Embed Size (px)
Citation preview

Compiling for Reconfigurable
Computing
Seminar Report
Sameer Mohamed Thahir
MTech CIS
Department of Computer Science
Cochin University of Science and Technology
May 21, 2011

Abstract
Reconfigurable Computing is a modern day architecture that would change the conventional outlook of proces-sor and computing architectures. Reconfigware would bring about a revolution in the field of processing andcomputing by introducing reconfigurable hardware that can be configured/ customized on the fly.
Reconfigurable computing uses reconfigurable cores to perform specific operations by customizing the hard-ware according to our needs(through FPGAs). Such Hardware would bring about drastic changes in terms ofperformance and energy efficiency. The ability to customize the hardware to our needs brings flexibility thatwe have now only seen in software. The seminar will introduce the concept of “Reconfigurable Computing” byexplaining its basic varieties, architecture and reconfigurable cores.
In order for reconfigurable computing to be adopted at a large scale, there must exist methods for program-mers to develop applications/ code that would possess features of reconfigurable architectures and utilize thetrue capabilities of reconfigware. Compilers are the first step to achieving this goal.Compilers have a biggerresponsibility of producing code that can map directly to the hardware in use. They must mimic operations ofHardware Description languages to enable them to produce reconfigurable code.
In order for programs to possess the above mentioned properties, the compilers must be able to providespecific techniques to produce reconfigurable code. The seminar will throw light on some important techniquesat different levels of the compilation process that need to be possessed by reconfigware compilers enabling themto leverage the true power of the reconfigurable architectures.
Keywords : reconfigware reconfigurable fpga compiler parallel supercomputer concurrency
Department of Computer Science, CUSAT 1

Contents
1 Reconfigware 41.1 Reconfigurable Computing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.1.1 Difference from a conventional processor . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.1.2 Practical Scenario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.2 FPGA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2.1 Reconfigurable Logic Devices . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2.2 Introduction to FPGAs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2.3 Advantages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2.4 Drawbacks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2.5 FPGA Layout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2.6 Common FPGA Role in Industry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.2.7 Configurable Computing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.2.8 Reconfigurable computing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.2.9 Real Life Scenario . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2 Reconfigurable Architectures 82.1 Categories of FPGA Based Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.1 Hybrid computers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.1.2 Fully FPGA based Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Architecture Layout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.3 Coupling Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3.1 RPUs Coupled to host bus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.3.2 RPUs coupled like coprocessors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.3.3 RPUs like Extended Datapath . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4 Granularity and Classification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3 Overview of Compilation Flows - Front End 113.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 113.2 Front End . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.3 Programming Languages and Execution Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.3.1 Programming Languages . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123.3.2 Solutions to Concurrency Challenges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.4 Intermediate Representations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 133.5 Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4 Middle End and Back End 144.1 Code Transformations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
4.1.1 Bit-Level Transformations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144.1.2 Bit Optimizations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144.1.3 Converting from Floating to Fixed point representations . . . . . . . . . . . . . . . . . . . 15
4.2 Instruction level Transformations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154.2.1 Tree Height Reductions (THR) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154.2.2 Operation Strength Reduction(OSR) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.3 Loop Level Transformations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164.4 Data Oriented Transformations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4.4.1 Data Distribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164.4.2 Data Replication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4.5 Scalar Replacement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174.6 Mapping Techniques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2

CONTENTS CONTENTS
4.7 Control Flow Optimization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174.7.1 Speculative Execution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174.7.2 Multiple Flows of control . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174.7.3 Data Flow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.8 Partitioning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184.8.1 Temporal Partitioning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184.8.2 Spatial Partitioning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.9 Resource Mapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.9.1 Register Assignment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.10 Pipelining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194.11 Memory Mapping Optimizations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.11.1 Partitioning and Mapping of Arrays to Memory Resources . . . . . . . . . . . . . . . . . . 204.11.2 Parallelization of Memory Accesses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204.11.3 Customization of Memory Controllers . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204.11.4 Elimination of Memory accesses using register promotion . . . . . . . . . . . . . . . . . . 20
4.12 Scheduling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204.13 Back End . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5 State of the art in Reconfigurable Computing 225.1 Compilers for Reconfigurable Architectures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.1.1 Commercial adoption of Compiler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225.2 Reconfigurable Supercomputer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
5.2.1 Kraken Supercomputer (Novo G) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5.3.1 Reconfigware Compilers today . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235.3.2 Future in Research . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 235.3.3 Future in Industry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
6 References 24
Department of Computer Science, CUSAT 3

Chapter 1
Reconfigware
1.1 Reconfigurable Computing
Reconfigurable Computing is basically a Computer Architecture with the comprising of ReconfigurableHardware that can be dynamically configured on the fly (on demand). Reconfigurable computing is referredto as Reconfigware. Reconfigurable Computing uses Programmable Logic like Field Programmable Gate Ar-rays(FPGA) to accelerate computation. The innovative development of FPGAs whose configuration could bereprogrammed an unlimited number of times spurred the invention of a new field in which many different hard-ware algorithms could execute, in turn on a single device, just as many different software alforithms can run aconventional processor.
Some important advantages of Reconfigurable computing are:
• Speed advantage of direct hardware execution on the FPGA.
• Suitable for high performance low volume applications.
• Reconfigurable computers advance technologically at a faster rate than microprocessors.
The speed advantage of reconfigware(FPGAs) derives from the fact that the prorgrammable hardware iscustomized to a particular algorithm. Thus the FPGA can be configured to contain exactly and only thoseoperations that appear in the algorithm. In contrast, the design of a fixed instruction set processor mustaccommodate all possible operations that an algorithm might require for all possible data types.
1.1.1 Difference from a conventional processor
An FPGA can be configured to contain exactly and only those operations that appear in the algorithm. Incontrast, the design on a fixed instruction set processor must accomodate all possible operations that an al-gorithm might require for all possible data types. An FPGA can be configured to perform arbitrary fixedprecision arithmetic with the number of arithmetic units, their type and their interconnection uniquely definedby the algorithm. The fixed instruction processor contains ALUSs of a specific widht(16,32,64bit) and haspredetermined control and data flow patterns.
1.1.2 Practical Scenario
For example, a given signal processing application might require only 12-bit fixed-point precision arithmeticand use custom rounding modes, whereas other application codes might make intensive use of a 14-bit butterflyrouting network used for fast parallel computation of a fast Fourier transform (FFT). In both cases, a traditionalprocessor does not have direct support for these structures, forcing programmers to use hand-coded routinesto implement the basic operations. In these kind of situations, it can be highly desirable to develop dedicatedhardware structures that can implement specific computations for performance, but also for other metricssuch as energy.
4

1.2. FPGA CHAPTER 1. RECONFIGWARE
1.2 FPGA
1.2.1 Reconfigurable Logic Devices
Recent developments in reconfigurable computing have been fueled by the availability of logic devices thatcan be quickly and easily programmed and reprogrammed to perform a large variety of functions. The firstdevices of this type that achieved enough density to perform significant portions of a computation and that hadsignificant availability were field- programmable gate arrays(FPGAs).
These chips provide the designer with arrays of simple logic functions and memories (such as flip-flops) thatcan be connected through programmable interconnection networks.
1.2.2 Introduction to FPGAs
A Field programmable Gate Array (FPGA) is an integrated circuit designed to be configured by the customer ordesigner after manufacturing, hence ”field programmable”.With their introduction in 1985, field-programmablegate arrays (FPGAs) have been an alternative for implementing digital logic in systems.To begin with, FP-GAs were used to provide a denser solution for glue logic within systems, but now they have expanded theirapplications to the point that it is not uncommon to find FPGAs as the central processing devices withinsystems.
FPGAs contain programmable logic components called ”logic blocks”, and a hierarchy of reconfigurableinterconnects that allow the blocks to be ”wired together” somewhat like many (changeable) logic gates thatcan be inter wired in (many) different configurations.Logic blocks can be configured to perform complex com-binational functions, or merely simple logic gates like AND and XOR. In most FPGAs, the logic blocks alsoinclude memory elements, which may be simple flip-flops or more complete blocks of memory.
1.2.3 Advantages
Being a standard product; no non-recurring engineering costs for fabrication; pre-tested silicon for use by thedesigner; and reprogrammability, allowing designers to upgrade or change logic through in-system programming.By reconfiguring the device with a new circuit, design errors can be fixed, new features can be added, or thefunction of the hardware can be entirely retargeted to other applications.
1.2.4 Drawbacks
Compared with ASICs (Application Specific Integrated Circuits) and MPGAs, FPGAs cost more per chip toperform a particular function so they are not good for extremely high volumes. Also, an FPGA implementationof a function is slower than the fixed-silicon options. Over time, though, the expense of doing custom siliconand the fact that FPGAs now tend to use state-of-the-art CMOS processes mean that FPGAs are performingmore of the functions that ASICs and MPGAs would have performed in many systems.
1.2.5 FPGA Layout
The FPGA layout depicts a grid like structure were the basic building blocks are the Logic Blocks. Thecommunication happens through the I/O cells in the periphery of the FPGA.
Department of Computer Science, CUSAT 5

1.2. FPGA CHAPTER 1. RECONFIGWARE
1.2.6 Common FPGA Role in Industry
• The most common use of an FPGA is for prototyping the design of an ASIC.
• System designers leave the FPGAs as part of the production hardware because of lower FPGA prices andhigher gate counts.
• Create systems that retain the execution speed of dedicated hardware but also have a great deal offunctional flexibility(hardware level).
1.2.7 Configurable Computing
The logic within the FPGA can be changed when it is necessary, basically by reprogramming the logic blocks.Sohardware that has been shipped comprising of FPGAs can be modified or changed.One use can be to administerhardware bug fixes and upgrades e.g. In order to support a new version of a network protocol, you can redesignthe internal logic of the FPGA, send the enhancement to the affected customers by email.Once they downloadthe new logic design to the system and restarted it, they will be able to use the new version of the protocol.Thisis configurable computing. Reconfigurable computing goes one step further.
1.2.8 Reconfigurable computing
Here users are given the power to configure the hardware on the fly, by downloading something similar tohardware profiles to redesign their FPGA and inturn their hardware.Design of the hardware may change inresponse to the demands placed while running.FPGA acts as an execution engine for a variety of differenthardware functions.Some executing in parallel, others in serial much as a CPU acts as an execution engine fora variety of software threads.Here the FPGA can be called a reconfigurable processing unit (RPU).
1.2.9 Real Life Scenario
A smart cellular phone that supports multiple communication and data protocols.When the phone passes froma geographic region that is served by one protocol into a region that is served by another, the hardware isautomatically reconfigured.It would be possible to support as many protocols as could be fit into the availableon-board ROM.New protocols could be uploaded from a base station to the handheld phone on an as-neededbasis.
Department of Computer Science, CUSAT 6

1.2. FPGA CHAPTER 1. RECONFIGWARE
Department of Computer Science, CUSAT 7

Chapter 2
Reconfigurable Architectures
2.1 Categories of FPGA Based Systems
FPGA based systems can be broadly classified into two categories based on their use of FPGA.
• Hybrid Computers
• Fully FPGA based Systems
2.1.1 Hybrid computers
These combine a single or a couple of reconfigurable logic chip FPGAs, with a standard microprocessor CPU.Itcan be done in many ways, two examples are:
• By exchanging one CPU of a multi CPU board with a FPGA (hybrid-core computing).
• Or adding a PCI or PCI Express based FPGA expansion card to the computer.
Simplified, they are Von-Neumann based architectures with an integrated FPGA accelerator.The advantageis that it enables users to get an acceleration of their algorithm without losing their standard CPU basedenvironment.The disadvantageis that architectural compromise results in reduced scalability and raises theirpower consumption.Same bottlenecks as all von Neumann based architectures.
Examples of Hybrid Computers
• XD1. A machine designed by OctigaBay
• SGI sells the RASC platform with their Altix series of supercomputers.
• SRC Computers, Inc. has developed a family of reconfigurable computers.
• Convey Computer Corporation’s HC-1
• CompactRIO from National Instruments.
2.1.2 Fully FPGA based Systems
A relatively new class is the fully FPGA based systems.They usually contain no CPUs or use the CPUs onlyas interface to the network environment.
Advantages
Their benefit is to transport the energy efficiency and scalability of FPGAs fully without compromise to theirusers.Fully scalable even across single machine borders(Depending on the Architecture of the interconnectionbetween the FPGAs).Bus system and overall architecture eliminate the bottlenecks of the von Neumann archi-tecture.
8

2.2. ARCHITECTURE LAYOUT CHAPTER 2. RECONFIGURABLE ARCHITECTURES
Examples of Fully FPGA Systems
• COPACOBANA: the Cost Optimized Codebreaker and Analyzer SciEngines company of the COPACOBANA-Project of the Universities of Bochum and Kiel in Germany.
• COPACOBANA RIVYERA(Reconfigure Versatally your raw architecture) the fourth generation offully FPGA based computers .
2.2 Architecture Layout
Reconfigurable computing systems are typically based on Reconfigurable processing units (RPUs) acting ascoprocessor units and coupled to a host system.(Hybrid).Wide variety of possible reconfigurable architecturesbased on:
• The type of interconnection between the RPUs and the host system.
• Granularity of the RPUs.
Some architectures map specific aspects of computations to RPUs.At present no single dominant RPU solutionhas emerged for all domains of applications.
2.3 Coupling Methods
Type of coupling of the RPUs to the existent computing system has impact on the communication cost, classifiedinto 3 groups in order of decreasing communication costs: Connection between RPUs and the host processorvia a local or a system bus:
• RPU can be tightly coupled to the host processor
• RPUs acting like an extended datapath of the processor
2.3.1 RPUs Coupled to host bus
• Connection between RPUs and the host processor via a local or a system bus.
• HOT-I, II,Xputer, SPLASH, ArMem, Teramac, DECPerLe-1, Transmogrifier, RAW and Spyder.
2.3.2 RPUs coupled like coprocessors
• RPU can be tightly coupled to the host processor, has autonomous execution and access to the systemmemory.
• In most architectures, when RPU is executing host processor is in stall mode.
• NAPA, REMARC, Garp, PipeRench, RaPiD, and MorphoSys
2.3.3 RPUs like Extended Datapath
RPUs acting like an extended datapath of the processor and without autonomous execution.The execution ofthe RPU is controlled by special opcodes of the host processor instruction-set.These datapath extensions arecalled reconfigurable functional units. Examples are Chimaera, PRISC, OneChip and ConCISe.
2.4 Granularity and Classification
Granularity refers to the data path width. Based on granularity the architectures can be classified into threebroad categories, as follows:
• Fine Grained
• Coarse Grained
• Mix-coarse-grained
Department of Computer Science, CUSAT 9

2.4. GRANULARITY AND CLASSIFICATION CHAPTER 2. RECONFIGURABLE ARCHITECTURES
• Fine-grained The use of the RPUs with fine-grained elements is used to define specialized datapath andcontrol units.
• Coarse-grained The RPUs in these architectures are often designated field-programmable ALU arrays(FPAAs), as they have ALUs as reconfigurable blocks. These architecture are especially adapted tocomputations over typical data-widths.
• Mix-coarse-grained These include architectures consisting of tiles that usually integrate one processorand possibly one RPU on each tile.
Department of Computer Science, CUSAT 10

Chapter 3
Overview of Compilation Flows - FrontEnd
3.1 Overview
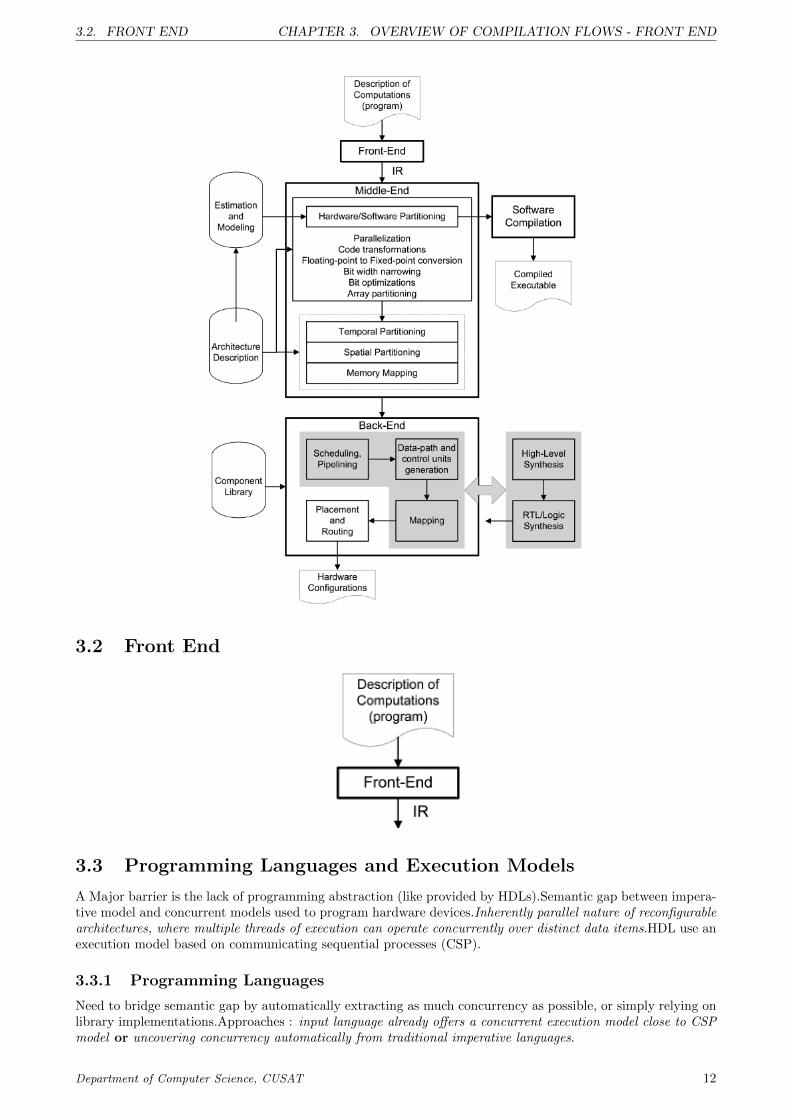
This section presents an overview of compilation flows that target reconfigurable computing architectures. Ageneric compilation flow is depicted in Figure below. As with traditional compilation, it first uses a front-endto decouple the specific aspects of the input programming language (e.g., its syntax) from an intermediate rep-resentation (IR). Next, the middle-end of the compiler applies a variety of architecture-neutral transformations
(e.g., constant folding, subexpression elimination, elimination of redundant memory accesses), and architecture-driven transformations (e.g., loop transformations, bit-width narrowing) to expose specialized data types andoperations and fine-grained as well as coarse-grained parallelism opportunities. While some transformationsexploit high-level architectural aspects such as the existence of multiple memories to increase the availability ofdata, other transformations exploit the ability to customize specific functional units in an RPU (reconfigurableprocessing unit), thereby directly implementing high-level instructions at the hardware level. The latter includesthe customization of arithmetic units to directly support fixed-point operations using nonstandard bit-widthformats that are representations or rounding modes. Finally, the flow includes a back-end. This compiler stage
schedules macro-operations and instructions, generates the definition of a concrete architecture by the synthesisof its datapaths and FUs, and performs the low-level steps of mapping and placement and routing (P&R), ifapplicable.
11
3.2. FRONT END CHAPTER 3. OVERVIEW OF COMPILATION FLOWS - FRONT END
3.2 Front End
3.3 Programming Languages and Execution Models
A Major barrier is the lack of programming abstraction (like provided by HDLs).Semantic gap between impera-tive model and concurrent models used to program hardware devices.Inherently parallel nature of reconfigurablearchitectures, where multiple threads of execution can operate concurrently over distinct data items.HDL use anexecution model based on communicating sequential processes (CSP).
3.3.1 Programming Languages
Need to bridge semantic gap by automatically extracting as much concurrency as possible, or simply relying onlibrary implementations.Approaches : input language already offers a concurrent execution model close to CSPmodel or uncovering concurrency automatically from traditional imperative languages.
Department of Computer Science, CUSAT 12

3.4. INTERMEDIATE REPRESENTATIONSCHAPTER 3. OVERVIEW OF COMPILATION FLOWS - FRONT END
3.3.2 Solutions to Concurrency Challenges
Data Streaming concept helps Inter Process Concurrency. (But Intra process concurrency still remains a chal-lenge).Languages with explicit mechanisms for specifying concurrency are needed.Languages with contructs forspecific type of applications(eg: SA-C is a language for Image processing).These languages can serve as inter-mediate languages used by a compiler tool when mapping a higher level abstraction languages to reconfigurablearchitecture(RA).Graphical systems allow the concurrency to be exposed at the task level.
3.4 Intermediate Representations
Intermediate Representation of a program should have two properties : it should be easy to produce and easyto translate into the target machine.IR of a compiler for these architectures should explicitly represent notionof concurrency.A basic flow of how the Intermediate Representation plays a role in the compilation process isshown below:
The hyperblock representation increases the amount of available concurrency in the representation whichcan be used to enlarge the number of operations considered at the same time. The HTG combined with aglobal DFG provided with program decision logic seems to be an efficient intermediate model to representfunctional parallelism at various levels.DDG and CDG can be used for showing multiple flows of control.Theunified specification model (USM) representation is used in the co-synthesis and HLS community.
3.5 Summary
There is still no clear migration path from more traditional imperative programming languages to such hardware-oriented representations.This mapping fundamentally relies on the ability of a compilation tool to uncover thedata dependences in the input computation descriptions.Important aspects such as the ability to map an existingsoftware code base to such a language and to facilitate the porting of library codes are likely to play key rolesin making reconfigurable systems attractive for the average programmer.To date, no programming model, highlevel language or intermediate representation has emerged as a widely accepted programming and compilationinfrastructure paradigm that would allow compilers to automatically map computations described in high-levelprogramming languages to reconfigurable systems.
Department of Computer Science, CUSAT 13

Chapter 4
Middle End and Back End
4.1 Code Transformations
Code Transformations can be used for customizing the hardware implementations to a specific computa-tions.They should have lower execution times and consume less hardware resources.Code transformations forReconfigurable computing platforms are:
• Low Level(Bit Level)(for fine-grained i.e FPGAs)
• Instruction Level (for Coarser grained)
4.1.1 Bit-Level Transformations
Bit Width Narrowing In many programs, the precision and range of the numeric data types are over-defined.The implementation size and/or the delay of an FU with the required bit-width can be substantiallyreduced.Bit Width Narrowing can be static, profiling-based, dynamic or both.BitValue used as advanced staticbit-width dataflow analysis.Propagation of value ranges can be used for dynamic Bit Width Inference for datapath specialization. Static analysis is Conservative and faster (eg: BitValue).Profiling-based analyses can havelong runtimes, reduce the bit-widths even more and is heavily dependent on the input data.
4.1.2 Bit Optimizations
Applying bit-width narrowing and bit-optimization to programs with intensive bit-manipulations (mask, shift byconstants, concatenation, etc.) is likely to lead to significant improvements by saving resources and decreasingexecution times.Bit-optimizations are frequently done in logic synthesis using binary decision diagram (BDD)representations.
For instance, the statement c=(a.b)[7,0] where b is an 8-bit variable, the operator . represents concatenation,and square brackets represent the bit-range of the expression assigned to c, simplifies to c=b[7,0] and permitsus to have wires only between the 8 least significant bits of b directly connected to c. The previous statementin DIL(language for the DIL compiler) is equivalent to the C statement: c = (0xff)&((a << 8)|((0xff)&b)),which requires more aggressive analysis to show the optimized circuit.
14

4.2. INSTRUCTION LEVEL TRANSFORMATIONS CHAPTER 4. MIDDLE END AND BACK END
4.1.3 Converting from Floating to Fixed point representations
This conversion can be used to reduce the costs(gates and clock cycles) associated with arithmetic operationsin floating-point format using an integer representation, i.e integer Functional Units.The operation assigns aunique fixed point representation for each variable in the source code.We can use a two step approach : Findingthe minimum number of bits of the integer part of the representation using value range propagation analysis(forward and backward).Then the approach seeks the minimum number of bits in the fractional part of thefixed-point representation.
4.2 Instruction level Transformations
These transformations reduce the hardware resources allocated for a given computation by using a combina-tion of algebraic simplification or circuit specialization.Simple algebraic transformations can be usedfor tree height reduction (THR), common subexpression elimination (CSE) and strength reduction.Algebraictransformations specific to specialized hardware implementations that are only possible due to the flexibility ofreconfigware.When compiling arithmetic expressions, some properties should be evaluated in order to find moreefficient hardware implementations.
4.2.1 Tree Height Reductions (THR)
Tree-height reduction/ minimization is a well-known technique to reduce the height of a tree of operations byreordering them in a way that the initial functionality is preserved.
4.2.2 Operation Strength Reduction(OSR)
The objective of operation strength reduction is to replace an operation by a computationally less expensiveone or a sequence of operations.
Department of Computer Science, CUSAT 15

4.3. LOOP LEVEL TRANSFORMATIONS CHAPTER 4. MIDDLE END AND BACK END
4.3 Loop Level Transformations
Transformations like loop unrolling, loop tiling, and unroll-and-jam enables matching of the instruction-levelparallelism in a given computation to the available hardware resources at hand.Loop unrolling is the mostcommonly used loop transformation, as it decreases the loop overhead while increasing the opportunities forInstruction Level Parallelism.Loop tiling can be applied to inner loops to create two nested loops,and is able tosplit the original iteration space.
4.4 Data Oriented Transformations
The flexibility of reconfigurable arhitectures, in terms of the configuration and organization of storage struc-tures, makes data-oriented transformations such as data distribution, data replication, and scalar replacementparticularly suited for these architectures.
4.4.1 Data Distribution
This transformation partitions a given program array variable (other data structures can also be considered)into many distinct arrays, each of which holds a disjoint subset of the original arrays data values.Each of thesenewly created arrays can then be mapped to many distinct internal memory units or modules,but the overallstorage capacity used by the arrays is preserved.
4.4.2 Data Replication
Another data-oriented transformation that increases the available data bandwidth, this time at the expense ofan increase in the storage used,is data replication.Data is copied as many times as desired into distinct arrayvariables, which can then be mapped to distinct memory modules to enable concurrent data access.
Department of Computer Science, CUSAT 16

4.5. SCALAR REPLACEMENT CHAPTER 4. MIDDLE END AND BACK END
4.5 Scalar Replacement
In this transformation the programmer selectively chooses which data items will be reused throughout a givencomputation and cached in scalar variables.In the context of traditional processors, the compiler then attemptsto map these scalar variables to internal registers for increased performance. When mapping computations toreconfigurable architectures, designers attempt to cache these variables either in discrete registers or in internalmemories.In this case, multiple accesses to each element of the array are eliminated by a prior loading of eachelement to a distinct scalar variable.
4.6 Mapping Techniques
We now present some of the most important aspects related to the mapping of computations to reconfigurablearchitecturesa very challenging task given the heterogeneity of modern reconfigurable architectures. As many ofthe platforms use a board with more than one reconfigurable device and multiple memories, a key step consistsin spatial partitioning of computations among the various reconfigurable devices in the board and/or itstemporal partitioning when the computations do not fit in a single device or in all devices, respectively.Atlower levels, operations and registers must be mapped to the resources of each reconfigurable device.Followingdescribe several mapping techniques:
4.7 Control Flow Optimization
4.7.1 Speculative Execution
Mapping of computational constructs on reconfigurable architectures in such a way that speculative executionof operations without side-effects is accomplished.Speculative Execution does not require additional hardwareresources.In the case of the operations with side-effects (e.g., memory writes) requires the compiler to quantifyif the restoring step.
4.7.2 Multiple Flows of control
Since the control units for the datapath are also generated by the compilation process, it is possible to addressmultiple flows of control.This can increase the number of operations executing on each cycle by increasing theILP.Used with loops without data dependencies among them or functional parallelism.
Department of Computer Science, CUSAT 17

4.8. PARTITIONING CHAPTER 4. MIDDLE END AND BACK END
4.7.3 Data Flow
Given the suitability in fine-grained reconfigurable architectures for implementing concurrent harware struc-tures.Program decision logic,that is, logic that enables/disables the execution of a certain instruction andpredicated execution are effective techniques for handling control constructs.
4.8 Partitioning
Both temporal and spatial partitioning may be performed at the structural or behavioral (also known as func-tional partitioning) levels. This description of partitioning techniques focuses mainly on the partitioning atbehavioral levels, since this article is about compilation of high-level descriptions to reconfigurable computingplatforms. Figure 12 presents an example depicting spatial and temporal partitioning.
4.8.1 Temporal Partitioning
Temporal partitioning allows us to map computations to reconfigurable architectures without sufficient hardwareresources.It reuses the available device resources by different circuits (configurations) by time-multiplexing thedevice, and is thus a form of virtualization of hardware resources.Compiling loops that require more resourcesfor each temporal partition than available can be attained by the application of two loop transformations,namely:
Loop distribution This partitions a loop into two or more loops, each of which now fits in the availablehardware resources.The Disadvantage is that uses more memory resources to store the values of certain scalarvariables computed in each iteration of the first loop and used by the second loop. The advantages is thatreconfiguration is only needed between the loops.
Loop dissevering To guarantee the compilation of any kind of loop, in the presence of any type of depen-dences, and with any nested structures this method converts a loop into a set of configurations, which can bemanaged by the host CPU.Does not depend on loop dependenecs and does not require expansion of certainscalar variables into arrays.More suitable for short loops and outer loops in loop nests.
Department of Computer Science, CUSAT 18

4.9. RESOURCE MAPPING CHAPTER 4. MIDDLE END AND BACK END
4.8.2 Spatial Partitioning
Refers to the task of automatically splitting a computation into a number of parts such that each of them canbe mapped to each reconfigurable device (RPU).Performed when computations cannot be fully mapped into asingle RPU and the reconfigurable computing platform has two or more RPUs with interconnection resourcesamong them.Does not need to preserve dependences when splitting the initial computations.
4.9 Resource Mapping
4.9.1 Register Assignment
Scalar variables are directly stored in the RPU registers, and compound data structures mapped to memo-ries.Hence scalar variables need not be loaded from and stored to memories and are always directly availableon the RPU.Register assignment algorithms can be used whenever the number of variables in the program (ineach temporal partition) exceeds the number of registers in the reconfigurable architecture.
Registers can also be used to store data computed or loaded in a loop iteration and used in subsequent itera-tions.Temporal common subexpression elimination to optimize the generated datapath.The technique identifiesexpressions that recompute values that were computed in previous iterations of the loop and replaces them withregisters.Data reuse is applied when the same array elements are loaded in different loop iterations, or when anarray element is stored in one loop iteration and loaded in subsequent loop iterations.
4.10 Pipelining
Pipeline execution overlaps different stages of a computation.complex operation is divided into a sequence ofsteps, each of which is executed in a specific clock cycle and by a given FU.The pipeline can execute steps of dif-ferent computations or tasks simultaneously, resulting in a substantial throughput increase and thus leading tobetter aggregate performance.Reconfigurable architectures, both fine and coarse-grained, present many opportu-nities for custom pipelining via the configuration of memories, FUs and pipeline interstage connectivity.Variousforms of pipelining enabled by these architectures are lister below:
Pipelined Resources: In this form of pipelining, operations are structured internally as multiple pipelinestages.
Pipelining Memory Accesses : Pipelining of memory operations is an extremely important source ofperformance gains in any computer architecture, given the growing gap between processor speeds and memorylatencies.
Pipelining Configuring-Computation Sequences : Since the configuration of the reconfigurable resourcestakes several clock cycles, it is important to hide such latency overheads by overlapping the steps to store thenext configuration on chip while the current active configuration is running.
Loop Pipelining Loop pipelining is a technique that aims at reducing the execution time of loops by explicitlyoverlapping computations of consecutive loop iterations.Only iterations (or parts of them) that do not dependon each other can be overlapped.Two distinct cases are loop pipelining of inner loops and pipelining acrossnested loops.
Department of Computer Science, CUSAT 19

4.11. MEMORY MAPPING OPTIMIZATIONS CHAPTER 4. MIDDLE END AND BACK END
4.11 Memory Mapping Optimizations
4.11.1 Partitioning and Mapping of Arrays to Memory Resources
Manual mapping of program data-structures onto the large number of available physical memory banks istoo complex, exhaustive search methods are too time-consuming.Compiler techniques can be used to partitionthe data structures and to assign each partition to a memory in the target architecture.Arrays can be easilypartitioned when the memory is disambiguated at runtime (Bank disambiguation is a form of intelligent datapartitioning).Locate the data as close as possible to the processing elements using it.
4.11.2 Parallelization of Memory Accesses
Reconfigurable computing systems can exploit this opportunity by defining different memory ports to interfacewith the available memory banks in a parallel fashion.
4.11.3 Customization of Memory Controllers
By creating specialized hardware components for generating addresses and packing and unpacking data items.Compilerscan analyze memory access patterns for pipelining of array references across multiple iterations of loops.Deriveinformation about the relative rates among various array references and embed that knowledge into the schedul-ing of memory operations.Modules that are generated by a compiler and a HLS tool that translates high-levelcomputations directly to FPGA hardware.Separated the memory interface into two components: 1:target-dependent and 2:architecture-independent.
4.11.4 Elimination of Memory accesses using register promotion
This mapping technique exploits the reuse of array values across iterations of a given loop and is typically usedin combination (either explicit or implicit) with the scalar replacement transformations.
4.12 Scheduling
Mapping assigns a register to each variable in the source code, thereby chaining all operations in an expression inone clock cycle.To control pipelined execution, the user must use auxiliary variables at operation level.Describea static scheduling algorithm that generates control units to coordinate the parallel execution of such concurrent
Department of Computer Science, CUSAT 20

4.13. BACK END CHAPTER 4. MIDDLE END AND BACK END
loops.The scheduler works at the top level of a HTG and merges blocks at loop boundaries based on an ASAPscheme.
4.13 Back End
The back-end support is related to the generation of the datapath and control unit structures (based onthe granularity of the target reconfigurable architecture).And the configuration data (also known as bitstreamin the FPGA domain) to be processed by the reconfigurable computing platform.For generating the hardwarestructure when a fine-grained architecture is targeted,three distinct approaches can be used: HLS tools, logicsynthesis tools, or module generators. Note, however, that the use of HLS tools needs the support of logicsynthesis and/or module generators.
Some compilers use back-end commercial logic synthesis and placement and routingtools. Such an approachhas been adapted from the traditional design flow for ASICs,and has the long runtimes and the inevitabilityof independent phases as its majordisadvantages. The compiler and the logic synthesis tool are connected bygenerating the description of the architecture in a textual model accepted by those tools.
Most of the compilers to reconfigware do not use complex logic synthesis steps for generating the controlstructure.For coarse-grained architectures, where most of the operations in the source language are directlysupported by the FUs existing in each cell of the target architecture,neither a circuit generator nor logic synthesisare needed to generate the datapath.
Department of Computer Science, CUSAT 21

Chapter 5
State of the art in ReconfigurableComputing
5.1 Compilers for Reconfigurable Architectures
• The SPC Compiler
• The DeepC Silicon Compiler
• The DEFACTO Project
• The Streams-C Compiler
• The CAMERON Project
Compilers for Coarse-Grained Reconfigurable Architectures
• The DIL Compiler for PipeRench
• The RaPiD-C Compiler
• The CoDe-X Framework
• The DRESC Compiler
5.1.1 Commercial adoption of Compiler
Although a theme that requires further research effort to be effective and competitive to manual design, anumber of research compilers have been adopted by companies as one of their main products.
5.2 Reconfigurable Supercomputer
A recent and powerful application of Reconfigware can be seen in the SuperComputer Novo-G(Kraken) developedat the university of California. It has the following specifications:
• Cray GNU/Linux Environment (CLE) 2.2
• A peak performance of 1.17 PetaFLOP
• 112,896 computer cores
• 129 TB of computer memory
• A 3.3 PB raw parallel file system of disk storage for scratch space (2.4 PB available)
• 9,408 computer nodes
Novo-G uses 192 reconfigurable processors and ”can rival the speed of the world’s largest supercomputers ata tiny fraction of their cost, size, power, and cooling.The designers claim that Novo-G can work at muchfaster speeds than the closest chinese counterpart,but at a fraction of the power consumed, due to the useof reconfigurable logic.This inherently new paradigm shift in the design of supercomputer for efficiency canbe viewed as a big breakthrough for Reconfigurable Computing. An image of the recently unveiled KrakenSuperComputer is shown below.
22

5.3. CONCLUSION CHAPTER 5. STATE OF THE ART IN RECONFIGURABLE COMPUTING
5.2.1 Kraken Supercomputer (Novo G)
5.3 Conclusion
5.3.1 Reconfigware Compilers today
Reconfigurable computing platforms present numerous challenges to the average software programmer as theyexpose a hardware-oriented computation model where programmers must also assume the role of hardware de-signers.Researchers have developed compilation techniques and systems supporting the notion of reconfigwareto automatically map computations described in high-level programming languages to reconfigurable architec-tures.Approaches have been influenced by research in the area of hardware/software codesign and hardwaresynthesis.Whereas others have attempted to bridge the gap directly using techniques from traditional compila-tion systems for which a dedicated hardware-oriented, and often architecture-specific, back-end was developed.
5.3.2 Future in Research
Automatic mapping of computations to reconfigurable computing architectures represents a relatively newand very promising area of research.Researchers have built on a wealth of research on software compilation,parallelizing compilers, and system-level and architectural synthesis.
5.3.3 Future in Industry
Given the traditional lengthy and error-prone process of hardware synthesis, many systems have used pre-existing compilation frameworks.Coupled with either commercial high-level synthesis tools or custom solutionsthat include module generators, to reduce the overall hardware/software solution development time.
Indeed an industry longing to create faster solutions and at the same time reducing power and costwill need to look beyond the conventional approaches and work with Reconfigurable computingtechnologies. Indeed the future path is clear, now all that is needed is an efficient developmentframework.
Department of Computer Science, CUSAT 23

Chapter 6
References
Bibliography
[1] http://www.netrino.com/Embedded-Systems/How-To/Reconfigurable-ComputingRetrieved (12/02/2011, 14:35)
[2] http://en.wikipedia.org/wiki/Granularity#Reconfigurable_computing_and_supercomputing
Retrieved (12/02/2011, 14:35)
[3] http://en.wikipedia.org/wiki/RDPARetrieved (12/02/2011, 14:35)
[4] http://www.netrino.com/Embedded\-Systems/How\-To/Reconfigurable\-Computing Retrieved (10/02/2011,
19:30)
[5] http://en.wikipedia.org/wiki/Communicating_sequential_processes Retrieved (12/02/2011, 20:00)
[6] http://en.wikipedia.org/wiki/Control_flow_graph Retrieved (12/02/2011, 21:00)
[7] http://en.wikipedia.org/wiki/High_Level_Synthesis Retrieved (16/02/2011, 8:30)
[8] http://en.wikipedia.org/wiki/Reconfigurable_computing Retrieved (9/02/2011, 8:30)
[9] http://en.wikipedia.org/wiki/Vectorization_parallel_computing#Building_the_dependency_
graph Retrieved (12/02/2011, 21:30)
[10] http://en.wikipedia.org/wiki/Data_flow_analysis Retrieved (13/02/2011, 7:30)
[11] http://en.wikipedia.org/wiki/Explicit_Data_Graph_Execution Retrieved (12/02/2011, 21:30)
[12] http://en.wikipedia.org/wiki/Streaming_algorithm Retrieved (12/02/2011, 21:30)
[13] http://en.wikipedia.org/wiki/Binary_decision_diagram Retrieved (13/02/2011, 8:10)
[14] http://en.wikipedia.org/wiki/Flow-based_programming Retrieved (15/02/2011, 10:10)
[15] Cardoso, J. M. P., Diniz, P. C., and Weinhardt, M. 2010. Compiling for reconfigurable computing: A survey.ACM Comput. Surv. 42, 4, Article 13 (June 2010), 65 pages.
[16] Polychronopoulos, Constantine D. 2011 The Hierarchical Task Graph and its Use in Auto-Scheduling Cen-ter for Supercomputing Research and Development, Dept. oj Electrical and Computer Engineering, Univer-sity of Illinois at Urbana-Champaign.
[17] Gokhale, Maya Streams-C Los Alamos National Laboratory, September, 1999.
24





























