Embed Size (px)
Citation preview

Ansgar [email protected]
FG DatenbankenMarch 2014Braunschweig
LOD in Digital Libraries -Current Issues

Index Newly Acquired Media
• Ancient world: Library of Alexandria• Today: database-oriented systems• Tomorrow: Web � Semantic Web in Libraries
- 2 -

SWIB = Melting pointfor librariansthat workwith LOD
Start: 2009Today:InternationalMeetup
- 3 -

„The Early Years …“ (they were grey)• Individually implemented solutions;proofs of concepts• First LOD cloud:
emerged in May 2007
• First Linked Library connection between Library of Congress, US and Swedish National Library
• Quick adoption of new technology
- 4 -

Linked (Library) Data: A Success Story
…
- 5 -

Current (Technological) Issues *)
1. Entity resolution2. Schema matching3. Distributed data management4. Automatic indexing5. Indexing non-textual content6. Data provenance
Out of scope here (but equally important)• Quality management (e.g., automated indexing)• Legal aspects• Job market
*) Disclaimer: No guarantee for completeness - 6 -

1. Entity Resolution• URI aliases to connect resources• Describing the same things in the real world
• Service for sameAs-links: .org
• Resolution of name, co-authors, title, and venue often not sufficient
- 7 -Source: J. Neubert, K. Tochtermann: Linked Library Data: Offering a Backbone for the Semantic Web, CiCIS, 2012.
Source Persons Organizations
DBpedia 364,000 148,000
Library of Congress Authorities 3,800,000 900,000
German NationalLibrary AuthorityFile 1,797,911 1,262,404
Virtual International Authority File 10 million 3.25 million

Example: DNB GND on Helmut Kohlhttp://d-nb.info/gnd/118564595
- 8 -

VIAF(Virtual International Authority File)• Combines multiple name authority files • Lower costs and increase utility of library authority files • Matching and linking widely-used authority files and
making that information available on the Web
- 9 -

2. Schema Matching• “When defining one’s vocabulary, refer to definition of
concepts and properties of existing vocabularies”• Goal: data becomes self-descriptive
• Integration of vocabularies is hard• Similar to the problem of identity
• Example: foaf:name vs. vcard:family-name
• Can be complex, even for very similar vocabularies
- 10 -

Example: STW and TheSoz
- 11 -
Standard Thesaurus Wirtschaft
• Manually created mappings (mostly 2004/2005)• OAEI Library Track for ontology matching (since 2012)• Also connected to GND and ACROVOC
TheSoz (GESIS)

Example: STW and TheSoz
- 12 -
Standard Thesaurus Wirtschaft
• Manually created mappings (mostly 2004/2005)• OAEI Library Track for ontology matching (since 2012)• Also connected to GND and ACROVOC
TheSoz (GESIS)

eGov‘ Example: Crimes in US vs. UK
Same or different?
Same or different?
- 13 -

3. Distributed Data ManagementSep. 2012

VIAF Example Source: Trevor Thornton – Linked Data for LibrariansSenior Applications Developer, NYPL LabsThe New York Public Library
http://archives.nypl.org/
mss/2071
http://viaf.org/viaf/5286
6196
‘142 linear feet’
http://archives.nypl.org/
mss/2071
http://purl.org/dc/term
s/creatorhttp://purl.org/dc/ter
ms/extent
http://purl.org/archival/vocab
/arch#heldBy
http://viaf.org/viaf/44312
399
http://purl.org/dc/ter
ms/creator
http://purl.org/dc/term
s/subject
Robert Moses Papers
The Power Broker
http://www.worldcat.org/
oclc/834874
- 15 -
Robert Moses(American city planner)
Robert Moses@ VIAF
Robert Caro writesabout Moses
Other work byCaro …

3. Distributed Data Management• Federated querying• Index structures (what information is where?)• SPARQL-based vs. traversal-based querying
• Ranking of results• User‘s expect same behavior as in web search• First hits implicitly more important and relevant• DFG project LibRank at ZBW
- 16 -

4. Automated Indexing
• Automated classification of PDFs into 100 classes (“Sachgruppen”) in PETRUS project at DNB
Source: E. Mödden Zukunftsfähige Inhaltserschließung – Strategienund Perspektiven in der Deutschen Nationalbibliothek, GBV, 2013. - 17 -
Delivered publications per year (print/online)at DNB

4. Automated Indexing• DFG project GERHARD in 90s on automatically
indexing scientific Web content (involved 1997-1999)• ~ 1 Mio documents crawled and automatically indexed• Classified using the 10.000 concepts from the
Universal Decimal Classification (UDC)• Trilingual (German, English, French)
• Single server machine ~ 750 MB RAM• Oracle RDBMS with full text indices ConText
(today: Oracle Text)
- 18 -
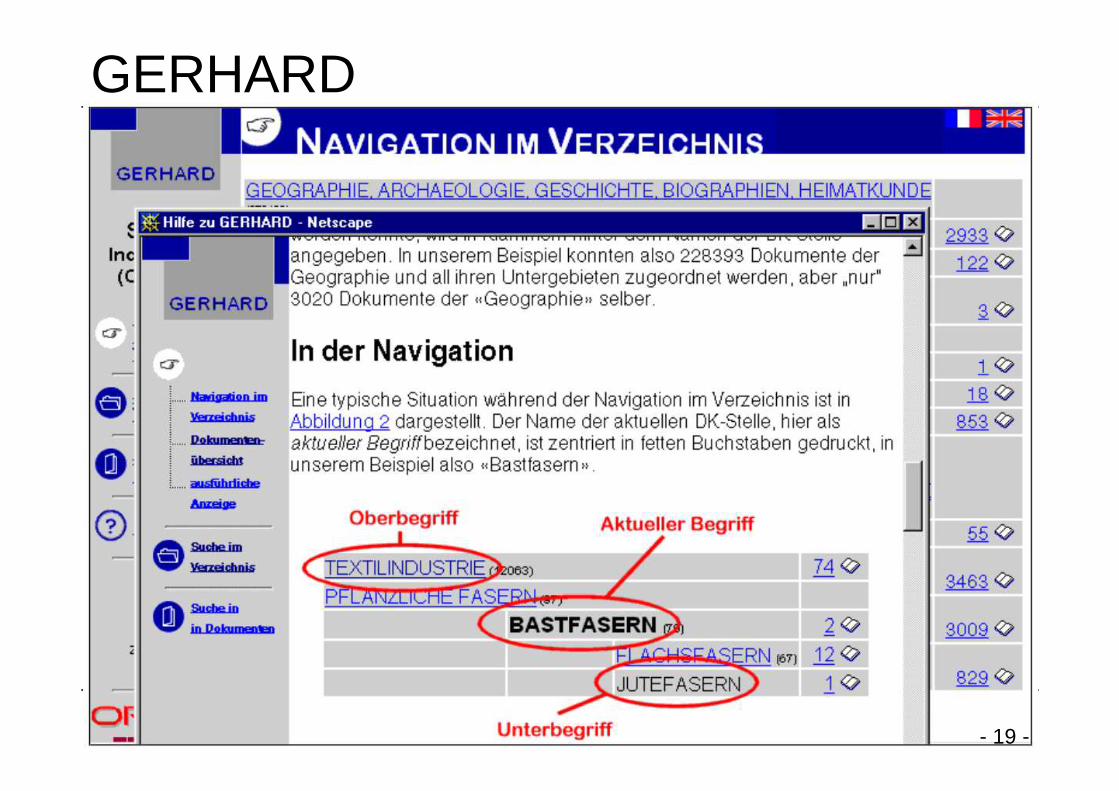
GERHARD
- 19 -

• Auto-completion suggests terms from PND, STW, …• Author confirms by selecting terms• Keyword is matched with the semantic concept
- 20 -
Erschließung in

• Mapping scientific content with social media • For example, PDFs + blogs, tweets, research data, …
Content analysisStructured
scientific content
(fulltexts,
paragraphs,
citations,…)
Informal + hasty
content from
social media
channels
Linking to
EEXCESS
topics/
objects/
users - 21 -
5. Indexing non-textual content

6. Data Provenance• VIAF: inter-organizational and cross-border and thus
cross-lingual record linkage
• How to track metadata (re)use?• How to refer to original metadata when
library A uses a (part of) record from library B?
- 22 -

Europeana Data Model
“Provenance”of Mona Lisa
Source: Slide adopted from Kai Eckert
Provenance of the meta data

DM2E Data Bridge for Legacy Systems

Resource Description and Access• New cataloging code to replace AACR2 from 1978• Describe content, online• But not to confuse with RDF
• Inspired by Functional Requirements for Bibliographic Records (FRBR)
• Applicable to any kind of resources („not only books“)• Provides guidelines

FRBR in a Nutshell
26
Work
Expression
Manifestation
Item
is realized through
is embodied in
is exemplified by
recursive
one
many
Group 1
Much more than just a „boring“ bibliographicdata record

ZBW – Services and Data• Leibnitz Information Center for Economics (Kiel and Hamburg)• 200+ employees, 3 professors (Scherp, Tochtermann, Peters)• Annual budget of 20,8 mio €
- 27 -
• 1 mio Open Access documents• 4,9 mio documents• Couple of thousand unique
visitors per month
• 70.000 open access documents
• Intelligent use of STW

Got Interested?
Contact me:
Ansgar Scherp
Email: [email protected]
Web: http://zwb.eu/en/research/knowledge-discovery
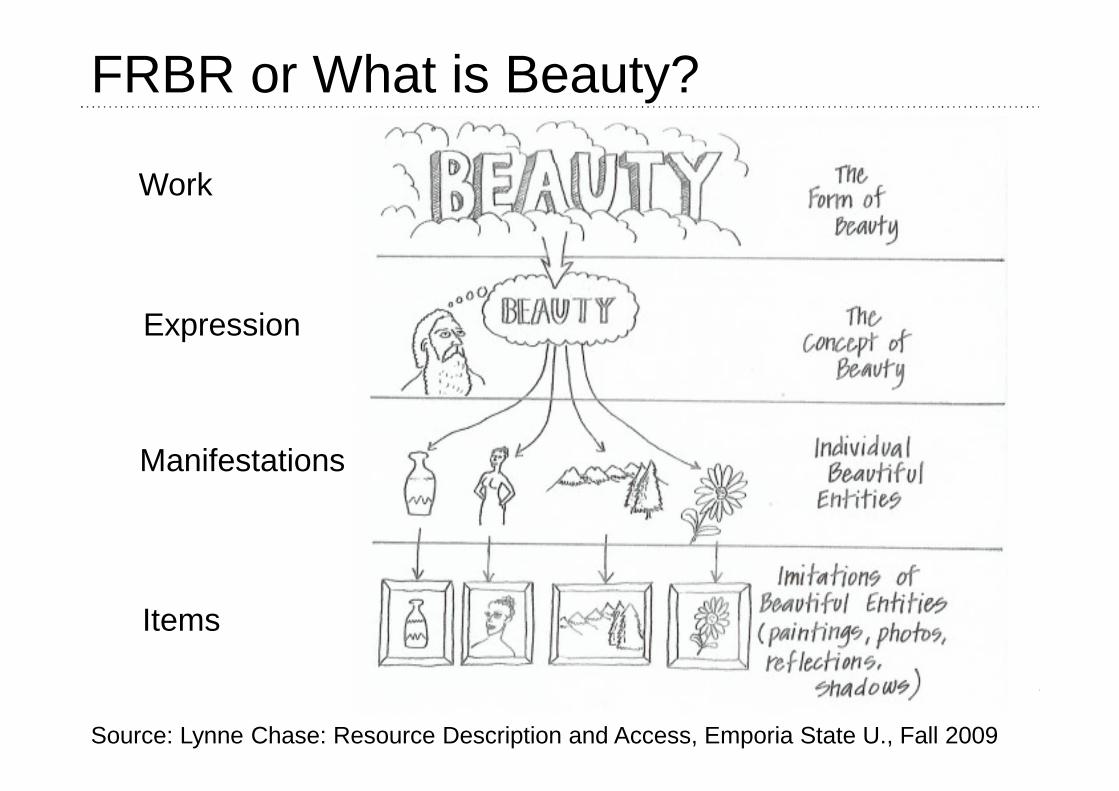
FRBR or What is Beauty?
Work
Expression
Manifestations
Items
Source: Lynne Chase: Resource Description and Access, Emporia State U., Fall 2009





























