Embed Size (px)
Citation preview

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 1
Mini Project Report
on
SIMULATION OF DATA STRUCTURE
AND ALGORITHMS
Submitted by
NIRMAL SURESH
SAID SINAN KOTTANGODAN
NIYAS P I
in partial fulfilment for the award of the degree
of
B. TECH DEGREE
in
COMPUTER SCIENCE & ENGINEERING
SCHOOL OF ENGINEERING
COCHIN UNIVERSITY OF SCIENCE & TECHNOLOGY
KOCHI-682022

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 2
CERTIFICATE
Certified that this is a bonafide record of the project work titled
SIMULATION OF DATA STRUCTURE
AND ALGORITHMS
done by
NIRMAL SURESH
SAID SINAN KOTTANGODAN
NIYAS.P.I
of VI semester Computer Science & Engineering in the year 2014 in
partial fulfilment of the requirements for the award of Degree of
Bachelor of Technology in Computer Science & Engineering of
Cochin University of Science & Technology.
DR.SUDHEEP ELAYIDOM M PRAMOD PAVITHRAN
Project Guide Head of division

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 3
ACKNOWLEDGEMENT
First of all we thank The Almighty God for blessing us and supporting us
throughout this endeavour.
We take this opportunity to express our profound and sincere gratitude to our
guide Mr. DR.SUDHEEP ELAYIDOM M for her exemplary guidance, monitoring
and constant encouragement throughout the course of this project.
We also take this opportunity to express a deep sense of gratitude to our class
co-ordinator Mrs. Preetha S for their cordial support, valuable suggestion and
guidance.
We gratefully acknowledge the support extended by Head Of the Division, Mr.
Pramod Pavithran and also thank him for letting us use the lab facilities.
We are also obliged to the staff members of the division for their cooperation
during the period of the project.
Lastly, we thank all our friends without whom this project would not be possible.
NIRMAL SURESH
SAID SINAN KOTTANGODAN
NIYAS.P.I

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 4
ABSTRACT
To make the student easier to study how the operations on data sturucture and various
algorithms are performed.the data structures can be stack,queue and linked list etc and
algorithms are sorting like bubble sort,insertion sort etc.
Aim behind implementation of this project to make a clear understandability of various
algorithms of data structures. Using a web page this will simulates the data structure
operations such as searching, sorting, insertion, deletion etc. In array, stack, queue, and
linked list as well. Thus,our web page provides effective and efficient knowledge of data
structures. This also provide some theoretical knowledge regarding the data structure.
Programming language
1.HTML
2.JAVA

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 5
LIST OF FIGURES
Figure No. Page No.
1. Bubble Sort 8
2. Insertion Sort 10
3. Quick Sort 12
4. Selection Sort 14
5. Binary Search Tree 16
6. Binary Tree Traversal 20
7. Linked List 22

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 6
TABLE OF CONTENTS
CHAPTER NO. TITLE PAG NO
ABSTRACT LIST OF FIGURES 1. INTRODUCTION 9
1.1 PROBLEM DEFENITION
1.2 OBJECTIVES OF PROJECT 9
2. REQUIREMENTS ENGINEERING 14
2.1 FEASIBILITY STUDY 14
2.1.1 TECHNICAL FEASIBILITY
2.1.2 OPERATIONAL FEASIBILITY
2.1.3 ECONOMICAL FEASIBILITY
3. SYSTEM REQUIREMENT 15
3.1 ALGORITHMS 15
3.1.1 BUBBLE SORT 17
3.1.2 INSERTION SORT 19
3.1.3 QUICK SORT 21

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 7
3.1.4 SELECTION SORT 23
3.2 DATA STRUCTURES 27
3.2.1 BINARY SEARCH TREE 23
3.2.2 BINARY TREE TRAVERSAL 27
3.2.3 LINKED LIST 29
4. SYSTEM ENVIRONMENT
4.1 MINIMUM HARDWARE CONFIGURATION 32
4.2 MINIMUM SOFTWARE CONFIGURATION 32
4.3 SOFTWARE FEATURES
4.3.1 HTML 32
4.3.2 JAVA 33
5. DESIGN 35
5.1 INPUT DESIGN 35
5.2 USER INTERFACE DESIGN 36
5.3 OUTPUT DESIGN 39
6. SYSTEM TESTING 40
6.1 UNIT TESTING 40
6.2 INTEGRATION TESTING 40
6.3 USER ACCEPTANCE TESTING 41

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 8
7. CONCLUSION 42 8. REFFERNCES 43

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 9
CHAPTER 1
1.INTRODUCTION
1.1 Problem Defenition
Aim behind implementation of this project to make a clear understandability of
various algorithms of data structures. Using a web page this will simulates the
data structure operations such as searching, sorting, insertion, deletion etc. In
array, stack, queue, and linked list as well. Thus our web page provides effective
and efficient knowledge of data structures. This also provide some theoretical
knowledge regarding the data structure.
1.2 Objectives
.To study how the operations on data structure and algorithms are performed.
And how the values are compared in a sorting algorithms and swapped. Total
Number of comparison and exchanges performed in a sorting algorithm.
And the corresponding code performed while sorting.
.To get a clear idea about various data structures and operations on it.
And how can we implement a data structure.
.1.3 Data Structure:
In computer science, a data structure is a particular way of storing and organizing
data in a computer so that it can be used efficiently.

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 10
Different kinds of data structures are suited to different kinds of applications, and
some are highly specialized to specific tasks. For example, B-trees are
particularly well-suited for implementation of databases, while compiler
implementations usually use hash tables to look up identifiers.
Data structures provide a means to manage large amounts of data efficiently,
such as large databases and internet indexing services. Usually, efficient data
structures are a key to designing efficient algorithms. Some formal design
methods and programming languages emphasize data structures, rather than
algorithms, as the key organizing factor in software design. Storing and retrieving
can be carried out on data stored in both main memory and in.
1.3.1 Tree:
A tree data structure can be defined recursively (locally) as a collection of nodes
(starting at a root node), where each node is a data structure consisting of a
value, together with a list of references to nodes (the "children"), with the
constraints that no reference is duplicated, and none points to the root.
Alternatively, a tree can be defined abstractly as a whole (globally) as an ordered
tree, with a value assigned to each node. Both these perspectives are useful:
while a tree can be analyzed mathematically as a whole, when actually
represented as a data structure it is usually represented and worked with
separately by node (rather than as a list of nodes and an adjacency list of edges
between nodes, as one may represent a digraph, for instance). For example,
looking at a tree as a whole, one can talk about "the parent node" of a given
node, but in general as a data structure a given node only contains the list of its
children, but does not contain a reference to its parent (if any).

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 11
1.3.2 Linked List:
Linked lists are among the simplest and most common data structures. They can
be used to implement several other common abstract data types, including lists
(the abstract data type), stacks, queues, associative arrays, and S-expressions,
though it is not uncommon to implement the other data structures directly without
using a list as the basis of implementation.
The principal benefit of a linked list over a conventional array is that the list
elements can easily be inserted or removed without reallocation or reorganization
of the entire structure because the data items need not be stored contiguously in
memory or on disk. Linked lists allow insertion and removal of nodes at any point
in the list, and can do so with a constant number of operations if the link previous
to the link being added or removed is maintained during list traversal.
On the other hand, simple linked lists by themselves do not allow random access
to the data, or any form of efficient indexing. Thus, many basic operations —
such as obtaining the last node of the list (assuming that the last node is not
maintained as separate node reference in the list structure), or finding a node
that contains a given datum, or locating the place where a new node should be
inserted — may require scanning most or all of the list elements.
1.4 Algorithms
1.4.1 Bubble Sort:
Bubble sort, sometimes incorrectly referred to as sinking sort, is a simple sorting
algorithm that works by repeatedly stepping through the list to be sorted,
comparing each pair of adjacent items and swapping them if they are in the
wrong order. The pass through the list is repeated until no swaps are needed,

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 12
which indicates that the list is sorted. The algorithm gets its name from the way
smaller elements "bubble" to the top of the list. Because it only uses comparisons
to operate on elements, it is a comparison sort. Although the algorithm is simple,
most of the other sorting algorithms are more efficient for large lists.
1.4.2 Selection Sort:
selection sort is a sorting algorithm, specifically an in-place comparison sort. It
has O(n2) time complexity, making it inefficient on large lists, and generally
performs worse than the similar insertion sort. Selection sort is noted for its
simplicity, and it has performance advantages over more complicated algorithms
in certain situations, particularly where auxiliary memory is limited.
The algorithm divides the input list into two parts: the sublist of items already
sorted, which is built up from left to right at the front (left) of the list, and the
sublist of items remaining to be sorted that occupy the rest of the list. Initially, the
sorted sublist is empty and the unsorted sublist is the entire input list. The
algorithm proceeds by finding the smallest (or largest, depending on sorting
order) element in the unsorted sublist, exchanging it with the leftmost unsorted
element (putting it in sorted order), and moving the sublist boundaries one
element to the right.
1.4.3 Insertion sort:
Insertion sort is a simple sorting algorithm that builds the final sorted array (or
list) one item at a time. It is much less efficient on large lists than more advanced
algorithms such as quicksort, heapsort, or merge sort. However, insertion sort
provides several advantages:
Simple implementation

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 13
Efficient for (quite) small data sets
Adaptive (i.e., efficient) for data sets that are already substantially sorted: the
time complexity is O(n + d), where d is the number of inversions
More efficient in practice than most other simple quadratic (i.e., O(n2)) algorithms
such as selection sort or bubble sort; the best case (nearly sorted input) is O(n)
Stable; i.e., does not change the relative order of elements with equal keys
In-place; i.e., only requires a constant amount O(1) of additional memory space
Online; i.e., can sort a list as it receives it
When humans manually sort something (for example, a deck of playing cards),
most use a method that is similar to insertion sort.[1]
1.4.4 Quick sort:
Quicksort, or partition-exchange sort, is a sorting algorithm developed by Tony
Hoare that, on average, makes O(n log n) comparisons to sort n items. In the
worst case, it makes O(n2) comparisons, though this behavior is rare. Quicksort
is often faster in practice than other O(n log n) algorithms.Additionally, quicksort's
sequential and localized memory references work well with a cache. Quicksort is
a comparison sort and, in efficient implementations, is not a stable sort. Quicksort
can be implemented with an in-place partitioning algorithm, so the entire sort can
be done with only O(log n) additional space used by the stack during the
recursion.

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 14
CHAPTER 2
2. REQUIREMENT ENGINEERING
Systematic requirements analysis is also known as requirements engineering. It
is sometimes referred to loosely by names such as requirements gathering,
requirements capture, or requirements specification. The term requirements
analysis can also be applied specifically to the analysis proper, as opposed to
elicitation or documentation of the requirements, for instance.
Requirement engineering according to Lap ante
(2007) is "a sub discipline of systems engineering and software engineering that
is concerned with determining the goals, functions, and constraints of hardware
and software systems. In some life cycle models, the requirement engineering
process begins with a feasibility study activity, which leads to a feasibility report.
If the feasibility study suggests that the product should be developed, then
requirement analysis can begin
2.1FEASIBILITY STUDY
Feasibility study conducted once the problem is clearly understood.
Feasibility study is a high level capsule version of the entire system-analysis and
design process. The objective is to determine quickly and at the minimum
expense how to solve the problem and to determine the problem is solved. The
system has been tested for feasibility in the following ways.
Technical feasibility
Operational feasibility
Economical feasibility

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 15
CHAPTER 3
3.Sysem Requirement
3.1.Algorithms
3.1.1.Bubble Sort
Figure 1: Bubble sort-This contain the text field for input values.The fields in
comparisons and Exchanges gives the number of comparison and exchanges.it
highlight the current code which is executing.
Code
public int[] bubbleSort(int[] data){
int lenD = data.length;
int tmp = 0;

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 16
for(int i = 0;i<lenD;i++){
for(int j = (lenD-1);j>=(i+1);j--){
if(data[j]<data[j-1]){
tmp = data[j];
data[j]=data[j-1];
data[j-1]=tmp;
return data;

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 17
3.1.2Insertion Sort
Figure 2: Insertion sort-This contain the text field for input values.The fields in
comparisons and Exchanges gives the number of comparison and exchanges.it
highlight the current code which is executing.n gives no.of values,x,k and i are
the pointers.
Code
void SortAlgo::insertionSort(int data[], int lenD)
{
int key = 0;
int i = 0;
for(int j = 1;j<lenD;j++){
key = data[j];

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 18
i = j-1;
while(i>=0 && data[i]>key){
data[i+1] = data[i];
i = i-1;
data[i+1]=key;
Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 19
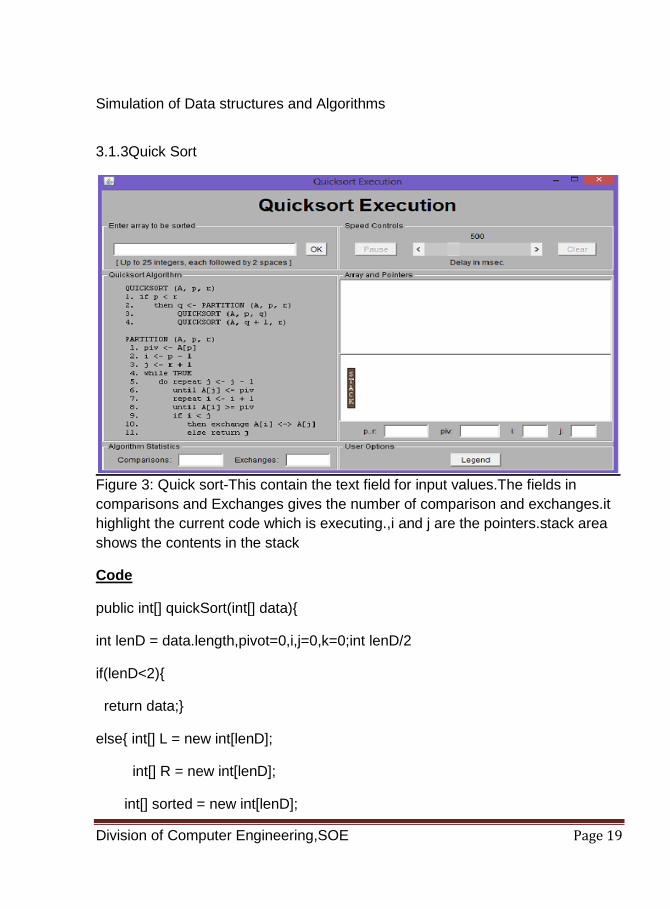
3.1.3Quick Sort
Figure 3: Quick sort-This contain the text field for input values.The fields in
comparisons and Exchanges gives the number of comparison and exchanges.it
highlight the current code which is executing.,i and j are the pointers.stack area
shows the contents in the stack
Code
public int[] quickSort(int[] data){
int lenD = data.length,pivot=0,i,j=0,k=0;int lenD/2
if(lenD<2){
return data;}
else{ int[] L = new int[lenD];
int[] R = new int[lenD];
int[] sorted = new int[lenD];

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 20
pivot = data[ind];
for(i=0;i<lenD;i++){ if(i!=ind){
if(data[i]<pivot){
L[j] = data[i]; j++
else{ R[k] = data[i];
k++;

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 21
3.1.4.Selection Sort
Figure 4:Selection Sort-This contain the text field for input values.The fields in
comparisons and Exchanges gives the number of comparison and exchanges.it
highlight the current code which is executing.n gives no.of values.,k and i are the
pointers.
Code
public int[] selectionSort(int[] data){
int lenD = data.length;
int j = 0;
int tmp = 0;

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 22
for(int i=0;i<lenD;i++){
j = i;
for(int k = i;k<lenD;k++){
if(data[j]>data[k]){
j = k;}}
tmp = data[i];
data[i] = data[j];
data[j] = tmp;}
return data;}
3.2.Data Structures

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 23
3.2.1.Binary Search Tree
Figure 5:Binary Search Tree-Contain 4 buttons.insert (input) for give value
dynamically.insert(Random) for random values of input and search button for
searching any value that in the tree.delete button for deleting a specified node
from the tree.

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 24
Code
private BSTNode insert(BSTNode node, int data)
{if (node == null)
node = new BSTNode(data);
else{
if (data <= node.getData())
node.left = insert(node.left, data);
else node.right = insert(node.right, data);}
return node;}
public void delete(int k)
{ BSTNode p, p2, n;
if (root.getData() == k)
{BSTNode lt, rt;
lt = root.getLeft();
rt = root.getRight();
if (lt == null && rt == null)
return null;
else if (lt == null)
{p = rt;
return p;}
else if (rt == null)

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 25
{p = lt;
return p;}
else
{ p2 = rt;
p = rt;
private BSTNode delete(BSTNode root, int k)
{if (isEmpty())
System.out.println("Tree Empty");
else if (search(k) == false)
System.out.println("Sorry "+ k +" is not present");
else{
root = delete(root, k);
System.out.println(k+ " deleted from the
tree");}}
while (p.getLeft() != null)
p = p.getLeft();
p.setLeft(lt);
return p2;}}
if (k < root.getData()){
n = delete(root.getLeft(), k);
root.setLeft(n);}

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 26
else
{ n = delete(root.getRight(), k);
root.setRight(n); }
return root;}
Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 27
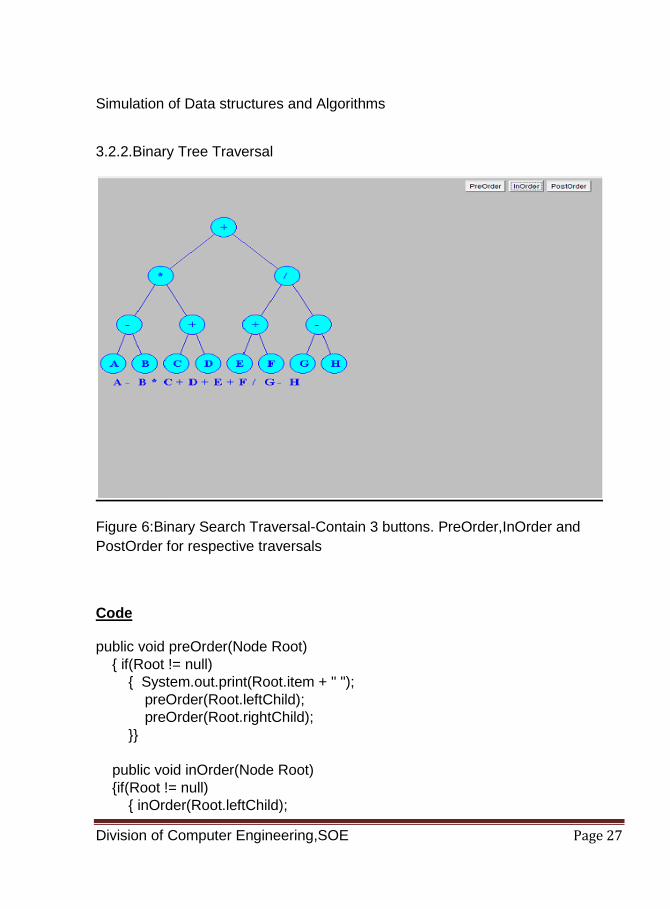
3.2.2.Binary Tree Traversal
Figure 6:Binary Search Traversal-Contain 3 buttons. PreOrder,InOrder and
PostOrder for respective traversals
Code
public void preOrder(Node Root)
{ if(Root != null)
{ System.out.print(Root.item + " ");
preOrder(Root.leftChild);
preOrder(Root.rightChild);
}}
public void inOrder(Node Root)
{if(Root != null)
{ inOrder(Root.leftChild);

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 28
System.out.print(Root.item + " ");
inOrder(Root.rightChild);
}}
public void postOrder(Node Root)
{ if(Root != null)
{ postOrder(Root.leftChild);
postOrder(Root.rightChild);
System.out.print(Root.item + " ");
}}
}

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 29
3.2.3.Linked List
Figure 7:Linked List-Contain 4 buttons. Ins front, Ins Rear Del front and Search
for insert from front,insert from Rear delete from Front and Search a specified
value respectively
Code
public class LinkList {
Node first = null;
Node last = null;
int siz = 0;

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 30
public void insertEnd(int val) {
Node n = new Node();
if (first == null) {
first = n;
} else {
last.next = n;
}
n.data = val;
last = n;
siz++;
}
public void insertBegin(int val) {
Node n = new Node();
n.next = first;
if (first == null) {
last = n;
}
first = n;
n.data = val;
siz++;
}

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 31
public void deleteBegin() {
if (first == null) {
return;
}
first = first.next;
siz--;
}
public int size() {
return siz;
}
public boolean isEmpty() {
return first == null;
}
}

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 32
CHAPTER 4
4.SYSTEM ENVIRONMENT
4.1 Minimum Hardware Configuration
1. Pentium IV Processor
2. 512 MB RAM
3. 40GB HDD
4. 1024 * 768 Resolution Color Monitor
Note: This is not the “System Requirements”.
4.2 Minimum Software Configuration
1. Operating System: Windows XP
2.HTML,JAVA
4.3 Software Features
4.3.1 HTML
HTML or HyperText Markup Language is the main markup language for
creating web pages and other information that can be displayed in a web
browser.
HTML is written in the form of HTML elements consisting of tags enclosed in
angle brackets (like <html>), within the web page content. HTML tags most
commonly come in pairs like <h1> and </h1>, although some tags represent

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 33
empty elements and so are unpaired, for example <img>. The first tag in a pair is
the start tag, and the second tag is the end tag (they are also called opening tags
and closing tags). In between these tags web designers can add text, further
tags, comments and other types of text-based content.
The purpose of a web browser is to read HTML documents and compose them
into visible or audible web pages. The browser does not display the HTML tags,
but uses the tags to interpret the content of the page.
HTML elements form the building blocks of all websites. HTML allows images
and objects to be embedded and can be used to create interactive forms. It
provides a means to create structured documents by denoting structural
semantics for text such as headings, paragraphs, lists, links, quotes and other
items. It can embed scripts written in languages such as JavaScript which affect
the behavior of HTML web pages.
4.3.2 JAVA
Java is a computer programming language that is concurrent, class-
based, object-oriented, and specifically designed to have as few implementation
dependencies as possible. It is intended to let application developers "write once,
run anywhere" (WORA), meaning that code that runs on one platform does not
need to be recompiled to run on another. Java applications are typically compiled
to bytecode (class file) that can run on any Java virtual machine (JVM)
regardless of computer architecture. Java is, as of 2014, one of the most popular

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 34
programming languages in use, particularly for client-server web applications,
with a reported 9 million developers.[10][11] Java was originally developed by
James Gosling at Sun Microsystems (which has since merged into Oracle
Corporation) and released in 1995 as a core component of Sun Microsystems'
Java platform. The language derives much of its syntax from C and C++, but it
has fewer low-level facilities than either of them.
The original and reference implementation Java compilers, virtual machines, and
class libraries were developed by Sun from 1991 and first released in 1995. As of
May 2007, in compliance with the specifications of the Java Community Process,
Sun relicensed most of its Java technologies under the GNU General Public
License. Others have also developed alternative implementations of these Sun
technologies, such as the GNU Compiler for Java (bytecode compiler), GNU
Classpath (standard libraries), and IcedTea-Web (browser plugin for applets).

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 35
CHAPTER 5
5.DESIGN
5.1 Input Design
Input design include the creation of the text fields and the space required input
the data dynamically.
A text box, text field or text entry box is a kind of widget used when building a
graphical user interface (GUI). A text box's purpose is to allow the user to input
text information to be used by the program. User-interface guidelines recommend
a single-line text box when only one line of input is required, and a multi-line text
box only if more than one line of input may be required. Non-editable text boxes
can serve the purpose of simply displaying text.
A typical text box is a rectangle of any size, possibly with a border that separates
the text box from the rest of the interface. Text boxes may contain zero, one, or
two scrollbars. Text boxes usually display a text cursor (commonly a blinking
vertical line), indicating the current region of text being edited. It is common for
the mouse cursor to change its shape when it hovers over a text box.

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 36
5.2 User Interface Design
User interface design (UID) or user interface engineering is the design of
websites, computers, appliances, machines, mobile communication devices, and
software applications with the focus on the user's experience and interaction. The
goal of user interface design is to make the user's interaction as simple and
efficient as possible, in terms of accomplishing user goals—what is often called
user-centered design. Good user interface design facilitates finishing the task at
hand without drawing unnecessary attention to itself. Graphic design may be
utilized to support its usability. The design process must balance technical
functionality and visual elements (e.g., mental model) to create a system that is
not only operational but also usable and adaptable to changing user needs.
Interface design is involved in a wide range of projects from computer systems,
to cars, to commercial planes; all of these projects involve much of the same
basic human interactions yet also require some unique skills and knowledge. As
a result, designers tend to specialize in certain types of projects and have skills
centered around their expertise, whether that be software design, user research,
web design, or industrial design

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 37
Processes
User interface design requires a good understanding of user needs. There are
several phases and processes in the user interface design, some of which are
more demanded upon than others, depending on the project. (Note: for the
remainder of this section, the word system is used to denote any project whether
it is a website, application, or device.)
Functionality requirements gathering – assembling a list of the functionality
required by the system to accomplish the goals of the project and the potential
needs of the users.
User analysis – analysis of the potential users of the system either through
discussion with people who work with the users and/or the potential users
themselves. Typical questions involve:
What would the user want the system to do?
How would the system fit in with the user's normal workflow or daily activities?
How technically savvy is the user and what similar systems does the user
already use?
What interface look & feel styles appeal to the user?
Information architecture – development of the process and/or information flow of
the system (i.e. for phone tree systems, this would be an option tree flowchart
and for web sites this would be a site flow that shows the hierarchy of the pages).

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 38
Prototyping – development of wireframes, either in the form of paper prototypes
or simple interactive screens. These prototypes are stripped of all look & feel
elements and most content in order to concentrate on the interface.
Usability inspection – letting an evaluator inspect a user interface. This is
generally considered to be cheaper to implement than usability testing (see step
below), and can be used early on in the development process since it can be
used to evaluate prototypes or specifications for the system, which usually can't
be tested on users. Some common usability inspection methods include cognitive
walkthrough, which focuses the simplicity to accomplish tasks with the system for
new users, heuristic evaluation, in which a set of heuristics are used to identify
usability problems in the UI design, and pluralistic walkthrough, in which a
selected group of people step through a task scenario and discuss usability
issues.
Usability testing – testing of the prototypes on an actual user—often using a
technique called think aloud protocol where you ask the user to talk about their
thoughts during the experience.
Graphic interface design – actual look and feel design of the final graphical user
interface (GUI). It may be based on the findings developed during the usability
testing if usability is unpredictable, or based on communication objectives and
styles that would appeal to the user. In rare cases, the graphics may drive the
prototyping, depending on the importance of visual form versus function. If the
interface requires multiple skins, there may be multiple interface designs for one
control panel, functional feature or widget. This phase is often a collaborative
effort between a graphic designer and a user interface designer, or handled by
one who is proficient in both disciplines.

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 39
5.3 OUTPUT DESIGN
Designing computer output should proceed in an organized, well throughout
manner; the right output element is designed so that people will find the system
whether or executed. When we design an output we must identify the specific
output that is needed to meet the system. The usefulness of the new system is
evaluated on the basis of their output. Once the output requirements are
determined, the system designer can decide what to include in the system and
how to structure it so that the require output can be produced. For the proposed
software, it is necessary that the output reports be compatible in format with the
existing reports. The output must be concerned to the overall performance and
the system’s working, as it should. It consists of developing specifications and
procedures for data preparation, those steps necessary to put the inputs and the
desired output, i.e. maximum user friendly. Proper messages and appropriate
directions can control errors committed by users. The output design is the key to
the success of any system. Output is the key between the user and the sensor.
The output must be concerned to the system’s working, as it should. Output
design consists of displaying specifications and procedures as data presentation.
User never left with the confusion as to what is happening without appropriate
error and acknowledges message being received.

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 40
CHAPTER 6
6.SYSTEM TESTING
System testing is the stage of implementation, which is aimed at ensuring that the system works accurately and efficiently before live operation commences. Testing is the process of executing the program with the intent of finding errors and missing operations and also a complete verification to determine whether the objectives are met and the user requirements are satisfied. The ultimate aim is quality assurance. Tests are carried out and the results are compared with the expected document. In the case of erroneous results, debugging is done. Using detailed testing strategies a test plan is carried out on each module. The various tests performed in “Network Backup System” are unit testing, integration testing and user acceptance testing.
6.1 Unit Testing
The software units in a system are modules and routines that are assembled and integrated to perform a specific function. Unit testing focuses first on modules, independently of one another, to locate errors. This enables, to detect errors in coding and logic that are contained within each module. This testing includes entering data and ascertaining if the value matches to the type and size supported. The various controls are tested to ensure that each performs its action as required.
6.2 Integration Testing
Data can be lost across any interface, one module can have an adverse effect on another, sub functions when combined, may not produce the desired major functions. Integration testing is a systematic testing to discover errors associated within the interface. The objective is to take unit tested modules and build a program structure. All the modules are combined and tested as a whole. Here the Server module and Client module options are integrated and tested. This testing provides the assurance that the application is well integrated functional unit with smooth transition of data.

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 41
6.3 User Acceptance Testing
User acceptance of a system is the key factor for the success of any system. The system under consideration is tested for user acceptance by constantly keeping in touch with the system users at time of developing and making changes whenever required.

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 42
7.CONCLUSION
From earlier classes itself,we were studying about the data structures and
algorithms. Some of us are just by hearting the code.ie, we don’t know how the
working is going on there.And also we didn’t get an idea about these things.
So our applet provides the clear and detail idea about the data structure and
algorithms,and more over how the operations are done in recursion algorithms
and data structure. And the animated representation makes more easier and
better understandability on this topic.Outcome of this applet is make easier and
simple way to understand about the algorithms.

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 43
8.REFFERNCE
. http://www.cosc.canterbury.ac.nz/
.http://www.w3schools.com/
.http://www.hawai.education.com/
.Michael Waite and Robert Lafore, “Data Structures and Algorithms in Java”
,Techmedia, NewDelhi, 1998.
.Adam drozdek,” Data Structures and Algorithms in Java” ,Thomson Publications
2nd Edition.
. Sartaj Sahni, 'Data Structures, Algorithms, and Applications in Java", McGraw

Simulation of Data structures and Algorithms
Division of Computer Engineering,SOE Page 44





























