Embed Size (px)
Citation preview

MáquinasdeFactorización{FactorizationMachines(FM)}
DenisParraSistemas Recomendadores
IIC36332dosemestre de2016
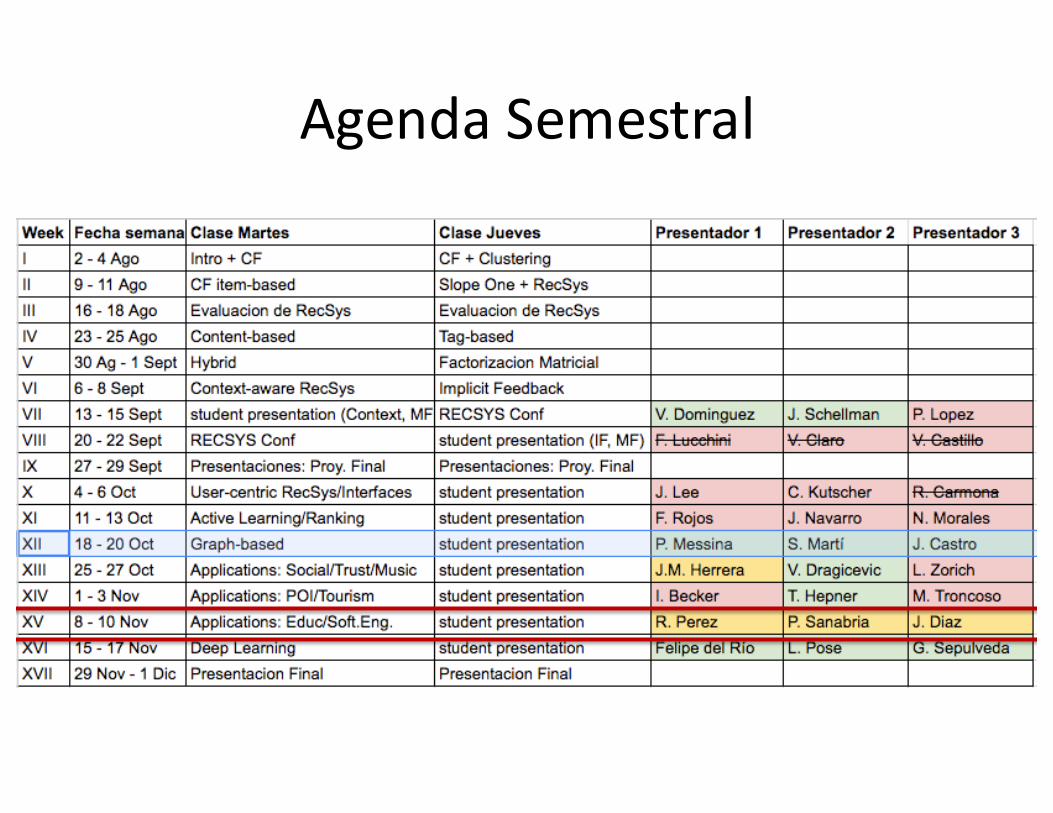
AgendaSemestral

Enesta clase
• Sugerencias parapresentar ProyectoFinal• FactorizationMachines• Resultado deproyecto final,clase RecSys 2014(usando MovieCity)

¿Cómo presento mis resultados enelproyecto final?
R:Usando como ejemplo lospapersdeRendleetal.
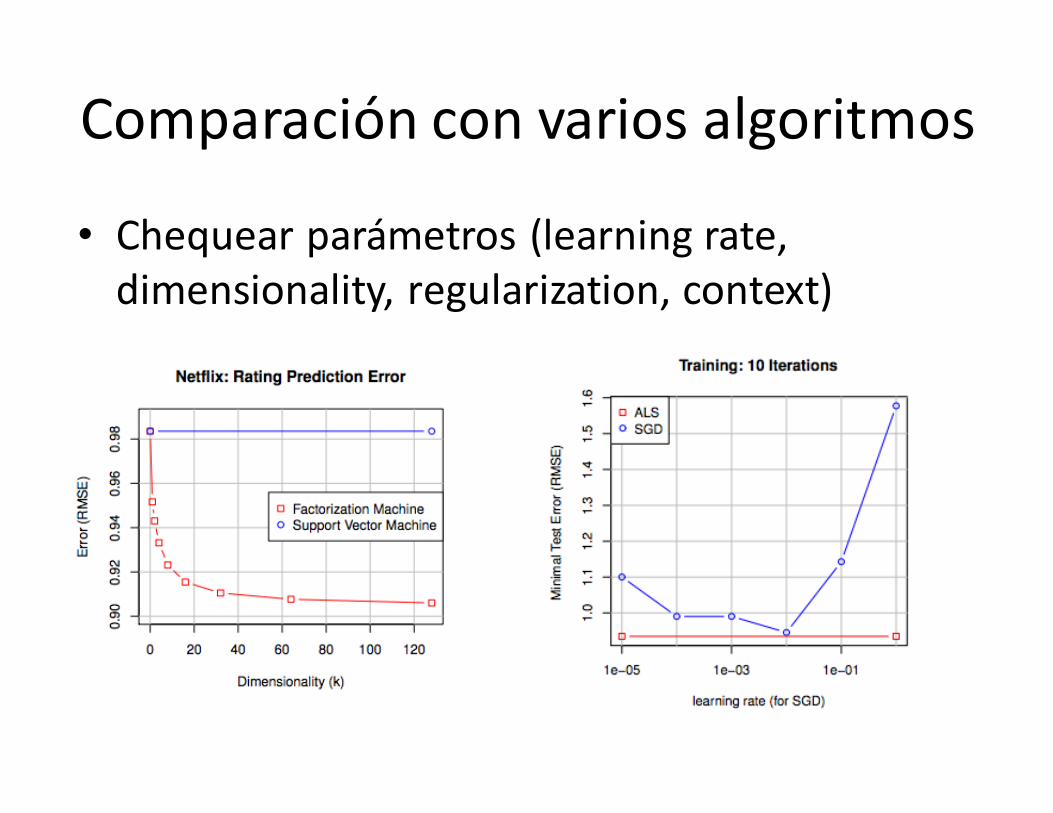
Comparación convarios algoritmos
• Chequear parámetros (learningrate,dimensionality,regularization,context)

Comparación convarios algoritmos
• Comparar distintos datasets/features
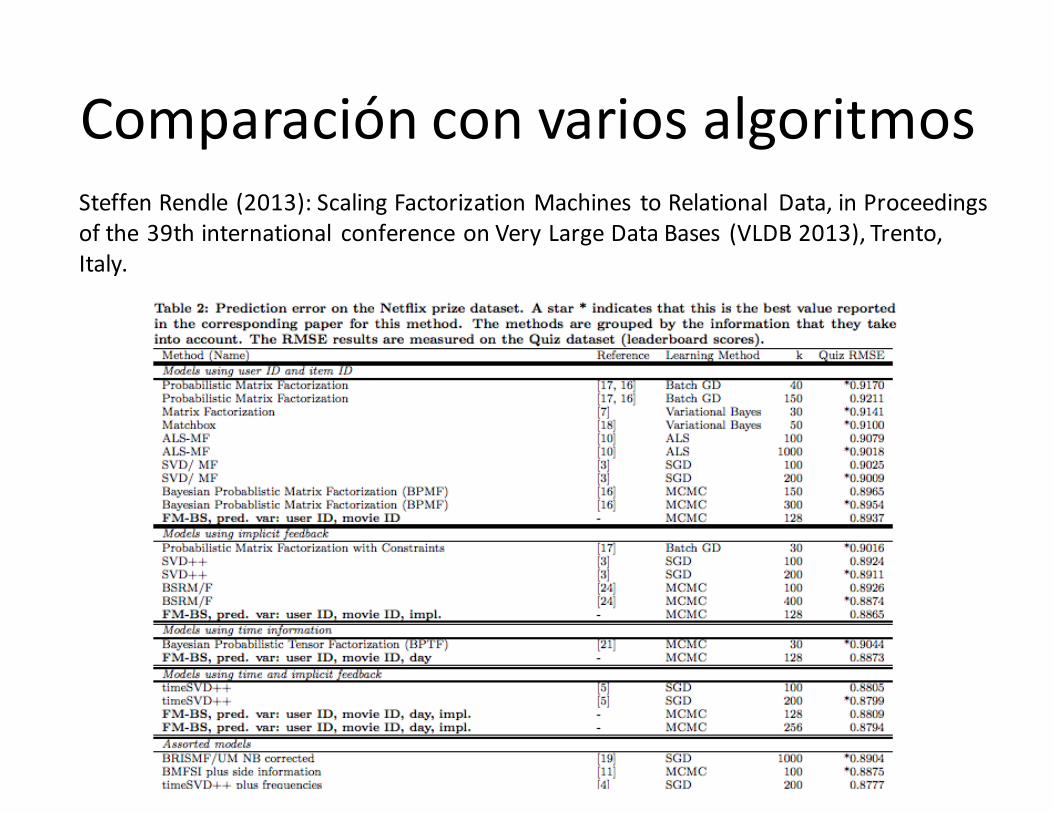
Comparación convarios algoritmosSteffenRendle (2013):ScalingFactorizationMachines toRelational Data,inProceedingsofthe39thinternational conferenceonVeryLargeDataBases (VLDB2013),Trento,Italy.

FactorizationMachines• Rendle,S.(2010,December).Factorizationmachines.InDataMining(ICDM),2010IEEE10thInternationalConferenceon(pp.995-1000).IEEE.
• Rendle,S.,Gantner,Z.,Freudenthaler,C.,&Schmidt-Thieme,L.(2011,July).Fastcontext-awarerecommendationswithfactorizationmachines.InProceedingsofthe34thinternationalACMSIGIRconferenceonResearchanddevelopmentinInformationRetrieval(pp.635-644).ACM.
• Rendle,S.(2012).FactorizationmachineswithlibFM.ACMTransactionsonIntelligentSystemsandTechnology(TIST),3(3),57.

Máquinas deFactorización (2010)• Inspiradas enSVM,permiten agregar unnúmeroarbitrario defeatures(user,item,contexto)perofuncionan bien con“sparsedata”alincorporarvariableslatentes factorizadas (inspiradas enFactorización Matricial).Nosenecesitan vectoresdesoporte para optimizar elmodelo.
• Generalizan diversos métodos defactorizaciónmatricial.
• Disminuyen lacomplejidad deaprendizaje delmodelo depredicción respecto demétodosanteriores.

Motivación deFM
• Cada tarea derecomendación (implicitfeedback,agregar tiempo,incorporar contexto)requiererediseño delmodelo deoptimización yre-implementación delalgoritmo deinferencia
• Loidealsería usar alguna herramienta comolibSVM,Weka,…agregar losvectores defeatures
• Pero para manejar datos tandispersos,sepodrían mantener las factorizaciones!

Ejemplo
• Supongamos lossiguientes usuarios,itemsytransacciones

RepresentaciónTradicional
http://dparra.sitios.ing.uc.cl/classes/recsys-2016-2/clase8_factorizacion_matricial.pdf

Otros ModelosEjemplos deDatos:Ejemplos deModelos:
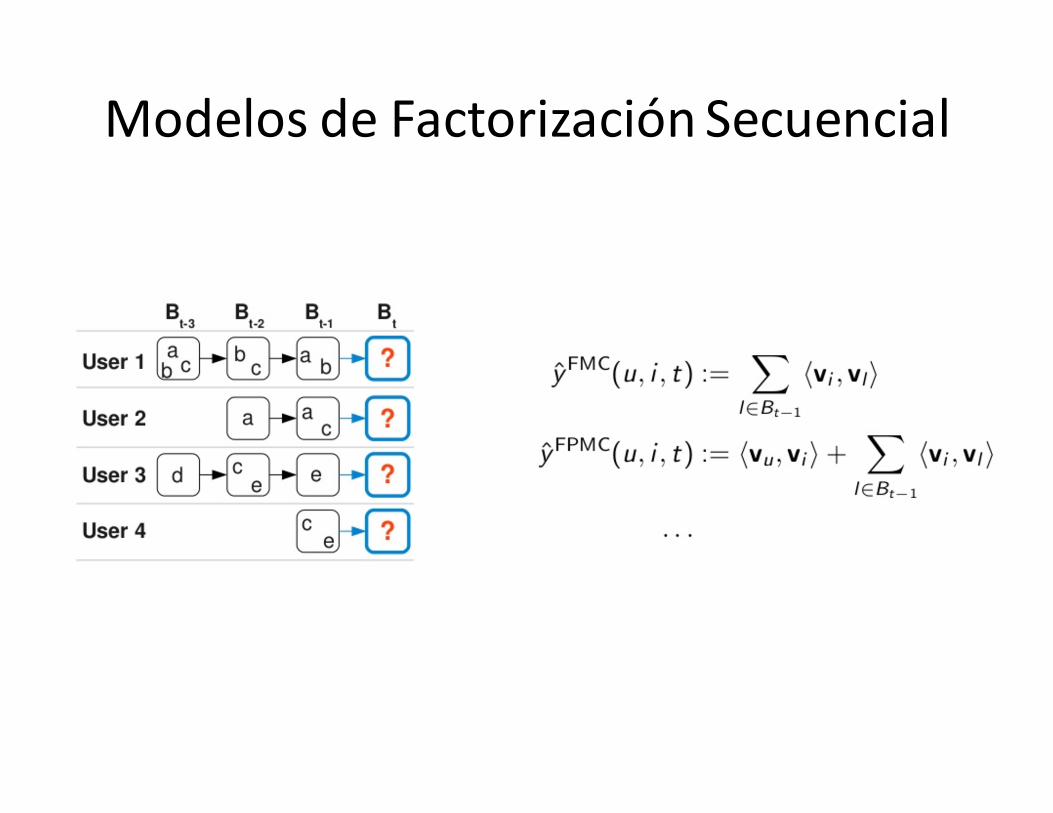
Modelos deFactorizaciónSecuencial

Modelos deFactorización
• Ventaja:– Permiten estimar interacciones entredos(omás)variablesincluso si lainteracciónnoesobservadaexplícitamente.
• Desventajas:–Modelos específicosparacadaproblema– Algoritmosdeaprendizajeeimplementacionesestándiseñadosparamodelosindividuales

Datos yRepresentacióndeVariables
• Muchos modelos deMLusan vectores devalores reales como input,loque permiterepresentar,por ejemplo:– Cualquier númerodevariables– Variablescategóricas->dummycoding
• Conestemodeloestándarpodemosusarregresión,SVMs,etc.

Modelo deRegresión Lineal
• Equivale aunpolinomio degrado 1• Queremos aprender w0 ylosp parámetros wj• Nologra capturar interacciones latentes comolafactorización matricial
• O(p)parámetrosenelmodelo.

Modelo coninteracciones (d=2)
• RegresiónPolinomial
• O(p2)parámetrosenelmodelo
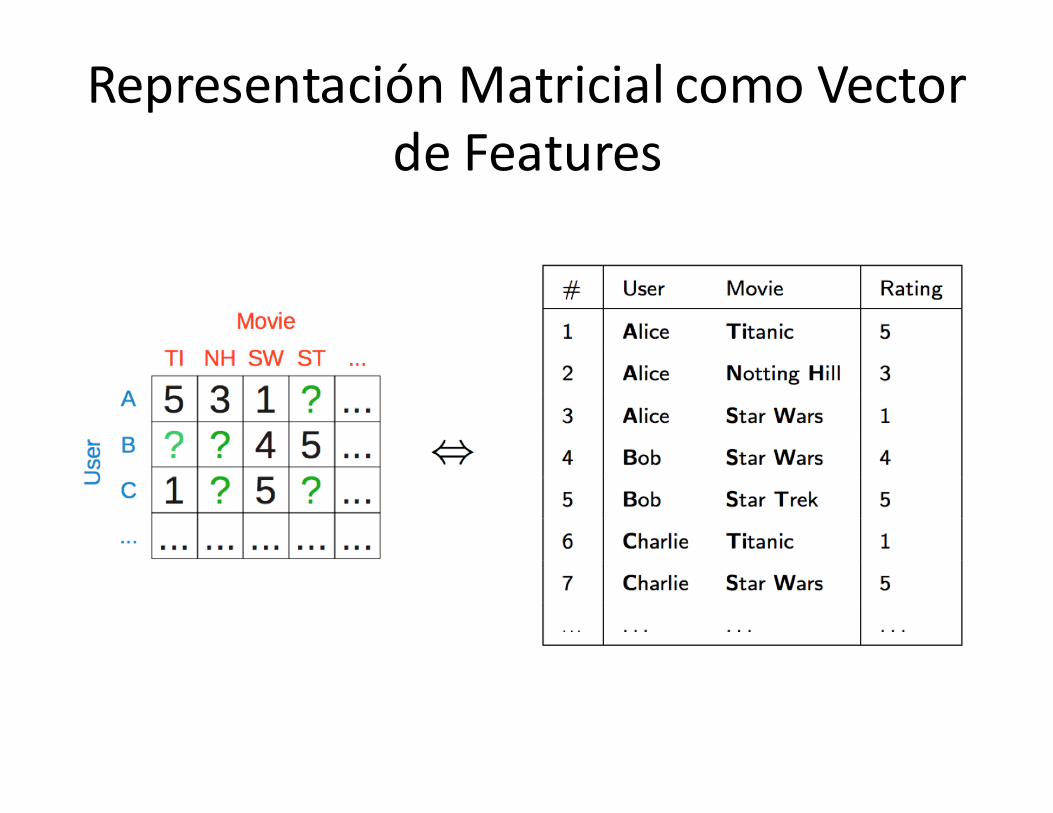
RepresentaciónMatricialcomoVectordeFeatures

Representación MatrizcomoVectordeFeatures

AplicacióndeRegresión
• RegresiónLineal:• RegresiónPolinomial:• FactorizaciónMatricial:

Problemas conRegresiónTradicional
• Regresiónlinealnoconsiderainteracionesusuario-item:poderdeexpresiónmuybajo
• RegresiónPolinomialincluyeinteraccionesdeparesperonosepuedeestimarporque– n<<p2:nro.decasosmuchomenorqueelnúmerodeparámetros.
– Regresiónpolinomialnopuedegeneralizarparacualquierefectodeparesdevariables.

Modelo coninteracción d=2yfactoreslatentes vs.Regresiónpolinomial
• MáquinadeFactorización
• RegresiónPolinomial

F.M.dadounmodelo cond=2
Sesgo (bias) global
Coeficientesde regresiónde la j-ésimavariable
Interacción de features
Factorización(variables latentes)

F.M.dadounmodelo cond=3
• Modelo
• Parámetros

Ensuma
• FMsusan como entradadatos numéricosreales
• FMsincluyeninteraccionesentrevariablescomolaregresiónpolinomial
• Losparámetrosdelmodeloparalasinteraccionessonfactorizados
• NúmerodeparámetrosesO(kp)vs.O(p2)enregresiónpolinomial.

Ejemplos
A. DosvariablescategóricasB. TresvariablescategóricasC. Dosvariablescategóricasytiempocomo
predictorcontinuoD. Dosvariablescategóricasytiempodiscretizado
enbinsE. SVD++F. Factorized Personalized Markov Chains (FPMC)

A.Dosvariablescategóricas
• Así,modelocorrespondeaMFconbiases

B.Tresvariablescategóricas• Prediccióndetripletas RDFconFM
• Equivalente aPITF(recomendacióndetags)

C.Dosvariablescategóricasytiempocomopredictorcontinuo
• Modelo corresponde a:
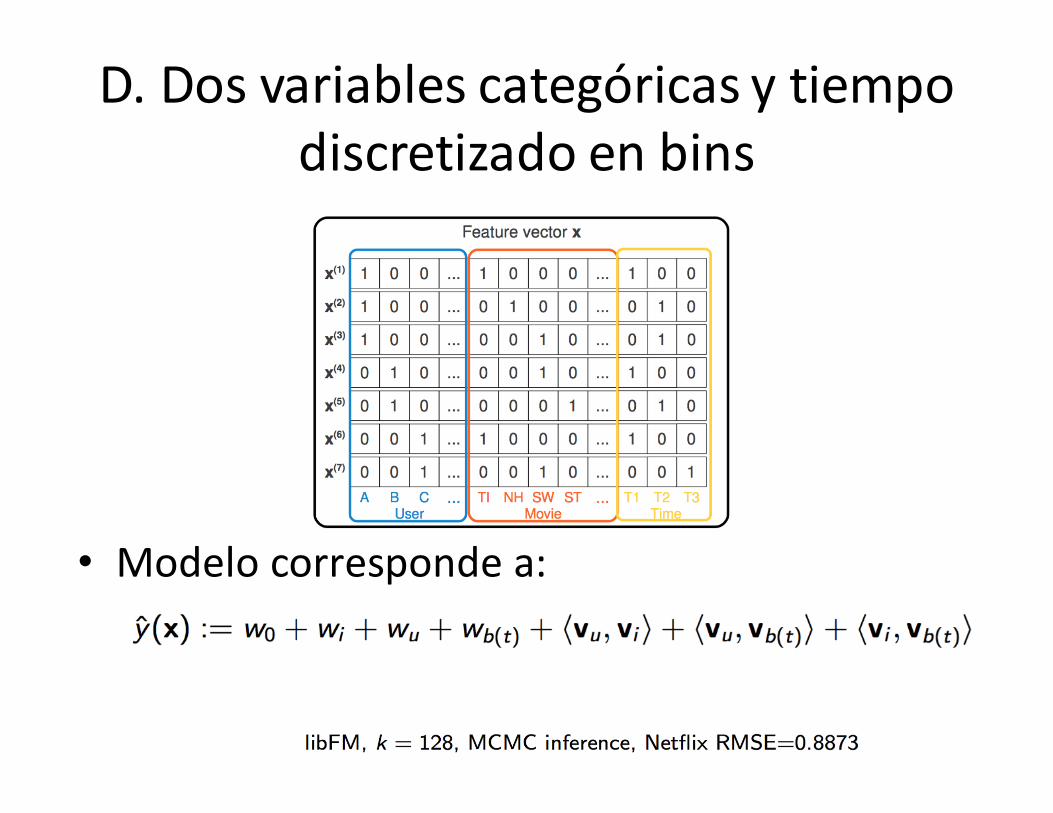
D.Dosvariablescategóricasytiempodiscretizado enbins
• Modelo corresponde a:

E.SVD++
• Modelo idénticoa:

F.FPMC
• Equivalente a:

Comparación conotros modelos
• EnelpaperRendle,S.(2010,December).Factorizationmachines,semuestra comodesde FMsepuede derivar:–MatrixFactorization– SVD++– Pair-wiseInteractionTag-Factorization(PITF)– FactorizedPersonalizedMarkovChains(FPMC)

Propiedades• Expresividad*(cualquier matrixsemi-definidapositiva)
• Multilinearidad**• Complexity
*,**ver detalles enRendle,S.(2010,December).Factorizationmachines.
O(kn^2)->O(kn)Ydebido adispersión delosdatos,O(kmD)

Complejidad
Númerodeparámetros :1 + p + k*p
linealrespectoaltamañodelinputyeltamañodelosfactoreslatentes

Reducción delmodelo

Aprendizaje
• RegularizaciónL2pararegresiónyclasificacion– SGD– ALS–MCMC
• RankingregularizadoL2TodoslosalgoritmostienentiempodeejecuciónO(kNz(x)i)dondei:iteraciones,Nz(X):elementosno-cero,yk:nro.defactoreslatentes.

Software:LibFM
• LibFM implementa FMs–Modelos:FMsde2doorden– Aprendizaje:SGD,ALS,MCMC– Clasificaciónyregresión– Formatodedatos:sparse(LIBSVM,LIBLINEAR,SVMlight,etc.)
– Soportaagrupacióndevariables– OpenSource:GPLv3
www.libfm.org

Predicciónderatings(Context-aware)

NetflixPrize

PredicciónderelacionesenRedes

KDDCup 2012:track1

PrediccióndeClicks

KDDCup 2012:Track2

Predecir Resultados deEstudiantes

Algunos Resultados

Algunos Resultados II

UsingLibfm
• Llamada 1:
• Llamada 2:

Ejemplo conlibFMexe
• WrapperdeLibFM paraR

Conclusiones
• FMscombinand regresiónlineal/polinomialconmodelosdefactorización.
• Interacciónentrevariablesseaprendenvíarepresentaciónlow-rank.
• Es posible laestimacióndeobservacionesnoobservadas.
• Sepueden calcular eficientemente ytienenuna buena calidad depredicción.

Referencias
• Rendle,S.(2010)“FactorizationMachines”(https://www.ismll.uni-hildesheim.de/pub/pdfs/Rendle2010FM.pdf)
• http://www.slideshare.net/hongliangjie1/libfm• http://www.slideshare.net/SessionsEvents/steffen-rendle-research-scientist-google-at-mlconf-sf
• http://www.slideshare.net/0x001/intro-to-factorization-machines?next_slideshow=1

Proyecto Finalcurso RecSys 2014• Trade-offsBetweenImplicitFeedbackandContext-AwareRecommendation– SantiagoLarraín,PUCChile– Nicolás Risso,PUCChile
• Moviecity Dataset

Proyecto Finalcurso RecSys 2014• Moviecity
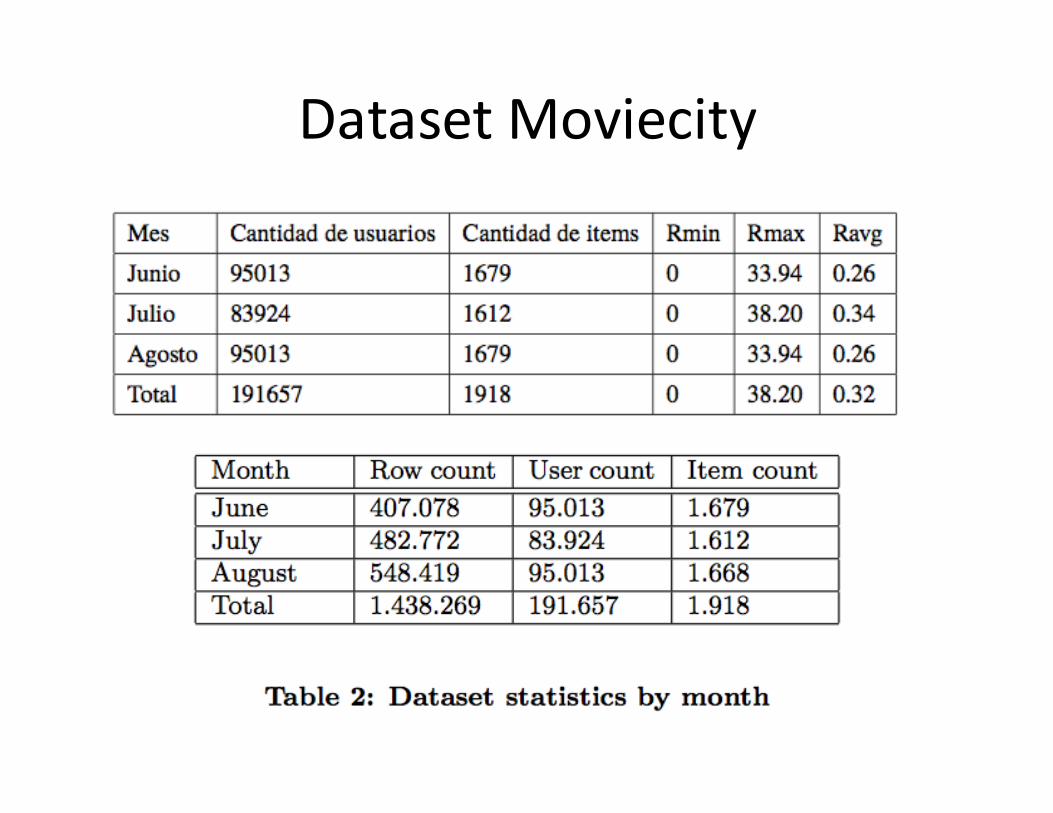
DatasetMoviecity

DatasetMovieCity II

Métodos I
• HuandKoren ~ImplicitFeedback

Métodos II
• Factorización Tensorial (usando HOSVD)

Métodos III
• FactorizationMachines,Rendle (2010)

Métricas deEvaluación
• RMSE:Diferencia detiempo entreprogramavisto ylopredicho

Optimización delosmodelos
Implicit Feedback
TensorFactorization
FactorizationMachines

Comparación delosModelos

Conclusiones
• ErrordeMAEentre40%y70%:diferenciapromedio entreeltiempo predicho yeltiempo que elusuario realmente vio.Mejormétodo es FactorizationMachines,indicandoque para esta tarea elcontexto ayuda.
• Ranking:elmejor método es ImplicitFeedbackrecommender.Extrañamente,estoindica que para rankear,elmejor método norequiere contexto.





























