.37 page 147 11 Voir [40] pour plus de détails
Donnée
Information (Qui, Quoi, Quand, Où ?)
Connaissance
(Comment ?)
Sagesse
(Pourquoi ?)
Contexte
Compréhension

54
Figure 12 : Structure du SKMS selon ITIL inspirée du schéma de [15, p. 302]
6.4. Le Web sémantique
Le Web Sémantique est une technologie du Web 3.0 [13, p. XI]. Bien qu’il ait de
nombreuses applications, le Web Sémantique est un outil très intéressant pour le Knowledge
Management et la capitalisation des connaissances en général.
Nous commencerons la présentation du Web Sémantique par un petit historique. Ensuite
nous aborderons les principales couches du Web Sémantique. Puis nous terminerons par les
applications pour la capitalisation des connaissances.
Le Web Sémantique ou Web des données, issu des technologies du Web, est une des
applications d’Internet. C’est en 1990 que l’idée d’un Web plus structuré apparaît et où le
World Wide Web Consortium ou W3C12 va jouer un rôle majeur [13, p. 8]. Vers 1994, Tim
Berners-Lee évoque pour la première fois la notion de Web Sémantique et en donne les
grandes lignes lors de la conférence WWW. Son idée est qu’il ne faut pas limiter le Web à un
12 Pour plus de détails voir le site web officiel du W3C : http://www.w3.org/
Couche de Présentation
Couche de Traitement
Base des
incidents
Erreurs
connues
Documents
Système de gestion de configuration (CMS)
Information sur les services
Information sur les éléments de configuration
CMDB1 CMDB2

55
simple espace documentaire. Dix ans seront nécessaires pour mettre au point les standards
qui permettrons de donner vie à son idée [13, p. 8].
Les standards du Web Sémantique représentant son architecture sont organisés en
couches. Ces couches forment une pile qui est représentée dans la figure 13.
Figure 13 : Pile des standards du Web Sémantique par le W3C
6.4.1. URI/IRI
Les URI ou « Uniform Ressource Identifier » sont des chaînes de caractères qui
permettent d’identifier une ressource sur un réseau informatique en respectant les normes
du Web. Les URI ont été définis dans la RFC 3986 en 2005. Une des utilisations les plus connus
des URI sont les URL ou « Uniform Ressource Locator » utilisées pour les adresses qui
permettent d’accéder à une page HTML sur le World Wide Web. Par exemple
« http://www.cnam.fr » est une URL.
Les IRI ou « Internationalized Ressource Identifier » sont des URI qui prennent en compte
plusieurs langues.
6.4.2. XML
XML est l’acronyme de « eXtensible Markup Language » qui signifie Langage à Balisage
Extensible. Il s’agit d’un langage structuré inventé par le W3C en 1988 et basé sur SGML
Jeu de caractères : Unicode
Echange de données : RDF
Requêtes : qSPARQL
RDFS
Ontologies : gOWL Règles : g
RIF
Logique d’unification
Preuve
Confiance
Cryptographie
Interface utilisateur et applications

56
(« Standard Generalized Markup Language » ou « Langage à Balisage Généralisé Normalisé »)
[13, p. 23]. XML sert principalement à structurer des données ce qui est très utile pour
échanger des informations normalisées entre les applications Web (exemple : le RSS pour la
diffusion de flux d’informations) et pour créer la syntaxe d’autre langage du Web sémantique
[13, p. 23].
Un fichier XML est composé d’un en-tête et d’un corps. Les données qui se trouvent dans
le corps du fichier sont structurées à l’aide de balises.
Voici un exemple de fichier XML qui décrit la fiche du livre « Knowledge Management et
Web 2.0 » d’Alphonse CARLIER sur le site Web du Sudoc13 :
Contenu de la fiche au format BibTeX :
@BOOK{Carli2013, url = "http://www.sudoc.fr/174324154", year = "2013", title = "Knowledge management et web 2.0 outils, méthodes et applications", author = "Carlier, Alphonse", address = "Paris", publisher = "Hermes science-Lavoisier", pages = "1 vol. (250 p.)", series = "Management et informatique", isbn = "978-2-7462-4549-5",}
Fichier XML correspondant :
<?xml version='1.0' encoding='utf-8' ?> <ns:livre ns:isbn='978-2-7462-4549-5' xmlns:ns='http://www.sudoc.fr/174324154'>
<ns:titre> Knowledge management et web 2.0 outils, méthodes et applications
</ns:titre> <ns:auteur>Carlier Alphonse</ns:auteur> <ns:annee>2013</ns:annee> <ns:editeur>Hermes science-Lavoisier</ns:editeur> <ns:nbpages>250</ns:nbpages> <ns:series>Management et informatique</ns:series>
</ns:livre>
Le fichier XML comporte donc une balise en-tête qui commence par le terme « <? » et se
termine par « ?> ». Elle spécifie qu’il s’agit d’un fichier XML avec le terme « xml », que le
document est en version 1.0 et que le jeu de caractères utilisé est « UFT-8 ».
13 Pour plus de détails voir la page Web http://www.sudoc.abes.fr

57
La deuxième balise définie l’espace de nom qui, dans notre exemple, est « ns » (ns peut
être vu comme le diminutif de « namespace » en anglais). Elle donne le type de ressources
qui, dans notre cas, est un livre, son identifiant qui est l’ISBN14 et son URI qui permet de le
retrouver sur le Web.
La troisième balise marque le début du corps du document. Elle décrit en détail la
ressource en donnant le titre du livre, le nom de l’auteur, l’année de publication, le nom de
l’éditeur.
6.4.3. RDF
RDF est l’acronyme de « Resource Description Framework ». C’est une syntaxe qui permet
de décrire de manière formelle les ressources Web. RDF permet de représenter des
métadonnées sous forme de graphes constitués de triplets (ressource, propriété, valeur) ou
(sujet, prédicat, objet) qui sont les plus petits éléments de RDF [13, p. 29]. Ces triplets
associent une ressource à une propriété et à la valeur de cette propriété comme le montre la
figure 14.
Figure 14 : Triplet RDF inspiré de la figure de [13, p. 29]
RDF a une syntaxe basée sur le langage XML. Il sert notamment à ajouter des
métadonnées à des ressources, comme par exemple des documents non structurés, ce qui est
particulièrement utile pour les outils de gestion électronique de documents (GED).
Si nous prenons comme exemple un livre intitulé « Management et ingénierie des
connaissances. Modèles et méthodes » publié en 2008 disponible sur les archives ouvertes
HAL au format PDF et dont l’auteur est Jean-Louis ERMINE, nous obtenons le graphe RDF de
la figure 15.
14 « International Standard Book Number » ou « Numéro International Normalisé du Livre »
Ressource Valeur Propriété
58
Figure 15 : Graphe RDF simplifié inspiré de [13, p. 32]
Il est aussi possible d’ajouter des espaces de nom dans le graphe RDF ce qui permet de
préciser la nature de chaque propriété. Ces différences sont présentées dans la figure 16.
Figure 16 : Exemple de l’ajout d’un espace de nom sur un triplet RDF
La figure 16 introduit deux espaces de nom « rdf » et « dt » dont voici les significations :
« rdf » fait référence à la ressource http://www.w3.org/1999/02/22-rdf-syntax-ns#
« dt » fait référence à la ressource http://purl.org/dc/dcmitype qui décrit les types de
documents
année
auteur
format
type
https://hal.archives-
ouvertes.fr/hal-
00986764/document
Texte
Management et ingénierie
des connaissances.
Modèles et méthodes
Jean-Louis ERMINE
« 2008 »
titre
https://hal.archives-ouvertes.fr/hal-
00986764/document
https://hal.archives-ouvertes.fr/hal-
00986764/document
texte type
dt:texte rdf:type

59
Il est intéressant de noter que la notation « rdf:type » est un moyen de déclarer une
ressource en tant que classe.
6.4.4. SPARQL
SPARQL est l’acronyme de « Simple Protocole and RDF Query Language ». Il s’agit d’un
langage permettant de formuler des requêtes sur des graphes RDF ce qui, en un sens, est
similaire au langage SQL pour les Base de données relationnelles [13, p. 50]. Cela consiste à
créer un graphe requête pour retrouver ses occurrences dans un graphe RDF [13, p. 50].
6.4.5. RDFS
RDFS signifie « Resource Description Framework Schema ». Il s’agit d’un langage de
description de vocabulaire du Web Sémantique inventé en 1998 et défini comme
recommandation par le W3C en 2004 [13, p. 88] qui étend RDF. Il permet de créer des
ontologies légères, d’une part, en donnant des descriptions aux classes des ressources et aux
propriétés et, d’autre part, en les hiérarchisant [13, p. 88].
6.4.6. OWL
OWL signifie « Web Ontology Language ». C’est un langage informatique basé sur RDF,
dont la recommandation par le W3C date de 2004, qui permet de décrire des ontologies
informatiques qui servent à représenter des connaissances. Contrairement à RDFS, OWL
permet de créer des ontologies lourdes, c’est-à-dire avec une description formelle des classes
et des propriétés. En effet, RDFS ne permet de décrire que des hiérarchies de classes et de
propriétés alors qu’OWL apporte en plus des notions d’équivalence de classes et de
propriétés, d’égalité de ressources et aussi d’autres fonctions comme la symétrie, les
cardinalités, la différence ou les contraires [13, p. 99].
6.4.7. Les applications du Web Sémantique
Aujourd’hui, le Web Sémantique permet principalement d’améliorer les applications Web
en essayant de rendre leurs données plus intelligibles. Il améliore considérablement
l’indexation des données et leurs échanges entre applications. Ces applications sont
massivement utilisées par les outils de gestion de la connaissance notamment dans les Wiki
et les portails collaboratifs.
De nombreuses applications pratiques du Web Sémantique existent déjà sur Internet [13,
p. 14]. Parmi les outils de gestion de connaissances qui utilisent le Web Sémantique, nous

60
pouvons citer en exemple « Semantic MediaWiki » qui est un module qui vient se greffer au
moteur Wiki « MediaWiki » pour donner une description aux données ajoutées par les
utilisateurs.
7. Lancement du projet
La mise en place d’un portail collaboratif pour la gestion de la connaissance collective,
même à l’échelle d’un Service de sept personnes et avec environ une vingtaine d’utilisateurs
en tout, est une tâche complexe qui nécessite une démarche Projet.
Afin de lancer le Projet, il est nécessaire de se fixer des objectifs aussi bien au niveau du
temps que prendra le Projet que pour la taille du livrable en fonction des ressources
disponibles. La démarche servira à déterminer si le projet va bien dans la bonne direction et
si les délais seront respectés. Il sera bien sûr possible d’effectuer des corrections au fur et à
mesure de l’avancée des travaux.
Nous allons donc étudier quatre aspects essentiels du Projet qui sont l’estimation de la
charge de travail en fonction des ressources disponibles, le planning prévisionnel pour donner
une vision d’ensemble du Projet ainsi qu’un repère graphique pour les différents jalons, une
tentative d’estimation du retour sur investissement et une analyse de risques. C’est
précisément l’objet des sections suivantes.
7.1. Estimation de la charge de travail
Chez EDF, la gestion des projets est, en quelque sorte, normalisée en se basant sur les
recommandations de PRINCE2. Etant donné que, dans le cas présent, notre projet est interne
au Service PFC, il n’est pas soumis à cette réglementation. Cependant, il est intéressant
d’examiner ces recommandations pour donner toutes les chances de réussite au projet. Selon
les recommandations, le projet doit être découpé en plusieurs jalons qui sont les suivants :
1. Jalon A : « Emergence » pour cadrer stratégiquement l’avant-projet
2. Jalon B : « Cadrage » pour la rédaction du cahier des charges
3. Jalon C : « Conception de la solution » pour l’élaboration des spécifications générales
4. Jalon D : « Réalisation » qui comporte une phase de réalisation, d’expérimentation et
de déploiement
5. Jalon E : « Suivi des bénéfices » pour faire le bilan

61
Comme nous allons le voir dans cette section, notre projet comporte l’ensemble de ces
jalons.
En se basant sur la demande initiale du Client, il est possible d’estimer la charge globale
de travail que nécessitera ce projet.
Au début du projet, le Client n’a souhaité mettre qu’une seule ressource sur la réalisation
des différentes tâches. Les raisons de ce choix sont que, d’une part, le nombre de sujets en
cours pour la mission est assez important par rapport au nombre de ressources disponibles
et, d’autre part, même si ce projet est considéré comme important pour le Service, ce n’est
pas le sujet le plus important du point de vu de la direction du groupe. Donc je suis la seul
ressource de ce projet et la charge sera calculée en fonction de cette contrainte, c’est-à-dire
en jour/homme sachant qu’il n’y a qu’une seule ressource disponible. Cependant, le Client
souhaite avoir une solution rapidement, c’est-à-dire en pas plus de six mois.
Comme la plupart des projets, il est possible de le diviser en plusieurs tâches élémentaires
afin d’arriver aux objectifs fixés par le Client. Il est possible de regrouper ces tâches
élémentaires en phases. Voici donc les grandes phases de ce projet :
1. Analyse du besoin et de l’existant (environ 20 jours/homme) : cette phase consiste à
déterminer quelles sont les limites de l’existant et pourquoi il est nécessaire de l’améliorer
par rapport aux souhaits du Client. Elle permet aussi de déterminer vers où le projet doit
se diriger. Cette phase doit comporter :
Une tâche d’analyse du besoin pour bien le comprendre. En effet, le Client a formulé
son besoin de manière très succincte et il est donc nécessaire de formaliser sa
demande et de rediscuter avec lui afin de garantir que chaque partie a bien la même
vision des objectifs (environ 10 jours/homme).
Une tâche d’analyse de l’existant qui consiste à déterminer les limites de l’existant par
rapport au besoin du Client. Il faut analyser, ici, les différents outils et méthodes à la
disposition du Client, essayer de comprendre pourquoi c’est insuffisant et tenter de
se projeter vers une meilleure solution (environ 5 jours/homme).
Une tâche de modélisation des processus métiers pour localiser où interviennent les
différents outils et méthodes étudiés précédemment (environ 5 jours/homme).

62
2. Etude des différentes méthodes existantes pour gérer la connaissance (environ 15
jours/homme) : cette phase consiste à chercher dans la littérature scientifique les
éléments qui pourraient éventuellement nous servir pour proposer une solution au Client.
3. Réalisation du planning du Projet (environ 2 jours/homme)
4. Etude comparative des différents outils du marché (environ 14 jours/homme) : dans
cette phase, nous confrontons les différents outils du marché pour identifier ceux qui nous
permettraient de mettre en œuvre la solution de gestion de connaissances du Client. En
effet, il est plus judicieux, étant donné les délais très courts du projet, de partir d’un outil
générique que nous adapterons à notre besoin. Il y a donc :
Une tâche de sélection des outils adéquats (environ 2 jours/homme)
Une tâche de test pour chaque outil (environ 5 jours/homme)
Une tâche d’étude plus approfondie des outils retenus (environ 5 jours/homme)
Une tâche de présentation des outils retenus au Client (environ 2 jours/homme)
5. Préparation de l’environnement et installation de l’outil générique (environ 6
jours/homme) : Afin de poursuivre le projet, il convient à ce stade d’installer l’outil
générique retenu sur une machine de l’infrastructure pour pouvoir engager une démarche
de personnalisation. Pour cela, il faut au préalable préparer l’environnement (la machine
où sera installé l’outil) en choisissant le Système d’exploitation et la configuration de la
machine. Cette phase comporte donc les tâches suivantes :
Une tâche d’identification de l’environnement cible avec le Client (environ 2
jours/homme)
Une tâche de sélection de la configuration de la machine en fonction des prérequis de
l’outil sélectionné (environ 2 jours/homme)
Une tâche d’installation de l’outil et des tests préliminaires (environ 2 jours/homme)
6. Cartographie des connaissances (22 jours/homme) : Cette phase consiste à réaliser une
carte de l’ensemble des connaissances du Service PFC. D’une part, il y a les connaissances
explicites représentées par l’ensemble des documents écrits disponibles qui
correspondent à environ 20% des connaissances et, d’autre part, il y a les connaissances
tacites qui constituent le savoir-faire des personnes sous forme non-écrite correspondant
à environ 80% des connaissances. Cette phase est divisée en trois tâches :
Une tâche d’inventaire et de classification des documents (environ 8 jours/homme)

63
Une tâche d’étude des processus métiers pour les intégrer au corpus de
connaissances (environ 7 jours/homme)
Une tâche d’interview des intervenants du Service PFC ou acteurs de la connaissance
(environ 7 jours/homme)
7. Analyse de risques (environ 5 jours/homme)
8. Adaptation de la solution au besoin du Client (environ 42 jours/homme) : Il s’agit d’une
phase très importante qui va, en quelque sorte, modeler l’outil générique sélectionné pour
l’adapter précisément au besoin du Client. C’est une phase complexe qui va nécessiter
plusieurs itérations avec des présentations régulières au Client. La phase s’arrêtera lorsque
la solution sera satisfaisante. La phase se compose donc des tâches suivantes :
Une tâche d’analyse de l’architecture et du fonctionnement de la solution (environ 20
jours/homme)
Une tâche d’étude des mécanismes de personnalisation de l’outil (environ 5
jours/homme)
Une tâche de création des modèles (tâche itérative d’environ 15 jours/homme)
Une tâche de présentation de la solution au Client (tâche itérative d’environ 2
jours/homme)
9. Rédaction de la documentation détaillée de la solution pour les utilisateurs et les
administrateurs (environ 5 jours/homme)
10. Gestion du peuplement de l’outil avec les connaissances (environ 10 jours/homme) :
Cette phase va consister à remplir l’outil avec les connaissances utiles au Service PFC. Il y
a, ici, deux tâches à accomplir :
Une tâche de transfert des connaissances existantes qui ont été sélectionnées (5
jours/ homme)
Une tâche d’ajout des nouvelles connaissances obtenues lors des recherches et des
interviews avec les acteurs (environ 5 jours/homme)
11. Conduite du changement (20 jours/homme) : La solution va nécessiter le changement des
méthodes de travail qu’il faudra faciliter par une formation des utilisateurs et la rédaction
de la documentation.

64
12. Maintenance corrective et évolutive (15 jours/homme) : Lors des premiers jours
d’utilisation de la solution, il y aura certainement des retours de la part des utilisateurs
concernant des problèmes ou des demandes d’évolution qu’il faudra traiter.
En additionnant la charge de chaque phase du projet, nous obtenons une charge totale
de 176 jours/homme. En considérant qu’il y a 20 jours ouvrés par mois, nous obtenons une
charge équivalente de 8.8 mois/homme ce qui dépasse légèrement les prévisions intiales.de
6 mois/homme.
7.2. Planning prévisionnel
Comme expliqué précédemment, le planning du projet permet d’avoir une vision
graphique d’ensemble de l’étendu du travail à réaliser. Ce planning évolue très souvent en
cours de projet. Il est donc intéressant de présenter, pour ce travail, l’évolution qu’à subit le
planning tout au long du projet.
Figure 17 : Copie d’écran du logiciel GanttProject avec le planning initial du projet
Sur la figure17, il apparaît qu’il y a eu beaucoup de changement en prenant en compte les
informations de la section précédente. Les ajustements apparaissent donc dans la figure 18.

65
Figure 18 : Copie d’écran du logiciel GanttProject avec le planning revu du projet
7.3. Estimation du retour sur investissement
Comme expliqué dans les sections précédentes, un calcul précis du retour sur
investissement d’un projet de gestion des connaissances est difficilement envisageable mais
il est possible d’en faire une estimation sachant que, dans le cas de ce projet, il s’agira de gains
non financiers.
Tout d’abord, il faut savoir qu’aucun fond particulier n’a été accordé spécifiquement pour
ce projet et que le budget initial est donc nul. L’investissement initial du projet correspond au
travail d’une ressource pendant 8 mois (8 mois/homme). Puis, après la mise en place de la
solution, il y a les coûts du serveur qui hébergera la solution et les coûts de maintenance et
d’évolution. La figure 19 montre comment Jacques PRINTZ représente l’investissement des
projets informatiques qui se déroulent bien.

66
Figure 19 : Représentation de l’investissement et du ROI inspirée de la figure de [16, p. 32]
Le ROI peut être calculé par la formule : 𝑅𝑂𝐼 =𝐺𝑎𝑖𝑛−𝐼𝑛𝑣𝑒𝑠𝑡𝑖𝑠𝑠𝑒𝑚𝑒𝑛𝑡
𝐼𝑛𝑣𝑒𝑠𝑡𝑖𝑠𝑒𝑚𝑒𝑛𝑡 [16, p. 33]
L’investissement est composé des coûts initiaux du projet avant la livraison et des coûts de
maintenance et d’évolution de la solution qui correspondent aux coûts du maintien en
condition opérationnelle (MCO).
Dans le meilleur des cas, nous aurons : lim𝑥→∞
(𝑅𝑂𝐼) =𝐺𝑎𝑖𝑛
𝐶𝑜û𝑡 𝑑𝑢 𝑀𝐶𝑂 avec x le temps [16,
p. 33].
Dans le cas de notre projet, il est peu probable que les coûts de MCO soient plus élevés
que prévus. En effet, d’une part, nous utiliserons comme matériel un serveur de
l’infrastructure PFC et, d’autre part, la maintenance et l’évolution de la solution seront assez
légères étant donné le nombre restreints d’utilisateurs. De plus, les tâches de maintenance
seront imputées dans le temps d’un des membres de l’équipe PFC. Par contre l’investissement
initial pourrait être légèrement supérieur si le projet prend du retard.
Les gains se feront essentiellement sur les performances de l’équipe PFC qui seront
améliorées par des délais de réactivité plus courts. En effet, même si chacun des sept acteurs
Investissement
initial
Investissement
Gain
Maintenance
et évolution
Effet de
l’apprentissage
Temps
Livraison
Palier de productivité
Point mort
Performance pour
l’organisation cible

67
du Service PFC gagne 15 minutes de son temps de travail par jour, cela représente 105 minutes
par jour pour toute l’équipe soit 35 heures par mois ou 1.46 jours par mois (avec des mois de
20 jours travaillés). Cela représente 17.5 jours de gagnés à l’année pour l’équipe si nous
omettons les congés. Cette réactivité accrue permettra donc d’économiser du temps pour
d’autres activités mais améliorera aussi la satisfaction des clients qui verront des temps de
traitement de leurs demandes et incidents plus courts.
Les autres gains se feront par les demandes évitées car les clients trouveront certaines
informations sans avoir besoin de prendre contact avec l’équipe PFC. Actuellement nous
traitons en moyenne 5 demandes par jours et si la solution évite au moins une demande
nécessitant 15 minutes de traitement par jour cela représente une économie de 2.5 jours par
an.
Les gains peuvent être bien plus importants si nous incluons le fait que la gestion des
connaissances évite aussi les pertes de connaissances critiques et favorise une meilleure
communication entre les acteurs et une situation propice à l’innovation. Cependant ces gains
semblent très difficiles, voire impossibles, à quantifier à cause de leur nature qui dépend de
plusieurs facteurs imprévisibles.
7.4. Analyse de risques
Comme l’ont montré les sections précédentes, il s’agit d’un projet ambitieux, il est donc
normal qu’il y ait des difficultés qui soient préjudiciables pour ce dernier. Afin d’éviter que le
projet n’échoue ou qu’il ne subisse un trop important retard, il est nécessaire d’effectuer une
analyse de risques. Elle permettra d’identifier certains problèmes mais probablement pas tous
et d’effectuer les ajustements nécessaires. Il est d’ailleurs essentiel de s’intéresser à cet aspect
avant de lancer tout projet informatique.
Dans un projet informatique, il est possible de retrouver généralement les risques suivants :
Des risques techniques
Des risques au niveau des délais
Des risques économiques
Des risques d’écart par rapport aux objectifs initiaux
Des risques juridiques
Des risques humains

68
Il convient donc d’étudier individuellement chacun de ces points, de déterminer s’ils
concernent notre projet et de trouver une solution pour limiter leurs impacts afin qu’ils
perturbent le moins possible le projet.
7.4.1. Les risques techniques et technologiques
Il s’agit d’un des risques les plus préoccupants pour ce projet. En effet, la ressource qui
travaille sur ce projet, en l’occurrence l’auteur de ce présent travail, n’a pas d’expérience en
matière de gestion de connaissances. Ce n’est donc ni un expert, ni un spécialiste. Cela a pour
conséquence que les outils à mettre en place ne sont ni connus ni maitrisés ce qui peut
provoquer un allongement significatif des délais et donc des coûts.
Afin d’éviter ces problèmes, il est possible de prendre certaines mesures préventives qui
consistent principalement à, d’une part, limiter les ambitions de ce projet et, d’autre part,
rechercher dans la littérature scientifique de nombreux retours d’expérience sur les portails
collaboratifs et leur mise en œuvre.
7.4.2. Les risques au niveau des délais
Outres le fait que les risques techniques et technologiques peuvent avoir un impact sur
les délais du projet, il y a aussi d’autres raisons pour lesquelles ce projet peut être retardé. En
effet, les projets de KM sont généralement difficiles à gérer car il y a une grande part liée au
comportement des individus par rapport à ces changements. Or, ce projet n’a bénéficié que
d’un cahier des charges assez succinct et il y a certainement, comme dans tout projet, un écart
entre ce que le Client veut, ce que le Client demande et ce que la ressource du projet
comprend et réalise. Ces décalages peuvent entraîner des erreurs de conception qui, si elles
sont détectées tardivement, peuvent causer d’importants retards.
Pour limiter ce risque, il convient de faire des réunions fréquentes avec le Client afin de
toujours valider que le projet va dans la bonne direction et que la solution répond bien à ses
attentes à l’instant t.
7.4.3. Les risques économiques
Les projets de KM sont réputés pour être coûteux. Cependant, notre projet n’est pas cher
car des contraintes ont été imposées, dès le début, par le Client. En effet, le budget initial est
nul, la solution doit se baser sur des outils gratuits et les ressources informatiques nécessaires
comme, par exemple, le serveur qui hébergera la solution ne représente qu’un coût

69
relativement faible à l’échelle de l’infrastructure en place. La seule variable qui ne peut être
réduite est le temps passé par la ressource sur le projet.
Les recommandations sur ce risque seront donc de surveiller étroitement les délais du
projet en fixant des jalons afin d’éviter qu’il n’y ait trop de retard et que les coûts
n’augmentent.
7.4.4. Les risques d’écarts par rapport aux objectifs initiaux
Comme expliqué précédemment, il y a un risque que la solution définitive ne convienne
pas aux besoins du Client, ce qui peut s’avérer très problématique. Ce risque n’est pas
spécifique à ce projet et dépend en général beaucoup des échanges entre la MOA (le Client)
et la MOE (la ressource sur ce projet). Si ces deux parties ne se comprennent pas bien les
dérives sont inévitables.
Pour éviter que cela n’arrive, il faut organiser des réunions fréquentes avec le Client pour
effectuer les ajustements nécessaires tout au long du projet. Cette démarche peut être mise
en œuvre en utilisant les réunions de suivi hebdomadaire déjà en place.
7.4.5. Les risques juridiques
Dans notre projet ce type de risque est très faible. En effet, il s’agit d’un projet réalisé en
interne et il n’y a donc pas de contrat entre deux partie si ce n’est celui de la prestation réalisée
par Open chez EDF. Cependant, il convient d’être prudent au niveau des choix des outils
technologiques et de vérifier que leur licence permette une utilisation professionnelle dans
une entreprise même s’ils sont gratuits. Pour cette raison nous avons fait le choix d’une
solution libre sous licence GNU GPL.
7.4.6. Les risques humains
Il s’agit d’un risque assez imprévisible qui peut toucher tous les projets. Dans notre cas, il
n’y a qu’une seule ressource et si cette dernière doit arrêter le projet pour une raison ou pour
une autre cela pourrait signifier la fin du projet.
Heureusement, comme le projet est réalisé dans le cadre d’une prestation, la ressource a
des collègues qui pourraient reprendre son travail au cas où cela serait nécessaire. Il faut
toutefois que le projet soit bien documenté et qu’il y ait un suivi régulier de l’avancée des
travaux. Dans ces circonstances, le projet pourra continuer même si cela impliquera
probablement un retard dans les délais.
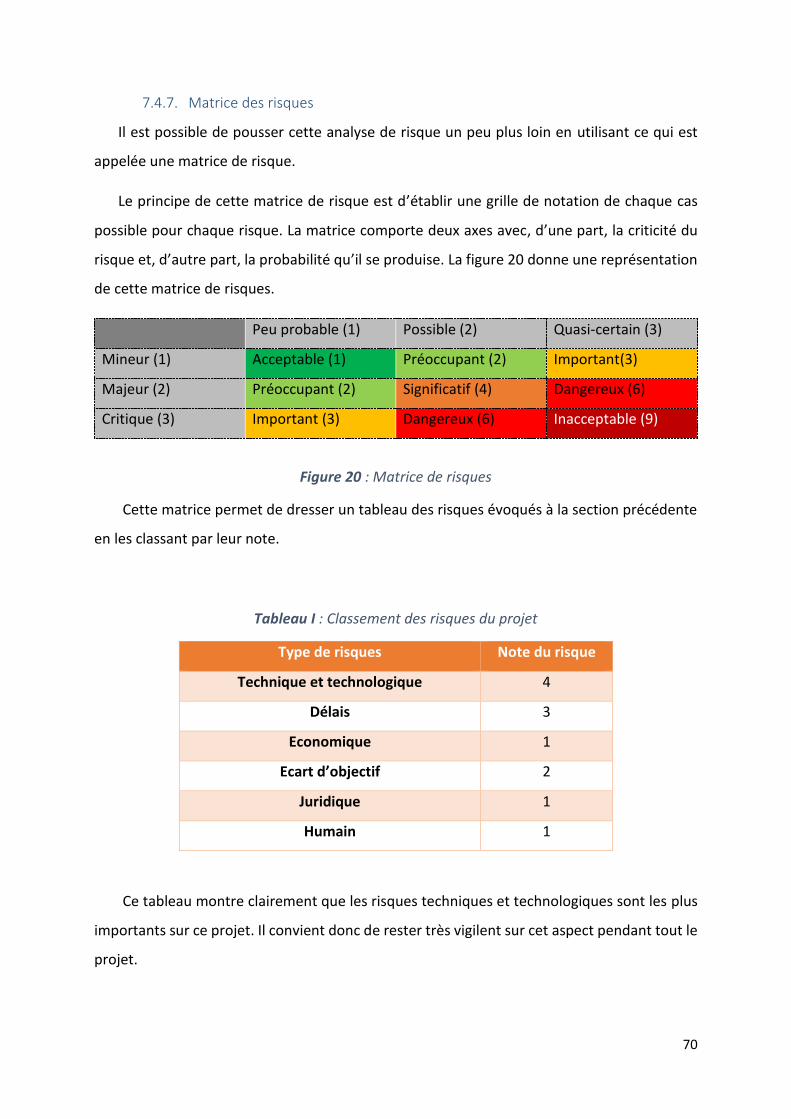
70
7.4.7. Matrice des risques
Il est possible de pousser cette analyse de risque un peu plus loin en utilisant ce qui est
appelée une matrice de risque.
Le principe de cette matrice de risque est d’établir une grille de notation de chaque cas
possible pour chaque risque. La matrice comporte deux axes avec, d’une part, la criticité du
risque et, d’autre part, la probabilité qu’il se produise. La figure 20 donne une représentation
de cette matrice de risques.
Peu probable (1) Possible (2) Quasi-certain (3)
Mineur (1) Acceptable (1) Préoccupant (2) Important(3)
Majeur (2) Préoccupant (2) Significatif (4) Dangereux (6)
Critique (3) Important (3) Dangereux (6) Inacceptable (9)
Figure 20 : Matrice de risques
Cette matrice permet de dresser un tableau des risques évoqués à la section précédente
en les classant par leur note.
Tableau I : Classement des risques du projet
Type de risques Note du risque
Technique et technologique 4
Délais 3
Economique 1
Ecart d’objectif 2
Juridique 1
Humain 1
Ce tableau montre clairement que les risques techniques et technologiques sont les plus
importants sur ce projet. Il convient donc de rester très vigilent sur cet aspect pendant tout le
projet.

71
8. Comment gérer les documents et le contenu du Service PFC
Dans les sections précédentes, nous avons présenté un large panel des méthodes et des
outils du KM. Il convient maintenant de sélectionner les outils qui vont nous permettre de
répondre aux besoins du Client.
Le premier besoin exprimé était d’avoir un meilleur moyen pour conserver, classer et
manipuler les documents déjà écrits ou en cours de rédaction qu’avec l’outil de l’entreprise
existant. Il fallait aussi un système permettant de sauvegarder du contenu différent de simples
documents comme des fichiers binaires.
Les outils de gestion électronique de documents et de contenu peuvent parfaitement
répondre à ces besoins. Ce sont ces derniers que nous allons présenter dans les sections
suivantes.
8.1. Rôle des GED et CMS
Les outils de gestion électronique de documents (GED) ou de gestion de contenu
(« Content Management System » ou CMS) font partie de la même catégorie. Ils permettent
tous les deux de mettre en ligne des éléments accessibles à un groupe d’individus. Ce qui
semble parfaitement adapté à notre besoin.
Les GED sont centrées sur la manipulation de toutes sortes de documents écrits comme,
par exemple, les fichiers au format DOC ou DOCX créés avec le logiciel de traitement de texte
Microsoft Word ou des fichiers au format PDF 15 . Elles contiennent donc des outils
complémentaires facilitant la manipulation de ce type de fichiers. Elles sont, par contre moins
adaptées à la gestion d’un contenu ne correspondant pas à des documents de type texte.
Les CMS permettent quant à eux de sauvegarder tout type de contenu qu’il s’agisse d’un
document ou non comme par exemple un fichier exécutable. Ils peuvent toutefois manquer
d’outils spécialisés dans la gestion des documents.
Ces deux outils sont assez souvent regroupés dans un seul et même système. En effet, ils
sont complémentaires et vont parfaitement ensembles.
15 « Portable Document Format » inventé par la société Adobe pour permettre l’affichage d’un document de manière uniforme quelle que soit la plateforme utilisée

72
La sauvegarde n’est pas la seule fonction de ces outils. En effet, outre le fait d’avoir cette
fonctionnalité, ils sont accessibles aux utilisateurs de n’importe quel terminal équipé d’un
navigateur Web et d’un accès au réseau de l’entreprise. Il s’agit en quelque sorte d’un type de
Cloud Computing qui se nomme Software As A Service (SaaS) même si nous pouvons relever
certaines différences. Il n’est pas nécessaire d’installer un client lourd sur la machine de
l’utilisateur.
Une autre fonctionnalité intéressante est la possibilité de travailler simultanément sur des
documents ou des contenus ce qui facilite grandement le travail collaboratif.
D’autre part, la plupart de ces systèmes proposent une gestion des droits des utilisateurs.
Il est très simple dans ce cas de réaliser une segmentation des droits à la maille d’un seul
fichier.
8.2. Apport d’une solution de GED par rapport au système actuel
Le système existant est basé sur le logiciel Lotus Notes. Bien que suffisant pour beaucoup
de tâches de l’entreprise comme la messagerie électronique ou la gestion de Bases
spécialisées (qui peuvent être soit de simples fiches explicatives avec des documents et du
contenu soit de véritable logiciel de gestion à l’intérieur de Lotus Notes), il se trouve qu’il est
assez limité pour les besoins du Service PFC.
En effet, un des souhaits de la cellule Ingénierie PFC est de pouvoir stocker des outils dans
la solution afin de pouvoir les retrouver facilement ce que Lotus Notes ne gère pas bien car il
n’est pas adapté pour ce type d’utilisation. Il sera par exemple impossible d’associer des tags
(des étiquettes) à des fichiers ou dossiers particuliers pour pouvoir les retrouver plus
facilement par la suite. Il existe bien un système de recherche mais ce dernier est peu
ergonomique et prend du temps de l’ordre de plusieurs dizaines de secondes à chaque
recherche. Il apparaît aussi que l’ajout des contenus est lent et peu structuré et la modification
n’est pas simple non plus.
L’autre demande du Client concerne la possibilité d’ajouter des commentaires aux
documents en cours de rédaction ce qui est possible sous Lotus Notes mais beaucoup moins
dynamique que dans une GED. En effet, les commentaires ne seront visibles que des
personnes qui vont consulter la fiche contenant le document alors qu’ils le seront de tous les
utilisateurs inscrit à un groupe de travail, par exemple, dès qu’il sera ajouté dans une GED.

73
Cette fonctionnalité permettant de commenter un document n’est d’ailleurs qu’une
facette des outils proposés pour le travail collaboratif qui ne sont pas très développés dans la
version de Lotus Notes qu’utilise l’entreprise. Comme expliqué dans la section précédente les
GED excellent dans les fonctionnalités de travail collaboratif sur les documents et c’est une
des demandes du Client pour cette solution.
8.3. Solution de gestion documentaire et de contenu pour le service PFC
La GED n’a pas ici pour but de remplacer l’outil Lotus Notes qui reste l’outil principal de
l’entreprise mais plutôt de le compléter.
L’outil ne contiendra donc que les documents les plus utiles dont les utilisateurs se
servent très fréquemment, les logiciels essentiels à l’administration de l’infrastructure PFC qui
sont difficiles à stocker et à retrouver dans Lotus Notes et les archives des boites aux lettres
génériques pour lesquelles nous ne savons pas, actuellement, trouver un emplacement de
stockage.
9. Comment capitaliser les connaissances du Service PFC
Le deuxième besoin exprimé par le Client concernait la capitalisation des connaissances.
Cette démarche consiste à éviter que les savoirs et savoir-faire ne se perdent et aussi à faciliter
la réutilisation des connaissances. Les outils à utiliser pour capitaliser les connaissances
dépendent en fait de la nature de ces dernières.
Pour les connaissances explicites, la capitalisation peut se faire à l’aide d’une GED, sachant
que ce type de connaissances représente environ 20% de l’ensemble des connaissances
globales de l’entreprise.
Pour les connaissances tacites, c’est plus complexe étant donné qu’il s’agit de
connaissances difficiles à formaliser comme, par exemple, l’expérience d’un expert sur un
processus métier donné. C’est d’autant plus problématique qu’il s’agit de la plus grande part
des connaissances avec environ 80% des connaissances globales de l’entreprise.
La capitalisation de ces connaissances tacites peut se faire par la formalisation de ces
dernières avec une méthode comme MASK proposant de réaliser des modèles. La
capitalisation peut aussi être réalisée en utilisant la méthode REX avec la création de fiche
d’expérience métier et le travail collaboratif pour améliorer les échanges d’informations et

74
pour que les individus de l’entreprise s’approprient plus facilement ces connaissances tacites.
Dans notre cas, il est préférable d’utiliser la méthode REX et le travail collaboratif plutôt que
de tenter de formaliser des connaissances via des modèles avec la méthode MASK. En effet,
la méthode MASK ne semble pas adaptée au besoin puisque le Client ne souhaite pas avoir
des modèles de ses connaissances tacites existantes car il dispose déjà de beaucoup de
documents et ne craint pas une perte de ses connaissances critiques. Par contre, il veut
pouvoir conserver des connaissances relatives à un incident ou une demande qui aurait été
traité par un collaborateur du Service PFC et que ces connaissances puissent être réutilisées
facilement par un autre collaborateur. Ceci peut donc être réalisé en utilisant la méthode REX
et en facilitant le travail collaboratif.
Il existe plusieurs outils pour arriver à cet objectif et nous avons retenus les CMS de type
Wiki. La GED joue aussi un rôle dans le travail collaboratif lors de la rédaction de nouveaux
documents.
9.1. Apport d’une solution de gestion de contenu par rapport au système actuel
Comme expliqué dans la section sur l’analyse de l’existant, le système actuellement en
place pour le Service PFC ne permet pas de capitaliser sur les connaissances. En effet, les
incidents et les demandes nous parviennent par les deux moyens de communication que sont
la messagerie électronique Lotus Notes et l’outil de gestion des demandes et des incidents
SCOPE GS (HP OpenView ServiceCenter). Cela est contraire aux recommandations ITIL qui
préconise un point d’entrée unique et cela rend difficile la recherche de la solution d’un
incident déjà rencontré.
Un système de gestion de contenu permettant de créer et stocker des fiches REX et
configuré en respectant les recommandations ITIL pourrait permettre une capitalisation sur
les incidents et les erreurs déjà rencontrés par les acteurs du Service PFC en regroupant ces
connaissances et en facilitant leur recherche et leur appropriation par l’équipe. Cette Base de
connaissances améliorerait l’efficacité du Service et permettrait d’innover sur les processus
métiers.
9.2. Solution de capitalisation des connaissances pour le service PFC
Tout comme pour la gestion des documents avec la GED, l’outil de gestion de contenu
n’aura pas pour but de remplacer Lotus Notes et SCOPE GS mais de les compléter.

75
Le KM propose de nombreuses méthodes de capitalisation des connaissances dont la
méthode REX semble, là aussi, être la plus adaptée à notre besoin. Cette méthode préconise
de créer des fiches d’expérience métiers qui peuvent être créées manuellement ou de
manière automatisée et c’est la deuxième option qui a été retenue. Pour cela, nous allons
utiliser un moteur Wiki. Le référentiel ITIL peut aussi nous aider mais il donne seulement des
recommandations pour gérer et capitaliser la connaissance et laisse libre choix pour les
implémenter. Il apparaît cependant que la gestion et la capitalisation des connaissances
passent par la mise en place d’un SKMS. Sans pour autant créer un SKMS complet, nous
pouvons prendre en compte cette structure lors de la mise en place du moteur Wiki.
10. Architecture de la solution
La solution que nous souhaitons mettre en place est un système informatique qui devrait
permettre de partager et de capitaliser les connaissances du Service PFC d’EDF. Notre
précédente analyse permet de dresser un portrait de solution qui devrait répondre aux
besoins du Client. En effet, elle a démontré que les outils informatiques qui permettent le
mieux de répondre à cette problématique sont ceux du Web 2.0 ou même 3.0. Nous en avons
donc déduit qu’il fallait regrouper un système de gestion documentaire (une GED) et un
système de gestion de contenu (CMS) de type moteur Wiki au sein d’un portail collaboratif.
Cette section va présenter en détail l’architecture fonctionnelle et technique de la
solution choisie en commençant par présenter les interactions fonctionnelles entre les
utilisateurs et le système grâce à un diagramme UML de cas d’utilisation. Puis, elle décrira en
détail chaque élément de la solution. Elle se terminera par une présentation des aspects de
personnalisation qui visent à rendre le système parfaitement adapté aux besoins du Client.
10.1. Diagramme UML de cas d’utilisation du système
La figure 21 nous montre le diagramme UML de cas d’utilisation du système pour donner
une représentation graphique des interactions fonctionnelles entre les utilisateurs et le
système.
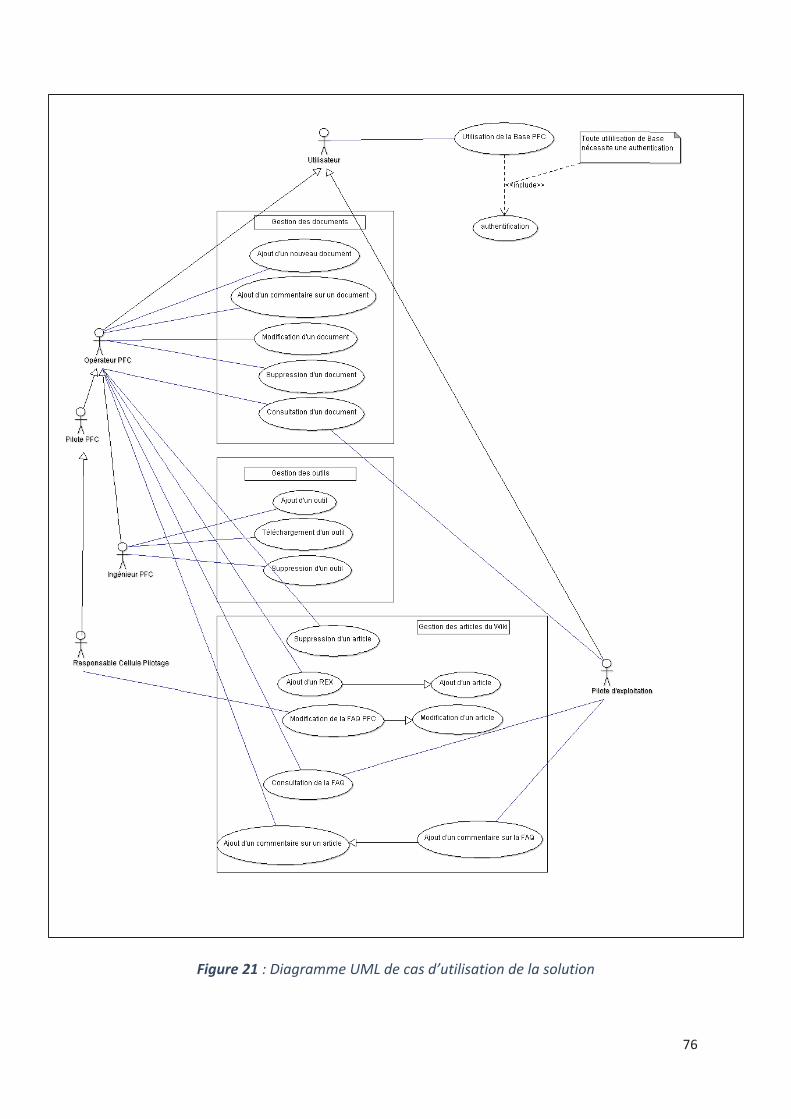
76
Figure 21 : Diagramme UML de cas d’utilisation de la solution

77
10.2. Exemples d’utilisation de la solution
Pour donner une meilleure idée de la façon dont fonctionne la solution, il parait
intéressant de présenter quelques exemples concrets d’utilisation de cette dernière.
Ajout ou modification d’un nouveau document :
Lors de l’ajout d’un nouvel infogérant à l’infrastructure PFC, un nouveau groupe est créé
dans l’AD ADAM pour que tous les comptes des membres de cette entité soient habilités à
accéder au portail vCloud Director et au Client AVAMAR. Suite à l’opération, des intervenants
de l’équipe ADAM nous font part de la nécessiter de mettre à jour la fiche des habilitations
ADAM. Nous ne connaissions pas cette procédure et une série d’échanges ont lieu entre un
intervenant de la cellule Pilotage PFC et un intervenant de l’équipe ADAM pour rédiger ce
nouveau document.
Une fois le document rédigé et validé, il faut le stocker à un emplacement accessible de
tous les membres de l’équipe PFC. La personne en charge de la rédaction du document peut
donc se connecter au portail collaboratif PFC pour y ajouter le document. Voici les étapes qu’il
doit suivre pour réaliser cette tâche avec la nouvelle solution :
1. Ouverture du navigateur Web
2. Saisie de l’URL du portail collaboratif
3. Saisie de l’identifiant et du mot de passe puis validation
4. Accès à l’espace documentaire réservé aux personnes de l’équipe PFC qui devront
utiliser le document
5. Ajout du document par un « drag and drop » (« glisser et déposer »)
6. Ajout d’un titre, d’un ou plusieurs tags et d’une description pour les recherches
ultérieures du document
Quelques jours plus tard la procédure a été modifiée pour décrire de manière plus globale
le processus d’ajout d’une entité. Le document correspondant est donc modifié et validé. La
personne qui a effectué les modifications doit mettre à jour le document qui a été ajouté
précédemment. Voici les étapes qu’il doit suivre :
1. Réalisation des étapes 1 à 3 de l’ajout d’un document
2. Recherche du document par mot clé

78
3. Sélection de l’option ajout d’une nouvelle version
4. Choix de l’évolution du document entre mineur et majeur
5. Recherche du nouveau document sur un disque local ou réseau grâce à l’explorateur
de fichiers du système d’exploitation de l’utilisateur
6. Confirmation de la mise à jour
Travail collaboratif sur un document en cours de rédaction :
Prenons l’exemple de la procédure technique d’exploitation AVAMAR pour l’exploitant
système. Ce document fait l’objet de mises à jour fréquentes, il convient donc d’en faciliter
ces dernières. Les fonctionnalités de travail collaboratif peuvent aider. Voici comment
peuvent se dérouler les événements :
1. L’utilisateur A devant modifier le document se connecte et s’authentifie sur le portail
collaboratif
2. L’utilisateur A recherche le document à mettre à jour via des mots clés
3. L’utilisateur A commence une édition du document en ligne
4. Quelques minutes plus tard, un utilisateur B de l’équipe qui a besoin du document se
connecte et s’authentifie sur le portail pour rechercher le document.
5. L’utilisateur B ouvre le document en cours de rédaction et le lit intégralement. Ce
faisant, il s’aperçoit de quelques incohérences et le signale en ajoutant un
commentaire au document
6. L’utilisateur A lit le commentaire et corrige les incohérences
Ajout d’un REX sur un document :
Lors de la réalisation d’un processus en suivant une procédure, un membre de l’équipe
s’aperçoit que certaines informations ne sont plus d’actualité. Cependant, les modifications
sont conséquentes et nécessitent aussi la modification d’autres documents qui ne peut être
réalisé immédiatement. En attendant, l’utilisateur peut ajouter un commentaire sur le
document pour prévenir tous les futurs lecteurs du problème. Cette action est réalisée de la
même façon que pour l’ajout d’un commentaire sur un document décrit précédemment.

79
Création d’une nouvelle fiche d’incident :
Lors du traitement d’un incident remonté par un PE, un intervenant de la cellule Pilotage
PFC constate que le PE a une erreur d’authentification sur le portail vCloud Director lorsqu’il
saisit ses identifiants qui sont corrects mais que l’adresse URL utilisée est incomplète. Il décide
de référencer cet incident et sa solution. Voici comment il procède avec la nouvelle solution :
1. Ouverture du navigateur Web
2. Saisie de l’URL du portail collaboratif
3. Saisie de l’identifiant et du mot de passe puis validation
4. Création d’une nouvelle page de Wiki avec le modèle « Fiche d’incident »
5. Remplissage de la fiche
6. Ajout des tags et des commentaires le cas échéant
7. Enregistrement de la page
Recherche d’une fiche sur un incident :
Un membre de l’équipe PFC souhaite savoir si l’incident qu’il est en train de traiter l’a déjà
été auparavant par une autre personne de l’équipe. Voici les actions qu’il réalise avec la
nouvelle solution :
1. Ouverture du navigateur Web
2. Saisie de l’URL du portail collaboratif
3. Saisie de l’identifiant et du mot de passe puis validation
4. Recherche de l’incident par mot clé
5. Observation de la liste pour retrouver un incident similaire et ouverture de la page
correspondante si elle existe
6. Lecture de la fiche et mise à jour si nécessaire
Mise à jour de la FAQ :
Suite à des erreurs fréquentes de la part des PE lors de la suppression des machines PFC,
le responsable de la cellule Pilotage décide de modifier la FAQ PFC sur le portail collaboratif.
Voici comment il peut réaliser cela avec le nouveau système :
1. Ouverture du navigateur Web
2. Saisie de l’URL du portail collaboratif

80
3. Saisie de l’identifiant et du mot de passe puis validation
4. Recherche du mot clé FAQ
5. Ouverture le page de Wiki correspondante dans la liste des résultats de la recherche
6. Modification de la page
7. Enregistrement de la page
Consultation de la FAQ :
Un PE veut obtenir des informations sur le service PFC. Voici comment il doit procéder
avec la nouvelle solution :
1. Ouverture du navigateur Web
2. Saisie de l’URL du portail collaboratif
3. Recherche du mot clé FAQ
4. Sélection du lien correspondant pour ouvrir la page
S’il constate une imprécision dans la FAQ, il peut ajouter un commentaire comme cela se
fait sur un document.
Ajout d’un outil d’administration PFC dans le portail collaboratif :
Un intervenant de la cellule Ingénierie PFC a trouvé sur Internet un outil qui pourrait lui
être très utile pour réaliser certaines tâches d’administration sur l’infrastructure PFC. Il
souhaite que l’outil soit accessible facilement et rapidement à tous les membres de la cellule
Ingénierie. Il décide donc de l’ajouter dans le portail collaboratif. Il dispose de plusieurs
possibilités pour réaliser cette action :
Cas 1 : Il l’ajoute via le portail Web
Cas 2 : Il utilise un Client FTP pour se connecter directement à l’entrepôt de données
Cas 3 : Il utilise un partage réseau connecté directement à l’entrepôt de données
Dans le premier cas la procédure est la même que pour l’ajout d’un document. Les autres
cas ne présentent pas de particularités.

81
Suppression d’un document, d’un outil ou d’une fiche d’incident :
Les suppressions d’un élément obsolète sur la nouvelle solution est très simple à réaliser.
Un utilisateur dispose de trois possibilités pour réaliser cette opération comme pour l’ajout
d’un outil. Voici la procédure à suivre lors d’une connexion au portail Web :
1. Ouverture du navigateur Web
2. Saisie de l’URL du portail collaboratif
3. Saisie de l’identifiant et du mot de passe puis validation
4. Recherche de l’élément à supprimer par mot clé
5. Sélection de l’option de suppression pour l’élément en question
La suppression d’un élément via le portail place ce dernier dans une corbeille, ce qui n’est
pas le cas des deux autres modes de suppression (par CIFS ou FTP).
10.3. Sécurité
Le portail collaboratif contient des informations potentiellement sensibles appartenant à
EDF. La question de la sécurité est donc primordiale. Il est possible d’aborder ce point sous
deux aspects qui sont l’accès aux données et la préservation des données d’une défaillance
système.
10.3.1. Accès aux données
Bien entendu, le portail collaboratif PFC n’est pas destiné à tout le monde. Il est réservé
aux membres de l’équipe PFC, aux Pilotes d’Exploitation, aux infogérants et dans une moindre
mesure à toute personne travaillant pour EDF qui désire des informations sur le Service PFC.
Il est donc important que le portail dispose d’un système d’authentification et de
segmentation des droits.
Le diagramme de cas d’utilisation donne déjà un premier aperçu de la segmentation des
droits. Voici les différents types d’utilisateurs qui auront des droits différents sur le portail
collaboratif :
L’administrateur du portail collaboratif
Le Pilote Opérationnel de Service (POS PFC)
Le responsable de la cellule Pilotage PFC
Le responsable de la cellule Ingénierie PFC

82
L’opérateur PFC (intervenant de la cellule Pilotage PFC)
L’ingénieur PFC (intervenant de la cellule Ingénierie PFC)
Le Pilote d’Exploitation
L’exploitant système
Un utilisateur travaillant pour EDF
Pour simplifier la segmentation des droits, il est possible de regrouper certains utilisateurs
en créant des groupes :
Un groupe pour la cellule Pilotage
Un groupe pour la cellule Ingénierie
Un groupe pour les autres utilisateurs
La solution sépare aussi les données par site ce qui permet de ne rendre accessible
certaines données qu’à un nombre limité d’utilisateurs ou groupes d’utilisateurs. Il y a donc
un site réservé à la cellule Pilotage PFC, un site réservé à cellule Ingénierie et un site commun
aux deux cellules.
Bien sûr, les différentes cellules PFC peuvent collaborer. La cellule Pilotage dispose donc
d’un accès en écriture sur son site mais seulement d’un accès en lecture au site de la cellule
Ingénierie et inversement. Les deux cellules auront un accès en lecture et en écriture sur le
site commun aux deux cellules PFC.
10.3.2. Préservation des données
Pour que le système soit fiable, il est important que les données ne soient pas perdues
suite à une défaillance système.
Comme la solution est installée sur un serveur PFC, elle bénéficie des mêmes sécurités à
ce niveau que les autres serveurs EDF. La partie stockage des VM PFC est gérée par un système
EMC qui supporte la tolérance de panne (système RAID). Si toutefois cette première sécurité
venait à céder, le serveur est sauvegardé par le système AVAMAR d’EMC. Cette sauvegarde a
lieu tous les jours avec un délai de rétention de 24 heures. Donc, en cas de problème critique
sur le système de stockage, la perte ne concernera que les données qui ont moins de 24
heures. Il faut aussi noter que les sauvegardes sont vérifiées tous les jours par l’infogérant OBS
pour tous les serveurs PFC.

83
11. Choix technologique de la solution
11.1. Etudes comparatives des différents outils du Marché
Comme expliqué dans les sections précédentes, le portail collaboratif doit regrouper une
GED et un Wiki. Le problème est que de nombreux acteurs sont apparus sur ce Marché et qu’il
existe un nombre considérable d’outils de chaque catégorie. En effet, en 2014, il n’existe pas
moins de 300 moteurs de Wiki différents16 et, de manière plus générale, on dénombre 1700
outils de gestion de connaissances [1, p. 266]. Cela rend le choix d’autant plus difficile.
Il convient donc de réaliser une étude comparative qui nous permettra de réduire notre
sélection en identifiant des critères de sélection établis en fonction des souhaits du Client.
Voici les critères que nous avons établis :
Le coût de l’outil : Le Client souhaite un outil gratuit, c’est-à-dire dont la licence est
gratuite. Cependant, même la mise en place d’un outil dont la licence est gratuite aura
un coût car elle nécessitera l’intervention d’une ou plusieurs personnes pendant un
certain temps.
Le type de licence : Il n’y a pas vraiment de restriction sur ce critère donc la solution
peut être propriétaire ou libre. Cependant, une solution libre sera plus souple car il
sera possible de la modeler de manière plus poussée pour l’adapter aux besoins du
Client à condition de disposer des compétences nécessaires pour manipuler le code
source.
Les fonctionnalités : La solution doit permettre de stocker des documents et des
fichiers binaires. Le système doit aussi proposer d’ajouter des métadonnées et des tags
à chaque élément et disposer d’un système d’indexation afin d’obtenir une vitesse de
recherche optimale. Elle doit également gérer l’authentification des utilisateurs ainsi
que la segmentation de leurs droits. D’autre part, elle doit permettre l’ajout de fiches
REX, de commentaires et la collaboration.
Le mode d’installation de l’outil : Le Client dispose déjà d’une infrastructure avancée
qui pourrait être comparée à une Cloud privé de type IaaS. Il souhaite donc installer la
solution sur son infrastructure pour en garder le contrôle et en maîtriser les coûts
16 Pour plus de détails voir la page Web « http://fr.wikipedia.org/wiki/Moteur_de_wiki »

84
d’exploitation. Les outils proposés en ligne via Cloud externe de type SaaS seront donc
exclus de notre sélection.
L’ergonomie : Le Client a particulièrement insisté sur le fait que la solution devait
rester simple et conviviale. En effet, il s’agit d’un des principaux défauts de la solution
existante qui, même si elle dispose de beaucoup de fonctionnalités avec de grandes
possibilités, n’est pas du tout conviviale et rebute les utilisateurs. Si notre solution
souffre des mêmes défauts elle ne sera probablement jamais utilisée. Il est donc
primordial de mettre un point d’honneur sur l’ergonomie de la solution. Pour cela
l’ensemble des acteurs doivent essayer tous les outils proposés et donner leur ressenti.
11.1.1. Choisir un moteur Wiki
Pour choisir le moteur Wiki de notre solution, nous allons nous baser sur les critères de
sélection qui ont été fixées dans la section précédente. Pour résumer, nous recherchons un
moteur Wiki gratuit et libre qui peut être installé sur notre infrastructure et qui convient à
tous les utilisateurs. Aujourd’hui, tous les moteurs Wiki disposent de fonctionnalités avancées
et il sera difficile de les différencier sur ce point.
Il existe de très nombreux outils de comparaison disponibles sur Internet comme par
exemple les sites Web Wiki Engine17 et WikiMatrix18. Nous avons choisi d’utiliser ces deux sites
Web pour effectuer notre choix mais il faut savoir qu’il existe beaucoup de sites pour cela.
Wiki Engine :
Wiki Engine répertorie environ 330 moteurs Wiki ce qui est beaucoup plus que WikiMatrix
qui n’en comptabilise que 142. Il permet de classer les moteurs Wiki par langage de
programmation utilisé pour les concevoir ou par ordre alphabétique (la liste alphabétique
semble plus courte avec 160 moteurs Wiki). Il est possible d’accéder à fiche détaillée pour la
plupart des moteurs Wiki cités.
Le site propose aussi un « Top 10 » des moteurs Wiki les plus populaires en se basant sur
le nombre de sites Web utilisant le moteur, le nombre de téléchargements, le classement dans
sa catégorie et les avis des utilisateurs. La liste en question figure dans le tableau II.
17 http://c2.com/cgi/wiki?WikiEngines 18 http://www.wikimatrix.org/

85
Il est également possible de retrouver des conseils pour choisir un moteur Wiki mais le
choix reste assez difficile.
WikiMatrix :
Ce site Web dispose d’une liste de moteurs Wiki moins complète que Wiki Engine avec
142 moteurs Wiki référencés mais il est beaucoup plus convivial pour le choix d’un Wiki. Il met
à disposition un outil permettant de comparer plusieurs moteurs Wiki de la liste et un assistant
pour choisir un moteur Wiki en fonction de ses besoins. Cet assistant est particulièrement
utile. A chaque étape, il pose une question et réduit la liste des moteurs Wiki en fonction de
la réponse. Voici comment il a été utilisé dans notre cas :
Gestion de l’historique : Oui
Disponibilité d’un WYSIWYG19 : Oui
Besoin d’un support commercial : Non
Besoin d’un pack de langue différent de l’anglais : Oui, le pack de langue Français
L’outil sera installé en local ou accessible en ligne : Installé en local
Stockage des données dans des bases de données ou dans des fichiers : dans des bases
de données généralement plus efficaces pour l’optimisation des recherches
Licence de l’outil : Gratuit et Open Source
Langage de programmation ayant servi à concevoir l’outil : Indifférent
La liste des moteurs Wiki respectant les critères ci-dessus apparaît dans le tableau II.
Le site Web propose aussi un « Top 25 » des moteurs Wiki les plus populaires auprès des
utilisateurs du site Web (en fait la liste ne comporte que 24 moteurs Wiki). En effet, le site
effectue une étude statistique sur les moteurs Wiki consultés et comparés sur le site,
cependant, cette liste semble moins objective que sur Wiki Engine. La liste en question figure
dans le tableau II.
Les deux listes ont des moteurs Wiki en commun. Le tableau II tente de regrouper les
listes des moteurs Wiki populaires sur les deux sites ainsi que les moteurs Wiki communs dans
ces deux listes.
19 « What You See Is What You Get » qui signifie littéralement « Ce Que Vous Voyez Est-ce Que Vous Obtenez »

86
Tableau II : Les moteurs Wiki populaires sur Wiki Engine et WikiMatrix
Top 10 des moteurs Wiki les plus
populaires sur Wiki Engine
Top 25 des moteurs Wiki les plus
populaires sur WikiMatrix
Moteurs Wiki populaires sur Wiki
Engine et WikiMatrix
Sélection des moteurs Wiki selon nos critères
sur WikiMatrix
1. MediaWiki 2. MoinMoin 3. PhpWiki 4. XWiki 5. OddMuseWiki 6. TikiWiki 7. PmWiki 8. DokuWiki 9. FoswikiEngine 10. MojoMojo
1. TWiki 2. Confluence 3. DokuWiki 4. MediaWiki 5. WikiNi 6. Drupal Wiki 7. MoinMoin 8. Tiki Wiki CMS
Groupware 9. PmWiki 10. Foswiki 11. MindTouch 12. BlueSpice for
MediaWiki 13. PhpWiki 14. JSPWiki 15. Traction TeamPage 16. XWiki 17. ScrewTurn Wiki 18. SharePoint Wiki
Plus 19. TiddlyWiki 20. Corendal Wiki 21. PBwiki 22. CentralDesktop 23. GeniusWiki 24. MojoMojo
MediaWiki
MoinMoin
PhpWiki
XWiki
PmWiki
DokuWiki
MojoMojo
bitweaver
BlueSpice for MediaWiki
Daisy
JSPWiki
MediaWiki
MindTouch
MojoMojo
PhpWiki
SMW plus
Tiki Wiki CMS Groupware
WackoWiki
XWiki
Les moteurs Wiki présents dans les quatre listes du tableau II sont les suivants :
1. MediaWiki
2. MojoMojo
3. PhpWiki
4. XWiki
Nous pouvons considérer que cette liste est acceptable. Il est possible d’aller plus loin en
analysant point par point les différences entre chacun de ces moteurs grâce à WikiMatrix.

87
Après comparaison, nous avons une préférence pour MediaWiki qui a pour avantage
d’être le moteur Wiki de Wikipédia donc qui a fait ses preuves. MediaWiki bénéficie aussi
d’une communauté importante et de modules additionnels comme Semantic MediaWiki qui
peut être très intéressant dans notre cas. A noter que MediaWiki est mis à jour très
régulièrement (la version 1.23.6 date du 29/10/201420)
11.1.2. Choisir une solution de GED
Pour les outils de GED, il existe aussi beaucoup de solutions sur le Marché mais le nombre
d’outils gratuits et Open Source est beaucoup plus réduit que pour les moteurs Wiki. Nous
pouvons utiliser les mêmes critères de sélection que pour le moteur Wiki. La solution
recherchée doit être gratuite et libre, être installable sur l’infrastructure du Client, disposer
de toutes les fonctions importantes d’une GED et être facile et agréable à utiliser avec un
système de recherche performant.
Voici les quelques solutions qui répondent à ces critères :
Alfresco : Elle est issue du travail sur Documentum, il s’agit d’un outil très puissant et
sans limitation dans sa version libre et gratuite « Alfresco Community »
Nuxeo Platform
OpenKM : C’est une solution qui est moins orientée sur l’aspect collaboratif que sur
l’aspect classification. Elle impose, par ailleurs, plus de limitation au niveau du nombre
maximum d’utilisateurs pouvant utiliser la solution dans sa version gratuite
Kimios : C’est une solution très légère et beaucoup moins ergonomique qu’un portail
collaboratif tel qu’Alfresco. Elle est plutôt réservée à de très petite infrastructure
Il y a aussi une solution propriétaire qui aurait pu être très intéressante pour le projet
mais qui ne sera pas sélectionnée en raison du coût de sa licence, il s’agit de Microsoft
SharePoint. Cependant, nous la décrirons brièvement car EDF souhaite migrer vers cette
solution pour toute l’entreprise en remplacement de Lotus Notes.
L’étude comparative du Gartner donne une comparaison intéressante des outils du
Marché en 2014 qui peut nous aider dans notre recherche. La figure 22 montre cette
représentation.
20 Pour plus de détails voir le site Web http://www.mediawiki.org/wiki/MediaWiki/fr

88
Figure 22 : Magic Quadrant pour les ECM. Source : Gartner21 (Septembre 2014)
La figure 22 nous montre bien les leaders des solutions de gestion de contenu sur le
Marché. Il s’agit, entre autres, d’IBM, Microsoft (SharePoint) et Oracle. Cependant, elle
montre aussi les acteurs visionnaires et c’est le cas notamment d’Alfresco.
Nous distinguons deux solutions qui se démarquent par rapport aux autres, il s’agit de
SharePoint et d’Alfresco. La description de ces logiciels sera l’objet des sections suivantes.
11.1.2.1. SharePoint
SharePoint est la solution très connue de gestion de contenu (GED/CMS) et de travail
collaboratif (forums et blogs) de Microsoft [17]. Il s’agit d’une des solutions leader sur le
Marché.
21 Pour plus de détail voir le site Web http://www.gartner.com

89
C’est une suite logicielle propriétaire développée par Microsoft avec les technologies
ASP.NET, IIS22 et SQL Server. La solution a été créée en 1999 [17].
11.1.2.2. Alfresco
La solution Alfresco est aussi une suite logicielle de gestion de contenu et de travail
collaboratif. Elle est beaucoup moins ancienne et connue que SharePoint.
Elle a été mise au point par la société Alfresco Software en 2005 [18]. Contrairement à
SharePoint, elle est distribuée gratuitement dans son édition Community sous licence GNU
LGPL23. La solution s’inspire fortement des travaux sur Documentum et Interwoven [18].
11.1.3. Choisir un portail d’entreprise
Alfresco Share et Microsoft SharePoint peuvent être considérés comme des portails
collaboratifs. Cependant, ces solutions sont plus développées sur la gestion de contenu et la
gestion documentaire que sur l’aspect portail collaboratif comme la solution Dupral24 ou
Liferay25 (Liferay est, d’après le Gartner, une solution leader parmi les portails horizontaux).
En effet, Liferay et Dupral offre de meilleures fonctionnalités de personnalisation et une très
bonne expérience utilisateur pour des clients extérieurs mais, en contrepartie, ils sont moins
puissants en matière de gestion de contenu et de gestion documentaire. Il n’y a pas de
frontière nette entre ces deux types de solutions mais Alfresco ou Sharepoint répondent
mieux aux besoins de notre projet que Liferay ou Dupral plus adaptés, semble-t-il, au B2C.
Toutefois, il est toujours possible d’intégrer Alfresco dans Liferay même si cela reste
expérimental avec la version 5 d’Alfresco.
11.2. Les contraintes
Afin de faire un choix pour notre solution parmi les outils présentés dans les sections
précédentes, il convient d’étudier les contraintes du projet. En effet, toutes les entreprises
sont soumises à des contraintes politiques, économiques, sociales, techniques,
environnementales et légales (PESTEL) qui influent sur ses projets [16]. Elles ont été abordées
une première fois dans ce travail à la section de l’analyse de risque. Cette partie a pour but
d’analyser ces contraintes d’un point de vue différent. Dans le cas de notre projet, les
22 « Internet Information Services » est une suite logicielle de serveur Web développée par Microsoft 23 Il s’agit d’une licence publique générale GNU limitée. Voir le site Web suivant pour plus de détails : https://www.gnu.org/licenses/lgpl.html 24 Pour plus de détails voir la page Web https://www.drupal.org/ 25 Pour plus de détails voir la page Web http://www.liferay.com/fr/

90
contraintes sont de nature économique, technologique et environnementale. Les contraintes
politiques, sociales et juridiques qui peuvent être rencontré dans certains projets sont
inexistantes dans le nôtre.
11.2.1. Economique
Sur ce point, le Client a fixé deux conditions sur le projet qui sont le nombre de ressources
pour le projet et le coût des outils à mettre en place.
La première condition est qu’il n’y a qu’une seule personne assignée à ce Projet. En effet,
il faut rappeler que le Service PFC a pour mission principale la fourniture de ressources
informatiques via un Cloud privé de type IaaS qui reste prioritaire sur les tâches d’organisation
interne du Service. La gestion de la connaissance est une tâche importante mais elle n’a pas
d’effet immédiat sur les performances du Service. Comme le Service bénéficie déjà du système
de gestion des connaissances de l’entreprise, la solution que nous mettons en place est
complémentaire et n’est, pour le moment, pas pris en compte par l’équipe dirigeante. Il n’y
aura donc pas de recrutement pour ce projet et étant donné que le Service a déjà une grande
charge de travail, il n’est pas possible d’affecter plusieurs personnes sur ce projet
La deuxième condition est de choisir, pour la solution à mettre en place, un outil dont la
licence est gratuite. En effet, EDF travaille déjà pour le changement de sa solution Lotus Notes
par SharePoint à travers le projet Néo, il sera donc très difficile au Service PFC de justifier
auprès de l’équipe dirigeante le coût d’une licence pour une solution complémentaire qui est
négligeable à l’échelle de toute l’entreprise. Cette contrainte réduit fortement les choix
possibles pour la solution.
11.2.2. Technologique
La premières contraintes technologiques est que la solution devra être accessible par des
utilisateurs utilisant des machines x86 avec comme système d’exploitation Microsoft
Windows 7 appelées postes ATLAS par EDF. Cependant, il se peut aussi que quelques rares
utilisateurs utilisent un autre type de poste de travail. Il faut donc privilégier des solutions
multiplateformes.
La deuxième contrainte technologique concerne le mode d’installation de l’outil. En effet,
l’outil doit rester local à l’infrastructure PFC. Cela signifie que la solution devra être installée
sur un serveur PFC. Il y a deux raisons à cela qui sont que, d’une part, les données enregistrées

91
dans la solution sont potentiellement sensibles et ne doivent pas être externalisées vers une
infrastructure extérieure comme un Cloud Public et, d’autre part, il serait difficile de garder le
contrôle total et de personnaliser une solution de type SaaS proposée par un fournisseur
extérieur. De plus, cela entrainerait un surcoût injustifié étant donné que le Client dispose déjà
de l’infrastructure et des compétences nécessaires pour la mise en place de la solution.
11.2.3. Contraintes de l’infrastructure actuelle
Il s’agit, ici, d’une contrainte plus complexe. En fait, en mettant en place la nouvelle
solution, il faut tenir compte de l’infrastructure en place chez EDF et ne pas proposer une
solution à l’opposé des règles de l’infrastructure qui conduirait à un échec du projet. La
solution doit être installable sur un serveur x86 virtualisé et compatible pour des échanges de
données avec des postes de travail x86. D’autre part, la solution devra permettra de stocker
et de consulter en ligne des documents générés par la suite Microsoft Office 2007 utilisée par
le Client ainsi que des documents au format PDF.
Il est également important de prendre en compte qu’il s’agit d’un outil complémentaire
à la solution existante et il faut donc que notre solution limite au maximum les doublons par
rapport aux données du système existant.
11.3. Choix définitif : la suite logicielle Alfresco
11.3.1. Motivation du choix
Le choix définitif de la solution doit se baser sur l’étude comparative qui a été réalisée, les
contraintes existantes et les souhaits du Client.
A ce stade de notre analyse, nous savons que la solution définitive devra comporter une
GED et un Wiki. Il existe donc deux possibilités qui consistent soit à prendre deux outils séparés
en créant un point d’entrée unique, soit d’utiliser une suite logiciel regroupant les deux outils
nécessaires.
Suite à l’étude comparative, deux outils ont été retenus et proposés au Client, il s’agit du
moteur Wiki MediaWiki et de la suite logicielle Alfresco. La solution définitive sera donc
composée soit uniquement de la suite logicielle Alfresco qui intègre son propre moteur Wiki,
soit de cette dernière accompagnée du moteur Wiki MediaWiki.

92
Les deux solutions ont été présentées au Client, dans un premier temps, lors d’un point
de suivi hebdomadaire en comité restreint puis devant toute l’équipe du Service PFC lors d’une
réunion de deux heures.
Après réflexion, il semble que la plateforme collaborative Alfresco présente toutes les
fonctionnalités nécessaires pour répondre aux besoins du Client tout en respectant les
contraintes que nous avons identifiées. De plus le Client a apprécié la démonstration qui lui a
été faite de l’outil. Le Client a donc porté son choix sur cette suite logicielle uniquement en
écartant MediaWiki pour deux raisons principales qui sont que d’une part, la suite dispose
déjà d’un moteur Wiki intégré avec les fonctionnalités suffisantes pour le besoin et d’autre
part, l’intégration de MediaWiki à Alfresco serait difficile à réaliser et à maintenir. Alfresco
semble donc le choix le plus pertinent pour notre Projet.
Il convient cependant de préciser que la suite Alfresco est plus construite dans l’esprit
d’une GED que de celui d’un moteur Wiki. Le moteur Wiki intégré peut donc paraître moins
ergonomique que celui de MediaWiki mais cette limite est acceptable pour les besoins du
Client. De plus, elle peut être partiellement comblée par l’installation d’un module
complémentaire qui permet de rendre le moteur Wiki intégré à Alfresco plus proche de celui
de MediaWiki en ajoutant, par exemple, la fonctionnalité de la génération automatique d’une
table des matières au début des articles Wiki.
11.3.2. Architecture technique de la suite Alfresco
Nous allons maintenant présenter un peu plus en détail la suite Alfresco. Nous nous
intéresserons en particulier à son architecture globale, aux interactions qu’elle peut avoir avec
son environnement, aux principaux services qu’elle offre et au mécanisme du système de
recherche.
La figure 23 montre l’architecture globale de la solution Alfresco.

93
Figure 23 : Architecture globale d’Alfresco inspirée de la 1 ère figure de [19]
Il est aussi intéressant de représenter l’ensemble des interfaces qui permettent
d’interagir avec le système. Une telle représentation est donnée dans la figure 24.
Figure 24 : Interaction d’Alfresco avec son environnement inspirée de la figure de [20, p. 10]
Pour permettre la gestion de documents et de contenu, Alfresco se base sur trois
principaux services [19] qui sont :
Navigateur Web
Applications Alfresco
Entrepôt
Serveur d’application
Stockage
Base de données Système de
fichiers
Moteur de Workflow
Recherche plein texte
Bibliothèque de services
Stockage de fichiers
Client Web Personnalisé
Navigateur Web
HTTP/S
Partage réseau
LDAP (Utilisateurs et Groupes)
Clients lourds
CIFS
WebDAV
FTP
SMTP
Alfresco
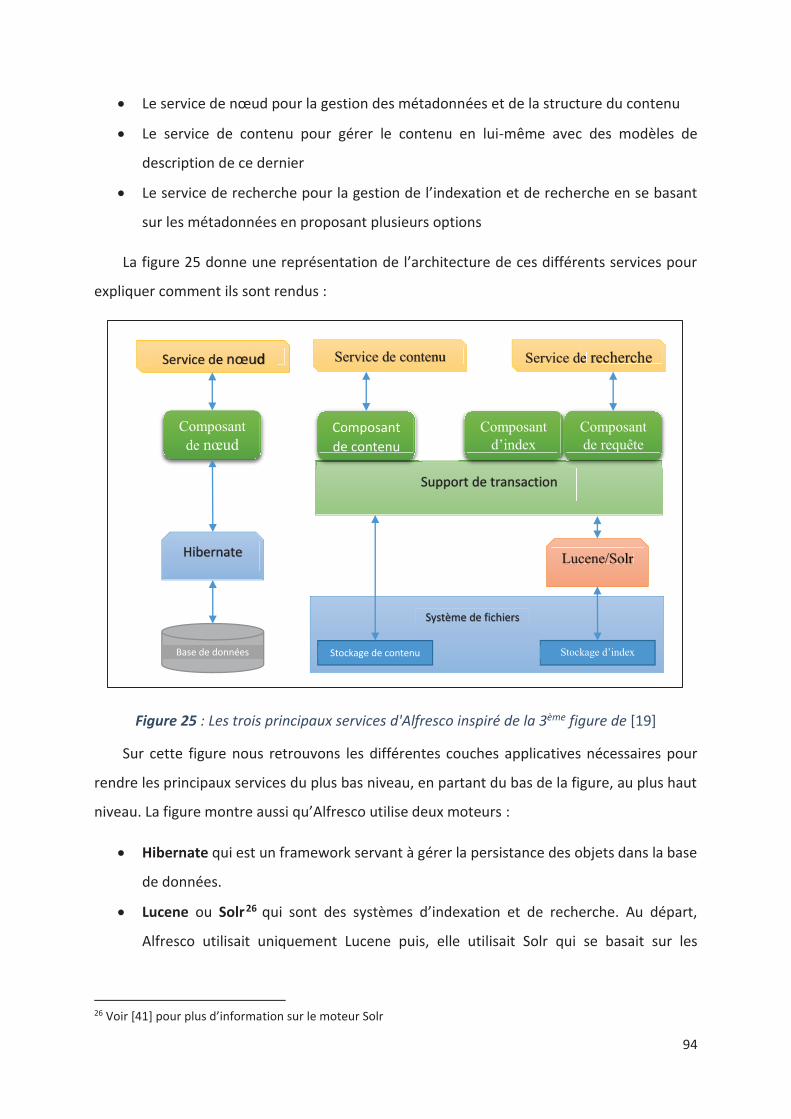
94
Le service de nœud pour la gestion des métadonnées et de la structure du contenu
Le service de contenu pour gérer le contenu en lui-même avec des modèles de
description de ce dernier
Le service de recherche pour la gestion de l’indexation et de recherche en se basant
sur les métadonnées en proposant plusieurs options
La figure 25 donne une représentation de l’architecture de ces différents services pour
expliquer comment ils sont rendus :
Figure 25 : Les trois principaux services d'Alfresco inspiré de la 3ème figure de [19]
Sur cette figure nous retrouvons les différentes couches applicatives nécessaires pour
rendre les principaux services du plus bas niveau, en partant du bas de la figure, au plus haut
niveau. La figure montre aussi qu’Alfresco utilise deux moteurs :
Hibernate qui est un framework servant à gérer la persistance des objets dans la base
de données.
Lucene ou Solr26 qui sont des systèmes d’indexation et de recherche. Au départ,
Alfresco utilisait uniquement Lucene puis, elle utilisait Solr qui se basait sur les
26 Voir [41] pour plus d’information sur le moteur Solr
Service de e nœudud
Support de transaction
Composant de contenu
Système de fichiers
Base de données Stockage de contenu
Hibernate

95
bibliothèques de Lucene et dans la version 5.0.b Solr intègre complètement les
bibliothèques de Lucene.
Les figure 26 et 27 vont un peu plus loin en montrant respectivement les architectures
détaillées des moteurs Hibernate et Solr.
Figure 26 : Architecture du moteur Hibernate inspirée de la 2ème figure de [21]
Figure 27 : Architecture du moteur Lucene/Solr inspirée de [22]
Application Java
JTA JDBC JNDI
Objets persistants
Hibernate
Configuration Session
/admin
Gestionnaires de requêtes
Schéma
Faceting
Apache Tika
Moteur de recherche IndexReader/Searcher
Apache Lucene

96
Pour donner une idée de l’interface, voici une copie d’écran de la page d’accueil du portail
Alfresco Share lorsqu’un utilisateur est connecté avec le compte administrateur :
Figure 28 : Page d’accueil par défaut du portail Alfresco Share

97
12. Mise en place du portail collaboratif au sein du Service PFC
La mise en place de la solution nécessite plusieurs étapes qui sont décrites en détail dans
cette section.
Nous aborderons donc en premier la procédure d’installation en décrivant le système
cible et les paramètres choisis lors de l’installation. Puis, nous décrirons le transfert des
données utiles et critiques de l’ancien système vers le nouveau. Par la suite, nous expliquerons
comment la solution sera personnalisée pour répondre parfaitement au besoin du Client. Les
quatre paragraphes suivants traiteront de la phase Pilote de la solution, du retour des
utilisateurs et de l’adaptation de la solution en prenant en compte ces remarques. Ces sujets
nous conduiront à la conduite du changement. Enfin nous parlerons du processus de mise à
jour et de maintenance de la solution.
12.1. Installation et configuration
12.1.1. Choix du système d’exploitation de la machine cible
Alfresco, qui a été choisi comme solution définitive, est une suite logicielle qui doit en
principe être installée sur un serveur. La suite logicielle s’installe aussi bien sur un système
Windows que Linux. Le choix du système d’exploitation s’est porté sur Windows Server 2012
parce que d’une part, il s’agit du système d’exploitation le plus récent utilisé par EDF (les
versions RHEL ou « Red Had Entreprise Linux » sont plus anciennes même si elles bénéficient
de mises à jour fréquentes) et d’autre part la ressource travaillant sur ce projet maitrise
beaucoup mieux Windows que Linux et le Client aura d’ailleurs plus de facilité à intervenir sur
l’outil avec une interface graphique celle-ci étant absente des systèmes Linux EDF. A noter
qu’il s’agit d’un système d’exploitation 64 bits ce qui est préférable étant donné qu’il y a une
grande perte de performance avec Alfresco sur les systèmes 32 bits [23].
12.1.2. Choix de la configuration du matériel de la machine cible
Une fois le système d’exploitation du Serveur choisi, il faut déterminer la configuration de
la machine virtuelle PFC que nous allons utiliser pour notre solution. Le choix de ces
caractéristiques s’est fait à partir des recommandations d’Alfresco Software en fonction de
l’usage qui est fait de sa suite logicielle. Le tableau III résume l’ensemble de ces
recommandations pour le cas des serveurs virtuels.

98
Tableau III : Ressources nécessaires pour Alfresco en fonction des accès concurrents27
Nb d’accès concurrents RAM28 nécessaires Nb vCPU29 nécessaires
1 utilisateur 1 Go 1 vCPU
50 utilisateurs simultanés ou
500 utilisateurs occasionnels
1.5 Go 2 vCPU
100 utilisateurs simultanés ou
1000 utilisateurs occasionnels
1.5 Go 4 vCPU
200 utilisateurs simultanés ou
2000 utilisateurs occasionnels
2.5 Go 8 vCPU
La configuration qui a été sélectionnée est un serveur PFC sauvegardé (classe de service
Argent) avec 2 vCPU, 8 Go de mémoire vive et 50 Go d’espace disque qui pourra évoluer à
terme.
En effet, selon un article Wiki d’Alfresco, pour 50 accès concurrents, c’est-à-dire 50 Clients
utilisant la solution en même temps, la suite nécessitera 1.5 Go de mémoire vive et un
processeur dual-core [23]. Si nous prévoyons les ressources utilisées par le système
d’exploitation, nous obtenons la configuration du serveur sélectionné.
12.1.3. Les prérequis à l’installation
Selon Alfresco Software 30 , la suite Alfresco nécessite les éléments suivants pour
fonctionner :
Java SE Development Kit (JDK) ou Java Runtime Environment (JRE).
Un serveur d’application. Par défaut, Alfresco utilise Tomcat.
Un système de gestion de bases de données. Par défaut, Alfresco utilise PostgreSQL.
La suite bureautique OpenOffice.org pour pouvoir lire les documents au sein d’Alfresco
et pour la conversion d’un document d’un format à un autre.
ImageMagik pour la gestion des images de prévisualisation.
27 Pour plus de détails, voir la page Web http://wiki.alfresco.com/wiki/Repository_Hardware 28 « Random Access Memory » ou mémoire à accès aléatoire correspond à la mémoire vive d’un ordinateur 29 « Virtual Central Processor Unit » ou Unité Centrale de Traitement Virtuelle 30 Pour plus de détails, voir la page Web http://docs.alfresco.com/3.4/concepts/prereq-install.html
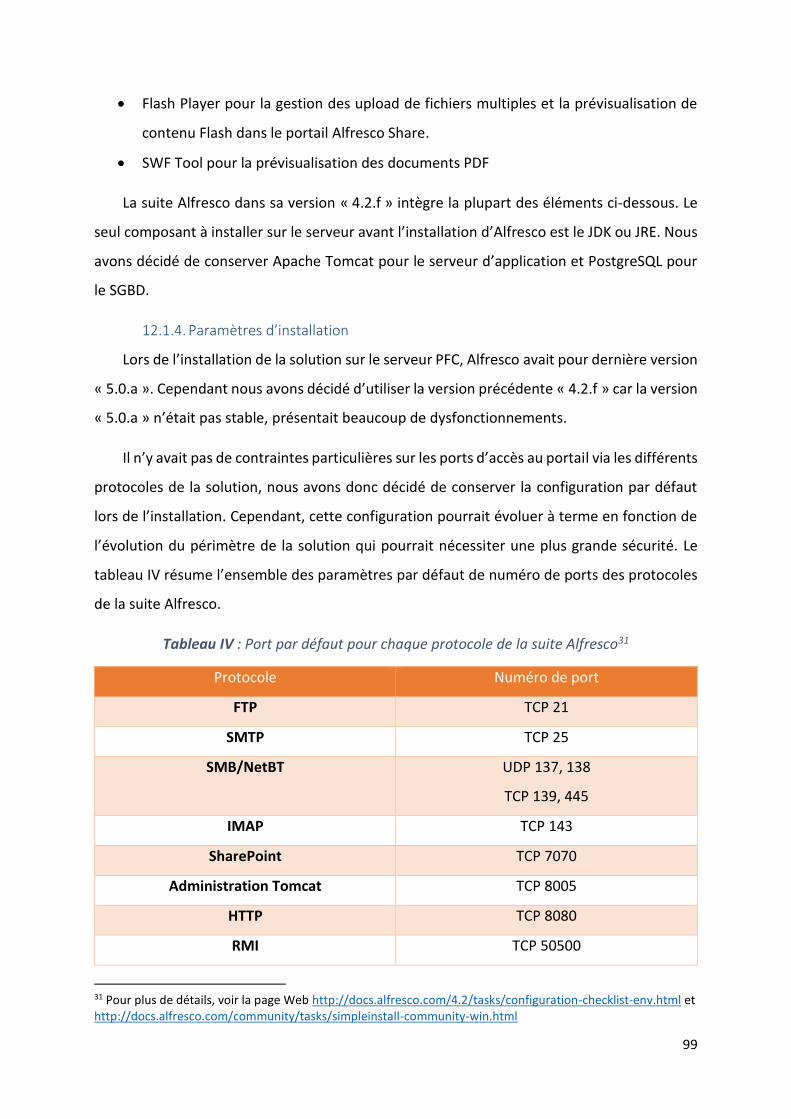
99
Flash Player pour la gestion des upload de fichiers multiples et la prévisualisation de
contenu Flash dans le portail Alfresco Share.
SWF Tool pour la prévisualisation des documents PDF
La suite Alfresco dans sa version « 4.2.f » intègre la plupart des éléments ci-dessous. Le
seul composant à installer sur le serveur avant l’installation d’Alfresco est le JDK ou JRE. Nous
avons décidé de conserver Apache Tomcat pour le serveur d’application et PostgreSQL pour
le SGBD.
12.1.4. Paramètres d’installation
Lors de l’installation de la solution sur le serveur PFC, Alfresco avait pour dernière version
« 5.0.a ». Cependant nous avons décidé d’utiliser la version précédente « 4.2.f » car la version
« 5.0.a » n’était pas stable, présentait beaucoup de dysfonctionnements.
Il n’y avait pas de contraintes particulières sur les ports d’accès au portail via les différents
protocoles de la solution, nous avons donc décidé de conserver la configuration par défaut
lors de l’installation. Cependant, cette configuration pourrait évoluer à terme en fonction de
l’évolution du périmètre de la solution qui pourrait nécessiter une plus grande sécurité. Le
tableau IV résume l’ensemble des paramètres par défaut de numéro de ports des protocoles
de la suite Alfresco.
Tableau IV : Port par défaut pour chaque protocole de la suite Alfresco31
Protocole Numéro de port
FTP TCP 21
SMTP TCP 25
SMB/NetBT UDP 137, 138
TCP 139, 445
IMAP TCP 143
SharePoint TCP 7070
Administration Tomcat TCP 8005
HTTP TCP 8080
RMI TCP 50500
31 Pour plus de détails, voir la page Web http://docs.alfresco.com/4.2/tasks/configuration-checklist-env.html et http://docs.alfresco.com/community/tasks/simpleinstall-community-win.html

100
12.1.5. Configuration complémentaire suite à l’installation
Malheureusement, Alfresco Community est livrée avec certaines fonctions utiles
désactivées et ne propose pas de moyen simple de les paramétrer. Parmi ces fonctionnalités,
celles qui nous intéressent le plus sont les notifications par mail, le lien avec un Active
Directory Microsoft et le CIFS (SMB) permettant de monter des lecteurs réseaux qui pointent
vers le système de fichiers d’Alfresco. Nous avons donc entrepris de modifier manuellement
les fichiers de configuration de la solution.
Alfresco se configure généralement via le fichier de configuration « alfresco-
global.properties » situé, par défaut, à l’emplacement « <volume du
disque>\Alfresco\tomcat\shared\classes ». Il s’agit d’un fichier « properties » Java classique.
Le fichier est composé de plusieurs lignes de type « <propriété>=<valeur> » et le symbole « # »
indique le début d’un commentaire sur la ligne. La prise en compte des modifications de ce
fichier par le système Alfresco nécessite le redémarrage du service Tomcat.
12.1.5.1. Configuration de l’authentification
Le premier aspect à prendre en compte est celui de l’authentification des utilisateurs qui
est vraiment spécifique dans le cas de ce projet. Comme le montre le diagramme UML de cas
d’utilisation de la figure 21, il y a plusieurs types d’utilisateurs qui seront amenés à utiliser
cette solution avec pour chacun des droits d’accès différents. Il semble judicieux de se baser
sur les droits d’accès aux données accordés aux utilisateurs de l’ancien système pour les
adapter au nouveau. Voici comment sont répartis ces droits dans le système actuel selon les
utilisateurs :
Les Pilotes d’Exploitation ont accès en lecture seule, d’une part, au référentiel PRODIS
pour télécharger les documents d’utilisation du portail vCloud Director et AVAMAR et,
d’autre part, à la Base Lotus Notes du RD&E pour lire la FAQ PFC. Ils ont aussi un accès
en lecture et en écriture sur les incidents qu’ils ont été créés dans l’outil SCOPE GS et
un accès en lecture sur les incidents ou les demandes créés par leur exploitant système
Les Infogérants et exploitant système des Clients du Service PFC ont les mêmes accès
que les Pilotes d’Exploitation.
L’infogérant PFC (OBS) a également les mêmes droits d’accès que les Pilotes
d’Exploitation avec en plus un accès en lecture et en écriture au DEX sur la Base PFC

101
ainsi qu’à d’autres documents d’exploitation. Ils ont aussi un accès à la boite aux lettres
générique (BAL) des Bascules PFC
Les membres du Service PFC ont un accès partiel aux BAL PFC PILOTAGE, INGENIERIE,
BASCULES et à la Base PFC. Ils ont un accès en lecture à la section PFC de la Base RD&E.
Ils ont aussi accès au référentiel PRODIS en tant qu’opérateur (c’est-à-dire avec la
possibilité de lire et de publier des documents ou des outils). Ils bénéficient également
d’un accès aux incidents ou aux demandes affectés via l’outil SCOPE GS.
Le Pilote Opérationnel de Service a des accès supplémentaires sur les BAL PFC
Le Responsable de la cellule Pilotage a un accès total à la BAL PILOTAGE et en lecture
et écriture sur la FAQ PFC dans la Base RD&E.
Le Responsable de la cellule Ingénierie a un accès total à la BAL INGENIERIE
Chaque personne travaillant pour EDF dispose d’un compte sur l’AD ATLAS et d’une
adresse de messagerie avec un identifiant Lotus Notes. Les personnes ayant à gérer ou à
utiliser des serveurs disposent aussi d’un compte sur l’AD ADAM et HADAM. Il est donc
possible grâce à ces comptes et ces identifiants de gérer les droits des personnes travaillant
pour EDF.
La suite Alfresco dispose des systèmes d’authentification suivants :
AlfrescoNTLM qui est le système d’authentification local de la suite. Il permet de créer
des comptes locaux pour les utilisateurs et les stocke dans la Base de données Alfresco.
LDAP (Lightweight Directory Access Protocol) qui permet une authentification et un
import des comptes utilisateur en passant par n’importe quel type de protocole
d’accès à un annuaire comme par exemple OpenLDAP.
LDAP AD qui autorise une authentification et un import des comptes utilisateur en
passant par un annuaire Active Directory
Passthru (Pass-through) qui permet une authentification via un serveur du domaine
Windows
Kerberos pour une authentification via le Java Authentication and Authorization
Service (JAAS) qui fonctionne avec le système Kerberos Realm
External qui est un système externe permettant une authentification de type Single
Sign On (SSO) ou Point d’Authentification Unique

102
Il est possible de combiner plusieurs systèmes d’authentification qui seront utilisés
successivement lors de la tentative de connexion d’un utilisateur. Par exemple, nous pouvons
très bien indiquer à Alfresco de rechercher le compte de l’utilisateur en premier dans la Base
de données interne (système AlfrescoNTLM) puis, s’il ne parvient pas à le trouver, dans l’Active
Directory (système LDAP AD). Il est aussi possible d’utiliser plusieurs instances de chaque
système, ce qui autorise, par exemple, de rechercher un compte, dans deux Active Directory
différentes. La séquence d’authentification est définie dans le fichier « alfresco-
global.properties » et se présente sous la forme :
authentication.chain=<instance_1>:<sous-système>,…,<instance_n>:<sous-système>
Donc, par exemple, pour qu’Alfresco recherche le compte utilisé pour l’authentification
dans la Base interne puis dans un Active Directory défini, il faudra écrire la chaîne
d’authentification suivante :
authentication.chain=<afrescoNtlm1>:<afrescoNtlm>,<ladap-ad1>:<ldap-ad>
L’ensemble des fichiers de configuration des systèmes d’authentification se trouvent dans
le répertoire :
« \Alfresco\tomcat\webapps\alfresco\WEB-INF\classes\alfresco\subsystems\Authentication\ »
Même s’il est possible de modifier les fichiers de configuration directement dans ce
répertoire, ce n’est pas recommandé. En effet, il s’agit de l’extraction de l’archive
« alfresco.war » qui est réalisée au premier lancement de l’application et il est préférable,
comme le précise les développeurs, de les surcharger dans le répertoire
« \Alfresco\tomcat\shared\classes\alfresco\extension\subsystems\Authentication » (ce
système est modifié dans Alfresco v5.0 où la configuration de la plupart des « subsystems »
se fait dans le fichier « alfresco-global.properties »).
Dans notre cas, la difficulté réside dans le fait qu’il faille trouver un système
d’authentification adapté au besoin du Client. En effet, les membres de l’équipe PFC doivent
pouvoir s’authentifier pour avoir les droits spécifiques qui leur sont associés. Par contre, le fait
de s’authentifier est un peu gênant pour Pilote d’Exploitation ou d’autres utilisateurs voulant
simplement découvrir l’offre PFC qui n’ont pas à le faire pour se connecter à la Base RD&E une

103
fois qu’ils sont authentifiés sur Lotus Notes. Une solution à ce problème aurait été d’utiliser
une des authentifications SSO disponibles dans Alfresco proposant des connexions
automatiques après la première connexion. Les systèmes en question sont « passthru » et
« kerberos » mais, malheureusement, ils ne pourront pas être utilisés. En effet, le système
« passthru » n’est compatible qu’avec le protocole d’identification NTLM (NT LAN Manager)
en version 1, or les poste de travail EDF utilisent tous NTLM v2 et il n’est pas envisageable
d’appliquer une nouvelle politique de sécurité à tous les postes uniquement pour cette
configuration. Le système « kerberos », quant à lui, nécessite d’effectuer des actions sur le
contrôleur de domaine pour sa mise en place ce qui n’est pas possible non plus étant donné
que nous n’avons pas accès à ces serveurs.
Il va donc falloir faire un compromis sur le SSO et coupler une authentification
« AlfrescoNTLM » pour les comptes locaux, « LDAP AD » pour l’AD ADAM et « Passthru » (sans
le SSO) pour l’AD ATLAS pour les comptes des membres. Les utilisateurs devront donc
s’identifier sur le portail Alfresco Share qui n’admet pas de connexion anonyme. Il est toutefois
possible de s’authentifier en tant qu’invité sur le portail Afresco Explorer qui est l’ancienne
version du portail Alfresco (cette ancienne version a disparu dans la version 5.0 d’Alfresco).
Pour cela nous allons dans un premier temps modifier la chaîne d’authentification dans
le fichier « alfresco-global.properties » de la façon suivante :
« authentication.chain=alfrescoNtlm1:alfrescoNtlm,ldap1:ldap-ad,passthru1:passthru » (la
chaîne contient les trois instances « Ntlm1 », « ldap1 » et « passthru1 »). Puis nous allons
modifier le fichier « ldap-ad-authentication.properties » dont l’emplacement par défaut est
« \Alfresco\tomcat\webapps\alfresco\WEB-
INF\classes\alfresco\subsystems\Authentication\ldap-ad » (à surcharger dans le répertoire
correspondant) en renseignant les informations sur l’Active Directory de rattachement.
Désormais les utilisateurs qui disposent d’un compte dans l’AD peuvent s’authentifier sur
les portails Alfresco Share et Alfresco Explorer. En fait, Alfresco effectue d’abord une
recherche dans la liste des comptes locaux puis, si le compte n’est pas trouvé, il le recherche
dans l’AD ADAM d’abord avec le sous-système « LDAP AD » puis dans l’AD ATLAS avec le sous-
système « Passthru » via le contrôleur de domaine ATLAS. S’il trouve le compte dans une des
AD, il le copie en tant que compte local.

104
12.1.5.2. Configuration des notifications par mail (protocole SMTP)
L’activation des notifications par e-mail des utilisateurs nécessite de configurer le sous-
système d’envoi de courrier via le protocole SMTP. Il est possible soit de créer son propre
sous-système de messagerie électronique, soit d’utiliser un système de messagerie
électronique existant. Etant donné qu’EDF dispose de son propre serveur de messagerie dont
l’API32 est utilisée par de nombreux outils tel que vCO, nous opterons pour la deuxième option.
Pour ce faire, il suffit d’ajouter quelques propriétés dans le fichier « alfresco-
global.properties », voici les lignes qui doivent être ajoutées :
mail.host=<serveur mail EDF> mail.port=25 mail.username=anonymous mail.password= mail.encoding=UTF-8 [email protected] mail.smtp.auth=false
12.1.5.3. Configuration du CIFS
L’activation du CIFS s’effectue également dans le fichier « alfresco-global.properties »
dans lequel il faut ajouter les lignes suivantes :
alfresco.authentication.authenticateCIFS=true cifs.enabled=true
Il est important de savoir que le système CIFS d’Alfresco peut rentrer en conflit avec celui
du système d’exploitation Windows Server 2012. Etant donné que nous n’avons pas besoin de
ce dernier nous avons désactivé le service « Server » de Windows afin d’éviter tout conflit
entre les deux systèmes. L’autre solution aurait été de créer un deuxième nom de serveur CIFS
pour Alfresco en ajoutant la ligne suivante dans le fichier de configuration :
cifs.serverName=${alfresco}<suffixe>
12.1.6. Installation d’un module de monitoring
Alfresco est une solution multi-utilisateurs, il convient donc d’en surveiller les
performances pour pouvoir analyser et même anticiper d’éventuels problèmes. Le Service PFC
dispose de l’outil VMware vCOps qui permet de surveiller l’infrastructure virtuelle et donc les
32 API est l’acronyme de « Application Programming Interface » qui signifie Interface de Programmation. Il s’agit d’un ensemble d’outils normalisés permettant d’accéder à une application sans passer par l’interface par défaut de cette dernière.

105
serveurs, cependant, le plus petit élément qu’il permet de surveiller est la VM. Dans le cas de
la solution Alfresco, il est préférable de surveiller directement les performances de
l’application et c’est justement ce que permet de faire le module JavaMelody qui s’intègre
parfaitement dans Alfresco.
L’installation consiste à copier les fichiers « JavaMelody.jar » et « jrobin-1.5.9.1.jar » du
projet JavaMelody (la version utilisée est 1.5.9.1) dans le répertoire
« \Alfresco\tomcat\shared\lib » puis de modifier le fichier
« \Alfresco\tomcat\conf\web.xml » en y ajoutant entre les balises <web-app> et </web-app>
les lignes suivantes :
<filter> <filter-name>monitoring</filter-name> <filter-class>net.bull.javamelody.MonitoringFilter</filter-class> </filter> <filter-mapping> <filter-name>monitoring</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> <listener> <listener-class>net.bull.javamelody.SessionListener</listener-class> </listener>
12.2. Transfert des données du système existant vers la nouvelle solution
Le transfert concernera principalement les documents et les informations de la FAQ PFC
présentes sur le système existant. La difficulté, ici, est de sélectionner les données qui doivent
être transférées et celles qui ne doivent pas l’être pour ne pas surcharger le nouveau système.
Pour cela il convient de cartographier les connaissances du Service PFC en utilisant les
démarches décrites dans la section sur la cartographie des connaissances et un MindMap. La
figure 29 montre la carte heuristique des connaissances du Service PFC.

106
Figure 29 : Carte des connaissances du Service PFC
L’intérêt de cette carte heuristique des connaissances n’est pas d’énumérer toutes les
connaissances du Service PFC mais plutôt de donner une vision d’ensemble de ces dernières
pour pouvoir les identifier et les répertorier plus facilement.
Cette carte va donc faciliter l’identification des connaissances critiques qui sont
susceptibles de disparaître et des connaissances difficiles d’accès sur l’ancien système afin de
les intégrer dans le nouveau système.
La plupart des domaines présentés dans la carte des connaissances sont très bien
documentés mais il s’agit de documents officiels validés lors du projet ou pendant
l’exploitation de la solution PFC. Ce ne sont pas ce type de données que le Client souhaite
ajouter, en priorité, dans le portail collaboratif car l’ancien système est déjà saturé de ce type
d’information. Il est préférable de s’intéresser aux connaissances liées au savoir-faire et à
l’expérience. Cela correspondrait, par exemple, à une information relative au suivi d’une
procédure standard. Pour, l’ajout de ce type de connaissances dans le nouveau système, la
carte ne suffit pas, il est nécessaire d’interroger les experts pour construire un socle de base.
Toutefois, la grande partie des connaissances seront ajoutées progressivement en fonction
des situations rencontrées par les différents acteurs.

107
Les seuls documents formels qui devront obligatoirement être transférés sont ceux qui
sont utiles aux PE comme le Guide utilisateur de portail vCloud Director, la PTE AVAMAR pour
l’exploitant système ou la FAQ PFC. Il faut cependant préciser que les données transférées
seront forcément en « doublon » par rapport au système existant où nous ne supprimerons
rien. Pour ce type de connaissances, il convient donc de s’interroger sur l’intérêt que
présenterait la copie de ces dernières dans le nouveau système. En fait, l’avantage se ferait
essentiellement sur le système d’indexation et de recherche beaucoup plus performant que
celui de l’ancien système ce qui représente un gain de temps significatif pour les utilisateurs.
Cela confirme le fait que seuls les documents les plus utiles doivent être transférés.
12.3. Premier retour des utilisateurs avant la personnalisation de la solution
Une fois que le portail était installé, les utilisateurs pouvaient commencer à l’utiliser. Il
s’agissait en quelque sorte d’une manière de réaliser une phase Pilote et d’obtenir l’avis et le
retour des utilisateurs sur la solution.
La première réaction a été plutôt positive et il apparaissait clairement que la solution
proposée répondait bien aux attentes des utilisateurs. Outre les questions sur le
fonctionnement et l’utilisation de l’outil, il y a eu quelques remarques sur l’interface qui devait
être épurée de certains éléments pour être présentable aux utilisateurs extérieurs au Service
PFC. Il s’agit des deux éléments suivants :
Le pied de page dans Alfresco Share qui indique que la solution ne bénéficie d’aucune
garantie et d’aucun support et propose de se rapprocher des équipes Alfresco
Software. Ce message n’est, en effet, pas très approprié car il pourrait faire douter un
utilisateur extérieur au Service PFC sur le travail de mise en place de la solution. Il
convenait donc de supprimer ce message.
Figure 30 : Pied de page dans le portail Alfresco Share
Le « Dashlet » de bienvenue aux nouveaux utilisateurs qui se connectent pour la
première fois. En effet, cet élément propose à l’utilisateur de se connecter à Internet
pour obtenir de nouveaux services ce qui n’est pas souhaité par le Client.

108
Figure 31 : Dashlet de bienvenue sur la page d’accueil du portail Alfresco Share
Ces deux éléments ne sont pas particulièrement difficiles à supprimer.
Le pied de page peut être retiré :
Soit en modifiant le fichier
« \Alfresco\tomcat\webapps\share\components\footer\footer.css » en ajoutant la
ligne « display:none!important; » dans le bloc (entre les accolades) « .footer { } » et
« .footer-com.copyright { } »
Soit en installant le module complémentaire « fme-hide-footer-0.1 » en copiant le
fichier « fme-hide-footer-0.1.jar » dans le répertoire « \Alfresco\tomcat\shared\lib ».
Nous avons opté pour cette solution moins intrusive.
Pour que le dashlet de Bienvenue ne soit plus visible ni des nouveaux utilisateurs qui se
connectent pour la première fois, ni des utilisateurs qui se sont déjà connectés au moins une
fois, il faut d’abord surcharger le fichier « \Alfresco\tomcat\webapps\share\WEB-
INF\classes\alfresco\site-webscripts\org\alfresco\components\dashlets\dynamic-
welcome.get.html.ftl » en le copiant à l’emplacement
« \Alfresco\tomcat\shared\classes\alfresco\web-extension\site-
webscripts\org\alfresco\components\dashlets ». Puis il faut modifier le fichier copié en
remplaçant l’instruction « <#if showDashlet> » par « <#if false> ».
Les autres remarques qui ont été formulées concernaient la gestion de l’obsolescence des
documents et l’optimisation du système de recherche pour un meilleur usage des tags.

109
12.4. Personnalisation de la solution
La personnalisation de la solution choisie constitue une étape très importante du projet
car elle détermine, en fait, sa convivialité et par conséquent, sa plus-value par rapport à
l’ancien système en termes d’accessibilité aux connaissances et de travail collaboratif. Cette
section aura donc pour objectif de présenter les éléments de la suite Alfresco qui ont été
personnalisés et la façon dont ils l’ont été.
Les personnalisations réalisées concernent principalement le portail Alfresco Share. Dans
ce dernier, il est intéressant de personnaliser les éléments suivants :
Le Wiki
Les Sites de collaboration
L’interface utilisateur
L’espace documentaire
12.4.1. Personnalisation du Wiki : création de modèles de fiches
Un des premiers éléments à personnaliser est l’utilisation du Wiki. En effet, lors de la
création d’un nouvel article, il peut être difficile pour les utilisateurs de créer une structure et
l’absence d’une structure unique des articles peut rendre confus l’ensemble des informations
et les rendre difficiles à retrouver.
Il faut donc, dans un premier temps, identifier les différentes structures de pages Wiki qui
peuvent nous intéresser en fonction des différents types d’articles qui pourraient être ajoutés.
Il sera ensuite possible d’ajouter le lien vers les articles intéressants sur la page d’accueil du
Wiki (chaque Wiki dispose de sa propre page d’accueil).
La mise en place de ces modèles peut être réalisée en créant un document de type HTML
dans le répertoire « Dictionnaire de données\Modèles de nœuds » dans l’entrepôt de
données d’Alfresco.
Nous avons identifié quatre types d’articles qui sont les incidents, les REX, les FAQ et les
mémos. Il est donc possible de créer un modèle de fiche Wiki pour chacun de ces articles que
nous allons décrire en détail dans les sections suivantes.

110
12.4.1.1. Le modèle des fiches d’incidents
Lorsque le Service PFC reçoit un incident via un mail Lotus Notes ou SCOPE GS, il est pris
en charge le plus rapidement possible, analysé puis traité. Le traitement permet d’obtenir une
solution définitive ou de contournement.
Cette procédure nous permet de déduire la structure du modèle de la fiche qui sera
intégrée au Wiki. Elle devra comporter les sections suivantes :
Nom de l’incident
Catégorie de l’incident
Description du problème rencontré
Solution définitive ou solution temporaire de contournement du problème
Informations complémentaires
Liste des articles en rapport avec cet incident
12.4.1.2. Le modèle des fiches de retour d’expérience
Lors de leur travail, les membres du Service PFC peuvent être amenés à réaliser une
opération inédite. La réalisation de cette opération peut s’avérer relativement complexe et
nécessiter un important travail de recherche. Afin d’éviter de perdre du temps inutilement, il
est intéressant que la solution permette de stocker des fiches qui contiendraient les
informations utiles pour réaliser des manipulations particulières.
Bien sûr, ces fiches peuvent avoir des structures différentes mais nous pouvons tout de
même dégager une structure de base qui conviendra à la plupart des retours d’expérience de
ce type :
Nom du REX
Catégorie du REX
Description du REX
Conseils
Articles liés
12.4.1.3. Le modèle des fiches de FAQ
Pour le moment, le Service PFC ne compte qu’une seule FAQ qui est destinée au PE. La
fiche aborde les différents services proposés (le service de bascule des machines de CONSER

111
vers PFC, le système d’approvisionnement des machines sur le portail PFC, le système de
sauvegarde) et les informations utiles (mail de contact et lien vers la documentation). De
manière général, une fiche de type FAQ doit comporter les éléments suivants :
Le titre du thème traité
Un ensemble de questions et réponses sur le thème en question
Le modèle ne peut que suggérer ces éléments mais il revient à l’auteur de la FAQ de
penser à toutes les questions que pourraient se poser les personnes qui vont la consulter et
aussi de se baser sur toutes les questions et réponses déjà écrites sur le sujet.
12.4.1.4. Le modèle des fiches des mémos
Les membres de l’équipe PFC ont parfois besoin de stocker des informations qui ne
figurent pas dans les référentiels de l’entreprise qui sont en quelque sorte des mémos
auxquels il sera possible de référer ultérieurement pour réaliser une tâche par exemple. Ces
fiches sont très diverses et les seuls éléments qui pourrait être communs à toutes les fiches
sont :
Le titre du mémo
Les articles associés
12.4.2. Nommage des nouveaux articles
La plupart des grandes entreprises comme Microsoft ou VMware, pour ne citer qu’eux,
disposent de bases de connaissances et elles ont généralement des points communs
notamment au niveau du nom des articles qui est de la forme KB<nombre>. Ce mécanisme
permet de donner un identifiant unique à chaque article ce qui permet un système de
classement efficace. Dans notre cas, ce système ne présente que peu d’intérêt et il est déjà
présent dans l’outil SCOPE GS de l’ancien système. En effet, nous préférons nous focaliser sur
la performance du système de recherche que sur le système de classement pour lequel ce
mécanisme pourrait être utile. De plus, Alfresco ne permet pas à deux articles d’avoir le même
nom, ce qui écarte les éventuels problèmes de « doublons ».
12.4.3. Rapprocher le Wiki intégré d’Alfresco de MediaWiki
Certains contributeurs au développement de la solution Alfresco ont pensé qu’il serait
peut être intéressant d’ajouter des fonctionnalités présentes dans MediaWiki dans le moteur

112
Wiki intégré d’Alfresco. C’est ce que propose Will ABSON du projet Share Extras avec le
module complémentaire « Wiki Rich Content ». Ce module permet d’ajouter la fonctionnalité
de génération automatique, en début d’article, d’une table des matières pour les articles
comportant plus de deux sections comme sur MediaWiki. Afin d’améliorer l’ergonomie du
moteur Wiki, nous avons donc décidé d’installer ce module complémentaire.
L’installation se fait, comme pour les autres modules, en copiant le fichier « wiki-rich-
content-2.1.2.jar » dans le répertoire « \Alfresco\tomcat\shared\lib ».
L’autre fonction qui rapproche encore un peu plus le moteur Wiki intégré d’Alfresco de
MediaWiki est la fonctionnalité discussion des sites de collaboration Alfresco. En effet, en
ajoutant cette page de fonctionnalité, il est possible de recueillir les avis et les remarques des
utilisateurs vis-à-vis d’un autre élément du site de collaboration comme un article Wiki. A
noter qu’il n’y a pas, comme dans MediaWiki, de lien direct entre la fonctionnalité discussion
et Wiki, il est donc nécessaire de préciser dans la discussion à quoi elle se réfère (exemple : il
est possible de choisir comme sujet de discussion « Vos remarques sur la FAQ PFC »).
12.4.4. Choix des Sites de collaboration
Nous avons déjà évoqué les Sites de collaboration de la suite logicielle Alfresco dans la
section de ce document qui traite de la sécurité. Cependant, nous revenons sur ce point car
ils interviennent aussi dans la personnalisation de la solution puisqu’ils vont déterminer la
visibilité que chaque utilisateur aura sur l’entrepôt de données mais aussi les interactions
qu’ils pourront avoir entre eux.
Le portail Alfresco offre la possibilité de créer trois types de Sites de collaboration qui
peuvent être :
Public : Ces types de Sites sont visibles de l’ensemble des utilisateurs pouvant
s’authentifier sur le portail Alfresco Share et ces utilisateurs peuvent rejoindre en tant
que Lecteur le Site sans contrôle particulier.
Public modéré : Ces types de Sites sont également visibles de l’ensemble des
utilisateurs authentifiés mais ces derniers doivent effectuer une demande auprès d’un
coordinateur du Site pour pouvoir le rejoindre33.
33 Il est possible de rejoindre un Site en effectuant une recherche de ce dernier et en appuyant sur le bouton « Demander à rejoindre le site » qui apparaît en face du nom du Site dans le résultat de la recherche.

113
Privé : Ces types de Sites ne sont visibles et accessibles que des utilisateurs
sélectionnés au préalable par un coordinateur du Site en question.
Un Site de collaboration peut être créé à partir de l’option « Créer un site » dans le menu
« Sites » de la barre d’outils du portail Alfresco Share. La figure 32 montre la fenêtre
permettant de créer le Site.
Figure 32 : Copie d'écran de la fenêtre de création d'un Site dans Alfresco Share
Pour créer les Sites Alfresco de base, il est possible de se baser sur les séparations existant
dans la Base PFC. Il y a un groupe pour la cellule Pilotage, un groupe pour la cellule Ingénierie
et un groupe commun aux deux cellules. Dans Alfresco nous avons donc créé un Site pour
chaque cellule et un Site commun aux deux cellules. Chaque utilisateur standard d’un Site
d’une cellule a, par défaut, un rôle de Collaborateur mais il a aussi un rôle de Contributeur de
l’autre cellule. Il y a un Gestionnaire par cellule (en plus de l’administrateur) qui est en fait le
responsable de la cellule. Cette disposition permet aux responsables de cellule de
personnaliser encore plus finement le Site de leur cellule en ajoutant des fonctionnalités
appelées « Pages de site ». La figure 33 donne un aperçu des fonctionnalités disponibles pour
un Site de collaboration dans le portail Alfresco Share accessible par le gestionnaire, une fois
connecté au Site, via l’option « Personnaliser le site » dans le menu avec pour icone un poulie.
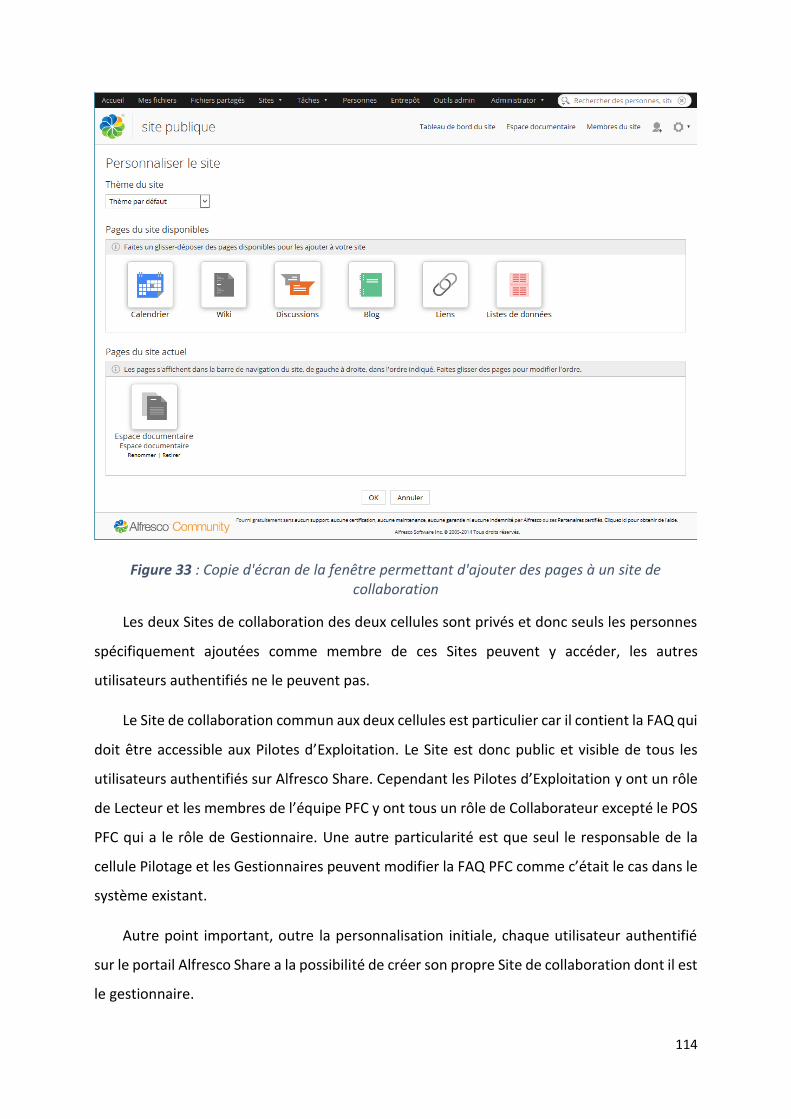
114
Figure 33 : Copie d'écran de la fenêtre permettant d'ajouter des pages à un site de collaboration
Les deux Sites de collaboration des deux cellules sont privés et donc seuls les personnes
spécifiquement ajoutées comme membre de ces Sites peuvent y accéder, les autres
utilisateurs authentifiés ne le peuvent pas.
Le Site de collaboration commun aux deux cellules est particulier car il contient la FAQ qui
doit être accessible aux Pilotes d’Exploitation. Le Site est donc public et visible de tous les
utilisateurs authentifiés sur Alfresco Share. Cependant les Pilotes d’Exploitation y ont un rôle
de Lecteur et les membres de l’équipe PFC y ont tous un rôle de Collaborateur excepté le POS
PFC qui a le rôle de Gestionnaire. Une autre particularité est que seul le responsable de la
cellule Pilotage et les Gestionnaires peuvent modifier la FAQ PFC comme c’était le cas dans le
système existant.
Autre point important, outre la personnalisation initiale, chaque utilisateur authentifié
sur le portail Alfresco Share a la possibilité de créer son propre Site de collaboration dont il est
le gestionnaire.

115
12.4.5. La fonctionnalité discussion pour les remarques des utilisateurs
Comme expliqué dans les sections précédentes, contrairement au moteur MediaWiki
présenté dans les sections de l’étude comparative de ce document, le moteur Wiki du portail
Alfresco Share ne dispose pas d’onglet discussion. Cette absence est gênante puisque les
utilisateurs ne peuvent pas formuler leurs remarques sur un article.
Pour remédier à ce problème, il est possible d’ajouter à un Site de collaboration la page
« Discussion ». Cette fonctionnalité permettra de compléter le ou les articles du Wiki en
autorisant la création de sujets. Par exemple pour l’article « FAQ PFC » du Wiki, nous avons
créé le sujet « Remarques sur la FAQ PFC » ce qui permet aux utilisateurs de communiquer
leurs remarques au rédacteur de la FAQ PFC qu’ils ne peuvent pas modifier.
Bien que cette fonctionnalité soit intéressante, elle ne fonctionne qu’à condition que les
utilisateurs aient au moins un rôle de Contributeur sur le Site de collaboration. En effet, par
défaut, les utilisateurs ont un rôle de Lecteur sur un Site de collaboration Public et il est donc
nécessaire de modifier leur rôle pour qu’ils aient la possibilité de répondre à un sujet existant
dans la page « Discussion » du Site. Le fait que ces utilisateurs soient Contributeur34 du site de
collaboration leur permet aussi de créer de nouveaux articles Wiki et de nouveaux sujets de
discussion (mais pas de modifier le contenu existant) ce qui n’est pas un mal en soit mais un
avantage puisqu’ils peuvent adresser leurs demandes et leurs remarques plus facilement à
l’équipe PFC. Le seul inconvénient est qu’il faut changer le rôle des utilisateurs du Site un à un
ce qui est très fastidieux. Il est, cependant, possible de simplifier la situation en modifiant les
droits d’accès du groupe « EVERYONE » sur un espace donné. Cette technique permet de
donner, par défaut, à tous les utilisateurs authentifiés, un rôle sur un espace spécifique d’un
site de collaboration. Dans notre cas, il sera, par exemple, possible de donner aux utilisateurs
le rôle de « Contributeur » sur l’espace « Entrepôt\Sites\PFC Commun\discussion » ce qui
évite la longue et fastidieuse tâche de modification individuelle de tous les comptes des
utilisateurs.
12.4.6. Personnalisation de l’interface utilisateur
Après son authentification sur le portail Alfresco Share, un utilisateur voit apparaître son
tableau de bord qui fait office de page d’accueil. Cette dernière est composée d’une barre
34 Hiérarchie des rôles dans Alfresco : Lecteur < Contributeur < Collaborateur < Coordinateur < Gestionnaire. Voir les annexes pour plus de détails.
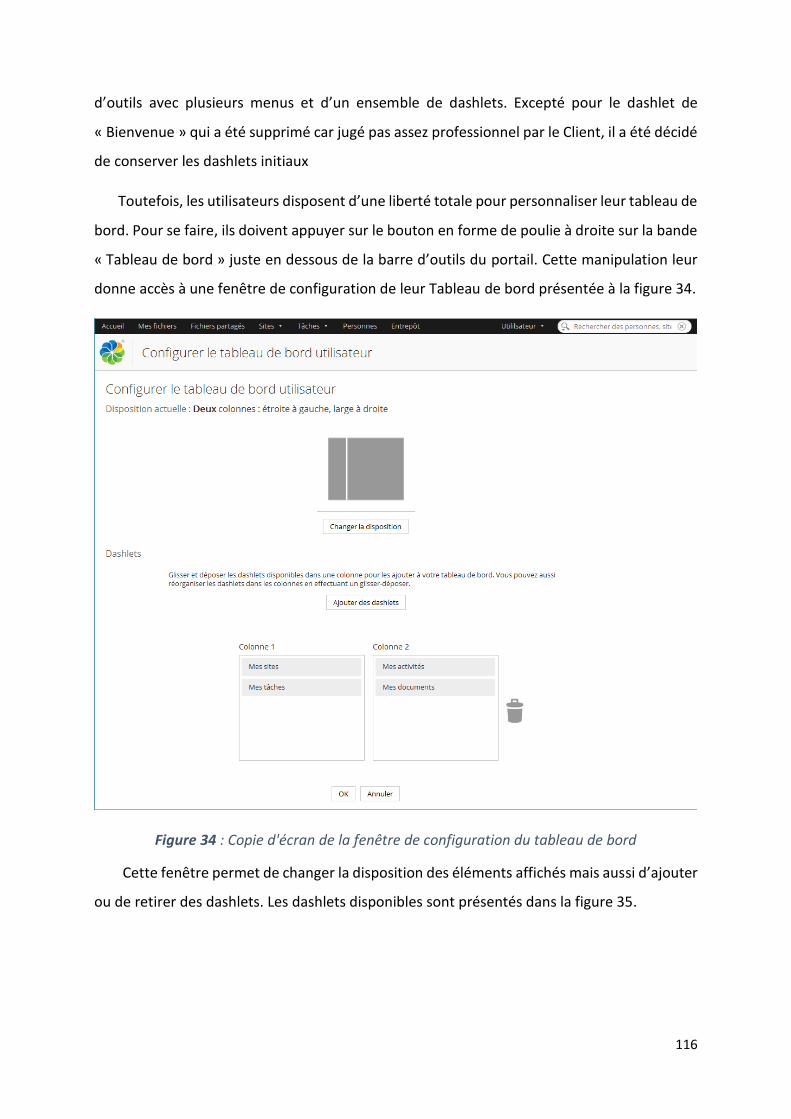
116
d’outils avec plusieurs menus et d’un ensemble de dashlets. Excepté pour le dashlet de
« Bienvenue » qui a été supprimé car jugé pas assez professionnel par le Client, il a été décidé
de conserver les dashlets initiaux
Toutefois, les utilisateurs disposent d’une liberté totale pour personnaliser leur tableau de
bord. Pour se faire, ils doivent appuyer sur le bouton en forme de poulie à droite sur la bande
« Tableau de bord » juste en dessous de la barre d’outils du portail. Cette manipulation leur
donne accès à une fenêtre de configuration de leur Tableau de bord présentée à la figure 34.
Figure 34 : Copie d'écran de la fenêtre de configuration du tableau de bord
Cette fenêtre permet de changer la disposition des éléments affichés mais aussi d’ajouter
ou de retirer des dashlets. Les dashlets disponibles sont présentés dans la figure 35.

117
Figure 35 : Dashlets disponibles pour le Tableau de bord utilisateur dans Alfresco Share
D’autres dashlets sont disponibles pour les sites de collaboration comme le montre la
figure 36. Cependant, ils ne peuvent être ajoutés ou retirés que par le gestionnaire du site.
Figure 36 : Dashlets disponibles pour le Tableau de bord des sites dans Alfresco Share
12.4.7. Personnalisation de l’espace documentaire
L’espace documentaire du portail Alfresco Share est une fenêtre vers l’entrepôt de
données de la suite Alfresco. Il est possible de passer par cette interface pour déposer des
fichiers de toute sorte dans l’entrepôt de données. Chaque Site de collaboration dispose de
son espace documentaire correspondant à un espace dédié dans l’entrepôt de données. Les
règles de visibilité des espaces documentaires correspondent, par défaut, aux règles de
visibilité de leur Site de collaboration. Cependant, il est possible de modifier ces règles pour
des fichiers en particulier.
Lors de la création des Sites de collaboration, nous avons créé une structure de base en
utilisant la carte des connaissances du Service PFC présentée à la figure 29. Cette structure est
décrite comme suit :
Pour le Site PFC Cellule Pilotage :
L’espace documentaire du site de la cellule Pilotage comporte essentiellement des
documents utilisés fréquemment par les membres de la cellule et les archives de la BAL
PILOTAGE. Voici l’arborescence qui est obtenue :

118
Archives Lotus Notes de la BAL PILOTAGE
Bascules
DEX
Guides utilisateurs
o PTE AVAMAR
o vCloud Director
Procédures opérateur
o Ajout et Suppression d’une entité PFC
o Documents contractuels
o Guide de l’opérateur PFC
o Interface Réseau
o OGC
Workflow OGC
Pour le Site PFC Cellule Ingénierie :
L’espace documentaire de la cellule ingénierie est divisé en deux. D’une part, il y a, comme
pour la cellule Pilotage, les documents les plus utiles et les archives de la BAL INGENIERIE et,
d’autre part, il y a les logiciels les plus utilisés. Voici l’arborescence obtenue :
Archive Lotus Notes de la BAL INGENIERIE
Ajout et mise à jour des templates
AVAMAR
DAT
Document d’architecture Vblock 300-320
Numéro de série des Vblock
Binaires
Pour le site PFC Commun :
L’espace documentaire PFC commun contient essentiellement des documents communs
aux deux cellules et utiles aux Pilotes d’Exploitation. Il est important aussi de signaler que c’est

119
le seule espace documentaire accessible depuis l’article FAQ PFC du Wiki 35 . Voici
l’arborescence obtenu :
Guides utilisateurs
Infrastructure
Présentation du Pôle et du Service
Bien sûr, sur chaque répertoire et chaque fichier ajouté, un maximum de tags ont été
ajoutées afin de faciliter les recherches ultérieures de ces éléments. En effet, le Client a
constaté que sur les outils qu’il a utilisés par le passé, bien que la structure de l’espace
documentaire soit bien construite, les documents restaient difficiles à retrouver car ils étaient
trop nombreux. Cela explique sa volonté d’aller vers un système de recherche non pas basé
sur une arborescence sophistiquée mais plutôt sur la performance du système d’indexation
utilisant en partie sur les tags et les métadonnées.
Remarque : Il n’est pas possible d’ajouter un dossier contenant plusieurs fichiers et/ou
plusieurs sous-dossiers par une seule opération de « glisser-déposer » dans le portail Alfresco
Share. Pour cela, il faut créer les dossiers et les sous-dossiers manuellement avant d’y déposer
les fichiers. Cependant cette difficulté peut être contournée en utilisant un Client FTP qui
permet d’accéder à l’entrepôt de données selon ses droits d’accès, ce qui permet de déposer
des dossiers contenant des fichiers et des sous-dossiers. C’est très utile pour déposer, par
exemple, les binaires de la cellule Ingénierie.
12.4.8. Gestion des documents obsolètes36
Un autre souhait du Client était de pouvoir gérer les documents obsolètes qui ne sont
plus utilisés par personnes et doivent être mis à jour. Afin de simplifier ce processus de
vérification, il est possible de mettre en place un script spécifique exécuté par une tache
planifiée et des règles sur certains espaces de l’espace documentaire d’un Site de
collaboration. Ces règles permettent de réaliser des actions sur des éléments en fonction de
critères précis. Les règles peuvent, par exemple, ajouter des « aspect » (correspondant à des
types de propriétés) sur des documents lorsqu’ils sont créés ou copiés dans un espace donné.
La propriété qui est intéressante ici est « Validité » qui permet de définir une période de
35 Le moteur Wiki du portail Alfresco Share permet de créer des liens vers l’espace documentaire du même Site de collaboration. 36 Voir les annexes pour plus de détails.

120
validité d’un document en spécifiant la date de début de validité et la date de fin de validité.
En effet, cela permet de déterminer si un document est obsolète et de le déplacer vers un
autre espace le cas échéant.
Pour gérer le contenu obsolète, le projet Share Extras propose un module
complémentaire « Content Expiration » qui permet d’avoir un dashlet supplémentaire qui
affiche le contenu obsolète sur le tableau de bord d’un site de collaboration.
Malheureusement, ce dashlet ne semble pas fonctionner correctement sur Alfresco 5.0.c.
12.5. Mise en place du processus de mise à jour et de maintenance
Les développeurs d’Alfresco ont effectivement prévu des possibilités d’évolution de leur
suite logicielle vers une version supérieure qui pourrait apporter des améliorations
significatives pour les utilisateurs.
Lors du lancement du projet nous avons sélectionné la version « 4.2.f » d’Alfresco car elle
semblait être la version la plus stable à ce moment et la nouvelle version « 5.0.a » ressemblait
à une version « alpha » non adaptée à une utilisation en production. Le projet ayant
commencé depuis déjà quelques mois, nous avons constaté que la suite Alfresco avait évolué
de la version « 5.0.a » à la version « 5.0.c » plus stable. Cette évolution à elle seule ne justifiait
pas un changement de la version choisie au début du projet. Cependant, Alfresco v5.0.c
apportait de grandes améliorations d’une part pour le module de recherche en proposant,
entre autre, des prévisualisations lors de la saisie du texte recherché37 et d’autre part pour
l’interface de l’éditeur du moteur Wiki. Comme ces deux éléments constituent des piliers
importants pour le projet, la mise à jour devenait donc pertinente et, de plus, elle permettrait
de mettre en place une procédure pour réaliser ce geste à l’avenir.
La mise à jour n’est pas particulièrement complexe. Cependant, comme nous utilisons la
version Community, elle est plus difficile que pour la version One (version commerciale) qui
propose des modules d’assistance à la mise à jour.
La mise à jour peut se résumer, dans les grandes lignes, par les étapes suivantes38 :
1. Copie de la base de données
37 Il s’agit d’une évolution du module de recherche « solr » qui passe de la version 3 à la version 4 38 La procédure complète pour une mise à jour d’Alfresco 4.2.f vers 5.0.c se trouve en annexe

121
2. Sauvegarde des fichiers binaires des données
3. Désinstallation de l’ancienne version
4. Installation de la nouvelle version
5. Copie des fichiers sauvegardés dans leurs répertoires respectifs
6. Restauration de la base de données
Les étapes 1 et 6 dépendent du SGBD choisi qui est PostgreSQL dans le cas de ce projet. Il
est aussi important d’arrêter les services Alfresco dès que possible pour éviter tout problème
de désynchronisation entre les informations contenues dans la base de données et les fichiers
binaires de données39.
Avant de lancer cette procédure, il convient de sauvegarder le serveur (dans notre cas le
serveur PFC utilisé est bien sauvegardé). Il faut ensuite, une fois que la mise à jour a été
réalisée, vérifier que tout fonctionne correctement dans un premier temps avec les fichiers de
logs puis avec la contribution des utilisateurs qui préviendraient l’administrateur au cas où ils
rencontreraient des anomalies lors de l’utilisation. Ces vérifications sont encore plus
importantes lors des mises à jour majeures (par exemple d’une version 4.2 à 5.0) que lors des
mises à jour mineures (par exemple de 5.0.b à 5.0.c).
Il est possible d’avancer que les mises à jour mineures présentent moins de risques que
les mises à jour majeures mais elles sont aussi souvent moins justifiées, excepté pour la
correction d’un défaut (« bug ») gênant. Un bon compromis serait donc d’analyser chaque
nouvelle version et d’estimer si elle est pertinente pour nous. Si c’est une évolution mineure,
la mise à jour pourra se faire sans encombre, par contre s’il s’agit d’une évolution majeure, il
sera plus sage d’attendre la deuxième version mineure de celle-ci ou, à minima, d’effectuer
des tests de stabilité de l’outil avant de le passer en production.
12.6. Conduite du changement
La plupart des projets informatiques conduisent habituellement à une modification des
processus métiers qui force les utilisateurs à changer leurs habitudes. Si ces modifications sont
imposées aux utilisateurs, ces derniers ont, en général, tendance à s’opposer à ces
39 Il est nécessaire que le service PostgreSQL soit lancé pour effectuer une sauvegarde de la base de données mais ce n’est pas le cas du service Tomcat pour copier les fichiers binaires de données.

122
changements ce qui peut s’avérer catastrophique pour le projet. La conduite du changement
va donc consister à limiter les risques de rejet en mettant l’accent sur :
L’implication des utilisateurs dans la mise en place de la solution en leur demandant
leur avis et en modelant la solution par rapport à ces derniers
La communication auprès des utilisateurs sur la solution proposée
La formation des utilisateurs sur l’utilisation de la solution
Dans notre cas, l’idée de ce projet est venue des membres de l’équipe qui seront les futurs
principaux utilisateurs de la solution. De ce point de vue, les risques de résistance au
changement sont faibles. Cependant, pour les autres utilisateurs de la solution qui sont les
Pilotes d’Exploitation et, éventuellement, les infogérants, ce risque est bien présent mais
comme cela ne modifie pas leurs processus métiers, il n’y a aucune contrainte pour eux. De
plus, il s’agit d’une solution complémentaire au système existant et, outre les problèmes
contractuels liés à l’utilisation obligatoire de la Base RD&E par les infogérants, les utilisateurs
auront plutôt tendance à utiliser une solution qui est plus facile à manipuler. La
communication est faite par mail pour proposer cette nouvelle solution comme un outil
complémentaire permettant de trouver facilement des informations sur le Service PFC.
Pour les utilisateurs principaux, les risques d’obtenir une solution inadaptée sont toujours
présents comme cela a été expliqué dans la section de la gestion des risques de ce document.
Pour éviter ce problème, une participation des utilisateurs a été requise tout au long du projet
pour éviter les dérives. De plus, la mise en place de la solution s’est terminée par une phase
Pilote qui permet aux utilisateurs de formuler leurs dernières remarques.
La formation à la solution s’est faite en fonction du type d’utilisateurs. Pour les membres
de l’équipe PFC, une réunion de deux heures a été organisée pour présenter les différentes
fonctionnalités du produit et la manière de s’en servir. Ils peuvent aussi utiliser la
documentation qui a été rédigée pour effectuer les principales tâches dans l’outil. Les autres
utilisateurs ne bénéficient, quant à eux, que de la documentation. Cependant, ils peuvent
toujours contacter le Service PFC pour que nous fassions un point téléphonique afin d’éclaircir
les éléments qui n’ont pas été compris.

123
12.7. Perspectives d’évolutions fonctionnelles et métiers de la solution
Lors du lancement du projet, la solution n’était prévue que pour les membres de l’équipe
PFC. Très vite, nous nous sommes rendu compte que cette solution pouvait être élargie à
d’autres utilisateurs tels que les Pilotes d’Exploitation et les infogérants. Il s’agissait donc
d’une modification du périmètre de la solution qui a été prise en compte lors du projet. Il est
donc tout à fait possible que le Client ait besoin à l’avenir d’élargir à nouveau le périmètre
d’utilisation de la solution. Dans ce cas, une étude sera nécessaire pour déterminer :
Si de nouveaux Sites de collaboration devront être créés
Si le système d’authentification devra être modifié
Si de nouvelles personnalisations seront nécessaires
Comment la gestion du portail sera organisée
L’élargissement du périmètre peut aussi affecter les performances et il est donc important
de revoir le dimensionnement du serveur qui héberge la solution pour en augmenter les
ressources voir même revoir l’architecture complète en répartissant la solution sur plusieurs
serveurs.
Il se peut aussi qu’un processus métier évolue et nécessite la modification de solution.
Dans ce cas également, une étude sera nécessaire pour déterminer si les outils choisis pendant
le projet répondent toujours aux besoins et, si oui, quelles fonctionnalités ou
personnalisations peuvent être ajoutées pour s’y adapter au mieux. Dans le cas contraire, il
faudra lancer un nouveau projet pour remplacer la solution en place.
A plus court terme, EDF a décidé de remplacer Lotus Notes par SharePoint et Microsoft
Outlook avec le projet Néo. Il est donc envisageable qu’une communication entre Alfresco et
SharePoint soit nécessaire à l’avenir. Bien que ces fonctionnalités ne soient pas implémentées
nativement dans la version Alfresco Community, il est possible que les deux systèmes
dialoguent via leur API respective en utilisant le protocole CMIS40.
40 « Content Management Interoperability Services ». Pour plus de détail voir [42]

124
13. Bilan et synthèse
Il convient à présent de dresser le bilan de ce projet, pour, d’une part, présenter les
résultats obtenus à la suite de la phase Pilote permettant de donner des indices sur le succès
ou l’échec du projet et, d’autre part, d’examiner le déroulement du projet et d’identifier les
points positifs et les axes d’amélioration.
13.1. Les résultats obtenus
Les premiers résultats concernant la solution sont plutôt encourageants malgré le fait que
la demande initiale manquait peut-être de précisions. Les utilisateurs ont donc commencé à
utiliser naturellement la solution en y ajoutant des documents divers soit sous forme de
fichiers, soit sous forme de page Wiki. La prise en main par les utilisateurs n’a pas été
problématique comme l’a montré le fait que les questions relatives à l’utilisation étaient
quasiment inexistantes bien que la réponse à la question « Avez-vous rencontré des difficultés
pour utiliser l’outil ? » posée à tous les utilisateurs principaux (les membres du Service PFC)
soit toujours « Non. ». Cela peut aussi s’expliquer par l’implication des utilisateurs dans la mise
en place de la solution, la présentation complète de celle-ci à ces derniers, l’apparente clarté
de la documentation ainsi que par le fait que les utilisateurs maîtrisent parfaitement l’outil
informatique. Nous constatons aussi que l’ergonomie générale de l’outil proposé semble
bonne puisqu’il n’y a pas eu d’erreurs lors de l’ajout des données par les utilisateurs ni de
plaintes particulières de ces derniers à ce propos. L’autre constat est que les membres du
Service PFC ont de plus en plus tendance à rechercher les informations qu’il leur manque dans
la solution ce qui dénote une volonté de réutilisation des connaissances stockées.
Les premiers résultats sont donc satisfaisants mais nous n’avons pas actuellement assez
de recul par rapport aux autres utilisateurs, extérieurs au Service PFC, pour tirer des
conclusions sur leur degré d’appréciation de la solution. Pour cela, il faudra réaliser une
enquête de satisfaction qui a d’ailleurs déjà été faite pour les offres du Service PFC. Dans une
moindre mesure, il faudrait essayer de déterminer si le nombre de demandes des utilisateurs
extérieurs sur le Service PFC a baissé suite à la mise en place de la solution.
Par contre, il apparaît clairement que la personnalisation de la solution devra encore
évoluer. En effet, les utilisateurs ont toujours des remarques sur les possibilités de réaliser
telle ou telle action. Il est donc important que la solution s’adapte en permanence, même dans

125
une moindre mesure, aux besoins des utilisateurs qui évoluent forcément dans une
organisation dynamique.
Il apparaît aussi, comme évoqué dans la section traitant du calcul du ROI, qu’il ne soit pas
possible de mesurer précisément le gain obtenu avec cette solution de gestion de
connaissance. Ce n’est pas propre à cette solution en particulier mais à toutes les solutions de
ce type se proposant de mieux gérer le capital immatériel de l’entreprise. En effet, d’une part,
il n’existe pas aujourd’hui une méthode fiable pour mesurer ce capital [10, Ch. 3], ni pour
évaluer les résultats d’une meilleure gestion de ce dernier et, d’autre part, les bénéfices
obtenus sont des gains non financiers d’où l’impossibilité de donner des résultats chiffrés. Les
gains de ce type de projets, lorsqu’ils sont réussis, deviennent, en général, substantiels mais
ils ne sont pas mesurables à l’avance.
L’autre aspect à prendre en compte, c’est le comportement de la solution d’un point de
vue technique lors de son utilisation. Là aussi, il n’y a pas eu de problème particulier car l’outil
n’est pas soumis à une grande charge de travail et le serveur qui l’héberge peut même paraître
surdimensionné. Cependant, il faut garder à l’esprit que le nombre d’utilisateurs va augmenter
prochainement et il faudra, bien évidemment, surveiller attentivement les performances lors
des changements du périmètre d’utilisation.
Il faut, toutefois, souligner que les résultats obtenus sont positifs parce que les utilisateurs
étaient demandeurs et ont été impliqués dans la mise en place de la nouvelle solution. Cela
aurait peut-être été différent dans le cas contraire. En effet, la solution proposée ici est
beaucoup plus axée sur la technique que sur l’organisationnel. Ce dernier aspect est, en
général, nécessaire au bon déroulement des projets de KM lorsque les utilisateurs ne sont pas
demandeurs et que nous leur promettons des améliorations hypothétiques avec telle ou telle
solution technique. Dans le cas de ce projet, Une modification des méthodes
organisationnelles aurait été difficile à mettre en place car ce n’était pas le premier souhait
du Client qui voulait, avant tout, une solution technique. A noter que, contrairement à l’aspect
organisationnel, l’aspect humain apparait bien dans le projet pour la mise en place d’un
système de travail collaboratif dans la nouvelle solution. L’aspect organisationnel devra être
considéré dans les prochains projets de ce type où les utilisateurs ne seront pas demandeurs.

126
13.2. Analyse de la démarche du projet
Concernant, la gestion du projet, elle s’est, dans l’ensemble, bien déroulée puisque les
délais prévus ont pu être respectés malgré tous les risques qu’il y avait.
Un des défis de ce projet résidait dans le choix des méthodes et des outils du KM
permettant de répondre à la problématique. En effet, les projets de gestion de connaissances
sont souvent très fortement liés à la situation à traiter. Le choix a donc été fait en se basant
sur une analyse approfondie du besoin et des types de connaissances qui circulent au sein du
Service PFC, ce qui a permis de réduire le nombre de méthodes utilisables. Il fallait ensuite
faire un choix parmi les méthodes restantes, ce qui n’était pas forcément évident étant donné
qu’il était nécessaire d’en comprendre assez bien les mécanismes sans pour autant être un
expert du sujet. Les deux méthodes du KM qui ont retenu mon attention sont MASK et REX.
J’ai finalement opté pour la méthode REX et ses fiches d’expérience beaucoup plus adaptée à
notre besoin que la méthode MASK qui propose de réaliser une modélisation des
connaissances existantes. Cependant, j’ai quand même gardé certains conseils utiles de la
méthode MASK sur la manipulation des connaissances. Une fois la méthode trouvée, il
devenait possible de faire un choix parmi les nombreux outils du marché via une étude
comparative. Le choix s’est finalement porté sur une GED et un Wiki. Bien que la méthode KM
choisie nous donnait une idée sur le type d’outils à utiliser, il restait toujours à départager une
solution unifiée avec un seul produit d’une solution avec plusieurs produits. Ici, nous avons
préféré la simplicité en optant pour la première solution avec un seul produit.
Il est maintenant intéressant de nous interroger sur la pertinence de cette démarche. En
effet, même si nous répondons bien à la problématique, peut-être qu’il existe de meilleures
solutions. Nous pouvons donc nous demander si la démarche choisie était justifiée. Dans ce
projet, nous nous appuyons fortement sur la littérature du KM et les retours d’expérience sur
les projets similaires. C’est le seul moyen que nous avons trouvé pour valider la pertinence de
la démarche et les premiers retours des utilisateurs semblent confirmer que cela a fonctionné.
Nous avons essayé de nous baser le plus possible sur des méthodes qui ont fait leurs preuves.
Un autre point important est aussi l’absence notable d’une uniformisation complète avec
la solution existante. Dans ce cas, il est difficile d’éviter les doublons mais cet aspect pourra
peut-être être pris en compte avec l’arrivée de SharePoint en remplacement de Lotus Notes.

127
L’idée serait à terme d’apporter une solution fusionnant avec le système existant, ce qui n’a
malheureusement pas été possible dans ce projet.
13.3. Analyse des difficultés rencontrées
La première difficulté du projet concernait principalement le cadrage de la demande et
l’objectif à atteindre. En effet, la gestion des connaissances est un sujet vaste et complexe où
les aspects technologiques sont souvent, aujourd’hui, minimisés en raison de l’échec de
nombreux projets misant trop sur cet aspect, au profit d’une gestion de la connaissance basée
sur l’humain et les relations sociales. Il a donc fallu expliquer au Client que mettre en place
une plateforme collaborative n’était qu’une partie du problème. Au début, le projet avançait
donc de manière un peu hésitante en essayant de trouver la méthode KM qui correspondrait
le mieux aux besoins du Client et de trouver un outil adapté et personnalisable permettant de
la mettre en place. Il n’était donc pas sûr que le projet puisse aboutir à solution concrète
rapidement ce qui a finalement était le cas. Cependant un meilleur cadrage aurait peut-être
permis au projet d’avancer plus vite au début.
Ce qui n’a pas vraiment marché sur ce projet, c’était la tentative de vouloir convaincre le
Client que le KM reposait sur un équilibre entre solution technique et modification
organisationnelle. En effet, il voulait juste une solution technique et l’aspect organisationnel
n’était effectivement pas très important dans ce cas puisque les utilisateurs adhéraient déjà à
la solution et disposaient déjà d’une méthode organisationnelle de gestion des connaissances
avec l’ancien système qui pouvait être utilisée dans le nouveau système. En voulant trop me
rapprocher de la démarche KM standard, je me suis peut-être éloigné, au début du projet, des
souhaits du Client et j’ai perdu du temps notamment sur l’étude de la méthode MASK qui
s’intéressait plus à l’aspect organisationnel que technique. Le fait est que cette étude aura pris
beaucoup de temps pour, finalement, ne pas se révéler capitale pour l’aboutissement de ce
projet.
L’autre point un peu sombre était le fait de n’avoir qu’une seule ressource sur le projet ce
qui a un peu limité les possibilités et l’ambition de la solution. Malgré cela, le bilan du projet
est plutôt positif car tout s’est déroulé comme prévu, les risques majeurs ont été évités et, de
plus, les utilisateurs étaient volontaires pour la mise en place de la solution ce qui a permis
d’éviter des écueils pour la conduite du changement.

128
Il faut aussi savoir que ce projet n’était pas prioritaire par rapport aux autres activités du
Service PFC ce qui pouvait avoir tendance à le ralentir.
Une autre difficulté technique majeure de ce projet a été rencontrée pour la configuration
de l’authentification des utilisateurs lors de la mise en place de la solution. En effet, le Client
souhaitait une authentification anonyme de certains utilisateurs alors que l’outil ne le
permettait pas. Je pensais pouvoir contourner le problème en utilisant le SSO mais j’ai été
confronté à des contraintes de l’environnement qui n’ont pas rendu possible sa mise en place.
J’ai donc dû faire un compromis en élaborant un système d’authentification plus complexe qui
utilisait plusieurs AD mais permettait une authentification de toutes les personnes de
l’entreprise sans création préalable de comptes locaux. La configuration n’a donc pas été
simple et a pris beaucoup de temps. Avec le recul, je ne pense pas que cette situation aurait
pu être évitée car elle était liée à une contradiction entre le fonctionnement de l’outil, les
souhaits du Client et l’environnement d’EDF qui ne pouvait pas être anticipée. L’important, au
final, c’est de trouver un compromis qui soit satisfaisant pour le Client.
Une autre difficulté technique concernait la personnalisation de l’interface. En effet, je
devais, tout d’abord, rendre Alfresco agréable à utiliser en tant que Wiki alors que c’est plutôt
une solution orientée GED. Puis je devais donner une certaine identité visuelle au portail. Ne
connaissant pas bien Alfresco, au départ, ces tâches se sont révélées complexes et
chronophages.

129
14. Conclusion
Comme l’a montré ce présent travail, la gestion des connaissances est aujourd’hui un
enjeu majeur pour les entreprises car elle permet de limiter la perte de leurs connaissances,
appelées aussi capital immatériel de l’entreprise, qui leur est indispensable pour rester
compétitives sur le marché actuel. EDF disposait déjà de nombreux outils de gestion des
connaissances, cependant, ces derniers ne pouvaient être efficaces pour toute l’entreprise car
trop rigides et généralistes. En effet, gérer des connaissances, c’est un peu comme gérer des
collaborateurs et plus il y a de personnes à gérer, plus il faudra subdiviser l’entreprise et créer
des groupes. Cette organisation implique que les groupes peuvent travailler différemment et
génèrent un savoir différent et donc que les outils permettant de conserver, manipuler et
capitaliser ces connaissances sont différents. C’est à ces groupes qu’il revient de gérer leur
propre connaissance et l’entreprise les invite à le faire.
Nous avons donc montré que pour arriver à une solution fiable, il fallait tout d’abord
éviter le piège des outils miracles qui ont conduit à l’échec de nombreux projets de Knowledge
Management mais plutôt essayer, avant tout, de comprendre les besoins du Client, analyser
la circulation des connaissances au sein du Service PFC puis déterminer la méthode de gestion
de connaissances qui convient le mieux à la situation. Puis ensuite, il fallait choisir parmi les
très nombreux outils disponibles sur le marché ceux qui permettraient de mettre un œuvre la
méthodologie retenue tout en respectant les contraintes imposées par le Client ou
l’environnement. Tout cela devait se faire avec la participation des futurs utilisateurs de la
solution. Très vite, il est apparu que nous étions en face de deux types de connaissances
explicites et tacites qu’il fallait gérer différemment. D’un côté, il y avait les connaissances
explicites qui devaient être gérées par un outil de stockage avec un système de recherche
puissant telle qu’une GED et d’un autre côté, il y avait les connaissances tacites qui devaient
être capitalisées par un outil de travail collaboratif comme un wiki. Nous avons donc constaté
que la gestion des connaissances, c’est en fait savoir trouver un équilibre entre méthodes de
management de l’humain et outils technologiques qui sont aussi importants l’un que l’autre.
Toutefois un tel objectif ne peut être obtenu sans une certaine organisation que nous
retrouvons ici à travers la gestion de projet avec le calcul du retour sur investissement, la mise
en place d’un planning et une analyse de risques pour éviter les mauvaises surprises en plein
milieu du projet.

130
Ce projet n’est que le début du cycle de vie d’une solution qui va évoluer au fil du temps
et qui va probablement devoir être adaptée aux changements des besoins du Client que ce
soit pour de nouvelles fonctionnalités ou pour l’agrandissement du périmètre de la solution.
Dans tous les cas, un processus de maintenance a été mis en place et des recommandations
ont été faites pour que le Client ne se retrouve pas démuni dans une telle situation.
Beaucoup négligée par le passé, à cause du manque de visibilité et des coûts élevés des
projets KM, la gestion des connaissances est devenue enjeu stratégique pour les entreprises
et il est important de ne pas rater ce tournant qui est en train de se jouer. L’ensemble des
méthodes et des technologies existantes aujourd’hui reposent sur une vingtaine d’années de
recherche qui commencent à porter leurs fruits ce qui rassure du point de vue de la fiabilité
de ces dernières mais nous montre aussi l’ampleur du travail qu’il reste à accomplir. En effet,
aujourd’hui encore le KM a beaucoup de limites qui se voient à travers le pseudo-échec de
l’intelligence artificielle des systèmes à bases de connaissances qui ne peuvent remplacer
l’homme, l’outillage inexistant pour gérer la sagesse et limité pour la gestion des
connaissances tacites et l’impossibilité de mesurer de manière précise le capital immatériel
de l’entreprise. En attendant les solutions à ces problèmes complexes, les entreprises doivent
s’en remettre au Knowledge Manager travaillant de concert avec les équipes IT pour gérer
leurs connaissances de manière automatisée. Chaque projet, comme celui que nous venons
de réaliser, est très enrichissant et représente une brique supplémentaire à l’édifice de la
gestion de la connaissance qui nous fait progresser chaque jour un peu plus.

131
Liste des figures
Figure 1 : Répartition des méthodes de production d’électricité en 2013 inspirée de [3] ................... 10
Figure 2 : Organisation de la direction des services partagés IT (DSP-IT) en 2014 ............................... 12
Figure 3 : Ma place au sein du Service PFC d’EDF ................................................................................. 17
Figure 4 : Pyramide de la sagesse inspirée du schéma de [1, p. 66] ..................................................... 35
Figure 5 : Matrice de Nonaka inspirée de [9, p. 62], de [1, p. 93] et de [6, p. 29] ................................ 37
Figure 6 : Le cycle de la méthode MASK inspiré des travaux de Jean-Louis ERMINE ........................... 38
Figure 7 : Macroscope de la connaissance inspiré de la figure de [10, p. 58] ...................................... 39
Figure 8 : Evolution du modèle OID vers le modèle AIK pour la gestion des connaissances inspirée de
[10, p. 64] .............................................................................................................................................. 40
Figure 9 : Ontologie simple inspirée de [6, p. 129] ............................................................................... 45
Figure 10 : Recherche du mot « Informatique » sur l’outil WikiMindMap ........................................... 46
Figure 11 : Flux de la donnée à la sagesse (inspiré d’ITIL Transition des services d’OGC) .................... 53
Figure 12 : Structure du SKMS selon ITIL inspirée du schéma de [15, p. 302] ...................................... 54
Figure 13 : Pile des standards du Web Sémantique par le W3C ........................................................... 55
Figure 14 : Triplet RDF inspiré de la figure de [13, p. 29] ...................................................................... 57
Figure 15 : Graphe RDF simplifié inspiré de [13, p. 32] ......................................................................... 58
Figure 16 : Exemple de l’ajout d’un espace de nom sur un triplet RDF ................................................ 58
Figure 17 : Copie d’écran du logiciel GanttProject avec le planning initial du projet ........................... 64
Figure 18 : Copie d’écran du logiciel GanttProject avec le planning revu du projet ............................. 65
Figure 19 : Représentation de l’investissement et du ROI inspirée de la figure de [16, p. 32]............. 66
Figure 20 : Matrice de risques ............................................................................................................... 70
Figure 21 : Diagramme UML de cas d’utilisation de la solution ............................................................ 76
Figure 22 : Magic Quadrant pour les ECM. Source : Gartner (Septembre 2014) .................................. 88
Figure 23 : Architecture globale d’Alfresco inspirée de la 1 ère figure de [19] ....................................... 93
Figure 24 : Interaction d’Alfresco avec son environnement inspirée de la figure de [20, p. 10] .......... 93
Figure 25 : Les trois principaux services d'Alfresco inspiré de la 3ème figure de [19] ............................ 94
Figure 26 : Architecture du moteur Hibernate inspirée de la 2ème figure de [21] ................................. 95
Figure 27 : Architecture du moteur Lucene/Solr inspirée de [22] ........................................................ 95
Figure 28 : Page d’accueil par défaut du portail Alfresco Share ........................................................... 96
Figure 29 : Carte des connaissances du Service PFC ........................................................................... 106
Figure 30 : Pied de page dans le portail Alfresco Share ...................................................................... 107
Figure 31 : Dashlet de bienvenue sur la page d’accueil du portail Alfresco Share ............................. 108
Figure 32 : Copie d'écran de la fenêtre de création d'un Site dans Alfresco Share ............................ 113
Figure 33 : Copie d'écran de la fenêtre permettant d'ajouter des pages à un site de collaboration . 114
Figure 34 : Copie d'écran de la fenêtre de configuration du tableau de bord .................................... 116
Figure 35 : Dashlets disponibles pour le Tableau de bord utilisateur dans Alfresco Share ................ 117
Figure 36 : Dashlets disponibles pour le Tableau de bord des sites dans Alfresco Share ................... 117

132
Liste des tableaux
Tableau I : Classement des risques du projet ....................................................................................... 70
Tableau II : Les moteurs Wiki populaires sur Wiki Engine et WikiMatrix ............................................. 86
Tableau III : Ressources nécessaires pour Alfresco en fonction des accès concurrents....................... 98
Tableau IV : Port par défaut pour chaque protocole de la suite Alfresco ............................................ 99

133
Bibliographie et Webographie [24] ; [25] ; [26] ; [27] ;[28] ; [29] ; [30] ; [31] ; [32] ; [33] ; [34] ; [35]
[1] J.-Y. Prax, Le manuel du knowledge management mettre en réseau les hommes et les savoirs pour créer de la valeur, 3e édition. Paris: Dunod, 2012, p. 1 vol. (XII–514 p.).
[2] Wikipedia, “Électricité de France.” [Online]. Available: http://fr.wikipedia.org/wiki/Électricité_de_France. [Accessed: 25-Sep-2014].
[3] EDF, “Chiffres Clés 2013.” [Online]. Available: http://presentation.edf.com/profil/chiffres-cles-40158.html. [Accessed: 25-Sep-2014].
[4] Wikipédia, “Henri Proglio.” [Online]. Available: http://fr.wikipedia.org/wiki/Henri_Proglio#cite_note-Bezat-8. [Accessed: 25-Sep-2014].
[5] Le Point, “Les dix principaux producteurs d’électricité dans le monde.” [Online]. Available: http://www.lepoint.fr/economie/les-dix-principaux-producteurs-d-electricite-dans-le-monde-10-08-2010-1223756_28.php. [Accessed: 25-Sep-2014].
[6] A. Carlier, Knowledge management et web 2.0: Outils, méthodes et applications. Paris: Hermes science-Lavoisier, 2013, p. 1 vol. (250 p.).
[7] J. Ermine, M. Moradi, and S. Brunel, “Une chaîne de valeur de la connaissance,” Management international, vol. 16. p. 29, 2012.
[8] Wikipédia, “Sagesse.” [Online]. Available: http://fr.wikipedia.org/wiki/Sagesse. [Accessed: 28-Sep-2014].
[9] I. Nonaka and H. Takeuchi, The knowledge-creating company how japanese companies create the dynamics of innovation. New York Oxford: Oxford university press, 1995, p. 1 vol. (XII–284 p.).
[10] Collectif, Management des connaissances en entreprise, 2e édition. Paris: Hermes Science publications Lavoisier, 2007, p. 1 vol. (353–VIII p.).
[11] Collectif, Management et ingénierie des connaissances modèles et méthodes. Paris: Hermes Science publications Lavoisier, 2008, p. 1 vol. (359–XII p.).
[12] Qualiteonline, “Qu’est-ce que la méthode REX ?” [Online]. Available: http://www.qualiteonline.com/question-257-qu-est-ce-que-la-methode-rex.html. [Accessed: 18-Feb-2015].
[13] F. Gandon, Le Web sémantique comment lier les données et les schémas sur le web ?. Paris: Dunod, 2012, p. 1 vol. (XIII–206 p.).
[14] A. Deslandes, J.-C. Grosjean, and M. Morel, Le poste de travail Web portail d’entreprise et accès au système d'information. Paris: Dunod SQLI group, 2010, p. 1 vol. (XVII–190 p.).
[15] J. L. Baud, ITIL V3-2011 préparation à la certification ITIL Foundation V3 [426 questions-réponses], 2e édition. Saint-Herblain: Éd. ENI, 2012, p. 1 vol. (498 p.).

134
[16] J. Printz and B. Mesdon, Ecosystème des projets informatiques agilité et discipline. Paris: Hermes science publ. Lavoisier, 2006, p. 1 vol. (315 p.).
[17] Wikipédia, “Microsoft SharePoint.” [Online]. Available: http://fr.wikipedia.org/wiki/Microsoft_SharePoint. [Accessed: 13-Nov-2014].
[18] Wikipédia, “Alfresco.” [Online]. Available: http://fr.wikipedia.org/wiki/Alfresco. [Accessed: 13-Nov-2014].
[19] Alfresco, “Alfresco Repository Architecture.” [Online]. Available: https://wiki.alfresco.com/wiki/Alfresco_Repository_Architecture. [Accessed: 16-Nov-2014].
[20] J. Potts, Alfresco developer guide : customizing Alfresco with actions, web scripts, web forms, workflows, and more. Birmingham: Packt Publishing, 2008, p. 1 vol. (x–533 p.).
[21] Tutorialspoint, “Hibernate Architecture.” [Online]. Available: http://www.tutorialspoint.com/hibernate/hibernate_architecture.htm. [Accessed: 25-Jan-2015].
[22] S. Gulabani, “Apache Solr - Introduction.” [Online]. Available: http://www.sunilgulabani.com/2013/01/apache-solr-introduction.html. [Accessed: 25-Jan-2015].
[23] Alfresco, “JVM Tunig.” [Online]. Available: http://wiki.alfresco.com/wiki/Repository_Hardware. [Accessed: 28-Nov-2014].
[24] S. J. Russell and P. Norvig, Intelligence artificielle, 3e édition. Paris: Pearson education, 2010, p. 1 vol. (XVI–1198 p.).
[25] B. Bachimont, Ingénierie des connaissances et des contenus le numérique entre ontologies et documents. Paris: Hermes science publ. Lavoisier, 2007, p. 1 vol. (279 p.).
[26] R. Teulier and P. Lorino, Entre connaissance et organisation l’activité collective l'entreprise face au défi de la connaissance colloque de Cerisy[-la-Salle, 11-18 septembre 2003]. Paris Bagneux: La Découverte Numilog, 2005.
[27] G. Paquette, J. Bourdeau, F. Henri, J. Basque, M. Leonard, and M. Maina, “Construction d’une base de connaissances et d'une banque de ressources pour le domaine du t{é}l{é}apprentissage,” Rev. des Sci. Technol. l’Information la Commun. pour l'Education la Form., vol. 10, p. ., 2003.
[28] M. Shariff, Alfresco 4 enterprise content management implementation install, administer, and manage this powerful open source Java-based Enterprise CMS, 3e ed. Birmingham: Packt Publishing, 2013, p. 1 vol. (xiii, 484 pages :).
[29] J.-L. Ermine, La gestion des connaissances. Paris: Hermes science publ. Lavoisier, 2003, p. 1 vol. (166 p.).
[30] J.-L. Ermine, Les systèmes de connaissances, 2e édition. Paris: Hermès, 2000, p. 1 vol. (236 p.).

135
[31] Collectif, Retour d’expérience en gestion des connaissances [facteurs culturels et humains, individuels, collectifs, confiance, réseau, réciprocité]. Paris: Tec & Doc Lavoisier, 2012, p. 1 vol. (XVII–238 p.).
[32] G. Balmisse, Guide des outils du knowledge management panorama, choix et mise en oeuvre. Paris: Vuibert, 2005, p. 1 vol. (XIV–315 p.).
[33] O. Castillo, N. Matta, and J. Ermine, “Une méthode pour l’appropriation de savoir-faire, capitalisé avec MASK,” Actes la conférence …, 2004.
[34] A. Bensoussan, “LA GESTION DES CONNAISSANCES Groupe de travail sous l’égide du GFII.”
[35] J. Charlet, “L’ingénierie des connaissances, entre science de l’information et science de gestion,” 2004.
[36] C. Morley, M. Bia Figueiredo, and Y. Gillette, Processus métiers et systèmes d’information gouvernance, management, modélisation, 3e édition. Paris: Dunod, 2011, p. 1 vol. (IX–307 p.).
[37] M. Chaillot and J. Ermine, “Le livre de connaissances électronique,” vol. 1, no. 1, p. 16, 1997.
[38] A. Besse, J. Ermine, and R. Camille, “Modéliser l’organisation, les pratiques et les procédures pour la réalisation des livres de connaissances,” 1999.
[39] T. Meilender, N. Jay, J. Lieber, and F. Palomares, “Les moteurs de wikis sémantiques : un état de l’art,” Europe, 2010.
[40] S. Herida, P. Bomel, J. Morice, and M. Prunier, “De l’utilité d’un système de gestion des connaissances de service ( SKMS ) pour favoriser les liens de l’IT avec les autres métiers de l’entreprise,” 2011.
[41] T. Grainger and T. Potter, Solr in action. Shelter Island (N.Y.): Manning, 2014, p. 1 vol. (XXVI–638 p.).
[42] M. Bergljung, Alfresco CMIS. Birmingham: Packt Publishing, 2014, p. 1 vol. (272 p.).
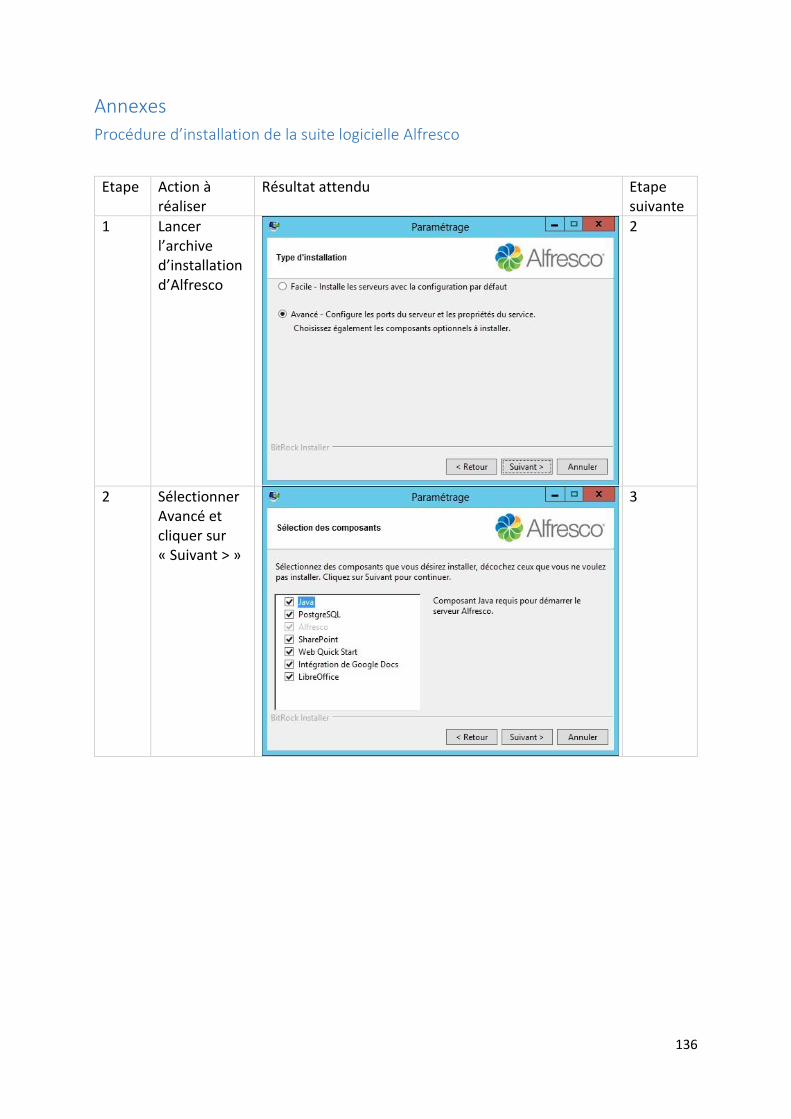
136
Annexes
Procédure d’installation de la suite logicielle Alfresco
Etape Action à réaliser
Résultat attendu Etape suivante
1 Lancer l’archive d’installation d’Alfresco
2
2 Sélectionner Avancé et cliquer sur « Suivant > »
3
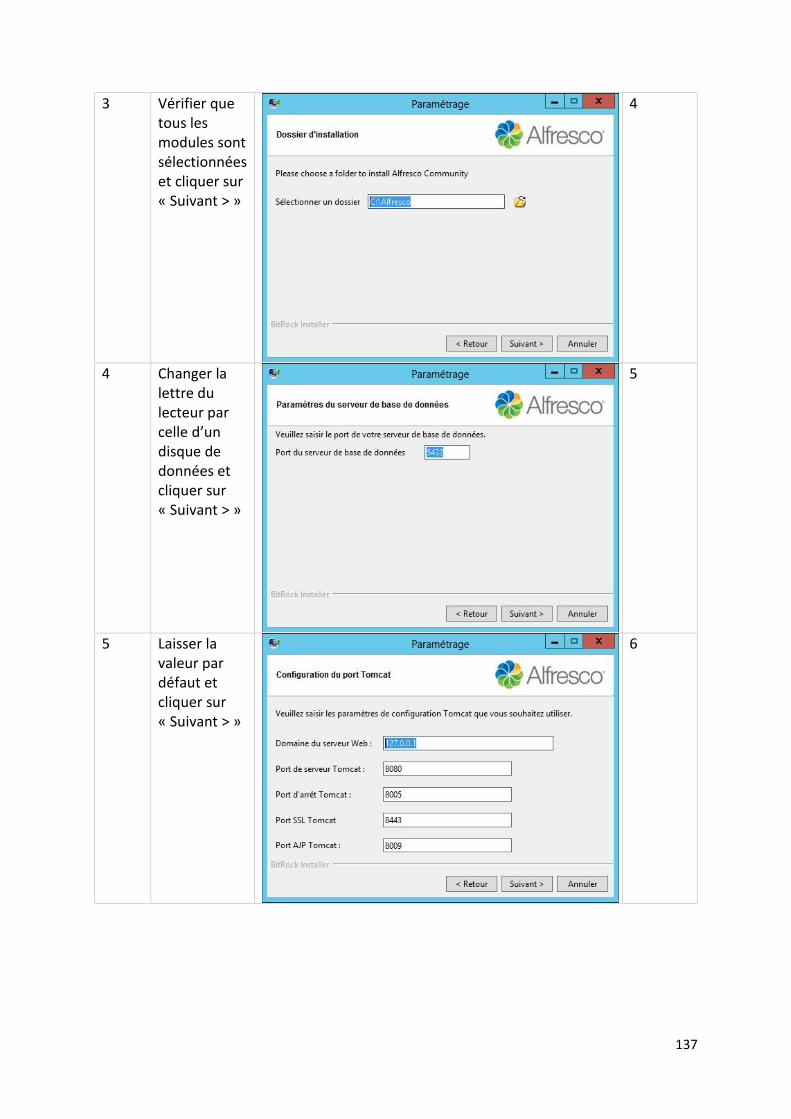
137
3 Vérifier que tous les modules sont sélectionnées et cliquer sur « Suivant > »
4
4 Changer la lettre du lecteur par celle d’un disque de données et cliquer sur « Suivant > »
5
5 Laisser la valeur par défaut et cliquer sur « Suivant > »
6
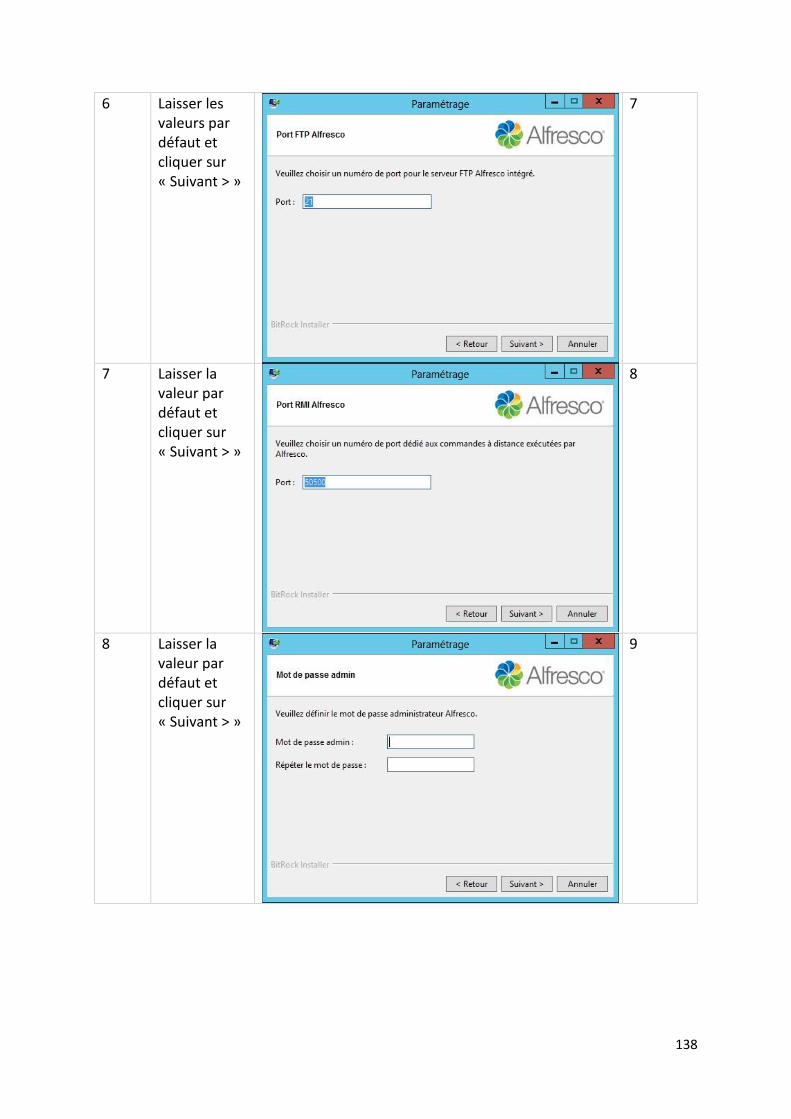
138
6 Laisser les valeurs par défaut et cliquer sur « Suivant > »
7
7 Laisser la valeur par défaut et cliquer sur « Suivant > »
8
8 Laisser la valeur par défaut et cliquer sur « Suivant > »
9
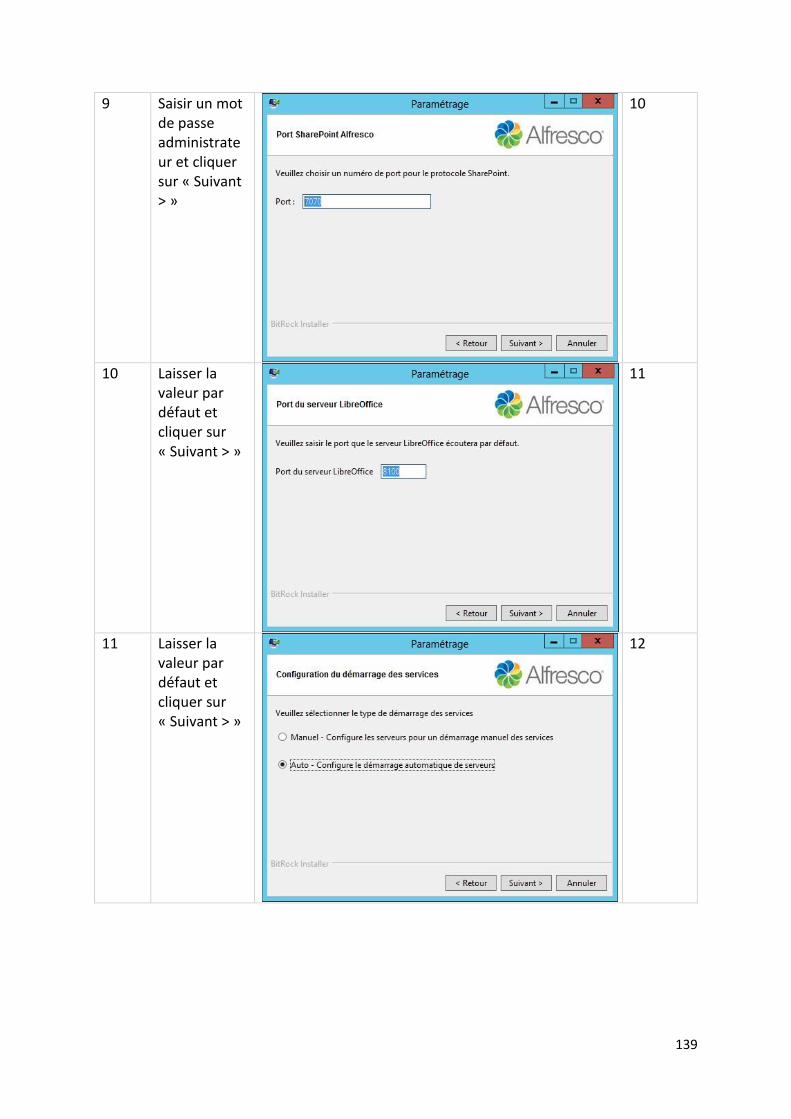
139
9 Saisir un mot de passe administrateur et cliquer sur « Suivant > »
10
10 Laisser la valeur par défaut et cliquer sur « Suivant > »
11
11 Laisser la valeur par défaut et cliquer sur « Suivant > »
12

140
12 Sélectionner Auto et cliquer sur « Suivant > »
13
13 Cliquer sur « Suivant > »
14
14 Patienter…
15
15 Cliquer sur « Terminer »
La fenêtre de l’assistant d’installation se ferme -

141
Procédure de mise à jour de la suite logicielle Alfresco
Voici la procédure de mise à jour de la suite Alfresco qui a été testée pour passer de la
version 4.2.f à 5.0.c, elle comporte 26 étapes :
1. Arrêter le service "alfresco Tomcat" si démarré
2. Démarrer le service postgressql si arrêté
3. Lancer l'invite de commande et se positionner dans le répertoire
"alfresco\postgresql\bin"
4. Faire un dump de la base alfresco avec la commande : "pg_dump.exe -h localhost -U
alfresco alfresco > alfrescodbdump.sql" (le mot de passe est celui du compte admin
saisi lors de l'installation d'Alfresco). Cela crée le fichier "alfrescodbdump.sql" dans le
répertoire "alfresco\postgresql\bin"
5. Arrêter le service "alfrescoPostgreSQL"
6. Copier le fichier "alfrescodbdump.sql" dans un répertoire de sauvegarde
7. Copier le répertoire "alfresco\alf_data" dans un répertoire de sauvegarde
8. Fermer l'invite de commande
9. Désinstaller l'ancienne version d'Alfresco de manière standard (supprimer le dossier
Alfresco si nécessaire)
10. Installer la nouvelle version d'Alfresco (utiliser "alfresco" comme mot de passe
"admin") et laisser les services arrêtés
11. Démarrer le service "alfrescoPostgreSQL"
12. Ouvrir l'invite de commande
13. Lancer l'invite de commande et se positionner dans le répertoire
"alfresco\postgresql\bin"
14. Effacer la base "alfresco" avec la commande "dropdb.exe -U alfresco alfresco" (le mot
de passe est "alfresco")
15. Créer la base "alfresco" avec la commande "createdb.exe -h localhost -U postgres -T
template0 alfresco" (le mot de passe est "alfresco")
16. Copier le fichier "alfrescodbdump.sql" du dossier de sauvegarde vers
"alfresco\postgresql\bin"
17. Restaurer le contenu de la base alfresco avec la commande "psql.exe alfresco -h
localhost < alfrescodbdump.sql"

142
18. Fermer l'invite de commande
19. Supprimer le fichier "alfrescodbdump.sql" du répertoire "alfresco\postgresql\bin"
20. Dans l'explorateur de fichier du système d'exploitation, se positionner dans le
répertoire "alfresco\alf_data" et copier tous les dossiers en remplaçant les répertoires
existants, à l'exception du dossier "postgresql", par ceux sauvegardés à l'étape 7
21. Ouvrir le fichier "Alfresco\tomcat\shared\classes\alfresco-global.properties" et
reconfigurer (e-mail, cifs, chaîne d'authentification)
22. Recopier les fichiers jar des add-on dans "Alfresco\tomcat\shared\lib"
23. Copier le fichier "dynamic-welcome.get.html.ftl" (pour supprimer de la dashlet de
bienvenue) dans le répertoire "Alfresco\tomcat\shared\classes\alfresco\web-
extension\site-webscripts\org\alfresco\components\dashlets" (il faut créer le
répertoire "site-webscripts" et ses sous-dossiers qui n'existent pas par défaut)
24. Démarrer le service "alfresco Tomcat" et attendre la création de l'arborescence
25. Mettre à jour les sous-systèmes d'authentification (si nécessaire)
26. Redémarrer les services "alfresco Tomcat" et "alfrescoPostgreSQL"
Fichiers de configuration de la suite Alfresco
alfrescoNtlm\alfresco-global.properties :
############################### ## Common Alfresco Properties # ############################### dir.root=C:/Alfresco/alf_data alfresco.context=alfresco alfresco.host=127.0.0.1 alfresco.port=8080 alfresco.protocol=http share.context=share share.host=127.0.0.1 share.port=8080 share.protocol=http ### database connection properties ### db.driver=org.postgresql.Driver db.username=alfresco db.password=alfresco db.name=alfresco db.url=jdbc:postgresql://localhost:5432/${db.name} # Note: your database must also be able to accept at least this many connections. Please see your database documentation for instructions on how to configure this. db.pool.max=275 db.pool.validate.query=SELECT 1 # The server mode. Set value here
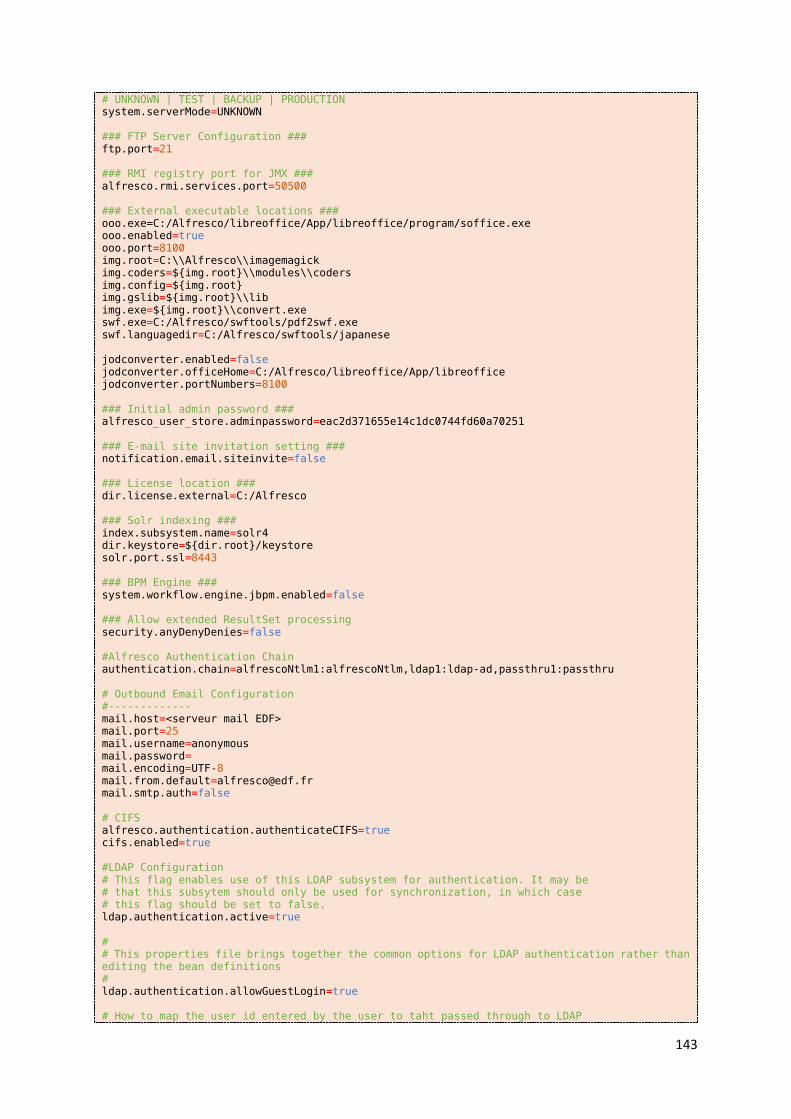
143
# UNKNOWN | TEST | BACKUP | PRODUCTION system.serverMode=UNKNOWN ### FTP Server Configuration ### ftp.port=21 ### RMI registry port for JMX ### alfresco.rmi.services.port=50500 ### External executable locations ### ooo.exe=C:/Alfresco/libreoffice/App/libreoffice/program/soffice.exe ooo.enabled=true ooo.port=8100 img.root=C:\\Alfresco\\imagemagick img.coders=${img.root}\\modules\\coders img.config=${img.root} img.gslib=${img.root}\\lib img.exe=${img.root}\\convert.exe swf.exe=C:/Alfresco/swftools/pdf2swf.exe swf.languagedir=C:/Alfresco/swftools/japanese jodconverter.enabled=false jodconverter.officeHome=C:/Alfresco/libreoffice/App/libreoffice jodconverter.portNumbers=8100 ### Initial admin password ### alfresco_user_store.adminpassword=eac2d371655e14c1dc0744fd60a70251 ### E-mail site invitation setting ### notification.email.siteinvite=false ### License location ### dir.license.external=C:/Alfresco ### Solr indexing ### index.subsystem.name=solr4 dir.keystore=${dir.root}/keystore solr.port.ssl=8443 ### BPM Engine ### system.workflow.engine.jbpm.enabled=false ### Allow extended ResultSet processing security.anyDenyDenies=false #Alfresco Authentication Chain authentication.chain=alfrescoNtlm1:alfrescoNtlm,ldap1:ldap-ad,passthru1:passthru # Outbound Email Configuration #------------- mail.host=<serveur mail EDF> mail.port=25 mail.username=anonymous mail.password= mail.encoding=UTF-8 [email protected] mail.smtp.auth=false # CIFS alfresco.authentication.authenticateCIFS=true cifs.enabled=true #LDAP Configuration # This flag enables use of this LDAP subsystem for authentication. It may be # that this subsytem should only be used for synchronization, in which case # this flag should be set to false. ldap.authentication.active=true # # This properties file brings together the common options for LDAP authentication rather than editing the bean definitions # ldap.authentication.allowGuestLogin=true # How to map the user id entered by the user to taht passed through to LDAP

144
# In Active Directory, this can either be the user principal name (UPN) or DN. # UPNs are in the form <sAMAccountName>@domain and are held in the userPrincipalName attribute of a user ldap.authentication.userNameFormat=%s@domain # The LDAP context factory to use ldap.authentication.java.naming.factory.initial=com.sun.jndi.ldap.LdapCtxFactory # The URL to connect to the LDAP server ldap.authentication.java.naming.provider.url=ldap://domaincontroller.company.com:389 # The authentication mechanism to use for password validation ldap.authentication.java.naming.security.authentication=simple # Escape commas entered by the user at bind time # Useful when using simple authentication and the CN is part of the DN and contains commas ldap.authentication.escapeCommasInBind=false # Escape commas entered by the user when setting the authenticated user # Useful when using simple authentication and the CN is part of the DN and contains commas, and the escaped \, is # pulled in as part of an LDAP sync # If this option is set to true it will break the default home folder provider as space names can not contain \ ldap.authentication.escapeCommasInUid=false # Comma separated list of user names who should be considered administrators by default ldap.authentication.defaultAdministratorUserNames=alfresco # This flag enables use of this LDAP subsystem for user and group # synchronization. It may be that this subsytem should only be used for # authentication, in which case this flag should be set to false. ldap.synchronization.active=true # The authentication mechanism to use for synchronization ldap.synchronization.java.naming.security.authentication=simple # The default principal to bind with (only used for LDAP sync). This should be a UPN or DN ldap.synchronization.java.naming.security.principal=alfresco@domain # The password for the default principal (only used for LDAP sync) ldap.synchronization.java.naming.security.credentials=secret # If positive, this property indicates that RFC 2696 paged results should be # used to split query results into batches of the specified size. This # overcomes any size limits imposed by the LDAP server. ldap.synchronization.queryBatchSize=1000 # If positive, this property indicates that range retrieval should be used to fetch # multi-valued attributes (such as member) in batches of the specified size. # Overcomes any size limits imposed by Active Directory. ldap.synchronization.attributeBatchSize=1000 # The query to select all objects that represent the groups to import. ldap.synchronization.groupQuery=(objectclass\=group) # The query to select objects that represent the groups to import that have changed since a certain time. ldap.synchronization.groupDifferentialQuery=(&(objectclass\=group)(!(whenChanged<\={0}))) # The query to select all objects that represent the users to import. ldap.synchronization.personQuery=(&(objectclass\=user)(userAccountControl\:1.2.840.113556.1.4.803\:\=512)) # The query to select objects that represent the users to import that have changed since a certain time. ldap.synchronization.personDifferentialQuery=(&(objectclass\=user)(userAccountControl\:1.2.840.113556.1.4.803\:\=512)(!(whenChanged<\={0}))) # The group search base restricts the LDAP group query to a sub section of tree on the LDAP server. ldap.synchronization.groupSearchBase=ou\=Security Groups,ou\=Alfresco,dc\=domain # The user search base restricts the LDAP user query to a sub section of tree on the LDAP server.
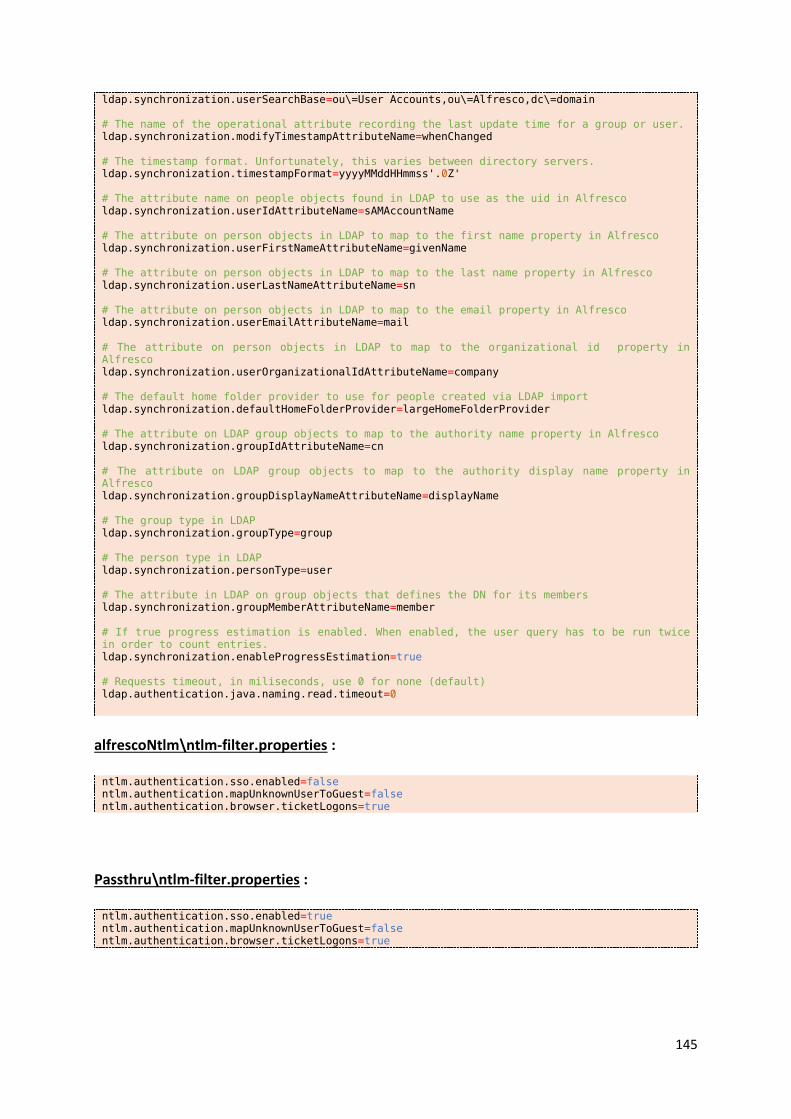
145
ldap.synchronization.userSearchBase=ou\=User Accounts,ou\=Alfresco,dc\=domain # The name of the operational attribute recording the last update time for a group or user. ldap.synchronization.modifyTimestampAttributeName=whenChanged # The timestamp format. Unfortunately, this varies between directory servers. ldap.synchronization.timestampFormat=yyyyMMddHHmmss'.0Z' # The attribute name on people objects found in LDAP to use as the uid in Alfresco ldap.synchronization.userIdAttributeName=sAMAccountName # The attribute on person objects in LDAP to map to the first name property in Alfresco ldap.synchronization.userFirstNameAttributeName=givenName # The attribute on person objects in LDAP to map to the last name property in Alfresco ldap.synchronization.userLastNameAttributeName=sn # The attribute on person objects in LDAP to map to the email property in Alfresco ldap.synchronization.userEmailAttributeName=mail # The attribute on person objects in LDAP to map to the organizational id property in Alfresco ldap.synchronization.userOrganizationalIdAttributeName=company # The default home folder provider to use for people created via LDAP import ldap.synchronization.defaultHomeFolderProvider=largeHomeFolderProvider # The attribute on LDAP group objects to map to the authority name property in Alfresco ldap.synchronization.groupIdAttributeName=cn # The attribute on LDAP group objects to map to the authority display name property in Alfresco ldap.synchronization.groupDisplayNameAttributeName=displayName # The group type in LDAP ldap.synchronization.groupType=group # The person type in LDAP ldap.synchronization.personType=user # The attribute in LDAP on group objects that defines the DN for its members ldap.synchronization.groupMemberAttributeName=member # If true progress estimation is enabled. When enabled, the user query has to be run twice in order to count entries. ldap.synchronization.enableProgressEstimation=true # Requests timeout, in miliseconds, use 0 for none (default) ldap.authentication.java.naming.read.timeout=0
alfrescoNtlm\ntlm-filter.properties :
ntlm.authentication.sso.enabled=false ntlm.authentication.mapUnknownUserToGuest=false ntlm.authentication.browser.ticketLogons=true
Passthru\ntlm-filter.properties :
ntlm.authentication.sso.enabled=true ntlm.authentication.mapUnknownUserToGuest=false ntlm.authentication.browser.ticketLogons=true

146
dynamic-welcome.get.html.ftl :
<@markup id="css" > <#-- CSS Dependencies --> <@link rel="stylesheet" type="text/css" href="${url.context}/res/components/dashlets/dynamic-welcome.css" group="dashlets" /> </@> <@markup id="js"> <#-- JavaScript Dependencies --> <@script type="text/javascript" src="${url.context}/res/components/dashlets/dynamic-welcome.js" group="dashlets"/> </@> <@markup id="widgets"> <@createWidgets group="dashlets"/> </@> <@markup id="html"> <@uniqueIdDiv> <#if false> <#assign el=args.htmlid?html> <div class="dashlet dynamic-welcome"> <a id="${el}-close-button" class="welcome-close-button" href="#"> <img src="${url.context}/res/components/images/delete-16.png" /> <span>${msg("welcome.close")}</span> </a> <div class="welcome-body"> <#-- OVERVIEW CONTAINER --> <@markup id="overviewContainer"> <div class="welcome-info"> <h1>${msg(title, user.fullName, site)?html}</h1> <#if description??> <p class="welcome-info-text">${msg(description)}</p> </#if> <h2>${msg("get.started.message")}</h2> </div> </@markup> <#-- DESCRIPTIONS CONTAINER --> <@markup id="actionsContainer"> <div> <div class="welcome-right-container"> <div class="welcome-middle-right-container welcome-border-container"> <div class="welcome-middle-left-container welcome-border-container"> <div class="welcome-left-container welcome-border-container"> <#list columns as column> <#if column??> <div class="welcome-details-column welcome-details-column-${column_index}"> <div class="welcome-details-column-image"> <img src="${url.context}${column.imageUrl}"/> </div> <div class="welcome-details-column-info"> <h3>${msg(column.title)}</h3> <#-- The following section allows us to insert arguments into the description using the "descriptionArgs" property of the column data. We construct a FreeMarker expression as a string iterating over any supplied arguments and then evaluate it. --> <#assign descArgs = "msg(column.description" /> <#if column.descriptionArgs??> <#list column.descriptionArgs as x> <#assign descArgs = descArgs + ",\"" + x?rtf?html + "\""> </#list>

147
</#if> <#assign descArgs = descArgs + ")"> <#assign displayText = descArgs?replace("{", "'{'")?replace("}", "'}'")?eval> <p class="welcome-details-column-info-text">${displayText?replace("%7B", "{")}</p> </div> <div class="welcome-height-adjuster" style="height:0;"> </div> </div> </#if> </#list> </div> </div> </div> </div> <div class="welcome-height-adjuster" style="height:0;"> </div> </div> </@markup> <#-- ACTIONS --> <@markup id="actionsContainer"> <div class="welcome-details"> <div class="welcome-right-container"> <div class="welcome-middle-right-container"> <div class="welcome-middle-left-container"> <div class="welcome-left-container"> <#list columns as column> <#if column??> <div class="welcome-details-column welcome-details-column-${column_index}"> <div class="welcome-details-column-info"> <#if column.actionMsg??> <div class="welcome-details-column-info-vertical-spacer"></div> <a <#if column.actionId??>id="${el}${column.actionId}" </#if> <#if column.actionHref??>href="${column.actionHref}" </#if> <#if column.actionTarget??>target="${column.actionTarget}" </#if>> <span>${msg(column.actionMsg)}</span> </a> <#else> <div class="welcome-details-column-info-vertical-spacer"></div> </#if> </div> </div> </#if> </#list> </div> </div> </div> </div> <div class="welcome-height-adjuster"> </div> </div> </@markup> </div> </div> </#if> </@> </@>

148
Procédure pour gérer les documents obsolètes
Avec la suite Alfresco, il est possible de gérer les documents obsolètes en se basant sur
leur propriété « Validité ». La gestion que nous proposons ici consiste à déplacer les
documents qui ont dépassé leur date de validité d’un répertoire à un autre afin qu’ils puissent
être examinés ultérieurement. Pour cela il faut suivre les étapes suivantes :
1. Définir les répertoires qui contiendront les documents en cours d’utilisation et les
répertoires qui recevront les documents obsolètes
2. Créer une règle sur les répertoires qui contiendront les documents en cours
d’utilisation. Cette règle ajoutera l’aspect « validité » à tous les documents qui
entreront dans le répertoire en question.
3. Créer un script « archive_expired_content.js » qui déplacera les documents dans le
répertoire des documents obsolètes et le déposer à l’emplacement « Dictionnaire de
données\Scripts » de l’Entrepôt de données Alfresco.
4. Créer une tâche planifiée en utilisant le fichier
« \Alfresco\tomcat\shared\classes\alfresco\extension\scheduled-action-services-
context.xml » qui lancera le script de manière périodique
Voici un exemple du script « archive_expired_content.js » :
// ----------------------------------------------------------------- // Nom: archive_expired_content.js // Description: Déplace le contenu expire vers un espace d’archivage // ----------------------------------------------------------------- var activeFolder = companyhome.childByNamePath("Sites/test/documentLibrary/En cours"); var archivedFolder = companyhome.childByNamePath("Sites/test/documentLibrary/Obsolete"); if(activeFolder != null) { var i=0; var today = new Date(); activeChildren = activeFolder.children; activeTotal = activeChildren.length; for(i=0; i<activeTotal; i++) { child = activeChildren[i]; if(child.properties["cm:to"] <= today) { child.move(archivedFolder); } } }

149
Ce script déplacera tous les documents ayant dépassé leur période de validité et se
trouvant dans le répertoire « Sites/test/documentLibrary/En cours » de l’Entrepôt de données
Alfresco vers le répertoire « Sites/test/documentLibrary/Obsolete »
Voici un exemple du fichier « scheduled-action-services-context.xml » décrivant la tâche
planifiée :
<?xml version='1.0' encoding='UTF-8'?> <!DOCTYPE beans PUBLIC '-//SPRING//DTD BEAN//EN' 'http://www.springframework.org/dtd/spring-beans.dtd'> <beans> <!-- Définit le concepteur de modèle utilisé pour générer les modèles d’objets adaptés pour une utilisation avec les templates freemarker. --> <bean id="templateActionModelFactory" class="org.alfresco.repo.action.scheduled.FreeMarkerWithLuceneExtensionsModelFactory"> <property name="serviceRegistry"> <ref bean="ServiceRegistry"/> </property> </bean> <!-- Definition de l'Action L'Action execute le script "Company Home > Data Dictionary > Scripts > archive_expired_content.js" --> <bean id="ExpiredContent_runScriptAction" class="org.alfresco.repo.action.scheduled.SimpleTemplateActionDefinition"> <property name="actionName"> <value>script</value> </property> <property name="parameterTemplates"> <map> <entry> <key> <value>script-ref</value> </key> <value>\$\{selectSingleNode('workspace://SpacesStore','lucene', 'PATH:"/app:company_home/app:dictionary/app:scripts/cm:archive_expired_content.js"' )\}</value> </entry> </map> </property> <property name="templateActionModelFactory"> <ref bean="templateActionModelFactory"/> </property> <property name="dictionaryService"> <ref bean="DictionaryService"/> </property> <property name="actionService"> <ref bean="ActionService"/> </property> <property name="templateService"> <ref bean="TemplateService"/> </property> </bean> <!-- Définition de la requête et de la tâche planifiée Requête - Aucune requête spécifique n'est utilisée Tâche planifiée - Exécute le script toutes les 15 minutes Action - Appelle ExpiredContent_runScriptAction défini ci-dessus -->

150
<bean id="ExpiredContent_runScript" class="org.alfresco.repo.action.scheduled.CronScheduledQueryBasedTemplateActionDefinition"> <property name="transactionMode"> <value>UNTIL_FIRST_FAILURE</value> </property> <property name="compensatingActionMode"> <value>IGNORE</value> </property> <property name="searchService"> <ref bean="SearchService"/> </property> <property name="templateService"> <ref bean="TemplateService"/> </property> <property name="queryLanguage"> <value>lucene</value> </property> <property name="stores"> <list> <value>workspace://SpacesStore</value> </list> </property> <property name="queryTemplate"> <value>PATH:"/app:company_home"</value> </property> <property name="cronExpression"> <value>0 0/15 * * * ?</value> </property> <property name="jobName"> <value>jobD</value> </property> <property name="jobGroup"> <value>jobGroup</value> </property> <property name="triggerName"> <value>triggerD</value> </property> <property name="triggerGroup"> <value>triggerGroup</value> </property> <property name="scheduler"> <ref bean="schedulerFactory"/> </property> <property name="actionService"> <ref bean="ActionService"/> </property> <property name="templateActionModelFactory"> <ref bean="templateActionModelFactory"/> </property> <property name="templateActionDefinition"> <ref bean="ExpiredContent_runScriptAction"/> <!-- C’est le nom de l’action (bean) qui est exécutée --> </property> <property name="transactionService"> <ref bean="TransactionService"/> </property> <property name="runAsUser"> <value>System</value> </property> </bean> </beans>
C’est l’expression « cron » qui définit quand la tâche planifiée exécute le script. Voici un
tableau qui décrit les paramètres de l’expression « cron »41 :
41 Pour plus de détails sur l’expression « cron » voir la page Web « http://wiki.alfresco.com/wiki/Scheduled_Actions »

151
Nom du champ Position Obligatoire Valeur autorisée Caractères spéciaux
Secondes 1 Oui 0-59 , - * /
Minutes 2 Oui 0-59 , - * /
Heures 3 Oui 0-23 , - * /
Jour du mois 4 Oui 1-31 , - * ? / L W
Mois 5 Oui 1-12 ou JAN-DEC , - * /
Jour de la semaine
6 Oui 1-7 ou SUN-SAT , - * ? / L #
Année 7 Non Vide, 1970-2099 , - * /
Dans notre cas, voici comment nous écrivons l’expression « cron » : « 0 0/15 * * * ? »
Créer un nouveau thème pour le portail Alfresco Share
Afin de rendre le portail Alfresco Share plus convivial, les développeurs d’Alfresco
Software ont mis au point un système de thème. Il est donc possible de créer autant de thèmes
que nous souhaitons. Dans le cadre du Service PFC, la création d’un nouveau thème permettra
de renforcer l’identité visuelle du Service dans le portail. Cela permet de montrer aux
utilisateurs que la solution a été personnalisée pour eux.
Voici la procédure à suivre pour créer un nouveau thème PFC pour le portail Alfresco
Share :
1. Se rendre dans le répertoire « \Alfresco\tomcat\webapps\share\themes » et
dupliquer un thème existant (par exemple « greenTheme »). Renommer le répertoire
du thème copié par « pfcTheme »
2. Modifier, si nécessaire, les images du thème présentes dans le répertoire
« \Alfresco\tomcat\webapps\share\themes\pfcTheme\images » pour obtenir
l’apparence souhaitée. Pour le thème PFC, nous avons changé l’image « logo.png » qui
correspond au logo affiché sur la page d’authentification du portail (le logo affiché en
haut à gauche sur toutes les pages du portail ne correspond pas à la même image et il
peut, lui, être changé directement sur le portail via l’onglet « Outils admin » lorsque
l’utilisateur est connecté en tant qu’administrateur).
3. Modifier le fichier « présentation.css » à la racine du répertoire du nouveau thème
pour obtenir l’apparence souhaitée.

152
4. Ouvrir le fichier « Skin.css » dans le répertoire
« \Alfresco\tomcat\webapps\share\themes\pfcTheme\yui\assets » et remplacer
toutes les chaînes de caractères « greenTheme » par « pfcTheme ». Le fichier peut
aussi être modifié pour obtenir l’apparence souhaitée.
5. Modifié, si nécessaire, les images se trouvant dans le répertoire
« \Alfresco\tomcat\webapps\share\themes\pfcTheme\yui\assets » pour obtenir
l’apparence souhaitée.
6. Se rendre dans le répertoire « \Alfresco\tomcat\webapps\share\WEB-
INF\classes\alfresco\site-data\themes » et dupliquer le fichier XML d’un thème
existant (exemple : « greenTheme.xml »). Renommer le fichier par « pfcTheme.xml ».
Ouvrir le fichier et modifier l’expression « <title>Green Theme</title> » par
« <title>PFC Theme</title> » et l’expression « <title-id>theme.greenTheme</title-
id> » par <title-id>theme.pfcTheme</title-id>.
7. Se rendre dans le répertoire « \Alfresco\tomcat\webapps\share\WEB-
INF\classes\alfresco\messages » et ouvrir tous les fichiers avec un nom de la forme
« slingshot_<langue>.properties ». Si nous prenons pour exemple le fichier
« slingshot_fr.properties », il faut se rendre dans la section « ## Themes » et ajouter
la ligne « theme.greenTheme=Th\u00e8me PFC ».
8. Redémarrer le service Tomcat.
9. Se connecter au portail Alfresco Share en tant qu’administrateur et se rendre dans
l’onglet « Outils admin » pour choisir le nouveau thème PFC.
La copie d’écran suivante montre la page permettant de modifier le thème et le logo :
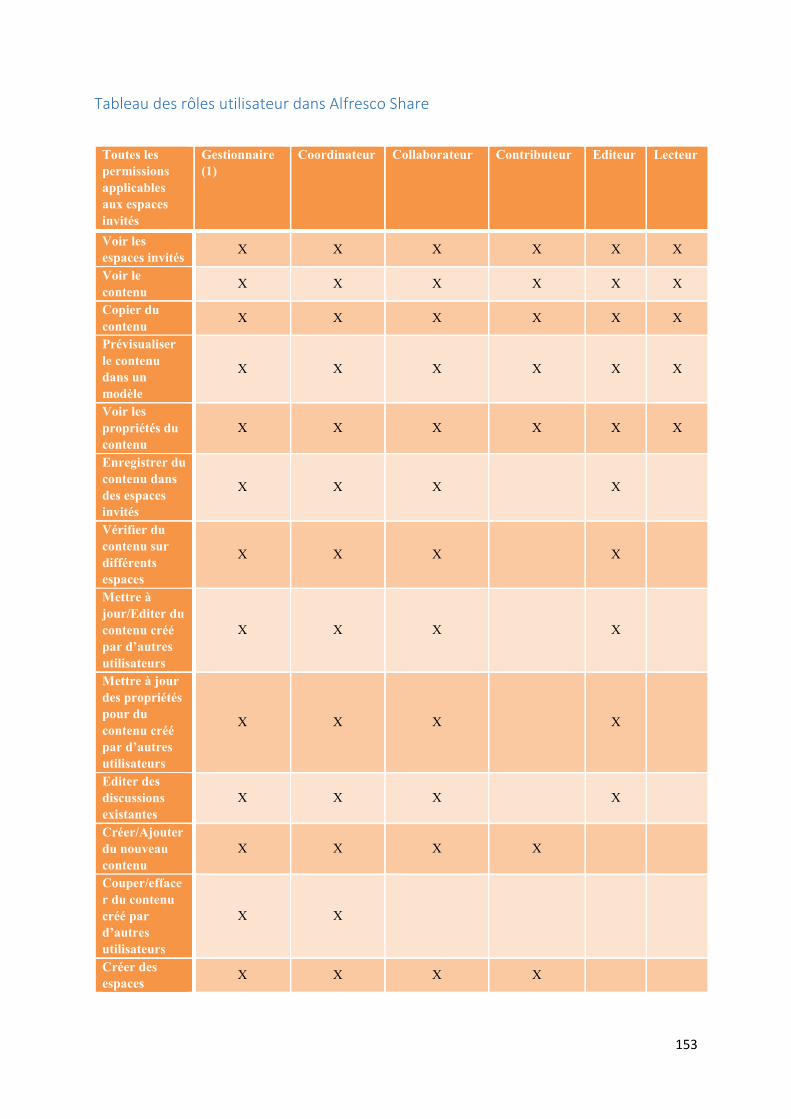
153
Tableau des rôles utilisateur dans Alfresco Share
Toutes les permissions applicables aux espaces invités
Gestionnaire (1)
Coordinateur Collaborateur Contributeur Editeur Lecteur
Voir les espaces invités X X X X X X
Voir le contenu X X X X X X
Copier du contenu X X X X X X
Prévisualiser le contenu dans un modèle
X X X X X X
Voir les propriétés du contenu
X X X X X X
Enregistrer du contenu dans des espaces invités
X X X X
Vérifier du contenu sur différents espaces
X X X X
Mettre à jour/Editer du contenu créé par d’autres utilisateurs
X X X X
Mettre à jour des propriétés pour du contenu créé par d’autres utilisateurs
X X X X
Editer des discussions existantes
X X X X
Créer/Ajouter du nouveau contenu
X X X X
Couper/effacer du contenu créé par d’autres utilisateurs
X X
Créer des espaces X X X X

154
enfants dans l’espace invité
Voir les règles de contenu X X X X
Vérifier du contenu d’un même espace
X X X (2)
Contribuer à une discussion existante
X X X X
Inviter les autres X X
Lancer un nouveau sujet de discussion
X X X X
Effacer du contenu créé par les autres utilisateurs
X X
Mêmes droits d’accès que le Gestionnaire
X X
Prendre la propriété de contenu
X X
Créer des règles d’espace
X X
(1) Un créateur est automatiquement considéré comme propriétaire du contenu qu’il crée (2) Parce qu’un éditeur ne peut pas créer un nouveau fichier dans un espace invité

Résumé
Aujourd’hui, la gestion des connaissances est devenue un enjeu stratégique pour les
entreprises. Après quelques expériences douloureuses, elles ont enfin pris conscience que
leurs connaissances font partie du capital de l’entreprise et qu’il est absolument nécessaire
de le gérer et de le capitaliser. Cependant, ce capital immatériel ne peut pas être assimilé au
capital classique de l’entreprise. Pour cette raison des spécialistes ont mis au point des
modèles, des méthodes et des outils pour gérer les connaissances. Ce travail nous montre
comment il est possible de gérer les connaissances d’un Service de Cloud privé chez EDF. Il
explique comment un portail collaboratif comportant une GED et un Wiki ont permis de
résoudre cette problématique en se basant sur la méthode de gestion de connaissances REX.
Mots clés : Gestion des connaissances, GED, Wiki, Système de gestion de contenu, portail
collaboratif, REX, MASK, EDF, Cloud privé, Communauté de Pratiques, Communauté d’intérêt
Today, Knowledge management has become a strategic issue for business. After many bad
experiences, they have complied with the fact that their knowledge is a part of company
capital and is absolutely necessary to manage and to capitalize it. But this intangible capital
can’t be considered as a classic capital of company. For this reason, some experts designed
templates, methodologies and tools to manage this knowledge. This work shows us how it is
possible to manage knowledge for private cloud department at EDF. It is explained how a
collaborative portal with an ECM and a Wiki allow to solve this problem by using REX
knowledge management methodology.
Key words : Knowledge Management, ECM, Wiki, Content Management System, CMS,
collaborative portal, REX, MASK, EDF, private Cloud, Community Of Practice, COP, Community
Of Interest Networks, CoINS





























