Embed Size (px)
Citation preview

Machine Translation- 4
Autumn 2008
Lecture 19
10 Sep 2008

IBM Model 1 Recap
IBM Model 1 allows for an efficient computation of
translation probabilities
No notion of fertility, i.e., it’s possible that the same
English word is the best translation for all foreign words
No positional information, i.e., depending on the
language pair, there might be a tendency that words
occurring at the beginning of the English sentence are
more likely to align to words at the beginning of the
foreign sentence

IBM Model 2
Model parameters: T(fj | eaj ) = translation probability of foreign word fj
given English word eaj that generated it
d(i|j,l,m) = distortion probability, or probability that fj is aligned to ei , given l and m

IBM Model 3
Model parameters: T(fj | eaj ) = translation probability of foreign word fj
given English word eaj that generated it
r(j|i,l,m) = reverse distortion probability, or probability of position fj, given its alignment to ei, l, and m
n(ei) = fertility of word ei , or number of foreign words
aligned to ei
p1 = probability of generating a foreign word by
alignment with the NULL English word

IBM Model 3
IBM Model 3 offers two additional features compared to IBM Model 1: How likely is an English word e to align to k foreign
words (fertility)? Positional information (distortion), how likely is a word
in position i to align to a word in position j?

IBM Model 3: Fertility
The best Model 1 alignment could be that a single English word
aligns to all foreign words
This is clearly not desirable and we want to constrain the number of
words an English word can align to
Fertility models a probability distribution that word e aligns to k
words: n(k,e)
Consequence: translation probabilities cannot be computed
independently of each other anymore
IBM Model 3 has to work with full alignments, note there are up to
(l+1)m different alignments

IBM Model 3
Generative Story: Choose fertilities for each English word Insert spurious words according to probability of being
aligned to the NULL English word Translate English words -> foreign words Reorder words according to reverse distortion
probabilities

IBM Model 3
For models 1 and 2: We can compute exact EM updates
For models 3 and 4: Exact EM updates cannot be efficiently computed Use best alignments from previous iterations to
initialize each successive model Explore only the subspace of potential alignments that
lies within same neighborhood as the initial alignments

IBM Model 4
Model parameters: Same as model 3, except uses more complicated
model of reordering (for details, see Brown et al. 1993)


IBM Model 1 + Model 3
Iterating over all possible alignments is computationally infeasible
Solution: Compute the best alignment with Model 1 and change some of the alignments to generate a set of likely alignments (pegging)
Model 3 takes this restricted set of alignments as input

Pegging
Given an alignment a we can derive additional alignments from it by making small changes: Changing a link (j,i) to (j,i’) Swapping a pair of links (j,i) and (j’,i’) to (j,i’) and (j’,i)
The resulting set of alignments is called the neighborhood of a

IBM Model 3: Distortion
The distortion factor determines how likely it is that an
English word in position i aligns to a foreign word in
position j, given the lengths of both sentences:
d(j | i, l, m)
Note, positions are absolute positions

Deficiency Problem with IBM Model 3: It assigns probability mass to
impossible strings Well formed string: “This is possible” Ill-formed but possible string: “This possible is” Impossible string:
Impossible strings are due to distortion values that generate different words at the same position
Impossible strings can still be filtered out in later stages of the translation process

Limitations of IBM Models
Only 1-to-N word mapping Handling fertility-zero words (difficult for decoding) Almost no syntactic information
Word classes Relative distortion
Long-distance word movement Fluency of the output depends entirely on the English
language model

Decoding
How to translate new sentences? A decoder uses the parameters learned on a parallel
corpus Translation probabilities Fertilities Distortions
In combination with a language model the decoder generates the most likely translation
Standard algorithms can be used to explore the search space (A*, greedy searching, …)
Similar to the traveling salesman problem

Three Problems for Statistical MT
Language model Given an English string e, assigns P(e) by formula good English string -> high P(e) random word sequence -> low P(e)
Translation model Given a pair of strings <f,e>, assigns P(f | e) by formula <f,e> look like translations -> high P(f | e) <f,e> don’t look like translations -> low P(f | e)
Decoding algorithm Given a language model, a translation model, and a new
sentence f … find translation e maximizing P(e) * P(f | e)
Slide from Kevin Knight

The Classic Language ModelWord N-Grams
Goal of the language model -- choose among:
He is on the soccer fieldHe is in the soccer field
Is table the on cup theThe cup is on the table
Rice shrineAmerican shrineRice companyAmerican company
Slide from Kevin Knight

Intuition of phrase-based translation (Koehn et al. 2003)
Generative story has three steps
1) Group words into phrases
2) Translate each phrase
3) Move the phrases around

Generative story again
1) Group English source words into phrases e1, e2, …, en
2) Translate each English phrase ei into a Spanish phrase fj.
1) The probability of doing this is (fj|ei)
3) Then (optionally) reorder each Spanish phrase
1) We do this with a distortion probability
2) A measure of distance between positions of a corresponding phrase in the 2 lgs.
3) “What is the probability that a phrase in position X in the English sentences moves to position Y in the Spanish sentence?”

Slide from Koehn 2008

Slide from Koehn 2008

Distortion probability
The distortion probability is parameterized by ai-bi-1
Where ai is the start position of the foreign (Spanish) phrase generated by the ith English phrase ei.
And bi-1 is the end position of the foreign (Spanish) phrase generated by the I-1th English phrase ei-1.
We’ll call the distortion probability d(ai-bi-1). And we’ll have a really stupid model:
d(ai-bi-1) = |ai-bi-1|
Where is some small constant.

Final translation model for phrase-based MT
Let’s look at a simple example with no distortion
P(F | E) ( f i,e ii1
l
)d(ai bi 1)

Phrase-based MT
Language model P(E) Translation model P(F|E)
Model How to train the model
Decoder: finding the sentence E that is most probable

Training P(F|E)
What we mainly need to train is (fj|ei)
Suppose we had a large bilingual training corpus A bitext In which each English sentence is paired with a Spanish
sentence And suppose we knew exactly which phrase in Spanish was the
translation of which phrase in the English We call this a phrase alignment If we had this, we could just count-and-divide:

But we don’t have phrase alignments
What we have instead are word alignments:

Getting phrase alignments
To get phrase alignments:
1) We first get word alignments
2) Then we “symmetrize” the word alignments into phrase alignments

Model 1 continued
Prob of choosing a length and then one of the possible alignments:
Combining with step 3:
The total probability of a given foreign sentence F:

Decoding
How do we find the best A?

Training alignment probabilities
Step 1: get a parallel corpus Hansards
Canadian parliamentary proceedings, in French and English Hong Kong Hansards: English and Chinese
Step 2: sentence alignment Step 3: use EM (Expectation Maximization) to train word
alignments

Step 1: Parallel corpora
English German
Diverging opinions about planned tax reform
Unterschiedliche Meinungen zur geplanten Steuerreform
The discussion around the envisaged major tax reform continues .
Die Diskussion um die vorgesehene grosse Steuerreform dauert an .
The FDP economics expert , Graf Lambsdorff , today came out in favor of advancing the enactment of significant parts of the overhaul , currently planned for 1999 .
Der FDP - Wirtschaftsexperte Graf Lambsdorff sprach sich heute dafuer aus , wesentliche Teile der fuer 1999 geplanten Reform vorzuziehen .
Example from DE-News (8/1/1996)
Slide from Christof Monz

Step 2: Sentence Alignment
The old man is happy. He has fished many times. His wife talks to him. The fish are jumping. The sharks await.
Intuition:
- use length in words or chars
- together with dynamic programming
- or use a simpler MT model
El viejo está feliz porque ha pescado muchos veces. Su mujer habla con él. Los tiburones esperan.
Slide from Kevin Knight

Sentence Alignment
1. The old man is happy.
2. He has fished many times.
3. His wife talks to him.
4. The fish are jumping.
5. The sharks await.
El viejo está feliz porque ha pescado muchos veces.
Su mujer habla con él. Los tiburones esperan.
Slide from Kevin Knight

Sentence Alignment
1. The old man is happy.
2. He has fished many times.
3. His wife talks to him.
4. The fish are jumping.
5. The sharks await.
El viejo está feliz porque ha pescado muchos veces.
Su mujer habla con él.
Los tiburones esperan.
Slide from Kevin Knight

Sentence Alignment
1. The old man is happy. He has fished many times.
2. His wife talks to him.
3. The sharks await.
El viejo está feliz porque ha pescado muchos veces.
Su mujer habla con él.
Los tiburones esperan.
Note that unaligned sentences are thrown out, andsentences are merged in n-to-m alignments (n, m > 0).
Slide from Kevin Knight

Step 3: word alignments
It turns out we can bootstrap alignments From a sentence-aligned bilingual corpus We use is the Expectation-Maximization or EM
algorithm

EM for training alignment probs
… la maison … la maison bleue … la fleur …
… the house … the blue house … the flower …
All word alignments equally likely
All P(french-word | english-word) equally likely
Slide from Kevin Knight

EM for training alignment probs
… la maison … la maison bleue … la fleur …
… the house … the blue house … the flower …
“la” and “the” observed to co-occur frequently,so P(la | the) is increased.
Slide from Kevin Knight

EM for training alignment probs
… la maison … la maison bleue … la fleur …
… the house … the blue house … the flower …
“house” co-occurs with both “la” and “maison”, butP(maison | house) can be raised without limit, to 1.0,
while P(la | house) is limited because of “the”
(pigeonhole principle)
Slide from Kevin Knight

EM for training alignment probs
… la maison … la maison bleue … la fleur …
… the house … the blue house … the flower …
settling down after another iteration
Slide from Kevin Knight

EM for training alignment probs
… la maison … la maison bleue … la fleur …
… the house … the blue house … the flower …
Inherent hidden structure revealed by EM training!For details, see:
•Section 24.6.1 in the chapter• “A Statistical MT Tutorial Workbook” (Knight, 1999).• “The Mathematics of Statistical Machine Translation” (Brown et al, 1993)• Software: GIZA++
Slide from Kevin Knight

Statistical Machine Translation
… la maison … la maison bleue … la fleur …
… the house … the blue house … the flower …
P(juste | fair) = 0.411P(juste | correct) = 0.027P(juste | right) = 0.020 …
new Frenchsentence
Possible English translations,to be rescored by language model
Slide from Kevin Knight

A more complex model: IBM Model 3Brown et al., 1993
Mary did not slap the green witch
Mary not slap slap slap the green witch n(3|slap)
Maria no dió una bofetada a la bruja verde
d(j|i)
Mary not slap slap slap NULL the green witchP-Null
Maria no dió una bofetada a la verde brujat(la|the)
Generative approach:
Probabilities can be learned from raw bilingual text.

How do we evaluate MT? Human tests for fluency
Rating tests: Give the raters a scale (1 to 5) and ask them to rate Or distinct scales for
Clarity, Naturalness, Style Or check for specific problems
Cohesion (Lexical chains, anaphora, ellipsis) Hand-checking for cohesion.
Well-formedness 5-point scale of syntactic correctness
Comprehensibility tests Noise test Multiple choice questionnaire
Readability tests cloze

How do we evaluate MT? Human tests for fidelity
Adequacy Does it convey the information in the original? Ask raters to rate on a scale
Bilingual raters: give them source and target sentence, ask how much information is preserved
Monolingual raters: give them target + a good human translation
Informativeness Task based: is there enough info to do some task? Give raters multiple-choice questions about
content

Evaluating MT: Problems
Asking humans to judge sentences on a 5-point scale for 10 factors takes time and $$$ (weeks or months!)
We can’t build language engineering systems if we can only evaluate them once every quarter!!!!
We need a metric that we can run every time we change our algorithm.
It would be OK if it wasn’t perfect, but just tended to correlate with the expensive human metrics, which we could still run in quarterly.
Bonnie Dorr

Automatic evaluation
Miller and Beebe-Center (1958) Assume we have one or more human translations of the
source passage Compare the automatic translation to these human
translations Bleu NIST Meteor Precision/Recall

BiLingual Evaluation Understudy (BLEU —Papineni, 2001)
Automatic Technique, but …. Requires the pre-existence of Human (Reference) Translations Approach:
Produce corpus of high-quality human translations Judge “closeness” numerically (word-error rate) Compare n-gram matches between candidate translation and
1 or more reference translations
http://www.research.ibm.com/people/k/kishore/RC22176.pdf
Slide from Bonnie Dorr

Reference (human) translation: The U.S. island of Guam is maintaining a high state of alert after the Guam airport and its offices both received an e-mail from someone calling himself the Saudi Arabian Osama bin Laden and threatening a biological/chemical attack against public places such as the airport .
Machine translation: The American [?] international airport and its the office all receives one calls self the sand Arab rich business [?] and so on electronic mail , which sends out ; The threat will be able after public place and so on the airport to start the biochemistry attack , [?] highly alerts after the maintenance.
BLEU Evaluation Metric(Papineni et al, ACL-2002)
• N-gram precision (score is between 0 & 1)– What percentage of machine n-grams can
be found in the reference translation? – An n-gram is an sequence of n words
– Not allowed to use same portion of reference translation twice (can’t cheat by typing out “the the the the the”)
• Brevity penalty– Can’t just type out single word “the”
(precision 1.0!)
*** Amazingly hard to “game” the system (i.e., find a way to change machine output so that BLEU goes up, but quality doesn’t)
Slide from Bonnie Dorr

Reference (human) translation: The U.S. island of Guam is maintaining a high state of alert after the Guam airport and its offices both received an e-mail from someone calling himself the Saudi Arabian Osama bin Laden and threatening a biological/chemical attack against public places such as the airport .
Machine translation: The American [?] international airport and its the office all receives one calls self the sand Arab rich business [?] and so on electronic mail , which sends out ; The threat will be able after public place and so on the airport to start the biochemistry attack , [?] highly alerts after the maintenance.
BLEU Evaluation Metric(Papineni et al, ACL-2002)
• BLEU4 formula (counts n-grams up to length 4)
exp (1.0 * log p1 + 0.5 * log p2 + 0.25 * log p3 + 0.125 * log p4 – max(words-in-reference / words-in-machine – 1, 0)
p1 = 1-gram precisionP2 = 2-gram precisionP3 = 3-gram precisionP4 = 4-gram precision
Slide from Bonnie Dorr
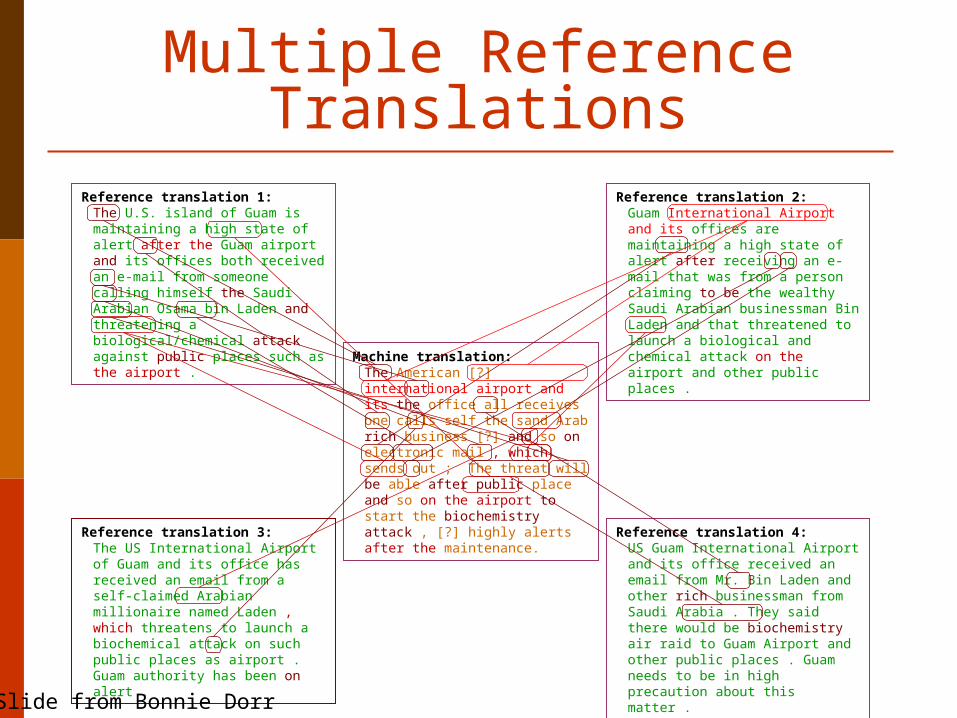
Reference translation 1: The U.S. island of Guam is maintaining a high state of alert after the Guam airport and its offices both received an e-mail from someone calling himself the Saudi Arabian Osama bin Laden and threatening a biological/chemical attack against public places such as the airport .
Reference translation 3: The US International Airport of Guam and its office has received an email from a self-claimed Arabian millionaire named Laden , which threatens to launch a biochemical attack on such public places as airport . Guam authority has been on alert .
Reference translation 4: US Guam International Airport and its office received an email from Mr. Bin Laden and other rich businessman from Saudi Arabia . They said there would be biochemistry air raid to Guam Airport and other public places . Guam needs to be in high precaution about this matter .
Reference translation 2: Guam International Airport and its offices are maintaining a high state of alert after receiving an e-mail that was from a person claiming to be the wealthy Saudi Arabian businessman Bin Laden and that threatened to launch a biological and chemical attack on the airport and other public places .
Machine translation: The American [?] international airport and its the office all receives one calls self the sand Arab rich business [?] and so on electronic mail , which sends out ; The threat will be able after public place and so on the airport to start the biochemistry attack , [?] highly alerts after the maintenance.
Multiple Reference Translations
Reference translation 1: The U.S. island of Guam is maintaining a high state of alert after the Guam airport and its offices both received an e-mail from someone calling himself the Saudi Arabian Osama bin Laden and threatening a biological/chemical attack against public places such as the airport .
Reference translation 3: The US International Airport of Guam and its office has received an email from a self-claimed Arabian millionaire named Laden , which threatens to launch a biochemical attack on such public places as airport . Guam authority has been on alert .
Reference translation 4: US Guam International Airport and its office received an email from Mr. Bin Laden and other rich businessman from Saudi Arabia . They said there would be biochemistry air raid to Guam Airport and other public places . Guam needs to be in high precaution about this matter .
Reference translation 2: Guam International Airport and its offices are maintaining a high state of alert after receiving an e-mail that was from a person claiming to be the wealthy Saudi Arabian businessman Bin Laden and that threatened to launch a biological and chemical attack on the airport and other public places .
Machine translation: The American [?] international airport and its the office all receives one calls self the sand Arab rich business [?] and so on electronic mail , which sends out ; The threat will be able after public place and so on the airport to start the biochemistry attack , [?] highly alerts after the maintenance.
Slide from Bonnie Dorr

Bleu Comparison
Chinese-English Translation Example:
Candidate 1: It is a guide to action which ensures that the military always obeys the commands of the party.
Candidate 2: It is to insure the troops forever hearing the activity guidebook that party direct.
Reference 1: It is a guide to action that ensures that the military will forever heed Party commands.
Reference 2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
Reference 3: It is the practical guide for the army always to heed the directions of the party.
Slide from Bonnie Dorr

How Do We Compute Bleu Scores? Intuition: “What percentage of words in candidate occurred in some
human translation?” Proposal: count up # of candidate translation words (unigrams) # in
any reference translation, divide by the total # of words in # candidate translation
But can’t just count total # of overlapping N-grams! Candidate: the the the the the the Reference 1: The cat is on the mat
Solution: A reference word should be considered exhausted after a matching candidate word is identified.
Slide from Bonnie Dorr

“Modified n-gram precision”
For each word compute: (1) total number of times it occurs in any single reference translation(2) number of times it occurs in the candidate translation
Instead of using count #2, use the minimum of #2 and #2, I.e. clip the counts at the max for the reference transcription
Now use that modified count. And divide by number of candidate words.
Slide from Bonnie Dorr

Modified Unigram Precision: Candidate #1
Reference 1: It is a guide to action that ensures that the military will forever heed Party commands.
Reference 2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
Reference 3: It is the practical guide for the army always to heed the directions of the party.
It(1) is(1) a(1) guide(1) to(1) action(1) which(1) ensures(1) that(2) the(4) military(1) always(1) obeys(0) the commands(1) of(1) the party(1)
What’s the answer???
17/18
Slide from Bonnie Dorr

Modified Unigram Precision: Candidate #2
It(1) is(1) to(1) insure(0) the(4) troops(0) forever(1) hearing(0) the activity(0) guidebook(0) that(2) party(1) direct(0)
What’s the answer????
8/14
Reference 1: It is a guide to action that ensures that the military will forever heed Party commands.
Reference 2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
Reference 3: It is the practical guide for the army always to heed the directions of the party.
Slide from Bonnie Dorr

Modified Bigram Precision: Candidate #1
It is(1) is a(1) a guide(1) guide to(1) to action(1) action which(0) which ensures(0) ensures that(1) that the(1) the military(1) military always(0) always obeys(0) obeys the(0) the commands(0) commands of(0) of the(1) the party(1)
What’s the answer????
10/17
Reference 1: It is a guide to action that ensures that the military will forever heed Party commands.
Reference 2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
Reference 3: It is the practical guide for the army always to heed the directions of the party.
Slide from Bonnie Dorr

Modified Bigram Precision: Candidate #2
Reference 1: It is a guide to action that ensures that themilitary will forever heed Party commands.
Reference 2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
Reference 3: It is the practical guide for the army always to heed the directions of the party.
It is(1) is to(0) to insure(0) insure the(0) the troops(0) troops forever(0) forever hearing(0) hearing the(0) the activity(0) activity guidebook(0) guidebook that(0) that party(0) party direct(0)
What’s the answer????
1/13
Slide from Bonnie Dorr

Catching Cheaters
Reference 1: The cat is on the mat
Reference 2: There is a cat on the mat
the(2) the the the(0) the(0) the(0) the(0)
What’s the unigram answer?
2/7
What’s the bigram answer?
0/7
Slide from Bonnie Dorr

Bleu distinguishes human from machine translations
Slide from Bonnie Dorr

Bleu problems with sentence length
Candidate: of the
Solution: brevity penalty; prefers candidates translations which are same length as one of the references
Reference 1: It is a guide to action that ensures that themilitary will forever heed Party commands.
Reference 2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
Reference 3: It is the practical guide for the army always to heed the directions of the party.
Problem: modified unigram precision is 2/2, bigram 1/1!
Slide from Bonnie Dorr

BLEU Tends to Predict Human Judgments
R2 = 88.0%
R2 = 90.2%
-2.5
-2.0
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
2.0
2.5
-2.5 -2.0 -1.5 -1.0 -0.5 0.0 0.5 1.0 1.5 2.0 2.5
Human Judgments
NIS
T S
co
re
Adequacy
Fluency
Linear(Adequacy)Linear(Fluency)
slide from G. Doddington (NIST)
(va
ria
nt
of
BL
EU
)

Summary
Intro and a little history Language Similarities and Divergences Four main MT Approaches
Transfer Interlingua Direct Statistical
Evaluation





























