Embed Size (px)
Citation preview

1
Machine Learning for Information RetrievalRong JinMichigan State University
Yi ZhangUniversity of California Santa Cruz

2
OutlineIntroduction to information retrieval, statistical inference and machine learningSupervised learning and its application to IRSemi-supervised learning and its application to IREmerging research directions
3
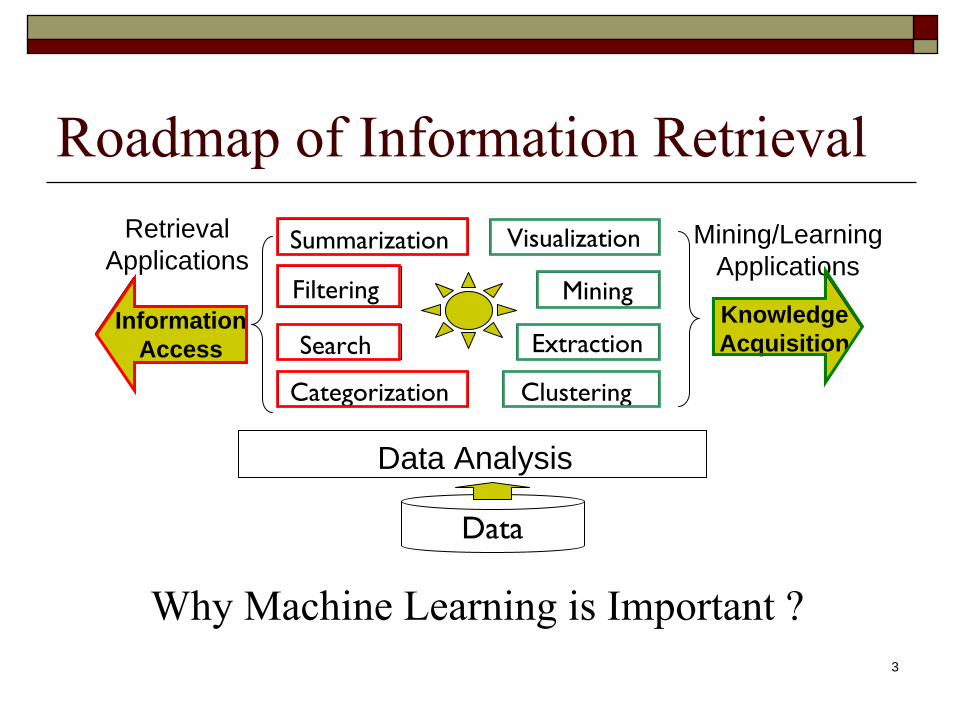
Roadmap of Information Retrieval
Search
Data
Filtering
Categorization
Summarization
Clustering
Data Analysis
Extraction
Mining
VisualizationRetrievalApplications
InformationAccess
Mining/LearningApplications
KnowledgeAcquisition
Why Machine Learning is Important ?
4
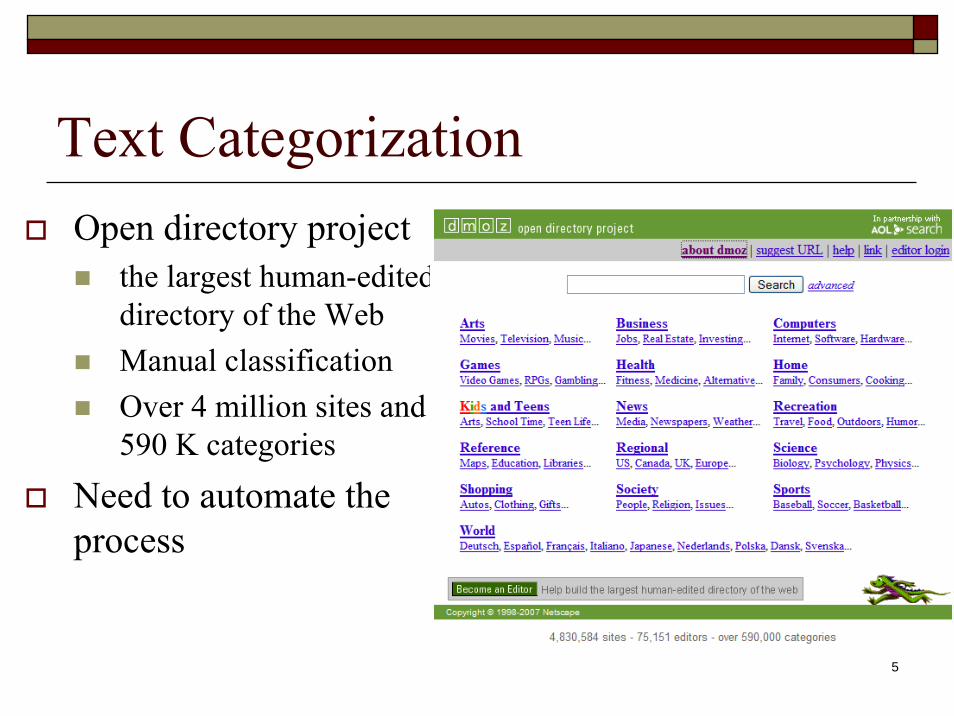
Text Categorization
5
Text CategorizationOpen directory project
the largest human-edited directory of the WebManual classificationOver 4 million sites and 590 K categories
Need to automate the process
6
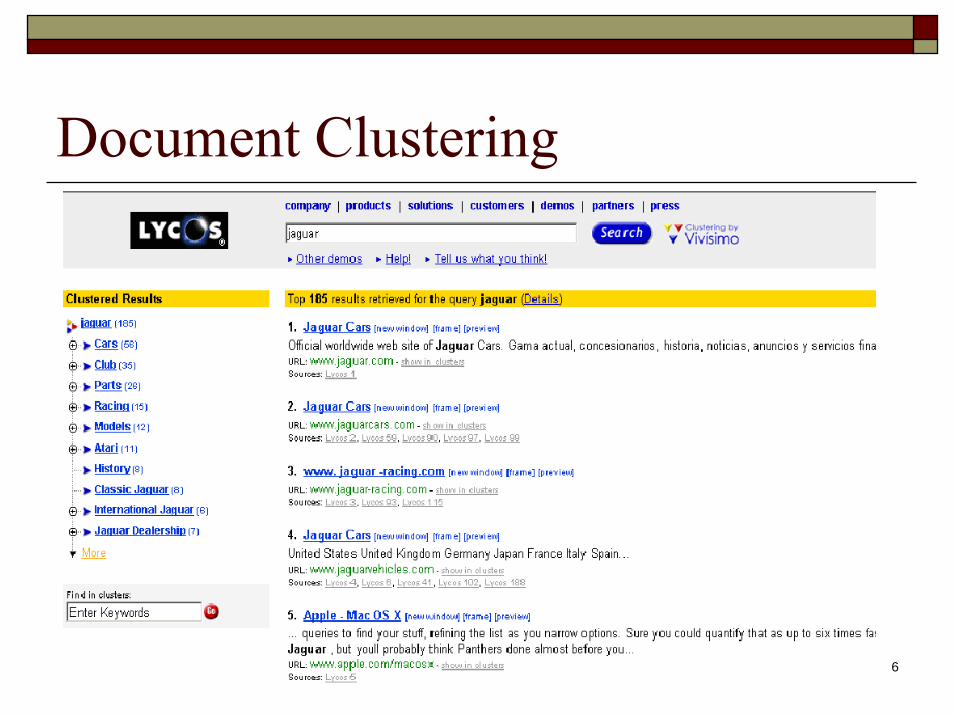
Document Clustering
7
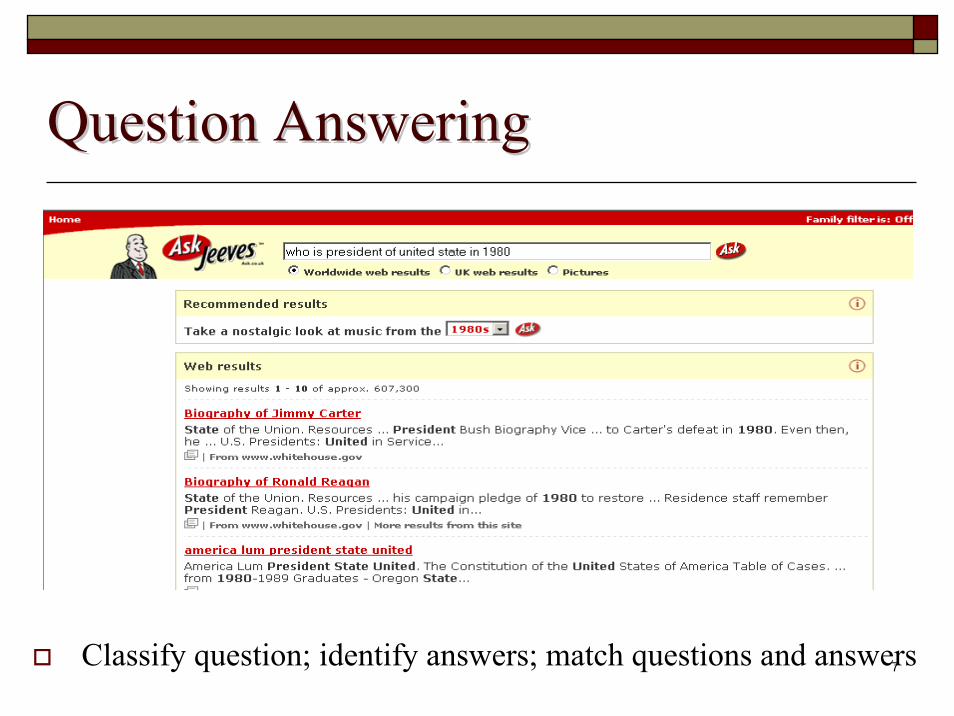
Question AnsweringQuestion Answering
Classify question; identify answers; match questions and answers

8
Image Retrieval
Image segmentation by data clustering
9
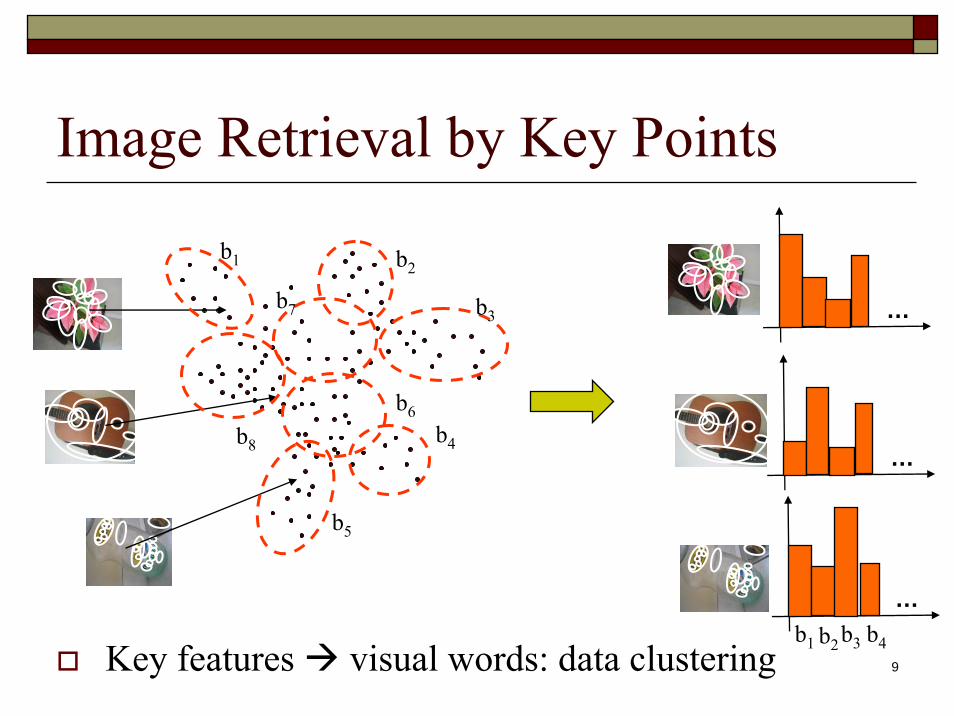
Image Retrieval by Key Points
Key features visual words: data clustering
b1 b2
b3
b4
b5
b6
b7
b8
…
…
…b1 b2b3 b4

10
Image Retrieval by Text QueryAutomatically annotate images with textual wordsRetrieve images with textual queriesKey technique: classification
Each keyword a different category

11
Information Extraction
Title J2EE Developer
Length 4 month
Salary ….
Location
Reference
Web page: free style text Relational DB
Structure prediction by Hidden Markov Model and Markov Random Field
12
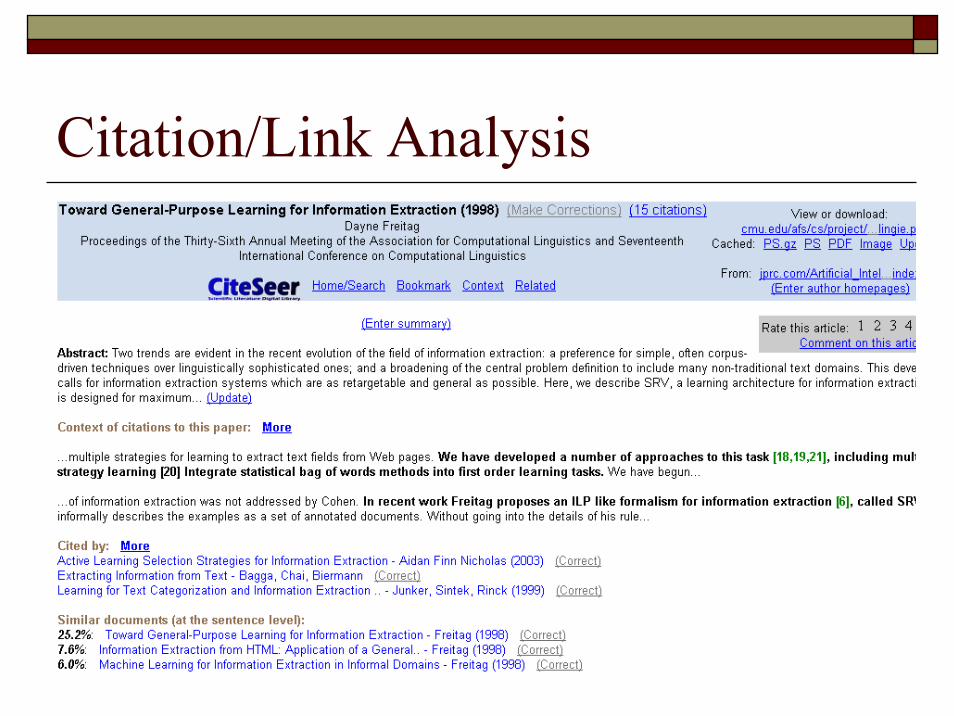
Citation/Link Analysis
13
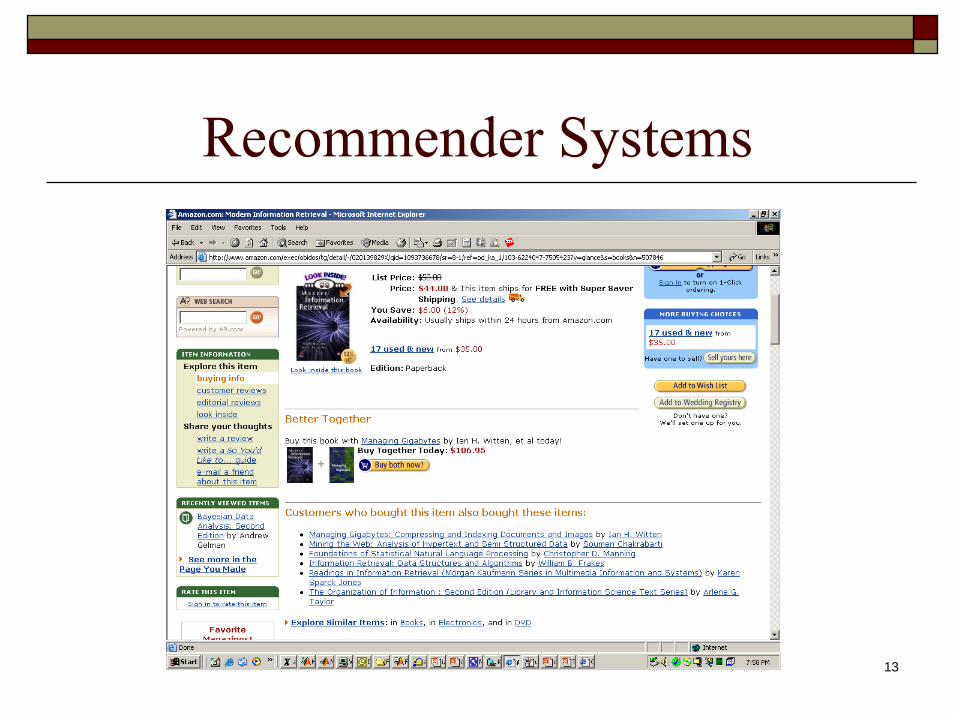
Recommender Systems

14
Recommender Systems
User 1 ? 5 3 4 2
User 2 4 1 5 ? 5
User 3 5 ? 4 2 5
User 4 1 5 3 5 ?
Sparse data problem: a lot of missing values
15
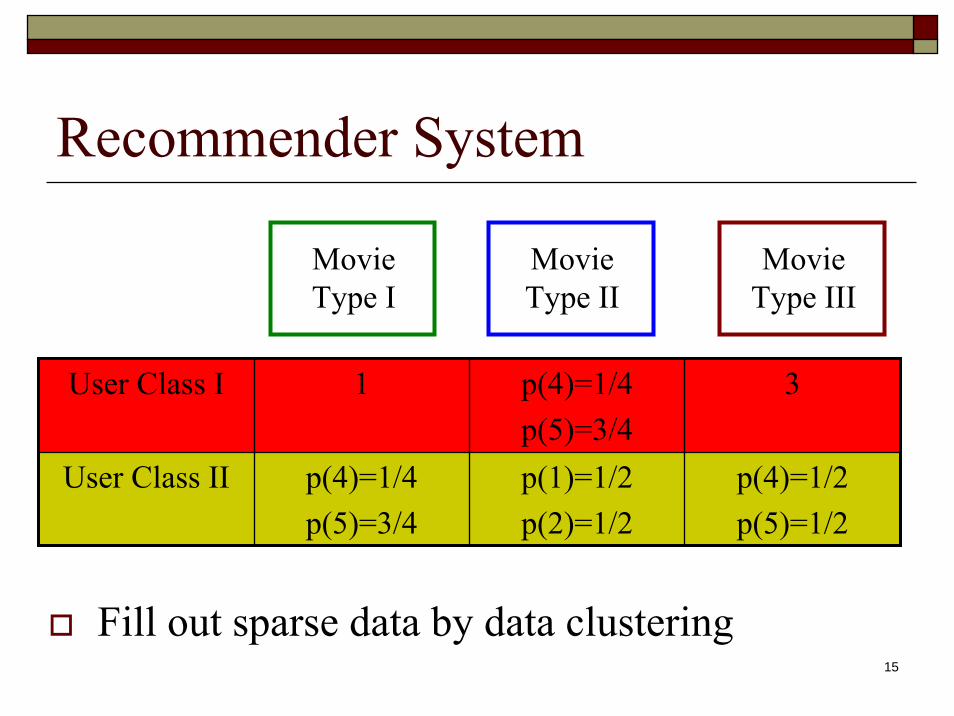
Recommender System
User Class I 1 p(4)=1/4p(5)=3/4
3
User Class II p(4)=1/4p(5)=3/4
p(1)=1/2p(2)=1/2
p(4)=1/2p(5)=1/2
Movie Type I
Movie Type II
Movie Type III
Fill out sparse data by data clustering
16
One More Reason for ML
$ 1,000,000 award

17
Review of Basic Prob. ConceptsProbability Pr(A): “the fraction of possible world in which A is true”
ExamplesA = Your paper will be accepted by SIGIR 2008A = It rains in SingaporeA = A document contains the word “IR”
A is true
Event space of all possible worlds. The area is 1.

18
Conditional ProbabilitySIGIR2008 = “a document contains the phrase SIGIR 2008”SINGAPORE = “a document contains the word singpaore”
P(SINGAPORE) = 0.000001P(SIGIR2008) = 0.00000001P(SINGAPORE|SIGIR2008) = 1/2
“Singapore” is rare and “SIGIR 2008” is rarer, but if you have a document with SIGIR 2008, there’s a 50-50 chance you’ll find the word “Singapore” in it

19
Conditional Prob.
B is trueA is true
Pr(A|B) = Pr(A,B)
Pr(B)Pr(A,B) = Pr(B)Pr(A|B)
Definition Chain rule

20
Conditional Prob.
B is trueA is true
Pr(A|B) = Pr(A,B)
Pr(B)Pr(A,B) = Pr(B)Pr(A|B)
Definition Chain rule
Independent variablesPr(A|B) = Pr(A) Pr(A,B) = Pr(B) Pr(A)

21
Conditional Prob.
Marginal probability B is trueA is true
Pr(A|B) = Pr(A,B)
Pr(B)Pr(A,B) = Pr(B)Pr(A|B)
Definition Chain rule
IndependencePr(A|B) = Pr(A) Pr(A,B) = Pr(B) Pr(A)
Pr(B) =
kXj=1
Pr(B,A = aj)

22
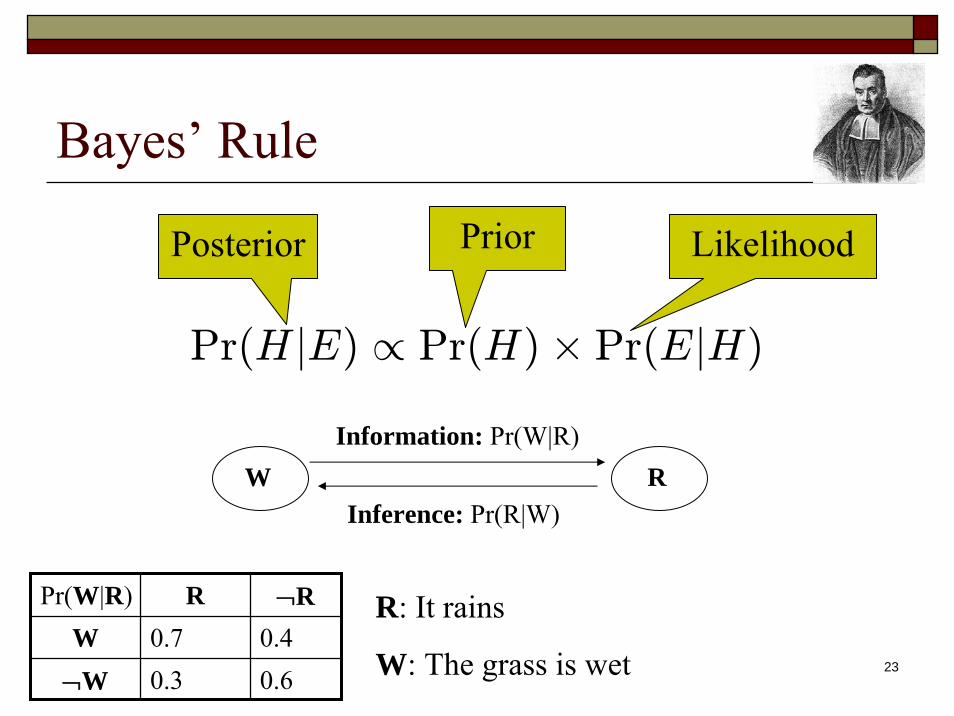
Bayes’ Rule
Pr(H |E) ∝ Pr(H)× Pr(E|H)
LikelihoodPriorPosterior
H EInference: Pr(H|E)
Information: Pr(E|H)
Hypothesis Evidence
23
Bayes’ Rule
Pr(H |E) ∝ Pr(H)× Pr(E|H)
LikelihoodPriorPosterior
W RInference: Pr(R|W)
Information: Pr(W|R)
Pr(W|R) R ¬RW 0.7 0.4¬W 0.3 0.6
R: It rains
W: The grass is wet

24
Statistical Inference
Learning stage: a parametric model for Pr(E|H)Inference stage: for a given observation E
Compute Pr(H|E) for each hypothesis HChoose the hypothesis with the largest Pr(H|E)
Pr(H |E) ∝ Pr(H)× Pr(E|H)
LikelihoodPriorPosterior

25
Example: Language Model (LM) for IR
d1… d1000
q: ‘Signapore SIGIR’
? ??
Estimating some statistics θ for each document
Estimating likelihood p(q| θ)
Hypothesis: H
Evidence: E
Pr(H |E)Pr(E|H)
Pr(H)

26
Probability DistributionsBinomial distributionsBeta distributionMultinomial distributionsDirichlet distributionGaussian distributionsLaplacian distribution
Language models
Smoothing LM
Sparse solution L1 regularizer

27
OutlineIntroduction to information retrieval, statistical inference andmachine learningSupervised learning and its application to IRSemi-supervised learning and its application to IREmerging research directions

28
Supervised Learning: Basic SettingGiven training data: {(x1,y1), (x2,y2)…(xN,yN)}Learning: infer a function f(X) from the training dataInference: predict future outcomes y=f(x) given x
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 50
0.5
1
1.5
2
2.5
y
x
f (x) = ax − b
Regression: Continuous Y`Regression: Continuous Y`

29
Supervised Learning: Basic SettingGiven training data: {(x1,y1), (x2,y2)…(xN,yN)}Learning: infer a function f(X) from the training dataInference: predict future outcomes y=f(x) given x
x1
x2
y = +1
x = (x1, x2)
y = -1
w>x− b = 0
f(x) = sign(w>x− b)
+
⎯Classification: Discrete YClassification: Discrete Y

30
ExamplesText categorization
Input x: word histogram Output y: document categories (e.g., 1 for “domestic economics”, 2 for “politics”, 3 “sports”, and 4 for “others”)
Question answering: classify question typesInput x: a parsing tree of a qestionOutput y: question types (e.g., when, where, …)
31
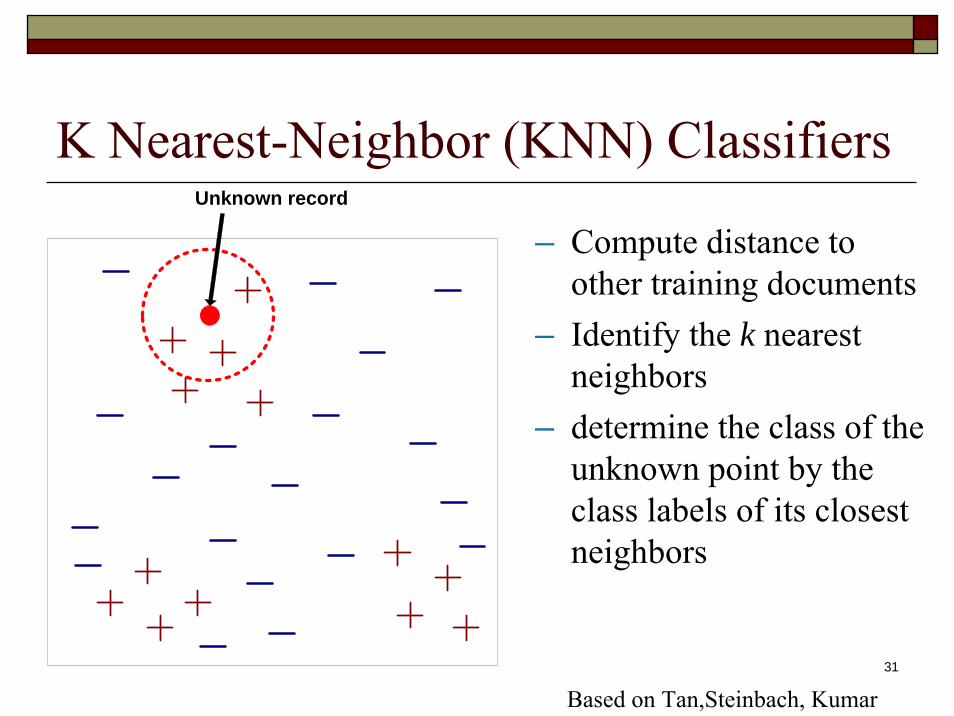
K Nearest-Neighbor (KNN) Classifiers
– Compute distance to other training documents
– Identify the k nearest neighbors
– determine the class of the unknown point by the class labels of its closest neighbors
Unknown record
Based on Tan,Steinbach, Kumar

32
K Nearest-Neighbor (KNN) ClassifiersCompute distance between two points
Euclidean distance, cosine distance, Kullback-Leiblerdistance, Bregman distance, …Learning distance function from data (Distance learning)
Determine the class Majority vote, or weighted majority vote
Bregman distance: generated by a convex function
33
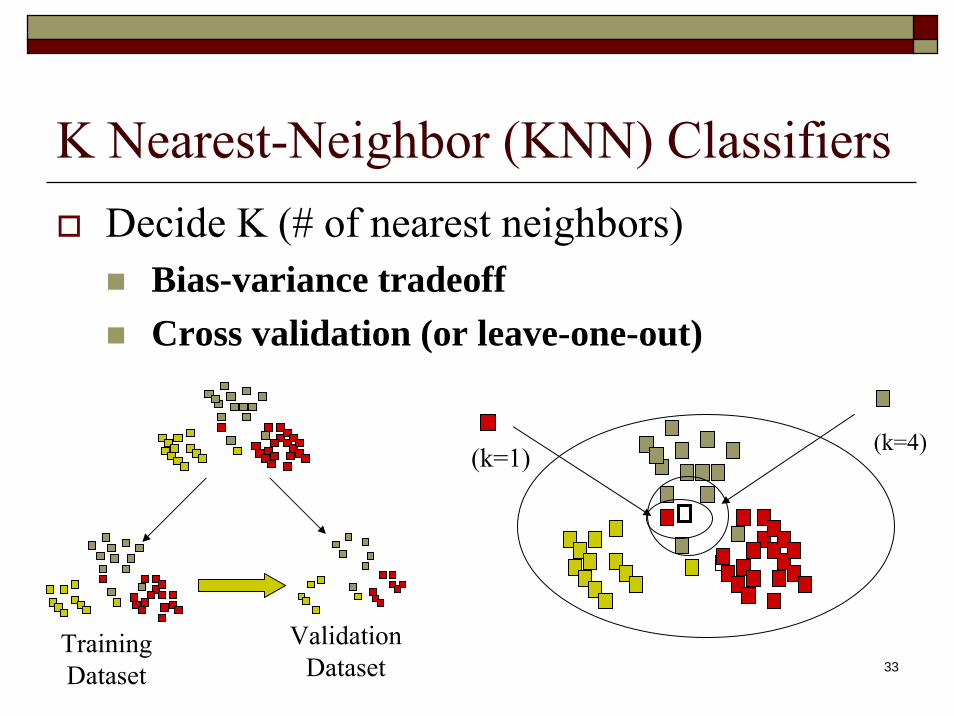
K Nearest-Neighbor (KNN) ClassifiersDecide K (# of nearest neighbors)
Bias-variance tradeoffCross validation (or leave-one-out)
(k=1) (k=4)
Training Dataset
Validation Dataset
34
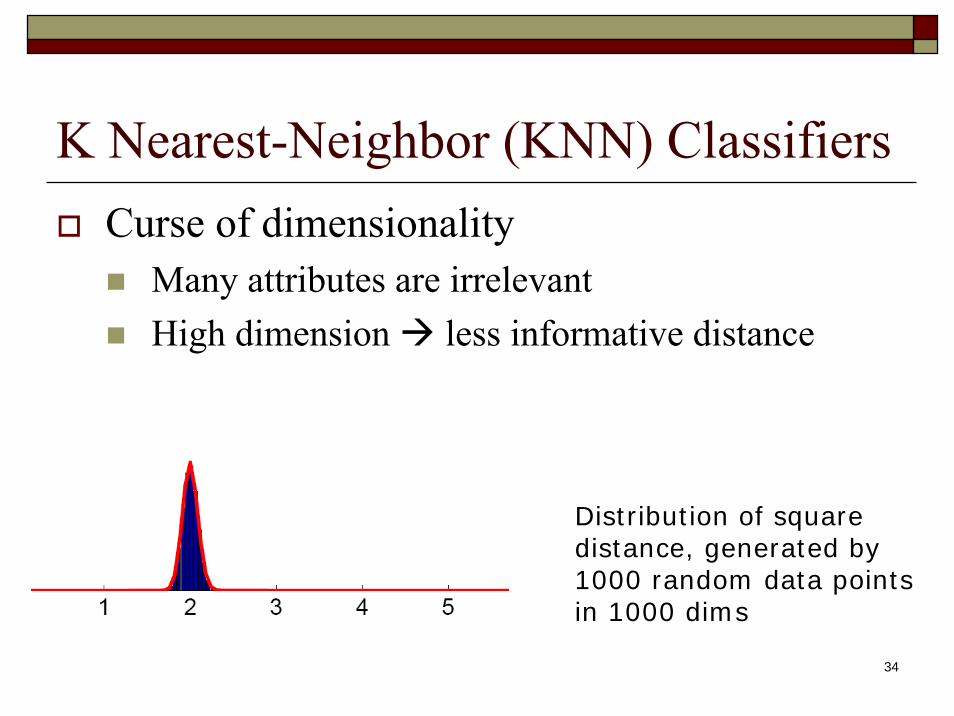
K Nearest-Neighbor (KNN) ClassifiersCurse of dimensionality
Many attributes are irrelevantHigh dimension less informative distance
Distribution of square distance, generated by 1000 random data points in 1000 dims

35
KNN for Collaborative FilteringCollaborative filtering
Will user u like item b?Assumption:
Users have similar tastes are likely to have similar preferences on items
Making filtering decisions for one user based on the feedback from other users that are similar to this user

36
KNN for Collaborative Filtering
User 1 1 5 3 4 3
User 2 4 1 5 2 5User 3 2 ? 3 5 4?

37
KNN for Collaborative Filtering
User 1 1 5 3 4 3
User 2 4 1 5 2 5User 3 2 ? 3 5 4
Similarity measure of user interests can be learned
5

38
Paradigm for Supervised LearningGathering training dataDetermine the input features (i.e., What’s x ?)
e.g., text categorization, bags of wordsFeature engineering is very very very important
Determine the functional form f(x)Linear or nonlinearWhat is the function form for KNN?
Determine the learning algorithmLearn optimal parameters (optimization, cross validation)Probabilistic or non-probabilistic
Test on a test set

39
Bayesian LearningLikelihoodPriorPosterior
Pr(H |E) ∝ Pr(H)× Pr(E|H)
MAP Learning: Maximum A Posterior
MAP Learning: Maximum A Posterior
Hypothesis space: H = {Y1, Y2, . . . , }Y ∗ = argmax
Y ∈HPr(Y |X)
= argmaxY ∈H
Pr(Y ) Pr(X|Y )
Baye’s Rule

40
Hypothesis space: H = {Y1, Y2, . . . , }Y ∗ = argmax
Y ∈HPr(Y |X)
= argmaxY ∈H
Pr(Y ) Pr(X|Y )
Bayesian Learning
MLE Learning: Maximum Likelihood Estimation
MLE Learning: Maximum Likelihood Estimation
LikelihoodPriorPosterior
Pr(H |E) ∝ Pr(H) × Pr(E|H) Baye’s Rule

41
Bayesian Learning: Conjugate Prior
Posterior Pr(Y|X) is in the same form as prior Pr(Y)e.g., Dirchlet dist. is conjugate prior for multinomial dist. (widely used in language model)
Hypothesis space: H = {Y1, Y2, . . . , }Y ∗ = argmax
Y ∈HPr(Y |X)
= argmaxY ∈H
Pr(Y ) Pr(X|Y )

42
Example: Text Categorization
How to estimate Pr(Y=Student) or Pr(Y= Prof.) ?How to estimate Pr(w|Y) ?
What is Y ?
What is feature X?
What is Y ?
What is feature X?
Web page for Prof. or student ?Web page for Prof. or student ?
Y ∗ = argmaxY ∈H
Pr(Y ) Pr(X|Y )
1. Counting = MLE2. Counting + Pseudo = MAP1. Counting = MLE2. Counting + Pseudo = MAP
Counting !

43
f(X) = logPr(X|Y = P)Pr(Y = P)Pr(X|Y = S)Pr(Y = S)
= logPr(Y = P)
Pr(Y = S)+x1 log
Pr(w1|Y = P)Pr(w1|Y = S)
+ . . .+xv logPr(wV |Y = P)Pr(wV |Y = S)
Pr(X |Y ) ≈ [Pr(w1|Y )]x1 · · · [Pr(wV |Y )]xV
Naïve Bayes
Pr(w|Y ) Pr(X|Y )?
[w1, w2, . . . , wV ]
Weight for wordsWeight for words
X = (x1, x2, . . . , xV )
ThresholdConstant
ThresholdConstant

44
f(X) = logPr(X|Y = P)Pr(Y = P)Pr(X|Y = S)Pr(Y = S)
= logPr(Y = P)
Pr(Y = S)+x1 log
Pr(w1|Y = P)Pr(w1|Y = S)
+ . . .+xv logPr(wV |Y = P)Pr(wV |Y = S)
Naïve Bayes: A Linear Classifier
x1
x2
y = +1
y = -1
f(x) = sign(w>x− b)+
⎯
Logistic Regression
Directly model f(x) or Pr(Y|X)
Logistic Regression
Directly model f(x) or Pr(Y|X)

45
logPr(X|Y = P )Pr(Y = P )Pr(X|Y = S)Pr(Y = S) = b+ t1x1 + . . .+ tV xV
logPr(X|Y = P )Pr(Y = P )Pr(X|Y = S)Pr(Y = S)
= logPr(Y = P )
Pr(Y = S)+ x1 log
Pr(w1|Y = P )Pr(w1|Y = S)
+ . . .+ xv logPr(wV |Y = P )Pr(wV |Y = S)
Logistic Regression (LR)
t1…tV are unknown weights that are learned from data by maximum likelihood estimation (MLE)
Pr(y =§1|X) = 1
1 + exp[−y(t1x1 + . . .+ tV xV + b)]

46
Logistic Regression (LR)Learning parameters: b, t1…tV
Maximum Likelihood Estimation (MLE)
(~t∗, b∗) = argmax~t,b
NXi=1
log Pr(yi|Xi;~t, b)

47
Logistic Regression (LR)Learning parameters: b, t1…tV
Maximum Likelihood Estimation (MLE)
(~t∗, b∗) = argmax~t,b
NXi=1
log Pr(yi|Xi;~t, b)
worse performance
OverfittingOverfitting
Maximum Likelihood Estimation
Maximum A Posterior
Maximum Likelihood Estimation
Maximum A Posterior
+Pr(t)
Why only word weights?Why only word weights?

48
Learning Logistic Regression
Pr(y =§1|X) = 1
1 + exp[−yf(X)]
(~t∗, b∗) = argmin~t,b
NXi=1
− log Pr(yi|Xi;~t, b)
Loss functionMismatch between y and f(X)
Loss functionMismatch between y and f(X)
Other Loss functionsOther Loss functions
f(X)

49
Logistic Regression (LR)Closely related to Maximum Entropy (ME)
Advantage of LRBayesian approachConvenient for incorporating prior knowledge Useful for semi-supervised learning, transfer learning, …
Logistic RegressionLogistic
RegressionMaximum
EntropyMaximum
EntropyDual
50
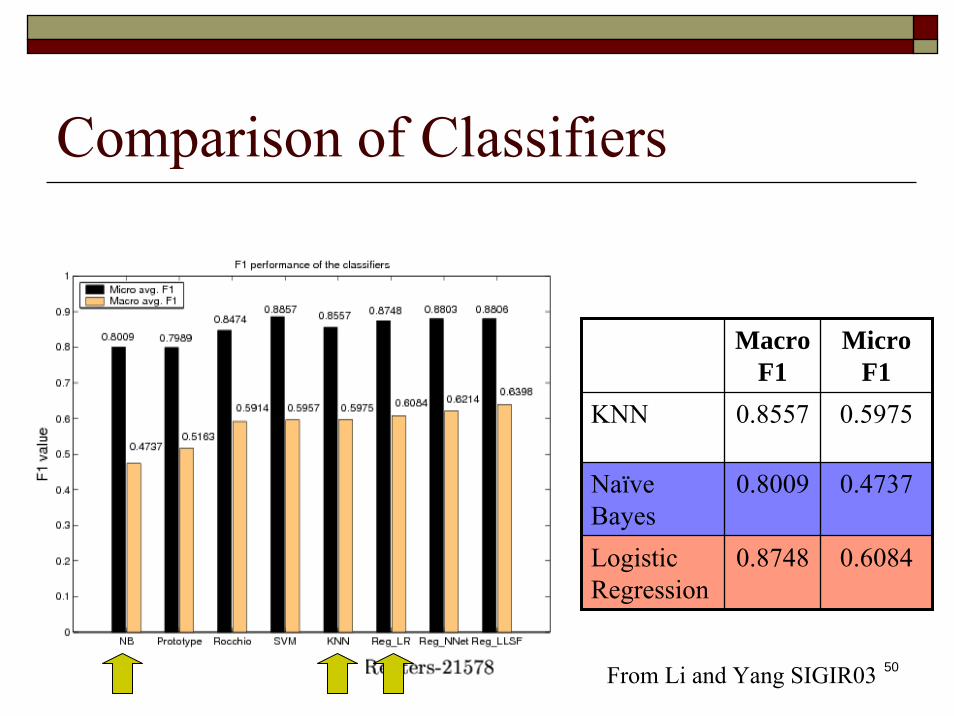
Comparison of Classifiers
From Li and Yang SIGIR03
Macro F1
Micro F1
KNN 0.8557 0.5975
Naïve Bayes
0.8009 0.4737
Logistic Regression
0.8748 0.6084
51x1
x2
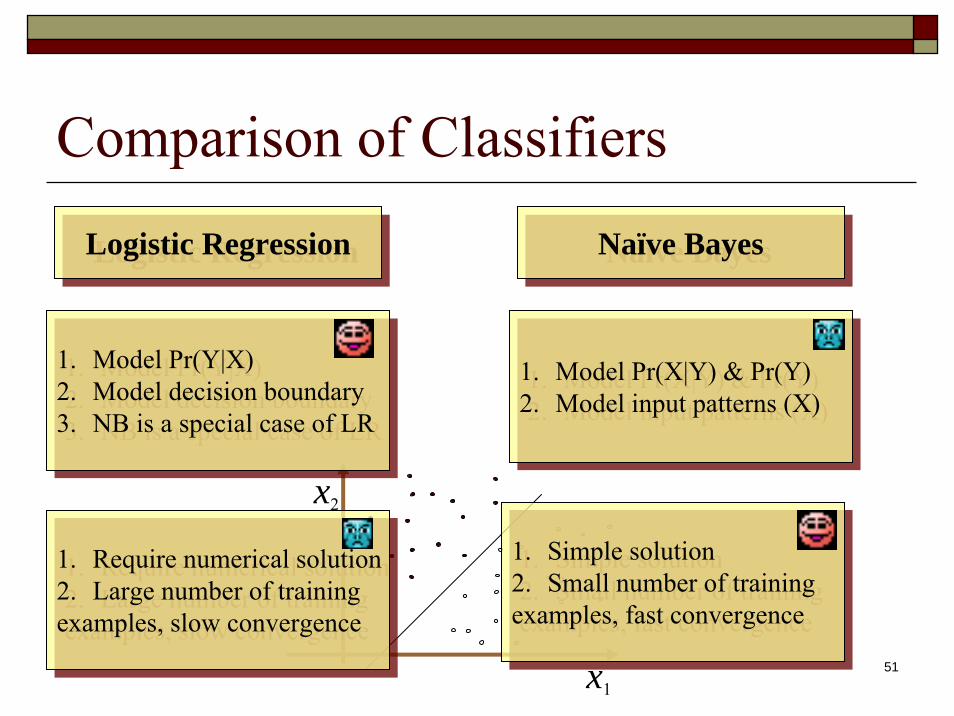
Comparison of Classifiers
Logistic RegressionLogistic Regression Naïve BayesNaïve Bayes
1. Model Pr(Y|X)2. Model decision boundary3. NB is a special case of LR
1. Model Pr(Y|X)2. Model decision boundary3. NB is a special case of LR
1. Model Pr(X|Y) & Pr(Y)2. Model input patterns (X)
1. Model Pr(X|Y) & Pr(Y)2. Model input patterns (X)
1. Require numerical solution2. Large number of training examples, slow convergence
1. Require numerical solution2. Large number of training examples, slow convergence
1. Simple solution2. Small number of training examples, fast convergence
1. Simple solution2. Small number of training examples, fast convergence

52x1
x2
Comparison of Classifiers
Discriminative ModelDiscriminative Model Generative ModelGenerative Model
1. Model Pr(Y|X)2. Model decision boundary3. Broader model assumption
1. Model Pr(Y|X)2. Model decision boundary3. Broader model assumption
1. Model Pr(X|Y) & Pr(Y)2. Model input patterns (X)
1. Model Pr(X|Y) & Pr(Y)2. Model input patterns (X)
1. Require numerical solution2. Large number of training examples, slow convergence
1. Require numerical solution2. Large number of training examples, slow convergence
1. Simple solution2. Small number of training examples, fast convergence
1. Simple solution2. Small number of training examples, fast convergence
Discriminative model if1. Enough training examples2. Enough computational power3. Classification accuracy is important
Generative model if 1. Lack of training examples2. Lack of computational power3. Training time is more important4. A quick test
Discriminative model if1. Enough training examples2. Enough computational power3. Classification accuracy is important
Generative model if 1. Lack of training examples2. Lack of computational power3. Training time is more important4. A quick test
Rule of Thumb

53
Comparison of Classifiers
Discriminative ModelDiscriminative Model Generative ModelGenerative Model
1. Model Pr(Y|X)2. Model decision boundary3. Broader model assumption
1. Model Pr(Y|X)2. Model decision boundary3. Broader model assumption
1. Model Pr(X|Y) & Pr(Y)2. Model input patterns (X)
1. Model Pr(X|Y) & Pr(Y)2. Model input patterns (X)
1. Require numerical solution2. Large number of training examples, slow convergence
1. Require numerical solution2. Large number of training examples, slow convergence
1. Simple solution2. Small number of training examples, fast convergence
1. Simple solution2. Small number of training examples, fast convergence
What about KNN ?What about KNN ?

54
Other Discriminative ClassifiersDecision tree
Aggregation of decision rules via a treeEasy interpretation

55
Other Discriminative ClassifiersDecision tree
Aggregation of decision rules via a treeEasy interpretation
Support vector machineA maximum marginclassifierbest text classifier
x1
x2
y = +1
y = -1
56
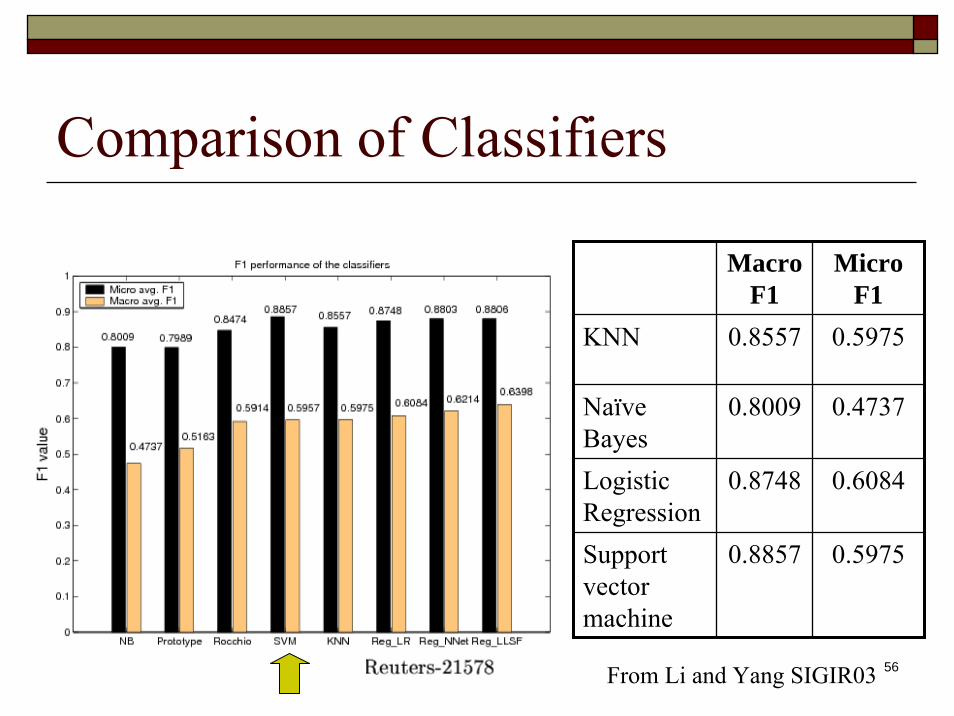
Comparison of Classifiers
From Li and Yang SIGIR03
Macro F1
Micro F1
KNN 0.8557 0.5975
Naïve Bayes
0.8009 0.4737
Logistic Regression
0.8748 0.6084
Support vector machine
0.8857 0.5975

57
Ensemble LearningGenerate multiple classifiersClassification by (weighted) majority votesBagging & Boosting
Train a classifier for a different sampling of training data
x1
x2
D
…
D1 D2 Dk
Sampling
h1 h2 hk
58
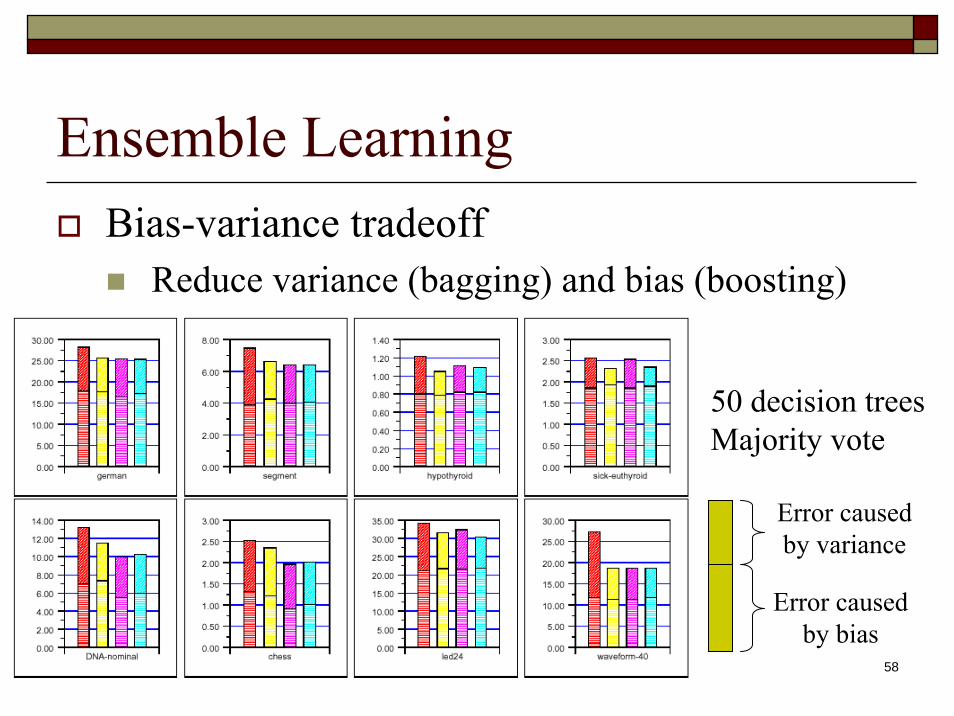
Ensemble LearningBias-variance tradeoff
Reduce variance (bagging) and bias (boosting)
Error caused by variance
Error caused by bias
50 decision trees Majority vote
59
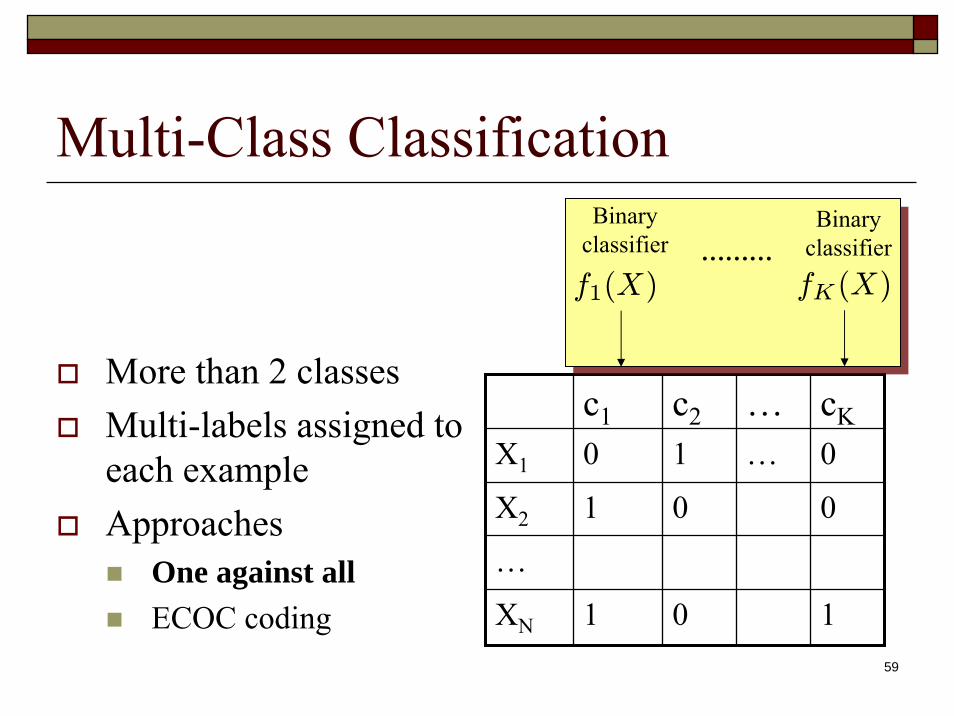
Multi-Class Classification
c1 c2 … cKX1 0 1 … 0
X2 1 0 0
…
XN 1 0 1
More than 2 classesMulti-labels assigned to each exampleApproaches
One against allECOC coding
Binary classifier
Binary classifier ………
fK(X)f1(X)
60
More than 2 classesMulti-labels assigned to each exampleApproaches
One against allECOC coding
……
f1(X)
fM (X)
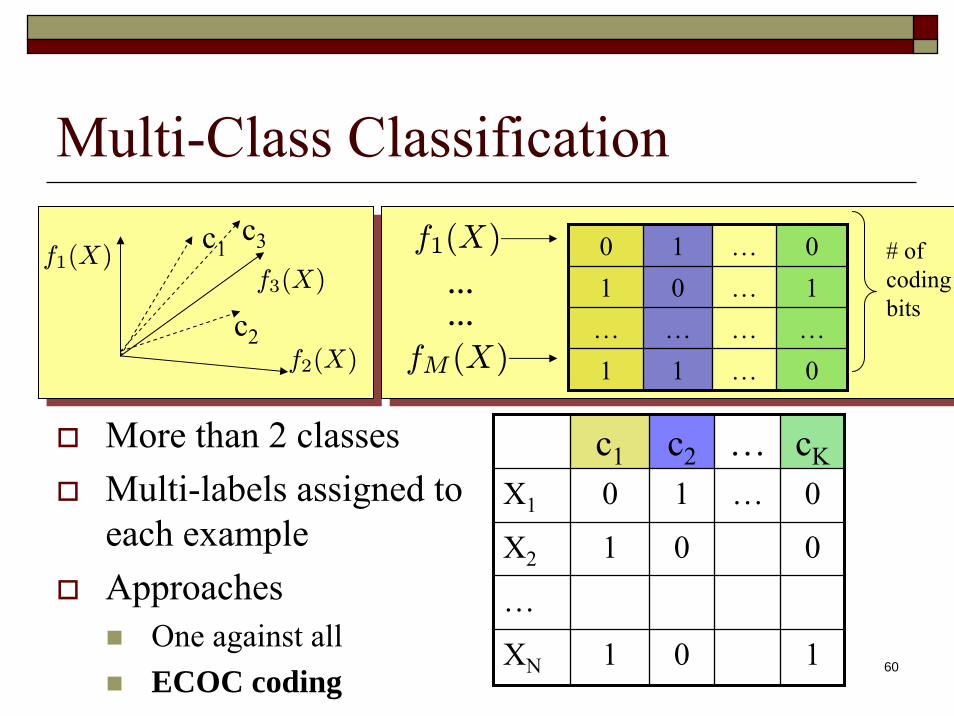
Multi-Class Classification
c1 c2 … cKX1 0 1 … 0
X2 1 0 0
…
XN 1 0 1
0 1 … 01 0 … 1… … … …1 1 … 0
# of codingbits
f1(X)
f2(X)
f3(X)
c1
c2
c3
61
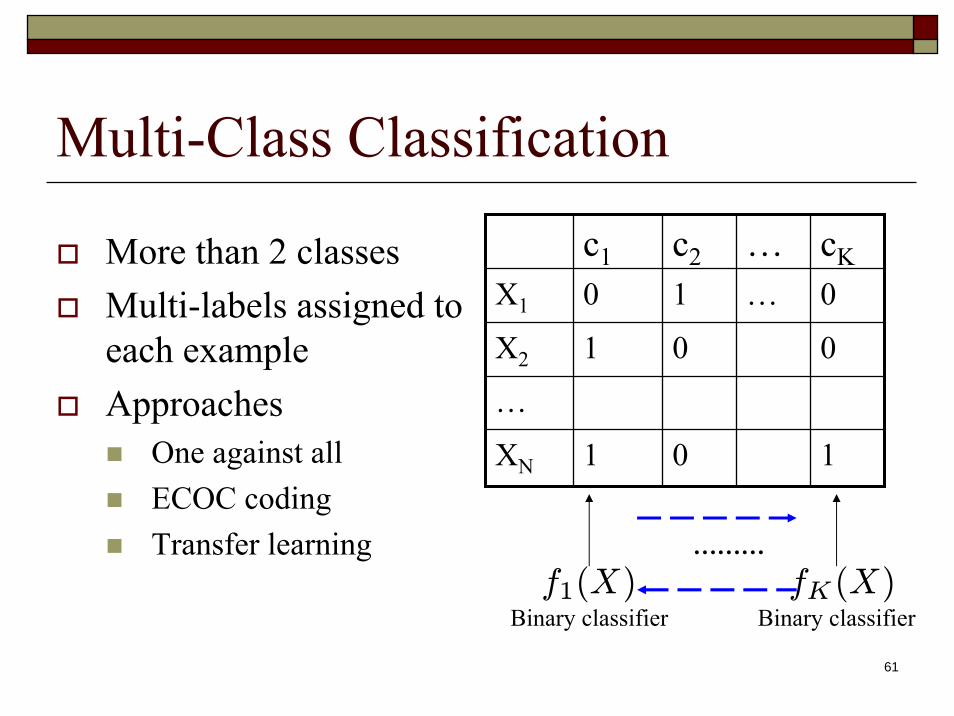
Multi-Class Classification
c1 c2 … cKX1 0 1 … 0
X2 1 0 0
…
XN 1 0 1
More than 2 classesMulti-labels assigned to each exampleApproaches
One against allECOC codingTransfer learning
f1(X)Binary classifier Binary classifier
fK(X)………
62
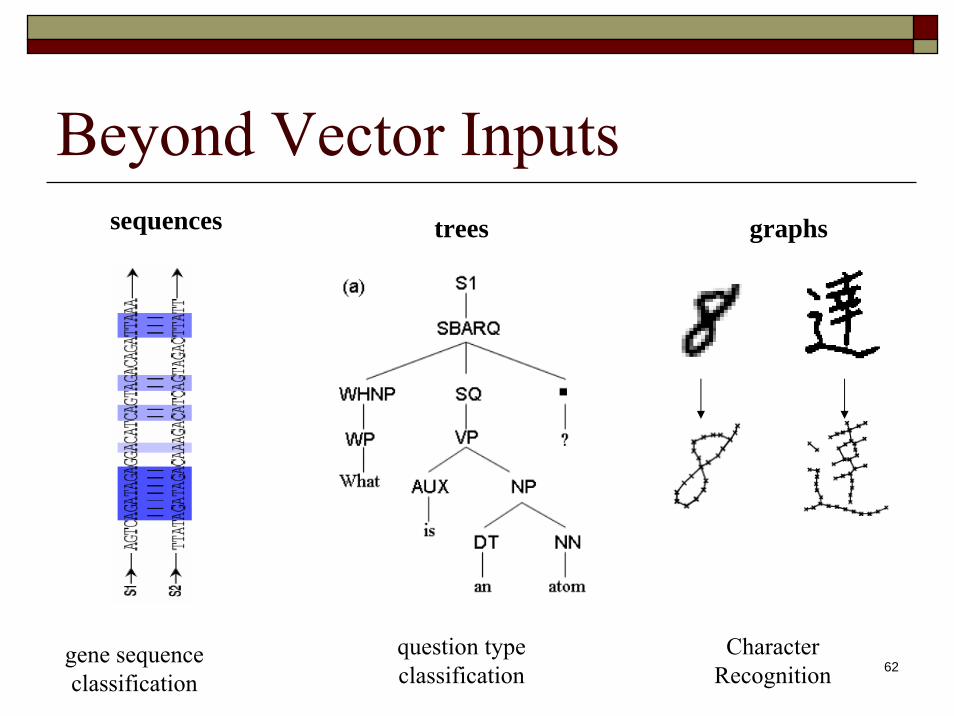
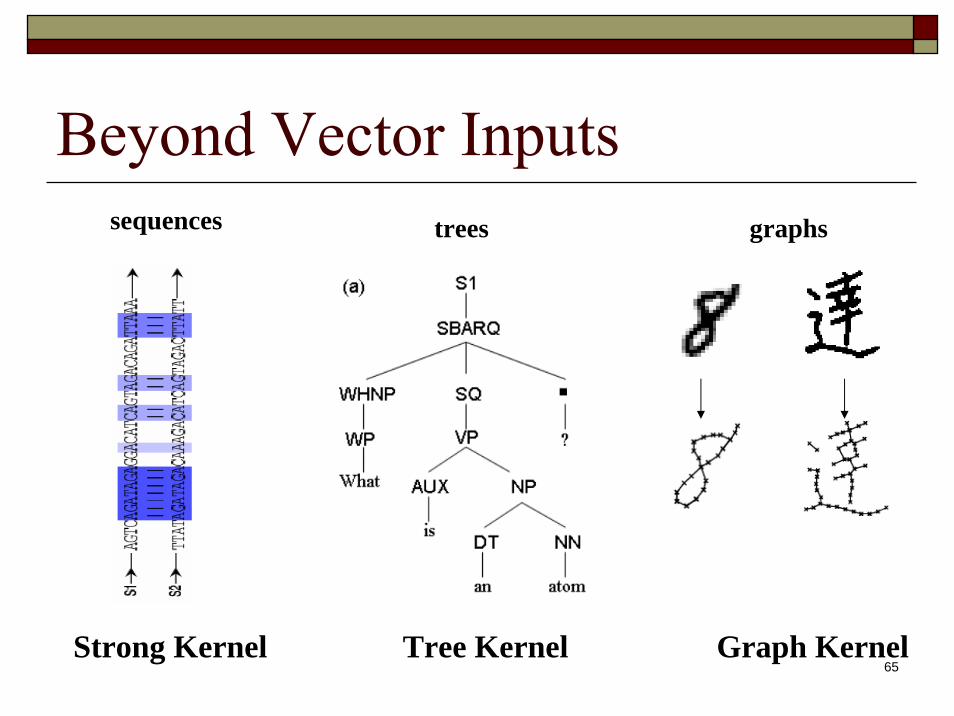
Beyond Vector Inputs
gene sequence classification
question type classification
Character Recognition
sequences trees graphs

63
Beyond Vector Inputs: KernelKernel function k(x1, x2)
Assess the similarity between two objects x1, x2
Don’t have to represent objects by vectors

64
Beyond Vector Inputs: KernelKernel function k(x1, x2)
Assess the similarity between two objects x1, x2
Don’t have to represent objects by vectorsVector representation by kernel function
Given training examplesRepresent any example x by vector
x1, . . . ,xN
[k(x1,x), k(x2,x), . . . , k(xN ,x)]
Related to representer theorem
65
Beyond Vector Inputs
Strong Kernel Tree Kernel Graph Kernel
sequences trees graphs

66
Kernel for Nonlinear Classifiers

67
Words are associated with KernelsReproducing Kernel Hilbert Space (RKHS)
Vector representationMercer’s conditions
Good kernelsRepresenter theoremKernel learning (e.g., multiple kernel learning)

68
Sequence Prediction
Part-of-speech taggingBut, all the taggings are related
Hidden Markov Model (HMM), Conditional Random Field (CRF), and Maximum Margin Markov Network (M3)
[He] [reckons] [the] [current] [account] [deficit]
[PRP] [VBZ] [DT] [JJ] [NN] [NN]
Pr(NN |“account)→ Pr(NN |“account, tag-for-“current)

69
OutlineIntroduction to information retrieval, statistical inference andmachine learningSupervised learning and its application to IRSemi-supervised learning and its application to IREmerging research directions

70
Topics of Semi-supervised Learning
Introduction to semi-supervised learningBasics of semi-supervised learningSemi-supervised classification algorithms
Label propagationGraph partitioning based approachesTransductive Support Vector Machine (TSVM)Co-training
Semi-supervised data clustering
71
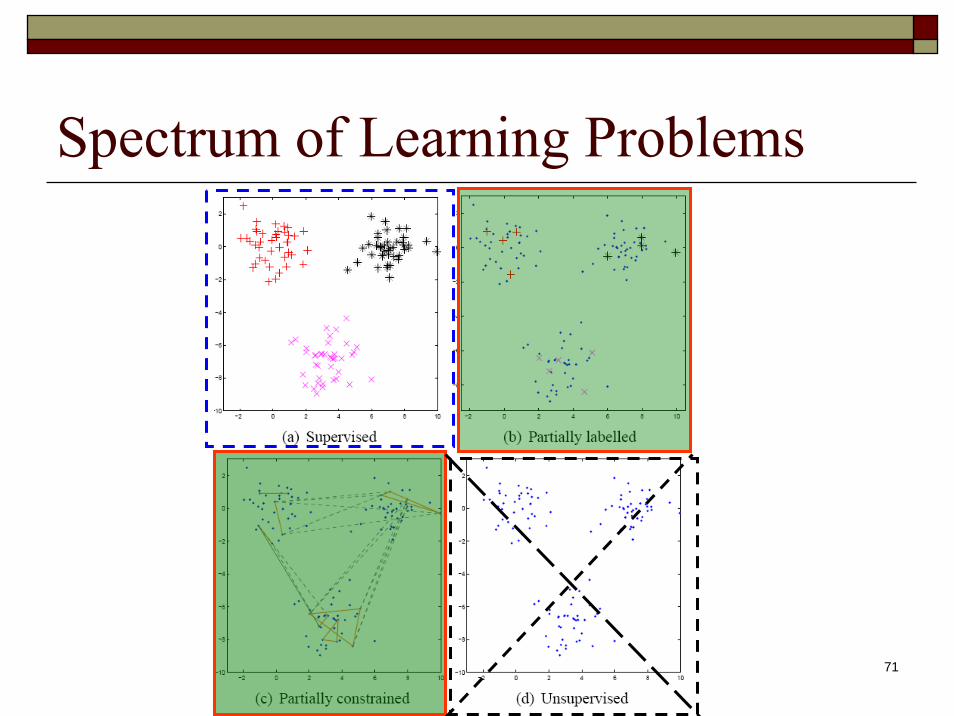
Spectrum of Learning Problems

72
What is Semi-supervised LearningLearning from a mixture of labeled and unlabeled examples
f(x) : X → Y
L = {(x1, y1), . . . , (xnl , ynl)}Labeled Data
U = {x1, . . . , xnu}Unlabeled Data
Total number of examples:N = nl + nu

73
Why Semi-supervised Learning?Labeling is expensive and difficultLabeling is unreliable
Ex. Segmentation applicationsNeed for multiple experts
Unlabeled examplesEasy to obtain in large numbersEx. Web pages, text documents, etc.

74
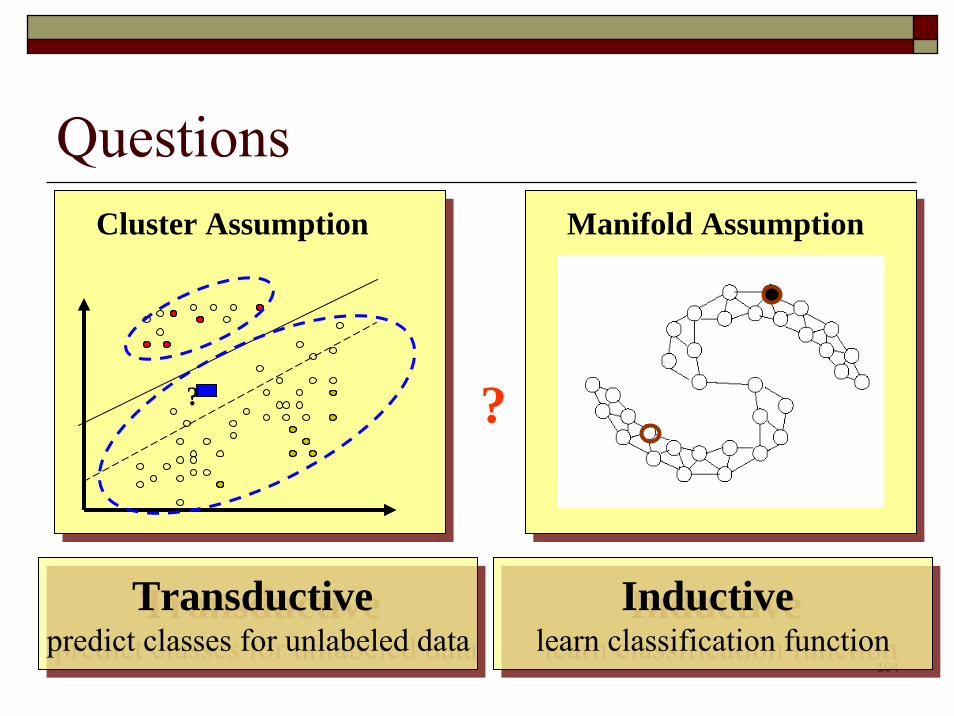
Semi-supervised Learning ProblemsClassification
Transductive – predict labels of unlabeled dataInductive – learn a classification function
Clustering (constrained clustering)Ranking (semi-supervised ranking)Almost every learning problem has a semi-supervised counterpart.

75
Topics of Semi-supervised Learning
Introduction to semi-supervised learningBasics of semi-supervised learningSemi-supervised classification algorithms
Label propagationGraph partitioning based approachesTransductive Support Vector Machine (TSVM)Co-training
Semi-supervised data clustering

76
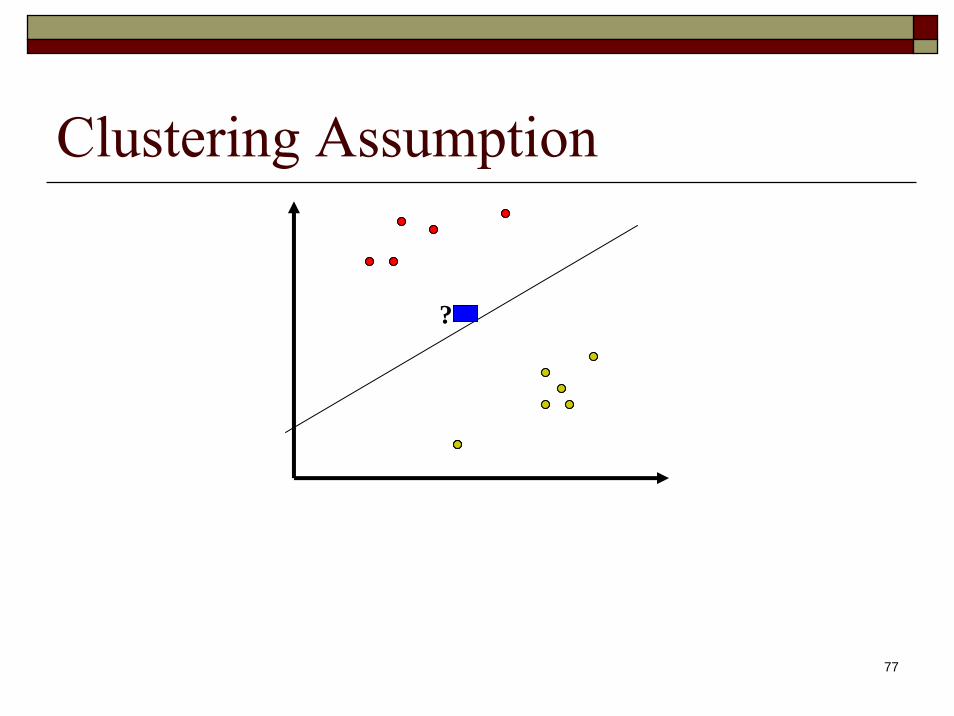
Why Unlabeled Could be HelpfulClustering assumption
Unlabeled data help decide the decision boundary
Manifold assumptionUnlabeled data help decide decision function
f(X) = 0
f(X)
77
Clustering Assumption
?

78
Clustering Assumption
?
Points with same label are connected through high density regions, thereby defining a cluster
Clusters are separated through low-density regions
Suggest a simple alg. forSemi-supervised Learning ?
Suggest a simple alg. forSemi-supervised Learning ?

79
Manifold Assumption
Regularize the classification function f(x)
Graph representationVertex: training example (labeled and unlabeled) Edge: similar examples
x1x2
x1 and x2 are connected −→ |f(x1)− f(x2)| is small
Labeled examples

80
Manifold Assumption
Manifold assumptionData lies on a low-dimensional manifoldClassification function f(x) should “follow” the data manifold
Graph representationVertex: training example (labeled and unlabeled) Edge: similar examples

81
Statistical View
Generative model for classification
θ
Y X
η
Pr(X, Y |θ, ´) = Pr(X|Y ; θ) Pr(Y |´)

82
Statistical View
Generative model for classification
Unlabeled data help estimateClustering assumption θ
Y X
η
Pr(X|Y ; θ)
Pr(X, Y |θ, ´) = Pr(X|Y ; θ) Pr(Y |´)

83
Statistical ViewDiscriminative model for classification
θ
Y X
μ
Pr(X, Y |θ, ´) = Pr(X|μ) Pr(Y |X; θ)

84
Statistical ViewDiscriminative model for classification
Unlabeled data help regularize θvia a prior
Manifold assumption
θ
Y X
μPr(θ|X)
Pr(X, Y |θ, ´) = Pr(X|μ) Pr(Y |X; θ)

85
Topics of Semi-supervised Learning
Introduction to semi-supervised learningBasics of semi-supervised learningSemi-supervised classification algorithms
Label propagationGraph partitioning based approachesTransductive Support Vector Machine (TSVM)Co-training
Semi-supervised data clustering

86
Topics of Semi-supervised Learning
Introduction to semi-supervised learningBasics of semi-supervised learningSemi-supervised classification algorithms
Label propagationGraph partitioning based approachesTransductive Support Vector Machine (TSVM)Co-training
Semi-supervised data clustering
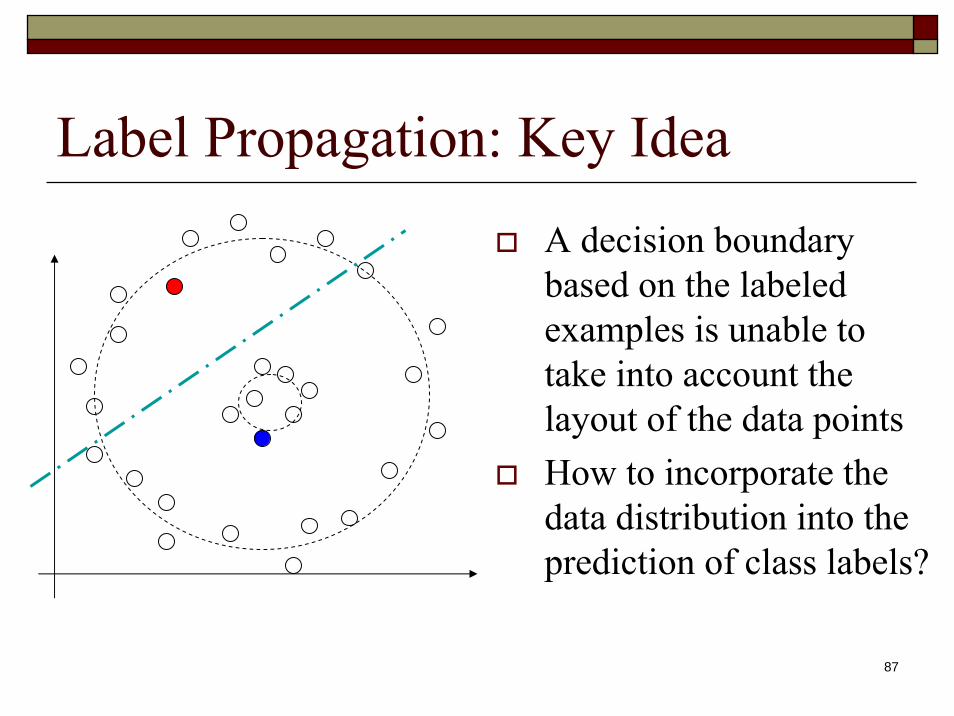
87
Label Propagation: Key IdeaA decision boundary based on the labeled examples is unable to take into account the layout of the data pointsHow to incorporate the data distribution into the prediction of class labels?
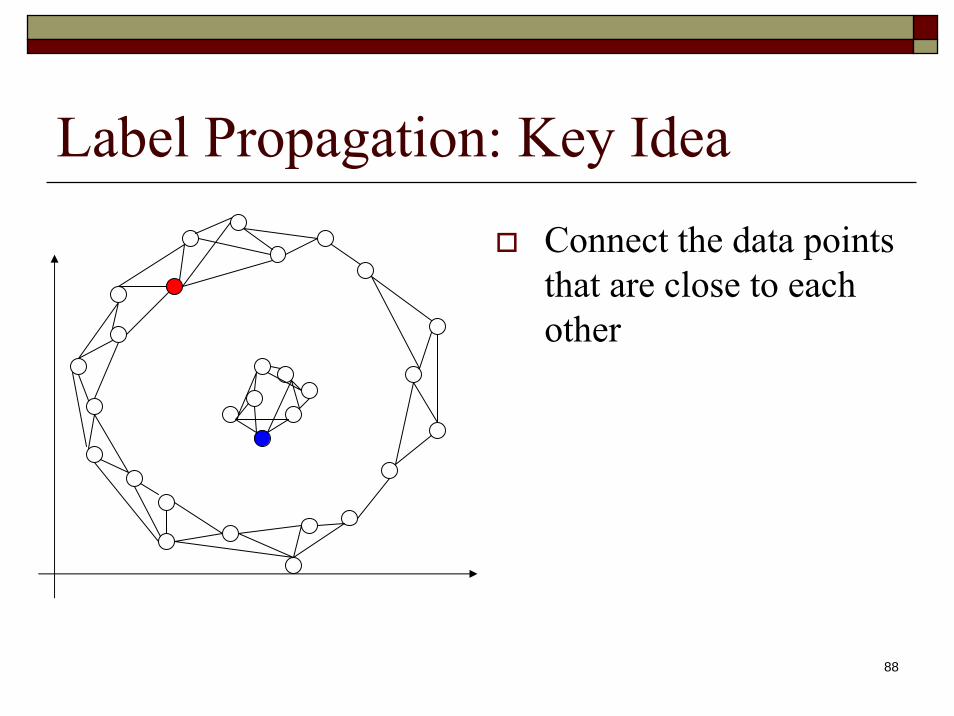
88
Label Propagation: Key IdeaConnect the data points that are close to each other
89
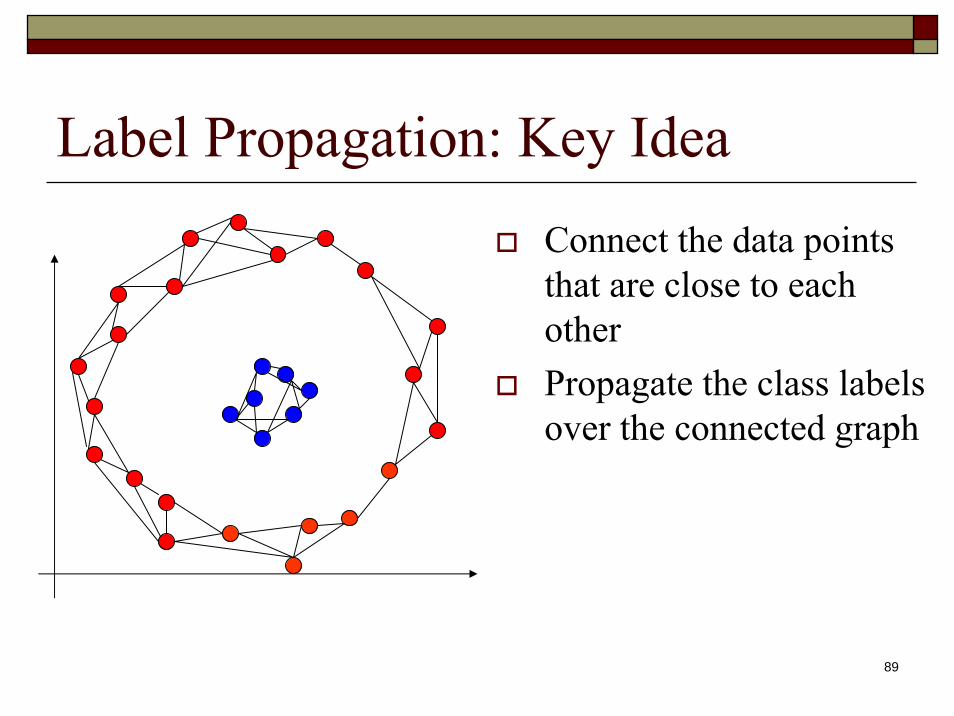
Label Propagation: Key IdeaConnect the data points that are close to each otherPropagate the class labels over the connected graph
90
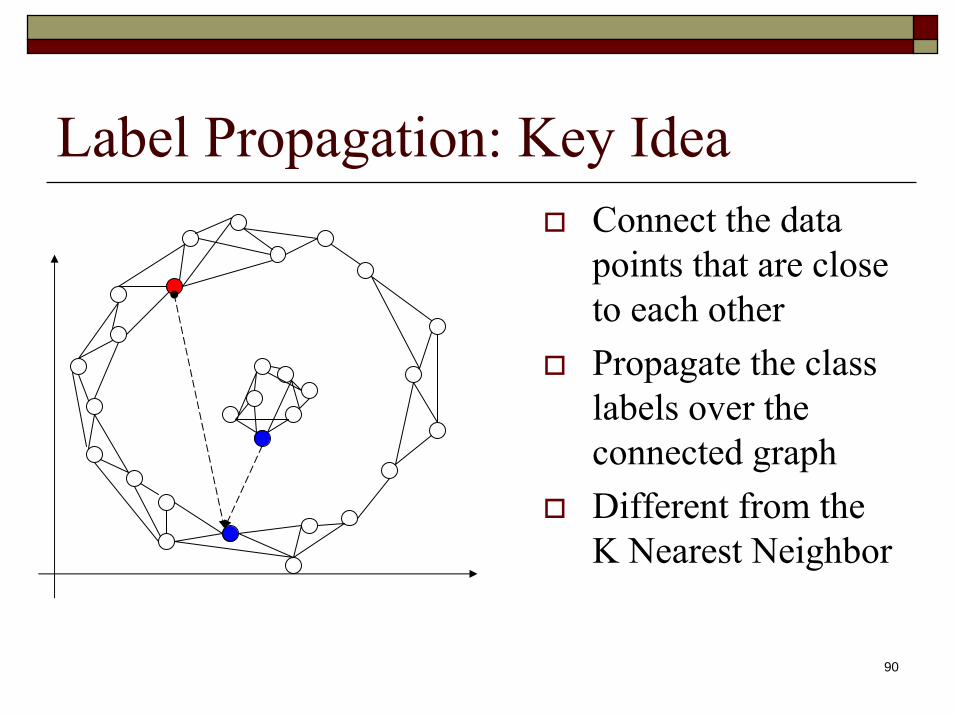
Label Propagation: Key IdeaConnect the data points that are close to each otherPropagate the class labels over the connected graphDifferent from the K Nearest Neighbor

91
Label Propagation: RepresentationAdjancy matrix
Similarity matrix
Matrix
Wi,j =
½1 xi and xj connect0 otherwise
W ∈ {0, 1}N×N
W ∈ RN×N+
Wi,j : similarity between xi and xj
D = diag(d1, . . . , dN )
di =Pj 6=iWi,j

92
Label Propagation: RepresentationAdjancy matrix
Similarity matrix
Degree matrix
Wi,j =
½1 xi and xj connect0 otherwise
W ∈ {0, 1}N×N
W ∈ RN×N+
Wi,j : similarity between xi and xj
D = diag(d1, . . . , dN ) di =Pj 6=iWi,j
93
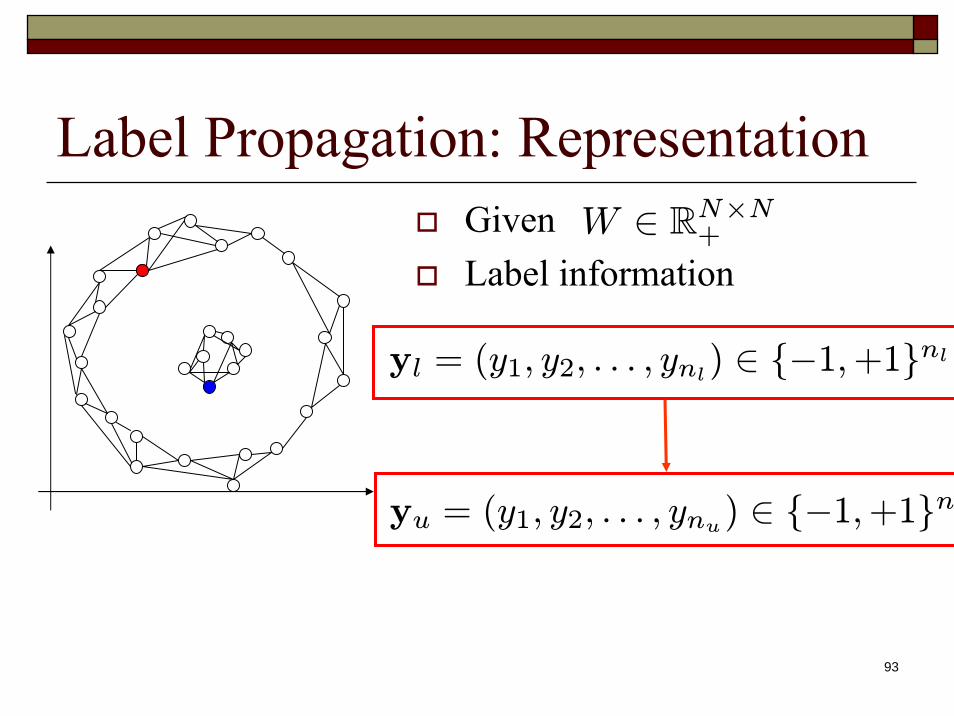
Label Propagation: RepresentationGivenLabel information
W ∈ RN×N+
yl = (y1, y2, . . . , ynl) ∈ {−1,+1}nl
yu = (y1, y2, . . . , ynu) ∈ {−1,+1}nu

94
Label Propagation: RepresentationGivenLabel information
W ∈ RN×N+
yl = (y1, y2, . . . , ynl) ∈ {−1,+1}nl
y = (yl,yu)

95
Label PropagationInitial class assignments
Predicted class assignmentsFirst predict the confidence scoresThen predict the class assignments
by ∈ {−1, 0,+1}N
y ∈ {−1,+1}Nf ∈ RN
yi =
½+1 fi > 0−1 fi ≤ 0
byi =
½§1 xi is labeled0 xi is unlabeled

96
Label PropagationInitial class assignments
Predicted class assignmentsFirst predict the confidence scoresThen predict the class assignments
by ∈ {−1, 0,+1}N
y ∈ {−1,+1}N
yi =
½+1 fi > 0−1 fi ≤ 0
byi =
½§1 xi is labeled0 xi is unlabeled
f = (f1, . . . , fN )
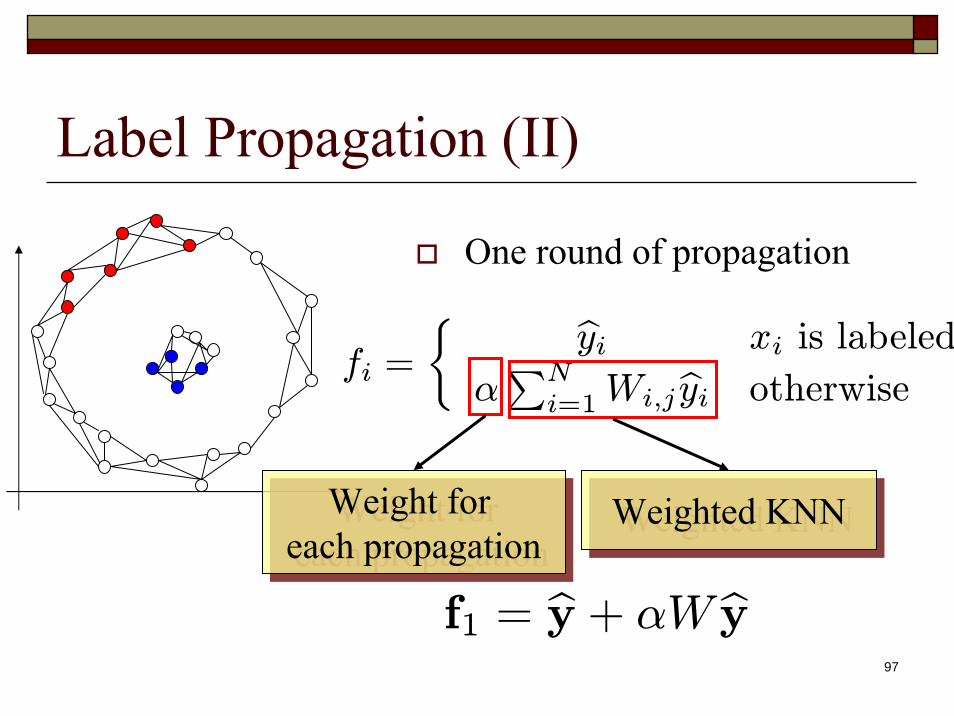
97
Label Propagation (II)
One round of propagation
fi =
½ byi xi is labeled
αPN
i=1Wi,jbyi otherwise
f1 = by + αW byWeighted KNNWeighted KNNWeight for
each propagationWeight for
each propagation
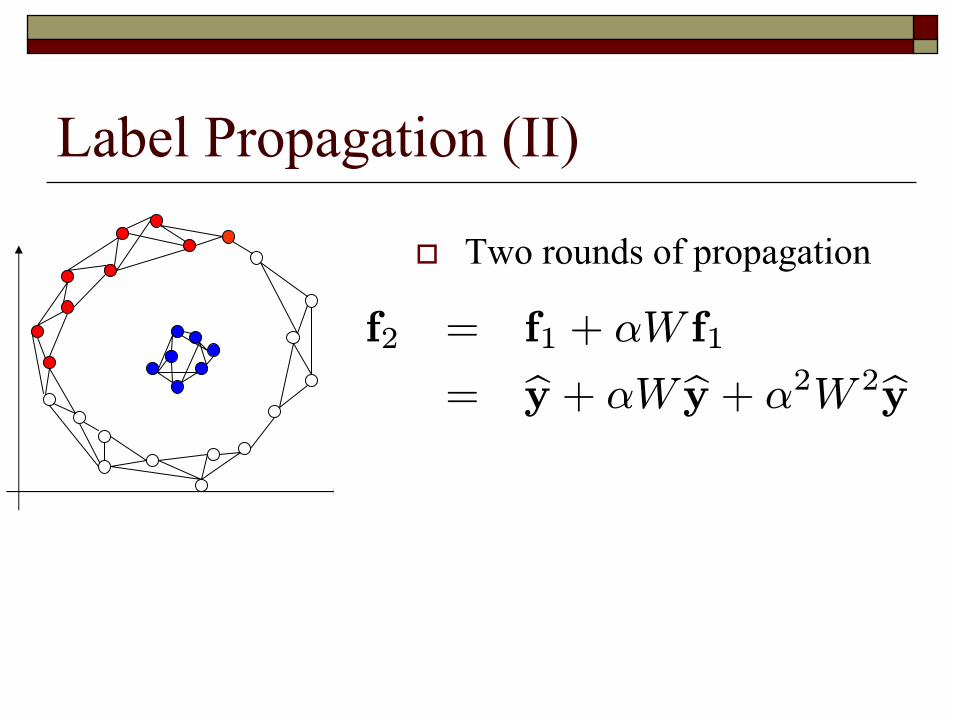
98
Label Propagation (II)
Two rounds of propagation
How to generate any number of iterations?
fk = by + kXi=1
αiW iby
f2 = f1 + αW f1
= by + αW by + α2W 2by
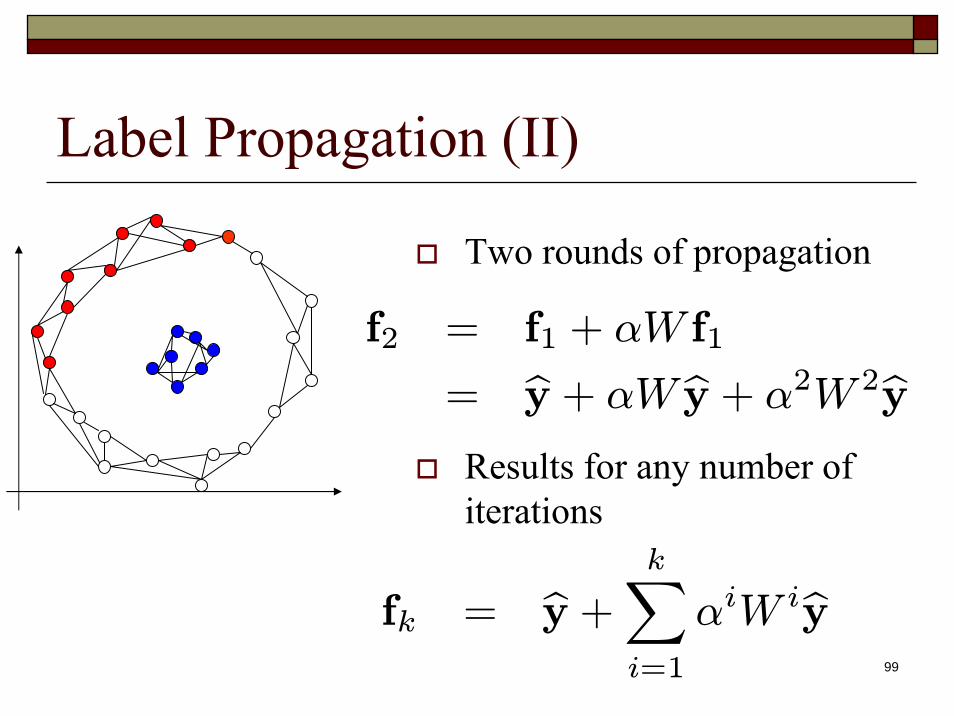
99
Label Propagation (II)
Two rounds of propagation
Results for any number of iterations
fk = by + kXi=1
αiW iby
f2 = f1 + αW f1
= by + αW by + α2W 2by
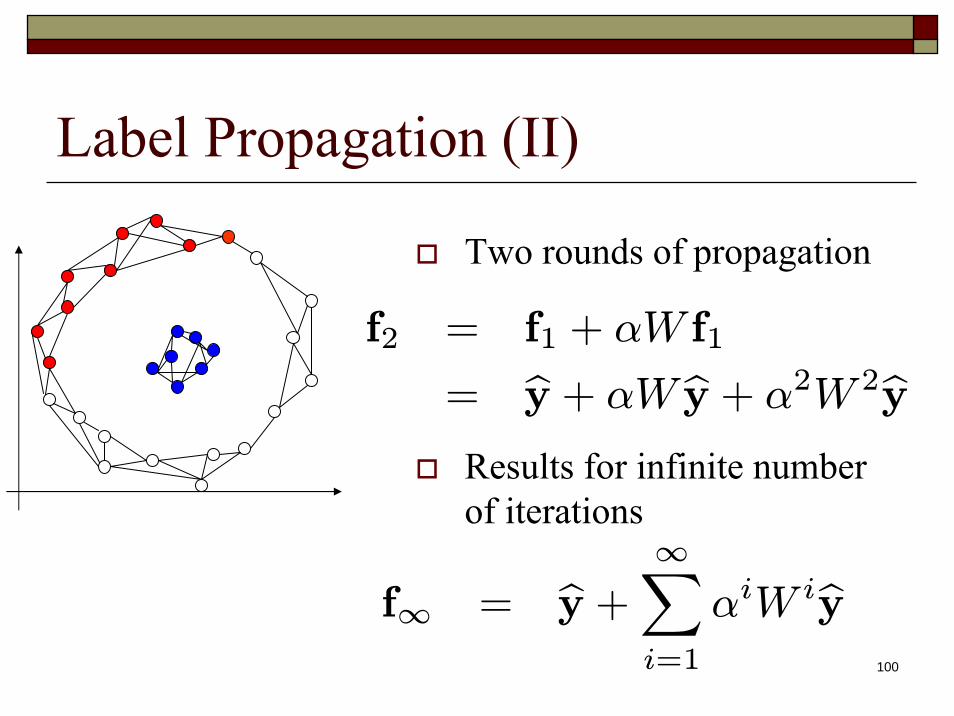
100
Label Propagation (II)
Two rounds of propagation
Results for infinite number of iterations
f∞ = by + ∞Xi=1
αiW iby
f2 = f1 + αW f1
= by + αW by + α2W 2by
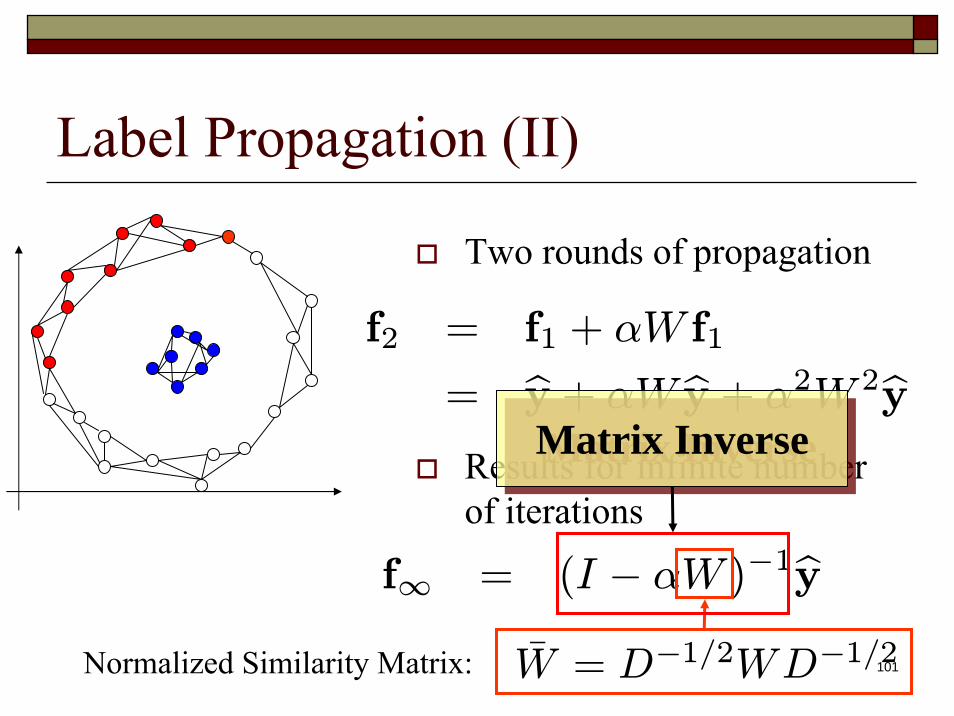
101
Label Propagation (II)
Two rounds of propagation
Results for infinite number of iterations
f∞ = (I − αW )−1byW̄ = D−1/2WD−1/2Normalized Similarity Matrix:
f2 = f1 + αW f1
= by + αW by + α2W 2byMatrix InverseMatrix Inverse

102
Local and Global Consistency [Zhou et.al., NIPS 03]
Local consistency:
Like KNN
Global consistency:
Beyond KNN

103
Summary:Construct a graph using pairwise similaritiesPropagate class labels along the graph Key parameters
α: the decay of propagationW: similarity matrix
Computational complexityMatrix inverse: O(n3) Chelosky decompositionClustering
f = (I − αW )−1by
104
Questions
?
Cluster Assumption Manifold Assumption
?
Transductivepredict classes for unlabeled data
Transductivepredict classes for unlabeled data
Inductive learn classification function
Inductive learn classification function
105
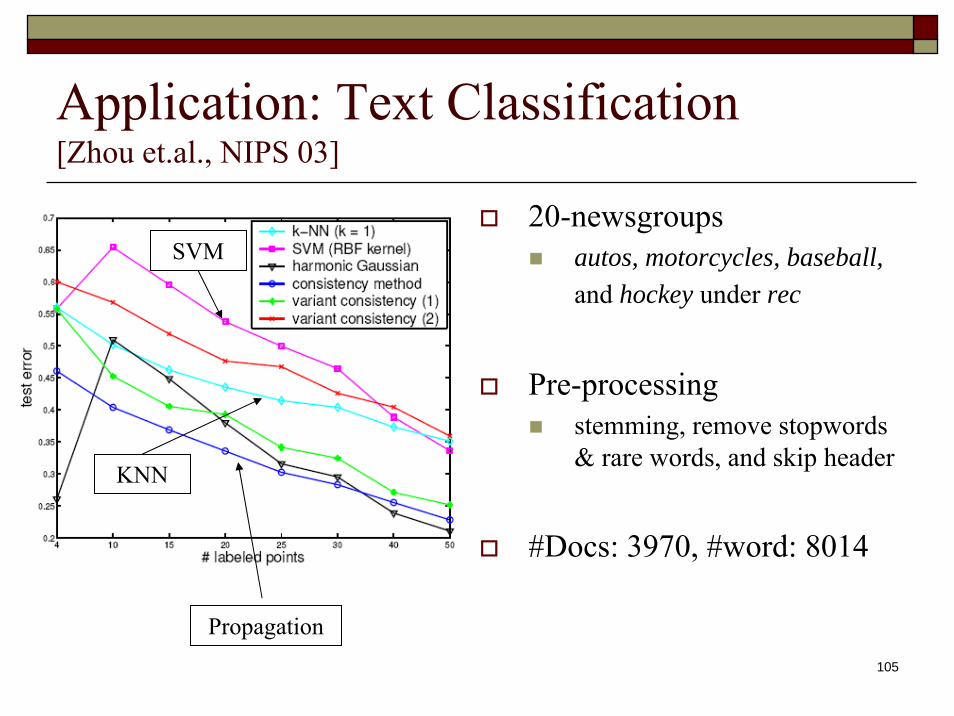
Application: Text Classification [Zhou et.al., NIPS 03]
20-newsgroupsautos, motorcycles, baseball, and hockey under rec
Pre-processing stemming, remove stopwords& rare words, and skip header
#Docs: 3970, #word: 8014
SVM
KNN
Propagation

106
Application: Image Retrieval [Wang et al., ACM MM 2004]
5,000 imagesRelevance feedback for the top 20 ranked imagesClassification problem
Relevant or not?f(x): degree of relevance
Learning relevance function f(x)Supervised learning: SVMLabel propagation
Label propagation
SVM

107
Topics of Semi-supervised Learning
Introduction to semi-supervised learningBasics of semi-supervised learningSemi-supervised classification algorithms
Label propagationGraph partition based approachesTransductive Support Vector Machine (TSVM)Co-training
Semi-supervised data clustering

108
Graph PartitionClassification as graph partitioningSearch for a classification boundary
Consistent with labeled examplesPartition with small graph cut
Graph Cut = 1Graph Cut = 2

109
Graph PartitioningClassification as graph partitioningSearch for a classification boundary
Consistent with labeled examplesPartition with small graph cut
Graph Cut = 1
110
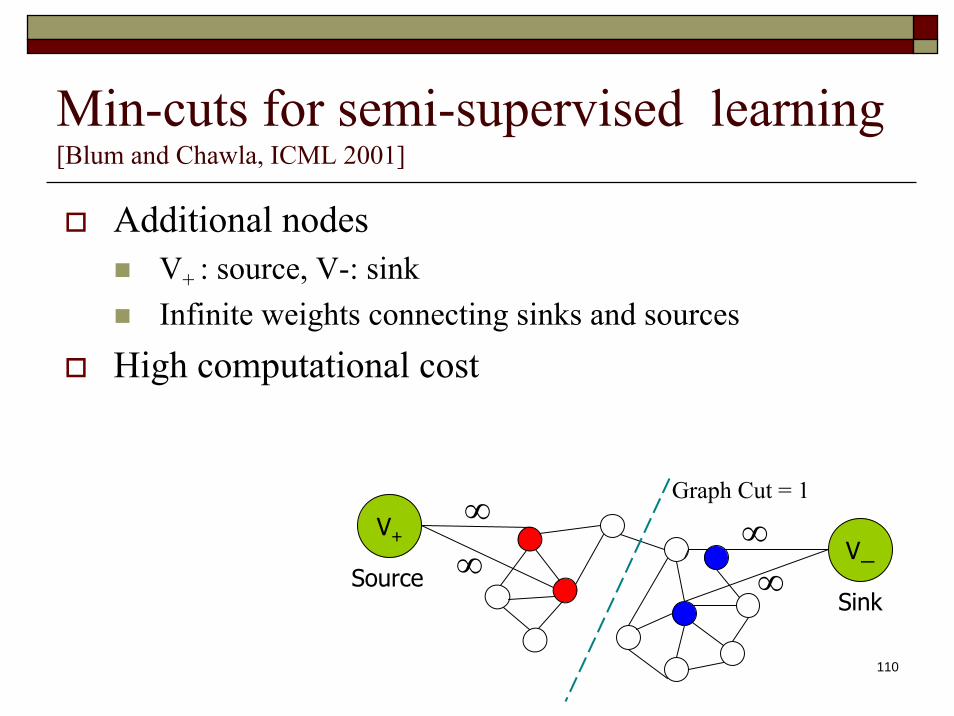
Min-cuts for semi-supervised learning [Blum and Chawla, ICML 2001]
Additional nodesV+ : source, V-: sinkInfinite weights connecting sinks and sources
High computational cost
V+V ̲∞
∞
∞∞
SourceSink
Graph Cut = 1
111
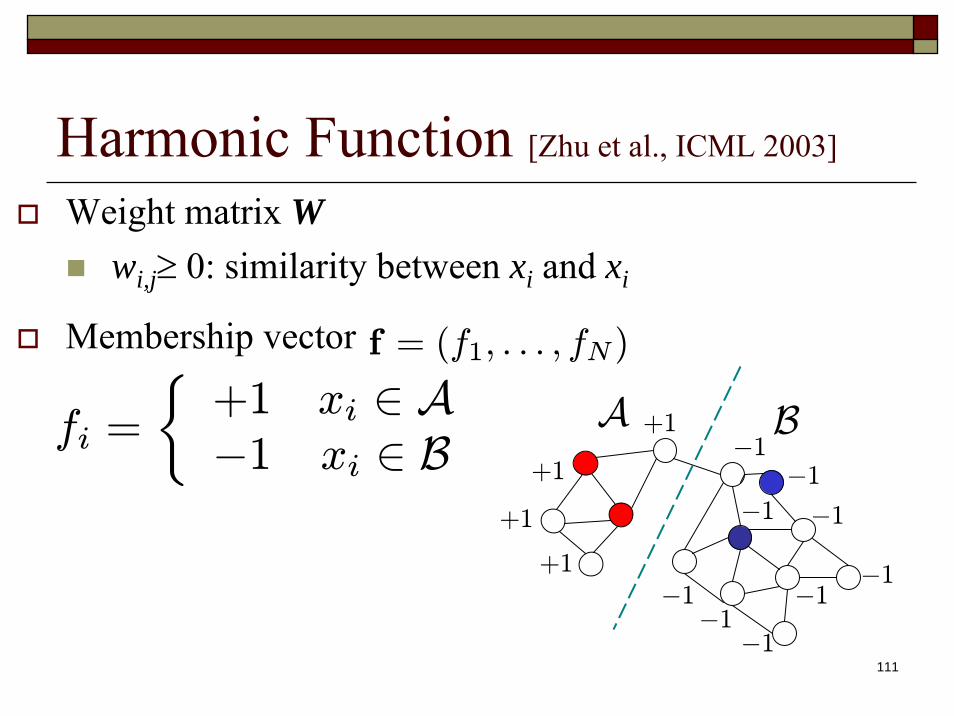
Harmonic Function [Zhu et al., ICML 2003]
Weight matrix Wwi,j≥ 0: similarity between xi and xi
Membership vector f = (f1, . . . , fN )
fi =
½+1 xi ∈ A−1 xi ∈ B
−1
A B
+1
+1
+1
+1−1
−1−1
−1−1
−1
−1
−1

112
Harmonic Function (cont’d)Graph cut
Degree matrixDiagonal element:
C(f) A B
+1
+1
+1
+1−1−1−1
−1−1
−1
−1
−1
D = diag(d1, . . . , dN )
di =P
j 6=iWi,j
C(f) =
NXi=1
NXj=1
(fi − fj)24
wi,j
=1
4f>(D −W )f = 1
4f>Lf

113
Harmonic Function (cont’d)Graph cut
Graph Laplacian L = D –WPairwise relationships among data poitnsMainfold geometry of data
C(f) A B
+1
+1
+1
+1−1−1−1
−1−1
−1
−1
−1
C(f) =
NXi=1
NXj=1
(fi − fj)24
wi,j
=1
4f>(D −W )f = 1
4f>Lf
114
Harmonic Function
A B
+1
+1
+1
+1−1−1−1
−1−1
−1
−1
−1
minf∈{−1,+1}N
C(f) =1
4f>Lf
s. t. fi = yi, 1 ≤ i ≤ nl
Consistency with graph structures
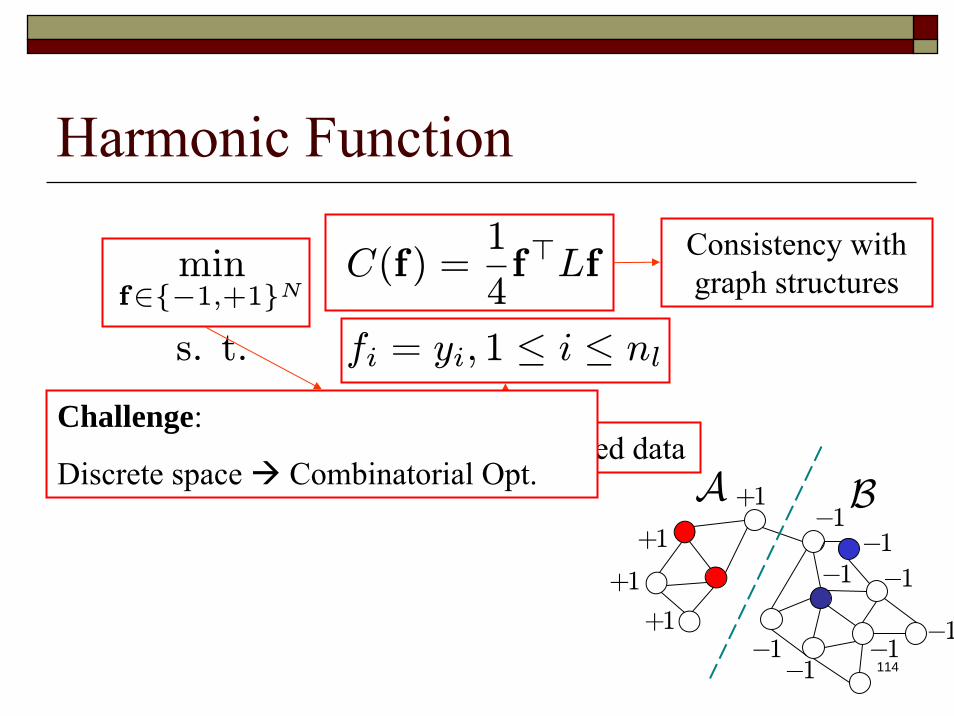
Consistent with labeled dataChallenge:
Discrete space Combinatorial Opt.

115
Harmonic Function
Relaxation: {-1, +1} continuous real number
Convert continuous f to binary ones
A B
+1
+1
+1
+1−1−1−1
−1−1
−1
−1
−1
minf∈{−1,+1}N
C(f) =1
4f>Lf
s. t. fi = yi, 1 ≤ i ≤ nl
minf∈RN
C(f) =1
4f>Lf
s. t. fi = yi, 1 ≤ i ≤ nl

116
Harmonic Function
minf∈RN
C(f) =1
4f>Lf
s. t. fi = yi, 1 ≤ i ≤ nl
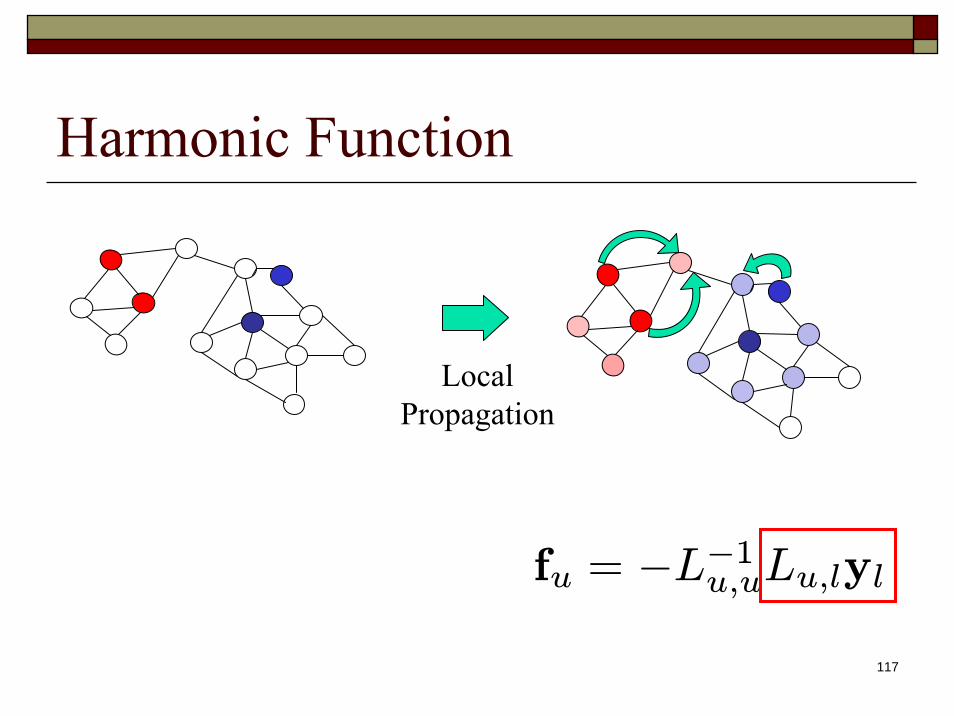
L =
µLl,l Lu,lLl,u Lu,u
¶, f = (fl, fu)
fu = −L−1u,uLu,lyl
117
Harmonic Function
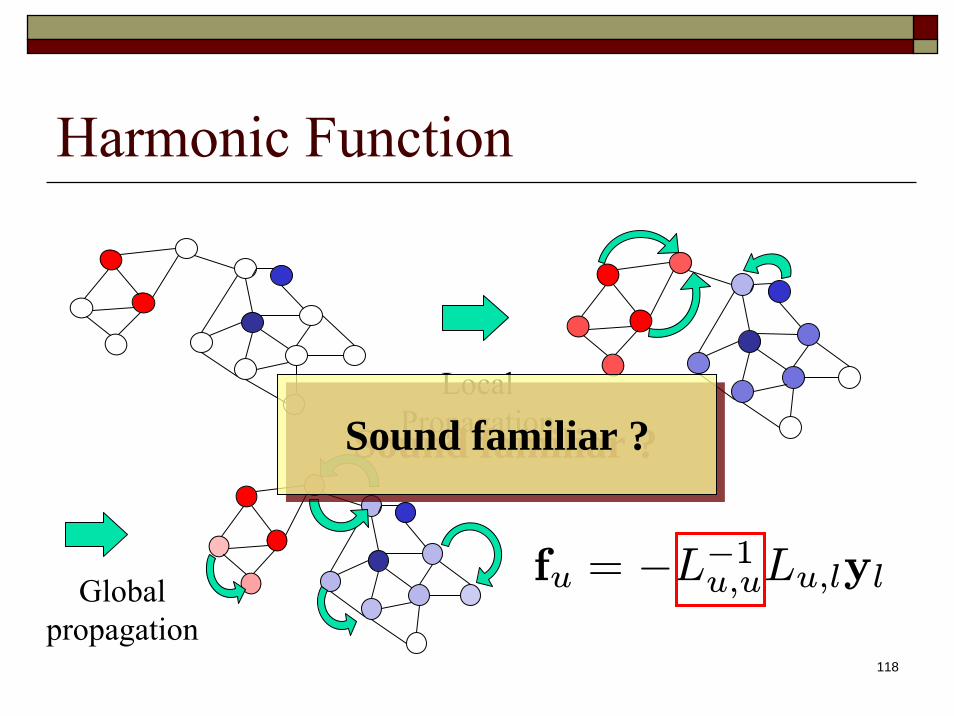
fu = −L−1u,uLu,lyl
Local Propagation
118
Harmonic Function
Local Propagation
Global propagation
fu = −L−1u,uLu,lyl
Sound familiar ?Sound familiar ?

119
Spectral Graph Transducer [Joachim , 2003]
minf∈RN
C(f) =1
4f>Lf
s. t. fi = yi, 1 ≤ i ≤ nl
Soften hard constraints
+αnlXi=1
(fi − yi)2

120
Spectral Graph Transducer [Joachim , 2003]
minf∈RN
C(f) =1
4f>Lf
s. t. fi = yi, 1 ≤ i ≤ nl
+αnlXi=1
(fi − yi)2
minf∈RN
C(f) =1
4f>Lf + α
nlXi=1
(fi − yi)2
s. t.NXi=1
f2i = N
Solved by Constrained Eigenvector ProblemSolved by Constrained Eigenvector Problem

121
Manifold Regularization [Belkin, 2006]
minf∈RN
C(f) =1
4f>Lf + α
nlXi=1
(fi − yi)2
s. t.NXi=1
f2i = N Loss function for misclassification
Regularize the norm of classifier
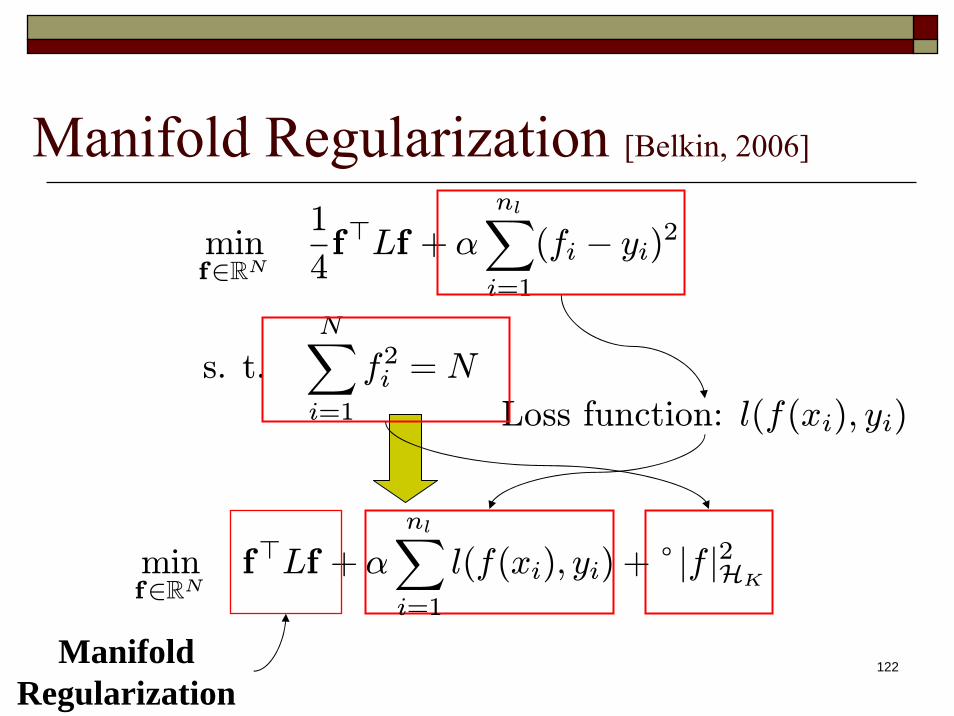
122
Manifold Regularization [Belkin, 2006]
minf∈RN
1
4f>Lf + α
nlXi=1
(fi − yi)2
s. t.NXi=1
f2i = N
Loss function: l(f (xi), yi)
minf∈RN
f>Lf + αnlXi=1
l(f(xi), yi) +°|f |2HK
Manifold Regularization

123
SummaryConstruct a graph using pairwise similarityKey quantity: graph Laplacian
Captures the geometry of the graphDecision boundary is consistent
Graph structureLabeled examples
Parametersα, γ, similarity
A B+1
+1
+1
+1 −1−1−1−1
−1−1
−1
−1
124
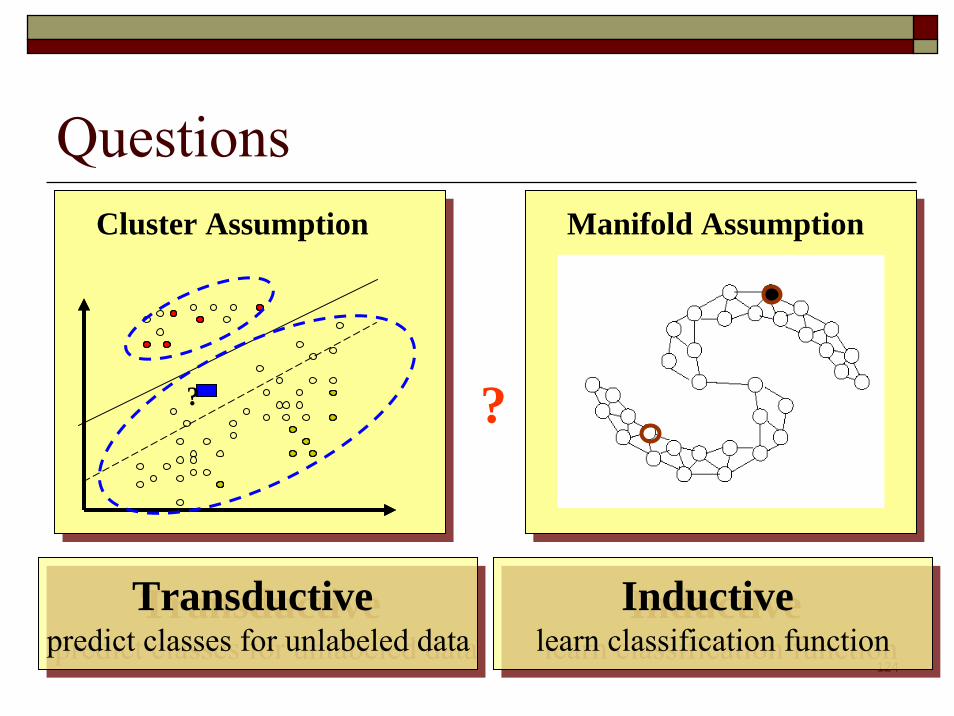
Questions
?
Cluster Assumption Manifold Assumption
?
Transductivepredict classes for unlabeled data
Transductivepredict classes for unlabeled data
Inductive learn classification function
Inductive learn classification function
125
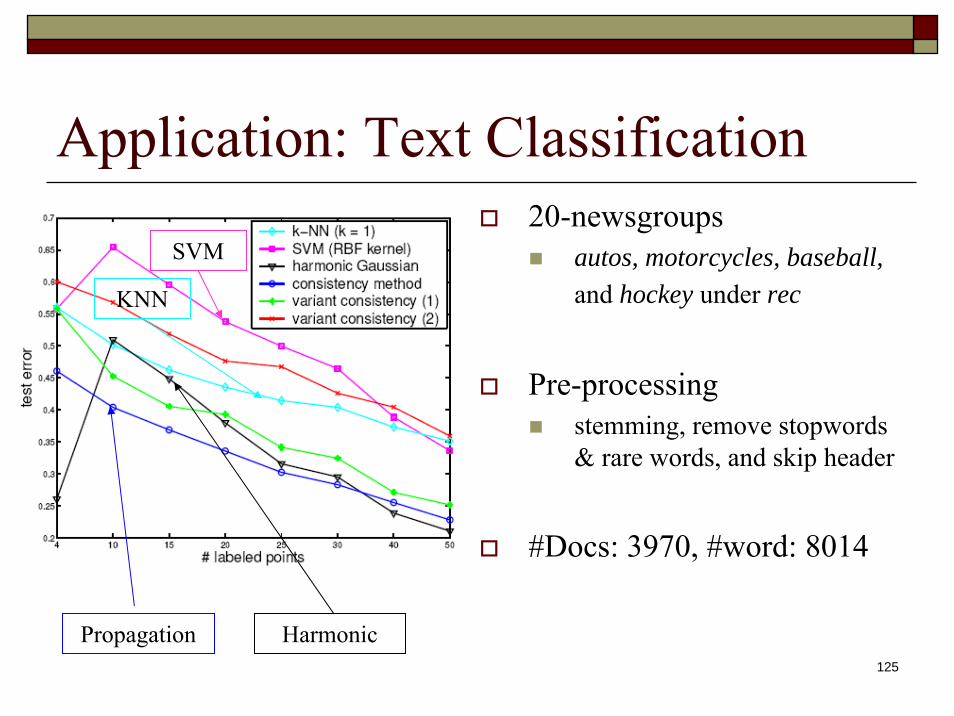
Application: Text Classification20-newsgroups
autos, motorcycles, baseball, and hockey under rec
Pre-processing stemming, remove stopwords& rare words, and skip header
#Docs: 3970, #word: 8014
Propagation Harmonic
SVM
KNN
126
Application: Text Classification
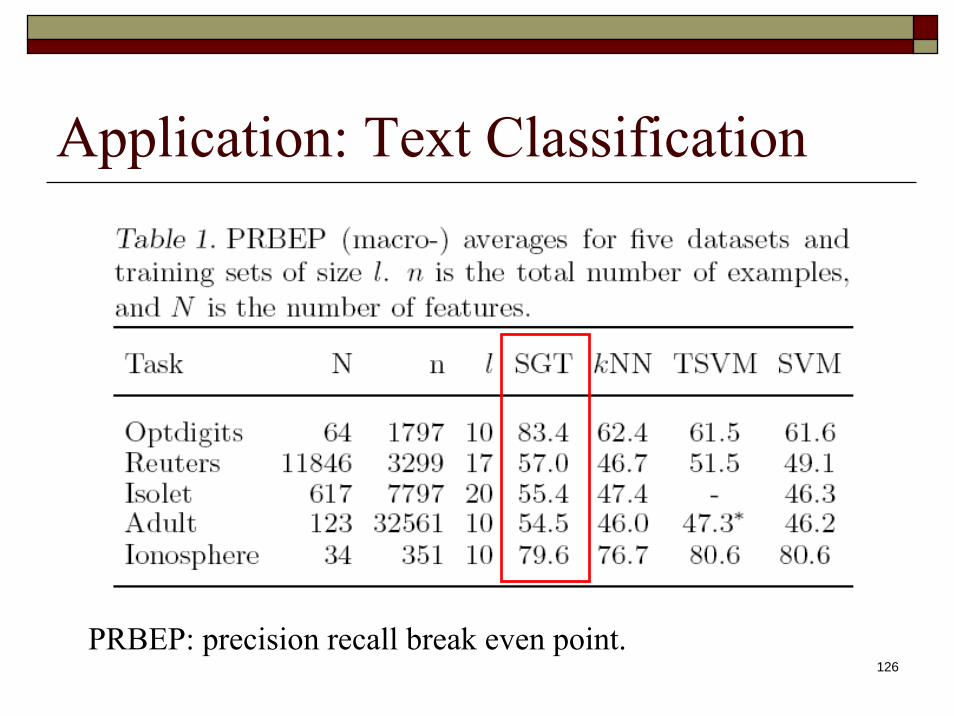
PRBEP: precision recall break even point.
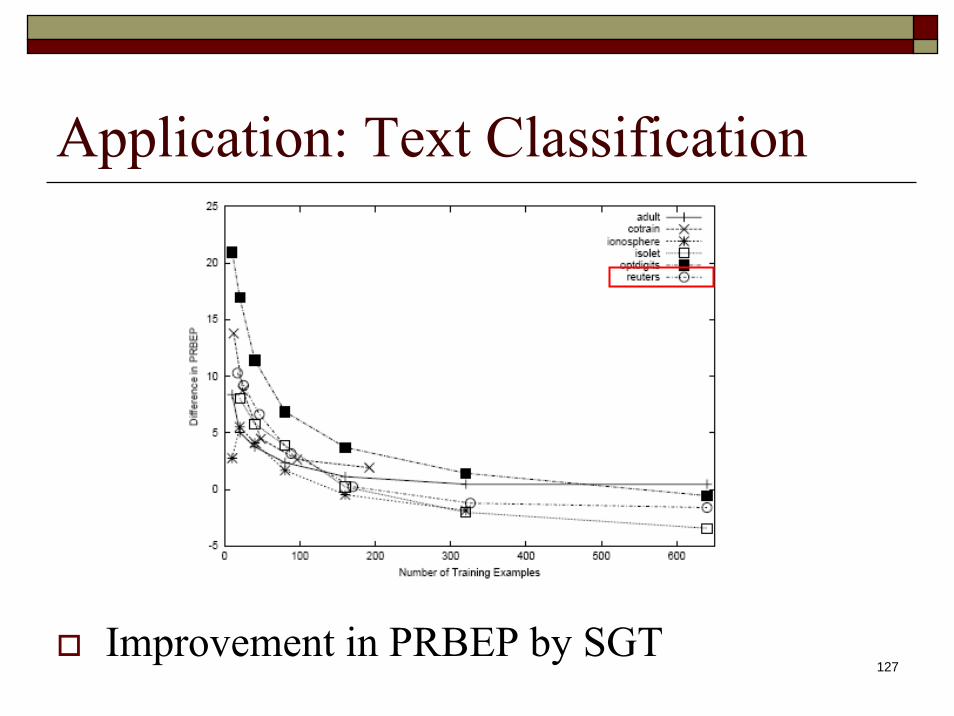
127
Application: Text Classification
Improvement in PRBEP by SGT

128
Topics of Semi-supervised Learning
Introduction to semi-supervised learningBasics of semi-supervised learningSemi-supervised classification algorithms
Label propagationGraph partitioning based approachesTransductive Support Vector Machine (TSVM)Co-training
Semi-supervised data clustering

129
Transductive SVMSupport vector machine
Classification marginMaximum classification margin
Decision boundary given a small number of labeled examples

130
Transductive SVMDecision boundary given a small number of labeled examplesHow to change decision boundary given both labeled and unlabeled examples ?

131
Transductive SVMDecision boundary given a small number of labeled examplesMove the decision boundary to low local density
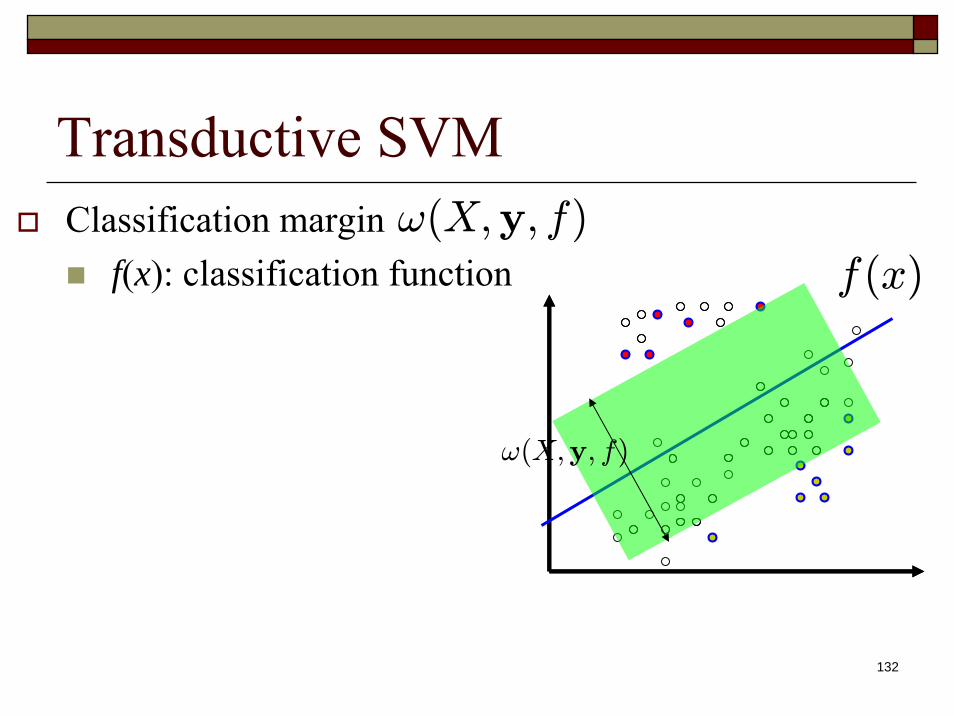
132
Transductive SVMClassification margin
f(x): classification functionSupervised learning
Semi-supervised learningOptimize over both f(x) and yu
ω(X,y, f)
f∗ = argmaxf∈HK
ω(X,y, f)
f(x)
ω(X,y, f)

133
Transductive SVMClassification margin
f(x): classification functionSupervised learning
Semi-supervised learningOptimize over both f(x) and yu
ω(X,y, f)
f∗ = argmaxf∈HK
ω(X,y, f)
f(x)

134
Transductive SVMClassification margin
f(x): classification functionSupervised learning
Semi-supervised learningOptimize over both f(x) and yu
ω(X,y, f)
f∗ = argmaxf∈HK
ω(X,y, f)
f(x)
(f∗,y∗u) = argmaxf∈HK ,yu∈{−1,+1}nu
ω(X,yl,yu, f)

135
Transductive SVMDecision boundary given a small number of labeled examplesMove the decision boundary to place with low local densityClassification resultsHow to formulate this idea?

136
Summary
Based on maximum margin principleClassification margin is decided by
Labeled examplesClass labels assigned to unlabeled data
High computational costVariants: Low Density Separation (LDS), Semi-Supervised Support Vector Machine (S3VM), ∇TSVM
137
Questions
?
Cluster Assumption Manifold Assumption
?
Transductivepredict classes for unlabeled data
Transductivepredict classes for unlabeled data
Inductive learn classification function
Inductive learn classification function
138
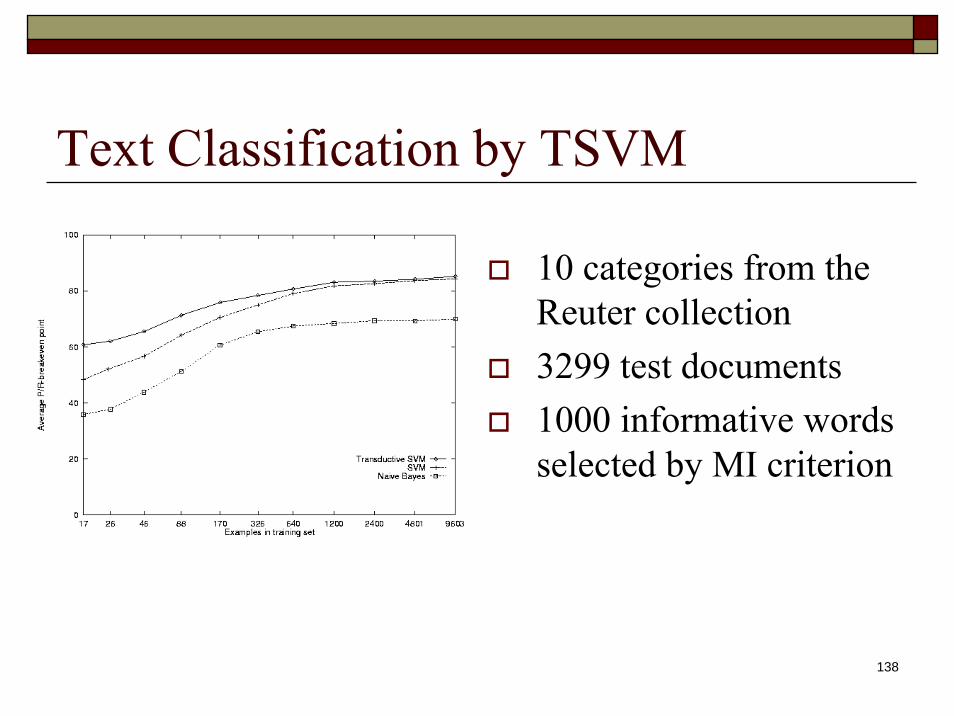
Text Classification by TSVM
10 categories from the Reuter collection3299 test documents1000 informative words selected by MI criterion

139
Topics of Semi-supervised Learning
Introduction to semi-supervised learningBasics of semi-supervised learningSemi-supervised classification algorithms
Label propagationGraph partitioning based approachesTransductive Support Vector Machine (TSVM)Co-training

140
Co-training [Blum & Mitchell, 1998]
Classify web pages into category for students and category for professors
Two views of web pagesContent
“I am currently the second year Ph.D. student …”
Hyperlinks“My advisor is …”“Students: …”
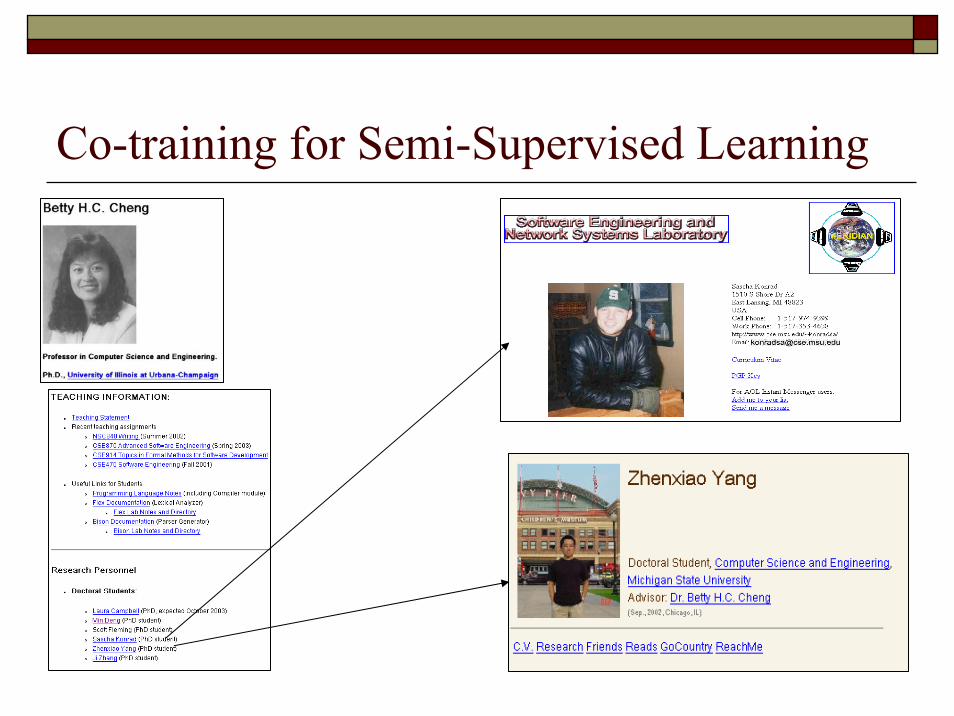
141
Co-training for Semi-Supervised Learning
142
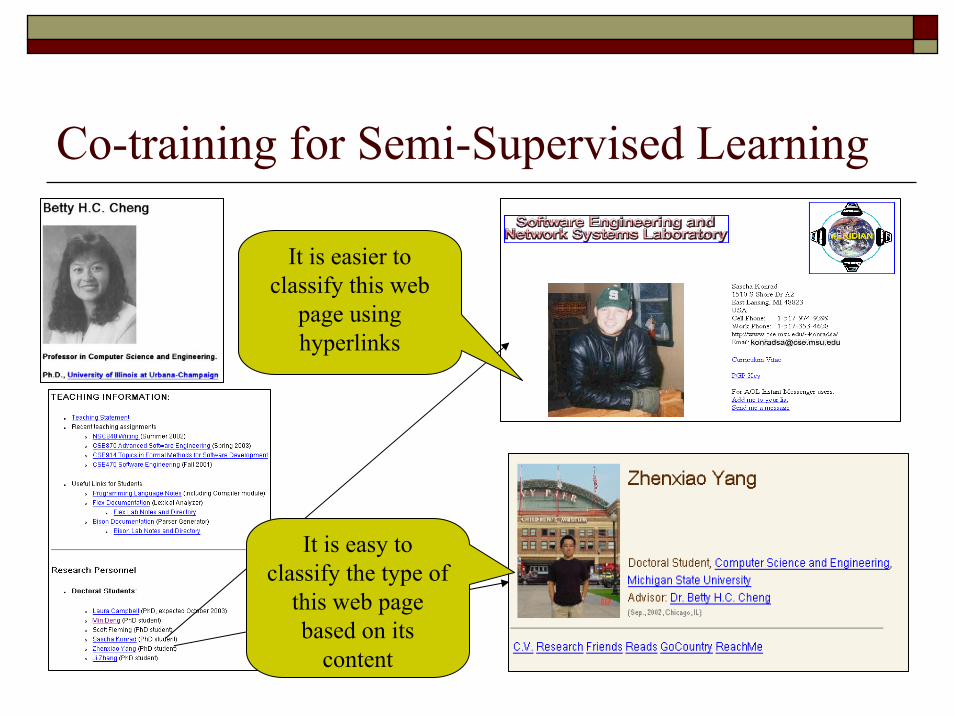
Co-training for Semi-Supervised Learning
It is easy to classify the type of
this web page based on its
content
It is easier to classify this web
page using hyperlinks

143
Co-trainingTwo representation for each web page
Content representation:
(doctoral, student, computer, university…)
Hyperlink representation:
Inlinks: Prof. Cheng
Oulinks: Prof. Cheng
144
Co-trainingTrain a content-based classifier
145
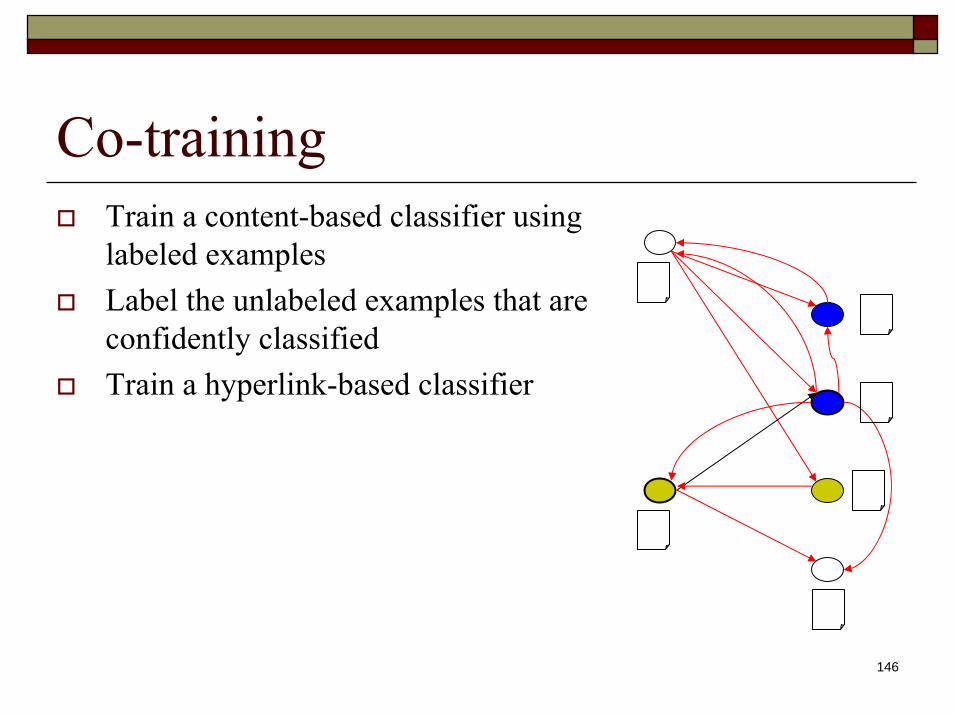
Co-trainingTrain a content-based classifier using labeled examplesLabel the unlabeled examples that are confidently classified
146
Co-trainingTrain a content-based classifier using labeled examplesLabel the unlabeled examples that are confidently classifiedTrain a hyperlink-based classifier

147
Co-trainingTrain a content-based classifier using labeled examplesLabel the unlabeled examples that are confidently classifiedTrain a hyperlink-based classifierLabel the unlabeled examples that are confidently classified

148
Co-trainingTrain a content-based classifier using labeled examplesLabel the unlabeled examples that are confidently classifiedTrain a hyperlink-based classifierLabel the unlabeled examples that are confidently classified

149
Co-trainingAssume two views of objects
Two sufficient representations
Key idea Augment training examples of one view by exploiting the classifier of the other view
Extension to multiple viewProblem: how to find equivalent views

150
A Few Words about Active LearningActive learning
Select the most informative examplesIn contrast to passive learning
Key question: which examples are informative
Uncertainty principle: most informative example is the one that is most uncertain to classifyMeasure classification uncertainty

151
A Few Words about Active LearningQuery by committee (QBC)
Construct an ensemble of classifiersClassification uncertainty largest degree of disagreement
SVM based approachClassification uncertainty distance to decision boundary
Simple but very effective approaches

152
Topics of Semi-supervised Learning
Introduction to semi-supervised learningBasics of semi-supervised learningSemi-supervised classification algorithms
Label propagationGraph partitioning based approachesTransductive Support Vector Machine (TSVM)Co-training
Semi-supervised clustering algorithms
153
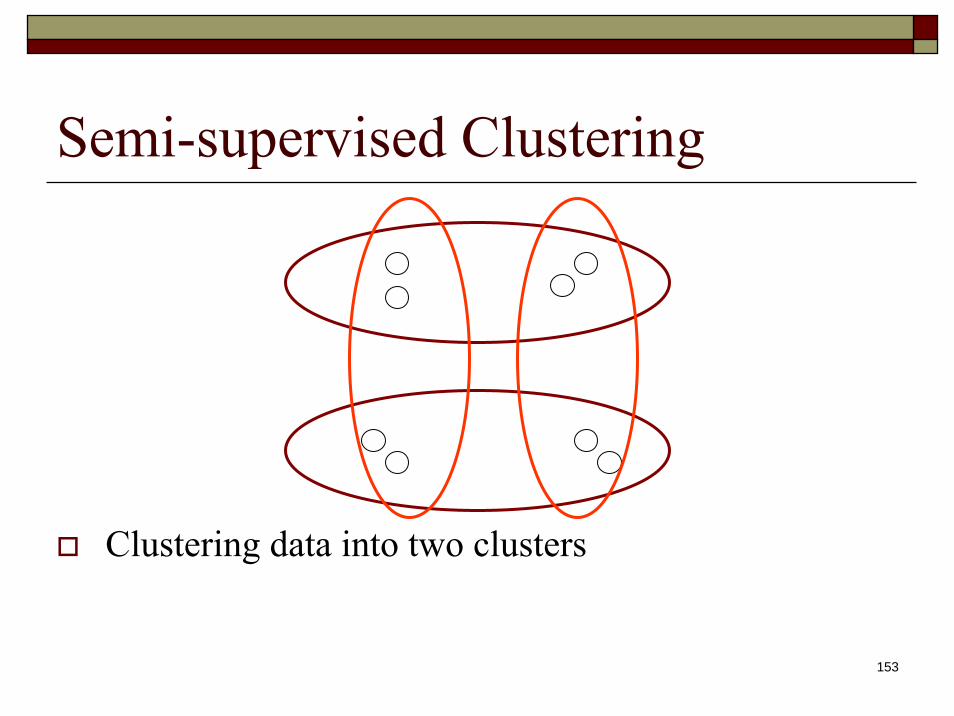
Semi-supervised Clustering
Clustering data into two clusters
154
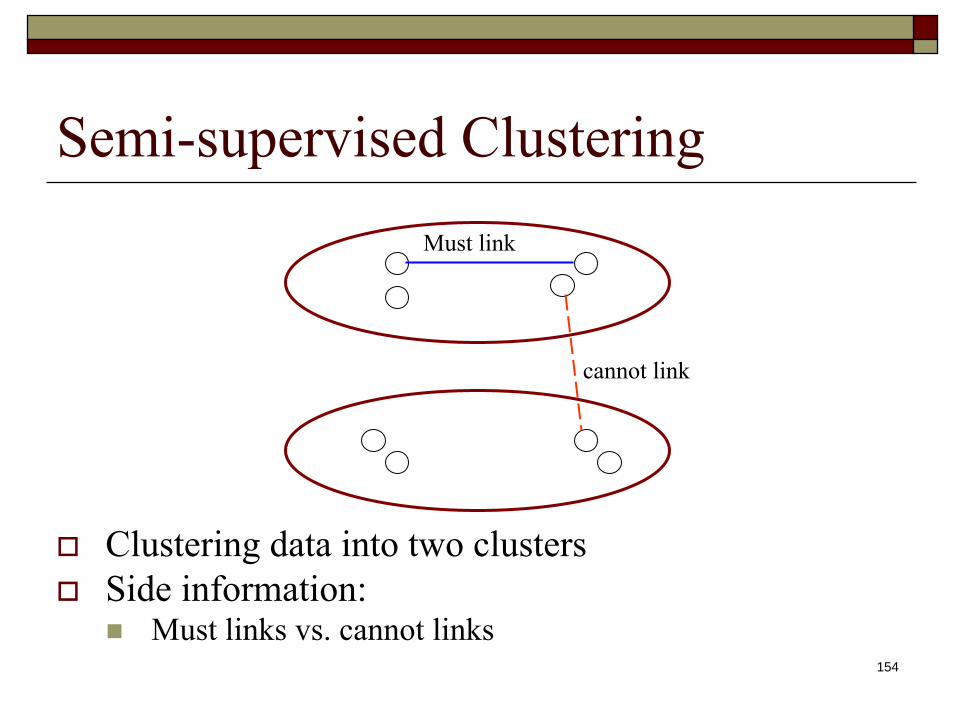
Semi-supervised Clustering
Clustering data into two clustersSide information:
Must links vs. cannot links
Must link
cannot link

155
Semi-supervised ClusteringAlso called constrained clusteringTwo types of approaches
Restricted data partitionsDistance metric learning approaches

156
Restricted Data PartitionRequire data partitions to be consistent with the given linksLinks hard constraints
E.g. constrained K-Means (Wagstaff et al., 2001)
Links soft constraintsE.g., Metric Pairwise Constraints K-means (Basu et al., 2004)

157
Restricted Data PartitionHard constraints
Cluster memberships must obey the link constraints
must link
cannot linkYes

158
Restricted Data PartitionHard constraints
Cluster memberships must obey the link constraints
must link
cannot linkYes

159
Restricted Data PartitionHard constraints
Cluster memberships must obey the link constraints
must link
cannot linkNo

160
Restricted Data PartitionSoft constraints
Penalize data clustering if it violates some links
must link
cannot linkPenality = 0

161
Restricted Data PartitionHard constraints
Cluster memberships must obey the link constraints
must link
cannot link
Penality = 0
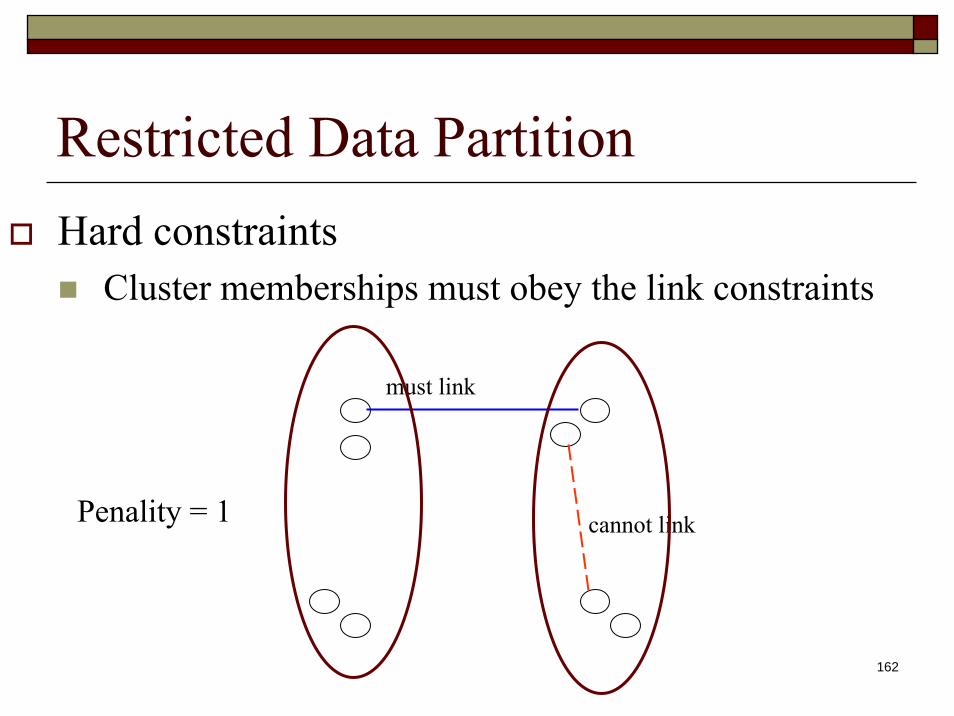
162
Restricted Data PartitionHard constraints
Cluster memberships must obey the link constraints
must link
cannot linkPenality = 1

163
Distance Metric LearningLearning a distance metric from pairwise links
Enlarge the distance for a cannot-linkShorten the distance for a must-link
Applied K-means with pairwise distance measured by the learned distance metric
must link
cannot link
Transformed by learned distance metric
164
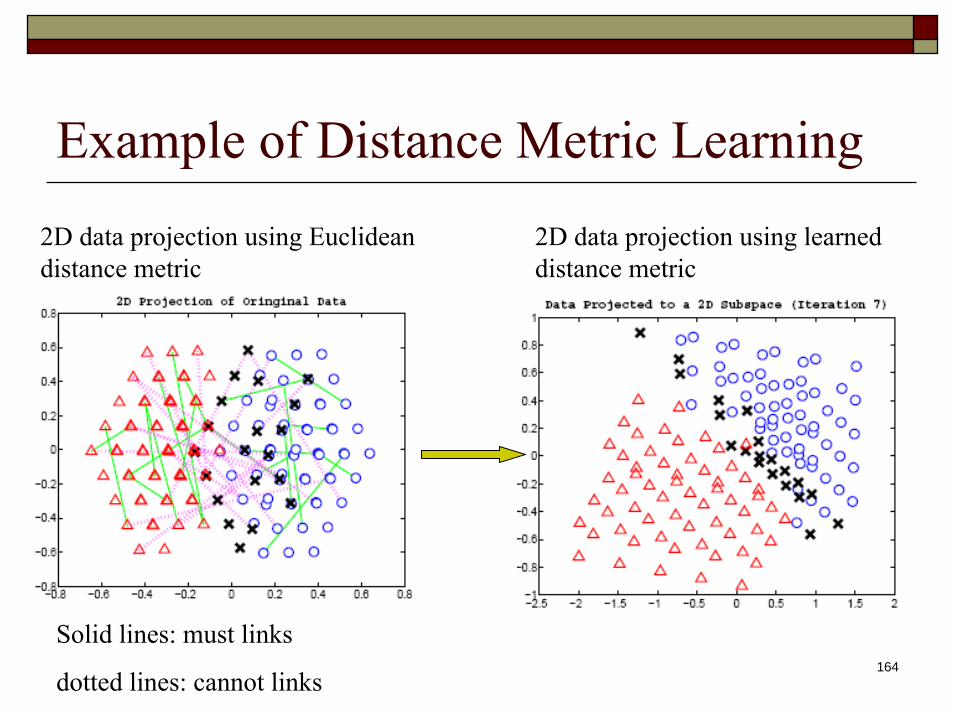
Example of Distance Metric Learning
Solid lines: must links
dotted lines: cannot links
2D data projection using Euclidean distance metric
2D data projection using learned distance metric

165
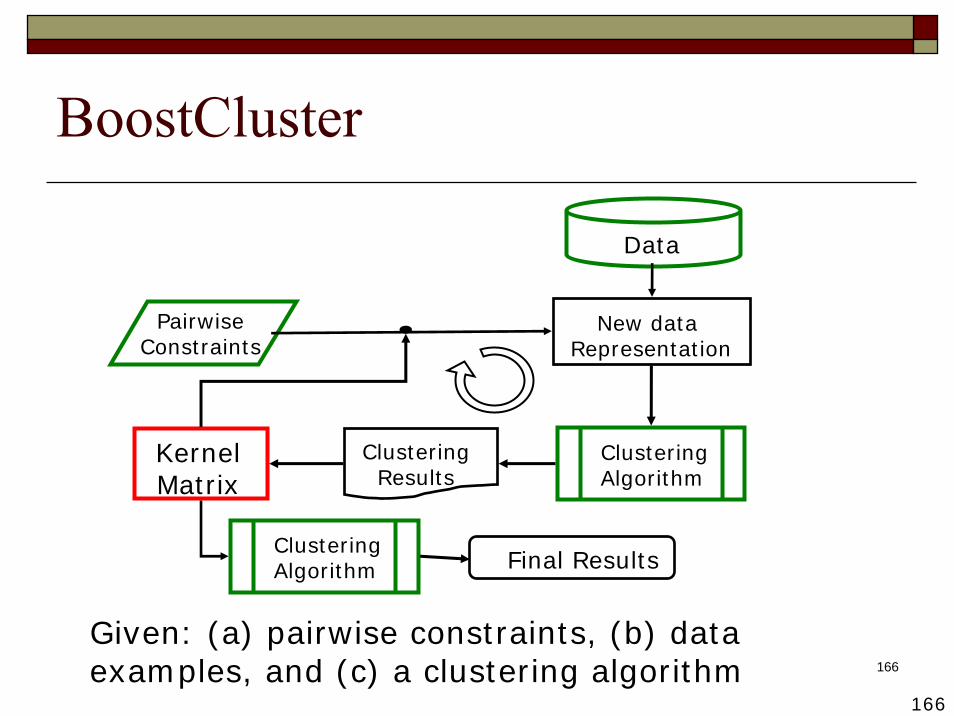
BoostCluster [Liu, Jin & Jain, 2007]
General framework for semi-supervised clusteringImproves any given unsupervised clustering algorithm with pairwise constraints
Key challengesHow to influence an arbitrary clustering algorithm by side information? Encode constraints into data representation
How to take into account the performance of underlying clustering algorithm?Iteratively improve the clustering performance
166
166
BoostCluster
Given: (a) pairwise constraints, (b) data examples, and (c) a clustering algorithm
Data
PairwiseConstraints
New data Representation
ClusteringAlgorithm
ClusteringResults
Final Results
KernelMatrix
ClusteringAlgorithm
167
167
BoostCluster
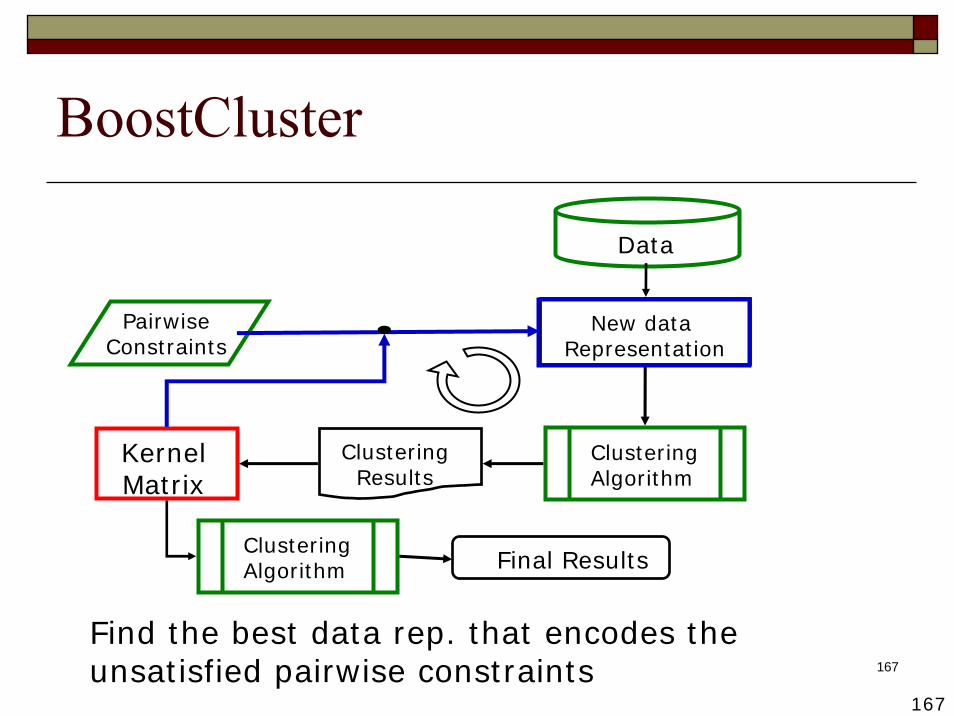
Find the best data rep. that encodes the unsatisfied pairwise constraints
Data
PairwiseConstraints
New data Representation
ClusteringAlgorithm
ClusteringResults
Final Results
KernelMatrix
ClusteringAlgorithm
168
168
BoostCluster
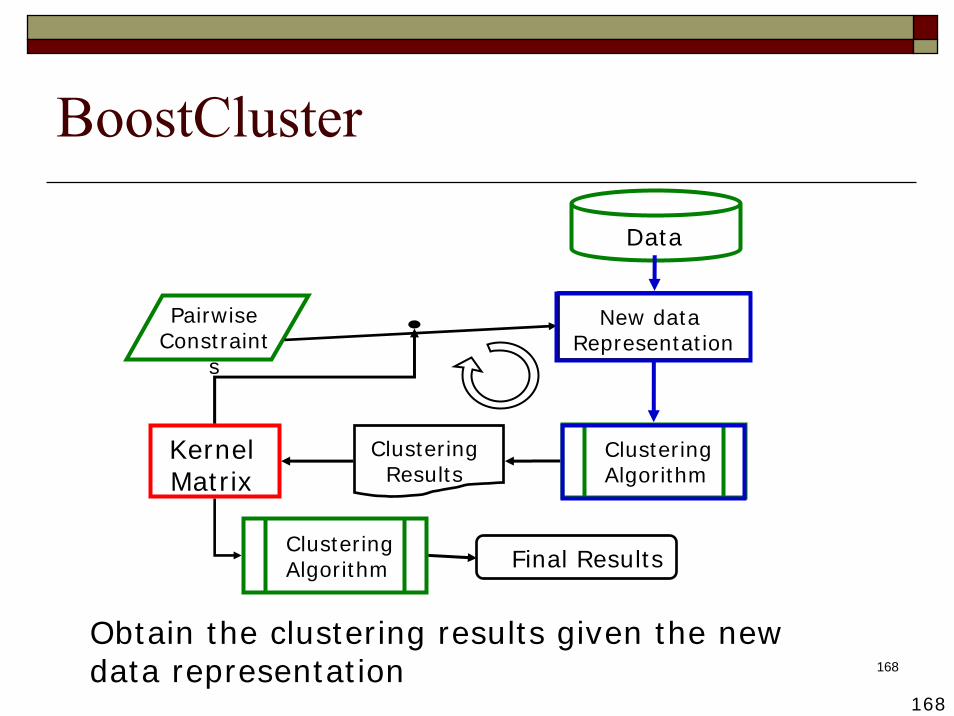
Obtain the clustering results given the new data representation
Data
PairwiseConstraint
s
New data Representation
ClusteringAlgorithm
ClusteringResults
Final Results
KernelMatrix
ClusteringAlgorithm
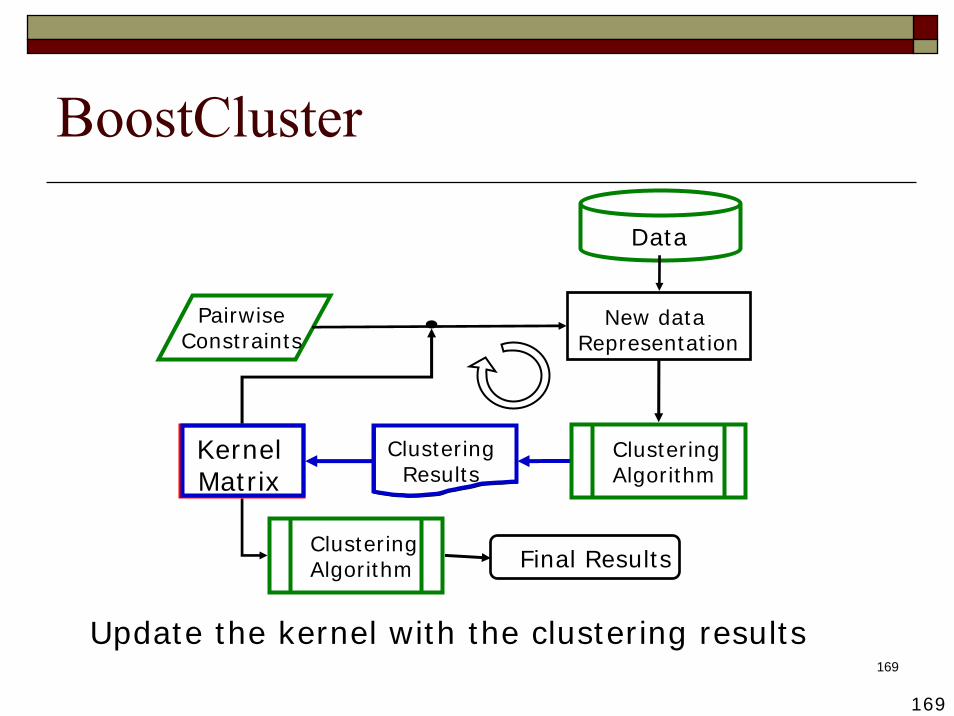
169
169
BoostCluster
Update the kernel with the clustering results
Data
PairwiseConstraints
New data Representation
ClusteringAlgorithm
ClusteringResults
Final Results
KernelMatrix
ClusteringAlgorithm
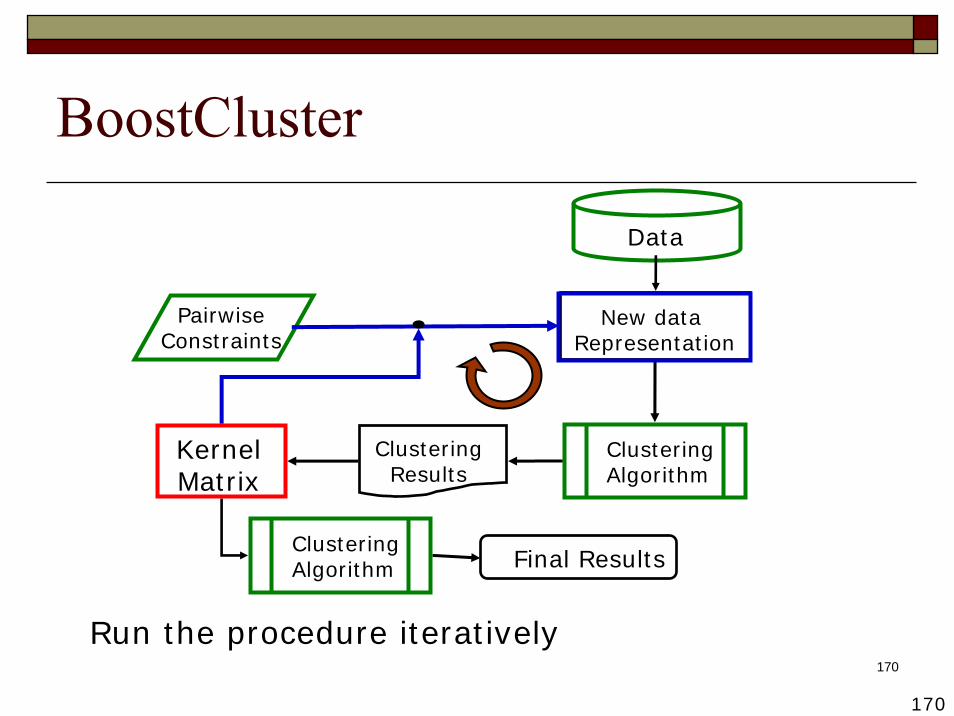
170
170
BoostCluster
Run the procedure iteratively
Data
PairwiseConstraints
New data Representation
ClusteringAlgorithm
ClusteringResults
Final Results
KernelMatrix
ClusteringAlgorithm
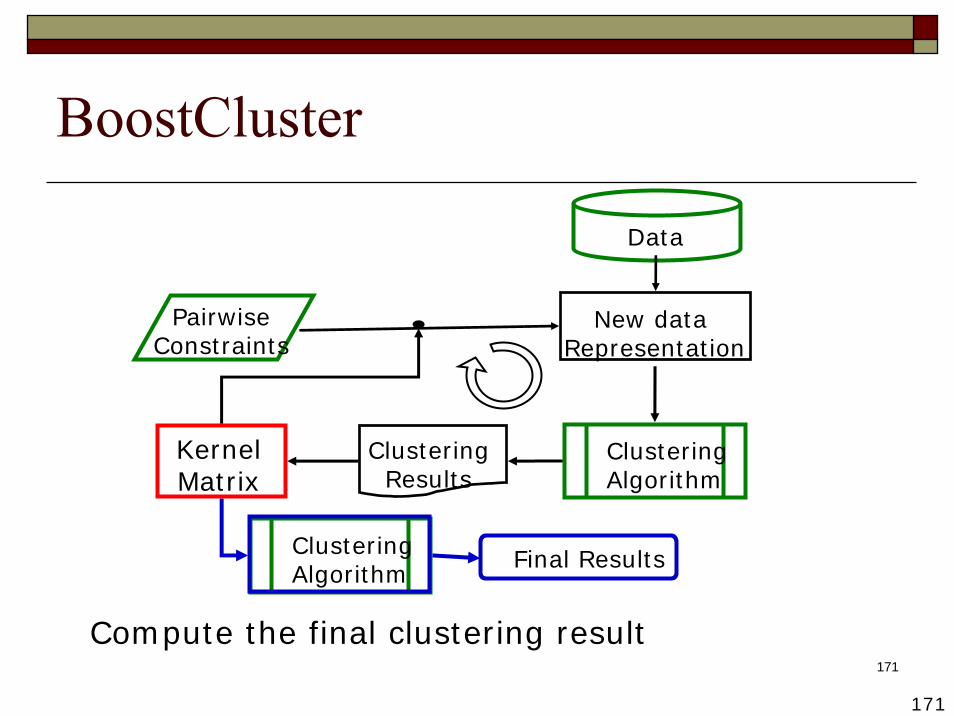
171
171
BoostCluster
Compute the final clustering result
Data
PairwiseConstraints
New data Representation
ClusteringAlgorithm
ClusteringResults
Final Results
KernelMatrix
ClusteringAlgorithm

172
SummaryClustering data under given pairwise constraints
Must links vs. cannot linksTwo types of approaches
Restricted data partitions (either soft or hard)Distance metric learning
Questions: how to acquire links/constraints?Manual assignmentsDerive from side information: hyper links, citation, user logs, etc.
May be noisy and unreliable
173
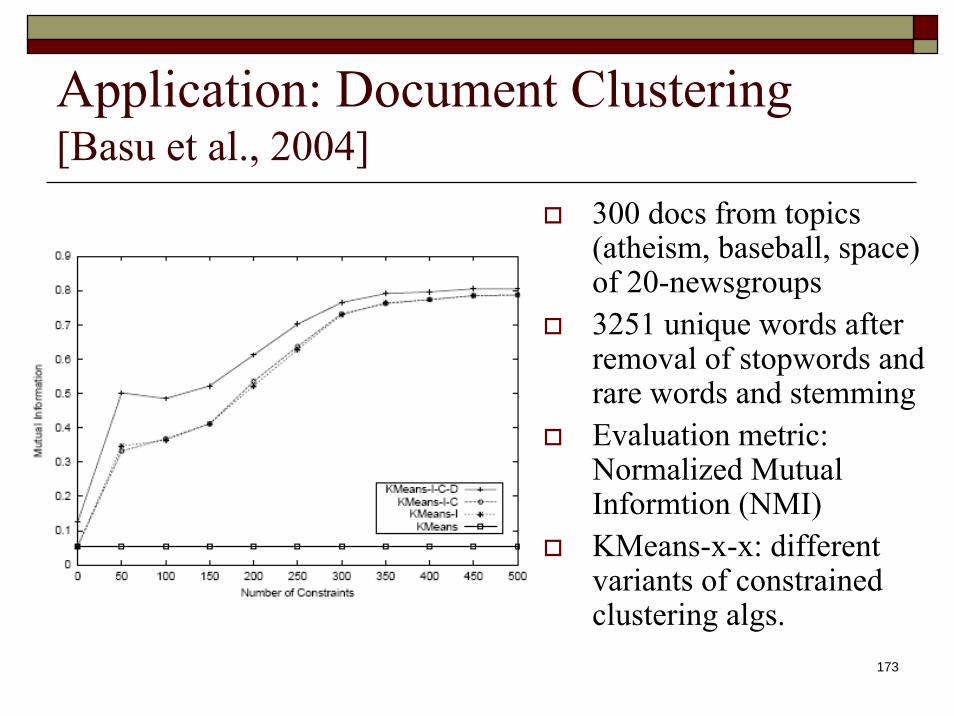
Application: Document Clustering[Basu et al., 2004]
300 docs from topics (atheism, baseball, space) of 20-newsgroups3251 unique words after removal of stopwords and rare words and stemmingEvaluation metric: Normalized Mutual Informtion (NMI)KMeans-x-x: different variants of constrained clustering algs.

174
OutlineIntroduction to information retrieval, statistical inference andmachine learningSupervised learning and its application to text classification, adaptive filtering, collaborative filtering and rankingSemi-supervised learning and its application to text classificationEmerging research directions

175
Efficient LearningIn IR, we have massive amount of dataBut, most learning algs. are relatively slow
Difficult to handle millions of documents
How to improve scalability ?Sampling, only use part of dataStochastic optimization, update model one example each time (related to online learning)
More interesting, more examples may mean more efficient training (Sebro, ICML 2008)

176
Kernel LearningKernel plays central role in machine learningKernel functions can be learned from data
Kernel alignment, multiple kernel learning, non-parametric learning, …
Kernel learning is suitable for IRSimilarity measure is key to IRKernel learning allows us to identify the optimal similarity measure automatically

177
Transfer LearningDifferent document categories are correlatedWe should be able to borrow information of one class to the training of another classKey question: what to transfer between classes?
Representation, model priors, similarity measure …

178
Active Learning IR ApplicationsRelevance feedback (text retrieval or image retrieval)Text classificationAdaptive information filteringCollaborative filteringQuery Rewriting

179
Discriminative Language ModelsLanguage models have shown to be effective for information retrievalBut most language models are generative, thus missing the discriminative powerKey difficulty in discriminative language models: no outputs!
Side informationMixture of generative and discriminative models

180
ReferencesA. McCallum and K. Nigam. A comparison of event models for Naive Bayes text classification. In AAAI-98 Workshop on Learning for Text Categorization, 1998 Tong Zhang and Frank J. Oles, Text Categorization Based on Regularized Linear ClassificationMethods, Journal of Information Retrieval, 2001F. Li and Y. Yang. A loss function analysis for classification methods in text categorization, The Twentieth International Conference on Machine Learning (ICML'03) Chengxiang Zhai and John Lafferty, A study of smoothing methods for language models applied to information retrieval, ACM Trans. Inf. System, 2004 A. Blum and T. Mitchell, Combining Labeled and Unlabeled Data with Co-training, COLT 1998D. Blei and M. Jordan, Variational methods for the Dirichlet process, ICML 2004T. Hofmann, Unsupervised Learning by Probabilistic Latent Semantic Analysis, Mach. Learn., 42(1-2), 2001D. Blei, A. Ng and M. Jordan, Latent Dirichlet allocation, NIPS*2002R. Jin, C. Ding, and F. Kang, A Probabilistic Approach for Optimizing Spectral Clustering, NIPS*2005D. Zhou, B. Scholkopf, and T. Hofmann, Semi-supervised learning on directed graphs, NIPS*2005.X. Zhu, Z. Ghahramani, and J. D. Lafferty, Semi-supervised learning using Gaussian fields and harmonic functions. ICML 2003.T. Joachims, Transductive Learning via Spectral Graph Partitioning, ICML 2003

181
ReferencesAndrew McCallum and Kamal Nigam, Employing {EM} in Pool-Based Active Learning for Text Classification, Proceeding of the International Conference on Machine Learning, 1998David A. Cohn and Zoubin Ghahramani and Michael I. Jordan, Active Learning with Statistical Models, Journal of Artificial Intelligence Research, 1996S. Tong and E. Chang. Support vector machine active learning for image retrieval. In ACM Multimedia, 2001Xuehua Shen and ChengXiang Zhai, Active feedback in ad hoc information retrieval, SIGIR '05J. Kivinen and M. K. Warmuth. Exponentiated gradient versus gradient descent for linear predictors. Information and Computation, 1997.X.-J. Wang, W.-Y. Ma, G.-R. Xue, X. Li. Multi-Model Similarity Propagation and its Application for Web Image Retrieval, ACM Multimedia, 2004M. Belkin and P. Niyogi and V. Sindhwani, Manifold Regularization, Technical Report, Univ. of Chicago, 2006K. Wagstaff, C. Cardie, S. Rogers, and S. Schroedl. Constrained k-means clustering with background knowledge. In ICML '01, 2001.S. Basu, M. Bilenko, and R. J. Mooney. A probabilistic framework for semi-supervised clustering. In SIGKDD '04, 2004.

182
ReferencesXiaofei He, Benjamin Rey, Wei Vivian Zhang, Rosie Jones, Query Rewriting using Active Learning for Sponsored Search, SIGIR07Y. Zhang, W. Xu, and J. Callan. Exploration and exploitation in adaptive filtering based on bayesianactive learning. In Proceedings of 20th International Conf. on Machine Learning, 2003.Z. Xu and R. Akella. A bayesian logistic regression model for active relevance feedback (SIGIR08)G. Schohn and D. Cohn. Less is more: Active learning with support vector machines. ICML 2000M. Saar-Tsechansky and F. Provost. Active sampling for class probability estimation and ranking. Machine learning, 2004J. Rocchio. Relevance feedback in information retrieval, In The Smart System: experiments in automatic document processing. Prentice Hall, 1971.H. S. Seung, M. Opper, and H. Sompolinsky. Query by committee. In Proceedings of the fifth annual workshop on Computational learning theory, 1992Y. Freund, H. S. Seung, E. Shamir, and N. Tishby. Selective sampling using the query by committee algorithm. Machine Learning, 28(2-3):133–168, 1997D. A. Cohn, L. Atlas, and R. Ladner. Improving generalization with active learn-ing. Machine learning, 1994.Robert M. Bell and Yehuda Koren, Lessons from the Netix Prize Challenge, KDD Exploration 2008Tie-Yan Liu, Tutorial: Learning to rankSoumen Chakrabarti, Learning to Rank in Vector Spaces and Social Networks, www 2007
183
Thank You
God, it is finally over !God, it is finally over !